基于持续深度学习的ECG数据分类方法
本发明涉及基于持续深度学习的ecg数据分类方法,属于ecg数据分类技术领域。
背景技术:
深度神经网络是模仿人脑机制构建的具有局部特征提取和学习能力的深层架构神经网络。近年,随着人工智能技术的不断发展和成熟,利用深度学习算法在实现心电数据分析引擎来自动提取患者心电图特征以及实现对心电数据的自动分类等方面已经取得了新的突破。例如,支持向量机(svm)、双子支持向量机、序列到序列的深度学习方法、基于注意力的lstm-cnn混合模型等方法。尽管利用这些深度学习模型可以准确地、客观地自动分类心拍类型;但是,这些模型目前都只是针对于一种采样率的心电数据;然而,当用针对一种采样率的心电数据训练好的模型去对另一种不同采样率的心电数据实现分类时,则会导致分类效果不佳,准确率较低,模型的泛化能力不强和迁移能力较弱的情况出现。
目前的深度学习模型并不能很好地适应新任务;当训练好模型再去学习新任务的过程中,效果并不是很好;不能够在学得新知识和保护旧知识之间达成平衡;因此,深度学习模型当下都面临着同样的问题:如何增强模型迁移能力和克服灾难性遗忘的发生。目前心电数据识别分类存在如下问题:
1)效率不高。在对心电信号进行分类时,分析心电信号耗费太长的时间将显示不出计算机分析信号的优势,并且诊断耗费的时间越长就越不利于患者的身体健康,就存在越多的隐患,效率不高。
2)仅针对与一种采样率的数据。目前,对于心拍分类的算法研究,大多数算法、模型利用计算机进行心拍分类时,都仅仅是针对于一种采样率的,这并不能够完美地体现出深度学习模型提出的初衷。而且,由于一些不常见的心拍类型所对应的数据较少,模型得不到足够的数据进行训练;所以在对心电信号处理的时候,计算机可能会无法判断出或误判这类不常见的心拍类型。因此,如果能够对不同采样率的心电数据分类,不仅可以提高算法的可移植性和可扩展性,还可以提高分类模型训练和更新的效率。
3)现有的数据较少。现实中已有的且被准确标记的ecg标准数据库较少;如何能够基于现有数据较少的情况下,设计有效的、自适应能力较强的分类模型,减少分类误差也是亟待解决的问题。
不同的采样率对心电图机测量精度的影响主要体现在对r-r间期和qrs复波高度的测量误差。持续学习是一种深度学习设置方法,其要求在保证重要旧知识不被遗忘的同时,能够从新任务中,获得新知识。如果我们能够利用一个加入持续学习方法的深度模型对不同采样率的心电数据实现心拍类型的自动分类,不仅可以提高模型的泛化能力、迁移能力和分类效率,打破当下深度学习模型仅对于一种采样率的心电数据实现心拍分类的状况;还可以检测出较少见的部分心拍类型;这将会更近一步地促进智慧医疗领域的发展。
技术实现要素:
本发明所要解决的技术问题是:提供基于持续深度学习的ecg数据分类方法,能够对两种不同采样率的心电数据进行自动、高效、准确地分类心拍类型,进一步提高分类精度,加强模型的泛化能力。
本发明为解决上述技术问题采用以下技术方案:
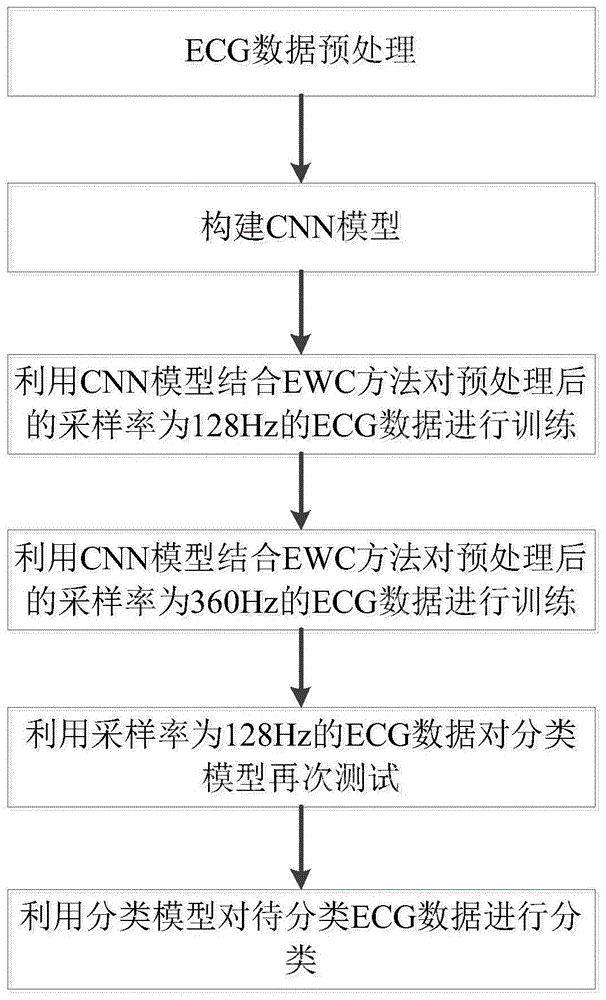
基于持续深度学习的ecg数据分类方法,包括如下步骤:
步骤1,获取采样率分别为128hz和360hz的ecg数据,对采样率为128hz的ecg数据进行预处理,得到采样率为128hz的心拍样本,同样对采样率为360hz的ecg数据进行预处理,得到采样率为360hz的心拍样本;
步骤2,构建卷积神经网络模型,并设置卷积神经网络模型的超参数:学习率、样本训练批次数和迭代次数;
步骤3,利用步骤2构建的卷积神经网络模型结合ewc方法对采样率为128hz的心拍样本进行训练并测试,得到第一次训练好的卷积神经网络模型;
步骤4,利用第一次训练好的卷积神经网络模型结合ewc方法对采样率为360hz的心拍样本进行训练并测试,得到第二次训练好的卷积神经网络模型即ecg数据分类模型;
步骤5,利用采样率为128hz的心拍样本对ecg数据分类模型进行测试;
步骤6,获取待分类的ecg数据,采用ecg数据分类模型对待分类的ecg数据进行分类,得到分类结果。
作为本发明的一种优选方案,步骤1所述对采样率为128hz的ecg数据进行预处理以及对采样率为360hz的ecg数据进行预处理,所采用的方法相同,对采样率为128hz的ecg数据进行预处理的具体过程为:
利用小波变换对采样率为128hz的ecg数据进行去噪,对于去噪后的ecg数据定位qrs波,根据qrs波中r波的位置截取一个心拍样本,共截取3000个心拍样本,每个心拍样本的长度均为250个点,每个心拍样本都是根据qrs波中r波的位置向左侧取100个点,向右侧取150个点。
作为本发明的一种优选方案,步骤2所述卷积神经网络模型包括依次连接的第一卷积层、第一池化层、第二卷积层、第二池化层以及全连接层,卷积神经网络模型的超参数:学习率设为0.01、样本训练批次数设为500和迭代次数设为25。
作为本发明的一种优选方案,所述步骤3的具体过程如下:
3.1,将采样率为128hz的所有心拍样本与各自对应的分类标签打乱,并划分其中50%的心拍样本为第一训练集,剩余的50%为第一测试集;
3.2,将第一训练集输入步骤2构建的卷积神经网络模型中进行训练,得到第一次训练好的卷积神经网络模型以及模型的参数,利用fisher信息矩阵计算每个参数的重要性,设定第一损失函数为:
其中,l1(θ)表示第一损失函数,l1cur(θ)表示第一次训练的损失,λ为学习率,f1,i表示第一次训练得到的第i个参数的重要性,θ0,i表示初始化的第i个参数,
3.3,利用第一测试集对第一次训练好的卷积神经网络模型进行测试。
作为本发明的一种优选方案,所述步骤4的具体过程如下:
利用第一次训练好的卷积神经网络模型结合ewc方法对采样率为360hz的心拍样本进行训练并测试,得到第二次训练好的卷积神经网络模型即ecg数据分类模型
4.1,将采样率为360hz的所有心拍样本与各自对应的分类标签打乱,并划分其中50%的心拍样本为第二训练集,剩余的50%为第二测试集;
4.2,将第二训练集输入第一次训练好的卷积神经网络模型中进行训练,得到第二次训练好的卷积神经网络模型以及模型的参数,利用fisher信息矩阵计算每个参数的重要性,设定第二损失函数为:
其中,l2(θ)表示第二损失函数,l2cur(θ)表示第二次训练的损失,λ为学习率,f2,i表示第二次训练得到的第i个参数的重要性,
4.3,利用第二测试集对第二次训练好的卷积神经网络模型进行测试。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
1、本发明适用于两种不同采样率的ecg数据分类。如今,工业界中几乎都是使用一个或多个模型来对应一个任务;但是为了让这些模型更具备人的思维方式,让模型能同时解决多个任务,同时把过去学到的先验知识运用到新的任务上,解决灾难性遗忘的问题。本发明一方面利用cnn模型来对ecg数据进行分类,提高模型的分类准确率;另一方面,将ewc方法融入到cnn模型的训练过程中,顺序地利用不同采样率的ecg数据进行同一个网络模型训练和测试,并有效地解决了灾难性遗忘的问题。因此,本发明可以适用于不同采样率的心电数据分类。
2、本发明虽然是对两种不同采样率的ecg数据进行训练和测试;可能在训练的过程中产生遗忘,但是最后结合ewc方法仍然可以保证模型的准确率。这是由于结合ewc方法的cnn模型;在训练过程中,可以保护重要性参数(即相当于存储先验知识),使其微小地变化;对于重要程度较小的参数,可以适当大幅度变化,来使得模型适应新的任务。因此,本发明可以保证模型的分类准确率。
附图说明
图1是本发明基于持续深度学习的ecg数据分类方法的流程图。
具体实施方式
下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
本发明利用持续学习(continuallearning,简称cl)中elasticweightconsolidation(简称ewc)方法和卷积神经网络(convolutionalneuralnetworks,简称cnn)建立心电数据的自动分类模型。本发明将结合ewc方法的cnn模型针对两种不同采样率的心电图数据(electrocardiogram,简称ecg)进行分类,解决训练过程中的灾难性遗忘问题;进一步提高心跳分类的效率和精度。如图1所示,本发明基于持续深度学习的ecg数据分类方法的具体流程如下:
步骤1,ecg数据预处理。预处理主要工作是小波变换去噪、定位qrs波、提取ecg信号中的心拍。
本发明中使用到的数据来自于美国mit-bih心律失常数据集。心拍类型一般分为正常搏动(normalbeat,简称n)、左束支传导阻滞(leftbundlebranchblockbeat,简称l)、右束支传导阻滞(rightbundlebranchblockbeat,简称r)、室性早搏(prematureventricularcontraction,简称v)、室上性早搏或者异位心搏(prematureorectopicsupraventricularbeat,简称s)等等;在本次实验中,我们主要分类的心拍类型有四种,分别是n、l、r、v。首先,我们利用小波变换对ecg数据进行去噪;仅接着,定位qrs波;根据qrs波中r波的位置截取一个心拍;这是由于qrs波是在心拍的各波段中,往往是最大的、最明显的、最尖锐的;而且qrs波具有奇异性,其存在不可导点;因此qrs波最利于检测。其中,对于采样率为128hz和360hz的ecg数据,本发明均分别取3000个心拍样本;我们截取的每个心拍长度均设定为250个点,向左侧取包含100个点,向右侧取包含150个点。
步骤2,构建cnn模型。
构建cnn模型,初始化cnn模型超参数,设置卷积神经网络模型的超参数:学习率、样本训练批次数、迭代次数。本次实验中,我们搭建的模型为2个卷积层、2个池化层和一个全连接层的cnn模型;其中,设定的超参数:学习率(learningrate)设为0.01,样本训练批次数(batch_size)为500,迭代次数(epoch)设为25。
步骤3,任务1:利用cnn模型结合ewc方法对预处理后的采样率为128hz的ecg数据进行训练。
3.1将采样率为128hz的所有的数据与对应的标签打乱。将相同标签的数据打乱主要是为了消除数据间的相关性,提高卷积神经网络模型的泛化能力。
3.2划分数据集。采样率为128hz的样本个数为3000;我们设定1500个作为训练样本,1500个作为测试样本。
3.3将训练集的数据输入到搭建好的cnn模型中进行训练,获取模型对于该任务的最优参数。利用ewc中的fisher信息矩阵计算参数的重要性,保护该任务的重要性参数,避免灾难性遗忘(catastrophicforgetting,简称cf)。为了保护对于任务1较重要的参数在后续任务的训练过程中不受影响,我们利用fisher信息矩阵来计算每个参数的重要程度;其中,每个参数的重要性我们使用fi来表示。此外,设定该训练的损失函数为:
其中,lcur(θ)为当前任务(任务1:训练128hz的任务)的损失,λ为学习率,f1,i是对任务1中每个参数重要性的评估,θ0,i表示初始化的参数值,
3.4训练完成后保留模型参数,输入测试集进行测试,此时的模型可以输入未知类别的ecg数据实现自动分类。训练完成后,对于该任务的最优参数我们用
步骤4,任务2:利用cnn模型结合ewc方法对预处理后的采样率为360hz的ecg数据进行训练。
4.1将采样率为360hz的所有的数据与对应的标签打乱。
4.2划分数据集。采样率为360hz的样本个数为3000;我们依旧设定1500个作为训练样本,1500个作为测试样本。
4.3利用任务1中训练好的模型进行训练,获取模型对于该任务的最优参数θi。利用fisher信息矩阵计算任务2中参数的重要性,保护该任务的重要性参数,避免灾难性遗忘。此外,我们将损失函数设定为:
其中,l2(θ)表示第二损失函数,l2cur(θ)为当前任务(任务2:训练360hz的任务)的损失,λ为学习率,f2,i是对任务2中每个参数重要性的评估,
步骤5:经过任务2的训练后,对任务1中采样率为128hz的数据再次测试;检测模型是否有效、是否会产生灾难性遗忘。经过任务1、任务2的训练后,需要使用两次训练后得到的模型再次对采样率为128hz的ecg数据进行测试,来验证本专利提出的模型在心拍分类上的有效性。
步骤6,获取待分类的ecg数据,采用步骤4训练得到的ecg数据分类模型对待分类的ecg数据进行分类,得到分类结果。
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!