用于使用多个引导RNA来破坏免疫耐受性的方法与流程
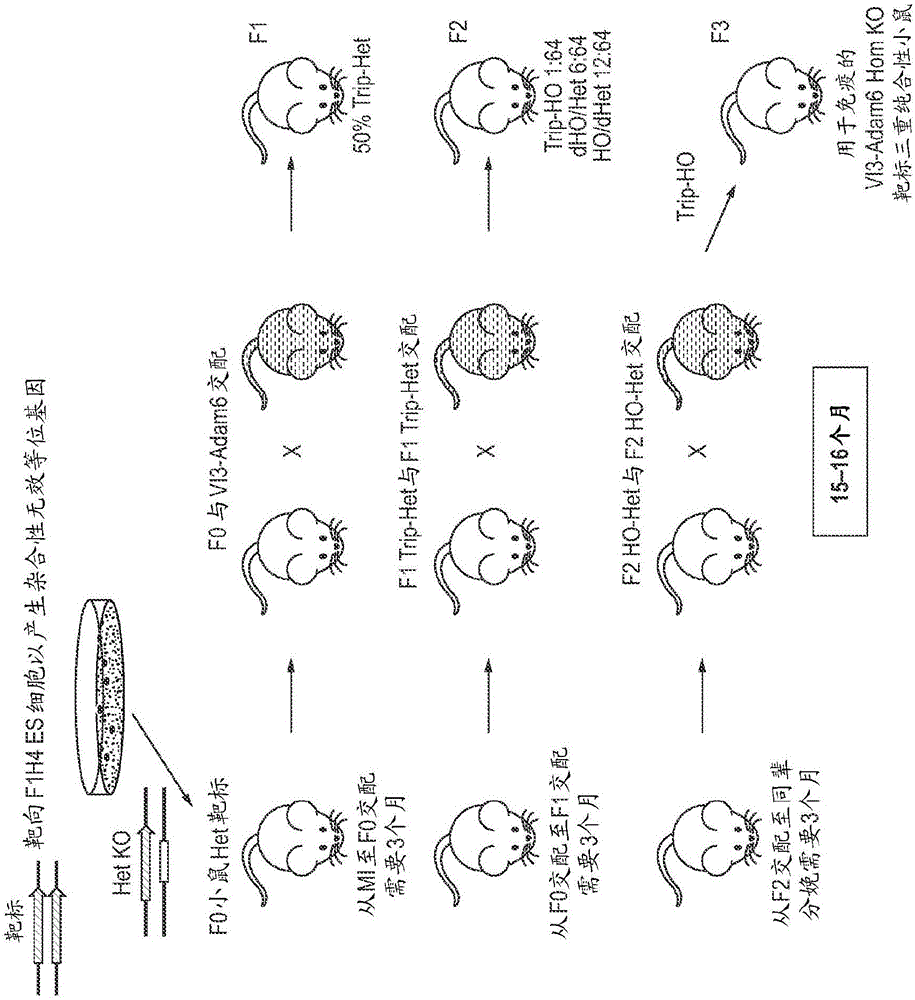
写入文件497023seqlist.txt中的序列表是38.3千字节,于2017年5月18日创建,并且据此以引用的方式并入。
背景技术:
:用“非自身”蛋白质使非人动物(例如啮齿动物,诸如小鼠或大鼠)免疫是一种通常使用的用以获得特异性抗原结合蛋白诸如单克隆抗体的方法。然而,这个方法依赖于非人动物中的天然蛋白质与经免疫以使得非人动物的免疫系统能够将免疫原识别为非自身(即外来)的蛋白质之间的序列趋异性。产生针对与自身抗原具有高度同源性的抗原的抗体可由于免疫耐受性而是一项困难任务。因为蛋白质的在功能上重要的区域在物种之间倾向于保守,所以对自身抗原的免疫耐受性常常对产生针对这些关键表位的抗体造成挑战。尽管已在靶向各种基因组基因座方面取得进展,但仍然有许多不能以常规靶向策略高效靶向的基因组基因座或不能以常规靶向策略高效实现的基因组修饰。crispr/cas系统已提供一种用于基因组编辑的新工具,但仍然存在困难。举例来说,当试图特别是在真核细胞和生物体中产生大型靶向基因组缺失或其他大型靶向遗传修饰时,困难可仍然在一些情形下出现。此外,可难以在无后续交配步骤下高效产生就靶向遗传修饰来说是纯合的细胞或动物,并且一些基因座相比于其他基因座可更加难以进行靶向以产生纯合性靶向修饰。举例来说,尽管就某一大型靶向基因组缺失来说是杂合的f0代小鼠可有时通过常规靶向策略来获得,但产生就所述缺失来说是纯合的f1代小鼠需要这些杂合性小鼠的后续交配。这些额外交配步骤是昂贵的和耗时的。技术实现要素:提供用于制备对目标外来抗原的耐受性降低的非人动物以及使用所述动物来产生结合所述目标外来抗原的抗原结合蛋白的方法和组合物。在一个方面,本发明提供一种制备对目标外来抗原的耐受性降低的非人动物的方法,其包括:(a)使不是单细胞期胚胎的非人动物多能细胞的基因组与以下各物接触:(i)cas9蛋白;(ii)杂交至第一靶基因组基因座内的第一引导rna识别序列的第一引导rna,其中所述第一靶基因组基因座影响与所述目标外来抗原同源或共有目标表位的第一自身抗原的表达;和(iii)杂交至所述第一靶基因组基因座内的第二引导rna识别序列的第二引导rna;其中一对第一染色体和第二染色体中的所述第一靶基因组基因座被修饰以产生具有双等位基因修饰的经修饰非人动物多能细胞,其中所述第一自身抗原的表达降低;(b)将所述经修饰非人动物多能细胞引入宿主胚胎中;和(c)将所述宿主胚胎植入代孕母体中以产生经遗传修饰的f0代非人动物,其中所述一对第一染色体和第二染色体中的所述第一靶基因组基因座被修饰以使所述第一自身抗原的表达降低。任选地,多能细胞是胚胎干(es)细胞。任选地,接触包括通过核转染来将cas9蛋白、第一引导rna和第二引导rna引入非人动物多能细胞中。任选地,将cas9蛋白以编码cas9蛋白的dna形式引入非人动物多能细胞中,将第一引导rna以编码第一引导rna的dna形式引入非人动物多能细胞中,并且将第二引导rna以编码第二引导rna的dna形式引入非人动物多能细胞中。在一些所述方法中,接触步骤(a)进一步包括使基因组与:(iv)杂交至第一靶基因组基因座内的第三引导rna识别序列的第三引导rna;和/或(v)杂交至第一靶基因组基因座内的第四引导rna识别序列的第四引导rna接触。在一些所述方法中,接触步骤(a)进一步包括使基因组与以下各物接触:(iv)杂交至第二靶基因组基因座内的第三引导rna识别序列的第三引导rna,其中所述第二靶基因组基因座影响第一自身抗原或与目标外来抗原同源或共有目标表位的第二自身抗原的表达;和/或(v)杂交至所述第二靶基因组基因座内的第四引导rna识别序列的第四引导rna。在一些所述方法中,接触步骤(a)进一步包括使基因组与包含会在靶基因组基因座处杂交于5’靶标序列的5’同源臂和会在靶基因组基因座处杂交于3’靶标序列的3’同源臂的外源性修复模板接触。任选地,外源性修复模板进一步包含由5’同源臂和3’同源臂侧接的核酸插入物。在一些所述方法中,核酸插入物与第一靶基因组基因座同源或直系同源。在一些所述方法中,外源性修复模板的长度在约50个核苷酸至约1kb之间。在一些所述方法中,外源性修复模板的长度在约80个核苷酸至约200个核苷酸之间。在一些所述方法中,外源性修复模板是单链寡脱氧核苷酸。在一些所述方法中,外源性修复模板是长度是至少10kb的大型靶向载体(ltvec),和/或外源性修复模板是ltvec,其中ltvec的5’同源臂和3’同源臂的总和的长度是至少10kb。一些所述方法进一步包括:(d)用目标外来抗原使在步骤(c)中产生的经遗传修饰的f0代非人动物免疫;(e)在足以引发对目标外来抗原的免疫应答的条件下维持经遗传修饰的f0代非人动物;和(f)从经遗传修饰的f0代非人动物获得编码人免疫球蛋白重链可变结构域的第一核酸序列和/或编码人免疫球蛋白轻链可变结构域的第二核酸序列。在一些所述方法中,相比于在使在第一靶基因组基因座处是野生型的对照非人动物免疫之后获得的抗原结合蛋白,在用目标外来抗原使经遗传修饰的f0代非人动物免疫之后获得的针对目标外来抗原的抗原结合蛋白具有更高效价。在一些所述方法中,相较于在使在第一靶基因组基因座处是野生型的对照非人动物免疫之后获得的抗原结合蛋白,在用目标外来抗原使经遗传修饰的f0代非人动物免疫之后获得更具多样性的针对目标外来抗原的抗原结合蛋白谱系。在一些所述方法中,第一自身抗原的表达被消除。在一些所述方法中,目标外来抗原是第一自身抗原的直系同源物。在一些所述方法中,目标外来抗原包含以下、基本上由以下组成或由以下组成:人蛋白质的全部或一部分。在一些所述方法中,第一靶基因组基因座被修饰以包含一个或多个核苷酸的插入、一个或多个核苷酸的缺失或一个或多个核苷酸的替换。在一些所述方法中,第一靶基因组基因座被修饰以包含一个或多个核苷酸的缺失。在一些所述方法中,接触步骤(a)包括使基因组与包含会在靶基因组基因座处杂交于5’靶标序列的5’同源臂和会在靶基因组基因座处杂交于3’靶标序列的3’同源臂的外源性修复模板接触,前提是如果基因组在单细胞期胚胎中,那么所述外源性修复模板的长度是不超过5kb,其中所述外源性修复模板包含由所述5’同源臂和所述3’同源臂侧接的核酸插入物,其中所述核酸插入物与经缺失核酸序列同源或直系同源,并且其中所述核酸插入物替换经缺失核酸序列。在一些所述方法中,缺失是无随机插入和缺失(插入缺失)的精确缺失。在一些所述方法中,接触步骤(a)包括使基因组与包含会在靶基因组基因座处杂交于5’靶标序列的5’同源臂和会在靶基因组基因座处杂交于3’靶标序列的3’同源臂的外源性修复模板接触,前提是如果基因组在单细胞期胚胎中,那么所述外源性修复模板的长度是不超过5kb,其中经缺失核酸序列由在5’靶标序列与3’靶标序列之间的核酸序列组成。在一些所述方法中,第一靶基因组基因座包含以下、基本上由以下组成或由以下组成:编码第一自身抗原的基因的全部或一部分。在一些所述方法中,修饰包括以下、基本上由以下组成或由以下组成:编码第一自身抗原的基因的全部或一部分的纯合性缺失。在一些所述方法中,修饰包括以下、基本上由以下组成或由以下组成:对编码第一自身抗原的基因的起始密码子的纯合性破坏。在一些所述方法中,第一引导rna识别序列包含编码第一自身抗原的基因的起始密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内,并且第二引导rna识别序列包含编码第一自身抗原的基因的终止密码子,或在终止密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。任选地,第一引导rna识别序列包含起始密码子,并且第二引导rna识别序列包含终止密码子。在一些所述方法中,第一引导rna识别序列包含第一cas9裂解位点,并且第二引导rna识别序列包含第二cas9裂解位点,其中第一靶基因组基因座被修饰以包含所述第一cas9裂解位点与所述第二cas9裂解位点之间的缺失。任选地,缺失是精确缺失,其中经缺失核酸序列由第一cas9裂解位点与第二cas9裂解位点之间的核酸序列组成。在一些所述方法中,第一引导rna识别序列和第二引导rna识别序列不同,并且第一引导rna识别序列和第二引导rna识别序列中的每一个包含编码第一自身抗原的基因的起始密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。任选地,第一引导rna识别序列和第二引导rna识别序列中的每一个包含起始密码子。在一些所述方法中,第一核酸序列和/或第二核酸序列从经遗传修饰的非人动物的淋巴细胞或从由所述淋巴细胞产生的杂交瘤获得。在一些所述方法中,非人动物包含人源化免疫球蛋白基因座。在一些所述方法中,非人动物是啮齿动物。在一些所述方法中,啮齿动物是小鼠。任选地,小鼠品系包括balb/c品系。任选地,小鼠品系包括balb/c、c57bl/6和129品系。任选地,小鼠品系是50%balb/c、25%c57bl/6和25%129。任选地,小鼠的mhc单倍型是mhcb/d。在一些所述方法中,小鼠在它的种系中包含插入在内源性小鼠免疫球蛋白基因座处的人未重排可变区基因区段。任选地,人未重排可变区基因区段是重链基因区段,并且小鼠免疫球蛋白基因座是重链基因座。任选地,人未重排可变区基因区段是轻链区段,并且小鼠免疫球蛋白基因座是轻链基因座。任选地,轻链基因区段是人κ或λ轻链基因区段。在一些所述方法中,小鼠在它的种系中包含可操作地连接至小鼠恒定区基因的人未重排可变区基因区段,其中小鼠缺乏人恒定区基因,并且其中所述小鼠恒定区基因在内源性小鼠免疫球蛋白基因座处。在一些所述方法中,小鼠包含:(a)杂合重链基因座,其包含人免疫球蛋白重链v、d和j基因区段的插入,其中所述人重链免疫球蛋白v、d和j基因区段可操作地连接至小鼠免疫球蛋白重链基因,其中所述小鼠免疫球蛋白重链基因在内源性小鼠免疫球蛋白基因座处;和(b)杂合轻链基因座,其包含人免疫球蛋白轻链v和j基因区段的插入,其中所述人v和j基因区段可操作地连接至小鼠免疫球蛋白轻链恒定区基因序列;其中(a)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合重链序列,以及(b)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合轻链序列,并且其中小鼠不能形成包含人可变区和人恒定区的抗体。在一些所述方法中,小鼠包含对免疫球蛋白重链基因座的修饰,其中所述修饰使内源性adam6功能降低或消除,并且其中小鼠包含编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性。任选地,编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列存在于人重链可变区基因座处。任选地,编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列存在于除人重链可变区基因座以外的位置处。在一些所述方法中,小鼠在它的种系中包含可操作地连接至轻链恒定区的人源化免疫球蛋白轻链可变基因座,其包含至多一个或至多两个重排人轻链v/j序列。任选地,轻链恒定区基因是小鼠基因。在一些所述方法中,小鼠进一步包含可操作地连接至重链恒定区基因的人源化免疫球蛋白重链可变基因座,其包含至少一个未重排人v、至少一个未重排人d和至少一个未重排人j区段。任选地,重链恒定区基因是小鼠基因。在一些所述方法中,小鼠包含人源化重链免疫球蛋白可变基因座和人源化轻链免疫球蛋白可变基因座,其中小鼠表达单一轻链。在一些所述方法中,小鼠包含:(a)编码免疫球蛋白轻链的人vl结构域的单一重排人免疫球蛋白轻链可变区(vl/jl),其中所述单一重排人vl/jl区选自人vκ1-39/j基因区段或人vκ3-20/j基因区段;和(b)内源性重链可变(vh)基因区段被一个或多个人vh基因区段的替换,其中所述人vh基因区段可操作地连接至内源性重链恒定(ch)区基因,并且所述人vh基因区段能够重排并形成人/小鼠嵌合重链基因。在一些所述方法中,小鼠表达抗体的群体,并且小鼠的种系仅包括是重排人种系κ轻链可变区基因的单一免疫球蛋白κ轻链可变区基因,其中小鼠就所述单一免疫球蛋白κ轻链可变区基因来说是杂合的,因为它仅含有一个拷贝,或就所述单一免疫球蛋白κ轻链可变区基因来说是纯合的,因为它含有两个拷贝,小鼠的特征在于活性亲和力成熟,以使:(i)所述群体的各免疫球蛋白κ轻链都包含由所述重排人种系κ轻链可变区基因或由其体细胞突变变体编码的轻链可变结构域;(ii)所述群体包括包含轻链可变结构域由所述重排人种系κ轻链可变区基因编码的免疫球蛋白κ轻链的抗体和包含轻链可变结构域由所述其体细胞突变变体编码的免疫球蛋白κ轻链的抗体;以及(iii)小鼠产生与所述免疫球蛋白κ轻链成功配对以形成所述群体的所述抗体的体细胞突变的高亲和力重链的多样性集合。任选地,小鼠在它的种系中就以下来说是杂合的或纯合的:(a)重排vκ/jκ序列在内源性小鼠κ免疫球蛋白轻链可变区基因座处的插入,所述重排vκ/jκ序列包含:(i)单一人种系vκ序列,所述单一人种系vκ序列存在于seqidno:148或seqidno:149中;和(ii)单一人种系jκ序列,其中所述重排vκ/jκ序列可操作地连接至内源性小鼠κ恒定区;和(b)多个人免疫球蛋白重链可变区基因区段在内源性小鼠免疫球蛋白重链可变区基因座处的插入,其中所述人免疫球蛋白重链可变区基因区段可操作地连接至内源性小鼠免疫球蛋白重链恒定区,并且所述人免疫球蛋白重链可变区基因区段能够重排并形成重排人/小鼠嵌合免疫球蛋白重链基因。在一些所述方法中,小鼠包含对免疫球蛋白重链基因座的修饰,其中所述修饰使内源性adam6功能降低或消除,并且其中小鼠包含编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性。任选地,编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列存在于人重链可变区基因座处。任选地,编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列存在于除人重链可变区基因座以外的位置处。在一些所述方法中,小鼠具有包含对免疫球蛋白重链基因座的修饰的基因组,其中所述修饰使内源性adam6功能降低或消除,并且小鼠进一步包含编码非人动物adam6蛋白或其直系同源物或同源物或相应adam6蛋白的功能性片段的核酸序列。任选地,小鼠的基因组包含:(a)adam6基因的异位放置;和(b)人免疫球蛋白重链可变区基因座,其包含一个或多个人vh基因区段、一个或多个人dh基因区段和一个或多个人jh基因区段向内源性非人动物重链基因座中的插入,其中所述人vh、dh和jh基因区段可操作地连接至重链恒定区基因;以使小鼠的特征在于:(i)它是能生育的;以及(ii)当它用抗原免疫时,它产生包含可操作地连接至由所述重链恒定区基因编码的重链恒定结构域的由所述一个或多个人vh、一个或多个人dh和一个或多个人jh基因区段编码的重链可变结构域的抗体,其中所述抗体显示与所述抗原的特异性结合。在一些所述方法中,非人动物是至少部分地源于balb/c品系的小鼠,其中所述小鼠包含人源化免疫球蛋白基因座,其中目标外来抗原是与第一自身抗原直系同源的人蛋白质的全部或一部分,并且第一靶基因组基因座包含编码所述第一自身抗原的基因的全部或一部分,其中第一引导rna识别位点包含编码所述第一自身抗原的所述基因的起始密码子,并且第二引导rna识别位点包含编码所述第一自身抗原的所述基因的终止密码子,并且其中修饰包括编码所述第一自身抗原的所述基因的全部或一部分的纯合性缺失,由此所述第一自身抗原的表达被消除。任选地,小鼠包含:(a)编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性;(b)杂合重链基因座,其包含人免疫球蛋白重链v、d和j基因区段的插入,其中所述人重链免疫球蛋白v、d和j基因区段可操作地连接至小鼠免疫球蛋白重链基因,其中所述小鼠免疫球蛋白重链基因在内源性小鼠免疫球蛋白基因座处;和(c)杂合轻链基因座,其包含人免疫球蛋白轻链v和j基因区段的插入,其中所述人v和j基因区段可操作地连接至小鼠免疫球蛋白轻链恒定区基因序列;其中(b)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合重链序列,以及(c)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合轻链序列,并且其中小鼠不能形成包含人可变区和人恒定区的抗体。任选地,小鼠在它的种系中就以下来说是杂合的或纯合的:(a)编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性;(b)重排vκ/jκ序列在内源性小鼠κ免疫球蛋白轻链可变区基因座处的插入,所述重排vκ/jκ序列包含:(i)单一人种系vκ序列,所述单一人种系vκ序列存在于seqidno:148或seqidno:149中;和(ii)单一人种系jκ序列,其中所述重排vκ/jκ序列可操作地连接至内源性小鼠κ恒定区;和(c)多个人免疫球蛋白重链可变区基因区段在内源性小鼠免疫球蛋白重链可变区基因座处的插入,其中所述人免疫球蛋白重链可变区基因区段可操作地连接至内源性小鼠免疫球蛋白重链恒定区,并且所述人免疫球蛋白重链可变区基因区段能够重排并形成重排人/小鼠嵌合免疫球蛋白重链基因。在一些所述方法中,其中非人动物是至少部分地源于balb/c品系的小鼠,其中所述小鼠包含人源化免疫球蛋白基因座,其中目标外来抗原是与第一自身抗原直系同源的人蛋白质的全部或一部分,并且第一靶基因组基因座包含编码所述第一自身抗原的基因的全部或一部分,其中第一引导rna识别位点包含编码所述第一自身抗原的所述基因的起始密码子,并且第二引导rna识别位点包含编码所述第一自身抗原的所述基因的终止密码子,并且其中修饰包括对编码所述第一自身抗原的所述基因的所述起始密码子的纯合性破坏,由此所述第一自身抗原的表达被消除。任选地,小鼠包含:(a)编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性;(b)杂合重链基因座,其包含人免疫球蛋白重链v、d和j基因区段的插入,其中所述人重链免疫球蛋白v、d和j基因区段可操作地连接至小鼠免疫球蛋白重链基因,其中所述小鼠免疫球蛋白重链基因在内源性小鼠免疫球蛋白基因座处;和(c)杂合轻链基因座,其包含人免疫球蛋白轻链v和j基因区段的插入,其中所述人v和j基因区段可操作地连接至小鼠免疫球蛋白轻链恒定区基因序列;其中(b)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合重链序列,以及(c)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合轻链序列,并且其中小鼠不能形成包含人可变区和人恒定区的抗体。任选地,小鼠在它的种系中就以下来说是杂合的或纯合的:(a)编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性;(b)重排vκ/jκ序列在内源性小鼠κ免疫球蛋白轻链可变区基因座处的插入,所述重排vκ/jκ序列包含:(i)单一人种系vκ序列,所述单一人种系vκ序列存在于seqidno:148或seqidno:149中;和(ii)单一人种系jκ序列,其中所述重排vκ/jκ序列可操作地连接至内源性小鼠κ恒定区;和(c)多个人免疫球蛋白重链可变区基因区段在内源性小鼠免疫球蛋白重链可变区基因座处的插入,其中所述人免疫球蛋白重链可变区基因区段可操作地连接至内源性小鼠免疫球蛋白重链恒定区,并且所述人免疫球蛋白重链可变区基因区段能够重排并形成重排人/小鼠嵌合免疫球蛋白重链基因。在一些方法中,非人动物多能细胞是杂交细胞,并且方法进一步包括:(a’)比较一对同源染色体中相应第一染色体和第二染色体在第一靶基因组基因座内的序列,以及在接触步骤(a)之前基于以下来选择第一靶基因组基因座内的靶区域:在所述一对同源染色体中所述相应第一染色体与第二染色体之间,相对于第一靶基因组基因座的其余部分的全部或一部分,所述靶区域具有更高序列同一性百分比。任选地,在一对同源染色体中相应第一染色体与第二染色体之间,相对于第一靶基因组基因座的其余部分,靶区域具有更高序列同一性百分比。任选地,在相应第一染色体与第二染色体之间,靶区域具有至少99.9%序列同一性,并且在相应第一染色体与第二染色体之间,第一靶基因组基因座的其余部分具有不超过99.8%序列同一性。任选地,在一对同源染色体中相应第一染色体和第二染色体中,靶区域相同。任选地,靶区域在第一靶基因组基因座内具有连续等位基因序列同一性的最长可能链段内。在一些所述方法中,靶区域包含以下、基本上由以下组成或由以下组成:第一引导rna识别序列和在第一引导rna识别序列的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,以及第二引导rna识别序列和在第二引导rna识别序列的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。任选地,步骤(a’)包括比较第一靶基因组基因座的两个或更多个区段,其中各区段包含以下、基本上由以下组成或由以下组成:不存在于基因组中其他地方的不同引导rna识别序列和在所述不同引导rna识别序列的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,以及将相对于其他区段具有最高序列同一性百分比的两个区段选作靶区域。任选地,一个或多个区段包含以下、基本上由以下组成或由以下组成:与第一靶基因组基因座中而非存在于基因组中其他地方的各不同引导rna识别序列相对应的区段。在一些所述方法中,靶区域包含以下、基本上由以下组成或由以下组成:在第一引导rna识别序列与第二引导rna识别序列之间的区域。任选地,步骤(a’)包括比较第一靶基因组基因座的两个或更多个区段,其中各区段包含以下、基本上由以下组成或由以下组成:在一对不同引导rna识别序列之间的区域,其中所述引导rna识别序列不存在于基因组中其他地方,以及将相对于其他区段具有最高序列同一性百分比的区段选作靶区域。任选地,一个或多个区段包含以下、基本上由以下组成或由以下组成:与第一靶基因组基因座中各对不同引导rna识别序列相对应的区段,其中所述引导rna识别序列不存在于基因组中其他地方。在一些所述方法中,靶区域包含以下、基本上由以下组成或由以下组成:在第一引导rna识别序列与第二引导rna识别序列之间的区域和在第一引导rna识别序列与第二引导rna识别序列之间的基因组区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。任选地,步骤(a’)包括比较第一靶基因组基因座的两个或更多个区段,其中各区段包含以下、基本上由以下组成或由以下组成:在一对不同引导rna识别序列之间的区域和在所述一对不同引导rna识别序列之间的基因组区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,其中所述引导rna识别序列不存在于基因组中其他地方,以及将相对于其他区段具有最高序列同一性百分比的区段选作靶区域。任选地,一个或多个区段包含以下、基本上由以下组成或由以下组成:与第一靶基因组基因座中各对不同引导rna识别序列相对应的区段,其中所述引导rna识别序列不存在于基因组中其他地方。在一些所述方法中,其中靶区域包含以下、基本上由以下组成或由以下组成:在第一引导rna识别序列与第二引导rna识别序列之间的基因组区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。任选地,步骤(a’)包括比较第一靶基因组基因座的两个或更多个非连续区段,其中各非连续区段包含以下、基本上由以下组成或由以下组成:在一对不同引导rna识别序列之间的基因组区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,其中所述引导rna识别序列不存在于基因组中其他地方,以及将相对于其他非连续区段具有最高序列同一性百分比的非连续区段选作靶区域。任选地,一个或多个非连续区段包含以下、基本上由以下组成或由以下组成:与第一靶基因组基因座中各对不同引导rna识别序列相对应的非连续区段,其中所述引导rna识别序列不存在于基因组中其他地方。在一些所述方法中,靶区域包含以下、基本上由以下组成或由以下组成:在第一引导rna识别序列与第二引导rna识别序列之间的基因组区域的各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。任选地,步骤(a’)包括比较第一靶基因组基因座的两个或更多个非连续区段,其中各非连续区段包含以下、基本上由以下组成或由以下组成:在一对不同引导rna识别序列之间的基因组区域的各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,其中所述引导rna识别序列不存在于基因组中其他地方,以及将相对于其他非连续区段具有最高序列同一性百分比的非连续区段选作靶区域。任选地,一个或多个非连续区段包含以下、基本上由以下组成或由以下组成:与第一靶基因组基因座中各对不同引导rna识别序列相对应的非连续区段,其中所述引导rna识别序列不存在于基因组中其他地方。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:由5’靶标序列和3’靶标序列侧接的区域。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:由5’靶标序列和3’靶标序列侧接且包括所述5’靶标序列和所述3’靶标序列的区域。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:5’靶标序列和/或3’靶标序列。任选地,步骤(a’)中的靶基因组基因座包含以下、基本上由以下组成或由以下组成:5’靶标序列和3’靶标序列。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:在5’靶标序列与3’靶标序列之间的区域和在5’靶标序列与3’靶标序列之间的区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:在5’靶标序列与3’靶标序列之间的区域和在5’靶标序列与3’靶标序列之间的区域的各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:在5’靶标序列与3’靶标序列之间的区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:在5’靶标序列与3’靶标序列之间的区域的各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。在另一方面,本发明提供一种制备对目标外来抗原的耐受性降低的非人动物的方法,其包括:(a)使非人动物单细胞期胚胎的基因组与以下各物接触:(i)cas9蛋白;(ii)杂交至第一靶基因组基因座内的第一引导rna识别序列的第一引导rna,其中所述第一靶基因组基因座影响与所述目标外来抗原同源或共有目标表位的第一自身抗原的表达;和(iii)杂交至所述第一靶基因组基因座内的第二引导rna识别序列的第二引导rna;其中一对第一染色体和第二染色体中的所述第一靶基因组基因座被修饰以产生双等位基因修饰,其中经修饰非人动物单细胞期胚胎中所述第一自身抗原的表达降低;和(b)将所述经修饰非人动物单细胞期胚胎植入代孕母体中以产生经遗传修饰的f0代非人动物,其中所述一对第一染色体和第二染色体中的所述第一靶基因组基因座被修饰以使所述第一自身抗原的表达降低。任选地,接触包括通过核转染来将cas9蛋白、第一引导rna和第二引导rna引入非人动物单细胞期胚胎中。任选地,将cas9蛋白以编码cas9蛋白的dna形式引入非人动物单细胞期胚胎中,将第一引导rna以编码第一引导rna的dna形式引入非人动物单细胞期胚胎中,并且将第二引导rna以编码第二引导rna的dna形式引入非人动物单细胞期胚胎中。在一些所述方法中,接触步骤(a)进一步包括使基因组与:(iv)杂交至第一靶基因组基因座内的第三引导rna识别序列的第三引导rna;和/或(v)杂交至第一靶基因组基因座内的第四引导rna识别序列的第四引导rna接触。在一些所述方法中,接触步骤(a)进一步包括使基因组与以下各物接触:(iv)杂交至第二靶基因组基因座内的第三引导rna识别序列的第三引导rna,其中所述第二靶基因组基因座影响第一自身抗原或与目标外来抗原同源或共有目标表位的第二自身抗原的表达;和/或(v)杂交至所述第二靶基因组基因座内的第四引导rna识别序列的第四引导rna。在一些所述方法中,接触步骤(a)进一步包括使基因组与包含会在靶基因组基因座处杂交于5’靶标序列的5’同源臂和会在靶基因组基因座处杂交于3’靶标序列的3’同源臂的外源性修复模板接触,其中所述外源性修复模板的长度在约50个核苷酸至约5kb之间。任选地,外源性修复模板进一步包含由5’同源臂和3’同源臂侧接的核酸插入物。在一些所述方法中,核酸插入物与第一靶基因组基因座同源或直系同源。在一些所述方法中,外源性修复模板的长度在约50个核苷酸至约1kb之间。在一些所述方法中,外源性修复模板的长度在约80个核苷酸至约200个核苷酸之间。在一些所述方法中,外源性修复模板是单链寡脱氧核苷酸。一些所述方法进一步包括:(c)用目标外来抗原使在步骤(b)中产生的经遗传修饰的f0代非人动物免疫;(d)在足以引发对目标外来抗原的免疫应答的条件下维持经遗传修饰的f0代非人动物;和(e)从经遗传修饰的f0代非人动物获得编码人免疫球蛋白重链可变结构域的第一核酸序列和/或编码人免疫球蛋白轻链可变结构域的第二核酸序列。在一些所述方法中,相比于在使在第一靶基因组基因座处是野生型的对照非人动物免疫之后获得的抗原结合蛋白,在用目标外来抗原使经遗传修饰的f0代非人动物免疫之后获得的针对目标外来抗原的抗原结合蛋白具有更高效价。在一些所述方法中,相较于在使在第一靶基因组基因座处是野生型的对照非人动物免疫之后获得的抗原结合蛋白,在用目标外来抗原使经遗传修饰的f0代非人动物免疫之后获得更具多样性的针对目标外来抗原的抗原结合蛋白谱系。在一些所述方法中,第一自身抗原的表达被消除。在一些所述方法中,目标外来抗原是第一自身抗原的直系同源物。在一些所述方法中,目标外来抗原包含以下、基本上由以下组成或由以下组成:人蛋白质的全部或一部分。在一些所述方法中,第一靶基因组基因座被修饰以包含一个或多个核苷酸的插入、一个或多个核苷酸的缺失或一个或多个核苷酸的替换。在一些所述方法中,第一靶基因组基因座被修饰以包含一个或多个核苷酸的缺失。在一些所述方法中,接触步骤(a)包括使基因组与包含会在靶基因组基因座处杂交于5’靶标序列的5’同源臂和会在靶基因组基因座处杂交于3’靶标序列的3’同源臂的外源性修复模板接触,前提是如果基因组在单细胞期胚胎中,那么所述外源性修复模板的长度是不超过5kb,其中所述外源性修复模板包含由所述5’同源臂和所述3’同源臂侧接的核酸插入物,其中所述核酸插入物与经缺失核酸序列同源或直系同源,并且其中所述核酸插入物替换经缺失核酸序列。在一些所述方法中,缺失是无随机插入和缺失(插入缺失)的精确缺失。在一些所述方法中,接触步骤(a)包括使基因组与包含会在靶基因组基因座处杂交于5’靶标序列的5’同源臂和会在靶基因组基因座处杂交于3’靶标序列的3’同源臂的外源性修复模板接触,前提是如果基因组在单细胞期胚胎中,那么所述外源性修复模板的长度是不超过5kb,其中经缺失核酸序列由在5’靶标序列与3’靶标序列之间的核酸序列组成。在一些所述方法中,第一靶基因组基因座包含以下、基本上由以下组成或由以下组成:编码第一自身抗原的基因的全部或一部分。在一些所述方法中,修饰包括以下、基本上由以下组成或由以下组成:编码第一自身抗原的基因的全部或一部分的纯合性缺失。在一些所述方法中,修饰包括以下、基本上由以下组成或由以下组成:对编码第一自身抗原的基因的起始密码子的纯合性破坏。在一些所述方法中,第一引导rna识别序列包含编码第一自身抗原的基因的起始密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内,并且第二引导rna识别序列包含编码第一自身抗原的基因的终止密码子,或在终止密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。任选地,第一引导rna识别序列包含起始密码子,并且第二引导rna识别序列包含终止密码子。在一些所述方法中,第一引导rna识别序列包含第一cas9裂解位点,并且第二引导rna识别序列包含第二cas9裂解位点,其中第一靶基因组基因座被修饰以包含所述第一cas9裂解位点与所述第二cas9裂解位点之间的缺失。任选地,缺失是精确缺失,其中经缺失核酸序列由第一cas9裂解位点与第二cas9裂解位点之间的核酸序列组成。在一些所述方法中,第一引导rna识别序列和第二引导rna识别序列不同,并且第一引导rna识别序列和第二引导rna识别序列中的每一个包含编码第一自身抗原的基因的起始密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。任选地,第一引导rna识别序列和第二引导rna识别序列中的每一个包含起始密码子。在一些所述方法中,第一核酸序列和/或第二核酸序列从经遗传修饰的非人动物的淋巴细胞或从由所述淋巴细胞产生的杂交瘤获得。在一些所述方法中,非人动物包含人源化免疫球蛋白基因座。在一些所述方法中,非人动物是啮齿动物。在一些所述方法中,啮齿动物是小鼠。任选地,小鼠品系包括balb/c品系。任选地,小鼠品系包括balb/c、c57bl/6和129品系。任选地,小鼠品系是50%balb/c、25%c57bl/6和25%129。任选地,小鼠的mhc单倍型是mhcb/d。在一些所述方法中,小鼠在它的种系中包含插入在内源性小鼠免疫球蛋白基因座处的人未重排可变区基因区段。任选地,人未重排可变区基因区段是重链基因区段,并且小鼠免疫球蛋白基因座是重链基因座。任选地,人未重排可变区基因区段是轻链区段,并且小鼠免疫球蛋白基因座是轻链基因座。任选地,轻链基因区段是人κ或λ轻链基因区段。在一些所述方法中,小鼠在它的种系中包含可操作地连接至小鼠恒定区基因的人未重排可变区基因区段,其中小鼠缺乏人恒定区基因,并且其中所述小鼠恒定区基因在内源性小鼠免疫球蛋白基因座处。在一些所述方法中,小鼠包含:(a)杂合重链基因座,其包含人免疫球蛋白重链v、d和j基因区段的插入,其中所述人重链免疫球蛋白v、d和j基因区段可操作地连接至小鼠免疫球蛋白重链基因,其中所述小鼠免疫球蛋白重链基因在内源性小鼠免疫球蛋白基因座处;和(b)杂合轻链基因座,其包含人免疫球蛋白轻链v和j基因区段的插入,其中所述人v和j基因区段可操作地连接至小鼠免疫球蛋白轻链恒定区基因序列;其中(a)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合重链序列,以及(b)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合轻链序列,并且其中小鼠不能形成包含人可变区和人恒定区的抗体。在一些所述方法中,小鼠包含对免疫球蛋白重链基因座的修饰,其中所述修饰使内源性adam6功能降低或消除,并且其中小鼠包含编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性。任选地,编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列存在于人重链可变区基因座处。任选地,编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列存在于除人重链可变区基因座以外的位置处。在一些所述方法中,小鼠在它的种系中包含可操作地连接至轻链恒定区的人源化免疫球蛋白轻链可变基因座,其包含至多一个或至多两个重排人轻链v/j序列。任选地,轻链恒定区基因是小鼠基因。在一些所述方法中,小鼠进一步包含可操作地连接至重链恒定区基因的人源化免疫球蛋白重链可变基因座,其包含至少一个未重排人v、至少一个未重排人d和至少一个未重排人j区段。任选地,重链恒定区基因是小鼠基因。在一些所述方法中,小鼠包含人源化重链免疫球蛋白可变基因座和人源化轻链免疫球蛋白可变基因座,其中小鼠表达单一轻链。在一些所述方法中,小鼠包含:(a)编码免疫球蛋白轻链的人vl结构域的单一重排人免疫球蛋白轻链可变区(vl/jl),其中所述单一重排人vl/jl区选自人vκ1-39/j基因区段或人vκ3-20/j基因区段;和(b)内源性重链可变(vh)基因区段被一个或多个人vh基因区段的替换,其中所述人vh基因区段可操作地连接至内源性重链恒定(ch)区基因,并且所述人vh基因区段能够重排并形成人/小鼠嵌合重链基因。在一些所述方法中,小鼠表达抗体的群体,并且小鼠的种系仅包括是重排人种系κ轻链可变区基因的单一免疫球蛋白κ轻链可变区基因,其中小鼠就所述单一免疫球蛋白κ轻链可变区基因来说是杂合的,因为它仅含有一个拷贝,或就所述单一免疫球蛋白κ轻链可变区基因来说是纯合的,因为它含有两个拷贝,小鼠的特征在于活性亲和力成熟,以使:(i)所述群体的各免疫球蛋白κ轻链都包含由所述重排人种系κ轻链可变区基因或由其体细胞突变变体编码的轻链可变结构域;(ii)所述群体包括包含轻链可变结构域由所述重排人种系κ轻链可变区基因编码的免疫球蛋白κ轻链的抗体和包含轻链可变结构域由所述其体细胞突变变体编码的免疫球蛋白κ轻链的抗体;以及(iii)小鼠产生与所述免疫球蛋白κ轻链成功配对以形成所述群体的所述抗体的体细胞突变的高亲和力重链的多样性集合。任选地,小鼠在它的种系中就以下来说是杂合的或纯合的:(a)重排vκ/jκ序列在内源性小鼠κ免疫球蛋白轻链可变区基因座处的插入,所述重排vκ/jκ序列包含:(i)单一人种系vκ序列,所述单一人种系vκ序列存在于seqidno:148或seqidno:149中;和(ii)单一人种系jκ序列,其中所述重排vκ/jκ序列可操作地连接至内源性小鼠κ恒定区;和(b)多个人免疫球蛋白重链可变区基因区段在内源性小鼠免疫球蛋白重链可变区基因座处的插入,其中所述人免疫球蛋白重链可变区基因区段可操作地连接至内源性小鼠免疫球蛋白重链恒定区,并且所述人免疫球蛋白重链可变区基因区段能够重排并形成重排人/小鼠嵌合免疫球蛋白重链基因。在一些所述方法中,小鼠包含对免疫球蛋白重链基因座的修饰,其中所述修饰使内源性adam6功能降低或消除,并且其中小鼠包含编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性。任选地,编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列存在于人重链可变区基因座处。任选地,编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列存在于除人重链可变区基因座以外的位置处。在一些所述方法中,小鼠具有包含对免疫球蛋白重链基因座的修饰的基因组,其中所述修饰使内源性adam6功能降低或消除,并且小鼠进一步包含编码非人动物adam6蛋白或其直系同源物或同源物或相应adam6蛋白的功能性片段的核酸序列。任选地,小鼠的基因组包含:(a)adam6基因的异位放置;和(b)人免疫球蛋白重链可变区基因座,其包含一个或多个人vh基因区段、一个或多个人dh基因区段和一个或多个人jh基因区段向内源性非人动物重链基因座中的插入,其中所述人vh、dh和jh基因区段可操作地连接至重链恒定区基因;以使小鼠的特征在于:(i)它是能生育的;以及(ii)当它用抗原免疫时,它产生包含可操作地连接至由所述重链恒定区基因编码的重链恒定结构域的由所述一个或多个人vh、一个或多个人dh和一个或多个人jh基因区段编码的重链可变结构域的抗体,其中所述抗体显示与所述抗原的特异性结合。在一些所述方法中,非人动物是至少部分地源于balb/c品系的小鼠,其中所述小鼠包含人源化免疫球蛋白基因座,其中目标外来抗原是与第一自身抗原直系同源的人蛋白质的全部或一部分,并且第一靶基因组基因座包含编码所述第一自身抗原的基因的全部或一部分,其中第一引导rna识别位点包含编码所述第一自身抗原的所述基因的起始密码子,并且第二引导rna识别位点包含编码所述第一自身抗原的所述基因的终止密码子,并且其中修饰包括编码所述第一自身抗原的所述基因的全部或一部分的纯合性缺失,由此所述第一自身抗原的表达被消除。任选地,小鼠包含:(a)编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性;(b)杂合重链基因座,其包含人免疫球蛋白重链v、d和j基因区段的插入,其中所述人重链免疫球蛋白v、d和j基因区段可操作地连接至小鼠免疫球蛋白重链基因,其中所述小鼠免疫球蛋白重链基因在内源性小鼠免疫球蛋白基因座处;和(c)杂合轻链基因座,其包含人免疫球蛋白轻链v和j基因区段的插入,其中所述人v和j基因区段可操作地连接至小鼠免疫球蛋白轻链恒定区基因序列;其中(b)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合重链序列,以及(c)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合轻链序列,并且其中小鼠不能形成包含人可变区和人恒定区的抗体。任选地,小鼠在它的种系中就以下来说是杂合的或纯合的:(a)编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性;(b)重排vκ/jκ序列在内源性小鼠κ免疫球蛋白轻链可变区基因座处的插入,所述重排vκ/jκ序列包含:(i)单一人种系vκ序列,所述单一人种系vκ序列存在于seqidno:148或seqidno:149中;和(ii)单一人种系jκ序列,其中所述重排vκ/jκ序列可操作地连接至内源性小鼠κ恒定区;和(c)多个人免疫球蛋白重链可变区基因区段在内源性小鼠免疫球蛋白重链可变区基因座处的插入,其中所述人免疫球蛋白重链可变区基因区段可操作地连接至内源性小鼠免疫球蛋白重链恒定区,并且所述人免疫球蛋白重链可变区基因区段能够重排并形成重排人/小鼠嵌合免疫球蛋白重链基因。在一些所述方法中,其中非人动物是至少部分地源于balb/c品系的小鼠,其中所述小鼠包含人源化免疫球蛋白基因座,其中目标外来抗原是与第一自身抗原直系同源的人蛋白质的全部或一部分,并且第一靶基因组基因座包含编码所述第一自身抗原的基因的全部或一部分,其中第一引导rna识别位点包含编码所述第一自身抗原的所述基因的起始密码子,并且第二引导rna识别位点包含编码所述第一自身抗原的所述基因的终止密码子,并且其中修饰包括对编码所述第一自身抗原的所述基因的所述起始密码子的纯合性破坏,由此所述第一自身抗原的表达被消除。任选地,小鼠包含:(a)编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性;(b)杂合重链基因座,其包含人免疫球蛋白重链v、d和j基因区段的插入,其中所述人重链免疫球蛋白v、d和j基因区段可操作地连接至小鼠免疫球蛋白重链基因,其中所述小鼠免疫球蛋白重链基因在内源性小鼠免疫球蛋白基因座处;和(c)杂合轻链基因座,其包含人免疫球蛋白轻链v和j基因区段的插入,其中所述人v和j基因区段可操作地连接至小鼠免疫球蛋白轻链恒定区基因序列;其中(b)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合重链序列,以及(c)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合轻链序列,并且其中小鼠不能形成包含人可变区和人恒定区的抗体。任选地,小鼠在它的种系中就以下来说是杂合的或纯合的:(a)编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性;(b)重排vκ/jκ序列在内源性小鼠κ免疫球蛋白轻链可变区基因座处的插入,所述重排vκ/jκ序列包含:(i)单一人种系vκ序列,所述单一人种系vκ序列存在于seqidno:148或seqidno:149中;和(ii)单一人种系jκ序列,其中所述重排vκ/jκ序列可操作地连接至内源性小鼠κ恒定区;和(c)多个人免疫球蛋白重链可变区基因区段在内源性小鼠免疫球蛋白重链可变区基因座处的插入,其中所述人免疫球蛋白重链可变区基因区段可操作地连接至内源性小鼠免疫球蛋白重链恒定区,并且所述人免疫球蛋白重链可变区基因区段能够重排并形成重排人/小鼠嵌合免疫球蛋白重链基因。在一些方法中,非人动物单细胞期胚胎是杂交单细胞期胚胎,并且方法进一步包括:(a’)比较一对同源染色体中相应第一染色体和第二染色体在第一靶基因组基因座内的序列,以及在接触步骤(a)之前基于以下来选择第一靶基因组基因座内的靶区域:在所述一对同源染色体中所述相应第一染色体与第二染色体之间,相对于第一靶基因组基因座的其余部分的全部或一部分,所述靶区域具有更高序列同一性百分比。任选地,在一对同源染色体中相应第一染色体与第二染色体之间,相对于第一靶基因组基因座的其余部分,靶区域具有更高序列同一性百分比。任选地,在相应第一染色体与第二染色体之间,靶区域具有至少99.9%序列同一性,并且在相应第一染色体与第二染色体之间,第一靶基因组基因座的其余部分具有不超过99.8%序列同一性。任选地,在一对同源染色体中相应第一染色体和第二染色体中,靶区域相同。任选地,靶区域在第一靶基因组基因座内具有连续等位基因序列同一性的最长可能链段内。在一些所述方法中,靶区域包含以下、基本上由以下组成或由以下组成:第一引导rna识别序列和在第一引导rna识别序列的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,以及第二引导rna识别序列和在第二引导rna识别序列的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。任选地,步骤(a’)包括比较第一靶基因组基因座的两个或更多个区段,其中各区段包含以下、基本上由以下组成或由以下组成:不存在于基因组中其他地方的不同引导rna识别序列和在所述不同引导rna识别序列的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,以及将相对于其他区段具有最高序列同一性百分比的两个区段选作靶区域。任选地,一个或多个区段包含以下、基本上由以下组成或由以下组成:与第一靶基因组基因座中而非存在于基因组中其他地方的各不同引导rna识别序列相对应的区段。在一些所述方法中,靶区域包含以下、基本上由以下组成或由以下组成:在第一引导rna识别序列与第二引导rna识别序列之间的区域。任选地,步骤(a’)包括比较第一靶基因组基因座的两个或更多个区段,其中各区段包含以下、基本上由以下组成或由以下组成:在一对不同引导rna识别序列之间的区域,其中所述引导rna识别序列不存在于基因组中其他地方,以及将相对于其他区段具有最高序列同一性百分比的区段选作靶区域。任选地,一个或多个区段包含以下、基本上由以下组成或由以下组成:与第一靶基因组基因座中各对不同引导rna识别序列相对应的区段,其中所述引导rna识别序列不存在于基因组中其他地方。在一些所述方法中,靶区域包含以下、基本上由以下组成或由以下组成:在第一引导rna识别序列与第二引导rna识别序列之间的区域和在第一引导rna识别序列与第二引导rna识别序列之间的基因组区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。任选地,步骤(a’)包括比较第一靶基因组基因座的两个或更多个区段,其中各区段包含以下、基本上由以下组成或由以下组成:在一对不同引导rna识别序列之间的区域和在所述一对不同引导rna识别序列之间的基因组区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,其中所述引导rna识别序列不存在于基因组中其他地方,以及将相对于其他区段具有最高序列同一性百分比的区段选作靶区域。任选地,一个或多个区段包含以下、基本上由以下组成或由以下组成:与第一靶基因组基因座中各对不同引导rna识别序列相对应的区段,其中所述引导rna识别序列不存在于基因组中其他地方。在一些所述方法中,其中靶区域包含以下、基本上由以下组成或由以下组成:在第一引导rna识别序列与第二引导rna识别序列之间的基因组区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。任选地,步骤(a’)包括比较第一靶基因组基因座的两个或更多个非连续区段,其中各非连续区段包含以下、基本上由以下组成或由以下组成:在一对不同引导rna识别序列之间的基因组区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,其中所述引导rna识别序列不存在于基因组中其他地方,以及将相对于其他非连续区段具有最高序列同一性百分比的非连续区段选作靶区域。任选地,一个或多个非连续区段包含以下、基本上由以下组成或由以下组成:与第一靶基因组基因座中各对不同引导rna识别序列相对应的非连续区段,其中所述引导rna识别序列不存在于基因组中其他地方。在一些所述方法中,靶区域包含以下、基本上由以下组成或由以下组成:在第一引导rna识别序列与第二引导rna识别序列之间的基因组区域的各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。任选地,步骤(a’)包括比较第一靶基因组基因座的两个或更多个非连续区段,其中各非连续区段包含以下、基本上由以下组成或由以下组成:在一对不同引导rna识别序列之间的基因组区域的各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,其中所述引导rna识别序列不存在于基因组中其他地方,以及将相对于其他非连续区段具有最高序列同一性百分比的非连续区段选作靶区域。任选地,一个或多个非连续区段包含以下、基本上由以下组成或由以下组成:与第一靶基因组基因座中各对不同引导rna识别序列相对应的非连续区段,其中所述引导rna识别序列不存在于基因组中其他地方。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:由5’靶标序列和3’靶标序列侧接的区域。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:由5’靶标序列和3’靶标序列侧接且包括所述5’靶标序列和所述3’靶标序列的区域。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:5’靶标序列和/或3’靶标序列。任选地,步骤(a’)中的靶基因组基因座包含以下、基本上由以下组成或由以下组成:5’靶标序列和3’靶标序列。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:在5’靶标序列与3’靶标序列之间的区域和在5’靶标序列与3’靶标序列之间的区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:在5’靶标序列与3’靶标序列之间的区域和在5’靶标序列与3’靶标序列之间的区域的各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:在5’靶标序列与3’靶标序列之间的区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。在一些所述方法中,步骤(a’)中的靶区域包含以下、基本上由以下组成或由以下组成:在5’靶标序列与3’靶标序列之间的区域的各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。在另一方面,提供一种产生针对目标外来抗原的抗原结合蛋白的方法,其包括:(a)制备对目标外来抗原的耐受性降低的经遗传修饰的非人动物,其包括:(i)向非人动物单细胞期胚胎或不是单细胞期胚胎的非人动物多能细胞中引入:(i)cas9蛋白;(ii)杂交至靶基因组基因座内的第一引导rna识别序列的第一引导rna,其中所述靶基因组基因座包含编码与所述目标外来抗原同源或共有目标表位的自身抗原的基因的全部或一部分;和(iii)杂交至所述靶基因组基因座内的第二引导rna识别序列的第二引导rna;其中一对相应第一染色体和第二染色体中的所述靶基因组基因座被修饰以产生具有双等位基因修饰的经修饰非人动物单细胞期胚胎或经修饰非人动物多能细胞,其中所述自身抗原的表达被消除;和(ii)从所述经修饰非人动物单细胞期胚胎或所述经修饰非人动物多能细胞产生经遗传修饰的f0代非人动物,其中所述经遗传修饰的f0代非人动物中所述一对相应第一染色体和第二染色体中的所述靶基因组基因座被修饰以使所述自身抗原的表达被消除;(b)用所述目标外来抗原使在步骤(a)中产生的所述经遗传修饰的f0代非人动物免疫;和(c)在足以引发对所述目标外来抗原的免疫应答的条件下维持所述经遗传修饰的f0代非人动物,其中所述经遗传修饰的f0代非人动物产生针对所述目标外来抗原的抗原结合蛋白。在一些方法中,步骤(a)(i)中的细胞是非人动物多能干细胞,并且在步骤(a)(ii)中产生经遗传修饰的f0代非人动物包括:(i)将经修饰非人动物多能细胞引入宿主胚胎中;和(ii)将所述宿主胚胎植入代孕母体中以产生经遗传修饰的f0代非人动物,其中一对相应第一染色体和第二染色体中的靶基因组基因座被修饰以使自身抗原的表达被消除。任选地,多能细胞是胚胎干(es)细胞。在一些方法中,步骤(a)(i)中的细胞是非人动物单细胞期胚胎,并且在步骤(a)(ii)中产生经遗传修饰的f0代非人动物包括将经修饰非人动物单细胞期胚胎植入代孕母体中以产生经遗传修饰的f0代非人动物,其中一对相应第一染色体和第二染色体中的靶基因组基因座被修饰以使自身抗原的表达被消除。一些所述方法进一步包括从分离自经免疫的经遗传修饰f0代非人动物的b细胞制备杂交瘤。一些所述方法进一步包括从经免疫的经遗传修饰f0代非人动物获得编码一种针对目标外来抗原的抗原结合蛋白的免疫球蛋白重链可变结构域的第一核酸序列和/或编码一种针对目标外来抗原的抗原结合蛋白的免疫球蛋白轻链可变结构域的第二核酸序列。任选地,第一核酸序列和/或第二核酸序列从经遗传修饰的f0代非人动物的淋巴细胞(例如b细胞)或从由所述淋巴细胞产生的杂交瘤获得。任选地,经遗传修饰的f0代非人动物包含人源化免疫球蛋白基因座,并且其中第一核酸序列编码人免疫球蛋白重链可变结构域,并且第二核酸序列编码人免疫球蛋白轻链可变结构域。在一些所述方法中,相比于在用目标外来抗原使对照非人动物免疫之后由在靶基因组基因座处是野生型的所述对照非人动物产生的抗原结合蛋白,由经遗传修饰的f0代非人动物产生的针对目标外来抗原的抗原结合蛋白具有更高效价。在一些所述方法中,相较于在用目标外来抗原使对照非人动物免疫之后由在靶基因组基因座处是野生型的所述对照非人动物产生的抗原结合蛋白,在用目标外来抗原使经遗传修饰的f0代非人动物免疫之后由经遗传修饰的f0代非人动物产生更具多样性的针对目标外来抗原的抗原结合蛋白谱系。在一些所述方法中,相较于在用目标外来抗原使对照非人动物免疫之后由在靶基因组基因座处是野生型的所述对照非人动物产生的抗原结合蛋白,由经遗传修饰的f0代非人动物产生的针对目标外来抗原的抗原结合蛋白使用更大多样性的重链v基因区段和/或轻链v基因区段。在一些所述方法中,由经遗传修饰的f0代非人动物产生的一些针对目标外来抗原的抗原结合蛋白与自身抗原交叉反应。在一些所述方法中,在靶基因组基因座中,第一引导rna识别序列在第二引导rna识别序列的5’,并且步骤(a)(i)进一步包括进行保留测定以确定在第一引导rna识别序列的5’以及约1kb内的区域和/或在第二引导rna识别序列的3’以及约1kb内的区域的拷贝数是2。在一些所述方法中,目标外来抗原是自身抗原的直系同源物。在一些所述方法中,目标外来抗原包含人蛋白质的全部或一部分。在一些所述方法中,靶基因组基因座被修饰以包含一个或多个核苷酸的插入、一个或多个核苷酸的缺失或一个或多个核苷酸的替换。任选地,缺失是无随机插入和缺失(插入缺失)的精确缺失。在一些所述方法中,第一引导rna识别序列包含编码自身抗原的基因的起始密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内,并且第二引导rna识别序列包含编码自身抗原的基因的终止密码子,或在终止密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。在一些所述方法中,第一引导rna识别序列和第二引导rna识别序列不同,并且第一引导rna识别序列和第二引导rna识别序列中的每一个包含编码自身抗原的基因的起始密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。在一些所述方法中,靶基因组基因座被修饰以包含在约0.1kb至约200kb之间的双等位基因缺失。在一些所述方法中,修饰包括编码自身抗原的基因的全部或一部分的双等位基因缺失。在一些所述方法中,修饰包括对编码自身抗原的基因的起始密码子的双等位基因破坏。在一些所述方法中,引入步骤(a)(i)进一步包括向非人动物多能细胞或非人动物单细胞期胚胎中引入:(iv)杂交至靶基因组基因座内的第三引导rna识别序列的第三引导rna;和/或(v)杂交至靶基因组基因座内的第四引导rna识别序列的第四引导rna。在一些所述方法中,步骤(a)(i)中的细胞是非人动物多能干细胞,并且将cas9蛋白、第一引导rna和第二引导rna各自以dna形式引入非人动物多能干细胞中。在一些所述方法中,步骤(a)(i)中的细胞是非人动物多能干细胞,并且将cas9蛋白、第一引导rna和第二引导rna各自通过电穿孔或核转染来引入非人动物多能干细胞中。在一些所述方法中,步骤(a)(i)中的细胞是非人动物单细胞期胚胎,并且将cas9蛋白、第一引导rna和第二引导rna各自以rna形式引入非人动物单细胞期胚胎中。在一些所述方法中,步骤(a)(i)中的细胞是非人动物单细胞期胚胎,并且将cas9蛋白、第一引导rna和第二引导rna通过原核注射或细胞质注射来引入非人动物单细胞期胚胎中。在一些所述方法中,不在步骤(a)(i)中引入外源性修复模板。在一些所述方法中,引入步骤(a)(i)进一步包括向非人动物多能细胞或非人动物单细胞期胚胎中引入外源性修复模板,其包含会在靶基因组基因座处杂交于5’靶标序列的5’同源臂和会在靶基因组基因座处杂交于3’靶标序列的3’同源臂,前提是如果步骤(a)(i)中的细胞是非人动物单细胞期胚胎,那么所述外源性修复模板的长度是不超过约5kb。任选地,外源性修复模板进一步包含由5'同源臂和3'同源臂侧接的核酸插入物。任选地,核酸插入物与靶基因组基因座同源或直系同源。任选地,外源性修复模板的长度在约50个核苷酸至约1kb之间。任选地,外源性修复模板的长度在约80个核苷酸至约200个核苷酸之间。任选地,外源性修复模板是单链寡脱氧核苷酸。任选地,步骤(a)(i)中的细胞是非人动物多能细胞,并且(a)外源性修复模板是长度是至少10kb的大型靶向载体(ltvec);或(b)外源性修复模板是ltvec,其中ltvec的5’同源臂和3’同源臂的总和的长度是至少10kb。任选地,靶基因组基因座被修饰以包含一个或多个核苷酸的缺失,并且经缺失核酸序列由在5’靶标序列与3’靶标序列之间的核酸序列组成。任选地,外源性修复模板包含由5’同源臂和3’同源臂侧接的核酸插入物,所述核酸插入物与经缺失核酸序列同源或直系同源,靶基因组基因座被修饰以包含一个或多个核苷酸的缺失,并且所述核酸插入物替换经缺失核酸序列。在一些所述方法中,非人动物包含人源化免疫球蛋白基因座。在一些所述方法中,非人动物是啮齿动物。任选地,啮齿动物是小鼠。任选地,小鼠品系包括balb/c品系。任选地,小鼠品系包括balb/c、c57bl/6和129品系。任选地,小鼠品系是50%balb/c、25%c57bl/6和25%129。任选地,小鼠的mhc单倍型是mhcb/d。在一些所述方法中,小鼠在它的种系中包含插入在内源性小鼠免疫球蛋白基因座处的人未重排可变区基因区段。任选地,人未重排可变区基因区段是重链基因区段,并且小鼠免疫球蛋白基因座是重链基因座,和/或其中人未重排可变区基因区段是κ或λ轻链区段,并且小鼠免疫球蛋白基因座是轻链基因座。任选地,小鼠在它的种系中包含可操作地连接至小鼠恒定区基因的人未重排可变区基因区段,其中小鼠缺乏人恒定区基因,并且其中所述小鼠恒定区基因在内源性小鼠免疫球蛋白基因座处。任选地,小鼠包含:(a)杂合重链基因座,其包含人免疫球蛋白重链v、d和j基因区段的插入,其中所述人重链免疫球蛋白v、d和j基因区段可操作地连接至小鼠免疫球蛋白重链基因,其中所述小鼠免疫球蛋白重链基因在内源性小鼠免疫球蛋白基因座处;和(b)杂合轻链基因座,其包含人免疫球蛋白轻链v和j基因区段的插入,其中所述人v和j基因区段可操作地连接至小鼠免疫球蛋白轻链恒定区基因序列;其中(a)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合重链序列,以及(b)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合轻链序列,并且其中小鼠不能形成包含人可变区和人恒定区的抗体。在一些所述方法中,小鼠在它的种系中包含可操作地连接至小鼠轻链恒定区的人源化免疫球蛋白轻链可变基因座,其包含至多一个或至多两个重排人轻链v/j序列,并且其中小鼠进一步包含可操作地连接至小鼠重链恒定区基因的人源化免疫球蛋白重链可变基因座,其包含至少一个未重排人v、至少一个未重排人d和至少一个未重排人j区段。任选地,小鼠包含人源化重链免疫球蛋白可变基因座和人源化轻链免疫球蛋白可变基因座,其中小鼠表达单一轻链。任选地,小鼠包含:(a)编码免疫球蛋白轻链的人vl结构域的单一重排人免疫球蛋白轻链可变区(vl/jl),其中所述单一重排人vl/jl区选自人vκ1-39/jκ5基因区段或人vκ3-20/jκ1基因区段;和(b)内源性重链可变(vh)基因区段被一个或多个人vh基因区段的替换,其中所述人vh基因区段可操作地连接至内源性重链恒定(ch)区基因,并且所述人vh基因区段能够重排并形成人/小鼠嵌合重链基因。任选地,小鼠表达抗体的群体,并且小鼠的种系仅包括是重排人种系κ轻链可变区基因的单一免疫球蛋白κ轻链可变区基因,其中小鼠就所述单一免疫球蛋白κ轻链可变区基因来说是杂合的,因为它仅含有一个拷贝,或就所述单一免疫球蛋白κ轻链可变区基因来说是纯合的,因为它含有两个拷贝,小鼠的特征在于活性亲和力成熟,以使:(i)所述群体的各免疫球蛋白κ轻链都包含由所述重排人种系κ轻链可变区基因或由其体细胞突变变体编码的轻链可变结构域;(ii)所述群体包括包含轻链可变结构域由所述重排人种系κ轻链可变区基因编码的免疫球蛋白κ轻链的抗体和包含轻链可变结构域由所述其体细胞突变变体编码的免疫球蛋白κ轻链的抗体;以及(iii)小鼠产生与所述免疫球蛋白κ轻链成功配对以形成所述群体的所述抗体的体细胞突变的高亲和力重链的多样性集合。任选地,小鼠在它的种系中就以下来说是杂合的或纯合的:(a)重排vκ/jκ序列在内源性小鼠κ免疫球蛋白轻链可变区基因座处的插入,所述重排vκ/jκ序列包含:(i)单一人种系vκ序列,所述单一人种系vκ序列存在于seqidno:148或seqidno:149中;和(ii)单一人种系jκ序列,其中所述重排vκ/jκ序列可操作地连接至内源性小鼠κ恒定区;和(b)多个人免疫球蛋白重链可变区基因区段在内源性小鼠免疫球蛋白重链可变区基因座处的插入,其中所述人免疫球蛋白重链可变区基因区段可操作地连接至内源性小鼠免疫球蛋白重链恒定区,并且所述人免疫球蛋白重链可变区基因区段能够重排并形成重排人/小鼠嵌合免疫球蛋白重链基因。在一些所述方法中,小鼠包含对免疫球蛋白重链基因座的修饰,其中所述修饰使内源性adam6功能降低或消除,其中小鼠包含编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性,并且其中编码所述小鼠adam6蛋白、其直系同源物、其同源物或其片段的所述异位核酸序列存在于人重链可变区基因座处。在一些所述方法中,非人动物是至少部分地源于balb/c品系的小鼠,并且所述小鼠包含人源化免疫球蛋白基因座,其中目标外来抗原是与自身抗原直系同源的人蛋白质的全部或一部分,其中第一引导rna识别序列包含编码自身抗原的基因的起始密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内,并且第二引导rna识别序列包含编码自身抗原的基因的终止密码子,或在终止密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内,并且其中修饰包括编码自身抗原的基因的全部或一部分的双等位基因缺失,由此自身抗原的表达被消除。在一些所述方法中,非人动物是至少部分地源于balb/c品系的小鼠,并且所述小鼠包含人源化免疫球蛋白基因座,其中目标外来抗原是与自身抗原直系同源的人蛋白质的全部或一部分,其中第一引导rna识别序列包含编码自身抗原的基因的起始密码子,并且第二引导rna识别序列包含编码自身抗原的基因的终止密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内,并且其中修饰包括对编码自身抗原的基因的起始密码子的双等位基因破坏,由此自身抗原的表达被消除。任选地,小鼠包含:(a)编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性;(b)杂合重链基因座,其包含人免疫球蛋白重链v、d和j基因区段的插入,其中所述人重链免疫球蛋白v、d和j基因区段可操作地连接至小鼠免疫球蛋白重链基因,其中所述小鼠免疫球蛋白重链基因在内源性小鼠免疫球蛋白基因座处;和(c)杂合轻链基因座,其包含人免疫球蛋白轻链v和j基因区段的插入,其中所述人v和j基因区段可操作地连接至小鼠免疫球蛋白轻链恒定区基因序列;其中(b)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合重链序列,以及(c)重排以形成包含可操作地连接至小鼠恒定区的人可变区的杂合轻链序列,并且其中小鼠不能形成包含人可变区和人恒定区的抗体。任选地,小鼠在它的种系中就以下来说是杂合的或纯合的:(a)编码小鼠adam6蛋白、其直系同源物、其同源物或其片段的异位核酸序列,其中所述adam6蛋白、其直系同源物、其同源物或其片段在雄性小鼠中具有功能性;(b)重排vκ/jκ序列在内源性小鼠κ免疫球蛋白轻链可变区基因座处的插入,所述重排vκ/jκ序列包含:(i)单一人种系vκ序列,所述单一人种系vκ序列存在于seqidno:148或seqidno:149中;和(ii)单一人种系jκ序列,其中所述重排vκ/jκ序列可操作地连接至内源性小鼠κ恒定区;和(c)多个人免疫球蛋白重链可变区基因区段在内源性小鼠免疫球蛋白重链可变区基因座处的插入,其中所述人免疫球蛋白重链可变区基因区段可操作地连接至内源性小鼠免疫球蛋白重链恒定区,并且所述人免疫球蛋白重链可变区基因区段能够重排并形成重排人/小鼠嵌合免疫球蛋白重链基因。在一些所述方法中,非人动物多能细胞是杂交细胞,或非人哺乳动物单细胞期胚胎是杂交单细胞期胚胎,并且其中方法进一步包括:(a’)比较一对相应第一染色体和第二染色体在靶基因组基因座内的序列,以及在接触步骤(a)之前基于以下来选择靶基因组基因座内的靶区域:在所述一对相应第一染色体与第二染色体之间,相对于靶基因组基因座的其余部分的全部或一部分,所述靶区域具有更高序列同一性百分比,其中所述靶区域包含:第一引导rna识别序列和在第一引导rna识别序列的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb或10kb的侧接序列,和/或第二引导rna识别序列和在第二引导rna识别序列的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb或10kb的侧接序列。任选地,在一对相应第一染色体与第二染色体之间,相对于靶基因组基因座的其余部分,靶区域具有更高序列同一性百分比。任选地,在一对相应第一染色体与第二染色体之间,靶区域具有至少99.9%序列同一性,并且在一对相应第一染色体与第二染色体之间,靶基因组基因座的其余部分具有不超过99.8%序列同一性。在另一方面,提供制备对目标外来抗原的耐受性降低的经遗传修饰的非人动物的方法,其包括:(a)向非人动物单细胞期胚胎或不是单细胞期胚胎的非人动物多能细胞中引入:(i)cas9蛋白;(ii)杂交至靶基因组基因座内的第一引导rna识别序列的第一引导rna,其中所述靶基因组基因座包含编码与所述目标外来抗原同源或共有目标表位的自身抗原的基因的全部或一部分;和(iii)杂交至所述靶基因组基因座内的第二引导rna识别序列的第二引导rna;其中一对相应第一染色体和第二染色体中的所述靶基因组基因座被修饰以产生具有双等位基因修饰的经修饰非人动物单细胞期胚胎或经修饰非人动物多能细胞,其中所述自身抗原的表达被消除;和(b)从所述经修饰非人动物单细胞期胚胎或所述经修饰非人动物多能细胞产生经遗传修饰的f0代非人动物,其中所述经遗传修饰的f0代非人动物中所述一对相应第一染色体和第二染色体中的所述靶基因组基因座被修饰以使所述自身抗原的表达被消除。所述方法可包括例如产生针对目标外来抗原的抗原结合蛋白的方法的任何以上公开的变化。举例来说,在一些所述方法中,步骤(a)中的细胞是非人动物多能干细胞,并且在步骤(b)中产生经遗传修饰的f0代非人动物包括:(i)将经修饰非人动物多能细胞引入宿主胚胎中;和(ii)将所述宿主胚胎植入代孕母体中以产生经遗传修饰的f0代非人动物,其中一对相应第一染色体和第二染色体中的靶基因组基因座被修饰以使自身抗原的表达被消除。任选地,多能细胞是胚胎干(es)细胞。在一些所述方法中,步骤(a)中的细胞是非人动物单细胞期胚胎,并且在步骤(b)中产生经遗传修饰的f0代非人动物包括将经修饰非人动物单细胞期胚胎植入代孕母体中以产生经遗传修饰的f0代非人动物,其中一对相应第一染色体和第二染色体中的靶基因组基因座被修饰以使自身抗原的表达被消除。在一些所述方法中,目标外来抗原是自身抗原的直系同源物。在一些所述方法中,第一引导rna识别序列包含编码自身抗原的基因的起始密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内,并且第二引导rna识别序列包含编码自身抗原的基因的终止密码子,或在终止密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。在一些所述方法中,第一引导rna识别序列和第二引导rna识别序列不同,并且第一引导rna识别序列和第二引导rna识别序列中的每一个包含编码自身抗原的基因的起始密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。在一些所述方法中,在靶基因组基因座中,第一引导rna识别序列在第二引导rna识别序列的5’,并且步骤(a)(i)进一步包括进行保留测定以确定在第一引导rna识别序列的5’以及约1kb内的区域和/或在第二引导rna识别序列的3’以及约1kb内的区域的拷贝数是2。在一些所述方法中,修饰包括编码自身抗原的基因的全部或一部分的双等位基因缺失。在一些所述方法中,修饰包括对编码自身抗原的基因的起始密码子的双等位基因破坏。在一些所述方法中,非人动物是小鼠。附图说明图1显示用以破坏小鼠(vi-3;在igh与igκ两者处均是纯合性人源化的)中的免疫耐受性的传统方法。在传统方法中,在f1h4胚胎干(es)细胞中产生编码与目标外来靶抗原同源的自身抗原的基因的杂合性敲除(无效)等位基因。从设计靶向载体至产生就敲除来说是杂合的f0小鼠的时间是约5个月。接着使vi-3小鼠与在编码与目标外来靶抗原同源的自身抗原的内源性基因处携带杂合性敲除突变的f0小鼠交配。为产生适于免疫的三重纯合性小鼠(目标靶标的纯合性无效和在igh与igκ两者处的纯合性人源化),需要再进行两代交配。从设计靶向载体至产生三重纯合性小鼠的整个过程花费约15至16个月。图2显示用于破坏(vi-3)小鼠中或通用轻链(ulc或共同轻链)小鼠中的免疫耐受性的加速方法。在这个方法中,靶向源于vi-3或ulc小鼠的es细胞以产生编码与目标外来靶抗原同源的自身抗原的内源性基因的杂合性无效等位基因。依序靶向步骤为获得纯合性无效vi-3或ulces细胞克隆所需。图3显示用于破坏(vi-3)小鼠中或通用轻链(或共同轻链)(ulc)小鼠中的耐受性的另一加速方法。在这个方法中,用crispr/cas9和成对引导rna靶向vi-3或ulces细胞以在单一步骤中产生编码与目标外来靶抗原同源的自身抗原的内源性基因的纯合性垮塌。筛选可包括例如等位基因丧失测定与保留测定两者。图4显示使用大型靶向载体(ltvec)和成对上游和下游引导rna(gu和gd)来同时使编码与目标外来靶抗原同源的自身抗原的小鼠基因缺失和用新霉素选择标记进行替换的一般性示意图。由两个引导rna引导的cas9裂解位点的位置由箭号指示在小鼠基因序列以下。测定探针由水平线指示,包括保留测定探针以及上游、中间和下游等位基因丧失(loa)测定探针。图的底部部分指示预期的靶向等位基因类型。图5显示使用大型靶向载体(ltvec)和各自靶向小鼠atg起始密码子的三个重叠引导rna来同时使编码与目标外来靶抗原同源的自身抗原的小鼠基因缺失和用flox化新霉素选择标记和lacz进行替换的一般性示意图。引导rna由水平箭号指示,并且测定探针由经包围水平线指示。图的底部部分指示预期的靶向等位基因类型。图6显示野生型通用轻链(ulc1-39)小鼠中以及就编码与靶标8直系同源的自身抗原(自身抗原8)的内源性基因来说是纯合性无效的ulc1-39小鼠中针对人靶抗原(靶标8)的抗体效价数据。图7显示被进行来产生杂交vgf1(f1h4)es细胞(c57bl6(xb6)/129s6(y129))的交配。图8显示使用ltvec以及一个或两个5’区域grna、中间区域grna和3’区域grna来同时使小鼠基因或小鼠基因的一部分缺失和用相应人形式进行替换的示意图。ltvec显示于图的顶部部分中,并且小鼠基因座显示于图的底部部分中。由八个引导rna引导的cas9裂解位点的位置由竖直箭号指示在小鼠基因序列以下。图9a显示使用ltvec和两个引导rna(引导rnaa和b)来同时使小鼠基因缺失和用相应人形式进行替换的一般性示意图。ltvec显示于图9a的顶部部分中,并且小鼠基因座显示于图9a的底部部分中。由两个引导rna引导的cas9裂解位点的位置由箭号指示在小鼠基因序列以下。图9b-图9e显示当使用两个引导rna时在更大频率下发生的独特双等位基因修饰(等位基因类型)。具有斜影线的粗线指示小鼠基因,虚线指示小鼠基因中的缺失,并且粗黑线指示人基因的插入。图9b显示纯合性垮塌等位基因(大型crispr诱导缺失)。图9c显示纯合性靶向等位基因。图9d显示半合性靶向等位基因。图9e显示复合杂合性等位基因。图10a和图10b显示确认所选克隆的基因型的pcr测定。图10a显示来自使用引物m-lr-f和m-5’-r针对所选es细胞克隆进行的长程pcr测定的结果,所述测定确定人插入物与在与5’同源臂同源的那些序列的外部的序列之间的关联,由此证明正确靶向。图10b显示来自5’delj、5’insj、dela+f和dela+e2pcr测定的结果。5’delj描绘使用m-5’-f和m-5-r引物获得的pcr产物,所述测定扩增围绕grnaa裂解位点的野生型序列以确定这个序列的保留或丧失。5’insj描绘使用m-5’-f和h-5’-r引物获得的pcr产物,所述测定确定人插入物与小鼠基因组之间的关联。测定将在靶向克隆与随机整合克隆两者的情况下给出阳性结果。dela+f描绘关于克隆bo-f10和aw-a8中由双重grnaa和f裂解介导的大型缺失的预期扩增子大小(359bp)和实际条带。dela+e2描绘用于克隆ba-a7的相同理念。nt指示无模板,+/+指示亲本vgf1杂交es细胞野生型对照,h/+指示杂合性人源化基因型,h/δ指示半合性人源化基因型,h/h指示纯合性人源化基因型,并且δ/δ指示纯合性缺失基因型。图11a-图11c显示对用lrp5人源化ltvec与cas9和两个grna组合靶向的小鼠es细胞克隆aw-d9(图11a)和ba-d5(图11c)以及用单独ltvec靶向的克隆bs-c4(图11b)的荧光原位杂交(fish)分析。箭号指示染色体19的条带b上的杂交信号的位置。红色信号指示仅与小鼠探针杂交(虚线箭号,图11b)。黄色混合颜色信号指示与红色小鼠探针和绿色人探针两者杂交。对于bs-c4克隆,一个染色体19条带b具有红色信号(虚线箭号)以及另一染色体19条带b具有黄色信号(实线箭号)确认靶向正确基因座以及杂合性基因型(图11b)。对于aw-d9和bs-c4克隆,两个染色体19的b条带均具有黄色信号(实线箭号,图11a和图11c)确认靶向正确基因座以及纯合性基因型。图12显示在vgf1杂交es细胞的情况下,染色体19连同被设计以通过分析杂合性丧失(loh)来考查由两个引导rna介导的基因转换或有丝分裂重组事件的测定一起的示意图。qpcr染色体拷贝数(ccn)探针的近似位置由箭号显示。结构变体(sv)多态性pcr探针的近似位置由v形符连同上方给出的它们离lrp5基因座的距离(以mb计)一起加以显示。单核苷酸变体(snv)等位基因辨别探针的近似位置由箭头连同下方给出的它们离lrp5基因座的距离(以mb计)一起加以显示。f、e2、d、b2和a的grna识别序列的位置由在lrp5基因图示的上方的斜箭号显示。图13a和图13b显示对用hc人源化ltvec与cas9和两个grna组合靶向的小鼠es细胞克隆q-e9(图13a)和o-e3(图13b)的荧光原位杂交(fish)分析。箭号指示染色体2的条带b上的杂交信号的位置。红色信号指示仅与小鼠探针杂交(虚线箭号,图13a)。黄色混合颜色信号指示与红色小鼠探针和绿色人探针两者杂交(实线箭号)。对于q-e9克隆,一个染色体2条带b具有红色信号(虚线箭号)以及另一染色体2条带b具有黄色信号(实线箭号)确认靶向正确基因座以及杂合性基因型(图13a)。对于o-e3克隆,两个染色体2的b条带均具有黄色信号(实线箭号,图13b)确认靶向正确基因座图以及纯合性基因型。图14显示在vgf1杂交es细胞的情况下,含有小鼠c5基因的染色体连同被设计以通过分析杂合性丧失(loh)来考查由两个引导rna介导的基因转换或有丝分裂重组事件的测定一起的示意图。结构变体(sv)多态性pcr探针的近似位置由水平箭号连同上方给出的它们离c5基因座的距离(以mb计)一起加以显示。e2和a的grna识别序列的位置由在c5基因座图示的上方的斜箭号显示。图15a-图15e显示克隆br-b4、bp-g7、bo-g11、bo-f10、b0-a8和bc-h9的结构变化(sv)测定的结果,其中vgf1(f1h4)、129和b6dna用作对照。在lrp5基因座的端粒方向在以下距离下进行测定:13.7mb(图15a)、20.0mb(图15b)、36.9mb(图15c)、48.3mb(图15d)和56.7mb(图15e)。b6和129等位基因的pcr产物的位置由箭号显示。图16a-图16c显示在lrp5的着丝粒方向0.32mb(图16a)、在lrp5的端粒方向1.2mb(图16b)以及在lrp5的端粒方向57.2mb(图16c)的等位基因辨别图。各轴上的值代表相对荧光强度。各图描绘各样品的四个重复测定,其显示为实心点(b6等位基因)、空心点(129等位基因)和具有斜线的点(b6等位基因/129等位基因两者)。图17a-图17c是显示在细胞周期的g2期期间可产生纯合性事件的有丝分裂重组和通过杂合性丧失检测的广泛分布的基因转换的可能机理的示意图。图17a显示就129同源物上的靶向人源化来说是杂合的杂交129/b6es细胞中的显示两个染色单体的经复制同源染色体。双头箭号指示由双重grna引导的cas9裂解产生的潜在双链断裂,所述裂解促进通过同源染色体上的染色单体之间的同源性重组达成的相互交换,在所靶向等位基因的着丝粒侧上显示为交叉,从而产生图17b中所示的杂交染色单体。图17c显示在有丝分裂和细胞分裂之后,有可能有四种类型的染色体分离进入子细胞中。保留杂合性的两种,即亲本型杂合子(hum/+,左上)和通过均等交换获得的杂合子(hum/+,右上)不能通过loh测定来区分。其他两种显示杂合性丧失,即丧失端粒方向b6等位基因的人源化纯合子(hum/hum,例如克隆bo-a8,左下)和丧失端粒方向129等位基因的野生型纯合子(+/+,右下)。这个后述类型将丧失,因为它未保留人源化等位基因的药物抗性盒。图18a-图18f显示解释在f1杂交小鼠es细胞的情况下在crispr/cas9辅助的人源化实验中观察到的包括杂合性丧失(loh)的结果的可能机理,所述细胞具有一个源于129s6/svevtac小鼠品系的单倍体染色体组和一个源于c57bl/6ntac(b6)小鼠品系的单倍体染色体组。图18a显示由有丝分裂交叉达成的相互染色单体交换,其中杂合性修饰在基因组复制之前或在基因组复制之后继之以姐妹染色单体之间的基因转换而发生在129染色体上。图18b显示由有丝分裂交叉达成的相互染色单体交换,其中单一129染色单体在基因组复制之后被修饰。图18c显示由有丝分裂交叉达成的相互染色单体交换,其中尚未发生ltvec靶向,但cas9裂解已发生在129或b6染色体上(显示的是b6裂解)。图18d显示由断裂诱导的复制达成的染色单体拷贝,其中杂合性修饰在基因组复制之前或在基因组复制之后继之以姐妹染色单体之间的基因转换而发生在129染色体上。图18e显示由断裂诱导的复制达成的染色单体拷贝,其中单一129染色单体在基因组复制之后被修饰。图18f显示由断裂诱导的复制达成的染色单体拷贝,其中尚未发生ltvec靶向,但cas9裂解已发生在129或b6染色体上(显示的是b6裂解)。图19显示在vgf1杂交es细胞中,使用ltvec和一个或多个grna加以靶向以达成缺失和用相应人lrp5基因座进行替换的小鼠lrp5基因座的示意图。在竖直虚线内部的区域是靶向区域(在ltvec的5’靶标序列和3’靶标序列内部的区域)。用于确定单核苷酸变化的参照序列是来自jacksonlaboratory的c57bl/6j小鼠品系的基因组序列。将这个参照序列与来自taconicbiosciences的129s6/svev品系、来自taconicbiosciences的c57bl/6n品系、以及由129s6/svev品系和c57bl/6n品系产生的vgf1杂交细胞系(表示在图的底部部分中的三行中)进行比较。三行中的各者中的竖直线代表相较于参照序列的单核苷酸变化。图20显示在vgf1杂交es细胞中,使用ltvec和一个或多个grna加以靶向以达成缺失和用相应人形式进行替换的小鼠hc基因座的示意图。在竖直虚线内部的区域是靶向区域(在ltvec的5’靶标序列和3’靶标序列内部的区域)。用于确定单核苷酸变化的参照序列是来自jacksonlaboratory的c57bl/6j小鼠品系的基因组序列。将这个参照序列与来自taconicbiosciences的129s6/svev品系、来自taconicbiosciences的c57bl/6n品系、以及由129s6/svev品系和c57bl/6n品系产生的vgf1杂交细胞系(表示在图的底部部分中的三行中)进行比较。三行中的各者中的竖直线代表相较于参照序列的单核苷酸变化。图21显示在vgf1杂交es细胞中,使用ltvec和一个或多个grna加以靶向以达成缺失和用相应人形式进行替换的小鼠trpa1基因座的示意图。在竖直虚线内部的区域是靶向区域(在ltvec的5’靶标序列和3’靶标序列内部的区域)。用于确定单核苷酸变化的参照序列是来自jacksonlaboratory的c57bl/6j小鼠品系的基因组序列。将这个参照序列与来自taconicbiosciences的129s6/svev品系、来自taconicbiosciences的c57bl/6n品系、以及由129s6/svev品系和c57bl/6n品系产生的vgf1杂交细胞系(表示在图的底部部分中的三行中)进行比较。三行中的各者中的竖直线代表相较于参照序列的单核苷酸变化。图22显示在vgf1杂交es细胞中,使用ltvec和一个或多个grna加以靶向以达成缺失和用相应人形式进行替换的小鼠adamts5基因座的示意图。在竖直虚线内部的区域是靶向区域(在ltvec的5’靶标序列和3’靶标序列内部的区域)。用于确定单核苷酸变化的参照序列是来自jacksonlaboratory的c57bl/6j小鼠品系的基因组序列。将这个参照序列与来自taconicbiosciences的129s6/svev品系、来自taconicbiosciences的c57bl/6n品系、以及由129s6/svev品系和c57bl/6n品系产生的vgf1杂交细胞系(表示在图的底部部分中的三行中)进行比较。三行中的各者中的竖直线代表相较于参照序列的单核苷酸变化。图23显示在vgf1杂交es细胞中,使用ltvec和一个或多个grna加以靶向以达成缺失和用相应人形式进行替换的小鼠folh1基因座的示意图。在竖直虚线内部的区域是靶向区域(在ltvec的5’靶标序列和3’靶标序列内部的区域)。用于确定单核苷酸变化的参照序列是来自jacksonlaboratory的c57bl/6j小鼠品系的基因组序列。将这个参照序列与来自taconicbiosciences的129s6/svev品系、来自taconicbiosciences的c57bl/6n品系、以及由129s6/svev品系和c57bl/6n品系产生的vgf1杂交细胞系(表示在图的底部部分中的三行中)进行比较。三行中的各者中的竖直线代表相较于参照序列的单核苷酸变化。图24显示在vgf1杂交es细胞中,使用ltvec和一个或多个grna加以靶向以达成缺失和用相应人形式进行替换的小鼠dpp4基因座的示意图。在竖直虚线内部的区域是靶向区域(在ltvec的5’靶标序列和3’靶标序列内部的区域)。用于确定单核苷酸变化的参照序列是来自jacksonlaboratory的c57bl/6j小鼠品系的基因组序列。将这个参照序列与来自taconicbiosciences的129s6/svev品系、来自taconicbiosciences的c57bl/6n品系、以及由129s6/svev品系和c57bl/6n品系产生的vgf1杂交细胞系(表示在图的底部部分中的三行中)进行比较。三行中的各者中的竖直线代表相较于参照序列的单核苷酸变化。图25显示在vgf1杂交es细胞中,使用ltvec和一个或多个grna加以靶向以达成缺失和用相应人形式进行替换的小鼠ror1基因座的示意图。在竖直虚线内部的区域是靶向区域(在ltvec的5’靶标序列和3’靶标序列内部的区域)。用于确定单核苷酸变化的参照序列是来自jacksonlaboratory的c57bl/6j小鼠品系的基因组序列。将这个参照序列与来自taconicbiosciences的129s6/svev品系、来自taconicbiosciences的c57bl/6n品系、以及由129s6/svev品系和c57bl/6n品系产生的vgf1杂交细胞系(表示在图的底部部分中的三行中)进行比较。三行中的各者中的竖直线代表相较于参照序列的单核苷酸变化。图26显示包括编码跨膜蛋白的基因的小鼠基因座的示意图;在vgf1杂交es细胞中,所述小鼠基因座使用ltvec和一个或多个grna加以靶向以达成缺失和用相应人形式进行替换。矩形代表靶标基因组区域内的不同基因。在竖直虚线内部的区域是靶向区域(在ltvec的5’靶标序列和3’靶标序列内部的区域)。用于确定单核苷酸变化的参照序列是来自jacksonlaboratory的c57bl/6j小鼠品系的基因组序列。将这个参照序列与来自taconicbiosciences的129s6/svev品系mp变体、来自taconicbiosciences的c57bl/6n品系rgc变体、以及由129s6/svev品系和c57bl/6n品系产生的vgf1杂交细胞系(表示在图的底部部分中的三行中)进行比较。mp变体和rgc变体是来自相同品系的不同小鼠。三行中的各者中的竖直线代表相较于参照序列的单核苷酸变化。图27a-图27c是显示在细胞周期的g2期期间可产生纯合性事件的有丝分裂重组和通过局部杂合性丧失检测的基因转换的可能机理的示意图。图27a显示就129同源物上的靶向人源化来说是杂合的杂交129/b6es细胞中的显示两个染色单体的经复制同源染色体。129同源物上的杂合性修饰在基因组复制之前发生,或单一129染色单体在基因组复制之后被修饰,继之以染色单体间基因转换。双头箭号指示由双重grna引导的cas9裂解产生的潜在双链断裂,所述裂解促进双重链侵入和合成引导的修复,由斜虚线箭号加以显示,从而产生通过拷贝一个经修饰染色单体的一小部分的基因转换事件产生的杂交染色单体,如图27b中所示。图27c显示在有丝分裂和细胞分裂之后,有可能有两种类型的染色体分离进入子细胞中:一种保留杂合性(不具有杂合性丧失的亲本型杂合子(hum/+,上部)),以及一种具有围绕靶向修饰的局部杂合性丧失(hum/hum,底部,保留129等位基因)。图28显示单独或与大型靶向载体组合使用靶向编码自身抗原的基因的起始密码子和终止密码子区域的成对引导rna,在vi-3和ulc1-39胚胎干(es)细胞中对于具有不同大小的不同自身抗原靶标进行crispr/cas9介导的缺失的效率。图29显示在使用靶向编码自身抗原的基因的起始密码子和终止密码子区域的成对引导rna,用靶向用于缺失的具有不同大小的不同自身抗原靶标的crispr/cas9靶向vi-3和ulc1-39单细胞期胚胎之后产生的具有垮塌等位基因的小鼠幼仔的百分比。图30a和图30b显示在用靶标9全长dna免疫之后,在亲本vi-3t3细胞和被工程化来表达靶标9的vi-3t3细胞情况下,野生型vi-3-adam6小鼠中(图30b)以及就编码与靶标9直系同源的自身抗原(自身抗原9)的内源性基因来说是纯合性无效的vi3-adam6小鼠中(图30a)针对人靶抗原(靶标9)的抗体效价数据。图31a和图31b显示针对人靶抗原(靶标4)以及针对相应直系同源小鼠自身抗原(自身抗原4)的抗体效价数据。图31a显示就编码自身抗原4的内源性基因来说是纯合性无效的vi3-adam6小鼠中针对人靶标4和小鼠自身抗原4的抗体效价数据。图31b显示就编码自身抗原4的内源性基因来说是纯合性无效的ulc1-39小鼠中针对人靶标4和小鼠自身抗原4的组合的抗体效价数据。图32显示vi3-adam6小鼠和ulc1-39小鼠中的免疫球蛋白重链基因座(顶部)和免疫球蛋白轻链基因座(底部)的示意图,所述小鼠各自具有50%balb/ctac、25%c57bl/6ntac和25%129s6/svevtac的遗传背景。在vi3-adam6小鼠中,内源性小鼠免疫球蛋白重链和轻链可变区用相应人dna以及重新插入的小鼠adam6基因(由梯形表示的adam6b和adam6a)替换。在通用轻链(ulc1-39)小鼠中,内源性小鼠免疫球蛋白重链可变区用相应人dna以及重新插入的小鼠adam6基因替换,并且免疫球蛋白轻链可变区包含可操作地连接至hvκ3-15启动子的单一重排人免疫球蛋白轻链核苷酸序列(vκ1-39/jκ5)。人区段以黑色描绘,并且小鼠区段由斜线指示。定义在本文中可互换使用的术语“蛋白质”、“多肽”和“肽”包括任何长度的聚合氨基酸形式,包括编码和非编码氨基酸以及化学或生物化学修饰或衍生的氨基酸。所述术语也包括已被修饰的聚合物,诸如具有经修饰肽骨架的多肽。蛋白质被称为具有“n末端”和“c末端”。术语“n末端”涉及蛋白质或多肽的起始部分,由具有游离胺基团(-nh2)的氨基酸封端。术语“c末端”涉及氨基酸链(蛋白质或多肽)的终止部分,由游离羧基(-cooh)封端。在本文中可互换使用的术语“核酸”和“多核苷酸”包括任何长度的聚合核苷酸形式,包括核糖核苷酸、脱氧核糖核苷酸或其类似物或经修饰形式。它们包括单链、双链和多链dna或rna、基因组dna、cdna、dna-rna杂合物、以及包含嘌呤碱基、嘧啶碱基或其他天然核苷酸碱基、化学修饰的核苷酸碱基、生物化学修饰的核苷酸碱基、非天然核苷酸碱基或衍生的核苷酸碱基的聚合物。核酸被称为具有“5'末端”和“3'末端”,因为单核苷酸以使得一个单核苷酸戊糖环的5'磷酸在一个方向上通过磷酸二酯键连接至它的相邻单核苷酸戊糖环的3'氧的方式反应以产生寡核苷酸。如果寡核苷酸的末端的5'磷酸未连接至单核苷酸戊糖环的3'氧,那么所述末端被称为“5'末端”。如果寡核苷酸的末端的3'氧未连接至另一单核苷酸戊糖环的5'磷酸,那么所述末端被称为“3'末端”。即使在较大寡核苷酸的内部,核酸序列也可被称为具有5'末端和3'末端。在线性或环状dna分子中,离散元件被称为在“下游”或3'元件的“上游”或5'。术语“野生型”包括具有如在正常(与突变、患病、改变等相对比)状态或情形下所见的结构和/或活性的实体。野生型基因和多肽常常以多种不同形式(例如等位基因)存在。关于蛋白质和核酸的术语“经分离”包括蛋白质和核酸关于可通常原位存在的其他细菌、病毒或细胞组分是相对纯化的,直至并包括蛋白质和多核苷酸的大致上纯净制剂。术语“经分离”也包括蛋白质和核酸不具有天然存在的对应物,已被化学合成,因此大致上未由其他蛋白质或核酸污染,或已与它们天然地与其相伴的大多数其他细胞组分(例如其他细胞蛋白质、多核苷酸或细胞组分)分离或从所述大多数其他细胞组分纯化。“外源性”分子或序列包括通常不以那个形式存在于细胞中的分子或序列。通常存在包括关于细胞的特定发育阶段和环境条件而存在。外源性分子或序列例如可包括细胞内的相应内源性序列的突变形式,诸如内源性序列的人源化形式,或可包括对应于细胞内的内源性序列,但呈不同形式(即不在染色体内)的序列。相比之下,内源性分子或序列包括通常以那个形式在特定发育阶段在特定环境条件下存在于特定细胞中的分子或序列。“密码子优化”通常包括通过用更频繁或最频繁用于宿主细胞的基因中的密码子替换天然序列的至少一个密码子,同时维持天然氨基酸序列来修饰核酸序列以达成在特定宿主细胞中的表达增强的过程。举例来说,编码cas9蛋白的多核苷酸可被修饰以用相较于天然存在的核酸序列,在给定原核或真核细胞(包括细菌细胞、酵母细胞、人细胞、非人细胞、哺乳动物细胞、啮齿动物细胞、小鼠细胞、大鼠细胞、仓鼠细胞或任何其他宿主细胞)中具有更高使用频率的密码子进行替代。密码子使用表例如可易于在“密码子使用数据库(codonusagedatabase)”处获得。这些表可以许多方式改适。参见nakamura等(2000)nucleicacidsresearch28:292,其出于所有目的以引用的方式整体并入本文。用于针对在特定宿主中的表达对特定序列进行密码子优化的计算机算法也是可用的(参见例如geneforge)。术语“基因座”是指基因(或有意义序列)、dna序列、多肽编码序列或位置在生物体的基因组的染色体上的特定位置。举例来说,“lrp5基因座”可指lrp5基因、lrp5dna序列、lrp5编码序列或lrp5位置在生物体的基因组的已被鉴定为这种序列驻留所处的染色体上的特定位置。“lrp5基因座”可包含lrp5基因的调控元件,包括例如增强子、启动子、5’utr和/或3’utr或其组合。术语“基因”是指染色体中的dna序列,其编码产物(例如rna产物和/或多肽产物),并且包括被非编码内含子中断的编码区和在5’末端与3’末端两者上邻近于编码区定位的序列,以致基因对应于全长mrna(包括5’非翻译序列和3’非翻译序列)。术语“基因”也包括其他非编码序列,包括调控序列(例如启动子、增强子和转录因子结合位点)、多腺苷酸化信号、内部核糖体进入位点、沉默子、绝缘序列和基质附着区。这些序列可接近于基因的编码区(例如在10kb内),或在远端位点处,并且它们影响基因的转录和翻译的水平或速率。术语“等位基因”是指基因的变异形式。一些基因具有多种不同形式,其位于染色体上的相同位置或遗传基因座处。二倍体生物体具有两个在各遗传基因座处的等位基因。各对等位基因代表特定遗传基因座的基因型。如果在特定基因座处存在两个相同等位基因,那么基因型被描述为纯合,而如果两个等位基因不同,那么基因型被描述为杂合。“启动子”是通常包含tata框的dna调控区,所述tata框能够指导rna聚合酶ii以使rna合成在特定多核苷酸序列的适当转录起始位点处起始。启动子可另外包含影响转录起始速率的其他区域。本文公开的启动子序列调节可操作地连接的多核苷酸的转录。启动子可在一个或多个本文公开的细胞类型(例如真核细胞、非人哺乳动物细胞、人细胞、啮齿动物细胞、多能细胞、单细胞期胚胎、分化细胞或其组合)中具有活性。启动子可为例如组成型活性启动子、条件型启动子、诱导型启动子、时间限制启动子(例如发育调控的启动子)、或空间限制启动子(例如细胞特异性或组织特异性启动子)。启动子的实例可例如见于以引用的方式整体并入本文的wo2013/176772中。诱导型启动子的实例包括例如化学调控的启动子和物理调控的启动子。化学调控的启动子包括例如醇调控的启动子(例如醇脱氢酶(alca)基因启动子)、四环素调控的启动子(例如四环素应答型启动子、四环素操纵子序列(teto)、tet-on启动子或tet-off启动子)、类固醇调控的启动子(例如大鼠糖皮质素受体的启动子、雌激素受体的启动子、或蜕皮激素(ecdysone)受体的启动子)、或金属调控的启动子(例如金属蛋白(metalloprotein)启动子)。物理调控的启动子包括例如温度调控的启动子(例如热激启动子)和光调控的启动子(例如光诱导型启动子或光阻遏型启动子)。组织特异性启动子可为例如神经元特异性启动子、神经胶质特异性启动子、肌肉细胞特异性启动子、心脏细胞特异性启动子、肾细胞特异性启动子、骨细胞特异性启动子、内皮细胞特异性启动子或免疫细胞特异性启动子(例如b细胞启动子或t细胞启动子)。发育调控的启动子包括例如仅在胚胎发育阶段期间或仅在成人细胞中具有活性的启动子。“可操作连接”或处于“可操作地连接”包括两个或更多个组分(例如启动子和另一序列元件)毗邻以使两个组分均正常起作用,并且使得有可能至少一个组分可介导对至少一个其他组分施加的作用。举例来说,如果启动子应答于存在或不存在一个或多个转录调控因子来控制编码序列的转录水平,那么所述启动子可为可操作地连接至所述编码序列。可操作连接可包括所述序列彼此邻接,或以反式起作用(例如调控序列可在某一距离下起控制编码序列的转录的作用)。作为另一实例,可使免疫球蛋白可变区(或v(d)j区段)的核酸序列可操作地连接至免疫球蛋白恒定区的核酸序列以便允许在序列之间适当重组以得到免疫球蛋白重链或轻链序列。核酸的“互补性”意指一个核酸链中的核苷酸序列由于它的核苷碱基基团的定向而与相对核酸链上的另一序列形成氢键。dna中的互补碱基通常是a与t以及c与g。在rna中,它们通常是c与g以及u与a。互补性可为完全的或大致上的/充分的。两个核酸之间的完全互补性意指两个核酸可形成双链体,其中所述双链体中的每个碱基都通过沃森-克里克(watson-crick)配对来键合于互补碱基。“大致上”或“充分”互补性意指一个链中的序列不全然和/或完全互补于相对链中的序列,但在一组杂交条件(例如盐浓度和温度)下在两个链上的碱基之间发生充分键合以形成稳定杂交复合物。所述条件可通过使用序列和用以预测杂交链的tm(熔解温度)的标准数学计算,或通过使用常规方法对tm进行经验确定来预测。tm包括在两个核酸链之间形成的一群杂交复合物被50%变性(即一群双链核酸分子变得有半数解离成单链)所处的温度。在低于tm的温度下,有利于形成杂交复合物,而在高于tm的温度下,有利于杂交复合物中各链的熔解或分离。可通过使用例如tm=81.5+0.41(%g+c)来估计具有已知g+c含量的核酸在1mnacl水溶液中的tm,但其他已知tm计算虑及核酸结构特征。“杂交条件”包括一个核酸链通过互补链相互作用和氢键合来键合于第二核酸链以产生杂交复合物所处的累积环境。所述条件包括含有核酸的水溶液或有机溶液的化学组分和它们的浓度(例如盐、螯合剂、甲酰胺)以及混合物的温度。其他因素诸如孵育时长或反应室尺寸可对环境有影响。参见例如sambrook等,molecularcloning,alaboratorymanual,第2版,第1.90-1.91、9.47-9.51、11.47-11.57页(coldspringharborlaboratorypress,coldspringharbor,n.y.,1989),其出于所有目的以引用的方式整体并入本文。杂交要求两个核酸含有互补性序列,但碱基之间的不匹配是可能的。适于两个核酸之间的杂交的条件取决于核酸的长度和互补程度、本领域中熟知的变量。两个核苷酸序列之间的互补程度越大,具有那些序列的核酸的杂交物的熔解温度(tm)的值越大。对于互补性链段较短(例如历经35个或更少、30个或更少、25个或更少、22个或更少、20个或更少、或18个或更少核苷酸具有互补性)的核酸之间的杂交,不匹配的位置变得重要(参见sambrook等,上文,11.7-11.8)。通常,可杂交核酸的长度是至少约10个核苷酸。可杂交核酸的说明性最小长度包括至少约15个核苷酸、至少约20个核苷酸、至少约22个核苷酸、至少约25个核苷酸和至少约30个核苷酸。此外,必要时可根据诸如互补区域的长度和互补程度的因素来调整温度和洗涤溶液盐浓度。多核苷酸的序列无需100%互补于它的将可特异性杂交的靶标核酸的序列。此外,多核苷酸可历经一个或多个区段进行杂交以使间插或邻近区段不涉及于杂交事件中(例如环结构或发夹结构)。多核苷酸(例如grna)可包含与靶标核酸序列内它们所靶向的靶标的至少70%、至少80%、至少90%、至少95%、至少99%、或100%序列互补性。举例来说,其中18/20核苷酸互补于靶标,并且将因此进行特异性杂交的grna将代表90%互补性。在这个实例中,其余非互补性核苷酸可群集或与互补性核苷酸交替分散,并且无需邻接于彼此或互补性核苷酸。核酸内特定核酸序列链段之间的互补性百分比可通过以下方式来常规确定:使用本领域中已知的blast程序(基本局部比对搜索工具)和powerblast程序(altschul等(1990)j.mol.biol.215:403-410;zhang和madden(1997)genomeres.7:649-656),或利用缺省设置,使用gap程序(威斯康星序列分析包(wisconsinsequenceanalysispackage),第8版,用于unix,geneticscomputergroup,universityresearchpark,madisonwis.),其使用smith和waterman的算法(adv.appl.math.,1981,2,482-489)。本文提供的方法和组合物采用多种不同组分。在整篇描述中都应认识到一些组分可具有活性变体和片段。所述组分包括例如cas9蛋白、crisprrna、tracrrna和引导rna。这些组分各自的生物活性在本文中其他地方描述。在两个多核苷酸或多肽序列的情形下的“序列同一性”或“同一性”涉及当历经指定比较窗进行比对以达成最大对应性时两个序列中相同的残基。当关于蛋白质使用序列同一性百分比时,应认识到不同一的残基位置常常差异在于保守性氨基酸取代,其中氨基酸残基被取代成具有类似化学性质(例如电荷或疏水性)的其他氨基酸残基,因此不改变分子的功能性质。当序列差异在于保守性取代时,序列同一性百分比可被调高以关于取代的保守性质加以修正。差异在于所述保守性取代的序列被称为具有“序列类似性”或“类似性”。用于进行这个调整的手段为本领域技术人员所熟知。通常,这涉及将保守性取代作为部分而非完全不匹配进行评分,由此使序列同一性百分比增加。因此,举例来说,当同一氨基酸被给与评分1,并且非保守性取代被给与评分0时,保守性取代被给与在0与1之间的评分。例如如程序pc/gene(intelligenetics,mountainview,california)中所执行来计算保守性取代评分。“序列同一性百分比”包括通过历经比较窗比较两个最优对准序列来确定的值,其中相较于参照序列(其不包含添加或缺失),比较窗中的多核苷酸序列的一部分可包含添加或缺失(即空位)以达成两个序列的最优比对。通过以下方式来计算百分比:确定同一核酸碱基或氨基酸残基存在于两个序列中所处的位置的数目以产生匹配位置的数目,用匹配位置的数目除以比较窗中的位置总数,以及用100乘以结果以产生序列同一性百分比。除非另外陈述,否则序列同一性/类似性值包括使用第10版gap利用以下参数获得的值:核苷酸序列的同一性%和类似性%,使用gap权重50和长度权重3以及nwsgapdna.cmp评分矩阵;氨基酸序列的同一性%和类似性%,使用gap权重8和长度权重2以及blosum62评分矩阵;或其任何等效程序。“等效程序”包括对于任何两个所论述的序列,当相较于由第10版gap产生的相应比对时,产生具有相同核苷酸或氨基酸残基匹配和相同序列同一性百分比的比对的任何序列比较程序。如本文用于涉及共有表位的术语“大致上同一性”包括在相应位置中含有同一残基的序列。举例来说,如果历经相关残基链段,两个序列的相应残基中的至少70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多是同一的,那么它们可被视为大致上同一。相关链段可为例如完整序列或可为至少5、10、15个或更多残基。术语“保守性氨基酸取代”是指用具有类似尺寸、电荷或极性的不同氨基酸取代通常存在于序列中的氨基酸。保守性取代的实例包括将非极性(疏水性)残基诸如异亮氨酸、缬氨酸或亮氨酸取代成另一非极性残基。同样,保守性取代的实例包括将一个极性(亲水性)残基取代成另一残基,诸如在精氨酸与赖氨酸之间,在谷氨酰胺与天冬酰胺之间,或在甘氨酸与丝氨酸之间。另外,将碱性残基诸如赖氨酸、精氨酸或组氨酸取代成另一残基,或将一个酸性残基诸如天冬氨酸或谷氨酸取代成另一酸性残基是保守性取代的额外实例。非保守性取代的实例包括将非极性(疏水性)氨基酸残基诸如异亮氨酸、缬氨酸、亮氨酸、丙氨酸或甲硫氨酸取代成极性(亲水性)残基诸如半胱氨酸、谷氨酰胺、谷氨酸或赖氨酸,和/或将极性残基取代成非极性残基。以下概述典型氨基酸分类。关于免疫球蛋白核酸序列的术语“种系”包括可传至子代的核酸序列。术语“抗原结合蛋白”包括结合抗原的任何蛋白质。抗原结合蛋白的实例包括抗体、抗体的抗原结合片段、多特异性抗体(例如双特异性抗体)、scfv、双scfv、微型双功能抗体、微型三功能抗体、微型四功能抗体、v-nar、vhh、vl、f(ab)、f(ab)2、dvd(双可变结构域抗原结合蛋白)、svd(单可变结构域抗原结合蛋白)、双特异性t细胞衔接物(bite)或davisbody(美国专利号8,586,713,其出于所有目的以引用的方式整体并入本文)。术语“抗原”是指是整个分子或分子内的结构域的物质,其能够引发产生与其具有结合特异性的抗体。术语抗原也包括在野生型宿主生物体中将借助于自身识别而不引发抗体产生,但可在进行适当遗传工程化以破坏免疫耐受性的宿主动物中引发这种应答的物质。术语“表位”是指抗原上由抗原结合蛋白(例如抗体)所结合的位点。表位可由连续氨基酸或通过一个或多个蛋白质的三级折叠而毗邻的非连续氨基酸形成。由连续氨基酸形成的表位(也称为线性表位)在暴露于变性溶剂时通常得以保留,而通过三级折叠形成的表位(也称为构象性表位)在用变性溶剂处理时通常丧失。表位通常包括至少3个,并且更通常至少5个或8-10个呈独特空间构象的氨基酸。确定表位的空间构象的方法包括例如x射线晶体照相术和2维核磁共振。参见例如epitopemappingprotocols,methodsinmolecularbiology,第66卷,glenne.morris编(1996),其出于所有目的以引用的方式整体并入本文。术语“自身”在与抗原或表位联合使用时描述抗原或表位将借助于包括在通常由宿主物种生物合成或宿主物种通常所暴露于的物质之中而不由宿主物种的野生型成员的b细胞受体识别或仅由其不良识别。所述物质诱导宿主免疫系统的耐受性。术语“外来”在与抗原或表位联合使用时描述抗原或表位不是自身抗原或自身表位。外来抗原是通常不由宿主物种产生的任何抗原。术语“抗体”包括免疫球蛋白分子,其包含四个多肽链,即通过二硫键相互连接的两个重(h)链和两个轻(l)链。各重链包含重链可变结构域和重链恒定区(ch)。重链恒定区包含三个结构域:ch1、ch2和ch3。各轻链包含轻链可变结构域和轻链恒定区(cl)。重链和轻链可变结构域可进一步再分成称为互补决定区(cdr)的高变区,其与称为框架区(fr)的更保守区域交替分散。各重链和轻链可变结构域包含三个cdr和四个fr,从氨基末端至羧基末端按以下顺序安置:fr1、cdr1、fr2、cdr2、fr3、cdr3、fr4(重链cdr可缩写为hcdr1、hcdr2和hcdr3;轻链cdr可缩写为lcdr1、lcdr2和lcdr3)。术语“高亲和力”抗体是指关于它的靶标表位具有约10-9m或更低(例如约1×10-9m、1×10-10m、1×10-11m或约1×10-12m)的kd的抗体。在一个实施方案中,kd通过表面等离子体共振例如biacoretm来测量;在另一实施方案中,kd通过elisa来测量。术语“重链”或“免疫球蛋白重链”包括来自任何生物体的免疫球蛋白重链序列,包括免疫球蛋白重链恒定区序列。除非另外规定,否则重链可变结构域包括三个重链cdr和四个fr区。重链的片段包括cdr、cdr和fr、及其组合。在可变结构域之后(从n末端至c末端),典型重链具有ch1结构域、铰链、ch2结构域和ch3结构域。重链的功能性片段包括能够特异性识别表位(例如以在微体积摩尔浓度、纳体积摩尔浓度或皮体积摩尔浓度的范围内的kd识别表位),能够由细胞表达并分泌,以及包含至少一个cdr的片段。重链可变结构域由可变区核苷酸序列编码,所述序列通常包含源于种系中存在的vh、dh和jh区段的谱系的vh、dh和jh区段。各种生物体的v、d和j重链区段的序列、位置和命名可见于imgt数据库中,所述数据库可通过因特网在万维网(www)上以url“imgt.org”访问。术语“轻链”包括来自任何生物体的免疫球蛋白轻链序列,并且除非另外规定,否则包括人κ和λ轻链和vpreb以及替代轻链。除非另外规定,否则轻链可变结构域通常包括三个轻链cdr和四个框架(fr)区。通常,全长轻链从氨基末端至羧基末端包括可变结构域(其包括fr1-cdr1-fr2-cdr2-fr3-cdr3-fr4)和轻链恒定区氨基酸序列。轻链可变结构域由轻链可变区核苷酸序列编码,所述序列通常包含源于种系中存在的轻链v和j基因区段的谱系的轻链vl和轻链jl基因区段。各种生物体的轻链v和j基因区段的序列、位置和命名可见于imgt数据库中,所述数据库可通过因特网在万维网(www)上以url“imgt.org”访问。轻链包括例如不选择性结合由它们出现于其中的表位结合蛋白选择性结合的第一或第二表位的那些。轻链也包括结合以及识别一个或多个由它们出现于其中的表位结合蛋白选择性结合的表位,或辅助重链结合以及识别所述表位的那些。如本文所用的术语“互补决定区”或“cdr”包括由生物体的免疫球蛋白基因的通常(即在野生型动物中)出现在免疫球蛋白分子(例如抗体或t细胞受体)的轻链或重链的可变区中两个框架区之间的核酸序列编码的氨基酸序列。cdr可由例如种系序列或重排序列以及例如由原初或成熟b细胞或t细胞编码。cdr可被以体细胞方式突变(例如从在动物的种系中编码的序列变化),人源化,和/或用氨基酸取代、添加或缺失来修饰。在一些情况下(例如对于cdr3),cdr可由两个或更多个不连续(例如在未重排核酸序列中),但例如由于对序列进行剪接或连接(例如v-d-j重组以形成重链cdr3)而在b细胞核酸序列中连续的序列(例如种系序列)编码。术语“未重排”包括免疫球蛋白基因座的以下状态:其中v基因区段和j基因区段(对于重链,也包括d基因区段)被分开维持,但能够接合以形成包含v(d)j谱系的单一v、(d)、j的重排v(d)j基因。术语重链可变区基因座包括例如小鼠染色体的染色体上见到野生型重链可变(vh)、重链多样性(dh)和重链接合(jh)区域dna序列所处的位置。术语κ轻链可变区基因座包括例如小鼠染色体的染色体上见到野生型κ可变(vκ)和κ接合(jκ)区域dna序列所处的位置。术语λ轻链可变区基因座包括例如小鼠染色体的染色体上见到野生型λ可变(vλ)和λ接合(jλ)区域dna序列所处的位置。“同源性”序列(例如核酸序列)包括以下序列:其与已知参照序列同一或大致上类似,以致它与所述已知参照序列例如至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%、或100%同一。同源序列可包括例如直系同源序列和旁系同源序列。同源性基因例如通常通过物种形成事件(直系同源基因)或遗传重复事件(旁系同源基因)而起源于共同祖先dna序列。“直系同源”基因包括不同物种中通过物种形成而从共同祖先基因进化的基因。直系同源物通常在进化的过程中保留相同功能。“旁系同源”基因包括由于基因组内的重复而相关的基因。旁系同源物可在进化的过程中进化出新功能。术语“体外”包括人工环境以及发生在人工环境(例如试管)内的过程或反应。术语“体内”包括天然环境(例如细胞或生物体或身体)以及发生在天然环境内的过程或反应。术语“离体”包括已从个体的身体移除的细胞以及发生在所述细胞内的过程或反应。术语“杂交物”包括在一对同源染色体中第一染色体与第二染色体之间,在一个或多个靶基因组基因座处具有一个或多个序列变化(例如具有等位基因变化)的细胞或品系。举例来说,杂交细胞可源于两个遗传相异亲本之间交配(即在一个或多个基因方面不同的亲本之间杂交)的子代。作为一实例,杂交物可通过使两个不同近交系(即被交配以获得遗传同质性的品系)杂交来产生。所有人都被视为杂交物。“包含”或“包括”一个或多个叙述的要素的组合物或方法可包括未明确叙述的其他要素。举例来说,“包含”或“包括”蛋白质的组合物可含有单独或与其他成分组合的所述蛋白质。对值的范围的指定包括所述范围内或界定所述范围的所有整数,以及由所述范围内的整数界定的所有子范围。除非另外根据上下文显而易知,否则术语“约”涵盖在陈述值的标准测量误差界限(例如sem)内的值。除非上下文另外明确规定,否则单数形式的冠词“一个(种)(a/an)”和“这个(种)(the)”包括复数个(种)指示物。举例来说,术语“一个(种)cas9蛋白”或“至少一个(种)cas9蛋白”可包括复数个(种)cas9蛋白,包括其混合物。统计显著意指p≤0.05。具体实施方式i.概述本文提供用于产生结合与自身抗原共有表位或与所述自身抗原同源的目标外来靶抗原(例如目标人靶抗原)上的所述表位的抗原结合蛋白(例如抗体)的组合物和改进方法。所述方法包括通过采用两个或更多个引导rna(grna)以在单一靶基因组基因座内的不同位点处产生成对双链断裂来使非人动物诸如啮齿动物(例如小鼠或大鼠)(任选在它们的种系中包含人源化免疫球蛋白重链和/或轻链基因座)中对外来抗原的耐受性降低。任选地,包含靶基因组基因座的细胞是杂交细胞,并且方法进一步包括选择靶基因组基因座内用以经受靶向遗传修饰的靶区域,以使在一对同源染色体中相应第一染色体与第二染色体之间,相对于所述靶基因组基因座的其余部分的全部或一部分,所述靶区域具有更高序列同一性程度。所述成对双链断裂影响自身抗原的表达以使自身抗原的表达降低或消除,或使来自自身抗原的与外来抗原共有的表位的表达降低或消除。包含人源化免疫球蛋白重链和轻链基因座以及也在靶基因组基因座中具有这种突变的所述经遗传修饰的非人动物可接着用外来抗原免疫,可在足以使非人动物产生对外来抗原的免疫应答的条件下维持非人动物,并且可从非人动物或来自非人动物的细胞获得结合外来抗原的抗原结合蛋白。用于产生针对人抗原的抗体的小鼠,诸如在它们的种系中包含人源化免疫球蛋白重链和/或轻链基因座的小鼠,通常源于品系的组合,所述组合由于相较于其他小鼠品系,balb/c品系用于产生多样性抗体谱系的能力增加而包括balb/c。然而,相较于通常用于在小鼠中产生靶向遗传修饰的胚胎干(es)细胞(例如本文所述的f1h4(vgf1)细胞),源于所述抗体产生性小鼠品系的es细胞在培养中被靶向的能力和/或用于产生具有靶向遗传修饰以及通过种系传递靶向修饰的f0代小鼠的能力通常降低。因此,用以产生靶标敲除小鼠以克服耐受性的常规方法涉及多轮交配和/或连续靶向,其中用于分娩就在目标靶标处的无效等位基因来说是纯合的以及准备用于免疫的小鼠的整个过程花费约15-16个月。本文所述的方法有利地使这个时间降低至约4至5个月(并且就在目标靶标处的无效等位基因来说是纯合的小鼠幼仔可在约3个月内分娩)。除时间范围较短之外,本文所述的方法也使为产生纯合性修饰所需的电穿孔的轮数降低,使所需传代数和培养时间降低,使所需细胞数降低,并且由于不需要靶向载体以及筛选相应地得以简化而使过程精简。相较于其中自身抗原的表达未被消除的小鼠,由于重链和轻链v基因区段的使用增加,所以本文所述的方法有利地导致在用目标外来抗原免疫之后,抗体的多样性增加。此外,由于产生与相应自身抗原交叉反应的抗体(即结合在自身抗原与目标外来抗原之间重叠的表位的抗体),本文所述的方法产生在用目标外来抗原免疫之后针对较大多样性的表位产生的抗体,由此使得能够产生较大的针对目标外来抗原的抗体汇集物。ii.修饰靶基因组基因座以破坏耐受性的方法用“非自身”蛋白质使在它们的种系中包含人源化免疫球蛋白重链和/或轻链基因座的非人动物(例如啮齿动物,诸如小鼠或大鼠)免疫是一种通常使用的用以获得特异性抗原结合蛋白诸如单克隆抗体的方法。免疫方法具有吸引力,因为它有可能提供已在体内成熟的高亲和力抗原结合蛋白,并且可具有成本效益与时间效益两者。然而,这个方法依赖于非人动物中的天然蛋白质与经免疫以使得非人动物的免疫系统能够将免疫原识别为非自身(即外来)的蛋白质之间的序列趋异性。b细胞受体通过一系列重组事件来由基因区段(例如v、d和j)的有序排列加以装配,并且已知这个基因区段装配是不精确的并产生对包括自身抗原的各种抗原具有亲和力的受体。尽管具有产生结合自身分子的b细胞受体的这个能力,但免疫系统具备若干自身耐受性机理以避免所述自体反应性b细胞受体的产生和扩增,并且辨别自身与非自身,由此防止自体免疫性。参见例如shlomchik(2008)immunity28:18-28以及kumar和mohan(2008)40(3):208-23,其各自出于所有目的以引用的方式整体并入本文。因此,在具有人源化免疫球蛋白基因座的非人动物中产生针对与非人动物的自身抗原具有高度同源性(例如结构同源性或序列同源性)的人抗原的人抗体可由于免疫耐受性而是一项困难任务。因为蛋白质的在功能上重要的区域在物种之间倾向于保守,所以对自身抗原的免疫耐受性常常对产生针对这些关键表位的抗体造成挑战。用高度类似或“同源”的外来(例如人)抗原使非人动物(例如啮齿动物,诸如小鼠或大鼠)免疫产生微弱或不存在抗体应答,因此,使得获得针对所述人抗原进行结合的抗原结合蛋白(例如抗体)成问题。作为一实例,由内源性蛋白质(自身抗原)和外来靶抗原共有的序列同一性的量可为至少50%、55%、60%、65%、70%、75%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性,以致免疫系统不将靶抗原识别为外来。举例来说,外来抗原与非人动物中的自身抗原之间共有的表位可使得在所述非人动物中发动针对所述外来抗原的有效免疫应答成问题,因为免疫耐受性使表达针对所述外来抗原的中和抗体的b细胞消减和/或缺失。为克服这个耐受性以及在非人动物中获得结合自身抗原或其同源物(例如人同源物)的单克隆抗体,可产生特定经遗传修饰或敲除非人动物以移除与它的编码用于免疫的抗原的人对应物基因共有显著同源性和/或高度保守的编码非人动物蛋白质的基因(或目标共有表位)。参见例如美国专利号7,119,248,其出于所有目的以引用的方式整体并入本文。然而,产生所述非人动物可为昂贵的和耗时的。用以产生靶标敲除小鼠以克服耐受性的常规方法涉及多轮交配和/或连续靶向。用于产生针对人抗原的抗体的小鼠,诸如在它们的种系中包含人源化免疫球蛋白重链和/或轻链基因座的小鼠(例如小鼠,其在igh基因座与igκ基因座两者处均是纯合性人源化的),通常源于品系的组合,所述组合由于相较于其他小鼠品系,balb/c品系用于产生多样性抗体谱系的能力增加而包括balb/c。然而,相较于通常用于在小鼠中产生靶向遗传修饰的胚胎干(es)细胞(例如本文所述的f1h4(vgf1)细胞,其包含50%129svs6品系和50%c57bl/6n品系),源于所述抗体产生性小鼠品系的es细胞在培养中被靶向的能力和/或用于产生具有靶向遗传修饰以及通过种系传递靶向修饰的f0代小鼠的能力通常降低。因此,用以破坏抗体产生性小鼠诸如小鼠中的免疫耐受性的传统方法涉及首先靶向更易于接受靶向以及通过种系传递靶向修饰的es细胞系(例如f1h4)中的编码自身抗原的基因。在这种方法中,设计大型靶向载体(ltvec),在f1h4es细胞中产生敲除(无效)等位基因,并且产生在目标靶标处携带杂合性敲除突变的f0小鼠(典型时间范围是5个月)。接着使小鼠与在目标靶标处携带杂合性敲除突变的f0小鼠交配。为产生适于免疫的三重纯合性小鼠(目标靶标的纯合性无效和在igh与igκ两者处的纯合性人源化),需要再进行两代交配。整个过程花费约15至16个月(参见例如图1),并且比下述连续靶向方法(参见例如图2)更有效。或者,可设计和构建大型靶向载体(ltvec),接着电穿孔至源于抗体产生性小鼠(例如小鼠或包含功能性异位小鼠adam6基因的小鼠(“vi-3小鼠”))的胚胎干(es)细胞中以在编码与靶抗原同源或共有目标表位的自身抗原的内源性基因中产生杂合性修饰。接着进行第二轮靶向以产生纯合性修饰。尽管耗时少于上述交配方法,但这个方法可仍然是耗时的,花费约9至10个月来产生准备用于用靶抗原进行的免疫的f0小鼠(参见例如图2)。此外,所述方法需要多轮电穿孔和伴有更多次传代的较长培养时间,其全都导致多能性降低和产生用于产生抗原结合蛋白的f0小鼠的能力降低。参见例如buehr等(2008)cell135:1287-1298;li等(2008)cell135(7):1299-1310;以及liu等(1997)dev.dyn.209:85-91,其各自出于所有目的以引用的方式整体并入本文。本文所述的方法有利地使这个时间降低至约4至5个月(参见例如图3;就在目标靶标处的无效等位基因来说是纯合的小鼠幼仔可在约3个月内分娩,但接着在免疫之前老化4-5周)。除时间范围较短之外,本文所述的方法也使为产生纯合性修饰所需的电穿孔的轮数降低,使所需传代数和培养时间降低,并且使所需细胞数降低。筛选更加简单和精简,因为例如不需要等位基因获得探针,并且不需要拷贝数校正。相较于其中自身抗原的表达未被消除的小鼠,由于重链和轻链v基因区段的使用增加,所以本文所述的方法也导致在用目标外来抗原免疫之后,抗体的多样性增加。此外,由于产生与相应自身抗原交叉反应的抗体(即结合在自身抗原与目标外来抗原之间重叠的表位的抗体),本文所述的方法可产生在用目标外来抗原免疫之后针对较大多样性的表位产生的抗体,由此使得能够产生较大的针对目标外来抗原的抗体汇集物。本文提供用于修饰靶基因组基因座以破坏耐受性的各种方法。方法可离体或在体内进行,并且它们可利用两个或更多个靶向影响与目标外来抗原同源或共有目标表位的自身抗原的表达的单一靶基因组基因座内的不同区域,并且与cas蛋白形成两个或更多个复合物并裂解靶标核酸的引导rna(例如两个grna、三个引导rna或四个引导rna)。两个或更多个引导rna可单独或与外源性修复模板组合使用,前提是如果细胞是例如单细胞期胚胎,那么外源性修复模板的长度可小于5kb。所述方法促进在靶基因座处产生双等位基因遗传修饰,并且可包括基因组垮塌或其他靶向修饰,诸如同时缺失基因组内的核酸序列和用外源性核酸序列进行替换。相较于在低频率下产生双等位基因修饰的用一个grna进行的靶向,用两个或更多个grna进行的靶向导致在显著增加的比率下产生双等位基因修饰(例如以纯合方式靶向的细胞、以纯合方式缺失的细胞和包括以半合方式靶向的细胞的复合的以杂合方式靶向的细胞)。应答于双链断裂(dsb)的修复主要通过以下两个保守dna修复路径来发生:非同源性末端接合(nhej)和同源性重组(hr)。参见kasparek和humphrey(2011)seminarsincell&dev.biol.22:886-897,其出于所有目的以引用的方式整体并入本文。nhej包括通过使断裂末端直接连接至彼此或外源性序列而无需同源性模板来修复核酸中的双链断裂。由nhej达成的对非连续序列的连接可常常在双链断裂的位点附近导致缺失、插入或易位。由外源性修复模板介导的对靶标核酸的修复可包括在两个多核苷酸之间交换遗传信息的任何过程。举例来说,nhej也可通过使断裂末端与外源性修复模板的末端直接连接(即基于nhej的捕集)来导致外源性修复模板的靶向整合。当同源性引导的修复(hdr)路径不易于可用时(例如在非分裂细胞、原代细胞和不良进行基于同源性的dna修复的细胞中),所述nhej介导的靶向整合可优选用于插入外源性修复模板。此外,与同源性引导的修复相比,不需要了解侧接于裂解位点的具有序列同一性的大型区域(超出由cas介导的裂解产生的突出部分),此在试图向具有对基因组序列的了解有限的基因组的生物体中进行靶向插入时可为有益的。整合可通过外源性修复模板与经裂解基因组序列之间的钝性末端连接,或通过使用由可与经裂解基因组序列中的由cas蛋白产生的那些突出部分相容的突出部分侧接的外源性修复模板进行的粘性末端(即具有5’或3’突出部分)连接来进行。参见例如us2011/020722、wo2014/033644、wo2014/089290以及maresca等(2013)genomeres.23(3):539-546,其各自出于所有目的以引用的方式整体并入本文。如果连接钝性末端,那么可需要进行靶标和/或供体切除以产生具有为片段接合所需的微同源性的区域,此可在靶标序列中产生非所要改变。修复也可通过同源性引导的修复(hdr)或同源性重组(hr)来发生。hdr或hr包括可需要核苷酸序列同源性,使用“供体”分子作为“靶标”分子(即经受双链断裂的分子)的修复模板,并且导致遗传信息从供体向靶标转移的核酸修复形式。在不希望受任何特定理论束缚下,所述转移可涉及对在断裂的靶标与供体之间形成的异源双链体dna的不匹配修正,和/或合成依赖性链退火,其中供体用于再合成将成为靶标的一部分的遗传信息,和/或相关过程。在一些情况下,供体多核苷酸、供体多核苷酸的一部分、供体多核苷酸的拷贝、或供体多核苷酸的拷贝的一部分整合至靶标dna中。参见wang等(2013)cell153:910-918;mandalos等(2012)plosone7:e45768:1-9;以及wang等(2013)natbiotechnol.31:530-532,其各自出于所有目的以引用的方式整体并入本文。为制备对目标外来靶抗原的耐受性降低的非人动物,可靶向一个或多个影响与所述目标外来抗原同源或共有表位的自身抗原的表达的靶基因组基因座以使所述自身抗原的表达降低。优选地,自身抗原的表达被消除。如果自身抗原不再表达(例如如果自身抗原是蛋白质,那么所述蛋白质不再表达,或如果自身抗原是蛋白质上的特定表位,那么包含那个表位的蛋白质不再表达),那么自身抗原的表达被视为得以消除。在一个实例中,可使不是单细胞期胚胎的非人动物多能细胞(例如胚胎干(es)细胞)的基因组与cas蛋白、杂交至靶基因组基因座内的第一引导rna识别序列的第一引导rna和杂交至靶基因组基因座内的第二引导rna识别序列的第二引导rna接触。在另一实例中,可使非人动物单细胞期胚胎的基因组与cas蛋白、杂交至靶基因组基因座内的第一引导rna识别序列的第一引导rna和杂交至靶基因组基因座内的第二引导rna识别序列的第二引导rna接触。在一些本文提供的方法中,所靶向的细胞是如在本文中其他地方定义的杂交细胞。所述方法也可包括选择靶基因组基因座内的靶区域,如在本文中其他地方所述。可选择靶区域以使在一对同源染色体中相应第一染色体与第二染色体之间,相对于靶基因组基因座的其他区段或靶基因组基因座的其余部分,它具有高序列同一性百分比。作为一实例,选择靶区域可包括比较一对同源染色体中相应第一染色体和第二染色体在靶基因组基因座内的序列,以及选择在所述一对同源染色体中所述相应第一染色体与第二染色体之间,相对于所述靶基因组基因座的其余部分的全部或一部分具有更高序列同一性百分比的靶区域。选择靶区域的方法如在本文中其他地方更详细所述。任选地,可进一步使基因组与杂交至靶基因组基因座内(或影响自身抗原的表达或影响与目标外来抗原同源或共有目标表位的第二自身抗原的表达的第二靶基因组基因座内)的引导rna识别序列的额外引导rna接触,诸如杂交至靶基因组基因座内的第三引导rna识别序列的第三引导rna,或所述第三引导rna和杂交至靶基因组基因座内的第四引导rna识别序列的第四引导rna。接触可包括将cas蛋白和引导rna以任何形式以及通过任何手段引入细胞中,如在本文中其他地方更详细所述。引导rna与cas蛋白形成复合物,并且将它引导至靶基因组基因座处的引导rna识别序列,在所述引导rna识别序列处,cas蛋白在引导rna识别序列内的cas蛋白裂解位点处裂解靶基因组基因座。由cas蛋白达成的裂解可产生双链断裂或单链断裂(例如如果cas蛋白是切口酶)。可用于方法中的cas蛋白和引导rna的实例和变化形式在本文中其他地方描述。由cas蛋白在靶基因组基因座处达成的裂解可修饰一对第一染色体和第二染色体中的靶基因组基因座以产生使自身抗原的表达降低的双等位基因修饰。目标外来抗原可为需要其抗原结合蛋白的任何外来抗原。举例来说,目标外来抗原可包含以下、基本上由以下组成或由以下组成:病毒蛋白质、细菌蛋白质、哺乳动物蛋白质、猿猴蛋白质、犬蛋白质、猫蛋白质、马蛋白质、牛蛋白质、啮齿动物蛋白质(例如大鼠或小鼠)或人蛋白质的全部或一部分。举例来说,目标外来抗原可包含以下、基本上由以下组成或由以下组成:具有一个或多个突变或变化的人蛋白质。目标外来抗原和自身抗原可为同源的。举例来说,目标外来抗原和自身抗原可为直系同源的或旁系同源的。或者或此外,目标外来抗原和自身抗原可包含以下、基本上由以下组成或由以下组成:共有表位。共有表位可存在于同源性蛋白质之间,或可存在于不同源的相异蛋白质之间。可共有表位的线性氨基酸序列和/或构象契合(例如甚至在不存在一级序列同源性下的类似抗原性表面)。举例来说,共有表位包括大致上相同的表位。如果两个抗原之间共有表位,那么针对第一抗原上的表位的抗体将通常也结合第二抗原上的表位。接触可在不存在外源性修复模板下或在存在与靶基因组基因座重组的外源性修复模板下发生以产生靶向遗传修饰。举例来说,细胞可为单细胞期胚胎,并且外源性修复模板的长度可小于5kb。外源性修复模板的实例在本文中其他地方描述。在一些所述方法中,通过外源性修复模板修复靶标核酸通过同源性引导的修复(hdr)来发生。当cas蛋白在靶基因组基因座处裂解两个dna链以产生双链断裂时,当cas蛋白是在靶基因组基因座处裂解一个dna链以产生单链断裂的切口酶时,或当成对cas切口酶用于产生由两个偏移切口形成的双链断裂时,可发生同源性引导的修复。在所述方法中,外源性修复模板包含对应于靶基因组基因座处的5’靶标序列和3’靶标序列的5’同源臂和3’同源臂。引导rna识别序列或裂解位点可邻近于5’靶标序列,邻近于3’靶标序列,邻近于5’靶标序列与3’靶标序列两者,或既不邻近于5’靶标序列,也不邻近于3’靶标序列。彼此邻近的序列包括在彼此的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内的序列。任选地,外源性修复模板进一步包含由5’同源臂和3’同源臂侧接的核酸插入物,并且所述核酸插入物插入在5’靶标序列与3’靶标序列之间。如果不存在核酸插入物,那么外源性修复模板可起使5’靶标序列与3’靶向序列之间的基因组序列缺失的作用。或者,通过外源性修复模板修复靶标核酸可通过非同源性末端接合(nhej)介导的连接来发生。在所述方法中,外源性修复模板的至少一个末端包含互补于至少一个由cas介导的在靶基因组基因座处的裂解产生的突出部分的短单链区域。外源性修复模板中的互补性末端可侧接于核酸插入物。举例来说,外源性修复模板的各末端都可包含互补于由cas介导的在靶基因组基因座处的裂解产生的突出部分的短单链区域,并且外源性修复模板中的这些互补性区域可侧接于核酸插入物。突出部分(即交错末端)可通过切除由cas介导的裂解产生的双链断裂的钝性末端来产生。所述切除可产生具有为片段接合所需的微同源性的区域,但这可在靶标核酸中产生非所要或不可控制的改变。或者,所述突出部分可通过使用成对cas切口酶来产生。举例来说,如果cas蛋白是切口酶,那么可使靶基因组基因座与靶向相对dna链的第一引导rna和第二引导rna接触,由此基因组通过进行双重切口来修饰。这可通过使靶基因组基因座与杂交至靶基因组基因座内的不同引导rna识别序列的两个引导rna接触来实现。两个引导rna与cas切口酶形成两个复合物,并且cas切口酶在一个引导rna识别序列内对具有靶基因组基因座的第一链进行切口,并且在另一引导rna识别序列内对具有靶基因组基因座的第二链进行切口。外源性修复模板接着与靶基因组基因座重组以产生靶向遗传修饰。在一些方法中,核酸插入物包含与自身抗原编码的基因的全部或一部分同源或直系同源的序列。这可例如在敲除自身抗原可导致胚胎致死时适用。核酸插入物可在呈本文所述的任何形式(例如靶向载体、ltvec、ssodn等)的外源性修复模板中,并且核酸插入物可进一步包含选择盒(例如自我缺失性选择盒)或可缺乏选择盒。在所述方法中,举例来说,编码自身抗原的基因的全部或一部分可被缺失以及用相应同源或直系同源序列替换。举例来说,编码自身抗原的基因的全部可被缺失以及用相应同源或直系同源序列替换,或所述基因的编码自身抗原的特定基序或区域的一部分可被缺失以及用相应同源或直系同源序列替换。任选地,相应同源或直系同源序列可来自另一物种。举例来说,如果自身抗原是小鼠抗原,那么相应同源或直系同源序列可为例如同源或直系同源大鼠、仓鼠、猫、狗、龟、狐猴或人序列。或者或另外,相较于所替换的序列,同源或直系同源序列可包含一个或多个点突变(例如1、2、3、4、5个或更多个)。所述点突变可例如起使自身抗原中的一个或多个表位的表达消除的作用。所述表位可为与目标外来抗原共有的表位。任选地,所述点突变可导致所编码多肽中的保守性氨基酸取代(例如天冬氨酸[asp,d]被谷氨酸[glu,e]取代)。所述氨基酸取代可导致表达保留野生型自身抗原的功能,但缺乏存在于目标外来抗原上以及与野生型自身抗原共有的表位的自身抗原。同样,缺失编码自身抗原的基因的全部或一部分以及用缺乏在目标外来抗原与自身抗原之间共有的表位的相应同源或直系同源序列替换可导致表达自身抗原的同源物或直系同源物,其保留野生型自身抗原的功能,但缺乏存在于目标外来抗原上以及与野生型自身抗原共有的表位。可接着产生针对那些表位的抗原结合蛋白。经修饰非人动物多能细胞可接着用于使用在本文中其他地方所述的方法来产生经遗传修饰的非人动物。举例来说,可将经修饰非人动物多能细胞引入宿主胚胎中,并且可将所述宿主胚胎植入代孕母体中以产生经遗传修饰的f0代非人动物,其中一对第一染色体和第二染色体中的靶基因组基因座被修饰以具有双等位基因修饰,以使自身抗原的表达被降低或消除。在单细胞期胚胎的情况下,可选择经遗传修饰的胚胎,接着植入代孕母体中以产生经遗传修饰的f0代非人动物,其中一对第一染色体和第二染色体中的靶基因组基因座被修饰以具有双等位基因修饰,以使自身抗原的表达被降低或消除。f0代非人动物可接着用于使用在本文中其他地方所述的方法来产生针对目标外来抗原的抗原结合蛋白。a.选择靶区域通过外源性修复模板(例如靶向载体)与靶基因组基因座之间的同源性重组达成的靶向基因修饰可极其低效,尤其是在除啮齿动物胚胎干细胞以外的细胞类型中。由crispr/cas9引导的裂解对一个或多个双链dna断裂的诱导可促进通过外源性修复模板(例如靶向载体)与靶基因组基因座之间的同源性重组(hr)进行纯合性基因靶向。crispr/cas9也可促进通过非同源性末端接合(nhej)修复机理进行纯合性插入或缺失突变(即相同的双等位基因改变)。对于涉及极大型人源化的基因修饰,使靶向载体与由靶向单一靶基因组基因座的两个引导rna引导的crispr/cas9核酸酶系统组合可进一步使靶向效率增强超过用一个引导rna实现的靶向效率。相较于在低频率下产生双等位基因修饰或完全不产生双等位基因修饰的用一个引导rna进行的靶向,用两个引导rna进行的靶向导致在显著增加的比率下产生以纯合方式靶向的细胞、以纯合方式缺失的细胞和复合的以杂合方式靶向的细胞(包括以半合方式靶向的细胞)。然而,在一些基因组基因座处,获得以纯合方式靶向的细胞或以纯合方式缺失的细胞可仍然是困难的。不同于在通常用于实验室环境下的在它们的实际上所有基因组基因座处都是纯合的近交小鼠和大鼠品系中,在杂交细胞(例如在所有人中)中的靶基因组基因座处的两个等位基因的序列将通常不是100%同一的。然而,如在本文提供的实施例中所证明,无论初始crispr/cas9诱导的修饰通过hr产生还是通过nhej产生,纯合性基因组改变的频率都取决于靶基因组基因座的两个等位基因之间的序列类似性的程度。这个观察结果暗示crispr/cas9诱导的纯合性基因修饰是一种同源性依赖性现象。支持这个的是,crispr/cas9诱导的纯合性修饰常常伴有在同一染色体上与靶基因组基因座相关联的等位基因序列和结构变体(单核苷酸变体snv或结构变体sv)的杂合性丧失(loh),如本文实施例中所证明。loh可涉及针对在靶基因组基因座的任一侧上的变体的局部基因转换机理或涉及在靶基因组基因座的端粒侧上的所有变体的长程基因转换(极性基因转换)。所述基因转换事件必须是同源性驱动的有丝分裂重组机理的结果。这个认识为设计crispr/cas9辅助的纯合性靶向实验提供指导。选择其中两个等位基因共有高度序列同一性的靶区域会赋予最高成功机会。crispr/cas9辅助的在两个等位基因之间具有高度序列变化的靶区域处进行的纯合性靶向取得成功的可能性较小。即使在具有高密度的snv和sv的基因座处,成功率也可通过使用识别在靶基因组基因座内具有连续等位基因序列同一性的最长可能链段内或在靶基因组基因座的其中等位基因序列同一性最大的链段内的序列的引导rna或核酸酶试剂来改进。本文所述的方法可涉及选择靶区域以使在一对同源染色体中相应第一染色体与第二染色体之间,靶区域的全部或一部分的序列同一性可最大化。在杂交细胞中,一对同源染色体的一个拷贝上的序列在相较于染色体对的另一拷贝时将通常具有一些差异(例如单核苷酸变化)。因此,所述方法可包括比较一对同源染色体(例如人细胞具有23对同源染色体)中相应第一染色体和第二染色体在靶基因组基因座中的序列,接着选择所述靶基因组基因座内的靶区域以使在一对同源染色体中相应第一染色体与第二染色体之间,所述靶区域的全部或一部分的序列同一性最大化。如果无序列可用,那么所述方法可进一步包括在比较序列之前对一对同源染色体内的各单一染色体上的靶基因组基因座测序。靶区域可包含以下、基本上由以下组成或由以下组成:例如在本文公开的方法中由两个或更多个引导rna中的一者或一个或多个外源性修复模板靶向的任何区段或区域,或侧接于在本文公开的方法中由两个或更多个引导rna中的一者或一个或多个外源性修复模板靶向的区段或区域的任何区段或区域。靶区域可为连续基因组序列或非连续基因组序列。举例来说,靶区域可包含以下、基本上由以下组成或由以下组成:通过本文公开的方法被靶向以达成缺失的基因组区段或区域、被靶向以达成替换的基因组区段或区域、或被靶向以达成插入的基因组区段或区域,和/或可包含以下、基本上由以下组成或由以下组成:侧接于通过本文公开的方法被靶向以达成缺失、替换或插入的基因组区段或基因组区域的5’和/或3’序列。优选地,靶区域包含以下、基本上由以下组成或由以下组成:紧靠通过本文公开的方法被靶向以达成缺失、替换或插入的区域的上游的序列和/或紧靠所述区域的下游的序列(例如在两个引导rna识别序列或裂解位点之间的区域的上游和/或下游的序列,或在外源性修复模板的5’靶标序列与3’靶标序列之间的区域的上游和/或下游的序列)。作为一实例,如果使用两个引导rna,那么靶区域可包含以下、基本上由以下组成或由以下组成:侧接于引导rna识别序列或cas裂解位点之间的区域的5’(即上游)和3’(即下游)序列。侧接序列的长度的实例在本文中其他地方公开。在一些方法中,举例来说,可首先设计外源性修复模板,并且可接着设计由外源性修复模板的5’靶标序列和3’靶标序列侧接的区域内的引导rna以使引导rna识别序列内的区域和/或侧接于(5’侧、3’侧或各侧)引导rna识别序列(例如如果使用两个或更多个引导rna,那么侧接于相隔最远的两个引导rna识别序列之间的区域)的区域中的序列同一性最大化。或者,在一些方法中,举例来说,可首先设计两个或更多个引导rna,并且可接着设计外源性修复模板以使5’靶标序列和3’靶标序列侧接于两个或更多个引导rna识别序列,并且以使5’靶标序列和3’靶标序列内的区域和/或侧接于(5’侧、3’侧或各侧)5’靶标序列和3’靶标序列(例如侧接于5’靶标序列与3’靶标序列之间的区域)的区域中的序列同一性最大化。作为一实例,靶区域可包含以下、基本上由以下组成或由以下组成:两个或更多个引导rna中的一者的引导rna识别序列。或者或此外,靶区域可包含以下、基本上由以下组成或由以下组成:侧接于引导rna识别序列的5’和/或3’序列。5’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。同样,3’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。作为另一实例,靶区域可包含以下、基本上由以下组成或由以下组成:两个或更多个引导rna识别序列。或者或此外,靶区域可包含以下、基本上由以下组成或由以下组成:侧接于引导rna识别序列的5’和/或3’序列。在其中使用两个引导rna的方法中,举例来说,靶区域可包含以下、基本上由以下组成或由以下组成:由两个引导rna识别序列或裂解位点侧接的基因组区域或由两个引导rna识别序列或裂解位点侧接且包括所述两个引导rna识别序列或裂解位点的基因组区域。或者或此外,靶区域可包含以下、基本上由以下组成或由以下组成:侧接于两个引导rna识别序列或裂解位点之间的区域的5’和/或3’序列,或侧接于两个引导rna识别序列或裂解位点之间的区域且包括所述两个引导rna识别序列或裂解位点的5’和/或3’序列。可在其中使用超过两个引导rna的方法中选择类似靶区域,例外之处是替代如上由两个引导rna识别序列或裂解位点侧接的基因组区域的将是由相隔最远的引导rna识别序列或裂解位点侧接的基因组区域。5’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。同样,3’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。在其中使用外源性修复模板的方法中,举例来说,靶区域可包含以下、基本上由以下组成或由以下组成:由5’靶标序列和3’靶标序列侧接的区域或由5’靶标序列和3’靶标序列侧接且包括所述5’靶标序列和所述3’靶标序列的区域。或者或另外,靶区域可包含以下、基本上由以下组成或由以下组成:侧接于5’靶标序列与3’靶标序列之间的基因组区域的5’和/或3’序列或侧接于5’靶标序列与3’靶标序列之间的基因组区域的5’和/或3’序列。5’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。同样,3’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。可使靶区域的全部或靶区域的一部分的等位基因序列同一性最大化。作为一实例,可使与至少一个或各个引导rna识别序列相对应的基因组区域或包含至少一个或各个引导rna识别序列的区域的等位基因序列同一性最大化。举例来说,可使至少一个或各个引导rna识别序列的等位基因序列同一性最大化。或者,可使至少一个或各个引导rna识别序列和侧接于所述至少一个或各个引导rna识别序列的5’和/或3’序列的等位基因序列同一性最大化。或者,可使侧接于至少一个或各个引导rna识别序列的5’和/或3’序列的等位基因序列同一性最大化。5’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。同样,3’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。或者或另外,可使与外源性修复模板的5’靶标序列和/或3’靶标序列相对应的基因组区域或包含5’靶标序列和3’靶标序列中的至少一者或各者的区域的等位基因序列同一性最大化。举例来说,可使5’靶标序列和3’靶标序列中的至少一者或各者的等位基因序列同一性最大化。或者,可使5’靶标序列和3’靶标序列中的至少一者或各者和侧接于所述5’靶标序列和所述3’靶标序列中的所述至少一者或各者的5’和/或3’序列的等位基因序列同一性最大化。或者,可使侧接于5’靶标序列和3’靶标序列中的至少一者或各者的5’和/或3’序列的等位基因序列同一性最大化。5’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。同样,3’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。或者或另外,可使侧接于被靶向以达成缺失、替换或插入的区域的序列的等位基因序列同一性最大化。举例来说,在使用两个引导rna的方法中,可使侧接于两个裂解位点或两个引导rna识别序列之间的区域的5’和/或3’序列的等位基因序列同一性最大化。在使用三个或更多个引导rna的方法中,可使侧接于相隔最远的两个裂解位点或两个引导rna识别序列之间的区域的5’和/或3’序列的等位基因序列同一性最大化。作为另一实例,在使用外源性修复模板的方法中,可使侧接于外源性修复模板的5’靶标序列与3’靶标序列之间的区域(即由外源性修复模板靶向以达成缺失的基因组区域)的5’和/或3’序列的等位基因序列同一性最大化。5’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。同样,3’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列。选择靶区域以使在一对同源染色体中相应第一染色体与第二染色体之间,所述靶区域的全部或一部分的序列同一性最大化未必意指着眼于一对同源染色体中第一染色体和第二染色体上的靶基因组基因座,以及挑选相对于所述靶基因组基因座的其余部分具有最高等位基因序列同一性的区域,而是代之以可考虑其他因素。举例来说,如果靶区域包含以下、基本上由以下组成或由以下组成:一个或多个引导rna识别序列和/或侧接于所述一个或多个引导rna识别序列的序列,那么可考虑的其他因素包括例如什么推定引导rna识别序列位于区域中,推定引导rna识别序列是否独特,推定引导rna识别序列位于区域内何处,预测区域中的推定引导rna识别序列多么有成效或特有,区域内的推定引导rna识别序列与适于外源性修复模板的5’靶标序列和3’靶标序列的邻近性,区域内的推定引导rna识别序列与其他推定引导rna识别序列的邻近性,区域内的推定引导rna识别序列与被靶向以达成修正的突变的邻近性等。举例来说,优选地,引导rna识别序列是不存在于基因组中其他地方的独特靶标位点。参见例如us2014/0186843,其出于所有目的以引用的方式整体并入本文。同样,引导rna特异性可涉及gc含量和靶向性序列长度并可通过改变gc含量和靶向性序列长度来优化,并且算法可用于设计或评估使引导rna的脱靶结合或相互作用最小化的引导rna靶向性序列。参见例如wo2016/094872,其出于所有目的以引用的方式整体并入本文。在一些方法中,可考虑或使用来自不同物种的cas9蛋白(例如化脓性链球菌(s.pyogenes)cas9和金黄色葡萄球菌(s.aureus)cas9)以使潜在引导rna识别序列的数目由于可用pam序列的数目增加而增加。在一个实例中,可选择靶区域以使在一对同源染色体中相应第一染色体与第二染色体之间,靶区域的全部或一部分具有高序列同一性百分比。举例来说,可选择靶区域以使在一对同源染色体中相应第一染色体与第二染色体之间,靶区域的全部或一部分具有诸如至少95%、95.5%、96%、96.5%、97%、97.5%、98%、98.5%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.55%、99.6%、99.65%、99.7%、99.75%、99.8%、99.85%、99.9%、99.95%或100%序列同一性的最小序列同一性百分比。在另一实例中,可选择靶区域以使在一对同源染色体中相应第一染色体与第二染色体之间,靶区域的全部或一部分具有低数目或低密度的单核苷酸变化。举例来说,可选择靶区域以使在一对同源染色体中相应第一染色体与第二染色体之间,靶区域的全部或一部分具有诸如每kb序列不超过5、4.9、4.8、4.7、4.6、4.5、4.4、4.3、4.2、4.1、4、3.9、3.8、3.7、3.6、3.5、3.4、3.3、3.2、3.1、3、2.9、2.8、2.7、2.6、2.5、2.4、2.3、2.2、2.1、2、1.9、1.8、1.7、1.6、1.5、1.4、1.3、1.2、1.1、1、0.9、0.8、0.7、0.6、0.5、0.4、0.3、0.2、0.1或0个单核苷酸变化的最大单核苷酸变化密度。任选地,在一对同源染色体中相应第一染色体和第二染色体中,靶区域可相同。任选地,靶区域可在靶基因组基因座内具有连续序列同一性的最长可能链段内。或者或另外,可选择靶基因组基因座内的靶区域以使在一对同源染色体中相应第一染色体与第二染色体之间,相对于所述靶基因组基因座内的其他区域,靶区域的全部或一部分具有高序列同一性百分比或低数目或低密度的单核苷酸变化。举例来说,相对于靶基因组基因座的其余部分的全部或一部分,靶区域可具有更高序列同一性百分比或更低密度的单核苷酸变化。举例来说,在相应第一同源染色体与第二同源染色体之间,靶区域可具有至少99.9%序列同一性,并且在相应第一染色体与第二染色体之间,靶基因组基因座的其余部分具有不超过99.8%序列同一性。举例来说,靶区域可包含以下、基本上由以下组成或由以下组成:一个或多个与一个或多个引导rna识别序列相对应的靶标基因组区域,并且相对于靶基因组基因座的其他区段,诸如与靶基因组基因座内的一个或多个其他潜在引导rna识别序列相对应的基因组区域,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。作为一个实例,靶区域可包含以下、基本上由以下组成或由以下组成:一个或多个引导rna识别序列中的至少一者或各者,并且相对于靶基因组基因座的其他区段,诸如靶基因组基因座内的一个或多个其他潜在引导rna识别序列,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。作为另一实例,靶区域可包含以下、基本上由以下组成或由以下组成:一个或多个引导rna识别序列中的至少一者或各者和侧接于所述一个或多个引导rna识别序列中的所述至少一者或各者的5’和/或3’序列,并且相对于靶基因组基因座的其他区段,诸如靶基因组基因座内的一个或多个其他潜在引导rna识别序列和它们的5’和/或3’侧接序列,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。作为另一实例,靶区域可包含以下、基本上由以下组成或由以下组成:侧接于一个或多个引导rna识别序列中的至少一者或各者的5’和/或3’序列,并且相对于靶基因组基因座的其他区段,诸如靶基因组基因座内的一个或多个其他潜在引导rna识别序列的5’和/或3’侧接序列,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。5’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。同样,3’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。在其中使用两个引导rna的方法中,靶区域可包含以下、基本上由以下组成或由以下组成:与第一引导rna识别序列相对应的第一靶标基因组区域和/或与第二引导rna识别序列相对应的第二靶标基因组区域,并且相对于靶基因组基因座的其他区段,诸如与靶基因组基因座内的一个或多个其他潜在引导rna识别序列相对应的基因组区域,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。举例来说,靶区域可包含以下、基本上由以下组成或由以下组成:第一引导rna识别序列和/或第二引导rna识别序列,并且相对于靶基因组基因座的其他区段,诸如靶基因组基因座内的一个或多个其他潜在引导rna识别序列,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。作为另一实例,靶区域可包含以下、基本上由以下组成或由以下组成:高百分比的第一引导rna识别序列和侧接于所述第一引导rna识别序列的5’和/或3’序列和/或第二引导rna识别序列和侧接于所述第二引导rna识别序列的5’和/或3’序列,并且相对于靶基因组基因座的其他区段,诸如与靶基因组基因座内的一个或多个其他潜在引导rna识别序列和它们的5’和/或3’侧接序列相对应的基因组区域,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。作为另一实例,靶区域可包含以下、基本上由以下组成或由以下组成:侧接于第一引导rna识别序列的5’和/或3’序列和/或侧接于第二引导rna识别序列的5’和/或3’序列,并且相对于靶基因组基因座的其他区段,诸如侧接于靶基因组基因座内的一个或多个其他潜在引导rna识别序列的5’和/或3’序列,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。5’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。同样,3’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。因此,在其中在选择靶区域时考虑一个引导rna的方法中,举例来说,选择靶区域可包括比较靶基因组基因座的两个或更多个区段,其中各区段包含以下、基本上由以下组成或由以下组成:不存在于基因组中其他地方的不同引导rna识别序列和在所述不同引导rna识别序列的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,以及将相对于其他区段具有最高序列同一性百分比的区段选作靶区域。如果使用两个或更多个引导rna,方法可包括将相对于其他区段具有最高序列同一性百分比的两个或更多个区段选作靶区域。任选地,一个或多个区段可包含以下、基本上由以下组成或由以下组成:与靶基因组基因座中而非存在于基因组中其他地方的各引导rna识别序列相对应的区段。或者或另外,在其中使用两个引导rna的方法中,靶区域可包含以下、基本上由以下组成或由以下组成:在第一引导rna识别序列与第二引导rna识别序列或第一裂解位点与第二裂解位点之间的区域,并且相对于靶基因组基因座的其他区段,诸如在靶基因组基因座内的一对或多对其他潜在引导rna识别序列或裂解位点之间的区域,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。如果使用三个或更多个引导rna,相关区域将是在相隔最远的两个引导rna识别序列或两个裂解位点之间的区域。因此,在其中使用两个引导rna的方法中,举例来说,选择靶区域可包括比较靶基因组基因座的两个或更多个区段,其中各区段包含以下、基本上由以下组成或由以下组成:在一对不同引导rna识别序列之间的区域,其中所述引导rna识别序列不存在于基因组中其他地方,以及将相对于其他区段具有最高序列同一性百分比的区段选作靶区域。任选地,一个或多个区段包含以下、基本上由以下组成或由以下组成:与靶基因组基因座中各对不同引导rna识别序列相对应的区段,其中所述引导rna识别序列不存在于基因组中其他地方。或者或另外,在其中使用两个引导rna的方法中,靶区域可包含以下、基本上由以下组成或由以下组成:在第一引导rna识别序列与第二引导rna识别序列或第一裂解位点与第二裂解位点之间的区域和侧接于在所述第一引导rna识别序列与所述第二引导rna识别序列或所述第一裂解位点与所述第二裂解位点之间的基因组区域的5’和/或3’序列,并且相对于靶基因组基因座的其他区段,诸如在靶基因组基因座内的一对或多对其他潜在引导rna识别序列或裂解位点之间的区域和侧接于在一对或多对其他潜在引导rna识别序列或裂解位点之间的基因组区域的5’和/或3’序列,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。优选地,靶区域可包含以下、基本上由以下组成或由以下组成:在第一引导rna识别序列与第二引导rna识别序列或第一裂解位点与第二裂解位点之间的基因组区域和侧接于在所述第一引导rna识别序列与所述第二引导rna识别序列或所述第一裂解位点与所述第二裂解位点之间的所述基因组区域的5’和3’序列,并且相对于靶基因组基因座的其他区段,诸如在靶基因组基因座内的一对或多对其他潜在引导rna识别序列或裂解位点之间的区域和侧接于在一对或多对其他潜在引导rna识别序列或裂解位点之间的基因组区域的5’和3’序列,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。如果使用三个或更多个引导rna,那么相关区域将是侧接于在相隔最远的两个引导rna识别序列或两个裂解位点之间的基因组区域的5’和/或3’序列。5’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。同样,3’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。因此,在其中使用两个引导rna的方法中,举例来说,选择靶区域可包括比较靶基因组基因座的两个或更多个区段,其中各区段包含以下、基本上由以下组成或由以下组成:在一对不同引导rna识别序列之间的区域和在所述一对不同引导rna识别序列之间的基因组区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,其中所述引导rna识别序列不存在于基因组中其他地方,以及将相对于其他区段具有最高序列同一性百分比的区段选作靶区域。任选地,一个或多个区段包含以下、基本上由以下组成或由以下组成:与靶基因组基因座中各对不同引导rna识别序列相对应的区段,其中所述引导rna识别序列不存在于基因组中其他地方。或者或另外,在其中使用两个引导rna的方法中,靶区域可包含以下、基本上由以下组成或由以下组成:侧接于在第一引导rna识别序列与第二引导rna识别序列或第一裂解位点与第二裂解位点之间的基因组区域的5’和/或3’序列,并且相对于靶基因组基因座的其他区段,诸如侧接于在靶基因组基因座内的一对或多对其他潜在引导rna识别序列或裂解位点之间的基因组区域的5’和/或3’序列,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。优选地,靶区域可包含以下、基本上由以下组成或由以下组成:侧接于在第一引导rna识别序列与第二引导rna识别序列或第一裂解位点与第二裂解位点之间的基因组区域的5’和3’序列,并且相对于靶基因组基因座的其他区段,诸如侧接于在靶基因组基因座内的一对或多对其他潜在引导rna识别序列或裂解位点之间的基因组区域的5’和3’序列,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。如果使用三个或更多个引导rna,那么相关区域将是侧接于在相隔最远的两个引导rna识别序列或两个裂解位点之间的基因组区域的5’和/或3’序列。5’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。同样,3’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。因此,在其中使用两个引导rna的方法中,举例来说,选择靶区域可包括比较靶基因组基因座的两个或更多个非连续区段,其中各非连续区段包含以下、基本上由以下组成或由以下组成:在一对不同引导rna识别序列之间的基因组区域的5’侧、3’侧或各侧上的至少10bp、20bp、30bp、40bp、50bp、100bp、200bp、300bp、400bp、500bp、600bp、700bp、800bp、900bp、1,000bp、1kb、2kb、3kb、4kb、5kb、6、kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb或150kb的侧接序列,其中所述引导rna识别序列不存在于基因组中其他地方,以及将相对于其他非连续区段具有最高序列同一性百分比的非连续区段选作靶区域。任选地,一个或多个非连续区段包含以下、基本上由以下组成或由以下组成:与靶基因组基因座中各对不同引导rna识别序列相对应的非连续区段,其中所述引导rna识别序列不存在于基因组中其他地方。在其中使用外源性修复模板的方法中,靶区域可包含以下、基本上由以下组成或由以下组成:在5’靶标序列与3’靶标序列之间的区域,并且相对于靶基因组基因座的其他区段,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。或者或另外,靶区域可包含以下、基本上由以下组成或由以下组成:5’靶标序列和/或3’靶标序列,并且相对于靶基因组基因座的其他区段,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。优选地,靶区域可包含以下、基本上由以下组成或由以下组成:5’靶标序列和3’靶标序列,并且相对于靶基因组基因座的其他区段,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。举例来说,靶区域可包含以下、基本上由以下组成或由以下组成:由5’靶标序列和3’靶标序列侧接且包括所述5’靶标序列和所述3’靶标序列的区域,并且相对于靶基因组基因座的其他区段,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。同样,在其中使用外源性修复模板的方法中,靶区域可包含以下、基本上由以下组成或由以下组成:侧接于在所述外源性修复模板的5’靶标序列与3’靶标序列之间的基因组区域的5’和/或3’序列或侧接于在所述外源性修复模板的5’靶标序列与3’靶标序列之间的基因组区域且包括所述5’靶标序列和所述3’靶标序列的5’和/或3’序列,并且相对于靶基因组基因座的其他区段,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。优选地,靶区域可包含以下、基本上由以下组成或由以下组成:侧接于在外源性修复模板的5’靶标序列与3’靶标序列之间的基因组区域的5’和3’序列或侧接于在外源性修复模板的5’靶标序列与3’靶标序列之间的基因组区域且包括所述5’靶标序列和所述3’靶标序列的5’和3’序列,并且相对于靶基因组基因座的其他区段,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。或者,靶区域可包含以下、基本上由以下组成或由以下组成:在外源性修复模板的5’靶标序列与3’靶标序列之间的区域和侧接于在所述5’靶标序列与所述3’靶标序列之间的基因组区域的5’和/或3’序列,并且相对于靶基因组基因座的其他区段,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。优选地,靶区域可包含以下、基本上由以下组成或由以下组成:在外源性修复模板的5’靶标序列与3’靶标序列之间的区域和侧接于在所述5’靶标序列与所述3’靶标序列之间的基因组区域的5’和3’序列,并且相对于靶基因组基因座的其他区段,靶区域可具有高序列同一性百分比或低密度的单核苷酸变化。5’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。同样,3’侧接序列可为例如至少10、20、30、40、50、100、200、300、400、500、600、700、800、900或1,000bp的侧接序列或至少1、2、3、4、5、6、7、8、9、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150kb的侧接序列。通过本文公开的方法修饰的靶区域可包括细胞内的任何dna区段或区域(连续或非连续)。靶区域可为细胞所天然具有,可为整合至细胞的基因组中的异源性或外源性dna区段,或可为其组合。所述异源性或外源性dna区段可包括转基因、表达盒、编码选择标记的多核苷酸、或基因组dna的异源性或外源性区域。b.crispr/cas系统本文公开的方法利用成簇规律散布短回文重复序列(crispr)/crispr相关蛋白(cas)系统或所述系统的组分来修饰细胞内的基因组。crispr/cas系统包括cas基因的表达中涉及或指导cas基因的活性的转录物和其他要素。crispr/cas系统可为i型、ii型或iii型系统。或者,crispr/cas系统可为例如v型系统(例如v-a亚型或v-b亚型)。本文公开的方法和组合物通过利用crispr复合物(包含引导rna(grna)与cas蛋白复合)对核酸进行定点裂解来采用crispr/cas系统。用于本文公开的方法中的crispr/cas系统是非天然存在的。“非天然存在”系统包括指示涉及人工的任何事物,诸如系统的一个或多个组分被从它们的天然存在状态改变或突变,至少大致上不含至少一种它们在自然界中与其天然相伴的其他组分,或与至少一种它们不天然与其相伴的其他组分相伴。举例来说,一些crispr/cas系统采用非天然存在的crispr复合物,其包含不天然存在在一起的grna和cas蛋白。其他crispr/cas系统采用不天然存在的cas蛋白,并且其他crispr/cas系统采用不天然存在的grna。(1)cas蛋白cas蛋白通常包含至少一个可与引导rna(grna,以下更详细描述)相互作用的rna识别或结合结构域。cas蛋白也可包含核酸酶结构域(例如dna酶或rna酶结构域)、dna结合结构域、解旋酶结构域、蛋白质-蛋白质相互作用结构域、二聚化结构域和其他结构域。核酸酶结构域具有用于核酸裂解的催化活性,其包括使核酸分子的共价键断裂。裂解可产生钝性末端或交错末端,并且这可为单链或双链。举例来说,野生型cas9蛋白将通常产生钝性裂解产物。或者,野生型cpf1蛋白(例如fncpf1)可产生具有5核苷酸5’突出部分的裂解产物,其中裂解在非靶向链上发生在从pam序列开始第18碱基对之后,而在靶向链上发生在第23碱基之后。cas蛋白可具有完全裂解活性以在靶标核酸中产生双链断裂(例如具有钝性末端的双链断裂),或它可为在靶标核酸中产生单链断裂的切口酶。cas蛋白的实例包括cas1、cas1b、cas2、cas3、cas4、cas5、cas5e(casd)、cas6、cas6e、cas6f、cas7、cas8a1、cas8a2、cas8b、cas8c、cas9(csn1或csx12)、cas10、casl0d、casf、casg、cash、csy1、csy2、csy3、cse1(casa)、cse2(casb)、cse3(case)、cse4(casc)、csc1、csc2、csa5、csn2、csm2、csm3、csm4、csm5、csm6、cmr1、cmr3、cmr4、cmr5、cmr6、csb1、csb2、csb3、csx17、csx14、csx10、csx16、csax、csx3、csx1、csx15、csf1、csf2、csf3、csf4和cu1966及其同源物或经修饰形式。一示例性cas蛋白是来自ii型crispr/cas系统的cas9蛋白或源于cas9蛋白的蛋白质。cas9蛋白来自ii型crispr/cas系统,并且通常共有四个具有保守构造的关键基序。基序1、2和4是ruvc样基序,并且基序3是hnh基序。示例性cas9蛋白来自化脓性链球菌(streptococcuspyogenes)、嗜热链球菌(streptococcusthermophilus)、链球菌属某种(streptococcussp.)、金黄色葡萄球菌(staphylococcusaureus)、达松维尔拟诺卡氏菌(nocardiopsisdassonvillei)、始旋链霉菌(streptomycespristinaespiralis)、绿色产色链霉菌(streptomycesviridochromogenes)、绿色产色链霉菌、玫瑰链孢囊菌(streptosporangiumroseum)、玫瑰链孢囊菌、酸热脂环芽孢杆菌(alicyclobacillusacidocaldarius)、假蕈状芽孢杆菌(bacilluspseudomycoides)、还原硒酸盐芽孢杆菌(bacillusselenitireducens)、西伯利亚微小杆菌(exiguobacteriumsibiricum)、戴耳布吕克氏乳酸杆菌(lactobacillusdelbrueckii)、唾液乳酸杆菌(lactobacillussalivarius)、海洋微颤菌(microscillamarina)、伯克氏菌目细菌(burkholderialesbacterium)、萘降解极地单胞菌(polaromonasnaphthalenivorans)、极地单胞菌某种(polaromonassp.)、瓦氏鳄球藻(crocosphaerawatsonii)、蓝丝菌属某种(cyanothecesp.)、铜绿微囊藻(microcystisaeruginosa)、聚球藻属某种(synechococcussp.)、阿拉伯糖醋盐杆菌(acetohalobiumarabaticum)、丹氏制氨菌(ammonifexdegensii)、毕氏热解纤维素菌(caldicelulosiruptorbecscii)、candidatusdesulforudis、肉毒梭菌(clostridiumbotulinum)、艰难梭菌(clostridiumdifficile)、大芬戈尔德菌(finegoldiamagna)、嗜热盐喊厌氧菌(natranaerobiusthermophilus)、热丙酸盐暗色厌氧香肠状菌(pelotomaculumthermopropionicum)、喜温嗜酸硫杆菌(acidithiobacilluscaldus)、氧化亚铁嗜酸硫杆菌(acidithiobacillusferrooxidans)、酒色别样着色菌(allochromatiumvinosum)、海杆菌属某种(marinobactersp.)、嗜盐亚硝化球菌(nitrosococcushalophilus)、沃特森亚硝化球菌(nitrosococcuswatsoni)、游海假交替单胞菌(pseudoalteromonashaloplanktis)、成簇细枝菌(ktedonobacterracemifer)、调查甲烷盐菌(methanohalobiumevestigatum)、多变鱼腥藻(anabaenavariabilis)、泡沫节球藻(nodulariaspumigena)、念珠藻属某种(nostocsp.)、极大节旋藻(arthrospiramaxima)、钝顶节旋藻(arthrospiraplatensis)、节旋藻属某种(arthrospirasp.)、鞘丝藻属某种(lyngbyasp.)、喜泥微鞘藻(microcoleuschthonoplastes)、颤藻属某种(oscillatoriasp.)、运动石袍菌(petrotogamobilis)、非洲栖热腔菌(thermosiphoafricanus)、acaryochlorismarina、脑膜炎奈瑟氏菌(neisseriameningitidis)或空肠弯曲杆菌(campylobacterjejuni)。cas9家族成员的额外实例描述于出于所有目的以引用的方式整体并入本文的wo2014/131833中。来自化脓性链球菌的cas9(spcas9)(指定swissprot登录号q99zw2)是一示例性cas9蛋白。来自金黄色葡萄球菌的cas9(sacas9)(指定uniprot登录号j7rua5)是另一示例性cas9蛋白。来自空肠弯曲杆菌的cas9(cjcas9)(指定uniprot登录号q0p897)是另一示例性cas9蛋白。参见例如kim等(2017)nat.comm.8:14500,其出于所有目的以引用的方式整体并入本文。sacas9小于spcas9,并且cjcas9小于sacas9与spcas9两者。cas蛋白的另一实例是cpf1(来自普雷沃菌属(prevotella)和弗朗西斯氏菌属(francisella)的crispr1)蛋白。cpf1是一种大型蛋白质(约1300个氨基酸),其含有与cas9的相应结构域同源的ruvc样核酸酶结构域以及cas9的特征性精氨酸富集簇的对应物。然而,cpf1缺乏存在于cas9蛋白中的hnh核酸酶结构域,并且ruvc样结构域在cpf1序列中是连续的,这不同于cas9,在cas9中,它含有包括hnh结构域的长插入物。参见例如zetsche等(2015)cell163(3):759-771,其出于所有目的以引用的方式整体并入本文。示例性cpf1蛋白来自野兔热弗朗西斯氏菌1(francisellatularensis1)、野兔热弗朗西斯氏菌新凶手亚种(francisellatularensissubsp.novicida)、苏格兰普雷沃菌(prevotellaalbensis)、毛螺菌科细菌mc20171(lachnospiraceaebacteriummc20171)、瘤胃溶纤维丁酸弧菌(butyrivibrioproteoclasticus)、异域菌门细菌gw2011_gwa2_33_10(peregrinibacteriabacteriumgw2011_gwa2_33_10)、俭菌总门细菌gw2011_gwc2_44_17(parcubacteriabacteriumgw2011_gwc2_44_17)、史密斯氏菌属某种scadc(smithellasp.scadc)、氨基酸球菌属某种bv3l6(acidaminococcussp.bv3l6)、毛螺菌科细菌ma2020(lachnospiraceaebacteriumma2020)、candidatusmethanoplasmatermitum、挑剔真杆菌(eubacteriumeligens)、牛眼莫拉菌237(moraxellabovoculi237)、稻田氏钩端螺旋体(leptospirainadai)、毛螺菌科细菌nd2006、狗口腔卟啉单胞菌3(porphyromonascrevioricanis3)、解糖胨普雷沃菌(prevotelladisiens)和猕猴卟啉单胞菌(porphyromonasmacacae)。来自新凶手弗朗西斯氏菌u112(francisellanovicidau112)的cpf1(fncpf1;指定uniprot登录号a0q7q2)是一示例性cpf1蛋白。cas蛋白可为野生型蛋白质(即存在于自然界中的那些)、经修饰cas蛋白(即cas蛋白变体)、或野生型或经修饰cas蛋白的片段。cas蛋白也可为关于野生型或经修饰cas蛋白的催化活性的活性变体或片段。关于催化活性的活性变体或片段可包含与野生型或经修饰cas蛋白或其一部分的至少80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更大的序列同一性,其中活性变体保留在所需裂解位点处切割的能力,因此保留切口诱导或双链断裂诱导活性。针对切口诱导或双链断裂诱导活性的测定是已知的,并且通常测量cas蛋白对含有裂解位点的dna底物的总体活性和特异性。经修饰cas蛋白的一个实例是经修饰spcas9-hf1蛋白,其是化脓性链球菌cas9的具有被设计来使非特异性dna接触降低的改变(n497a/r661a/q695a/q926a)的高保真变体。参见例如kleinstiver等(2016)nature529(7587):490-495,其出于所有目的以引用的方式整体并入本文。经修饰cas蛋白的另一实例是被设计来使脱靶效应降低的经修饰espcas9变体(k848a/k1003a/r1060a)。参见例如slaymaker等(2016)science351(6268):84-88,其出于所有目的以引用的方式整体并入本文。其他spcas9变体包括k855a和k810a/k1003a/r1060a。cas蛋白可被修饰以使核酸结合亲和力、核酸结合特异性和酶活性中的一者或多者增加或降低。cas蛋白也可被修饰以改变蛋白质的任何其他活性或性质,诸如稳定性。举例来说,cas蛋白的一个或多个核酸酶结构域可被修饰、缺失或失活,或cas蛋白可被截短以移除不为蛋白质的功能所必需的结构域或使cas蛋白的活性最优化(例如增强或降低)。cas蛋白可包含至少一个核酸酶结构域,诸如dna酶结构域。举例来说,野生型cpf1蛋白通常包含会裂解靶标dna的两个链,或许呈二聚构型的ruvc样结构域。cas蛋白也可包含至少两个核酸酶结构域,诸如dna酶结构域。举例来说,野生型cas9蛋白通常包含ruvc样核酸酶结构域和hnh样核酸酶结构域。ruvc结构域和hnh结构域可各自切割双链dna的不同链以在dna中产生双链断裂。参见例如jinek等(2012)science337:816-821,其出于所有目的以引用的方式整体并入本文。一个或两个核酸酶结构域可被缺失或突变以使它们不再具有功能性或具有降低的核酸酶活性。如果一个核酸酶结构域被缺失或突变,那么所得cas蛋白(例如cas9)可被称为切口酶,并且可在双链dna内在引导rna识别序列处产生单链断裂而非双链断裂(即它可裂解互补链或非互补链,而非两者)。如果两个核酸酶结构域均被缺失或突变,那么所得cas蛋白(例如cas9)裂解双链dna的两个链的能力将降低(例如核酸酶无效cas蛋白)。使cas9转变成切口酶的突变的一实例是来自化脓性链球菌的cas9的ruvc结构域中的d10a(在cas9的位置10处,天冬氨酸变为丙氨酸)突变。同样,来自化脓性链球菌的cas9的hnh结构域中的h939a(在氨基酸位置839处,组氨酸变为丙氨酸)或h840a(在氨基酸位置840处,组氨酸变为丙氨酸)或n863a(在氨基酸位置n863处,天冬酰胺变为丙氨酸)可使cas9转变成切口酶。使cas9转变成切口酶的突变的其他实例包括来自嗜热链球菌(s.thermophilus)的cas9的相应突变。参见例如sapranauskas等(2011)nucleicacidsresearch39:9275-9282和wo2013/141680,其各自出于所有目的以引用的方式整体并入本文。所述突变可使用诸如定点诱变、pcr介导的诱变或全基因合成的方法来产生。产生切口酶的其他突变的实例可例如见于wo2013/176772和wo2013/142578中,所述专利各自出于所有目的以引用的方式整体并入本文。如果cas蛋白中的所有核酸酶结构域都被缺失或突变(例如cas9蛋白中的两个核酸酶结构域均被缺失或突变),那么所得cas蛋白(例如cas9)裂解双链dna的两个链的能力将降低(例如核酸酶无效或核酸酶非活性cas蛋白)。一个特定实例是d10a/h840a化脓性链球菌cas9双重突变体,或在来自另一物种的cas9的情况下在与化脓性链球菌cas9最优比对时的相应双重突变体。另一特定实例是d10a/n863a化脓性链球菌cas9双重突变体,或在来自另一物种的cas9的情况下在与化脓性链球菌cas9最优比对时的相应双重突变体。金黄色葡萄球菌cas9蛋白的催化结构域中的失活性突变的实例也是已知的。举例来说,金黄色葡萄球菌cas9酶(sacas9)可包含在位置n580处的取代(例如n580a取代)和在位置d10处的取代(例如d10a取代)以产生核酸酶非活性cas蛋白。参见例如wo2016/106236,其出于所有目的以引用的方式整体并入本文。cpf1蛋白的催化结构域中的失活性突变的实例也是已知的。关于来自新凶手弗朗西斯氏菌u112(fncpf1)、氨基酸球菌属某种bv3l6(ascpf1)、毛螺菌科细菌nd2006(lbcpf1)和牛眼莫拉菌237(mbcpf1cpf1)的cpf1蛋白,所述突变可包括在ascpf1的位置908、993或1263或cpf1直系同源物中的相应位置、或lbcpf1的位置832、925、947或1180或cpf1直系同源物中的相应位置处的突变。所述突变可包括例如ascpf1的突变d908a、e993a和d1263a或cpf1直系同源物中的相应突变、或lbcpf1的突变d832a、e925a、d947a和d1180a或cpf1直系同源物中的相应突变中的一者或多者。参见例如us2016/0208243,其出于所有目的以引用的方式整体并入本文。cas蛋白也可被可操作地连接至异源性多肽,呈融合蛋白形式。举例来说,可使cas蛋白融合于裂解结构域、表观遗传修饰结构域、转录活化结构域或转录阻遏物结构域。参见wo2014/089290,其出于所有目的以引用的方式整体并入本文。也可使cas蛋白融合于异源性多肽,从而提供增加或降低的稳定性。融合结构域或异源性多肽可位于n末端、c末端或cas蛋白内部。cas融合蛋白的一实例是融合于提供亚细胞定位的异源性多肽的cas蛋白。所述异源性多肽可包括例如用于靶向核的一个或多个核定位信号(nls)诸如sv40nls、用于靶向线粒体的线粒体定位信号、er保留信号等。参见例如lange等(2007)j.biol.chem.282:5101-5105,其出于所有目的以引用的方式整体并入本文。其他适合nls包括α-输入蛋白nls。所述亚细胞定位信号可位于n末端、c末端或cas蛋白内的任何地方。nls可包含碱性氨基酸链段,并且可为单分型序列或双分型序列。任选地,cas蛋白包含两个或更多个nls,包括在n末端的nls(例如α-输入蛋白nls)和/或在c末端的nls(例如sv40nls)。也可使cas蛋白可操作地连接至细胞穿透结构域。举例来说,细胞穿透结构域可源于hiv-1tat蛋白、来自人乙型肝炎病毒的tlm细胞穿透基序、mpg、pep-1、vp22、来自单纯疱疹病毒的细胞穿透肽或聚精氨酸肽序列。参见例如wo2014/089290,其出于所有目的以引用的方式整体并入本文。细胞穿透结构域可位于n末端、c末端或cas蛋白内的任何地方。也可使cas蛋白可操作地连接至异源性多肽以便追踪或纯化,诸如荧光蛋白、纯化标签或表位标签。荧光蛋白的实例包括绿色荧光蛋白(例如gfp、gfp-2、taggfp、turbogfp、egfp、emerald、azamigreen、monomericazamigreen、copgfp、acegfp、zsgreenl)、黄色荧光蛋白(例如yfp、eyfp、citrine、venus、ypet、phiyfp、zsyellowl)、蓝色荧光蛋白(例如ebfp、ebfp2、azurite、mkalamal、gfpuv、sapphire、t-sapphire)、青色荧光蛋白(例如ecfp、cerulean、cypet、amcyanl、midoriishi-cyan)、红色荧光蛋白(mkate、mkate2、mplum、dsredmonomer、mcherry、mrfp1、dsred-express、dsred2、dsred-monomer、hcred-tandem、hcredl、asred2、eqfp611、mraspberry、mstrawberry、jred)、橙色荧光蛋白(morange、mko、kusabira-orange、monomerickusabira-orange、mtangerine、tdtomato)和任何其他适合荧光蛋白。标签的实例包括谷胱甘肽-s-转移酶(gst)、几丁质结合蛋白(cbp)、麦芽糖结合蛋白、硫氧还蛋白(trx)、聚(nanp)、串联亲和纯化(tap)标签、myc、acv5、au1、au5、e、ecs、e2、flag、血凝素(ha)、nus、softag1、softag3、strep、sbp、glu-glu、hsv、kt3、s、s1、t7、v5、vsv-g、组氨酸(his)、生物素羧基载体蛋白(bccp)和钙调蛋白(calmodulin)。也可使cas9蛋白栓系于外源性修复模板或经标记核酸。所述栓系(即物理连接)可通过共价相互作用或非共价相互作用来实现,并且栓系可为直接的(例如通过直接融合或化学缀合,此可通过对蛋白质上半胱氨酸或赖氨酸残基的修饰或内含肽修饰来实现),或可通过一个或多个间插接头或衔接物分子诸如链霉亲和素或适体来实现。参见例如pierce等(2005)minirev.med.chem.5(1):41-55;duckworth等(2007)angew.chem.int.ed.engl.46(46):8819-8822;schaeffer和dixon(2009)australianj.chem.62(10):1328-1332;goodman等(2009)chembiochem.10(9):1551-1557;以及khatwani等(2012)bioorg.med.chem.20(14):4532-4539,其各自出于所有目的以引用的方式整体并入本文。用于合成蛋白质-核酸缀合物的非共价策略包括生物素-链霉亲和素和镍-组氨酸方法。共价蛋白质-核酸缀合物可通过使用广泛多种化学过程使适当官能化的核酸和蛋白质连接来合成。这些化学过程中的一些涉及使寡核苷酸直接连接至蛋白质表面上的氨基酸残基(例如赖氨酸胺或半胱氨酸硫醇),而其他更复杂流程需要蛋白质的翻译后修饰或涉及催化性或反应性蛋白质结构域。用于使蛋白质共价连接至核酸的方法可包括例如使寡核苷酸化学交联于蛋白质赖氨酸或半胱氨酸残基、表达蛋白连接、化学酶法和使用光适体。可使外源性修复模板或经标记核酸栓系于c末端、n末端或cas9蛋白内的内部区域。优选地,使外源性修复模板或经标记核酸栓系于cas9蛋白的c末端或n末端。同样,可使cas9蛋白栓系于5’末端、3’末端或外源性修复模板或经标记核酸内的内部区域。也就是说,外源性修复模板或经标记核酸可以任何定向和极性加以栓系。优选地,使cas9蛋白栓系于外源性修复模板或经标记核酸的5’末端或3’末端。cas蛋白可以任何形式提供。举例来说,cas蛋白可以蛋白质形式诸如与grna复合的cas蛋白提供。或者,cas蛋白可以编码所述cas蛋白的核酸形式诸如rna(例如信使rna(mrna))或dna提供。任选地,编码cas蛋白的核酸可经密码子优化以达成在特定细胞或生物体中高效翻译成蛋白质。举例来说,编码cas蛋白的核酸可被修饰以用相较于天然存在的多核苷酸序列,在细菌细胞、酵母细胞、人细胞、非人细胞、哺乳动物细胞、啮齿动物细胞、小鼠细胞、大鼠细胞或任何其他目标宿主细胞中具有更高使用频率的密码子进行替代。当将编码cas蛋白的核酸引入细胞中时,cas蛋白可在细胞中短暂、条件性或组成性表达。编码cas蛋白的核酸可被稳定整合在细胞基因组中,并且可操作地连接至在细胞中具有活性的启动子。或者,编码cas蛋白的核酸可被可操作地连接至表达构建体中的启动子。表达构建体包括能够指导基因或其他目标核酸序列(例如cas基因)的表达,以及可将这种目标核酸序列转移至靶标细胞中的任何核酸构建体。举例来说,编码cas蛋白的核酸可在包含核酸插入物的靶向载体和/或包含编码grna的dna的载体中。或者,它可在不同于包含核酸插入物的靶向载体和/或不同于包含编码grna的dna的载体的载体或质粒中。可用于表达构建体中的启动子包括例如在真核细胞、人细胞、非人细胞、哺乳动物细胞、非人哺乳动物细胞、啮齿动物细胞、小鼠细胞、大鼠细胞、仓鼠细胞、兔细胞、多能细胞、胚胎干(es)细胞或接合子中的一者或多者中具有活性的启动子。所述启动子可为例如条件型启动子、诱导型启动子、组成型启动子或组织特异性启动子。任选地,启动子可为在一个方向上驱动cas蛋白的表达,并且在另一方向上驱动引导rna的表达的双向启动子。所述双向启动子可由以下组成:(1)完整常规单向poliii启动子,其含有3个外部控制元件:远端序列元件(dse)、近端序列元件(pse)和tata框;和(2)包括pse和tata框的第二基本poliii启动子,其以相反定向融合于dse的5′末端。举例来说,在h1启动子中,dse邻近于pse和tata框,并且可通过产生杂合启动子来致使启动子具有双向性,其中通过附接源于u6启动子的pse和tata框来控制在反向上的转录。参见例如us2016/0074535,其出于所有目的以引用的方式整体并入本文。使用双向启动子来同时表达编码cas蛋白的基因和编码引导rna的基因允许产生紧凑表达盒以有助于进行递送。(2)引导rna“引导rna”或“grna”是结合cas蛋白(例如cas9蛋白),并且使所述cas蛋白靶向靶标dna内的特定位置的rna分子。引导rna可包含两个区段:“dna靶向区段”和“蛋白质结合区段”。“区段”包括分子的节段或区域,诸如rna中的连续核苷酸链段。一些grna,诸如针对cas9的那些,可包含两个单独rna分子:“活化rna”(例如tracrrna)和“靶向rna”(例如crisprrna或crrna)。其他grna是单一rna分子(单一rna多核苷酸),其也可称为“单分子grna”、“单引导rna”或“sgrna”。参见例如wo2013/176772、wo2014/065596、wo2014/089290、wo2014/093622、wo2014/099750、wo2013/142578和wo2014/131833,其各自出于所有目的以引用的方式整体并入本文。对于cas9,举例来说,单引导rna可包含crrna融合于tracrrna(例如通过接头)。对于cpf1,举例来说,仅crrna为实现与靶标序列的结合或裂解所需。术语“引导rna”和“grna”包括双分子grna(即模块grna)与单分子grna两者。一示例性双分子grna包含crrna样(“crisprrna”或“靶向rna”或“crrna”或“crrna重复”)分子和相应tracrrna样(“反式作用性crisprrna”或“活化rna”或“tracrrna”)分子。crrna包含grna的dna靶向区段(单链)与形成grna的蛋白质结合区段的dsrna双链体的一半的核苷酸链段两者。相应tracrrna(活化rna)包含形成grna的蛋白质结合区段的dsrna双链体的另一半的核苷酸链段。crrna的核苷酸链段与tracrrna的核苷酸链段互补和杂交以形成grna的蛋白质结合结构域的dsrna双链体。因此,各crrna可被称为具有相应tracrrna。在其中需要crrna与tracrrna两者的系统中,crrna和相应tracrrna杂交以形成grna。在其中仅需要crrna的系统中,crrna可为grna。crrna另外提供杂交至引导rna识别序列的单链dna靶向区段。如果用于在细胞内的修饰,那么给定crrna或tracrrna分子的确切序列可被设计来对其中将使用rna分子的物种来说具有特异性。参见例如mali等(2013)science339:823-826;jinek等(2012)science337:816-821;hwang等(2013)nat.biotechnol.31:227-229;jiang等(2013)nat.biotechnol.31:233-239;以及cong等(2013)science339:819-823,其各自出于所有目的以引用的方式整体并入本文。给定grna的dna靶向区段(crrna)包含互补于靶标dna中的序列(即引导rna识别序列)的核苷酸序列。grna的dna靶向区段与靶标dna以序列特异性方式通过杂交(即碱基配对)来相互作用。因此,dna靶向区段的核苷酸序列可变化,并且决定靶标dna内grna和靶标dna将进行相互作用的位置。主题grna的dna靶向区段可被修饰以杂交于靶标dna内的任何所需序列。天然存在的crrna视crispr/cas系统和生物体而不同,但常常含有长度在21至72个核苷酸之间的靶向区段,由长度在21至46个核苷酸之间的两个同向重复序列(dr)侧接(参见例如wo2014/131833,其出于所有目的以引用的方式整体并入本文)。在化脓性链球菌的情况下,dr的长度是36个核苷酸,并且靶向区段的长度是30个核苷酸。位于3’的dr与相应tracrrna互补和杂交,所述tracrrna转而结合cas蛋白。dna靶向区段可具有至少约12个核苷酸、至少约15个核苷酸、至少约17个核苷酸、至少约18个核苷酸、至少约19个核苷酸、至少约20个核苷酸、至少约25个核苷酸、至少约30个核苷酸、至少约35个核苷酸或至少约40个核苷酸的长度。所述dna靶向区段可具有约12个核苷酸至约100个核苷酸、约12个核苷酸至约80个核苷酸、约12个核苷酸至约50个核苷酸、约12个核苷酸至约40个核苷酸、约12个核苷酸至约30个核苷酸、约12个核苷酸至约25个核苷酸、或约12个核苷酸至约20个核苷酸的长度。举例来说,dna靶向区段可为约15个核苷酸至约25个核苷酸(例如约17个核苷酸至约20个核苷酸、或约17个核苷酸、约18个核苷酸、约19个核苷酸或约20个核苷酸)。参见例如us2016/0024523,其出于所有目的以引用的方式整体并入本文。对于来自化脓性链球菌的cas9,典型dna靶向区段的长度在16与20个核苷酸之间,或长度在17与20个核苷酸之间。对于来自金黄色葡萄球菌的cas9,典型dna靶向区段的长度在21与23个核苷酸之间。对于cpf1,典型dna靶向区段的长度是至少16个核苷酸,或长度是至少18个核苷酸。tracrrna可呈任何形式(例如全长tracrrna或活性部分tracrrna),并且具有不同长度。它们可包括初级转录物或经加工形式。举例来说,tracrrna(作为单引导rna的一部分,或呈作为双分子grna的一部分的单独分子形式)可包含以下或由以下组成:野生型tracrrna序列的全部或一部分(例如野生型tracrrna序列的约或超过约20、26、32、45、48、54、63、67、85个或更多个核苷酸)。来自化脓性链球菌的野生型tracrrna序列的实例包括171核苷酸、89核苷酸、75核苷酸和65核苷酸形式。参见例如deltcheva等(2011)nature471:602-607;wo2014/093661,其各自出于所有目的以引用的方式整体并入本文。单引导rna(sgrna)内的tracrrna的实例包括见于sgrna的+48、+54、+67和+85形式内的tracrrna区段,其中“+n”指示直至野生型tracrrna的+n核苷酸被包括在sgrna中。参见us8,697,359,其出于所有目的以引用的方式整体并入本文。dna靶向序列与靶标dna内的引导rna识别序列之间的互补性百分比可为至少60%(例如至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少97%、至少98%、至少99%或100%)。历经约20个连续核苷酸,dna靶向序列与靶标dna内的引导rna识别序列之间的互补性百分比可为至少60%。作为一实例,在靶标dna的互补链内的引导rna识别序列的5’末端,历经14个连续核苷酸,dna靶向序列与靶标dna内的引导rna识别序列之间的互补性百分比是100%,并且历经其余部分,互补性百分比低至0%。在这种情况下,dna靶向序列的长度可被视为是14个核苷酸。作为另一实例,在靶标dna的互补链内的引导rna识别序列的5’末端,历经7个连续核苷酸,dna靶向序列与靶标dna内的引导rna识别序列之间的互补性百分比是100%,并且历经其余部分,互补性百分比低至0%。在这种情况下,dna靶向序列的长度可被视为是7个核苷酸。在一些引导rna中,dna靶向序列内的至少17个核苷酸互补于靶标dna。举例来说,dna靶向序列的长度可为20个核苷酸,并且可包含1、2或3个与靶标dna(引导rna识别序列)的不匹配。优选地,不匹配不邻近于原间隔体邻近基序(pam)序列(例如不匹配在dna靶向序列的5’末端,或不匹配离pam序列至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18或19个碱基对)。grna的蛋白质结合区段可包含彼此互补的两个核苷酸链段。蛋白质结合区段的互补性核苷酸杂交以形成双链rna双链体(dsrna)。主题grna的蛋白质结合区段与cas蛋白相互作用,并且grna通过dna靶向区段来将结合的cas蛋白引导至靶标dna内的特定核苷酸序列。单引导rna具有dna靶向区段和骨架序列(即引导rna的蛋白质结合或cas结合序列)。示例性骨架序列包括:gttggaaccattcaaaacagcatagcaagttaaaataaggctagtccgttatcaacttgaaaaagtggcaccgagtcggtgc(seqidno:150);gttttagagctagaaatagcaagttaaaataaggctagtccgttatcaacttgaaaaagtggcaccgagtcggtgc(seqidno:151);和gtttaagagctatgctggaaacagcatagcaagtttaaataaggctagtccgttatcaacttgaaaaagtggcaccgagtcggtgc(seqidno:152)。引导rna可包括提供额外合乎需要特征(例如经改进或经调控稳定性;亚细胞靶向;用荧光标记进行追踪;蛋白质或蛋白质复合物的结合位点等)的修饰或序列。所述修饰的实例包括例如5'帽(例如7-甲基鸟苷酸帽(m7g));3'聚腺苷酸化尾部(即3'聚腺苷酸(poly(a))尾部);核糖开关序列(例如以允许达成经调控稳定性和/或经调控蛋白质和/或蛋白质复合物可及性);稳定性控制序列;形成dsrna双链体(即发夹)的序列;使rna靶向亚细胞位置(例如核、线粒体、叶绿体等)的修饰或序列;提供追踪的修饰或序列(例如直接缀合于荧光分子,缀合于有助于荧光检测的部分,允许达成荧光检测的序列,等);提供蛋白质(例如作用于dna的蛋白质,包括转录活化子、转录阻遏物、dna甲基转移酶、dna脱甲基酶、组蛋白乙酰基转移酶、组蛋白脱乙酰基酶等)的结合位点的修饰或序列;及其组合。修饰的其他实例包括工程化的茎环双链体结构、工程化的突起区域、在茎环双链体结构的3’的工程化发夹或其任何组合。参见例如us2015/0376586,其出于所有目的以引用的方式整体并入本文。突起可为由crrna样区域和最小tracrrna样区域组成的双链体内的未配对核苷酸区域。突起可在双链体的一侧包含未配对5'-xxxy-3',其中x是任何嘌呤,并且y可为可与相对链上的核苷酸形成摇摆配对的核苷酸,并且突起可在双链体的另一侧包含未配对核苷酸区域。引导rna可以任何形式提供。举例来说,grna可以呈两个分子形式(单独crrna和tracrrna)或呈一个分子形式(sgrna)的rna形式提供,并且任选以与cas蛋白的复合物形式提供。举例来说,grna可通过使用例如t7rna聚合酶进行体外转录来制备(参见例如wo2014/089290和wo2014/065596,其各自出于所有目的以引用的方式整体并入本文)。引导rna也可通过化学合成制备。grna也可以编码grna的dna形式提供。编码grna的dna可编码单一rna分子(sgrna)或单独rna分子(例如单独crrna和tracrrna)。在后述情况下,编码grna的dna可以一个dna分子形式或以分别编码crrna和tracrrna的单独dna分子形式提供。当grna以dna形式提供时,所述grna可在细胞中短暂、条件性或组成性表达。编码grna的dna可被稳定整合至细胞基因组中,并且可操作地连接至在细胞中具有活性的启动子。或者,编码grna的dna可被可操作地连接至表达构建体中的启动子。举例来说,编码grna的dna可在包含外源性修复模板的载体和/或包含编码cas蛋白的核酸的载体中。或者,它可在不同于包含外源性修复模板的载体和/或包含编码cas蛋白的核酸的载体的载体或质粒中。可用于所述表达构建体中的启动子包括例如在真核细胞、人细胞、非人细胞、哺乳动物细胞、非人哺乳动物细胞、啮齿动物细胞、小鼠细胞、大鼠细胞、仓鼠细胞、兔细胞、多能细胞、胚胎干(es)细胞或接合子中的一者或多者中具有活性的启动子。所述启动子可为例如条件型启动子、诱导型启动子、组成型启动子或组织特异性启动子。所述启动子也可为例如双向启动子。适合启动子的特定实例包括rna聚合酶iii启动子,诸如人u6启动子、大鼠u6聚合酶iii启动子或小鼠u6聚合酶iii启动子。(3)引导rna识别序列术语“引导rna识别序列”包括存在于靶标dna中的由grna的dna靶向区段将与其结合的核酸序列,前提是存在足以达成结合的条件。举例来说,引导rna识别序列包括引导rna被设计来与其具有互补性的序列,其中引导rna识别序列与dna靶向序列之间的杂交促进形成crispr复合物。未必需要完全互补性,前提是存在足以导致杂交和促进形成crispr复合物的互补性。引导rna识别序列也包括cas蛋白的裂解位点,以下更详细描述。引导rna识别序列可包含任何多核苷酸,其可位于例如细胞的核或细胞质中或细胞的细胞器诸如线粒体或叶绿体内。靶标dna内的引导rna识别序列可由cas蛋白或grna靶向(即由其结合,与其杂交,或与其互补)。适合dna/rna结合条件包括通常存在于细胞中的生理条件。其他适合dna/rna结合条件(例如在无细胞系统的情况下的条件)在本领域中是已知的(参见例如molecularcloning:alaboratorymanual,第3版(sambrook等,harborlaboratorypress2001),其出于所有目的以引用的方式整体并入本文)。靶标dna的与cas蛋白或grna互补和杂交的链可称为“互补链”,并且靶标dna的互补于“互补链”(并且因此不互补于cas蛋白或grna)的链可称为“非互补链”或“模板链”。cas蛋白可在存在于靶标dna中的由grna的dna靶向区段将与其结合的核酸序列的内部或外部的位点处裂解核酸。“裂解位点”包括核酸的由cas蛋白产生单链断裂或双链断裂所处的位置。举例来说,形成crispr复合物(包含grna杂交于引导rna识别序列以及与cas蛋白复合)可导致在存在于靶标dna中的由grna的dna靶向区段将与其结合的核酸序列中或附近(例如在离所述核酸序列1、2、3、4、5、6、7、8、9、10、20、50个或更多个碱基对内)对一个或两个链的裂解。如果裂解位点在grna的dna靶向区段将与其结合的核酸序列的外部,那么裂解位点仍然被视为在“引导rna识别序列”内。裂解位点可在核酸的仅一个链上或在两个链上。裂解位点可在核酸的两个链上的相同位置处(产生钝性末端),或可在各链上的不同位点处(产生交错末端(即突出部分))。交错末端可例如通过使用两个cas蛋白来产生,所述cas蛋白各自在不同链上的不同裂解位点处产生单链断裂,由此产生双链断裂。举例来说,第一切口酶可在双链dna(dsdna)的第一链上产生单链断裂,并且第二切口酶可在dsdna的第二链上产生单链断裂,以致产生突出序列。在一些情况下,切口酶在第一链上的引导rna识别序列与切口酶在第二链上的引导rna识别序列分隔至少2、3、4、5、6、7、8、9、10、15、20、25、30、40、50、75、100、250、500或1,000个碱基对。由cas蛋白对靶标dna的位点特异性结合和裂解可发生在由(i)grna与靶标dna之间的碱基配对互补性与(ii)靶标dna中的称为原间隔体邻近基序(pam)的短基序两者决定的位置处。pam可侧接于引导rna识别序列。任选地,引导rna识别序列可由pam侧接在3’末端上。或者,引导rna识别序列可由pam侧接在5’末端上。举例来说,cas蛋白的裂解位点可为在pam序列的上游或下游的约1至约10或约2至约5个碱基对(例如3个碱基对)。在一些情况下(例如当使用来自化脓性链球菌的cas9或密切相关cas9时),非互补链的pam序列可为5'-n1gg-3',其中n1是任何dna核苷酸,并且紧靠靶标dna的非互补链的引导rna识别序列的3'。因此,互补链的pam序列将是5'-ccn2-3',其中n2是任何dna核苷酸,并且紧靠靶标dna的互补链的引导rna识别序列的5'。在一些所述情况下,n1和n2可互补,并且n1-n2碱基对可为任何碱基对(例如n1=c且n2=g;n1=g且n2=c;n1=a且n2=t;或n1=t且n2=a)。在来自金黄色葡萄球菌的cas9的情况下,pam可为nngrrt(seqidno:146)或nngrr(seqidno:147),其中n可为a、g、c或t,并且r可为g或a。在来自空肠弯曲杆菌的cas9的情况下,pam可为例如nnnnacac或nnnnryac,其中n可为a、g、c或t,并且r可为g或a。在一些情况下(例如对于fncpf1),pam序列可在5’末端的上游,并且具有序列5’-ttn-3’。引导rna识别序列的实例包括互补于grna的dna靶向区段的dna序列,或这种dna序列加上pam序列。举例来说,靶标基序可为紧靠在由cas9蛋白识别的ngg基序之前的20核苷酸dna序列,诸如gn19ngg(seqidno:1)或n20ngg(seqidno:2)(参见例如wo2014/165825,其出于所有目的以引用的方式整体并入本文)。在5’末端的鸟嘌呤可有助于在细胞中通过rna聚合酶达成的转录。引导rna识别序列的其他实例可在5’末端包括两个鸟嘌呤核苷酸(例如ggn20ngg;seqidno:3)以有助于在体外通过t7聚合酶达成的高效转录。参见例如wo2014/065596,其出于所有目的以引用的方式整体并入本文。其他引导rna识别序列可具有seqidno:1-3的长度在4-22个之间的核苷酸,包括5’g或gg和3’gg或ngg。其他引导rna识别序列可具有seqidno:1-3的长度在14与20个之间的核苷酸。引导rna识别序列可为任何细胞内源性或外源性核酸序列。引导rna识别序列可为编码基因产物(例如蛋白质)的序列或非编码序列(例如调控序列),或可包括两者。c.外源性修复模板本文公开的方法和组合物可利用外源性修复模板来在用cas蛋白裂解靶基因组基因座之后修饰所述靶基因组基因座。举例来说,细胞可为单细胞期胚胎,并且外源性修复模板的长度可小于5kb。在除单细胞期胚胎以外的细胞类型中,外源性修复模板(例如靶向载体)可更长。举例来说,在除单细胞期胚胎以外的细胞类型中,外源性修复模板可为如在本文中其他地方所述的大型靶向载体(ltvec)(例如具有至少10kb的长度或具有总和是至少10kb的5’同源臂和3’同源臂的靶向载体)。使用外源性修复模板与cas蛋白组合可通过促进同源性引导的修复来在靶基因组基因座处产生更精确修饰。在所述方法中,cas蛋白裂解靶基因组基因座以产生单链断裂(切口)或双链断裂,并且外源性修复模板通过非同源性末端接合(nhej)介导的连接或通过同源性引导的修复事件来使靶标核酸重组。任选地,用外源性修复模板进行的修复会移除或破坏引导rna识别序列或cas裂解位点以使已被靶向的等位基因不能再由cas蛋白靶向。外源性修复模板可包含脱氧核糖核酸(dna)或核糖核酸(rna),它们可为单链或双链,并且它们可呈线性或环状形式。举例来说,外源性修复模板可为单链寡脱氧核苷酸(ssodn)。参见例如yoshimi等(2016)nat.commun.7:10431,其出于所有目的以引用的方式整体并入本文。一示例性外源性修复模板的长度在约50个核苷酸至约5kb之间,在约50个核苷酸至约3kb之间,或在约50至约1,000个核苷酸之间。其他示例性外源性修复模板的长度在约40至约200个核苷酸之间。举例来说,外源性修复模板的长度可在约50至约60、约60至约70、约70至约80、约80至约90、约90至约100、约100至约110、约110至约120、约120至约130、约130至约140、约140至约150、约150至约160、约160至约170、约170至约180、约180至约190、或约190至约200个核苷酸之间。或者,外源性修复模板的长度可在约50至约100、约100至约200、约200至约300、约300至约400、约400至约500、约500至约600、约600至约700、约700至约800、约800至约900、或约900至约1,000个核苷酸之间。或者,外源性修复模板的长度可在约1kb至约1.5kb、约1.5kb至约2kb、约2kb至约2.5kb、约2.5kb至约3kb、约3kb至约3.5kb、约3.5kb至约4kb、约4kb至约4.5kb、或约4.5kb至约5kb之间。或者,外源性修复模板的长度可为例如不超过5kb、4.5kb、4kb、3.5kb、3kb、2.5kb、2kb、1.5kb、1kb、900个核苷酸、800个核苷酸、700个核苷酸、600个核苷酸、500个核苷酸、400个核苷酸、300个核苷酸、200个核苷酸、100个核苷酸或50个核苷酸。在除单细胞期胚胎以外的细胞类型中,外源性修复模板(例如靶向载体)可更长。举例来说,在除单细胞期胚胎以外的细胞类型中,外源性修复模板可为如在本文中其他地方所述的大型靶向载体(ltvec)。在一个实例中,外源性修复模板是长度在约80个核苷酸与约200个核苷酸之间的ssodn。在另一实例中,外源性修复模板是长度在约80个核苷酸与约3kb之间的ssodn。这种ssodn可具有例如各自长度在约40个核苷酸与约60个核苷酸之间的同源臂。这种ssodn也可具有例如各自长度在约30个核苷酸与100个核苷酸之间的同源臂。同源臂可为对称的(例如各自长度是40个核苷酸或各自长度是60个核苷酸),或它们可为不对称的(例如一个同源臂的长度是36个核苷酸,并且一个同源臂的长度是91个核苷酸)。外源性修复模板可包括提供额外合乎需要特征(例如经改进或经调控稳定性;用荧光标记进行追踪或检测;蛋白质或蛋白质复合物的结合位点等)的修饰或序列。外源性修复模板可包含一个或多个荧光标记、纯化标签、表位标签或其组合。举例来说,外源性修复模板可包含一个或多个荧光标记(例如荧光蛋白或其他荧光团或染料),诸如至少1、至少2、至少3、至少4或至少5个荧光标记。示例性荧光标记包括荧光团诸如荧光素(例如6-羧基荧光素(6-fam))、texasred、hex、cy3、cy5、cy5.5、pacificblue、5-(和-6)-羧基四甲基若丹明(tamra)和cy7。广泛范围的用于标记寡核苷酸的荧光染料可商购获得(例如从integrateddnatechnologies)。所述荧光标记(例如内部荧光标记)可例如用于检测已被直接整合至具有可与外源性修复模板的末端相容的突出末端的经裂解靶标核酸中的所述外源性修复模板。标记或标签可在5’末端、3’末端或外源性修复模板内部。举例来说,可使外源性修复模板在5’末端与来自integrateddnatechnologies的ir700荧光团(700)缀合。外源性修复模板也可包含包括待整合在靶基因组基因座处的dna区段的核酸插入物。在靶基因组基因座处整合核酸插入物可导致向所述靶基因组基因座中添加目标核酸序列,使在所述靶基因组基因座处的目标核酸序列缺失,或替换在所述靶基因组基因座处的目标核酸序列(即缺失和插入)。一些外源性修复模板被设计来在靶基因组基因座处插入核酸插入物而在所述靶基因组基因座处无任何相应缺失。其他外源性修复模板被设计来使在靶基因组基因座处的目标核酸序列缺失而无核酸插入物的任何相应插入。其他外源性修复模板被设计来使在靶基因组基因座处的目标核酸序列缺失,并且用核酸插入物替换它。核酸插入物或在靶基因组基因座处被缺失和/或替换的相应核酸可具有各种长度。一示例性核酸插入物或在靶基因组基因座处被缺失和/或替换的相应核酸的长度在约1个核苷酸至约5kb之间,或长度在约1个核苷酸至约1,000个核苷酸之间。举例来说,核酸插入物或在靶基因组基因座处被缺失和/或替换的相应核酸的长度可在约1至约10、约10至约20、约20至约30、约30至约40、约40至约50、约50至约60、约60至约70、约70至约80、约80至约90、约90至约100、约100至约110、约110至约120、约120至约130、约130至约140、约140至约150、约150至约160、约160至约170、约170至约180、约180至约190、或约190至约200个核苷酸之间。同样,核酸插入物或在靶基因组基因座处被缺失和/或替换的相应核酸的长度可在约1至约100、约100至约200、约200至约300、约300至约400、约400至约500、约500至约600、约600至约700、约700至约800、约800至约900、或约900至约1,000个核苷酸之间。同样,核酸插入物或在靶基因组基因座处被缺失和/或替换的相应核酸的长度可在约1kb至约1.5kb、约1.5kb至约2kb、约2kb至约2.5kb、约2.5kb至约3kb、约3kb至约3.5kb、约3.5kb至约4kb、约4kb至约4.5kb、或约4.5kb至约5kb之间。从靶基因组基因座缺失的核酸也可在约1kb至约5kb、约5kb至约10kb、约10kb至约20kb、约20kb至约30kb、约30kb至约40kb、约40kb至约50kb、约50kb至约60kb、约60kb至约70kb、约70kb至约80kb、约80kb至约90kb、约90kb至约100kb、约100kb至约200kb、约200kb至约300kb、约300kb至约400kb、约400kb至约500kb、约500kb至约600kb、约600kb至约700kb、约700kb至约800kb、约800kb至约900kb、约900kb至约1mb之间或更长。或者,从靶基因组基因座缺失的核酸可在约1mb至约1.5mb、约1.5mb至约2mb、约2mb至约2.5mb、约2.5mb至约3mb、约3mb至约4mb、约4mb至约5mb、约5mb至约10mb、约10mb至约20mb、约20mb至约30mb、约30mb至约40mb、约40mb至约50mb、约50mb至约60mb、约60mb至约70mb、约70mb至约80mb、约80mb至约90mb、或约90mb至约100mb之间。核酸插入物可包含基因组dna或任何其他类型的dna。举例来说,核酸插入物可来自原核生物、真核生物、酵母、鸟(例如鸡)、非人哺乳动物、啮齿动物、人、大鼠、小鼠、仓鼠、兔、猪、牛、鹿、绵羊、山羊、猫、狗、雪貂、灵长类动物(例如狨猴、恒河猴)、驯化哺乳动物、农业哺乳动物、龟或任何其他目标生物体。核酸插入物可包含与编码自身抗原的基因的全部或一部分(例如所述基因的编码自身抗原的特定基序或区域的一部分)同源或直系同源的序列。同源序列可来自不同物种或相同物种。举例来说,核酸插入物可包含相较于在靶基因组基因座处被靶向以进行替换的序列,包含一个或多个点突变(例如1、2、3、4、5个或更多个)的序列。任选地,所述点突变可导致所编码多肽中的保守性氨基酸取代(例如天冬氨酸[asp,d]被谷氨酸[glu,e]取代)。核酸插入物或在靶基因组基因座处被缺失和/或替换的相应核酸可为编码区诸如外显子;非编码区诸如内含子、非翻译区或调控区(例如启动子、增强子或转录阻遏物结合元件);或其任何组合。核酸插入物也可包含条件性等位基因。条件性等位基因可为如us2011/0104799中所述的多功能性等位基因,所述专利出于所有目的以引用的方式整体并入本文。举例来说,条件性等位基因可包含:(a)关于靶标基因的转录的处于有义定向的触动序列;(b)处于有义或反义定向的药物选择盒(dsc);(c)处于反义定向的目标核苷酸序列(nsi);和(d)处于相反定向的倒位条件性模块(coin,其利用外显子隔裂性内含子和可倒位基因捕集样模块)。参见例如us2011/0104799。条件性等位基因可进一步包含可重组单元,其在暴露于第一重组酶后重组以形成(i)缺乏触动序列和dsc;和(ii)含有处于有义定向的nsi和处于反义定向的coin的条件性等位基因。参见例如us2011/0104799。核酸插入物也可包含编码选择标记的多核苷酸。或者,核酸插入物可缺乏编码选择标记的多核苷酸。选择标记可含于选择盒中。任选地,选择盒可为自我缺失性盒。参见例如us8,697,851和us2013/0312129,其各自出于所有目的以引用的方式整体并入本文。作为一实例,自我缺失性盒可包含可操作地连接至小鼠prm1启动子的crei基因(包含编码cre重组酶的两个外显子,由内含子分隔)和可操作地连接至人泛素启动子的新霉素抗性基因。通过采用prm1启动子,自我缺失性盒可在f0动物的雄性生殖细胞中被特异性缺失。示例性选择标记包括新霉素磷酸转移酶(neor)、潮霉素b磷酸转移酶(hygr)、嘌呤霉素-n-乙酰基转移酶(puror)、杀稻瘟菌素s脱氨酶(bsrr)、黄嘌呤/鸟嘌呤磷酸核糖基转移酶(gpt)、或单纯疱疹病毒胸苷激酶(hsv-k)或其组合。编码选择标记的多核苷酸可被可操作地连接至在所靶向的细胞中具有活性的启动子。启动子的实例在本文中其他地方描述。核酸插入物也可包含报道体基因。示例性报道体基因包括编码以下的那些:荧光素酶、β-半乳糖苷酶、绿色荧光蛋白(gfp)、增强绿色荧光蛋白(egfp)、青色荧光蛋白(cfp)、黄色荧光蛋白(yfp)、增强黄色荧光蛋白(eyfp)、蓝色荧光蛋白(bfp)、增强蓝色荧光蛋白(ebfp)、dsred、zsgreen、mmgfp、mplum、mcherry、tdtomato、mstrawberry、j-red、morange、mko、mcitrine、venus、ypet、emerald、cypet、cerulean、t-sapphire和碱性磷酸酶。所述报道体基因可被可操作地连接至在所靶向的细胞中具有活性的启动子。启动子的实例在本文中其他地方描述。核酸插入物也可包含一个或多个表达盒或缺失盒。给定盒可包含目标核苷酸序列、编码选择标记的多核苷酸和报道体基因中的一者或多者以及影响表达的各种调控组分。可包括的可选择标记和报道体基因的实例在本文中其他地方详细讨论。核酸插入物可包含侧接有位点特异性重组靶标序列的核酸。或者,核酸插入物可包含一个或多个位点特异性重组靶标序列。尽管整个核酸插入物可由所述位点特异性重组靶标序列侧接,但核酸插入物内的任何目标区域或个别目标多核苷酸也可由所述位点侧接。可侧接于核酸插入物或核酸插入物中的任何目标多核苷酸的位点特异性重组靶标序列可包括例如loxp、lox511、lox2272、lox66、lox71、loxm2、lox5171、frt、frt11、frt71、attp、att、frt、rox或其组合。在一个实例中,位点特异性重组位点侧接于核酸插入物内含有的编码选择标记的多核苷酸和/或报道体基因。在核酸插入物整合在所靶向基因座处之后,可移除位点特异性重组位点之间的序列。任选地,可使用两个外源性修复模板,各自具有包含位点特异性重组位点的核酸插入物。可使外源性修复模板靶向侧接于目标核酸的5’和3’区域。在两个核酸插入物整合至靶基因组基因座中之后,可移除两个经插入位点特异性重组位点之间的目标核酸。核酸插入物也可包含限制核酸内切酶(即限制酶)的一个或多个限制位点,所述限制核酸内切酶包括i型、ii型、iii型和iv型核酸内切酶。i型和iii型限制核酸内切酶识别特定识别位点,但通常在离开核酸酶结合位点的可变位置处进行裂解,所述结合位点可远离裂解位点(识别位点)数百个碱基对。在ii型系统中,限制活性不依赖于任何甲基酶活性,并且裂解通常发生在结合位点内或附近的特定位点处。大多数ii型酶切割回文序列,然而,iia型酶识别非回文识别位点并在识别位点的外部进行裂解,iib型酶切割序列两次,其中两个位点均在识别位点的外部,并且iis型酶识别不对称识别位点并在一侧以及在离识别位点约1-20个核苷酸的确定距离下进行裂解。iv型限制酶靶向甲基化dna。例如在rebase数据库(网页在rebase.neb.com处;roberts等,(2003)nucleicacidsres.31:418-420;roberts等,(2003)nucleicacidsres.31:1805-1812;以及belfort等(2002),mobilednaii,第761-783页,craigie等人编,(asmpress,washington,dc))中进一步描述和分类限制酶。(1)用于非同源性末端接合介导的插入的修复模板一些外源性修复模板在5’末端和/或3’末端具有互补于一个或多个由cas蛋白介导的在靶基因组基因座处的裂解产生的突出部分的短单链区域。这些突出部分也可被称为5’同源臂和3’同源臂。举例来说,一些外源性修复模板在5’末端和/或3’末端具有互补于一个或多个由cas蛋白介导的在靶基因组基因座处的5’靶标序列和/或3’靶标序列处的裂解产生的突出部分的短单链区域。一些所述外源性修复模板仅在5’末端或仅在3’末端具有互补性区域。举例来说,一些所述外源性修复模板仅在5’末端具有互补于在靶基因组基因座处的5’靶标序列处产生的突出部分的互补性区域,或仅在3’末端具有互补于在靶基因组基因座处的3’靶标序列处产生的突出部分的互补性区域。其他所述外源性修复模板在5’末端与3’末端两者处均具有互补性区域。举例来说,其他所述外源性修复模板在5’末端与3’末端两者处均具有互补性区域,其例如分别互补于由cas介导的在靶基因组基因座处的裂解产生的第一突出部分和第二突出部分。举例来说,如果外源性修复模板是双链,那么单链互补性区域可从修复模板的顶链的5’末端和修复模板的底链的5’末端延伸,从而在各末端上产生5’突出部分。或者,单链互补性区域可从修复模板的顶链的3’末端和从模板的底链的3’末端延伸,从而产生3’突出部分。互补性区域可具有足以促进外源性修复模板与靶标核酸之间的连接的任何长度。示例性互补性区域的长度在约1至约5个核苷酸之间,在约1至约25个核苷酸之间,或在约5至约150个核苷酸之间。举例来说,互补性区域的长度可为至少约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24或25个核苷酸。或者,互补性区域的长度可为约5至约10、约10至约20、约20至约30、约30至约40、约40至约50、约50至约60、约60至约70、约70至约80、约80至约90、约90至约100、约100至约110、约110至约120、约120至约130、约130至约140、约140至约150个核苷酸,或更长。所述互补性区域可互补于由两对切口酶产生的突出部分。两个具有交错末端的双链断裂可通过使用裂解相对dna链以产生第一双链断裂的第一切口酶和第二切口酶、以及裂解相对dna链以产生第二双链断裂的第三切口酶和第四切口酶来产生。举例来说,cas蛋白可用于对与第一、第二、第三和第四引导rna相对应的第一、第二、第三和第四引导rna识别序列进行切口。第一引导rna识别序列和第二引导rna识别序列可被定位来产生第一裂解位点以使由第一切口酶和第二切口酶在第一dna链和第二dna链上产生的切口产生双链断裂(即所述第一裂解位点包含第一引导rna识别序列和第二引导rna识别序列内的切口)。同样,第三引导rna识别序列和第四引导rna识别序列可被定位来产生第二裂解位点以使由第三切口酶和第四切口酶在第一dna链和第二dna链上产生的切口产生双链断裂(即所述第二裂解位点包含第三引导rna识别序列和第四引导rna识别序列内的切口)。优选地,第一引导rna识别序列和第二引导rna识别序列和/或第三引导rna识别序列和第四引导rna识别序列内的切口可为产生突出部分的偏移切口。偏移窗可为例如至少约5bp、10bp、20bp、30bp、40bp、50bp、60bp、70bp、80bp、90bp、100bp或更多。参见ran等(2013)cell154:1380-1389;mali等(2013)nat.biotech.31:833-838;以及shen等(2014)nat.methods11:399-404,其各自出于所有目的以引用的方式整体并入本文。在所述情况下,双链外源性修复模板可被设计成具有互补于由第一引导rna识别序列和第二引导rna识别序列内的切口以及由第三引导rna识别序列和第四引导rna识别序列内的切口产生的突出部分的单链互补性区域。这种外源性修复模板可接着通过非同源性末端接合介导的连接来插入。(2)用于通过同源性引导的修复进行的插入的修复模板一些外源性修复模板包含同源臂。如果外源性修复模板也包含核酸插入物,那么同源臂可侧接于所述核酸插入物。为便于引用,同源臂在本文中被称为5’和3’(即上游和下游)同源臂。这个术语涉及同源臂相对于外源性修复模板内的核酸插入物的相对位置。5’同源臂和3’同源臂分别对应于靶基因组基因座内的在本文中被称为“5’靶标序列”和“3’靶标序列”的区域。当两个区域彼此共有足以充当同源性重组反应的底物的序列同一性水平时,同源臂和靶标序列“对应”或彼此“对应”。术语“同源性”包括dna序列与相应序列同一或共有与相应序列的序列同一性。给定靶标序列与见于外源性修复模板中的相应同源臂之间的序列同一性可为允许发生同源性重组的任何程度的序列同一性。举例来说,由外源性修复模板的同源臂(或其片段)和靶标序列(或其片段)共有的序列同一性的量可为至少50%、55%、60%、65%、70%、75%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%序列同一性,以使序列经受同源性重组。此外,同源臂与相应靶标序列之间具有同源性的相应区域可具有足以促进同源性重组的任何长度。示例性同源臂的长度在约25个核苷酸至约2.5kb之间,在约25个核苷酸至约1.5kb之间,或在约25至约500个核苷酸之间。举例来说,给定同源臂(或各同源臂)和/或相应靶标序列可包含长度在约25至约30、约30至约40、约40至约50、约50至约60、约60至约70、约70至约80、约80至约90、约90至约100、约100至约150、约150至约200、约200至约250、约250至约300、约300至约350、约350至约400、约400至约450、或约450至约500个核苷酸之间的相应同源性区域,以使同源臂具有足以经受与靶标核酸内的相应靶标序列的同源性重组的同源性。或者,给定同源臂(或各同源臂)和/或相应靶标序列可包含长度在约0.5kb至约1kb、约1kb至约1.5kb、约1.5kb至约2kb、或约2kb至约2.5kb之间的相应同源性区域。举例来说,同源臂的长度可各自是约750个核苷酸。同源臂可为对称的(各自长度大小大约相同),或它们可为不对称的(一个长于另一个)。同源臂可对应于为细胞所天然具有的基因座(例如所靶向基因座)。或者,举例来说,它们可对应于整合至细胞的基因组中的异源性或外源性dna区段的区域,所述区段包括例如转基因、表达盒或异源性或外源性dna区域。或者,靶向载体的同源臂可对应于酵母人工染色体(yac)、细菌人工染色体(bac)、人人工染色体的区域或适当宿主细胞中含有的任何其他工程化区域。更进一步,靶向载体的同源臂可对应于或源于bac文库、粘粒文库或p1噬菌体文库的区域,或可源于合成dna。当crispr/cas系统与外源性修复模板组合使用时,5’靶标序列和3’靶标序列优选足够邻近于cas裂解位点加以定位(例如在引导rna识别序列的足够邻近内),以便在cas裂解位点处的单链断裂(切口)或双链断裂后,促进在靶标序列与同源臂之间发生同源性重组事件。术语“cas裂解位点”包括由cas酶(例如与引导rna复合的cas9蛋白)产生切口或双链断裂所处的dna序列。如果距离诸如将在cas裂解位点处的单链断裂或双链断裂后促进在5’靶标序列和3’靶标序列与同源臂之间发生同源性重组事件,那么所靶向基因座内的对应于外源性修复模板的5’同源臂和3’同源臂的靶标序列“足够邻近于所述cas裂解位点加以定位”。因此,对应于外源性修复模板的5’同源臂和/或3’同源臂的靶标序列可例如在给定cas裂解位点的至少1个核苷酸内或在给定cas裂解位点的至少10个核苷酸至约1,000个核苷酸内。作为一实例,cas裂解位点可紧邻靶标序列中的至少一者或两者。或者,给定裂解位点离5’靶标序列、3’靶标序列或两个靶标序列具有不同长度。举例来说,如果使用两个引导rna,那么第一引导rna识别序列和/或第二引导rna识别序列或第一裂解位点和/或第二裂解位点可位于5’靶标序列与3’靶标序列之间,或可邻近于或接近于5’靶标序列和/或3’靶标序列,诸如在5’靶标序列和/或3’靶标序列的1kb、2kb、3kb、4kb、5kb、6kb、7kb、8kb、9kb、10kb、20kb、30kb、40kb、50kb、60kb、70kb、80kb、90kb、100kb、110kb、120kb、130kb、140kb、150kb、160kb、170kb、180kb、190kb、200kb、250kb、300kb、350kb、400kb、450kb或500kb内。或者,第一引导rna识别序列和/或第二引导rna识别序列或第一裂解位点和/或第二裂解位点可离5’靶标序列和/或3’靶标序列至少50bp、至少100bp、至少200bp、至少300bp、至少400bp、至少500bp、至少600bp、至少700bp、至少800bp、至少900bp、至少1kb、至少2kb、至少3kb、至少4kb、至少5kb、至少6kb、至少7kb、至少8kb、至少9kb、至少10kb、至少20kb、至少30kb、至少40kb、至少50kb、至少60kb、至少70kb、至少80kb、至少90kb、至少100kb、至少110kb、至少120kb、至少130kb、至少140kb、至少150kb、至少160kb、至少170kb、至少180kb、至少190kb、至少200kb、至少250kb、至少300kb、至少350kb、至少400kb、至少450kb或至少500kb加以定位。举例来说,第一引导rna识别序列和/或第二引导rna识别序列或第一裂解位点和/或第二裂解位点可离5’靶标序列和/或3’靶标序列在约50bp至约100bp、约200bp至约300bp、约300bp至约400bp、约400bp至约500bp、约500bp至约600bp、约600bp至约700bp、约700bp至约800bp、约800bp至约900bp、约900bp至约1kb、约1kb至约2kb、约2kb至约3kb、约3kb至约4kb、约4kb至约5kb、约5kb至约10kb、约10kb至约20kb、约20kb至约30kb、约30kb至约40kb、约40kb至约50kb、约50kb至约100kb、约100kb至约150kb、约150kb至约200kb、约200kb至约300kb、约300kb至约400kb、或约400kb至约500kb之间加以定位。或者,第一引导rna识别序列和/或第二引导rna识别序列或第一裂解位点和/或第二裂解位点可离5’靶标序列和/或3’靶标序列超过50bp、超过100bp、超过200bp、超过300bp、超过400bp、超过500bp、超过600bp、超过700bp、超过800bp、超过900bp、超过1kb、超过2kb、超过3kb、超过4kb、超过5kb、超过6kb、超过7kb、超过8kb、超过9kb、超过10kb、超过20kb、超过30kb、超过40kb、超过50kb、超过60kb、超过70kb、超过80kb、超过90kb或超过100kb加以定位。举例来说,第一引导rna识别序列或第一裂解位点可离5’靶标序列或离5’靶标序列与3’靶标序列两者超过50bp、超过100bp、超过200bp、超过300bp、超过400bp、超过500bp、超过600bp、超过700bp、超过800bp、超过900bp、超过1kb、超过2kb、超过3kb、超过4kb、超过5kb、超过6kb、超过7kb、超过8kb、超过9kb、超过10kb、超过20kb、超过30kb、超过40kb、超过50kb、超过60kb、超过70kb、超过80kb、超过90kb或超过100kb加以定位。同样,第二引导rna识别序列或第二裂解位点可离3’靶标序列或离5’靶标序列与3’靶标序列两者超过50bp、超过100bp、超过200bp、超过300bp、超过400bp、超过500bp、超过600bp、超过700bp、超过800bp、超过900bp、超过1kb、超过2kb、超过3kb、超过4kb、超过5kb、超过6kb、超过7kb、超过8kb、超过9kb、超过10kb、超过20kb、超过30kb、超过40kb、超过50kb、超过60kb、超过70kb、超过80kb、超过90kb或超过100kb加以定位。对应于外源性修复模板的同源臂的靶标序列和cas裂解位点的空间关系可不同。举例来说,靶标序列可位于cas裂解位点的5’,靶标序列可位于cas裂解位点的3’,或靶标序列可侧接于cas裂解位点。在除单细胞期胚胎以外的细胞中,外源性修复模板可为“大型靶向载体”或“ltvec”,其包括包含同源臂的靶向载体,所述同源臂对应于和源于大于通常由意图在细胞中进行同源性重组的其他方法使用的那些核酸序列的核酸序列。ltvec也包括包含核酸插入物的靶向载体,所述核酸插入物具有大于通常由意图在细胞中进行同源性重组的其他方法使用的那些核酸序列的核酸序列。举例来说,ltvec使得有可能修饰由于它们的大小限制而不能被传统基于质粒的靶向载体容纳的大型基因座。举例来说,所靶向基因座可为(即5’同源臂和3’同源臂可对应于)细胞的不可使用常规方法靶向或在不存在由核酸酶试剂(例如cas蛋白)诱导的切口或双链断裂下仅可不正确靶向或仅可以显著较低效率靶向的基因座。ltvec的实例包括源于细菌人工染色体(bac)、人人工染色体或酵母人工染色体(yac)的载体。ltvec和用于制备它们的方法的非限制性实例例如描述于美国专利号6,586,251;6,596,541;和7,105,348中;以及wo2002036789中,所述专利各自出于所有目的以引用的方式整体并入本文。ltvec可呈线性形式或呈环状形式。ltvec可具有任何长度,并且长度通常是至少10kb。举例来说,ltvec可为约50kb至约300kb、约50kb至约75kb、约75kb至约100kb、约100kb至125kb、约125kb至约150kb、约150kb至约175kb、约175kb至约200kb、约200kb至约225kb、约225kb至约250kb、约250kb至约275kb或约275kb至约300kb。ltvec也可为约50kb至约500kb、约100kb至约125kb、约300kb至约325kb、约325kb至约350kb、约350kb至约375kb、约375kb至约400kb、约400kb至约425kb、约425kb至约450kb、约450kb至约475kb、或约475kb至约500kb。或者,ltvec可为至少10kb、至少15kb、至少20kb、至少30kb、至少40kb、至少50kb、至少60kb、至少70kb、至少80kb、至少90kb、至少100kb、至少150kb、至少200kb、至少250kb、至少300kb、至少350kb、至少400kb、至少450kb或至少500kb或更大。ltvec的大小可太大以致不能通过常规测定例如southern印迹和长程(例如1kb至5kb)pcr来筛选靶向事件。ltvec中的5’同源臂和3’同源臂的总和通常是至少10kb。作为一实例,5’同源臂可在约5kb至约100kb的范围内和/或3’同源臂可在约5kb至约100kb的范围内。作为另一实例,5’同源臂可在约5kb至约150kb的范围内和/或3’同源臂可在约5kb至约150kb的范围内。各同源臂可为例如约5kb至约10kb、约10kb至约20kb、约20kb至约30kb、约30kb至约40kb、约40kb至约50kb、约50kb至约60kb、约60kb至约70kb、约70kb至约80kb、约80kb至约90kb、约90kb至约100kb、约100kb至约110kb、约110kb至约120kb、约120kb至约130kb、约130kb至约140kb、约140kb至约150kb、约150kb至约160kb、约160kb至约170kb、约170kb至约180kb、约180kb至约190kb、或约190kb至约200kb。5’同源臂和3’同源臂的总和可为例如约10kb至约20kb、约20kb至约30kb、约30kb至约40kb、约40kb至约50kb、约50kb至约60kb、约60kb至约70kb、约70kb至约80kb、约80kb至约90kb、约90kb至约100kb、约100kb至约110kb、约110kb至约120kb、约120kb至约130kb、约130kb至约140kb、约140kb至约150kb、约150kb至约160kb、约160kb至约170kb、约170kb至约180kb、约180kb至约190kb、或约190kb至约200kb。5’同源臂和3’同源臂的总和也可为例如约200kb至约250kb、约250kb至约300kb、约300kb至约350kb、或约350kb至约400kb。或者,各同源臂可为至少5kb、至少10kb、至少15kb、至少20kb、至少30kb、至少40kb、至少50kb、至少60kb、至少70kb、至少80kb、至少90kb、至少100kb、至少110kb、至少120kb、至少130kb、至少140kb、至少150kb、至少160kb、至少170kb、至少180kb、至少190kb或至少200kb。同样,5’同源臂和3’同源臂的总和可为至少10kb、至少15kb、至少20kb、至少30kb、至少40kb、至少50kb、至少60kb、至少70kb、至少80kb、至少90kb、至少100kb、至少110kb、至少120kb、至少130kb、至少140kb、至少150kb、至少160kb、至少170kb、至少180kb、至少190kb或至少200kb。各同源臂也可为至少250kb、至少300kb、至少350kb或至少400kb。ltvec可包含核酸插入物,其具有大于通常由意图在细胞中进行同源性重组的其他方法使用的那些核酸序列的核酸序列。举例来说,ltvec可包含在约5kb至约10kb、约10kb至约20kb、约20kb至约40kb、约40kb至约60kb、约60kb至约80kb、约80kb至约100kb、约100kb至约150kb、约150kb至约200kb、约200kb至约250kb、约250kb至约300kb、约300kb至约350kb、约350kb至约400kb的范围内或更大的核酸插入物。ltvec也可包含例如在约1kb至约5kb、约400kb至约450kb、约450kb至约500kb的范围内或更大的核酸插入物。或者,核酸插入物可为至少1kb、至少5kb、至少10kb、至少20kb、至少30kb、至少40kb、至少60kb、至少80kb、至少100kb、至少150kb、至少200kb、至少250kb、至少300kb、至少350kb、至少400kb、至少450kb或至少500kb。d.接触细胞的基因组以及将核酸或蛋白质引入细胞中接触细胞的基因组可包括将一个或多个cas蛋白或编码cas蛋白的核酸、一个或多个引导rna或编码引导rna的核酸(即一个或多个crisprrna和一个或多个tracrrna)和一个或多个外源性修复模板引入细胞中,前提是如果细胞是例如单细胞期胚胎,那么外源性修复模板的长度可小于5kb。接触细胞的基因组(例如接触细胞)可包括将仅一个以上组分、一个或多个组分或全部组分引入细胞中。“引入”包括以序列进入细胞的内部的方式向细胞递呈核酸或蛋白质。引入可通过任何手段来实现,并且一个或多个组分(例如两个组分或全部组分)可以任何组合同时或依序引入细胞中。举例来说,外源性修复模板可在引入cas蛋白和引导rna之前引入,或它可在引入所述cas蛋白和所述引导rna之后引入(例如所述外源性修复模板可在引入所述cas蛋白和所述引导rna之前或之后约1、2、3、4、8、12、24、36、48或72小时施用)。参见例如us2015/0240263和us2015/0110762,其各自出于所有目的以引用的方式整体并入本文。cas蛋白可以蛋白质形式诸如与grna复合的cas蛋白,或以编码所述cas蛋白的核酸形式诸如rna(例如信使rna(mrna))或dna引入细胞中。当以dna形式引入时,编码引导rna的dna可被可操作地连接至在细胞中具有活性的启动子。所述dna可在一个或多个表达构建体中。引导rna可以rna形式或以编码所述引导rna的dna形式引入细胞中。当以dna形式引入时,编码引导rna的dna可被可操作地连接至在细胞中具有活性的启动子。所述dna可在一个或多个表达构建体中。举例来说,所述表达构建体可为单一核酸分子的组分。或者,它们可以任何组合分开在两个或更多个核酸分子之中(即编码一个或多个crisprrna的dna和编码一个或多个tracrrna的dna可为单独核酸分子的组分)。在一些方法中,编码核酸酶试剂(例如cas蛋白和引导rna)的dna和/或编码外源性修复模板的dna可通过dna小环来引入细胞中。参见例如wo2014/182700,其出于所有目的以引用的方式整体并入本文。dna小环是可用于非病毒性基因转移的超卷曲dna分子,其既不具有复制起点,也不具有抗生素选择标记。因此,dna小环在大小方面通常小于质粒载体。这些dna缺乏细菌dna,因此缺乏见于细菌dna中的未甲基化cpg基序。本文提供的方法不取决于用于将核酸或蛋白质引入细胞中的特定方法,只是为了核酸或蛋白质进入至少一个细胞的内部。用于将核酸和蛋白质引入各种细胞类型中的方法在本领域中是已知的,并且包括例如稳定转染方法、短暂转染方法和病毒介导的方法。转染方案以及用于将核酸或蛋白质引入细胞中的方案可变化。非限制性转染方法包括基于化学的转染方法,使用脂质体;纳米粒子;磷酸钙(graham等(1973)virology52(2):456–67,bacchetti等(1977)proc.natl.acad.sci.usa74(4):1590–4以及kriegler,m(1991).transferandexpression:alaboratorymanual.newyork:w.h.freemanandcompany.第96–97页);树枝状聚合物;或阳离子聚合物诸如deae-右旋糖酐或聚乙烯亚胺。非化学方法包括电穿孔、声致穿孔和光学转染。基于粒子的转染包括使用基因枪或磁体辅助转染(bertram(2006)currentpharmaceuticalbiotechnology7,277–28)。病毒方法也可用于转染。将核酸或蛋白质引入细胞中也可由电穿孔、细胞质内注射、病毒性感染、腺病毒、慢病毒、逆转录病毒、转染、脂质介导的转染或核转染介导。将核酸或蛋白质引入细胞中也可由腺相关病毒介导。核转染是一种改进电穿孔技术,其使得核酸基质能够不仅被递送至细胞质中,而且也穿过核膜以及进入核中。此外,在本文公开的方法中使用核转染通常需要比常规电穿孔少得多的细胞(例如相较于由常规电穿孔所需的700万,仅需要约200万)。在一个实例中,核转染使用nucleofectortm系统来进行。将核酸或蛋白质引入细胞(例如单细胞期胚胎)中也可通过显微注射来实现。在单细胞期胚胎中,显微注射可向母亲和/或父亲前核中或向细胞质中进行。如果显微注射仅向一个前核中进行,那么父亲前核由于它的尺寸较大而是优选的。mrna的显微注射优选向细胞质中进行(例如以将mrna直接递送至翻译机构中),而cas蛋白或编码cas蛋白或编码rna的核酸的显微注射优选向核/前核中进行。或者,显微注射可通过向核/前核与细胞质两者中注射来进行:可首先将针引入核/前核中,并且可注射第一量,以及当从单细胞期胚胎移除针时,可将第二量注射至细胞质中。如果将cas蛋白注射至细胞质中,那么所述cas蛋白优选包含核定位信号以确保递送至核/前核中。用于进行显微注射的方法是熟知的。参见例如nagy等(nagya,gertsensteinm,vinterstenk,behringerr.,2003,manipulatingthemouseembryo.coldspringharbor,newyork:coldspringharborlaboratorypress);meyer等(2010)proc.natl.acad.sci.usa107:15022-15026以及meyer等(2012)proc.natl.acad.sci.usa109:9354-9359。向单细胞期胚胎中的引入也可通过电穿孔来实现。用于将核酸或蛋白质引入细胞中的其他方法可包括例如载体递送、粒子介导的递送、外体介导的递送、脂质纳米粒子介导的递送、细胞穿透肽介导的递送或可植入装置介导的递送。将核酸或蛋白质引入细胞中可一次或历经一段时期多次进行。举例来说,引入可历经一段时期至少两次,历经一段时期至少三次,历经一段时期至少四次,历经一段时期至少五次,历经一段时期至少六次,历经一段时期至少七次,历经一段时期至少八次,历经一段时期至少九次,历经一段时期至少十次,至少十一次,历经一段时期至少十二次,历经一段时期至少十三次,历经一段时期至少十四次,历经一段时期至少十五次,历经一段时期至少十六次,历经一段时期至少十七次,历经一段时期至少十八次,历经一段时期至少十九次,或历经一段时期至少二十次进行。在一些情况下,方法和组合物中采用的细胞具有稳定并入它们的基因组中的dna构建体。在所述情况下,接触可包括提供具有已稳定并入它的基因组中的构建体的细胞。举例来说,本文公开的方法中采用的细胞可具有稳定并入它的基因组中的预先存在的cas编码基因(即cas就绪细胞)。“稳定并入”或“稳定引入”或“稳定整合”包括将多核苷酸引入细胞中以使核苷酸序列整合至细胞基因组中,并且能够通过其子代遗传。任何方案都可用于稳定并入dna构建体或靶向基因组整合系统的各种组分。e.靶基因组基因座以及引导rna识别序列的位置靶基因组基因座可为影响与目标外来靶抗原同源或共有目标表位的自身抗原的表达的任何基因组基因座。优选地,靶基因组基因座包含以下、基本上由以下组成或由以下组成:编码自身抗原的基因的全部或一部分。作为一实例,靶基因组基因座可包含以下、基本上由以下组成或由以下组成:包含编码自身抗原的基因的起始密码子的区域,或可包含以下、基本上由以下组成或由以下组成:所述基因的整个编码区。或者,靶基因组基因座可包含以下、基本上由以下组成或由以下组成:影响编码自身抗原的基因的表达的另一基因组基因座。这种基因组基因座的一实例是编码为编码自身抗原的基因的表达所需的转录调控子的基因的全部或一部分。在一些方法中,可靶向多个靶基因组基因座。作为一实例,如果存在编码与目标外来抗原同源或共有目标表位的多个自身抗原的多个基因,那么多个基因各自可被依序或同时靶向。第一引导rna识别序列和第二引导rna识别序列可在靶基因组基因座内的任何地方。举例来说,第一引导rna识别序列和第二引导rna识别序列可侧接于编码与目标外来靶抗原同源或共有目标表位的自身抗原的基因的全部或一部分。在一个实例中,第一引导rna识别序列包含编码自身抗原的基因的起始密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内,并且第二引导rna识别序列包含编码自身抗原的基因的终止密码子,或在终止密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。举例来说,第一引导rna识别序列可包含起始密码子,并且第二引导rna识别序列可包含终止密码子。如果也使用第三引导rna和第四引导rna,那么第三引导rna识别序列和第四引导rna识别序列也可在靶基因组基因座内的任何地方。举例来说,两个引导rna识别序列(例如第一和第三,其中第一引导rna识别序列和第三引导rna识别序列不同且任选重叠)可包含编码自身抗原的基因的起始密码子,或可在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内,并且另外两个引导rna识别序列(例如第二和第四,其中第二引导rna识别序列和第四引导rna识别序列不同且任选重叠)可包含编码自身抗原的基因的终止密码子或可在终止密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。靶向起始密码子与终止密码子两者可导致编码自身抗原的基因的编码序列的缺失,并且由此消除自身抗原的表达。在另一实例中,第一引导rna识别序列和第二引导rna识别序列不同,并且中的每一个包含编码自身抗原的基因的起始密码子,或在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。举例来说,第一引导rna识别序列和第二引导rna识别序列可重叠,并且可各自包含起始密码子。如果也使用第三引导rna和/或第四引导rna,那么第三引导rna识别序列和第四引导rna识别序列可在靶基因组基因座内的任何地方。举例来说,第三引导rna识别序列和第四引导rna识别序列可不同于彼此以及不同于第一引导rna识别序列和第二引导rna识别序列,并且第三引导rna识别序列和第四引导rna识别序列各自也可包含编码自身抗原的基因的起始密码子,或可在起始密码子的约10、20、30、40、50、100、200、300、400、500或1,000个核苷酸内。靶向起始密码子可破坏起始密码子,并且由此消除编码自身抗原的基因的表达。如果使用第三引导rna和第四引导rna(或额外引导rna),那么也可靶向影响第一自身抗原的表达或影响与目标外来抗原同源或共有目标表位的其他自身抗原(例如第二自身抗原)的表达的额外靶基因组基因座以使第一自身抗原和/或其他自身抗原的表达降低。作为一实例,在一些方法中,可靶向编码与目标外来抗原同源或共有目标表位的第一自身抗原的基因,并且可靶向编码与目标外来抗原同源或共有目标表位的第二自身抗原的第二基因。f.重组机理以及用于改变非同源性末端接合、基因转换或同源性重组的普遍性的方法重组包括在两个多核苷酸之间交换遗传信息的任何过程,并且可通过任何机理来发生。应答于双链断裂(dsb)的重组主要通过以下两个保守dna修复路径来发生:非同源性末端接合(nhej)和同源性重组(hr)。参见kasparek和humphrey(2011)seminarsincell&dev.biol.22:886-897,其出于所有目的以引用的方式整体并入本文。同样,由外源性修复模板介导的对靶标核酸的修复可包括在两个多核苷酸之间交换遗传信息的任何过程。nhej包括通过使断裂末端直接连接至彼此或外源性序列而无需同源性模板来修复核酸中的双链断裂。由nhej达成的对非连续序列的连接可常常在双链断裂的位点附近导致缺失、插入或易位。举例来说,nhej也可通过使断裂末端与外源性修复模板的末端直接连接(即基于nhej的捕集)来导致外源性修复模板的靶向整合。当同源性引导的修复(hdr)路径不易于可用时(例如在非分裂细胞、原代细胞和不良进行基于同源性的dna修复的细胞中),所述nhej介导的靶向整合可优选用于插入外源性修复模板。此外,与同源性引导的修复相比,不需要了解侧接于裂解位点的具有序列同一性的大型区域(超出由cas介导的裂解产生的突出部分),此在试图向具有对基因组序列的了解有限的基因组的生物体中进行靶向插入时可为有益的。整合可通过外源性修复模板与经裂解基因组序列之间的钝性末端连接,或通过使用由可与经裂解基因组序列中的由cas蛋白产生的那些突出部分相容的突出部分侧接的外源性修复模板进行的粘性末端(即具有5’或3’突出部分)连接来进行。参见例如us2011/020722、wo2014/033644、wo2014/089290以及maresca等(2013)genomeres.23(3):539-546,其各自出于所有目的以引用的方式整体并入本文。如果连接钝性末端,那么可需要进行靶标和/或供体切除以产生具有为片段接合所需的微同源性的区域,此可在靶标序列中产生非所要改变。重组也可通过同源性引导的修复(hdr)或同源性重组(hr)来发生。hdr或hr包括可需要核苷酸序列同源性,使用“供体”分子作为“靶标”分子(即经受双链断裂的分子)的修复模板,并且导致遗传信息从供体向靶标转移的核酸修复形式。在不希望受任何特定理论束缚下,所述转移可涉及对在断裂的靶标与供体之间形成的异源双链体dna的不匹配修正,和/或合成依赖性链退火,其中供体用于再合成将成为靶标的一部分的遗传信息,和/或相关过程。在一些情况下,供体多核苷酸、供体多核苷酸的一部分、供体多核苷酸的拷贝、或供体多核苷酸的拷贝的一部分整合至靶标dna中。参见wang等(2013)cell153:910-918;mandalos等(2012)plosone7:e45768:1-9;以及wang等(2013)natbiotechnol.31:530-532,其各自出于所有目的以引用的方式整体并入本文。重组可在一对同源染色体中第一染色体与第二染色体之间。所述手段可包括例如杂合性丧失(loh)、基因转换或通过任何已知重组机理而发生的交叉事件。在不希望受理论束缚下,loh可例如通过伴有或不伴有基因转换的有丝分裂重组,或通过染色体损失和重复来发生。参见例如lefebvre等(2001)nat.genet.27:257-258,其出于所有目的以引用的方式整体并入本文。在这个情形下的基因转换可包括遗传物质从供体序列向高度同源性接受体的单向转移(即遗传信息从一个分子向它的同源物的非相互交换)。基因转换包括用于通过任何已知重组机理来拷贝等位基因的任何手段。举例来说,基因转换可涉及遗传信息从完整序列向含有双链断裂的同源性区域的非相互转移,并且它可发生在姐妹染色单体、同源染色体、或同一染色单体上或不同染色体上的同源序列之间。参见例如chen等(2007)nat.rev.genet.8:762-775,其出于所有目的以引用的方式整体并入本文。在特定情况下,基因转换直接由作为从同源染色体拷贝遗传信息的结果的同源性重组所致。当同源序列不同一时,这可导致局部化杂合性丧失(loh)。作为一实例,loh可通过由有丝分裂交叉达成的相互染色单体交换,或通过利用断裂诱导的复制进行的染色单体拷贝来发生。在任一情况下,都可发生杂合性修饰,其中一个染色体在基因组复制之前被靶向。或者,单一染色单体可在基因组复制之后被靶向,继之以染色单体间基因转换。在任何本文公开的方法中,细胞可为已被修饰来使nhej活性增加或降低的细胞。同样,细胞可为已被修饰来使基因转换或hdr活性增加的细胞。所述修饰可包括在调控nhej、基因转换和/或hdr中涉及的基因的表达或活性方面的改变。举例来说,使nhej的活性降低和/或使hdr的活性增加可促进对应于两个核酸酶试剂(例如cas蛋白和两个引导rna)的核酸酶识别序列(例如引导rna识别序列)之间的基因组区域的双等位基因垮塌。在不希望受任何特定理论束缚下,双等位基因基因组垮塌可发生所采用的一种机理通过在第一等位基因内nhej介导的修复或hdr介导的修复以及通过hdr机理诸如基因转换来产生相同第二等位基因来进行(参见实施例1)。因此,促进hdr介导的路径(例如通过使nhej活性降低或通过使hdr活性增加)也可促进基因组区域的双等位基因垮塌。类似地,在不希望受任何特定理论束缚下,如果nhej活性降低,并且hdr活性(例如基因转换活性)相应增加,那么通过使用靶向单一基因座的成对核酸酶试剂(例如cas蛋白和成对引导rna)进行的杂合性细胞向纯合性细胞的转换可得到促进。抑制剂可用于使nhej活性增加或降低或使hdr活性增加或降低。所述抑制剂可为例如对基因转录物具有特异性的小分子或抑制性核酸,诸如短干扰核酸(例如短干扰rna(sirna)、双链rna(dsrna)、微小rna(mirna)和短发夹rna(shrna))或反义寡核苷酸。抑制剂可针对nhej或hdr中涉及的酶或它们的由通过例如磷酸化、泛素化和苏素化进行的翻译后修饰达成的上游调控。在哺乳动物细胞中,nhej是主要dsb修复机理,并且在整个细胞周期中都具有活性。在脊椎动物中,“典型”或“经典”nhej路径(c-nhej)需要包括dna-pk、ku70-80、artemis、连接酶iv(lig4)、xrcc4、clf和polμ的若干核心因子来修复dsb。参见kasparek和humphrey(2011)seminarsincell&dev.biol.22:886-897,其出于所有目的以引用的方式整体并入本文。在nhej期间,dna末端由高度丰富的末端保护性ku蛋白结合,所述ku蛋白充当用于装载其他nhej组分的对接站。因此,在一些本文公开的方法中,细胞已被修饰来使c-nhej中涉及的因子的表达或活性降低或消除或使所述表达或活性增加。举例来说,在一些方法中,细胞已被修饰来使dna-pk、ku70-80、artemis、连接酶iv(lig4)、xrcc4、clf和/或polμ表达或活性降低或消除。在特定方法中,细胞已被修饰来使dna-pk表达或活性降低或消除,或使dna-pk表达或活性(例如dna-pkcs的表达或活性;示例性uniprot序列指定为p97313)增加。dna-pkcs抑制剂的实例包括例如nu7026和nu7441。参见例如美国专利号6,974,867,其出于所有目的以引用的方式整体并入本文。在特定方法中,细胞已被修饰来使连接酶iv表达或活性降低或消除,或使连接酶iv表达或活性增加。连接酶iv抑制剂的一实例是scr7。靶向细胞周期检查点蛋白如atm(例如ku55933)、chk1/chk2(例如kld1162或chir-124)和atr(例如ve821)的抑制剂也可用于协同增强特定dna修复抑制剂的作用,或防止非意图副作用如细胞周期阻滞和/或凋亡(参见ciccia等(2010)molcell40:179,其出于所有目的以引用的方式整体并入本文)。破坏c-nhej可使由“替代性”nhej(a-nhej)路径介导的异常接合的水平增加,并且也可使hr修复增加。a-nhej路径显示朝向微同源性介导的接合的偏倚,并且相比于c-nhej,遵循较慢动力学。已提出包括mrn复合物(mre11、rad50、nbs1)、ctip、xrcc1、parp、lig1和lig3的若干因子进行参与。参见kasparek和humphrey(2011)seminarsincell&dev.biol.22:886-897以及claybon等(2010)nucleicacidsres.38(21):7538-7545,其各自出于所有目的以引用的方式整体并入本文。因此,在一些本文公开的方法中,细胞已被修饰来使a-nhej中涉及的因子的表达或活性降低或消除或使所述表达或活性增加。举例来说,在一些方法中,细胞已被修饰来使mre11、rad50、nbs1、ctip、xrcc1、parp(例如parp1)、lig1和/或lig3表达或活性降低或消除。在其他方法中,细胞已被修饰来使mre11、rad50、nbs1、ctip、xrcc1、parp(例如parp1)、lig1和/或lig3表达或活性增加。在特定方法中,细胞已被修饰来使parp1表达或活性降低或消除,或使parp1表达或活性增加(示例性uniprot序列指定为p11103)。parp抑制剂(例如nu1025、依尼帕尼(iniparib)、奥拉帕尼(olaparib))的实例包括烟酰胺;异喹啉酮和二氢异喹啉酮;苯并咪唑和吲哚;酞嗪-1(2h)-酮和喹唑啉酮;异吲哚啉酮及其类似物和衍生物;啡啶和菲啶酮;苯并吡喃酮及其类似物和衍生物;不饱和羟肟酸衍生物及其类似物和衍生物;哒嗪,包括稠合哒嗪及其类似物和衍生物;和/或其他化合物诸如咖啡因(caffeine)、茶碱(theophylline)和胸苷及其类似物和衍生物。参见例如美国专利号8,071,579,其出于所有目的以引用的方式整体并入本文。c-nhej也与hr展现竞争性关系,以致破坏c-nhej也可导致hr修复增加。可利用nhej与hr之间的所述竞争,因为破坏nhej可由于随机整合降低以及有可能由于通过同源性重组进行的靶标整合增加而导致基因靶向增强。存在若干形式的同源性重组修复,包括单链退火、基因转换、交叉以及断裂诱导的复制。单链退火是次要形式的hr修复,其中在经切除dsb的任一侧上的同源性单链序列进行退火,从而导致染色体重构。视分隔具有序列同源性的两个区域的距离而定,单链退火产生不同大小的缺失。基因转换包括遗传信息从一个分子向它的同源物的非相互交换,直接由作为从同源染色体拷贝遗传信息的结果的hr所致。当同源序列不同一时,这可导致局部化loh。通常,基因转换的程度限于几百个碱基对。然而,已报道在包括rad51c缺乏的一些遗传背景下的长地带基因转换。参见nagaraju等(2006)mol.cell.biol.26:8075-8086,其出于所有目的以引用的方式整体并入本文。交叉可例如发生在同源染色体之间,并且如果发生在g1期,那么有可能导致相互易位,或如果发生在g2期,那么有可能导致非相互易位和从断裂位点延伸至远端端粒的loh。断裂诱导的复制是hr的一种变化形式,其中在链侵入之后,dna复制继续进行直至染色体的末端。因此,存在hr可促进loh所采用的许多机理。因此,在一些本文公开的方法中,细胞已被修饰来使hr中涉及的因子的表达或活性降低或消除或使所述表达或活性增加。举例来说,在一些方法中,细胞已被修饰来使rad51、rad52、rad54、rad55、rad51c、brca1和/或brca2表达或活性增加。在其他方法中,细胞已被修饰来使rad51、rad52、rad54、rad55、rad51c、brca1和/或brca2表达或活性降低或消除。在一些方法中,可改变调控nhej和/或hr中涉及的其他蛋白质的表达或活性。举例来说,在一些方法中,细胞已被修饰来使chk2表达或活性降低或消除,使clspn表达或活性降低或消除,使setd2表达或活性降低或消除,使kat2a表达或活性增加,和/或使rad51表达或活性增加。在其他方法中,细胞已被修饰来使chk2表达或活性增加,使clspn表达或活性增加,使setd2表达或活性增加,使kat2a表达或活性降低或消除,和/或使rad51表达或活性降低或消除。chk2(也称为chek2和rad53;裂殖酵母(s.pombe)同源物是cds1)是一种为检查点介导的细胞周期阻滞、dna修复的活化、以及应答于存在dna双链断裂的凋亡所需的丝氨酸/苏氨酸蛋白质激酶。参见blaikley等(2014)nucleicacidsresearch42:5644-5656,其出于所有目的以引用的方式整体并入本文。clspn(也称为claspin;裂殖酵母同源物是mrc1)是一种为应答于dna损害的由检查点介导的细胞周期阻滞所需的蛋白质。已报道裂殖酵母中的chk2或clspn同源物的缺失会导致高重组表型,其相较于野生型展现显著升高水平的断裂诱导的基因转换。具体来说,基因转换的水平据报道得以显著增加,而非同源性末端接合(nhej)、姐妹染色单体转换(scc)和杂合性丧失(loh)的水平据报道得以降低。参见blaikley等(2014)nucleicacidsresearch42:5644-5656。kat2a(也称为gcn5和gcn5l2)是一种促进转录活化,并且已被报道与双链断裂修复相关联的遍在性组蛋白乙酰基转移酶。kat2a依赖性组蛋白h3赖氨酸36(h3k36)乙酰化使染色质可及性增加,使切除增加,并且促进同源性重组,同时抑制非同源性末端接合。参见pai等(2014)nat.commun.5:4091,其出于所有目的以引用的方式整体并入本文。setd2(也称为kiaa1732、kmt3a和set2)是一种组蛋白甲基转移酶,其使用脱甲基化赖氨酸36(h3k36me2)作为底物,使组蛋白h3的赖氨酸36特异性三甲基化(h3k36me3)。setd2依赖性h3k36甲基化使染色质可及性降低,使切除降低,并且促进nhej。参见pai等(2014)nat.commun.5:4091。rad51(也称为reca、rad51a和dna修复蛋白rad51同源物1)是一种与rad52和其他蛋白质一起在同源性重组期间起实现链交换,从而形成异源双链体dna的作用的蛋白质,所述异源双链体dna通过不匹配修复来解决以产生基因转换地带。在哺乳动物细胞中,已报道rad51和rad52过度表达会使同源性重组和基因转换的频率增加。参见yanez和porter(1999)genether.6:1282-1290以及lambert和lopez(2000)emboj.19:3090-3099,其出于所有目的以引用的方式整体并入本文。调控nhej、基因转换和/或同源性引导的修复中涉及的基因的表达或活性的改变可具有空间特异性或时间特异性,并且也可为可诱导的或暂时的和可逆的。举例来说,可构建各种盒形式以允许在特定细胞或组织类型中,在特定发育阶段或在诱导后达成缺失。所述盒可采用重组酶系统,其中盒由重组酶识别位点侧接在两侧上,并且可使用在所需细胞类型中表达,在所需发育阶段表达,或在诱导后得以表达或活化的重组酶移除。所述盒可进一步构建来包括一系列各对不同重组酶识别位点,其被放置以致可产生无效等位基因、条件性等位基因、或组合条件性/无效等位基因,如出于所有目的以引用的方式整体并入本文的us2011/0104799中所述。对重组酶基因的调控可以各种方式控制,诸如通过使重组酶基因可操作地连接至细胞特异性、组织特异性或发育调控启动子(或其他调控元件),或通过使重组酶基因可操作地连接至包含仅在特定细胞类型、组织类型或发育阶段中具有活性的mirna的识别位点的3’-utr。重组酶也可例如通过采用融合蛋白,将重组酶置于效应物或代谢物的控制下(例如creert2,其活性由他莫昔芬(tamoxifen)正性控制),或通过将重组酶基因置于诱导型启动子的控制下(例如活性由多西环素(doxycycline)和tetr或tetr变体控制的重组酶)来调控。各种盒形式和调控重组酶基因的手段的实例例如提供在us8,518,392;us8,354,389;和us8,697,851中,所述专利各自以引用的方式整体并入本文。在其他本文公开的方法中,细胞已被修饰来通过阻断处于细胞周期的某一时期诸如细胞周期的m期或s期的细胞来使nhej活性增加或降低,或使基因转换或hdr活性增加。参见例如wo2016/036754,其出于所有目的以引用的方式整体并入本文。这可用细胞周期阻断组合物实现。所述组合物的实例包括诺考达唑(nocodazole)、羟基脲(hydroxyurea);秋水仙碱(colchicine);地美可辛(demecolcine)(秋水仙胺(colcemid));洛伐他汀(lovastatin);含羞草氨酸(mimosine);胸苷;阿非迪霉素(aphidicolin);拉春库林a(latrunculina);和拉春库林b。所述修饰可包括在调控nhej、基因转换和/或hdr中涉及的基因的表达或活性方面的改变。g.靶向遗传修饰的类型各种类型的靶向遗传修饰可使用本文所述的方法加以引入。所述靶向遗传修饰可包括使与目标外来靶抗原同源或共有目标表位的自身抗原的表达降低或消除的任何修饰。优选地,所述修饰破坏靶基因组基因座。破坏的实例包括改变调控元件(例如启动子或增强子),错义突变,无义突变,框移突变,截短突变,无效突变,或插入或缺失少数核苷酸(例如导致框移突变)。破坏可导致等位基因的失活(即功能丧失)或丧失。所述靶向遗传修饰可包括例如插入一个或多个核苷酸,缺失一个或多个核苷酸,或取代(替换)一个或多个核苷酸。所述插入、缺失或替换可例如导致点突变,敲除目标核酸序列或其一部分,敲入目标核酸序列或其一部分,用异源性或外源性核酸序列替换内源性核酸序列,改变调控元件(例如启动子或增强子),错义突变,无义突变,框移突变,截短突变,无效突变或其组合。举例来说,可改变(例如缺失、插入或取代)至少1、2、3、4、5、7、8、9、10个或更多个核苷酸以形成靶向遗传修饰。缺失、插入或替换可具有任何大小,如在本文中其他地方所公开。参见例如wang等(2013)cell153:910-918;mandalos等(2012)plosone7:e45768;以及wang等(2013)natbiotechnol.31:530-532,其各自以引用的方式整体并入本文。所述突变可导致自身抗原的表达(例如mrna和/或蛋白质表达)降低或表达消除(例如等位基因的缺失)。靶向遗传修饰(例如插入、缺失或取代)可发生在靶基因组基因座中的一个或多个位置处。举例来说,如果使用两个外源性修复模板,那么靶向遗传修饰可包括在靶基因组基因座内的两个位置处的两个单独修饰。在其中使用外源性修复模板的方法中,举例来说,缺失可在5’靶标序列与3’靶标序列之间。在其中使用两个或更多个引导rna的方法中,缺失可在第一引导rna识别序列与第二引导rna识别序列或第一cas裂解位点与第二cas裂解位点之间。所述缺失可为任何长度。经缺失核酸可为例如约1bp至约5bp、约5bp至约10bp、约10bp至约50bp、约50bp至约100bp、约100bp至约200bp、约200bp至约300bp、约300bp至约400bp、约400bp至约500bp、约500bp至约1kb、约1kb至约5kb、约5kb至约10kb、约10kb至约20kb、约20kb至约40kb、约40kb至约60kb、约60kb至约80kb、约80kb至约100kb、约100kb至约150kb、或约150kb至约200kb、约200kb至约300kb、约300kb至约400kb、约400kb至约500kb、约500kb至约1mb、约1mb至约1.5mb、约1.5mb至约2mb、约2mb至约2.5mb、或约2.5mb至约3mb。或者,经缺失核酸可为例如至少1bp、至少5bp、至少10bp、至少50bp、至少100bp、至少200bp、至少300bp、至少400bp、至少500bp、至少1kb、至少5kb、至少10kb、至少20kb、至少30kb、至少40kb、至少50kb、至少60kb、至少70kb、至少80kb、至少90kb、至少100kb、至少110kb、至少120kb、至少130kb、至少140kb、至少150kb、至少160kb、至少170kb、至少180kb、至少190kb、至少200kb、至少250kb、至少300kb、至少350kb、至少400kb、至少450kb或至少500kb或更大。在一些情况下,经缺失核酸可为至少550kb、至少600kb、至少650kb、至少700kb、至少750kb、至少800kb、至少850kb、至少900kb、至少950kb、至少1mb、至少1.5mb、至少2mb、至少2.5mb、至少3mb、至少4mb、至少5mb、至少10mb、至少20mb、至少30mb、至少40mb、至少50mb、至少60mb、至少70mb、至少80mb、至少90mb或至少100mb(例如染色体的大部分)。在一特定实例中,缺失大小可在约0.1kb与约1mb之间,在约0.1kb与约900kb之间,在约0.1kb与约400kb之间,在约0.1kb与约200kb之间,在约0.1kb与约100kb之间,或多达约1mb,多达约900kb,多达约400kb,多达约200kb或多达约100kb。在一特定实例中,缺失大小可在约0.1-200、0.1-190、0.1-180、0.1-170、0.1-160、0.1-150、0.1-140、0.1-130、0.1-120、0.1-110、0.1-100、0.1-90、0.1-80、0.1-70、0.1-60、0.1-50、0.1-40、0.1-30、0.1-20、0.1-10、0.1-9、0.1-8、0.1-7、0.1-6、0.1-5、0.1-4、0.1-3、0.1-2、或0.1-1kb之间。所靶向细胞克隆诸如所靶向胚胎干细胞克隆中的双等位基因缺失(垮塌)效率(即具有双等位基因缺失的筛选克隆的百分比)可在约1-100%、1-90%、1-80%、1-70%、1-60%、1-50%、1-40%、1-30%、或1-27%之间,或可为至少约1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%或25%。举例来说,在一个实施方案中,缺失大小是约50kb或更小,并且双等位基因缺失效率在约1-30%或1-27%之间,或缺失大小是约50kb或更大(例如在约50kb至约200kb之间),并且双等位基因缺失效率是约1-5%或1-3%。在其中靶向单细胞期胚胎的实验中,在单细胞期胚胎中进行crispr/cas注射之后出生的活体幼仔中的双等位基因缺失(垮塌)效率(即具有双等位基因缺失的活体幼仔的百分比)可在约1-100%、1-90%、或1-85%之间,或可为至少约1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、25%、30%、40%、50%、60%、70%、80%、或85%。举例来说,在一个实施方案中,缺失大小是约50kb或更小,并且双等位基因缺失效率在约1-85%或20-85%之间,或缺失大小是约50kb或更大(例如在约50kb至约100kb之间),并且双等位基因缺失效率是约1-20%或1-15%。在其中使用外源性修复模板的方法中,举例来说,插入可在5’靶标序列与3’靶标序列之间。所述插入可具有任何长度。举例来说,插入核酸可为例如约1bp至约5bp、约5bp至约10bp、约10bp至约50bp、约50bp至约100bp、约100bp至约200bp、约200bp至约300bp、约300bp至约400bp、约400bp至约500bp、约500bp至约1kb、约1kb至约5kb、约5kb至约10kb、约10kb至约20kb、约20kb至约40kb、约40kb至约60kb、约60kb至约80kb、约80kb至约100kb、约100kb至约150kb、约150kb至约200kb、约200kb至约250kb、约250kb至约300kb、约300kb至约350kb、约350kb至约400kb、约400kb至约450kb、约450kb至约500kb或更大。或者,插入可为至少1bp、至少5bp、至少10bp、至少50bp、至少100bp、至少200bp、至少300bp、至少400bp、至少500bp、至少1kb、至少5kb、至少10kb、至少20kb、至少30kb、至少40kb、至少60kb、至少80kb、至少100kb、至少150kb、至少200kb、至少250kb、至少300kb、至少350kb、至少400kb、至少450kb或至少500kb。靶向遗传修饰可为精确修饰或不精确修饰。举例来说,在使用外源性修复模板的方法中,缺失可为精确缺失,其中经缺失核酸仅由5’同源臂与3’同源臂之间的核酸序列组成,以致在经修饰靶基因组基因座处不存在额外插入或缺失(插入缺失)。类似地,如果使用侧接于编码自身抗原的基因的整个编码区的成对grna,那么第一cas蛋白裂解位点与第二cas蛋白裂解位点之间的缺失可为精确缺失,其中经缺失核酸仅由第一cas蛋白裂解位点与第二cas蛋白裂解位点之间的核酸序列组成,以致在经修饰靶基因组基因座处不存在额外插入或缺失(插入缺失)。在其中使用外源性修复模板与侧接于目标区域的成对grna两者的方法中,缺失可为以上提及的精确缺失中的任一者。或者,第一cas蛋白裂解位点与第二cas蛋白裂解位点之间的缺失可为延伸超出第一cas蛋白裂解位点和第二cas蛋白裂解位点的不精确缺失,这符合通过非同源性末端接合(nhej)进行的不精确修复,从而在经修饰基因组基因座处产生额外缺失和/或插入。举例来说,缺失可延伸超出第一cas蛋白裂解位点和第二cas蛋白裂解位点约1、2、3、4、5、10、20、30、40、50、100、200、300、400或500bp或更多。同样,经修饰基因组基因座可包含符合通过nhej进行的不精确修复的额外插入,诸如插入约1、2、3、4、5、10、20、30、40、50、100、200、300、400、或500bp或更多。使用外源性修复模板(例如单链寡脱氧核苷酸(ssodn))以及crispr/cas9可通过促进同源性引导的修复而非nhej来使精确修饰的机会增加。靶向修饰可包括用相应同源或直系同源序列替换在靶基因组基因座处的序列(例如编码自身抗原的基因的全部或一部分,诸如所述基因的编码自身抗原的特定区域或基序的一部分)。缺失编码自身抗原的基因的全部或一部分以及用缺乏在目标外来抗原与自身抗原之间共有的表位的相应同源或直系同源序列替换可导致表达自身抗原的同源物或直系同源物,其保留野生型自身抗原的功能,但缺乏存在于目标外来抗原上以及与野生型自身抗原共有的表位。或者或另外,靶向修饰可包括在靶基因组基因座(例如编码自身抗原的基因的全部或一部分)处的一个或多个点突变(例如1、2、3、4、5个或更多个)。所述点突变可例如起使自身抗原中与目标外来抗原共有的一个或多个表位的表达消除的作用。任选地,所述点突变可导致所编码多肽中的保守性氨基酸取代(例如天冬氨酸[asp,d]被谷氨酸[glu,e]取代)。所述氨基酸取代可导致表达保留野生型自身抗原的功能,但缺乏存在于目标外来抗原上以及与野生型自身抗原共有的表位的自身抗原。本文所述的方法促进和增加双等位基因修饰并且特别是纯合性修饰的频率。特定来说,相较于使细胞与任一单独引导rna接触,通过使细胞与靶向靶基因组基因座内的第一引导rna识别序列和第二引导rna识别序列的第一引导rna和第二引导rna接触,产生双等位基因修饰的效率可得以增加。通过使细胞与靶向靶基因组基因座内的引导rna识别序列的第一引导rna、第二引导rna和第三引导rna接触,或与靶向靶基因组基因座内的引导rna识别序列的第一引导rna、第二引导rna、第三引导rna和第四引导rna接触,产生双等位基因修饰的效率也可得以增加。此外或或者,通过选择靶基因组基因座以使在一对同源染色体中相应第一染色体与第二染色体之间,在靶基因组基因座的全部或一部分中的序列同一性最大化,产生双等位基因修饰并且特别是纯合性修饰的效率可得以增加。用于选择所述靶基因组基因座的方法在本文中其他地方进一步详细描述。优选地,靶向遗传修饰是双等位基因修饰。双等位基因修饰包括其中对相应同源染色体(例如在二倍体细胞中)上的相同基因座进行相同修饰,或其中对相应同源染色体上的相同基因座进行不同修饰的事件。同源染色体(即一对同源染色体)包括在相同基因座处具有相同基因,但可能具有不同等位基因的染色体(例如在减数分裂期间成对的染色体)。术语等位基因包括遗传序列的一种或多种替代性形式中的任一者。在二倍体细胞或生物体中,给定序列的两个等位基因通常占据一对同源染色体上的相应基因座。双等位基因修饰可产生就靶向遗传修饰来说的纯合性。纯合性包括靶基因组基因座的两个等位基因(即两个同源染色体上的相应等位基因)均具有靶向遗传修饰所处的情况。举例来说,双等位基因修饰可包括以下、基本上由以下组成或由以下组成:编码自身抗原的基因的全部或一部分的纯合性缺失,或双等位基因修饰可包括以下、基本上由以下组成或由以下组成:对编码自身抗原的基因的起始密码子的纯合性破坏,以致起始密码子不再具有功能性。或者,双等位基因修饰可产生就靶向修饰来说的复合杂合性(例如半合性)。复合杂合性包括靶基因座的两个等位基因(即两个同源染色体上的等位基因)均已被修饰,但它们已以不同方式被修饰(例如一个等位基因中具有靶向修饰,而另一等位基因被失活或破坏)所处的情况。举例来说,在不具有靶向修饰的等位基因中,由cas蛋白产生的双链断裂可已通过非同源性末端接合(nhej)介导的dna修复来修复,此产生包含核酸序列的插入或缺失的突变等位基因,并且由此导致对那个基因组基因座的破坏。举例来说,如果细胞具有一个具有靶向修饰的等位基因和另一不能够被表达的等位基因,那么双等位基因修饰可产生复合杂合性。复合杂合性包括半合性。半合性包括仅存在靶基因座的一个等位基因(即两个同源染色体中的一者上的等位基因)所处的情况。举例来说,如果靶向修饰发生在一个等位基因中,伴有另一等位基因的相应丧失或缺失,那么双等位基因修饰可产生就所述靶向修饰来说的半合性。在一特定实例中,双等位基因修饰可包括一对第一同源染色体和第二同源染色体中第一引导rna识别序列或cas裂解位点与第二引导rna识别序列或cas裂解位点之间的纯合性缺失。或者,双等位基因修饰可包括一对第一同源染色体和第二同源染色体中第一引导rna识别序列或cas裂解位点与第二引导rna识别序列或cas裂解位点之间的双等位基因缺失(即两个染色体中的缺失,但未必在各自中具有相同缺失)。缺失可同时发生,或缺失可初始在第一同源染色体中发生,纯合性接着由细胞使用第一同源染色体作为供体序列以通过同源性重组诸如通过基因转换修复第二同源染色体中的一个或多个双链断裂来实现。在另一特定实例中,双等位基因修饰可包括对一对第一同源染色体和第二同源染色体中的靶标基因的起始密码子区域的纯合性破坏。或者,对一对第一同源染色体和第二同源染色体中的靶标基因的起始密码子区域进行双等位基因破坏(即两个染色体中的破坏,但未必在各自中具有相同修饰)。修饰可同时发生,或修饰可初始在第一同源染色体中发生,纯合性接着由细胞使用第一同源染色体作为供体序列以通过同源性重组诸如通过基因转换修复第二同源染色体中的一个或多个双链断裂来实现。如果使用供体序列(例如外源性修复模板),那么双等位基因修饰可包括在一对第一同源染色体和第二同源染色体中第一引导rna识别序列或cas裂解位点与第二引导rna识别序列或cas裂解位点之间的缺失以及5’靶标序列与3’靶标序列之间的核酸插入物插入,由此产生纯合性经修饰基因组。或者,双等位基因修饰可包括在一对第一同源染色体和第二同源染色体中5’靶标序列与3’靶标序列之间的缺失以及5’靶标序列与3’靶标序列之间的核酸插入物插入,由此产生纯合性经修饰基因组。缺失和插入可同时发生在两个染色体中,或缺失和插入可初始发生在第一同源染色体中,纯合性接着由细胞使用第一同源染色体作为供体序列以通过同源性重组诸如通过基因转换修复第二同源染色体中的双链断裂来实现。举例来说,在不希望受任何特定理论束缚下,核酸插入物的插入可发生在第一同源染色体中(伴有或不伴有由cas蛋白达成的裂解),并且第二同源染色体可接着通过由cas蛋白对第二同源染色体的裂解刺激的基因转换事件来修饰。或者,如果外源性修复模板包含不具有核酸插入物的5’同源臂和3’同源臂,那么双等位基因修饰可包括一对第一同源染色体和第二同源染色体中5’靶标序列与3’靶标序列之间的缺失,由此产生纯合性经修饰基因组。缺失可同时发生在两个染色体中,或缺失可初始发生在第一同源染色体中,纯合性接着由细胞使用第一同源染色体作为供体序列以通过同源性重组诸如通过基因转换修复第二同源染色体中的双链断裂来实现。举例来说,在不希望受任何特定理论束缚下,缺失可发生在第一同源染色体中(伴有或不伴有由cas蛋白达成的裂解),并且第二同源染色体可接着通过由cas蛋白对第二同源染色体的裂解刺激的基因转换事件来修饰。第一引导rna识别序列与第二引导rna识别序列之间的缺失或5’靶标序列与3’靶标序列之间的缺失可为精确缺失,其中经缺失核酸仅由第一核酸酶裂解位点与第二核酸酶裂解位点之间的核酸序列组成,或仅由5’靶标序列与3’靶标序列之间的核酸序列组成,以致在经修饰基因组靶基因座处不存在额外缺失或插入。第一引导rna识别序列与第二引导rna识别序列之间的缺失也可为延伸超出第一核酸酶裂解位点和第二核酸酶裂解位点的不精确缺失,这符合通过非同源性末端接合(nhej)进行的不精确修复,从而在经修饰基因组基因座处产生额外缺失和/或插入。举例来说,缺失可延伸超出第一cas蛋白裂解位点和第二cas蛋白裂解位点约1bp、约2bp、约3bp、约4bp、约5bp、约10bp、约20bp、约30bp、约40bp、约50bp、约100bp、约200bp、约300bp、约400bp、约500bp或更多。同样,经修饰基因组基因座可包含符合通过nhej进行的不精确修复的额外插入,诸如插入约1bp、约2bp、约3bp、约4bp、约5bp、约10bp、约20bp、约30bp、约40bp、约50bp、约100bp、约200bp、约300bp、约400bp、约500bp或更多。通过使用外源性修复模板产生的靶向插入可具有任何大小。外源性修复模板中的核酸插入物的实例和核酸插入物的大小的实例在本文中其他地方描述。纯合性靶向遗传修饰是有利的,因为用于制备具有这些修饰的经遗传修饰的动物的方法(以下更详细描述)可更高效和耗时较少。在许多情况下,诸如移除或破坏基因以研究不存在它时的影响,仅有就靶向遗传修饰来说的杂合性(即在一个等位基因中具有修饰而对另一等位基因无变化)是不足够的。在常规靶向策略的情况下,就大型靶向基因组缺失来说是杂合的f0代动物可能是可获得的,但产生就缺失来说是纯合的f1代动物需要这些杂合性动物的后续异种交配。这些额外交配步骤是昂贵的和耗时的。能够产生就靶向遗传修饰来说是纯合的f0代经遗传修饰的动物会导致显著效率增加和时间节约,因为需要的交配步骤较少。h.鉴定具有靶向遗传修饰的细胞本文公开的方法可进一步包括鉴定具有经修饰靶标核酸(例如经修饰基因组)的细胞。各种方法可用于鉴定具有靶向遗传修饰诸如缺失或插入的细胞。所述方法可包括鉴定一个在靶基因组基因座处具有靶向遗传修饰的细胞。可进行筛选以鉴定具有经修饰基因组基因座的所述细胞。筛选步骤可包括用于评估亲本染色体的等位基因修饰(moa)的定量测定(例如等位基因丧失(loa)和/或等位基因获得(goa)测定)。举例来说,定量测定可通过定量pcr诸如实时pcr(qpcr)来进行。实时pcr可利用识别靶基因组基因座的第一引物组和识别非靶向参照基因座的第二引物组。引物组可包含识别扩增的序列的荧光探针。为鉴定纯合性垮塌es细胞克隆,相较于传统方法,探针qpcr策略可以更大效率和准确性加以使用。由于包括“中间”loa测定(参见例如图4中的mtm探针)以及不存在goa测定,纯合性垮塌等位基因可用一个qpcr板鉴定。因为用于筛选es细胞克隆的每个测定都是loa测定,所以可在不使用任何非小鼠dna校正物下准确计算每个测试区域的拷贝数。筛选步骤也可包括保留测定,其是一种用于区分核酸插入物向靶基因组基因座中的正确靶向插入与所述核酸插入物向所述靶基因组基因座的外部的基因组位置中的随机转基因插入的测定。保留测定也可用于区分正确缺失与延伸超出靶向缺失区域的缺失。用于筛选靶向修饰的常规测定诸如长程pcr或southern印迹使所插入靶向载体与所靶向基因座相关联。然而,由于它们的同源臂大小较大,ltvec不容许通过所述常规测定来筛选。为筛选ltvec靶向,可使用等位基因修饰(moa)测定,包括等位基因丧失(loa)测定和等位基因获得(goa)测定(参见例如us2014/0178879以及frendewey等(2010)methodsenzymol.476:295-307,其各自出于所有目的以引用的方式整体并入本文)。等位基因丧失(loa)测定使常规筛选逻辑倒转,并且对突变所针对的天然基因座的拷贝数定量。在正确靶向的细胞克隆中,loa测定检测两个天然等位基因中的一者(针对不在x或y染色体上的基因),另一等位基因由靶向修饰破坏。相同原理可相反地用作等位基因获得(goa)测定以对所插入靶向载体的拷贝数定量。举例来说,组合使用goa测定和loa测定将会把正确靶向的杂合性克隆揭示为已丧失天然靶标基因的一个拷贝,并且获得药物抗性基因或其他插入标记的一个拷贝。作为一实例,定量聚合酶链式反应(qpcr)可用作等位基因定量的方法,但可可靠地区分零个、一个和两个靶标基因拷贝之间的差异或零个、一个和两个核酸插入物拷贝之间的差异的任何方法都可用于开发moa测定。举例来说,可用于定量基因组dna样品中的dna模板的拷贝数,尤其是通过与参照基因进行比较(参见例如us6,596,541,其出于所有目的以引用的方式整体并入本文)。对与一个或多个靶标基因或基因座在相同基因组dna中的参照基因定量。因此,进行两个扩增(各自具有它的相应探针)。一个探针测定参照基因的“ct”(阈值循环),而另一探针测定一个或多个通过成功靶向而被替换的所靶向基因或基因座的区域的ct(即loa测定)。ct是反映各探针的起始dna的数量的量,即丰度较小的序列需要更多个pcr循环来达到阈值循环。使反应的模板序列的拷贝数降低一半将导致增加约一个ct单位。当相较于来自非靶向细胞的dna时,在其中一个或多个靶标基因或基因座的一个等位基因已通过同源性重组而被替换的细胞的情况下的反应将导致靶标反应增加一个ct,而参照基因的ct不增加。对于goa测定,另一探针可用于测定通过成功靶向而替换一个或多个所靶向基因或基因座的核酸插入物的ct。因为成对grna可在靶基因组基因座处产生大型cas介导的缺失,所以可适用的是使标准loa和goa测定加强以验证由ltvec达成的正确靶向(即在除单细胞期胚胎以外的细胞中)。举例来说,单独loa和goa测定可能不区分正确靶向的细胞克隆与其中靶基因组基因座的大型cas诱导缺失符合ltvec随机整合在基因组中其他地方的克隆,特别是如果goa测定采用针对ltvec插入物内的选择盒的探针。因为所靶向细胞中的选择压力基于选择盒,所以ltvec在基因组中其他地方进行的随机转基因整合将通常包括ltvec的选择盒和邻近区域,但将排除ltvec的更远端区域。举例来说,如果ltvec的一部分随机整合至基因组中,并且ltvec包含长度约5kb或更多,具有邻近于3’同源臂的选择盒的核酸插入物,那么通常3’同源臂而非5’同源臂将与所述选择盒一起以转基因方式整合。或者,如果选择盒邻近于5’同源臂,那么通常5’同源臂而非3’同源臂将与选择盒一起以转基因方式整合。作为一实例,如果loa测定和goa测定用于评估ltvec的靶向整合,并且goa测定利用针对选择盒的探针,那么在靶基因组基因座处的杂合性缺失与ltvec的随机转基因整合组合将与ltvec在靶基因组基因座处的杂合性靶向整合给出相同读出。为验证由ltvec达成的正确靶向,可单独或与loa和/或goa测定联合使用保留测定。保留测定对5’靶标序列(对应于ltvec的5’同源臂)和/或3’靶标序列(对应于ltvec的3’同源臂)中的dna模板的拷贝数进行测定。特定来说,测定对应于与选择盒邻近的同源臂的靶标序列中的dna模板的拷贝数是适用的。在二倍体细胞中,大于2的拷贝数通常指示ltvec随机转基因整合在靶基因组基因座的外部而非在靶基因组基因座处,此是不合需要的。正确靶向的克隆将保留拷贝数2。此外,在所述保留测定中拷贝数小于2通常指示存在延伸超出靶向缺失区域的大型cas介导的缺失,此也是不合需要的。在用于鉴定核酸插入物在二倍体细胞中的靶基因组基因座处的靶向插入的一示例性保留测定中,首先从具有已与大型靶向载体(ltvec)接触的基因组的细胞获得dna,所述大型靶向载体包含由杂交至第一靶标序列的第一同源臂和杂交至第二靶标序列的第二同源臂侧接的核酸插入物,其中所述核酸插入物包含邻近于所述第一同源臂的选择盒。任选地,选择盒可包含药物抗性基因。然后使dna暴露于在第一靶标序列内结合的探针、在核酸插入物内结合的探针和在具有已知拷贝数的参照基因内结合的探针,其中各探针在结合后产生可检测信号。接着检测来自各探针的结合的信号。将来自参照基因探针的信号与来自第一靶标序列探针的信号进行比较以测定第一靶标序列的拷贝数,并且将来自参照基因探针的信号与来自核酸插入物探针的信号进行比较以测定核酸插入物的拷贝数。核酸插入物拷贝数1或2以及第一靶标序列拷贝数2通常指示核酸插入物靶向插入在靶基因组基因座处,而核酸插入物拷贝数1或更多以及第一靶标序列拷贝数3或更多通常指示核酸插入物随机插入在除靶基因组基因座以外的基因组基因座处。来自第一靶标序列探针的结合的信号可用于测定第一靶标序列的阈值循环(ct)值,来自参照基因探针的结合的信号可用于测定参照基因的阈值循环(ct)值,并且第一靶标序列的拷贝数可通过将第一靶标序列ct值与参照基因ct值进行比较来测定。同样,来自核酸插入物探针的结合的信号可用于测定核酸插入物的阈值循环(ct)值,并且核酸插入物的拷贝数可通过将第一靶标序列ct值与参照基因ct值进行比较来测定。ltvec中的核酸插入物可为例如至少5、10、20、30、40、50、60、70、80、90、100、150、200、250、300、350、400、450或500kb。探针在第一靶标序列和选择盒中所结合的序列之间的距离可为例如不超过100个核苷酸、200个核苷酸、300个核苷酸、400个核苷酸、500个核苷酸、600个核苷酸、700个核苷酸、800个核苷酸、900个核苷酸、1kb、1.5kb、2kb、2.5kb、3kb、3.5kb、4kb、4.5kb、或5kb。所述方法可进一步包括额外保留测定以对第二靶标序列的拷贝数进行测定。举例来说,所述方法可进一步包括使细胞的dna暴露于结合第二靶标序列的探针,检测来自第二靶标序列探针的结合的信号,以及将来自参照基因探针的信号与来自第二靶标序列探针的信号进行比较以测定第二靶标序列的拷贝数。同样,所述方法可进一步包括额外goa测定以对核酸插入物内的一个或多个额外序列的拷贝数进行测定。举例来说,所述方法可进一步包括使细胞的dna暴露于一个或多个结合核酸插入物的额外探针,检测来自一个或多个额外探针的结合的信号,以及将来自参照基因探针的信号与来自一个或多个额外核酸插入物探针的信号进行比较以测定核酸插入物内的一个或多个额外序列的拷贝数。同样,当ltvec被设计来使内源性序列从靶基因组基因座缺失时,或当使用成对grna(例如以在单一基因组靶基因座内的不同位点处产生成对双链断裂以及使间插内源性序列缺失)时,所述方法可进一步包括loa测定以对在靶基因组基因座处的内源性序列的拷贝数进行测定。举例来说,所述方法可进一步包括使细胞的dna暴露于结合在靶基因组基因座处的内源性序列的探针,检测来自内源性序列探针的结合的信号,以及将来自参照基因探针的信号与来自内源性序列探针的信号进行比较以测定内源性序列的拷贝数。保留测定也可用于其中使用成对grna,但未必使用外源性修复模板的实验中。因为成对grna可在靶基因组基因座处产生大型cas介导的缺失,所以可适用的是使标准loa测定加强以与由于在nhej修复之后的插入缺失而延伸超出靶向缺失区域的缺失相对比来验证由成对grna达成的正确靶向性缺失。保留测定对包含第一引导rna识别序列(即5’引导rna识别序列)和/或在第一引导rna识别序列的上游的区域和/或包含第二引导rna识别序列(即3’引导rna识别序列)和/或在第二引导rna识别序列的下游以及邻近于第二引导rna识别序列的区域中的dna模板的拷贝数进行测定。在二倍体细胞中,拷贝数小于1将指示存在延伸超出靶向缺失区域的大型nhej介导的缺失,此是不合需要的。正确靶向的克隆将保留拷贝数2。用以测定拷贝数的探针可例如在引导rna识别序列的约100个核苷酸、200个核苷酸、300个核苷酸、400个核苷酸、500个核苷酸、600个核苷酸、700个核苷酸、800个核苷酸、900个核苷酸、1kb、1.5kb、2kb、2.5kb、3kb、3.5kb、4kb、4.5kb或5kb内。适合定量测定的其他实例包括荧光介导的原位杂交(fish)、比较基因组杂交、等温dna扩增、与固定化探针定量杂交、探针、分子信标探针或eclipsetm探针技术(参见例如us2005/0144655,其出于所有目的以引用的方式整体并入本文)。也可使用用于筛选靶向修饰的常规测定,诸如长程pcr、southern印迹或sanger测序。所述测定通常用于获得所插入靶向载体与所靶向基因组基因座之间存在关联的证据。举例来说,对于长程pcr测定,一个引物可识别所插入dna内的序列,而另一引物识别超出靶向载体的同源臂的末端的靶基因组基因座序列。下一代测序(ngs)也可用于筛选,特别是在已被修饰的单细胞期胚胎的情况下。下一代测序也可被称为“ngs”或“大规模平行测序”或“高通量测序”。除moa测定和保留测定之外,所述ngs也可用作筛选工具以确定靶向遗传修饰的确切性质以及检测镶嵌现象。镶嵌现象是指在一个已从单一受精卵(即接合子)发育的个体中存在两个或更多个具有不同基因型的细胞群体。在本文公开的方法中,并非必须使用选择标记筛选所靶向克隆。举例来说,可在不使用选择盒下依赖于本文所述的moa测定和ngs测定。也可针对与目标外来抗原同源或共有目标表位的自身抗原的表达降低或消除来筛选所靶向细胞。举例来说,如果自身抗原是蛋白质,那么可通过用于测定蛋白质表达的任何已知技术来评估表达,所述技术包括例如western印迹分析或蛋白质免疫染色。iii.制备经遗传修饰的非人动物的方法可采用各种本文公开的方法产生经遗传修饰的非人动物。用于产生经遗传修饰的生物体的任何适宜方法或方案,包括本文所述的方法,都适于产生这种经遗传修饰的非人动物。以对多能细胞诸如胚胎干(es)细胞进行遗传修饰起始的所述方法通常包括:(1)使用本文所述的方法修饰不是单细胞期胚胎的多能细胞的基因组;(2)鉴定或选择经遗传修饰的多能细胞;(3)将所述经遗传修饰的多能细胞引入宿主胚胎中;和(4)在代孕母体中植入和孕育包含所述经遗传修饰的多能细胞的所述宿主胚胎。代孕母体可接着产生包含靶向遗传修饰以及能够通过种系传递靶向遗传修饰的f0代非人动物。携带经遗传修饰的基因组基因座的动物可通过如本文所述的等位基因修饰(moa)测定来鉴定。可将供体细胞引入处于任何时期诸如胚泡期或前桑椹胚期(即4细胞期或8细胞期)的宿主胚胎中。产生能够通过种系传递遗传修饰的子代。多能细胞可为例如如在本文中其他地方讨论的es细胞(例如啮齿动物es细胞、小鼠es细胞或大鼠es细胞)。参见例如美国专利号7,294,754,其出于所有目的以引用的方式整体并入本文。或者,以对单细胞期胚胎进行遗传修饰起始的所述方法通常包括:(1)使用本文所述的方法修饰单细胞期胚胎的基因组;(2)鉴定或选择经遗传修饰的胚胎;和(3)在代孕母体中植入和孕育所述经遗传修饰的胚胎。代孕母体可接着产生包含靶向遗传修饰以及能够通过种系传递靶向遗传修饰的f0代非人动物。携带经遗传修饰的基因组基因座的动物可通过如本文所述的等位基因修饰(moa)测定来鉴定。核转移技术也可用于产生非人哺乳动物。简要来说,用于核转移的方法可包括以下步骤:(1)使卵母细胞去核或提供去核卵母细胞;(2)分离或提供待与所述去核卵母细胞组合的供体细胞或核;(3)将所述细胞或核插入所述去核卵母细胞中以形成重构细胞;(4)将所述重构细胞植入非人动物的子宫中以形成胚胎;和(5)使所述胚胎发育。在所述方法中,卵母细胞通常从死亡动物检索,但它们也可从活体动物的输卵管和/或卵巢分离。可在去核之前使卵母细胞在为本领域普通技术人员所知的多种培养基中成熟。可以为本领域普通技术人员所熟知的许多方式进行卵母细胞去核。可通过在融合之前将供体细胞显微注射在透明带下来将供体细胞或核插入去核卵母细胞中以形成重构细胞。融合可通过跨越接触/融合平面施加dc电脉冲(电融合),通过使细胞暴露于融合促进化学物质诸如聚乙二醇,或通过失活病毒诸如仙台病毒(sendaivirus)的方式来诱导。重构细胞可在使核供体和接受卵母细胞融合之前、期间和/或之后通过电学和/或非电学手段来活化。活化方法包括电脉冲、化学诱导冲击、通过精子来渗透、增加卵母细胞中的二价阳离子的水平、以及降低卵母细胞中的细胞蛋白质的磷酸化(如通过激酶抑制剂的方式)。活化的重构细胞或胚胎可在为本领域普通技术人员所熟知的培养基中培养,接着转移至动物的子宫中。参见例如us2008/0092249、wo1999/005266、us2004/0177390、wo2008/017234和美国专利号7,612,250,其各自出于所有目的以引用的方式整体并入本文。各种本文提供的方法允许产生经遗传修饰的非人f0动物,其中所述经遗传修饰的f0动物的细胞包含靶向遗传修饰。应认识到视用于产生f0动物的方法而定,f0动物内具有靶向遗传修饰的细胞的数目将变化。通过例如方法来将供体es细胞引入来自相应生物体的前桑椹胚期胚胎(例如8细胞期小鼠胚胎)中使得f0动物的细胞群体中有较大百分比包含具有靶向遗传修饰的细胞。举例来说,非人f0动物的至少50%、60%、65%、70%、75%、85%、86%、87%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%的细胞贡献可由具有靶向遗传修饰的细胞群体组成。此外,f0动物的至少一个或多个生殖细胞可具有靶向遗传修饰。a.非人动物和细胞的类型本文提供的方法采用非人动物和细胞以及来自非人动物的胚胎。所述非人动物优选是哺乳动物,诸如啮齿动物(例如大鼠、小鼠和仓鼠)。其他非人哺乳动物包括例如人、非人灵长类动物、猴、猿、猫、狗、兔、马、公牛、鹿、野牛、家畜(例如牛物种诸如母牛、阉牛等;羊物种诸如绵羊、山羊等;以及猪物种诸如猪和公猪)。术语“非人”排除人。在一些本文提供的方法中,非人动物和细胞以及来自非人动物的胚胎是杂交物。本文提供的方法中采用的非人动物细胞可为例如全能细胞或多能细胞(例如胚胎干(es)细胞诸如啮齿动物es细胞、小鼠es细胞或大鼠es细胞)。全能细胞包括可产生任何细胞类型的未分化细胞,并且多能细胞包括具有发育成超过一种分化细胞类型的能力的未分化细胞。所述多能和/或全能细胞可为例如es细胞或es样细胞,诸如诱导多能干(ips)细胞。es细胞包括在引入胚胎中后能够促成发育胚胎的任何组织的胚胎源性全能或多能细胞。es细胞可源于胚泡的内细胞群,并且能够分化成三个脊椎动物胚层(内胚层、外胚层和中胚层)中的任一者的细胞。本文提供的方法中采用的非人动物细胞也可包括单细胞期胚胎(即受精卵母细胞或接合子)。单细胞期胚胎是通过两个配子之间的受精事件来形成的真核细胞。所述单细胞期胚胎可来自任何遗传背景(例如balb/c、c57bl/6、129或其组合),可为新鲜的或冷冻的,并且可源于自然交配或体外受精。本文提供的方法中采用的小鼠和小鼠细胞可例如来自129品系、c57bl/6品系、balb/c品系、swisswebster品系、129品系和c57bl/6品系的混合物、balb/c品系和c57bl/6品系的混合物、129品系和balb/c品系的混合物、以及balb/c品系、c57bl/6品系和129品系的混合物。举例来说,本文提供的方法中采用的小鼠或小鼠细胞可至少部分地来自balb/c品系(例如至少约25%、至少约50%、至少约75%源于balb/c品系,或约25%、约50%、约75%或约100%源于balb/c品系)。在一个实例中,小鼠或小鼠细胞可具有包含50%balb/c、25%c57bl/6和25%129的品系。或者,小鼠或小鼠细胞可包括排除balb/c的品系或品系组合。在所述小鼠中,balb/c背景不为产生针对目标外来抗原的足够抗原结合蛋白谱系所需。129品系的实例包括129p1、129p2、129p3、129x1、129s1(例如129s1/sv、129s1/svlm)、129s2、129s4、129s5、129s9/svevh、129s6(129/svevtac)、129s7、129s8、129t1和129t2。参见例如festing等(1999)mammaliangenome10(8):836,其出于所有目的以引用的方式整体并入本文。c57bl品系的实例包括c57bl/a、c57bl/an、c57bl/grfa、c57bl/kal_wn、c57bl/6、c57bl/6j、c57bl/6byj、c57bl/6nj、c57bl/10、c57bl/10scsn、c57bl/10cr和c57bl/ola。本文提供的方法中采用的小鼠和小鼠细胞也可来自以上提及的129品系和以上提及的c57bl/6品系的混合物(例如50%129和50%c57bl/6)。同样,本文提供的方法中采用的小鼠和小鼠细胞可来自以上提及的129品系的混合物或以上提及的bl/6品系的混合物(例如129s6(129/svevtac)品系)。小鼠es细胞的一特定实例是vgf1小鼠es细胞。vgf1小鼠es细胞(也称为f1h4)源于通过使雌性c57bl/6ntac小鼠与雄性129s6/svevtac小鼠杂交产生的杂交胚胎。参见例如auerbach等(2000)biotechniques29,1024–1028,其出于所有目的以引用的方式整体并入本文。本文提供的方法中采用的小鼠和小鼠细胞也可具有mhc单倍型的任何组合。mhc分子的功能在于结合外来肽片段,并且将它们展示在细胞表面上以由适当t细胞识别。举例来说,小鼠和小鼠细胞可包含mhcb单倍型(例如c57bl/6)、mhcd单倍型(例如balb/c),或可包含mhcb与mhcd两者(例如c57bl/6和balb/c的组合)。所述mhc组合可导致抗体效价增加。本文提供的方法中采用的大鼠或大鼠细胞可来自任何大鼠品系,包括例如aci大鼠品系、darkagouti(da)大鼠品系、wistar大鼠品系、lea大鼠品系、spraguedawley(sd)大鼠品系或fischer大鼠品系诸如fisherf344或fisherf6。大鼠或大鼠细胞也可从源于两个或更多个以上叙述的品系的混合物的品系获得。举例来说,大鼠或大鼠细胞可来自da品系或aci品系。aci大鼠品系被表征为具有黑色环纹,具有白色腹部和足部以及rt1av1单倍型。所述品系可从包括harlanlaboratories的多种来源获得。来自aci大鼠的大鼠es细胞系的一实例是aci.g1大鼠es细胞。darkagouti(da)大鼠品系被表征为具有环纹皮毛和rt1av1单倍型。所述大鼠可从包括charlesriver和harlanlaboratories的多种来源获得。来自da大鼠的大鼠es细胞系的实例是da.2b大鼠es细胞系和da.2c大鼠es细胞系。在一些情况下,大鼠或大鼠细胞来自近交大鼠品系。参见例如us2014/0235933a1,其出于所有目的以引用的方式整体并入本文。在其他情况下,大鼠或大鼠细胞来自杂交大鼠品系。已被植入宿主胚胎中的细胞可被称为“供体细胞”。供体细胞可与宿主胚胎来自相同品系,或与宿主胚胎来自不同品系。同样,代孕母体可与供体细胞和/或宿主胚胎来自相同品系,或代孕母体可与供体细胞和/或宿主胚胎来自不同品系。多种宿主胚胎可用于本文公开的方法和组合物中。举例来说,可将供体细胞(例如供体es细胞)引入来自相应生物体的前桑椹胚期胚胎(例如8细胞期胚胎)中。参见例如us7,576,259;us7,659,442;us7,294,754;和us2008/0078000,其各自出于所有目的以引用的方式整体并入本文。在其他方法中,可将供体细胞植入处于2细胞期、4细胞期、8细胞期、16细胞期、32细胞期或64细胞期的宿主胚胎中。宿主胚胎也可为胚泡,或可为前胚泡胚胎、前桑椹胚期胚胎、桑椹胚期胚胎、未致密桑椹胚期胚胎或致密桑椹胚期胚胎。当采用小鼠胚胎时,宿主胚胎时期可为蒂勒期1(theilerstage1,ts1)、ts2、ts3、ts4、ts5和ts6,参照theiler(1989)"thehousemouse:atlasofmousedevelopment,"springer-verlag,newyork中所述的蒂勒期,所述文献出于所有目的以引用的方式整体并入本文。举例来说,蒂勒期可选自ts1、ts2、ts3和ts4。在一些方法中,宿主胚胎包含透明带,并且供体细胞是穿过透明带中的孔引入宿主胚胎中的es细胞。在其他方法中,宿主胚胎是无带胚胎。在其他方法中,桑椹胚期宿主胚胎是聚集的。b.用于产生抗原结合蛋白的非人动物用于本文提供的方法中的非人动物可为能够产生抗原结合蛋白的任何非人动物,诸如哺乳动物、啮齿动物、大鼠或小鼠。举例来说,可使用被遗传修饰来使抗体产生最优化的非人动物(例如啮齿动物,诸如大鼠或小鼠)。所述非人动物可为被工程化来有助于大规模生产可用作人治疗剂的抗体的非人动物,包括包含人源化免疫球蛋白基因座的非人动物。举例来说,非人动物(例如啮齿动物,诸如大鼠或小鼠)可在它的种系中包含一个或多个以下修饰:非人动物(例如啮齿动物,诸如大鼠或小鼠)重链可变区基因座完全或部分被人重链可变基因座替换;非人动物(例如啮齿动物,诸如大鼠或小鼠)κ轻链可变区基因座完全或部分被人κ轻链可变区基因座替换;非人动物(例如啮齿动物,诸如大鼠或小鼠)λ轻链可变区基因座完全或部分被人λ轻链可变区基因座替换;并且重链和轻链可变区基因座完全被它们的人同源物或直系同源物替换。非人动物(例如啮齿动物,诸如大鼠或小鼠)也可在它的种系中包含一个或多个以下修饰:完全人重链和轻链可变区基因座可操作地连接至非人动物(例如啮齿动物,诸如大鼠或小鼠)恒定区核酸序列以使所述非人动物(例如啮齿动物,诸如大鼠或小鼠)产生包含人可变结构域融合于非人动物(例如啮齿动物,诸如大鼠或小鼠)恒定结构域的b细胞或抗体;或人重链和/或轻链可变区可操作地连接至非人动物(例如啮齿动物,诸如大鼠或小鼠)恒定区核酸序列以使所述非人动物(例如啮齿动物,诸如大鼠或小鼠)产生包含人可变结构域融合于非人动物(例如啮齿动物,诸如大鼠或小鼠)恒定区的b细胞或抗体。作为一实例。可使用小鼠。参见例如us6,596,541、us8,791,323、us8,895,802、us8,895,801、us7,105,348、us2002/0106629、us2007/0061900、us2011/0258710、us2011/0283376、us2013/0210137、us2014/0017781、us2014/0020124、us2014/0020125、us2014/0017782、us2014/0018522、us2014/0033337、us2014/0033336、us2014/0041068、us2014/0073010、us2014/0023637、us2014/0017238、us2014/0013457、us2014/0017229、us2002/0183275、us8,502,018、us2012/0322108、us2013/0254911、us2014/0213773、us2015/0201589、us2015/0210776、us2014/0017228、us8,642,835、us8,697,940以及murphy等(2014)proc.natl.acad.sci.u.s.a.111(14):5153-5158,其各自出于所有目的以引用的方式整体并入本文。小鼠含有在内源性基因座处用相应人免疫球蛋白可变区对编码小鼠免疫球蛋白重链(igh)和免疫球蛋白轻链(例如κ轻链,igκ)的种系可变区的精确大规模替换。这个精确替换产生具有制备具有人可变区和小鼠恒定区的重链和轻链的杂合免疫球蛋白基因座的小鼠。对小鼠vh-dh-jh和vκ-jκ区段的精确替换保持侧接小鼠序列在杂合免疫球蛋白基因座处完整并具有功能性。所述小鼠的体液免疫系统如同野生型小鼠的体液免疫系统起作用。b细胞发育在任何重要方面都未受阻碍,并且在抗原激发后在小鼠中产生丰富多样性的人可变区。上述非人动物(例如啮齿动物,诸如大鼠或小鼠)(例如小鼠)也可在它们的种系中包含编码非人动物(例如啮齿动物,诸如大鼠或小鼠)adam6基因或其同源物或直系同源物或功能性片段的功能性异位核酸序列。举例来说,这种非人动物(例如啮齿动物,诸如大鼠或小鼠)可缺乏功能性内源性adam6基因,并且包含功能性异位核酸序列以弥补非人动物(例如啮齿动物,诸如大鼠或小鼠)adam6功能的丧失。举例来说,功能性异位序列可包含一个或多个adam6基因,诸如小鼠adam6a基因、小鼠adam6b基因、或adam6a基因与adam6b基因两者。异位核酸序列可存在于人重链可变区基因座处或其他地方。参见例如us2012/0322108;us2013/0254911;us2014/0213773;us2015/0201589;us2015/0210776;us2014/0017228;和us2013/0198879,其各自出于所有目的以引用的方式整体并入本文。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括被遗传修饰来从有限人轻链可变区基因区段谱系表达有限人轻链可变结构域谱系或单一人轻链可变结构域的非人动物(例如啮齿动物,诸如大鼠或小鼠)。所述非人动物产生“通用轻链”或“共同轻链”,并且可适用于制备双特异性抗体。参见例如us2011/0195454;us2012/0021409;us2012/0192300;us2015/0059009;us2013/0045492;us2013/0198880;us2013/0185821;us2013/0302836;us2013/0247234;us2014/0329711;和us2013/0198879,其各自出于所有目的以引用的方式整体并入本文。举例来说,非人动物(例如啮齿动物,诸如大鼠或小鼠)可被遗传工程化来包括单一未重排人轻链可变区基因区段(或两个人轻链可变区基因区段),其重排以形成表达单一轻链(或表达两个轻链中的任一者或两者)的重排人轻链可变区基因(或两个重排轻链可变区基因)。重排人轻链可变结构域能够与由非人动物(例如啮齿动物,诸如大鼠或小鼠)选择的多个亲和力成熟的人重链配对,其中重链可变区特异性结合不同表位。为实现有限轻链选项谱系,非人动物(例如啮齿动物,诸如大鼠或小鼠)可被工程化来致使它的制备或重排天然非人动物(例如啮齿动物,诸如大鼠或小鼠)轻链可变结构域的能力具有非功能性或大致上非功能性。这可例如通过使非人动物(例如啮齿动物,诸如大鼠或小鼠)的轻链可变区基因区段缺失来实现。内源性非人动物(例如啮齿动物,诸如大鼠或小鼠)基因座可接着通过所选外源性适合人轻链可变区基因区段来修饰,所述人轻链可变区基因区段以使得所述外源性人可变区基因区段可重排以及与内源性非人动物(例如啮齿动物,诸如大鼠或小鼠)轻链恒定区基因重组并形成重排反向嵌合轻链基因(人可变,非人动物(例如啮齿动物,诸如大鼠或小鼠)恒定)的方式可操作地连接至非人动物(例如啮齿动物,诸如大鼠或小鼠)轻链恒定区。上述非人动物(例如啮齿动物,诸如大鼠或小鼠)(例如“通用轻链”或“共同轻链”)也可在它们的种系中包含编码非人动物(例如啮齿动物,诸如大鼠或小鼠)adam6基因或其同源物或直系同源物或功能性片段的功能性异位核酸序列。类似地,任何本文所述的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)都也可在它们的种系中包含编码非人动物(例如啮齿动物,诸如大鼠或小鼠)adam6基因或其同源物或直系同源物或功能性片段的功能性异位核酸序列。举例来说,这种非人动物(例如啮齿动物,诸如大鼠或小鼠)可缺乏功能性内源性adam6基因,并且包含功能性异位核酸序列以弥补非人动物(例如啮齿动物,诸如大鼠或小鼠)adam6功能的丧失。异位核酸序列可存在于人重链可变区基因座处或其他地方。参见例如us2012/0322108;us2013/0254911;us2014/0213773;us2015/0201589;us2015/0210776;us2014/0017228;和us2013/0198879,其各自出于所有目的以引用的方式整体并入本文。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括在它的种系中包含可操作地连接至重链恒定区核酸序列的未重排轻链v区段和未重排j区段的非人动物。参见例如us2012/0096572、us2014/0130194和us2014/0130193,其各自出于所有目的以引用的方式整体并入本文。这种非人动物的一个实例是其种系基因组包含经修饰内源性免疫球蛋白重链基因座的非人动物,所述经修饰内源性免疫球蛋白重链基因座包含用包含多个未重排人免疫球蛋白轻链可变(vκ)基因区段和多个未重排人免疫球蛋白轻链接合(jκ)基因区段,并且可操作地连接至内源性非人动物免疫球蛋白重链恒定(ch)区的核苷酸序列对在内源性非人动物免疫球蛋白重链基因座处的所有功能性内源性非人动物免疫球蛋白重链可变(vh)基因区段、所有功能性内源性非人动物免疫球蛋白重链多样性(dh)基因区段和所有功能性内源性非人动物免疫球蛋白重链接合(jh)基因区段的替换,其中所述多个未重排人免疫球蛋白轻链v基因区段和所述多个未重排人免疫球蛋白轻链j基因区段在b细胞发育期间参与b细胞中的重排以形成重排人免疫球蛋白轻链vκ/jκ基因序列,其可操作地连接至在所述经修饰内源性重链基因座处的内源性非人动物免疫球蛋白重链ch区。这种非人动物的另一实例是在它的种系中包含可操作地连接至在内源性非人动物重链基因座处的内源性非人动物重链恒定区的第一未重排人κ轻链可变(vκ)基因区段和未重排人κ轻链接合(jκ)基因区段的非人动物,其中所述第一未重排人vκ基因区段和所述未重排人jκ基因区段替换所有功能性内源性非人动物重链可变(vh)基因区段、所有功能性内源性非人动物多样性(dh)基因区段和所有功能性内源性非人动物重链接合(jh)基因区段,其中所述第一未重排人vκ基因区段和所述未重排人jκ基因区段在所述非人动物中参与重排以形成可操作地连接至内源性非人动物重链恒定区的重排vκ/jκ序列,并且其中所述非人动物在它的种系中进一步包含可操作地连接至非人动物轻链恒定基因的第二人轻链可变(vl)基因区段和人轻链接合(jl)基因区段。这种非人动物的另一实例是其基因组包含以下的非人动物:(a)内源性免疫球蛋白重链基因座,其被修饰来包含用第一多个未重排人轻链可变(vκ)基因区段和第一多个未重排人轻链接合(jκ)基因区段对在内源性非人动物免疫球蛋白重链基因座处的所有功能性内源性非人动物免疫球蛋白重链可变(vh)基因区段、所有功能性内源性非人动物免疫球蛋白重链多样性(dh)基因区段和所有功能性内源性非人动物免疫球蛋白重链接合(jh)基因区段的替换,其中所述第一多个未重排人免疫球蛋白轻链vκ和jκ基因区段可操作地连接至在内源性免疫球蛋白重链基因座处的内源性重链恒定(ch)区,并且在b细胞发育期间参与b细胞中的重排以形成可操作地连接至内源性非人动物ch区核酸序列的第一重排人轻链vκ/jκ基因序列;和(b)经修饰免疫球蛋白轻链基因座,其包含可操作地连接至在内源性非人动物轻链基因座处的内源性非人动物轻链恒定(cκ)区核酸序列的第二多个未重排人轻链可变(vκ)基因区段和第二多个未重排人轻链接合(jκ)基因区段,其中所述第二多个未重排人免疫球蛋白轻链vκ和jκ基因区段替换在内源性链基因座处的所有功能性内源性非人动物轻链可变(vκ)基因区段和所有功能性内源性非人动物轻链接合(jκ)基因区段,并且在b细胞发育期间参与b细胞中的重排以形成可操作地连接至内源性非人动物cκ区核酸序列的第二重排人免疫球蛋白轻链vκ/jκ区基因序列。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括在它的种系基因组中包含免疫球蛋白重链基因座的非人动物,所述免疫球蛋白重链基因座包含可操作地连接至内源性非人动物免疫球蛋白恒定区基因序列的重排人免疫球蛋白重链可变区核苷酸序列。参见例如us2015/0020224、us2014/0245468、us2016/0100561、us9,204,624和us14/961,642,其各自出于所有目的以引用的方式整体并入本文。这种非人动物的一个实例是在它的种系基因组中在内源性免疫球蛋白重链基因座处包含可操作地连接至内源性重链恒定区基因序列的重排人免疫球蛋白重链可变区核苷酸序列的非人动物,其中所述重排重链可变区核苷酸序列编码序列vh3-23/x1x2/jh,其中x1是任何氨基酸,并且x2是任何氨基酸。这种非人动物的另一实例是在它的种系基因组中包含经遗传修饰的内源性免疫球蛋白重链基因座的非人动物,所述经遗传修饰的内源性免疫球蛋白重链基因座包含可操作地连接至内源性非人免疫球蛋白恒定区基因序列的重排人免疫球蛋白重链可变区核苷酸序列,其中所述非人动物关于b细胞群体展现大致上类似于野生型非人动物的体液免疫系统。这种非人动物的另一实例是包含经遗传修饰的内源性免疫球蛋白重链基因座的非人动物,所述经遗传修饰的内源性免疫球蛋白重链基因座包含重排人免疫球蛋白重链可变区核苷酸序列,其包含通过间隔体可操作地连接至重链j区段(jh)序列的重链v区段(vh)序列,其中所述间隔体包含编码至少两个氨基酸残基,其中所述重排人免疫球蛋白重链可变区核苷酸序列可操作地连接至内源性非人动物免疫球蛋白恒定区基因序列。在一个实例中,vh区段是vh3-23。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括其种系基因组包含以下的非人动物:限制免疫球蛋白重链基因座,其特征在于存在可操作地连接至非人免疫球蛋白重链恒定区核酸序列的单一人未重排vh基因区段、一个或多个人未重排dh基因区段和一个或多个人未重排jh基因区段,其中所述非人动物进一步包含含有源于所述限制免疫球蛋白重链基因座的重排人重链可变区基因序列的b细胞。参见例如us2013/0323791和us2013/0096287,其各自出于所有目的以引用的方式整体并入本文。在一些所述非人动物中,单一未重排人vh基因区段是vh1-69。在一些所述非人动物中,单一未重排人vh基因区段是vh1-2。可使用的其他非人动物包括其内源性免疫球蛋白重链基因座由于它包含单一人vh基因区段、一个或多个人dh基因区段和一个或多个人jh基因区段而受限制,并且不包含功能性内源性免疫球蛋白重链可变区基因座的非人动物;所述非人动物进一步包含一个或多个可操作地连接至一个或多个人jl基因区段的人免疫球蛋白vl基因区段,其中所述单一人vh基因区段、一个或多个人dh基因区段和一个或多个jh基因区段可操作地连接至非人免疫球蛋白重链恒定区基因,其中所述单一人vh基因区段是vh1-69或其多态性变体。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括在它的种系基因组中包含经遗传修饰的免疫球蛋白重链基因座的非人动物,所述经遗传修饰的免疫球蛋白重链基因座包含未重排人免疫球蛋白重链可变区核苷酸序列,其中所述未重排重链可变区核苷酸序列包含至少一个组氨酸密码子的添加或至少一个非组氨酸密码子被组氨酸密码子的取代,其中所述组氨酸密码子不由相应人种系重链可变区基因区段编码;并且其中添加或进行取代的组氨酸密码子存在于互补决定区3(cdr3)编码序列中。参见例如us2013/0247235、us9,301,510和us14/046,501,其各自出于所有目的以引用的方式整体并入本文。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括包含种系遗传修饰的非人动物,所述种系遗传修饰包括编码内源性igg恒定区基因的ch1结构域的核苷酸序列的至少一部分的缺失;其中所述非人动物表达包含功能性ch1结构域的igm恒定区基因,并且所述非人动物在它的血清中表达完全或部分缺乏ch1结构域并且缺乏同源轻链的igg抗体。参见例如us2011/0145937、us2014/0289876、us2015/0197553、us2015/0197554、us2015/0197555、us2015/0196015、us2015/0197556、us2015/0197557和us8,754,287,其各自出于所有目的以引用的方式整体并入本文。这种非人动物的一实例是包含种系修饰的非人动物,所述修饰包括:(a)编码内源性igg恒定区基因的ch1结构域的核苷酸序列的缺失;和(b)一个或多个人重链可变区基因区段的纳入,其中所述一个或多个人重链可变区基因区段可操作地连接至(a)的内源性igg恒定区;其中所述非人动物包含完整igm恒定区基因,并且所述非人动物表达包含人可变结构域,完全或部分缺乏ch1结构域,并且缺乏同源轻链的igg重链抗体,并且将所述igg重链抗体分泌至它的血清中。参见例如us2011/0145937。这种非人动物的另一实例是包含种系修饰的非人动物,所述修饰包括:(a)编码内源性igg恒定区基因的ch1结构域和铰链区的核酸序列的缺失;和(b)一个或多个人重链可变区基因区段的纳入,其中所述一个或多个人重链可变区基因区段可操作地连接至(a)的内源性igg恒定区;其中所述非人动物包含完整igm恒定区基因。参见例如us2015/0197553。这种非人动物的另一实例是包含种系修饰的非人动物,所述修饰包含:(a)编码内源性igg恒定区基因的ch1结构域的核酸序列的缺失;(b)内源性igg2a恒定区基因的缺失;(c)内源性igg2b恒定区基因的缺失;和(d)一个或多个人重链可变区基因区段的纳入,其中所述一个或多个人重链可变区基因区段可操作地连接至(a)的内源性igg恒定区;其中所述非人动物包含完整igm恒定区基因。参见例如us2015/0197554。这种非人动物的另一实例是包含种系修饰的非人动物,所述修饰包含:(a)编码内源性igg恒定区基因的ch1结构域和铰链区的核酸序列的缺失;(b)内源性igg2a恒定区基因的缺失;(c)内源性igg2b恒定区基因的缺失;和(d)一个或多个人重链可变区基因区段的纳入,其中所述一个或多个人重链可变区基因区段可操作地连接至(a)的内源性igg恒定区;其中所述非人动物包含完整igm恒定区基因。参见例如us2015/0197555。这种非人动物的另一实例是包含种系修饰的非人动物,所述修饰包含:(a)编码内源性igg1恒定区基因的ch1结构域的核酸序列的缺失;(b)内源性igd恒定区基因的缺失;(c)内源性igg3恒定区基因的缺失;(d)内源性igg2a恒定区基因的缺失;(e)内源性igg2b恒定区基因的缺失;(f)内源性ige恒定区基因的缺失;(g)内源性iga恒定区基因的缺失;和(h)一个或多个人重链可变区基因区段的纳入,其中所述一个或多个人重链可变区基因区段可操作地连接至(a)的内源性igg1恒定区;其中所述非人动物包含完整igm恒定区基因。参见例如us2015/0196015。这种非人动物的另一实例是包含种系修饰的非人动物,所述修饰包含:(a)编码内源性igg1恒定区基因的ch1结构域的核酸序列的缺失;(b)编码内源性igg2a恒定区基因的ch1结构域的核酸序列的缺失;(c)内源性igd恒定区基因的缺失;(d)内源性igg3恒定区基因的缺失;(e)内源性igg2b恒定区基因的缺失;(f)内源性ige恒定区基因的缺失;(g)内源性iga恒定区基因的缺失;和(h)一个或多个人重链可变区基因区段的纳入,其中所述一个或多个人重链可变区基因区段可操作地连接至(a)的内源性igg1恒定区;其中所述非人动物包含完整igm恒定区基因。参见例如us2015/0197556。这种非人动物的另一实例是包含种系修饰的非人动物,所述修饰包含:(a)编码内源性igg1恒定区基因的ch1结构域和铰链区的核酸序列的缺失;(b)内源性igd恒定区基因的缺失;(c)内源性igg3恒定区基因的缺失;(d)内源性igg2a恒定区基因的缺失;(e)内源性igg2b恒定区基因的缺失;(f)内源性ige恒定区基因的缺失;(g)内源性iga恒定区基因的缺失;和(h)一个或多个人重链可变区基因区段的纳入,其中所述一个或多个人重链可变区基因区段可操作地连接至(a)的内源性igg1恒定区;其中所述非人动物包含完整igm恒定区基因。参见例如us2015/0197557。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括包含与非人动物κ轻链恒定区序列邻接的λ轻链可变区序列(vλ)和至少一个j序列(j)的非人动物。参见例如us2012/0073004、us2014/0137275、us2015/0246976、us2015/0246977、us2015/0351371、us9,035,128、us9,066,502、us9,163,092和us9,150,662,其各自出于所有目的以引用的方式整体并入本文。这种非人动物的一个实例是包含以下的非人动物:(a)在内源性非人动物轻链基因座处的至少12至至少40个未重排人λ轻链可变区基因区段和至少一个人jλ基因区段;(b)位于所述至少12至至少40个人轻链可变区基因区段与所述至少一个人jλ序列之间的人vκ-jκ基因间序列;其中所述非人动物表达包含含有人vλ结构域和非人动物cκ结构域的轻链的抗体。这种非人动物的另一实例是在它的种系中在内源性κ轻链基因座处包含以下的非人动物:(a)未重排轻链可变区,其包含多个连续未重排功能性人λ轻链v(hvλ)基因区段和多个连续未重排功能性人λ轻链j(hjλ)基因区段,其中所述多个hvλ基因区段和所述多个hjλ基因区段是所述未重排轻链可变区中仅有的功能性可变区基因区段;和(b)非人动物κ轻链恒定区基因,其中所述多个连续未重排人λ轻链v(hvλ)基因区段和所述多个连续未重排人λ轻链j(hjλ)基因区段可操作地连接至所述非人动物κ轻链恒定区基因以使所述未重排轻链可变区能够重排以形成重排人λ轻链可变区,并且所述非人动物表达包含含有由所述重排人λ轻链可变区编码的可变区和由所述非人动物κ轻链恒定区基因编码的恒定区的轻链的抗体。这种非人动物的另一实例是在它的种系中在内源性κ轻链基因座处包含以下的非人动物:(a)未重排轻链可变区,其包含:(i)至少12个连续未重排功能性人λ轻链可变区(hvλ)基因区段和多个连续未重排功能性人λ轻链j(hjλ)基因区段,其中所述至少12个功能性hvλ基因区段和所述多个功能性hjλ基因区段是所述未重排轻链可变区中仅有的功能性可变区基因区段;和(ii)位于所述连续hvλ基因区段与所述多个连续hjλ基因区段之间的人vκ-jκ基因间序列;和(b)非人动物κ轻链恒定区基因;其中所述至少12个连续未重排功能性人λ轻链v(hvλ)基因区段和所述多个连续未重排功能性人λ轻链j(hjλ)基因区段可操作地连接至所述非人动物κ轻链恒定区基因以使所述未重排轻链可变区能够重排以形成重排人λ轻链可变区,并且所述非人动物表达包含含有由所述重排人λ轻链可变区编码的可变区和由所述非人动物κ轻链恒定区基因编码的恒定区的轻链的抗体。这种非人动物的另一实例是在它的种系中包含以下的非人动物:(a)未重排轻链可变区,其包含多个连续未重排功能性人λ轻链v(hvλ)基因区段和多个连续未重排功能性人λ轻链j(hjλ)基因区段,其中所述多个hvλ基因区段和所述多个hjλ基因区段是所述未重排轻链可变区中仅有的功能性可变区基因区段;和(b)非人动物κ轻链恒定区基因,其中所述多个连续未重排功能性hvλ基因区段和所述多个连续未重排功能性hjλ基因区段可操作地连接至所述非人动物κ轻链恒定区基因以使所述未重排轻链可变区能够重排以形成重排人λ轻链可变区,并且所述非人动物表达包含含有由所述重排人λ轻链可变区编码的可变结构域和由所述非人动物κ轻链恒定区基因编码的恒定结构域的轻链的抗体。这种非人动物的另一实例是在它的种系中包含以下的非人动物:(a)未重排轻链可变区,其包含:(i)至少12个连续未重排功能性人λ轻链v(hvλ)基因区段和多个连续未重排功能性人λ轻链j(hjλ)基因区段,其中所述至少12个功能性hvλ基因区段和所述多个功能性hjλ基因区段是所述未重排轻链可变区中仅有的功能性可变区基因区段;和(ii)位于所述连续hvλ基因区段与所述多个连续hjλ基因区段之间的人vκ-jκ基因间序列;和(b)非人动物κ轻链恒定区基因;其中所述至少12个连续未重排功能性hvλ基因区段和所述多个连续未重排功能性hjλ基因区段可操作地连接至所述非人动物κ轻链恒定区基因以使所述未重排轻链可变区能够重排以形成重排人λ轻链可变区,并且所述非人动物表达包含含有由所述重排人λ轻链可变区编码的可变结构域和由所述非人动物κ轻链恒定区基因编码的恒定结构域的轻链的抗体。这种非人动物的另一实例是其基因组包含免疫球蛋白基因座的非人动物,所述免疫球蛋白基因座包含可操作地连接至非人动物cκ基因的人vλ和jλ基因区段,以致所述非人动物表达包含人λ可变结构域序列与非人动物κ恒定结构域融合的免疫球蛋白轻链。参见例如us9,226,484。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括在它的种系中在内源性非人动物轻链基因座处包含人λ轻链可变区序列的非人动物,其中所述人λ可变区序列表达在包含非人动物免疫球蛋白恒定区基因序列的轻链中。参见例如us2013/0323790、us2013/0326647、us2015/0089680、us2015/0173331、us2015/0176002、us2015/0173332、us2012/0070861、us2015/0320023、us2016/0060359、us2016/0057979、us9,029,628、us9,006,511、us9,012,717、us9,206,261、us9,206,262、us9,206,263和us9,226,484,其各自出于所有目的以引用的方式整体并入本文。这种非人动物的一实例是表达包含人λ可变序列与非人动物恒定区融合的免疫球蛋白轻链的非人动物,其中所述非人动物展现约1:1的κ使用与λ使用比率。参见例如us9,029,628。这种非人动物的另一实例是其基因组包含内源性未重排κ轻链免疫球蛋白基因座的非人动物,所述内源性未重排κ轻链免疫球蛋白基因座包含用人vλ和jλ基因区段对内源性vκ和jκ基因区段的替换,并且其中所述人vλ和jλ基因区段可操作地连接至非人动物cκ基因以使所述非人动物表达包含人λ可变序列与非人动物κ恒定区融合的免疫球蛋白轻链。参见例如us9,006,511。这种非人动物的另一实例是其基因组包含内源性λ轻链免疫球蛋白基因座的非人动物,所述内源性λ轻链免疫球蛋白基因座包含:(i)第一内源性vλ-jλ-cλ基因簇的缺失;和(ii)用人vλ和jλ基因区段对第二内源性vλ-jλ-cλ基因簇中的内源性vλ和jλ基因区段的片段的替换,其中所述人vλ和jλ基因区段包含至少一个人vλ基因区段和至少一个人jλ基因区段,并且其中所述人vλ和jλ基因区段可操作地连接至非人动物cλ基因。参见例如us9,012,717。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括具有包含对免疫球蛋白重链基因座的修饰的基因组的非人动物,其中所述修饰使内源性adam6功能降低或消除,并且所述非人动物进一步包含编码非人动物adam6蛋白或其直系同源物或同源物或相应adam6蛋白的功能性片段的核酸序列。参见例如us2012/0322108、us2013/0254911、us2014/0213773、us2015/0201589、us2015/0210776、us2014/0017228、us8,642,835和us8,697,940,其各自出于所有目的以引用的方式整体并入本文。这种非人动物的一实例是其基因组包含以下的非人动物:(a)adam6基因的异位放置;和(b)人免疫球蛋白重链可变区基因座,其包含一个或多个人vh基因区段、一个或多个人dh基因区段和一个或多个人jh基因区段向内源性非人动物重链基因座中的插入,其中所述人vh、dh和jh基因区段可操作地连接至重链恒定区基因;以使所述非人动物的特征在于:(i)它是能生育的;以及(ii)当它用抗原免疫时,它产生包含可操作地连接至由所述重链恒定区基因编码的重链恒定结构域的由所述一个或多个人vh、一个或多个人dh和一个或多个人jh基因区段编码的重链可变结构域的抗体,其中所述抗体显示与所述抗原的特异性结合。参见例如us8,642,835。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括包含以下的非人动物:(a)一个或多个人vλ和jλ基因区段在非人免疫球蛋白轻链恒定区的上游的插入,(b)一个或多个人vh、一个或多个人dh和一个或多个人jh基因区段在非人免疫球蛋白重链恒定区的上游的插入,和(c)编码adam6蛋白或其功能性片段的核苷酸序列,其中所述adam6蛋白从异位adam6核酸序列表达。参见例如us2013/0160153和us2014/0017228,其各自出于所有目的以引用的方式整体并入本文。这种非人动物的一实例是其基因组包含以下的非人动物:(a)一个或多个人vλ基因区段和一个或多个人jλ基因区段在非人动物免疫球蛋白轻链恒定区基因的上游的插入,(b)一个或多个人vh基因区段、一个或多个人dh基因区段和一个或多个人jh基因区段在非人动物免疫球蛋白重链恒定区基因的上游的插入,和(c)编码非人动物adam6蛋白的异位核苷酸序列,其中所述非人动物adam6蛋白从所述异位核苷酸序列表达。参见例如us2013/0160153。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括在它的种系中包含免疫球蛋白基因座的非人动物,所述免疫球蛋白基因座包含未重排免疫球蛋白可变基因序列,其在cdr3编码序列中包含至少一个非组氨酸密码子被组氨酸密码子的取代或至少一个组氨酸密码子的插入,其中所述非人动物进一步在体内包含多样性抗体谱系,所述抗体各自对目标抗原具有特异性,并且在可变结构域的cdr3中包含至少一个由所述未重排免疫球蛋白可变基因序列中的至少一个组氨酸密码子取代或插入编码的组氨酸氨基酸。参见例如us2013/0247236和us2014/0082760,其各自出于所有目的以引用的方式整体并入本文。在一个实例中,第一免疫球蛋白可变区基因座包含未重排免疫球蛋白重链可变区序列的包含未重排vh、dh和jh基因区段的功能性部分,并且其中所述未重排vh、dh和jh基因区段中的一者或多者包含不由相应野生型种系基因区段编码的插入或进行取代的组氨酸密码子。在另一实例中,未重排vh、dh和jh基因区段是未重排人vh、未重排人dh和未重排人jh基因区段。在另一实施方案中,在它的种系中包含含有免疫球蛋白轻链可变区序列的第二免疫球蛋白可变区基因座,所述免疫球蛋白轻链可变区序列包含至少一个组氨酸密码子的插入或至少一个非组氨酸密码子被组氨酸密码子的取代,其中插入或进行取代的组氨酸密码子不由相应野生型种系免疫球蛋白可变区序列编码,其中非人动物表达包含由非人动物的种系中的组氨酸取代或插入获得的组氨酸的免疫球蛋白轻链可变结构域。参见例如us2013/0247236。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括包含以下的非人动物:(a)一个或多个人vl和一个或多个人jl基因区段在非人免疫球蛋白轻链恒定区的上游的插入;(b)一个或多个人vl和一个或多个人jl基因区段在非人免疫球蛋白重链恒定区的上游的插入;和(c)编码adam6蛋白或其功能性片段的核苷酸序列,其中所述adam6蛋白从异位adam6核酸序列表达。参见例如us2013/0212719,其出于所有目的以引用的方式整体并入本文。这种非人动物的一实例是其基因组包含以下的非人动物:(a)一个或多个人vl基因区段和一个或多个人jl基因区段在非人免疫球蛋白轻链恒定区基因的上游的插入,其中所述一个或多个人vl基因区段和一个或多个人jl基因区段可操作地连接至所述非人免疫球蛋白轻链恒定区基因;(b)一个或多个人vl基因区段和一个或多个人jl基因区段在非人免疫球蛋白重链恒定区基因的上游的插入,其中所述一个或多个人vl基因区段和一个或多个人jl基因区段可操作地连接至所述非人免疫球蛋白重链恒定区基因;和(c)编码非人动物(例如啮齿动物,诸如大鼠或小鼠)adam6蛋白的插入核酸序列,其中所述非人动物(例如啮齿动物,诸如大鼠或小鼠)adam6蛋白从所述插入核酸序列表达,以使所述非人动物的b细胞表达各自包括两个免疫球蛋白轻链与两个免疫球蛋白重链配对的抗体,其中各轻链包含人轻链可变结构域和非人轻链恒定结构域,并且各重链包含人轻链可变结构域和非人重链恒定结构域。参见例如us2013/0212719。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括在它的种系中具有以下的非人动物:(a)包含单一人vh基因区段、一个或多个dh基因区段和一个或多个jh基因区段的人基因组序列;和(b)编码在雄性非人动物中具有功能性的adam6蛋白的序列,其中编码所述adam6的所述序列位于不同于野生型非人动物的adam6基因座的位置处。参见例如us2013/0333057,其出于所有目的以引用的方式整体并入本文。这种非人动物的一实例是在它的种系中具有以下的非人动物:(a)包含单一人vh基因区段、一个或多个人dh基因区段和一个或多个人jh基因区段的未重排人基因组序列,其中所述单一人vh基因区段是vh1-2、vh1-69、vh2-26、vh2-70或其多态性变体;和(b)编码在雄性非人动物中具有功能性的adam6蛋白的序列,其中编码所述adam6蛋白的所述序列位于不同于野生型非人动物的adam6基因座的位置处。参见例如us2013/0333057。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括包含以下的非人动物:(a)编码免疫球蛋白轻链的人vl结构域的单一重排人免疫球蛋白轻链可变区(vl/jl),其中所述单一重排人vl/jl区选自人vκ1-39/j基因区段或人vκ3-20/j基因区段(例如vκ1-39/jκ5基因区段或人vκ3-20/jκ1基因区段);和(b)用一个或多个人vh基因区段对内源性重链可变(vh)基因区段的替换,其中所述人vh基因区段可操作地连接至内源性重链恒定(ch)区基因,并且所述人vh基因区段能够重排并形成人/非人动物嵌合重链基因。所述非人动物可被称为“通用轻链”(ulc)或“共同轻链”非人动物。参见例如us2011/0195454、us2012/0021409、us2012/0192300、us2015/0059009、us2013/0045492、us2013/0198880、us2013/0185821、us2013/0302836、us2015/0313193和us15/056,713,其各自出于所有目的以引用的方式整体并入本文。同样,可使用的另一非人动物(例如啮齿动物,诸如大鼠或小鼠)包括表达抗体群体的非人动物,其中所述非人动物的种系仅包括是重排人种系κ轻链可变区基因的单一免疫球蛋白κ轻链可变区基因,所述非人动物就所述单一免疫球蛋白κ轻链可变区基因来说是杂合的,因为它仅含有一个拷贝,或就所述单一免疫球蛋白κ轻链可变区基因来说是纯合的,因为它含有两个拷贝;所述非人动物的特征在于活性亲和力成熟,以使:(i)所述群体的各免疫球蛋白κ轻链都包含由所述重排人种系κ轻链可变区基因或由其体细胞突变变体编码的轻链可变结构域;(ii)所述群体包括包含轻链可变结构域由所述重排人种系κ轻链可变区基因编码的免疫球蛋白κ轻链的抗体和包含轻链可变结构域由所述其体细胞突变变体编码的免疫球蛋白κ轻链的抗体;以及(iii)所述非人动物产生与所述免疫球蛋白κ轻链成功配对以形成所述群体的所述抗体的体细胞突变的高亲和力重链的多样性集合。这种非人动物的一实例是在它的种系中就以下来说是杂合的或纯合的非人动物:(a)重排vκ/jκ序列在内源性非人动物κ免疫球蛋白轻链可变区基因座处的插入,所述重排vκ/jκ序列包含:单一人种系vκ序列,所述单一人种系vκ序列存在于seqidno:148或seqidno:149中;和单一人种系jκ序列,其中所述重排vκ/jκ序列可操作地连接至内源性非人动物κ恒定区;和(b)多个人免疫球蛋白重链可变区基因区段在内源性非人动物免疫球蛋白重链可变区基因座处的插入,其中所述人免疫球蛋白重链可变区基因区段可操作地连接至内源性非人动物免疫球蛋白重链恒定区,并且所述人免疫球蛋白重链可变区基因区段能够重排并形成重排人/非人动物嵌合免疫球蛋白重链基因。seqidno:148是工程化的人vκ1-39jκ5基因座的序列,并且seqidno:149是工程化的人vκ3-20jκ1基因座的序列。参见例如us2011/0195454,其出于所有目的以引用的方式整体并入本文。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括适用于产生人vl/chxulc结构域的非人动物,其在它的种系基因组中包含:(i)编码免疫球蛋白杂合链的杂合免疫球蛋白基因座,其中所述杂合免疫球蛋白基因座包含可操作地连接至包含一个或多个重链恒定区基因的免疫球蛋白重链恒定区核酸序列的未重排人免疫球蛋白轻链可变区基因区段(vl和jl),所述重链恒定区基因各自至少编码功能性ch1结构域,其中所述vl和jl基因区段能够重排以形成包含可操作地连接至所述免疫球蛋白重链恒定区核酸序列的重排人vl/jl基因序列的杂合序列;(ii)编码人通用轻链,并且包含可操作地连接至免疫球蛋白轻链恒定区核酸序列的人通用重排轻链可变区核苷酸序列的轻链基因座;其中所述非人动物能够产生包含源于所述杂合基因座的人免疫球蛋白杂合链和源于所述轻链基因座的同源人通用轻链的抗原结合蛋白,其中所述人免疫球蛋白杂合链包含人免疫球蛋白轻链可变(hvl/chxulc)结构域融合于包含功能性ch1结构域的重链恒定igd、igg、ige或iga区,并且其中所述人通用轻链包含人免疫球蛋白轻链融合于轻链恒定结构域。参见例如pct/us2016/023289,其出于所有目的以引用的方式整体并入本文。这种非人动物的一实例是适用于产生人vl/chxulc结构域的非人动物,其在它的种系基因组中包含:(i)经修饰内源性免疫球蛋白重链基因座,其包含用可操作地连接至包含一个或多个重链恒定区基因的内源性非人动物免疫球蛋白重链恒定区核酸的多个未重排人免疫球蛋白轻链可变vκ基因区段和多个未重排人免疫球蛋白轻链接合jκ基因区段对所有功能性内源性非人动物免疫球蛋白重链可变vh基因区段、所有功能性内源性非人动物免疫球蛋白重链多样性dh基因区段和所有功能性内源性非人动物免疫球蛋白重链接合jh基因区段的替换,所述重链恒定区基因各自至少编码功能性ch1结构域,其中所述多个未重排人免疫球蛋白轻链vκ基因区段和所述多个未重排人免疫球蛋白轻链jκ基因区段在b细胞发育期间参与b细胞中的重排以形成可操作地连接至在内源性非人动物免疫球蛋白重链基因座处的所述内源性非人动物免疫球蛋白重链恒定区核酸序列的第一重排人免疫球蛋白轻链可变区vκ/jκ核苷酸序列;和(ii)经修饰内源性轻链基因座,其包含源于重排vκ1-39/jκ5或vκ3-20/jκ1基因序列的单一重排人免疫球蛋白轻链可变区基因序列,其中所述单一重排人免疫球蛋白轻链可变区基因序列可操作地连接至内源性非人动物免疫球蛋白轻链恒定区k基因序列;其中所述非人动物能够产生包含源于所述经修饰内源性免疫球蛋白重链基因座的人免疫球蛋白杂合链和源于所述经修饰内源性轻链基因座的同源人通用轻链的抗原结合蛋白,其中所述人免疫球蛋白杂合链包含人免疫球蛋白轻链可变(hvl/chxulc)结构域融合于包含功能性ch1结构域的重链恒定igd、igg、ige或iga区,并且其中所述人通用轻链包含人免疫球蛋白轻链融合于轻链恒定结构域。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括在它的种系基因组中例如在内源性非人轻链基因座处包含轻链免疫球蛋白基因座的非人动物,所述轻链免疫球蛋白基因座包含可操作地连接至免疫球蛋白轻链恒定区核酸序列的重排人免疫球蛋白轻链可变区核苷酸序列,其中可操作地连接至免疫球蛋白轻链恒定区核酸序列的所述重排人免疫球蛋白轻链可变区核苷酸序列编码通用轻链,并且其中所述非人动物能够产生或会产生表达包含免疫球蛋白杂合链和所述通用轻链的抗原结合蛋白的细胞例如淋巴细胞例如b细胞。参见例如us2013/0247234、us2014/0329711、us2014/0013456、us2015/0119556、us2015/0250151、us9,334,334和us9,332,742,其各自出于所有目的以引用的方式整体并入本文。一些所述非人动物就重排人免疫球蛋白轻链可变区核苷酸序列来说是纯合的。一些所述非人动物就重排人免疫球蛋白轻链可变区核苷酸序列来说是杂合的。在一些所述非人动物中,轻链恒定区核酸序列是κ序列。在一些所述非人动物中,轻链恒定区核酸序列是λ序列。在一些所述非人动物中,第二免疫球蛋白基因座是轻链κ基因座。在一些实施方案中,第二免疫球蛋白基因座是轻链λ基因座。这种非人动物的一实例是在它的种系中包含免疫球蛋白轻链基因座的非人动物,所述免疫球蛋白轻链基因座包含单一重排人免疫球蛋白轻链可变区基因序列,其包含人vκ和jκ区段序列,其中所述vκ区段序列源于人vκ1-39或vκ3-20基因区段,并且其中所述单一重排人免疫球蛋白轻链可变区基因序列包含所述vκ区段序列的至少一个非组氨酸密码子被在选自由105、106、107、108、109、111及其组合(根据imgt编号)组成的组的位置处的组氨酸密码子的取代。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括其基因组包含以下的非人动物:(a)可操作地连接至重链恒定区基因的人源化免疫球蛋白重链可变基因座,其包含至少一个未重排人vh、至少一个未重排人dh和至少一个未重排人jh区段;(b)可操作地连接至轻链恒定区基因的人源化免疫球蛋白轻链可变基因座,其包含不超过一个或不超过两个重排人轻链v/j序列;和(c)表达功能性非人动物adam6蛋白或其功能性直系同源物或功能性同源物或功能性片段的异位核酸序列。参见例如us2013/0198879,其出于所有目的以引用的方式整体并入本文。这种非人动物的一实例是在它的种系中包含以下的非人动物:(a)人源化免疫球蛋白重链可变基因座,其包含至少一个未重排人vh基因区段、至少一个未重排人dh基因区段和至少一个未重排人jh基因区段,其中所述人源化免疫球蛋白重链可变基因座可操作地连接至免疫球蛋白重链恒定区基因;(b)人源化免疫球蛋白轻链可变基因座,其包含(i)单一重排人轻链v/j序列,其中所述单一重排人轻链v/j序列是重排人vκ1-39/jκ序列或重排人vκ3-20/jκ序列,或(ii)不超过一个人轻链v基因区段和不超过一个人轻链j基因区段,其中所述不超过一个人轻链v基因区段是vκ1-39或vκ3-20,其中所述人源化免疫球蛋白轻链可变基因座可操作地连接至免疫球蛋白轻链恒定区基因;和(c)表达在雄性非人动物中具有功能性的非人动物adam6蛋白或其直系同源物或同源物或功能性片段的异位核酸序列。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括在它的种系中包含以下的非人动物:(a)编码在内源性免疫球蛋白重链基因座处的至少一个内源性免疫球蛋白重链恒定区基因的ch1结构域的核苷酸序列中的缺失或失活性突变,其中所述至少一个内源性免疫球蛋白重链恒定区基因是igg、iga、ige、igd或其组合;和(b)以下中的任一者或两者:(i)包含至少一个未重排免疫球蛋白轻链可变区(vl)基因区段和至少一个未重排免疫球蛋白轻链接合(jl)基因区段的核酸序列,其中所述未重排vl和jl基因区段能够重组以形成可操作地连接至包含编码所述ch1结构域的所述核苷酸序列中的所述缺失或失活性突变的免疫球蛋白重链恒定区基因的重排免疫球蛋白轻链可变区(vl/jl)核苷酸序列;和/或(ii)包含含有vl和jl基因区段序列的单一重排免疫球蛋白轻链可变区vl/jl基因序列的免疫球蛋白轻链基因座,其中所述单一重排免疫球蛋白轻链可变区基因序列可操作地连接至免疫球蛋白轻链恒定区基因序列。参见例如us2015/0289489,其出于所有目的以引用的方式整体并入本文。这种非人动物的一实例是包含以下的非人动物:(a)用以下在非人动物重链基因座处对所有或大致上所有内源性免疫球蛋白重链v、d和j基因区段的替换:(i)一个或多个未重排人免疫球蛋白重链vh基因区段、一个或多个未重排人免疫球蛋白重链dh基因区段和一个或多个未重排人免疫球蛋白重链jh基因区段,其中所述一个或多个人未重排免疫球蛋白重链vh、dh和jh基因区段可操作地连接至非人动物重链恒定区基因序列;或(ii)一个或多个未重排人轻链vl基因区段和一个或多个人未重排轻链jl基因区段,其中所述一个或多个未重排人轻链vl和jl基因区段可操作地连接至非人动物重链恒定区基因序列,其中所述非人动物重链恒定区基因序列包含全长igm基因和编码选自由igg1、igg2a、igg2b、igg2c、igg3及其组合组成的组的igg基因中的ch1结构域的核苷酸序列中的缺失或失活性突变;和(b)用单一重排人可变vκ/jκ基因序列对所有或大致上所有内源性免疫球蛋白轻链v和j基因区段的替换,并且其中所述非人动物表达包含igm重链与同源轻链缔合的b细胞受体。可使用的其他非人动物(例如啮齿动物,诸如大鼠或小鼠)包括在它的种系中包含免疫球蛋白轻链基因座的非人动物,所述免疫球蛋白轻链基因座包含可操作地连接至免疫球蛋白轻链恒定区序列的不超过两个人vl基因区段和一个或多个人jl基因区段,其中所述不超过两个人vl基因区段中的每一个包含至少一个不由相应人种系vl基因区段编码的组氨酸密码子,并且其中所述人vl基因区段和jl基因区段能够重排以及编码抗体的人轻链可变结构域。参见例如us2014/0013456、us2015/0119556、us2015/0250151、us2013/0247234和us9,332,742,其各自出于所有目的以引用的方式整体并入本文。这种非人动物的一实例是包含不超过两个人vl基因区段的非人动物,所述人vl基因区段各自能够与人jl基因区段(选自一个或多个jl区段)重排以及编码免疫球蛋白轻链的人可变结构域,其中所述不超过两个vl基因区段各自和/或所述jl基因区段包含至少一个非组氨酸残基被组氨酸残基的取代。参见例如us2014/0013456。这种非人动物的另一实例是在它的种系中包含免疫球蛋白轻链基因座的非人动物,所述免疫球蛋白轻链基因座包含可操作地连接至免疫球蛋白轻链恒定区序列的两个未重排人vκ基因区段和一个或多个未重排人jκ基因区段,其中所述两个未重排人vκ基因区段是人vκ1-39和vκ3-20基因区段,中的每一个包含非组氨酸密码子被组氨酸密码子的一个或多个取代,并且其中所述人vκ和jκ基因区段能够重排,并且所述人vκ和jκ基因区段编码在选自由105、106、107、108、109、111(根据imgt编号)及其组合组成的组的位置处包含一个或多个组氨酸的人轻链可变结构域,其中所述一个或多个组氨酸由所述一个或多个取代获得。参见例如us2015/0250151。iv.产生抗原结合蛋白的方法通过本文公开的方法产生的经遗传修饰的f0代非人动物可用于制备针对目标外来靶抗原的抗原结合蛋白。已描述用于产生抗原结合蛋白(例如抗体)的若干技术。抗原结合蛋白可直接从经免疫小鼠的b细胞分离(参见例如us2007/0280945,其出于所有目的以引用的方式整体并入本文),和/或经免疫小鼠的b细胞可用于制备杂交瘤(参见例如kohler和milstein(1975)nature256:495-497,其出于所有目的以引用的方式整体并入本文)。编码来自如本文所述的非人动物的抗原结合蛋白(重链和/或轻链)的dna可易于使用常规技术来分离和测序。源于如本文所述的非人动物的杂交瘤和/或b细胞充当所述dna的优选来源。一旦分离,即可将dna放置至表达载体中,接着将所述表达载体转染至不另外产生免疫球蛋白的宿主细胞中,以在重组宿主细胞中获得对单克隆抗体的合成。举例来说,可使通过本文公开的方法产生的经遗传修饰的f0代非人动物暴露于靶抗原,并且在足以引发对目标外来靶抗原的免疫应答的条件下加以维持。可接着从经遗传修饰的f0代非人动物获得编码人免疫球蛋白重链可变结构域的第一核酸序列和/或编码人免疫球蛋白轻链可变结构域的第二核酸序列。或者,可接着从经遗传修饰的f0代非人动物分离抗原结合蛋白。作为一实例,可鉴定表达特异性结合目标外来抗原的抗体的克隆选择的淋巴细胞。在一个实例中,抗原结合蛋白可通过以下方式来产生:用目标外来靶抗原使经遗传修饰的f0代非人动物免疫,使非人动物发动免疫应答,从经免疫动物收集淋巴细胞(例如b细胞),使所述淋巴细胞与骨髓瘤细胞融合以形成杂交瘤细胞,从所述杂交瘤细胞获得编码特异性结合靶抗原的vh结构域的核酸序列和/或编码特异性结合靶抗原的vl结构域的核酸序列,将所述核酸序列与编码免疫球蛋白恒定区或其功能性片段序列的核酸序列同框克隆(即可操作连接)以产生免疫球蛋白重链和/或免疫球蛋白轻链,以及在能够表达抗原结合蛋白的细胞(例如cho细胞)中表达所述重链和所述轻链。在另一实例中,抗原结合蛋白可通过以下方式来产生:用目标外来靶抗原使经遗传修饰的f0代非人动物免疫,使非人动物发动免疫应答,从经免疫动物收集淋巴细胞(例如b细胞),从所述淋巴细胞获得编码特异性结合靶抗原的vh结构域的核酸序列和/或编码特异性结合靶抗原的vl结构域的核酸序列,将所述核酸序列与编码免疫球蛋白恒定区或其功能性片段序列的核酸序列同框克隆(即可操作连接)以产生免疫球蛋白重链和/或免疫球蛋白轻链,以及在能够表达抗原结合蛋白的细胞(例如cho细胞)中表达所述重链和所述轻链。用目标外来抗原免疫可用蛋白质、dna、dna和蛋白质的组合、或表达目标外来抗原的细胞进行。获得的淋巴细胞可来自经免疫动物的任何来源,包括例如脾、淋巴结或骨髓。在一些所述方法中,vh结构域和/或vl结构域是人结构域(例如当经遗传修饰的f0代非人动物在igh与igκ两者处均是纯合性人源化的时),将vh结构域和/或vl结构域与编码人恒定区的核酸序列同框克隆,并且产生的抗原结合蛋白是完全人抗体。当相较于对照非人动物(即在第一靶基因组基因座处是野生型)时,在本文所述的经遗传修饰的f0代非人动物(即在第一靶基因组基因座处经遗传修饰)中产生的针对目标外来抗原的抗原结合蛋白的产量通常增加。也就是说,相比于在使在第一靶基因组基因座处是野生型的对照非人动物免疫之后获得的抗原结合蛋白,在本文所述的经遗传修饰的f0代非人动物(即在第一靶基因组基因座处经遗传修饰)中产生的针对目标外来抗原的抗原结合蛋白通常具有更高效价。举例来说,效价可为至少1.5倍、2倍、3倍、4倍、5倍、6倍、7倍、8倍、9倍、或10倍高。术语抗体效价包括存在于血清中的特异性抗体的浓度的测量结果。举例来说,抗体效价可为生物体已产生多少识别特定表位的抗体的测量结果,表示为仍然产生阳性结果的最大稀释度的倒数。同样,相较于在使在第一靶基因组基因座处是野生型的对照非人动物免疫之后获得的抗原结合蛋白,在用目标外来抗原使经遗传修饰的f0代非人动物免疫之后,通常获得更具多样性的针对目标外来抗原的抗原结合蛋白谱系。对照非人动物是指在第一靶基因组基因座处是野生型的非人动物。优选地,经遗传修饰的f0代非人动物与对照动物之间的唯一实质性差异是第一靶基因组基因座的状况。举例来说,优选地,对照动物不具有其他实质性遗传修饰,并且是与非人动物相同的物种,是与非人动物相同的品系,具有相同遗传背景(除第一靶基因组基因座以外),并且与经遗传修饰的f0代非人动物具有相同龄期。以上或以下引用的所有专利申请、网站、其他出版物、登录号等都出于所有目的以引用的方式整体并入本文,所述引用的程度就好像明确地和个别地指示将各个别条目都如此以引用的方式并入本文一样。如果在不同时间有序列的不同版本与登录号相关联,那么意指的是在本申请的有效申请日期时与所述登录号相关联的版本。有效申请日期意指实际申请日期或涉及所述登录号的优先权申请的申请日期(如果可适用)的早先日期。同样,如果在不同时间有出版物、网站等的不同版本被公布,那么除非另外指示,否则意指的是在申请的有效申请日期时最新近公布的版本。除非另外明确指示,否则本发明的任何特征、步骤、要素、实施方案或方面都可与任何其他特征、步骤、要素、实施方案或方面组合使用。尽管本发明已出于明晰和理解的目的通过说明和举例的方式相当详细地加以描述,但将显而易知的是某些变化和修改可在随附权利要求的范围内加以实施。序列简述使用标准核苷酸碱基字母缩写和氨基酸三字母代码显示随附序列表中所列的核苷酸和氨基酸序列。核苷酸序列遵循在序列的5’末端开始,并且前进(即在各行中从左至右)直至3’末端的标准惯例。仅显示各核苷酸序列的一个链,但互补链应理解为通过对所显示链的任何提及来包括。氨基酸序列遵循在序列的氨基末端开始,并且前进(即在各行中从左至右)直至羧基末端的标准惯例。表1.序列描述。实施例实施例1.使用靶向起始密码子和终止密码子的成对引导rna产生用于抗体产生的ko胚胎干(es)细胞、单细胞期胚胎和小鼠。和技术已允许产生使得能够产生完全人抗体的小鼠。小鼠表达免疫球蛋白κ(igκ)和重(igh)链,其中完全人源化可变区连结至小鼠恒定区。因为蛋白质的在功能上重要的区域在物种之间倾向于保守,所以对自身抗原的免疫耐受性常常对产生针对这些关键表位的抗体造成挑战。在传统上,使小鼠与在目标自身抗原靶标处携带杂合性敲除突变的f0小鼠交配以克服免疫耐受性。为产生适于免疫的三重纯合性小鼠(目标靶标的纯合性无效和在igh与igκ两者处的纯合性人源化),需要再进行两代交配以及15至16个月的总时间。为使这个过程加速,获得胚胎干(es)细胞,其可被靶向来在目标靶标处产生无效等位基因。然而,不幸的是,需要依序靶向步骤来获得纯合性无效es细胞克隆,此是耗时的。更重要的是,不仅es细胞克隆在传统上在用于免疫计划的ko情况下展现用以产生完全es细胞源性f0(即由将es细胞注射至8细胞期胚胎中获得的完全es细胞源性f0代小鼠)的能力低下(参见例如表2),而且依序靶向的es细胞克隆展现用以产生完全es细胞源性f0(即由将es细胞注射至8细胞期胚胎中获得的完全es细胞源性f0代小鼠)的能力甚至进一步降低。参见例如表3(比较使用用于产生靶向遗传修饰和的典型es细胞系(f1h4es细胞系)以及两种通用轻链(ulc)es细胞系和es细胞系(vi-3adam6)达成的产生效率)。表2.es细胞系在用于免疫计划的ko情况下的产生效率。表3.es细胞系的总体产生效率。为产生对目标外来人靶抗原的耐受性降低的小鼠,我们已开发一种用以在单一修饰步骤中快速产生包含功能性异位小鼠adam6基因的就在目标靶标处的无效等位基因来说是纯合的es细胞的方法。我们已使使用一对引导rna来在包含功能性异位小鼠adam6基因的es细胞中的目标靶标的两个等位基因上高效产生大型缺失的程序最优化,由此避免需要设计和产生大型靶向载体(ltvec)。使用这个方法,就在目标靶标处的无效等位基因来说是纯合的以及准备用于免疫的f0可在4至5个月而非15至16个月内分娩(就在目标靶标处的无效等位基因来说是纯合的小鼠幼仔可在约3个月内分娩,但接着老化4-5周以进行免疫)。在这个实验中,设计和克隆成对引导rna以靶向用于纯合性缺失的与那些目标外来靶抗原直系同源的自身抗原。引导rna被设计来靶向编码自身抗原的内源性基因的起始密码子和终止密码子区域。对于一些靶标,设计两对grna(v1和v2)。引导rna设计过程描述于以下材料和方法中。将引导rna连同cas9一起电穿孔或核转染至源于小鼠的es细胞中,所述小鼠包括功能性异位小鼠adam6基因(vi-3adam6)小鼠(用相应人dna以及重新插入的小鼠adam6基因替换内源性小鼠免疫球蛋白重链和轻链可变区)或通用轻链(ulc1-39)小鼠(具有是人vκ1-39/j基因区段的单一重排人免疫球蛋白轻链可变区的小鼠)。参见图32。电穿孔和核转染方案描述于以下材料和方法中。在一些实验中,将cas9和成对引导rna连同靶向用于缺失的编码自身抗原的内源性基因的大型靶向载体(ltvec)一起电穿孔(参见例如图4)。在与或不与ltvec一起使用crispr/cas9(cc9)的情况下观察到相当的缺失效率(参见表4)。表4.双等位基因缺失效率。从实验开始(grna设计)至结束(对于编码自身抗原的内源性基因,具有纯合性无效等位基因的经基因分型的f0小鼠)的时间安排是约3个月。作为一实例,用于产生就对应于靶标1的自身抗原(自身抗原1)来说是纯合性无效的f0小鼠的时间安排显示于表5中。表5.用以在vi-3adam6小鼠中递送自身抗原1的纯合性无效等位基因的时间安排。单独或连同靶向用于缺失的自身抗原的大型靶向载体(ltvec)一起使用靶向各自身抗原的起始密码子和终止密码子区域的成对引导rna,进行若干实验以靶向来自vi-3-adam6小鼠和ulc1-39小鼠的胚胎干(es)细胞中的用于缺失的各种自身抗原。将cas9和引导rna以dna形式引入es细胞中。如表6和图28中所示,对于所有测试自身抗原都实现缺失(即垮塌),其中缺失大小在0.1kb与165kb之间的范围内,并且在缺失(即垮塌)的大小与产生缺失(即垮塌)的效率之间存在负性相关。也可实现大得多的大小的双等位基因垮塌。举例来说,我们已实现约400kb的缺失大小的双等位基因垮塌。同样,通过使用两个5’grna和两个3’grna以及修复载体,以约1.2%的效率实现在小鼠igh基因座处的约900kb-1mb双等位基因垮塌(数据未显示)。表6.缺失(垮塌)大小对缺失(垮塌)效率的影响。类似于使用es细胞的程序,为产生对目标外来人靶抗原的耐受性降低的小鼠,我们也已开发一种用以在单一修饰步骤中快速产生就在目标靶标处的无效等位基因来说是纯合的单细胞期胚胎的方法。我们已使使用一对引导rna来在单细胞期胚胎中的目标靶标的两个等位基因上高效产生大型缺失的程序最优化,由此避免需要设计和产生大型靶向载体(ltvec)。此外,相较于使用es细胞系(例如ulc1-39es细胞系),使用单细胞期胚胎可改进所靶向小鼠的产生效率。使用这个方法,准备用于免疫的就在目标靶标处的无效等位基因来说是纯合的f0小鼠可在4至5个月(就在目标靶标处的无效等位基因来说是纯合的f0小鼠幼仔可在约3个月内分娩)而非15至16个月内分娩。在这个实验中,设计和克隆成对引导rna以靶向用于纯合性缺失的与那些目标外来靶抗原直系同源的自身抗原。引导rna被设计来靶向编码自身抗原的内源性基因的起始密码子和终止密码子区域。引导rna设计过程描述于以下材料和方法中。简要来说,使超排卵雌性与配种雄性交配以产生胚胎。如果仅有少许雄性可用,那么使用体外受精。雌性龄期范围是3-16周,每个供体的卵母细胞在15-46的范围内(中值=32个卵母细胞),并且每个供体的接合子在5-32的范围内(中值=15个接合子)。将引导rna连同cas9mrna一起显微注射(细胞质注射)至来自小鼠的单细胞期胚胎中,所述小鼠包括功能性异位小鼠adam6基因(vi-3adam6)小鼠(用相应人dna以及重新插入的小鼠adam6基因替换内源性小鼠免疫球蛋白重链和轻链可变区)或通用轻链(ulc1-39)小鼠(具有是人vκ1-39/jκ5基因区段的单一重排人免疫球蛋白轻链可变区的小鼠)。注射的胚胎的数目在99-784的范围内(中值=334),存活的胚胎的百分比在56%-73%的范围内(中值=63%),转移的胚胎的数目在59-442的范围内(中值=226),各计划的幼仔的数目在10-46的范围内(中值=32),并且出生率在2%-59%的范围内(中值=13%)。如表7和图29中所示,对于所有测试自身抗原都产生携带靶向缺失(即垮塌)的活体幼仔,其中缺失大小在0.1kb与94kb之间的范围内,并且在缺失(即垮塌)的大小与产生携带缺失(即垮塌)的小鼠幼仔的效率之间存在负性相关。表7.通过在胚胎中进行cas9注射达成的敲除。*ivf或三联体(而非成对自然交配)材料和方法引导rna和测定设计:基于各基因座的共有编码序列(ccds)以格式5’nnnnnnnnnnnnnnnnnnnnngg3’(seqidno:2)设计具有23个碱基对的长度的引导rna(grna),其中n是任何核苷酸。最后三个核苷酸(ngg)是原间隔体邻近基序(pam),并且由cas9酶达成的双链钝性末端dna裂解发生在ngg的5’的3个核苷酸处(在以上小写残基之间)。基于从包括crispr.mit.edu,crispr.med.harvard.edu/sgrnascorer/和broadinstitute.org/rnai/public/analysis-tools/sgrna-design的各种grna搜索引擎获得的评分选择grna。简要来说,在两个dna链上分别测定紧邻起始atg的5’和3’的100-150bp序列和紧邻终止密码子的5’和3’的100-150bp以获得grna。进一步探询根据使用的所有搜索引擎都具有高分的接近atg的两个grna(彼此重叠不超过25%)和接近终止密码子的两个grna在小鼠基因组中的独特性,以及在通用轻链(ulc或共同轻链)、包含功能性异位小鼠adam6基因的小鼠(vi-3-adam6)和vgb6小鼠胚胎干细胞(esc)系中无单核苷酸变化(snv)。如果使用以上搜索规程未发现高评分引导物,那么搜索在atg和终止密码子周围的额外序列直至发现两个高品质引导物。采用applied定制mgb探针,使用primer设计测定以使探针序列始终重叠于各引导物的cas9切割位点。一些测定也使用biosearchtechnologies双重标记的探针(biosearchtech.com/probeity/design/inputsequences.aspx)获得。如果cas9切割由引导物结合的序列,那么这些测定充当等位基因丧失测定。所有测定都针对snv加以筛选。如下对引导物命名:mgu和mgu2(针对小鼠基因组上游);以及mgd和mgd2(针对小鼠基因组下游)。如下对测定命名:mtgu和mtgu2(针对分别涵盖mgu和mgu2的测定),以及mtgd和mtgd2(针对分别涵盖mgd和mgd2的测定)。设计大致与引导物mgu/mgu2和mgd/mgd2等距离,在待垮塌的基因座的中间进行的额外测定,被称为mtm(针对小鼠middle)。这个等位基因丧失测定确定是否发生由引导物侧接的区域的缺失(垮塌)。设计在mgu/mgu2(无论哪个在最5’)的上游以及在mgd/mgd2(无论哪个在最3’)的下游200-800bp进行的其他测定。这些测定被分别称为retu(针对上游保留)和retd(针对下游保留)。这些测定描绘最大可接受的缺失大小,并且如上针对snv加以筛选。引导rna克隆:设计和合成引导rna双链体。因为u6启动子优选以鸟嘌呤起始,所以如果序列未已以鸟嘌呤起始,那么将鸟嘌呤添加至5’。将冻干grna双链体用无菌水再混悬至100μm,并且在0.5ml微量离心管中建立以下连接反应:14.5μlpcr合格水;2μl10xt4dna连接酶缓冲液(neb)、1μlpmb_sgrna_bsmbi载体(约60ng)、1μlgrna双链体(100μm)和1.5μlt4dna连接酶(40u/μl;neb)。接着在室温下孵育连接反应物1小时,并且随后用于在top10细胞的情况下进行的转化反应中。接着挑选菌落,并且通过pcr和测序来检查。电穿孔方案:如下制备引导混合物:10μg各sgrna质粒和5μgcas9野生型质粒。在电穿孔当天,在电穿孔过程之前半小时至一小时,将细胞用es培养基喂养。接着将细胞用pbs洗涤两次,并且添加0.25%胰蛋白酶-edta并在37℃下孵育细胞15分钟。在孵育之后将一个或多个板轻叩,添加es培养基以中和胰蛋白酶,将细胞温和吸移4次以拆散细胞凝块并转移至一个或多个凝胶板中,并且在37℃下孵育细胞20分钟。将一个或多个板振荡并用培养基温和洗涤一次,并且接着将所有细胞都转移至15-ml管中,接着在1200rpm下使所述管旋转5分钟。在10mlpbs中合并所有沉淀,并且对细胞计数并在必要时进行稀释。将20μl体积的细胞混悬液添加至载片,并且使用nexcelomcellometerautot4tm细胞活力计数器进行计数。接着在1200rpm下使管离心5分钟。将沉淀再混悬于电穿孔缓冲液中,各次电穿孔使用7.5x106个细胞。将细胞添加至微型离心管中的引导混合物中,其中各管中的体积是120μl。将管混合2-3次并使用宽孔尖端转移至96孔电穿孔比色皿(2mm间隙)中,并且将比色皿密封。使用630电穿孔仪,在700v、400ω、25uf下递送电脉冲。接着在冰上孵育比色皿10分钟。接着将经电穿孔细胞转移至深孔板中(在比色皿在冰上时添加0.8ml/孔)。将细胞涂铺于2x15cm凝胶板上/用25ml培养基在各板中进行扩散。短暂选择以1μg/ml嘌呤霉素起始,持续3天,并且直至电穿孔后10天将培养基变换为非选择培养基,此时挑选集落。电穿孔方案:在电穿孔当天,在电穿孔过程之前半小时至一小时,将细胞用es培养基喂养。接着将细胞用10mlpbs洗涤两次,并且添加2ml0.25%胰蛋白酶-edta并在37℃下孵育细胞15分钟。在孵育之后将一个或多个板轻叩,添加8mles培养基以中和胰蛋白酶,将细胞温和吸移4次以拆散细胞凝块并转移至一个或多个凝胶板中,并且在37℃下孵育细胞20分钟。将一个或多个板振荡并用培养基温和洗涤一次,并且接着将所有细胞都转移至15-ml管中,接着在90xg下使所述管旋转3分钟。将沉淀再混悬于10mlpbs中,并且对细胞计数并在必要时进行稀释。将20μl体积的细胞混悬液添加至载片中,并且使用nexcelomvisioncba系统进行计数。将总计2x106个细胞等分,并且在管中在90xg下离心3分钟。接着以100μl的总体积将沉淀再混悬于与5μgcas9野生型质粒和2.5μg各sgrna质粒混合的p4缓冲液中。接着将细胞转移至大的比色皿中。使用4d-nucleofectortm和程序cp-105递送电脉冲。添加400μl体积的新鲜es培养基,并且将细胞转移至新的管中以进行混合。接着将细胞涂铺于具有10mles培养基的2x10cm凝胶板上。短暂选择在ep后2天用嘌呤霉素(1.5μg/ml)起始,持续2天。在选择之后,直至电穿孔后10天使用非选择培养基,此时挑选集落。筛选:使用测定mtgu、mtgu2、mtgd和mtgd2评估采用引导物mgu、mgu2、mgd和mgd2由cas9达成的切割。当拷贝数从2(亲本未修饰对照dna)降低至1时,确定在一个等位基因而非另一等位基因处进行切割。当测定产生拷贝数0时,确定由cas9达成纯合性裂解。因为cas9在atg和终止密码子附近的切割不保证移除间插序列,所以当mtm测定数值从2(亲本)变为1或0时分别评估杂合性垮塌和纯合性垮塌。最后,使用retu测定和retd测定设置缺失大小的外部限值。在拷贝数是2的情况下,保留测定将保持完整(得以保留),如同亲本一样。在用mgu、mgu2、mgd和mgd2或其某一组合进行电穿孔之后获得的esc克隆首先使用测定mtgu、mtgu2、mtm、mtgd和mtgd2或其某一组合针对cas9裂解和/或垮塌加以筛选。对于所有测定都具有0拷贝数的集落接着使用retu和retd加以进一步筛选,并且仅有retu和retd拷贝数是2的集落得以通过以进行进一步分析。对小鼠胚胎干细胞的初级和再确认筛选:通过loa(等位基因丧失)多路(4路)qpcr来针对靶基因座的纯合性缺失筛选经修饰mesc集落。对于第一轮筛选(初级),在两个96孔板的第1-11列中分离176个独特克隆的dna。第12列用先前从相同mesc亲本品系分离并用作拷贝数校正物的野生型es细胞dna填充;因此待筛选的各dna板含有88个经修饰克隆和8个校正克隆。将各克隆的dna一式四份分配至384孔板中,并且利用用于同时在靶基因的相对上游、中间和下游区域中测定拷贝数的采用fam、vic、aby和quasar的探针,在单一反应混合物中跨越靶基因座的三个区域测定纯合性loa,其中quasar扩增wnt-2b以校正dna浓度。在测定拷贝数之后,选择跨越靶基因座的所有三个测定的多达8个具有0拷贝的“最佳”品质克隆以进行后续生长扩增,再涂铺,以及经受扩增谱系的拷贝数测定(再确认)。将各扩增克隆涂铺,并且以6个重复分离dna,从而占据96孔板的1行(a-h)的前6列,由此为使用的额外测定提供额外遗传物质和数据重复。重复用于初级筛选中的测定以确认初级基因型,并且保留测定用于确定缺失程度。保留测定定位在就在靶向缺失区域的上游和下游,并且通常等于2个拷贝。额外测定用于确认在小鼠免疫球蛋白重(igh)和κ(igκ)基因座处的亲本esc基因型(对于igh和igκ小鼠是loa,并且对于人源化是goa)。用以鉴定cas9介导的等位基因的下一代测序(ngs):使用标准盐沉淀方法提取来自cas9修饰的f0小鼠的小型尾部活检组织的基因组dna。对于各靶基因座,在虑及以下考虑事项下设计pcr引物:(1)扩增子大小的长度在280-380bp之间;(2)grna裂解位点在pcr产物内的中心,其中引物离grna裂解位点至少35bp以容纳较大插入/缺失(插入缺失),(3)引物的长度是22-25bp,具有在62-65℃之间的熔解温度(tm),在3’末端上具有2bpcg钳;和(4)针对balb/c、c57bl/6或129品系的基因组序列单核苷酸变化检查引物。接着将由提供的特定通用衔接子序列添加至基因座特异性序列。所得扩增子在琼脂糖凝胶上可视化,并且使用thermofishersequalpreptm标准化板试剂盒加以纯化/标准化。产物通过来定量,并且1ng各产物用作用于通过用引物和pcr主混合物进行的额外pcr确定条型码的模板。在热循环仪中采用以下条件进行pcr:在72℃下持续3分钟,在95℃下持续30秒,12个循环的{95℃持续10秒,55℃持续30秒,72℃持续30秒},72℃持续5分钟,以及10℃保持。所得条型码化pcr产物通过xp珠粒来纯化,使用xt试剂盒中的标准化珠粒加以标准化,汇合,并且装载至miseqtm中以进行测序和原始数据收集。对8细胞期小鼠胚胎的显微注射:将约2ml标准es细胞培养基(-lif)添加至无菌35mm培养皿盖中,并且用经过滤矿物油覆盖。使用口吸移器将es细胞涂铺于培养皿的下半部上。将低温保存的8细胞期sw宿主胚胎朝向培养皿的上部放置。为帮助使在注射期间的胚胎损害最小化,新的注射吸移器的尖端通过相对于固持吸移器进行温和敲击来钝化。基于形态和亮度选择es细胞,并且采集至注射吸移器中。使胚胎位于固持吸移器上以使分裂球之间的间隙存在于3点钟位置。通过在3点钟位置小心穿过透明带进行穿刺以及将细胞放置在那个点处来将es细胞引入胚胎的卵黄周隙中。每个胚胎引入总计7-9个es细胞。将经注射胚胎放置至含有用经过滤矿物油覆盖的一滴ksom胚胎培养基的35mm培养皿中,并且将胚胎在37.0℃下在7.5%co2下培养过夜。次日早晨,将胚胎通过手术转移至假妊娠雌性中。实施例2.使用靶向起始密码子的区域的多个引导rna产生用于抗体产生的koes细胞和小鼠。在用以产生对目标外来靶抗原的耐受性降低的小鼠的另一实验中,设计和克隆三个引导rna以靶向用于纯合性缺失的与那些外来靶抗原直系同源的自身抗原。三个重叠引导rna被设计来靶向涵盖编码自身抗原的内源性基因的起始密码子的重叠区域(参见图5)。将引导rna连同cas9一起电穿孔或核转染至源于通用轻链(ulc1-39)小鼠(在它们的种系中包含以下的小鼠:(i)重排vκ/jκ序列在内源性小鼠κ免疫球蛋白轻链可变区基因座处的插入,所述重排vκ/jκ序列包含:单一人种系vκ序列;和单一人种系jκ序列,其中所述重排vκ/jκ序列可操作地连接至内源性小鼠κ恒定区;和(ii)可操作地连接至内源性小鼠免疫球蛋白重链恒定区的多个人免疫球蛋白重链可变区基因区段在内源性小鼠免疫球蛋白重链可变区基因座处的插入)的es细胞中。在一些实验中,将cas9和三个引导rna连同靶向用于缺失的编码自身抗原的内源性基因的大型靶向载体(ltvec)一起电穿孔(参见例如图5)。与crispr/cas9(cc9)组合使用ltvec使在靶基因座处得到双等位基因突变的机会显著增加(参见表8),但用ltvec和crispr/cas9进行靶向需要多得多的筛选来排除假阳性。表8.双等位基因缺失效率。实施例3.使小鼠免疫以及分析对免疫原的血清抗体应答。免疫使用多种免疫原诸如蛋白质,用众多跨膜靶标使包含功能性异位小鼠adam6基因的小鼠(vi-3)、通用轻链(ulc1-39)小鼠(在它们的种系中包含以下的小鼠:(i)重排vκ/jκ序列在内源性小鼠κ免疫球蛋白轻链可变区基因座处的插入,所述重排vκ/jκ序列包含:单一人种系vκ序列;和单一人种系jκ序列,其中所述重排vκ/jκ序列可操作地连接至内源性小鼠κ恒定区;和(ii)可操作地连接至内源性小鼠免疫球蛋白重链恒定区的多个人免疫球蛋白重链可变区基因区段在内源性小鼠免疫球蛋白重链可变区基因座处的插入)、ko(敲除)/vi-3小鼠(其中与外来靶抗原直系同源的自身抗原被敲除的vi-3小鼠)和ko/ulc1-39小鼠(其中与外来靶抗原直系同源的自身抗原被敲除的ulc1-39小鼠)免疫。在启动免疫之前从小鼠收集免疫前血清。使用标准佐剂,通过不同途径在不同时间间隔下使小鼠加强免疫,总计进行3-6次加强免疫。将小鼠定期放血,并且测定关于相应抗原的抗血清效价。在靶标8的实例中,通过足垫途径用靶标8的具有小鼠fc标签的重组细胞外结构域使小鼠免疫。效价来自第2次放血(对于ulc1-39,在致敏+6次加强免疫之后)或第3次放血(对于自身抗原-8-ko/ulc1-39,在致敏+3次加强免疫之后)。抗血清效价测定使用elisa测定血清中的针对相应免疫原的抗体效价。将96孔微量滴定板(thermo)用于磷酸盐缓冲盐水(pbs,irvine)中的相应靶抗原在2μg/ml下涂布过夜。将板用含有0.05%吐温20(tween20)的磷酸盐缓冲盐水(pbs-t,)洗涤,并且用250μl含0.5%牛血清白蛋白(bsa,)的pbs在室温下阻断1小时。将板用pbs-t洗涤。将免疫前抗血清和免疫抗血清于0.5%bsa-pbs中连续稀释3倍,并且在室温下添加至板中,持续1小时。将板洗涤,并且将山羊抗小鼠igg-fc-辣根过氧化物酶(hrp)缀合的二级抗体(jacksonimmunoresearch)添加至板中并在室温下孵育1小时。将板洗涤,并且使用tmb/h2o2作为底物,通过孵育20分钟来显色。反应用酸终止,并且在分光光度计上在450nm下对板进行读取。使用软件计算抗体效价。在靶标8的实例中,使用的滴定抗原是人靶标8的具有myc-myc-his标签的重组细胞外结构域。结果通过用不同跨膜靶标进行免疫来探究在vi-3、ulc1-39、ko/vi-3和ko/ulc1-39小鼠中的体液免疫应答。对于免疫的所有靶标,在ko/vi-3和ko/ulc1-39品系中都引发高抗体效价。在vi-3和ulc1-39小鼠品系中,效价也较高。然而,一般来说,ko品系似乎具有更大的效价应答。引发的免疫应答在表9中表示为抗体效价,其定义为抗原结合吸光度是本底的两倍高所处的最高血清稀释度的倒数。因此,数值越高,对免疫原的体液免疫应答越大。总之,超过16种靶标已在ko品系中得以成功免疫。针对靶标1和9的单克隆抗体已通过bst和杂交瘤平台来分离,并且针对靶标4和5的单克隆抗体已通过bst来分离,并且正在进行对这些抗体的进一步表征。ulc1-39和自身抗原-8-ko/ulc1-39小鼠中针对一种目标人靶抗原(靶标8;与小鼠自身抗原8直系同源,上文)的抗体产生的数据提供于表9中和图6中。相比于野生型ulc1-39小鼠,f0ko小鼠引发的对蛋白质激发的应答是约5倍高,如由针对靶标的中值抗体效价所指示。表9中也提供特异性结合至抗原的抗体的数目(在两倍于本底吸光度的吸光度下)。在自身抗原-9-ko/vi-3小鼠相较于vi-3小鼠的情况下显示类似结果。参见图30a和图30b。在这个实验中,通过真皮内途径来用编码野生型靶标9的任一dna使野生型vi-3-adam6小鼠和自身抗原-9-ko/vi-3-adam6小鼠免疫。使用被工程化来表达靶标9的细胞或亲本vi-3t3细胞测定效价。尽管来自vi-3-adam6小鼠的抗体效价与对照差不多,但自身抗原-9-ko/vi-3-adam6小鼠中的抗体效价得以极大增加。这显示ko/vi-3品系与ko/ulc品系两者均引发稳健免疫应答。表9.比较ulc1-39品系和ko/ulc1-39品系中的免疫应答。实施例4.使小鼠免疫以及分析抗体多样性和v基因区段的使用用靶标3使包含功能性异位小鼠adam6基因的小鼠(vi-3)和自身抗原-3-ko(敲除)/vi-3小鼠免疫。在启动免疫之前从小鼠收集免疫前血清。使用标准佐剂,通过不同途径在不同时间间隔下使小鼠加强免疫,总计进行3-6次加强免疫。将小鼠定期放血,并且测定关于相应抗原的抗血清效价。从野生型vi-3小鼠和自身抗原-3-kovi-3小鼠的脾分离b细胞,并且对抗体测序以确定v基因使用。直接从单一抗原阳性b细胞分离编码vh结构域和vl结构域的dna,并且测序。参见例如us7,582,298,其出于所有目的以引用的方式整体并入本文。野生型vi-3小鼠的v基因使用数据呈现于表10中,并且自身抗原-3-kovi-3小鼠的v基因使用数据呈现于表11中。如表10和表11中所示,相较于野生型vi-3小鼠,在自身抗原-3-kovi-3小鼠的情况下观察到在重链v基因区段与轻链v基因区段两者的使用方面的更大多样性。举例来说,在野生型vi-3小鼠中,仅4个重链v基因区段和6个轻链v基因区段用于抗体,并且79%的抗体使用ighv4-59和igκv1-12v基因区段。相比之下,在自身抗原-3-kovi-3小鼠中,6个重链v基因区段和10个轻链v基因区段用于抗体,其中最普遍的使用组合(ighv3-23和igκv4-1)占抗体的仅42%。表10.野生型vi-3小鼠中针对靶标3的抗体的v基因使用。表11.自身抗原-3-kovi-3小鼠中针对靶标3的抗体的v基因使用。此外,在自身抗原-3-kovi-3小鼠中产生与小鼠自身抗原3具有交叉反应性的抗体(即结合人靶标3与小鼠自身抗原3两者的抗体)(参见例如表12)。类似结果用自身抗原4和人靶标4在vi-3小鼠与ulc1-39小鼠两者中观察到。参见图31a和图31b。在这个实验中,使用足垫途径,用his标签化人靶标4蛋白和/或his标签化小鼠自身抗原4蛋白(his标签化)使自身抗原-4-ko/vi-3-adam6小鼠和自身抗原-4-ko/ulc1-39小鼠免疫。使用his标签化人靶标4、his标签化小鼠自身抗原4或his标签化feld1(对照)作为涂布抗原来测定效价。产生针对在小鼠自身抗原3与靶标3之间共有(或在小鼠自身抗原4与人靶标4之间共有)的表位的抗体的能力是有利的,因为这使抗体汇集物扩增:在野生型vi-3小鼠中未产生与小鼠自身抗原3具有交叉反应性的抗体。此外,由于交叉反应性抗体与野生型小鼠中的内源性自身抗原具有交叉反应性,所以可更易于在体内测试它们的药物动力学性质。因此,可不需要产生被遗传工程化来表达所述交叉反应性抗体的靶抗原(例如人靶抗原)的小鼠。表12.自身抗原-3-kovi-3小鼠中产生的与自身抗原3具有交叉反应性的抗体。vhvκ抗体的数目ighv3-23igκv1-172ighv3-23igκv1-91ighv3-23igκv4-155ighv4-59igκv3-201实施例5.使用一个引导rna或两个引导rna达成的crispr/cas9介导的靶向。材料和方法es细胞培养、筛选和电穿孔本文所述的实验用vgf1(即我们的c57bl6ntac/129s6svevf1杂交xyes细胞系)进行(poueymirou等(2007)nat.biotechnol.25:91-99;valenzuela等(2003)nat.biotechnol.21:652-659)。es细胞如先前所述加以培养(matise等(2000),joyner,a.l.编genetargeting:apracticalapproach,第100-132页,oxforduniversitypress,newyork)。vgf1细胞通过使雌性c57bl/6ntac小鼠与雄性129s6/svevtac小鼠杂交以产生c57bl6(xb6)/129s6(y129)小鼠来产生。参见图7。用750万个细胞在2mm间隙比色皿中以0.12ml的最终体积进行电穿孔(ep)。用于ep的电学条件是700v、400欧姆电阻和25μf电容,使用btxecm630电穿孔系统(harvardapparatus,holliston,ma)。每次ep的ltvec量是0.0015mg,cas9表达性质粒是0.005mg,并且sgrna表达性质粒是0.010mg。一些ep在添加100ng赋予嘌呤霉素抗性的质粒下进行以允许在不关于由ltvec表达的新霉素抗性进行选择下选择克隆。在ep之后,将细胞涂铺于两个15cm凝胶化培养皿上,并且每日更换培养基。含有100ug/mlg-418硫酸盐或0.0015mg/ml嘌呤霉素的选择培养基在ep之后48小时开始,并且持续直至ep后10天。将集落挑选于pbs中,并且添加至含有0.05%胰蛋白酶的96孔培养皿中并使其解离15分钟,用培养基中和,并且用于分离dna以进行筛选。等位基因修饰方法(frendewey等(2010)methodsenzymol.476:295-307)用于鉴定正确靶向的es细胞克隆以及确定小鼠等位基因基因型。引导序列的设计将在上游与下游两者围绕lrp5或其他所靶向基因的经缺失部分内部50bp、100bp、500bp或1kb位置的约200bp的dna输入crispr设计工具(crispr.mit.edu)中以检索可能的grna序列。接着过滤潜在grna序列以确保它们将仅允许切割内源性dna而非ltvec中的人源化插入物。单引导rna克隆将sgrna以双链体寡聚物(idt)形式在融合于77bp骨架的bsmbi位点处克隆至pmb_sgrna(u6启动子)中以达成无缝rna表达,或以经验证表达质粒形式从genecopoeia购买(lrp5引导物a、b、b2、e2、e和f)。通过pcr和sanger测序来确认内部产生的质粒。用于基因型确认的dna模板从es细胞、源于已用靶向载体以及表达cas9的质粒和表达若干引导rna(grna)中的一者的质粒或表达不同grna组合的两个质粒电穿孔的es细胞的克隆纯化dna。选择由等位基因修饰(即等位基因丧失或等位基因获得)定量pcr测定鉴定为具有小鼠靶基因座的靶向缺失和靶向载体的插入或具有cas9/grna诱导的缺失的克隆进行追踪常规pcr测定。寡核苷酸设计设计用于grna的每个组合的两个pcr测定。第一pcr是用以检测不同grna组合的引导rna识别序列之间的垮塌的缺失测定。作为5’测定的第二pcr测定包括两个pcr测定。第一是针对人源化等位基因的5’人测定,并且跨越小鼠-人接合部加以设计。第二是针对内源性小鼠等位基因的5’小鼠测定,并且跨越5’靶向缺失接合部加以设计。pcr反应和topo克隆takaralataqdna聚合酶(目录号rr002m)用于扩增es细胞dna模板。各pcr测定反应混合物与水阴性对照一起运行。测定混合物含有以下各物:0.005mles细胞dna模板;1xlapcr缓冲液ii(mg2++);0.01mmdntp混合物;0.0075mm正向寡聚物(各自);0.0075mm反向寡聚物(各自);5000单位/mllataq聚合酶;和ddh2o,补足至0.025ml。pcr热循环程序由以下组成:94℃,持续1分钟;继之以35个循环的94℃,持续30秒,60℃退火梯度,持续30秒,以及68℃,持续1分钟(每扩增1kb);随后在72℃下聚合10分钟。pcr产物通过在2%琼脂糖凝胶上进行电泳来分级分离,采用invitrogen1kbplusdna梯状条带(目录号10787-018)和/或invitrogen50bpdna梯状条带(目录号10416-014)。遵循来自invitrogen的用于测序的topota克隆试剂盒(目录号k4575-02)的说明书,将剩余pcr产物克隆至pcr4-topo载体中。将克隆反应物化学转化至oneshottop10细胞中,并且涂铺在0.06mg/mlx-gal和0.025mg/ml卡那霉素琼脂板上。测序将白色菌落接种至含有0.025mg/ml卡那霉素的lb中,并且在37℃下在振荡下孵育过夜。各菌落代表来自测定产物群体的一个扩增子。使用qiagen质粒小型制备试剂盒(目录号12123)从各细菌培养物提取dna。在包括0.002mltopo克隆pcr产物、1xpcrx增强溶液(10x储备物)(目录号x11495-017)、0.0075mm寡聚物(m13f或m13r)和补足至0.015ml的ddh2o的测序反应混合物中测定插入物的dna序列。测序分析从测序结果去除不确定序列和pcr4-topo载体序列,从而分离pcr插入物序列。接着将经测序片段与参照进行比对并分析变化。对垮塌克隆测序遵循制造商说明书(invitrogen目录号k4575-02),将来自垮塌阳性克隆的pcr产物克隆至pcr4-topo载体中,接着化学转化至oneshottop10细胞中,并且涂铺在0.060mg/mlx-gal和0.025mg/ml卡那霉素琼脂板上。使用qiagen质粒小型制备试剂盒(目录号12123)从细菌培养物提取dna。接着将插入物测序结果与预测垮塌参照进行比对,并且分析插入缺失变化。预测cas9会在离pam3个碱基对处进行裂解以获得由grna识别的序列。将经预测裂解内的序列从参照缺失,并且剩余序列用于与结果进行比对。针对单核苷酸变体(snv)的等位基因辨别测定等位基因辨别反应是0.008ml,含有基因组dna、针对各多态性的特异性探针/引物以及基因表达pcr主混合物。探针从lifetechnologies(thermo)订购,并且引物来自idt。针对等位基因129的探针用vic染料标记;针对等位基因b6的探针用fam染料标记。各等位基因测定一式四份在384孔板上进行,并且在appliedbiosystemsviia7平台上运行。snvpcr循环程序如下:95℃,持续10分钟,继之以40个以下循环:95℃,持续15秒,60℃,持续60秒,以及60℃,持续30秒。对运行的分析以及对结果的评估使用viia7软件v1.1进行。fish分析由celllinegenetics(madison,wisconsin)或vanandelinstitute(grandrapids,michigan)通过它们的标准程序来使用荧光原位杂交(fish)对所选es细胞克隆进行分析。我们提供小鼠bac和人bac作为用于2色分析的探针。靶基因座的增强基因组垮塌和/或人源化为实现啮齿动物基因的全部或一部分的精确单步缺失以及任选同时用它的人同源物的全部或一部分进行的替换,我们通过电穿孔来将以下核酸分子引入啮齿动物es细胞中:(1)ltvec;(2)编码cas9核酸内切酶的质粒或mrna;和(3)一种或多种编码一个或多个crispr单引导rna(grna)的质粒或grna自身。在各实验中,ltvec是线性化的。在一些实验中,ltvec包含编码基因产物(蛋白质或rna)的人基因的全部或一部分,其由被设计来引导使啮齿动物基因缺失以及插入人基因的同源性重组事件的啮齿动物dna同源臂侧接。在其他实验中,ltvec被设计来靶向单独基因座,诸如ch25h基因座。在任一情况下,ltvec都也携带指导赋予对抗生素药物(例如g418)的抗性的酶(例如新霉素磷酸转移酶)的表达的药物选择盒。摄取ltvec并将它掺入它们的基因组中的es细胞能够在组织培养皿上在含有抗生素药物的生长培养基中生长并形成集落。因为我们引入的crispr/cas9编码核酸分子和grna编码核酸分子相比于ltvec分子是500至1,000倍多,所以大多数含ltvec的药物抗性集落也至少短暂含有crispr/cas9组分。我们挑选药物抗性集落,并且通过等位基因修饰方法(valenzuela等(2003)nat.biotech.21:652-660;frendewey等(2010)methodsenzymol.476:295-307;以引用的方式整体并入本文)来筛选它们以鉴定具有正确靶向的人源化等位基因的克隆。此外,被称为保留测定的识别ltvec的同源臂中的序列的实时pcr测定用于验证ltvec向小鼠基因组中的正确靶向。这些保留测定对拷贝数的测定提供用以帮助区分保留拷贝数2的正确靶向的es克隆与其中靶标小鼠基因座的大型cas9诱导缺失符合ltvec随机整合在基因组中其他地方(在所述情况下,保留测定具有拷贝数3(或更多))的克隆的进一步阐明。成对grna能够在靶标小鼠基因座处产生大型cas9介导的缺失意味着如先前所述的标准loa和goa测定可由保留测定加强以提供进一步阐明以及验证正确靶向。因此,设计保留测定,并且与loa和goa测定联合使用。在各实验中,使用一个或两个grna。单一使用的grna引导cas9在靶基因座的5’末端、靶基因座的中间、或靶基因座的3’末端附近的裂解(即靶向小鼠基因缺失)。当使用两个grna时,一个grna引导cas9在靶基因座的5’末端附近的裂解,并且另一grna引导cas9在靶基因座的中间或在靶基因座的3’末端附近的裂解。lrp5基因座在一组实验中,ltvec被设计来产生小鼠lrp5(低密度脂蛋白受体相关蛋白5)基因的编码外结构域的部分的68kb缺失,以及同时用来自人lrp5基因的同源序列的91kb片段进行的替换(参见图8)。ltvec包含人lrp5基因的91kb片段,其由含有源于小鼠lrp5基因座的侧接于小鼠lrp5基因的意图缺失的68kb序列的部分的7kb和33kb的基因组dna的同源臂侧接。在单独实验中,使lrp5人源化ltvec与编码cas9的质粒和编码被设计来在小鼠lrp5基因的靶向缺失区域内产生双链断裂的八个grna(a、b、b2、c、d、e2、e、f)中的一者的第二质粒组合。grna被设计来避免识别人lrp5基因的插入部分中的任何序列。在其他实验中,我们使ltvec和cas9编码质粒与编码靶向小鼠lrp5基因的靶向缺失区域内的不同位点的两个不同grna的质粒组合。通过针对缺失内的序列以及针对药物选择盒和人基因插入物内的序列的等位基因修饰测定(valenzuela等(2003)nat.biotechnol.21:652-659;frendewey等(2010)methodsenzymol.476:295-307)来针对靶向人源化筛选药物抗性es细胞克隆。如果克隆已丧失两个内源性小鼠基因序列中的一者并获得人插入物的一个拷贝,并且也保留两个拷贝的保留序列(位于ltvec的同源臂中),那么将它们评分为被正确靶向。用于这个筛选的两个保留测定是使用以下引物和探针进行的测定:7064retu正向引物cctcctgagctttcctttgcag(seqidno:100);7064retu反向引物cctagacaacacagacactgtatca(seqidno:101);7064retu探针ttctgcccttgaaaaggagaggc(seqidno:102);7064retd正向引物cctctgaggccacctgaa(seqidno:103);7064retd反向引物ccctgacaagttctgccttctac(seqidno:104);7064retd探针tgcccaagcctctgcagcttt(seqidno:105)。crispr/cas9辅助的lrp5基因人源化的结果概述于表13中。当将单独ltvec引入es细胞中时,1.9%的筛选药物抗性克隆携带正确靶向的杂合性人源化等位基因(参见表13中的杂合性靶向列,其包括其中非靶向等位基因完全未突变或具有小型crispr诱导突变诸如由nhej引起的小型缺失的克隆)。相比之下,使ltvec与由八个测试grna(a、b、b2、c、d、e2、e和f;参见表1)中的七者引导的cas9核酸内切酶组合在2.1至7.8%的范围内的效率下产生正确靶向的单等位基因杂合性突变。对于由b2和d达成的cas9引导的裂解,除单等位基因靶向之外,也在1.0-2.1%的频率下检测到双等位基因纯合性人源化。我们从未用独自ltvec观察到双等位基因靶向,即使对于小型简单缺失等位基因。纯合性lrp5人源化es细胞可通过方法(poueymirou等(2007)nat.biotech.25:91-99,以引用的方式整体并入本文)来直接转化至准备用于表型和药物功效研究的完全es细胞源性小鼠中。被设计来检测在预测裂解位点处或附近的grna/cas9诱导的nhej突变的moa测定证明所有测试grna都具有突变活性(数据未显示)。在所有测定克隆之中检测的单等位基因grna诱导突变或双等位基因grna诱导突变的比例根据基因座和位置而变化。在grna突变活性与ltvec靶向性之间不存在强烈关联,但最低靶向效率常常与具有最低突变频率的grna相关联。将识别lrp5基因的靶向缺失区域的不同末端的两个grna组合使总体人源化靶向效率增加,主要是通过使五个测试组合中的三者的纯合性靶向事件的频率增加(表13)。因为grna的组合有可能在cas9裂解位点之间产生由grna加以程序化的大型缺失,所以我们也观察到携带在一个lrp5等位基因上的靶向人源化和在另一等位基因上的大型crispr诱导缺失的半合性es细胞克隆(grna组合a+f,表13)。此外,对于两个grna组合(a+f和a+e2),我们鉴定了具有以下独特基因型的es细胞克隆:在两个lrp5等位基因上的大型crispr介导的缺失。表13.使用个别grna和组合grna对lrp5外结构域进行的crispr/cas9辅助人源化的筛选结果。如表13中所证明,当使用靶向单一基因座的两个grna而非一个grna时(参见图9a),观察到具有双等位基因靶向的克隆的百分比显著增加,从而指示使用grna组合会促进双等位基因修饰。图9a显示使用ltvec和两个引导rna(a和b)来同时使小鼠基因缺失和用相应人形式进行替换的一般性示意图。当使用两个grna时在高得多的频率下观察到的独特突变等位基因类型包括纯合性垮塌的等位基因(图9b;δ/δ)、以纯合方式靶向的等位基因(图9c;hum/hum)、以半合方式靶向的等位基因(图9d;(hum/δ))以及其他复合的以杂合方式靶向的等位基因(例如一个等位基因具有ltvec靶向的人源化,并且另一等位基因具有crispr诱导突变诸如小型缺失)(图9e)。进行若干pcr测定以支持和确认基于moa测定的基因型。引物可见于表1中。lrp5ltvec具有足够短(6.9kb)以通过pcr来证明靶向性的5′同源臂,所述pcr测定人插入物与邻近小鼠基因组序列之间的实体连接。我们用来自评分为杂合性、半合性或纯合性的克隆的dna,而非用来自亲本es细胞系或来自评分为具有双等位基因大型缺失的克隆的dna观察到预期7.5kbpcr产物(图10a),因此确认通过moa(即loa和goa)筛选得到的靶向识别,并且支持推断的双等位基因大型缺失。考查在缺失和插入接合部处的序列的5′-del-jpcr测定(图10b)在来自亲本es细胞系以及来自大多数杂合性人源化克隆的dna的情况下产生330bp产物(数据未显示)。对于杂合性克隆aw-c3,5′-del-j测定产生小于预期的产物(图10b),从而表明grnaa/cas9裂解在非靶向等位基因上诱导小型缺失突变,其也通过针对grnaa裂解的moa测定检测到(数据未显示)。如所预期,5′-del-j测定对于具有半合性、纯合性和双等位基因缺失等位基因的克隆是阴性的。考查在人dna插入物的5′末端与邻近小鼠侧接序列之间的接合部处的序列的5′-ins-jpcr(图10b)在杂合性、半合性和纯合性克隆的情况下产生478bp产物,因为这些克隆具有至少一个所靶向人源化等位基因。对于具有双等位基因大型缺失的克隆,5′-ins-jpcr测定不产生产物(图10b)。为确认半合性和双等位基因缺失克隆中的大型缺失,我们用识别双重grna靶标位点的外部的序列的引物进行pcr。测定agrna位点与fgrna位点之间的缺失的del(a+f)pcr在来自克隆aw-a8和bo-f10的dna的情况下产生约360bp的单一产物(图10b),从而确认至少一个lrp5等位基因具有大型缺失。同样,测定agrna位点与e2grna位点之间的大型缺失的del(a+e2)pcr在来自克隆ba-a7的dna的情况下产生约250bp的单一产物。缺失pcr连同接合部测定、loa测定和goa测定一起支持双等位基因大型缺失基因型。图10a和图10b中所示的测定结果是我们除荧光原位杂交(fish;图11a-图11c)之外也进行的用以确认表13中概述的双等位基因基因型的类似测定的代表性实例。荧光原位杂交(fish)用于确认lrp5基因的纯合性靶向人源化。将来自其中使lrp5人源化ltvec与cas9和两个grna(a加f或a加e2)组合的靶向实验的由定量和常规pcr测定评分为被纯合性靶向的es细胞克隆送给商业细胞学服务机构以进行fish和核型分析。将携带小鼠lrp5基因的细菌人工染色体(bac)用红色荧光标记加以标记并用作用以鉴定内源性lrp5基因座的探针,并且将携带人lrp5基因的bac用绿色荧光标记加以标记并用作用以鉴定用人插入物靶向的染色单体的探针。使经标记bac探针与来自所靶向克隆的中期涂片杂交,并且通过荧光显微术来可视化。涂片上的染色体通过用dapi(4',6-二脒基-2-苯基吲哚)染色来可视化,并且各克隆的单独核型通过吉姆萨染色(giemsastaining)来测定。克隆aw-d9的典型结果显示于图11a中,发现所述克隆具有正常40xy核型(未显示)。图11a中的复合照片显示红色小鼠bac探针信号与绿色人bac探针信号两者共同定位于作为lrp5基因的已知位置的小鼠染色体19的两个拷贝上的细胞学条带b。图11c中的复合照片显示对于另一克隆(ba-d5)的相同纯合性靶向。这些结果确认在克隆aw-d9和ba-d5中,人源化ltvec中的人lrp5基因的91kb片段被正确插入在两个染色体19同源物上的预定小鼠lrp5基因座处。相比之下,图11b中的复合照片显示红色小鼠bac探针信号与绿色人bac探针信号两者共同定位于小鼠染色体19的单一拷贝上的细胞学条带b(实线箭头),而仅有红色小鼠bac探针信号定位于小鼠染色体19的另一拷贝上的细胞学条带b。这些结果确认人源化ltvec中的人lrp5基因的91kb片段被正确插入在染色体19的仅一个拷贝上的预定小鼠lrp5基因座处(杂合性靶向)。它们也指示(连同未显示的其他对照一起)人bac探针不与小鼠lrp5基因座交叉杂交,而是仅识别人lrp5插入物。在某些克隆中存在通过明显非同源性末端接合修复来在两个等位基因处形成的相同crispr诱导插入缺失突变表明在f1h4杂交细胞(其包含50%129svs6品系和50%c57bl/6n品系)中发生基因转换事件。为获得对在使用两个grna时增强双等位基因靶向的背后机理的见地,在用ltvec以及a加f或a加e2grna组合进行靶向之后筛选了具有靶向纯合性人源化或纯合性crispr诱导大型缺失的七个克隆。图12显示被设计来考查由两个引导rna介导的基因转换事件的测定的实例。具体来说,通过分析f1h4杂交es细胞(其包含50%129svs6品系和50%c57bl/6n品系)中的杂合性丧失(loh)来考查基因转换的可能性。基因转换可通过129svs6(129)与c57bl/6n(b6)之间的已知多态性的杂合性丧失来证明,因此pcr测定被设计来区分这两种等位基因类型。结构变体(sv)多态性通过被设计来检测129等位基因与b6等位基因之间的差异的常规pcr来测定。尽管仅一个以下使用的sv测定显示于图12中,但该概念对于各个sv测定都是相同的。基于b6小鼠品系与129小鼠品系之间的结构变化(sv)设计引物,并且显示于表1中。约束引物设计条件以鉴定约25bpsv以及产生约300bppcr产物;选择这些条件以使任何变化都将可通过凝胶电泳见到。在对克隆运行pcr之前,相对于来自b6品系、129品系以及来自f1h4es细胞系的野生型es细胞dna对测定进行验证和优化。选择产生为b6或129等位基因所特有的可区分pcr条带并且在使用f1h4dna的情况下在产生这两个相同可区分条带方面一致的引物组用于对克隆进行测试。对于染色体19(lrp5基因的位置),选择六个引物组—id190045、190061、190068、190030、190033、190013—对由等位基因修饰(moa)测定和常规pcr将基因分型为“纯合性靶向”或“纯合性垮塌”的lrp5人源化克隆进行使用。svpcr测定沿染色体19,从lrp5基因座至染色体的端粒端加以隔开,离lrp5基因座在约13.7至约56.2mb的范围内。sv测定在染色体19上离lrp5基因座的近似距离(以mb计)如下:对于测定190045是13.7,对于测定190061是19.0,对于测定190068是35.0,对于测定190030是37.4,对于测定190033是48.3,并且对于测定190013是56.2。仅有测定190033显示于图12中(显示为sv48.3),但用于测定190045、190061、190068、190030、190033和190013的引物显示于表1中。对来自这些克隆的dna以及对f1h4对照dna、129对照dna和b6对照dna运行pcr。pcr产物通过在6%聚丙烯酰胺凝胶上进行电泳来分级分离,所述凝胶随后用gelred染色。产生两个条带的克隆符合f1h4对照,此根据先前优化显示顶部条带为129等位基因所特有,并且底部条带为b6等位基因所特有。仅产生一个条带的克隆显示只是b6条带或只是129条带。克隆aw-a7、aw-f10、ba-d5、ba-f2、bc-h9和br-b4对于所有六个测定都仅显示b6条带,而克隆bo-a8对于所有六个测定都仅显示129条带。如先前所提及,这些克隆由moa和/或pcr将基因分型为纯合性靶向或纯合性垮塌,并且涉及各种grna组合(a加f、a加e2、b2和d)。只是存在单一等位基因条带表明基因转换事件正在发生—如果不存在转换,那么两个条带均将仍然如同在f1h4对照的情况下而存在。此外,129等位基因与b6等位基因之间的单核苷酸变体(snv)通过等位基因辨别测定来测定。snv测定在图12中的染色体19图谱上的近似位置由箭头连同下方给出的它们离lrp5基因座的距离(以mb计)一起加以显示。离lrp5基因座的距离(以mb计)如下:在lrp5的着丝粒方向0.32(c2),在lrp5的端粒方向1.2(t3),在lrp5的端粒方向11.1(t6),在lrp5的端粒方向13.2(t7),在lrp5的端粒方向17.5(t8),在lrp5的端粒方向25.8(t9),在lrp5的端粒方向33.0(t10),在lrp5的端粒方向38.3(t11),在lrp5的端粒方向49.6(t13),以及在lrp5的端粒方向57.2(t14)。129特异性探针和b6特异性探针以及引物对显示于表1中。表14显示根据sv等位基因与snv等位基因的loh,在染色体19的长臂上,在lrp5靶基因座的端粒方向上展现明显基因转换事件的es细胞克隆的七个实例。es细胞克隆源于如所指示的使lrp5人源化ltvec与一个或两个grna组合的独立靶向实验。grna识别序列的位置显示在图12中lrp5基因图示的上方(指向左侧的粗箭号)。基因分型测定指示七个克隆中的六者具有lrp5基因的以纯合方式靶向的人源化,而一者具有纯合性垮塌(在grna位点之间的大型缺失)。在七个克隆中的六者中,129等位基因丧失,从而仅保留b6等位基因。在另一克隆中,b6等位基因丧失,从而仅保留129等位基因。所有克隆就在lrp5基因座的着丝粒侧上测定的等位基因来说都保持杂合(即在c2snv测定的情况下,所有克隆都是杂合性b6/129)。在七个克隆中观察到的loh指示当使ltvec与一个grna或更经常与两个grna组合时获得纯合性经遗传修饰的等位基因所采用的一种机理是在一个等位基因上进行第一靶向遗传修饰,继之以同源性引导的重组基因转换事件,其从一个染色体将所述靶向遗传修饰拷贝至它的同源物。表14.杂合性丧失测定结果。克隆grnalrp5等位基因类型杂合性丧失测定(sv和snv)aw-a7a+f纯合性靶向仅检测到b6等位基因aw-f10a+f纯合性垮塌仅检测到b6等位基因bo-a8a+f纯合性靶向仅检测到129等位基因ba-d5a+e2纯合性靶向仅检测到b6等位基因ba-f2a+e2纯合性靶向仅检测到b6等位基因bc-h9b2纯合性靶向仅检测到b6等位基因br-b4d纯合性靶向仅检测到b6等位基因c5(hc)基因座在另一组实验中,ltvec被设计来产生小鼠补体组分5(c5或hc(溶血补体))基因的76kb缺失,以及同时用同源性人c5基因的97kb片段进行的替换。靶基因座包含c5(hc)基因的外显子2至终止密码子。ltvec包含人c5基因的97kb片段,其由含有源于小鼠c5(hc)基因座的侧接于小鼠c5(hc)基因的意图缺失的76kb序列的部分的35kb和31kb的基因组dna的同源臂侧接。在单独实验中,使c5(hc)人源化ltvec与编码cas9的质粒和编码被设计来在小鼠c5(hc)基因的靶向缺失区域内产生双链断裂的六个grna(a、b、c、d、e和e2;参见表1)中的一者的第二质粒组合。grna被设计来避免识别人c5基因的插入部分中的任何序列。在其他实验中,我们使ltvec和cas9编码质粒与编码靶向小鼠c5(hc)基因的靶向缺失区域内的不同位点的两个不同grna的质粒组合。在一些实验中,靶向ch25h基因座的对照ltvec替代c5(hc)人源化ltvec加以使用。被设计来使ch25h的整个编码序列(约1kb)缺失以及将嘌呤霉素和新霉素选择盒插入ch25h基因座中的对照ltvec用作用以选择未被靶向以达成在c5(hc)基因座处的同源性重组的药物抗性克隆的手段。crispr/cas9辅助的c5(hc)基因人源化的结果显示于表15中,并且类似于对于crispr/cas9辅助的lrp5基因人源化获得的结果。相比于对于lrp5,用单独ltvec对于c5(hc)人源化达成的靶向效率更高(6.1%),但添加cas9和grna使六个测试grna中的四者的靶向效率增强。如同lrp5一样,将grna组合(即使用两个grna)用于c5(hc)人源化使总体靶向效率进一步增加,主要是通过使半合性和纯合性靶向事件的频率增加。我们也发现在两个等位基因上均具有大型crispr诱导缺失的es细胞克隆(在1.8%至3.6%的频率下观察到)。此外,当靶向ch25h基因座的ltvec与两个c5(hc)grna组合使用时,在1.2%至6%的频率下观察到具有在两个引导rna识别序列之间垮塌的纯合性等位基因的克隆,从而指示在靶基因座处,垮塌事件独立于同源性重组事件而发生。如同lrp5一样,保留测定用于确认正确靶向的克隆。用于这个筛选的两个保留测定是使用以下引物和探针进行的测定:7140retu正向引物cccagcatctgacgacacc(seqidno:106);7140retu反向引物gaccactgtgggcatctgtag(seqidno:107);7140retu探针ccgagtctgctgttactgttagcatca(seqidno:108);7140retd正向引物cccgacaccttctgagcatg(seqidno:109);7140retd反向引物tgcaggctgagtcaggatttg(seqidno:110);7140retd探针tagtcacgttttgtgacaccccaga(seqidno:111)。表15.使用个别grna和组合grna对c5(hc)基因进行的crispr/cas9辅助人源化的筛选结果。荧光原位杂交(fish)用于确认c5(hc)基因的纯合性靶向人源化。将来自其中使c5(hc)人源化ltvec与cas9和两个grna组合的靶向实验的由定量和常规pcr测定评分为被纯合性靶向的es细胞克隆送给商业细胞学服务机构以进行fish和核型分析。将携带小鼠c5(hc)基因的细菌人工染色体(bac)用红色荧光标记加以标记并用作用以鉴定内源性基因座的探针,并且将携带人c5基因的bac用绿色荧光标记加以标记并用作用以鉴定用人插入物靶向的染色单体的探针。使经标记bac探针与来自所靶向克隆的中期涂片杂交,并且通过荧光显微术来可视化。涂片上的染色体通过用dapi(4',6-二脒基-2-苯基吲哚)染色来可视化,并且各克隆的单独核型通过吉姆萨染色来测定。克隆o-e的典型结果显示于图13b中。图13b中的复合照片显示红色小鼠bac探针信号与绿色人bac探针信号两者共同定位于作为c5(hc)基因的已知位置的小鼠染色体2的两个拷贝上的c5(hc)基因座。这些结果确认在克隆o-e3中,人源化ltvec中的人c5基因的97kb片段被正确插入在两个染色体2同源物上的预定小鼠c5(hc)基因座处。相比之下,图13a中的复合照片显示红色小鼠bac探针信号与绿色人bac探针信号两者共同定位在小鼠染色体2的单一拷贝上(实线箭头),而仅有红色小鼠bac探针信号定位于小鼠染色体2的另一拷贝上的c5(hc)基因座。这些结果确认在克隆q-e9中,人源化ltvec中的人c5基因的97kb片段被正确插入在染色体2的仅一个拷贝上的预定小鼠c5(hc)基因座处(杂合性靶向)。接着测定克隆以考查由两个引导rna介导的基因转换事件。具体来说,通过分析f1h4杂交es细胞(其包含50%129svs6品系和50%c57bl/6n品系)中的杂合性丧失(loh)来考查基因转换的可能性。基因转换可通过129svs6(129)与c57bl/6n(b6)之间的已知多态性的杂合性丧失来证明,因此pcr测定被设计来区分这两种等位基因类型。结构变体(sv)多态性通过被设计来检测129等位基因与b6等位基因之间的差异的常规pcr来测定。基于b6小鼠品系与129小鼠品系之间的结构变化(sv)设计引物,并且显示于表1中。约束引物设计条件以鉴定约25bpsv以及产生约300bppcr产物;选择这些条件以使任何变化都将可通过凝胶电泳可视化。在对克隆运行pcr之前,相对于来自b6品系、129品系以及来自f1h4es细胞系的野生型es细胞dna对测定进行验证和优化。选择产生为b6或129等位基因所特有的可区分pcr条带并且在使用f1h4dna的情况下在产生这两个相同可区分条带方面一致的引物组用于对克隆进行测试。选择五个引物组-idsv6.1、sv6.3、sv7.8、sv16和sv25.5—对来自靶向实验的克隆进行使用。四个svpcr测定沿染色体,从c5基因座至染色体的端粒端加以隔开,离c5基因座在约6.3至约25.5mb的范围内。最终svpcr测定在c5基因座的着丝粒方向约6.1mb处。sv测定离c5基因座的近似距离(以mb计)如下:对于测定sv6.1是6.1(在着丝粒方向),对于测定sv6.3是6.3(在端粒方向),对于测定sv7.8是7.8(在端粒方向),对于测定sv16.0是16.0,并且对于测定sv25.5是25.5(参见图14)。所有21个克隆就在c4基因座的着丝粒侧上测定的等位基因来说都保持杂合(即所有克隆都是杂合性b6/129)。根据loh,21个测试克隆中的两者在c5靶基因座的端粒方向上展现明显基因转换事件(参见表16)。基因分型测定指示克隆之一具有c5基因的以纯合方式靶向的人源化,并且另一克隆具有纯合性垮塌。在两个克隆中观察到的loh指示当使ltvec与一个grna或更经常与两个grna组合时获得纯合性经遗传修饰的等位基因所采用的一种机理是在一个等位基因上进行第一靶向遗传修饰,继之以同源性引导的重组基因转换事件,其从一个染色体将所述靶向遗传修饰拷贝至它的同源物。表16.杂合性丧失测定结果。克隆grnac5等位基因类型基因转换测定r-e2a+e2纯合性靶向仅检测到129等位基因r-e8a+e2纯合性垮塌仅检测到129等位基因ror1基因座在另一组实验中,ltvec被设计来产生小鼠ror1(酪氨酸蛋白质激酶跨膜受体ror1)基因的110kb缺失,以及同时用同源性人ror1基因的134kb片段进行的替换。ltvec包含人ror1基因的134kb片段,其由含有源于小鼠ror1基因座的侧接于小鼠ror1基因的意图缺失的110kb序列的部分的41.8kb和96.4kb的基因组dna的同源臂侧接。在单独实验中,使ror1人源化ltvec与编码cas9的质粒和编码被设计来在小鼠ror1基因的靶向缺失区域内产生双链断裂的六个grna(a、b、c、d、e和f;参见表1)中的一者的第二质粒组合。grna被设计来避免识别人ror1基因的插入部分中的任何序列。在其他实验中,我们使ltvec和cas9编码质粒与编码靶向ror1基因内的被靶向以达成缺失的不同位点的两个不同grna的质粒组合。crispr/cas9辅助的ror1基因人源化的结果显示于表17中,并且类似于对于crispr/cas9辅助的lrp5和c5(hc)基因人源化获得的结果。用单独ltvec达成的靶向效率是0.3%,并且添加cas9和grna使六个测试grna中的两者的靶向效率略微增加。将agrna和fgrna组合通过使杂合性靶向事件与半合性靶向事件两者的频率增加来使总体ror1靶向效率增加至6.3%。我们也发现在两个等位基因上均具有大型crispr诱导缺失的es细胞克隆(在1.6%的频率下观察到)。未观察到纯合性靶向克隆。在额外实验中,也使grnaa和d组合,但仍然未观察到纯合性靶向。表17.使用个别grna和组合grna对ror1基因进行的crispr/cas9辅助人源化的筛选结果。trpa1基因座在另一组实验中,ltvec被设计来产生小鼠trpa1(瞬时受体电位阳离子通道,亚家族a,成员1)基因的45.3kb缺失,以及同时用同源性人trpa1基因的54.5kb片段进行的替换。ltvec包含人trpa1基因的54.5kb片段,其由含有源于小鼠trpa1基因座的侧接于小鼠trpa1基因的意图缺失的45.3kb序列的部分的41.0kb和58.0kb的基因组dna的同源臂侧接。在单独实验中,使trpa1人源化ltvec与编码cas9的质粒和编码被设计来在小鼠trpa1基因的靶向缺失区域内产生双链断裂的八个grna(a、a2、b、c、d、e2、e和f;参见表1)中的一者的第二质粒组合。grna被设计来避免识别人trpa1基因的插入部分中的任何序列。在其他实验中,我们使ltvec和cas9编码质粒与编码靶向被靶向以达成缺失的trpa1基因内的不同位点的两个不同grna的质粒组合。crispr/cas9辅助的trpa1基因人源化的结果显示于表18中,并且类似于对于crispr/cas9辅助的lrp5和c5(hc)基因人源化获得的结果。用单独ltvec达成的靶向效率是0.3%,并且添加cas9和grna使八个测试grna中的六者的靶向效率增加。将bgrna和fgrna组合通过使杂合性、半合性和纯合性靶向事件的频率增加来使总体trpa1靶向效率增加至3.4%。我们也发现在两个等位基因上均具有大型crispr诱导缺失的es细胞克隆(在0.3%的频率下观察到)。表18.使用个别grna和组合grna对trpa1基因进行的crispr/cas9辅助人源化的筛选结果。如这些实例所说明,相较于单一grna,在广泛分隔的位点处使用双重引导rna使对杂合性人源化的增强作用改进。此外,相较于单一grna,使用双重引导rna促进双等位基因事件。与用一个grna进行的靶向相比,用两个grna进行的靶向导致产生以纯合方式靶向的细胞(hum/hum),其中两个等位基因均具有靶向人源化;以纯合方式缺失的细胞(δ/δ),其中两个等位基因都不被人源化ltvec靶向,但两者均具有大型缺失;以及以半合方式靶向的细胞(hum/δ),其中一个等位基因具有靶向人源化,并且另一等位基因具有大型双重grna/cas9诱导缺失。首先,我们发现在两个靶标等位基因处均具有精确和相同的极其大型人源化的正确靶向的克隆(例如就靶向基因修饰来说是纯合的细胞)。尽管当我们使用一个grna来实现lrp5人源化时也观察到以纯合方式靶向的克隆,但相比于当我们采用两个grna时,它们在低得多的频率下出现(参见表13)。同样,当使用一个grna来实现c5(hc)人源化或trpa1人源化时,我们未观察到纯合性靶向,但当与靶向载体一起使用两个grna时,我们确实观察到纯合性靶向(参见表15和表18)。类似地,对于lrp5靶向、c5(hc)靶向、ror1靶向和trpa1靶向,我们发现就基因修饰来说是半合的正确靶向的克隆(即它们具有在一个等位基因上的精确靶向的人源化,以及在另一等位基因上的极其大型(有时是基因消除性)缺失)。当使用一个grna来实现lrp5、c5(hc)、ror1或trpa1人源化时,所述修饰完全不发生(分别参见表13、表15、表17和表18)。其次,我们发现在两个所靶向等位基因上均具有由受两个grna引导的cas9裂解事件诱导的相同极其大型缺失(>45kb)的克隆(即细胞就在靶基因座处的大型(有时是基因消除性)缺失来说是纯合的)。这些类型的突变不需要针对同一基因的靶向载体。举例来说,如表15中所示,我们已通过使cas9和两个grna与针对与由grna靶向的基因无关的不同基因的靶向载体组合来获得具有纯合性crispr诱导缺失的es细胞。因此,由两个grna引导的cas9核酸酶可在不添加靶向载体下在细胞中诱导大型缺失。在所述情况下,由表达药物抗性基因的载体提供的短暂或稳定药物选择可有助于通过使已摄取dna的es细胞富集来分离稀有纯合性缺失克隆。实施例6.分析由组合grna诱导的大型缺失。由组合grna诱导的大型缺失的等位基因结构对包含由受两个grna引导的cas9裂解事件诱导的大型缺失的克隆进行额外序列分析(参见表19)。这些大型缺失似乎独立于在同一基因座处的ltvec引导的同源性重组事件,因为当我们使grna与lrp5ltvec或靶向相距接近30mb的ch25h基因的ltvec组合时,我们在lrp5基因座处在近似相同频率下获得了大型缺失(数据未显示)。为表征大型缺失,我们对来自6个人源化操作的40个克隆(15个是半合性的,并且25个具有双等位基因大型缺失)进行缺失跨越性pcr,并且对pcr产物的个别克隆测序。序列确认在38kb至109kb的范围内的大型缺失。三个es细胞克隆(lrp5克隆aw-a8和bp-d3以及adamts5克隆x-b11)在预测的cas9裂解位点之间具有完全修复的精确缺失(68.2kb),而一个克隆(hc克隆p-b12)除38.1kb缺失之外也具有单一碱基对插入。27个es细胞克隆具有延伸超出cas9裂解位点的缺失,这符合通过非同源性末端接合(nhej)进行的不精确修复。其余9个es细胞克隆具有组合了明显nhej诱导的缺失和插入的突变(例如lrp5克隆bp-f6和hc克隆o-e4),其中五者具有我们可作图至它们的来源基因组基因座的大于200bp的插入(数据未显示)。lrp5克隆bo-e9中的210bp插入相对于在着丝粒方向的位于grnaf靶标位点的外部约2,600bp的相同序列(染色体19+,3589138–3589347)处于反向定向。这个序列存在于lrp5ltvec的长3′同源臂中。lrp5克隆bp-f6和bp-g7源于其中我们使lrp5grnaa和f与cas9和靶向在端粒方向离开lrp530mb的ch25h基因的ltvec组合的实验。克隆bp-f6具有似乎源于ch25hltvec的一端的266bp插入,因为它由与载体骨架的一部分相同的103bp片段连接于与在ch25h附近的序列相同,并且也存在于ltvec的长臂中的163bp片段(染色体19+,34478136–34478298)组成;这个片段相对于内源性染色体序列以反向定向插入在缺失处。hc克隆o-e4具有254bp插入,其相对于见于经缺失序列内的离开grnaa识别序列约3.1kb的相同序列处于反向。hc克隆s-d5中的1,304bp插入由以下两个片段组成:1,238bp片块,其与见于经缺失序列内的离开预测的grnae2引导的cas9裂解位点约1.4kb的相同序列处于相同定向;和第二66bp片块,其是处于在grnae2切割位点的外部25bp的相同序列的反向定向的重复序列。表19.由组合grna诱导的大型缺失的等位基因结构。1hum/+,两个天然等位基因中的一者具有靶向人源化,从而产生杂合性基因型;hum/δ,双等位基因修饰,其中一个等位基因具有靶向人源化,并且另一等位基因具有大型cas9-grna诱导缺失,从而产生半合性基因型;hum/hum,双等位基因修饰,其中两个等位基因均具有靶向人源化,从而产生纯合性基因型;δ/δ,双等位基因修饰,其中两个等位基因均具有大型cas9-grna诱导缺失。在纯合性等位基因处的基因转换的证据具有双等位基因大型缺失的25个es细胞克隆中的24者仅具有单一独特序列(表19),从而指示它们是纯合性等位基因。对于hc克隆s-a11,我们发现在12个pcr克隆中的11者中具有相同序列。具有不同序列的单一克隆可能表明两个不同缺失等位基因,但我们也发现两个hc半合性克隆n-d11和o-f12具有相同结果。多个克隆中的不同纯合性缺失等位基因表明它们可能已通过基因转换机理而出现,其中一个染色体上的缺失充当用于对同源染色体上的cas9裂解进行同源性重组修复的模板。我们利用vgf1es细胞系的129s6svevtac(129)和c57bl/6ntac(b6)f1杂交组合物(poueymirou等(2007)nat.biotechnol.25:91-99;valenzuela等(2003)nat.biotechnol.21:652-659)来将基因转换测定为品系之间在染色体19上的lrp5基因座(对于以下使用的五个sv测定和十个snv测定,参见图12)和染色体2上的hc基因座(未显示)周围的结构变体(sv)和单核苷酸变体(snv)的杂合性丧失(lefebvre等(2001)nat.genet.27:257-258)。为确认任何杂合性丧失都不是整个染色体丧失的结果,我们在129品系与b6品系之间相同的位点处进行染色体拷贝数(ccn)测定。对于lrp5人源化或经缺失等位基因,我们测定在端粒方向离开lrp51.2mb加以定位直至染色体19的长臂的末端的多个sv和snv(图12)。由于lrp5的位置靠近着丝粒,所以我们未发现sv,并且仅在基因的着丝粒侧上发现一个snv。对于hc,我们能够在染色体2上的基因的任一侧上测定多个sv和snv(未显示)。六个lrp5克隆的结果显示于图15a-图15e和图16a-图16c中。图15a-图15e显示五个sv测定的结果,所述测定的位置在离开lrp513.7mb至56.7mb(在长臂的端粒端附近)的范围内。五个sv测定对于129、b6和vgf1对照中的129(较大)和b6(较小)等位基因产生两个不同大小的产物。sv测定在染色体19图谱上的近似位置显示于图12中(参见测定sv13.7、测定sv20.0、测定sv36.9、测定sv48.3和测定sv56.7)。测定编号代表在lrp5的端粒方向的mb数目。用于这些测定的引物显示于表1中,并且结果显示于图15a-图15e中。两个克隆bc-h9(lrp5hum/hum,grnab2)和br-b4(lrp5hum/hum,grnad)显示保留所有b6sv等位基因的杂合性丧失,而第三克隆b0-a8(lrp5hum/hum,grnaa+f)保留所有129等位基因。其他三个克隆bo-f10(lrp5hum/hum,grnaa+f)、bo-g11(lrp5hum/hum,grnaa+f)和bp-g7(lrp5δ/δ,grnaa+f)保持杂合。此外,129等位基因与b6等位基因之间的单核苷酸变体(snv)通过等位基因辨别测定来测定。snv测定在图12中的染色体19图谱上的近似位置由箭头连同在下部的测定编号一起加以显示,并且下方给出它们离lrp5基因座的距离(以mb计)。离lrp5基因座的距离(以mb计)如下:在lrp5的着丝粒方向0.32(c2),在lrp5的端粒方向1.2(t3),在lrp5的端粒方向11.1(t6),在lrp5的端粒方向13.2(t7),在lrp5的端粒方向17.5(t8),在lrp5的端粒方向25.8(t9),在lrp5的端粒方向33.0(t10),在lrp5的端粒方向38.3(t11),在lrp5的端粒方向49.6(t13),以及在lrp5的端粒方向57.2(t14)。129特异性探针和b6特异性探针以及引物对显示于表1中。根据sv测定,显示端粒方向杂合性丧失(loh)的三个克隆(bc-h9、bo-a8和br-b4)的结果显示于图16a-图16c中。snv测定(图16a-图16c并且数据未显示)确认在lrp5的端粒侧上在染色体19的长臂上的基因转换事件(snv1.2和snv57.2;分别参见图16b和图16c),但snv0.32测定(参见图16a)显示所有克隆就在着丝粒侧上离开lrp5320kb的等位基因来说都保持杂合。在24个lrp5hum/hum或lrp5δ/δ测定克隆中,我们发现六个在lrp5的端粒侧上在染色体19的整个长臂上具有杂合性丧失的迹象。五个克隆(四个lrp5hum/hum和一个lrp5δ/δ)从杂合性b6转换成纯合性b6,而第六克隆(lrp5hum/hum)转换成纯合性129。ccn测定证明染色体19的两个拷贝得以保留。用于21个hc纯合性克隆的类似杂合性丧失测定揭示对于在hc基因的端粒侧上的所有sv和snv,两个克隆r-e2(hchum/hum,grnaa+f)和r-e8(hcδ/δ,grnaa+f)显示杂合性丧失而成为纯合性129,而对于在着丝粒侧上的所有等位基因,保留杂合性。ccn测定指示染色体2未丧失。我们的结果首次证明crispr/cas9可增强用于达成超过100kb的大型单步人源化的同源性引导的修复,此使大规模基因组工程化的可能性扩大。使ltvec和grna/cas9组合的最显著和出乎意料的益处是它们能够促进纯合性靶向人源化。尽管双等位基因突变和纯合性靶向事件已在其他crispr/cas9实验中加以报道,但这些基因修饰和插入中的大多数具有的数量级小于我们的人源化等位基因。在使用crispr/cas9之前,我们从未发现由ltvec达成的纯合性靶向,我们也尚未在我们使靶向单独基因的多个ltvec组合时观察到同时靶向超过一个基因。鉴于这个经验,grna/cas9诱导的纯合性靶向表明并非两个ltvec分别靶向两个等位基因,在一个等位基因上的初始靶向事件可能充当用于由一个或多个cas9切割促进的使另一等位基因同源性转换的模板。对双重grna/cas9诱导的大型双等位基因缺失也具有纯合性的揭示(表19)提供对基因转换机理的进一步支持。杂合性丧失测定(图12)证明多个等位基因的涵盖在靶标基因的端粒侧上的大型染色体片段的大规模基因转换导致一些纯合性人源化和大型缺失。这个类型的长程有方向性基因转换与在细胞周期的g2期,同源染色体的经复制染色单体之间的有丝分裂重组一致(lefebvre等(2001)nat.genet.27:257-258)(图17a-图17c)。尽管这仅解释少数纯合性事件,但这个机理可提供grna/cas9裂解可用于促进在染色体的大部分上的多个等位基因从杂合向纯合进行大规模转换所采用的手段。然而,大多数纯合性事件似乎已是其机理值得进一步探究的局部基因转换的结果。长程有方向性基因转换的其他证据通过分析在用编码lrp5grnaa和f的质粒、编码cas9的质粒和靶向在端粒方向离开lrp530mb的ch25h基因的ltvec对f1h4杂交es细胞(其包含50%129svs6品系和50%c57bl/6n品系)进行电穿孔之后获得的三个克隆来提供。在使用测定在2个grna之间的预测缺失内部(离5’末端500bp以及离3’末端2kb)进行初级筛选之后,三个克隆初始被评分为野生型,但测定129等位基因与b6等位基因之间的单核苷酸变体(snv)的后续等位基因辨别测定惊人地揭示杂合性丧失。所用snv测定是一个着丝粒方向测定(snv0.32)和两个端粒方向测定(snv1.2和snv57.2)(参见图12)。如表20中所示,着丝粒方向snv测定(0.32mb)确认在所有三个克隆中都保留杂合性。然而,两个端粒方向snv测定均显示bp-e7和bp-h4就129等位基因来说是纯合的,并且两个端粒方向snv测定均显示bp-e6就b6等位基因来说是纯合的。所有三个克隆都显示染色体19的两个拷贝得以保留,并且所有三个克隆就ltvec靶向来说都是转基因的(即ch25h基因座被靶向)。这些结果打开了使用靶向crispr/cas9裂解达成强制纯合性的可能性。表20.snv等位基因辨别测定的筛选结果。克隆snv0.32snv1.2snv57.2bp-e7129/b6129/129129/129bp-h4129/b6129/129129/129bp-e6129/b6b6/b6b6/b6若干可能机理可解释在小鼠f1h4杂交es细胞(其包含50%129svs6品系和50%c57bl/6n品系)的情况下在crispr/cas9辅助的ltvec人源化实验中观察到的结果(参见图18a-图18f)。所述机理可通过由有丝分裂交叉达成的相互染色单体交换(参见图18a-图18c),或通过利用断裂诱导的复制进行的染色单体拷贝(参见图18d-图18e)来发生。在任一情况下,都可发生杂合性修饰,其中在基因组复制之前129染色体或b6染色体由ltvec靶向(参见图18a和图18d)。或者,单一129染色单体或单一b6染色单体可在基因组复制之后由ltvec靶向,继之以染色单体间基因转换(参见图18b和图18e)。或者,在靶基因组基因座处可缺乏ltvec靶向,但cas9裂解可在129或b6染色体上发生(参见图18c和图18f)。这个后述可能性可解释用bp-e7、bp-h4和bp-e6克隆观察到的结果。潜在结果显示于图18a-图18f中。对于图18f,如果cas9裂解129染色单体,那么也有可能观察到保留b6等位基因的杂合性丧失(loh)。在上述实验中,已观察到导致两个等位基因均被靶向(hum/hum)或两个等位基因均是野生型等位基因(+/+)的杂合性丧失事件。实施例7.对在b6等位基因与129等位基因之间具有最小变化的基因的纯合性靶向。也测试若干其他基因座的纯合性靶向。在另一实验中,ltvec被设计来产生小鼠adamts5(具有血栓反应素基序的解整合素和金属蛋白酶5)基因的38kb缺失,以及同时用人adamts5基因的43kb片段进行的替换。ltvec包含人adamts5基因的43kb片段,其由含有源于小鼠adamts5基因座的侧接于小鼠adamts5基因的意图缺失的38kb序列的部分的22kb和46kb的基因组dna的同源臂侧接。在单独实验中,我们使adamts5人源化ltvec与编码cas9的质粒和编码被设计来在小鼠adamts5基因的靶向缺失区域内产生双链断裂的八个sgrna(ga、ga2、gb、gc、gd、ge、ge2、和gf)中的一者或两者的第二质粒或多个质粒组合。sgrna被设计来避免识别人adamts5的插入部分中的任何序列。crispr/cas9辅助的adamts5基因人源化的结果显示于表21中。当将单独ltvec引入es细胞中时,我们发现96个筛选的药物抗性克隆都不携带正确靶向的单等位基因杂合性人源化等位基因。相比之下,使ltvec与由八个测试sgrna中的两者(b和f;参见表1)引导的cas9核酸内切酶组合在1.0%的效率下产生正确靶向的单等位基因杂合性突变或双等位基因复合杂合性突变。未观察到纯合性靶向修饰。在额外实验中,也使grnaa2和e2组合,但仍然未观察到纯合性靶向。表21.crispr/cas9辅助的adamts5基因人源化的筛选结果。在另一实验中,ltvec被设计来产生小鼠dpp4(二肽基肽酶4)基因的79kb缺失,以及同时用同源性人dpp4基因的82kb片段进行的替换。ltvec包含由5’同源臂和3’同源臂侧接的人dpp4基因的82kb片段,所述同源臂各自含有源于小鼠dpp4基因座的侧接于小鼠dpp4基因的意图缺失的79kb序列的部分的46kb的基因组dna。在单独实验中,我们使dpp4人源化ltvec与编码cas9的质粒和编码被设计来在小鼠dpp4基因的靶向缺失区域内产生双链断裂的八个sgrna(ga、gb、gb2、gc、gd、ge、ge2和gf)中的一者或两者的第二质粒或多个质粒组合。sgrna被设计来避免识别人dpp4基因的插入部分中的任何序列。crispr/cas9辅助的dpp4基因人源化的结果显示于表22中。当将单独ltvec引入es细胞中时,我们发现2.1%的筛选药物抗性克隆携带正确靶向的单等位基因杂合性人源化等位基因。相比之下,使ltvec与由八个测试sgrna(a、b、b2、c、d、e、e2和f;参见表1)中的任一者引导的cas9核酸内切酶组合在2.1至7.3%的范围内的效率下产生正确靶向的单等位基因杂合性突变。未观察到纯合性靶向修饰。在额外实验中,使grnaa和f或grnaa和d组合,但仍然未观察到纯合性靶向。表22.crispr/cas9辅助的dpp4基因人源化的筛选结果。在另一实验中,ltvec被设计来产生小鼠folh1(谷氨酸羧肽酶2)基因的55kb缺失,以及同时用同源性人folh1基因的61kb片段进行的替换。ltvec包含人folh1基因的61kb片段,其由含有源于小鼠folh1基因座的侧接于小鼠folh1基因的意图缺失的55kb序列的部分的22kb和46kb的基因组dna的同源臂侧接。在单独实验中,我们使folh1人源化ltvec与编码cas9的质粒和编码被设计来在小鼠folh1基因的靶向缺失区域内产生双链断裂的八个sgrna(ga、ga2、gb、gc、gd、gf、ge和ge2)中的一者或两者的第二质粒或多个质粒组合。sgrna被设计来避免识别人folh1基因的插入部分中的任何序列。crispr/cas9辅助的folh1基因人源化的结果显示于表23中。当将单独ltvec引入es细胞中时,我们发现96个筛选的药物抗性克隆都不携带正确靶向的单等位基因杂合性人源化等位基因。相比之下,使ltvec与由六个测试sgrna中的三者(a、d和e2;参见表1)引导的cas9核酸内切酶组合在1.0至3.1%的范围内的效率下产生正确靶向的单等位基因杂合性突变。未观察到纯合性靶向修饰。在额外实验中,使grnaa和e2或grnaa和d组合,但仍然未观察到纯合性靶向。表23.crispr/cas9辅助的folh1基因人源化的筛选结果。在靶向不同基因座时观察到的纯合性靶向克隆的概述提供于表24中。表24.在不同基因座的情况下的纯合性靶向克隆的数目。在这些实验中,对于在b6等位基因与129等位基因之间具有最小序列变化的基因,纯合性靶向性最高。这在图19-图25中加以说明。在各图中,在竖直虚线内部的区域指示靶向区域(在ltvec的5’靶标序列和3’靶标序列内部的区域)。举例来说,对于lrp5(参见图19),基于129基因组来设计ltvec的同源臂。用于确定单核苷酸变化的参照序列是来自jacksonlaboratory的c57bl/6j小鼠品系的基因组序列。将这个参照序列与来自taconicbiosciences的129s6/svev品系、来自taconicbiosciences的c57bl/6n品系、以及由129s6/svev品系和c57bl/6n品系产生的vgf1杂交细胞系进行比较。竖直线代表相较于参照序列的单核苷酸变化。图20-图25分别提供对hc、trpa1、adamts5、folh1、dpp4、ror1和cd3的类似分析。如表24中以及图19-图25中所示,在lrp5基因座(12个纯合性克隆)和hc/c5基因座(4个纯合性克隆)的情况下产生最高数目的纯合性靶向克隆。这些靶基因组基因座各自具有极少数单核苷酸变化,特别是在grna识别序列处或附近或侧接于意图进行缺失和替换的区域(参见图19(lrp5)和图20(c5))。相比之下,对于在b6等位基因与129等位基因之间,特别是在grna识别序列处或附近或侧接于意图进行缺失和替换的区域具有高密度的等位基因序列变化的基因,纯合性靶向低下或不存在。举例来说,当靶向adamts5、folh1、dpp4或ror1基因座时,未产生纯合性克隆(分别是图22-图25)。然而,当靶向在意图进行缺失和替换的区域的3’具有高密度的等位基因序列变化,但在意图进行缺失和替换的区域的5’(即在5’grna识别序列处或附近)具有低密度的等位基因序列变化的trpa1基因座时,产生纯合性克隆(图21)。实施例8.使用相对于同源染色体对中的各染色体设计的靶向载体不使纯合性靶向增加。为进一步测试纯合性靶向修饰是通过在同源染色体对中的各染色体上发生独立靶向事件,还是通过在同源染色体对中的一个染色体上发生靶向事件,接着还在所述同源染色体对之间进行基因转换或杂合性丧失来产生,靶向在同源染色体对之间、在grna识别序列处或附近或侧接于意图进行缺失和替换的区域具有大量等位基因序列变化的另一基因组基因座。参见例如图26。这允许我们考查等位基因变化对纯合性垮塌或纯合性靶向的影响。在竖直虚线内部的区域是靶向区域(在ltvec的5’靶标序列和3’靶标序列内部的区域)。用于确定单核苷酸变化的参照序列是来自jacksonlaboratory的c57bl/6j小鼠品系的基因组序列。将这个参照序列与来自taconicbiosciences的129s6/svev品系mp变体、来自taconicbiosciences的c57bl/6n品系rgc变体、以及由129s6/svev品系和c57bl/6n品系产生的vgf1杂交细胞系(表示在图的底部部分中的三行中)进行比较。三行中的各者中的竖直线代表相较于参照序列的单核苷酸变化。在这个实验中,两个ltvec被设计来产生小鼠基因座的33kb缺失,以及同时用直系同源人基因的包括三个区段(6.8kb、0.1kb和1.7kb)的34.5kb片段进行的替换,其中在人区段之间具有小鼠基因座的间插区段。实验用vgf1(f1h4)(即我们的c57bl6ntac/129s6svevf1杂交xyes细胞系)进行(poueymirou等(2007)nat.biotechnol.25:91-99;valenzuela等(2003)nat.biotechnol.21:652-659)。es细胞如先前所述加以培养(matise等(2000),joyner,a.l.编genetargeting:apracticalapproach,第100-132页,oxforduniversitypress,newyork)。vgf1细胞通过使雌性c57bl/6ntac小鼠与雄性129s6/svevtac小鼠杂交以产生c57bl6(xb6)/129s6(y129)小鼠来产生。参见图7。一个ltvec具有相对于vgf1细胞中的129染色体设计的同源臂,并且包括neo选择盒(maid#7170),并且另一ltvec具有相对于c57bl6染色体设计的同源臂,并且包括hyg选择盒(maid#7314)。两个ltvec在其他方面相同。在单独实验中,我们使两个人源化ltvec与编码cas9的质粒和编码被设计来在小鼠基因的靶向缺失区域内产生双链断裂的四个sgrna(mgu、mgu2、mgd、mgd2)的第二质粒或多个质粒组合。sgrna被设计来避免识别人基因的插入部分中的任何序列。筛选总计192个neo+克隆,128个hyg+克隆,以及16个neo+/hyg+克隆。使ltvec与由四个sgrna引导的cas9核酸内切酶组合产生一些杂合性靶向克隆、半合性靶向克隆、双等位基因垮塌克隆、具有nhej缺失的杂合性靶向克隆、具有双等位基因nhej缺失的克隆、以及具有nhej缺失的杂合性垮塌克隆。然而,未观察到纯合性靶向克隆。这表明并非是在同源染色体对内的各染色体上发生的单独靶向事件,而是局部基因转换事件导致在其他实验中观察到的纯合性靶向克隆。如果同源染色体对内的各染色体上发生的独立靶向事件导致在其他实验中观察到的纯合性靶向克隆,那么使用针对同源染色体对内的两个染色体中的各者特别加以调适的两个靶向载体将被预期会产生纯合性靶向克隆,尽管在5’同源臂和3’同源臂的5’靶标序列和3’靶标序列内具有高百分比的等位基因序列变化,因为针对各染色体加以调适的靶向载体将那个等位基因序列变化定址在5’靶标序列和3’靶标序列内。然而,使用两个ltvec未产生任何纯合性靶向克隆。这进一步支持纯合性靶向修饰通过局部基因转换事件来产生的理念,如图27中所描绘。相比于极性基因转换,我们已在更高比率下观察到在靶向缺失和插入的两侧上的局部杂合性丧失。序列表<110>瑞泽恩制药公司<120>用于使用多个引导rna来破坏免疫耐受性的方法<130>057766/497023<150>62/339,472<151>2016-05-20<150>62/368,604<151>2016-07-29<160>152<170>用于windows的4.0版fastseq<210>1<211>23<212>dna<213>人工序列<220><223>引导rna识别序列<220><221>尚未归类的特征<222>(2)...(21)<223>n=a、t、c或g<400>1gnnnnnnnnnnnnnnnnnnnngg23<210>2<211>23<212>dna<213>人工序列<220><223>引导rna识别序列<220><221>尚未归类的特征<222>(1)...(21)<223>n=a、t、c或g<400>2nnnnnnnnnnnnnnnnnnnnngg23<210>3<211>25<212>dna<213>人工序列<220><223>引导rna识别序列<220><221>尚未归类的特征<222>(3)...(23)<223>n=a、t、c或g<400>3ggnnnnnnnnnnnnnnnnnnnnngg25<210>4<211>20<212>dna<213>人工序列<220><223>c5(hc)grnaadna靶向区段(离靶基因座端点100bp)<400>4atcacaaaccagttaaccgg20<210>5<211>20<212>dna<213>人工序列<220><223>c5(hc)grnabdna靶向区段(离靶基因座端点500bp)<400>5tttcagacgagccgacccgg20<210>6<211>20<212>dna<213>人工序列<220><223>c5(hc)grnacdna靶向区段(离靶基因座端点38200和37500bp)<400>6tgtgtgtcatagcgatgtcg20<210>7<211>20<212>dna<213>人工序列<220><223>c5(hc)grnaddna靶向区段(离靶基因座端点43500和32200bp)<400>7aacaggtaccctatcctcac20<210>8<211>20<212>dna<213>人工序列<220><223>c5(hc)grnaedna靶向区段(离靶基因座端点500bp)<400>8ggcccggacctagtctctct20<210>9<211>20<212>dna<213>人工序列<220><223>c5(hc)grnae2dna靶向区段(离靶基因座端点100bp)<400>9tcgtggttgcatgcgcactg20<210>10<211>20<212>dna<213>人工序列<220><223>lrp5grnaadna靶向区段(离靶基因座端点50bp)<400>10gggaacccacagcatactcc20<210>11<211>20<212>dna<213>人工序列<220><223>lrp5grnabdna靶向区段(离靶基因座端点500bp)<400>11gaatcatgcacggctacccc20<210>12<211>20<212>dna<213>人工序列<220><223>lrp5grnab2dna靶向区段(离靶基因座端点1000bp)<400>12tgctcctatggggaggcgcg20<210>13<211>20<212>dna<213>人工序列<220><223>lrp5grnacdna靶向区段(离靶基因座端点29900和38430bp)<400>13actgagatcaatgaccccga20<210>14<211>20<212>dna<213>人工序列<220><223>lrp5grnaddna靶向区段(离靶基因座端点29950和38380bp)<400>14gggtcgcccggaacctctac20<210>15<211>20<212>dna<213>人工序列<220><223>lrp5grnae2dna靶向区段(离靶基因座端点1000bp)<400>15cttggataacattgataccc20<210>16<211>20<212>dna<213>人工序列<220><223>lrp5grnaedna靶向区段(离靶基因座端点500bp)<400>16ggggcagagcccttatatca20<210>17<211>20<212>dna<213>人工序列<220><223>lrp5grnafdna靶向区段(离靶基因座端点50bp)<400>17tcgctcacattaatccctag20<210>18<211>20<212>dna<213>人工序列<220><223>ror1grnaadna靶向区段(离靶基因座端点200bp)<400>18tgtgggcctttgctgatcac20<210>19<211>20<212>dna<213>人工序列<220><223>ror1grnabdna靶向区段(离靶基因座端点1000bp)<400>19aatctatgatcctatggcct20<210>20<211>20<212>dna<213>人工序列<220><223>ror1grnaddna靶向区段(离靶基因座端点54300和55500bp)<400>20tgccaatagcagtgacttga20<210>21<211>20<212>dna<213>人工序列<220><223>ror1grnacdna靶向区段(离靶基因座端点54500和55300bp)<400>21gggaagaatgggctattgtc20<210>22<211>20<212>dna<213>人工序列<220><223>ror1grnaedna靶向区段(离靶基因座端点1000bp)<400>22ggttgtttgtgctgatgacg20<210>23<211>20<212>dna<213>人工序列<220><223>ror1grnafdna靶向区段(离靶基因座端点200bp)<400>23ccgtcctaggccttctacgt20<210>24<211>20<212>dna<213>人工序列<220><223>trpa1grnaadna靶向区段(离靶基因座端点100bp)<400>24gtactggggaatcggtggtc20<210>25<211>20<212>dna<213>人工序列<220><223>trpa1grnaa2dna靶向区段(离靶基因座端点500bp)<400>25cacgcactccaaatttatcc20<210>26<211>20<212>dna<213>人工序列<220><223>trpa1grnabdna靶向区段(离靶基因座端点1000bp)<400>26ctaagtgtgtatcagtacat20<210>27<211>20<212>dna<213>人工序列<220><223>trpa1grnacdna靶向区段(离靶基因座端点25600和19740bp)<400>27tgccctgcacaataagcgca20<210>28<211>20<212>dna<213>人工序列<220><223>trpa1grnaddna靶向区段(离靶基因座端点26970和18370bp)<400>28actcattgaaacgttatggc20<210>29<211>20<212>dna<213>人工序列<220><223>trpa1grnae2dna靶向区段(离靶基因座端点1000bp)<400>29agtaagggtggattaaattc20<210>30<211>20<212>dna<213>人工序列<220><223>trpa1grnaedna靶向区段(离靶基因座端点500bp)<400>30gccatctagattcatgtaac20<210>31<211>20<212>dna<213>人工序列<220><223>trpa1grnafdna靶向区段(离靶基因座端点100bp)<400>31gactagaaatgttctgcacc20<210>32<211>21<212>dna<213>人工序列<220><223>190045正向引物<400>32gagctcatagccaacagcttg21<210>33<211>20<212>dna<213>人工序列<220><223>190061正向引物<400>33atgcatcagatcacgctcag20<210>34<211>20<212>dna<213>人工序列<220><223>190068正向引物<400>34gtccttgtggcatttccaac20<210>35<211>24<212>dna<213>人工序列<220><223>190030正向引物<400>35ccagtatggtgtcagttaatagcg24<210>36<211>19<212>dna<213>人工序列<220><223>190033正向引物(与图6中的sv48.3的正向引物相同)<400>36ctgtgcagaaagcagcctc19<210>37<211>20<212>dna<213>人工序列<220><223>190013正向引物<400>37cctctccctctaggcacctg20<210>38<211>20<212>dna<213>人工序列<220><223>190045反向引物<400>38tctttaagggctccgttgtc20<210>39<211>20<212>dna<213>人工序列<220><223>190061反向引物<400>39aagaccaaccattcacccag20<210>40<211>20<212>dna<213>人工序列<220><223>190068反向引物<400>40ttcccagtccaagtcaaagg20<210>41<211>20<212>dna<213>人工序列<220><223>190030反向引物<400>41ctgttatctgcaaggcaccc20<210>42<211>20<212>dna<213>人工序列<220><223>190033反向引物(与图6中的sv48.3的反向引物相同)<400>42acaactggatcctgattcgc20<210>43<211>20<212>dna<213>人工序列<220><223>190013反向引物<400>43taagagggcatgggtgagac20<210>44<211>20<212>dna<213>人工序列<220><223>c2探针(b6)-图6中的snv0.32<400>44aattcagaagacctatcgta20<210>45<211>21<212>dna<213>人工序列<220><223>t3探针(b6)-图6中的snv1.2<400>45tatgtgtataggtgtttggat21<210>46<211>19<212>dna<213>人工序列<220><223>t6探针(b6)-图6中的snv11.1<400>46tacattgctaaatgaaacc19<210>47<211>16<212>dna<213>人工序列<220><223>t7探针(b6)-图6中的snv13.2<400>47cgcagtcatgcacata16<210>48<211>20<212>dna<213>人工序列<220><223>t8探针(b6)-图6中的snv17.5<400>48ttataaagcccagtatgtac20<210>49<211>14<212>dna<213>人工序列<220><223>t9探针(b6)-图6中的snv25.8<400>49tgctgcataatcag14<210>50<211>18<212>dna<213>人工序列<220><223>t10探针(b6)-图6中的snv33.0<400>50tcaggagtgaattggata18<210>51<211>16<212>dna<213>人工序列<220><223>t11探针(b6)-图6中的snv38.3<400>51ctgctacttacctttg16<210>52<211>13<212>dna<213>人工序列<220><223>t13探针(b6)-图6中的snv49.6<400>52aggaggaaaacgc13<210>53<211>17<212>dna<213>人工序列<220><223>t14探针(b6)-图6中的snv57.2<400>53cctttgttcctcataag17<210>54<211>20<212>dna<213>人工序列<220><223>c2探针(129)-图6中的snv0.32<400>54aattcagaagacctattgta20<210>55<211>21<212>dna<213>人工序列<220><223>t3探针(129)-图6中的snv1.2<400>55tatgtgtataggtgtttgcat21<210>56<211>16<212>dna<213>人工序列<220><223>t6探针(129)-图6中的snv11.1<400>56cattgctacatgaaac16<210>57<211>16<212>dna<213>人工序列<220><223>t7探针(129)-图6中的snv13.2<400>57cgcagtcatgcacgta16<210>58<211>23<212>dna<213>人工序列<220><223>t8探针(129)-图6中的snv17.5<400>58tgagaatttataaagcccaatat23<210>59<211>14<212>dna<213>人工序列<220><223>t9探针(129)-图6中的snv25.8<400>59tgctgcatgatcag14<210>60<211>15<212>dna<213>人工序列<220><223>t10探针(129)-图6中的snv33.0<400>60tcaggagtgaatcgg15<210>61<211>16<212>dna<213>人工序列<220><223>t11探针(129)-图6中的snv38.3<400>61ctgctagttacctttg16<210>62<211>15<212>dna<213>人工序列<220><223>t13探针(129)-图6中的snv49.6<400>62aggaggaagacgcag15<210>63<211>17<212>dna<213>人工序列<220><223>t14探针(129)-图6中的snv57.2<400>63ctttgttcttcataagc17<210>64<211>25<212>dna<213>人工序列<220><223>c2正向引物-图6中的snv0.32<400>64atgagggatttccttaatcagacaa25<210>65<211>29<212>dna<213>人工序列<220><223>t3正向引物-图6中的snv1.2<400>65tggtatgtttattcttactcaaggttttg29<210>66<211>22<212>dna<213>人工序列<220><223>t6正向引物-图6中的snv11.1<400>66gggcaactgatggaaagaactc22<210>67<211>23<212>dna<213>人工序列<220><223>t7正向引物-图6中的snv13.2<400>67gactgacgcacaaacttgtcctt23<210>68<211>26<212>dna<213>人工序列<220><223>t8正向引物-图6中的snv17.5<400>68cccaaagcatataacaagaacaaatg26<210>69<211>18<212>dna<213>人工序列<220><223>t9正向引物-图6中的snv25.8<400>69gcaggacgcaggcgttta18<210>70<211>23<212>dna<213>人工序列<220><223>t10正向引物-图6中的snv33.0<400>70gcatcctcatggcagtctacatc23<210>71<211>20<212>dna<213>人工序列<220><223>t11正向引物-图6中的snv38.3<400>71cctgccccttgatgagtgtt20<210>72<211>23<212>dna<213>人工序列<220><223>t13正向引物-图6中的snv49.6<400>72ccctctttgatatgctcgtgtgt23<210>73<211>22<212>dna<213>人工序列<220><223>t14正向引物-图6中的snv57.2<400>73tcccacaggtccatgtctttaa22<210>74<211>28<212>dna<213>人工序列<220><223>c2反向引物-图6中的snv0.32<400>74agactacaatgagctaccatcataaggt28<210>75<211>24<212>dna<213>人工序列<220><223>t3反向引物-图6中的snv1.2<400>75caaccatctaaaactccagttcca24<210>76<211>28<212>dna<213>人工序列<220><223>t6反向引物-图6中的snv11.1<400>76tgtgtaacaggacagttgaatgtagaga28<210>77<211>19<212>dna<213>人工序列<220><223>t7反向引物-图6中的snv13.2<400>77cttaaaacccgccctgcat19<210>78<211>26<212>dna<213>人工序列<220><223>t8反向引物-图6中的snv17.5<400>78ctacaggagatgtggctgttctatgt26<210>79<211>22<212>dna<213>人工序列<220><223>t9反向引物-图6中的snv25.8<400>79tcagcgtgattcgcttgtagtc22<210>80<211>26<212>dna<213>人工序列<220><223>t10反向引物-图6中的snv33.0<400>80tgcatagctgtttgaataatgacaag26<210>81<211>21<212>dna<213>人工序列<220><223>t11反向引物-图6中的snv38.3<400>81tgcagcatctctgtcaagcaa21<210>82<211>24<212>dna<213>人工序列<220><223>t13反向引物-图6中的snv49.6<400>82gcaacaacataacccacagcataa24<210>83<211>23<212>dna<213>人工序列<220><223>t14反向引物-图6中的snv57.2<400>83gctaagcgtttggaagaaattcc23<210>84<211>20<212>dna<213>人工序列<220><223>图6中的sv13.7的正向引物<400>84taggctctaaggatgctggc20<210>85<211>20<212>dna<213>人工序列<220><223>图6中的sv13.7的反向引物<400>85aagcagcttcaaaccctctg20<210>86<211>20<212>dna<213>人工序列<220><223>图6中的sv20.0的正向引物<400>86ttacttggccttggaactgc20<210>87<211>21<212>dna<213>人工序列<220><223>图6中的sv20.0的反向引物<400>87tgattcgtaatcgtcactgcc21<210>88<211>20<212>dna<213>人工序列<220><223>图6中的sv36.9的正向引物<400>88tcctgtcccgagaaactgtc20<210>89<211>20<212>dna<213>人工序列<220><223>图6中的sv36.9的反向引物<400>89agctggctttcagagagctg20<210>90<211>20<212>dna<213>人工序列<220><223>图6中的sv56.7的正向引物<400>90ttagaaagtgccaaccaggc20<210>91<211>20<212>dna<213>人工序列<220><223>图6中的sv56.7的反向引物<400>91ctctggctaggaacaatggc20<210>92<211>25<212>dna<213>人工序列<220><223>lrp5基因座的m-lr-f引物<400>92gttaggtgcagggtctactcagctg25<210>93<211>20<212>dna<213>人工序列<220><223>lrp5基因座的m-5’-f引物<400>93ggaggagaggagaagcagcc20<210>94<211>20<212>dna<213>人工序列<220><223>lrp5基因座的m-a引物<400>94ggaggagaggagaagcagcc20<210>95<211>26<212>dna<213>人工序列<220><223>lrp5基因座的h-lr-r引物<400>95gcaaacagccttcttcccacattcgg26<210>96<211>24<212>dna<213>人工序列<220><223>lrp5基因座的m-5’-r引物<400>96ttgctttcagtagttcaggtgtgc24<210>97<211>20<212>dna<213>人工序列<220><223>lrp5基因座的h-5’-r引物<400>97ggcgttgtcaggaagttgcc20<210>98<211>22<212>dna<213>人工序列<220><223>lrp5基因座的m-f引物<400>98tgaagttgagaggcacatgagg22<210>99<211>24<212>dna<213>人工序列<220><223>lrp5基因座的m-e2引物<400>99tagagtagccacaggcagcaaagc24<210>100<211>22<212>dna<213>人工序列<220><223>7064retu正向引物<400>100cctcctgagctttcctttgcag22<210>101<211>25<212>dna<213>人工序列<220><223>7064retu反向引物<400>101cctagacaacacagacactgtatca25<210>102<211>23<212>dna<213>人工序列<220><223>7064retutaqman探针<400>102ttctgcccttgaaaaggagaggc23<210>103<211>18<212>dna<213>人工序列<220><223>7064retd正向引物<400>103cctctgaggccacctgaa18<210>104<211>23<212>dna<213>人工序列<220><223>7064retd反向引物<400>104ccctgacaagttctgccttctac23<210>105<211>21<212>dna<213>人工序列<220><223>7064retdtaqman探针<400>105tgcccaagcctctgcagcttt21<210>106<211>19<212>dna<213>人工序列<220><223>7140retu正向引物<400>106cccagcatctgacgacacc19<210>107<211>21<212>dna<213>人工序列<220><223>7140retu反向引物<400>107gaccactgtgggcatctgtag21<210>108<211>27<212>dna<213>人工序列<220><223>7140retutaqman探针<400>108ccgagtctgctgttactgttagcatca27<210>109<211>20<212>dna<213>人工序列<220><223>7140retd正向引物<400>109cccgacaccttctgagcatg20<210>110<211>21<212>dna<213>人工序列<220><223>7140retd反向引物<400>110tgcaggctgagtcaggatttg21<210>111<211>25<212>dna<213>人工序列<220><223>7140retdtaqman探针<400>111tagtcacgttttgtgacaccccaga25<210>112<211>20<212>dna<213>人工序列<220><223>folh1grnaadna靶向区段<400>112tgaaccaattgtgtagcctt20<210>113<211>20<212>dna<213>人工序列<220><223>folh1grnaa2dna靶向区段<400>113aatagtggtaaagcaccatg20<210>114<211>20<212>dna<213>人工序列<220><223>folh1grnabdna靶向区段<400>114gtgtgctaaggatcgaagtc20<210>115<211>20<212>dna<213>人工序列<220><223>folh1grnacdna靶向区段<400>115caccgagatgcttgggtatt20<210>116<211>20<212>dna<213>人工序列<220><223>folh1grnaddna靶向区段<400>116tgtaaccgccctgaatgacc20<210>117<211>20<212>dna<213>人工序列<220><223>folh1grnaedna靶向区段<400>117aaaagggcatcataaatccc20<210>118<211>20<212>dna<213>人工序列<220><223>folh1grnae2dna靶向区段<400>118tcaaaaatagtcatacacct20<210>119<211>20<212>dna<213>人工序列<220><223>folh1grnafdna靶向区段<400>119ggtctctagtacattgtaga20<210>120<211>20<212>dna<213>人工序列<220><223>adamts5grnaadna靶向区段<400>120ggtggtggtgctgacggaca20<210>121<211>20<212>dna<213>人工序列<220><223>adamts5grnaa2dna靶向区段<400>121tatgagatcaacactcgcta20<210>122<211>20<212>dna<213>人工序列<220><223>adamts5grnabdna靶向区段<400>122ccaaggacttccccacgtta20<210>123<211>20<212>dna<213>人工序列<220><223>adamts5grnacdna靶向区段<400>123tgcttcccttatgcaagatt20<210>124<211>20<212>dna<213>人工序列<220><223>adamts5grnaddna靶向区段<400>124ttaggtaccctatttgaata20<210>125<211>20<212>dna<213>人工序列<220><223>adamts5grnae2dna靶向区段<400>125tgcagtgggtgacaggtcca20<210>126<211>20<212>dna<213>人工序列<220><223>adamts5grnaedna靶向区段<400>126agggttatactgacgttgtg20<210>127<211>20<212>dna<213>人工序列<220><223>adamts5grnafdna靶向区段<400>127tgtctttcaaggagggctac20<210>128<211>20<212>dna<213>人工序列<220><223>dpp4grnaadna靶向区段<400>128actagtagacctgaggggtt20<210>129<211>20<212>dna<213>人工序列<220><223>dpp4grnabdna靶向区段<400>129gctccagtgtttaggccttg20<210>130<211>20<212>dna<213>人工序列<220><223>dpp4grnab2dna靶向区段<400>130ggcaagctgaaaacgcatgc20<210>131<211>20<212>dna<213>人工序列<220><223>dpp4grnacdna靶向区段<400>131gtagatcgctttccactacc20<210>132<211>20<212>dna<213>人工序列<220><223>dpp4grnaddna靶向区段<400>132gaactccactgctcgtgagc20<210>133<211>20<212>dna<213>人工序列<220><223>dpp4grnae2dna靶向区段<400>133ataggtgggcactattgaag20<210>134<211>20<212>dna<213>人工序列<220><223>dpp4grnaedna靶向区段<400>134atgggaaggtttataccagc20<210>135<211>20<212>dna<213>人工序列<220><223>dpp4grnafdna靶向区段<400>135cggtgtaaaaacaacgggaa20<210>136<211>20<212>dna<213>人工序列<220><223>图8中的sv6.1的正向引物<400>136ggaatgccaaggctactgtc20<210>137<211>20<212>dna<213>人工序列<220><223>图8中的sv6.1的反向引物<400>137aaaagtctgctttgggtggt20<210>138<211>21<212>dna<213>人工序列<220><223>图8中的sv6.3的正向引物<400>138cttcatgaacctcactcagga21<210>139<211>21<212>dna<213>人工序列<220><223>图8中的sv6.3的反向引物<400>139tctcggagtcaggatttacct21<210>140<211>20<212>dna<213>人工序列<220><223>图8中的sv7.8的正向引物<400>140tgtctctttgcctgttgctg20<210>141<211>22<212>dna<213>人工序列<220><223>图8中的sv7.8的反向引物<400>141tctgctctacaaggcttacgtg22<210>142<211>20<212>dna<213>人工序列<220><223>图8中的sv16的正向引物<400>142caaccaggcagacttacagc20<210>143<211>20<212>dna<213>人工序列<220><223>图8中的sv16的反向引物<400>143ggcctaggaaccagtcaaaa20<210>144<211>23<212>dna<213>人工序列<220><223>图8中的sv25.5的正向引物<400>144gcttactggaaagctacataggg23<210>145<211>22<212>dna<213>人工序列<220><223>图8中的sv25.5的反向引物<400>145caacaacatagaaacccctgtc22<210>146<211>6<212>dna<213>人工序列<220><223>金黄色葡萄球菌cas9pam序列<220><221>尚未归类的特征<222>(1)...(2)<223>n=a、t、c或g<220><221>尚未归类的特征<222>(4)...(5)<223>r=a或g<400>146nngrrt6<210>147<211>5<212>dna<213>人工序列<220><223>金黄色葡萄球菌cas9pam序列<220><221>尚未归类的特征<222>(1)...(2)<223>n=a、t、c或g<220><221>尚未归类的特征<222>(4)...(5)<223>r=a或g<400>147nngrr5<210>148<211>3155<212>dna<213>人工序列<220><223>工程改造的人vk1-39jk5基因座<400>148ggcgcgccgtagctttgaattttaaacatctatttgacaagaaatgcatagttccttctc60tttaaaataatgtaatgtttctttcaagaataagcttggtttgatgcctctctccccaac120atgatagaagtgtagcataaatctatgaaaaattccatttccctgtgcctacaacaacta180cctgggattgaaaacttcttcccttgctctagtcctttcttctacacctacttccacatc240atctgtgactcaaaacaatacttgtcaggaaagatcccggaaagagcaaaaaagacttcc300ttagaggtgtcagagattcctatgccactatctgtcatctctagaaggggttgtgagtat360gaggaagagcagagcttgtaaattttctacttgctttgacttccactgtatttcctaaca420acaacaaccacagcaacacccataacatcacaggacaaacttctagtacttccaaggctt480tagtctcagtaaatcttctctacctccatcacagcagctagaaggtttgatactcataca540aatagtactgtagctttctgttcataattggaaaaatagacaagacccaatgtaatacag600gctttccttcagccagttagcgttcagtttttggatcaccattgcacacatatacccagc660atatgtctaatatatatgtagaaatccgtgaagcaagagttataatagcttgtgttttct720attgtattgtattttcctcttatatcatcttcttcttcgttcattaaaaaaaaaccgttc780aagtaggtctaaattaattattggatcataagtagataaaatattttatttcataacaca840ttgacccgatgaatatgtttctttgccagacatagtcctcatttccaaggtaacaagcct900gaaaaaattatactggagcaagtcaacaggtaatgatggtagcttttccttattgtcctg960gggcaagaataagacaaaagataacagggtagaataaagattgtgtaagaaagaaggaca1020gcaacaggacatgggaaccttttatagagtaacattttgataatggatgatgagaattaa1080tgagttagacagggatgggtgggaatgattgaaggtgtgagtactttagcacagattaag1140accaaatcattaggatttaaagagttgtgtagagttagtgaaggaaaagccttagaatta1200aatttggctgcggataaaacattcttggattagactgaagactcttttctgtgctaagta1260agtatatttatgataatgatgatgactgtagtgctgaatatttaataaataaaaacaaaa1320ttaattgccgcatacataatgtcctgaatactattgtaaatgttttatcttatttccttt1380aaactgtctacagcactataaggtaggtaccagtattgtcacagttacacagatatggaa1440accgagacacagggaagttaagttacttgatcaatttcaagcaatcggcaagccatggag1500catctatgtcagggctgccaggacatgtgactgtaaacagaagtttttcactttttaact1560caaagagggtatgtggctgggttaatggaaagcttcaggaccctcagaaaacattactaa1620caagcaaatgaaaggtgtatctggaagattaagttttaacagactcttcatttccatcga1680tccaataatgcacttagggagatgactgggcatattgaggataggaagagagaagtgaaa1740acacagctttttatattgttcttaacaggcttgtgccaaacatcttctgggtggatttag1800gtgattgaggagaagaaagacacaggagcgaaattctctgagcacaagggaggagttcta1860cactcagactgagccaacagacttttctggcctgacaaccagggcggcgcaggatgctca1920gtgcagagaggaagaagcaggtggtctttgcagctgaaagctcagctgatttgcatatgg1980agtcattatacaacatcccagaattctttaagggcagctgccaggaagctaagaagcatc2040ctctcttctagctctcagagatggagacagacacactcctgctatgggtgctgctgctct2100gggttccaggtgagggtacagataagtgttatgagcaacctctgtggccattatgatgct2160ccatgcctctctgttcttgatcactataattagggcatttgtcactggttttaagtttcc2220ccagtcccctgaattttccattttctcagagtgatgtccaaaattattcttaaaaattta2280aatgaaaaggtcctctgctgtgaaggcttttaaagatatataaaaataatctttgtgttt2340atcattccaggtgccagatgtgacatccagatgacccagtctccatcctccctgtctgca2400tctgtaggagacagagtcaccatcacttgccgggcaagtcagagcattagcagctattta2460aattggtatcagcagaaaccagggaaagcccctaagctcctgatctatgctgcatccagt2520ttgcaaagtggggtcccatcaaggttcagtggcagtggatctgggacagatttcactctc2580accatcagcagtctgcaacctgaagattttgcaacttactactgtcaacagagttacagt2640acccctccgatcaccttcggccaagggacacgactggagattaaacgtaagtaatttttc2700actattgtcttctgaaatttgggtctgatggccagtattgacttttagaggcttaaatag2760gagtttggtaaagattggtaaatgagggcatttaagatttgccatgggttgcaaaagtta2820aactcagcttcaaaaatggatttggagaaaaaaagattaaattgctctaaactgaatgac2880acaaagtaaaaaaaaaaagtgtaactaaaaaggaacccttgtatttctaaggagcaaaag2940taaatttatttttgttcactcttgccaaatattgtattggttgttgctgattatgcatga3000tacagaaaagtggaaaaatacattttttagtctttctcccttttgtttgataaattattt3060tgtcagacaacaataaaaatcaatagcacgccctaagatctagatgcatgctcgagtgcc3120atttcattacctctttctccgcacccgacatagat3155<210>149<211>3166<212>dna<213>人工序列<220><223>工程改造的人vk3-20jk1基因座<400>149ggcgcgccgtagctttgaattttaaacatctatttgacaagaaatgcatagttccttctc60tttaaaataatgtaatgtttctttcaagaataagcttggtttgatgcctctctccccaac120atgatagaagtgtagcataaatctatgaaaaattccatttccctgtgcctacaacaacta180cctgggattgaaaacttcttcccttgctctagtcctttcttctacacctacttccacatc240atctgtgactcaaaacaatacttgtcaggaaagatcccggaaagagcaaaaaagacttcc300ttagaggtgtcagagattcctatgccactatctgtcatctctagaaggggttgtgagtat360gaggaagagcagagcttgtaaattttctacttgctttgacttccactgtatttcctaaca420acaacaaccacagcaacacccataacatcacaggacaaacttctagtacttccaaggctt480tagtctcagtaaatcttctctacctccatcacagcagctagaaggtttgatactcataca540aatagtactgtagctttctgttcataattggaaaaatagacaagacccaatgtaatacag600gctttccttcagccagttagcgttcagtttttggatcaccattgcacacatatacccagc660atatgtctaatatatatgtagaaatccgtgaagcaagagttataatagcttgtgttttct720attgtattgtattttcctcttatatcatcttcttcttcgttcattaaaaaaaaaccgttc780aagtaggtctaaattaattattggatcataagtagataaaatattttatttcataacaca840ttgacccgatgaatatgtttctttgccagacatagtcctcatttccaaggtaacaagcct900gaaaaaattatactggagcaagtcaacaggtaatgatggtagcttttccttattgtcctg960gggcaagaataagacaaaagataacagggtagaataaagattgtgtaagaaagaaggaca1020gcaacaggacatgggaaccttttatagagtaacattttgataatggatgatgagaattaa1080tgagttagacagggatgggtgggaatgattgaaggtgtgagtactttagcacagattaag1140accaaatcattaggatttaaagagttgtgtagagttagtgaaggaaaagccttagaatta1200aatttggctgcggataaaacattcttggattagactgaagactcttttctgtgctaagta1260agtatatttatgataatgatgatgactgtagtgctgaatatttaataaataaaaacaaaa1320ttaattgccgcatacataatgtcctgaatactattgtaaatgttttatcttatttccttt1380aaactgtctacagcactataaggtaggtaccagtattgtcacagttacacagatatggaa1440accgagacacagggaagttaagttacttgatcaatttcaagcaatcggcaagccatggag1500catctatgtcagggctgccaggacatgtgactgtaaacagaagtttttcactttttaact1560caaagagggtatgtggctgggttaatggaaagcttcaggaccctcagaaaacattactaa1620caagcaaatgaaaggtgtatctggaagattaagttttaacagactcttcatttccatcga1680tccaataatgcacttagggagatgactgggcatattgaggataggaagagagaagtgaaa1740acacagctttttatattgttcttaacaggcttgtgccaaacatcttctgggtggatttag1800gtgattgaggagaagaaagacacaggagcgaaattctctgagcacaagggaggagttcta1860cactcagactgagccaacagacttttctggcctgacaaccagggcggcgcaggatgctca1920gtgcagagaggaagaagcaggtggtctttgcagctgaaagctcagctgatttgcatatgg1980agtcattatacaacatcccagaattctttaagggcagctgccaggaagctaagaagcatc2040ctctcttctagctctcagagatggagacagacacactcctgctatgggtgctgctgctct2100gggttccaggtgagggtacagataagtgttatgagcaacctctgtggccattatgatgct2160ccatgcctctctgttcttgatcactataattagggcatttgtcactggttttaagtttcc2220ccagtcccctgaattttccattttctcagagtgatgtccaaaattattcttaaaaattta2280aatgaaaaggtcctctgctgtgaaggcttttaaagatatataaaaataatctttgtgttt2340atcattccaggtgccagatgtataccaccggagaaattgtgttgacgcagtctccaggca2400ccctgtctttgtctccaggggaaagagccaccctctcctgcagggccagtcagagtgtta2460gcagcagctacttagcctggtaccagcagaaacctggccaggctcccaggctcctcatct2520atggtgcatccagcagggccactggcatcccagacaggttcagtggcagtgggtctggga2580cagacttcactctcaccatcagcagactggagcctgaagattttgcagtgtattactgtc2640agcagtatggtagctcaccttggacgttcggccaagggaccaaggtggaaatcaaacgta2700agtaatttttcactattgtcttctgaaatttgggtctgatggccagtattgacttttaga2760ggcttaaataggagtttggtaaagattggtaaatgagggcatttaagatttgccatgggt2820tgcaaaagttaaactcagcttcaaaaatggatttggagaaaaaaagattaaattgctcta2880aactgaatgacacaaagtaaaaaaaaaaagtgtaactaaaaaggaacccttgtatttcta2940aggagcaaaagtaaatttatttttgttcactcttgccaaatattgtattggttgttgctg3000attatgcatgatacagaaaagtggaaaaatacattttttagtctttctcccttttgtttg3060ataaattattttgtcagacaacaataaaaatcaatagcacgccctaagatctagatgcat3120gctcgagtgccatttcattacctctttctccgcacccgacatagat3166<210>150<211>82<212>dna<213>人工序列<220><223>引导rna骨架v1<400>150gttggaaccattcaaaacagcatagcaagttaaaataaggctagtccgttatcaacttga60aaaagtggcaccgagtcggtgc82<210>151<211>76<212>dna<213>人工序列<220><223>引导rna骨架v2<400>151gttttagagctagaaatagcaagttaaaataaggctagtccgttatcaacttgaaaaagt60ggcaccgagtcggtgc76<210>152<211>86<212>dna<213>人工序列<220><223>引导rna骨架v3<400>152gtttaagagctatgctggaaacagcatagcaagtttaaataaggctagtccgttatcaac60ttgaaaaagtggcaccgagtcggtgc86当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1