机器人交互方法及系统与流程
本发明实施例涉及机器人技术领域,尤其涉及一种机器人交互方法及系统。
背景技术:
机器人(robot)是自动执行工作的机器系统。它既可以接受人类指挥,又可以运行预先编排的程序,也可以根据以人工智能技术制定的原则纲领行动,用于协助或取代人类工作。
目前,随着科学技术的快速发展,机器人可以语音识别,也可以面部识别,因此机器人能够实现与人类的正常交互与行为互动。我们的母语为汉语,正如英文对于我们的陌生程度一样,用户的语言对于机器人也很陌生。例如,我们和外国人沟通时,先要把外国人的英语翻译成汉语,了解外国人的意思后,再将应答的信息用汉语整理出来,将整理的汉语翻译成英文进行应答。机器人与用户的沟通亦是如此。
当机器人听到用户的语音信息后,将语音信息转换成文字,通过文字搜索匹配应答文字信息,再将应答文字信息转换成语音信息进行应答,这样繁琐的应答过程导致机器人的应答速度过慢。
技术实现要素:
本发明实施例提供一种机器人交互方法及系统,能够改善现有技术中机器人应答速度慢的问题。
第一方面,本发明实施例提供了一种机器人交互方法,包括:
获取用户的第一语音波形图;
根据所述第一语音波形图所对应的第一应答信息作为目标应答信息进行答复。
进一步的,所述获取用户的第一语音波形图包括:
接收所述用户的第一语音信息;
将所述第一语音信息转换为所述第一语音波形数据,并将所述第一语音波形数据转换为所述第一语音波形图。
进一步的,在所述获取用户的第一语音波形图之前,还包括:
设定预设次数阈值;
于获取所述第一语音波形图的次数达到所述预设次数阈值时,建立所述第一应答信息与所述第一语音波形图的匹配关系。
进一步的,还包括:
根据声纹特征,将所述声纹特征相同的语音信息与语音波形图存储至同一声纹信息库;
获取所述用户的第二语音波形图与第二语音信息;
对用户的第二语音信息进行声纹特征识别,并匹配出相对应的声纹信息库;
基于所述声纹信息库,获取与所述第二语音波形图相对应的第二应答信息作为目标应答信息进行答复。
进一步的,所述语音波形图包括波形、频率与振幅;
设定第一误差范围和第二误差范围;
于同一波形条件下,将同时处于第一误差范围内的频率与第二误差范围内的振幅的语音波形图设定为同一语音波形图。
第二方面,本发明实施例还提供了一种机器人交互系统,包括:
第一语音波形图获取模块,用于获取用户的第一语音波形图;
第一答复模块,用于根据所述第一语音波形图所对应的第一应答信息作为目标应答信息进行答复。
进一步的,所述第一语音波形图获取模块具体用于:
接收所述用户的第一语音信息;
将所述第一语音信息转换为所述第一语音波形数据,并将所述第一语音波形数据转换为所述第一语音波形图。
进一步的,还包括:
阈值设定模块,用于在所述获取用户的第一语音波形图之前,设定预设次数阈值;于获取所述第一语音波形图的次数达到所述预设次数阈值时,建立所述第一应答信息与所述第一语音波形图的匹配关系。
进一步的,还包括:
第二答复模块,用于根据声纹特征,将所述声纹特征相同的语音信息与语音波形图存储至同一声纹信息库;获取所述用户的第二语音波形图与第二语音信息;对用户的第二语音信息进行声纹特征识别,并匹配出相对应的声纹信息库;基于所述声纹信息库,获取与所述第二语音波形图相对应的第二应答信息作为目标应答信息进行答复。
进一步的,所述语音波形图包括波形、频率与振幅;
设定第一误差范围和第二误差范围;
于同一波形条件下,将同时处于第一误差范围内的频率与第二误差范围内的振幅的语音波形图设定为同一语音波形图。
本发明实施例提供了一种机器人交互方法及系统,通过获取用户的第一语音波形图;根据所述第一语音波形图所对应的第一应答信息作为目标应答信息进行答复,解决了现有技术中机器人应答速度过慢的问题,通过训练机器人熟悉用户的声音特征来提高了机器人的应答速度。
附图说明
图1是本发明实施例一中的一种机器人交互方法的流程图;
图2是本发明实施例二中的一种机器人交互系统的结构示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例一
图1为本发明实施例一提供的一种机器人交互方法的流程图,本实施例可适用于各种机器人交互的情况,该方法可以由本发明实施例提供的机器人交互系统来执行。如图1所示,具体包括:
s110、获取用户的第一语音波形图。
由于机器人的存储容量有限,且存储数据的多少影响了机器人的运行速度,因此,将机器人与机器人服务器相连,将大容量的数据存储以及复杂运算转移到机器人服务器端,由服务器进行处理,在不影响机器人原有运行状态的同时,能够实现更多数据的存储与处理。
第一语音波形图为反应用户个人音色与语音信息的波形图。关于用户的个人音色特征,可以通过比较波形的附加小振动,关于用户的音调高低,可以比较波形的疏密程度,而关于用户的响度大小,可以比较波形的幅度。因此,机器人获取用户的每句语音信息都有其特定的语音波形图,且获取的每句语音信息的语音波形图均不同。通过获取用户的第一语音波形图,能够确定用户当前语音的波形图特征。
示例性的,所述获取用户的第一语音波形图包括:接收所述用户的第一语音信息;将所述第一语音信息转换为所述第一语音波形数据,并将所述第一语音波形数据转换为所述第一语音波形图。
其中,第一语音信息为机器人与用户进行交流时产生的交互信息,第一语音波形数据为记录第一语音信息声音特征的数据,通过对第一语音波形数据进行处理能够得到反应第一语音信息特征的第一语音波形图。
具体的,第一语音信息可以是机器人与用户面对面交流时,接收的用户语音信息,也可以是机器人与用户通过手机等通讯设备所接收的用户语音信息。机器人将接收的第一语音信息上传至机器人服务器,上传方式可以通过蓝牙或者无线网络进行上传。机器人服务器接收到第一语音信息后,不会对第一语音信息进行文本转换,而是通过声音处理技术将第一语音信息转换为第一语音波形数据,再将第一语音波形数据转换为波形图。
需要说明的是,第一语音信息转换为第一语音波形数据通过将接收到的第一语音信息转换为数字信号,再通过数字模拟转换器将数字信号转换为波形电子信号,将关于第一语音信息的所有波形电子信号进行处理以形成第一语音波形图。
s120、根据所述第一语音波形图所对应的第一应答信息作为目标应答信息进行答复。
其中,第一应答信息为能够针对接收到的第一语音信息作出应答的信息,可以为文本信息,也可以为语音信息。当第一应答信息为文本信息时,将第一应答信息为文本信息后,再将第一应答信息作为目标应答信息进行答复。
需要说明的是,机器人服务器针对本实施例的应答方式建立语音波形数据库。其中,语音波形数据库中不仅存储了大量语音波形图,还存储了语音波形图与应答信息的匹配关系。当服务器获取到用户的第一应答波形图后,将在语音波形数据库中匹配与该第一应答波形图相匹配的第一应答信息,并将第一应答信息作为目标答复信息进行应答。
其中,语音波形数据库中保存的数据可以是机器人服务器获取的关于影视资讯,如电视剧中的对话信息处理而得,也可以根据在日常生活中,机器人与用户之间的对话信息以及用户与其他用户之间的对话信息处理而得。
例如,若第一语音波形图为二维正弦波形图时,同一个人由于说话语气不同,所获取的波形图也不会一样,如下述公式f1(t)与f2(t)为机器人服务器分别获取到的用户使用愉快的语气和愤怒的语气说出的“过来和我玩儿”相对应的语音波形图的公式为:
f1(t)=sin(kt)+a1sin(2kt)+a2sin(3kt)+······
f2(t)=sin(kt)+b1sin(2kt)+b2sin(3kt)+······
上述公式f1(t)与f2(t)反应在二维正弦波形图上的区别可以是振幅的大小。因此,机器人可以通过记录语音波形图用于识别用户的不同语气,从而更能匹配合适语音信息进行应答。
本发明实施例提供了一种机器人交互方法,通过获取用户的第一语音波形图;根据所述第一语音波形图所对应的第一应答信息作为目标应答信息进行答复,解决了现有技术中机器人应答速度过慢的问题,提高了机器人的应答速度。
示例性的,在所述获取用户的第一语音波形图之前,还包括:设定预设次数阈值;于获取所述第一语音波形图的次数达到所述预设次数阈值时,建立所述第一应答信息与所述第一语音波形图的匹配关系。
其中,预设次数阈值用于确定是否将第一应答信息与第一语音波形图建立匹配关系的判断依据。预设次数阈值可以按照机器人的默认参数进行设定,也可以是根据用户特征,由用户进行设定的动态值。例如,当预设次数阈值为10次时,只有机器人获取的第一语音波形图的次数达到10时,才建立第一应答信息与第一语音波形图的匹配关系。
设定预设次数阈值的方法避免了不常使用的交互信息占用语音波形数据库的存储空间的问题,有助于节省语音波形数据库的存储空间,从而有利于机器人的快速匹配与应答。
示例性的,本实施例提供的方法还包括:根据声纹特征,将所述声纹特征相同的语音信息与语音波形图存储至同一声纹信息库;获取所述用户的第二语音波形图与第二语音信息;对用户的第二语音信息进行声纹特征识别,并匹配出相对应的声纹信息库;基于所述声纹信息库,获取与所述第二语音波形图相对应的第二应答信息作为目标应答信息进行答复。
在实际生活中,每个人说话时的语声,都有自己的特点。很熟悉的人之间,可以只听声音而相互辨别出来,这就是每个人声纹特征各不同的特性。其中,声纹是用电声学仪器显示的携带言语信息的声波频谱。声纹不仅具有特定性,而且有相对稳定性的特点。成年以后,人的声音可保持长期相对稳定不变。无论讲话者是故意模仿他人声音和语气,还是耳语轻声讲话,即使模仿得惟妙惟肖,其声纹却始终不相同。因此,可以通过声纹特征,对用户的语音波形数据库进行个性化存储,建立用户的声纹信息库。
其中,声纹信息库是基于语音波形数据库的基础上,对语音波形数据库根据声纹特征进行进一步的分类,使得机器人能够对不同用户的声音进行独立存储。例如,若接收到用户a的语音信息,则在用户a的声纹信息库中匹配应答信息,若接收到用户b的语音信息,则在用户b的声纹信息库中匹配应答信息。
具体的,机器人服务器接收到用户第二语音信息后,可以对第二语音信息进行声纹特征的识别,根据声纹特征,将声纹特征相同的语音信息与语音波形图存储至同一声纹信息库。当获取用户的第二语音波形图与第二语音信息时,先对用户的第二语音信息进行声纹特征识别,匹配出相对应的声纹信息库,再基于所述声纹信息库,获取与第二语音波形图相对应的第二应答信息作为目标应答信息进行答复。
需要说明的是,将声纹特征相同的语音信息与语音波形图存储至同一声纹信息库,该同一声纹信息库还需要考虑用户处于任意情景状态下的声纹特征,例如感冒、咳嗽以及口中含有实物等情况下的语音信息与语音波形图也一并存储至属于该用户的同一声纹信息库。
需要说明的是,声纹特征的提取可以利用数学建模的方法建立声纹自动识别模型,其中声纹自动识别模型可以考虑声学特征(倒频谱)、词法特征、韵律特征以及语种、方言和口音信息等多种特征因素。
示例性的,所述语音波形图包括波形、频率与振幅;设定第一误差范围和第二误差范围;于同一波形条件下,将同时处于第一误差范围内的频率与第二误差范围内的振幅的语音波形图设定为同一语音波形图。
其中,每个人语音波形图中的波形是固定不变的。由于机器人服务器获取的用户处于不同环境下的语音波形图有可能会不同,因此允许语音波形图中的频率与振幅存在误差范围,即允许频率存在第一误差范围,振幅存在第二误差范围,将同时处于第一误差范围内的频率与第二误差范围内的振幅的语音波形图设定为同一语音波形图,有助于节省服务器的存储空间,提高运行速度。
本实施例通过对用户的声纹特征进行提取,对语音波形数据库分类为不同声纹信息库,通过识别用户的声纹特征后,能够在该用户的声纹信息库中匹配应答信息,由于减少了数据库的匹配运算量,因此提高了机器人的应答速度。
实施例二
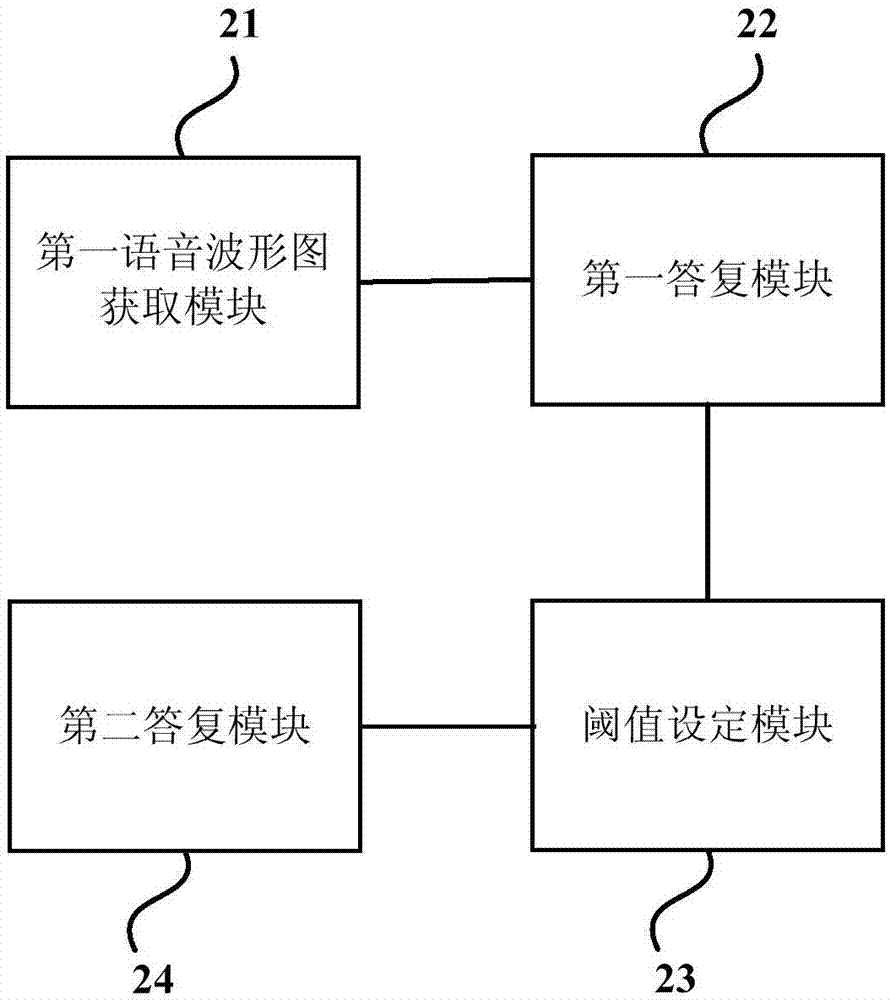
图2为本发明实施例二提供的一种机器人交互系统的结构示意图,本实施例可适用于各种机器人的交互的情况。如图2所示,具体包括:第一语音波形图获取模块21和第一答复模块22。
第一语音波形图获取模块21,用于获取用户的第一语音波形图;
第一答复模块22,用于根据所述第一语音波形图所对应的第一应答信息作为目标应答信息进行答复。
在上述实施例基础上,所述第一语音波形图获取模块21具体用于:接收所述用户的第一语音信息;将所述第一语音信息转换为所述第一语音波形数据,并将所述第一语音波形数据转换为所述第一语音波形图。
在上述实施例基础上,还包括:阈值设定模块23。
阈值设定模块23,用于在所述获取用户的第一语音波形图之前,设定预设次数阈值;于获取所述第一语音波形图的次数达到所述预设次数阈值时,建立所述第一应答信息与所述第一语音波形图的匹配关系。
在上述实施例基础上,还包括:第二答复模块24。
第二答复模块24,用于根据声纹特征,将所述声纹特征相同的语音信息与语音波形图存储至同一声纹信息库;获取所述用户的第二语音波形图与第二语音信息;对用户的第二语音信息进行声纹特征识别,并匹配出相对应的声纹信息库;基于所述声纹信息库,获取与所述第二语音波形图相对应的第二应答信息作为目标应答信息进行答复。
在上述实施例基础上,所述语音波形图包括波形、频率与振幅;设定第一误差范围和第二误差范围;于同一波形条件下,将同时处于第一误差范围内的频率与第二误差范围内的振幅的语音波形图设定为同一语音波形图。
本发明实施例提供了一种机器人交互系统,通过获取用户的第一语音波形图;根据所述第一语音波形图所对应的第一应答信息作为目标应答信息进行答复,解决了现有技术中机器人应答速度过慢的问题,提高了机器人的应答速度。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!