全息方言语音取样技术的制作方法
本发明提出了一种多维度方言声学物理数据采集与分析管理技术方案。方言完整信息保存技术,则将这一数据扩充到方言发声人的所有声学影响部位,对方言的进行多维采集。本发明对方言发声人进行多方位空气音(常用的声音)、皮肤音与体内音的同步声数据采集,并对应人的地域与身份(方言属性)进行自动的分类。依据声学参数标准,建立方言专业分析数据源。本发明着重应用在方言文化研究与保护方面。
背景技术:
言语声学研究涉及到三个方面的设备与仪器支持。传统的以话筒、听筒加存储器的方式构成录音后的文件分析,检索性能差且仪器的稳定性不好,言语声学文件可比较性不好,典型设备如录音机设备;数字化与集成电子传感构成的录音分析系统,仍然是以空气为介质的声学分析与言语研究,在标准化与方便性、文件可计算方面,在声学数据提升与控制方面形成了较好控制能力,典型如调音台[1]、言语声学分析仪[2],但对大量数据与音素级分析误差极大。空气介质录音技术在非气态介质中仪器可靠性、可用性极差[3,4],面对皮肤音、人体内共鸣声、体内音采集,受技术瓶颈影响无法获取。而这些在无线传感器网络技术支持下,瓶颈已经消失。近年以来htk为代表的软件分析言语声学技术应用成熟[5],标准化与分析过程的逻辑性有了很大改进[6],但仅仅限于对标准言语数据的分析,对于大量历史或不规范的声学文件,应用效果不好[7,8]。另一方面,在声采样技术中,空间多声道采样技术成熟[9],但异构声道采样技术相对落后,而与空间声道的混合同步比较技术更没有出现。本发明在空间声道采样与异构声道采样上,首次采用亚毫秒级同步取样技术,并在声学文件上与硬件dsp结合,构造出快速的多声像、多方位的声采样技术,同时所获得的声数据可以快速计算与处理,使得言语研究的工具性技术,更加进步。
[1]李融.音乐录音调音台信号流程分析.《电子技术与软件工程》2014年21期;
[2]http://cn.ap.com/;
[3]孙黉杰,汤一平,袁莹.智能睡眠枕的研究[j].浙江工业大学学报,2010,38(3):294-298;
[4]ashidanobuyuki,nasuyasuhiro,teshimataiki,yamakawamiyae,makimotokiyoko,higashiterumasa.trialofmeasurementofsleepapneasyndromewithsoundmonitoringandspo2athome.healthcom'09proceedingsofthe11thinternationalconferenceone-healthnetworking,applicationsandservices,ieeepress,2009:66-69;
[5]http://htk.eng.cam.ac.uk;
[6]石现峰,张学智,张峰.基于htk的语音识别系统设计.计算机技术与展,2006,(10):16-10;
[7]]a.jansen,k.church,andh.hermansky,towardsspokentermdiscoveryatscalewithzeroresources.inproc.iscainterspeech,2010,4:1677-1678;
[8]r.c.hendriks,r.heusdens,andj.jensen,mmsebasednoisepsdtrackingwithlowcomplexity[c],inproc.icassp'10,dallas,tx,2010,12:4268-4269;
[9]杨志华.录音棚声学设计[j].电声技术,2011,35(12):14-17。
技术实现要素:
本发明公开了一种标准化、电子多参数多位置同步口腔声取样技术。产品通过同时使用普通话筒、皮肤声传感器、内腔体声学传感器与环境声音传感器的同步取样,使用专用dsp芯片函数定制技术,参照htk声音分析软件标准,对口腔发音进行全方位声学参数采样、格式化存储,并进行言语学、语义与残体发声研究。产品主要用于言语声学、特殊声(伤病残)、声场调试研究与分析。产品解决了方言研究、残体发音与多数发声研究中,声音采样不标准、分析数据量大采集困难、采集数据不完整、后期分析研究周期长的问题,可以解除目前言语研究、残体发声研究难题,从而大大加快研究的进度,提高方便性。
本发明通过对多声传感器的位置定位、数据同步与亚毫秒级的信号同步,形成单声源与混合声源的腔体内(人体)、近口腔声场、环境声同步数据获取,形成声源的言语声学描述。所获取的样本通过htk软件的接口连接线路,形成支持htk的声学分析与计算。
图1为产品的框架图,通过声电转换后的电信号,传入声源的格式生成器①,形成定位设备id(位置)、时标(同步时间)、声数字信号片段以及片段编号(序号)的信号片段;同步信号与帧数据发生器②,用于同步设备时标,并将多声源信号片段进行数据帧生成,所生成的声数据帧为多片段合成,使用连续片段序号形成帧数据并进行编号(文件生成序列号),不同的源(设备)数据形成一个位置声通道(连续帧流);接收到连续数据帧的文件合成器③,对连续的帧进行通用声文件格式化封装,并生成声音文件;文件存储器④由缓存+磁盘结构形成,构成声的流文件大容量存储,形成多声道路数据文件;所有数据文件与软件htk的参数集对应,形成硬件级的参数连接器⑤,连接器可以与计算机的htk系统直接联结,形成可供htk分析的声学言语分析设备。
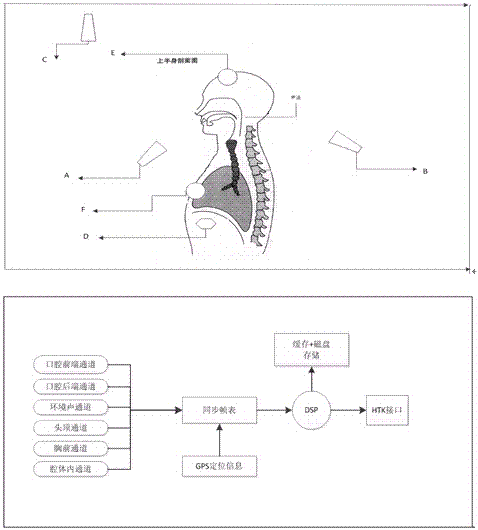
产品的传感器部分由四类位置与性质不同的传感器组成,如图2所示。包括口腔前端(后端)宽频传感器(a、b)、环境声传感器(c)、皮肤声传感器(e,f)、腔体内传感器(d)。不同传感接入声信号格式传感器①。
声信号格式传感器①由a/d转换与数字电子报(ieee1452.x)形成,电路如图3所示。
图3中ad574为ad转换芯片,在电路中起到把音频信号转换成数字电子报的作用。74ls04为反相器,起到电平转换的作用。74fct162373为16d锁存器,起到实时更新、锁存、转发数字电子报的作用。v0为音频信号,adclk为转换频率信号,由文件合成器③电路提供;adc_ok为转换完成信号,通知74fct162373读取更新电子报文;en1为通道选取使能信号,由同步信号与帧数据发生器②电路提供;ad0_data[0、、、15]为暂存的音频信号数据;其余器件共同组成该功能电路。
同步帧数据发生成由dsp时钟与电子报生成二个部分组成,框架如图4。时钟信号以片内亚毫秒时钟向每个设备发送,包括无线通道与有线通道二个部分同步,电路原理如图;电子报采用dsp合成函数形成,以确定的每设备的数据同步合成。
如图四是同步帧的电子报生成部分,其中u3、u4为74fct162373(十六d锁存器),u20为74alvc164245,u8、u9为74ls393,u10、u11为74ls138。u9的作用是对数据电子报的读取进行计数、当读取到指定次数时就会触发clk1、en0信号,同时u9清零以便于下一次计数。u8、u10和u11共同完成通道的选取、译码和标示,u8接收clk1信号就会完成加一计数,再经过u11完成通道译码标示id即帧序号,u10的作用是选取通道并且定时完成标示的插入,通道标示插入由en0信号触发。u12a和u2b分别是74ls08,74ls04分别起到逻辑线与和电平转换的功能。u20是把5v电平信号转换到3.3v电平,完成电平匹配。同步帧数据的dsp时钟部分由文件合成器③提供。
输出的数据报到达文件合成器③,由帧序号进行确定格式下的数据重新装配,形成文件格式的声音结构。文件合成由dsp功能函数与文件格式库形成流文件合成,合成电路框架由格式电路与数据装配电路组成如图5。
如图5所示u18单片机其型号为stc89ie58rd+,其功能是读取转发电子报并协调前后级电路。u17是主处理芯片采用ti公司生产的c5000系列的dsp,其型号为tms320vc5402,它是16位定点处理芯片,有运算速度快、具有可编程、接口灵活和外围电路丰富等特点。通过功能函数定制,完成流文件合成。
文件流输入到存储管理器后生成标准磁盘文件,数据转换过程如图6所示,图中htk格式数据由倒谱mel系数集形成,用于形成声音文件的完整过程。存储由流数据缓存转换电路、缓存格式化存储形成。
可存储的文件与htk系统的计算机系统匹配,并由htk的言语分析平台形成言语分析应用。所形成的方言语音数据,通过通用接口如usb、com接口,接入htk计算系统。所形成的电路如图7所示。
如图7所示,本模块为htk连接器即为通用的usb接口。该模块的主芯片为ch376,ch376是文件管理控制芯片,支持usb设备方式和usb主机方式,即可以支持计算机和usb设备。
如图8为方言声学采集的完整过程框架,用于形成具有htk规范的方言朗读人的数据采集与分析监控过程。
图9为htk格式文件形成电路,电子文件流为声音存储到存储器中,由dsp进行处理的声音源。dsp读取数据后调入快速傅里叶变换(fastfouriertransformation,fft),以能量为主要参数,结合mfcc(melfrequencycepstrumcoefficient)进行音素(子)分割,形成以时间为id的对应音素队列(图10)。
其中的字-音模块,是由标准字与方言声音对应数据库模块,其中声音数据由mfcc系数集,每个文字(词、短句)对应一组声音分解后的音素队列,每个音素由一mfcc系数集(结构)对应。
所选用的dsp由tms320c5402芯片组成计算系统,并使用通用的ftt(fastfouriertransformation,fft)代码与hmm(hiddenmarkovmodels,hmm)代码形成声音的数据处理,并输出mfcc(melfrequencycepstrumcoefficient,mfcc)值。朗读的每字或词(句)对应的声音文件,由dsp的fft标准函数进行频率-能量峰转换,形成能量帧,以供mfcc形成计算,mfcc使用了通用的隐马尔科夫(hiddenmarkovmodels,hmm)通用计算函数,形成音素队列。每音素索引数据结构,由标准mfcc系数生成,对应六个变量选择声音的六个能量集中频率点,为170hz、280hz、400hz、870hz、1200hz、1700hz对应mfcc变量。每次方言声文件由音素排列,形成id,并形成音素对应的数据结构,如表1所示:
表1音素的mfcc构造的数据结构
字-音模块,由单音字、双音字与短句计100个字组成朗读文本,标准朗读字(词、句)逐一显示在显示器上,供朗读者对应该朗读并录入形成声音文件,形成“标准字-方言音”对应文件数据,数据由dsp的fft函数与mfcc变量数组进行过滤计算,形成mfcc参数集,构成字对应的声音数据索引,字-音模块形成。字-音模块生成的数据存储到flash数据库中,flash存储格式由音素队列组成对标准字描述索引。
音素队列形成标准库,是由逐字读音、逐词读音、逐句读音形成,要求可靠且唯一对应。所形成的方言标准音-字库格式,是方言识别的核心数据库,结构由字索引与音素索引二个方式。字-音标准库为dsp系统的一部分。
附图说明:
图1方言语音数据多维度采集框架图;
图2多维度声采样数据位置与框架图;
图3数字信号电子报文生成器;
图4同步帧格式数据报生成器;
图5声音文件合成电路框架;
图6htk格式文件存储;
图7htk连接器;
图8方言采集取样过程框架;
图9tms320c5402芯片组成htk格式文件形成电路;
图10音素队列与图像帧队列形成框架示意图。
- 还没有人留言评论。精彩留言会获得点赞!