一种声音识别方法及装置与流程
本发明涉及声音识别技术,尤其涉及一种声音识别方法及装置。
背景技术:
语音识别的研究工作开始于上世纪50年代,贝尔实验室开发出了第一个可以识别十个英文数字的语音识别系统,开启了语音识别的先河。在目前常用的声音识别的方案中,主要是对人类发出的语音进行识别,识别方法主要是利用基于人工智能技术的语音识别技术,对人类发出的语音进行识别,从而通过语音实现人机交互。
在生活中,除了人类发出的语音之外,还存在着其它形形色色的声音,例如流水声、炒菜声、敲门声等,人们在做完饭菜后可能会忘记关水龙头或油烟机,将造成资源的浪费;或者,玻璃杯或瓷器掉落地上,碎片未及时处理可能会伤到人。因此,亟需一种可以识别非人类声音的技术方案,从而通过识别此类声音可以进行相应的自动控制或提示。
技术实现要素:
针对上述的技术问题,本发明实施例期望提供一种声音识别方法及装置,可以识别除人类语音之外的声音。
本发明的技术方案是这样实现的:
本发明实施例提供一种声音识别方法,所述方法包括:
采集声音信号,确定所述声音信号中各脉冲的保持时间;
基于所述保持时间计算所述声音信号的频率;
将所述声音信号的频率与预设参考频率进行对比,确定所述声音信号的频率与所述预设参考频率之间的相似度,将相似度大于预设阈值且最大的预设参考频率所对应的声音类型确定为采集的声音的类型。
上述方案中,所述将所述声音信号的频率与预设参考频率进行对比之前,所述方法还包括:对所述声音信号的频率进行采样,得到采样频率;
将所述采样频率划分为至少一个频段;
统计所述至少一个频段中各频段内的频率个数,根据所述频率个数计算各频道内的频率占比,所述频率占比为各频段内的频率个数与采样所得的频率总数之间的比值;
所述将所述声音信号的频率与预设参考频率进行对比,确定所述声音信号的频率与所述预设参考频率之间的相似度,包括:
将所述至少一个频段中各频段内的所述频率占比分别与所述预设参考频率的参考占比进行对比,得到占比相似度;
将所述至少一个频段中各频段内的频率分别与所述预设参考频率进行对比,得到频率相似度;
基于所述占比相似度和所述频率相似度获得所述相似度。
上述方案中,所述确定所述声音信号中各脉冲的保持时间,包括:确定所述声音信号中信号强度大于预设强度所对应的时间,基于所述时间获得所述声音信号中各脉冲的保持时间。
上述方案中,所述基于所述保持时间计算所述声音信号的频率,包括:对所述保持时间求倒数,将所计算的结果作为所述声音信号的频率。
上述方案中,所述将所述采样频率划分为至少一个频段,包括:基于频谱识别范围和频谱分辨率将所述采样频率划分为至少一个频段。
本发明实施例还提供了一种声音识别装置,所述装置包括:采集模块,用于采集声音信号;
确定模块,用于确定所述声音信号中各脉冲的保持时间;
第一计算模块,用于基于所述保持时间计算所述声音信号的频率;
对比模块,用于将所述声音信号的频率与预设参考频率进行对比,确定所述声音信号的频率与所述预设参考频率之间的相似度,将相似度大于预设阈值且最大的预设参考频率所对应的声音类型确定为采集的声音的类型。
上述方案中,所述装置还包括:采样模块,用于在对比模块将所述声音信号的频率与预设参考频率进行对比之前,对所述声音信号的频率进行采样,得到采样频率;
划分模块,用于将所述采样频率划分为至少一个频段;
统计模块,用于统计所述至少一个频段中各频段内的频率个数;
第二计算模块,用于根据所述频率个数计算各频道内的频率占比,所述频率占比为各频段内的频率个数与采样所得的频率总数之间的比值;
所述对比模块包括:
第一对比子模块,用于将所述至少一个频段中各频段内的所述频率占比分别与所述预设参考频率的参考占比进行对比,得到占比相似度;
第二对比子模块,用于将所述至少一个频段中各频段内的频率分别与所述预设参考频率进行对比,得到频率相似度;
第三计算模块,用于基于所述占比相似度和所述频率相似度获得所述相似度。
上述方案中,所述确定模块,具体用于确定所述声音信号中信号强度大于预设强度所对应的时间,基于所述时间获得所述声音信号中各脉冲的保持时间。
上述方案中,所述第一计算模块,具体用于对所述保持时间求倒数,将所计算的结果作为所述声音信号的频率。
上述方案中,所述划分模块,具体用于基于频谱识别范围和频谱分辨率将所述采样频率划分为至少一个频段。
本发明实施例提供的声音识别方法及装置,采集声音信号,确定所述声音信号中各脉冲的保持时间;基于所述保持时间计算所述声音信号的频率;将所述声音信号的频率与预设参考频率进行对比,确定所述声音信号的频率与所述预设参考频率之间的相似度,将相似度大于预设阈值且最大的预设参考频率所对应的声音类型确定为采集的声音的类型。可见,本发明实施例通过采集声音信号,计算该信号的脉冲保持时间,从而得到相应的频率,将该频率与标准的频率进行对比,从而分辨出该声音的类型。
此外,将所述声音信号的频率划分多个频段,按频段分别与标准的频率进行对比,降低了计算量。
附图说明
图1为本发明实施例一公开的一种声音识别方法的实现流程示意图;
图2为本发明实施例一公开的一种声音识别装置的组成结构示意图;
图3为本发明实施例二公开的一种声音识别装置的组成结构示意图;
图4为本发明实施例二公开的一种声音识别方法的实现流程示意图;
图5为声音信号的频谱特性随时间的变化示意图;
图6为采集到的声音信号与标准特征声音模型之间的相似度随时间变化的示意图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
实施例一
图1为本发明实施例公开的一种声音识别方法的实现流程示意图,如图1所示,本实施例的声音识别方法包括以下步骤:
步骤101:声音识别装置采集声音信号,确定所述声音信号中各脉冲的保持时间。
这里,所述声音包括但不限于:流水声、炒菜声、敲门声、走路声和玻璃或陶器掉地的声音。
具体地,当发出流水声、炒菜声、敲门声、走路声或玻璃或陶器掉地的声音这些声音中的任一种时,声音识别装置采集到该声音信号,通过该声音信号的脉冲与时间之间的关系,确定所述声音信号中各脉冲的保持时间。这里,所述保持时间为脉冲从形成到结束的时间。声音识别装置在开启后,将一直采集声音信号,当环境中未发出声音时,采集到信号功率为零;当环境中发出声音时,采集到信号功率大于零。因此,采集到的声音信号在某个时间段内值为零,在另外的某个时间的值大于零;在频谱中,若横坐标为时间,纵坐标为功率或能量,声音信号的纵坐标大于零时,说明采集到的信号出现了有用的声音信号。
具体地,确定所述声音信号中各脉冲的保持时间包括:确定所述声音信号中信号强度大于预设强度所对应的时间,基于所述时间获得所述声音信号中各脉冲的保持时间。例如,声音识别装置计算所述声音信号中各脉冲的上升沿和下降沿之间的时间差,将所述时间差确定为所述声音信号中各脉冲的保持时间。
例如,当产生了流水声,声音识别装置采集到流水声音信号,假设该流水声音信号的脉冲有a和b两个,脉冲a的上升沿和下降沿对应的时间分别为t1、t2,脉冲b的上升沿和下降沿对应的时间分别为t3、t4,从而得到脉冲a和脉冲b的保持时间为t2-t1、t4-t3。上述脉冲仅仅是举例,不是穷举,包括但不仅限于a和b两个。
步骤102:声音识别装置基于所述保持时间计算所述声音信号的频率。
具体地,基于所述保持时间计算所述声音信号的频率包括:声音识别装置对所述保持时间求倒数,将所计算的结果作为所述声音信号的频率。
例如,当产生了流水声,声音识别装置采集到流水声音信号,假设该流水声音信号的脉冲有a和b两个,对应的保持时间分别为t2-t1、t4-t3时,将t2-t1、t4-t3分别求倒数,得到1/(t2-t1)、1/(t4-t3),因此,所述声音信号的频率f1=1/(t2-t1)、f2=1/(t4-t3)。
步骤103:声音识别装置将所述声音信号的频率与预设参考频率进行对比,确定所述声音信号的频率与所述预设参考频率之间的相似度,将相似度大于预设阈值且最大的预设参考频率所对应的声音类型确定为采集的声音的类型。
具体地,所述将相似度大于预设阈值且最大的预设参考频率所对应的声音类型确定为采集的声音的类型,包括:从所述相似度中获取大于预设阈值的相似度值,并从获取到的相似度中选取最大的值作为目标相似度,得到与所述目标相似度对应的目标预设参考频率,并将所述目标预设参考频率对应的声音类型确定为采集的声音的类型。
进一步地,在将所述声音信号的频率与预设参考频率进行对比之前,声音识别装置对所述声音信号的频率进行采样,得到采样频率;将所述采样频率划分为至少一个频段;统计所述至少一个频段中各频段内的频率个数,根据所述频率个数计算各频道内的频率占比,所述频率占比为各频段内的频率个数与采样所得的频率总数之间的比值。
进一步地,将将所述采样频率划分为至少一个频段包括:声音识别装置基于频谱识别范围和频谱分辨率将所述采样频率划分为至少一个频段。具体地,并根据频谱识别范围和频谱分辨率进行数学统计,根据统计结果划分频段,假设频谱识别范围为0~6千赫兹(khz),频谱分辨率为1khz,此时,可以将所述采样频率划分为小于或等于6个频段。
例如,在将所述声音信号的频率与预设参考频率进行对比之前,声音识别装置将所述频率存放于数组中,按照一定的采样频率对数组中的频率进行采样,从而获得每个频段所占比例随时间的变化,即频谱随时间的变化。
具体地,所述将所述声音信号的频率与预设参考频率进行对比,确定所述声音信号的频率与所述预设参考频率之间的相似度,包括:声音识别装置将所述至少一个频段中各频段内的所述频率占比分别与所述预设参考频率的参考占比进行对比,得到占比相似度;将所述至少一个频段中各频段内的频率分别与所述预设参考频率进行对比,得到频率相似度;基于所述占比相似度和所述频率相似度获得所述相似度。将声音信号划分频段,降低计算的复杂度。
例如,声音识别装置将所述声音信号的频率与标准特征声音模型的频率进行比对,从而获得所述声音信号的频率与标准特征声音模型的频率的相似度。当相似度大于预先设定的阈值时,则判定所述声音信号与标准特征声音是一致的。当标准特征声音模型为多个时,且相似度大于预先设定阈值的标准特征声音模型数量大于1时,则判定所述声音信号与相似度最高的标准特征声音是一致的。当标准特征声音模型为多个时,且相似度大于预先设定阈值的标准特征声音模型数量为0时,则判定采集到的声音与标准特征声音不一致。
为了便于更好地实施本发明实施例的上述声音识别方法,本发明还提供了用于实现实施上述方法的声音识别装置。
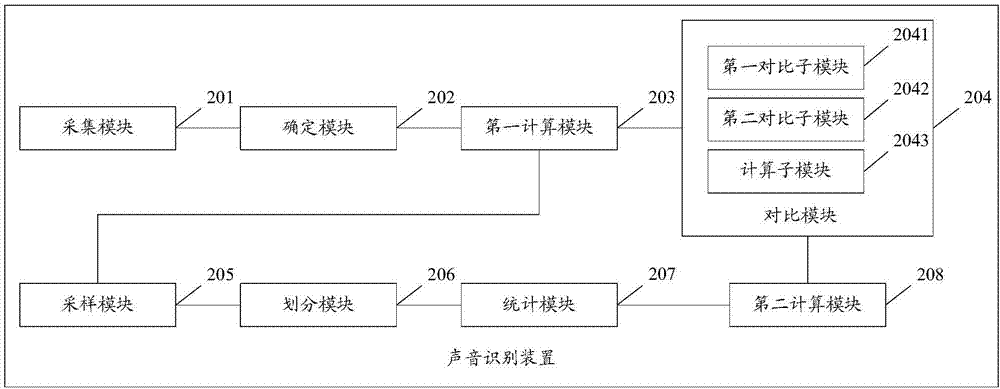
图2为本发明实施例公开的一种声音识别装置的组成结构示意图,如图2所示,本实施例的声音识别装置包括:
采集模块201,用于采集声音信号;
确定模块202,用于确定所述声音信号中各脉冲的保持时间;
第一计算模块203,用于基于所述保持时间计算所述声音信号的频率;
对比模块204,用于将所述声音信号的频率与预设参考频率进行对比,确定所述声音信号的频率与所述预设参考频率之间的相似度,将相似度大于预设阈值且最大的预设参考频率所对应的声音类型确定为采集的声音的类型。
进一步地,所述装置还包括:采样模块205,用于在对比模块将所述声音信号的频率与预设参考频率进行对比之前,对所述声音信号的频率进行采样,得到采样频率;
划分模块206,用于将所述采样频率划分为至少一个频段;
统计模块207,用于统计所述至少一个频段中各频段内的频率个数;
第二计算模块208,用于根据所述频率个数计算各频道内的频率占比,所述频率占比为各频段内的频率个数与采样所得的频率总数之间的比值;
所述对比模块204包括:
第一对比子模块2041,用于将所述至少一个频段中各频段内的所述频率占比分别与所述预设参考频率的参考占比进行对比,得到占比相似度;
第二对比子模块2042,用于将所述至少一个频段中各频段内的频率分别与所述预设参考频率进行对比,得到频率相似度;
计算子模块2043,用于基于所述占比相似度和所述频率相似度获得所述相似度。
进一步地,所述确定模块202,具体用于确定所述声音信号中信号强度大于预设强度所对应的时间,基于所述时间获得所述声音信号中各脉冲的保持时间。
进一步地,所述第一计算模块203,具体用于对所述保持时间求倒数,将所计算的结果作为所述声音信号的频率。
进一步地,所述划分模块206,具体用于基于频谱识别范围和频谱分辨率将所述采样频率划分为至少一个频段。
由上述组成结构示意图组成的声音识别装置,可以执行以下方法和步骤:
(1)采集模块201采集声音信号,确定模块202确定所述声音信号中各脉冲的保持时间。
这里,所述声音包括但不限于:流水声、炒菜声、敲门声、走路声和玻璃或陶器掉地的声音。
具体地,当发出流水声、炒菜声、敲门声、走路声或玻璃或陶器掉地的声音这些声音中的任一种时,采集模块201采集到该声音信号,确定模块202通过该声音信号的脉冲与时间之间的关系,确定所述声音信号中各脉冲的保持时间。这里,所述保持时间为脉冲从形成到结束的时间。声音识别装置在开启后,将一直采集声音信号,当环境中未发出声音时,采集到信号功率为零;当环境中发出声音时,采集到信号功率大于零。因此,采集到的声音信号在某个时间段内值为零,在另外的某个时间的值大于零;在频谱中,若横坐标为时间,纵坐标为功率或能量,声音信号的纵坐标大于零时,说明采集到的信号出现了有用的声音信号。
具体地,确定模块202确定所述声音信号中各脉冲的保持时间包括:确定模块202确定所述声音信号中信号强度大于预设强度所对应的时间,基于所述时间获得所述声音信号中各脉冲的保持时间。例如,确定模块202计算所述声音信号中各脉冲的上升沿和下降沿之间的时间差,将所述时间差确定为所述声音信号中各脉冲的保持时间。
例如,当产生了流水声,采集模块201采集到流水声音信号,假设该流水声音信号的脉冲有a和b两个,脉冲a的上升沿和下降沿对应的时间分别为t1、t2,脉冲b的上升沿和下降沿对应的时间分别为t3、t4,确定模块202通过计算得到脉冲a和脉冲b的保持时间为t2-t1、t4-t3。上述脉冲仅仅是举例,不是穷举,包括但不仅限于a和b两个。
(2)第一计算模块203基于所述保持时间计算所述声音信号的频率。
具体地,基于所述保持时间计算所述声音信号的频率包括:第一计算模块203对所述保持时间求倒数,将所计算的结果作为所述声音信号的频率。
例如,当产生了流水声,声音识别装置采集到流水声音信号,假设该流水声音信号的脉冲有a和b两个,对应的保持时间分别为t2-t1、t4-t3时,第一计算模块203将t2-t1、t4-t3分别求倒数,得到1/(t2-t1)、1/(t4-t3),因此,所述声音信号的频率f1=1/(t2-t1)、f2=1/(t4-t3)。
(3)对比模块204将所述声音信号的频率与预设参考频率进行对比,确定所述声音信号的频率与所述预设参考频率之间的相似度,将相似度大于预设阈值且最大的预设参考频率所对应的声音类型确定为采集的声音的类型。
具体地,对比模块204从所述相似度中获取大于预设阈值的相似度值,并从获取到的相似度中选取最大的值作为目标相似度,得到与所述目标相似度对应的目标预设参考频率,并将所述目标预设参考频率对应的声音类型确定为采集的声音的类型。
进一步地,在将所述声音信号的频率与预设参考频率进行对比之前,采样模块205对所述声音信号的频率进行采样,得到采样频率;划分模块206将所述采样频率划分为至少一个频段;统计模块207统计所述至少一个频段中各频段内的频率个数,第二计算模块208根据所述频率个数计算各频道内的频率占比,所述频率占比为各频段内的频率个数与采样所得的频率总数之间的比值。
进一步地,划分模块206将将所述采样频率划分为至少一个频段包括:划分模块206基于频谱识别范围和频谱分辨率将所述采样频率划分为至少一个频段。具体地,并根据频谱识别范围和频谱分辨率进行数学统计,根据统计结果划分频段,假设频谱识别范围为0~6khz,频谱分辨率为1khz,此时,可以将所述采样频率划分为小于或等于6个频段。
例如,在将所述声音信号的频率与预设参考频率进行对比之前,声音识别装置将所述频率存放于数组中,按照一定的采样频率对数组中的频率进行采样,从而获得每个频段所占比例随时间的变化,即频谱随时间的变化。
具体地,对比模块204将所述声音信号的频率与预设参考频率进行对比,确定所述声音信号的频率与所述预设参考频率之间的相似度,包括:第一对比子模块2041将所述至少一个频段中各频段内的所述频率占比分别与所述预设参考频率的参考占比进行对比,得到占比相似度;第二对比子模块2042将所述至少一个频段中各频段内的频率分别与所述预设参考频率进行对比,得到频率相似度;计算子模块2043基于所述占比相似度和所述频率相似度获得所述相似度。将声音信号划分频段,降低计算的复杂度。
例如,对比模块204将所述声音信号的频率与标准特征声音模型的频率进行比对,从而获得所述声音信号的频率与标准特征声音模型的频率的相似度。当相似度大于预先设定的阈值时,则判定所述声音信号与标准特征声音是一致的。当标准特征声音模型为多个时,且相似度大于预先设定阈值的标准特征声音模型数量大于1时,则判定所述声音信号与相似度最高的标准特征声音是一致的。当标准特征声音模型为多个时,且相似度大于预先设定阈值的标准特征声音模型数量为0时,则判定采集到的声音与标准特征声音不一致。
通过本发明实施例方案,可以通过采集声音信号,计算该信号的脉冲保持时间,从而得到相应的频率,将该频率与标准的频率进行对比,从而分辨出该声音的类型。将所述声音信号的频率划分多个频段,按频段分别与标准的频率进行对比,降低了计算量。
实施例二
图3为本发明实施例二公开的一种声音识别装置的组成结构示意图,如图3所示,本实施例的声音识别装置包括:
麦克风301,用于信号处理的滤波电路,用于小信号放大的放大电路和信号处理芯片。
滤波电路302,用于信号处理,将采集到的声音信号传送到滤波电路中进行降噪处理。
放大电路303,用于将经过降噪处理的声音信号进行功率放大,降低信号检测的难度,提高信号检测的准确性。
信号处理芯片304,用于对信号进行处理。
存储器305,用于存储信号处理芯片中的软件算法、存储声音识别方法的指令,其中,软件算法包括:测量频率的软件算法、生成频谱的软件算法和特征声音识别的软件算法。
测量频率的软件算法通过信号处理芯片对声音信号进行采样,计算每一个脉冲的保持时间,再将其转化为频率信息;
生成频谱的软件算法是指将一定数量脉冲中的每一个脉冲的频率依采集顺序保存在一个数组内,并根据频谱识别范围a和频谱分辨率b进行数学统计,从而获得每个频段ai所占比例。从而实现了将声音信号从时域转化到频域的功能。按照一定的采样频率对频段ai进行采样,从而获得每个频段所占比例随时间的变化,即频谱随时间的变化。
特征声音识别的软件算法是指将采集到的包含一定数量脉冲的声音信号的频谱与标准特征声音模型的频谱进行比对,从而获得采集到的声音信号的频谱与标准特征声音模型的频谱的相似度。当相似度大于预先设定的阈值时,则判定采集到的声音与标准特征声音是一致的。当标准特征声音模型为多个时,且相似度大于预先设定阈值的标准特征声音模型数量大于1时,则判定采集到的声音与相似度最高的标准特征声音是一致的。当标准特征声音模型为多个时,且相似度大于预先设定阈值的标准特征声音模型数量为0时,则判定采集到的声音与标准特征声音不一致。
图4为本发明实施例二公开的一种声音识别方法的实现流程示意图,如图4所示,本实施例的声音识别方法包括以下步骤:
假设选取脉冲信号数量为300,频谱识别范围a为0~6khz范围,频谱分辨率b为1khz,频谱采样率为1hz。
步骤401:采集声音信号并进行信号滤波。
麦克风301收集到声音信号,并将该信号通过总线或其它方式传输至的滤波电路302。该滤波电路302设计为低通滤波器,截止频率为6khz,使得声音信号中大于6khz频率部分被衰减。
由于滤波电路302在滤波的同时对声音信号也有衰减作用,使得声音信号的振幅减小。因此,需要对滤波后的声音信号进行放大。
步骤402:将声音信号振幅放大至电源电压的一半。
放大电路303将声音信号的振幅放大至大于电源电压的一半,再将信号传输至信号处理芯片304。
步骤403:计算每个脉冲信号的频率。
信号处理芯片304利用存储在存储器305中的频率测量算法计算脉冲信号上升沿和下降沿的时间差t,从而得到脉冲信号的频率f=1/t。
步骤404:统计一定数量脉冲信号的频谱特性。
已知统计300个脉冲信号的频率分布,即每采集到300个脉冲信号生成一次频谱信息,信号处理芯片304按照1hz的采样频率对频谱信息进行采样,从而获得如图5所示的声音信号频谱随时间的变化过程。
步骤405:将采样频率与标准特征声音模型比较得到相似度。
信号处理芯片304将每一个采样频率与标准特征声音模型进行比对得到如图6所示的相似度随时间的变化曲线。图6中虚线为预先设定的阈值,当相似度大于阈值时,判定声音信号与标准特征声音模型一致;当相似度小于阈值时,判定声音信号与标准特征声音模型不一致,从而识别出该声音信号对应的声音类型。例如,检测的声音信号频率与标准特征声音模型中的流水声之间的频率相似度大于所述阈值时,表示该声音与流水声一致,即该声音为流水声。
实际应用中,采集模块201、确定模块202、第一计算模块203、对比模块204(包括:第一对比子模块2041、第二对比子模块2042和计算子模块2043)、采样模块205、划分模块206、统计模块207和第二计算模块208均可由位于声音识别装置中的(cpu,centralprocessingunit)、微处理器(mpu,microprocessorunit)、数字信号处理器(dsp,digitalsignalprocessor)、或现场可编程门阵列(fpga,field-programmablegatearray)等实现。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和范围之内所作的任何修改、等同替换和改进等,均包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!