音频信号处理设备、方法和电子设备与流程
本申请涉及音频技术领域,且更具体地,涉及一种音频信号处理设备、音频信号处理方法、电子设备、计算机程序产品和计算机可读存储介质。
背景技术:
无论是智能化的语音识别系统(例如,智能家电、机器人等),还是传统的语音通信系统(例如,会议系统、因特网协议传送话音VoIP系统等),都会遇到噪声消除的问题。
目前现有的噪声消除技术是基于全向麦克风阵列和波束形成算法的结合。全向麦克风都具有全向拾音响应,也就是能够均等地响应来自四面八方的声音。多个全向麦克风可以配置成阵列,形成定向响应,以做到对于来自单角度的声源进行增强。
然而,全向麦克风阵列在降噪处理中存在以下局限,即无法对声源的类型进行区分,单纯地利用空域算法消除噪声,对一个声源角度增强,对其余声源角度进行削弱,容易对关注信号造成损伤。
技术实现要素:
为了解决上述技术问题,提出了本申请。本申请的实施例提供了一种音频信号处理设备、音频信号处理方法、电子设备、计算机程序产品和计算机可读存储介质,其可以利用指向麦克风和摄像头的双重定位来实现声源的精确分类。
根据本申请的一个方面,提供了一种音频信号处理设备,包括:麦克风阵列,包括具有不同拾音区的多个指向麦克风,每个指向麦克风用于在自身的拾音区内采集分路输入信号;音频定位器件,用于根据所述分路输入信号来识别第一组声源并确定其中的每个声源在所述麦克风阵列所确定的音频坐标系下的位置;摄像头,用于捕捉当前场景的场景图像,所述当前场景至少覆盖所述多个指向麦克风的拾音区;图像定位器件,用于在所述场景图像中识别第二组声源并确定其中的每个声源在所述摄像头所确定的图像坐标系下的位置;以及声源分类器,用于根据所述音频坐标系与所述图像坐标系之间的配准关系、所述第一组声源中每个声源在所述音频坐标系下的位置、和所述第二组声源中每个声源在所述图像坐标系下的位置来对所述第一组声源和所述第二组声源中的每个声源进行分类。
根据本申请的另一方面,提供了一种音频信号处理方法,包括:从麦克风阵列中的每个指向麦克风接收分路输入信号,所述麦克风阵列包括具有不同拾音区的多个指向麦克风,每个指向麦克风用于在自身的拾音区内采集所述分路输入信号;根据所述分路输入信号来识别第一组声源并确定其中的每个声源在所述麦克风阵列所确定的音频坐标系下的位置;从摄像头接收当前场景的场景图像,所述当前场景至少覆盖所述多个指向麦克风的拾音区;在所述场景图像中识别第二组声源并确定其中的每个声源在所述摄像头所确定的图像坐标系下的位置;以及根据所述音频坐标系与所述图像坐标系之间的配准关系、所述第一组声源中每个声源在所述音频坐标系下的位置、和所述第二组声源中每个声源在所述图像坐标系下的位置来对所述第一组声源和所述第二组声源中的每个声源进行分类。
根据本申请的另一方面,提供了一种电子设备,包括:处理器;存储器;以及存储在所述存储器中的计算机程序指令,所述计算机程序指令在被所述处理器运行时使得所述处理器执行上述的音频信号处理方法。
根据本申请的另一方面,提供了一种计算机程序产品,包括计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器执行上述的音频信号处理方法。
根据本申请的另一方面,提供了一种计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器执行上述的音频信号处理方法。
与现有技术相比,采用根据本申请实施例的音频信号处理设备、音频信号处理方法、电子设备、计算机程序产品和计算机可读存储介质,可以根据麦克风阵列中的每个指向麦克风所采集的分路输入信号来识别第一组声源并确定其中的每个声源在所述麦克风阵列所确定的音频坐标系下的位置,在摄像头所采集的场景图像中识别第二组声源并确定其中的每个声源在所述摄像头所确定的图像坐标系下的位置,并且根据所述音频坐标系与所述图像坐标系之间的配准关系、所述第一组声源中每个声源在所述音频坐标系下的位置、和所述第二组声源中每个声源在所述图像坐标系下的位置来对所述第一组声源和所述第二组声源中的每个声源进行分类。因此,可以利用指向麦克风和摄像头的双重定位来实现声源的精确分类。
附图说明
通过结合附图对本申请实施例进行更详细的描述,本申请的上述以及其他目的、特征和优势将变得更加明显。附图用来提供对本申请实施例的进一步理解,并且构成说明书的一部分,与本申请实施例一起用于解释本申请,并不构成对本申请的限制。在附图中,相同的参考标号通常代表相同部件或步骤。
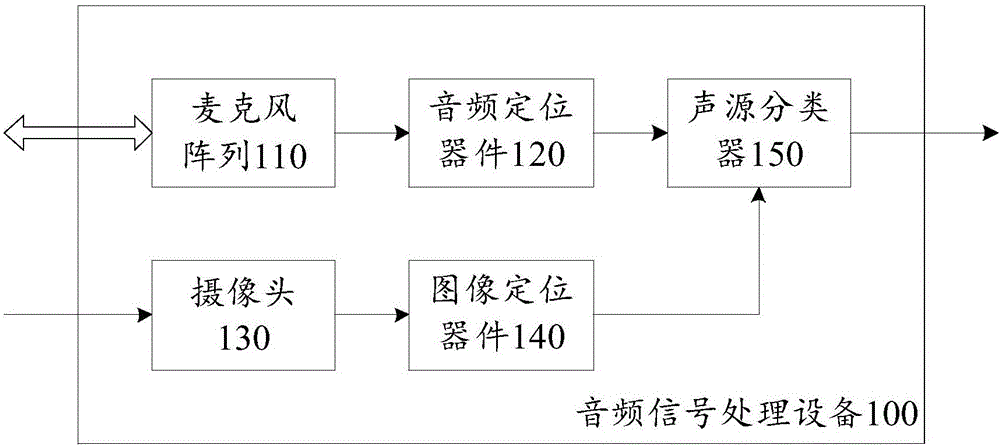
图1图示了根据本申请第一实施例的音频信号处理设备的结构示意图。
图2图示了根据本申请实施例的麦克风阵列的结构示意图。
图3图示了根据本申请实施例的音频定位器件的结构示意图。
图4图示了根据本申请实施例的声源分类器的结构示意图。
图5图示了根据本申请第二实施例的音频信号处理设备的结构示意图。
图6图示了根据本申请实施例的增益控制器件的结构示意图。
图7图示了根据本申请实施例的麦克风阵列和声源的示例位置关系示意图。
图8图示了根据本申请实施例的音频信号处理方法的流程示意图。
图9图示了根据本申请实施例的电子设备的框图。
具体实施方式
下面,将参考附图详细地描述根据本申请的示例实施例。显然,所描述的实施例仅仅是本申请的一部分实施例,而不是本申请的全部实施例,应理解,本申请不受这里描述的示例实施例的限制。
申请概述
如上所述,传统的全向麦克风阵列结合波束形成算法的噪声消除方案无法区分声源的类型,单纯地利用空域算法进行处理,对一个声源角度增强,对其余声源角度进行削弱,容易对关注信号造成损伤。
针对该技术问题,本申请的基本构思是提出一种音频信号处理设备、音频信号处理方法、电子设备、计算机程序产品和计算机可读存储介质,其可以利用摄像头和指向麦克风阵列组成的定位系统对各个声源进行精准定位,确定声源的类型是否属于真实信号源、潜在信号源、噪声源等,以便后续根据声源的类型来对它们进行标记,并继而对真实信号源进行增强、对噪声源进行削弱、对潜在信号源保持以最小能量进行监听等。
在介绍了本申请的基本原理之后,下面将参考附图来具体介绍本申请的各种非限制性实施例。
示例性音频信号处理设备
图1图示了根据本申请第一实施例的音频信号处理设备的结构示意图。
如图1所示,根据本申请实施例的音频信号处理设备100包括:麦克风阵列110、音频定位器件120、摄像头130、图像定位器件140、和声源分类器150。
在一个实施例中,麦克风阵列110可以包括具有不同拾音区的多个指向麦克风,每个指向麦克风用于在自身的拾音区内采集分路输入信号。
例如,麦克风阵列110是由一定数目的麦克风组成、用来对声场的空间特性进行采样并处理的系统。麦克风的指向性是麦克风对来自空间各个方向声音灵感度模式的一个描述,是它的一个重要属性。根据指向性不同,麦克风可以分为:全向麦克风和指向麦克风。全向麦克风对于来自不同角度的声音,其灵敏度是基本相同的,其头部采用压力感应的原理设计,振膜只接受来自外界的压力。指向麦克风主要采用压力梯度的原理设计,通过头部腔体后面的小孔,振膜接受到正反两面的压力,因此振膜受不同方向的压力并不相同,麦克风具有了指向性。指向麦克风阵列相比于全向麦克风阵列,是利用麦克风本身的特性、而不引入空域算法的形式,其对于语音的损伤更小。
例如,取决于各个麦克风的相对位置关系,麦克风阵列110可以分为:线性阵列,其阵元中心位于同一条直线上;平面阵列,其阵元中心分布在一个平面上;以及空间阵列,其阵元中心分布在立体空间中。
例如,麦克风阵列110可以包括具有不同拾音区的多个指向麦克风MIC1到MICn,其中n是大于等于2的自然数。下面,将在一个示例中以平面阵列为例对麦克风阵列进行描述。
图2图示了根据本申请实施例的麦克风阵列的结构示意图。
如图2所示,例如,在音频信号处理设备100上装备有一平面型的麦克风阵列110,所述麦克风阵列110包括具有同一中心点且呈现中心对称的8个指向麦克风MIC1到MIC8。所述8个指向麦克风并联后用于在自身的拾音区内采集分路输入信号。
具体地,指向麦克风MIC1到MIC8设置在同一平面,各指向麦克风之间的距离根据实际需求和所采用的算法设置。相邻的指向麦克风在二维平面围绕中心点均匀分布,相互之间呈45°角。如图2所示,假设MIC1位于音频信号处理设备100的基准方向,即0°方向,则MIC2位于45°方向,MIC3位于90°方向,MIC4位于135°方向,MIC5位于180°方向,MIC6位于225°方向,MIC7位于270方向,MIC8位于315°方向。
当然,本申请不限于此。在其他实施例中,麦克风阵列也可以是其他平面阵列,也可以是线性阵列或空间立体阵列等。麦克风阵列中的各个指向麦克风可根据实际需求设置在同一平面或不同平面,可根据实际需求设置成围绕中心点均匀分布以获取尽可能大的采集定位范围,或设置成非均匀分布以重点对某些方向的声源进行采集。并且,所述指向麦克风也可以是以单独、成组等非成对方式设置的。
MIC1到MIC8可以分别具有朝向自己正前方的拾音区,即分别朝向0°方向、45°方向、90°方向、135°方向、180°方向、225°方向、270方向和315°方向的拾音区。为了避免出现信号的漏检,相邻的拾音区可以具有重叠区域。MIC1到MIC8中的每个可以在自身的拾音区内采集各自的分路输入信号。当正在输出关注信号的信号源处于其拾音区内时,该分路输入信号包括来自信号源的关注信号分量;当正在输出噪声信号的噪声源处于其拾音区内时,该分路输入信号包括来自所述噪声源的噪声信号分量;当该信号源和该噪声源同时处于其拾音区内时,该分路输入信号包括来自信号源的关注信号分量和来自所述噪声源的噪声信号分量两者;当该信号源和该噪声源均未处于其拾音区内时,该分路输入信号为零。
在一个实施例中,音频定位器件120可以用于根据所述分路输入信号来识别第一组声源并确定其中的每个声源在所述麦克风阵列所确定的音频坐标系下的位置。
图3图示了根据本申请实施例的音频定位器件的结构示意图。
如图3所示,所述音频定位器件120可以包括:信号分离单元121,用于从每个指向麦克风所采集的分路输入信号中分离不同声源的音频信号分量并确定所述第一组声源;以及声音识别单元122,用于针对所述第一组声源中的每个声源,根据从至少两路分路输入信号中分离出的所述声源的音频信号分量的相位来确定所述声源在所述音频坐标系下的位置。
这里,术语“位置”更加关注声源相对于所述音频坐标系的基准方向(例如,图2中的0°方向)的夹角。
例如,信号分离单元121可以从每路分路输入信号中分离来自不同声源的音频信号分量,从而确定出第一组声源中包括几个声源。
在一个示例中,信号分离单元121可以基于声源的频率特性来分离其音频信号分量。例如,在智能化电子设备(例如,智能家电、机器人等)的语音识别场景下,信号源可以是与电子设备进行交互的用户,噪声源可以是周围的高频噪声。由于用户的语音与高频噪声处于不同的频段,所以信号分离单元121可以在频域上根据不同的频段来对麦克风所采集的分路输入信号进行划分,以区分来自不同声源的音频信号分量。
在另一示例中,信号分离单元121也可以基于声源的内容特性来分离其音频信号分量。例如,噪声源可以是在当前电子设备中装备的扬声器产生的回声。由于可以已知扬声器当前正在播放的声音信号,所以信号分离单元可以在时域和/或频域上从麦克风所采集的分路输入信号中分离该声音信号分量(相当于回声信号分量)和来自信号源的关注信号分量。
在又一示例中,信号分离单元121也可以基于声源的发声特性来分离其音频信号分量。例如,信号源也可以是多个正在说话的用户。由于不同用户的发声规律、发声方式显著不同,所以信号分离单元121可以基于声纹识别等算法来实现上述分离操作。
然后,声音识别单元122可以针对所述第一组声源中的每个声源,基于至少两路分离出来的来自所述声源的音频信号分量,利用现有的、或者将来开发的声源定位方法来直接得到信号源与麦克风阵列的基准方向(即,0°方向)之间的夹角。
例如,声源识别单元122可以根据每个声源的音频信号分量到达麦克风阵列中不同麦克风的时间差来计算角度信息,从而确定识别到的该声源在音频坐标系中的位置。
需要说明的是,发出关注信号的信号源并不限于用户,而也可以是其他任何可能的声音来源,例如,电视、车辆、动物等;而发出噪声信号的噪声源也不限于上述说明的示例,也可以是其他任何可能的声音来源。
在一个实施例中,摄像头130可以用于捕捉当前场景的场景图像,所述当前场景至少覆盖所述多个指向麦克风的拾音区。
例如,该摄像头130可以用于捕捉当前场景(例如,其至少覆盖所有指向麦克风的拾音区)的场景图像,其可以是单独的摄像头130或摄像头130阵列。例如,摄像头130所采集到的场景图像可以是单帧图像、连续图像帧序列(即,视频流)或离散图像帧序列(即,在预定采样时间点采样到的图像数据组)等。例如,该摄像头130可以是如单目相机、双目相机、多目相机等,另外,其可以用于捕捉灰度图,也可以捕捉带有颜色信息的彩色图。当然,本领域中已知的以及将来可能出现的任何其他类型的相机都可以应用于本申请,本申请对其捕捉图像的方式没有特别限制,只要能够获得输入图像的灰度或颜色信息即可。为了减小后续操作中的计算量,在一个实施例中,可以在进行分析和处理之前,将彩色图进行灰度化处理。
在一个实施例中,图像定位器件140可以用于在所述场景图像中识别第二组声源并确定其中的每个声源在所述摄像头所确定的图像坐标系下的位置。
这里,术语“位置”可以更加关注声源相对于所述图像坐标系的基准方向的夹角,也可以同时关注该声源相对于图像坐标系的基准位置的距离。
例如,图像定位器件140可以不断分析和处理摄像头130捕捉的图像帧,以识别其中的信号源。例如,在智能化电子设备(例如,智能家电、机器人等)的语音识别场景下,信号源可以是与电子设备进行交互的用户。这时,信号源的识别可以基于人体识别、人脸识别、口部识别等算法来实现。例如,简单地,可以在识别出在当前场景中存在用户的情况下,即判断识别出作为信号源的用户;更精确地,也可以在识别到在当前场景中存在用户并且用户的嘴唇在开合的情况下,判断识别出作为信号源的用户。
需要说明的是,发出关注信号的信号源并不限于用户,而可以是其他任何可能的声音来源,例如,电视、车辆、动物等。相应地,信号源的识别算法也可以对应地调整为电视识别、车辆识别、动物识别等识别算法。
然后,所述图像定位器件140根据所述信号源在所述场景图像中的位置来确定所述信号源与所述摄像头确定的基准位置之间的相对位置。
例如,图像定位器件140可以根据人脸信息锁定用户在图像坐标系下的位置坐标或者角度信息,从而确定识别到的信号源(例如,用户或用户口部)在图像坐标系中的位置。
在一个实施例中,声源分类器150可以用于根据所述音频坐标系与所述图像坐标系之间的配准关系、所述第一组声源中每个声源在所述音频坐标系下的位置、和所述第二组声源中每个声源在所述图像坐标系下的位置来对所述第一组声源和所述第二组声源中的每个声源进行分类。
图4图示了根据本申请实施例的声源分类器的结构示意图。
如图4所示,所述声源分类器150可以包括:映射单元151,用于根据所述音频坐标系与所述图像坐标系之间的配准关系来将所述第一组声源中每个声源的位置和所述第二组声源中每个声源的位置映射到同一坐标系下,所述同一坐标系为所述音频坐标系和所述图像坐标系之一;对比单元152,用于对比所述第一组声源和所述第二组声源中每个声源在所述同一坐标系下的相对位置关系;以及分类单元153,用于根据所述相对位置关系来对所述第一组声源和所述第二组声源中的每个声源进行分类。
例如,映射单元151可以获取事先校准好的摄像头130的基准方向与麦克风阵列110的基准方向之间的映射关系。例如,该映射关系由摄像头的外参矩阵和麦克风阵列的阵列结构共同决定,并且可以通过配置将两个基准方向统一标定。然后,映射单元151可以将所述第一组声源和所述第二组声源中每个声源的位置统一到同一坐标系下。例如,可以根据该映射关系,将所述第一组声源中每个声源在所述音频坐标系下的位置转换到所述图像坐标系下,或者将所述第二组声源中每个声源在所述图像坐标系下的位置转换到所述音频坐标系下。接下来,对比单元152可以将麦克风阵列获取的角度信息与摄像头获取的角度信息进行核对,以便分类单元153根据核对的结果对所有声源进行分类。
在一个示例中,所述分类单元153可以执行以下操作:响应于位于所述同一坐标系下某一位置处的声源同时存在于所述第一组声源和所述第二组声源中,将所述声源标记为正在输出关注信号的真实信号源;以及响应于位于所述同一坐标系下某一位置处的声源仅仅存在于所述第一组声源中,将所述声源标记为正在输出噪声信号的噪声源。进一步地,所述分类单元还可以执行以下操作:响应于位于所述同一坐标系下某一位置处的声源仅仅存在于所述第二组声源中,将所述声源标记为当前未输出音频信号的潜在信号源。
例如,处于一个位置(角度)的声源被麦克风阵列和摄像头同时检测到的,可以将该声源分类为正在输出关注信号的真实信号源;如果摄像头检测到、但麦克风阵列没有检测到,可以将该声源分类为尚未输出关注信号的潜在信号源;如果麦克风阵列检测到、但摄像头没有检测到,可以将该声源分类为正在输出噪声信号的噪声源。
由此可见,采用根据本申请第一实施例的音频信号处理设备,可以根据麦克风阵列中的每个指向麦克风所采集的分路输入信号来识别第一组声源并确定其中的每个声源在所述麦克风阵列所确定的音频坐标系下的位置,在摄像头所采集的场景图像中识别第二组声源并确定其中的每个声源在所述摄像头所确定的图像坐标系下的位置,并且根据所述音频坐标系与所述图像坐标系之间的配准关系、所述第一组声源中每个声源在所述音频坐标系下的位置、和所述第二组声源中每个声源在所述图像坐标系下的位置来对所述第一组声源和所述第二组声源中的每个声源进行分类。因此,可以利用指向麦克风和摄像头的双重定位来实现声源的精确分类。
需要说明的是,尽管上面仅仅描述了对信号源进行音频和图像的双重定位,但是本申请不限于此。例如,在已知噪声源的外形特征的情况下,同样也可以对噪声源进行图像识别和定位,以用于后续的分类操作,从而将其进一步划分为潜在噪声源和真实噪声源。
在本申请的第二实施例中,可以进一步利用声源分类的结果来实现无损的关注信号增强和噪声信号抑制。
图5图示了根据本申请第二实施例的音频信号处理设备的结构示意图。
在图5中,采用了相同的附图标记来指示与图1相同的部件。因此,图5中的麦克风阵列110、音频定位器件120、摄像头130、图像定位器件140、和声源分类器150与图1中相同,并因而,在此省略其详细描述。图5与图1的不同之处在于,该音频信号处理设备100还包括:复用器160和增益控制器件170。
在一个实施例中,复用器160用于将每个指向麦克风所采集的分路输入信号合并为总输入信号,所述分路输入信号包括来自真实信号源的关注信号分量和来自噪声源的噪声信号分量。
例如,该复用器简单地可以是加法器,用于将各路分路输入信号在时域上对齐并且叠加为一路总输入信号。替换地,该复用器也可以是加权加法器,用于通过在叠加的过程中向不同的分路输入信号施加不同的权重,以使得关注的分路输入信号在总输入信号中具有更高的峰值。
在一个实施例中,增益控制器件170用于根据每个声源的类型及其在所述音频坐标系下的位置来调整每个指向麦克风的增益,以使得在所述总输入信号中从所述真实信号源接收到的关注信号分量的功率与从所述噪声源接收到的噪声信号分量的功率之间的信噪比最大。
图6图示了根据本申请实施例的增益控制器件的结构示意图。
如图6所示,所述增益控制器件170可以包括:比较单元171,用于比较所述真实信号源和所述噪声源与每个指向麦克风的拾音区之间的位置关系;以及增益调整单元172,用于根据所述位置关系来调整每个指向麦克风的增益,以使得在所述总输入信号中从所述真实信号源接收到的关注信号分量的功率与从所述噪声源接收到的噪声信号分量的功率之间的信噪比最大。
例如,该比较单元171简单地可以是比较器,在由麦克风阵列110、音频定位器件120、摄像头130、图像定位器件140构成的声源定位器件检测到真实信号源与麦克风阵列的基准方向(即,0°方向)之间的夹角和噪声源与麦克风阵列的基准方向(即,0°方向)之间的夹角之后,确定真实信号源和噪声源分别位于哪一个或多个指向麦克风的拾音区内。
例如,该增益调整单元172可以是模拟放大器和数字放大器中的一个或两者,用于基于上述位置关系来生成每个指向麦克风的增益因子,并且根据所述增益因子对每个指向麦克风所采集的分路输入信号进行放大或缩小,以在增强关注信号功率(例如,来自用户的语音信号)的同时,抑制噪声信号功率。例如,该增益调整单元172可以基于最大信噪比原则、最小可唤醒能量原则、最大能量不失真原则来执行增益调整。该最大信噪比原则是指将真实信号源角度信号增益控制为最大,并且将噪声源角度信号增益控制为最小。该最小可唤醒能量原则是指将潜在信号源角度信号增益配置为确保一旦该潜在信号源转换为真实信号源则可以立刻拾取其关注信号的监听状态,可选地,还可以进一步是指将除了真实信号源角度和噪声源角度之外的信号增益配置为上述监听状态,以在功耗和灵敏度之间取得权衡。该最大能量不失真原则是指使得从每个真实信号源角度接收到的信号都不会出现失真。
下面,在几个具体的场景中描述该增益调整过程。
在第一场景中,假设存在正在输出关注信号的一个或多个真实信号源且不存在正在输出噪声信号的噪声源。
这时,该比较单元171可以用于比较所述一个或多个真实信号源与每个指向麦克风的拾音区之间的第一位置关系。该增益调整单元172可以用于根据所述第一位置关系来调整每个指向麦克风的增益,以使得在所述总输入信号中从所述一个或多个真实信号源接收到的关注信号分量的功率最大。
例如,所述增益调整单元172可以增大所述一个或多个真实信号源位于其拾音区的一个或多个指向麦克风的增益,以使得在所述总输入信号中从所述一个或多个真实信号源接收到的关注信号分量的功率最大且没有任何一个关注信号分量发生失真。
在多个真实信号源的情况下,所述增益调整单元172可以根据一个或多个真实信号源在所述图像坐标系下的位置和来自每个真实信号源的关注信号分量的幅度大小来将所述一个或多个指向麦克风的增益增大为不同值。这样,可以确保来自所有的真实信号源的关注信号都可以被清晰且均衡地输入到本设备中。
假设在该第一场景中,还存在当前未输出关注信号的一个或多个潜在信号源。所述比较单元171比较所述一个或多个潜在信号源与每个指向麦克风的拾音区之间的第三位置关系,并且所述增益调整单元172根据所述第三位置关系来调整每个指向麦克风的增益,以使得所述麦克风阵列的功耗最小、但又能够随时从所述潜在信号源采集音频信号分量。
例如,所述增益调整单元172可以简单地将所述一个或多个潜在信号源位于其拾音区的一个或多个指向麦克风的增益减小为一个预定值,以满足最小能量要求Emin,从而在功率节省和实时检测之间取得权衡。
替换地,所述增益调整单元172还可以将所述一个或多个潜在信号源位于其拾音区的一个或多个指向麦克风的增益设置为估计值,所述估计值是根据所述一个或多个潜在信号源在所述图像坐标系下的位置来确定的。例如,在多个潜在信号源的情况下,可以为朝向距离麦克风阵列较远的潜在信号源的指向麦克风设置为较大的增益,而为朝向距离麦克风阵列较近的潜在信号源的指向麦克风设置为较小的增益。
更进一步地,所述增益调整单元172还可以减小所述麦克风阵列中除了上述一个或多个指向麦克风的其他麦克风的增益,以降低从潜在噪声源接收到噪声分量的可能性。例如,可以将其他麦克风的增益减小为0,即禁用相应麦克风,以减小噪声输入并节省功率。替换地,可以将其他麦克风的增益减小为一个预定值,以满足最小能量要求Emin,从而在功率节省和实时检测之间取得权衡。
在第二场景中,假设不存在正在输出关注信号的真实信号源且存在正在输出噪声信号的一个或多个噪声源。
这时,该比较单元171可以用于比较所述一个或多个噪声源与每个指向麦克风的拾音区之间的第二位置关系。该增益调整单元172可以用于根据所述第二位置关系来调整每个指向麦克风的增益,以使得在所述总输入信号中从所述一个或多个噪声源接收到的噪声信号分量的功率最小。
例如,所述增益调整单元172可以减小所述一个或多个噪声源位于其拾音区的一个或多个指向麦克风的增益。例如,可以将所述一个或多个麦克风的增益减小为0,以保证噪声信号所产生的干扰最小。当然,为了防止在场景中突然出现真实信号源,也可以将所述麦克风的增益减小为一个预定值,例如Emin。
与第一场景中类似地,假设在该第二场景中,还存在当前未输出关注信号的一个或多个潜在信号源。所述增益调整单元172可以将所述一个或多个潜在信号源位于其拾音区的一个或多个指向麦克风的增益减小为一个预定值或估计值。更进一步地,所述增益调整单元172还可以减小所述麦克风阵列中除了上述一个或多个指向麦克风的其他麦克风的增益,以降低从潜在噪声源接收到噪声分量的可能性。
在第三场景中,假设同时存在正在输出关注信号的一个或多个真实信号源和正在输出噪声信号的一个或多个噪声源。本场景是第一场景与第二场景的结合。
这时,该比较单元171可以用于比较所述一个或多个真实信号源与每个指向麦克风的拾音区之间的第一位置关系和所述一个或多个噪声源与每个指向麦克风的拾音区之间的第二位置关系。该增益调整单元172用于根据所述第一位置关系和所述第二位置关系来调整每个指向麦克风的增益,以使得在所述总输入信号中从所述一个或多个真实信号源接收到的关注信号分量的功率与从所述一个或多个噪声源接收到的噪声信号分量的功率之间的信噪比最大。
例如,所述增益调整单元172可以生成每个指向麦克风的第一组增益,其中,所述一个或多个真实信号源位于其拾音区的一个或多个指向麦克风的增益被增大,以使得在所述总输入信号中从所述一个或多个真实信号源接收到的关注信号分量的功率最大。然后,所述增益调整单元172可以生成每个指向麦克风的第二组增益,其中,所述一个或多个噪声源位于其拾音区的一个或多个指向麦克风的增益被减小,以使得在所述总输入信号中从所述一个或多个噪声源接收到的噪声信号分量的功率最小。接下来,所述增益调整单元172可以生成用于第一组增益的第一组权重和用于第二组增益的第二组权重,以使得在所述总输入信号中从所述一个或多个真实信号源接收到的关注信号分量的功率与从所述一个或多个噪声源接收到的噪声信号分量的功率之间的信噪比最大。最后,所述增益调整单元172可以使用所述第一组增益、所述第一组权重、所述第二组增益、和所述第二组权重来调整每个指向麦克风的增益。
与前两个场景中类似地,假设在该第三场景中,还存在当前未输出关注信号的一个或多个潜在信号源。所述增益调整单元172可以将所述一个或多个潜在信号源位于其拾音区的一个或多个指向麦克风的增益减小为一个预定值或估计值。更进一步地,所述增益调整单元172还可以减小所述麦克风阵列中除了上述一个或多个指向麦克风的其他麦克风的增益,以降低从潜在噪声源接收到噪声分量的可能性。
下面,将参考图7来在一个具体示例中描述上述不同场景中的该增益调整过程。
图7图示了根据本申请实施例的麦克风阵列和声源的示例位置关系示意图。
如图7所示,在音频信号处理设备100中包括麦克风阵列110。所述麦克风阵列110包括具有同一中心点且呈现中心对称的4个指向麦克风MIC1到MIC4。假设MIC1位于音频信号处理设备100的基准方向,即0°方向,则MIC2位于90°方向,MIC3位于180°方向,MIC4位于270方向。假设在该应用场景中包括:一个真实信号源(与智能化电子设备进行交互的用户),位于麦克风阵列的基准方向(即,0°方向)的135°方向;一个噪声源,位于该基准方向的45°方向;两个潜在信号源1和2,潜在信号源1位于该基准方向的315°方向且距离较近;潜在信号源2位于该基准方向的225°方向且距离较远。
例如,摄像头可以获取图像中所有的人脸信息,并根据人脸信息锁定用户在摄像头的坐标系中的位置坐标(或角度信息)。麦克风阵列通过获取声音,通过声音到达的延迟也可以计算声音传输的角度信息。通过配置将摄像头的坐标系和麦克风的坐标系相统一,这样两个坐标系中的坐标可以相互转换。摄像头记录所有的人脸角度坐标,认为是可能说话的用户,即可疑信号源。麦克风阵列记录所有的声源角度信息,认为是正在发声的声源,并且与摄像头获取的角度信息核实。如果两个器件同时检测到的角度为真实信号源角度(例如,图7中的135°);如果摄像头检测到、麦克风阵列没有检测到的角度为潜在信号源角度(例如,图7中的225°和315°);如果摄像头没有检测到、麦克风阵列检测到的角度为噪声源角度(例如,图7中的45°)。
一旦判断出当前场景不存在真实信号源、存在仅仅一个真实信号源、存在多个真实信号源,则可以根据最大信噪比原则、最小可唤醒能量原则、最大能量不失真原则来对MIC1到MIC4中的每个执行增益调整,将真实信号源角度、潜在信号源角度和噪声源角度输入本设备,寻找与这些角度指向最接近的指向麦克风,使得并配置该角度麦克风增益控制。
如图7所示,在当前场景中仅仅一个真实信号源和一个噪声源的情况下,只需要配置该真实信号源角度的麦克风增益(例如,图7中的MIC2和MIC3)和该噪声源角度的麦克风增益(例如,图7中的MIC1和MIC2),以使得该真实信号源输出的关注信号的能量与该噪声源输出的噪声信号的能量之比在设备中最大即可。
此外,如图7所示,在当前场景中还存在两个潜在信号源。这时,还可以配置该潜在信号源角度的麦克风增益(例如,图7中的MIC1、MIC3、和MIC4),确保一旦该潜在信号源开始说话,该角度的声音可被立刻拾取到。由于潜在信号源1距离麦克风阵列较近,而潜在信号源2距离较远,所以可以进一步不同地设置MIC1、MIC3、和MIC4的增益,例如,将MIC3的增益设置为较大,将MIC4的增益设置为中等,而将MIC1的增益设置为较小,以更好地检测距离不同的在潜在信号源的发声情况。
接下来,摄像头和麦克风阵列可以持续获取场景图像和音频信号,一旦摄像头检测到潜在信号源角度人脸有说话嘴型且麦克风阵列检测到该角度确定有人说话,则开始切换模式,根据最大信噪比原则、最小可唤醒能量原则、最大能量不失真原则来重新对MIC1到MIC4中的每个执行增益调整。也就是说,可以循环地执行上述过程,即,当声源变化(例如,数量改变、位置改变)时,自适应更新多声源方向向量,通过上述3个准则自适应地更新增益控制向量。另外,上述参数还可以被存储起来,以便在稍后相同的场景下被直接读取出来,而无需再次执行增益和向量计算操作,从而加快处理音频信号的速度。
在一个实施例中,音频信号处理设备100还可以包括:位置滤波器180,用于根据声源分类的结果和每个声源在所述音频坐标系下的位置来对增益调整后的总输入信号进行滤波,以仅仅保留来自每个真实信号源的音频信号分量。
在经过上述增益调整之后,可以将各个麦克风采集的、包括已经在空域上实现增强的关注信号分量和削弱后的噪声信号分量的分路输入信号在通过复用器160合并为一路总输入信号之后,再一次通过基于位置(角度)滤波的噪声抑制器件,位置滤波器180。
例如,可以将麦克风阵列和摄像头两个定位系统综合确定的真实信号源角度确定为最后角度筛选器中的角度,该角度外的信号被认为是噪声。角度筛选器可以通过音频信号的时延来保留指定角度内的关注信号分量,滤除角度外的噪声信号分量。由于此时噪声信号分量在总输入信号中所占比重已经较小,再次滤波可以更加彻底地去除不希望的噪声信号,进一步提高信噪比。
最后,取决于音频信号处理设备是纯近端设备还是近/远端设备,还可以执行对于滤波处理后的信号的音频识别操作,或将它发送到远端设备,以用于远程通信目的。
由此可见,采用根据本申请第二实施例的音频信号处理设备,可以在对每个声音进行分类之后,进一步将每个指向麦克风所采集的分路输入信号合并为总输入信号,并且根据每个声源的类型及其在所述音频坐标系下的位置来调整每个指向麦克风的增益,以使得在所述总输入信号中从所述真实信号源接收到的关注信号分量的功率与从所述噪声源接收到的噪声信号分量的功率之间的信噪比最大。
具体地,本申请的第二实施例具有以下优点:
1.可以利用摄像头和麦克风阵列组成的定位器件对进行精准定位,以将各个声源分类为真实信号源、潜在信号源、噪声源等,并且对声源的变化(如用户开口说话、用户走动、用户的增加减少)都可以实时监测;
2.利用指向麦克风阵列可以对多声源,多角度地进行同时增强;
3.利用指向麦克风阵列配合最大信噪比、最小可唤醒能量、最大声源角度能量不失真准则来无损地增强语音。
示例性音频信号处理方法
图8图示了根据本申请实施例的音频信号处理方法的流程示意图。
根据本申请实施例的音频信号处理方法可以应用于参考图1到图7所描述的音频信号处理设备100。
如图8所示,所述音频信号处理方法可以包括:
在步骤S110中,从麦克风阵列中的每个指向麦克风接收分路输入信号,所述麦克风阵列包括具有不同拾音区的多个指向麦克风,每个指向麦克风用于在自身的拾音区内采集所述分路输入信号;
在步骤S120中,根据所述分路输入信号来识别第一组声源并确定其中的每个声源在所述麦克风阵列所确定的音频坐标系下的位置;
在步骤S130中,从摄像头接收当前场景的场景图像,所述当前场景至少覆盖所述多个指向麦克风的拾音区;
在步骤S140中,在所述场景图像中识别第二组声源并确定其中的每个声源在所述摄像头所确定的图像坐标系下的位置;以及
在步骤S150中,根据所述音频坐标系与所述图像坐标系之间的配准关系、所述第一组声源中每个声源在所述音频坐标系下的位置、和所述第二组声源中每个声源在所述图像坐标系下的位置来对所述第一组声源和所述第二组声源中的每个声源进行分类。
在一个实施例中,该步骤S120可以包括:从每个指向麦克风所采集的分路输入信号中分离不同声源的音频信号分量并确定所述第一组声源;以及针对所述第一组声源中的每个声源,根据从至少两路分路输入信号中分离出的所述声源的音频信号分量的相位来确定所述声源在所述音频坐标系下的位置。
在一个实施例中,该步骤S150可以包括:根据所述音频坐标系与所述图像坐标系之间的配准关系来将所述第一组声源中每个声源的位置和所述第二组声源中每个声源的位置映射到同一坐标系下,所述同一坐标系为所述音频坐标系和所述图像坐标系之一;比对所述第一组声源和所述第二组声源中每个声源在所述同一坐标系下的相对位置关系;以及根据所述相对位置关系来对所述第一组声源和所述第二组声源中的每个声源进行分类。
在一个实施例中,根据所述相对位置关系来对所述第一组声源和所述第二组声源中的每个声源进行分类包括:响应于位于所述同一坐标系下某一位置处的声源同时存在于所述第一组声源和所述第二组声源中,将所述声源标记为正在输出关注信号的真实信号源;以及响应于位于所述同一坐标系下某一位置处的声源仅仅存在于所述第一组声源中,将所述声源标记为正在输出噪声信号的噪声源。
在一个实施例中,根据所述相对位置关系来对所述第一组声源和所述第二组声源中的每个声源进行分类还可以包括:响应于位于所述同一坐标系下某一位置处的声源仅仅存在于所述第二组声源中,将所述声源标记为当前未输出关注信号的潜在信号源。
在一个实施例中,所述音频信号处理方法还可以包括:
在步骤S160中,将每个指向麦克风所采集的分路输入信号合并为总输入信号,所述分路输入信号包括来自真实信号源的关注信号分量和来自噪声源的噪声信号分量;以及
在步骤S170中,根据每个声源的类型及其在所述音频坐标系下的位置来调整每个指向麦克风的增益,以使得在所述总输入信号中从所述真实信号源接收到的关注信号分量的功率与从所述噪声源接收到的噪声信号分量的功率之间的信噪比最大。
在一个实施例中,步骤S170可以包括:响应于存在正在输出关注信号的一个或多个真实信号源且不存在正在输出噪声信号的噪声源,比较所述一个或多个真实信号源与每个指向麦克风的拾音区之间的第一位置关系;以及根据所述第一位置关系来调整每个指向麦克风的增益,以使得在所述总输入信号中从所述一个或多个真实信号源接收到的关注信号分量的功率最大。
在一个实施例中,根据所述第一位置关系来调整每个指向麦克风的增益可以包括:增大所述一个或多个真实信号源位于其拾音区的一个或多个指向麦克风的增益,以使得在所述总输入信号中从所述一个或多个真实信号源接收到的关注信号分量的功率最大且没有任何一个关注信号分量发生失真。
在一个实施例中,步骤S170可以包括:响应于不存在正在输出关注信号的真实信号源且存在正在输出噪声信号的一个或多个噪声源,比较所述一个或多个噪声源与每个指向麦克风的拾音区之间的第二位置关系;以及根据所述第二位置关系来调整每个指向麦克风的增益,以使得在所述总输入信号中从所述一个或多个噪声源接收到的噪声信号分量的功率最小。
在一个实施例中,根据所述第二位置关系来调整每个指向麦克风的增益可以包括:所述增益调整单元将所述一个或多个噪声源位于其拾音区的一个或多个指向麦克风的增益设置为零。
在一个实施例中,步骤S170可以包括:响应于同时存在正在输出关注信号的一个或多个真实信号源和正在输出噪声信号的一个或多个噪声源,比较所述一个或多个真实信号源与每个指向麦克风的拾音区之间的第一位置关系和所述一个或多个噪声源与每个指向麦克风的拾音区之间的第二位置关系;以及根据所述第一位置关系和所述第二位置关系来调整每个指向麦克风的增益,以使得在所述总输入信号中从所述一个或多个真实信号源接收到的关注信号分量的功率与从所述一个或多个噪声源接收到的噪声信号分量的功率之间的信噪比最大。
在一个实施例中,步骤S170还可以包括:响应于还存在当前未输出关注信号的一个或多个潜在信号源,比较所述一个或多个潜在信号源与每个指向麦克风的拾音区之间的第三位置关系,并且根据所述第三位置关系来调整每个指向麦克风的增益,以使得所述麦克风阵列能够随时从所述潜在信号源采集音频信号分量。
在一个实施例中,根据所述第三位置关系来调整每个指向麦克风的增益可以包括:将所述一个或多个潜在信号源位于其拾音区的一个或多个指向麦克风的增益设置为估计值,所述估计值是根据所述一个或多个潜在信号源在所述图像坐标系下的位置来确定的。
在一个实施例中,所述音频信号处理方法还可以包括:在步骤S180中,根据声源分类的结果和每个声源在所述音频坐标系下的位置来对增益调整后的总输入信号进行滤波,以仅仅保留来自每个真实信号源的音频信号分量。
上述音频信号处理方法中的各个步骤的具体功能和操作已经在上面参考图1到图7描述的音频信号处理设备100中详细介绍,并因此,将省略其重复描述。
示例性电子设备
下面,参考图9来描述根据本申请实施例的电子设备。该电子设备可以是智能化的语音识别系统(例如,智能家电、机器人等)、传统的语音通信系统(例如,会议系统、因特网协议传送话音VoIP系统等)中的近端设备或远端设备等。
图9图示了根据本申请实施例的电子设备的框图。
如图9所示,电子设备10包括一个或多个处理器11和存储器12。
处理器11可以是中央处理单元(CPU)或者具有数据处理能力和/或指令执行能力的其他形式的处理单元,并且可以控制电子设备10中的其他组件以执行期望的功能。
存储器12可以包括一个或多个计算机程序产品,所述计算机程序产品可以包括各种形式的计算机可读存储介质,例如易失性存储器和/或非易失性存储器。所述易失性存储器例如可以包括随机存取存储器(RAM)和/或高速缓冲存储器(cache)等。所述非易失性存储器例如可以包括只读存储器(ROM)、硬盘、闪存等。在所述计算机可读存储介质上可以存储一个或多个计算机程序指令,处理器11可以运行所述程序指令,以实现上文所述的本申请的各个实施例的音频信号处理方法以及/或者其他期望的功能。在所述计算机可读存储介质中还可以存储诸如各个声源的位置和类型、各个麦克风增益等信息。
在一个示例中,电子设备10还可以包括:输入装置13和输出装置14,这些组件通过总线系统和/或其他形式的连接机构(未示出)互连。
例如,该输入装置13可以包括例如键盘、鼠标、以及通信网络及其所连接的远程输入设备等等。替换地或附加地,该输入装置13也可以是上述的麦克风阵列110,包括具有不同拾音区的多个指向麦克风,每个指向麦克风用于在自身的拾音区内采集分路输入信号;或者也可以是上述的摄像头130,用于捕捉当前场景的场景图像,所述当前场景至少覆盖所述多个指向麦克风的拾音区。
输出装置14可以向外部(例如,用户)输出各种信息,包括各个声源的位置和类型、调整后的每个指向麦克风的增益、噪声消除后的总输入信号等。该输出设备14可以包括例如显示器、打印机、以及通信网络及其所连接的远程输出设备等等。
当然,为了简化,图9中仅示出了该电子设备10中与本申请有关的组件中的一些,省略了诸如总线、输入/输出接口等等的组件。应当注意,图9所示的电子设备10的组件和结构只是示例性的,而非限制性的,根据需要,电子设备10也可以具有其他组件和结构。
示例性计算机程序产品和计算机可读存储介质
除了上述方法和设备以外,本申请的实施例还可以是计算机程序产品,其包括计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器执行本说明书上述“示例性方法”部分中描述的根据本申请各种实施例的音频信号处理方法中的步骤。
所述计算机程序产品可以以一种或多种程序设计语言的任意组合来编写用于执行本申请实施例操作的程序代码,所述程序设计语言包括面向对象的程序设计语言,诸如Java、C++等,还包括常规的过程式程序设计语言,诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。
此外,本申请的实施例还可以是计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器执行本说明书上述“示例性方法”部分中描述的根据本申请各种实施例的音频信号处理方法中的步骤。
所述计算机可读存储介质可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以包括但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。
以上结合具体实施例描述了本申请的基本原理,但是,需要指出的是,在本申请中提及的优点、优势、效果等仅是示例而非限制,不能认为这些优点、优势、效果等是本申请的各个实施例必须具备的。另外,上述公开的具体细节仅是为了示例的作用和便于理解的作用,而非限制,上述细节并不限制本申请为必须采用上述具体的细节来实现。
本申请中涉及的器件、装置、设备、系统的方框图仅作为例示性的例子并且不意图要求或暗示必须按照方框图示出的方式进行连接、布置、配置。如本领域技术人员将认识到的,可以按任意方式连接、布置、配置这些器件、装置、设备、系统。诸如“包括”、“包含”、“具有”等等的词语是开放性词汇,指“包括但不限于”,且可与其互换使用。这里所使用的词汇“或”和“和”指词汇“和/或”,且可与其互换使用,除非上下文明确指示不是如此。这里所使用的词汇“诸如”指词组“诸如但不限于”,且可与其互换使用。
还需要指出的是,在本申请的装置、设备和方法中,各部件或各步骤是可以分解和/或重新组合的。这些分解和/或重新组合应视为本申请的等效方案。
提供所公开的方面的以上描述以使本领域的任何技术人员能够做出或者使用本申请。对这些方面的各种修改对于本领域技术人员而言是非常显而易见的,并且在此定义的一般原理可以应用于其他方面而不脱离本申请的范围。因此,本申请不意图被限制到在此示出的方面,而是按照与在此公开的原理和新颖的特征一致的最宽范围。
为了例示和描述的目的已经给出了以上描述。此外,此描述不意图将本申请的实施例限制到在此公开的形式。尽管以上已经讨论了多个示例方面和实施例,但是本领域技术人员将认识到其某些变型、修改、改变、添加和子组合。
- 还没有人留言评论。精彩留言会获得点赞!