一种实现音频处理的方法及装置与流程
本文涉及但不限于多媒体应用技术,尤指一种实现音频处理的方法及装置。
背景技术:
早期教育,广义指从人出生到小学以前阶段的教育,狭义主要指上述阶段的早期学习。
目前,针对早期教育的产品较少;其中,公开号为cn200420022023.4的专利公开了一种多功能婴儿监护和教学机,包括:利用语音识别技术,识别出婴儿的情绪;利用无线收发功能,实现远程婴儿睡眠监控;利用定时器,实现定时语音教学和音乐教育。公开号为cn104635574a的专利公开了一种面向幼儿的早教陪护机器人系统,包括:根据用户年龄和已有用户数据来推送适用的教学资源,同时为了保证内容的丰富性,服务器定时推送最新应用及资源,方便用户自主选择下载。
上述早期教育的产品根据对婴幼儿的情绪或年龄等进行确定后,推送已存的早教内容,一定程度上可以达到早期教育的目的;但上述产品推送的早教内容有时不能吸引婴幼儿的关注,可能影响用户的使用体验。
技术实现要素:
以下是对本文详细描述的主题的概述。本概述并非是为了限制权利要求的保护范围。
本发明实施例提供一种实现音频处理的方法及装置,能够提升用户的使用体验。
本发明实施例提供了一种实现音频处理的方法,包括:
根据婴幼儿的声波信号,确定对早教内容进行音频播放的语音信号;
在婴幼儿处于清醒活动状态时,根据确定的语音信号进行早教内容的音频播放。
可选的,所述根据确定的语音信号进行早教内容的音频播放之前,该方法还包括:
根据预设的摄像头获取实时图像信息,以确定婴幼儿是否睁开眼睛;通过预设的音频传感器获取实时音频信息,以确定婴幼儿是否哭闹;
确定婴幼儿睁开眼睛且未哭闹时,确定婴幼儿处于所述清醒活动状态。
可选的,所述确定对早教内容进行音频播放的语音信号包括:
采用原始音频波形深度生成模型对所述声波信号进行处理,生成所述对早教内容进行音频播放的语音信号;或,
获取所述声波信号的特征参数,根据获取的所述特征参数合成所述对早教内容进行音频播放的语音信号;或,
根据所述声波信号,从预设的音频数据库中根据相似性度量匹配并选择出所述对早教内容进行音频播放的语音信号。
可选的,所述特征参数包括以下部分或全部参数:
音量强度曲线、基频轨迹、梅尔倒谱参数。
可选的,所述预设的音频数据库包括:
存储有与所述婴幼儿年龄在预设时间差值内、体重在预设重量差值内、性别相同、和/或第一语言相同的语音信号的数据库。
可选的,所述根据确定的语音信号进行早教内容的音频播放包括:
所述早教内容为文本文件时,将文本文件根据所述确定的语音信号转换为音频文件后播放;
所述早教内容为音频文件时,将音频文件中的原始语音信号替换为所述确定的语音信号后播放。
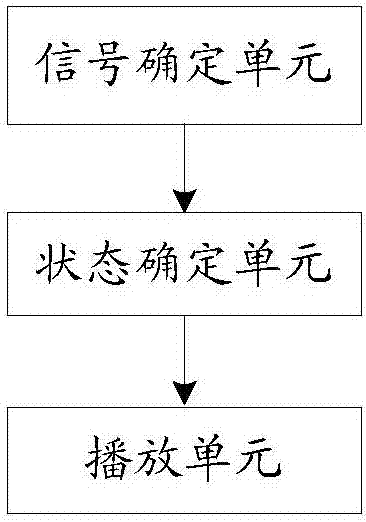
另一方面,本发明实施例还提供一种实现音频处理的装置,包括:信号确定单元和播放单元;其中,
信号确定单元用于:根据婴幼儿的声波信号,确定对早教内容进行音频播放的语音信号;
播放单元用于:在婴幼儿处于清醒活动状态时,根据确定的语音信号进行早教内容的音频播放。
可选的,所述装置还包括状态确定单元,用于:
根据预设的摄像头获取实时图像信息,以确定婴幼儿是否睁开眼睛;通过预设的音频传感器获取实时音频信息,以确定婴幼儿是否哭闹;
确定婴幼儿睁开眼睛且未哭闹时,确定婴幼儿处于所述清醒活动状态。
可选的,所述信号确定单元具体用于:
采用原始音频波形深度生成模型对所述声波信号进行处理,生成所述对早教内容进行音频播放的语音信号;或,
获取所述声波信号的特征参数,根据获取的所述特征参数合成所述对早教内容进行音频播放的语音信号;或,
根据所述声波信号,从预设的音频数据库中根据相似性度量匹配并选择出所述对早教内容进行音频播放的语音信号。
可选的,所述播放单元具体用于:在婴幼儿处于清醒活动状态时,
如果所述早教内容为文本文件,将文本文件根据所述确定的语音信号转换为音频文件后播放;
如果所述早教内容为音频文件,将音频文件中的原始语音信号替换为所述确定的语音信号后播放。
与相关技术相比,本申请技术方案包括:根据婴幼儿的声波信号,确定对早教内容进行音频播放的语音信号;在婴幼儿处于清醒活动状态时,根据确定的语音信号进行早教内容的音频播放。本发明实施例根据婴幼儿的声波信号确定对早教内容进行音频播放的语音信号,提高了婴幼儿对早教内容的兴趣,提升了早期教育的效果和用户使用体验。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图说明
附图用来提供对本发明技术方案的进一步理解,并且构成说明书的一部分,与本申请的实施例一起用于解释本发明的技术方案,并不构成对本发明技术方案的限制。
图1为本发明实施例实现音频处理的方法的流程图;
图2为本发明实施例实现音频处理的装置的结构框图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下文中将结合附图对本发明的实施例进行详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互任意组合。
在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行。并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
图1为本发明实施例实现音频处理的方法的流程图,如图1所示,包括:
步骤100、根据婴幼儿的声波信号,确定对早教内容进行音频播放的语音信号;
需要说明的是,本发明实施例步骤100之前可以包括获取婴幼儿的声波信号,获取方法可以是相关技术中已有的方法,声波信号可以在婴幼儿成长过程中,根据其发音状况进行更新,即用户发现婴幼儿的发音发生变化时,就可以进行声波信号的重新获取。
步骤101、在婴幼儿处于清醒活动状态时,根据确定的语音信号进行早教内容的音频播放。
可选的,所述根据确定的语音信号进行早教内容的音频播放之前,本发明实施例方法还包括:
根据预设的摄像头获取实时图像信息,以确定婴幼儿是否睁开眼睛;通过预设的音频传感器获取实时音频信息,以确定婴幼儿是否哭闹;
确定婴幼儿睁开眼睛且未哭闹时,确定婴幼儿处于所述清醒活动状态。
需要说明的是,是否睁开眼睛可以通过对获取的图像采用相关技术中已有的方法进行特征分析后确定;是否哭闹可以通过相关技术中已有的实现方法对音频信号进行频率分析后确定。
可选的,所述确定对早教内容进行音频播放的语音信号包括:
方法一:采用原始音频波形深度生成模型对所述声波信号进行处理,生成所述对早教内容进行音频播放的语音信号;
需要说明的是,原始音频波形深度生成模型包括:波形网络(wavenet)深度学习算法中的模型,wavenet深度学习算法为相关技术中已有的实现方法,在此不做赘述。
方法二:获取所述声波信号的特征参数,根据获取的所述特征参数合成所述对早教内容进行音频播放的语音信号;
需要说明的是,根据获取的所述特征参数合成所述对早教内容进行音频播放的语音信号可以是相关技术中已有的算法。
方法三:根据所述声波信号,从预设的音频数据库中根据相似性度量匹配并选择出所述对早教内容进行音频播放的语音信号。
需要说明的是,基于相似性度量从预设的音频数据库中匹配选择所述对早教内容进行音频播放的语音信号可以包括:基于音量强度曲线、基频轨迹、和/或梅尔倒谱参数将声波信号与音频数据库中的语音信号进行相似性度量,根据相似性度量确定最接近与声波信号最接近的语音信号。相似性度量的方法为相关技术中已有的实现方法,在此不再赘述。
可选的,所述特征参数包括以下部分或全部参数:音量强度曲线、基频轨迹、梅尔倒谱参数。
可选的,所述预设的音频数据库包括:存储有与所述婴幼儿年龄在预设时间差值内、体重在预设重量差值内、性别相同、和/或第一语言相同的语音信号的数据库。
需要说明的是,本发明实施例预设的音频数据库也可以采用其他参数进行设定,例如、在存储数据时,添加区域信息,是否添加辅食信息,休息时间信息等。
可选的,所述根据确定的语音信号进行早教内容的音频播放包括:早教内容为文本文件时,将文本文件根据所述确定的语音信号转换为音频文件后播放;早教内容为音频文件时,将音频文件中的原始语音信号替换为所述确定的语音信号后播放。
需要说明的是,音频文件包括朗诵诗词、拼音、词语的没有伴音的音频文件;还包括具有伴音的朗诵或歌曲等音频文件。将音频文件中的原始语音信号替换为确定的语音信号的方法可以是相关技术中已有的实现方法,在此不做赘述。
可选的,本发明实施例还可以对婴幼儿的活动状态进行录制,以实现监护管理;还可以采集婴幼儿早教内容,以进行更新改进。
与相关技术相比,本申请技术方案包括:根据婴幼儿的声波信号,确定对早教内容进行音频播放的语音信号;在婴幼儿处于清醒活动状态时,根据确定的语音信号进行早教内容的音频播放。本发明实施例根据婴幼儿的声波信号确定对早教内容进行音频播放的语音信号,提高了婴幼儿对早教内容的兴趣,提升了早期教育的效果和用户使用体验。
图2为本发明实施例实现音频处理的装置的结构框图,如图2所示,包括:信号确定单元和播放单元;其中,
信号确定单元用于:根据婴幼儿的声波信号,确定对早教内容进行音频播放的语音信号;
需要说明的是,本发明实施例还可以包括用于获取婴幼儿声波信号的获取单元,获取方法可以是相关技术中已有的方法,声波信号可以在婴幼儿成长过程中,根据其发音状况进行更新,即用户发现婴幼儿的发音发生变化时,就可以进行声波信号的重新获取。
播放单元用于:在婴幼儿处于清醒活动状态时,根据确定的语音信号进行早教内容的音频播放。
需要说明的是,本发明实施例装置可以是早教机,陪护机等婴幼儿早教期间使用的设备,也可以设置在现有的早教设备中。另外,本发明实施例装置可以设置于摇篮、婴幼儿推车等位置。
可选的,所述装置还包括状态确定单元,用于:
根据预设的摄像头获取实时图像信息,以确定婴幼儿是否睁开眼睛;通过预设的音频传感器获取实时音频信息,以确定婴幼儿是否哭闹;
确定婴幼儿睁开眼睛且未哭闹时,确定婴幼儿处于所述清醒活动状态。
需要说明的是,是否睁开眼睛可以通过对获取的图像采用相关技术中已有的方法进行特征分析后确定;是否哭闹可以通过相关技术中已有的实现方法对音频信号进行频率分析后确定。
可选的,所述信号确定单元具体用于:
采用原始音频波形深度生成模型对所述声波信号进行处理,生成所述对早教内容进行音频播放的语音信号;或,
获取所述声波信号的特征参数,根据获取的所述特征参数合成所述对早教内容进行音频播放的语音信号;或,
根据所述声波信号,从预设的音频数据库中根据相似性度量匹配并选择出所述对早教内容进行音频播放的语音信号。
需要说明的是,原始音频波形深度生成模型包括:波形网络(wavenet)深度学习算法中的模型,wavenet深度学习算法为相关技术中已有的实现方法,在此不做赘述。根据获取的所述特征参数合成所述对早教内容进行音频播放的语音信号可以是相关技术中已有的算法。基于相似性度量从预设的音频数据库中匹配选择所述对早教内容进行音频播放的语音信号可以包括:基于音量强度曲线、基频轨迹、和/或梅尔倒谱参数将声波信号与音频数据库中的语音信号进行相似性度量,根据相似性度量确定最接近与声波信号最接近的语音信号。相似性度量的方法为相关技术中已有的实现方法,在此不再赘述。
可选的,本发明实施例特征参数包括以下部分或全部参数:
音量强度曲线、基频轨迹、梅尔倒谱参数。
可选的,本发明实施例预设的音频数据库包括:
存储有与所述婴幼儿年龄、性别、体重、和/或第一语言相同的语音信号的数据库。
需要说明的是,本发明实施例预设的音频数据库也可以采用其他参数进行设定,例如、在存储数据时,添加区域信息,是否添加辅食信息,休息时间信息等。
可选的,所述播放单元具体用于:在婴幼儿处于清醒活动状态时,
如果所述早教内容为文本文件,将文本文件根据所述确定的语音信号转换为音频文件后播放;
如果所述早教内容为音频文件,将音频文件中的原始语音信号替换为所述确定的语音信号后播放。
与相关技术相比,本申请技术方案包括:根据婴幼儿的声波信号,确定对早教内容进行音频播放的语音信号;在婴幼儿处于清醒活动状态时,根据确定的语音信号进行早教内容的音频播放。本发明实施例根据婴幼儿的声波信号确定对早教内容进行音频播放的语音信号,提高了婴幼儿对早教内容的兴趣,提升了早期教育的效果和用户使用体验。
本领域普通技术人员可以理解上述方法中的全部或部分步骤可通过程序来指令相关硬件(例如处理器)完成,所述程序可以存储于计算机可读存储介质中,如只读存储器、磁盘或光盘等。可选地,上述实施例的全部或部分步骤也可以使用一个或多个集成电路来实现。相应地,上述实施例中的每个模块/单元可以采用硬件的形式实现,例如通过集成电路来实现其相应功能,也可以采用软件功能模块的形式实现,例如通过处理器执行存储于存储器中的程序/指令来实现其相应功能。本发明不限制于任何特定形式的硬件和软件的结合。
虽然本发明所揭露的实施方式如上,但所述的内容仅为便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!