吹气声识别系统及采用该系统的吹气识别方法与流程
本发明涉及信号处理技术领域,具体涉及一种吹气声识别系统及采用该系统的吹气识别方法。
背景技术:
随着科学技术的进步,具有语音关键词唤醒功能的设备(如手机或智能家电等)以及具有翻腕唤醒功能的设备(如智能手环或智能手表)的应用也越来越广泛。
但上述设备不仅功耗较大,而且识别率低。此外,依靠语音智能唤醒不仅识别延迟大,而且语音唤醒需要发出较大声音,容易交叉触发,成本高昂。
因此,有必要提供一种新型的唤醒系统。
技术实现要素:
本发明的目的在于提供一种功耗低、识别率高、非语言依赖、响应迅速、私密性高、不交叉触发及成本低的吹气声识别系统及吹气声识别方法。
本发明的技术方案如下:一种吹气声识别系统,包括:
传感器,用于采集声音并发送声音信号;
识别器,用于识别所述声音信号中是否有吹气声信号,当识别有所述吹气声信号时发送唤醒指令;
处理器,用于根据所述唤醒指令唤醒待唤醒的设备。
优选的,所述吹气声识别系统还包括分别与所述传感器和所述识别器连接的模拟数字转换器及与所述模拟数字转换器连接的输出端口,所述模拟数字转换器用于将所述声音信号转换成数字信号后发送至所述识别器。
优选的,所述模拟数字转换器声音信号转换成数字信号,所述识别器识别有吹气声信号时,所述模拟数字转换器根据唤醒指令将除吹气声信号外的其他声音信号转换成的数字信号发送至所述输出端口。
优选的,所述传感器和所述识别器连接并将所述声音信号直接发送至所述识别器,所述吹气声识别系统还包括分别与所述传感器和所述识别器连接的模拟数字转换器及与所述模拟数字转换器连接的输出端口,当识别有所述吹气声信号时,所述模拟数字转换器还根据所述唤醒指令唤醒并将除吹气声信号外的其他声音信号转换成数字信号后发送至所述输出端口。
优选的,所述传感器封装于一麦克风封装结构中,所述识别器封装在所述麦克风封装结构内,或者所述识别器集成于编译码器、辅助处理器及放大器中任意一种。
优选的,所述识别器封装在所述麦克风封装结构内时,所述识别器独立封装为芯片或者与ASIC芯片集成。
本发明还提供一种吹气声识别系统,包括:
传感器,用于采集声音并发送声音信号;
识别器,用于识别所述声音信号中是否有吹气声信号,当识别有所述吹气声信号时发送唤醒指令;
模拟数字转换器,接收唤醒指令时用于将声音信号转换为数字信号;
输出端口,输出数字信号。
本发明还提供一种吹气声识别方法,包括以下步骤:
声音采集:提供传感器,所述传感器采集声音并发送声音信号;
声音识别:提供识别器,所述识别器识别所述声音信号中是否有吹气声信号,当识别有所述吹气声信号时发送唤醒指令;
唤醒:提供处理器,所述处理器根据所述唤醒指令唤醒待唤醒的设备。
优选的,所述唤醒步骤还提供模拟数字转换器,当识别有所述吹气声信号时,所述模拟数字转换器根据所述唤醒指令唤醒并将所述声音信号转换成数字信号后发送至所述输出端口。
优选的,在所述声音采集步骤和所述声音识别步骤之间还包括信号转换步骤:所述模拟数字转换器将所述声音信号转换成数字信号后发送至所述识别器。
与相关技术相比,本发明提供的吹气声识别系统及采用该系统的吹气声识别方法的具有如下有益效果:
功耗低:由于吹气声的频域特性相当显著,因此可以容易的由模拟电路处理,而不需要功耗较大的数字DSP。
识别率高:语音关键词唤醒在嘈杂环境下识别率大幅下降,近乎失效。而吹气唤醒信号强度大,频域特性明显,不会和环境噪声相混淆。
非语言依赖:不依赖于语言、方言和口音,通用性强。
响应迅速:不需要完整的语音段,可以在毫秒量级完成唤醒。而语音关键词唤醒或翻腕唤醒都依赖完整的时域信息,需要等待完整的动作再进行识别,存在可察觉的延迟。
私密性高:不会因语音唤醒打扰他人。由于吹气声事实上源于气流经过设备声孔附近固体表面产生的湍流,因此几乎不会被周围的人听到。
不交叉触发:由于工作距离较近,并且有显著的指向性,不会像语音口令一样唤醒他人设备,或被他人的口令唤醒。
成本低:简单的模拟电路进行处理,无需昂贵的数字芯片和语音识别算法授权。
【附图说明】
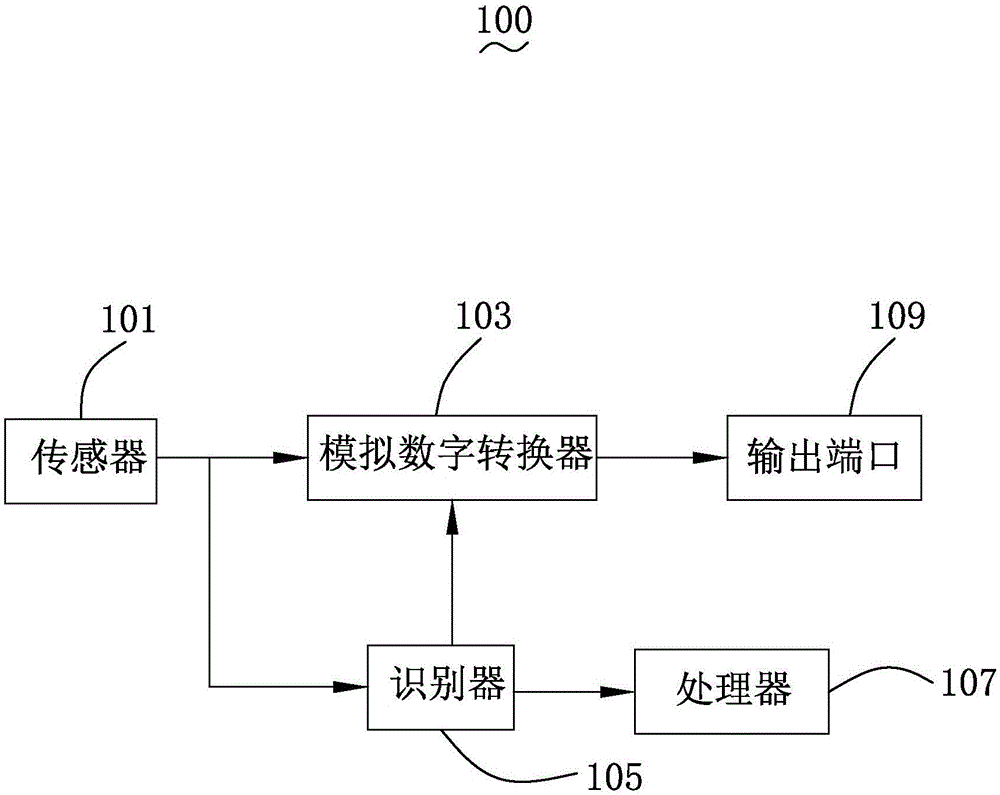
图1为本发明提供的吹气声识别系统的实施例一的结构框图;
图2为图1所示吹气声识别系统的吹气声识别的步骤流程图;
图3为本发明提供的吹气声识别系统的实施例二的结构框图;
图4为图3所示吹气声识别系统的吹气声识别的步骤流程图。
【具体实施方式】
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部份实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
请参阅图1,所述吹气声识别系统100包括传感器101、模拟数字转换器103、识别器105、处理器107及输出端口109。所述模拟数字转换器103分别与所述传感器101和所述输出端口109电连接,所述识别器105分别与所述传感器101、所述模拟数字转换器103及所述处理器107电连接。
所述传感器101用于采集声音并发送声音信号至所述识别器105。所述传感器101封装于一麦克风封装结构中。
所述声音信号包括吹气声信号及至少一个与所述吹气声信号不同频域特性的其他声音信号。
其他声音信号可以是在安静环境下的交谈声,也可以是在嘈杂环境下的不同车辆喇叭声,还可以其他环境噪声(如近距离咳嗽声、撕胶带声等)。
经过在安静环境下交谈声、在嘈杂环境下不同车辆喇叭声以及其他环境噪声(如近距离咳嗽声、撕胶带声等)与吹气声的声谱对比可知,各种常见的外界杂音与吹气声之间的频域特征非常明显。因此,常见外界杂音与吹气声非常易于识别。
所述识别器105用于识别所述声音信号中是否有吹气声信号。当识别有所述吹气声信号时,所述识别器105发送唤醒指令至所述处理器107和所述模拟数字转换器103。由于不同频域特性的声音信号之间具有明显的近场特性,可以明显增强所述识别器105的识别率。
所述处理器107用于根据所述唤醒指令唤醒待唤醒的设备。在本实施例中,所述识别器105可以封装在麦克风封装结构内,也可以集成于编译码器、辅助处理器及放大器中任意一种。当所述识别器105封装在麦克风封装结构内时,所述识别器可以独立封装为芯片,也可以与ASIC芯片集成。
所述模拟数字转换器103用于根据所述唤醒指令唤醒将所述声音信号转换成数字信号后发送至所述输出端口109。
当然,本实施例的识别器105还可以只连接模拟数字转换器103,从而至唤醒声音的输出,或者识别器105只连接处理器107,从而只唤醒其他设备工作。
所述输出端口109用于输出所述数字信号。
在本实施例中,由于所述传感器101将所述声音信号直接发送至所述识别器105。即所述传感器101发送的所述声音信号不用经过所述模拟数字转换103的转换。因此,所述模拟数字转换器103只有在接收所述唤醒指令后才会运作,从而可以省电。请参阅图2,本发明还提供一种吹气声识别方法,所述吹气声识别方法包括以下步骤:步骤S1、声音采集:所述传感器101采集声音并发送声音信号至所述识别器105,其中,声音包括吹气声信号或/和除吹气声信号外的其他声音信号。
步骤S2、声音识别:所述识别器105识别所述声音信号中是否有吹气声信号,当识别有所述吹气声信号时发送唤醒指令至所述模拟数字转换器103和所述处理器107。
具体的,当所述识别器105识别出所述声音信号中没有所述吹气声信号时,结束进程;当所述识别器105识别出所述声音信号中有所述吹气声信号时,所述识别器105分别向所述模拟数字转换器103和所述处理器107发送唤醒指令。
在本实施例中,优选的,所述吹气声信号的信号源与所述传感器101的距离为0-30cm。
步骤S3、唤醒:所述处理器7根据所述唤醒指令唤醒待唤醒的设备;同时,所述模拟数字转换器103根据所述唤醒指令唤醒并将除吹气声信号外的其他声音信号转换成数字信号后发送至所述输出端口109。
实施例二
请参阅图3,所述吹气声识别系200包括传感器201、模拟数字转换器203、识别器205、处理器207及输出端口209。所述模拟数字转换203分别与所述传感器201、所述识别器105及所述输出端口209电连接,所述处理器107与所述识别器105电连接。其中,所述传感器201、所述模拟数字转换器203、所述识别器205、所述处理器207及所述输出端口209的作用与实施例一中的相应部件的作用相同,所述传感器201和所述识别器205与实施例一中的相应部件的封装方式相同。实施例二与实施例一的区别在于:所述模拟数字转换器203还用于将所述传感器201发送的所述声音信号转换成数字信号后发送至所述识别器205进行识别。因此,在本实施例中,所述模拟数字转换器203需要一直工作,只是在接收到唤醒信号时才会向输出端口有所输出。请参阅图4,本发明还提供一种吹气声识别方法,所述吹气声识别方法包括以下步骤:
步骤S1、声音采集:所述传感器201采集声音并发送声音信号至所述模拟数字转换器203。
步骤S2、信号转换:所述模拟数字转换器203将所述传感器201发送的所述声音信号转换成数字信号后发送至所述识别器205。
步骤S3、声音识别:所述识别器205识别所述声音信号中是否有吹气声信号,当识别有所述吹气声信号时发送唤醒指令至所述模拟数字转换器203和所述处理器207。
具体的,当所述识别器205识别出所述声音信号中没有所述吹气声信号时,结束进程;当所述识别器205识别出所述声音信号中有所述吹气声信号时,所述识别器205分别向所述模拟数字转换器203和所述处理器207发送唤醒指令。
在本实施例中,优选的,所述吹气声信号的信号源与所述传感器201的距离为0-30cm。
步骤S4、唤醒:所述处理器7根据所述唤醒指令唤醒待唤醒的设备;同时,所述模拟数字转换器203根据所述唤醒指令将除吹气声信号外的其他声音信号转换成的数字信号发送至所述输出端口209进行输出。
本发明提供的吹气声识别系统及采用该系统的吹气声识别方法的具有如下有益效果:
功耗低:由于吹气声的频域特性相当显著,因此可以容易的由模拟电路处理,而不需要功耗较大的数字DSP。
识别率高:语音关键词唤醒在嘈杂环境下识别率大幅下降,近乎失效。而吹气唤醒信号强度大,频域特性明显,不会和环境噪声相混淆。
非语言依赖:不依赖于语言、方言和口音,通用性强。
响应迅速:不需要完整的语音段,可以在毫秒量级完成唤醒。而语音关键词唤醒或翻腕唤醒都依赖完整的时域信息,需要等待完整的动作再进行识别,存在可察觉的延迟。
私密性高:不会因语音唤醒打扰他人。由于吹气声事实上源于气流经过设备声孔附近固体表面产生的湍流,因此几乎不会被周围的人听到。
不交叉触发:由于工作距离较近,并且有显著的指向性,不会像语音口令一样唤醒他人设备,或被他人的口令唤醒。
成本低:简单的模拟电路进行处理,无需昂贵的数字芯片和语音识别算法授权。
以上所述的仅是本发明的实施方式,在此应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出改进,但这些均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!