低信噪比环境下基于多频带能量分布的动物声音检测方法与流程
本发明涉及一种低信噪比环境下基于多频带能量分布的动物声音检测方法。
背景技术:
低信噪比声音事件检测,就是试图检测、分类和识别嵌入在各种噪声和混响音频信号中的相对微弱的声音对象。近来,声音事件检测引起广泛关注。随着网络中多媒体数据的快速增长,基于音频数据的多媒体搜索具有极大的应用价值,同时,声音事件检测也是分析环境的关键组成之一。如,它对于音频取证、环境声音识别、生物声音监控、声场景分析,实时军事关注点的检测、定位跟踪和声源分类,病人监护、非正常事件监测及故障诊断、递交早期维护的关键信息等都具有重要意义。
关于声音事件检测,目前的研究包括吵闹环境下特定的声音事件检测方法;声音事件检测分类的有效特征及方法;背景/前景检测、声音事件分类和声音事件定位方法;声音场景、室内声音事件以及室内综合声音事件的检测与分类方法;特定环境下特定声音的检测方法等。
其中,Sharan和Moir用灰度共生矩阵(gray-level co-occurrence matrix,GLCM)图像纹理分析技术,提取耳蜗谱图(cochleogram image,CI)的纹理、得到耳蜗谱图纹理特征(cochleogram image texture feature,CITF),并把CITF与线性gammatone倒谱系数(gammatone cepstral coefficients,GTCCs)相结合,用CITF-GTCCs,对0dB的 声音事件的分类检测精度可以达到78%。McLoughlin等提出经过降噪(de-noising,DN)处理的时频谱特征(spectrogram image feature,SIF),通过深度神经网络(deep neural network,DNN)结合多条件(multi-conditions,MC)训练与e-尺度的声音事件分类,即SIF-DNN-DN-MC-e,对0dB的声音事件的分类检测精度可以达到87%。Dennis等抽取声谱图的局部最大成份作为峰值码,用改进的脉冲神经网络(spiking neural network,SNN)学习峰值码的时间分布,对0dB的声音事件的分类精度可以达到82%。Espi等提出多个单分辨分解的DNN并行工作和局部谱图的卷积神经网络(convolution neural network,CNN)的模型进行声音事件的有效检测。Phan等用超帧训练三个随机森林分类器,分别识别背景/前景、声音事件类型和声音事件的起始与偏移点。Stowell等报告了自动分类声音场景及检测声音事件的最新进展,并提供城市、办公和居住环境相关、可用于声音场景分类和声音事件检测的声音参考数据。Wang等用匹配追踪(matching pursuit,MP),在Gabor原子字典选取原子近似表示声音信号,再用主成分分析(principal component analysis,PCA)和线性判别分析(linear discriminant analysis,LDA)对不一致的频率-尺度进行映射形成特征,通过支持向量机(support vector machine,SVM)进行分类检测。Sharma和Kaul用二级分类器,在室内、户外、谈话、大型集会、机械和多媒体设备声音等六种声场景中,进行尖叫和哭泣声的危难检测。
Feng等根据目标事件及场景声音的特性,用小波包滤波器选择性地过滤场景声音,可以检测到特定声场景下-10dB的特定声音事件。目前,对于非特定声音事件的分类检测,提出了基于子带能量分布(sub-band power distribution,SPD)图形及相关处理的声音事件分类方法,分类检测效果最为明显。这种方法对各种信噪比下的声音事件识别获得卓越的效果。尤其,在信噪比低至0dB时,能够获得接近90%的检测率。然而,对于更低的信噪比声音事件的分类检测,这种方法的检测效果却受到了限制。
技术实现要素:
有鉴于此,本发明的目的在于提供一种低信噪比环境下基于多频带能量分布的动物声音检测方法,在低信噪比的情况下具有良好的鲁棒性。
为实现上述目的,本发明采用如下技术方案:一种低信噪比环境下基于多频带能量分布的动物声音检测方法,其特征在于,包括以下步骤:
步骤S1:利用多滤波器组对待测声音样本进行时频分析,获得多频带频谱图;
步骤S2:分析所述多频带频谱图的频率及能量分布,获取多频带能量分布图;
步骤S3:对所述多频带能量分布图进行分块DCT,并提取DCT系数矩阵中的低频系数作为所述待测声音样本的特征;
步骤S4:根据步骤S1至步骤S3对若干训练声音样本进行处理,获取训练声音样本的特征,并采用随机森林分类器对所述训练声音样本的特征进行训练,得到随机森林;
步骤S5:将所述待测声音样本的特征代入随机森林进行测试,确定所述待测声音样本的类标。
进一步的,所述步骤S1的具体内容如下:待测声音样本y(t)通过gammatone滤波器组滤波得到yf[t],对yf[t]取对数进行动态压缩,形成相应的gammatone频谱图Sg(f,t):
Sg(f,t)=log|yf[t]|
其中,f表示gammatone滤波器组的滤波器的中心频率,t是所述待测声音样本的帧索引。
进一步的,所述gammatone滤波器组的数目为256。
进一步的,所述步骤S2的具体内容如下:
步骤S21:对所述gammatone频谱图Sg(f,t)进行归一化处理,得到归一化能量谱G(f,t):
步骤S22:按下式对归一化能量谱G(f,t)的负值进行调整:
步骤S23:对归一化能量谱G(f,t)的能量分布进行统计,得到多频带能量分布图:
其中,W为待测声音样本的长度,M(f,b)表示在频带f中能量等级为b的元素占该频带元素总数的比例,Ib(G(f,t))为指示函数,当G(f,t)属于能量等级b时,其值为1,否则为0。
进一步的,所述步骤S23中,设置能量等级数目为:B=64。
进一步的,所述步骤S3的具体内容如下:
步骤S31:对多频带能量分布图进行8×8分块,并对子块进行DCT得到DCT系数矩阵;
步骤S32:对所述DCT系数矩阵进行Zigzag扫描编码得到DCT系数的一维Zigzag排列;
步骤S33:选取所述一维Zigzag排列的前k个系数作为所述待测声音样本的特征。
进一步的,所述k=5。
进一步的,所述步骤S5的具体内容如下:
步骤S51:将所述待测声音样本的特征置于随机森林中所有n棵决策树的根节点处;
步骤S52:按照决策树的分类规则,由根节点依次向下传递直到到达某一叶节点,该叶节点对应类标签便是这棵决策树对待测声音样本的特征所属类别所做的投票;
步骤S53:随机森林的n决策树均对待测声音样本的特征的类别进行了投票,统计随机森林中n棵决策树投票,其中票数最多的类标签便是待测声音样本最终对应的类标。
进一步的,所述训练声音样本为取自Freesound声音数据库的50种声音事件,每种声音事件包括30个样本。
本发明与现有技术相比具有以下有益效果:本发明在低信噪比的情况下,能保持良好的检测性能,受噪声环境影响较小,具备良好的鲁棒性。
附图说明
图1是现有低信噪比声音事件的分类检测方法的示意图。
图2是本发明的方法流程图。
图3a是本发明一实施例的茶隼叫声对应的gammatone频谱图。
图3b是本发明一实施例的茶隼叫声对应的多频带能量分布图。
图4a是本发明一实施例的多频带能量分布图的8×8分块示意图。
图4b是图4a中方框子块的放大图。
图4c是本发明一实施例的DCT系数矩阵。
图4d是图4c的一维Zigzag排列示意图。
图4e是图4d的前5个系数排列示意图。
图5是随机森林分类器的训练与检测过程示意图。
图6是本发明在三种信噪比的六种噪声环境下随机森林的平均检测结果示意图。
图7a至图7d分别是4种信噪比在粉噪声、风声、雨声和流水噪声条件下的对比结果图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
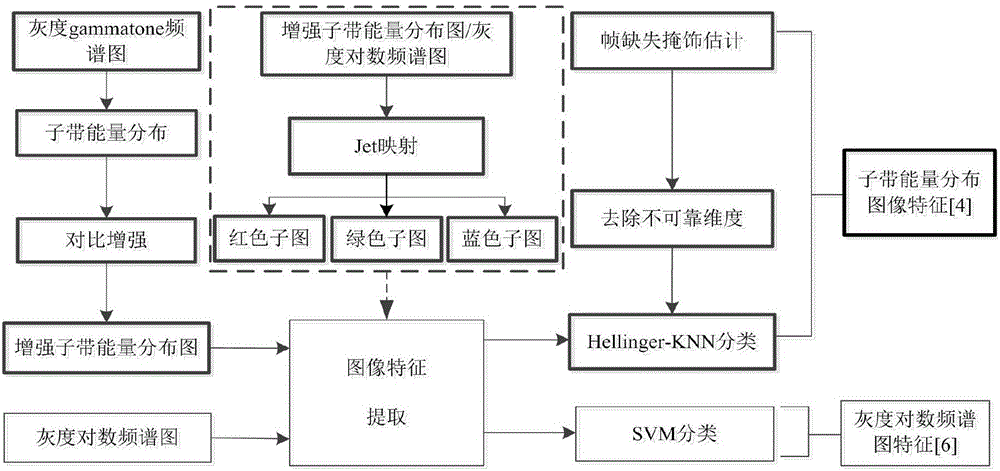
现有低信噪比声音事件的分类检测方法如图1下半部分的细线框所示,即灰度对数频谱图、图像特征抽取、SVM分类。采用这种方法,对声音事件的分类达到较好的效果。对信噪比为20dB和10dB声音事件的检测率分别达到87.8%和87.1%,尤其在0dB的情况下,检测率达到74.4%。图1中的虚线框所示,对图像特征抽取是通过Jet映射,把灰度对数谱图,映射成三张子图,对每张子图进行9×9分块,再提取每一块均值与方差,即共486(2×3×9×9)维向量作为特征进行支持向量机(SVM)的建模与分类检测。
以上述的图像特征抽取方法为基础,如图1的上半部分的粗线框所示,现有技术在频谱、频谱分析及分类器的选择上进行了进一步的处理。其中,频谱及分析包括:灰度gammatone频谱图、子带能量分布(SPD)、对比增强形成增强的子带能量分布图。对图像特征的进一步处理包括帧缺失掩饰估计(missing feature mask estimation),去除不可靠维度(marginalize unreliable dimensions)。然后再用基于Hellinger距离的k近邻分类器(k-nearest neighbor,kNN)分类。采用这种方法,在信噪比为0dB情况下,对声音事件的检测率可以达到88.43±0.7%。对图像特征抽取的处理也是通过Jet映射,把增强的子带能量分布图,映射成三张子图,对每张子图进行10×10分块,再提 取每一块均值与方差,即共600(2×3×10×10)维向量作为特征进行kNN的建模与分类检测.
现有技术还实现了低信噪比声音事件分类,采用帧缺失掩饰估计与去除不可靠维度。其中,帧缺失掩饰估计,先估算背景噪声的SPD,再估算背景噪声频率子带与声音事件的相关度。去除不可靠维度,就是根据估算的背景噪声的SPD及估算的背景噪声与声音事件的相关度,去除SPD图中与背景噪声相关的部分。这样,使得声音事件保留部分的SPD只与对应的声音事件相关。因此改善了在0dB情况下,对声音事件的检测率。
对SPD进一步分析发现,对于更低信噪比的声音事件,如-5bB或-10dB采用现有的方法,可能存在问题,其中包括:1)通过统计信号中50个频率子带内的共100个不同等级能量的概率密度,使得声音事件在低信噪比的情况下,高能的背景噪声将引起高能分布增值,SPD中原有的能量等级分布下移并因此减少可靠SPD成分;2)声音事件在低信噪比的情况下,高能的背影噪声可能影响到更多的子频带,使得可能得到的SPD的可靠部分减少;3)更低信噪比的情况下,噪声与声音事件的分界更加模糊,估计背景噪声的SPD误差增大,因此增加可靠SPD部分的误差。这些问题进而使得对低信噪比声音事件分类检测性能受到严重影响。
请参照图2,本发明提供一种低信噪比环境下基于多频带能量分布的动物声音检测方法,其特征在于,包括以下步骤:
步骤S1:利用多滤波器组对待测声音样本进行时频分析,获得多频带频谱图;具体内容如下:待测声音样本y(t)通过gammatone滤波器组滤波得到yf[t],对yf[t]取对数进行动态压缩,形成相应的gammatone频谱图Sg(f,t),图3a所示为茶隼叫声对应的gammatone频谱图:
Sg(f,t)=log|yf[t]|
其中,f表示gammatone滤波器组的滤波器的中心频率,t是所述待测声音样本的帧索引。所述gammatone滤波器组的数目为256,划分更细的频带使得高能噪声对频带的影响细化,因此降低被影响频带的比例。
步骤S2:分析所述多频带频谱图的频率及能量分布,获取多频带能量分布图(MBPD);具体内容如下:
步骤S21:对所述gammatone频谱图Sg(f,t)进行归一化处理,得到归一化能量谱G(f,t):
步骤S22:为了将归一化结果统一在[0,1]区间内,保证不同声音片段相关的高能量成分都可以被转换到多频带能量分布图的相同区域中按下式对归一化能量谱G(f,t)的负值进行调整:
步骤S23:对归一化能量谱G(f,t)的能量分布进行统计,得到如图3b所示的多频带能量分布图:
其中,W为待测声音样本的长度,M(f,b)表示在频带f中能量等级为b的元素占该频带元素总数的比例,Ib(G(f,t))为指示函数,当G(f,t)属于能量等级b时,其值为1,否则为0。
于本实施例中,步骤S23设置能量等级数目为:B=64,采用基于统计的非参数法,对每个频率子带f的能量元素进行概率密度统计,得到特定频带在整个采样时间W上的能量分布情况。把能量等级数目从现有的100减少到64,减少高能噪声引起的能量分布下移。
步骤S3:对所述多频带能量分布图进行分块DCT,并提取DCT系数矩阵中的低频系数作为所述待测声音样本的特征;
对一幅图像进行离散余弦变换(discrete cosine transform,DCT),可以将图像的重要可视信息都集中到DCT的一小部分系数中[13]。DCT系数矩阵可以认为是图像信号在频率不断增大的余弦函数上投影。所以它们也被称为低频系数、中频系数和高频系数。大体上,DCT系数矩阵中,沿左上至右下的方向,DCT系数是依次递减的。也就是说,一幅图像的DCT低频系数分布在DCT系数矩阵的左上角,高频系数分布在右下角,低频系数的绝对值大于高频系数的绝对值。左上角的第一个系数,cos0=1,被称为DCT的直流(direct current,DC)系数,是图像像素的均值,也是最大的一个值。其它系数被称为交流 (alternating current,AC)系数。一般情况下,越靠近左上角,AC系数包含着越多的图像信息。因此,图像大部分信息都包含在低、中频系数中。
步骤S3的具体内容如下:
步骤S31:如图4a所示对64×256大小的多频带能量分布图进行8×8分块,分为256个8×8子块,每个子块携带着声音数据在相应频带及能量等级的分布情况。图4b是对应于4a中方框子块,即对应于MBPD图中,频带从96到103,能量等级从25至32的能量分布情况。
接着并对子块进行DCT,对于每个8×8子块,DCT后可以得到如图4c所示同样的8×8的DCT系数矩阵;
步骤S32:为了有效地将系数中的低频系数置于高频系数之前,本文采用Z字形行程扫描,即Zigzag行程扫描,其路径如图4c的线条及箭头所示。
步骤S33:8×8的DCT系数矩阵经过Zigzag扫描编码可以得到如图4d所示,64个DCT系数的一维Zigzag排列。由于DCT将图像的重要信息都集中分布在DCT系数的左上角性质,以及Zigzag扫描将低频系数置于高频系数之前的特性,在提取特征参数时,如图4e所示,只取一维排列的前部分数据即可表征图像的主要特征。通过综合实验分析,本实施例中,只取64个DCT系数的一维Zigzag排列的前5个系数作为该8×8图像块的特征。这个特征即为多频带能量分布子块的DCT系数矩阵经Zigzag扫描编码的特征,简称为MBPD-DCTZ。
步骤S4:根据步骤S1至步骤S3对若干训练声音样本进行处理,获取训练声音样本的特征,并采用随机森林分类器对所述训练声音样本的特征进行训练,得到随机森林;所述训练声音样本为取自Freesound声音数据库的50种声音事件,每种声音事件包括30个样本。
随机森林(random forests,RF)分类器是一种利用多个决策树分类器来对数据进行判别的集成分类器算法,其过程如图5所示。首先,通过自助重采样(Bootstrap)技术,从训练样本的能量分布特征集自助重采样,生成新的n个训练数据集。然后,将新生成的n个训练数据集按照决策树的构建方法生长成n棵决策树,并组合成n棵决策树形成森林.测试数据的判别结果则由森林中n棵树进行投票得到。
步骤S5:将所述待测声音样本的特征代入随机森林进行测试,确定所述待测声音样本的类标;具体内容如下:
步骤S51:将所述待测声音样本的特征置于随机森林中所有n棵决策树的根节点处;
步骤S52:按照决策树的分类规则,由根节点依次向下传递直到到达某一叶节点,该叶节点对应类标签便是这棵决策树对待测声音样本的特征所属类别所做的投票;
步骤S53:随机森林的n决策树均对待测声音样本的特征的类别进行了投票,统计随机森林中n棵决策树投票,其中票数最多的类标签便是待测声音样本最终对应的类标。
为了让一般技术人员更好的理解本发明的技术方案,以下结合具体实验数据对本发明进一步介绍。
实验数据
实验采用的50种声音事件均来自Freesound声音数据库,包括不同鸟鸣声和哺乳动物叫声;每种声音事件有30个样本,具体如表1所示。实验用到的六种噪声环境可分为两类,即一种平稳噪声和五种非平稳噪声,平稳噪声为粉噪声(pink),非平稳噪声包括模拟真实场景声音的流水声、风声、马路声、海浪声和雨声;噪声样本与声音事件的格式统一为单声道“.wav”格式,采样频率为44.1kHz、声音长度为2s、量化精度为16bits。
表1声音事件样本集
实验设计
实验中,gammatone滤波器参数为:帧长为25ms,帧移为10ms,滤波器组数目为256;取随机森林分类器中决策树的个数k=500,决 策树中非叶节点分裂时预选特征成分的数量m=5。为了验证本文方法的检测性能,我们进行了如下的实验。
1)确定MBPD-DCTZ特征的参数设置。
2)验证MBPD-DCTZ特征与RF分类器结合在不同信噪比不同噪声环境下的检测性能。
3)MBPD-DCTZ特征与其它几种特征的性能对比。这些特征包括:Mel频率倒谱系数(mel-frequency cepstrum coefficient,MFCC)、幂归一化倒谱系数(power normalized cepstral coefficients,PNCC)、灰度共生矩阵的和差统计特征(sum and difference histogram based on gray-level co-occurrence matrix,GLCM-SDH)、局部二元模式特征(local binary pattern,LBP)、渐变直方图特征(histogram of oriented gradients,HOG)等。
4)分类器的性能对比。对比MBPD-DCTZ特征在随机森林(random forests,RF)分类器、支持向量机(support vector machine,SVM)分类器和K近邻(k-nearest neighbor,kNN)分类器中的检测效果。
5)本文方法与现有方法的对比。
试验结果与分析
1)多频带能量分布特征提取主要涉及的参数是DCT后Zigzag排列中低频主要部分Z的选取,我们分别选择提取MBPD-DCT的Zigzag排列的前面1-10个系数进行实验.在-10dB、-5dB和0dB三种信噪比的六种噪声环境下随机森林的平均检测结果如图6所示。
由图6可知,对DCT系数进行Zigzag排列提取Z个重要系数在一定程度上均能提高DCT系数对声音事件的表征性能。具体而言,当Z=4和Z=5时,对-10dB、-5dB和0dB检测率达到最佳。相对而言,Z=5时平均检测率,略高于Z=4时的平均检测率。因此我们在后面的实验中,取Z=5。
2)为说明MBPD-DCTZ与RF分类器结合的有效性,我们进行了交叉验证实验。将每类声音样本的30个“.wav”音频文件,均分为3个集合,分别标记为1、2和3,每个集合有10个音频文件。每次取两个集合进行随机森林模型训练,一个集合进行测试。在-10dB、-5dB、-0dB和5dB等四种不同信噪比,及流水、粉噪声、风声、海良、马路和雨声等六种背景噪声条件下,三次交叉验证实验的平均检测结果如表2所示。由表2可知,不论在平稳噪声条件还是非平稳噪声条件下,MBPD-DCTZ特征都表现出了良好的性能,在-5dB低信噪比时,达到平均81.0%的平均检测率。
表2MBPD-DCTZ特征的交叉验证结果
3)为了进一步说明MBPD-DCTZ特征表征低信噪比声音事件的性能,我们进行了MBPD-DCTZ特征与MFCC、PNCC、GLCM-SDH、LBP、HOG几种特征的对比实验。实验中,噪声环境与信噪比条件均为相同,且测试阶段都没有进行声音增强处理,直接对4种信噪比的声音事件 提取相应特征送入随机森林分类器进行检测。其中,MFCC特征采用24个滤波器的三角滤波器组,提取12维DCT系数;PNCC特征采用32阶的gammatone滤波器,DCT时取12维系数。
表3不同信噪比噪声条件下不同特征检测率(%)
不同信噪比及不同背景噪声条件下,几种特征的检测结果如表3所示。由表3可知,不同信噪比噪声条件下,MBPD-DCTZ特征的检测性能整体优于其他几种特征,尤其是当信噪比为0dB、-5dB和-10dB时,能量分布特征的平均检测率依然分别达到89.2%、81.0%和43.2%,明显优于LBP、HOG、MFCC和PNCC几种特征的检测率。
4)分类器性能验证。将不同信噪比的不同环境下的MBPD-DCTZ特征,分别送入RF、SVM、KNN分类器进行检测。4种信噪比在粉噪声、风声、雨声和流水噪声条件下的对比结果如图7a至图7d所示。由图7a至图7d可知,在不同信噪比及不同背景噪声条件下,本文提出的MBPD-DCTZ特征比较适合于用RF分类器进行分类检测。尤其在0dB以下信噪比时,RF分类器对MBPD-DCTZ特征的检测远远高于KNN和SVM的检测性能。因此,本文在对MBPD-DCTZ特征的检测过程中选用RF分类器。
5)不同信噪比及不同环境下,本文方法与MFCC-SVM、SIF-SVM、MP-SVM和SPD-KNN方法的对比。
由表4可知,在低信噪比的情况下,本文所提的多频带能量分布特征MBPD-DCTZ与RF结合的方法均能保持较好的检测性能,且受噪声环境影响较小。尤其,在低信噪比时,本文所提的方法大幅度优于其它几种方法.这说明本文所提的方法能检测不同信噪比噪声条件下的各种声音事件,且具有良好的鲁棒性。
表4本文方法与其它方法的比较(%)
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!