一种语种的快速识别方法与流程
本发明涉及语种识别技术,尤其涉及基于语音的语种识别技术。
背景技术:
语音识别技术,越来越广泛的使用到使用和应用到人们的生活当中。例如从技术角度中:苹果的语音识别技术是全球领导者。从应用角度中,语音识别已应用到声控开关、地图导航、支付、语音打字等实际应用当中。但不论是苹果语音识别、还是百度语音识别,都需要依托于系统的语言版本,既系统为中文系统,语音识别只能识别中文;系统为英文系统,语音识别只能识别英文。如果不计算少数民族的方言,全世界约有2790多种语言,那么如何解决在同一系统平台上,使用语音识别技术快速的判定语种,并以不同的语种进行响应操作,成为本领域需要解决的技术问题。
除了旅游和翻译之外,在日常生活中,也会面临不同语种无法识别的问题,例如,在信息服务方面,很多信息查询中可提供多语言服务,但一开始必须用多种语言提示用户选择用户语言。语种辨识系统必须预先区分用户的语言种类,以提供不同语言种类的服务。这类典型服务的例子包括旅游信息、应急服务、以及购物和银行、股票交易。又或者,使用语音识别技术连接的蓝牙,用户通过对某品牌手机说“配对蓝牙”、“蓝牙配对”,与蓝牙设备连接的功能应用,如果手机是中文手机、蓝牙设备是英文,则会导致无法连接,另外类似的还有车载导航等生活中经常需要用到的产品,在语音识别方面都可能会遇到类似情况。
为了解决这个问题,本领域也有相关研究,例如,在美国,为了更好的帮助外籍人员得到帮助,使用gmm和hmm算法是对整个语言的编码,如汉语编码本和英语编码本等,在匹配整个编码本,才能识别语种。但是这种技术存在复杂的算法,算法成本非常高无法应用在企业和产品当中;而且编码本需要几乎全语种的采集,采集工作量只能政府承担;对于普通用户来说,全语的编码本容量太大无法再小型设备中使用。
技术实现要素:
本发明所要解决的技术问题是提供一种语种的快速识别方法,解决了统同一设备和系统直接识别多国语言语种的问题,适用范围广。
本发明解决技术问题所采用的技术方案是:一种语种的快速识别方法,包括以下步骤:
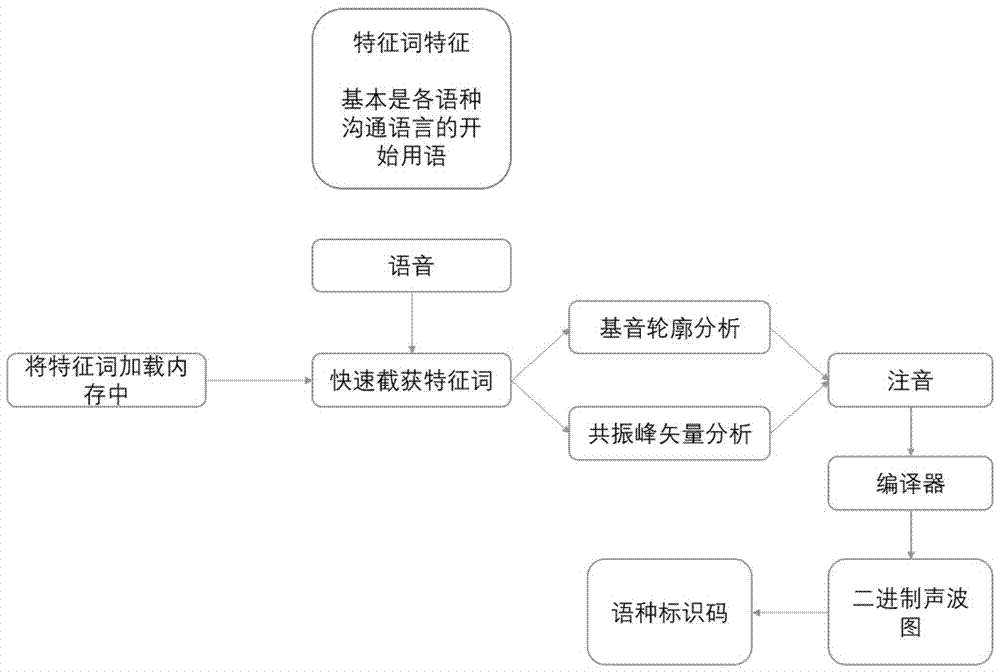
(1)采集语音信息并截获特征词;
(2)分析特征词,获得基因轮廓和共振峰矢量;
(3)分析基因轮廓和共振峰矢量,获得特征字所组成的注音;
(4)将特征词中的特征字注音绘制成注音连续图,获得注音排列序列,将注音排列序列构造成特征词信号;
(5)将特征词信号编码,形成样本值;
(6)将样本值与样板库进行比对,获得对应的语种标识码,
(7)将语种标标识码反馈给指定系统。
进一步地,特征字的注音是21个声母和16个韵母中任意两个或两个以上的组合。
进一步地,本发明还包括建立样板库的步骤,建立样板库的步骤包括:
(1)为某一语种分配一个唯一对应的语种标识码;
(2)采集该语种的语音信息并截获特征词;
(3)分析特征词,获得基因轮廓和共振峰矢量;
(4)分析基因轮廓和共振峰矢量,获得特征字所组成的注音;
(5)将特征字注音绘制成注音连续图,形成该语种所对应的特征词图谱;
(6)将注音排列成序列,并由注音排列序列构造特征词信号;
(7)将特征词信号进行编码,形成该语种所对应的样板值;
(8)将语种标识码、特征词图谱和样板值打包存储为一个样板库标签;
(9)对其他语种重复步骤(1)-(8)直到建立样板库。
进一步地,在步骤(6)中,当样本值与样板库中所有的样板值均不匹配时,标注该语音所对应的语种为新语种,对新语种采用权利要求3的方法写入样板库。
本发明的有益效果是:首先,本发明是基于分析注音的方式进行特征提取的,无需复杂的算法,避免了庞大的系统和运算,因此也不需要大容量的设备,本发明的方法可以应用于很多中小型的便携设备,扩大了适用范围,本发明采用计算机二进制技术,对注音进行编码,无需大量的重复训练阶段,降低了系统的开发成本,避免了多语言版本导致的系统软件差异,可以做到全球统一标准。本发明的识别方法可辨识多语种和方言,并能够保证识别的有效性和准确性。
附图说明
图1是本发明的原理图。
图2是本发明的使用图。
具体实施方式
参照附图1。
本发明的语音识别方法基于以下原理实现:
(1)截获特征字组成的特征词为最小单元进行语音采集;
(2)分析特征词,获得基音轮廓和共振峰矢量;
(3)分析基音轮廓和共振峰矢量,获得其中特征字所组成的注音(注音37个包含:声母21个,韵母16个);
(4)将特征词中的特征字的注音连续图,获得注音排列序列,由排列序列构造成特征词信号;
(5)采用计算机二进制技术,将特征词信号编码,成为二进制信息,形成样本值;
(6)将样本值与语种标识码绑定,完成对语种的识别。
特征词例如:你好、hello、こんにちは等组成特征词样本库。
特征词备注:基本是各语种沟通语言的开始用第一句话中重要用语,或者特定词汇,例如,“报告”、“黑白”、“地球”。
对用户来说,使用方法如下:
(1)对安装了本发明的设备说出特征词“你好”;
(2)截获用户说出的语音特征词,分析声波建立基音轮廓和共振峰矢量;
(3)分析基音轮廓和共振峰矢量,获得其中特征字所组成的注音(注音37个包含:声母21个,韵母16个);
(4)将特征词中的特征字的注音连续图,获得注音排列序列,由排列序列构造成特征词信号;
(5)采用计算机二进制技术,将特征词信号编码,成为二进制信息,形成样板值;
(6)比对样板库中的样板值,获得语种标识码;
(7)将语种标识码发送给设备中的指定系统,向用户推送语种信息。
技术特征:
技术总结
本发明提供一种语种的快速识别方法,包括:采集语音信息并截获特征词;分析特征词,获得基因轮廓和共振峰矢量;分析基因轮廓和共振峰矢量,获得特征字所组成的注音;将特征词中的特征字注音绘制成注音连续图,获得注音排列序列,将注音排列序列构造成特征词信号;将特征词信号编码,形成样本值;将样本值与样板库进行比对,获得对应的语种标识码。首先,本发明是基于分析注音的方式进行特征提取的,无需复杂的算法,避免了庞大的系统和运算,因此也不需要大容量的设备,并能够保证识别的有效性和准确性。
技术研发人员:梁镇爽
受保护的技术使用者:中译语通科技(青岛)有限公司
技术研发日:2017.08.07
技术公布日:2018.01.12
- 还没有人留言评论。精彩留言会获得点赞!