基于客户语音情感的客服服务质量评价方法及系统与流程
本发明涉及语音数据处理
技术领域:
,特别涉及一种基于客户语音情感的客服服务质量评价方法及系统。
背景技术:
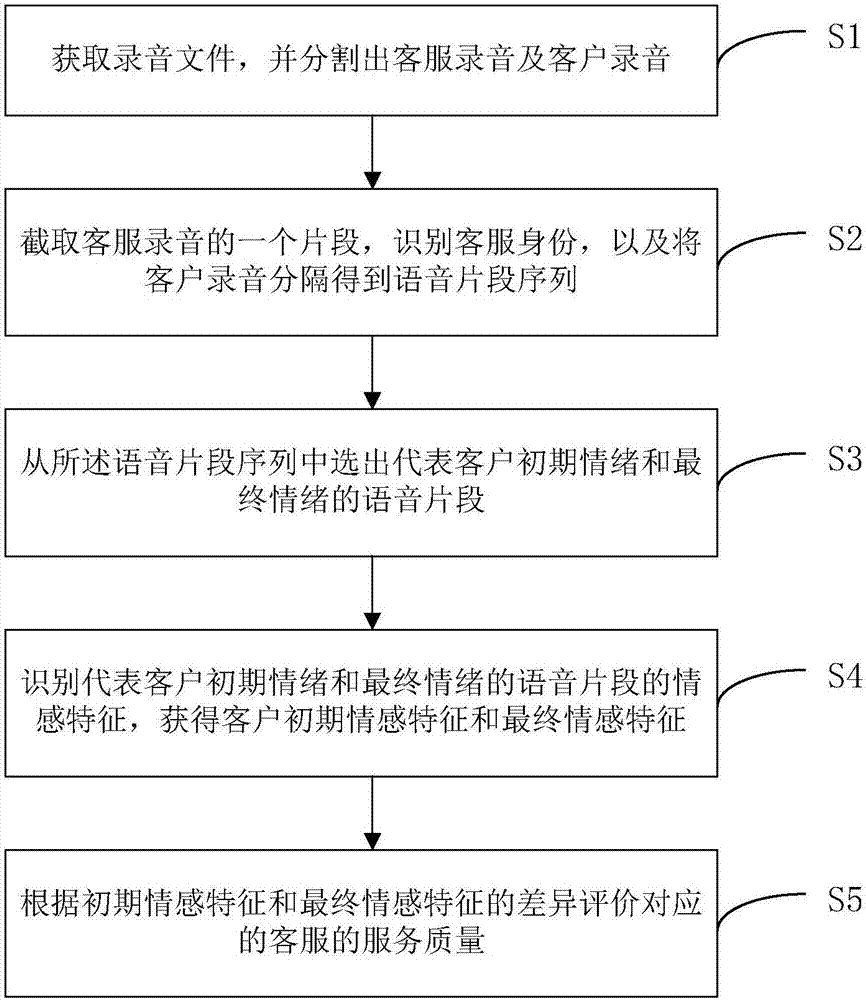
:在现代生活中,每天我们都会接到大量的推销电话,内容覆盖股票、贷款、房产等内容,背后都是有公司提供callcenter服务。这些公司每天生成大量的客服录音文件,为了考核客服人员,一般需要另外雇佣质检人员手工听取录音文件。然而,质检人员往往只是抽查部分录音,既浪费人力又容易遗漏有用信息。事实上,如何能够从录音文件中分析出客户的情感变化,以评价客服的服务质量是一种能够实现自动考核克服的有用方法。现有的技术中,目前的情感识别研究还是基于单个人的说话录音,比如台州学院的赵小明和张石清提出的专利“基于压缩感知的鲁棒性语音情感识别方法”,江苏大学提出的专利“非特定人语音情感识别方法及系统”等,都没有考虑对话中一个人的情感和另外一个人存在着某种关系。因此,并不适用于考核客服人员的服务质量。技术实现要素:本发明的目的在于提供一种基于客户语音情感的客服服务质量评价方法及系统,以解决现有的客服评价方法需依赖人工检测所造成的效率较低、有效性较差的问题。为实现上述目的,本发明提供了一种基于客户语音情感的客服服务质量评价方法,包括以下步骤:获取录音文件并提取得到其中的客户录音;对所述客户录音进行处理得到代表客户初期情绪和最终情绪的语音片段;根据初期情绪和最终情绪的语音片段的情感差异评价对应的客服的服务质量。较佳地,具体包括:将所述客户录音分隔得到不含杂音的语音片段序列;然后从所述语音片段序列中选出代表客户初期情绪和最终情绪的语音片段。较佳地,获取录音文件后,还包括分割出客服录音及客户录音后,截取客服录音的一个片段,识别客服身份。较佳地,截取客服录音的一个片段后,提取其中的mfcc特征,利用高斯模型识别客服身份。较佳地,将客户录音分隔得到语音片段序列的过程包括:s21:根据客户录音的频率及强度的不同,标注有声语音片段和静音语音片段;s22:从所述客户录音中分隔出有声语音片段;s23:识别出所述有声语音片段中的杂音片段并删除;s24:将剩余的有声语音片段对应的数据组合作为所述语音片段序列。较佳地,进一步包括:获取所述语音片段序列中每个语音片段的时长;则初期情绪的语音片段的选取方法为:选取所述语音片段序列中的前k个语音片段作为代表客户初期情绪的语音片段,该k个语音片段满足:k个语音片段的时长总和小于等于t,当所述语音片段序列中的第一个语音片段时长大于t时,则将第一个语音片段作为代表客户初期情绪的语音片段;最终情绪的语音片段的选取方法为:选取所述语音片段序列中的后l个语音片段作为代表客户最终情绪的语音片段,该l个语音片段满足:l个语音片段的时长总和小于等于t,当所述语音片段序列中的最后一个语音片段时长大于t时,则将该最后一个语音片段作为代表客户最终情绪的语音片段;其中,k、l均为正整数,t为预设的语音时长阈值。较佳地,进一步包括:分别提取所述初期情绪和最终情绪的语音片段的声学特征,并采用情感识别算法分析所述声学特征,得到客户的初期情感特征和最终情感特征。较佳地,进一步包括:为所述初期情感特征和最终情感特征分别赋予情感权值,得到初期情感值rs和最终情感值ts,采用(ts-rs)作为情感差异来评价对应的客服的服务质量。较佳地,还包括获取基本情感分类表,并在所述基本情感分类表中查找所述初期情感特征和最终情感特征分别对应的预设权值,将预设权值作为情感权值分别对应赋予给所述初期情感特征和最终情感特征。本发明还提供了一种基于客户语音情感的客服服务质量评价系统,包括:录音文件预处理模块,用于获取录音文件并提取得到其中的客户录音;语音片段提取模块,用于获取所述客户录音并处理得到代表客户初期情绪和最终情绪的语音片段;服务质量评价模块,用于根据初期情绪和最终情绪的语音片段进行分析,得到两者的情感差异以评价对应的客服的服务质量。本发明具有以下有益效果:通过对录音文件中对话的语音进行分离,再使用单个人(客户)的情感识别算法,从对话录音中解析出客户的情感序列,通过分析情感序列的情感的变化程度来评价客服的服务质量,实现自动进行客服的服务质量的评价。附图说明图1为本发明方法基本流程图;图2为一优选实施例提供的基于客户语音情感的客服服务质量评价方法流程图;图3为具体实施例的原始录音文件数据波形图;图4为具体实施例获取的客服录音的数据波形图;图5为具体实施例提取的客服录音的片段的数据波形图;图6为优选实施例将提取的片段的客户录音分隔得到语音片段序列的流程图;图7为优选实施例中处理后得到的客户语音对应的语音片段序列;图8为进一步优选实施例中对录音片段提取声学特征的结构示意图;图9为优选实施例基于客户语音情感的客服服务质量评价系统组成图。具体实施方式以下将结合本发明的附图,对本发明实施例中的技术方案进行清楚、完整的描述和讨论,显然,这里所描述的仅仅是本发明的一部分实例,并不是全部的实例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明的保护范围。为了便于对本发明实施例的理解,下面将结合附图以具体实施例为例作进一步的解释说明,且各个实施例不构成对本发明实施例的限定。本实施例提供了一种基于客户语音情感的客服服务质量评价方法,如图1所示,该方法包括以下步骤:a.获取录音文件并提取得到其中的客户录音;b.对客户录音进行处理得到代表客户初期情绪和最终情绪的语音片段;c.根据初期情绪和最终情绪的语音片段的情感差异评价对应的客服的服务质量。该方法不需要手工听取录音,可完全自动进行评价客服质量;且服务质量评价综合考虑最终结果和服务难度(具体通过最终情绪与初期情绪的差异的大小即可判断客户情绪的变化,通过初期情绪即可有效地判断服务难度),因而评价方法更为客观。在一优选实施例中,上述过程进一步包括将所述客户录音分隔得到不含杂音的语音片段序列;然后从上述语音片段序列中选出代表客户初期情绪和最终情绪的语音片段。这个过程可以剔除录音文件中的非客户声音的杂音,进而提高后续进行情感分析的准确度。在另一优选实施例中,获取录音文件后,还包括分割出客服录音及客户录音后,截取客服录音的一个片段,识别客服身份。通过自动识别客服的身份,进而方便对后续该客服的服务质量进行评价。进一步的,如图2所示,本实施例的一种优选实施例中,上述方法具体地包括以下步骤:s1:获取录音文件,并分割出客服录音及客户录音;s2:截取客服录音的一个片段,识别客服身份,以及将客户录音分隔得到语音片段序列;s3:从所述语音片段序列中选出代表客户初期情绪和最终情绪的语音片段;s4:识别代表客户初期情绪和最终情绪的语音片段的情感特征,获得客户初期情感特征和最终情感特征;s5:根据初期情感特征和最终情感特征的差异评价对应的客服的服务质量。其中,这里的步骤s2中,识别客服身份与分隔得到语音片段序列两个过程可以先后进行也可同时进行,可根据方法具体应用时的需要而自定义设置。此外,识别客服身份的过程也可在其他实施例中单独完成,而不必整合在步骤s2中。本实施例的方法通过首先根据录音文件中不同的人物而分割出客服录音及客户录音,再对客户录音进行情绪的识别、判断及分析,实现了充分考虑对话中一个人的情感与另外一个人存在关系的情况下的对客户情感变化的分析。并基于客户初期情感和最终情感进行比较,通过两者的差异来评价对应的客服的服务质量,这种方式实现了基于情感变化的自动的客服服务质量评价,进而实现了全面的、系统的、不依赖人工的客服服务质量评价,避免了传统需依赖人工进行客服服务质量评价的不全面性。此外,通过结合语音情感的数据特征,还可以进行海量数据的对比分析,对客服服务质量的整体有效提升提供了有益的辅助手段。下面以对一个录音文件进行处理以评估客服的服务质量为例,对上述方法做进一步的详细说明(其中,各步骤的具体内容可独立于上述方法组成互相独立的多个优选实施例):首先,执行步骤s1,读取获取录音文件(如图3所示),并分割出该录音文件中的客服录音及客户录音。具体地:录音文件由两个通道组成,分别对应客服录音或客户录音。采用语音学软件能够分别获取通道1(channel1)及通道2(channel2)对应的语音文件,本实施例中,设通道1对应的语音文件为客服语音,通道2对应的语音文件为客户录音。如图3中所示,这里采用praat软件抽取得到通道1的语音文件及通道2的语音文件,其中,通道1的语音文件即为客服录音,通道2的语音文件即为客户录音。当然,在其他的实施例中,也可设通道1对应的语音文件为客户录音,而通道2对应的语音文件为客服语音。因而,不同的通道与不同的语音文件的对应关系取决于实际的录音系统的通道设置形式。然后,执行步骤s2,截取客服录音的一个片段,参见图4所示,为本实施例中所提取的客服录音中的一个片段(该片段参见图4中虚线标注的第一个语音片段),通过提取该片段中的mfcc特征,利用高斯模型即可识别客服身份。这里的mfcc是指梅尔倒谱系数(mel-scalefrequencycepstralcoefficients,简称mfcc),其为在mel标度频率域提取出来的倒谱参数,mel标度描述了人耳频率的非线性特性。而本实施例中,采用高斯模型识别客服身份具体包括以下两个阶段:训练阶段和预测阶段。在训练阶段,对于带有标签的录音片段,采用工具(比如praat)读取mfcc特征,得到一个p*l矩阵,p不妨设为12,l是帧的数目。在行方向计算平均值后,每个录音片段得到一个p维数组,和标签一起作为训练样本。然后,混合高斯模型(gmm)对所有训练样本的概率密度分布进行期望最大化估计,而估计采用的模型是k个高斯模型的加权和,每个高斯模型就代表了一个类。在预测阶段,类似的取得语音片断的mfcc平均值后,分别在k个高斯模型上投影,就会分别得到在各个类上的概率,然后选取概率最大的类作为判决结果。不同的判决结果对应不同的客服,根据判决结果即可识别客服身份。同时,还需要将客户录音分隔得到语音片段序列,具体地,由于客户录音是由声音片段和静音片段组成,而声音片段中还包括铃声片段、环境噪声片段等不属于客户声音的杂音片段,未分隔的客户录音数据参见图5所示。则参见图6所示,本步骤中将上述的客户录音分隔得到语音片段序列的过程具体包括:s21:根据客户录音的频率及强度的不同,标注出有声语音片段和静音语音片段;s22:从所述客户录音中分隔出有声语音片段;s23:识别出所述有声语音片段中的杂音片段并删除;s24:将剩余的有声语音片段对应的数据组合作为所述语音片段序列。其中,根据图6中的数据,步骤s21中标注的有声语音片段和静音语音片段的数据具体如下(第一行为数据类型,其余为数据具体内容):根据上述数据中的标签类型,剔除静音的语音片段的数据后,即可从所述客户录音中分隔出有声语音片段。然后,应用说话人识别算法,识别出说话人的语音片段,并筛出说话人的语音片段,即可进一步的识别并剔除铃声片段、环境噪声片段等不属于客户声音的杂音片段。说话人识别算法参考上述的高斯模型识别人员的方法,其中,在预测阶段,先把语音片断转化为代表mfcc特征的p*l矩阵,然后取平均值得到p维数组。然后分别在k个高斯模型上投影,就会分别得到在各个类上的概率,然后选取概率最大的类作为判决结果。根据判决结果即可识别说话人。剔除了杂音片段后,将剩余的有声语音片段对应的数据组合作为语音片段序列,例如,如图7所示的语音片段,本实施例剔除杂音后,对应的客户语音内容为:“我听不清楚,你说的什么意思呢,你说?”得到上述的语音片段序列后,再执行步骤s3,从所述语音片段序列中选出代表客户初期情绪和最终情绪的语音片段。具体地,对于客户语音片段序列,其由多个语音片断组成,语音片断序列可以用向量表示,例如:s=<(s1,e1),(s2,e2),…,(sn,en)>,其中sx代表第x个语音片断的开始时间,ex代表第x个语音片断的结束时间,n代表序列总的片断数。则本步骤进一步包括:首先获取所述语音片段序列中每个语音片段的时长,例如,(s1,e1)的时长为(e1-s1),对应地,(sn,en)的时长为(en-sn),其余片段以此类推。则初期情绪的语音片段的选取方法为:选取语音片段序列中的前k个语音片段作为代表客户初期情绪的语音片段,该k个语音片段需满足:k个语音片段的时长总和小于等于t。定义客户初期情绪的语音片段为sstart,这里的t值预设为3秒,则对应的,sstart=<(s1,e1),(s2,e2),…,(sk,ek)>,且需满足(e1-s1)+(e2-s2)+…+(ek-sk)<=3秒,然后合并该k个语音片断成为一个更大的语音片断<sstart,estart>作为初期情绪的语音片段为sstart。当所述语音片段序列中的第一个语音片段时长大于t时,e1-s1>3秒,则将第一个语音片段作为代表客户初期情绪的语音片段,此时<sstart,estart>=<s1,e1>。同理,最终情绪的语音片段的选取方法为:选取语音片段序列中的后l个语音片段作为代表客户最终情绪的语音片段,该l个语音片段满足:l个语音片段的时长总和小于等于t。定义最终情绪的语音片段为send,且这里的t的取值也为3秒,其中,l=n-m+1,则有send=<(sm,em),(sm+1,em+1),…,(sn,en)>,且(em-sm)+(em+1-sm+1)+…+(en-sn)<=3秒,然后合并该l个语音片断成为一个更大的语音片断<send,eend>作为最终情绪的语音片段为send。同样地,当上述的语音片段序列中的最后一个语音片段时长大于t时,即当en-sn>3秒时,则将该最后一个语音片段作为代表客户最终情绪的语音片段,此时有<send,eend>=<sn,en>。其中,上述的k、l、m均为正整数,而t为预设的语音时长阈值,t值还可以为4s、2s或其他值,其值的大小可根据不同实施例或应用场景而适应性改变,不限制为上述的3秒。得到上述的代表客户初期情绪和最终情绪的语音片段后,再执行步骤s4,对得到的语音片段进行处理,以识别代表客户初期情绪和最终情绪的语音片段的情感特征,进而获得客户初期情感特征和最终情感特征。处理的过程进一步的包括以下内容:首先,获取代表客户的初期情绪的语音片段和代表客户的最终情绪的语音片段,也即上述的<sstart,estart>及<send,eend>对应的录音片段。然后分别提取初期情绪和最终情绪的语音片段的声学特征,这里的声学特征包括但不限于mfcc、频幅微扰及/或振幅微扰中的一种或多种的组合。最后,采用情感识别算法分析得到的声学特征,从而得到客户的初期情感特征和最终情感特征。如图8所示,为praat处理得到的包含了12个特征的mfcc图,该12个特征在3.264秒内在频率微扰和振幅微扰方面(其中这里的频率微扰和振幅微扰并不是mfcc直接的映射,而是一种变化趋势),分别表现为为:jitter(频率微扰):local(局部):2.147%local,absolute(局部,绝对):105.810e-6秒rap(拍击):0.914%ppq5(间期系数5):0.844%ddp(周期二次差):2.743%shimmer(振幅微扰):local(局部):10.935%local,db(局部,分贝):1.041apq3(间期系数3):3.762%apq5(间期系数5):4.877%apq11(间期系数11):9.804%ddp(周期二次差):11.285%。对于每个声音片段,通过分析上述的特征,然后应用hmm(hiddenmarkovmodel)作为识别器,即可对应地识别出<sstart,estart>及<send,eend>中所隐藏的情感。最后,再执行步骤s5,根据初期情感特征和最终情感特征的差异评价对应的客服的服务质量,具体地,本步骤进一步包括:为所述初期情感特征和最终情感特征分别赋予情感权值,得到初期情感值rs和最终情感值ts,采用(ts-rs)作为差异来评价对应的客服的服务质量。本步骤中还包括获取基本情感分类表,并在基本情感分类表中查找初期情感特征和最终情感特征分别对应的预设权值,将预设权值作为情感权值分别对应赋予给初期情感特征和最终情感特征。由于现有技术中对基本情感的定义有所区别,本实施例中以美国心理学家ekman提出的6大基本情感为例对上述的基本情感分类表的定义进行说明,其中,6大基本情感包括愤怒、厌恶、害怕、高兴、悲伤、惊奇,再加上中性情感,共有7大情感。预先根据需要指定每个情感具有对应的权值,,其中,正数代表正面情感,负数代表负面情感,具体参见下表1的内容所示:表1基本情感分类及对应权值情感权值愤怒-2厌恶-2害怕-1悲伤-1中性0高兴2惊奇1那么,上述处理得到的客户初期情感特征和最终情感特征即可转化为rs和ts,进而可以用(ts-rs)代表客服服务质量的高低。这里的ts越高,代表服务质量越高;反而服务质量越低。而rs代表着服务难度,rs越高,意味着客服需要更多的耐心和更专业的能力去服务客户;反之,服务要求则偏低。当然,在其他优选实施例中,上述的情感分类及权值赋予可根据需要采取其他形式,上表仅为本发明方法的一种执行示例,根据需要作出的其他的情感分类或权值赋予方法用于解决本发明技术问题的,均包含在本发明范围内。此外,应当理解,本发明方法中各个步骤中的具体细节均分别为图1所示方法流程的优选实施例,各个步骤的具体实现方案之间可相互结合,也可分别作为附图1对应方案的优选实施方案而作为彼此独立的独立实施例,并不必须限定于上述的实施例的陈述方式。这种差值对客服的服务质量评价时考虑了客户初期的情绪及最终情绪与初期情绪间的差异,进而对服务质量进行评价时,更加科学和有效。在本发明的另一个实施例中,还提供了基于客户语音情感的客服服务质量评价系统,该系统如图9所示,具体包括:录音文件预处理模块901,用于获取录音文件并提取得到其中的客户录音;语音片段提取模块902,用于获取所述客户录音并处理得到代表客户初期情绪和最终情绪的语音片段;服务质量评价模块903,用于根据初期情绪和最终情绪的语音片段进行分析,得到两者的情感差异以评价对应的客服的服务质量。进一步的,上述的录音文件预处理模块901还包括客服身份识别单元,用于在录音文件预处理模块901获取录音文件后,分割录音文件得到客服录音及客户录音后截取客服录音的一个片段,识别客服身份。具体可通过提取其中的mfcc特征,利用高斯模型识别客服身份进一步的,上述的语音片段提取模块902还包括客户语音识别模块、杂音剔除模块及语音片段提取模块。其中,客户语音识别模块用于识别和提取有声语音片段,并从所述有声语音片段中提取客户语音对应的片段;杂音剔除模块用于根据提取得到的客户语音片段而剔除杂音片段得到语音片段序列,如铃音,环境噪声等;语音片段提取模块用于从语音片段序列中选出代表客户初期情绪和最终情绪的语音片段。进一步的,上述的服务质量评价模块903还包括:情感特征提取模块、情感赋值模块及服务质量评价模块。其中,情感特征提取模块用于提取初期情绪和最终情绪的语音片段的声学特征并进行分析,得到客户的初期情感特征和最终情感特征;情感赋值模块用于根据基本情感分类表为初期情感特征和最终情感特征进行赋值;服务质量评价模块用于根据初期情感特征和最终情感特征的值所代表的情感差异评价对应的客服的服务质量。当然,上述系统的各个组成模块中的具体工作细节可参考上述方法对应的各个实施例的具体细节,此处不再赘述。以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何本领域的技术人员在本发明揭露的技术范围内,特别是基于本发明方法,通过对话录音进行评价服务质量的设备或软件方法等均属于本发明的保护范围,此外,本领域技术人员在本发明的启发下对本发明所做的变形或替换,也都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述的权利要求的保护范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1