一种音质增强的方法和麦克风与流程
本发明涉及音频处理领域,特别涉及一种音质增强的方法和麦克风。
背景技术:
在现有技术中,涉及到音频处理的场景,特别是在会议的场景下,由于存在有外界噪音的存在,且本身人声的处理不合理,在很多会议场所由于空间大且参会人员多会出现离麦克风远的说话声音小,说话断字或不清晰的现象,导致用户的体验不好。
技术实现要素:
针对现有技术中的缺陷,本发明提出了一种音质增强的方法和麦克风,用以保证用户的使用体验。
具体的,本发明提出了以下具体的实施例:
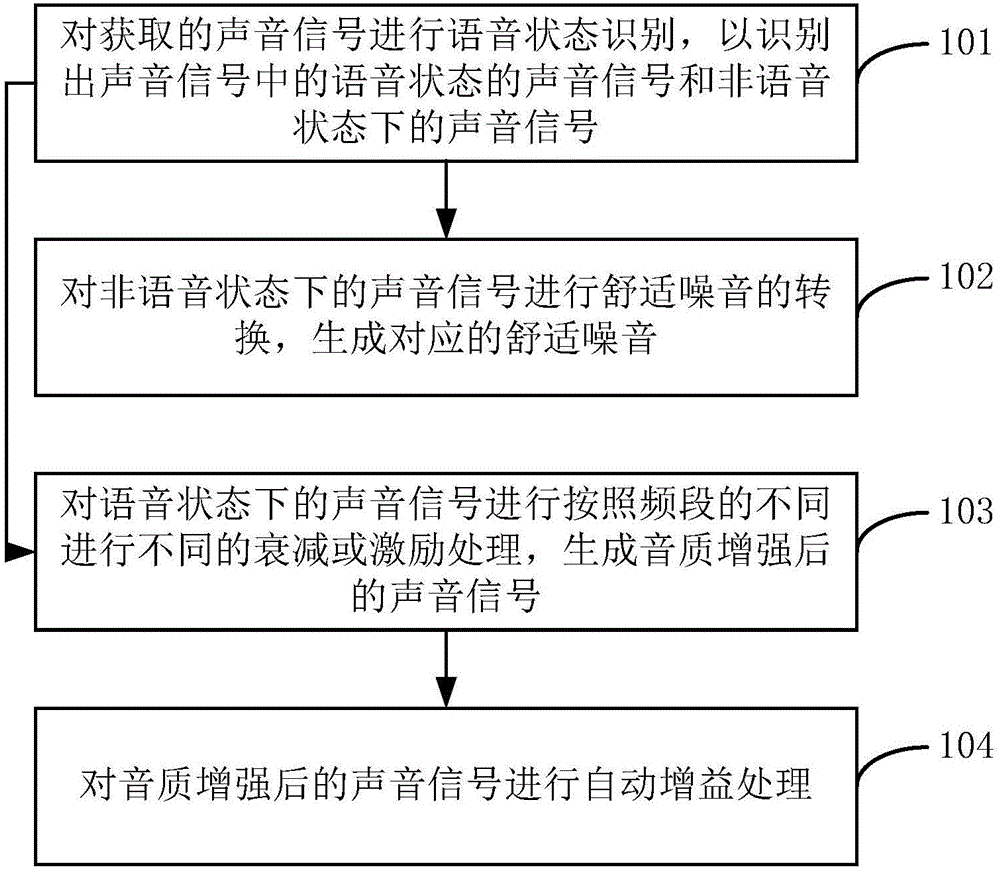
本发明实施例提出了一种音质增强的方法,应用于内部嵌入浮点库的ARM架构的系统,该方法包括:
对获取的声音信号进行语音状态识别,以识别出声音信号中的语音状态的声音信号和非语音状态下的声音信号;
对非语音状态下的声音信号进行舒适噪音的转换,生成对应的舒适噪音;
对语音状态下的声音信号进行按照频段的不同进行不同的衰减或激励处理,生成音质增强后的声音信号;并对音质增强后的声音信号进行自动增益处理。
在一个具体的实施例中,所述对获取的声音信号进行语音状态识别,以识别出声音信号中的语音状态的声音信号和非语音状态下的声音信号,具体包括:
对获取的声音信号进行能量检测,以获取声音信号的能量值;
若声音信号在一定延时范围内所保持的能量值都大于预设能量阈值,确定所述声音信号为语音状态的声音信号;
若声音信号在一定延时范围内所保持的能量值都小于预设能量阈值,确定所述声音信号为非语音状态的声音信号。
在一个具体的实施例中,该方法还包括:
对确定声音信号为语音状态的声音信号,确定在一定延时范围内所保持的能量值所处的范围;
基于不同的范围,对声音信号进行不同的衰减处理,以实现语音状态的声音信号与非语音状态的声音信号之间的平缓过渡。
在一个具体的实施例中,对语音状态下的声音信号进行按照频段的不同进行不同的衰减或激励处理,生成音质增强后的声音信号,具体包括:
对语音状态下的声音信号进行按照频段的不同划分为多个不同的频段;
对于高频的频段进行衰减处理,同时对处于低频的频段进行激励处理,以生成音质增强后的声音信号。
在一个具体的实施例中,对音质增强后的声音信号进行自动增益处理,具体包括:
获取音质增强后的声音信号的音量信息;
利用平均滤波器将超过预设音量范围的音质增强后的声音信号的音量调整到预设音量范围内。
本发明实施例还提出了一种麦克风,所述麦克风内部嵌入浮点库的ARM架构的系统,该麦克风包括:
识别模块,用以对获取的声音信号进行语音状态识别,以识别出声音信号中的语音状态的声音信号和非语音状态下的声音信号;
转换模块,用于对非语音状态下的声音信号进行舒适噪音的转换,生成对应的舒适噪音;
第一处理模块,用于对语音状态下的声音信号进行按照频段的不同进行不同的衰减或激励处理,生成音质增强后的声音信号;
第二处理模块,用于对音质增强后的声音信号进行自动增益处理。
在一个具体的实施例中,所述识别模块,具体用于:
对获取的声音信号进行能量检测,以获取声音信号的能量值;
若声音信号在一定延时范围内所保持的能量值都大于预设能量阈值,确定所述声音信号为语音状态的声音信号;
若声音信号在一定延时范围内所保持的能量值都小于预设能量阈值,确定所述声音信号为非语音状态的声音信号。
在一个具体的实施例中,该麦克风还包括:
过渡模块,用于对确定声音信号为语音状态的声音信号,确定在一定延时范围内所保持的能量值所处的范围;
基于不同的范围,对声音信号进行不同的衰减处理,以实现语音状态的声音信号与非语音状态的声音信号之间的平缓过渡。
在一个具体的实施例中,所述第一处理模块,具体用于:
对语音状态下的声音信号进行按照频段的不同划分为多个不同的频段;
对于高频的频段进行衰减处理,同时对处于低频的频段进行激励处理,以生成音质增强后的声音信号。
在一个具体的实施例中,所述第二处理模块,具体用于:
获取音质增强后的声音信号的音量信息;
利用平均滤波器将超过预设音量范围的音质增强后的声音信号的音量调整到预设音量范围内。
与现有技术相比,本发明实施例提出了一种音质增强的方法和麦克风,其中该方法包括:对获取的声音信号进行语音状态识别,以识别出声音信号中的语音状态的声音信号和非语音状态下的声音信号;对非语音状态下的声音信号进行舒适噪音的转换,生成对应的舒适噪音;对语音状态下的声音信号进行按照频段的不同进行不同的衰减或激励处理,生成音质增强后的声音信号;并对音质增强后的声音信号进行自动增益处理。以此通过对声音信号进行处理,以获取到更优质的声音信号,提高用户的使用体验。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本发明实施例提出的一种音质增强的方法的流程示意图;
图2为本发明实施例提出的一种音质增强的方法的示意图;
图3为本发明实施例提出的一种麦克风的结构示意图;
图4为本发明实施例提出的一种麦克风的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和出示的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
以下,根据实施例及附图对本发明作进一步的详细说明:
本发明公开了一种音质增强的方法,应用于内部嵌入浮点库的ARM架构的系统,如图1所示,该方法包括:
步骤101、对获取的声音信号进行语音状态识别,以识别出声音信号中的语音状态的声音信号和非语音状态下的声音信号;
步骤102、对非语音状态下的声音信号进行舒适噪音的转换,生成对应的舒适噪音;
步骤103、对语音状态下的声音信号进行按照频段的不同进行不同的衰减或激励处理,生成音质增强后的声音信号;
步骤104、对音质增强后的声音信号进行自动增益处理。
由于对音频的处理以及产生舒适噪音时需要使用大量的浮点运算。如果使用定点计算,会花费很长的时间,也耗费较多的资源,精度相对也会比较差,相比浮点运算也差一些;因此本发明提出了具体的处理的系统为内部嵌入浮点库的ARM架构的系统,以此可以提高处理的效率,消耗的资源相对较小,且精度更高。
步骤101的执行可以利用VAD(Voice Activity Detection,语音活动检测、又称语音端点检测、或语音边界检测)技术来实现;具体的,识别出的非语音状态下的声音信号即为噪音。
步骤102中的舒适噪音是一类特殊的噪音,由算法生成,起到使人放松或者引起警觉的作用;不同于一般噪音,不会使人产生烦躁或对人身体产生伤害。通过对非语音状态下的声音信号也即一般的噪音进行转换,转换为舒适噪音,以提高具体应用场景下,例如会议的语音质量。
而步骤103的执行可以利用带通滤波器来实现,特别是FIR滤波器,也即Finite Impulse Response滤波器,或有限长单位冲激响应滤波器,以及非递归型滤波器来实现。
以此,一种具体的方法流程示意图可以如图2所示。
通过以上方式,兼顾了语音传输高速性和准确性,降低了硬件成本;提高了麦克风的音质;提高了麦克风的拾音距离;本发明采用的新型舒适噪音生成改善了会议环境,使得参会的人员获得舒适的听感。以此通过对音频信号进行处理,获取到更优质的声音信号,提高用户的使用体验。
实施例1
本发明实施例1公开了一种音质增强的方法,应用于内部嵌入浮点库的ARM架构的系统,如图1所示,该方法包括:
步骤101、对获取的声音信号进行语音状态识别,以识别出声音信号中的语音状态的声音信号和非语音状态下的声音信号;
步骤102、对非语音状态下的声音信号进行舒适噪音的转换,生成对应的舒适噪音;
步骤103、对语音状态下的声音信号进行按照频段的不同进行不同的衰减或激励处理,生成音质增强后的声音信号;
步骤104、对音质增强后的声音信号进行自动增益处理。
在一个具体的实施例中,步骤101,也即所述对获取的声音信号进行语音状态识别,以识别出声音信号中的语音状态的声音信号和非语音状态下的声音信号,具体包括:
对获取的声音信号进行能量检测,以获取声音信号的能量值;
若声音信号在一定延时范围内所保持的能量值都大于预设能量阈值,确定所述声音信号为语音状态的声音信号;
若声音信号在一定延时范围内所保持的能量值都小于预设能量阈值,确定所述声音信号为非语音状态的声音信号。
具体的,语音状态识别是VAD判断来实现的,VAD判断又称语音端点检测,语音边界检测。目的是从声音信号流里识别和语音状态和非语音状态。本发明实施例主要使用了信号的能量阈值判别。基本的思路是当信号的能量低于某一经验门限并达到一定延时,判断该信号为噪音;当信号的能量高一某一门限值并达到一定延时,判断该信号为语音,也即语音状态的声音信号。
为了实现语音和非语音状态的声音信号的过渡带平稳,该方法还可以包括:
对确定声音信号为语音状态的声音信号,确定在一定延时范围内所保持的能量值所处的范围;
基于不同的范围,对声音信号进行不同的衰减处理,以实现语音状态的声音信号与非语音状态的声音信号之间的平缓过渡。
在此以一个具体的实施例来进行说明,在该具体的实施例中,设置了多3个阈值区间(分别为三个阈值E1、E2、E3)和理想能量值,其中,理想能量值是开会时正常通话音量长时采样平均能量。3个阈值分别取标准能量值的0.2-0.4、0.08-0.2和0.05-0.08。也即E1>E2>E3。
以此,对于只达到了第一个阈值E1的声音做3db衰减;达到第二个阈值E2声音做6db衰减。
若达到最后一个阈值E3的声音,则会进行转换处理,替换成舒适噪音。
此外,以上每达到一个阈值时还需要做100毫秒的延时判断,必须在这100ms内的能量持续的低于阈值才能进行下一步计算。如此使得语音和非语音状态的声音信号的过渡带平稳,不会出现卡字和掉字的现象。
步骤102,也即对噪音进行转换,在一个具体的实施例中,可以采用"线性同余法",每次调用时需要输入不同的“seed”值,以此产生不同的“噪声”序列。
此外,本发明时实施例还会对噪音的高频部分进行衰减处理。具体的,可以采用FIR滤波器制作一个低通滤波对5000Hz以上的噪音进行过滤以及衰减处理,在实际的应该中,可以有效减小6000Hz以上对人耳刺激较大的频段。当然,具体的,还可以根据需要对其他的频段进行处理,以满足不同的需要。
在一个具体的实施例中,步骤103,也即对语音状态下的声音信号进行按照频段的不同进行不同的衰减或激励处理,生成音质增强后的声音信号,具体包括:
对语音状态下的声音信号进行按照频段的不同划分为多个不同的频段;
对于高频的频段进行衰减处理,同时对处于低频的频段进行激励处理,以生成音质增强后的声音信号。
在此,一个具体的实施例来进行说明,在该实施例中,考虑到人声乐音的频谱分布以2500Hz为中点,因此对该频谱下的声音进行激励,具体的,可以进行3-6db的增强,所产生的效果比较自然舒适、对增加音源突出感的作用也比较明显。
而对人声鼻音频谱分布以500Hz为中点,对其进行激励处理,具体的,可以进行3-6db的增强,可以有效地增大人声的劲度感。
至于对人声3500-6800Hz范围内的频谱,不宜使用激励处理,因为它容易使音源产生令人不悦的嘈杂声响,可以适当衰减;例如,可以做了6db的衰减。
此外,在实际的应该中,对人声的齿音一般应避免使用激励处理,因为此频段的失真很容易被人察觉。当然如果是使用激励效果比较柔和的数字式激励器,也可以对齿音做轻微的激励处理,以用于加重齿音的清晰感。其处理的频谱应在7200Hz以上。
本实施例可以采用FIR滤波器(Finite Impulse Response滤波器:有限长单位冲激响应滤波器,又称为非递归型滤波器)来设计带通滤波器,对500Hz和3400Hz段进行增强过度带宽是200Hz。对6800Hz段的声音做了6db的衰减,过度带宽是500Hz。采用FIR滤波器,结构简单,只用了乘法加法,计算时间确定,没有迭代的过程,很适合计算机计算,也很容易地设计成特定相位的滤波器。只需要对一个乘加循环就可以完成FIR滤波计算。
在一个具体的实施例中,步骤104、也即对音质增强后的声音信号进行自动增益处理,具体包括:
获取音质增强后的声音信号的音量信息;
利用平均滤波器将超过预设音量范围的音质增强后的声音信号的音量调整到预设音量范围内。
由于信号在经过滤波降噪等一系列的处理之后,信号的幅度会出现一定幅度的衰减,同时为了获得比较稳定响亮舒适的听觉效果,需要在话音激活检测之后,根据检测结果对语音信号进行自动增益调节。其数学模型为:
其中,Xi为当前输入信号,M为平均滤波器的长度。AGC_maxinum和AGC_minum是期望的音量范围。以此任何超过了这个范围的音量会被算法调整到这个范围附近。以此自动增益帮助下麦克风会根据人与会议电话之间的距离远近来调整收音的大小,人离的远一点讲话,会把声音放大传给对方,人离的近讲话,会议电话会把声音变小一点传给对方,使对方听上去声音大小差不多。本发明拾音距离可以达到5米,是市场同类产品的三倍。
本发明实施例提出了一种音质增强的方法和麦克风,其中该方法包括:对获取的声音信号进行语音状态识别,以识别出声音信号中的语音状态的声音信号和非语音状态下的声音信号;对非语音状态下的声音信号进行舒适噪音的转换,生成对应的舒适噪音;对语音状态下的声音信号进行按照频段的不同进行不同的衰减或激励处理,生成音质增强后的声音信号;并对音质增强后的声音信号进行自动增益处理。以此通过对声音信号进行处理,以获取到更优质的声音信号,提高用户的使用体验。
实施例2
本发明实施例2还公开了一种麦克风,所述麦克风内部嵌入浮点库的ARM架构的系统,如图3所示,该麦克风包括:
识别模块201,用以对获取的声音信号进行语音状态识别,以识别出声音信号中的语音状态的声音信号和非语音状态下的声音信号;
转换模块202,用于对非语音状态下的声音信号进行舒适噪音的转换,生成对应的舒适噪音;
第一处理模块203,用于对语音状态下的声音信号进行按照频段的不同进行不同的衰减或激励处理,生成音质增强后的声音信号;
第二处理模块204,用于对音质增强后的声音信号进行自动增益处理。
在一个具体的实施例中,所述识别模块201,具体用于:
对获取的声音信号进行能量检测,以获取声音信号的能量值;
若声音信号在一定延时范围内所保持的能量值都大于预设能量阈值,确定所述声音信号为语音状态的声音信号;
若声音信号在一定延时范围内所保持的能量值都小于预设能量阈值,确定所述声音信号为非语音状态的声音信号。
如图4所示,该麦克风还包括:
过渡模块205,用于对确定声音信号为语音状态的声音信号,确定在一定延时范围内所保持的能量值所处的范围;
基于不同的范围,对声音信号进行不同的衰减处理,以实现语音状态的声音信号与非语音状态的声音信号之间的平缓过渡。
在一个具体的实施例中,所述第一处理模块203,具体用于:
对语音状态下的声音信号进行按照频段的不同划分为多个不同的频段;
对于高频的频段进行衰减处理,同时对处于低频的频段进行激励处理,以生成音质增强后的声音信号。
在一个具体的实施例中,所述第二处理模块204,具体用于:
获取音质增强后的声音信号的音量信息;
利用平均滤波器将超过预设音量范围的音质增强后的声音信号的音量调整到预设音量范围内。
本发明实施例提出了一种音质增强的方法和麦克风,其中该方法包括:对获取的声音信号进行语音状态识别,以识别出声音信号中的语音状态的声音信号和非语音状态下的声音信号;对非语音状态下的声音信号进行舒适噪音的转换,生成对应的舒适噪音;对语音状态下的声音信号进行按照频段的不同进行不同的衰减或激励处理,生成音质增强后的声音信号;并对音质增强后的声音信号进行自动增益处理。以此通过对声音信号进行处理,以获取到更优质的声音信号,提高用户的使用体验。
本领域技术人员可以理解附图只是一个优选实施场景的示意图,附图中的模块或流程并不一定是实施本发明所必须的。
本领域技术人员可以理解实施场景中的装置中的模块可以按照实施场景描述进行分布于实施场景的装置中,也可以进行相应变化位于不同于本实施场景的一个或多个装置中。上述实施场景的模块可以合并为一个模块,也可以进一步拆分成多个子模块。
上述本发明序号仅仅为了描述,不代表实施场景的优劣。
以上公开的仅为本发明的几个具体实施场景,但是,本发明并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!