基于负相关增量学习的声纹识别方法与流程
本发明涉及的是一种声纹识别方法。
背景技术:
声纹是指反映说话人语音频谱的声波信息图,声纹识别就是根据语音的波形图中所反映的包含说话人特征的语音参数来自动对说话者身份进行识别和判断的技术。由于每个人发音器官的不同,所发出来的声音特性以及其音调也各不相同,因此,将声纹作为个性特征来实现不同人的身份识别和验证具有快速、稳定和准确率高等特性,声纹识别的技术也正在广泛地被应用于信息和网络的各个领域。
但是在大量的应用场景下,训练数据无法一次性获得,并且声纹识别也具有一些众所周知的缺陷,对于个人而言,语音信号虽然具有相对稳定性,但是也不是绝对一成不变的,也具有易变性,容易受到来自身体状况、心理情绪以及录音设备的影响。同一个人的发音在不同时段、不同的生理状况下,或者是被不同的麦克风和信道参数下录制,其语音的声学特征均有可能发生变化,从而对识别的性能产生影响,这时传统的批量式的机器学习方式显得难以适应。
负相关学习(negativecorrelationlearning,ncl)是一种神经网络集成学习算法,能很好的解决增量问题,负相关学习是一种基于ann的集成学习算法,使用bp算法并行的训练集成中的每个个体神经网络。对于训练样本集{(x1,t1),...,(xn,tn)}网络集成的输出为:
其中,m是集成的大小,即在集成中个体神经网络的个数,fi(n)是第i个神经网络对于第n个样本的输出。
负相关学习最大的特点是其误差函数的设计,该误差函数由均方误差和惩罚项构成,第i个网络对于第n个样本的误差函数如下:
其中tn是样本i的目标输出,pi(n)是惩罚项,λ是一个控制参数,用来调节惩罚的力度,取值为[0,1],称为惩罚项系数,当λ为0时,每个网络之间不存在交互。使用该误差函数可以使得影响个体精度的均方误差和影响个体间差异的惩罚项之间到达一个平衡。其中惩罚项定义为:
pi(n)=(fi(n)-f(n))∑j≠ifj(n)-f(n)
式中fi(n)是网络i的输出,f(n)是集成的输出。
ncl在增量学习中展示了良好的性能,最早ncl被简单应用于增量学习中时,研究者分别设计了两种算法:一种是集成大小固定式的ncl(fixedsizencl,fsncl),另一种是集成规模增长式的ncl(growingncl,gncl)。这两种算法的优势和缺陷已经在2.2.2节中进行过分析,针对其优缺点,minlonglin等人提出了选择性负相关学习(selectivenegativecorrelationlearning,sncl)算法。
该算法的基本思想是,每次当新数据到来时,将原来集成中的所有神经网络复制一份,假设集成大小为n,使用复制后的网络在新的数据集上进行学习,将所有的神经网络整合起来得到2n个网络,然后进行一次选择操作,刷选出其中的n个网络,这样得到的网络中既有使用新数据训练过的网络,又包含了前面训练过的,既保证了集成的大小保持不变,也使得保留下来的网络能够适应新的数据,并且能较好地保留旧的知识。sncl具有较优的泛化性能,然而在时间复杂度上却远高于其他算法,此外,还存在着个体网络的隐藏层节点个数难以确定,容易产生过拟合等现象。
技术实现要素:
本发明的目的在于提供一种能提高效率和识别准确率,降低时间复杂度的基于负相关增量学习的声纹识别方法。
本发明的目的是这样实现的:
步骤一、对输入的语音信号进行预处理和特征提取;
步骤二、初始化网络集成,如果之前已存在网络集成,则复制当前所有网络;
步骤三、对网络集成进行训练;
步骤四、对网络集成中的每个网络进行结构调整;
步骤五、对当前网络进行筛选,选出其中最优的一部分网络;
步骤六、将当前得到的网络进行应用,如果有新数据到来,则从步骤一开始循环执行。
本发明还可以包括:
1、所述对输入的语音信号进行预处理和特征提取具体包括:首先对于原始语音信号进行采样量化,再将模拟信号以一定的频率采样处理、变成离散数据,然后进行预加重处理,接下来进行分帧和加窗处理,将一段时间内的信号分成一帧、以帧为单位进行分析,再采用双门限法过滤掉静音段,接下来对处理过后的语音信号提取梅尔频率倒谱系数(mel-frequencycepstralcoefficients,mfcc)和一阶差分mfcc作为模型训练和识别的特征参数。
2、步骤二具体包括:如果之前没有进行过网络训练,即当前得到的数据集是第一批,则初始化m个神经网络用于网络集成,其中每个神经网络隐藏节点的个数使用如下的公式来确定:
否则将当前已经训练过的网络进行复制。在公式中,n为输入节点个数,l为输出节点个数,输入节点和输出节点的个数由输入样本的特征和所要解决的问题决定,α是一个在区间[1,10]上的随机数。
3、所述对网络集成进行训练具体包括:对训练数据进行重复采样得到d个不同的数据集,数据集的个数和网络的个数相同,即d=m。然后使用负相关学习算法进行并行地训练,在训练的过程中引入陡度因子加快网络训练的速率,如果已经对网络进行了复制,即当前的网络个数为2m,则训练在复制之后的网络上进行,否则对原始网络进行训练。
4、所述对网络集成中的每个网络进行结构调整具体包括:当训练结束后,判断其是否满足预设的目标误差,如果满足则进行下一步,否则对于步骤三进行训练的每个网络,计算其每个隐藏节点的重要性,对于每个非重要的节点,找到一个与之相关性最大的重要节点,将两个相关性最大的节点进行合并,合并的方式是将两者相对应的权值进行合并,重要性ηi的计算公式如下:
其中σi是隐藏节点i的标准差,由该隐藏节点在所有样本数据的输出计算而来;μi是该节点目前为止被训练的次数。
计算两个节点相关性的公式为:
其中hi(p)和hj(p)分别是对i个和第j个隐藏节点在训练集中的样本p上的输出,变量
本发明是以增量学习的方法对声纹识别进行研究,提高其在数据增量到来场景下的效率和识别准确率。基于负相关学习的增量学习算法能有效地解决增量问题,然而现有的分类准确度最高的选择性负相关学习算法(sncl)仍然存在着时间复杂度过高,个体网络的隐藏层节点个数难以确定,容易产生过拟合等问题。本发明分别从模型训练和模型选择两个方面进行改进,提出了一种新的算法以解决上述的问题,然后将其应用到增量学习中。
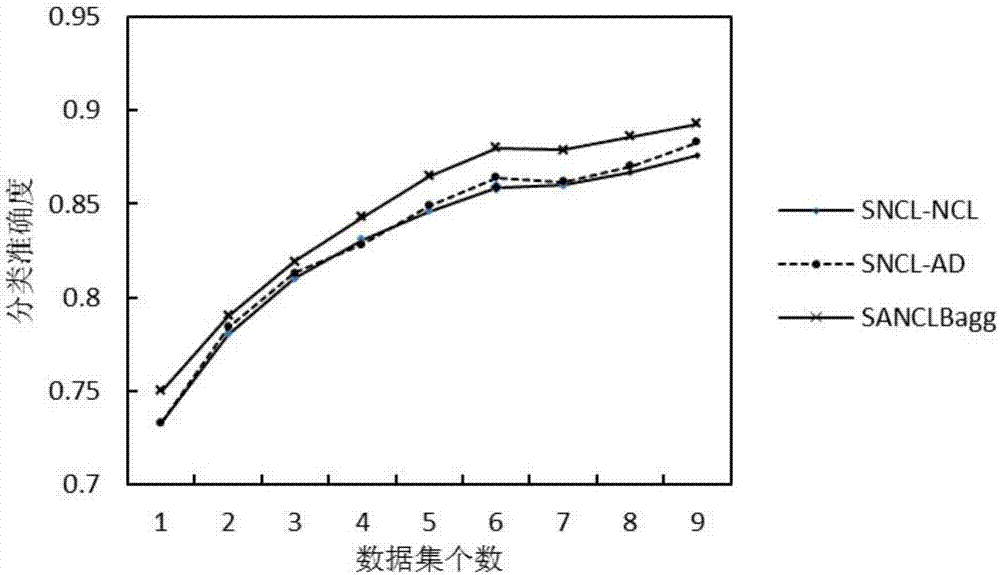
本发明使用基于负相关学习(negativecorrelationlearning,ncl)的增量学习算法作为声纹的识别算法,在已有的相关算法中,大小固定的fsncl(fixedsizencl)容易对已学过的知识产生遗忘,增长式的gncl(growingncl)整体泛化性能不佳,基于选择性集成的sncl(selectivencl)精度较高但训练时间过长。本发明对sncl算法从模型训练和模型选择两个方面进行了改进。首先,ncl算法以bp网络作为基础并进行了修改,使得个体网络在训练的过程中误差向负相关方向变化,增加了网络之间的差异性,但是忽略的网络本身在训练过程中容易出现隐藏层节点个数不易确定,训练时间过长,容易产生过拟合等问题,本发明针对这些问题对ncl算法进行了改进,使得网络结构自适应变化,并将其与bagging算法相结合,简称为anclbag算法,该算法避免了纯手动设定隐藏节点个数,使其根据当前网络训练的情况自适应地增加或删除隐藏层节点,减少了人为的误差,在调整的过程中,尽可能地挖掘网络本身的信息处理能力,保持节点个数较少,一方面在训练过程中减少了迭代次数,另一方面,较小了多余的隐藏节点可能造成过拟合的可能性。此外,与bagging算法相结合后,两者分别在训练集生成和网络训练方面对整个集成产生影响,使得个体网络之间的差异进一步增加,并且保证了整体的泛化性能。随后,本发明在该算法的基础上进行了增量学习的研究。在研究增量学习的过程中,本发明借鉴了sncl的框架,并对其模型选择的方法进行修改,使用基于分簇和排序的选择性集成方法,在该方法中同时考虑了模型的准确性和差异性,提出一种新的sanclbag算法,实验表明该算法的泛化性能略高于sncl,在时间复杂度方面则明显优于后者。
最后,将该模型应用到声纹识别中,实现了一个能够对语音信号进行预处理、特征提取、模型增量训练和模式识别的声纹识别模型,并使用该模型进行了参数选择和增量验证的实验,实验结果表明该模型具有较高的识别准确率,并且能有效地解决增量学习的问题。
附图说明
图1为本发明的流程框图;
图2为本发明算法与改进之前的算法在分类准确率方面的对比图;
图3为本发明算法与改进之前的算法在算法时间方面的对比图;
图4为本发明算法与其他传统算法分类准确率对比图。
具体实施方式
下面举例对本发明做更详细的描述。
结合图1,本发明的方法通过以下步骤实现:
步骤一、对语音信号进行预处理和特征提取。首先对于原始的语音信号进行采样量化,在将模拟信号以一定的频率采样处理,从而实现模数转换,变成离散数据。然后进行预加重处理,使频率高的区段凸显出来,过滤掉频率较低区段的干扰。接下来对上一步得到的结果分帧和加窗处理,语音信号具备短时有效性,即10ms到30ms内的语音信号是相对平稳的。因此,将一段时间内的信号分成一帧,以帧为单位进行分析,再采用双门限法过滤掉静音段。接下来对处理过后的语音信号提取mfcc和一阶差分mfcc作为模型训练和识别的特征参数;
步骤二、如果之前没有进行过网络训练,即当前得到的数据集是第一批,则初始化m个神经网络用于集成,其中每个神经网络隐藏节点的个数使用如下的经验公式来确定:
否则将当前已经训练过的网络进行复制。在公式中,n为输入节点个数,l为输出节点个数,输入节点和输出节点的个数由输入样本的特征和所要解决的问题决定,α是一个在区间[1,10]上的随机数。
步骤三、对训练数据进行重复采样得到d个不同的数据集,数据集的个数和网络的个数相同,即d=m。然后使用负相关学习算法进行并行地训练,在训练的过程中引入陡度因子以加快网络训练的速率,如果上一步对网络进行了复制,即当前的网络个数为2m,则训练在复制之后的网络上进行,否则对原始网络进行训练;
步骤四、当训练结束后,判断其是否满足预设的目标误差,如果满足则进行下一步,否则对于步骤三进行训练的每个网络,计算其每个隐藏节点的重要性,对于每个非重要的节点,找到一个与之相关性最大的重要节点(除去非重要节点,剩下的都是重要节点),将两个相关性最大的节点进行合并,合并的方式是将两者相对应的权值进行合并,重要性ηi的计算公式如下:
这里的σi是隐藏节点i的标准差,该标准差由该隐藏节点在所有样本数据的输出计算而来,这个值能很好的表现该节点对于不同样本数据的变化情况。当标准差较小时,说明该隐藏节点对于所有的样本,几乎都输出一个十分相近的值,换句话说,该节点对于不同样本的区分能力较差。由于在三层的前向反馈网络中,隐藏层和输出层直接相连接,隐藏层对不同数据的处理结果的差异将直接对网络的输出产生影响,因此可以认为该节点对于网络而言是不重要的。公式中的另一个参数μi是该节点目前为止被训练的次数,这里使用训练次数的原因是,由于调整操作产生了新的节点,新的节点和之前的节点训练次数是不同的。计算两个节点相关性的公式如下:
其中hi(p)和hj(p)分别是对i个和第j个隐藏节点在训练集中的样本p上的输出。变量
步骤五、如果当前的网络个数为2m,则对所有的网络进行分簇,将相关性最大的网络分成一簇,然后从每一簇中选择出一个分类准确度最高的网络,如果当前网络个数为m,则直接进行下一个步骤;
步骤六、将此时得到的网络用于应用,如果之后有新的数据到来,则返回步骤一。
- 还没有人留言评论。精彩留言会获得点赞!