一种基于神经网络算法的川崎病风险评估模型的构建方法及构建系统与流程
本发明涉及一种模型的构建方法,具体来说涉及一种基于神经网络算法的预测川崎病风险的评估模型的构建方法、构建系统,以及评估系统,属于风险评估模型构建技术领域。
技术背景
川崎病又称皮肤黏膜淋巴结综合征,是一种以全身血管炎为主要病变的自身免疫性疾病,目前已累及全球60多个国家。其中冠状动脉是较易受累部位,是原因不明的发热性出疹性疾病,川崎病主要表现为持续性发热5天以上,还包括:(1)两眼结膜出现充血症状,但未出现渗出物;(2)口唇发红,出现杨梅舌,口腔和咽部黏膜存在弥漫性充血症状;(3)皮肤出现多形性红斑和皮疹;部分患儿可出现卡介苗接种处红肿,是一种特异性表现;(4)四肢末端发生变化;若手足存在硬性肿胀,掌跖和指端充血,则为急性期;若指端甲床皮肤移行部位膜状蜕皮,则为恢复期;肛门周围也多见脱皮症状;(5)急性期表现为非化脓性颈部淋巴结肿大,普遍为单侧,直径在1.5cm以上等临床症状。2017年美国心脏病协会(aha)制定的川崎病诊断标准:若患者发热≥5天,且以上主要条件中≥4项者确诊为川崎病。含有上述若发热≥5天,主要临床表现不足4项,但在超声心动图或者血管造影发现有冠状动脉病变者,也诊断为川崎病。
川崎病高发人群为5岁以下儿童,最主要且严重的并发症是冠状动脉病变,如果不能进行及时诊断和治疗,会对心血管系统造成严重损伤,冠状动脉扩张和动脉瘤均是该病临床上发生率较高的并发症,还可能直接导致患者发生缺血性心脏病和猝死,目前已成为小儿后天获得性心脏病最常见的病因之一,也是成年后缺血性心脏病发生的危险因素。由此可见,kd的早期诊断具有重要地位。
目前的诊断依据必须发热≥5天,且需要等待临床症状出现,辅以实验室诊断和超心电图检查,容易使患儿错过最佳治疗时间。同时川崎病病因病理目前尚不明确,且发病后可引起多种症状,在一定程度上增加了小儿川崎病的诊断难度。由于患儿本身年龄较小,在没有确诊的情况下,治疗风险较大。小儿川崎病治疗的前提就是要明确诊断,这样才能够及时地对患儿实施治疗。目前尚没有特异性的诊断方法,容易造成患儿临床治疗延误。此外,川崎病的临床症状表现复杂多样,发病初期临床症状不明显,而且与临床上的败血症、淋巴结炎、急性扁挑体炎、药物过敏综合征等疾病症状极为相似,早期误诊率较高。出现误诊的患儿很容易延误病情,进而造成更大的危害。
综上所述,难确诊、易误诊是川崎病患者在诊断过程中的两大难题,是川崎病诊断过程中的临床痛点。因此,研发灵敏度高,特异性强的诊断方式成为川崎病诊疗的中急需满足的需求。
基于医疗数据建模的川崎病患病预测模型可以辅助诊断,有助于降低其漏诊率和误诊率,进一步指导其后续治疗过程。目前存在的基于数据的川崎病分类模型多采用线性方法,典型代表为逻辑回归分析方法。因其敏感性、特异性不足而造成川崎病患者漏诊、误诊情况,从而延误患者治疗。
因此,如何对现有的川崎病患病预测模型进行优化,构建一种具有高敏感性、特异性的风险评估模型,已然成为业界研究人员长期以来一直努力的方向。
技术实现要素:
本发明的主要目的在于提供一种基于神经网络算法的川崎病风险评估模型的构建方法及构建系统,以克服现有技术中的不足。
本发明的另一目的还在于提供一种基于神经网络算法的川崎病风险评估系统。
为实现前述发明目的,本发明采用的技术方案包括:
本发明实施例提供了一种基于神经网络算法的川崎病风险评估模型的构建方法,其包括:
从样本数据集中提取可用于建模评估模型的有效样本;
从所述有效样本的特征集中筛选出符合现场医疗辅助诊断应用的10项特征;
将所述有效样本的不完整数据集随机分割为训练集和验证集;
使用神经网络的方法拟合训练集进行模型构建,采用十折交叉验证法,记录最优模型参数;同时,根据roc曲线使用验证集计算模型分类阈值t,从而构建得到川崎病风险评估模型。
本发明实施例还提供了一种基于神经网络算法的川崎病风险评估模型的构建系统,应用于前述的构建方法,其包括:
数据采集模块,至少用于数据采集,获取样本数据集;
数据处理模块,至少用于从样本数据集中提取可用于构建评估模型的有效样本;
模型构建模块,至少用于将所述有效样本的不完整数据集随机分割为训练集和验证集,并使用神经网络的方法拟合训练集,采用十折交叉验证法,记录最优模型参数;
阈值计算模块,至少用于根据roc曲线使用验证集计算模型分类阈值。
本发明实施例还提供了由前述方法构建得到的基于神经网络算法的川崎病风险评估模型。
本发明实施例还提供了一种基于神经网络算法的川崎病风险评估系统,其包括:
输入模块,至少用于输入待评估数据;
由前述方法构建得到的基于神经网络算法的川崎病风险评估模型,至少用于对该待评估数据进行评估;
显示模块,至少用于显示评估结果,即kdx评分。
1)与现有技术相比,本发明提供的基于神经网络算法的川崎病风险评估模型构建方法及系统,使用与川崎病相关的医疗数据进行系统的统计分析、建模,并给出模型评价方法,神经网络克服了大多数分类器产生的过拟合问题,是一种表现极好的集成分类器,通过该模型能够基于已有的川崎病医疗数据,对疑似川崎病的患者进行科学有效的辅助评估,有助于降低其误诊率和漏诊率,使患者在发病早期可以获得有效的预防、干预,并科学可靠地指导后续治疗过程,为达到最佳治疗效果提供依据,有效地避免了现有诊断方式中因没有高敏感性和特异性的评估模型而造成川崎病患者漏诊、误诊情况,防止延误患者治疗情况的发生;
2)出于对诊断用时的考虑,本发明所选特征项的检测用时较短,大大缩短医生诊断所用时间。并且,特征项选取较少,降低检测所用成本。
3)本发明数据样本量庞大,优势突出。
附图说明
为了更清楚地说明本发明的技术方案,下面将对实施例或现有技术描述中所需要使用的附图进行简单的介绍,显而易见地,下面描述的附图仅仅作为本文发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
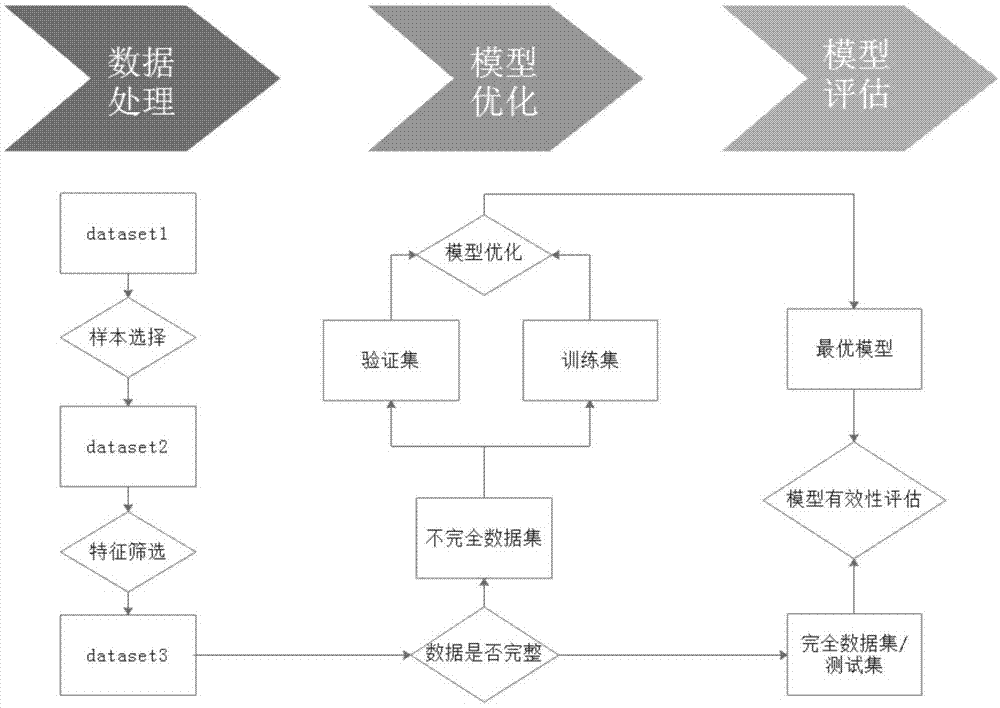
图1是本发明的一典型实施例中一种基于神经网络算法的川崎病风险评估模型的构建方法的流程示意图。
图2是本发明实施例1中基于神经网络算法的川崎病风险评估模型的roc曲线图。
具体实施方式
如前所述,鉴于现有技术的不足,本案发明人经长期研究和大量实践,得以提出本发明的技术方案。下面结合附图以及本发明的实施例对一种基于神经网络算法的川崎病风险评估模型的构建方法及构建系统等作进一步详细的说明。本发明的保护内容包含但不局限于以下实施案例。在不背离发明构思的精神和范围下,本领域技术人员能够想到的变化和优点都被包括在本发明中,并且以所附的权利要求书为保护范围。
人工神经网络是由大量处理单元互联组成的非线性、自适应信息处理系统。它是在现代神经科学研究成果的基础上提出的,试图通过模拟大脑神经网络处理、记忆信息的方式进行信息处理。它的构筑理念是受到生物(人或其他动物)神经网络功能的运作启发而产生的。人工神经网络通常是通过一个基于数学统计学类型的学习方法(learningmethod)得以优化,所以人工神经网络也是数学统计学方法的一种实际应用,通过统计学的标准数学方法我们能够得到大量的可以用函数来表达的局部结构空间,另一方面在人工智能学的人工感知领域,我们通过数学统计学的应用可以来做人工感知方面的决定问题(也就是说通过统计学的方法,人工神经网络能够类似人一样具有简单的决定能力和简单的判断能力),这种方法比起正式的逻辑学推理演算更具有优势。
本发明主要基于电子病例中的医疗数据进行建模,使用数据中蕴含的信息对病人患有川崎病的风险进行评估,并将评估结果进行数字化描述,即得到kdx评分。本发明包括针对医疗数据进行建模的数据处理流程和进行川崎病分类预测、分析、数字化等重要方法和结果。本发明结合了医疗数据和数据挖掘方法,是医疗数据与大数据分析方法结合的一种创新,本发明在一定程度上填补了国内医疗数据研究的空白,在利用医疗数据进行川崎病辅助检测分析方面具有创新性。
本发明实施例的一个方面提供的一种基于神经网络算法的川崎病风险评估模型的构建方法,其包括:
从样本数据集中提取可用于建模评估模型的有效样本;
从所述有效样本的特征集中筛选出符合现场医疗辅助诊断应用的10项特征;
将所述有效样本的不完整数据集随机分割为训练集和验证集;
使用神经网络的方法拟合训练集进行模型构建,采用十折交叉验证法,记录最优模型参数;同时,根据roc曲线使用验证集计算模型分类阈值t,从而构建得到川崎病风险评估模型。
在一些实施例中,所述构建方法包括:
第一步:数据样本选择;从样本数据集中提取可用于建模及模型评估的有效样本,其具体步骤如下:
1.对重复数据进行删除处理;
2.对数据量不足80%的指标进行删除处理;
3.对残缺、错误数据进行中位数填充;
4.对整体样本离差标准化,将样本数据压缩到[0,1]区间内,并消除量纲:
其中,xi为第i个特征向量,maxi、mini分别为第i个特征向量的最大值、最小值,xi*代表经过变换后的特征向量i;
第二步:特征筛选;从构建样本数据的特征集中筛选出符合现场医疗辅助诊断应用的10项特征;其具体步骤如下:
1.对训练集d,使用神经网络默认参数建立模型;
2.将其中一个特征变量vi的数值加上或减少10%并进行替换,得到新数据集d1,d2;
3.将d1,d2作为仿真数据集,利用步骤1)中的模型进行仿真预测,记录其正确率的差值mivi=d1-d2;
4.重复步骤2)~3),得到每一个变量的miv值并进行排序;
5.根据步骤4)所得结果,并结合在实际应用于现场医疗辅助诊断中,取得各项特征值所用时间较短者,进行综合比较得到。
第三步:川崎病患病风险预测模型构建;采用神经网络的方法进行模型构建,其步骤如下:
(1)现有不完整数据集和完整数据集:将不完整数据集随机分割为训练集xrain、验证集xderivation,比例为1:1~10:1,并以完整数据集作为测试集xtest;其具体步骤如下:
1.将训练集数据平均分为十部分;
2.取其中九折数据,使用神经网络的方法进行拟合,得到模型;
3.利用步骤2所得模型,对剩余一折的数据集进行预测,并计算其预测误差;
4.改变模型参数,重复步骤2~3;
5.比较预测误差,记录使得预测误差最小的模型所对应的参数,作为最优模型参数。
(2)使用神经网络的方法拟合xtrain数据集进行模型构建,采用十折交叉验证法,记录最优模型参数;
(3)根据roc曲线使用验证集计算模型分类阈值t,阈值t计算具体步骤如下:
1.利用最优参数模型,在训练集上建立最优模型;
2.使用验证集观测值,在模型上进行预测,得到分类得分;
3.在[0,1]范围内,选取不同数值作为分类阀域值,对步骤2所得分类得分进行划分;
4.计算不同分类阀域下,预测的敏感度、特异度和正确率,并绘制roc曲线图;
5.根据roc曲线图选取使得同时满足预测的敏感度、特异度和正确率较优的分类阀域。
在一些实施例中,所述10项特征分别为:
a.性别;
b.年龄;
c.c-反应蛋白浓度(crpg/l);
d.纤维蛋白原浓度(fgg/l);
e.白蛋白浓度(albg/l);
f.球蛋白浓度(glbg/l);
g.补体c3浓度(c3g/l);
h.免疫球蛋白g浓度(iggg/l);
i.前白蛋白pab浓度(pabg/l);
j.白球比例(a/g)。
在一些实施例中,训练集(xrain)与验证集(xderivation)的分割比例为1:1~10:1。
在一些实施例中,所述构建方法包括:根据roc曲线使用验证集计算得到模型分类阈值t,kdx评分高于此分类阈值t预测为川崎病高风险,数值越高,代表川崎病患病概率越大;低于此分类阈值t预测为川崎病低风险,数值越低,代表川崎病患病概率越小。
进一步地,所述构建方法还包括:以完整数据集作为测试集(xtest),对构建得到的川崎病风险评估模型进行测试。根据计算所得分类阀域t,进行测试集样本的预测分析。
例如,更具体的,根据训练集构建预测模型并对测试集数据进行预测的步骤包括:
1)使用拟合训练集得到的最优神经网络预测模型,对测试集中每个病人预测其分类得分,即kdx评分。分类得分大于t为川崎病患病高风险患者,分类得分小于t为川崎病患病低风险患者;
2)根据测试集的分类得分计算此模型在辅助川崎病诊断中的敏感性、特异性和准确性。
例如,在一些更为具体的实施方案中,获得可用于构建评估模型的有效样本的过程包括:
(a)根据2017年美国心脏病协会(aha)制定的川崎病诊断标准将样本数据分为川崎病和普通发热疾病两组,对不能明确诊断结果的样本数据进行删除处理;
(b)对重复数据进行删除处理;
(c)对数据量不足80%的指标进行删除处理;
(d)对残缺、错误数据进行中位数填充,从而获得可用于构建评估模型的有效样本。
本发明使用的医疗数据即样本数据集,来源于医院edc在线电子病例录入系统,包括医嘱、检验、检查、病程、门诊病历数据、院外随访数据、多中心样本数据、标本分子检测数据等多维数据。
在一些更为具体的实施方案中,参见图1所示,一种基于神经网络算法的川崎病风险评估模型的构建方法,具体步骤如下:
1、样本选择
原始数据集为dataset1,不具有明确诊断结果、重复数据、数据量不足80%的病人被从数据集中移除,此时数据集为dataset2。
2、对整体数据离差标准化,将样本数据压缩到[0,1]区间内,并消除量纲,此时数据集为dataset3。
3、特征筛选
对于dataset2进行特征筛选,通过信息增益计算浏览各特征变量的重要性,删去信息增益接近0的特征变量,同时考虑到特征项数值获得时间长短,取获得时间较短的特征项,此时数据集为dataset4。
4、川崎病分类模型构建
1)现有不完整数据集和完整数据集:将不完整数据集随机分割为训练集xrain、验证集xderivation,比例为1:1~10:1,并以完整数据集作为测试集xtest;
2)使用神经网络的方法拟合xtrain数据集进行模型构建,采用十折交叉验证法,记录最优模型参数;
3)根据roc曲线使用验证集计算模型分类阈值t。
本发明实施例的另一个方面还提供了一种基于神经网络算法的川崎病风险评估模型的构建系统,应用于前述的构建方法,其包括:
数据采集模块,至少用于数据采集,获取样本数据集;
数据处理模块,至少用于从样本数据集中提取可用于构建评估模型的有效样本;
模型构建模块,至少用于将所述有效样本的不完整数据集随机分割为训练集和验证集,并使用神经网络的方法拟合训练集,采用十折交叉验证法,记录最优模型参数;
阈值计算模块,至少用于根据roc曲线使用验证集计算模型分类阈值。
本发明实施例的另一个方面还提供了由前述方法构建得到的基于神经网络算法的川崎病风险评估模型。
相应的,本发明实施例的另一个方面还提供了一种基于神经网络算法的川崎病风险评估系统,其包括:
输入模块,至少用于输入待评估数据;
由前述方法构建得到的基于神经网络算法的川崎病风险评估模型,至少用于对该待评估数据进行评估;
显示模块,至少用于显示评估结果,即kdx评分。
综上所述,本发明的模型构建方法及系统,使用与川崎病相关的医疗数据进行系统的统计分析、建模,并给出模型评价方法,通过该模型能够基于已有的川崎病医疗数据,对疑似川崎病的患者进行科学有效的辅助评估,有助于降低其误诊率和漏诊率,使患者在发病早期可以获得有效的预防、干预,并科学可靠地指导后续治疗过程,为达到最佳治疗效果提供依据,有效地避免了现有诊断方式中因没有高敏感性和特异性的评估模型而造成川崎病患者漏诊、误诊情况,防止延误患者治疗情况的发生。
为使本发明的目的、技术方案和优点更加清楚,下面结合若干优选实施例对本发明的技术方案进行进一步具体描述,但本发明并不仅仅局限于下述实施例,该领域技术人员在本发明核心指导思想下做出的非本质改进和调整,仍然属于本发明的保护范围。
实施例1:
为了验证本发明一种基于神经网络算法的川崎病风险评估模型的构建系统的有效性,本实施例选取时间范围为2008.7-2018.3电子病例中42498个病人数据。本实施例采用神经网络方法。
1、数据处理:
原始数据集经过删除处理之后不完整数据集包括8204个样本,完全数据集包含471个样本。根据本发明采用数据集具有形式为:每行表示为一个病人的信息,每列表示为其一特征信息,如id,组别,性别,年龄,crp,fg等,数据集格式如表格1。
通过数据样本选择和特征筛选,最终生成数据集包含的8675行,11列特征,如表1所示。
表1
2、最优模型数据
将不完整数据集随机分为训练集(5742),验证集(2462),比例为7:3,完整数据集作为测试集(471),得到最优模型参数如表2所示:
表2
3、选择分类阀域t
用最优参数模型预测验证集,在[0,1]范围内自动随机生成1259个分类阀域,计算可得对应敏感度、特异度和正确率,并绘制roc曲线图,如图2所示。
选取靠近曲线左上角并使得敏感度、特异度和正确率较优的分类阀域t=0.5。
4、对预测结果进行数字化打分
以上模型将作为一种川崎病患病风险评估系统,将测试集中的观测值应用到该系统中进行预测。
测试集结果如表3-1和表3-2所示,本实验中,测试集包括471人。
表3-1
表3-2
附注:关于分类问题一些指标解释,对于二分类问题,定义两个分类分别为正类和负类,正类中的每一个对象成为正实例,负类中的每一个对象成为负实例。通常,在预测川崎病时,川崎病样本为正类,其他发烧患者为负类。使用分类模型对测试样本进行预测,会有四种情况,如果一个实例是正类并被预测为真正类(truepositive,tp),如果实例是负类被预测为正类,称之为假正类(falsepositive,fp)。相应的,如果实例是负类被预测为负类,称之为真负类(truenegative,tn),正实例被预测为负类则为假负类(falsenegative,fn)。
tp:正实例预测为正类数目;
fn:正实例预测为负类数目;
fp:负实例预测为正类数目;
tn:负实例预测为负类数目;
敏感性(sensitivity):正类中正确预测为正类的实例比例,即tp/(tp+fn);
特异性(specificity):负类中被正确预测为负类的实例比例,即tn/(tn+fp);
阳性预测值(positivepredictivevalue,ppv):预测为正类的实例中,正实例占得比例,即tp/(tp+fp)。
正确性:在全部实例中被正确预测的实例比例,即(tp+tn)/(tp+fn+tn+fp)。
实验结果
由测试集数据的真实分类情况可知:278人患有川崎病,193为普通发热。将测试集数据运用到最优神经网络模型中,以其观测值预测其响应值的分类概率kdx(如表3-1所示),并根据分类阀域t=0.5对该结果进行划分,得到结果:277人被预测为患有川崎病,194人被预测为普通发热。与测试集中的真实分类比较可得:真正类(tp)为259人,真负类(tn)为166人,假正类(fp)为27人,假负类(fn)为19人(如表3-2所示)。
由测试分类结果可得:敏感度(sensitivity)为93.17%,特异性(specificity)为86.01%,阳性预测值(ppv)为90.56%,正确性为90.23%。
综上所述,由以上数据,本发明一种川崎病患病风险评估系统,通过该模型能够基于已有的川崎病医疗数据,对疑似川崎病的患者进行科学有效的辅助评估,有助于降低其误诊率和漏诊率,使患者在发病早期可以获得有效的预防、干预,并科学可靠地指导后续治疗过程,为达到最佳治疗效果提供依据。出于对诊断用时的考虑,本发明所选特征项的检测用时较短,大大缩短医生诊断所用时间。并且,特征项选取较少,降低检测所用成本。本发明数据样本量庞大,优势突出,原始数据集经过删除处理之后不完整数据集包括8204个样本,完全数据集包含471个样本。
以上所述的实施例对本发明的技术方案进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充或类似方式替代等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!