一种基于处方数据挖掘的药物推荐方法与流程
本发明属于计算机技术领域,具体涉及一种基于处方数据挖掘的药物推荐方法。
背景技术:
科学用药对于提高疾病治疗效果具有重要作用,然而,药物处方的开具当前主要依赖于医师个人的专业知识和经验。实际上,医疗信息系统积累有大量历史病患的处方日志,而且,同一病种所需的药物功效、用药模式通常有一定的规律可循。基于处方数据对所需药物及用药模式进行挖掘分析、进而为医生制定用药方案时提供药物推荐功能具有重要意义。但是现有的推荐方法要么粒度过细、模型复杂,得到的结果解释性差,要么推荐的准确性差,应用性不强。
技术实现要素:
针对现有技术中存在的上述技术问题,本发明提出了一种基于处方数据挖掘的药物推荐方法,设计合理,克服了现有技术的不足,具有良好的效果。
为了实现上述目的,本发明采用如下技术方案:
一种基于处方数据挖掘的药物推荐方法,首先进行如下假设:
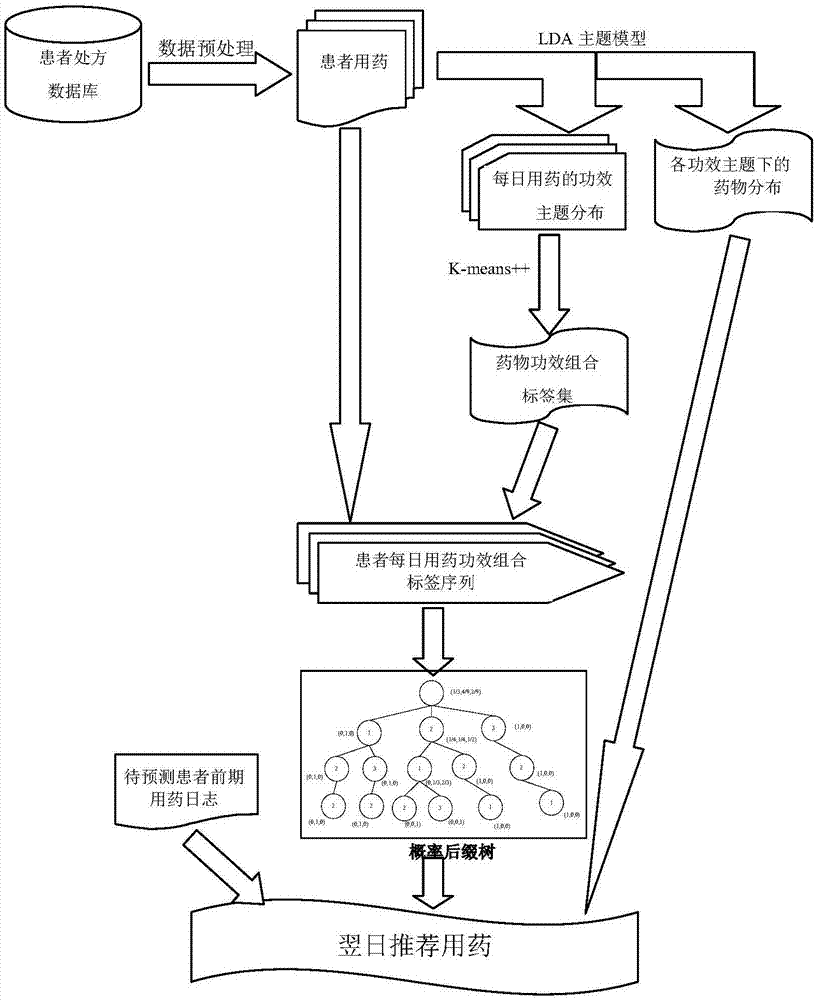
(1)假设特定病种治疗所需的药物功效分为多个主题,患者每日所服药物按照多项分布服务于部分功效主题,且每个功效主题下需要采用的药物也服从多项分布,在此假定下借助lda模型从服药日志中训练患者每个诊疗日的功效主题分布以及每个功效主题下的药物分布;(2)根据功效主题分布的相似性对不同的诊疗日进行聚类,同一簇中各个诊疗日用药具有类似的功效组合,用相同的标签对其进行标注,将每个患者的用药流程转换为一个功效组合标签序列;(3)假设每日用药的功效组合服从变阶马尔科夫模型,基于历史患者的功效组合标签序列构造概率后缀树,基于此概率后缀树对处于诊疗过程中的患者进行逐日用药推荐;
所述的基于处方数据挖掘的药物推荐方法,具体包括如下步骤:
步骤1:获取数据;通过医院信息系统获取往届病人的处方药物信息,并进行脱敏处理,包括病人编号、病人确诊病种、病人用药开始、结束时间以及药物名称,最终整理成所需的日志格式;
步骤2:数据预处理;为保证原始数据的准确可靠,选择以药物治疗为主要治疗手段的病症为研究对象,通过诊断结论筛选某一病种病人,过滤住院时间过长或者过短的病人日志,此外,剔除处方中出现总次数少于或者多于某一阈值的药物,保留的记录包括病人id和服药时间信息、药物名称;
步骤3:类比lda主题模型中词、文档、文档集的概念,将患者单日所服药物的总和类比为一个文档,每种药物类比为一个词,借助lda主题模型对药物进行聚类,每个类实际对应一个药物功效主题,同时得到各个患者各个诊疗日的药物功效主题分布以及各个功效主题下药物的多项式分布;
步骤4:使用k-means++算法对功效主题分布相似的诊疗日进行聚类,聚类标签作为这些诊疗日药物功效组合的标识;
步骤5:结合患者历史用药信息构建各个患者的每日用药功效组合标签序列,以这些序列为输入训练出该类病症药物治疗过程的概率后缀树模型;
步骤6:从概率后缀树模型的根节点出发,按序列倒序的方式与各层节点进行匹配,寻找能匹配成功的原序列的最长后缀,假设匹配成功时位于节点node(s)处,该节点之标签对应的后继标签概率向量记为pnext(node(s));记功效组合标签x对应的功效主题多项式分布中,主题t对应的出现概率为pefftop|dateclu(x)|t,功效主题t对应的药物多项式分布中,药物drug对应的出现概率为pdrug|efftop(t)|drug,则对于任意药物d,其翌日服用的概率计算公式如下所示,其中t与x分别取尽所有的药物功效主题与功效组合标签:
pdrug|seq(d,s)=∑x∑tpdrug|efftop(t)|d*peffitop|dateclu(x)|t*pnext(node(s))|x。
本发明所带来的有益技术效果:
1、在药物或者治疗手段推荐方面,传统手段综合运用患者各项检查数据、医嘱指令数据,通过关联规则分析、最近邻算法、逻辑回归、贝叶斯网络等方法进行治疗手段预测和推荐,但这类方法通常要求掌握患者的病症和各项身体指标数据,而这些数据有时难以掌握和利用,而本发明直接使用病人的处方药物日志,具有较高的完备性且容易获得。
2、与传统方法直接在医嘱指令级粒度进行推荐不同,本发明首先在较高粒度级预测翌日可能的诊疗主题组合,再结合各个诊疗主题下的药物分布预测各个药物的服用概率,得到的预测结果具有较好的可解释性。
3、本发明使用概率后缀树进行医疗诊治过程的建模和服用药物的预测,该模型更加接近诊疗过程的实际情况,基于概率后缀树得到的药物推荐结果准确率较传统方法有较高的提升。
附图说明
图1是本发明方法的流程图。
图2是某病人诊疗过程所对应的概率后缀树实例图。
具体实施方式
下面结合附图以及具体实施方式对本发明作进一步详细说明:
一种基于处方数据挖掘的药物推荐方法,其流程如图1所示,包括如下步骤:
步骤1:以来自多参数智能监测数据库(mimic-iiiclinicaldatabase)的医疗数据为例,该数据库主要记录了自2001-2012年间约40000名入住重症监护室病人的诊疗信息。其中表1中各列依次为医嘱行号、病人id,用药类型以及用药起止日期(数据集中的时间进行了脱敏处理)。另有住院信息表(admissions)记录了病人住院时的登记信息,包括住院时间、出院时间以及诊断结论等信息。
表1患者处方表示例
步骤2:为保证原始数据的准确可靠,选择以药物治疗为主要治疗手段的病症为研究对象。具体而言,选择诊断结论为“sepsis”且诊疗记录数量介于200到400之间的患者处方数据为数据源。此外,剔除处方中出现总次数少于5次、多于2000的药物,剩余药物323种。在此基础上,基于患者处方数据生成表2所示的患者用药日志,共包含用药记录34929条,2328个诊疗日,病人日均用药大约在15种左右。每条记录包括病人id和服药时间信息、药物名称。
表2患者用药日志示例
步骤3:将患者的每日用药记录类比为文档,将药物类比为单词,并假定医生制定用药方案时以一定的概率按照多项式分布服务于多个功效主题,每个功效主题下的药物也服从一个多项式分布,借助lda模型对患者的用药日志数据进行主题模型训练,进而得到患者每个诊疗日的功效主题分布以及每个功效主题下的药物分布,如表3所示展示了各个主题下概率最高的前十个词。
表3各药物主题数为12时主题下概率最大的前十个项目
步骤4:使用k-means++算法对功效主题分布相似的诊疗日进行聚类,共聚成16个类,聚类标签作为这些诊疗日药物功效组合的标识;
步骤5:结合患者历史用药信息可以构建各个患者的每日用药功效组合标签序列,以这些序列为输入可以训练出该类病症药物治疗过程的概率后缀树模型;图2所示为某一病人的诊疗序列为:“1-2-2-1-2-3-1-2-3”的概率后缀树。
步骤6:以图2所示概率后缀树为例,假设待预测患者前三天用药的功效组合标签序列为“112”。首先,从根节点出发找不到与序列“112”的逆序“211”完全匹配的路径,为此,舍弃原序列“112”中的第一个元素。对于剩余的子序列“12”,显然存在根节点出发的路径与其逆序完全匹配,且匹配完成后位于树中第三层标签为“1”的节点,该节点对应的后继标签条件概率向量为pnext(node("112"))=(0,1/3,2/3)。
假设共有3类药物功效组合标签、4个药物功效主题、5种药物。第2个功效组合标签下功效主题的出现概率向量peffitop|dateclu(2)=(0,1/4,3/4,0),第3个功效组合标签下功效主题的概率向量peffitop|dateclu(3)=(0,0,1/2,1/2);第2个功效主题下药物的出现概率向量为pdrug|efftop(2)=(0,2/5,3/5,0,0),类似地,pdrug|efftop(3)=(0,0,1/5,4/5,0),pdrug|efftop(4)=(0,0,0,3/5,2/5)。则根据前述计算公式,第四天患者服用第二种药物b的概率为
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!