一种针对脑力疲劳的语音疲劳度检测方法与流程
本发明涉及语音处理识别领域,具体涉及一种针对脑力疲劳的语音疲劳度检测方法。
背景技术:
疲劳是人类机体复杂的生理心理变化过程,属于人体机能自然的自我保护机制,可以分为两种:生理疲劳和心理疲劳,分别指体力或脑力到达一定阶段时出现的正常生理现象。人体疲劳的加深会引起运动能力和工作效率降低、差错事故增多,甚至使人体出现器质性疾病。显然,了解人体疲劳程度对不同人群的身体健康、安全生产、安全工作(例如安全操作、安全驾驶)等方面的影响具有十分重要的作用。
目前,学术界针对疲劳度的检测可以分为主观检测和客观检测这两种方法。主观检测即根据主观调查表、自我记录表以及睡眠习惯调查表和斯坦福睡眠尺度表来检测受试者的疲劳程度。这种通过主观感受进行的疲劳度检测技术带有的主观因素较多,说服力不够。客观检测即利用仪器、设备等工具对人体的心理、生理以及生化方面的参数进行检测,如:(1)检测表面肌电信号、脑电信号及心电信号等生理信号;(2)检测血睾酮、血尿素及血红蛋白等生化指标。这种通过测量生理指标进行的疲劳度检测技术已经比较成熟,但是在实际运用上却美中不足,存在一些不可操作性。首先,疲劳度检测需具有实时性,但是通过生化指标测疲劳,需要一定的化验时间,且带有一定的侵入性;表面肌电信号、脑电信号以及心电信号等接触式的生理参数测量方法,虽免去化验时间,但是其接触性会导致受试者的反感,并且检测设备在一定程度上会限制受试者的活动,甚至影响其运动时的表现,采集到的数据将受到仪器本身的禁锢,从而导致生理信号分析结果的有效性产生偏差;当然,复杂、高精度的设备也需要大量的投资和维护,这并非疲劳度检测的初衷。
因此,基于语音分析的疲劳度检测应运而生。通过语音传递信息是常用的一种信息交换方式,语音中通常携带有一定量的信息,其中也包括疲劳度的相关信息。基于语音信号处理的疲劳度检测可避免上述方法中存在的各种问题。首先,语音检测疲劳只需采集人的声音信号来进行训练识别,语音信号中包含的丰富信息,并且相对于其他生理参数,语音信号更容易被获取得到;简单的录音设备也避免了复杂的仪器接触给受试者带来的巨大心理压力,从一定程度上使得分析结果的客观性得到了提高。综上,语音信号具有实时性高、维护简单、性价比高的优势。
学术界基于语音分析的疲劳度检测研究主要集中在运动疲劳、驾驶疲劳的特定情境下,对单纯脑力疲劳的研究少之又少。因此,如何提供一种针对脑力疲劳的语音疲劳度检测方法,是本领域技术人员所要解决的问题。
技术实现要素:
本发明的发明目的是提供一种针对脑力疲劳的语音疲劳度检测方法。
为达到上述发明目的,本发明采用的技术方案是:一种针对脑力疲劳的语音疲劳度检测方法,包括如下步骤:
步骤一、选取人数相等的男性和女性受试者;
步骤二、参照疲劳度量表将受试者持续的疲劳感知人为划分为3个疲劳度等级,并在0度疲劳状态、稍疲劳状态以及精疲力竭状态下的语音录制,并创建语料库,所述语料库中包括运动疲劳语料和脑力疲劳语料;
步骤三、对语料库中的语料进行标记,包括语料种类编号、受试者性别、受试者年龄和疲劳等级;
步骤四、根据心率与脑力疲劳度的相关性验证受试者的脑力疲劳等级;
步骤五、提取语料库中语料的语音特征参数,包括语音段短时平均能量、语音段短时平均过零率、语音段语速、回答反应时长和基频;
步骤六、利用支持向量机进行同性别内脑力疲劳检测,并利用迁移学习进行跨性别间脑力疲劳检测,得出被检测者的疲劳等级。
上文中,所述疲劳度量表为疲劳量表-14(fatiguescale-14,fs-14),是1992年由英国king’scollegehospital心理医学研究室的t.chalder及queenmary’suniversityhospital的g.berelowitz等许多专家等共同编制的、可有效反映脑力疲劳程度的主观疲劳量表。
上述技术方案中,所述步骤一中,男性受试者为不少于15人,女性受试者为不少于15人。
对于所述男性和女性受试者的人数,本发明不做具体限定,典型但非限制性的可以是15人、20人、25人、30人、35人、40人、45人、50人、55人、60人等等,且受试者人数越多,语料库越丰富,脑力疲劳的检测越准确。
优选地,所述步骤一中,男性受试者为15~30人,女性受试者为15~30人。
进一步地,所述步骤二中,每位受试者录制4~7条运动疲劳语料和3~6条脑力疲劳语料。
优选地,所述步骤二中,每位受试者录制4条运动疲劳语料和3条脑力疲劳语料。
进一步地,所述步骤二中,所述疲劳度量表中0分对应0度疲劳状态,1~4分对应稍疲劳状态,5~6分对应精疲力竭状态。
进一步地,所述步骤六中,利用支持向量机进行同性别内脑力疲劳检测的步骤包括:
(1)准备数据集;
(2)设置合适的svm类型并设置对应的参数;
(3)选择合适的核函数并设置对应的参数;
(4)对训练集进行训练获取支持向量机的模型;
(5)利用步骤(4)中所得模型进行预测。
优选地,所述步骤六中,采用tradaboost算法进行跨性别间脑力疲劳检测。
由于上述技术方案运用,本发明与现有技术相比具有下列优点:
本发明采用主观疲劳量表将连续的脑力疲劳简化为若干个明确的疲劳度等级,从而建立有效脑力疲劳语料库,并采用心率验证疲劳状态标注的准确性,再利用支持向量机进行同性别内脑力疲劳检测,以及利用迁移学习进行跨性别间脑力疲劳检测,实现针对脑力疲劳的语音疲劳度检测。
附图说明
图1是本发明实施例一的方法流程图。
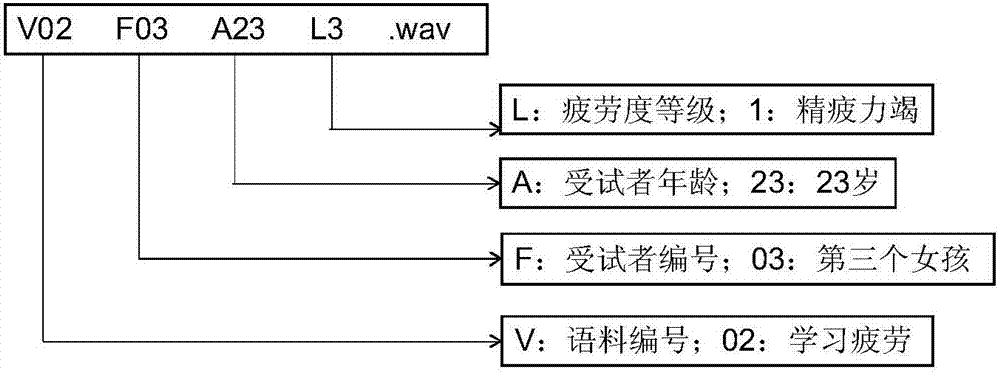
图2是本发明实施例一的步骤三中语料库命名示意图。
图3是本发明实施例一的脑力疲劳状态下心率随疲劳度变化情况示意图。
图4是本发明实施例一中受试者为女性时基于svm的同性别内脑力疲劳度识别率部分数据示意图。
图5是本发明实施例一中基于tradaboost的跨性别间脑力疲劳度识别准确率的部分数据示意图。
具体实施方式
下面结合附图及实施例对本发明作进一步描述:
实施例一:
参见图1所示,一种针对脑力疲劳的语音疲劳度检测方法,包括如下步骤:
步骤一、选取15为男性受试者和15位女性受试者;
步骤二、参照疲劳度量表将受试者持续的疲劳感知人为划分为3个疲劳度等级,并在0度疲劳状态、稍疲劳状态以及精疲力竭状态下的语音录制,并创建语料库,所述语料库中包括运动疲劳语料和脑力疲劳语料;
步骤三、对语料库中的语料进行标记,包括语料种类编号v、受试者性别f、受试者年龄a和疲劳等级l;
步骤四、根据心率与脑力疲劳度的相关性验证受试者的脑力疲劳等级;
步骤五、提取语料库中语料的语音特征参数,包括语音段短时平均能量、语音段短时平均过零率、语音段语速、回答反应时长和基频;
步骤六、利用支持向量机进行同性别内脑力疲劳检测,并利用迁移学习进行跨性别间脑力疲劳检测,得出被检测者的疲劳等级。
上文中,所述疲劳度量表为疲劳量表-14(fatiguescale-14,fs-14),是1992年由英国king’scollegehospital心理医学研究室的t.chalder及queenmary’suniversityhospital的g.berelowitz等许多专家等共同编制的、可有效反映脑力疲劳程度的主观疲劳量表,参见表1。
表1疲劳量表-14(fs-14)
其中,14个条目分别从不同角度反映疲劳的轻重,受试者只需根据实际情况回答“是”或“否”。总分值最高为14分,分值越高,则表示疲劳越严重;反之,疲劳感越轻。同理,若只针对脑力疲劳,则总分值最高为6分,分值越高表示疲劳越深;反之越轻。
基于fs-14量表通过受试者的主观感受将人体脑力疲劳划分为3类:0分对应自然状态,即0度疲劳状态;1-4分对应稍疲劳状态;5-6对应精疲力竭状态。
本实施例中,所述步骤二中,每位受试者录制4条运动疲劳语料共120条;以及3条脑力疲劳语料,共90条。其中,语音录制包括第一部分的朗读和第二部分的问答,问答的问题是由实验员事先设计好的常识性问题,受试者正常作答即可。
步骤三中,对语料库中的语料进行标注,其规则参见表2和图2所示。
表2语料库中语料标注规则
上述语料库中脑力疲劳的问答环节是用于提取反应时时长的重要语音段,针对脑力疲劳,主要的加工标注工作就是通过人耳将朗读段跟回答问题的衔接处、每个问题结束和开始回答的点标注出来,以便后续特征参数的提取。
所述步骤四中,利用心率随疲劳度变化的趋势进行客观的疲劳度分类验证,参见图3所示,受试者的心率随脑力疲劳程度变化的趋势与理论值相符,因此,基于主观疲劳量表的疲劳度等级划分具有有效性,后续可利用语料库进行语音疲劳度检测的研究。
所述步骤六中,利用支持向量机进行同性别内脑力疲劳检测的步骤包括:
(1)准备数据集。其使用的训练数据和校验数据格式为:<label><index1>:<value1><index2>:<value2>等,则本发明中分别建立了训练集特征向量(train_vector),训练集特征标签向量(train_label_vector),测试集特征向量(test_vector)及测试集特征标签向量(test_label_vector)。为了避免训练模型时为计算核函数而计算内积时引起数值计算的困难,对训练集特征向量和测试集特征向量都事先进行了归一化。其中用于训练的语音特征参数用排列组合(22*3种)的方法分别进行测试,以获取不同特征参数组合的疲劳度识别率。
(2)设置合适的svm类型并设置对应的参数。“-s”用于设置svm类型,其中:0对应c-svc;1对应v-svc;2对应一类svm;3对应
(3)选择合适的核函数并设置对应的参数。“-t”是livsvm中用于设置核函数类型的参数,分别有线性(0)、多项式(1)、rbf函数(2)、sigmoid(3)。本发明针对rbf核函数涉及到的参数有:gamma函数(-g)。
(4)对训练集进行训练获取支持向量机的模型。函数形式为:
算法1libsvm训练算法描述
modle=svmtrain(train_label_vector,train_vector,'libsvm_options')
其中,train_label表示训练集特征标签向量,train_vector为训练集特征向量,libsvm_options则为包括步骤(2)、(3)中需要设置的参数的训练集参数。
(5)利用上述模型进行预测。
算法2libsvm识别算法描述
[predict_label,accuracy,decision_values]=
svmpredict(test_label_vector,test_vector,model,'libsvm_options')
其中,predict_label是通过训练模型预测得到的测试集的标签向量,accuracy是一个三维向量,上至下依次是:分类准确率、平均平方误差及平方相关系数。前者是分类问题中的参数指标,后两者均用于回归问题中。
脑力疲劳研究中,单性别受试者男女各15人,疲劳程度分为3级,故可用于训练和测试的样本各45条。本发明进行了三种训练-测试模式的识别率比较,以此得到识别效果最好的训练-测试样本比例。本发明在进行实验数据对比时,为简化参数形式,将短时平均能量缩写为e,基频为p,语速为s,喘息段时长为w,短时平均能量为z,反应时为r。部分数据如图4所示。
通过观察基于svm的脑力疲劳识别效果,不难发现:横向对比各特征组合下不同训练-测试模型的疲劳度识别效果,识别率最好往往出现在训练12-测试3的情况下,说明训练参数越多,训练出的分类器分类效果越好;纵向观察各训练-测试模型下不同特征参数组合的疲劳识别效果,所有特征参数综合起来得到的识别率略低于60%,由于实施例中受试者数量不足,导致样本数据数量不够大,所以相比较运动疲劳而言,多特征组合识别疲劳效果的能力较弱,由短时平均能量和反应时这两种特征参数组合对脑力疲劳具有最好的识别效果,为76.3%,并且在不同的训练-测试模型中,训练12-测试3模型的识别效果最好,其识别率接近90%;观察单特征对脑力疲劳识别的效果,可以看出,短时平均过零率的识别效果最佳。后续的工作中将增加受试样本的个数,以达到更好的训练效果。
采用tradaboost算法,用于跨性别迁移学习。
其具体的流程为:
算法3tradaboost算法描述
输入:辅助样例空间大量标注的训练数据集ta,
目标样例空间少量标注的训练数据集tb,
目标样例空间大量未标注的测试数据集s,
基本分类算法learner,
迭代次数n
初始化:
1.初始化权重向量w1;
2.设置
fort=1,……,n,
1.设置权重分布
2.调用learner,根据ta和tb合并后的训练数据t,权重pt以及未标注数据s,得到在目标空间的分类器ht,并计算ht在tb上的错误率:
3.令
输出:最终分类器hf:
参见图5所示,纵向比较不同特征参数组合的迁移学习准确率,可以发现eprs、prs、eps、ps等特征参数的组合在跨性别间脑力疲劳度检测具有最好的识别率,故可以推断:男声、女声这两个不同领域共享知识主要集中在语速随疲劳度的变化上;横向比较每行的准确率,用男声预测女声效果不佳,但是女声预测男声具有较高的准确率,即大量的女声数据加上少量的男声数据,能有效预测剩余的男声数据,实现跨性别疲劳度检测且效果比svm的跨性别疲劳度检测更有说服力。
- 还没有人留言评论。精彩留言会获得点赞!