通过修饰内源性MADS盒转录因子改善玉蜀黍中的农艺特征的制作方法
以电子方式递交的序列表的引用所述序列表的官方副本经由efs-web以ascii格式的序列表以电子方式提交,文件名为7847_st25.txt,创建于2019年3月3日,且具有51千字节的大小,并与本说明书同时提交。包含在该ascii格式的文件中的序列表是本说明书的一部分并且以其全文通过引用并入本文。本公开涉及用于提高植物产量的组合物和方法。
背景技术:
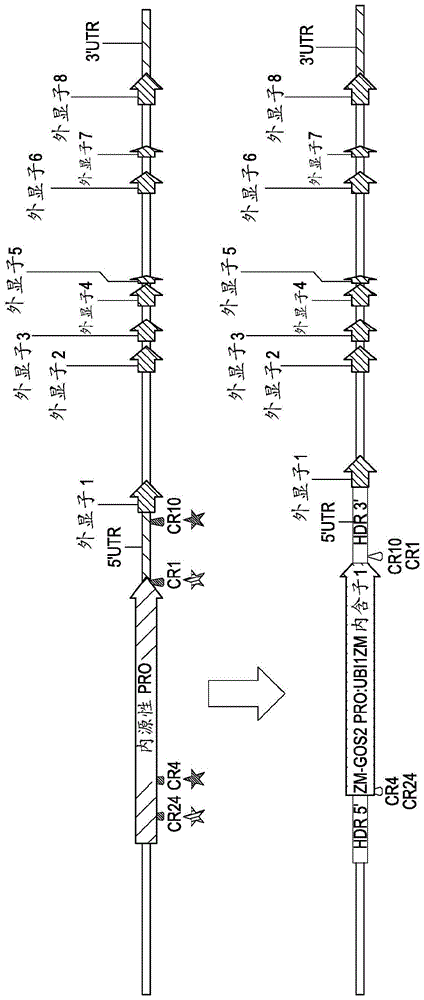
:全球对农作物的需求和消费正在迅速增长。因此,需要开发新的组合物和方法以增加植物产量。本发明提供此类组合物和方法。技术实现要素:靶向植物细胞(例如,玉蜀黍)的内源性基因组基因座的指导多核苷酸分子,其中所述基因组基因座包含编码多肽的多核苷酸,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少80%、85%、90%、95%、或99%同一性的氨基酸序列。在一个实施例中,所述指导多核苷酸靶向多核苷酸的调节区。提供了包括这些指导多核苷酸的植物细胞,其中所述指导多核苷酸在内源性基因组基因座处与cas内切核酸酶相互作用。在一个实施例中,所述指导多核苷酸靶向内源性基因组基因座的调节区,所述内源性基因组基因座具有与选自由seqidno:5-6组成的组的序列具有至少90%同一性的基因组序列。在一个实施例中,所述内源性基因组基因座包含编码多肽的多核苷酸的调节区,其中所述调节区包含与seqidno:5-6中的一个具有至少90%同一性的多核苷酸序列。一种植物细胞在基因组基因座处包括靶向遗传修饰,所述基因组基因座编码多肽,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少90%同一性的氨基酸序列,其中所述靶向遗传修饰调控所编码的多肽的表达水平和/或活性。在一个实施例中,所述靶向修饰导致所述多核苷酸表达水平的增加。在一个实施例中,所述靶向遗传修饰选自由以下组成的组:插入、缺失、单核苷酸多态性(snp)、和多核苷酸修饰组成的组。在一个实施例中,所述靶向遗传修饰存在于编码多肽的基因组基因座的(a)编码区;(b)非编码区;(c)调节序列;(d)非翻译区;或(e)(a)-(d)的任何组合。在一个实施例中,所述植物细胞来自单子叶植物。在一个实施例中,所述单子叶植物是玉蜀黍。在一个实施例中,所述靶向修饰是在基因组基因座处插入调节元件,其中所述基因组基因座包含与seqidno:5-6中的一个具有至少90%同一性的多核苷酸序列。在一个实施例中,所述调节元件是异源启动子。在一个实施例中,所述异源启动子是中等组成型启动子。在一个实施例中,所述调节元件是增强子元件。一种植物,所述植物在基因组基因座处包含靶向遗传修饰,所述基因组基因座编码多肽,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少95%同一性的氨基酸序列,其中与不包含遗传修饰的对照植物相比,所述靶向遗传修饰调控所编码的多肽的表达水平和/或活性。在一个实施例中,所述植物是玉蜀黍。在一个实施例中,当与对照植物相比时,所述植物表现出增加的多核苷酸表达,所述多核苷酸编码与选自由seqidno:1或2组成的组的氨基酸序列具有至少95%同一性的多肽。在一个实施例中,所述植物是玉蜀黍植物,并且所述玉蜀黍植物表现出增加的籽粒产量。一种玉蜀黍种子,所述玉蜀黍种子在基因组基因座处包含靶向遗传修饰,所述基因组基因座编码多肽,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少95%同一性的氨基酸序列,其中所述靶向遗传修饰调控所编码的多肽的表达水平和/或活性。在一个实施例中,在种子和/或植物中,所述在玉蜀黍种子中的靶向修饰导致多核苷酸的表达水平增加,所述多核苷酸编码多肽,所述多肽包含与seqidno:1具有至少95%同一性的氨基酸序列。在一个实施例中,所述玉蜀黍种子进一步包含编码除草剂耐受性和/或昆虫抗性的多肽。在一个实施例中,所述靶向修饰包含用zmgos2启动子的异源性调节元件插入或替代内源性调节元件。一种用于增加玉蜀黍植物中籽粒产量的方法,所述方法包括在可再生的玉蜀黍植物细胞中在基因组基因座处引入靶向遗传修饰,所述基因组基因座编码多肽,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少90%同一性的氨基酸序列;以及产生所述植物,其中当与不包含所述遗传修饰的对照植物相比时,所编码的多肽的水平和/或活性在所述植物中被调控。在一个实施例中,所述靶向遗传修饰使用基因组修饰技术引入,所述基因组修饰技术选自由以下组成的组:多核苷酸指导的内切核酸酶、crispr-cas内切核酸酶、靶向性碱基编辑脱氨酶、锌指核酸酶、转录激活子样效应子核酸酶(talen)、工程化位点特异性大范围核酸酶、或argonaute。在一个实施例中,所述靶向遗传修饰存在于编码多肽的基因组基因座的(a)编码区;(b)非编码区;(c)调节序列;(d)非翻译区;或(e)(a)-(d)的任何组合。一种用于增加玉蜀黍植物中光合作用活性的方法,所述方法包括在可再生的植物细胞中在基因组基因座处引入靶向遗传修饰,所述基因组基因座编码多肽,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少90%同一性的氨基酸序列;以及产生所述植物,其中所编码的多肽的水平和/或活性在玉蜀黍植物中增加。在一个实施例中,所述方法包括多核苷酸编码多肽,所述多肽包含与选自由seqidno:1组成的组的氨基酸序列具有至少95%同一性的氨基酸序列。在一个实施例中,所述靶向修饰导致异源植物来源的增强子元件的整合,这样使得所述多核苷酸的表达水平增加。一种在基因组基因座处引入定点修饰以增加多核苷酸表达水平的方法,所述方法包括在可再生植物细胞(例如,玉蜀黍)中在基因组基因座处引入靶向遗传修饰,所述基因组基因座编码多肽,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少90%同一性的氨基酸序列;以及获得所述植物,其中与对照植物相比,所述编码的多肽的表达水平增加。在一个实施例中,所述靶向修饰使在基因组基因座处的内源性启动子元件与异源调节元件交换,这样使得异源调节元件增加所述多核苷酸的表达水平。一种鉴定植物的基因组区域中的基因组变异的方法,所述方法包括进行一种或多种玉蜀黍品系的一个或多个分离的多核苷酸样品的基因分型,所述多核苷酸样品包含所述基因组区域的多核苷酸的一部分,所述基因组区域编码包含与seqidno:1具有至少95%同一性的氨基酸序列的多肽;并且基于基因分型鉴定基因组变异。在一个实施例中,所述玉蜀黍品系是近交系。在一个实施例中,所述玉蜀黍品系来自热带或亚热带种质来源。在一个实施例中,所述基因组变异是在编码所述多肽的基因组区域的编码区中。在一个实施例中,所述基因组变异是在非编码区。在一个实施例中,所述基因组变异导致单倍型,所述单倍型增加编码所述多肽的多核苷酸的表达。还提供了重组dna构建体,其包含可操作地连接到编码多肽的多核苷酸的调节元件,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少80%同一性的氨基酸序列。在某些实施例中,所述调节元件是异源启动子,诸如例如,gos2中等组成型启动子。进一步提供了在基因组基因座处包含靶向遗传修饰的植物细胞、植物、和种子,所述基因组基因座编码多肽,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少80%同一性的氨基酸序列,其中所述遗传修饰增加所编码的多肽的水平和/或活性。在某些实施例中,所述遗传修饰选自由以下组成的组:插入、缺失、单核苷酸多态性(snp)、和多核苷酸修饰。在某些实施例中,所述靶向遗传修饰存在于编码多肽的基因组基因座的(a)编码区;(b)非编码区;(c)调节序列;(d)非翻译区;或(e)(a)-(d)的任何组合。提供了用于通过在可再生植物细胞中表达重组dna构建体并产生所述植物来增加植物产量的方法,所述重组dna构建体包含可操作地连接到编码多肽的多核苷酸的调节元件,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少80%同一性的氨基酸序列;其中所述植物在其基因组中包含所述重组dna构建体。在某些实施例中,所述调节元件是异源启动子。在某些实施例中,所述植物是单子叶植物。在某些实施例中,所述单子叶植物是玉蜀黍。在某些实施例中,所述产量是籽粒产量。进一步提供了用于通过在可再生植物细胞中在基因组基因座处引入靶向遗传修饰并产生所述植物来增加植物产量的方法,所述基因组基因座编码多肽,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少80%同一性的氨基酸序列;其中所编码的多肽的水平和/或活性在所述植物中增加。在某些实施例中,所述遗传修饰使用基因组修饰技术引入,所述基因组修饰技术选自由以下组成的组:多核苷酸指导的内切核酸酶、crispr-cas内切核酸酶、碱基编辑脱氨酶、锌指核酸酶、转录激活子样效应子核酸酶(talen)、工程化位点特异性大范围核酸酶、或argonaute。在某些实施例中,所述靶向遗传修饰存在于编码多肽的基因组基因座的(a)编码区;(b)非编码区;(c)调节序列;(d)非翻译区;或(e)(a)-(d)的任何组合。在某些实施例中,所述植物细胞来自单子叶植物。在某些实施例中,所述单子叶植物是玉蜀黍。在某些实施例中,所述产量是籽粒产量。提供了用于通过在可再生植物细胞中表达重组dna构建体并产生所述植物来增加植物中光合作用活性的方法,所述重组dna构建体包含可操作地连接到编码多肽的多核苷酸的调节元件,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少80%同一性的氨基酸序列;其中所述植物在其基因组中包含所述重组dna构建体。还提供了用于通过在可再生植物细胞中在基因组基因座处引入靶向遗传修饰并产生所述植物来增加植物中光合作用活性的方法,所述基因组基因座编码多肽,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少80%同一性的氨基酸序列;其中所编码的多肽的水平和/或活性在所述植物中增加。在某些实施例中,所述遗传修饰使用基因组修饰技术引入,所述基因组修饰技术选自由以下组成的组:多核苷酸指导的内切核酸酶、crispr-cas内切核酸酶、碱基编辑脱氨酶、锌指核酸酶、转录激活子样效应子核酸酶(talen)、工程化位点特异性大范围核酸酶、或argonaute。在某些实施例中,所述靶向遗传修饰存在于编码多肽的基因组基因座的(a)编码区;(b)非编码区;(c)调节序列;(d)非翻译区;或(e)(a)-(d)的任何组合。在某些实施例中,所述植物细胞来自单子叶植物。在某些实施例中,所述单子叶植物是玉蜀黍。附图和序列表的说明图1是表示通过具有玉蜀黍gos2启动子与ubi1zm内含子1替代物的同源重组介导的基因组编辑,替代编码seqidno:1(品系e)的基因组基因座的内源性启动子区的位置和方法的示意图。cr指示用于cas9-介导的基因组编辑的crispr识别位点。注意示意图未按比例绘制。图2是表示通过具有玉蜀黍zm-eif5cpro:adh1内含子插入的同源重组介导的基因组编辑,来将异源玉蜀黍启动子插入编码seqidno:1(品系e)的基因组基因座的内源性启动子区的位置和方法的示意图。cr指示用于cas9-介导的基因组编辑的crispr识别位点。注意示意图未按比例绘制。图3是表示通过具有玉蜀黍gos2启动子与ubi1zm内含子1插入的同源重组介导的基因组编辑,来将异源玉蜀黍启动子插入编码seqidno:1(品系e)的基因组基因座的内源性启动子区的位置和方法的示意图。cr指示用于cas9-介导的基因组编辑的crispr识别位点。注意示意图未按比例绘制。图4是显示用于启动子改变的额外crispr识别位点的示意图。图5显示玉蜀黍植物中的表达水平,所述玉蜀黍植物用表达调控元件进行了基因组编辑。图6显示玉蜀黍植物中的表达水平,其中表达调控元件插入内源性调节区。根据下列的详细描述和附图以及序列表,可以更全面地理解本公开,所述详细描述和附图以及序列表形成本申请的一部分。这些序列描述以及所附序列表遵守如37c.f.r.§§1.821和1.825所列出的管理专利申请中核苷酸和氨基酸序列公开内容的规则。这些序列描述包含如在37c.f.r.§§1.821和1.825中所定义的用于氨基酸的三字母代码,将其通过引用结合在此。表1:序列表i.组合物a.多核苷酸和多肽本公开提供编码多肽的多核苷酸。因此,如本文使用的“多肽”、“蛋白质”等是指由seqidno表示的蛋白质。本公开的一个方面提供编码多肽的多核苷酸,所述多肽包含与seqidno:1-4中的任一个的氨基酸序列具有至少80%-99%%同一性的氨基酸序列)。图1b显示来自拟南芥属(arabidopsis)、稻、高粱、大麦、短柄草属(brachypodium)、和玉蜀黍的具有ap1-ful进化枝mads盒基因的zmm28(zm00001d022088)的系统发育分析。zmm28分别与高粱sb02g038780.1、大麦ak361063和ak361227、和稻loc_os07g41370.1(osmads18)蛋白质成簇,并且分别于它们共享94%、75%、69%、和76%氨基酸序列同一性。如本文使用的,关于指定核酸的“编码”(“encoding”、“encoded”等)是指包含用于翻译成指定蛋白质的信息。编码蛋白质的核酸在所述核酸的翻译区之内可以包含非翻译序列(例如,内含子)或可能缺乏此类插入的非翻译序列(例如,在cdna中)。通过密码子使用来详细说明用来编码蛋白质的信息。典型地,所述氨基酸序列通过使用“通用”遗传密码的核酸来编码。然而,当核酸使用以下这些生物体表达时,可以使用通用密码的变体,诸如存在于一些植物、动物、和真菌线粒体、细菌山羊支原体(mycoplasmacapricolum)(yamao,等人,(1985)proc.natl.acad.sci.usa[美国科学院院报]82:2306-9)或纤毛虫大核中的通用密码变体。当合成地制备或改变核酸时,可以利用要表达核酸的预期宿主的已知密码子偏好性。例如,虽然在单子叶和双子叶植物物种中均可以表达本发明的核酸序列,但是可以修饰序列,以解释单子叶植物或双子叶植物的特定密码子偏好和gc含量偏好,因为这些偏好已经表现出了差异(murray等人(1989)nucleicacidsres.[核酸研究]17:477-98)。如本文使用的,“多核苷酸”包括提及具有天然核糖核苷酸的基本性质的脱氧核糖多核苷酸、核糖多核苷酸、或其类似物,因为在严格的杂交条件下,它们与和天然存在的核苷酸基本上相同的核苷酸序列杂交和/或允许翻译成与一种或多种天然存在的核苷酸相同的一种或多种氨基酸。多核苷酸可以是结构基因或调控基因的全长或子序列。除非另外指明,所述术语包括提及指定序列以及其互补序列。因此,出于稳定性或其他原因而具有经修饰的主链的dna或rna是“多核苷酸”,如该术语在本文中所意指的。此外,仅举两个例子,包含稀有碱基(诸如肌苷)或修饰的碱基(诸如三苯甲基化的碱基)的dna或rna是多核苷酸,如该术语在本文中所使用的。应当理解,已经对dna和rna进行了多种修饰,所述修饰具有本领域技术人员已知的许多有用目的。如本文采用的术语多核苷酸涵盖诸如多核苷酸的化学修饰形式、酶修饰形式或代谢修饰形式,以及病毒和细胞(尤其包括简单和复杂细胞)所特有的dna和rna的化学形式。术语“多肽”、“肽”以及“蛋白质”在本文中可互换使用,是指氨基酸残基的聚合物。这些术语适用于其中一个或多个氨基酸残基是相应的天然存在的氨基酸的人工化学类似物的氨基酸聚合物,以及适用于天然存在的氨基酸聚合物。如本文使用的,在两个核酸或多肽序列的上下文中的“序列同一性”或“同一性”包括,当在指定比较窗口上对齐最大对应性时,提及两个序列中的相同残基。当使用关于蛋白质的序列同一性百分比时,认识到不相同的残基位置通常相差保守氨基酸取代,其中氨基酸残基被具有相似化学性质(例如电荷或疏水性)的其他氨基酸残基取代,并且因此不改变分子的功能性质。当序列在保守取代方面不同时,可以向上调节序列同一性百分比,以校正所述取代的保守性质。相差这些保守取代的序列被称为具有“序列相似性”或“相似性”。用于进行此调节的方法是本领域技术人员所熟知的。典型地,这涉及作为部分而不是完全错配对保守取代打分,从而提高百分比序列同一性。因此,例如,当相同的氨基酸得分为1,并且非保守取代的得分为零时,保守取代的得分在零和1之间。例如,根据meyers和miller,(1988)computerapplic.biol.sci.[计算机应用生物科学]4:11-17的算法来计算保守取代的得分,例如如在程序pc/gene(易达利遗传学公司(intelligenetics),山景城,加利福尼亚州,美国)中实现的。如本文使用的,“序列同一性百分比”意指在比较窗口上比较两个最佳比对序列所确定的值,其中与参比序列(其不包含添加或缺失)相比,所述比较窗中的多核苷酸序列部分可以包含添加或缺失(即空位),以进行这两个序列的最佳比对。通过以下方式计算所述百分比:确定在两个序列中出现相同核酸碱基或氨基酸残基的位置的数目以产生匹配位置的数目,将匹配位置的数目除以比较窗口中的位置的总数目,然后将所述结果乘以100以产生序列同一性的百分比。如本文使用的,“参比序列”是用作序列比较的基础的所定义的序列。参比序列可以是指定序列的子集或整体;例如,作为全长cdna或基因序列的区段、或完整的cdna或基因序列。如本文使用的,“比较窗口”意指包括提及多核苷酸序列的连续且指定的区段,其中所述多核苷酸序列可以与参比序列进行比较,并且其中与用于两个序列的最佳比对的参比序列(其不包含添加或缺失)相比,比较窗口中的多核苷酸序列部分可能包含添加或缺失(即空位)。通常,比较窗口的长度为至少20个连续核苷酸,并且任选地可以是30个、40个、50个、100个或更长。本领域技术人员应当理解,由于多核苷酸序列中含有空位,为了避免与参比序列的高相似性,典型地引入空位罚分,并且将其从匹配数中减去。用于比较的核苷酸序列和氨基酸序列的比对方法是本领域熟知的。smith和waterman(1981)adv.appl.math.[应用数学进展]2:482的局部同源性算法(bestfit)可进行比较的序列的最佳比对;通过needleman和wunsch,(1970)j.mol.biol.[分子生物学杂志]48:443-53的同源性比对算法(gap);通过pearson和lipman,(1988)proc.natl.acad.sci.usa[美国科学院院报]85:2444的相似性搜索法(tfasta和fasta);通过这些算法的计算机化实现,包括但不限于:加利福尼亚州山景城的易达利遗传学公司(intelligenetics)的pc/基因程序中的clustal,wisconsingeneticssoftware(版本8)中的gap、bestfit、blast、fasta、和tfasta(可获得自遗传学计算机集团(geneticscomputergroup)(程序(accelrys公司,圣地亚哥,加利福尼亚州))。以下充分描述了clustal程序:higgins和sharp,(1988)gene[基因]73:23744;higgins和sharp,(1989)cabios[计算机应用生物科学]5:1513;corpet等人,(1988)nucleicacidsres.[核酸研究]16:10881-90;huang等人(1992)computerapplicationsinthebiosciences[计算机应用生物科学]8:155-65;以及pearson等人(1994)meth.mol.biol.[分子生物学方法]24:307-31。用于多个序列的最佳全局比对的优选程序是pileup(feng和doolittle,(1987)j.mol.evol.[分子进化杂志],25:351-60,其类似于higgins和sharp,(1989)cabios[计算机应用生物科学]5:151-53描述的方法并且通过引用并入本文)。可用于数据库相似性搜索的blast程序家族包括:blastn,用于比较核苷酸查询序列与核苷酸数据库序列;blastx,用于比较核苷酸查询序列与蛋白质数据库序列;blastp,用于比较蛋白质查询序列与蛋白质数据库序列;tblastn,用于比较蛋白质查询序列与核苷酸数据库序列;以及tblastx,用于比较核苷酸查询序列与核苷酸数据库序列。参见,currentprotocolsinmolecularbiology[分子生物学实验指南],第19章,ausubel等人编辑,greenepublishingandwiley-interscience[格林出版与威利交叉科学出版社],纽约(1995)。gap使用上文的needleman和wunsch的算法来找到使匹配数目最大化并且使空位数目最小化的两个完整序列的对齐。gap考虑所有可能的对齐和空位位置,并且产生具有最大匹配碱基数量和最少空位的对齐。它允许以匹配碱基单位提供空位产生罚分和空位延伸罚分。gap必须为它插入的每个空位获取空位产生罚分匹配数目的收益。如果选择大于零的空位延伸罚分,gap必须另外地为每个所插入空位获取空位长度乘以空位延伸罚分的收益。在wisconsingeneticssoftware的版本10中,默认空位产生罚分值和空位延伸罚分值分别为8和2。空位产生罚分和空位延伸罚分可以表示为选自下组的整数,该组由0至100组成。因此,例如,空位产生罚分和空位延伸罚分可以为0、1、2、3、4、5、6、7、8、9、10、15、20、30、40、50或更大。gap代表最佳对齐家族的一个成员。可以存在这个家族的许多成员,但是其他成员没有更好的品质。gap展示出用于对齐的四个性能因数:质量、比率、同一性和相似性。为了对齐序列,质量是最大化的度量。比率是质量除以更短区段中的碱基数。同一性百分比是实际匹配的符号的百分比。相似性百分比是相似符号的百分比。空位对面的符号被忽略。当一对符号的评分矩阵值大于或等于相似性阈值0.50时,相似性得分。wisconsingeneticssoftware的版本10中使用的评分矩阵为blosum62(参见henikoff和henikoff,(1989)proc.natl.acad.sci.usa[美国科学院院报]89:10915)。除非另外说明,否则在此提供的序列同一性/相似性值是指使用blast2.0程序包、使用默认参数获得的值(altschul等人,(1997)nucleicacidsres.[核酸研究]25:3389-402)。如本领域技术人员将理解,blast搜索假设蛋白质可被建模为随机序列。然而,许多真实蛋白质包含非随机序列的区域,其可是同聚序列段(homopolymerictracts)、短周期重复序列、或富含一种或多种氨基酸的区域。即使蛋白质的其他区域完全不同,这种低复杂性的区域也可在不相关蛋白质之间对齐。许多低复杂性滤波器程序可用来减少这些低复杂性比对。例如,可单独使用或组合使用seg(wooten和federhen,(1993)comput.chem.[计算机化学]17:149-63)和xnu(claverie和states,(1993)comput.chem.[计算机化学]17:191-201)低复杂性滤波器。因此,在本文所述的任何实施例中,所述多核苷酸可编码与seqidno:1-4中的任一个具有至少80%同一性的多肽。例如,所述多核苷酸可编码与seqidno:1-4中的任一个的氨基酸序列具有至少81%同一性、至少82%同一性、至少83%同一性、至少84%同一性、至少85%同一性、至少86%同一性、至少87%同一性、至少88%同一性、至少89%同一性、至少90%同一性、至少91%同一性、至少92%同一性、至少93%同一性、至少94%同一性、至少95%同一性、至少96%同一性、至少97%同一性、至少98%同一性、或至少99%同一性的多肽。b.重组dna构建体还提供了包含本文所述的任何多核苷酸的重组dna构建体。在某些实施例中,所述重组dna构建体进一步包含至少一种调节元件。在某些实施例中,所述重组dna构建体的至少一种调节元件包含启动子。在某些实施例中,所述启动子是异源启动子。如本文使用的,“重组dna构建体”包含两个或更多个可操作地连接的dna区段,优选在自然界中不可操作地连接(即,异源)的dna区段。重组dna构建体的非限制性实例包括与异源序列(也称为调节元件)可操作地连接的目的多核苷酸,这些异源序列有助于目的序列的表达、自主复制和/或基因组插入。此类调节元件包括例如启动子、终止序列、增强子等,或表达盒的任何组分;质粒、粘粒、病毒、自主复制序列、噬菌体、或线性或环状单链或双链dna或rna核苷酸序列;和/或编码异源多肽的序列。本文所述的多核苷酸能以用于在目的植物或任何目的生物体中表达的表达盒提供。所述盒可以包括可操作地连接到多核苷酸的5′和3′调节序列。“可操作地连接”旨在表示两个或更多个元件之间的功能性连接。例如,目的多核苷酸和调节序列(例如,启动子)之间的可操作连接是允许目的多核苷酸表达的功能性连接。可操作地连接的元件可以是连续的或非连续的。当用于指两个蛋白质编码区的连接时,可操作地连接意指这些编码区处于相同的阅读框中。所述盒可以另外含有至少一个待共转化到生物体中的额外的基因。可替代地,所述一个或多个额外的基因可以在多个表达盒上提供。此类表达盒装备有多个限制性位点和/或重组位点,用于将多核苷酸插入到调节区的转录调节之下。表达盒可另外含有选择性标记基因。所述表达盒以5′-3′转录的方向包括转录和翻译起始区(例如,启动子)、多核苷酸、和在植物中起作用的转录和翻译终止区(例如,终止区)。所述调节区(例如,启动子、转录调节区、和翻译终止区)和/或多核苷酸对于宿主细胞而言或彼此之间可以是天然的/同功的。可替代地,所述调节区和/或多核苷酸对于宿主细胞或彼此之间可以是异源的。如本文使用的,关于序列的“异源性”是指该序列源于外来物种,或者,如果源于相同物种的话,则是通过蓄意人为干预从其在组合物和/或基因组基因座中的天然形式进行实质性修饰得到的序列。例如,可操作地连接到异源多核苷酸的启动子来自与从其衍生所述多核苷酸的物种不同的物种,或者,如果来自相同/类似的物种,那么一方或双方基本上由它们的原来形式和/或基因组基因座修饰得到,或者所述启动子不是可操作地连接到多核苷酸的天然启动子。所述终止区对于转录起始区、对于植物宿主而言可是天然的,或可衍生自对于所述启动子、多核苷酸、植物宿主、或其任何组合而言的另一种来源(即外源的或异源的)。所述表达盒可以另外含有5′前导序列。此类前导序列可以起到增强翻译的作用。翻译前导子在本领域是已知的并且包括病毒翻译前导序列。在制备表达盒时,可以操作各种dna片段,以提供处于适当取向以及合适时,处于适当阅读框中的dna序列。为此,可采用衔接子(adapter)或接头以连接dna片段,或可以涉及其他操作以提供方便的限制位点、移除多余的dna、移除限制位点等。出于这个目的,可以涉及体外诱变、引物修复、限制性酶切(restriction)、退火、再取代(例如转换和颠换)。如本文使用的“启动子”指dna的在转录开始的上游并参与rna聚合酶以及其他蛋白质的识别和结合以启动转录的区域。“植物启动子”是能够在植物细胞中启动转录的启动子。示例性植物启动子包括但不局限于从植物、植物病毒以及包含在植物细胞中表达的基因的细菌(如农杆菌属(agrobacterium)或根瘤菌属(rhizobium))获得的那些启动子。某些启动子类型优先在某些组织(如叶、根、种子、纤维、木质部导管、管胞或厚壁组织)中启动转录。这样的启动子被称为“组织偏好的”。“细胞类型”特异性启动子主要驱动在一个或多个器官中的某些细胞类型(例如,根或叶中的维管细胞)中的表达。“诱导型”或“调节型”启动子是指在环境控制下的启动子。可通过诱导型启动子影响转录的环境条件的实例包括厌氧条件或光照的存在。另一类型的启动子是发育调节启动子,例如在花粉发育期间驱动表达的启动子。组织偏好性启动子、细胞类型特异性启动子、发育调节启动子、和诱导型启动子构成“非组成型”启动子类别。“组成型”启动子是在大多数环境条件下有活性的启动子。组成型启动子包括,例如rsyn7启动子的核心启动子和其他在wo99/43838和美国专利号6,072,050中公开的组成型启动子;核心camv35s启动子(odell等人,(1985)nature[自然]313:810-812);稻肌动蛋白(mcelroy等人,(1990)plantcell[植物细胞]2:163-171);泛素(christensen等人,(1989)plantmol.biol.[植物分子生物学]12:619-632和christensen等人,(1992)plantmol.biol.[植物分子生物学]18:675-689);pemu(last等人(1991)theor.appl.genet.[理论与应用遗传学]81:581-588);mas(velten等人,(1984)emboj.[欧洲分子生物学学会杂志]3:2723-2730);als启动子(美国专利号5,659,026);zmgos2(美国专利号6,504,083)等。其他组成型启动子包括例如美国专利号5,608,149;5,608,144;5,604,121;5,569,597;5,466,785;5,399,680;5,268,463;5,608,142;和6,177,611。还考虑了包括一种或多种异源调节元件的组合的合成启动子。c.植物和植物细胞提供了包含本文所述的多核苷酸序列或本文所述的重组dna构建体的植物、植物细胞、植物部分、种子、和谷物,于是植物、植物细胞、植物部分、种子、和/或谷物具有增加的多肽表达。在某些实施例中,植物、植物细胞、植物部分、种子、和/或谷物将本文所述的外源多核苷酸稳定地掺入其基因组中。在某些实施例中,植物、植物细胞、植物部分、种子、和/或谷物可以包含多个多核苷酸(即,至少1个、2个、3个、4个、5个、6个或更多个)。在具体实施例中,植物、植物细胞、植物部分、种子、和/或谷物中的一种或多种多核苷酸可操作地连接到异源调节元件,例如,但不限于组成型启动子、组织偏好性启动子、或用于在植物中表达的合成启动子、或组成型增强子。例如,在某些实施例中,所述异源调节元件是玉蜀黍gos2启动子。本文还提供了在基因组基因座处包含引入的遗传修饰的植物、植物细胞、植物部分、种子、和谷物,所述基因组基因座编码多肽,所述多肽包含与选自由seqidno:1-4组成的组的氨基酸序列具有至少80%同一性的氨基酸序列。在某些实施例中,所述遗传修饰增加了蛋白质的活性。在某些实施例中,所述遗传修饰增加了蛋白质的水平。在某些实施例中,所述遗传修饰增加了蛋白质的水平和活性两者。如本文使用的,“基因组基因座”通常指在植物的染色体上的位置,在该位置上发现了基因,诸如编码多肽的多核苷酸。如本文使用的,“基因”包括表达功能性分子的核酸片段,诸如但不限于特定蛋白质编码序列和调节元件,诸如在编码序列之前(5’非编码序列)和之后(3’非编码序列)的那些调节元件。“调节元件”通常是指参与调节核酸分子(例如基因或靶基因)的转录的转录调节元件。调节元件是核酸,并且可以包括启动子、增强子、内含子、5’-非翻译区(5’-utr,还被称为前导序列)、或3’-utr或其组合。调节元件能以“顺式”或“反式”起作用,并且通常以“顺式”起作用,即其激活位于调节元件所在的相同核酸分子(例如染色体)上的基因的表达。“增强子”元件是当功能性连接至启动子时(无论其相对位置如何)都可增加核酸分子的转录的任何核酸分子。将“阻遏物”(本文中有时也被称为沉默子)定义为当在功能上与启动子连接时(无论相对位置如何)都抑制转录的任何核酸分子。术语“顺式元件”通常是指影响或调控可操作地连接的可转录的多核苷酸表达的转录调节元件,其中所述可转录的多核苷酸存在于相同dna序列中。顺式元件可以起到结合转录因子的作用,所述转录因子是调节转录的反式作用多肽。“内含子”是转录成rna、但是然后在产生成熟mrna的过程中被切除的基因中的间插序列。所述术语也用于切除的rna序列。“外显子”是经转录的基因的序列的一部分,并且在源自所述基因的成熟信使rna中被发现,但不一定是编码最终基因产物的序列的一部分。5′非翻译区(5’utr)(也称为翻译前导序列或前导rna)是直接位于起始密码子上游的mrna的区域。该区域涉及通过病毒、原核生物和真核生物中的不同机制对转录物的翻译的调节。“3′非编码序列”是指位于编码序列下游的dna序列,并且包括聚腺苷酸化识别序列和编码能够影响mrna加工或基因表达的调节信号的其他序列。聚腺苷酸化信号通常表征为影响聚腺苷酸片添加到mrna前体的3′末端。“遗传修饰”、“dna修饰”等是指在植物的特定基因组基因座上改变或变更核苷酸序列的位点特异性修饰。本文所述的组合物和方法的遗传修饰可以是本领域已知的任何修饰,诸如,例如,插入、缺失、单核苷酸多态性(snp)、和或多核苷酸修饰。另外,基因组基因座上的靶向dna修饰可位于基因组基因座上的任何位置,诸如,例如,所编码的多肽的编码区(例如,外显子)、非编码区(例如,内含子)、调节元件、或非翻译区。如本文使用的,“靶向”遗传修饰或“靶向”dna修饰是指对生物体基因的直接操作。所述靶向修饰可以使用本领域已知的任何技术引入,诸如,例如,植物育种、基因组编辑、或单基因座转化。多核苷酸的dna修饰的类型和位置不受特别限制,只要dna修饰导致由相应多核苷酸编码的蛋白质的表达和/或活性增加即可。在某些实施例中,植物、植物细胞、植物部分、种子、和/或谷物包含存在于编码多肽的内源性多核苷酸的(a)编码区;(b)非编码区;(c)调节序列;(d)非翻译区,或(e)(a)-(d)的任何组合中的一种或多种核苷酸修饰。在某些实施例中,所述dna修饰是在基因组基因座中插入一个或多个核苷酸(优选是连续的)。例如,插入表达调控元件(eme),诸如pct/us2018/025446中描述的eme,其与本文所述的目的基因可操作地连接。在某些实施例中,所述靶向dna修饰可以是用本领域已知的具有较高表达的另一种启动子(诸如,例如,玉蜀黍gos2启动子)替代内源性启动子。在某些实施例中,所述靶向dna修饰可以是将本领域已知的具有较高表达的启动子(诸如,例如,玉蜀黍gos2启动子)插入5’utr,从而通过插入的启动子控制内源性多肽的表达。在某些实施例中,所述dna修饰是优化kozak背景以增加表达的修饰。在某些实施例中,所述dna修饰是多核苷酸修饰或在调节所表达的蛋白的稳定性的位点上的snp。如本文使用的“增加的”、“增加”等是指与对照组(例如,不包含dna修饰的野生型植物)相比,实验组(例如,具有本文所述的dna修饰的植物)中的任何可检测的增加。因此,增加的蛋白质表达包含样品中蛋白质总水平的任何可检测的增加,并且可使用本领域的常规方法来确定,例如,蛋白质印迹法和elisa。在某些实施例中,所述基因组基因座具有超过一个(例如,2个、3个、4个、5个、6个、7个、8个、9个、或10个)dna修饰。例如,基因组基因座的翻译区和调节元件可各自包含靶向dna修饰。在某些实施例中,植物的超过一个基因组基因座可包含dna修饰。可以使用本领域已知的或本文所述的任何基因组修饰技术来完成基因组基因座的dna修饰。在某些实施例中,通过基因组修饰技术进行靶向dna修饰,所述基因组修饰技术选自由以下组成的组:多核苷酸指导的内切核酸酶、crispr-cas内切核酸酶、碱基编辑脱氨酶、锌指核酸酶、转录激活子样效应子核酸酶(talen)、工程化位点特异性大范围核酸酶、或argonaute。在某些实施例中,可以通过在所需改变附近的基因组中的确定位置诱导双链断裂(dsb)或单链断裂来促进基因组修饰。可以使用任何可用的dsb诱导剂诱导dsb,所述诱导剂包括但不限于,talen、大范围核酸酶、锌指核酸酶、cas9-grna系统(基于细菌性crispr-cas系统)、指导的cpf1内切核酸酶系统等。在一些实施例中,可以将dsb的引入与多核苷酸修饰模板的引入组合。本文公开的多核苷酸或重组dna构建体可用于任何植物物种(包括但不限于单子叶植物和双子叶植物)的转化。另外,本文所述的遗传修饰可用于修饰任何植物物种(包括但不限于单子叶植物和双子叶植物)。在特定实施例中,本公开的植物是作物植物(例如,玉米、苜蓿、向日葵、芸苔属植物、大豆、棉花、红花、花生、高粱、小麦、粟、烟草等)。在其他实施例中,玉米和大豆植物是最佳的,并且在又其他的实施例中,玉米植物是最佳的。其他目的植物包括例如提供目的种子的谷物类植物、油料种子植物和豆科植物。目的种子包括例如谷物种子,诸如玉米、小麦、大麦、稻、高粱、黑麦等。油料种子植物包括例如棉花、大豆、红花、向日葵、芸苔属植物、玉蜀黍、苜蓿、棕榈、椰子等。豆科植物包括豆类和豌豆。豆类包括瓜耳豆、槐豆、胡芦巴、大豆、四季豆、豇豆、绿豆、利马豆、蚕豆、小扁豆、鹰嘴豆。例如,在某些实施例中,提供了玉蜀黍植物,其在其基因组中包含重组dna构建体,所述重组dna构建体包含编码多肽的多核苷酸,所述多肽包含与seqidno:1-4中的任一个具有至少80%同一性的氨基酸序列。在某些实施例中,所述多肽包含与seqidno:1-4中的任一个的氨基酸序列具有至少80%同一性的氨基酸序列。在某些实施例中,所述多肽包含与seqidno:1-4中的任一个的氨基酸序列具有至少80%同一性的氨基酸序列。在另一个实施例中,提供了玉蜀黍植物,其在基因组基因座处包含遗传修饰,所述基因组基因座编码多肽,所述多肽包含与seqidno:1-4中的任一个的氨基酸序列具有至少80%同一性的氨基酸序列。在某些实施例中,所述多肽包含与seqidno:1-4中的任一个的氨基酸序列具有至少80%同一性的氨基酸序列。在某些实施例中,所述多肽包含与seqidno:1-4中的任一个的氨基酸序列具有至少80%同一性的氨基酸序列。d.堆叠其他目的性状在一些实施例中,本文公开的多核苷酸被工程化为分子堆叠物。因此,本文公开的各种宿主细胞、植物、植物细胞、植物部分、种子、和/或谷物可进一步包含一种或多种目的性状。在某些实施例中,宿主细胞、植物、植物部分、植物细胞、种子、和/或谷物与目的多核苷酸序列的任何组合堆叠,以产生具有所需性状的组合的植物。如本文所使用,术语“堆叠”是指具有存在于同一目的植物或生物体中的多种性状。例如,“堆叠性状”可包含其中序列在物理上彼此相邻的分子堆叠物。如本文所使用的性状是指源自特定序列或序列组群的表型。在一个实施例中,所述分子堆叠物包含赋予对草甘膦的耐受性的至少一种多核苷酸。赋予对草甘膦的耐受性的多核苷酸是本领域已知的。在某些实施例中,所述分子堆叠物包含赋予对草甘膦的耐受性的至少一种多核苷酸和赋予对第二除草剂的耐受性的至少一种额外的多核苷酸。在某些实施例中,具有本发明的多核苷酸序列的植物、植物细胞、种子、和/或谷物可与赋予对以下的耐受性的一个或多个序列堆叠:als抑制剂;hppd抑制剂;2,4-d;其他苯氧基生长素除草剂;芳氧基苯氧基丙酸除草剂;麦草畏;草铵膦除草剂;靶向原卟啉原氧化酶(也称为“原卟啉原氧化酶抑制剂”)的除草剂。具有本发明的多核苷酸序列的植物、植物细胞、植物部分、种子、和/或谷物也可与至少一个其他性状组合,以产生进一步包含多种所需性状组合的植物。例如,具有本发明的多核苷酸序列的植物、植物细胞、植物部分、种子、和/或谷物可以与编码具有杀有害生物活性和/或杀昆虫活性的多肽的多核苷酸堆叠,或具有本发明的多核苷酸序列的植物、植物细胞、植物部分、种子、和/或谷物可以与植物抗病性基因组合。这些堆叠的组合可以通过如下任何方法产生,该方法包括但不限于,通过任何常规的方法学进行植物育种、或遗传转化。如果通过遗传转化植物来堆叠序列,则目的多核苷酸序列可以在任意时间并以任意顺序组合。可以用共转化方案将所述性状与转化盒的任何组合所提供的目的多核苷酸一起引入。例如,若引入两个序列,则这两个序列可包含在分开的转化盒(反式)或包含在同一个转化盒(顺式)中。所述序列的表达可以通过相同的启动子或通过不同的启动子驱动。在某些情况下,可能需要引入将抑制目的多核苷酸的表达的转化盒。这可以与其他抑制盒或过度表达盒的任何组合进行组合以在所述植物中产生所需性状组合。进一步应当认识到,可以使用位点特异性重组系统在所需的基因组位置堆叠多核苷酸序列。参见例如,wo99/25821、wo99/25854、wo99/25840、wo99/25855、以及wo99/25853,将其全部通过引用并入本文。可以使用具有本文公开的本发明的多核苷酸序列的任何植物来制造食品或饲料产品。此类方法包括获得包含多核苷酸序列的植物、外植体、种子、植物细胞、或细胞,并且加工所述植物、外植体、种子、植物细胞、或细胞以生产食品或饲料产品。ii.使用方法a.在植物中增加产量和/或增加多核苷酸活性的方法提供了用于增加植物产量、改变植物开花时间、和/或增加植物中的本文公开的一种或多种多核苷酸活性的方法,所述方法包括将重组dna构建体引入植物、植物细胞、植物部分、种子和/或谷物中,借此使多肽在植物中表达,所述重组dna构建体包含本文所述的任何本发明的多核苷酸。还提供了用于增加植物产量、改变植物开花时间、和/或增加植物中活性的方法,所述方法包括在植物的基因组基因座处引入遗传修饰,所述基因组基因座编码多肽,所述多肽包含与seqidno:1-4中的任一个所列出的氨基酸序列具有至少80%-99%或100%同一性的氨基酸序列。用于在本发明的方法中使用的植物可以是本文所述的任何植物物种。在某些实施例中,所述植物是谷物类植物、油料种子植物和豆科植物。在某些实施例中,所述植物是谷物类植物,诸如玉蜀黍。如本文使用的,“产量”是指收获的农业产量/单位土地,并且可包括提及收获时农作物的蒲式耳/英亩,如针对籽粒水分进行了调整(例如,玉蜀黍典型地为15%)。在籽粒收获时测量籽粒水分。确定调整后的籽粒测试重量为重量(磅)/蒲式耳,在收获时针对籽粒水分水平进行了调整。在某些实施例中,在最佳生长条件下生长的植物中测量产量。如本文使用的,“最佳条件”是指在水分充足或无干旱的条件下生长的植物。在某些实施例中,基于实验中野生型对照植物的产量确定最佳生长条件。如本文使用的,当野生型植物提供至少75%的预测籽粒产量时,植物被认为是在最佳条件下生长。如本文使用的,“改变开花时间”是指植物开花所需的天数或生长热单位的改变。在某些实施例中,在多肽表达增加后,植物的开花时间延迟。还考虑了在多肽表达降低后,开花时间减少的实施例(即,植物开花所需的更少的天数或生长热单位)。如本文使用的,与合适的对照相比,光合作用活性的增加是指蛋白质功能活性的任何可检测的增加。功能活性可以是本文公开的一种或多种多肽的任何已知的生物特性,并且包括例如蛋白质复合物的形成增加、生化途径的调节、和/或增加的籽粒产量。可以使用各种方法来将目的序列引入植物、植物部分、植物细胞、种子、和/或谷物。“引入”旨在意指以这样一种方式将本发明的多核苷酸或所得多肽提供给植物、植物细胞、种子、和/或谷物,使得所述序列得以进入所述植物的细胞内部。本公开的方法不取决于将序列引入植物、植物细胞、种子、和/或谷物的具体方法,只要所述多核苷酸或多肽进入植物的至少一个细胞的内部即可。“稳定转化”旨在表示被引入植物中的多核苷酸整合到目的植物的基因组中,并且能够被其子代遗传。“瞬时转化”旨在表示将多核苷酸引入目的植物中并且不整合到所述植物或生物体的基因组中,或者将多肽引入植物或生物体中。转化方案连同用于将多肽或多核苷酸序列引入植物中的方案可以取决于被靶向转化的植物或植物细胞的类型(即,单子叶植物或双子叶植物)而变化。在具体实施例中,可以使用各种瞬时转化方法将本文公开的多核苷酸序列提供给植物。这类瞬时转化法包括但不限于将编码的多肽直接引入植物中。此类方法包括例如显微注射或粒子轰击。参见,例如,crossway等人,(1986)molgen.genet.[分子遗传学和普通遗传学]202:179-185;nomura等人,(1986)plantsci.[植物科学]44:53-58;hepler等人(1994)proc.natl.acad.sci.[美国科学院院报]91:2176-2180以及hush等人(1994)thejournalofcellscience[细胞科学杂志]107:775-784,所有这些文献都通过引用并入本文。在其他实施例中,可以通过使植物与病毒或病毒核酸接触将本文公开的本发明的目的多核苷酸引入植物中。通常,这类方法涉及将本公开的核苷酸构建体并入dna或rna分子内。应当认识到,本发明的多核苷酸序列最初可以被合成为病毒多蛋白的一部分,然后可以通过体内或体外蛋白水解而被加工,以产生所需的重组蛋白。此外,应当认识到,本文公开的启动子也涵盖用于通过病毒rna聚合酶进行转录的启动子。涉及病毒dna或rna分子、用于将多核苷酸引入植物中并表达其中所编码的蛋白质的方法是本领域已知的。参见,例如,美国专利号5,889,191、5,889,190、5,866,785、5,589,367、5,316,931,以及porta等人(1996)molecularbiotechnology[分子生物技术]5:209-221;通过引用并入本文。可以使用各种方法来将编码和多肽的基因组基因座上的遗传修饰引入植物、植物部分、植物细胞、种子、和/或谷物。在某些实施例中,通过基因组修饰技术进行靶向dna修饰,所述基因组修饰技术选自由以下组成的组:多核苷酸指导的内切核酸酶、crispr-cas内切核酸酶、碱基编辑脱氨酶、锌指核酸酶、转录激活子样效应子核酸酶(talen)、工程化位点特异性大范围核酸酶、或argonaute。在一些实施例中,可以通过在所需改变附近的基因组中的确定位置诱导双链断裂(dsb)或单链断裂来促进基因组修饰。可以使用任何可用的dsb诱导剂诱导dsb,所述诱导剂包括但不限于,talen、大范围核酸酶、锌指核酸酶、cas9-grna系统(基于细菌性crispr-cas系统)、指导cpf1内切核酸酶系统等。在一些实施例中,可以将dsb的引入与多核苷酸修饰模板的引入组合。可以通过本领域已知的任何方法将多核苷酸修饰模板引入细胞中,所述方法例如但不限于瞬时引入方法、转染、电穿孔、显微注射、粒子介导的递送、局部施用、晶须介导的递送、经由细胞穿透肽的递送或介孔二氧化硅纳米粒子(msn)介导的直接递送。可以将多核苷酸修饰模板作为单链多核苷酸分子、双链多核苷酸分子或作为环状dna(载体dna)的一部分引入细胞中。所述多核苷酸修饰模板还可以与指导rna和/或cas内切核酸酶进行系链。系链的dna可以允许共定位靶标和模板dna,可用于基因组编辑和靶向的基因组调控,并且还可以用于靶向有丝分裂后期细胞,在这些细胞中内源性hr机制的功能预计会大大降低(mali等人2013naturemethods[自然方法]第10卷:957-963)。所述多核苷酸修饰模板可以瞬时地存在于细胞中,或可以经由病毒复制子引入。“经修饰的核苷酸”或“经编辑的核苷酸”是指当与其非修饰的核苷酸序列相比时,包含至少一个改变的目的核苷酸序列。此类“改变”包括,例如:(i)至少一个核苷酸的替代、(ii)至少一个核苷酸的缺失、(iii)至少一个核苷酸的插入、或(iv)(i)-(iii)的任何组合。术语“多核苷酸修饰模板”包括,当与待编辑的核苷酸序列相比时,包含至少一个核苷酸修饰的多核苷酸。核苷酸修饰可以是至少一个核苷酸取代、添加或缺失。任选地,多核苷酸修饰模板可以进一步包含位于至少一个核苷酸修饰侧翼的同源核苷酸序列,其中侧翼同源核苷酸序列为待编辑的希望的核苷酸序列提供了充足同源性。编辑组合有dsb和修饰模板的基因组序列的过程通常包括:向宿主细胞提供dsb诱导剂或编码dsb诱导剂的核酸(识别染色体序列中的靶序列并且能够诱导基因组序列中的dsb),和与待编辑的核苷酸序列相比时包含至少一个核苷酸变化的至少一个多核苷酸修饰模板。多核苷酸修饰模板还可以包含侧翼于所述至少一个核苷酸变化的核苷酸序列,其中侧翼序列与侧翼于dsb的染色体区域基本同源。内切核酸酶可以通过本领域已知的任何方法提供给细胞,所述方法例如但不限于瞬时引入方法、转染、显微注射、和/或局部施用、或间接经由重组构建体。内切核酸酶可以作为蛋白质或作为指导多核苷酸复合物直接提供给细胞或经由重组构建体间接提供。使用本领域已知的任何方法,可以瞬时地将内切核酸酶引入细胞中,或可以将内切核酸酶并入宿主细胞的基因组中。在crispr-cas系统的情况下,如2016年5月12日公开的wo2016073433中所述的,可以用细胞穿透肽(cpp)促进内切核酸酶和/或指导多核苷酸摄入进细胞。除通过双链断裂技术进行修饰之外,无此类双链断裂的一种或多种碱基的修饰使用碱基编辑技术实现,参见例如,gaudelli等人,(2017)programmablebaseeditingofa*ttog*cingenomicdnawithoutdnacleavage.[在无dna切割时基因组dna中a*t至g*c的可编程碱基编辑]nature[自然]551(7681):464-471;komor等人,(2016)programmableeditingofatargetbaseingenomicdnawithoutdouble-strandeddnacleavage[在无双链dna切割时基因组dna中靶碱基的可编程编辑],nature[自然]533(7603):420-4。这些融合物含有dcas9或cas9切口酶和合适的脱氨酶,并且它们例如可以将胞嘧啶转化为尿嘧啶而不引起靶dna的双链断裂。然后尿嘧啶通过dna复制或修复被转化为胸腺嘧啶。具有目的灵活性和特异性的改善的碱基编辑器被用于编辑内源基因座以产生靶标变异并且提高籽粒产量。类似地,腺嘌呤碱基编辑器能使腺嘌呤向肌苷变化,然后通过修复或复制将其转化为鸟嘌呤。因此,使用适当的位点特异性碱基编辑器在一个多个位置上进行靶向性基因改变,即,c·g至t·a转化和a·t至g·c转化。在一个实施例中,碱基编辑是基因组编辑方法,其可在靶基因组基因座上将一个碱基对直接转化为另一个碱基对,而无需双链dna断裂(dsb)、同源定向修复(hdr)过程、或外部供体dna模板。在一个实施例中,碱基编辑器包括(i)催化受损的crispr-cas9突变体,其是突变的,这样使得其核酸酶结构域中的一个无法产生dsb;(ii)单链特异性胞苷/腺嘌呤脱氨酶,其可在通过cas9产生的单链dna气泡中的适当核苷酸窗口内将c转化成u或将a转化成g;(iii)尿嘧啶糖基化酶抑制剂(ugi),其阻止尿嘧啶切除以及降低碱基编辑效率和产物纯度的下游过程;以及(iv)切口酶活性以切割未编辑的dna链,然后细胞dna修复过程以替代含g的dna链。如本文使用的,“基因组区域”是存在于靶位点任一侧上的细胞的基因组中的染色体的区段,或者可替代地,还包含靶位点的一部分。基因组区域可以包含至少5-10、5-15、5-20、5-25、5-30、5-35、5-40、5-45、5-50、5-55、5-60、5-65、5-70、5-75、5-80、5-85、5-90、5-95、5-100、5-200、5-300、5-400、5-500、5-600、5-700、5-800、5-900、5-1000、5-1100、5-1200、5-1300、5-1400、5-1500、5-1600、5-1700、5-1800、5-1900、5-2000、5-2100、5-2200、5-2300、5-2400、5-2500、5-2600、5-2700、5-2800。5-2900、5-3000、5-3100或更多个碱基,这样使得基因组区域具有足够的同源性以与相应的同源区域进行同源重组。tal效应子核酸酶(talen)是一类序列特异性核酸酶,其可以被用于在植物或其他生物体的基因组中特异性靶序列处造成双链断裂。(miller等人(2011)naturebiotechnology[自然生物技术]29:143-148)。内切核酸酶是在多核苷酸链内切割磷酸二酯键的酶。内切核酸酶包括限制性内切核酸酶,其在特异性位点处切割dna而不损坏碱基;并且包括大范围核酸酶,也称为归巢内切核酸酶(he酶),其相似于限制性内切核酸酶,在特异性识别位点处结合并且切割,然而对于大范围核酸酶,识别位点典型地更长,约18bp或更长(于2012年3月22日提交的专利申请pct/us12/30061)。基于保守序列基序,大范围核酸酶已被分为四个家族。这些基序参与金属离子的配位和磷酸二酯键的水解。he酶的显著之处在于它们的长识别位点,并且还在于耐受其dna底物中的一些序列多态性。对于大范围核酸酶的命名约定相似于对其他限制性内切核酸酶的约定。大范围核酸酶还分别表征为针对由独立的orf、内含子、和内含肽编码的酶的前缀f-、i-、或pi-。在重组过程中的一个步骤涉及在识别位点处或在所述识别位点附近的多核苷酸切割。可以将切割活性用于产生双链断裂。对于位点特异性重组酶和它们的识别位点的综述,参见,sauer(1994)curropbiotechnol[生物技术新见]5:521-7;以及sadowski(1993)faseb[美国实验生物学学会联合会杂志]7:760-7。在一些实例中,重组酶来自整合酶(integrase)或解离酶(resolvase)家族。锌指核酸酶(zfn)是由锌指dna结合结构域和双链-断裂-诱导剂结构域组成的工程化双链断裂诱导剂。识别位点特异性由锌指结构域赋予,所述锌指结构域典型地包含两个、三个、或四个锌指,例如具有c2h2结构,然而其他锌指结构是已知的并且已经被工程化。锌指结构域适于设计特异性结合所选择的多核苷酸识别序列的多肽。zfn包括连接至非特异性内切核酸酶结构域(例如来自iis型内切核酸酶例如foki的核酸酶结构域)的工程化dna结合锌指结构域。额外的功能性可以融合到锌指结合结构域中,所述额外的功能性包括转录激活子结构域、转录阻遏物结构域、和甲基化酶。在一些实例中,核酸酶结构域的二聚化是切割活性所需的。每个锌指在靶dna中识别三个连续的碱基对。例如,3指结构域识别9个连续核苷酸的序列,由于所述核酸酶的二聚化需要,因此两组锌指三联体用于结合18个核苷酸的识别序列。例如在2015年3月19日公开的美国专利申请us2015-0082478a1、2015年2月26日公开的wo2015/026886a1、2016年1月14日公开的wo2016007347、以及2016年2月18日公开的wo201625131(将其全部通过引用并入本文)中已经描述了使用dsb诱导剂(例如cas9-grna复合物)进行的基因组编辑。指导多核苷酸/cas内切核酸酶复合物可以切割dna靶序列的一条或两条链。可以切割dna靶序列的两条链的指导多核苷酸/cas内切核酸酶复合物典型地包含具有处于功能状态的所有其内切核酸酶结构域的cas蛋白(例如野生型内切核酸酶结构域或其变体在每个内切核酸酶结构域中保留一些或全部活性)。适用于本文使用的cas9切口酶的非限制性实例公开于美国专利申请公开号2014/0189896中,将其通过引用并入本文。其他cas内切核酸酶系统已经在2016年5月12日提交的pct专利申请pct/us16/32073和2016年5月12日提交的pct/us16/32028中描述,将这两个申请通过引用并入本文中。术语“靶位点”、“靶序列”、“靶位点序列”、“靶dna”、“靶基因座”、“基因组靶位点”、“基因组靶序列”、“基因组靶基因座”和“前间区”在本文中可互换地使用,并且意指多核苷酸序列,例如,但不限于,在细胞的染色体、附加体,或基因组中的任何其他dna分子(包括染色体dna、叶绿体dna、线粒体dna、质粒dna)上的核苷酸序列,在所述序列处指导多核苷酸/cas内切核酸酶复合物可以进行识别、结合并任选地产生切口或进行切割。靶位点可以是细胞的基因组中的内源位点,或者可替代地,靶位点对于该细胞可以是异源的并且从而不是天然存在于细胞的基因组中,或者与在自然界发生的位置相比,可以在异质基因组位置中找到靶位点。如本文使用的,术语“内源性靶序列”和“天然靶序列”在本文中可互换使用,是指对细胞基因组来说是内源的或天然的、并且位于细胞的基因组中该靶序列的内源或天然位置处的靶序列。细胞包括但不限于人、非人、动物、细菌、真菌、昆虫、酵母、非常规酵母和植物细胞,以及通过本文所述的方法产生的植物和种子。“人工靶位点”或“人工靶序列”在本文中可互换使用,并且是指已经引入细胞的基因组中的靶序列。这种人工靶序列可以在序列上与细胞的基因组中的内源或天然靶序列相同,但是位于细胞的基因组中的不同位置(即,非内源的或非天然的位置)处。“改变的靶位点”、“改变的靶序列”、“修饰的靶位点”、“修饰的靶序列”在本文中可互换使用,并且是指如本文公开的靶序列,当与非改变的靶序列相比时,所述靶序列包含至少一个改变。此类“改变”包括,例如:(i)至少一个核苷酸的替代、(ii)至少一个核苷酸的缺失、(iii)至少一个核苷酸的插入、或(iv)(i)-(iii)的任何组合。用于“修饰靶位点”和“改变靶位点”的方法在本文中可互换使用,并且是指用于产生改变的靶位点的方法。靶dna序列(靶位点)的长度可以变化,并且包括例如为至少12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30或更多个核苷酸长度的靶位点。还有可能靶位点可以是回文的,即,一条链上的序列与在互补链上以相反方向的读取相同。切口/切割位点可以在靶序列内,或者切口/切割位点可以在靶序列之外。在另一种变异中,切割可以发生在彼此正好相对的核苷酸位置处,以产生平端切割,或者在其他情况下,切口可以交错以产生单链突出端,也称为“粘性端”,其可以是5′突出端抑或3′突出端。还可以使用基因组靶位点的活性变体。此类活性变体可以包含与给定靶位点至少65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更高的序列同一性,其中所述活性变体保留生物活性,因此能够被cas内切核酸酶识别和切割。测量由内切核酸酶引起的靶位点的单链或双链断裂的测定是本领域已知的,并且通常测量试剂在含有识别位点的dna底物上的总体活性和特异性。本文中的“前间区序列邻近基序”(pam)指与由本文所述的指导多核苷酸/cas内切核酸酶系统识别的(靶向的)靶序列(前间区序列)邻近的短核苷酸序列。如果靶dna序列不在pam序列后面,则cas内切核酸酶可能无法成功识别所述靶dna序列。本文中的pam的序列和长度可以取决于所使用的cas蛋白或cas蛋白复合物而不同。所述pam序列可以是任何长度,但典型地是1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个核苷酸长度。术语“靶向”、“基因靶向”和“dna靶向”在本文中可互换地使用。本文中的dna靶向可能是在特异性的dna序列(例如细胞的染色体或质粒)中特异性引入敲除、编辑、或敲入。通常,本文中可以通过在具有与合适的多核苷酸组分缔合的内切核酸酶的细胞中的特异性dna序列处切割一条或两条链来进行dna靶向。这种dna切割,如果是双链断裂(dsb),可以促进nhej或hdr过程,这可能导致靶位点处的修饰。本文的靶向方法能以例如在该方法中靶向两个或更多个dna靶位点的这样的方式进行。这种方法可以任选地被表征为多重方法。在某些实施例中,可以同时靶向两个、三个、四个、五个、六个、七个、八个、九个、十个或更多个靶位点。多路复用方法典型地通过本文的靶向方法进行,其中提供了多个不同的rna组分,每一个被设计成将多核苷酸/cas内切核酸酶复合物引导到唯一的dna靶位点。术语“敲除”、“基因敲除”和“遗传敲除”在本文中可互换使用。敲除表示已经通过用cas蛋白进行靶向使得细胞的dna序列部分或完全无效;例如,这种dna序列在敲除之前可能已编码氨基酸序列,或可能已具有调节功能(例如启动子)。可以通过插入缺失(通过nhej在靶dna序列中插入或缺失核苷酸碱基),或通过特异性去除在靶向位点处或其附近处降低或完全破坏序列功能的序列来产生敲除。指导多核苷酸/cas内切核酸酶系统可以与共同递送的多核苷酸修饰模板组合使用以允许编辑(修饰)目的基因组核苷酸序列。(还参见于2015年3月19日公开的美国专利申请us2015-0082478a1和2015年2月26日公开的wo2015/026886a1,两者均通过引用以其全文特此并入)。术语“敲入”、“基因敲入”、“基因插入”和“遗传敲入”在本文中可互换使用。敲入代表通过用cas蛋白靶向在细胞中的特异性dna序列处进行的dna序列的替代或插入(通过hr,其中还使用合适的供体dna多核苷酸)。敲入的实例是异源氨基酸编码序列在基因的编码区中的特异性插入,或转录调节元件在遗传基因座中的特异性插入。以下是本发明一些方面的具体实施例的实例。提供这些实例仅出于说明目的而无意以任何方式限制本发明的范围。实例1通过启动子插入或替代来表达内源性转录因子该实例证实了内源性玉蜀黍mads转录因子zmm28(seqidno:1)的表达是由异源启动子元件调控的。在一个实施例中,来自玉蜀黍的异源zmgos2启动子被用于替代基因组基因座的内源性调节区,所述基因组基因座编码seqidno:1多肽或与seqidno:1基本上相似的序列。通过靶位点特异性内源性重组替代异源调节元件(例如,启动子和内含子)。例如,设计指导rna以靶向基因组基因座的上游调节区,所述基因组基因座驱动编码seqidno:1的多核苷酸的表达。示意图提供于图1中。在一个实施例中,cas9基因组编辑技术被用于替代基因组基因座的内源性启动子区以增加一种或多种农艺参数,所述基因组基因座编码具有启动子的seqidno:1。对于一种此类方法,中等组成型启动子启动子(zm-gos2)被用于替代内源性启动子。在另一个实施例中,一种不同的中等表达组成型启动子os-actin被用于替代内源性启动子。因此,通过利用靶向基因组编辑方法调控编码seqidno:1的多核苷酸的表达,可评估农艺参数。本文总结了筛选针对seqidno:1编码基因的cas9基因编辑的t0事件和随后的t1植物的方法。这些方法包括启动子插入、两个不同启动子替代、以及通过启动子替代尝试产生的缺失(cr4-cr11)敲除。通过插入质粒、cas9质粒、一个或多个grna质粒、和三个辅助质粒的共轰击,使用粒子枪轰击来产生t0植物。从t0植物中分离基因组dna并且进行质粒的拷贝数分析。进行hr1和hr2连接pcr以选择t0进行进一步评估。随后,进行了更详细的筛选,其中进行了长片段(long-range)pcr(hr1和hr2pcr)以覆盖预期插入区域的广阔区域以及在每侧的一些锚定天然侧翼区。基于与支持实验室的拷贝数信息组合的hr1和hr2pcr产品大小,选择事件进行胚拯救(以缩短两代之间的时间)以延续到t1代。将t1植物放平后,在幼龄期对其取样以进行基因组dna分离,并且再次进行拷贝数分析以检查所有质粒,并且然后进行hr1和hr2长片段pcr来检查正确大小。使用组合的信息,选择五株至十株植物/事件以进行移植。来自这些选择的t1植物的hr1和hr2pcr被克隆和测序。为了预期的修饰,还从植物中收集组织以提交sbs和另一个支持实验室以进行基因分型和拷贝数测定。在t1上进行hr1/hr2片段测序和sbs分析后,对于启动子插入或启动子替代,未鉴定具有完美替代的事件。几个事件具有删除的cr4-cr11区并且回到sbs干净状态。此外,鉴定出一个替代的无效等位基因,所述无效等位基因由引起cr11位点移码的一个碱基对插入产生。表2:用于grna设计的基因组编辑方法考虑了几种去除和替代内源性启动子区的设计,并且这些设计中的一些示于表2中。例如,设计1包括:zm-zmm28-cr4//zm-zmm28-cr10(981bp);zm-gos2pro:ubi1zm内含子1(1912bp),以及设计2包括zm-zmm28-cr24//zm-zmm28-cr1(1066bp);zm-gos2pro:ubi1zm内含子1(1914bp),如图1所示。在另一个实施例中,zm-eifc启动子+adh1内含子被插入编码seqidno:1的多核苷酸的基因座中。例如,如图2所示,用于cas-内切核酸酶介导的双链断裂的cr1和cr10识别区被用于将zm-zmm28-cr1-插入物zm-eif5cpro:adh1内含子插入天然zm-zmm285’utr(2112bp)中,并且在另一种方法中,将zm-zmm28-cr10-插入物zm-eif5cpro:adh1内含子插入天然zm-zmm285’utr(2112bp)中。用于启动子替代或插入的其他实例包括ubi1zmpro:adh1内含子1作为替代物,zm-h1bpro(1.2kb)(mod1):adh1内含子1作为替代物,以及zm-h1bpro(1.2kb)(mod1):adh1内含子1作为插入物。因此,本实例证明异源启动子可被插入和/或被编码seqidno:1的基因组基因座的内源性启动子区替代。实例2通过插入和/或产生异源表达调控元件来表达内源性转录因子通过玉蜀黍中的一种或多种异源增强子元件调控内源性玉蜀黍mads28的表达增强了籽粒产量。zmm28基因的上游启动子和/或非翻译区示于图4中。增强子元件,诸如wo2018183878a1(通过引用并入本文)的表1中描述的那些。合适的表达调控元件(eme)包括例如来自wo2018183878a1的表1的seqidno:1-10的一个或多个拷贝(1x-4x)。基于含有zmm28基因的基因组基因座的上游调节区,可将eme序列作为离散的异源序列插入或可对调节区进行基因组编辑(使用模板指导的双链断裂修复或通过碱基编辑脱氨酶)以产生调节zmm28表达水平的异源增强子序列。通过各种不同方法完成eme的掺入,所述方法包括一个或多个eme拷贝的靶向插入和/或与在zmm28的内源基因座的启动子区中产生一个或多个eme拷贝组合。例如,在转录起始位点(tss)上游约10-100bp处,可通过同源重组或通过碱基编辑或模板驱动的修复来插入eme的一个或多个拷贝。在zmm28基因座的合适区域包含eme导致编码seqidno:1或2的多核苷酸的表达增加和扩展。表3:异源玉蜀黍来源的增强子元件在调控原生质体中编码seqidno:1的基因组基因座的调节区中的基因表达方面的作用。如上表所示,zmm28基因的启动子区中源自玉蜀黍的异源表达调控元件(例如,seqidno:23)的存在增加了测试系统中的表达。例如,当eme存在于约-21bp和-92bp的区域中时(如从tata测量),zm-as2eme的两个拷贝增加了表达水平。此外,当存在于来自tata的-21bp区域中时,eme的一个拷贝将在玉蜀黍原生质体系统中的基因表达(标记基因)增加至比当存在于来自tata盒的约-92bp处时的相同eme更高的水平。seqidno:24-28中显示了zmm28基因的启动子区内的eme的各种实施例。通过定点基因组编辑-例如cas内切核酸酶和/或使用一种或多种脱氨酶进行的碱基编辑,在zmm28基因的内源基因组区域中容易进行这些改变。使用通过在编码seqidno:1的基因组基因座中的模板指导的双链断裂修复进行基因组编辑,成功地产生了玉蜀黍植物。鉴定玉蜀黍植物具有插入tata的-21处的22bp的玉蜀黍eme的一个拷贝(如wo2018183878a1中所述的seqidno:3,将该文献通过引用并入本文),而鉴定的另一种玉蜀黍植物在天然启动子中具有7bp改变以产生在tata上游21个核苷酸处的16bp的玉蜀黍eme的一个拷贝(如wo2018183878a1中所述的seqidno:4)。因此,将eme的一个拷贝添加至这两种玉蜀黍植物的天然启动子中。然而,在一种情况下,将额外的序列添加至天然启动子,而在另一种植物中,改变天然启动子序列而不改变启动子的该区域的大小。当与仅具有天然调节序列的野生型植物相比,其中通过改变天然序列而产生eme序列的玉蜀黍植物具有2.2至2.7倍的mrna(编码seqidno:1)表达增加(图5)。在vt发育阶段,从每株植物的最上层展开的叶中取三个或四个样品,并且评估rna表达。植物1和植物2是独立地衍生的植物,它们通过在zmm28启动子区域中插入eme的一个拷贝而具有所需变化。野生型(wt)植物具有比植物2的后代(列为2a-2e)高1.4至2.1倍的表达。表现出类似wt的表达水平的一种植物是植物1的后代。植物1a对zmm28基因座内的序列具有不希望的改变并且显示比野生型(wt)更低的rna表达。植物2的后代(列为2a-2g)具有产生eme的一个拷贝的所需编辑,并且与wt相比,显示rna表达增加2.2至2.7倍。在zmm28基因座启动子的天然调节区中插入有eme序列的玉蜀黍植物不导致内源基因的mrna表达显著增加。具有该希望的改变的一株植物的后代(图6中的植物2a-2e)显示rna表达的减少,而具有所需编辑的第二株独立植物的后代(图6中的植物1a)显示的rna表达水平与在野生型植物中检测到的水平相似(图6)。另一株玉蜀黍植物具有在tata序列的-53处插入的27bp序列的两个拷贝。该27bp序列包括22bp的eme序列(如wo2018183878a1中所述的seqidno:3)。当与无eme的天然启动子相比时,插入zmm28启动子的该eme序列的2个拷贝的瞬时数据显示标准化的荧光表达增加4.88倍。具有如先前所述的在tata序列的-53处插入的27bp玉蜀黍序列的两个拷贝的所需编辑的玉蜀黍植物后代是自花授粉的,产生在zmm28基因座处的该改变的纯合、杂合、或无效的植物的分离群体。对幼苗进行采样以进行基因组dna分离,并且然后进行拷贝数分析以确定每个植物的合子型。在v3发育阶段的玉蜀黍叶片组织中,当与对照/空白中的zmm28mrna表达水平相比时,对于针对2xeme插入为纯合或杂合的玉蜀黍植物,确定zmm28rna表达显著增加(表4)。在不同的合子型中,zmm28rna表达有显著变化,其中在针对2xeme插入为纯合的植物中检测到最高的zmm28rna表达。表4:zmm28启动子中的玉蜀黍来源的2xeme插入在调控植物分离群体中的rna基因表达中的作用,所述植物对2xeme是纯合的、对2xeme是杂合的、或在zmm28基因座处是空白的(无eme拷贝)。还评估了相同遗传背景中的野生型(wt)植物的天然zmm28rna表达水平。合子型平均值标准误差杂合2.7389910.050522纯合4.7231870.106618空白0.118960.037889wt0.015860.001897因此,该实例证明,在编码seqidno:1的内源性基因或其等位基因变体的表达的这一方面中,工程改造到基因组的内源性位置的异源表达元件增加了玉蜀黍mads盒蛋白的表达。预计玉蜀黍中所述内源性mads盒蛋白的这种表达增加将表现出一种或多种农艺特征(诸如增加的籽粒结实率、重量或数目、籽粒产量、以及其他籽粒产量相关的次要特征)的增加或改善。实例3通过内源性启动子和/或内含子操作来表达内源性转录因子该实例证实了这一分析:通过内含子操作增加玉蜀黍中内源性mads盒蛋白表达。如图1-3中任一个所示,编码seqidno:1的基因组基因座具有内含子。本文提供组合物和方法以编辑、删除、替代zmm28的一个或多个内源性内含子。例如,zmm28的内含子1较大并且可含有(负)调节元件,特别是关于空间调节的调节元件。类似地,内源性zmm28启动子区被删除以提高表达水平和/或模式。表5a中示出一些启动子缺失,表5b中示出一些内含子缺失。表5a:启动子缺失。表5b:内含子缺失如表5a和5b所示,内源zmm28基因基因座的几个启动子和/或内含子缺失可调控内源性基因表达。不同的启动子和/或调节元件修饰可导致例如表达强度(量级)和/或特异性(例如,组织优选的)的增加,这种增加可被进一步评估以用于产量增加目的并且在各种应激环境(诸如干旱和/或低氮生长条件)下进行测试。实例4调节基因表达和/或多肽活性的多态性基于本文提供的指导和教导,通过定点诱变或筛选种质中的变异,该实例证明了玉蜀黍中编码mads盒蛋白的内源性基因组基因座中的遗传多态性。如本文所示,seqidno:1表示的多肽具有几个结构域,所述结构域包括蛋白质-蛋白质相互作用结构域和蛋白质-dna相互作用结构域(例如,转录因子)。编码seqidno:1的核苷酸序列中的一个或多个突变或变化可导致蛋白质变体的活性增加或者可以增加产生seqidno:1的转录物的表达水平。例如,zmm28转录因子是mikc蛋白,其含有参与dna结合的n-末端mads结构域(seqidno:1的氨基酸1-61),然后是间插(i)区(seqidno:1的氨基酸62-87)和角蛋白样(k)盒(seqidno:1的氨基酸88-169)(它们二者都参与dna结合和蛋白质-蛋白质相互作用),以及参与活性和三元复合物形成的c-末端结构域(seqidno:1的氨基酸170-251)。由seqidno:1表示mikc结构和相应的zmm28氨基酸序列。本文提供组合物和方法以编辑、删除、替代、或以其他方式对编码seqidno:1-3中的一个或与那些序列中的一个具有至少90%同一性的氨基酸序列的基因组基因座的一个或多个核苷酸或区域或片段进行修饰。这些变化中的一个或多个调控结合和/或其他激活特性,以调节例如玉蜀黍植物细胞中的seqidno:1的相互作用配偶体或seqidno:1的直接靶标。因此,该实例证明,与不具有此类修饰的玉蜀黍植物相比,通过修饰seqidno:1的一个或多个基序、结构域、或氨基酸残基,可增加玉蜀黍籽粒产量。实例5内源性玉蜀黍mads盒转录因子的靶向激活本实例证明,存在几种方法来指导靶向激活玉蜀黍中编码seqidno:1或与所述内源序列具有至少90%同一性的氨基酸序列的内源性基因座的表达。例如,一种此类方法包括工程化失活的cas内切核酸酶,例如与激活结构域(例如,转录因子激活结构域)偶联的dcas9,由此通过指导多核苷酸来指导与激活结构域偶联或以其他方式与激活结构域缔合的dcas9结合编码seqidno:1或其玉蜀黍同源物的内源基因并激活其表达。在另一个实例中,内源性mirna靶标可被编辑,使得mirna在编码seqidno:1多肽的基因组区域中不靶向其同源序列。在另一个实例中,存在于基因组区域中的内源性mirna靶序列可被编辑,使得内源性mirna不再有效地靶向和抑制基因表达。实例6鉴定单倍型和玉蜀黍mads转录因子的玉蜀黍种质变异本实例表明,基于本文提供的教导,通过测序、标记辅助选择、全基因组预测、或任何其他类型的基因分型方法鉴定了编码seqidno:1的基因组基因座的基因组区域中的遗传变异。例如,对优良玉蜀黍自交系和/或杂交系进行基因分型以结合编码seqidno:1或其同源物的基因组序列中的基因型变异来预测产量增加或评估籽粒产量。这通过例如基于可用于设计和/或推断基因型关联知识的序列信息,对编码seqidno:1多肽的基因组区域进行测序或以其他方式进行基因分型来实现。鉴定出表达与seqidno:1相似的多肽的基因座内和周围的基因组区域中的变化,和/或所述变化与一种或多种观察或预测的表型特征(例如产量或生物量)有关。将一种或多种此类等位基因渗入希望的背景玉蜀黍背景中。在另一个实例中,使用seqidno:1的序列信息对任何数量性状基因座(qtl)关联进行精细作图。在种质中的编码seqidno:1或与seqidno:1基本相似的多肽的基因组基因座的这些遗传变异可以通过传统诱变方法(例如ems)引入或可选自天然发生的变异。例如,靶向基因组编辑技术可被用于在编码seqidno:1的基因组基因座中引入变异或特定变化,并且然后传统诱变方法可被用于引入变化,但基于从基因组编辑后的变化中获得的知识进行筛选。除非另有指定,否则权利要求书和说明书中使用的术语如下文阐述定义。必须注意,除非上下文另外清楚地指明,否则如本说明书及所附权利要求书中所用,单数形式“一个/一种(a/an)”和“所述(the)”包括复数指示物。本说明书中的所有出版物和专利申请都指示了本发明所属领域的普通技术人员的水平。将所有出版物和专利申请通过引用并入本文,其程度就像明确且单独指出通过引用每个单独出版物或专利申请一样。除非另外定义,本文所使用的全部技术术语和科学术语具有与本发明所属领域的普通技术人员通常所理解的相同意义。除非另外提及,否则本文采用或考虑的技术是本领域普通技术人员熟知的标准方法。材料、方法和实例仅为说明性的并且不是限制性的。借助前面的描述和随附的附图中给出的教导,这些发明所属领域的技术人员将会想到本发明的许多修改及其他实施例。因此,应当理解,本发明不限于所公开的特定实施例,并且修改和其他实施例旨在包括在所附权利要求的范围内。尽管本文中采用了具体的术语,但这些术语仅在一般性和描述性意义上使用而并非用于限制目的。单位、前缀和符号可以按它们si接受的形式来表示。除非另外指明,否则核酸从左向右以5’至3’方向书写;氨基酸序列都从左向右以氨基到羧基方向书写。数值范围包括限定所述范围的数值在内。本文氨基酸可以通过它们普遍已知的三字母符号或通过iupac-iub生物化学术语委员会推荐的单字母符号来表示。同样,核酸可以通过它们普遍接受的单个字母代码来表示。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1