用于预测样品中的成分的定量的分光光度法和装置的制作方法
本公开涉及用于预测待定量的样品中的成分的定量的分光光度法和装置。
背景技术:
光谱法是代谢物的间接测量,用于它们的鉴定或定量。每个分子或原子具有通过吸收或发射、反射、荧光、磷光和拉曼散射获得的特征光谱指纹;且谱带强度与样品浓度成正比。
在纯物质或简单混合物中,光谱几乎没有干扰。在这些情况下,样品鉴定可直接通过谱带匹配进行,且强度与浓度成比例。
在更复杂的混合物中,诸如例如化学或医药产品中,光谱信号是主要吸收谱带和泛频峰的谱带干扰的结果;形成重叠谱带的连续光谱。成分之间的干扰增加,使得难以通过峰强度进行定量。在这种情况下,优选地必须通过代谢物的干扰模式对其进行定量(geladi和kowalski:1986;phatak和jong:1997)。
此外,取决于光谱技术,谱带分辨率和光谱卷积显著不同,因此,光谱信息通过光学部件的循环卷积而局部分布,这在低质量的极端情况下导致高度自相关的信号。该光谱既包含物理和化学信息,又包含其成分之间的复杂干扰模式。光谱学的量子性质意味着,关于任何纯化合物的信息都以几种强度等级分布在不同波长。由于光的波特性,信息的叠加导致样品成分谱带之间的相长干涉或相消干涉。因此,观察到的体液变化与局部混沌变化是高度非线性的,不能简单地通过最先进的化学计量学、机器学习或人工智能方法来建模。为了避免开发用于从非线性效应中提取光谱信息的理论支持,许多化学计量学家试图应用机器学习算法,例如人工神经网络、核方法和支持向量机。可以预期,更复杂的模型结构可以捕获所有非线性并提供更好的预测。
先前的方法在光谱建模中存在以下困难。
大数据光谱可变性-深度神经网络和非线性支持向量机(svm)是适合所有数据的复杂函数模型。也就是说,针对大量数据生成了结构化的整体模型。由于信号的局部混沌特性,这导致高度复杂的架构,对于光谱学中的大数据而言,这并不是最好的。一旦引入具有新的局部变化的新样品,该模型将无法在光谱谱带和组合物之间找到正确的协方差。此外,如果不提供大量数据,则ann和svn的预测极有可能遭受重大偏差。这些方法只有在特征空间几乎全部被表示时才变得有趣;这很困难,因为生物变异性极大。
重新训练计算成本-由于ann和svm是全局方法,因此一旦确定了一组新的离群值,就必须重新优化复杂的模型结构。一旦用大型数据库完成此操作,就必须使用大量的计算资源来重新计算模型结构(huangetal:2015年)。
离群值检测-如果新光谱是离群值,则ann和svn的复杂结构使得很难确定“先验”。由于没有明显的规律可得出关于任何新结果的可预测性的结论,因此很难知道光谱测量值是否是离群值。这在医学、兽医或甚至危险的工业过程中尤其重要,在这些过程中,物质的精确定量至关重要,并且预测失败会带来灾难性后果。
因此,考虑到光学和光谱学的系统变化的信息处理技术更可能解决该问题,而无需高昂的计算成本。例如,开发了局部校准方法,以将全局光谱方差分解为其中是系统变化的特征组(ramirez-lopesetal:2013)。在许多情况下,局部方法优于ann和svm(solomatineetal:2008)。诸如局部加权偏最小二乘法(lw-pls)(naesetal:1990,christyanddyer:2006),local(shenketal:1997)、局部偏差回归(fearnanddavies:2003)和carnac(daviesandfearn:2006)的技术以及局部pls建模方法(gogeetal:2012年)提供了降低复杂性和稳定校准。
最新进展之一是用于对近红外土壤组成大数据建模的“基于光谱的学习器”(sbl)方法(ramirez-lopezetal:2013)。sbl基于使用优化的主成分(opc)构建的知识库(ramirez-lopezetal:2013),其中通过使用opc的维度距离邻居(例如,由k个最近邻居或其他距离度量确定)来获得局部校准,通过化学组成的相似性,使用组成的均方根差(rsmd)来确定(ramirez-lopezetal:2013)。局部样品选择仅基于主要成分的影响,即,以较低频率或信号基线影响光谱指纹的物质。sbl将始终努力定量较低的浓度,其中信息以较小的光谱变化范围存在。
当前最先进的方法无法从技术上解决光谱定量的复杂性,并且无法提供用于关键应用(例如医学)的必要准确性和精确度(偏差和方差)。正确的医疗决定只能由分析等级数据支持。本公开提出了一种旨在克服所提及的技术问题以及光谱学中的人工智能和模式识别的当前技术难题的方法和装置,以提供在复杂可变性和多尺度干扰下的光谱样品的准确定量和分类。
技术实现要素:
本公开涉及一种大数据自学习人工智能方法和装置,用于从光谱信息中准确定量健康状况的代谢物分类,其中存在复杂的生物变异性和多尺度光谱干扰。特别地,本公开允许将高度复杂的生物光谱信号分解为高维特征空间,其中每个子空间的局部特征与特定代谢物浓度或分类条件都准确相关。这是通过一种不需要人为干预的自学习方法来实现的。当通过执行特征空间转换、搜索协方差方向以及优化局部组成-光谱相关性来馈送新数据时,开发的人工智能能够建立其自己的知识库。
这些方法允许建立定量和分类的知识图谱,可以兑现这些知识图谱用于更高的计算性能。特别地,直接搜索包括在整个特征空间中寻找允许代谢组合物和谱带方差之间的直接线性对应关系的数据和维度。此外,从体液光谱得出用于定义不同类别健康状况的凸包区域的类似方法。这导致创建用于定量和分类的知识图谱。
本公开还允许“先验地”评估新估计值的可预测性、准确性和精确度。此外,本公开提供了一种自学习方法来使用大数据定义全局特征空间,以用于其在高可变性下的正确表征,对局部异常的精确检测以及可能污染知识库的离群值。
本公开适用于光谱分析中使用的电磁光谱(电磁波谱)的所有区域(x射线、紫外光、可见光、近红外光、红外光、远红外光和微波),或任何其他类型的光谱(吸收、反射、荧光、磷光、拉曼散射),其中存在复杂的多尺度干扰和生物变异性。它进一步扩展到诸如医疗保健、兽医、生物技术、制药、食品和农业的领域中的非破坏性、非侵入性光谱应用领域。
公开了用于预测待定量的样品中的成分的定量的分光光度法,
包括以下步骤:
从所述生物样品获得电磁光谱;
将所述获得的光谱投影到与特征向量相关联的多维度向量空间的样本点中,从而得到特征空间,该特征空间由预先确定的向量基础定义,其中每个所述维度为预测特征;
如果存在,则从所述特征空间内的样本点中选择最小的相邻样本点,所述样本点已从先前获得的光谱中投影,每个光谱均具有已知的成分量,使得所述最小值最大化待定量的所述样品的投影光谱以及选定的相邻样本点的投影光谱的协方差;
考虑到待定量的所述样品的投影光谱和所述选定的相邻样本点的投影光谱,通过将来自所选相邻样本点的已知成分量关联来预测待定量的样品的成分的定量。
一个实施方案包括,用于确定待定量的样品的成分的定量的可预测性,通过:
从所选择的相邻样本点计算成分量的预测误差的正态分布;
从所述计算的正态分布和待定量的所述样品的投影光谱获得p值;
使用获得的p值作为待定量的样品成分的定量的可预测性。
如果不存在相邻样本点的最小值,则一个实施方案包括以下步骤:
标记从待定量的样品中预测成分的定量不可能。
一个实施方案包括:
将从所述生物样品获得的光谱放入隔离数据库中;
从待定量的样品中接收成分的测量的定量;
在所述隔离数据库中累积从待定量的生物样品中获得的多个光谱以及来自待定量的样品的成分的各个测量的定量;
确定所述隔离数据库中的累积光谱和测量的定量的子集是否允许对待定量的样品成分进行定量的可预测性;
如果子集允许可预测性,则从隔离数据库中释放该子集以用于本分光光度法中预测成分的定量。
一个实施方案包括,用于确定累积光谱和测量的定量的子集是否允许对待定量的样品成分的定量的可预测性:
将从所述生物样品获得的光谱放入隔离数据库中;和
从对应于生物样品的待定量的样品中接收成分的测量的定量;
以下步骤:
将所述获得的光谱投影到与特征向量相关联的多维度向量空间的样本点中,从而得到特征空间,该特征空间由预先确定的向量基础定义,其中每个所述维度为预测特征;
如果存在,从所述隔离数据库中,从所述特征空间内的样本点中选择最小的相邻样本点,所述样本点已从先前获得的光谱中投影,每个光谱均具有已知的成分量,使得所述最小值最大化待定量的所述样品的投影光谱以及所述隔离数据库的选定的相邻样本点的投影光谱的协方差;
考虑到待定量的所述样品的投影光谱和所述隔离数据库的所述选定的相邻样本点的投影光谱,通过将来自所述隔离数据库的所选相邻样本点的已知成分量关联来预测待定量的样品的成分的定量;
确定待定量的样品的成分的定量的可预测性;
如果认为可预测性高于预定阈值,则从所述隔离数据库中释放选定的相邻样本点,以用于本分光光度法中预测成分的定量。
在一个实施方案中,所述释放的选定的相邻样本点构成局部模型。
在一个实施方案中,从所述特征空间内的样本点中选择相邻样本点的最小值,包括以下步骤:
将所获得的光谱投影到多维度向量空间的样本点中,从而得到特征空间;
在所述特征空间中定义多个搜索方向;
定义包含在所述特征空间内的多个定向搜索量,每个定向搜索量被定义为特征空间的包括所述投影光谱样本点的区域,其沿着搜索方向从所述投影样本点延伸预定的搜索半径距离,并且从所述搜索方向延伸预定的搜索宽度距离;
为每个搜索方向计算多个相应的预测模型,其中每个所述模型通过从特征空间的维度中选择一个维度子集来计算,所述模型使用与搜索方向相对应的定向搜索量内的投影样本点计算使得协方差最大化;
选择具有对应的预测模型的搜索方向,该预测模型具有对待定量的成分的定量的最大可预测性;
使用与所选搜索方向相对应的所选定向搜索量内的投影样本点作为相邻样本点的所选最小值。
在一个实施方案中,每个定向搜索量被定义为源自所述投影光谱样本点的特征空间的区域。
一个实施方案包括:
通过减小预定的搜索宽度距离来最小化所选的定向搜索量,使得通过由所选维度子集计算并使用最小化的定向搜索量内的投影样本点计算的模型来最大化待定量的成分的定量的可预测性。
在一个实施方案中,通过以下方式计算每个搜索方向的预测模型:
在特征空间和成分的定量之间定义协方差矩阵;
最小化从协方差矩阵中提取的特征向量的数量,从而最小化预测误差;
选择与所述最小值对应的那些特征向量;
使用由所选特征向量定义的多元线性预测模型作为每个搜索方向的计算预测模型。
在一个实施方案中,与由预先确定向量基础定义的投影相结合的所计算的多元线性预测模型提供输入光谱与成分定量之间的解释相关性。
在一个实施方案中,每个所述定向搜索量是通过与由相应搜索方向和投影光谱样本点定义的线相距预定距离定义的多维盒或圆柱体。
一个实施方案包括:
相对于所选定向搜索量内的投影样本点,正交过滤由所选定向搜索量的相应模型计算的待定量的成分的定量的变化。
一个实施方案包括通过以下步骤从所述特征空间内的样本点重复选择相邻样本点的最小值:
在所述特征空间中定义多个搜索方向;
定义包含在所述特征空间中的多个定向搜索量,每个定向搜索量被定义为源自沿着先前选定的定向搜索量的选定的搜索方向的预定搜索半径距离的末端的特征空间的区域;
为每个所述搜索方向计算多个相应的预测模型,其中每个所述模型通过从特征空间的维度中选择一个维度子集来计算,所述模型使用与搜索方向相对应的所述定向搜索量内的投影样本点计算;
选择具有对应的预测模型的所述搜索方向,所述预测模型具有对待定量的成分的定量的最大可预测性;
使用与所述所选搜索方向相对应的所选定向搜索量内的投影样本点作为相邻样本点的所选最小值。
一个实施方案包括重复上述步骤,直到关于待定量的样本的投影光谱以及所选的相邻样本点的投影光谱的协方差达到预定标准为止。
一个实施方案包括:
重复从所述特征空间内的投影样本点中选择相邻样本点的最小值,递归计算所述预测模型;
将所述计算出的预测模型聚集到聚集的预测模型中,从而得到路径模型。
在一个实施方案中,所述路径模型被高速缓存用于成分定量的后续预测,而无需重新计算预测模型。
在一个实施方案中,待预测的定量是要从样品的一种或多种成分确定的类别的逻辑函数。
在一个实施方案中,特征空间中的预定搜索半径距离、预定搜索宽度距离以及多个搜索方向的数量使用迭代优化方法,特别是单纯形算法来确定。
在一个实施方案中,从所述特征空间内的样本点中选择相邻样本点的最小值包括选择高于预定协方差阈值的最小数量的样本点。
在一个实施方案中,预先确定的向量基础是将正交信息保留分解为组成函数或矩阵因子分解,特别是奇异值分解-svd、小波、傅立叶转换、小波或曲波(curvelets)。
在一个实施方案中,所获得的光谱的预处理包括所述光谱的去卷积和/或分辨率增强。
在一个实施方案中,样品是生物的,并且一种或多种成分是生物代谢物,特别是血液代谢物。
还公开了一种非暂时性存储介质,其包括用于实施分光光度法的程序指令,该分光光度法用于从待定量的样品中预测成分的定量,该程序指令包括可执行以进行任何公开的实施方案的方法的指令。
还公开了一种用于从待定量的样品中预测成分的定量的分光光度法装置,该装置包括电子数据处理器,该电子数据处理器被配置用于进行所公开的实施方案中的任何一个的分光光度法。
一个实施方案包括分光光度计和包括用于实现所述分光光度法的程序指令的非暂时性存储介质。
具体实施方式
使用投影模型y=f{x}从光谱知识库x获得准确定量y变得可行:i)协方差是稳定的(xty);ii)光谱特征空间的方差是稳定的(xtx);iii)预测的
不存在跨大数据生物光谱特征空间的全局稳定的xty和xtx。协方差方向是非线性的,且特征向量根据局部特征在整个特征空间上旋转。给定无限数量的可能的x观测值,如果特征空间的方差在整个特征空间上是非线性的,则定量新的未知光谱x新变得不可行。
给定这样的物理约束,在本公开中公开了基于以下事实的关于光谱预测的方法:任何未知光谱x新应与局部子空间处的特征空间一致,使得根据组成数据(xty)的协方差它也可以保持一致的信息。
可以考虑到,没有一种“先验”模型可以定量给定未知x新的物质,因为它与先前的方法(pcr、pls、ls-svm、ann和深度学习)一样。可以假设,对于任何给定的x新,都会存在能够保持一致性来预测
在光谱学中使用子空间识别具有显着的优势:i)由于复杂度降低,子空间的判读变得可行;ii)数据代表性(数据数量)的局部独立性,也就是说,预测不会受到知识库中更多数据的影响;iii)局部多尺度一致性;iv)用于执行定量的谱带的判读;iv)更好地控制定量中使用的哪种谱带;v)光谱校正更准确,因为如果光谱方差一致,则基线、mie和瑞利散射校正会增强光谱带变化;vi)局部一致性之间的特征空间转换(例如,内核、导数、小波);和vii)适应性:由于定量是自学习的,局部适应性将始终在可提供
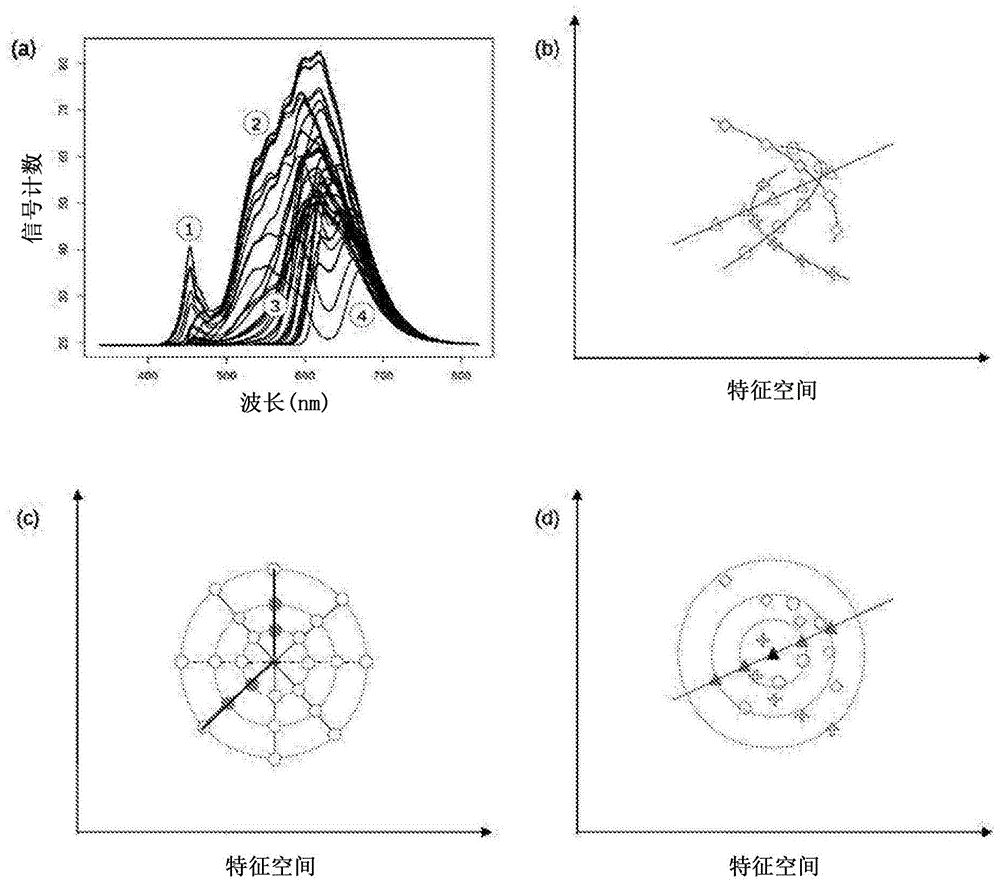
在图1中凭经验解释了基于复杂光谱信息的定量问题。图1a显示了光谱集合,其中成分是不同数量的相同成分的混合物。混合物中存在的物质彼此之间是高度干扰的,因此无法直接导出与浓度的峰相关性以提供简单的定量方法。然而,有四类光谱非线性变化,即,可以提供与特定物质的组成直接相关的四种模式。即使在这样简单的实例下,使用glm(例如pls)也会提供具有高方差的
因此,为了对给定的x新提供准确的定量,必须跨特征空间搜索允许最佳投影的一组邻居,如图1d所示。
图2a显示了当使用集群技术(例如,现有技术(基于光谱的学习者)中使用的分级集群,k-最近邻算法(knn))时,将始终导致带有偏差和可能离群值的次优投影。图2b显示了未知光谱#1和#3在不同局部共变下的最佳投影,而#2是可能通过知识库无法预测的离群值。
在此,公开了一种用于光谱学大数据的自学习方法和装置。新方法能够找到维持一致的xtx和xty的定量一致特征向量。所提出的自学习不会产生整体模型。对于每个新数据,系统必须学习xtx和xty的一致性,以投影x新并估算
所公开的方法的实施方案包括以下三个主要步骤:i)局部几何和子空间识别-其中光谱信息的局部几何被提取为具有支持局部定量/分类的特征特征向量的特征子空间;ii)建立非线性特征映射的知识库-通过应用递归局部几何和子空间识别,可以基于光谱信息的非线性映射构建人工智能知识库的方法;iii)光谱信息的局部优化-通过滤除y和x或它们对应的特征空间转换k和f中的不相关信息,通过最小化局部凸包体积和预测误差来局部优化定量或分类的方法。
以下涉及局部几何和子空间识别。如前所述,推测总是存在能够维持定量的一致特征向量的数据的局部方向集群。该局部集群代表广阔的非线性特征空间内的局部变化模式。因此,让我们考虑n维特征空间f,其中特征空间的坐标与光谱特征的线性组合成比例,这些光谱特征隐式地与样本组成相关。还假设在特征空间的局部点处的离散有限方向代表光谱的变化模式,与样本浓度的局部水平一致。这样就可能实现从光谱x和组成y之间的局部协方差(xty)提取一致特征向量。此外,高度非线性特征空间可以由具有一致定量方向的超维多面体局部表征,即,其对应的凸包所包含的所有数据都呈现一种模式,其中其内部的所有光谱都遵循以低偏差方差定量不同的参数的变化模式。
因此,局部几何与该局部子空间处的组成直接相关,可以找到最佳的定量特征向量。大数据光谱定量和分类的问题减少了对局部几何的搜索,使得:i)最小化多面体的方向/维度的数量;ii)获得使偏差方差最小化的主方向;和iii)使选定的最佳定向多面体的凸壳体积最小化;因此直接线性模型适用于该有限空间近似。
图3用特征空间映射说明了特征空间中的问题。在该实例中,呈现了具有占据不同空间区域的不同类的高度非线性变化的二维特征空间。实线代表具有样本浓度的一致协方差特征,即,沿着这条线,可以找到局部xty的一致特征向量,以便产生
自学习过程着重于搜索一致多面体子空间,其允许以低偏差和方差的样本定量,如图3所示,并使用算法1中存在的进程的伪代码(也参见图17a)。假设新的xi被投影到特征空间中。一旦投影,自学习过程就必须找到相对于y的xi的变化方向范围内的最近邻居。因此,有必要搜索在特征空间中提供正确方向的凸包以进行定量。这种凸包还必须提供最小体积和最小数量的预测
步骤a.方向寻找
目的:找到xi的最小方向和局部子空间几何。
1.初始化:i)在xi投影周围定义具有搜索半径的圆形区域;ii)定义方向的数量;iii)定义每个方向搜索的维度。
2.初始搜索:i)确定最佳特征向量的数量并预测局部模型的误差;ii)去除统计上不一致的方向;
3.准备新的迭代:i)在一致的方向内,去除最差贡献,去除搜索长度或以特定方式增加;ii)考虑每个凸包和xi的极端顶点,计算新的搜索方向;
4.搜索循环:i)确定特征向量的数量和新方向的预测误差;ii)消除最坏的方向;iii)通过消除最差(较小或较大)的长度来重新定义搜索的维度,并相应地增加或减少搜索长度;iii)循环先前的操作,直到没有统计上显着的方向或维度变化发生。
5.输出:最小可行方向数和每个方向的凸包体积。
步骤b.凸包的优化
目的:最小化凸包体积和预测误差
1.初始化:将先前的输出数据合并到定义初始凸包的初始集群中。
2.定义:i)凸包的外部顶点;ii)凸包自适应几何的最小和最大移动边界。
3.主循环:i)确定模型误差;ii)去除离群值;iii)使用单纯形几何优化定义凸包的新边界-对于每个被去除的离群值,向内移动边界;iv)计算新的凸包。进行此循环,直到找不到更多离群值并且模型误差稳定为止。
4.输出:最优凸包和局部模型预测
在此程序的最后,人们希望获得能够预测任何新光谱xi的最佳数据几何。数学和算法细节在算法1中给出。
以下内容涉及特征空间的映射-建立定量知识库。遵循类似的原理,可以在所有特征空间上递归映射自学习过程。这种映射构成了大数据光谱数据特征空间的全球知识库。让我们考虑算法1中的所有步骤,并按照图4所示的逐步顺序协议将其递归地应用于整个特征空间。程序如下:
目的:在特征空间(4a)中顺序映射(4b)协方差的几何。
1.初始化:i)从特征空间的任何给定点开始;ii)定义:搜索圆直径、搜索方向的数量和搜索区域的维度;
2.执行算法1:为光谱xi定义凸包的局部线性几何
3.递归映射:在xi的优化的凸包中选择,新的数据点xi+1,递归执行算法1,直到提取更多的方向来扩展凸包不可行为止。
4.重采样:继续到特征空间中的另一个未覆盖的位置
5.主循环:重复操作3和4,直到确保特征空间体积的给定的覆盖率
6.编译:通过注册要用作缓存模型的所有模型路径,在特征空间映射中编译知识库定量路径(4c)
7.输出:缓存模型的编译映射(4c)
该程序的数学和算法细节在算法2中给出。递归映射的详细信息也可以在图17b中找到。
该过程的结果是在图4c中构建了特征空间定量图。该图构成了人工智能方法和装置的自学习过程。图中的线代表模型局部预测的一致路径,即,当新光谱x新投影到线凸包附近时,很可能会遵循凸包内部其邻居的相似变化模式,并且可以基于局部模型的数据预测。特征空间的特征允许:
i.使用现金模型来加速计算效率-如果将新光谱投影到先前预测线的凸包中,则可以直接使用现金模型直接进行计算,其中计算是直接的;
ii.导致不同定量模式的典型病况的特征描述–许多预测线为不同类型的健康状况及其演变提供代谢信息;
iii.确定信息在整个特征空间中的表现程度如何-只有具有足够数据的区域才允许产生正确的定量和有效的搜索;
iv.提供一张图,以了解随着时间的推移的光谱模式,即,解释光谱模式识别以实施精准医疗;
v.为使用非监督式光谱信息的病况诊断提供更高级别的人工智能基础,允许构建复杂和多因素健康状况的非线性分类图。
以下涉及分类映射。用于分类的自学习人工智能方法的主要目的是通过以下方法在特征空间中找到类几何:i)最大化类的局部体积;ii)在非线性类的情况下,将整个特征空间的总体积最小化;和iii)最小化类预测的误差;通过使用相关特征向量变化来划分类边界。此外,可以预料许多类在整个特征空间中可能是高度非线性的,并且被极度分割。许多类在整个特征空间中也可能具有分散的集群,因为其他条件是特征空间变化的主导因素。
由于健康状况的复杂分类,并且由于许多状况是多变量的,因此,将监督的集群设计为以下几类:i)单一单变量诊断-其中判别函数为单个参数区间或阈值;ii)排他性单变量或多变量诊断-其中仅识别特征空间中每个类别的孤立案件,而与其他类别没有任何重叠;iii)多变量/复杂诊断-其中仅考虑来自特征空间中多个条件的数据重叠(参见图5)。
集群标准允许表征复杂的健康状况并将其映射到光谱特征空间中,构成分类知识库。开发以下程序来构建分类知识图:
目的:在特征空间中顺序映射分类逻辑概率协方差的几何。
1.初始化:a)定义集群标准:a)单变量类;b)排他类或c)多变量类;和d)每个类阈值;b)提供:监督向量s或矩阵s
2.凸包确定:i)在特征空间中选择监督数据;ii)在特征空间中找到监督数据的最大和最小坐标;iii)选择其中一个顶点;iv)定义方向搜索盒的大小;iv)定义凸包的体积增量准则(δv)。
3.检查集群个性:如果min和max无法保持一致的类预测,则集群将以不常见的信息为边界,并且需要按最小全局容量标准进行分段,其中voptimal=maxσi=1nvlocalcluster+minvglobal;如果所有集群都已分离,则minvglobal→maxσi=1nvlocalcluster;如果只有一个局部集群,则:voptimal=maxσi=1nvlocalcluster;
4.初始搜索:i)确定特征向量的数量并预测分类误差;ii)去除统计上不一致的数据;iii)如果未找到相关方向,则通过向内移动到δv重新成形凸包几何,并执行步骤4;重复步骤1和2,直到它稳定。
5.确定集群边界:对于每个集群,执行算法2,其中监督向量s或矩阵s是与相应光谱关联的集群类别的逻辑函数概率。参见图5,如何使用算法2查找集群预测凸包。
6.编译:通过注册它们的凸包,在特征空间图中编译知识库分类集群
7.输出:缓存集群的编译映射
该程序的数学和算法细节在算法3中给出。
在该程序结束时,将特征空间的完整集群图记录为分类知识库。不同条件下所有类型分类的完整组合代表知识库的分类复杂性,其中可以研究条件之间的相互作用及其代谢原因。通过将新的光谱投影到该分类图中,可以基于知识库映射的坐标预测对应条件的预期概率。
以下涉及局部变化的几何。先前的部分解释了本公开的ai如何能够通过使用协方差特征向量提取在特征空间上重复搜索算法来提供定量和分类,从而能够提供定量和分类图。局部变化几何的研究是ai披露的核心。
考虑可以将光谱x和组成数据y的任何集合分别转换(例如,核、导数、傅立叶、小波、曲波)到特征空间f和k中。我们必须找到基数w和c,以便使f和k、t和u的局部潜在方差之间的协方差最大化。该问题被简化为以下特征空间中的局部优化:
f(w,c)=argmax(ttu)
其中:f=twt;和k=uct并经受wtw=1和ctc=1。通过应用拉格朗日乘数法来解决优化问题,可以将其恢复为:
ktf=wσct
这是ktf的奇异值分解,其中w=w[1,],c=c[1,],以及相关的方差σ[1,]。可以进一步得出结论,ftkkftw=λw和ktfftkc=λc。因此,w和c是隐空间ttu中表示的cov(f,k)2=cov(k,f)2的特征特征向量,其中w和c大量生产协方差几何的特征维。
假设以下条件,则相同的推导是可行的:当t=u时,f(w,c)=argmax(ttu)特别有用,因为在收缩法后t变成正交的。该假设也是其他特征向量提取算法的基础(indahl:2014)。
为了研究ttu的几何形状,特征向量w和c的标准正交基是必要的,使得对于每个局部f,可以推导其局部特征维度和几何。这样通过f和k的收缩法来实现:
fi+1=fi-tiwit
ki+1=ki–uicit
其中:ti=fiwi,ui=kici,和wi=wi/||wi||,ci=ci/||ci||。通过解释每个特征向量的ti,wi及其相对于捕获的协方差σ的对应重要性,循环收缩法直到f的最大秩可以确定协方差的几何及其复杂性(pelletal:2007,woldetal:2009)。
当使用其中t是正交的方法时,按以下步骤进行收缩法:
其中p和q通过以下各项确定:
fi+1=fi-tipit
ki+1=ki–uiqit
pi=ftiti(titti)-1
qi=ktiti(titti)-1
从p和q的关系中,可以得出直接线性模型,例如k=fβpls+e,其中:
βpls=w(ptw)-1q
其中βpls是pls回归系数。
t的复杂几何被浓缩为斜投影βpls(phatakandjong:1997),并生成glm的事实,是大数据中pls效率低下的原因,尤其是由于非线性特征空间,如果使用相对大量的维数或组件。因此,该策略意味着ktf的局部结构几乎只具有关于x中包含的y的系统信息,而在不同光谱信号范围内几乎没有随机效应。此外,正确的特征空间转换是一种可以获得相似的ftf和ktf信息结构的转换,因此理想地:
(ktk-λk)vk=0
(ftf-λf)vf=0
(ktf-λkf)vkf=0
局部优化问题仍然构成为f(w,c)=argmax(ttu),但是信息结构的理想限制是相似的(vk~vf~vkf)。在完美条件下,光谱信息与成分共享共线特征向量结构,例如它发生在纯化合物或物质中,干扰可以忽略不计。因此,在第一分量中提供共变最大化是最重要的。
向ai提供对t和w的解释的一种方法是使两者成对正交。我们可以使用产生正交w的pls定义使t正交:
f=twt;t=usvt
f=usvtwt=us(vtwt)
f=towto
其中to=us和wto=(wv)t(ergon:2007,ergon:2009)。通过
tw=t(ptw)-1与正交分数tw有直接对应关系。
因此,ai具有在具有相应的正交w的正交tw或to中执行模式分析的方法,以便得出局部子空间和模型的一致性。
尊重以下特征空间内部关系:
ti=twβt
由最小二乘估计得出:
βt=(twttw})-1twtti
因此,将任何特征空间样本投影到tw都遵循局部相关特征结构的一致线性干涉图样。因此,投影到twt中的任何给定新数据都包含在ti=twβt的置信区间中。
可以通过优化样本和变量来降低局部数据集的复杂性,如图6所示。在算法1的局部方向选择内,必须找到提供一致特征结构的样本和变量组。因此,与简单使用残差的交叉验证相反,也提出了一种将协方差局部稳定性转换的适应函数作为优化程序。局部优化问题具有以下特性:i)盲目选择起始数据集的数量;ii)对每个数据集执行相关的pls回归;iii)投影到分数空间(t=fw);iv)使用稳健的线性回归来确定t内部的特征结构(例如,ransac);v)重做该程序直到达到阈值。然而,在t分数空间中存在线性模型意味着收缩法正在模拟用于构建局部线性pls模型的所有数据中的系统变化。
每个协方差方向的一致性由交叉验证(例如,留一法交叉验证)确定,其中所有数据点都必须维持局部特征结构。对于任何新的未知数据,执行预测如下:
i)确定所选子空间中的预测的一致性;ii)所有训练集的低偏差方差;iii)使用所选数据集中的不同数据来预测未知数据的低偏差方差;iv)以t特征结构的线性度存在。而且,通过导出t中提取的线性特征结构的置信区间,可以获得任何新的未知数据的可预测性,使得还预测了预测的p值。高于预定义阈值的p值可以被认为是分类的或不可预测的。ai可能“先验”地知道预测是否具有必要的准确性,因为它仅使用众所周知的一致特征结构化数据来执行预测。
要提供正确的局部优化模型,必须执行以下操作:
i)最小化残差及其收缩结构;
ii)在相同协方差内最大化样本数量并最小化变量数量;iii)确保t空间内部的一致性;iv)f和k之间的特征结构相似性。考虑到所有这些目的,我们可以使用以下优化函数将其表示为:
其可被认为是“校正”的press(预测的误差平方和),其中:npc是分量数,n是数据数,nsel.vars是从变量总数nvars中选择的f变量数,cov(v,w)是ftf和ktf特征向量的协方差,且p值是t空间中最小二乘模型的概率值。在该优化结束时,获得了最佳的局部模型。通过正交信息过滤执行进一步的模型求精。
以下涉及局部子空间的一致性。局部特征空间f的一致性通过以下方式得到保证:i)f和k之间的特征结构相似性;ii)低复杂度;和iii)信息确定性。在以下情况时,f和k具有相似的特征结构:
j=argmax(vkt\vf)
其中:f=ufsfvft=tfvft;和k=ukskvkt=tkvkt。
存在x和y的有效转换,其中f=f(x)和k=f(y),因此理想地tk=tf。由于光谱信息是多尺度的,因此可以提出以下信号基础的多尺度优化(例如,傅立叶、小波、曲波):
f=σi=1zθjμj
其中i's是选定的单个信号标度,因此vktvf被最大化。
优选地,ktf的特征结构是极其重要的。f的复杂度可以通过其特征值σ的分布来估计,其定义特征空间的特征维数。在光谱信号中,人们期望σ指数地减小到极限值:
σi=σr+(σ1-σr)e-ki
其中,σi是期望的第i个特征值,σr是残余特征值,是最大特征值,且k是衰减因子。特征空间的局部复杂度可以通过以下度量来衡量:
c=npc/(kn)
当k→+∞时,意味着c→0。当npc→1且n>>npc时,这种极限是渐近近似的。当σr→0时,ktf是秩亏的。特征结构的随机性通过f、k和ktf的随机化获得(martinsetal:2007d)。行随机化可以确定样本光谱的极限,该极限确定了大量生产行向量的特征向量的数量;其中,列随机化确定允许变量大量生产列向量的特征向量的限制。通过交叉验证可以提供特征向量数量的统计稳定性。
以下涉及子空间信息优化。给定前面的程序,特征空间的选定方向已经提供了稳定的线性模型。进一步预期,最少数量的特征向量是预测y所必需的。尽管信号已经过预处理(例如,基线、散射效应、杂散光)并转换为更好的特征空间基础,但数据中总会有系统的干扰。此类干扰影响在第一分量之外的分数加载(t-p)关系。因此,理想关系应仅使用一个特征向量来获得。这并不总是可行的,但是可以通过正交滤波极大地简化模型关系。
f和k可能具有彼此不相关的系统信息。因此,必须知道本地信息是如何构造的,信息f和k有多少共同点,以及通过执行正交过滤有多少是独立的(tryggandwold:2002;tryggandwold:2003;bylesjoetal:2008)。图7显示了正交过滤如何导致较低的复杂特征结构。图7a至7c显示了前面的步骤如何使用x1、x2和x3子集优化局部校准数据集,从而将线性模型的复杂度大大降低到只有三个预测潜在变量。这样的结果仍然表明,x1、x2和x3子集具有系统性干扰并且可以进行正交过滤,因此:
f=tpt+topot
k=tqt+uopot
其中t是最大化协方差的具有在f和k之间的公共信息的分数,而p、q是相应的加载。to和uo为协方差的正交分数,且po、qo为相应的正交加载;即,to与k正交,而uo与f正交(trygg和wold:2003)。
通过递归选择样本和变量,可以使tpt最大化(图7c至7d),其中潜在变量的数量被最小化到接近1的最佳较低水平,即,不需要收缩,并且在f和k之间存在直接对应关系。期望正确的特征空间转换导致topot→0,并且由常规pls算法获得的f=tpt。
类似地,uopot将为零。具有分析级质量的任何定量都不应有与其定量正交的任何系统变化。当uopot显著时,这意味着无法对ai进行适当的训练以提供准确的预测,因为原始训练信息会遭受系统误差。在正确的条件下,uopot→0并且tpt>>>topot使得k=fβpls。
如果topot显著,则特征空间转换无效。在这些情况下,通过首先将正交过滤器应用于to=fpo/(potpo)和fcorr=f-topot,和k=fcorrβpls来执行预测。为了完整性,该方法在算法5中进行描述(也参见图17c)。
以下涉及用于子空间特征的度量。所提出的方法的主要优点之一是通过合并本地学习指标图来表征自学习知识库的可能性,例如:i)数据表示的数量;ii)特征结构复杂度;iii)f和k之间的共线性;iv)预测的平方和(press);v)ktf的方差;和vi)模型信息结构。表1列出了知识库的详细度量。
通过表征特征空间,ai系统通过了解特征空间的不同区域如何准确地覆盖定性与定量,来管理自学习和预测二者。
以下涉及自学习机制。前面的部分演示了自学习方法和装置的算法和代数过程。在此,它提供了如何将程序整合到一个系统中,该系统无需人工干预即可从馈送数据自动实现自学习,使得它可以:i)通过数据馈送从零数据到大数据海量数据自主学习光谱数据;ii)确定最佳捕获协方差的最佳多尺度特征空间;iii)根据知识库以及如何处理不可预测的数据来预测新的未知数据;iv)自学习构建定量和分类图,并使用它们执行计算有效的预测并从新数据中学习。
体液和身体组织的生物变异性极大。在大数据中,可能永远无法确定代表性样本的含义来构建强大的知识库,以能够构建能够应对所有可能光谱组合的整体模型策略。而且,生物系统逐渐发展,其生物化学也在不断变化、新的细胞、新的蛋白质、新的代谢物。因此,应用于生物系统的光谱ai必须始终自学习。通过不断添加系统无法预测的新数据,开发的系统能够从非常有限的初始知识库中进行自学习。该系统通过使用前面各节的度量和方法通过计算特征空间和初始知识库开始。通过管理特征空间的每个子空间的可预测性,系统可以维持新获取的数据是可预测的还是应该进入学习周期。如果无法预测,则将数据添加到隔离数据库中,该隔离数据库充当没有邻居(例如,一开始,任何系统都不会覆盖所有特征空间)或一致建模的数据存储库。一旦新收集的数据完成允许开发一致的子空间知识库的特征空间的相应区域,就可以将在隔离数据库中的收集数据仅传递给知识库。
图8显示了自学习过程的主要机制。让我们考虑,最初给系统提供有限数量的光谱对以及相应的组分x和y。记录任何新的x时,会将其投影到初始特征空间图中,并测试它是否属于现有的知识库。如果投影在现有模型路径的附近,并且使用现有缓存模型进行直接预测,则制定预测。如果预测不在期望的质量之内,并且如果存在可能的邻居,则通过算法1建立新模型,执行预测,并兑现通过算法2获得的相应模型和路径。
当任何新光谱投影到特征空间且没有近邻时,其立即被隔离。系统进入学习周期,并要求用户或系统提供待隔离的样本的组成。一旦它具有配对x和y,它就搜索隔离邻居。如果它没有邻居,数据只是保持隔离。如果它具有邻居,学习过程将开始使用算法1和2搜索两个局部模型并构建局部协方差图。仅当新数据连同隔离数据能够产生一致的局部模型和模型路径时,才可以证明该数据可以传递到知识库中。随着新数据的添加,知识库接收不断更新,并将预测扩展到特征空间的新区域。
从这个意义上说,系统:i)永远不会产生不在知识库中的预测;ii)维护和研究隔离数据库;iii)验证隔离数据以传递到认证的知识库中;iv)仅使用认证数据来构建知识库和预测;v)在没有人工干预的情况下自学习;vi)与数据大小无关,使用馈送数据扩展知识库。此外,该方法不需要大型数据库来开始构建知识库并执行预测,例如深度学习神经网络。该系统仅使用经过认证的知识库,因此,预测不会像其他建模方法那样遭受偏差,因为它们需要大量数据才能生成全局稳定的模型架构。协方差、分类图和缓存的模型使系统的计算效率很高。该系统可以将任何光谱仪变成独立运行的机器,与当今的现有技术系统一样,不需要人工干预即可建立数学模型。
找到正确的x转换为f和y转换为k的基础是构建全面的特征空间的核心,其中如第v节所述,该空间提取局部线性模型。特征空间转换的基本原理是最大化f和k之间的特征结构相似性。如果基本转换能够过滤x和y与噪声之间不相关的系统方差,则f和k的特征结构变为相等的。
图9显示了如何执行特征空间转换。任何光谱信号都会分解为标准正交基(例如傅立叶、小波、曲波)。这些基础提供了独立的基础,以根据基础性质重构信号的尺度。如果存在,有关任何代谢物的信息会分散在不同的光谱范围内,因此,必须使用尺度重构从原始信号中提取特定分子的最佳光谱变化。
在全光谱分解之后,必须找到最佳的基础,以提供使f和k之间的特征结构相似性最大化的组合,其中f=tfvtf和k=tkvt,且vtkvf是最大的。在信息完全匹配的情况下,tf=tk=t,使得f和k都具有相同的特征结构。请注意,在nipalspls下,正面假设最大化使未转换的x和y相关,即信息结构的一部分具有相同的特征结构,即相同的分数t。在此,我们首先构建特征空间,其允许分数相似性假设,极大地促进了所公开内容的成功。期望一旦实现特征空间转换,k和f之间将存在直接线性关系:k=fβ。因此,我们证明的是,只有在k和f的特征结构相似的情况下,才可能使用假设的pls或svm类型。否则,系统信息将污染分数内部关系假设和一致性。相同的原理可以应用于人工神经网络或“深度学习”。
因此,让我们考虑一个分解为标准正交基μk和f二者:
f=ufμ
k=ukμ
其中存在使uf=uk的误差e最小化的uf和uk的组合,其中β=(uftuf)-1uftuk。查找特征结构的最大相似性的问题是查找最大化f和k之间的公共信息的uf和uk的最佳线性组合的优化问题,从而自动定义特征空间转换。
通过执行此转换,消除了光谱和组分的大多数不相关的系统性和随机性成分。该系统自学习如何通过进化算法(例如,单纯形法、粒子群优化算法和遗传算法)提取定量特定代谢物的μ的最佳组合。一旦了解到特定子空间的特征空间转换,系统就无需重新计算,而是直接使用该转换来产生预测。
图10显示了特征空间转换的流程图,其中:i)原始信号被分解;ii)最佳基础的初始估计通过线性回归估计;iii)通过进化方法优化基础组合。如果找到基础的组合,从而满足特征结构标准,则有关转换的信息将被缓存,并在未来的预测中用作构建特征空间的特征空间转换。
以下涉及缓存模型、协方差和分类图。使用缓存模型、协方差和分类图对于计算效率高的自学习人工智能至关重要,从而可显着节省计算资源。图11a显示了如何使用缓存的模型来加快预测。记录新光谱后,将其投影到特征空间并检查附近的模型路径。如果是这样,则通过使用第iv节中的方法执行预测;一旦记录了任何新光谱,就会执行以下动作:
i)是能够准确执行预测的缓存模型,并将结果呈现给最终用户;
ii)如果邻居模型能够提供边界阈值质量预测,则系统可以在计算新模型和更新知识库之前提供共识预测;
iii)如果邻居模型不能提供足够的质量预测,则将对局部模型进行新的搜索,在知识库中部署新的模型路径。
以下涉及结果和讨论,特别是定量。在此,通过对未知血液和血清样本的预测进行基准测试,演示了自学习人工智能方法的有效性。将结果与最先进的化学计量学偏最小二乘(pls)全局模型进行比较,以提供与现有技术进行比较的简单基础。通过交叉验证获得在偏差方差之间平衡的全局偏最小二乘法,以得出最小数量的特征向量或潜在变量(lv)。全血和血清未知样品的预测根据以下方面进行分析:i)模型复杂性;ii)平均预测误差(%);和iii)共线性-皮尔逊相关性(r2)。
图13举例说明了pls为什么无法应付诸如血液的生物流体的复杂性。尽管红细胞是血液的主要细胞成分,并且与血红蛋白含量直接相关,但可以预期线性模型将足以准确预测红细胞的数量。图13a显示恰好相反的情况,红细胞光谱定量受到显着干扰高度非线性影响,使得pls模型在高红细胞计数(例如>5×1012细胞/l)下显示出非常高的方差和显着的偏差。干扰以pls模型的7个lv表示。这意味着非线性迭代最小二乘必须压缩7个特征向量才能在定量红细胞计数的数据中找到共同方向。这种较大的差异意味着,即使主要成分表现出复杂的光谱模式,一旦将其简化为线性定量,就可以获得显着的预测偏差(11.50%,表1)。通用线性模型难以实现医疗保健中的分析等级预测。
图13c显示了白细胞的pls预测。白细胞以低于红细胞的浓度存在于血液中,但仍然是相当大比例的细胞成分。量级的差异足以表明其不可能用pls预测白细胞。图13c的结果表明,预测具有非常显着的方差和较大的偏差。pls只能提供误差为27%(r2=0.45)且具有大量lv(10)的模型,这表明大量的光谱干扰会影响孔血中白细胞的定量。
红细胞和白细胞是一个很好的例子,说明自学习方法如何处理光谱信息的复杂性,以基于局部多尺度建模提供准确的预测。图13b和13d分别显示了红细胞和白细胞的自学习人工智能结果。
这两个参数均显示出极低的方差和偏差,允许对医学等级进行定量,误差只有2.4%和5.15%,并且相关性非常显着(表1)。
最重要的是,两个模型的复杂度降低到仅一个lv。自学习人工智能能够找到局部多尺度线性关系,过滤变量和样本,使得发现光谱信息与定量之间的直接对应关系,从而滤除生物样本中的复杂干扰效应。
表1恢复了全血和血清参数的定量结果。血象参数,例如红细胞、血红蛋白、血细胞比容、mcv、mchc、白细胞和血小板。结果表明,通过自学习方法和装置进行的改进如何非常显着,其中所有参数估计值显示在研究范围内的低于6%的误差。
图14显示了血清中胆红素和肌红蛋白定量的结果。胆红素是血清的重要成分,呈黄棕色颜色。肌红蛋白以较低含量存在,但在存在时,其可见指纹图谱在可见近红外区的血清中非常显着。因此,还可以预期可以通过pls模型对两个分子进行线性定量。图14a和14c中的结果表明,胆红素和肌红蛋白pls预测显示出非常显着的方差,误差分别为12.5%和31.0%。尽管这些分子在光谱信号中提供了非常强的指纹,但它们仍然遭受明显的干扰。
最相关的结果是当使用公开文本14b和14d的自学习人工智能方法时,偏差方差显着减小的事实。大多数模型降低了复杂度,并且以较高浓度呈现的所有参数仅使用1个特征向量投影(一个lv)。所提出的方法能够找到与分子定量线性相关的局部多尺度光谱信息。从这个意义上讲,所有研究的血象参数(红细胞、血红蛋白、血细胞比容、mcv、mchc、白细胞和血小板)均能够达到分析级质量,偏差低于6%。
对于血清,也可以得出类似的结论,其中仅使用1lv即可直接定量高浓度参数(如胆红素)或高吸收率(如肌红蛋白)。其他较低浓度的参数(例如葡萄糖、肌酐、crp、甘油三酸酯、尿素和尿酸)将其模型复杂度大大降低到2至3个lv。这表明较低的浓度参数会受到更多的干扰和局部变化,并且其精度开始受到检测器背景噪声的影响。
图15呈现了本公开的pls与自学习人工智能的基准测试程序。pls建模只能维持:红细胞、血红蛋白、mcv、mchc、血小板、胆红素和crp的poc定性定量分析。这些参数的误差为约7%至12%。使用pls建模估算的所有其他参数均未满足poc的15%误差标准(参见图15)。自学习ai可以在以下参数中达到医学分析级质量:红细胞、血红蛋白、血细胞比容、mcv、mchc、白细胞、血小板、胆红素、葡萄糖、肌红蛋白、crp、甘油三酸酯和尿酸。只有肌酐和尿素定量高于5%的限制,但有资格进行poc定性分析。所提出的自学习人工智能方法极大地解决了背景技术中存在的先前的技术障碍,允许光谱学获得分析等级误差。
以下涉及结果和讨论,特别是分类。本文还证明了所提出的自学习方法对已知健康状况进行分类的有效性,例如:贫血、白细胞增多、血小板减少、血小板增多、肝功能不全、糖尿病、急性心肌梗塞、肾功能不全和炎症。根据诊断截止值对这些疾病进行分类:i)贫血-红细胞计数水平低于4*1012/l,血红蛋白水平低于13g/dl;ii)白细胞增多-白细胞水平高于1010/l;iii)血小板减少-血小板水平低于100*109/l;iv)血小板增多症-血小板水平高于400*109/l;v)肝功能不全-胆红素水平高于1.2mg/dl;vi)糖尿病-葡萄糖水平高于100mg/dl;vii)急性心肌梗塞-肌红蛋白水平高于147ng/ml;viii)肾功能不全-肌酐水平高于1.3mg/ml;ix)炎症-c反应蛋白水平高于2.0mg/dl。
表2分别以真假、正负组合呈现了所提出条件的分类结果。结果表明,自学习分类优于线性分类器,逻辑pls。对于其中诊断的截止值处于低浓度的情况(例如血小板减少)或遭受复杂干扰的情况(例如,高水平白细胞感染(白细胞增多))而言,这尤其重要。全局pls模型仅能够维持针对贫血、血小板增多和急性心肌梗塞的定点照护(point-of-care)(分类误差为15%)。大多数参数显示出50%到80%的水平的正确诊断的机会,因此使用线性分类器证明对健康状况的分类非常有限。
自学习方法始终能够执行高于85%的正确诊断机会。自学习方法能够正确诊断100%的贫血、血小板增多和急性心肌梗塞病例。诸如白细胞增多、糖尿病和肝功能的疾病也获得了近乎完全正确的分类(97%的正确概率)。这是因为未分类的值接近截止值,并且在分类方法中未考虑实验室误差。如果考虑到这一点,则误差容限为5%,这些条件也将被100%分类。血小板减少和肾功能不全的分类率分别为87%和89%(参见表2)。由于血小板和肌酐值在光谱中的信号信息非常低(例如,肌酐具有14%的使用自学习的预测,参见表1),因此这样的结果是可预期的。然而,这两个条件均低于15%的分类误差。
本领域普通技术人员将理解,除非本文另外指出,否则在所描述的文字或流程图中的步骤的特定顺序仅是说明性的,并且在不脱离本公开的情况下可以改变。因此,除非另有说明,否则所描述的步骤是如此无序的,意味着在可能的情况下,可以任何方便或期望的顺序来执行步骤。
应当理解,本文所描述的本公开的某些实施方案可以作为驻留在固件和/或具有控制逻辑的计算机可用介质中的代码(例如,软件算法或程序)并入,该代码具有控制逻辑以使得能够在具有计算机处理器的计算机系统上执行,例如本文所述的任何服务器。这种计算机系统通常包括存储器,该存储器被配置为提供来自代码执行的输出,该代码根据该执行来配置处理器。可以将代码布置为固件或软件,并且可以将其组织为一组模块,包括本文所述的各种模块和算法,例如,面向对象的编程环境中的离散代码模块、函数调用、过程调用或对象。如果使用模块来实现,则代码可以包括单个模块或多个模块,彼此协作操作以配置在其中执行它的机器,以进行相关联的功能,如本文所述。
不应以任何方式将本公开局限于所描述的实施方案,并且本领域普通技术人员将预见到对其修改的许多可能性。上述实施方案是可组合的。所附权利要求进一步阐述了本公开的特定实施方案。
参考文献
p.geladiandb.kowalsky.partialleastsquaresregression:atutorial.analyticalchemicalacta,185:1-17,1986.
a.phatakands.jong.thegeometryofpartialleastsquares.journalofchemometrics,11:311-338,1997.
huang,g.b.huan,s.song,andk.you.trendsinextremelearningmachines:areview.neuralnetworks,61:32–48,2013.
l.ramirez-lopez,t.behrensa,k.schmidt,a.stevens,j.a.m.demattê,andt.scholten.thespectrum-basedlearner:anewlocalapproachformodelingsoilvis-nirspectraofcomplexdatasets.geoderma,195-196:268-279,2013.
d.p.solomatine,maskey.m.,andshrestha.d.l.instance-basedlearningcomparedtootherdata-drivenmethodsinhydrologicalforecasting.hydrol.process,22:275-287,2008.
t.naes,t.isaksson,andb.kowalski.locallyweightedregressionandscattercorrectionfornear-infraredreflectancedata.anal.chem.,62(7):664-673,1990.
c.d.christyands.a.dyer.estimationofsoilpropertiesusingacombinationofspectralandscalarsensordata.
j.s.shenk,m.o.westerhaus,andp.erzaghi.localpredictionwithnearinfraredmulti-productdatabases.journalofnearinfraredspectroscopy,5:223-232,1997.
t.fearnanda.m.c.davies.locally-biasedregression.journalofnearinfrared,11(6):467-478,2003.
a.m.cdaviesandt.earn.quantitativeanalysisvianearinfrareddatabases:comparisonanalysisusingrestructurednearestinfraredandconstituentdata-deux(carnac-d).journalofnearinfrared,14(6):403-411,2003.
f.goge,r.joffre,c.jolivet,i.ross,andl.ranjard.optimizationcriteriainsampleselectionstepoflocalregressionforquantitativeanalysisoflargesoilnirsdatabase.chemometricsandintelligentlaboratorysystems,110(1):168-176,2012.
l.ramirez-lopez,t.behrens,k.schmidt,a.stevens,j.a.m.demattê,andt.scholten.
thespectrum-basedlearner:anewlocalapproachformodellingsoilvis-nirspectraofcomplexdatasets.
geoderma,195-196:268-279,2013.
l.ramirez-lopez,t.behrens,k.schmidt,r.a.viscarrarossel,j.a.m.demattê,andt.scholten.distanceandsimilarity-searchmetricsforusewithsoilvisnirspectra.geoderma,199:43-53,2013.
u.g.indahl.thegeometryofpls1explainedproperly:10keynotesonmathematicalpropertiesofandsomealternativealgorithmicapproachestopls1modelling.journalofchemometrics,24:168-180,2014.
r.j.pell,l.s.ramos,andr.manne.themodelspaceinpartialleastsquaresregression.journalofchemometrics,21:165-172,2007.
s.wold,m.hoyc,h.martens,j.trygg,f.westade,j.macgregor,andb.m.wise.theplsmodelspacerevisited.journalofchemometrics,23:67-68,2009.
r.ergon.findingy-relevantpartofxbyuseofpcrandplsrmodelreductionmethods.journalofchemometrics,21:537-546,2007.
r.ergon.re-interpretationofnipalsresultssolvesplsrinconsistencyproblem.journalofchemometrics,23:72-75,2009.
r.c.martins,v.v.lopes,p.
- 还没有人留言评论。精彩留言会获得点赞!