子带谱减与广义旁瓣抵消的双微阵列语音增强方法与流程
本发明涉及语音信号处理领域,具体涉及一种子带谱减与广义旁瓣抵消的双微阵列语音增强方法。
背景技术:
众所周知,各种各样的噪声存在严重影响了语音质量及语音识别系统的识别率,过大的干扰噪声甚至会影响到语音的可懂度。为了抑制噪声的影响提高语音可懂度,噪声消除技术在现代语音通信系统中是至关重要的一个功能。在语音通信系统中噪声消除技术可分为两大类:其一为单通道语音增强,其二为多通道语音增强。
在单通道语音增强方法中,谱减法是最常用的方法之一,谱减法通过从含噪语音功率谱中估计噪声功率谱以获得纯净语音功率谱。
由于传统谱减法的过减因子是固定值以及含噪语音信号的频率特征,导致语音失真或者噪声不能足够的消除。
多通道语音增强可以利用时域与频域信息,而且基于空间信息能够抑制其他方向的噪声干扰的特性利用到了空域信息。广义旁瓣抵消(generalizedsidelobecanceller,gsc)在较好抑制强相关噪声的同时也能适当地抑制弱相关性噪声,但是对弱相关性噪声的抑制能力有限。
针对这个问题,各种基于相干滤波(coherencefiltering,cf)的二元麦克风语音增强方法被提出。这些方法通过在两个麦克风之间使用相干滤波抑制非相干噪声并且能有效地消除音乐噪声,但在现实环境中既存在非相干或弱相干噪声,也存在强相关噪声。
技术实现要素:
针对现有技术的不足,本发明所解决的技术问题是如何进一步提高噪声抑制性能、减少语音失真及进一步抑制强相关性噪声的影响。
为解决上述技术问题,本发明采用的技术方案是一种子带谱减与广义旁瓣抵消的双微阵列语音增强方法,对含噪语音的不同频带使用不同的谱减算法消噪,初步消噪后结合广义旁瓣抵消及端点检测的方法抑制强相关性噪声,包括如下步骤:
(1)基于kemar人工头构建双微阵列模型。在kemar人工头的左耳与右耳分别固定一个麦克风数量为2且麦克风之间的距离为2cm的微型阵。
麦克风接收到的含噪语音信号模型为语音信号叠加背景噪声
yi(n)=si(n)+vi(n)i=12lm
y(n)表示含噪语音信号;s(n)表示纯净语音信号;v(n)表示背景噪声;m为麦克风数量。
上式的短时傅里叶变换为
yi(u,w)=si(u,w)+vi(u,w)i=12lm
u表示帧数;w表示离散频域。
(2)先将每个麦克风接收到的含噪语音信号分成不同的频带,即低频带与高频带,截止频率为fc=c/(2d),其中c为声速,d为微型阵之间的距离。使用127阶的有限长单位冲激响应低通滤波器来获得低频带含噪语音信号,低通滤波器的截止频率为;使用相同阶次与截止频率的有限长单位冲激响应高通滤波器来获得高频带含噪语音信号。
(3)根据后验信噪比获得可变过减因子的值:
αmin表示过减因子的最小值,其值在[0,1]之间;αmax表示过减因子的最大值,其值大于1;γ(u,w)表示后验信噪比;σ是一个正整数用来控制噪声消除;η用来避免当γ(u,w)接近或等于0时过减因子过大。
上式中,
snrth是一个常量。
过减因子的值依赖于后验信噪比。后验信噪比表达式为:
(4)在低频带采用可变过减因子谱减,抑制噪声的影响:
p为指数,当p=1时采用的是幅度谱谱减,当p=2时采用的是功率谱谱减;α(u,w)为过减因子;β为增益补偿因子以避免减法处理后语音估计值的幅度谱或者功率谱出现负值。
(5)根据前一帧的互功率谱谱减的相干滤波传递函数更新估计互功率谱与自功率谱的平滑因子:λ(u,w)=0.98-0.3h(u-1,w),其中h(u,w)为互功率谱谱减的相干滤波传递函数。
(6)根据平滑因子更新互功率谱与自功率谱
*表示共轭;λ(u,w)表示平滑因子。
(7)使用过高估计噪声自功率谱替代噪声互功率谱,即:
上式中,
g=1/(1-h)且0<l<1;
(8)在高频带使用修改后的互功率谱谱减,根据互功率谱谱减获得相干滤波的传递函数:
(9)通过低频带谱减与高频带互功率谱谱减抑制噪声后重构,形成全带语音信号:
yi,sss(n)=yi,ss(n)+yi,mcss(n)
(10)利用子带谱减后产生的增强语音通过固定波束形成产生语音期望信号:
ysss(n)=[y1,sss(n),y2,sss(n),y3,sss(n),y4,sss(n)]
d(n)表示期望语音信号;wf表示固定波束形成加权权值,其权值模都为1/m,ti1为时延,采用广义互相关法获得。
(11)利用子带谱减后产生的增强语音通过阻塞矩阵产生参考噪声:
u(n)=ysss(n)bt。
b为阻塞矩阵且b为3×4维矩阵。阻塞矩阵满足约束条件b1=0。
(12)利用参考噪声采用归一化最小均方算法获得噪声估计值且配合端点检测算法仅在噪声段更新滤波器系数:
ve(n)=u(n)wt(n)
w(n)=[w1(n),w2(n),w3(n)],表示滤波器权值系数,其权值系数仅在非语音段更新滤波器权值系数;在语音段时则不更新滤波器的权值系数:
w(n+1)=w(n)+2δygsc(n)u(n)
(13)根据噪声估计值抵消语音期望信号的残留部分噪声:
ygsc(n)=d(n)-ve(n)。
附图说明
图1为基于kemar人工头的双微麦克风阵列模型;
图2为子带谱减原理框图;
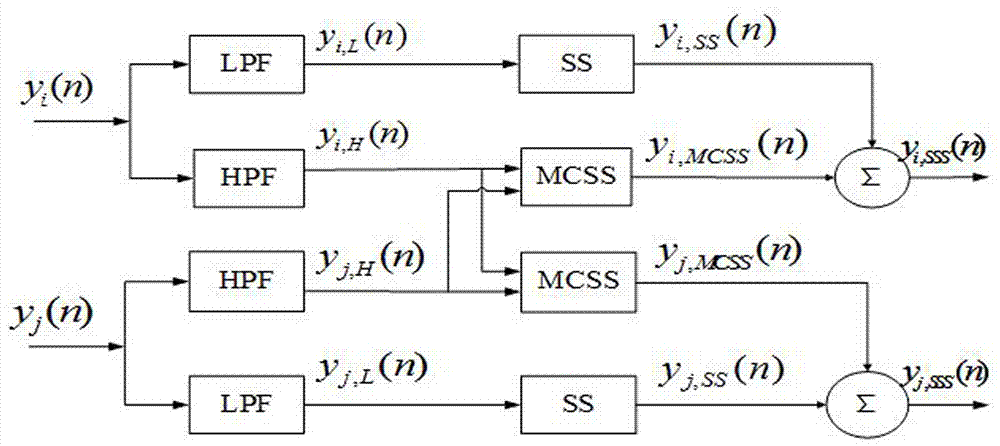
图3为子带谱减与广义旁瓣抵消原理框图;
图4为本发明流程图。
具体实施方式
下面结合附图和实施例对本发明的具体实施方式作进一步的说明,但不是对本发明的限定。
图1示出了基于kemar人工头的双微麦克风阵列模型,m1与m2构成一个微型阵列且固定kemar人工头的左耳处,m1与m2之间距离为2cm;m3与m4构成一个微型阵列且固定在kemar人工头的右耳处,m3与m4之间距离为2cm。两个微型阵之间相距大约为16cm;
图2示出了子带谱减原理框图,通过有限长单位冲激响应低通滤波器与高通滤波器获得低频带含噪语音与高频带含噪语音;在低频带采用可变过减因子谱减抑制噪声,在高频带采用修改的互功率谱谱减抑制非相干噪声;最后重构成全带语音;
图3示出了子带谱减与广义旁瓣抵消原理框图,在通过子带谱减后采用广义旁瓣抵消结合端点检测进一步抑制相关性噪声;
图4示出了本发明的流程,一种子带谱减与广义旁瓣抵消的双微阵列语音增强方法,对含噪语音的不同频带使用不同的谱减算法消噪,初步消噪后结合广义旁瓣抵消及端点检测的方法进一步抑制强相关性噪声,包括如下步骤:
(1)基于kemar人工头构建双微阵列模型。在kemar人工头的左耳与右耳分别固定一个麦克风数量为2且麦克风之间的距离为2cm的微型阵。
麦克风接收到的含噪语音信号模型为语音信号叠加背景噪声
yi(n)=si(n)+vi(n)i=12lm
y(n)表示含噪语音信号;s(n)表示纯净语音信号;v(n)表示背景噪声;m为麦克风数量。
上式的短时傅里叶变换为
yi(u,w)=si(u,w)+vi(u,w)i=12lm
u表示帧数;w表示离散频域。
(2)先将每个麦克风接收到的含噪语音信号分成不同的频带,即低频带与高频带,截止频率为fc=c/(2d),其中c为声速,d为微型阵之间的距离。使用127阶的有限长单位冲激响应低通滤波器来获得低频带含噪语音信号,低通滤波器的截止频率为;使用相同阶次与截止频率的有限长单位冲激响应高通滤波器来获得高频带含噪语音信号。
(3)根据后验信噪比获得可变过减因子的值:
αmin表示过减因子的最小值,其值在[0,1]之间;amax表示过减因子的最大值,其值大于1;γ(u,w)表示后验信噪比;σ是一个正整数用来控制噪声消除;η用来避免当γ(u,w)接近或等于0时过减因子过大。
上式中,
snrth是一个常量。
过减因子的值依赖于后验信噪比。后验信噪比表达式为:
(4)在低频带采用可变过减因子谱减,抑制噪声的影响:
p为指数,当p=1时采用的是幅度谱谱减,当p=2时采用的是功率谱谱减;α(u,w)为过减因子;β为增益补偿因子以避免减法处理后语音估计值的幅度谱或者功率谱出现负值。
(5)根据前一帧的互功率谱谱减的相干滤波传递函数更新估计互功率谱与自功率谱的平滑因子:λ(u,w)=0.98-0.3h(u-1,w),其中h(u,w)为互功率谱谱减的相干滤波传递函数。
(6)根据平滑因子更新互功率谱与自功率谱
*表示共轭;λ(u,w)表示平滑因子。
(7)使用过高估计噪声自功率谱替代噪声互功率谱,即:
上式中,
g=1/(1-h)且0<l<1;
(8)在高频带使用修改后的互功率谱谱减,根据互功率谱谱减获得相干滤波的传递函数:
(9)通过低频带谱减与高频带互功率谱谱减抑制噪声后重构,形成全带语音信号:
yi,sss(n)=yi,ss(n)+yi,mcss(n)
(10)利用子带谱减后产生的增强语音通过固定波束形成产生语音期望信号:
ysss(n)=[y1,sss(n),y2,sss(n),y3,sss(n),y4,sss(n)]
d(n)表示期望语音信号;wf表示固定波束形成加权权值,其权值模都为1/m,ti1为时延,采用广义互相关法获得
(11)利用子带谱减后产生的增强语音通过阻塞矩阵产生参考噪声:
u(n)=ysss(n)bt。
b为阻塞矩阵且b为3×4维矩阵。阻塞矩阵满足约束条件b1=0。
(12)利用参考噪声采用归一化最小均方算法获得噪声估计值且配合端点检测算法仅在噪声段更新滤波器系数:
ve(n)=u(n)wt(n)
w(n)=[w1(n),w2(n),w3(n)],表示滤波器权值系数,其权值系数仅在非语音段更新滤波器权值系数;在语音段时则不更新滤波器的权值系数:
w(n+1)=w(n)+2δygsc(n)u(n)
(13)根据噪声估计值抵消语音期望信号的残留部分噪声:
ygsc(n)=d(n)-ve(n)。
以上结合附图对本发明的实施方式做出了详细说明,但本发明不局限于所描述的实施方式。对于本领域技术人员而言,在不脱离本发明的原理和精神的情况下,对这些实施方式进行各种变化、修改、替换和变型仍落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!