一种数据质量的评估方法及评估系统与流程
本发明涉及一种数据质量的评估方法及评估系统,属于数据分析领域。
背景技术:
语音识别技术需要大量的说话人语音数据,该语音数据用来模拟真实应用场景中的用户语音输入,计算机运用深度学习等算法从该语音数据中进行处理生成语音识别模型,从而运用于真实场景的用户语音识别中。语音数据是计算机学习的基础,语音数据的质量对语音识别技术的准确性有决定性的作用,尤其是深度学习算法对语音数据有极大的依赖性,计算机迫切需要高质量的语音数据。
现有技术对语音数据的质量评估主要有两种方法,第一种方法主要用于传统的语音通信网络传输中,通过语音信号层的分析来判断语音的清晰度,然而这种方法不适用于语音识别技术的语音数据评价。第二种方法主要用于教育领域,说话人按照预先设定的文本进行朗读,通过分析说话人声音和文本的差异性来判断说话人的朗读准确性。语音识别需要的语音数据有不同的质量要求,清晰度及文本差异性并不是决定性因素,然而目前并没有一种专门评估语音数据的质量评估方法。
技术实现要素:
针对上述问题,本发明的目的是提供一种专门评估语音数据的数据质量的评估方法及评估系统。
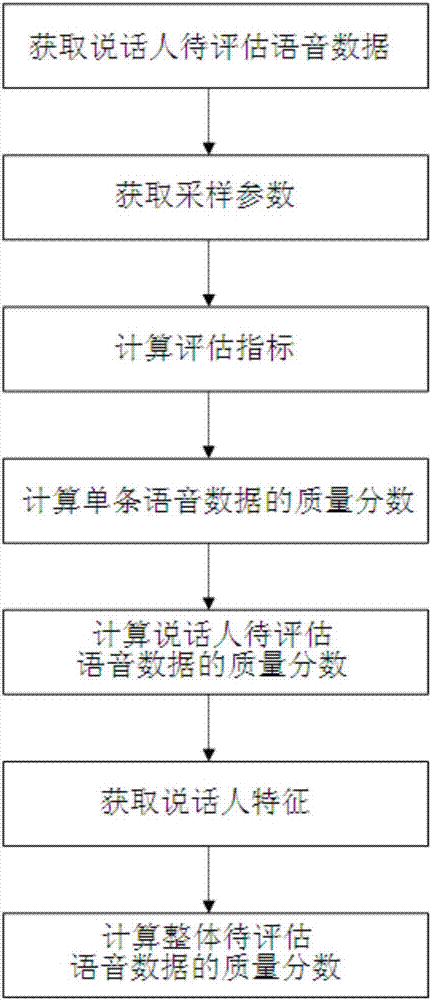
为实现上述目的,本发明采取以下技术方案:一种数据质量的评估方法,其特征在于,包括以下步骤:
1)获取说话人的待评估语音数据;
2)获取待评估语音数据的采样参数;
3)计算待评估语音数据的评估指标;
4)根据采样参数和评估指标计算说话人待评估语音数据中所有单条语音数据的质量分数;
5)根据所有单条语音数据的质量分数计算该说话人待评估语音数据的质量分数;
6)重复步骤1)~5)计算所有说话人待评估语音数据的质量分数;
7)获取说话人的特征;
8)根据说话人的特征和预先设定的质量目标计算匹配度,并根据匹配度和所有说话人待评估语音数据的质量分数计算整体待评估语音数据的质量分数。
进一步地,采样参数包括采样格式、采样率、采样频率和声道数。
进一步地,计算评估指标具体为:评估指标包括截幅比例、低音量比例、前后静音长度和信噪比,其中:
截幅比例:
截幅比例=超过预先设定截幅阈值的采样点数目/采样点总数(1)
低音量比例:
低音量比例=小于预先设定低音阈值的采样点数目/采样点总数(2)
前后静音长度:设定从待评估语音数据的开头位置向后平移,检测出连续超过预先设定静音阈值的采样点作为前静音结束位置,则:
前静音长度=前静音结束位置(3)
设定从待评估语音数据的结束位置向前平移,检测出连续超过预先设定静音阈值的采样点作为后静音开始位置,则:
后静音长度=语音数据长度-后静音开始位置(4)
信噪比:
snr=10lg(ps/pn)(5)
其中,snr为信噪比,ps为信号有效功率,pn为噪音有效功率。
进一步地,计算单条语音数据的质量分数具体为:说话人待评估语音数据中单条待评估语音数据的质量分数为分别基于采样参数和评估指标进行计算后再进行综合计算,单条语音数据的质量分数在0~1之间,基于采样参数的单条语音数据质量分数为各个采样参数权重的乘积:
qp(d)=w(采样格式)*w(采样率)*w(采样频率)*w(声道数)(6)
其中,qp(d)为基于采样参数的单条语音数据质量分数,w(采样格式)为采样格式的权重,w(采样率)为采样率的权重,w(采样频率)为采样频率的权重,w(声道数)为声道数的权重,每一采样参数的权重在0~1之间;基于评估指标的单条语音数据质量分数为各个评估指标权重的乘积:
qe(d)=w(截幅比例)*w(低音量比例)*w(前静音长度)*w(后静音长度)*w(信噪比)(7)
其中,qe(d)为基于评估指标的单条语音数据质量分数,w(截幅比例)为截幅比例的权重,w(低音量比例)为低音量比例的权重,w(前静音长度)为前静音长度的权重,w(后静音长度)为后静音长度的权重,w(信噪比)为信噪比的权重,每一评估指标的权重在0~1之间;综上,单条语音数据的质量分数q(d)为:
q(d)=qp(d)*qe(d)(8)
进一步地,计算该说话人待评估语音数据的质量分数具体为:说话人待评估语音数据的质量分数为综合说话人待评估语音数据的所有单条语音数据的质量分数并求平均值,即:
其中,q(s)为说话人待评估语音数据的质量分数,q(di)为说话人第i条单条语音数据的质量分数,n为说话人所有单条语音数据的数量。
进一步地,说话人的特征包括说话人年龄、说话人性别、说话人籍贯、录音设备、录音方式和录音环境。
进一步地,计算整体待评估语音数据的质量分数具体为:
a)预先设定质量目标:质量目标通常对待评估语音数据的录音设备、录音方式、录音环境以及不同说话人的年龄比例、性别比例和籍贯比例进行要求;
b)计算匹配度:对所有说话人按特征分别创建目标向量和实际向量,分别计算所有说话人的各特征目标向量和实际向量的相似度:
上述公式(10)进一步表示为:
其中,cosθ为相似度,ak为目标向量a的第k个目标向量,bk为实际向量b的第k个实际向量,n为目标向量a或实际向量b的个数;根据公式(11)计算所有说话人的各特征相似度,并根据计算的各特征相似度计算整体待评估语音数据与预先设定质量目标的匹配度:
m=年龄相似度*性别相似度*籍贯相似度*录音设备相似度*录音方式相似度*录音环境相似度(12)
其中,m为整体待评估语音数据与预先设定质量目标的匹配度;
c)计算整体待评估语音数据的质量分数:整体待评估语音数据的质量分数为所有说话人的待评估语音数据质量分数的平均值乘以整体待评估语音数据与预先设定质量目标的匹配度,即:
其中,q(all)为整体待评估语音数据的质量分数,q(si)为第i个说话人待评估语音数据的质量分数,m为说话人的数量。
一种数据质量的评估系统,其特征在于,该评估系统包括:一用于获取说话人待评估语音数据的待评估语音数据获取单元;一用于获取待评估语音数据采样参数的待评估语音数据采样参数获取单元;一用于计算待评估语音数据评估指标的待评估语音数据评估指标计算单元;一用于根据采样参数和评估指标计算说话人待评估语音数据中所有单条语音数据的质量分数的单条语音数据质量分数计算单元;一用于根据所有单条语音数据的质量分数计算该说话人待评估语音数据的质量分数的待评估语音数据质量分数计算单元;一用于获取说话人特征的特征获取单元;以及,一用于根据说话人特征和预先设定的质量目标计算匹配度,并根据匹配度和所有说话人待评估语音数据的质量分数计算整体待评估语音数据的质量分数的整体待评估语音数据质量分数计算单元。
本发明由于采取以上技术方案,其具有以下优点:1、本发明根据采样参数和评估指标计算说话人待评估语音数据的质量分数,并通过说话人特征、预先设定的质量目标计算所有说话人的整体待评估语音数据的质量分数,相对于以往只能通过人工抽查以及使用语音数据后对语音识别设备准确率提升的效果来评估语音数据质量好坏的方法,本发明可以帮助语音识别设备研发企业或机构在事前进行更准确、更高效的语音数据质量评估,还可以帮助语音数据提供商发现语音数据的问题并及时采取优化措施。2、本发明通过获取采样参数、评估指标和说话人特征等各种影响语音识别性能的因素,进而能够保障语音数据质量评估的准确性,可以广泛应用于语音识别技术领域中。
附图说明
图1是本发明的流程示意图。
具体实施方式
以下结合附图来对本发明进行详细的描绘。然而应当理解,附图的提供仅为了更好地理解本发明,它们不应该理解成对本发明的限制。
如图1所示,本发明提供的数据质量的评估方法具体包括以下内容:
1、获取说话人的待评估语音数据
待评估语音数据可以为有意识录制的待评估语音数据,例如:说话人在室内通过手机等设备每人按照事先准备好的句子进行朗读后保存的语音数据,也可以为无意识录制的待评估语音数据,例如:企业客服和说话人通话完成后自动保存的语音数据。
2、获取待评估语音数据的采样参数
采样参数通常由录音设备及存储设置决定,可以通过读取文件属性或文件头获取,采样参数包括采样格式(pcm、wav和mp3等)、采样率(8位或16位)、采样频率(8khz、16khz、44khz和48khz等)和声道数(单声道和立体声)。
3、计算待评估语音数据的评估指标
在说话人录制语音时,由于说话人的原因影响语音数据质量的情况有多种,例如说话人的音量过高或过低、噪音过大、说话人没有录音完整、说话录音不自然等,本发明的数据质量的评估方法针对主要影响语音数据质量的评估指标进行计算,评估指标包括:
截幅比例:待评估语音数据是由一系列连续的采样点构成,每一采样点均代表音量的高低,以16khz、16位的wav待评估语音数据为例,该待评估语音数据的峰值为32768,截幅是指说话人音量超过峰值从而造成削波,通过统计待评估语音数据中超过预先设定截幅阈值(如截幅阈值设定为30000)的采样点数目计算截幅比例:
截幅比例=超过预先设定截幅阈值的采样点数目/采样点总数(1)
低音量比例:通过待评估语音数据中小于预先设定低音阈值的采样点数目计算低音量比例:
低音量比例=小于预先设定低音阈值的采样点数目/采样点总数(2)
前后静音长度:说话人因为操作录音设备的原因容易出现在设备还未开启录制时就抢先说话以及未说完停止录制的情况,因此需要对前后静音长度进行计算。设定从待评估语音数据的开头位置向后平移,检测出连续超过预先设定静音阈值的采样点作为前静音结束位置,则:
前静音长度=前静音结束位置(3)
从待评估语音数据的结束位置向前平移,检测出连续超过预先设定静音阈值的采样点作为后静音开始位置,则:
后静音长度=语音数据长度-后静音开始位置(4)
信噪比:通过现有技术中音频信噪比的计算方法对信噪比snr进行计算:
snr=10lg(ps/pn)(5)
其中,ps为信号有效功率,pn为噪音有效功率。
此外,其他的评估指标可以通过人工进行判断,包括说话人语速是否正常、说话人说话是否自然、说话人的说话内容与原始文本的差异性。
4、计算单条语音数据的质量分数
说话人待评估语音数据中单条待评估语音数据d的质量分数为分别基于采样参数和评估指标进行计算后再进行综合计算,单条语音数据d的质量分数在0~1之间。
基于采样参数的单条语音数据质量分数qp(d)为各个采样参数权重的乘积:
qp(d)=w(采样格式)*w(采样率)*w(采样频率)*w(声道数)(6)
其中,w(采样格式)为采样格式的权重,w(采样率)为采样率的权重,w(采样频率)为采样频率的权重,w(声道数)为声道数的权重,每一采样参数的权重在0~1之间,均可以根据经验值得出,经验值可以根据实际情况进行设置,但需符合以下规则:
采样格式:mp3的权重<pcm的权重=wav的权重;
采样率:8位的权重<16位的权重;
采样频率:8khz的权重<16khz的权重<44khz的权重<48khz的权重;
声道数:单声道的权重<立体声的权重。
基于评估指标的单条语音数据质量分数qe(d)为各个评估指标权重的乘积:
qe(d)=w(截幅比例)*w(低音量比例)*w(前静音长度)*w(后静音长度)*w(信噪比)(7)
其中,w(截幅比例)为截幅比例的权重,w(低音量比例)为低音量比例的权重,w(前静音长度)为前静音长度的权重,w(后静音长度)为后静音长度的权重,w(信噪比)为信噪比的权重,每一评估指标的权重在0~1之间,均可以根据经验值得出,经验值可以根据实际情况进行设置,但需符合以下规则:
截幅比例:截幅比例越大,权重越小;
低音量比例:低音量比例越大,权重越小;
前静音长度:前静音长度大于阈值(通常为0.2~0.5s之间)时,权重最大,否则前静音长度越小,权重越小;
后静音长度:后静音长度大于阈值(通常为0.2~0.5s之间)时,权重最大,否则后静音长度越小,权重越小;
信噪比:信噪比越小,权重越小。
综上,单条语音数据d的质量分数q(d)为:
q(d)=qp(d)*qe(d)(8)
5、计算说话人待评估语音数据的质量分数
说话人待评估语音数据的质量分数q(s)为综合说话人待评估语音数据的所有单条语音数据d的质量分数并求平均值,即:
其中,q(di)为说话人第i条单条语音数据的质量分数,n为说话人所有单条语音数据的数量。
6、重复步骤1~5,计算所有说话人待评估语音数据的质量分数。
7、获取说话人的特征
说话人的特征可以包括说话人年龄、说话人性别、说话人籍贯、录音设备(手机、麦克风等)、录音方式(朗读、自然、电话呼入、电话呼出等)以及录音环境(室内、室外、车载等)。
8、计算整体待评估语音数据的质量分数
1)预先设定质量目标
质量目标通常对待评估语音数据的录音设备、录音方式、录音环境以及不同说话人的年龄比例、性别比例和籍贯比例进行要求,具体质量目标可以根据实际情况进行设定,例如某质量目标为1000名说话人,男女各半,年龄在6~60岁均匀分布,籍贯在全国各省均匀分布,录音设备为手机,录音方式为朗读,录音环境为室内。
2)计算匹配度
对所有说话人按特征为年龄、性别、籍贯、录音设备、录音方式和录音环境分别创建一目标向量和一实际向量,例如性别的目标要求为500男500女,实际语音数据为600男400女,则性别的目标向量为<500,500>,实际向量为<600,400>。
分别计算所有说话人的各特征目标向量和实际向量的相似度,相似度可以通过现有向量相似度计算方法例如夹角余弦法进行计算,即对于目标向量a=<a1,a2,…an>和实际向量b=<b1,b2,…bn>,可以采用夹角余弦的概念衡量两个向量间的相似度cosθ:
上述公式(10)可以进一步表示为:
其中,ak为目标向量a的第k个目标向量,bk为实际向量b的第k个实际向量,n为目标向量a或实际向量b的个数。
根据公式(11)计算所有说话人的各特征相似度,并根据计算的各特征相似度计算整体待评估语音数据与预先设定质量目标的匹配度m:
m=年龄相似度*性别相似度*籍贯相似度*录音设备相似度*录音方式相似度*录音环境相似度(12)
3)计算整体待评估语音数据的质量分数
整体待评估语音数据的质量分数q(all)为所有说话人的待评估语音数据质量分数的平均值乘以整体待评估语音数据与预先设定质量目标的匹配度m,即:
其中,q(si)为第i个说话人待评估语音数据的质量分数,m为说话人的数量。
根据计算的整体待评估语音数据的质量分可以帮助语音识别设备研发企业或机构在使用语音数据前对语音数据进行更准确、更高效的质量评估,还可以帮助语音数据提供商发现语音数据的问题并及时采取优化措施。
基于上述数据质量的评估方法,本发明还提出一种数据质量的评估系统,该评估系统包括待评估语音数据获取单元、待评估语音数据采样参数获取单元、待评估语音数据评估指标计算单元、单条语音数据质量分数计算单元、待评估语音数据质量分数计算单元、特征获取单元以及整体待评估语音数据质量分数计算单元;其中,
待评估语音数据获取单元用于获取说话人的有意识待评估语音数据或无意识待评估语音数据。待评估语音数据采样参数获取单元用于获取说话人待评估语音数据的采样格式、采样率、采样频率和声道数等采样参数,并将获取的采样参数发送到单条语音数据质量分数计算单元。待评估语音数据评估指标计算单元用于计算包括截幅比例、低音量比例、前后静音长度和信噪比等的待评估语音数据评估指标,并将计算的评估指标发送到单条语音数据质量分数计算单元。单条语音数据质量分数计算单元用于根据接收的采样参数和评估指标计算说话人待评估语音数据中所有单条语音数据的质量分数并发送到待评估语音数据质量分数计算单元。待评估语音数据质量分数计算单元用于根据接收的所有单条语音数据的质量分数计算该说话人待评估语音数据的质量分数并发送到整体待评估语音数据质量分数计算单元。特征获取单元用于获取说话人年龄、说话人性别、说话人籍贯、录音设备、录音方式以及录音环境等特征并发送到整体待评估语音数据质量分数计算单元。整体待评估语音数据质量分数计算单元用于根据接收的说话人特征和预先设定的质量目标计算匹配度,并根据匹配度和所有说话人待评估语音数据的质量分数计算整体待评估语音数据的质量分数。
上述各实施例仅用于说明本发明,其中各部件的结构、连接方式和制作工艺等都是可以有所变化的,凡是在本发明技术方案的基础上进行的等同变换和改进,均不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!