一种基于MELP的低比特数字语音矢量量化方法和系统与流程
本发明涉及信号处理技术领域,尤其涉及一种基于melp的低比特数字语音矢量量化方法。
背景技术:
在现阶段,低比特的数字语音压缩算法的研究越来越成熟,而在低比特数字语音算法中,混合激励线性预测melp(mixedexcitationlinearprediction)算法具有自己特有的优势,2.4kbpsmelp是在基于lpc(线性预测编码)的基础上结合混合激励,多带激励以及原型波形内插等编码方法的优点,采用一种新的更符合人的发音的语音生成模型来合成语音。melp算法的特点是采用了多带混合激励、非周期脉冲、残差谐波处理、自适应谱增强和脉冲整形滤波。
针对以上问题,现有技术中通常提出了采用识别合成型声码器,利用语音识别和合成技术对语音信号编码,编码单元是语音基元,这样可把编码速率降至1kb/s以下。另外,在2.4k/s线性预测编码lpc(linearpredictivecoding)的基础上,也有利用矢量量化技术以及语音的帧间相关性,进一步压缩语音数据。所谓矢量量化,是指将一组标量数据看成一个矢量,在矢量空间对其进行整体量化,这样既压缩了数据又不损失多少信息。矢量量化的效率高低决定了编码器的效率高低。在低速率编码的参数量化中,由于lsp(linespectrumpa量化占用的比特数比较高,因此,如果能对lsp参数量化的方法做一定的改进,必然可以带来编码速率的显著降低。由于语音信号的相邻帧之间,尤其在语音的平稳段,存在着很大的相关性。如果每隔一 帧编码传输一次语音参数的话,编码速率将大大降低。因此,还有人提出了利用帧间相关性进一步降低参数量化的比特数。即把某几帧连续信号当作一帧进行编码,对超级帧的参数进行整体矢量量化从而压缩帧间冗余。还有学者提出了一种叫可变段长的分段量化方法,即将输入语音看成是一个序列长度可变的段,每段由一帧或几帧信号组成,每帧用增益、基音和频谱等参数来表示。虽然实现起来比较复杂,但却可以大大降低编码率,缩短编码延迟,并且能够得到较高质量的合成语音。
技术实现要素:
本发明的实施例提供了一种基于melp的低比特数字语音矢量量化方法和系统,本发明提供了如下方案:
采用混合激励线性预测melp算法对调整后的基音信号进行线性预测系数矢量量化,包括:对lsf参数采用两级分裂矢量量化,先获取第一级矢量量化的lsf参数,基于所述第一级矢量量化的lsf参数获取第二级矢量量化的lsf参数;
采用第二级矢量量化后的lsf参数进行数字语音矢量量化。
根据本发明的另一方面,还提供一种基于melp的低比特数字语音矢量量化系统,包括:
系数获取模块:其用于采用混合激励线性预测melp算法对调整后的基音信号进行线性预测系数矢量量化,包括:对lsf参数采用两级分裂矢量量化,先获取第一级矢量量化的lsf参数,基于所述第一级矢量量化的lsf参数获取第二级矢量量化的lsf参数;
量化模块:其用于采用第二级矢量量化后的lsf参数进行数字语音矢量量化。
由上述本发明的实施例提供的技术方案可以看出,本发明实施例提供了一种基于melp的低比特数字语音矢量量化方法和系统。本发明采用混合激励 线性预测melp算法对调整后的基音信号进行线性预测系数矢量量化,包括:对lsf参数采用两级分裂矢量量化,先获取第一级矢量量化的lsf参数,基于所述第一级矢量量化的lsf参数获取第二级矢量量化的lsf参数;采用第二级矢量量化后的lsf参数进行数字语音矢量量化。本发明的一种基于melp低比特数字语音算法设计方案基于已有的设计方法并针对其存在的缺陷提出了一种新的基于melp的低比特数字语音构造方法。在melp算法的基础上,就算法的量化进行分析,着重分析了基音周期的量化和线性预测系数的量化,并进一步对线性预测系数的量化提出了一种改进的方法,采用lsf两级矢量量化方案,降低码率,减少了码本的存储量与计算复杂度,与原有方案相比更具有优势。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例一提供的一种基于melp的低比特数字语音矢量量化方法的处理流程图;
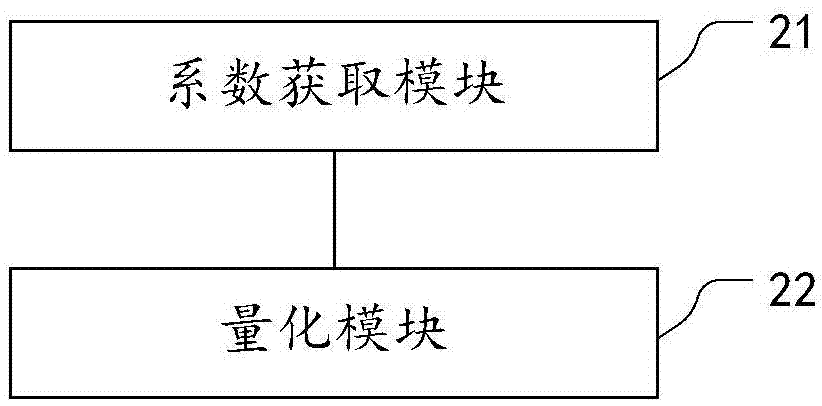
图2为本发明实施例二提供的一种基于melp的低比特数字语音矢量量化系统的模块图。
具体实施方式
为便于对本发明实施例的理解,下面将结合附图以几个具体实施例为例做进一步的解释说明,且各个实施例并不构成对本发明实施例的限定。
实施例一
本发明的实施例中,首先需要获取基音信号;本实施中获取所述基音信号,具体包括:
将采样的数字语音信号通过高通滤波器,获取滤波信号;
对所述滤波信号采用多带混合激励进行清浊音判决,并计算所述滤波信号增益,以获取所述基音信号;
具体地,将所述滤波信号分为若干个子带,分别进行清浊音判决,对所述子带的声音强度分别标注清浊音,
对所述子带的声音强度采用参数vbpi(i=1,2…,n)表示,vbpi代表了各个子带的声音强度,其值为1时表示浊音,为0时表示清音,
本实施例中,以每22.5ms长的语音作为一个分析帧,对应于8khz采样率下的180个采样点(8000采样点/s),经过处理后每帧输出54比特进行传输,这样它的速率是2.4kbps;
以将滤波信号分为5个子带为例,每个子带参数为vbpi(i=1,2…,5),
优选地,将输入信号分别通过5个6阶的butterworth带通滤波器,将输入信号分割为0hz~500hz,500hz~1000hz,1000hz~2000hz,2000hz~3000hz,3000hz~4000hz五个子带。语音信号经0hz~500hz的带通滤波器滤波后的输出用来进行一次分数基音的估算,由此得到分数基音周期p2和相对应的自相关函数值r(p2),r(p2)的值决定了最低带和总的清/浊音判决结果。根据分数基音周期p2相对应的自相关函数值r(p2)设置第一强度阈值,本实施例中取值为0.6;
当第一子带的声音强度参数vbp1不大于第一强度阈值时,当前帧为清音帧,其余带通清浊强度vbpi(i=1,2,3,4,5)全部都采用清音帧量化编码;
当第一子带的声音强度参数vbp1大于第一强度阈值时,当前帧为浊音帧,其余带通清浊强度vbpi(i=1,2,3,4,5)全部都采用浊音帧量化编码。
当vbp1≤0.6时,说明当前帧为清音帧,其余带通清浊强度 vbpi(i=1,2,3,4,5)全部都量化编码为0;
当vbp1>0.6时,i=2,3,4,5时,说明当前帧为浊音帧,vbp1编码为1。
计算所述滤波信号增益,之前需要对采样的数字语音信号进行加窗调整处理,具体地,
根据第一子带的声音强度参数,调整对采样的数字语音信号所采用的窗长,具体地,当第一子带的声音强度大于第一强度阈值时,且分数基音周期p2的最小因数积不大于窗长阈值,则调整窗长为大于分数基音周期p2的最小因数积;
当第一子带的声音强度大于第一强度阈值时,且分数基音周期p2的最小因数积大于窗长阈值,则调整窗长为分数基音周期的最小因数积的一半;
当第一子带的声音强度小于或等于第一强度阈值时,调整窗长等于分数基音周期的最小因数积。
例如,本实施例中以0.6为第一强度阈值,当vbp1>0.6时,窗长是大于p2分数基音周期的最小因数积;在本实施例中,以以每22.5ms长的语音作为一个分析帧,对应于8khz采样率下的180个采样点(8000采样点/s),经过处理后每帧输出54比特进行传输,这样它的速率是2.4kbps为例,此时调整窗长为大于120个样点,
此时,以窗长阈值为320个样点为例,若上述计算调整的窗长大于320个样点,则将上述计算的窗长除以2。
当vbp1≤0.6时,调整窗长为120个样点。
其次,需要对所述基音信号进行线性预测编码,获取残差信号,并计算所述基音信号的基音周期,并根据所述基音周期和所述残差信号调整所述基音信号,获取调整后的的基音信号;具体地,包括:
步骤a、对所述基音信号的采样的数字语音信号进行lpc(linearpredictivecoding)线性预测编码;
本实施例中用25ms长的语音信号包含的200个样点的汉明窗对采样的数字语音信号进行加权,再进行10阶线性预测编码,窗的中心是当前帧的参考点。
步骤b、经线性预测编码后,获取残差信号;获取的残差信号不包含声道响应信息但包含完整的激励信息,作用是可以减少声道特性的影响,提高基音周期估计效果;
为了得到残差信号,将采样的数字语音信号通过线性预测误差滤波器,传递函数为:
其中,ai为线性预测系数,残差信号为:
其中n为残差分析的窗长。线性预测误差滤波器为fir滤波器,其输出为残差信号。
步骤c、计算所述基音信号的基音周期,并根据所述基音周期和所述残差信号调整所述基音信号,获取调整后的的基音信号;
步骤c1、对于整数基因周期的计算,采样的数字语音信号先通过一个截止频率为1khz的6阶butterworth低通滤波器,消除在参数分析中语音的高频成分对基音周期估算的干扰。归一化自相关函数r(τ)定义为:
其中
整数基音周期的值等于归一化自相关函数r(τ)达到最大值时所对应的t值,从上面的计算式求出max(r(τ)),作为整数基音周期p1。
步骤c2、第一个子带带通滤波器(0~500hz)的输出信号为sb1(n),信号sb1(n)的主要作用是用于分数基音周期的搜索。由于sb1(n)信号在通过第一子带滤波器的时候已经将基音周期的四次以上谐波滤除掉了,从而排除了 高次谐波对基音搜索的影响,经过以上操作后,再结合之前粗略估计的整数基音周期p1,使得可以更加准确地对基音周期进行估计。使用当前帧和前一帧粗略估算得到的整数基音周期,在(p1-5,p1+5)的范围内进行整数基音的细搜索得到p2,再利用p2计算分数基音周期。分数基音周期的计算能够大大提高基音周期估计的准确性。真正的基音周期也有可能在(p2-1,p2)之间,或(p2,p2+1)之间,因此,通常是采用公式cτ(m,n)比较cp2(0,p2-1)和cp2(0,p2+1)大小的方法来决定。在确定了基音周期的范围[p,p+1]之间后,就可以采用插值的方法来确定分数基音周期。
本实施例中,对于分数基因周期的计算,分数基音周期的提取使用带通分析中的第一带(0~500hz)输出信号,两个候选值分别是当前帧和前一帧的整数基音周期。假设真实的基音周期与整数基音周期的偏移量为△,0<△<1,计算△的公式如下所示:
分数基音周期的归一化自相关值为:
分别设:a=ct(0,0);b=ct(0,t);c=ct(0,t+1);d=ct(t,t);e=ct(t,t+1);f=(t+1,t+1)代入上面两式求值获取分数基音周期;
步骤c3:基于上述步骤c1和步骤c2的基音周期侯选值的基础上,进行基音周期的最终计算。p3是最终的基音周期估计值,对应的归一化自相关值为r(p3);当自相关值较大时(r(p3)≥0.6),说明基音周期的估计较精确,最后用低通滤波的残差信号进行基音周期的倍数检测,即可得到最终的基音周期估计值。基音周期影响到语音识别的识别率,影响到语音压缩编码的正确率。
当自相关值较小时(r(p3)<0.6),说明lpc残差信号中的基音信号可能 被噪声破坏,或者该帧信号不平稳,用采样的数字语音信号代替lpc残差信号在只附近进行分数基音周期的搜索,得到新的p3和r(p3)。
本发明实施例提供了一种基于melp的低比特数字语音矢量量化方法的处理流程如图1所示,包括如下的处理步骤:
步骤11、采用混合激励线性预测melp(mixedexcitationlinearprediction)算法对调整后的基音信号进行线性预测系数矢量量化,包括:对lsf参数采用两级分裂矢量量化,先获取第一级矢量量化的lsf(linespectrumfrequency)参数,基于所述第一级矢量量化的lsf参数获取第二级矢量量化的lsf参数;
具体地,本实施例中,采用5比特对lsf参数进行第一级矢量量化,获取10维的lsf参数;
将10维的lsf参数分成前5维和后5维,分别对前5维的lsf参数采用7比特码本进行第二级矢量量化,后5维的lsf参数采用5比特码本进行第二级矢量量化;
具体地,本实施例中,对所述调整后的基音信号的第2子帧和第4子帧的lsf参数采用17比特进行矢量量化;
对所述调整后的基音信号的第1子帧和第3子帧的lsf参数采用如下公式进行计算:
j=1,2,...,9
其中,
所述a1(j),a2(j)采用4比特的码本进行矢量量化,包括:
建立如下矢量量化的目标函数,即矢量量化对象:
其中,w1(j),w3(j)为加权系数,l1(j),l3(j)是没有量化的第1子帧和第3子帧lsf参数。
步骤12、采用第二级矢量量化后的lsf参数进行数字语音矢量量化。
具体地,还包括,对所述第二级矢量量化后的lsf参数与原lsf量化值采用谱畸变指标进行比较,n代表谱畸变指标;
其中,l为子帧中基音谐波个数,aml为原始的谱幅度值,amrl为采用第二级矢量量化后的lsf参数后重建的谱幅度值。
实施例二
该实施例提供了一种基于melp的低比特数字语音矢量量化系统,其具体实现结构如图2所示,具体可以包括如下的模块:
系数获取模块21:其用于采用混合激励线性预测melp算法对调整后的基音信号进行线性预测系数矢量量化,包括:对lsf参数采用两级分裂矢量量化,先获取第一级矢量量化的lsf参数,基于所述第一级矢量量化的lsf参数获取第二级矢量量化的lsf参数;
量化模块23:其用于其用于采用第二级矢量量化后的lsf参数进行数字语音矢量量化。
用本发明实施例的系统进行数字语音矢量量化的具体过程与前述方法实施例类似,此处不再赘述。
综上所述,本发明实施例获取调整后的的基音信号;采用混合激励线性预测melp算法对所述调整后的基音信号进行线性预测系数矢量量化,包括:将lpc参数转化为线谱对矢量lsf参数,其中,对所述lsf参数采用两级分裂 矢量量化,包括:采用5比特对lsf参数进行第一级矢量量化,获取10维的lsf参数;将10维的lsf参数分成前5维和后5维,分别对前5维的lsf参数采用7比特码本进行第二级矢量量化,后5维的lsf参数采用5比特码本进行第二级矢量量化;本发明的一种基于melp低比特数字语音算法设计方案基于已有的设计方法并针对其存在的缺陷提出了一种新的基于melp的低比特数字语音构造方法。在melp算法的基础上,就算法的量化进行分析,着重分析了基音周期的量化和线性预测系数的量化,并进一步对线性预测系数的量化提出了一种改进的方法,采用lsf两级矢量量化方案,降低码率,减少了码本的存储量与计算复杂度,与原有方案相比更具有优势。
本领域普通技术人员可以理解:附图只是一个实施例的示意图,附图中的模块或流程并不一定是实施本发明所必须的。
通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到本发明可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例或者实施例的某些部分所述的方法。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置或系统实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的装置及系统实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元 上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!