声音处理装置、声音处理方法及程序与流程
本技术涉及音频处理装置、音频处理方法及程序。更具体地,本技术涉及可以通过适当地消除噪声来提取期望提取的音频的音频处理装置、音频处理方法及程序。
背景技术:
近来,使用音频的用户界面已经普及。当打电话或搜索信息时,使用音频的用户界面被用在例如移动电话(称为智能手机等的设备)中。
然而,如果它在具有许多噪声的环境下使用,那么不能正确地分析由用户产生的音频,并且可能错误地执行处理。因此,专利文献1提出了通过减小噪声的影响来提取期望音频。
引文列表
专利文献
专利文献1:日本专利申请特许公开号2009-49998
技术实现要素:
本发明所要解决的问题
在专利文献1中,设置后置滤波器构件,且该后置滤波器构件被构造为以便执行最大后验(MAP)优化,且反馈回路为了使噪声为零而操作。利用这种构造,如果有例如多点声源噪声(非点声源噪声)或扩散性噪声,那么在输出信号中可以产生音乐噪声。
当产生音乐噪声时,引起听觉上的陌生感,此外,音频识别性能劣化。无论噪声类型,诸如点声源噪声、多点声源噪声和扩散性噪声,都期望适当地消除噪声,使得不产生音乐噪声等。
本技术鉴于这种情况而提出,且能够适当地消除噪声并提取期望音频。
解决问题的方法
在本技术的一个方面中的一种音频处理装置包括:集声器,该集声器收集音频;音频增强器,该音频增强器使用由集声器收集到的音频信号来增强待提取音频;音频衰减器,该音频衰减器使用由集声器收集到的音频信号来衰减待提取音频;噪声环境估计器,该噪声环境估计器估计周围噪声环境;和后置滤波单元,该后置滤波单元使用来自音频增强器的音频增强信号和来自音频衰减器的音频衰减信号来执行后置滤波处理,其中该后置滤波单元根据由噪声环境估计器估计的噪声环境来设定消噪处理强度。
噪声环境估计器可使用由集声器收集到的音频来估计噪声环境。
集声器包括多个麦克风,且噪声环境估计器可计算由所述多个麦克风收集到的信号之间的相关性并将该相关性的值设定为噪声环境的估计结果。
噪声环境估计器可使用音频增强信号和音频衰减信号来估计噪声环境。
噪声环境估计器可计算音频增强信号的振幅频谱和音频衰减信号的振幅频谱之间的相关性,并将该相关性的值设定为噪声环境的估计结果。
噪声环境估计器可根据从外部输入的信息来估计噪声环境。
从外部输入的信息可为由用户提供的关于周围噪声环境的信息、位置信息或时间信息中的至少一条信息。
该音频处理装置还包括发声区间估计器,该发声区间估计器使用音频增强信号和音频衰减信号来估计发声区间,其中噪声环境估计器可估计在由发声区间估计器估计为非发声区间的区间中的噪声环境。
音频增强器可使用加法型波束成形、延迟-求和波束成形或自适应波束成形来产生音频增强信号。
音频衰减器可使用减法型波束成形、NULL波束成形或自适应NULL波束成形来产生音频衰减信号。
集声器中所包括的麦克风数量以及音频增强器和音频衰减器的输入数量可根据由噪声环境估计器提供的估计结果而改变。
所述改变可在启动时或操作期间执行。
在本技术的一个方面中的一种音频处理方法包括以下步骤:通过集声器来收集音频;产生音频增强信号,其中使用由集声器收集到的音频信号来增强待提取音频;产生音频衰减信号,其中使用由集声器收集到的音频信号来衰减待提取音频;估计周围噪声环境;以及使用音频增强信号和音频衰减信号来执行后置滤波处理,其中后置滤波处理包括根据估计噪声环境来设定消噪处理强度的步骤。
在本技术的一个方面中的一种程序使计算机执行包括以下步骤的处理:通过集声器来收集音频;产生音频增强信号,其中使用由集声器收集到的音频信号来增强待提取音频;产生音频衰减信号,其中使用由集声器收集到的音频信号来衰减待提取音频;估计周围噪声环境;以及使用音频增强信号和音频衰减信号来执行后置滤波处理,其中后置滤波处理包括根据估计噪声环境来设定消噪处理强度的步骤。
在本技术的一个方面中的音频处理装置、音频处理方法及程序中,收集音频,产生音频增强信号,其中使用收集到的音频信号来增强待提取音频,产生音频衰减信号,其中使用收集到的音频信号来衰减待提取音频,估计周围噪声环境,以及使用音频增强信号和音频衰减信号来执行后置滤波处理。在后置滤波处理中,根据估计噪声环境来设定消噪处理强度。
本发明的有益效果如下:
根据本技术的一个方面,可以适当地消除噪声并提取期望音频。
请注意,效果并不一定限于这里所述的效果,且可为本公开中所述的任何一个效果。
附图说明
图1为示意图,示出了应用本技术的音频处理装置的实施例的构造。
图2为示意图,说明了声源。
图3为示意图,示出了第一(a)音频处理装置的内部构造。
图4为流程图,说明了第一(a)音频处理装置的操作。
图5为流程图,说明了第一(a)音频处理装置的操作。
图6为示意图,说明了在时间/频率转换器中的处理。
图7为示意图,说明了在音频增强器中的处理。
图8为示意图,说明了在音频衰减器中的处理。
图9为示意图,说明了在发声区间检测器中的处理。
图10为示意图,说明了在噪声环境估计器中的处理。
图11为示意图,说明了在后置滤波单元处的校正。
图12为示意图,说明了在后置滤波单元处的校正。
图13为示意图,说明了在后置滤波单元处的校正。
图14为示意图,说明了音频识别率的提高。
图15为示意图,示出了第一(b)音频处理装置的内部构造。
图16为示意图,说明了噪声环境估计器的构造。
图17为流程图,说明了第一(b)音频处理装置的操作。
图18为流程图,说明了第一(b)音频处理装置的操作。
图19为示意图,示出了第一(c)音频处理装置的内部构造。
图20为流程图,说明了第一(c)音频处理装置的操作。
图21为流程图,说明了第一(c)音频处理装置的操作。
图22为示意图,示出了第二(a)音频处理装置的内部构造。
图23为示意图,说明了后置滤波单元的构造。
图24为流程图,说明了第二(a)音频处理装置的操作。
图25为流程图,说明了第二(a)音频处理装置的操作。
图26为流程图,说明了第二(a)音频处理装置的另一个操作。
图27为流程图,说明了第二(a)音频处理装置的另一个操作。
图28为示意图,示出了第二(b)音频处理装置的内部构造。
图29为流程图,说明了第二(b)音频处理装置的操作。
图30为流程图,说明了第二(b)音频处理装置的操作。
图31为流程图,说明了第二(b)音频处理装置的另一个操作。
图32为流程图,说明了第二(b)音频处理装置的另一个操作。
图33为示意图,示出了第二(c)音频处理装置的内部构造。
图34为流程图,说明了第二(c)音频处理装置的操作。
图35为流程图,说明了第二(c)音频处理装置的操作。
图36为流程图,说明了第二(c)音频处理装置的另一个操作。
图37为流程图,说明了第二(c)音频处理装置的另一个操作。
图38为示意图,示出了第三(a)音频处理装置的内部构造。
图39为流程图,说明了第三(a)音频处理装置的操作。
图40为流程图,说明了第三(a)音频处理装置的操作。
图41为流程图,说明了第三(a)音频处理装置的另一个操作。
图42为流程图,说明了第三(a)音频处理装置的另一个操作。
图43为示意图,示出了第三(b)音频处理装置的内部构造。
图44为流程图,说明了第三(b)音频处理装置的操作。
图45为流程图,说明了第三(b)音频处理装置的操作。
图46为流程图,说明了第三(b)音频处理装置的另一个操作。
图47为流程图,说明了第三(b)音频处理装置的另一个操作。
图48为示意图,示出了第三(c)音频处理装置的内部构造。
图49为流程图,说明了第三(c)音频处理装置的操作。
图50为流程图,说明了第三(c)音频处理装置的操作。
图51为流程图,说明了第三(c)音频处理装置的另一个操作。
图52为流程图,说明了第三(c)音频处理装置的另一个操作。
图53为示意图,说明了记录介质。
具体实施方式
下文中,对具体实施方式(下文中,称为实施例)进行说明。请注意,按下列顺序进行说明。
1.音频处理装置的外观构造
2.关于声源
3.第一音频处理装置(第一(a)音频处理装置至第一(c)音频处理装置)的内部构造和操作
4.第二音频处理装置(第二(a)音频处理装置至第二(c)音频处理装置)的内部构造和操作
5.第三音频处理装置(第三(a)音频处理装置至第三(c)音频处理装置)的内部构造和操作
6.关于记录介质
<音频处理装置的外观构造>
图1为示意图,示出了应用本技术的音频处理装置的外观构造。本技术可应用于处理音频信号的装置。例如,本技术可应用于移动电话(包括称为智能手机等的设备)、处理来自游戏机的麦克风的信号的单元、消噪耳机、耳机等。此外,本技术可应用于配备有实现免提通话、音频交互系统、音频命令输入、语音聊天等的应用程序的装置。
应用本技术的音频处理装置可为移动终端或通过安装在预定位置处而使用的装置。此外,本技术可应用于称为可穿戴设备等的设备,该设备为眼镜式终端或安装在臂等上的终端。
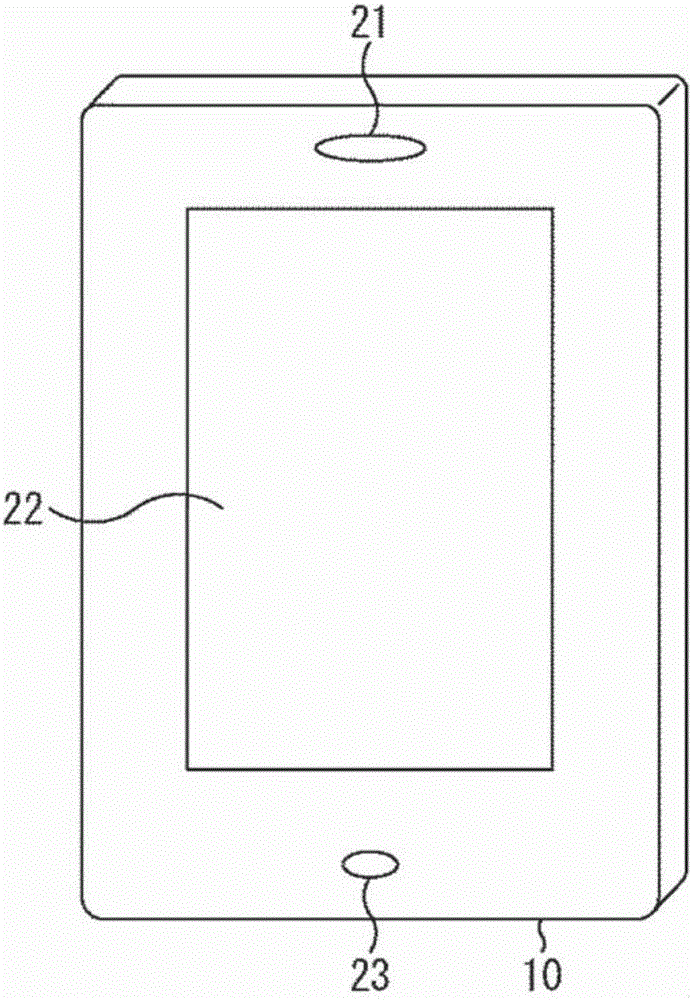
这里,以移动电话(智能手机)为例进行说明。图1为示意图,示出了移动电话10的外观构造。扬声器21、显示器22和麦克风23设置在移动电话10的一侧上。
当进行音频通话时,使用扬声器21和麦克风23。显示器22显示各种类型的信息。显示器22可为触控面板。
麦克风23具有收集由用户发出声音的音频的功能且为单元,待进行处理(下面将要说明)的音频被输入给该单元。麦克风23为驻极体电容式麦克风、MEMS麦克风等。麦克风23的采样为例如16000Hz。
请注意,虽然图1中示出了一个麦克风23,但是如下所述可设置两个或更多个麦克风23。在图3及后面附图中,多个麦克风23被示出为集声器。该集声器包括两个或更多个麦克风23。
在移动电话10上的麦克风23的安装位置仅仅作为示例,且这并不意味着安装位置限于图1所示的中下部。例如,虽然未示出,但是麦克风23可设置在移动电话10的左下部和右下部中的各部处或在与显示器22不同的面上,诸如移动电话10的侧面。
麦克风23的安装位置和数量不同于设置麦克风23且麦克风23只需安装在每个设备的适当安装位置处的单独设备。
<关于声源>
参照图2,对以下说明中使用的术语“声源”进行说明。图2A为示意图,说明了点声源。麦克风51位于中部。假设声源61产生将由麦克风51收集的声音。
点声源为空间声源,且为可以近似为点的声源。例如,一个用户正在说话的音频或从电视接收器或音频设备的扬声器产生的声音为来自点声源的声音。
图2B为示意图,说明了非点声源(多点声源)。类似于图2A,麦克风51位于中部,且声源62正在产生声音,但是声源62为不能近似为点的声源。非点声源为例如车辆的行进声音,且车辆的行进声音都从车辆的四个轮胎产生。该声源不能近似为点,且为从具有一定大小的区域产生声音的声源。
非点声源为空间声源,且为不能近似为点的声源。例如,除了以上车辆的行进声音等,非点声源还包括空调、风扇噪声等。
图2中的C为示意图,说明了扩散性声源。类似于图2中的A,麦克风51位于中部,但是多个声源63围着它。扩散性声源为有无数声源的情况或由于反射或混响而变得与有无数声源的情况相同的情况,且为当声音波阵面向四面八方散开时的声源。
如果从点声源产生的声音为噪声,那么从点声源中去除噪声并提取期望音频就相对容易。然而,如果从非点声源或扩散性声源产生的声音为噪声,那么相比于从点声源中去除噪声的情况,从非点声源或扩散性声源中去除所有噪声并提取期望音频就很难。
然而,例如,通过音频的用户界面需要处理当来自点声源的噪声与期望提取的音频混合时、当混合来自非点声源的噪声时、当混合来自扩散性声源的噪声时等的各种情况。
换言之,如果消噪处理限定于点声源、非点声源或扩散性声源中的任何一个声源,那么对未限定消噪处理的声源的消噪性能劣化,且消噪处理需要适当地处理各种噪声。因此,下文对能够适当地处理各种噪声的音频处理装置进行说明。
<第一音频处理装置的内部构造和操作>
<第一(a)音频处理装置的内部构造和操作>
图3为示意图,示出了第一(a)音频处理装置100的构造。音频处理装置100设置在移动电话10的内部并构成移动电话10的一部分。图3所示的音频处理装置100包括集声器101、噪声环境估计器102、时间/频率转换器103、音频方位估计器104、音频增强器105、音频衰减器106、发声区间检测器107、后置滤波单元108和时间/频率逆变器109。
请注意,虽然移动电话10包括通信单元,该通信单元具有电话机的功能以及用于与网络连接的功能,但是这里示出了与音频处理有关的音频处理装置100的构造,并省略对其他功能的示出和说明。
集声器101包括多个麦克风23,且在图3所示的实例中包括麦克风23-1和麦克风23-2。请注意,虽然这里假设集声器101包括两个麦克风23,但是集声器101可包括两个或更多个麦克风23。
例如,下面将要说明的第二音频处理装置和第三音频处理装置各包括两个或更多个麦克风23。此外,通过设置两个或更多个麦克风23,可以提高通过下面将要说明的处理(诸如波束成形)而获得的结果的精确度。
由集声器101收集到的音频信号被提供给时间/频率转换器103和噪声环境估计器102。来自发声区间检测器107的信息还被提供给噪声环境估计器102。时间/频率转换器103将所提供的时域信号转换为频域信号,并将转换的信号提供给音频方位估计器104、音频增强器105和音频衰减器106。
音频方位估计器104估计声源的方向。音频方位估计器104估计相对于集声器101从哪一个方向产生由用户发出声音的音频。关于由音频方位估计器104估计的方位的信息被提供给音频增强器105和音频衰减器106。
音频增强器105使用从时间/频率转换器103提供的麦克风23-1的音频信号和麦克风23-2的音频信号以及关于由音频方位估计器104估计的方位的信息来执行处理以增强估计为由用户发出声音的音频。
音频衰减器106使用从时间/频率转换器103提供的麦克风23-1的音频信号和麦克风23-2的音频信号以及关于由音频方位估计器104估计的方位的信息来执行处理以衰减估计为由用户发出声音的音频。
从音频增强器105和音频衰减器106输出的音频数据被提供给发声区间检测器107和后置滤波单元108。发声区间检测器107根据所提供的音频数据来检测估计为由用户发出声音的区间。
估计为由用户发出声音的区间被称为发声区间,以及其他区间被称为非发声区间。发声区间为具有音频信号和噪声信号的区间,以及非发声区间为具有噪声信号的区间。
来自发声区间检测器107的信息被提供给后置滤波单元108和噪声环境估计器102。噪声环境估计器102使用来自集声器101在非发声区间中的音频信号来估计噪声环境。噪声环境为环境是否具有许多噪声或环境是否只具有易消除噪声,且可为例如关于参照图2所述的声源的信息。
具体地,噪声环境为从点声源产生噪声的环境、不是从点声源产生噪声(即,从非点声源或扩散性声源产生噪声)的环境等。如下所述,噪声环境估计器102不是具体地估计声源数量,而是计算表示环境具有多少噪声的值,并将该值提供给后置滤波单元108。
后置滤波单元108接收从音频增强器105提供的音频增强信号、从音频衰减器106提供的音频衰减信号、从发声区间检测器107提供关于发声区间的信息以及从噪声环境估计器102提供关于噪声环境的信息,并使用这些信号和信息来执行后置滤波处理。
如下所述,后置滤波单元108可根据噪声环境使用这些信号和信息来执行后置滤波处理。由后置滤波单元108处理的信号被提供给时间/频率逆变器109。时间/频率逆变器109将所提供的频域信号转换为时域信号,并将转换的信号输出给后级处理单元(未示出)。
参照图4和图5的流程图,对图3所示的第一(a)音频处理装置100的操作进行说明。
在步骤S101中,集声器101的麦克风23-1和麦克风23-2各收集音频信号。请注意,这里收集到的音频为由用户产生的声音、噪声或与噪声混合的声音。
在步骤S102中,输入信号被分割成每个帧。当分割时,以例如16000Hz执行采样。这里,假设来自麦克风23-1分割成帧的信号为信号x1(n),以及来自麦克风23-2分割成帧的信号为信号x2(n)。
分割信号x1(n)和信号x2(n)被提供给噪声环境估计器102和时间/频率转换器103。
在步骤S103中,噪声环境估计器102将所提供的信号x1(n)和信号x2(n)存储在缓冲器中。因为发声区间检测器107估计在检测为非发声区间的区间中的噪声环境,所以噪声环境估计器102接收由发声区间检测器107提供的检测结果,但是直到判定检测结果为非发声区间才可开始对所提供的信号进行处理。因此,提供给噪声环境估计器102的信号x1(n)和信号x2(n)暂时地存储在缓冲器中。
虽然图2中未示出缓冲器,但是缓冲器可包括在噪声环境估计器102中或缓冲器可与噪声环境估计器102分开设置并与其他单元共享。此外,如果由发声区间检测器107提供的检测结果为发声区间,那么通过丢弃存储在缓冲器中的信号x1(n)和信号x2(n),可以减小缓冲器尺寸。
在步骤S104中,时间/频率转换器103将所提供的信号x1(n)和信号x2(n)转换为时间/频率信号。通过参照图6A,时域信号x1(n)和信号x2(n)被输入给时间/频率转换器103。信号x1(n)和信号x2(n)分别被转换为在不同频域中的信号。
这里,假设时域信号x1(n)被转换为频域信号x1(f,t),以及时域信号x2(n)被转换为频域信号x2(f,t)。请注意,(f,t)中的f为表示频带的指数,以及(f,t)中的t为帧指数。
如图6中的B所示,时间/频率转换器103将输入时域信号x1(n)或信号x2(n)(下文中,以信号x1(n)为例进行说明)分割成每个样本为帧大小N的帧,将分割信号与窗口函数相乘,并利用快速傅立叶变换(FFT)将相乘的信号转换为频域信号。在帧分割中,用来提取样本的区间各偏移了N/2。
图6中的B示出了帧大小N设定为512且偏移大小设定为256的实例。在这种情况下,输入信号x1(n)被分割成帧大小N为512的帧,与窗口函数相乘,并通过执行FFT计算被转换为频域信号。
回到图4中流程图的说明,在步骤S104中,通过时间/频率转换器103转换为频域信号的信号x1(f,t)和信号x2(f,t)被提供给音频方位估计器104、音频增强器105和音频衰减器106。
在步骤S105中,音频方位估计器104使用时间/频率信号来执行声源方位估计。声源方位估计可根据例如多重信号分类(MUSIC)方法来执行。关于MUSIC方法,可以应用以下文献中所述的方法。
R.O.Schmidt,“Multiple emitter location and signal parameter estimation,”IEEE Trans.Antennas Propagation,vol.AP-34,no.3,pp.276~280,Mqrch 1986.
假设由音频方位估计器104提供的估计结果为M(f,t)。估计结果M(f,t)被提供给音频增强器105和音频衰减器106。
在步骤S106中,音频增强器105执行音频增强处理。此外,在步骤S107中,音频衰减器106执行音频衰减处理。这里,参照图7和图8,对由音频增强器105执行的音频增强处理和由音频衰减器106执行的音频衰减处理进行说明。音频增强处理和音频衰减处理可利用使用波束成形的处理来执行。
波束成形为通过多个麦克风(麦克风阵列)来收集声音并通过调整输入到每个麦克风的相位来执行加法或减法的处理。利用波束成形,可以增强或衰减在特定方向上的声音。
音频增强处理可利用加法型波束成形来执行。延迟-求和(下文中,称为DS)为加法型波束成形,且为用来增强期望声音方位的增益的波束成形。
音频衰减处理可利用衰减型波束成形来执行。NULL波束成形(下文中,称为NBF)为衰减型波束成形,且为用来衰减期望声音方位的增益的波束成形。
首先,参照图7,对由音频增强器105执行的音频增强处理进行说明。这里,以使用DS波束成形的情况为例进行说明,DS波束成形为加法型波束成形。如图7中的A所示,音频增强器105输入来自时间/频率转换器103的信号x1(f,t)和信号x2(f,t),并输入来自音频方位估计器104的估计结果M(f,t)。然后,作为处理结果,信号D(f,t)被输出给发声区间检测器107和后置滤波单元108。
当音频增强器105根据DS波束成形来执行音频增强处理时,音频增强器105具有图7中的B所示的构造。音频增强器105包括延迟单元131和加法器132。在图7中的B中,未示出时间/频率转换器103。
来自麦克风23-1的音频信号被提供给加法器132,以及来自麦克风23-2的音频信号通过延迟单元131延迟了预定时间,然后被提供给加法器132。因为麦克风23-1和麦克风23-2被安装成隔开了预定距离,所以音频信号被作为由于路线差而具有不同传播延迟时间的信号而接收。
在波束成形中,来自一个麦克风23的信号被延迟以补偿与在预定方向上到达的信号相关的传播延迟。延迟单元131执行延迟。在图7中的B所示的DS波束成形中,延迟单元131设置在麦克风23-2侧。
在图7中的B中,假设麦克风23-1侧为-90°,麦克风23-2侧为90°,以及麦克风23的前侧为0°,该前侧为相对于穿过麦克风23-1和麦克风23-2的轴的垂直方向。此外,在图7中的B中,朝向麦克风23的箭头表示从预定声源产生的声音的声波。
当声波来自图7中的B所示的方向时,这意味着声波来自相对于麦克风23位于0°和90°之间的声源。利用DS波束成形,可以获得图7中的C所示的方向特性。方向特性为为每个方位绘制的波束成形的输出增益。
在执行DS波束成形且如图7中的B所示在音频增强器105中的加法器132的输入中,当从预定方向到达的信号的相位(即,0°和90°之间的方向)匹配时,从该方向到达的信号得到增强。另一方面,因为相位未匹配,所以从除了预定方向以外的方向到达的信号未和从预定方向到达的信号增强得一样多。
从以上原因可以看出,如图7中的C所示,增益在有声源的方位处变高。从音频增强器105输出的信号D(f,t)具有图7中的C所示的方向特性。此外,从音频增强器105输出的信号D(f,t)为由用户产生的音频,且为期望提取的音频(下文中,适当地称为期望音频)与期望抑制的噪声混合的信号。
在从音频增强器105输出的信号D(f,t)中的期望音频比包括在输入给音频增强器105的信号x1(f,t)和信号x2(f,t)中的期望音频增强得更多。此外,在从音频增强器105输出的信号D(f,t)中的噪声比包括在输入给音频增强器105的信号x1(f,t)和信号x2(f,t)中的噪声减少得更多。
还对音频增强处理进行说明。如上所述,音频增强器105输入信号x1(f,t)和信号x2(f,t)并输出期望音频得到增强的信号D(f,t)。当利用DS波束成形来执行音频增强处理时,输入信号和输出信号之间的关系利用以下表达式(1)来表示。
【表达式1】
D(f,t)=WT(f,t)X(f,t)···(1)
在表达式(1)中,X(f)表示L个数量的麦克风23的输入信号向量,W(f)为DS波束成形的滤波器系数向量,以及上标“T”表示转置。此外,表达式(1)中的X(f,t)和W(f,t)分别被表示为以下表达式(2)。此外,DS波束成形的滤波器系数从以下表达式(3)获得。
【表达式2】
X(f,t)=[X1(f,t),X2(f,t)]T
W(f,t)=[W1(f,t),W2(f,t)]T····(2)
【表达式3】
在表达式(3)中,L为表示麦克风数量的常数,fs为表示采样频率的常数,N为表示DFT点的常数,d为表示麦克风间隔的常数,以及c为表示声速的常数。
音频增强器105通过将值代入表达式(1)至表达式(3)来执行音频增强处理。请注意,虽然这里已经以DS波束成形为例进行说明,但是其他波束成形(诸如自适应波束成形)或通过除了该波束成形以外的方法的音频增强处理可适用于本技术。
接着,参照图8,对由音频衰减器106执行的音频衰减处理进行说明。这里,以使用NULL波束成形(NBF)的情况为例进行说明,NULL波束成形为减法型波束成形。
如图8中的A所示,音频衰减器106输入来自时间/频率转换器103的信号x1(f,t)和信号x2(f,t),并输入来自音频方位估计器104的估计结果M(f,t)。然后,作为处理结果,信号D(f,t)被输出给发声区间检测器107和后置滤波单元108。
当音频衰减器106根据NULL波束成形来执行音频衰减处理时,音频衰减器106具有图8中的B所示的构造。音频衰减器106包括延迟单元141和减法器142。在图8中的B中,未示出时间/频率转换器103。
来自麦克风23-1的音频信号被提供给减法器142,以及来自麦克风23-2的音频信号通过延迟单元141延迟了预定时间,然后被提供给减法器142。用来执行NULL波束成形的构造和参照图7已经说明用来执行DS波束成形的构造基本相同,且差异在于由加法器132执行加法或由减法器142执行减法。因此,这里省略关于构造的详细说明。此外,适当地省略关于与图7中的单元相同的单元的说明。
当声波来自由图8中的B中的箭头表示的方向时,这意味着声波来自相对于麦克风23位于0°和90°之间的声源。利用NULL波束成形,可以获得图8中的C所示的方向特性。
在执行NULL波束成形且如图8中的B所示在音频衰减器106中的减法器142的输入中,当从预定方向到达的信号的相位(即,0°和90°之间的方向)匹配时,从该方向到达的信号得到衰减。理论上,作为衰减结果,期望音频变为零。另一方面,因为相位未匹配,所以从除了预定方向以外的方向到达的信号未和从预定方向到达的信号衰减得一样多。
从以上原因可以看出,如图8中的C所示,增益在有声源的方位处变低。从音频衰减器106输出的信号N(f,t)具有图8中的C所示的方向特性。此外,从音频衰减器106输出的信号N(f,t)为期望音频被消除且噪声仍然存在的信号。
在从音频衰减器106输出的信号N(f,t)中的期望音频比包括在输入给音频衰减器106的信号x1(f,t)和信号x2(f,t)中的期望音频衰减得更多。此外,包括在输入给音频衰减器106的信号x1(f,t)和信号x2(f,t)中的噪声与在从音频衰减器106输出的信号N(f,t)中的噪声大致相同。
还对音频衰减处理进行说明。如上所述,音频衰减器106输入信号x1(f,t)和信号x2(f,t)并输出期望音频得到衰减的信号N(f,t)。当利用NULL波束成形来执行音频衰减处理时,输入信号和输出信号之间的关系利用以下表达式(4)来表示。
【表达式4】
N(f,t)=FT(f,t)X(f,t)····(4)
在表达式(4)中,X(f)表示L个数量的麦克风23的输入信号向量,F(f)为NULL波束成形的滤波器系数向量,以及上标“T”表示转置。此外,表达式(4)中的X(f,t)和F(f,t)分别被表示为以下表达式(5)。此外,NULL波束成形的滤波器系数从以下表达式(6)获得。
【表达式5】
X(f,t)=[X1(f,t),X2(f,t)]T
F(f,t)=[F1(f,t),-F2(f,t)]T···(5)
【表达式6】
在表达式(6)中,L为表示麦克风数量的常数,fs为表示采样频率的常数,N为表示DFT点的常数,d为表示麦克风间隔的常数,以及c为表示声速的常数。
音频衰减器106通过将值代入表达式(4)至表达式(6)来执行音频衰减处理。请注意,虽然这里已经以NULL波束成形为例进行说明,但是其他波束成形(诸如自适应NULL波束成形)或通过除了波束成形以外的方法的音频衰减处理可适用于本技术。
回到图4中流程图的说明。在步骤S106中,音频增强器105执行音频增强处理,在步骤S107中,音频衰减器106执行音频衰减处理,并且这些结果被提供给发声区间检测器107和后置滤波单元108。
在步骤S108中,发声区间检测器107执行发声区间检测(语音活动检测:VAD)。参照图9对该检测进行说明。如图9中的A所示,来自音频增强器105的音频增强信号D(f,t)和来自音频衰减器106的音频衰减信号N(f,t)被输入给发声区间检测器107。发声区间检测器107输出检测结果V(t)。
图9中的B的上面一行表示输入信号的波形实例,中间一行表示音频增强信号D(f,t)的波形实例,以及下面一行表示音频衰减信号N(f,t)的波形实例。请注意,虽然图9中的B所示的波形表示时域波形,但是因为音频处理装置100在将信号转换为频域信号之后执行处理,如上所述,所以实际处理在频域中执行。这里,为了说明,示出了时域波形。
假设图9中的B的上面一行所示的输入信号的波形为例如由麦克风23-1收集到的音频的波形。波形在中心部分处变大的部分为发声区间,以及它前后的部分为非发声区间。发声区间为用户发出声音的区间,以及非发声区间为用户未发出声音的区间。
在图9中的B的中间一行所示的音频增强信号中,相比于输入信号,在发声区间处的信号变得更大,以及在非发声区间处的信号变得更小。在图9B的下面一行所示的音频衰减信号中,相比于输入信号,在发声区间处的信号变得更小,以及在非发声区间处的信号变得基本相同。
图9中的B的中间一行所示的音频增强信号与下面一行所示的音频衰减信号在图中用矩形围住的区间171和区间172中进行比较。区间171为在非发声区间中的区间,且当音频增强信号与音频衰减信号在非发声区间中进行比较时,例如,当选取该差时,该差小。相反,区间172为在发声区间中的区间,且当音频增强信号与音频衰减信号在发声区间中进行比较时,例如,当选取该差时,该差大。
为此,可以根据音频增强信号和音频衰减信号之差来识别发声区间或非发声区间。具体地,通过使用在基于以下表达式(7)的计算中计算出的值,发声区间和非发声区间的检测结果通过基于以下表达式(8)的判定而产生并输出。
【表达式7】
【表达式8】
在表达式(7)中,fa和fb分别为在发声区间检测计算中使用的频带的下限和上限。通过将包括许多音频分量的频带设定为该频带,可以获得更好性能。例如,下限设定为200Hz,以及上限设定为2000Hz。
在表达式(8)中,Thr表示阈值并设定为例如约10db。如表达式(8)所示,当用表达式(7)计算出的值vad的值小于阈值Thr时,输出0作为检测结果V(t),以及当值vad的值大于阈值Thr时,输出1作为检测结果V(t)。
假设当检测结果V(t)为0时,这表示判定为非发声区间(只有噪声信号),以及当检测结果V(t)为1时,这表示判定为发声区间(有音频信号和噪声信号)。
请注意,虽然这里基于以上设定进行说明,但是这并不意味着当输出0或1作为检测结果V(t)时,本技术的应用范围受到限制。
回到图4中的流程图,当在步骤S108中由发声区间检测器107执行发声区间检测时,处理进入步骤S109(图5)。在步骤S109中,噪声环境估计器102判定当前帧是否为发声区间。
该判定通过参照从发声区间检测器107提供的检测结果V(t)来执行。具体地,当检测结果V(t)为“0”时,在步骤S109中判定当前帧不是发声区间,以及当检测结果V(t)为“1”时,在步骤S109中判定为发声区间。
当在步骤S109中判定当前帧不是发声区间时,换言之,当判定为非发声区间时,处理进入步骤S110。在步骤S110中,噪声环境估计器102使用分割成帧的输入信号来估计噪声环境。
参照图10,对通过噪声环境估计器102的噪声环境估计进行说明。如图10中的A所示,由集声器101的麦克风23-1收集到的声音的信号x1(n)和由麦克风23-2收集到的声音的信号x2(n)被输入给噪声环境估计器102。此外,来自发声区间检测器107的检测结果V(t)被输入给噪声环境估计器102。
当参照所提供的检测结果V(t)被判定为非发声区间时,噪声环境估计器102使用信号x1(n)和信号x2(n)来估计噪声环境。估计结果被作为相关性系数C(t)提供给后置滤波单元108。利用以下表达式(9)来计算相关性系数C(t)。
【表达式9】
在表达式(9)中,N表示帧大小。利用基于表达式(9)的计算,计算收集到的信号的相关性。利用表达式(9)计算出的相关性系数C(t)为从-1.0到1.0的值。
相关性系数C(t)与麦克风23(集声器101)周围的声源数量有关。参照图10中的B对此进行说明。在图10中的B所示的曲线图中,横坐标表示声源数量,纵坐标表示相关性系数。
当声源数量为1时,相关性系数为接近1的值。当声源数量为5时,相关性系数为接近0.8的值。当声源数量为20时,相关性系数为接近0.6的值。然后,当声源数量无穷大时,换言之,当声源数量为无数噪声或扩散性噪声时,相关性系数为接近0的值。
如上所述,麦克风周围的声源数量和从多个麦克风获得的信号之间的相关性值有关系。具体地,如图10中的B所示,有以下关系:随着声源数量增大,相关性系数变小。通过使用这种关系,对噪声环境进行估计。
这里,因为在非发声区间中计算相关性系数,所以将要计算的相关性系数与产生噪声的声源数量有关。因此,可以根据相关性系数来估计环境是否具有许多产生噪声的声源或环境是否具有少许产生噪声的声源。
然后,在环境具有许多产生噪声的声源的情况下,如果强烈地执行抑制噪声的处理,那么产生称为音乐噪声等的噪声的可能性变高。因此,当判定环境具有许多产生噪声的声源时,轻微地执行抑制噪声的处理以执行控制,使得不产生音乐噪声。
另一方面,在环境具有少许产生噪声的声源的情况下,如果强烈地执行抑制噪声的处理,那么产生称为音乐噪声等的噪声的可能性低。因此,当判定环境具有少许产生噪声的声源时,强烈地执行抑制噪声的处理以执行控制,使得抑制噪声并提取期望音频。
为了根据噪声环境来控制抑制噪声的处理强度,在步骤S111中计算将在后置滤波中使用的噪声校正系数。这里,对噪声校正系数进行说明。
图11中的A为曲线图,示出了在非音频区间(只有噪声的区间)中的音频衰减信号的频谱和音频增强信号的频谱。图11中的B为曲线图,示出了在音频区间(有音频和噪声的区间)中的音频衰减信号的频谱和音频增强信号的频谱。在图11中的A和图11中的B所示的曲线图中,横坐标表示频率,纵坐标表示增益。
在图11中的B中,在由椭圆形虚线(频带)围住的部分中有期望获得的音频分量。在图11中的A所示的非音频区间中的曲线图用频率示出了音频衰减信号和音频增强信号之差。通过参照图11中的B,示出了音频增强信号的增益在有期望获得的音频分量的部分中高。
基于以上原因,通过从音频增强信号中减去音频衰减信号,可以留有期望获得的音频分量。此外,如果简单地从音频增强信号中减去音频衰减信号,那么如图11中的A所示在只有噪声的区间中有音频增强信号和音频衰减信号之差,且需要考虑该差。
如将参照图12进行说明,需要考虑噪声的声源数量,换言之,噪声环境。图12中的A为曲线图,其中当噪声为一个点声源时的音频衰减信号和音频增强信号的方向特性重叠。图12中的B为曲线图,其中当噪声为扩散性声源(在扩散性噪声环境下)时的音频衰减信号和音频增强信号的方向特性重叠。
图12中的A和图12中的B都示出了在麦克风23的右前方(0°)有期望提取的声源的情况。此外,图12中的A和图12中的B示出了产生噪声的声源的位置。
通过参照图12中的A,在包括在音频衰减信号和音频增强信号中的噪声的增益中产生差a。通过噪声校正系数(下面进行说明)对差a进行校正。如图12中的A所示,当噪声为一个点声源时,待校正点为有噪声的部分,且可以唯一地设定噪声校正系数。
通过参照图12中的B,在扩散性噪声环境下或在非点声源噪声环境下有许多待校正点,且所述点可以暂时地改变。在图12中的B所示的实例中,虽然噪声有四个声源,并需要用来在声源处校正差b、差c、差d和差e的校正系数,但是很难唯一地判定校正系数。此外,因为这些差b至e可以暂时地改变,所以更难唯一地判定校正系数。
在本技术中,因为估计噪声环境并根据噪声环境对噪声校正系数本身进行校正,所以可以执行适合噪声环境的校正。换言之,后置滤波单元108执行校正(噪声抑制),下文进行说明。
通过参照图13中的A,来自音频增强器105的音频增强信号D(f,t)和来自音频衰减器106的音频衰减信号N(f,t)被提供给后置滤波单元108。此外,来自发声区间检测器107的发声区间检测结果V(t)和来自噪声环境估计器102的噪声环境的估计结果C(t)(相关性系数C(t))被提供给后置滤波单元108。
后置滤波单元108使用所提供的这些信号和信息来执行后置滤波处理,并输出估计音频频谱Y(f,t)作为其结果。估计音频频谱Y(f,t)为消除噪声的音频。
例如,频谱相减法、MMSE-STSA方法等可应用于由后置滤波单元108执行的后置滤波处理。在以下文献中公开了频谱相减法,且频谱相减法可适用于本技术。
S.F.Boll,“Suppression of acoustic noise in speech using spectral subtraction,”IEEE Trans.Acoustics,Speech,and Signal Processing,vol.27.no,2,pp.113-120,1979.
此外,在以下文献中公开了MMSE-STSA方法,且MMSE-STSA方法可适用于本技术。
Y.Ephraim and D.Malah,“Speech enhancement using a minimum mean-square error short-time spectral amplitude estimator.”IEEE Trans.Acoustics,Speech.,end Signal Processing,vol.32,no.6,pp.1109-1121,1984.
这里,以应用基于频谱相减法的后置滤波处理的情况为例进行说明。在简单频谱相减法中,从音频增强信号D(f,t)的振幅频谱中减去音频衰减信号N(f,t)的振幅频谱。然而,如参照图11和图12所述,因为音频增强信号D(f,t)的振幅频谱和音频衰减信号N(f,t)的振幅频谱之间有误差,所以需要对噪声频谱进行校正。
在由发声区间检测器107判定为非发声区间(v(t)=0)的区间中根据以下表达式(10)和(11)来执行噪声频谱校正。
【表达式10】
H(f,t)=G(f,t)N(f,t)···(10)
【表达式11】
在表达式(10)和表达式(11)中,G(f,t)为用来获得校正频谱的校正系数,且为通过对过去k个帧的数据进行平滑化而计算出的值。H(f,t)为通过将校正系数G(f,t)与音频衰减信号N(f,t)相乘而获得的噪声校正系数。
接着,根据以下表达式(12),从音频增强信号D(f,t)和估计噪声校正系数H(f,t)获得估计音频频谱Y(f,t)。
【表达式12】
在表达式(12)中,a为减法系数且设定为约1.0至2.0的值。c为向下取整系数且为设定为约0.01至0.5的值。b为根据噪声环境的估计结果而改变的值并执行如下。
C(t)的绝对值大的情况:噪声为少量点声源的可能性高,并强烈地执行消噪。
C(t)的绝对值小的情况:噪声为非点声源或扩散性声源的可能性高,并微弱地执行消噪。
因为消噪强度根据噪声环境而设定,并以此方式执行与消噪有关的处理,所以可以对噪声变化精确地执行消噪。
在表达式(12)中,可利用例如以下表达式(13)来计算系数b的值。
【表达式13】
b=|C(t)| …(13)
根据表达式(13),系数b的值为相关性系数C(t)的绝对值。以此方式,可直接使用相关性系数C(t)。可选择地,可通过使用图13中的B所示的曲线图或基于曲线图的表来计算系数b的值。此外,可从外部(从记录介质)加载系数b,或可在需要时计算系数b。
在图13中的B所示的曲线图中,横坐标为相关性系数C(t),纵坐标为系数b。系数b可以设定为使用相关性系数C(t)计算出的预定函数。
此外,系数b的值不需要在等于或小于1.0的范围内,且可以根据应用本技术的音频处理装置的用途(诸如免提通话或音频识别)而设定为适当值。
根据本技术,因为消噪强度根据噪声环境而设定,并以此方式执行与消噪有关的处理,所以可以对各种噪声环境精确地执行消噪。
回到图5中的流程图,当在步骤S111中计算将在由后置滤波单元108执行的后置滤波处理中使用的噪声校正系数时,处理进入步骤S112。当在步骤S109中判定当前帧为发声区间时,处理还进入步骤S112。
在步骤S112中,后置滤波单元108根据噪声环境来执行后置滤波处理。
请注意,当没有非发声区间并不计算噪声校正系数时,在步骤S112中使用设定为初始值的噪声校正系数来执行后置滤波处理。
由后置滤波单元108计算出的估计音频频谱Y(f,t)被提供给时间/频率逆变器109。在步骤S113中,时间/频率逆变器109将时间/频率信号转换为时间信号。待转换为时域信号的估计音频频谱Y(f,t)为如上所述根据噪声环境而进行消噪的频域信号。
在步骤S114中,时间/频率逆变器109通过将帧移位来对样本进行相加并产生输出信号y(n)。如参照图6所述,当时间/频率转换器103执行处理时,时间/频率逆变器109为每个帧执行反向FFT,因此,通过将样本移位256,通过叠加输出的512个样本,产生输出信号y(n)。
在步骤S115中,从时间/频率逆变器109产生的输出信号y(n)被输出给后级处理单元(未示出)。
以此方式,在应用本技术的音频处理装置100中,因为估计噪声环境并根据估计噪声环境来设定消噪强度,所以可以根据噪声环境来执行适当的消噪处理。因此,可以防止产生音乐噪声等。
参照图14,图14示出了音频识别率在应用本技术的音频处理装置和未应用本技术的音频处理装置之间如何变化的实验结果。图14中的A示出了假设噪声为点声源的情况,产生期望提取的音频的声源安装在麦克风阵列前面,且产生噪声的一个声源安装在对角左前侧。
图14中的B示出了假设噪声为扩散性噪声的情况,产生期望提取的音频的声源安装在麦克风阵列前面,且产生噪声的多个声源被安装成以便围绕麦克风阵列。
图14中的C和图14中的D为示意图,示出了当在图14中的A所示的情况下和在图14中的B所示的情况下测量音频识别率时的测量结果。音频识别率为正确识别发出声音的预定短语的概率。
在图14中的C和图14中的D中,1mic表示当利用一个麦克风来执行测量时的结果,DS表示当只用延迟-求和波束成形来执行测量时的结果,Conventional表示当在不考虑噪声环境的情况下执行后置滤波处理时的测量结果,以及Proposed表示当在利用图3所示的音频处理装置100并考虑噪声环境的情况下执行后置滤波处理时的测量结果。
通过参照图14中的C和图14中的D,示出了应用本技术的音频处理装置100的音频识别率既在点声源噪声中又在扩散性噪声中为最高。为此,如上所述,示出了通过估计噪声环境并根据估计噪声环境执行消噪处理来提高音频识别率。
<第一(b)音频处理装置的内部构造和操作>
接着,对第一(b)音频处理装置的构造和操作进行说明。虽然上述第一(a)音频处理装置100(图3)使用从集声器101获得的音频信号来估计噪声环境,但是第一(b)音频处理装置200(图15)的不同之处在于它使用从音频增强器105获得的音频增强信号和从音频衰减器106获得的音频衰减信号来估计噪声环境。
图15为示意图,示出了第一(b)音频处理装置200的构造。在图15所示的音频处理装置200中,相同附图标记被附到具有与图3所示的第一(a)音频处理装置100相同的功能的单元,并省略其说明。
图15所示的音频处理装置200具有来自音频增强器105的音频增强信号D(f,t)和来自音频衰减器106的音频衰减信号N(f,t)还被提供给噪声环境估计器201的构造,且与图3所示的音频处理装置100的不同构造之处在于来自集声器101的信号未被提供给噪声环境估计器201。
如图16所示,噪声环境估计器201被构造为使得提供来自音频增强器105的音频增强信号D(f,t)和来自音频衰减器106的音频衰减信号N(f,t)并还提供来自发声区间检测器107的发声区间检测结果V(t)。
类似于上述噪声环境估计器102(图3),噪声环境估计器201使用所提供的信号和信息来提供从-1.0到1.0的值C(t)给后置滤波单元108。此外,噪声环境估计器201计算在由发声区间检测器107检测到的非发声区间中从-1.0到1.0的值C(t)并将该值提供给后置滤波单元108。
当噪声为点声源时,从音频增强器105输出的音频增强信号D(f,t)的振幅频谱和从音频衰减器106输出的音频衰减信号N(f,t)的振幅频谱的形状趋向彼此基本匹配。此外,当噪声为扩散性时,音频增强信号D(f,t)的振幅频谱和音频衰减信号N(f,t)的振幅频谱的形状趋向彼此不匹配。
通过使用这种趋向,可以根据音频增强信号D(f,t)的振幅频谱和音频衰减信号N(f,t)的振幅频谱的匹配率(相似性)来估计周围噪声环境。例如,它可具有计算每个帧中的振幅频谱之间的相关性并输出相关性值作为由噪声环境估计器201提供的估计结果C(t)的构造。
当它被构造为以便以此方式估计噪声环境时,存储器等可以省略。在图3所示的音频处理装置100(图3)中,噪声环境估计需要缓冲区(存储器)以暂时地保存分割成帧的时域信号。然而,音频处理装置200(图15)可具有省略缓冲区(存储器)的构造,这是因为噪声环境估计不需要暂时地保存分割成帧的时域信号。
参照图17和图18中的流程图对具有这种构造的音频处理装置200的操作进行说明。基本操作类似于图3所示的音频处理装置100的操作,并省略类似操作的说明。
与图4中的步骤S101、S102、S104至S108中的处理类似地执行步骤S201至S207(图17)中的处理。换言之,虽然在第一(a)音频处理装置100中,在步骤S103中执行将分割信号存储在噪声环境估计器102的缓冲器中的处理,但是在第一(b)音频处理装置200中不需要该处理并在处理过程中省略该处理。
除了步骤S209(对应于步骤S110的处理)不同,基本上与图5所示的步骤S109至S115中的处理类似地执行步骤S208至S214(图18)中的处理。
当在步骤S208中判定当前帧不是发声区间时,在步骤S209中,噪声环境估计器201使用音频增强信号和音频衰减信号来估计噪声环境。如上所述,使用音频增强信号和音频衰减信号来执行该估计。
因为类似于第一(a)音频处理装置100的噪声环境估计器102,从-1.0到1.0的值C(t)的估计结果被提供给后置滤波单元108,所以可以与第一(a)音频处理装置100类似地执行后置滤波单元108等中的处理。
在第一(b)音频处理装置200中,可以以此方式根据从音频增强器105获得的信号和从音频衰减器106获得的信号来估计噪声环境。类似于第一(a)音频处理装置100,第一(b)音频处理装置200还可估计噪声环境并根据估计的噪声环境来执行消噪处理,并可以提高音频处理的精确度,诸如音频识别率。
<第一(c)音频处理装置的内部构造和操作>
接着,对第一(c)音频处理装置的构造和操作进行说明。虽然上述第一(a)音频处理装置100(图3)使用从集声器101获得的音频信号来估计噪声环境,但是第一(c)音频处理装置300(图19)的不同之处在于它使用从外部输入的信息来估计噪声环境。
图19为示意图,示出了第一(c)音频处理装置300的构造。在图19所示的音频处理装置300中,相同附图标记被附到具有与图3所示的第一(a)音频处理装置100相同的功能的单元,并省略其说明。
图19所示的音频处理装置300具有噪声环境估计所需的信息从外部提供给噪声环境估计器301的构造,且与图3所示的音频处理装置100的不同构造之处在于来自集声器101的信号未被提供给噪声环境估计器301。
例如,由用户输入的信息被用作待提供给噪声环境估计器301的噪声环境估计所需的信息。例如,它可具有用户在开始发出声音之前选择环境是否具有许多噪声的构造,并输入选定信息。
此外,根据外部传感器(诸如全球定位系统(GPS))的信息来判定用户的位置,并可判定该位置是否为具有许多噪声的环境。例如,它被构造为当根据GPS信息判定该位置为室内时,判定环境具有少许噪声,或当判定该位置为室外时,判定环境具有许多噪声,且它可被构造为使得输入基于该判定的信息。
此外,可使用时间信息以及位置信息(诸如GPS信息)或时间信息。例如,因为夜间等与日间相比不太可能具有许多噪声,所以当根据时间信息判定它为夜间时,可判定环境具有少许噪声,或当判定它为日间时,可判定环境具有许多噪声。
此外,它可被构造为使得通过组合信息来估计噪声环境。此外,学习估计结果和用户反馈,获得从学习获得的信息,例如,当环境为安静时的时间信息,且学习结果可被用于噪声环境估计。
参照图20和图21中的流程图对具有这种构造的音频处理装置300的操作进行说明。基本操作类似于图3所示的音频处理装置100的操作,并省略类似操作的说明。
与图4中的步骤S101、S102、S104至S108中的处理类似地执行步骤S301至S307(图20)中的处理。
换言之,虽然在第一(a)音频处理装置100中,在步骤S103中执行将分割信号存储在噪声环境估计器102的缓冲器中的处理,但是在第一(c)音频处理装置300中不需要该处理并在处理过程中省略该处理。处理过程与图17所示的流程图的过程相同,图17所示的流程图为第一(b)音频处理装置200(图15)的操作。
除了步骤S309(对应于步骤S110的处理)不同,基本上与图5所示的步骤S109至S115中的处理类似地执行步骤S308至S314(图21)中的处理。
当在步骤S308中判定当前帧不是发声区间时,在步骤S309中,噪声环境估计器201使用从外部输入的信息来估计噪声环境。
类似于第一(a)音频处理装置100的噪声环境估计器102,从-1.0到1.0的值C(t)的估计结果被提供给后置滤波单元108。可以与第一(a)音频处理装置100类似地执行后置滤波单元108等中的处理。
在第一(c)音频处理装置300中,可以以此方式根据从外部输入的信号来估计噪声环境。类似于第一(a)音频处理装置100,第一(c)音频处理装置300还可估计噪声环境并根据估计噪声环境来执行消噪处理,并可以提高音频处理的精确度,诸如音频识别率。
此外,在图3所示的音频处理装置100(图3)中,噪声环境估计需要缓冲区(存储器)以暂时地保存分割成帧的时域信号。然而,音频处理装置300(图19)可具有省略缓冲区(存储器)的构造,这是因为噪声环境估计不需要暂时地保存分割成帧的时域信号。
此外,因为第一(c)音频处理装置300具有未执行第一(a)音频处理装置100或第一(b)音频处理装置200所需的相关性计算的构造,所以可以降低计算成本。
<第二音频处理装置的内部构造和操作>
<第二(a)音频处理装置的内部构造>
图22为示意图,示出了第二(a)音频处理装置400的构造。音频处理装置400设置在移动电话10的内部并构成移动电话10的一部分。图22所示的音频处理装置400包括集声器401、噪声环境估计器402、时间/频率转换器403、音频方位估计器404、音频增强器405、音频衰减器406、发声区间检测器407、后置滤波单元408和时间/频率逆变器409。
虽然这种构造类似于第一音频处理装置的构造,但是第二音频处理装置与第一音频处理装置的不同构造之处在于处理部件改变指令单元410包括集声器401、噪声环境估计器402、时间/频率转换器403、音频方位估计器404、音频增强器405和音频衰减器406。
上述第一音频处理装置具有估计噪声环境并根据估计噪声环境来控制后置滤波单元108中的消噪强度的构造和操作。第二音频处理装置具有估计噪声环境并在保持消噪性能的同时根据估计噪声环境通过改变处理部件改变指令单元410中的构造来降低功耗的构造和操作。
集声器401包括多个麦克风23-1至23-N。在第二音频处理装置中,如下面将要说明,为了改变根据噪声环境而使用的麦克风23的数量,在集声器401中包括两个或更多个麦克风23。
虽然未示出,但是当它被构造为以便包括多个麦克风23时,后级时间/频率转换器403等用导线连接到来自麦克风23的输入信号以及处理信号。此外,时间/频率转换器403等被构造为以便处理来自麦克风23的信号以及处理信号。
集声器401包括多个麦克风23,且例如,当估计有扩散性噪声时,使用麦克风23(两个或更多个麦克风23)来执行处理,或当估计有来自点声源的噪声时,使用两个麦克风23来执行处理。
集声器401包括麦克风23,且除了麦克风23,集声器401还包括AD转换器、采样率转换器等(它们均未示出)。利用根据噪声环境来减少麦克风23的数量的构造,可以切断对AD转换器、采样率转换器等的供电并抑制功耗。
此外,因为时间/频率转换器403、音频方位估计器404、音频增强器405和音频衰减器406中的所有单元被构造为以便处理通过麦克风23获得的音频,所以麦克风23的数量为两个,且输入数量减为两个。因为在波束成形中引起大量积-和计算,所以减少估计音频方位和输入数量的处理,并可以减少计算量。从这一点来说,可以降低功耗。
虽然音频处理装置400的集声器401、噪声环境估计器402、时间/频率转换器403、音频方位估计器404、音频增强器405、音频衰减器406、发声区间检测器407和时间/频率逆变器409的不同之处在于处理多条音频,但是基本上与音频处理装置100(图3)的集声器101、噪声环境估计器102、时间/频率转换器103、音频方位估计器104、音频增强器105、音频衰减器106、发声区间检测器107、后置滤波单元108和时间/频率逆变器109类似地执行处理,并省略其详细说明。
后置滤波单元408不同于第一音频处理装置的后置滤波单元108,并具有图23所示的构造,这是因为未输入来自噪声环境估计器402的估计结果C(t)。
后置滤波单元408输入来自音频增强器405的音频增强信号D(f,t)和来自音频衰减器406的音频衰减信号N(f,t)。此外,后置滤波单元408输入来自发声区间检测器407的发声区间检测结果V(t)。
后置滤波单元408根据以下表达式(14)使用输入信号和信息来输出估计音频频谱Y(f,t)。估计音频频谱Y(f,t)为消除噪声的音频。
【表达式14】
在表达式(14)中,a为减法系数并设定为约1.0至2.0的值。此外,c为向下取整系数并设定为约0.01至0.5的值。
<第二(a)音频处理装置的第一操作>
参照图24和图25中的流程图对具有这种构造的音频处理装置400的操作进行说明。基本操作类似于图4所示的第一(a)音频处理装置100的操作,并省略类似操作的说明。
与图4所示的步骤S101至S108中的处理类似地执行步骤S401至S408(图24)中的处理。
换言之,第二(a)音频处理装置400的集声器401、噪声环境估计器402、时间/频率转换器403、音频方位估计器404、音频增强器405、音频衰减器406和发声区间检测器407与第一(a)音频处理装置100的集声器101、噪声环境估计器102、时间/频率转换器103、音频方位估计器104、音频增强器105、音频衰减器106和发声区间检测器107类似地执行处理。
然而,因为从在音频处理装置400中执行处理时将使用的设定数量的麦克风23获得信号,所以可以处理两个或更多个音频信号。
在步骤S409(图25)中,当判定当前帧不是发声区间时,在步骤S410中,噪声环境估计器402使用分割成帧的输入信号来估计噪声环境。
如参照图10所述,噪声环境估计器102使用从麦克风23获得的音频信号来估计噪声环境。与在步骤S110(图5)中由图3所示的音频处理装置100执行的估计类似地执行这种估计并省略其说明。
当在步骤S410中估计噪声环境时,在步骤S411中判定环境是否具有少量噪声。例如,通过基于上述表达式(9)的计算来计算收集到的信号之间的相关性作为噪声环境的估计结果,且所计算的相关性系数C(t)为从-1.0到1.0的值。
例如,预先设定阈值,并在相关性系数C(t)大于或小于预定阈值的情况下,可判定环境是否具有大量噪声。当阈值设定为例如0.8且相关性系数C(t)的绝对值等于或大于0.8时,可以估计在麦克风23周围有少量噪声且它为点声源噪声。
当在步骤S411中判定环境具有少量噪声时,处理进入步骤S412。在步骤S412中,处理部件改变指令单元410的集声器401、噪声环境估计器402、时间/频率转换器403、音频方位估计器404、音频增强器405和音频衰减器406改变为减少输入数量的设定。
换言之,因为判定环境具有少量噪声且在虽然待使用麦克风23的数量减少但是不会降低消噪处理的精确度的情况下可以执行处理,所以指示处理部件改变指令单元410以改变减少待处理信号的设定。
通过执行处理,在环境具有少量噪声的情况下可以降低功耗,而不会降低消除噪声的精确度。
请注意,虽然这里以处理部件改变指令单元410的所有单元改变为降低功耗的设定的情况为例进行说明,但是设定可以与它相反。换言之,正常设定为降低功耗的设定,并且当判定环境具有大量噪声时,所述单元可以改变为提高精确度的设定。
例如,在步骤S510中判定环境是否具有大量噪声,并且当判定环境具有大量噪声时,处理部件改变指令单元410的所有单元可以改变为提高精确度而不是降低功耗的设定,即,增大输入数量的设定,以使用两个或更多个麦克风23来执行处理。
可选择地,待使用麦克风23的数量可根据估计噪声环境而设定。例如,在包括配备有四个麦克风23的集声器401的音频处理装置400中,环境被分为具有大量噪声、中量噪声和少量噪声的三个环境,并且当判定环境具有大量噪声时,所述单元改变为使用四个麦克风23的设定,当判定环境具有中量噪声时,所述单元改变为使用三个麦克风23的设定,以及当判定环境具有少量噪声时,所述单元改变为使用两个麦克风23的设定。
此外,通过设置多个阈值,比较由噪声环境估计器402提供的估计结果与阈值,并使用比较结果,可对具有大量噪声、中量噪声或少量噪声的环境的判定进行分类。待使用麦克风23的数量可以以此方式根据噪声数量而设定。
当在步骤S412中改变处理部件改变指令单元410中的设定时,处理进入步骤S413,并计算将由后置滤波单元408使用的噪声校正系数。因为与步骤S112(图5)中的处理类似地执行步骤S413中的处理,所以省略其说明,但在步骤S413中,根据在计算噪声校正系数时使用麦克风23的数量来执行计算。
另一方面,当在步骤S411中判定环境具有大量噪声时,处理进入步骤S413。在这种情况下,使用麦克风23的数量不变,并利用此时已经设定的设定来计算将由后置滤波单元408使用的噪声校正系数。
当在步骤S413中计算噪声校正系数时,或当在步骤S409中判定当前帧为发声区间时,处理进入步骤S414。
在步骤S414中,后置滤波单元408执行后置滤波处理。在这种情况下,如参照图23所述,当使用来自音频增强器405的音频增强信号D(f,t)和来自音频衰减器406的音频衰减信号N(f,t)的检测结果示出来自发声区间检测器407的发声区间检测结果V(t)为发声区间时,估计音频频谱Y(f,t)根据表达式(14)而计算并输出给后级时间/频率逆变器409。估计音频频谱Y(f,t)为消除噪声的音频。
与在图5中的步骤S113至S115中由时间/频率逆变器109(图3)执行的处理类似地执行在步骤S415至S417中由时间/频率逆变器409执行的处理,并省略其说明。
在第二(a)音频处理装置400中,音频处理装置400中的构造可以以此方式根据噪声环境而改变,并可以改变能够执行适合噪声环境的消噪处理的构造。因此,在具有少许噪声的环境下可以降低功耗。
当根据图24和图25所示的流程图来执行处理时,在音频处理装置400操作期间重复步骤S410至S413中的处理。因此,可以处理噪声环境变化。例如,当在音频处理装置400操作期间(例如,在通话期间)通过从嘈杂环境移动到安静环境来改变噪声环境时,适当地改变设定,并可以降低功耗等。
<第二(a)音频处理装置的第二操作>
参照图26和图27所示的流程图对图22所示的音频处理装置400的另一个操作进行说明。在基于图26和图27所示的流程图的操作中,在系统启动时执行根据噪声环境来改变处理部件改变指令单元410的构造的处理。
系统启用时为例如用户指示由音频处理装置400执行的处理将要开始时等。例如,当预定音频识别应用程序启动时,或当打电话时,开始由音频处理装置400执行的处理。
在步骤S451中,判定系统是否启动并且是否需要执行初始化。当在步骤S451中判定系统启动并且需要执行初始化时,处理进入步骤S452。
在步骤S452中,通过具有麦克风23的集声器401来获得音频信号。在步骤S453中,输入信号被分割成每个帧。可以与例如图24中的步骤S401和S402中的处理类似地执行步骤S452中的处理和步骤S453中的处理。
在步骤S454中,噪声环境估计器402使用分割成帧的输入信号来估计噪声环境,并在步骤S455中使用估计结果来判定环境是否具有少量噪声。当在步骤S455中判定环境具有少量噪声时,处理进入步骤S456。在步骤S456中,改变处理部件改变指令单元410的所有单元中的设定。
与步骤S410至S412(图25)中的处理类似地执行步骤S454至S456中的处理。换言之,如上所述,当在系统启动时估计噪声环境并判定为安静环境时,处理部件改变指令单元410的集声器401、噪声环境估计器402、时间/频率转换器403、音频方位估计器404、音频增强器405和音频衰减器406改变为减少输入数量的设定。
当在步骤S456中执行处理部件改变指令单元410中的改变和设定时,处理进入步骤S457。在这种情况下,设定适合于噪声环境。
另一方面,当在步骤S455中判定环境具有大量噪声时,处理进入步骤S457。在这种情况下,设定为初始值的设定应用于处理部件改变指令单元410的所有单元,并开始处理。
此外,当在步骤S451中判定系统未启动时,处理进入步骤S457。当音频处理装置400操作时,判定系统未启动,并且处理进入步骤S457。
与图24中的步骤S401至S408中的处理类似地执行步骤S457至S464(图27)中的处理。换言之,在系统启动时执行初始化处理,随后利用通过初始化设定的设定来执行音频处理。
在步骤S465(图27)中,判定当前帧是否为发声区间,并且当判定当前帧不是发声区间时,处理进入步骤S466。在步骤S466中,计算将在通过后置滤波单元408的后置滤波处理中使用的噪声校正系数。
当在步骤S466中计算噪声校正系数时,或当在步骤S465中判定当前帧为发声区间时,处理进入步骤S467,并且后置滤波单元408执行后置滤波处理。
步骤S465至S467中的处理为从图25所示的流程图的步骤S409至S414中的处理中删去步骤S410至S412中的处理的处理。因为步骤S410至S412中的处理在步骤S452至S456中作为初始化处理而执行,所以省略该处理。
由噪声环境估计器402执行的噪声环境估计在系统启动时执行,并且在启动后在系统操作期间未执行。因此,在系统启动时执行噪声环境估计之后,通过噪声环境估计器402来估计噪声环境的处理停止,且对噪声环境估计器402的供电等也可停止。通过以此方式操作,可以降低功耗。
与步骤S415至S417(图25)中的处理类似地执行步骤S468至S470中的处理。
在第二(a)音频处理装置400中,音频处理装置400的构造可以以此方式根据噪声环境而改变,并且可以改变能够执行适合噪声环境的消噪处理的构造。因此,在具有少许噪声的环境下可以降低功耗。
<第二(b)音频处理装置的内部构造>
接着,对第二(b)音频处理装置的构造和操作进行说明。虽然上述第二(a)音频处理装置400(图22)使用从集声器401获得的音频信号来估计噪声环境,但是第二(b)音频处理装置500(图28)的不同之处在于它使用从音频增强器405获得的音频增强信号和从音频衰减器406获得的音频衰减信号来估计噪声环境。这种构造类似于图15所示的音频处理装置200的构造。
图28为示意图,示出了第二(b)音频处理装置500的构造。在图28所示的音频处理装置500中,相同附图标记被附到具有与图22所示的第二(a)音频处理装置400相同的功能的单元,并省略其说明。
图28所示的音频处理装置500具有来自音频增强器405的音频增强信号D(f,t)和来自音频衰减器406的音频衰减信号N(f,t)还被提供给噪声环境估计器501的构造,且与图22所示的音频处理装置400的不同构造之处在于来自集声器401的信号未被提供给噪声环境估计器501。
噪声环境估计器501被构造为使得提供来自音频增强器405的音频增强信号D(f,t)和来自音频衰减器406的音频衰减信号N(f,t)并还提供来自发声区间检测器407的发声区间检测结果V(t)。
类似于上述噪声环境估计器402(图22),噪声环境估计器501使用所提供的信号和信息来提供从-1.0到1.0的值C(t)给后置滤波单元408。与由图15所示的第一(b)音频处理装置200的噪声环境估计器201执行的噪声环境估计类似地执行由噪声环境估计器501执行的噪声环境估计。
当它被构造为以便以此方式估计噪声环境时,存储器等可以省略。在图22所示的音频处理装置400中,噪声环境估计需要缓冲区(存储器)以暂时地保存分割成帧的时域信号。然而,音频处理装置500(图28)可具有省略缓冲区(存储器)的构造,这是因为噪声环境估计不需要暂时地保存分割成帧的时域信号。
<第二(b)音频处理装置的第一操作>
参照图29和图30中的流程图对具有这种构造的音频处理装置500的操作进行说明。基本操作类似于图15所示的音频处理装置200或图22所示的音频处理装置400的操作,并省略类似操作的说明。
与图17中的步骤S201至S207中的处理类似地执行步骤S501至S507(图29)中的处理。
除了步骤S509(对应于步骤S410的处理)不同,基本上与图25所示的步骤S409至S417中的处理类似地执行步骤S508至S516(图30)中的处理。
当在步骤S508中判定当前帧不是发声区间时,在步骤S509中,噪声环境估计器501使用音频增强信号和音频衰减信号来估计噪声环境。类似于第二(a)音频处理装置400的噪声环境估计器402的估计结果,估计结果被计算为从-1.0到1.0的值C(t),并通过比较值C(t)与预定阈值来判定环境是否具有少量噪声(步骤S510)。
因为由噪声环境估计器501执行以上处理,所以可以与在步骤S412(图25)之后的处理类似地执行在步骤S510之后的处理,并且可以与通过第二(a)音频处理装置400的处理类似地执行通过处理部件改变指令单元410等的处理。
在第二(b)音频处理装置500中,可以以此方式根据从音频增强器405获得的信号和从音频衰减器406获得的信号来估计噪声环境。类似于第二(a)音频处理装置400,第二(b)音频处理装置500还可估计噪声环境并利用根据估计噪声环境的设定来执行消噪处理,并且可以降低功耗。
<第二(b)音频处理装置的第二操作>
参照图31和图32所示的流程图对图28所示的音频处理装置500的另一个操作进行说明。在基于图31和图32所示的流程图的操作中,在系统启动时执行根据噪声环境来改变处理部件改变指令单元410的构造的处理。
在步骤S551中,判定系统是否启动并且是否需要执行初始化。当在步骤S551中判定系统启动并且需要执行初始化时,处理进入步骤S552。
在步骤S552中,通过具有麦克风23的集声器401来获得音频信号。在步骤S553中,输入信号被分割成每个帧。在步骤S554中,时间/频率转换器403将分割信号转换为时间/频率信号。
在步骤S555中,音频方位估计器404使用时间/频率信号来执行声源方位估计。在步骤S556中,音频增强器505执行音频增强处理,在步骤S557中,音频衰减器506执行音频衰减处理。然后,在步骤S558中,噪声环境估计器501使用音频增强信号和音频衰减信号来估计噪声环境。
在步骤S558中参照估计结果之后,在步骤S559中判定环境是否具有少量噪声,并且当判定环境具有少量噪声时,处理进入步骤S560。在步骤S560中,处理部件改变指令单元410的所有单元的设定改变为降低功耗的设定。
可以与步骤S501至S506(图29)中和步骤S509至S511(图30)中的处理类似地执行步骤S552至S560中的处理。在步骤S551至S560中,当执行初始化时,处理进入步骤S561。
如上所述,当在系统启动时估计噪声环境并判定为安静环境时,处理部件改变指令单元410的集声器401、噪声环境估计器402、时间/频率转换器403、音频方位估计器404、音频增强器405和音频衰减器406改变为减少输入数量的设定。
另一方面,当在步骤S559中判定环境具有大量噪声时,处理进入步骤S561。在这种情况下,设定为初始值的设定应用于处理部件改变指令单元410的所有单元,并开始处理。
此外,当在步骤S551中判定系统未启动时,处理进入步骤S561。与图29中的步骤S501至S507中的处理类似地执行步骤S561至S567(图32)中的处理。换言之,在系统启动时执行初始化处理,随后利用通过初始化设定的设定来执行音频处理。
与在步骤S465至S470中由图27所示的第二(a)音频处理装置400执行的处理类似地执行步骤S568至S573(图32)中的处理。
在第二(b)音频处理装置500中,可以以此方式根据从音频增强器405获得的信号和从音频衰减器406获得的信号来估计噪声环境。类似于第二(a)音频处理装置400,第二(b)音频处理装置500还可估计噪声环境并利用根据估计噪声环境的设定来执行消噪处理,并且可以降低功耗。
<第二(c)音频处理装置的内部构造>
接着,对第二(c)音频处理装置的构造和操作进行说明。虽然上述第二(a)音频处理装置400(图22)使用从集声器401获得的音频信号来估计噪声环境,但是第二(c)音频处理装置600(图33)的不同之处在于它使用从外部输入的信息来估计噪声环境。这种构造类似于图19所示的音频处理装置300的构造。
图33为示意图,示出了第二(c)音频处理装置600的构造。在图33所示的音频处理装置600中,相同附图标记被附到具有与图22所示的第二(a)音频处理装置400相同的功能的单元,并省略其说明。
图33所示的音频处理装置600具有噪声环境估计所需的信息从外部提供给噪声环境估计器601的构造,且与图22所示的音频处理装置400的不同构造之处在于来自集声器401的信号未被提供给噪声环境估计器601。
此外,例如,类似于第一(c)音频处理装置300的噪声环境估计器301,由用户输入的信息、位置信息(诸如GPS)或时间信息被用作待提供给噪声环境估计器601的噪声环境估计所需的信息。
<第二(c)音频处理装置的第一操作>
参照图34和图35中的流程图对具有这种构造的音频处理装置600的操作进行说明。基本操作类似于图22所示的音频处理装置400或图28所示的音频处理装置500的操作,并省略类似操作的说明。
与图29所示的步骤S501至S507中的处理类似地执行步骤S601至S607(图34)中的处理。换言之,处理部件改变指令单元410的所有单元以及发声区间检测器407具有与图28所示的音频处理装置500的处理部件改变指令单元410的所有单元以及发声区间检测器407类似的构造,并类似地执行处理。
除了步骤S609(对应于步骤S509的处理)不同,基本上与图30所示的步骤S508至S516中的处理类似地执行步骤S608至S616(图35)中的处理。
当在步骤S608中判定当前帧不是发声区间时,在步骤S609中,噪声环境估计器601使用从外部输入的信息来估计噪声环境。
类似于第二(a)音频处理装置400的噪声环境估计器402或第二(b)音频处理装置500的噪声环境估计器501的估计结果,估计结果被计算为从-1.0到1.0的值C(t),并通过比较值C(t)与预定阈值来判定环境是否具有少量噪声(步骤S610)。
因为由噪声环境估计器601执行以上处理,所以可以与步骤S510(图30)之后的处理类似地执行步骤S610之后的处理,并且可以与通过第二(b)音频处理装置500(或第二(a)音频处理装置400)的处理类似地执行通过处理部件改变指令单元410等的处理。
在第二(c)音频处理装置600中,可以以此方式根据从外部输入的信号来估计噪声环境。类似于第二(a)音频处理装置400,第二(c)音频处理装置600还可估计噪声环境并利用根据估计噪声环境的设定来执行消噪处理,并且可以降低功耗。
<第二(c)音频处理装置的第二操作>
参照图36和图37所示的流程图对图33所示的音频处理装置600的另一个操作进行说明。在基于图36和图37所示的流程图的操作中,在系统启动时执行根据噪声环境来改变处理部件改变指令单元410的构造的处理。
在步骤S651中,判定系统是否启动并且是否需要执行初始化。当在步骤S651中判定系统启动并且需要执行初始化时,处理进入步骤S652。
在步骤S652中,噪声环境估计器501使用从外部输入的信息来估计噪声环境。
在步骤S652中参照估计结果之后,在步骤S653中判定环境是否具有少量噪声,并且当判定环境具有少量噪声时,处理进入步骤S654。在步骤S654中,处理部件改变指令单元410的所有单元的设定改变为降低功耗的设定。
可以与图35中的步骤S609至S611中的处理类似地执行步骤S652至S654中的处理。在步骤S652至S654中,当执行初始化时,处理进入步骤S655。
如上所述,当在系统启动时估计噪声环境并判定为安静环境时,处理部件改变指令单元410的集声器401、噪声环境估计器402、时间/频率转换器403、音频方位估计器404、音频增强器405和音频衰减器406改变为减少输入数量的设定。
另一方面,当在步骤S653中判定环境具有大量噪声时,处理进入步骤S655。在这种情况下,设定为初始值的设定应用于处理部件改变指令单元410的所有单元,并开始处理。
此外,当在步骤S651中判定系统未启动时,处理进入步骤S655。与步骤S561(图31)至步骤S573(图32)中的处理(由第二(b)音频处理装置500执行的处理)类似地执行步骤S655(图36)至S667(图37)中的处理。换言之,在系统启动时执行初始化处理,随后利用通过初始化设定的设定来执行音频处理。
在第二(c)音频处理装置600中,可以以此方式根据从外部输入的信息来估计噪声环境。类似于第二(a)音频处理装置400,第二(c)音频处理装置600还可估计噪声环境并利用根据估计噪声环境的设定来执行消噪处理,并且可以降低功耗。
此外,在图22所示的音频处理装置400中,噪声环境估计需要缓冲区(存储器)以暂时地保存分割成帧的时域信号。然而,音频处理装置600(图33)可具有省略缓冲区(存储器)的构造,这是因为噪声环境估计不需要暂时地保存分割成帧的时域信号。
此外,因为第二(c)音频处理装置600具有未执行第二(a)音频处理装置400或第二(b)音频处理装置500所需的相关性计算的构造,所以可以降低计算成本。
<第三音频处理装置的内部构造和操作>
<第三(a)音频处理装置的内部构造>
对音频处理装置的另一个构造进行说明。第三音频处理装置通过组合上述第一音频处理装置和第二音频处理装置而构造。
图38为示意图,示出了第三(a)音频处理装置700的构造。第三(a)音频处理装置700通过组合上述第一(a)音频处理装置100(图3)和第二(a)音频处理装置400(图22)而构造。
音频处理装置700设置在移动电话10的内部并构成移动电话10的一部分。图38所示的音频处理装置700包括集声器701、噪声环境估计器702、时间/频率转换器703、音频方位估计器704、音频增强器705、音频衰减器706、发声区间检测器707、后置滤波单元708和时间/频率逆变器709。
虽然这种构造类似于第一音频处理装置或第二音频处理装置的构造,但是第三音频处理装置与第一音频处理装置不同但与第二音频处理装置类似的构造之处在于处理部件改变指令单元710包括集声器701、噪声环境估计器702、时间/频率转换器703、音频方位估计器704、音频增强器705和音频衰减器706。
处理部件改变指令单元710的内部构造根据由噪声环境估计器702提供的噪声环境的估计结果而改变。这种构造类似于第二(a)音频处理装置400(图22)的构造。
由噪声环境估计器702提供的估计结果还被提供给后置滤波单元708,且后置滤波单元708被构造为以便根据估计噪声环境来控制消噪强度。这种构造类似于第一(a)音频处理装置100(图3)的构造。
第三(a)音频处理装置700的集声器701、噪声环境估计器702、时间/频率转换器703、音频方位估计器704、音频增强器705、音频衰减器706、发声区间检测器707和时间/频率逆变器709与第二(a)音频处理装置400(图22)的集声器401、噪声环境估计器402、时间/频率转换器403、音频方位估计器404、音频增强器405、音频衰减器406、发声区间检测器407、后置滤波单元408和时间/频率逆变器409类似地执行处理,并省略其详细说明。
类似于第一音频处理装置的后置滤波单元108,来自噪声环境估计器702的估计结果C(t)被输入给后置滤波单元708,且后置滤波单元708使用估计结果C(t)来执行后置滤波处理。
<第三(a)音频处理装置的第一操作>
参照图39和图40所示的流程图对图38所示的音频处理装置700的操作进行说明。音频处理装置700通过组合如上所述的第一(a)音频处理装置100和第二(a)音频处理装置400而构造,且其操作为组合第一(a)音频处理装置100的操作(基于图4和图5所示的流程图的操作)和第二(a)音频处理装置400的操作(基于图24和图25所示的流程图的操作)的操作。
基本上与由图24和图25所示的第二(a)音频处理装置400执行的步骤S401至S417类似地执行步骤S701至S717。
类似于第二(a)音频处理装置400,在第三(a)音频处理装置700中,处理部件改变指令单元710中的设定根据噪声环境而改变。因此,类似于第二(a)音频处理装置400,在第三(a)音频处理装置700中,可以降低功耗。
此外,在第三(a)音频处理装置700中,在步骤S714中,后置滤波单元708根据噪声环境来执行后置滤波处理。与在步骤S112(图5)中由第一(a)音频处理装置100执行的处理类似地执行这种处理。
类似于第一(a)音频处理装置100,在第三(a)音频处理装置700中,后置滤波单元708根据噪声环境来执行后置滤波处理。因此,类似于第一(a)音频处理装置100,在第三(a)音频处理装置700中,可以根据噪声环境适当地执行消噪处理并防止产生音乐噪声等。
<第三(a)音频处理装置的第二操作>
参照图41和图42所示的流程图对图38所示的音频处理装置700的另一个操作进行说明。第三(a)音频处理装置700的第二操作为通过组合第一(a)音频处理装置100的操作(基于图4和图5所示的流程图的操作)和第二(a)音频处理装置400的第二操作(基于图26和图27所示的流程图的操作)的操作。
基本上与由图26和图27所示的第二(a)音频处理装置400执行的步骤S451至S470类似地执行步骤S751至S770。
类似于第二(a)音频处理装置400,在第三(a)音频处理装置700中,在系统启动时,处理部件改变指令单元710中的设定根据噪声环境而改变。因此,类似于第二(a)音频处理装置400,在第三(a)音频处理装置700中,可以降低功耗。
此外,在第三(a)音频处理装置700中,在步骤S767中,后置滤波单元708根据噪声环境来执行后置滤波处理。与在步骤S112(图5)中由第一(a)音频处理装置100执行的处理类似地执行这种处理。
类似于第一(a)音频处理装置100,在第三(a)音频处理装置700中,后置滤波单元708根据噪声环境来执行后置滤波处理。因此,类似于第一(a)音频处理装置100,在第三(a)音频处理装置700中,可以根据噪声环境适当地执行消噪处理并防止产生音乐噪声等。
<第三(b)音频处理装置的内部构造>
图43为示意图,示出了第三(b)音频处理装置800的构造。音频处理装置800设置在移动电话10的内部并构成移动电话10的一部分。图43所示的第三(b)音频处理装置800通过组合上述第一(b)音频处理装置200(图15)和第二(b)音频处理装置500(图28)而构造。
此外,类似于上述第三(a)音频处理装置700,在第三(b)音频处理装置800中,处理部件改变指令单元710的内部构造根据由噪声环境估计器801提供的噪声环境的估计结果而改变。
此外,由噪声环境估计器801提供的估计结果还被提供给后置滤波单元708,且后置滤波单元708被构造为以便根据估计噪声环境来控制消噪强度。
<第三(b)音频处理装置的第一操作>
参照图44和图45所示的流程图对图43所示的音频处理装置800的另一个操作进行说明。
音频处理装置800通过组合如上所述的第一(b)音频处理装置200和第二(b)音频处理装置500而构造,且其操作为组合第一(b)音频处理装置200的操作(基于图17和图18所示的流程图的操作)和第二(b)音频处理装置500的操作(基于图29和图30所示的流程图的操作)的操作。
基本上与由图29和图30所示的第二(b)音频处理装置500执行的步骤S501至S516类似地执行步骤S801至S816。
类似于第二(b)音频处理装置500,在第三(b)音频处理装置800中,处理部件改变指令单元710中的设定根据噪声环境而改变。因此,类似于第二(b)音频处理装置500,在第三(b)音频处理装置800中,可以降低功耗。
在第三(b)音频处理装置800中,在步骤S813中,后置滤波单元708根据噪声环境来执行后置滤波处理。与在步骤S211(图18)中由第一(b)音频处理装置200执行的处理类似地执行这种处理。
类似于第一(b)音频处理装置200,在第三(b)音频处理装置800中,后置滤波单元708根据噪声环境来执行后置滤波处理。因此,类似于第一(b)音频处理装置200,在第三(b)音频处理装置800中,可以根据噪声环境适当地执行消噪处理并防止产生音乐噪声等。
此外,音频处理装置800(图43)可具有省略缓冲区(存储器)的构造,这是因为噪声环境估计不需要暂时地保存分割成帧的时域信号。
<第三(b)音频处理装置的第二操作>
参照图46和图47所示的流程图对图43所示的音频处理装置800的另一个操作进行说明。
第三(b)音频处理装置800的第二操作为通过组合第一(b)音频处理装置200的操作(基于图17和图18所示的流程图的操作)和第二(b)音频处理装置500的第二操作(基于图31和图32所示的流程图的操作)的操作。
基本上与由图31和图32所示的第二(b)音频处理装置500执行的步骤S551至S573类似地执行步骤S851至S873。
类似于第二(b)音频处理装置500,在第三(b)音频处理装置800中,在系统启动时,处理部件改变指令单元710中的设定根据噪声环境而改变。因此,类似于第二(b)音频处理装置500,在第三(b)音频处理装置800中,可以降低功耗。
此外,在第三(b)音频处理装置800中,在步骤S870中,后置滤波单元708根据噪声环境来执行后置滤波处理。与在步骤S211(图18)中由第一(b)音频处理装置200执行的处理类似地执行这种处理。
类似于第一(b)音频处理装置200,在第三(b)音频处理装置800中,后置滤波单元708根据噪声环境来执行后置滤波处理。因此,类似于第一(b)音频处理装置200,在第三(b)音频处理装置800中,可以根据噪声环境适当地执行消噪处理并防止产生音乐噪声等。
此外,音频处理装置800(图43)可具有省略缓冲区(存储器)的构造,这是因为噪声环境估计不需要暂时地保存分割成帧的时域信号。
<第三(c)音频处理装置的内部构造>
图48为示意图,示出了第三(c)音频处理装置900的构造。音频处理装置900设置在移动电话10的内部并构成移动电话10的一部分。图48所示的第三(c)音频处理装置900通过组合上述第一(c)音频处理装置300(图19)和第二(c)音频处理装置600(图33)而构造。
此外,类似于上述第三(a)音频处理装置700,在第三(c)音频处理装置900中,处理部件改变指令单元710的内部构造根据由噪声环境估计器901提供的噪声环境的估计结果而改变。
此外,由噪声环境估计器901提供的估计结果还被提供给后置滤波单元708,且后置滤波单元708被构造为以便根据估计噪声环境来控制消噪强度。
噪声环境估计器901根据从外部输入的信息来估计噪声环境。
<第三(c)音频处理装置的第一操作>
参照图49和图50所示的流程图对图48所示的音频处理装置900的操作进行说明。
音频处理装置900通过组合如上所述的第一(c)音频处理装置300和第二(c)音频处理装置600而构造,且其操作为组合第一(c)音频处理装置300的操作(基于图20和图21所示的流程图的操作)和第二(c)音频处理装置600的操作(基于图34和图35所示的流程图的操作)的操作。
基本上与由图34和图35所示的第二(c)音频处理装置600执行的步骤S601至S616类似地执行步骤S901至S916。
类似于第二(c)音频处理装置600,在第三(c)音频处理装置900中,处理部件改变指令单元710中的设定根据噪声环境而改变。因此,类似于第二(c)音频处理装置600,在第三(c)音频处理装置900中,可以降低功耗。
在第三(c)音频处理装置900中,在步骤S913中,后置滤波单元708根据噪声环境来执行后置滤波处理。与在步骤S311(图21)中由第一(c)音频处理装置300执行的处理类似地执行这种处理。
类似于第一(c)音频处理装置300,在第三(c)音频处理装置900中,后置滤波单元708根据噪声环境来执行后置滤波处理。因此,类似于第一(c)音频处理装置300,在第三(c)音频处理装置900中,可以根据噪声环境适当地执行消噪处理并防止产生音乐噪声等。
此外,音频处理装置900(图48)可具有省略缓冲区(存储器)的构造,这是因为噪声环境估计不需要暂时地保存分割成帧的时域信号。
<第三(c)音频处理装置的第二操作>
参照图51和图52所示的流程图对图48所示的音频处理装置900的另一个操作进行说明。第三(c)音频处理装置900的第二操作为通过组合第一(c)音频处理装置300的操作(基于图20和图21所示的流程图的操作)和第二(c)音频处理装置600的第二操作(基于图36和图37所示的流程图的操作)的操作。
基本上与由图36和图37所示的第二(c)音频处理装置600执行的步骤S651至S667类似地执行步骤S951至S967。
类似于第二(c)音频处理装置600,在第三(c)音频处理装置900中,在系统启动时,处理部件改变指令单元710中的设定根据噪声环境而改变。因此,类似于第二(c)音频处理装置600,在第三(c)音频处理装置900中,可以降低功耗。
此外,在第三(c)音频处理装置900中,在步骤S964中,后置滤波单元708根据噪声环境来执行后置滤波处理。与在步骤S311(图21)中由第一(c)音频处理装置300执行的处理类似地执行这种处理。
类似于第一(c)音频处理装置300,在第三(c)音频处理装置900中,后置滤波单元708根据噪声环境来执行后置滤波处理。因此,类似于第一(c)音频处理装置300,在第三(c)音频处理装置900中,可以根据噪声环境适当地执行消噪处理并防止产生音乐噪声等。
此外,音频处理装置900(图48)可具有省略缓冲区(存储器)的构造,这是因为噪声环境估计不需要暂时地保存分割成帧的时域信号。
在上述音频处理装置100至900中,音频方位估计器104、404和704以及估计音频方位的操作可以省略。例如,对应用本技术的音频处理装置应用于眼镜式终端的情况进行说明。
当眼镜式终端中的麦克风位置为固定时,用户的嘴(声源)和麦克风之间的位置关系不变,且在用户安装眼镜式终端期间基本恒定。在这种情况下,因为在不估计方位的情况下,音频的方位基本上相同,所以移除音频方位估计器,且音频处理装置可能不估计音频的方位。
虽然上述音频处理装置100至900被构造为使得所有单元中的处理在音频信号通过时间/频率转换器103、403和703转换为时间/频率信号之后执行,但是可直接使用由麦克风23收集到的音频信号,而无需转换为时间/频率信号,并可执行所有单元中的处理。换言之,时间/频率转换器103、403和703可以省略,且在这种情况下,时间/频率逆变器109、409和709也可以省略。
根据本技术,因为估计噪声并根据估计结果来改变消噪处理,所以可以获得以下效果。
通过应用本技术,不仅可以在有一个点声源噪声的情况下适当地执行消噪,而且可以在多个声源或扩散性噪声环境下执行最佳消噪处理。
此外,可以传播为信号处理所特有的失真得到抑制的自然音频,并实现高质量免提通话。
可以防止因噪声或处理失真的影响所致的音频识别系统的性能劣化,并实现使用高质量音频的用户界面。
此外,可以防止因在音频识别中由用户不想要的错误识别引起的事件,例如,突然打电话、发邮件等。
可以只用小型非定向麦克风和信号处理而不使用具有大壳体的定向麦克风(枪式麦克风)来获得期望提取的音频,并有助于产品小型化和轻量化。
可以根据噪声环境来停止对声音提取不需要的信号处理模块和麦克风的供电,并有助于降低功耗。
<关于记录介质>
上述一系列处理可由硬件或软件执行。当一系列处理由软件执行时,构成软件的程序安装在计算机中。这里,计算机包括嵌入在专用硬件中的计算机和通过安装各种程序能够执行各种功能的个人计算机。
图53为方块图,示出了通过程序执行上述一系列处理的计算机的硬件构造实例。在计算机中,中央处理单元(CPU)2001、只读存储器(ROM)2002和随机存取存储器(RAM)2003通过总线2004相互连接。总线2004还连接到输入/输出接口2005。输入/输出接口2005与输入单元2006、输出单元2007、存储单元2008、通信单元2009和驱动器2010连接。
输入单元2006包括键盘、鼠标和麦克风。输出单元2007包括显示器和扬声器。存储单元2008包括硬盘和非易失性存储器。通信单元2009包括网络接口。驱动器2010驱动可移除介质2011,诸如磁盘、光盘、磁光盘或半导体存储器。
在具有以上构造的计算机中,CPU 2001通过输入/输出接口2005和总线2004将存储在例如存储单元2008中的程序加载到RAM 2003中并执行该程序,从而执行上述一系列处理。
由计算机(CPU 2001)执行的程序可通过在可移除介质2011中存储为例如封装介质等而提供。此外,该程序可通过有线或无线传输介质而提供,诸如局域网、因特网、数字卫星广播。
在计算机中,通过将可移除介质2011附接到驱动器2010,程序可通过输入/输出接口2005安装在存储单元2008中。此外,程序可通过有线或无线传输介质由通信单元2009接收并安装在存储单元2008中。除了以上所述,程序可预先安装在ROM 2002或存储单元2008中。
请注意,由计算机执行的程序可为按本说明书中所述的顺序依次地执行处理的程序或并行地或需要时(例如,当调用时)执行处理的程序。
此外,本说明书中的系统是指包括多个装置的整个装置。
请注意,本说明书中所述的效果仅仅作为示例而不是限制,且可能有其他效果。
请注意,本技术的实施例并不限于上述实施例,且在不脱离本技术的范围的情况下可以进行各种修改。
请注意,本技术可具有以下构造:
(1)一种音频处理装置,包括:
集声器,该集声器收集音频;
音频增强器,该音频增强器使用由所述集声器收集到的音频信号来增强待提取音频;
音频衰减器,该音频增强器使用由所述集声器收集到的音频信号来衰减待提取音频;
噪声环境估计器,该噪声环境估计器估计周围噪声环境;和
后置滤波单元,该后置滤波单元使用来自所述音频增强器的音频增强信号和来自所述音频衰减器的音频衰减信号来执行后置滤波处理,其中
所述后置滤波单元根据由所述噪声环境估计器估计的噪声环境来设定消噪处理强度。
(2)根据(1)所述的音频处理装置,其中所述噪声环境估计器使用由所述集声器收集到的音频来估计噪声环境。
(3)根据(1)所述的音频处理装置,其中
所述集声器包括多个麦克风,并且
所述噪声环境估计器计算由所述多个麦克风收集到的信号之间的相关性并将所述相关性的值设定为噪声环境的估计结果。
(4)根据(1)所述的音频处理装置,其中所述噪声环境估计器使用所述音频增强信号和所述音频衰减信号来估计噪声环境。
(5)根据(1)所述的音频处理装置,其中计算所述音频增强信号的振幅频谱和所述音频衰减信号的振幅频谱之间的相关性,并将所述相关性的值设定为噪声环境的估计结果。
(6)根据(1)所述的音频处理装置,其中所述噪声环境估计器根据从外部输入的信息来估计噪声环境。
(7)根据(6)所述的音频处理装置,其中从外部输入的信息为由用户提供的关于周围噪声环境的信息、位置信息或时间信息中的至少一条信息。
(8)根据(1)至(7)中任一项所述的音频处理装置,还包括:
发声区间估计器,该发声区间估计器使用所述音频增强信号和所述音频衰减信号来估计发声区间,其中
所述噪声环境估计器在由所述发声区间估计器估计为非发声区间的区间中估计所述噪声环境。
(9)根据(1)至(8)中任一项所述的音频处理装置,其中所述音频增强器使用加法型波束成形、延迟-求和波束成形或自适应波束成形来产生所述音频增强信号。
(10)根据(1)至(9)中任一项所述的音频处理装置,其中所述音频衰减器使用减法型波束成形、NULL波束成形或自适应NULL波束成形来产生所述音频衰减信号。
(11)根据(1)至(10)中任一项所述的音频处理装置,其中所述集声器中所包括的麦克风数量以及所述音频增强器和所述音频衰减器的输入数量根据由所述噪声环境估计器提供的估计结果而改变。
(12)根据(11)所述的音频处理装置,其中所述改变在启动或操作期间执行。
(13)一种音频处理方法,包括以下步骤:
通过集声器来收集音频;
产生音频增强信号,其中使用由所述集声器收集到的音频信号来增强待提取音频;
产生音频衰减信号,其中使用由所述集声器收集到的音频信号来衰减待提取音频;
估计周围噪声环境;以及
使用所述音频增强信号和所述音频衰减信号来执行后置滤波处理,其中
所述后置滤波处理包括根据所述估计噪声环境来设定消噪处理强度的步骤。
(14)一种程序,使计算机执行包括以下步骤的处理:
通过集声器来收集音频;
产生音频增强信号,其中使用由所述集声器收集到的音频信号来增强待提取音频;
产生音频衰减信号,其中使用由所述集声器收集到的音频信号来衰减待提取音频;
估计周围噪声环境;以及
使用所述音频增强信号和所述音频衰减信号来执行后置滤波处理,其中
所述后置滤波处理包括根据所述估计噪声环境来设定消噪处理强度的步骤。
附图标记列表
100 音频处理装置
101 集声器
102 噪声环境估计器
103 时间/频率转换器
104 音频方位估计器
105 音频增强器
106 音频衰减器
107 发声区间检测器
108 后置滤波单元
109 时间/频率逆变器
200 音频处理装置
201 噪声环境估计器
300 音频处理装置
301 噪声环境估计器
400 音频处理装置
402 噪声环境估计器
410 处理部件改变指令单元
500 音频处理装置
501 噪声环境估计器
600 音频处理装置
601 噪声环境估计器
700 音频处理装置
702 噪声环境估计器
800 音频处理装置
801 噪声环境估计器
900 音频处理装置
901 噪声环境估计器。
- 还没有人留言评论。精彩留言会获得点赞!