数字音频编码中码率分配的方法和装置与流程
本发明涉及数字音频编码技术,更具体地说,涉及一种数字音频编码中码率分配的方法和装置。
背景技术:
随着超高清电视等应用的发展,对于音频的要求也进一步提高,以便获得身临其境的沉浸式听觉效果。为此,输入音频信号的声道数明显增多(例如5.1.4、7.1.4和22.2等),甚至还有多个独立的目标音频信号。在给定编码总码率条件下,如何处理各声道(包含目标信号)的码率分配以及每个声道内的码率分配将会影响总的编码质量。
当前的多声道数字音频编码,如DRA5.1、AAC5.1、DD(DD+)、DTS等,都是属于感知音频编码技术,在变换域或子带域通过心理声学模型计算出的掩蔽门限对频率谱系数进行量化和熵编码,通常在码率分配时没有考虑声道的特点,所有声道同样对待。以DRA多声道编码技术为例(其他编码算法类似),对于输入的多声道PCM信号,首先通过心理声学模型,以人类听觉的临界频带为单位进行掩蔽门限计算,同时,将输入的多声道PCM信号通过滤波器组采用改进离散余弦变换(MDCT)从时域变换到频域,得到多个声道的MDCT系数。根据设定的比特率,比如立体声128kbps或者5.1环绕声384kbps,一般有两种码率分配方式:
第一种:多个声道平均分配码率,这是一种简单的分配方法,每个声道内再采用自由竞争的方式(具体参考以下第二种方式)分配比特。对于立体声128kbps时,每个声道64kbps;对于5.1环绕声时,低频效果声道一般仅仅编码120Hz以下的低频部分,可以分配较少的码率,比如24kbps,其它5个全频带声道每个声道分配72kbps。
第二种:自由竞争模式。首先计算每帧总比特数,对于DRA编码,立体声每帧为128*1024/48比特,即约为2731比特;5.1环绕声384kbs,每帧为8192比特。然后,根据每个声道的每个比例因子带(或称为量化单元)的掩蔽门限值,首先对量化噪声最大(即最不容易掩蔽掉量化噪声)的子带中的系数增加量化精度,从总比特中分出一部分比特,之后再分析所有声道所有子带中哪一个子带内的MDCT系数最需要提高量化精度,则进一步从总比特数中分配出一部分比特来增加其量化精度,以此类推,直到最后消耗掉所有比特数为止,则码率(比特)分配完毕。
第二种分配方式在实现时比较复杂,较少采用。一般都采用第一种的平均分配方法。从以上两种分配方式可以看出,虽然针对5.1声道的情况,考虑到.1声道实际需要编码的频带仅仅到120Hz,其他全频带一般要编码到20kHz,已经进行了非平均码率分配,但是对于立体声、5.1中的全频带声道一般采用各个声道平均分配码率然后每个声道内自由竞争方式分配比特(或码率)。这种方法没有考虑到以下两点:(1)对于5.1以上等多声道情况,各个全频带声道(包含目标信号)在对总主观声音质量上的贡献并不相同;(2)在一定码率要求条件下,每个声道的低频和高频失真对总的主观声音质量的影响也不相同。
在对立体声或多声道音频信号编码时,如果码率低于某一个值,例如DRA立体声96kbps、5.1环绕声256kbps时,通常采用强度立体声编码(Intensity Stereo Coding)。这是因为当在这个码率以下编码时,无法达到透明编码质量,需要改进编码策略。人类听觉系统对于音频高频部分的包络更敏感,而其细节不太重要,基于此原理,强度立体声编码技术可以将立体声信号的高频(或者5.1声道的5个全频带信号的高频部分)混合成一个声道,同时传输所有声道的高频包络。这种编码策略保证了在较低的码率下获得更好的编码主观声音质量。例如对于立体声编码时,通常左(L)右(R)声道强度立体声编码处理如下:
若强度立体声编码的频率点(通常全频带声道高频一直到20kHz)为8kHz,则处理后的L声道构成为:L声道的0~8kHz+(L声道8~20kHz高频与R声道8~20kHz高频)混合后的高频部分;处理后的R声道构成为:R声道的0~8kHz。然后对重构的左右声道进行自由竞争的码率分配方式处理。
可以看出,强度立体声编码方法存在以下码率分配上的问题:由于只传输一个混合的高频细节,在解码时通过这个高频细节和各个声道的高频包络来恢复各个声道的高频部分。如果作为像传统(没有采用强度立体声模式)的多个声道码率分配方式来编码这种多个声道共用的高频细节,这个共用的高频部分在码率分配时并没有任何优势,在独立的声道编码时,各个声道的高频部分失真都限定在各声道内,而强度立体声编码的高频部分细节编码失真会带入各个声道。
技术实现要素:
本发明要解决的技术问题在于,针对现有技术的上述缺陷,提供数字音频编码中码率分配的方法和装置,能够获得更好的主观声音质量。
本发明为解决其技术问题在第一方面提出一种数字音频编码中声道内码率分配的方法,包括如下步骤:
S1、选择一组特定的调整系数对一个声道内从低频到高频各子带的掩蔽门限进行自适应调整;
S2、基于调整后的掩蔽门限进行声道内的全局比特分配。
根据本发明第一方面的一个实施例中,所述步骤S1中一组特定的调整系数基于个人对失真的不敏感来选择。
根据本发明第一方面的一个实施例中,所述步骤S1中一组特定的调整系数基于输入音频信号的类型来选择。
根据本发明第一方面的一个实施例中,所述步骤S1进一步包括:
对于语音类信号,选择一个小于1的系数以降低高频子带的掩蔽门限;
对于音乐类信号,选择适当的调整系数以降低最低频带的掩蔽门限,并相对于最低频带较次之的降低中间频带的掩蔽门限。
本发明为解决其技术问题在第二方面提出一种数字音频编码中声道间码率分配的方法,包括如下步骤:
S1、对输入的多声道音频信号进行声道特性分析,获得声道配置信息;
S2、根据所述声道配置信息,在平均分配码率的基础上对各声道的码率进行不同权重系数的调整;
S3、基于调整后的各声道的码率进行全局比特分配。
根据本发明第二方面的一个实施例中,对于5.1声道音频信号,所述步骤S2中码率的调整包括:对前置声场的L声道和R声道给予相较于后置声场的LS声道和RS声道更高的权重系数;对中央声道,在总的编码码率较高时给予相较于其他声道更小的权重系数,在总的编码码率较低时给予相较于其他声道更高的权重系数。
根据本发明第二方面的一个实施例中,对于3D多声道音频信号,所述步骤S2中码率的调整包括:中间层声道的权重系数高于顶层声道的权重系数,顶层声道的权重系数高于底层声道的权重系数,且前置声道的权重系数高于后置声道的权重系数。
根据本发明第二方面的一个实施例中,对于输入的多声道音频信号中包含目标信号的情况,所述步骤S1进一步包括:分析目标信号的特性,获得目标信号描述信息;所述步骤S2进一步包括:基于目标信号描述信息来确定目标信号码率分配的权重系数。
根据本发明第二方面的一个实施例中,所述步骤S2中确定目标信号的码率分配的权重系数进一步包括:
当目标信号为不同语种的伴音时,给予和中央声道一样的权重系数;
当目标信号为方向性活动目标信号时,给予较声道信号更低的码率分配权重系数。
本发明为解决其技术问题在第三方面提出一种数字音频的强度立体声编码中码率分配的方法,包括如下步骤:
S1、选择一特定的权重系数对混合的高频信号部分的掩蔽门限进行自适应调整;
S2、基于调整后的掩蔽门限进行自由竞争码率分配。
根据本发明第三方面的一个实施例中,所述步骤S1中基于对混合的高频信号的分析来选择所述权重系数,其中高频分量越多,权重系数越高。
本发明为解决其技术问题在第四方面提出一种数字音频编码中声道内码率分配的装置,包括:
掩蔽门限调整模块,用于选择一组特定的调整系数对一个声道内从低频到高频各子带的掩蔽门限进行自适应调整;
比特分配模块,用于基于调整后的掩蔽门限进行声道内的全局比特分配。
本发明为解决其技术问题在第五方面提出一种数字音频编码中声道间码率分配的装置,包括:
分析模块,用于对输入的多声道音频信号进行声道特性分析,获得声道配置信息;
码率调整模块,用于根据所述声道配置信息,在平均分配码率的基础上对各声道的码率进行不同权重系数的调整;
比特分配模块,用于基于调整后的各声道的码率进行全局比特分配。
本发明为解决其技术问题在第六方面提出一种数字音频的强度立体声编码中码率分配的装置,包括:
掩蔽门限调整模块,用于选择一特定的权重系数对混合的高频信号部分的掩蔽门限进行自适应调整;
码率分配模块,用于基于调整后的掩蔽门限进行自由竞争码率分配。
本发明实施例的数字音频编码中码率分配的方法和装置,能够自适应的处理各声道间的码率分配、每个声道内的码率分配、以及使用强度立体声编码时的码率分配,从而获得更好的主观声音质量。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明一个实施例的数字音频编码中声道内码率分配的方法的流程图;
图2是本发明一个实施例中数字音频编码中声道内码率分配的方法的原理示意图;
图3是本发明一个实施例中语音类信号自动调整系数的示意图;
图4是本发明一个实施例中音乐类信号自动调整系数的示意图;
图5是本发明一个实施例的数字音频编码中声道间码率分配的方法的流程图;
图6是本发明一个实施例中数字音频编码中声道间码率分配的方法的原理示意图;
图7是本发明一个实施例的数字音频的强度立体声编码中码率分配的方法的流程图;
图8是本发明一个实施例中数字音频的强度立体声编码中码率分配的方法的原理示意图;
图9是本发明一个实施例的数字音频编码中声道内码率分配的装置的逻辑框图;
图10是本发明一个实施例的数字音频编码中声道间码率分配的装置的逻辑框图;
图11是本发明一个实施例的数字音频的强度立体声编码中码率分配的装置的逻辑框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提出数字音频编码中码率分配的方法和装置,主要应用于超高清电视的3D音频系统等多声道编码的应用领域。本发明提出的数字音频编码中码率分配的方法和装置主要考虑以下问题:(1)在一定码率条件下,每个声道的低频和高频失真对总的主观声音质量的影响不相同;(2)各个全频带声道(目标信号)在对总主观声音质量上的贡献并不相同;(3)强度立体声编码时,混合的高频部分的编码码率分配应适当给予增加。
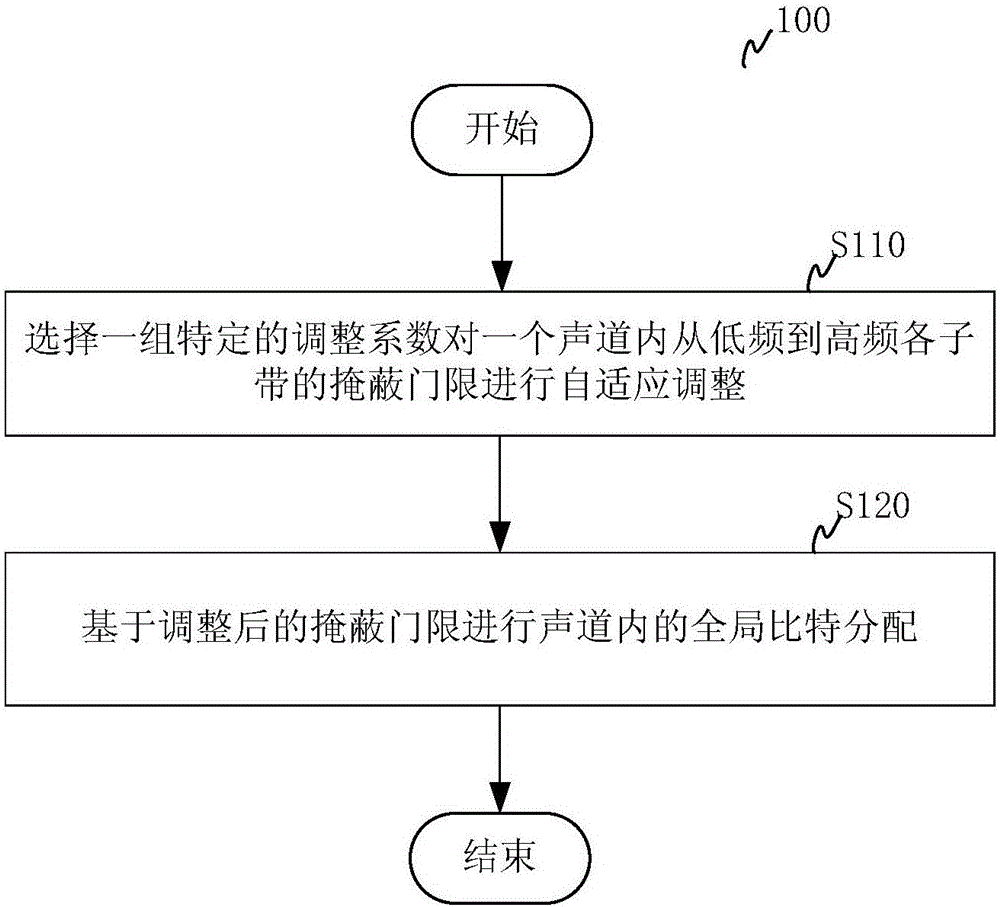
基于以上问题,本发明首先对声道内码率分配的方式提出改进。图1示出了根据本发明一个实施例的数字音频编码中声道内码率分配的方法100的流程图。如图1所示,该方法100包括如下步骤:
步骤S110中,选择一组特定的调整系数对一个声道内从低频到高频各子带的掩蔽门限进行自适应调整;
步骤S120中,基于调整后的掩蔽门限进行声道内的全局比特分配。
对于给定码率条件为高码率的情况,编码时每个声道分配的码率足够,因而不需要进行调整。但是,对于给定码率条件为中低码率的情况,编码声音的主观声音质量达不到透明,即已经出现码率不够的情况,这时会出现各种失真,如低频部分的量化噪声、高频丢失等。为了确保最终整体主观声音质量更好,一方面,步骤S110中可以根据个人对失真的不敏感来选择一组调整系数对各子带的掩蔽门限进行适当的调整,从而改变一个声道内的码率分配,获得需要的结果。另一方面,步骤S110中可以基于输入音频信号的类型而自动选择一组调整系数对各子带的掩蔽门限进行调整,从而改变一个声道内的码率分配,获得综合最优效果。
基于输入音频信号的类型来自适应调整掩蔽门限的原理如图2所示,对输入音频信号通过心理声学模型进行掩蔽门限计算,得到掩蔽门限值,同时,对该输入音频信号进行信号类型分析,获得信号类型信息,然后基于不同的信号类型选择特定的调整系数来对掩蔽门限值进行调整,最后基于调整后的掩蔽门限值来进行声道内的全局比特分配。调整系数可以基于信号类型在内部进行自动选择,亦可以手动设置。例如,对于语音类信号,可以对高频子带的掩蔽门限乘以一个小于1的系数,比如0.5,以降低高频子带的掩蔽门限,从而适当降低高频的量化精度,如图3所示。又例如,对于音乐类信号,可以选择适当的调整系数以降低最低频带的掩蔽门限,并相对于最低频带以较次之的程度降低中间频带的掩蔽门限,从而使得高频子带通过自由竞争获得稍高的码率,最终使得整个音乐类音频的高频失真降低,如图4所示。
本发明以上实施例的数字音频编码中声道内码率分配的方法,在给定码率条件下能够自适应的处理声道内的码率分配,从而获得更好的主观声音质量。
基于前述的第二个问题,本发明对多声道音频信号编码时声道间的码率分配亦提出改进。图5示出了根据本发明一个实施例的数字音频编码中声道间码率分配的方法200的流程图。如图5所示,该方法200包括如下步骤:
步骤S210中,对输入的多声道音频信号进行声道特性分析,获得声道配置信息;
步骤S220中,根据所述声道配置信息,在平均分配码率的基础上对各声道的码率进行不同权重系数的调整;
步骤S230中,基于调整后的各声道的码率进行全局比特分配。
以5.1声道音频信号为例,首先分析其声道信号特性,得到声道配置包括0.1低频效果声道、前置声场的L和R声道、后置声场的LS和RS声道、以及中央声道C。其中,低频效果声道一般仅仅编码120Hz以下的低频部分,可单独进行较低的码率分配。其他5个全频带声道通常情况下是每个声道分配相同的码率。在给定码率条件为足够高的码率(透明质量)时,可以采用这种分配方式。然而在不透明质量码率条件下,考虑到人耳听觉系统对前置声场(L&R)更重要,而后置LS和RS一般用来产生后置环境声场,因此前置声场的L&R声道应该给予相较于后置声场的LS声道和RS声道更高的权重系数。中央声道C一般为对白信号(语音信号),因此在总的编码码率较高时C声道可以给予相较于其他声道更小的权重系数,而在总的编码码率较低时要给予相较于其他声道更高的权重系数,以保证对白声道具有一定的主观声音质量。例如,较高码率(如320kpbs)时,L、R、C、LS和RS比例关系为1.05:1.05:0.95:0.975:0.975;当码率为288kbps时,L、R、C、LS和RS比例关系为1.05:1.05:1.0:0.95:0.95;当码率为256kbps时,L、R、C、LS和RS比例关系为1.05:1.05:1.05:0.925:0.925;当码率为192kbps时,L、R、C、LS和RS比例关系为1.05:1.05:1.1:0.9:0.9。
对于3D多声道音频信号,例如22.2的3层声道、5.1.4的双层声道等情况,上述步骤S220中码率的调整原则是:中间层声道的权重系数高于顶层声道的权重系数,顶层声道的权重系数高于底层声道的权重系数,且前置声道的权重系数高于后置声道的权重系数。以5.1.4声道的3D音频为例,除了传统的5.1声道之外,在L&R和LS&RS上方各有一个声道(命名为TopL、TopR、TopLs和TopRs),用于产生上方的声场。这时如果仍然采用各个声道均匀分配码率,显然不能获得更好的主观声音质量。通常情况下大部分声音处于人耳同一平面,上层声道仅仅提供环境声来提高整个声场的真实感。因此,上层4个声道(即TopL、TopR、TopLs和TopRs)可以给予相较于平均码率较少的码率,如果再细分,上层后置2个声道(即TopLs和TopRs)可以给予相较于平均码率更少的码率。因此,可以选择的几种典型的码率配置按照比例优先级顺序排列如下:
(1)均匀分配;
(2)L&R>C>LS&RS>TopL&TopR>TopLs&TopRs;
(3)L&R>C>TopL&TopR>LS&RS>TopLs&TopRs;
(4)C>L&R>LS&RS>TopL&TopR>TopLs&TopRs;
(5)C>L&R>TopL&TopR>LS&RS>TopLs&TopRs。
对于以上5.1.4声道的多种码率分配选项,编码时可以选择固定的某种配置,例如配置(2),也可以通过对音频信号实时分析,根据各个声道复杂性和重要性从以上几种配置中动态选择每帧的码率配置。
对于输入的多声道音频信号中包含目标信号的情况,例如5.1.4声道信号基础上增加一些特定的目标信号,其中5.1.4声道码率分配的权重系数可按照前述的方法来来确定,而目标信号的码率分配需要考虑目标信号的特性,来确定其码率分配的权重系数。如图6所示,在输入信号的声道配置的同时,需要对其中包含的目标信号进行分析,获得目标信号描述信息,然后基于不同的目标信号特性来确定不同的权重系数。例如,如果目标信号是不同语种的伴音,则需要和5.1.4声道中的中央声道C一样给予相同的权重系数;而当目标信号为某一个方向性活动目标信号时,更注重其信号的空间方向性,而信号本身的失真情况可以适当放宽,因而可以给予较声道信号更低的码率分配权重系数,例如可小于中间层声道的权重系数而大于上层4个声道的权重系数。
本发明以上实施例的数字音频编码中声道间码率分配的方法,在给定码率条件下能够自适应的处理各声道间的码率分配,从而获得更好的主观声音质量。
基于前述的第三个问题,本发明对多声道音频信号强度立体声编码时的码率分配也提出改进。图7示出了根据本发明一个实施例的数字音频的强度立体声编码中码率分配的方法300的流程图。如图7所示,该方法300包括如下步骤:
步骤S310中,选择一特定的权重系数对混合的高频信号部分的掩蔽门限进行自适应调整;
步骤S320中,基于调整后的掩蔽门限进行自由竞争码率分配。
以5.1声道强度立体声编码为例,5个全频带声道的高频混和成一个高频带细节信号,和该5个声道高频包络一起传输,此时一般的自由竞争码率分配方式并不合理,而需要给予混合的高频信号部分较高的权重系数,比如1.2倍权重系数,由此可以适当降低高频信号部分的掩蔽曲线,然后加入自由竞争码率分配,这样高频信号部分可以获得更高的码率编码。有关自由竞争码率分配的具体情况,属于现有技术,在此便不再详述。此外,如图8所示,步骤S310中还可以通过对混合的高频信号部分进行信号分析的方式,来确定高频信号部分的码率分配权重系数,然后基于该权重系数对高频信号部分的掩蔽门限进行自适应调整。例如,如果高频分量越多,则权重系数越高;如果高频分量为噪声类,则可适当降低权重系数。
本发明以上实施例的数字音频的强度立体声编码中码率分配的方法,能够自适应的调整混合的高频信号部分的码率分配,从而获得更好的主观声音质量。
基于以上所介绍的数字音频编码中声道内码率分配的方法,本发明还提出一种数字音频编码中声道内码率分配的装置。图9示出了根据本发明一个实施例的数字音频编码中声道内码率分配的装置400的逻辑框图。如图9所示,该装置400包括掩蔽门限调整模块410和比特分配模块420。其中,掩蔽门限调整模块410用于选择一组特定的调整系数对一个声道内从低频到高频各子带的掩蔽门限进行自适应调整;比特分配模块420用于基于调整后的掩蔽门限进行声道内的全局比特分配。图9所示的装置400可用于执行前述图1所示的数字音频编码中声道内码率分配的方法100,具体可参见前述对方法100的描述。
基于以上所介绍的数字音频编码中声道间码率分配的方法,本发明还提出一种数字音频编码中声道间码率分配的装置。图10示出了根据本发明一个实施例的数字音频编码中声道间码率分配的装置500的逻辑框图。如图10所示,该装置500包括分析模块510、码率调整模块520和比特分配模块530。其中,分析模块510用于对输入的多声道音频信号进行声道特性分析,获得声道配置信息;码率调整模块520用于根据所述声道配置信息,在平均分配码率的基础上对各声道的码率进行不同权重系数的调整;比特分配模块530用于基于调整后的各声道的码率进行全局比特分配。对于输入的多声道音频信号中包含目标信号的情况,分析模块510还分析目标信号的特性,获得目标信号描述信息;码率调整模块520还基于目标信号描述信息来确定目标信号码率分配的权重系数。图10所示的装置500可用于执行前述图5所示的数字音频编码中声道间码率分配的方法200,具体可参见前述对方法200的描述。
基于以上所介绍的数字音频的强度立体声编码中码率分配的方法,本发明还提出一种数字音频的强度立体声编码中码率分配的装置。图11示出了根据本发明一个实施例的数字音频的强度立体声编码中码率分配的装置600的逻辑框图。如图11所示,该装置600包括掩蔽门限调整模块610和比特分配模块620。其中,掩蔽门限调整模块610用于选择一特定的权重系数对混合的高频信号部分的掩蔽门限进行自适应调整;比特分配模块620用于基于调整后的掩蔽门限进行自由竞争码率分配。图11所示的装置600可用于执行前述图7所示的数字音频的强度立体声编码中码率分配的方法300,具体可参见前述对方法300的描述。
基于本发明前述的数字音频编码中码率分配的方法和装置,对于数字音频编码算法中某些中等码率情况下采用强度立体声编码时,可以进行自适应码率分配以改善主观声音质量;在中低码率情况下,还可以进行声道内自适应码率分配以改善主观声音质量;对于多声道音频编码(例如5.1以上),可以利用声道间的特性自适应码率分配来改善总的主观声音质量。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!