口头话语流中的不同于暂停或中止的口头话语停止事件的制作方法
背景技术:
使用语音命令已经成为用户与计算设备通信的流行方式。例如,用户可以向诸如智能电话之类的移动计算设备发出语音命令,以发起电话呼叫、接收导航指引、以及向待办事项列表中添加任务等功能。用户可以直接与计算设备(例如,智能电话)经由其麦克风进行通信,或者通过计算设备已经通信地链接的另一设备(例如,汽车)的麦克风进行通信。
技术实现要素:
一种示例性方法包括:在发起口头话语流的语音识别之后,由发起流的语音识别的计算设备检测用于停止语音识别的口头话语停止事件。所述口头话语停止事件与口头话语流中的暂停或中止不同。所述方法包括:响应于检测到所述口头话语停止事件,由所述计算设备停止口头话语流的语音识别,同时口头话语流继续进行。所述方法包括:在停止所述口头话语流的语音识别之后,由所述计算设备引起执行对应于从流的开始直到所述口头话语停止事件的口头话语的动作。
一种示例性系统包括麦克风,用于检测口头话语流。所述系统包括处理器;以及存储计算机可执行代码的非瞬态计算机可读数据存储介质。所述处理器执行所述代码以用于:在麦克风正在检测流的同时,发起口头话语流的语音识别。所述处理器执行代码以用于:在发生口头话语流的语音识别的同时,确定已经发生了与流相关的口头话语停止事件。所述口头话语停止事件与流中的暂停或中止不同。所述处理器执行代码以用于:响应于确定已经发生了口头话语停止事件,引起执行对应于直到口头话语停止事件的流的语音识别的动作。
一种存储计算机可执行代码的非瞬态计算机可读数据存储介质。计算设备执行所述代码以用于:在发生口头话语流的语音识别的同时,确定已经发生了与流相关的口头话语停止事件。所述口头话语停止事件与所述流中的暂停或中止不同。所述计算设备执行所述代码以用于:响应于确定已经发生了口头话语停止事件,引起执行对应于直到所述口头话语停止事件的流的语音识别的动作。
附图说明
这里提及的附图形成说明书的一部分。附图中所示的特征仅用于说明本发明的一些实施例,而不是本发明的所有实施例,除非另有明确指出,否则不作相反暗示。
图1是示例性的口头话语流的图,其中,发生不同于流中的暂停或中止的口头话语停止事件。
图2a和2b是示例性的口头话语停止事件的图,该口头话语停止事件是口头话语流中的方向改变。
图3是示例性的口头话语停止事件的图,该口头话语停止事件是口头话语流中的语音模式改变。
图4是示例性的口头话语停止事件的图,该口头话语停止事件是口头话语流中的语音上下文改变。
图5是示例性的口头话语停止事件的图,该口头话语停止事件是一个或多个预定词语的短语的口头话语。
图6是示例性方法的流程图,其中,检测与口头话语流中的暂停或中止不同的口头话语停止事件。
图7是示例性系统的图,其中,检测与口头话语流中的暂停或中止不同的口头话语停止事件。
具体实施方式
在下面对本发明的示例性实施例的详细描述中,参考形成其一部分的附图,并且其中通过说明的方式示出了可以实践本发明的具体示例性实施例。对这些实施例进行了足够详细的描述,以使得本领域技术人员能够实践本发明。可以利用其他实施例,并且在不背离本发明的精神或范围的情况下,可以进行逻辑、机械和其他的改变。因此,以下详细描述不应被认为是限制性的,并且本发明的实施例的范围仅由所附权利要求限定。
如背景技术部分所述,用户越来越多地采用语音命令与其计算设备进行交互。用户可以通过按下计算设备或者该计算设备所链接的另一设备上的物理按钮,或者在计算设备时常侦听预定的短语的口头话语时通过说出该短语,来向计算设备(例如,智能手机)指示他或她希望发送语音命令。一旦用户做出了这个指示,他或她随后就会讲出语音命令。
语音命令采用口头话语流的形式。取决于所关注的语音命令,该流可能相对简短,例如“呼叫sally的手机号码”;或者相对较长。作为后者的示例,用户可以要求在用户驾驶时提供复杂的导航指引。例如,用户可以请求“向我提供到第五大道上的bob'seatery的指引,但是我不想走任何高速公路到那儿”。
在用户已经向计算设备指示他或她想要发送语音命令之后,计算设备因此在用户说出的话语流上执行语音识别。然而,计算设备没有任何方式知道用户何时已经说完形成语音命令的话语流。因此,通常,计算设备等待口头话语流中的暂停或中止,并且假设在用户暂停或停止口头话语流时用户已经完成了语音命令。
然而,迫使用户暂停以在口头话语流中停止来向计算设备指示他或她已经完成了传送语音命令是有问题的。例如,用户可能处于与其他人的设置中,如用户是机动车辆的驾驶员而其他人是乘客的情况。当用户想要发出语音命令时,他或她可能正与乘客交谈。在完成语音命令之后,用户不得不不自然地停止说话—并且实际上可能不得不迫使其他乘客也停止说话—直到计算设备识别到形成语音命令的口头话语流已经完成。换句话说,一旦完全清楚地表达了语音命令,用户就不能简单地继续与车辆中的乘客谈话,而是在继续交谈之前必须等待。
通过比较,本文公开的技术允许用户在没有暂停或中止的情况下继续说出话语流。接收语音命令的计算设备识别出口头话语流何时不再与用户发出的语音命令相关。具体来说,计算设备在口头话语流中检测不同于暂停或中止的口头话语停止事件。一旦已经检测到这样的口头话语停止事件,计算设备就引起执行与口头话语流中的从流的开始直到口头话语停止事件的口头话语相对应的动作。
图1图示地描绘了示例性口头话语流100,可以关于该口头话语流来描述本文公开的技术。用户正在讲出话语流100。口头话语流100可以是连续的流,在其中没有任何不适当的暂停或中止,除了在人类语言中存在的用于界定相邻词语或一个句子的结尾以及随后下一句的开始的那些暂停或中止以外。
如在图1的示例性口头话语流100中所描绘的,用户正在说话,然后在流100开始之后发出开始事件102。然而,作为另一示例,直到在用户已经发起开始事件102之后或者与发起同时地或已经发出开始事件102的发出时,用户可能才开始说出话语流100。开始事件102的一个示例是用户按压或抓住物理控件,例如智能电话上的按钮或汽车的方向盘上的按钮。开始事件102的另一示例是用户说出一个或多个词语的特定短语,作为口头话语流100的一部分,其被预先设置为对应于开始事件100。例如,用户可以说“嘿,智能手机。”
一旦已经发起开始事件102,则在之后时间上的口头话语流100就对应于用户希望执行的语音命令104。更具体地,从开始事件102之后直到口头话语停止事件106的口头话语流100对应于语音命令104。计算设备可以在已经接收到开始事件102之后开始流100的语音识别,并且在已经检测到停止事件106之后停止语音识别。在另一实现方式中,语音识别可以在接收到开始事件102之前开始,并且可以在停止事件106之后继续。例如,如果开始事件102是用户说出一个或多个词语的特定短语,则计算设备必须在口头话语流100上持续执行语音识别以检测开始事件。一般而言,可以说,关于语音命令104对流100的语音识别本身在开始事件102之后开始,并且在停止事件106处结束。
稍后在详细描述中描述口头话语停止事件106的不同示例。然而,一般而言,停止事件106不是口头话语流100中的暂停或中止。也就是说,用户可以在停止事件106之前和之后继续说出流100,而不必故意暂停或停止说话以向计算设备传达语音命令104已经完成。停止事件106相对于与计算设备相关的用户可以是主动的或被动的。主动停止事件是用户在流100内有目的地向计算设备传达用户正在发出停止事件106的事件。被动停止事件是计算设备检测到用户已经发出停止事件106而在用户这边不存在向计算设备的任何有目的的传达的事件。
可以实时地或接近实时地实现计算设备对口头话语流100从开始事件102到口头话语停止事件106执行的语音识别。一旦发生停止事件106,则计算设备就引起执行对应于由用户传送的语音命令104的动作。也就是说,一旦发生停止事件106,计算设备就引起与从流100的开始(其可以被定义为在开始事件102之后发生)直到停止事件106的口头话语相对应的动作被执行。计算设备可以自己执行动作,或者可以与一个或多个其他设备交互以引起动作。例如,如果语音命令104用于提供到目的地的导航指令,则智能电话本身可以提供导航指令,或者可以使其所在的汽车的导航系统向用户提供导航指令。
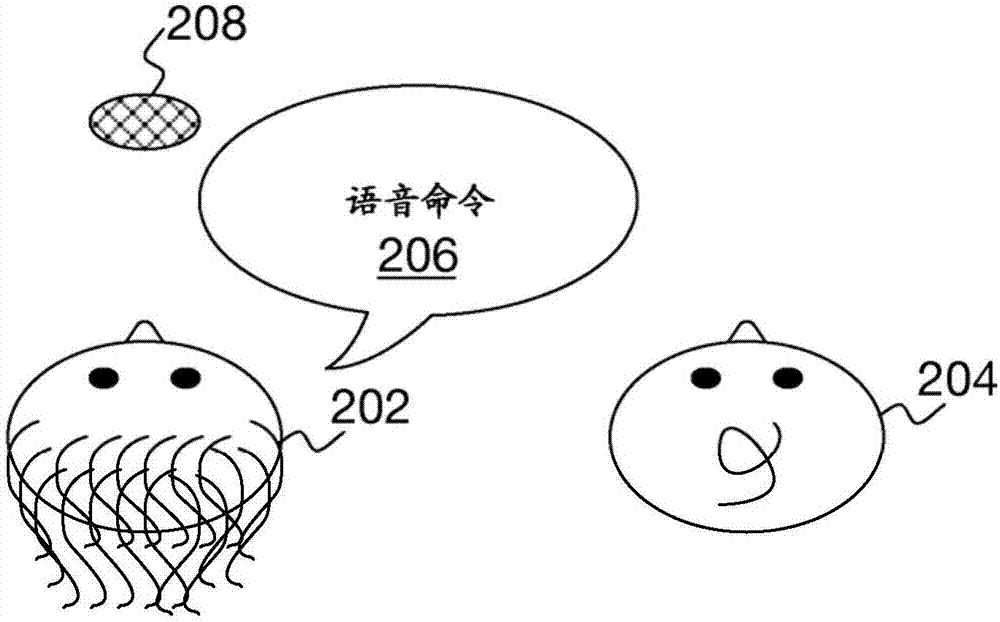
图2a和2b示出了图1的口头话语停止事件106的示例。通过图2a和2b描绘的停止事件106是图1的口头话语流100的方向被用户202从朝向麦克风208的第一方向改变到远离麦克风208的第二方向。在图2a和2b的示例中,另一个人204在用户202旁边。麦克风208在用户202的前面。例如,用户202和人204可以坐在汽车的前排,其中用户202是车辆的驾驶员,人204是乘客。在该示例中,麦克风208可以在车辆内被布置在用户202的前方。
在图2a中,用户202已经发起了开始事件102,并且说出了图1的口头话语流100中被标识为口头话语206的部分,其对应于图1的语音命令104。用户202朝向麦克风208说话。在图2b中,用户202已经完成了图1的口头话语流100的对应于图1的语音命令104的部分。相反,用户202现在说出流100中对应于图1的语音命令104之后的部分,其被标识为口头话语210。用户202已将他或她的头部转向远离麦克风208,从而可以与人204进行会话。
因此,图2a和2b中描述的口头话语停止事件是图1的流100内的口头话语的方向改变。口头话语在图2a中的流100内具有第一方向(即,话语206),并且在图2b中的流100内具有不同于第一方向的第二方向(即,话语210)。当用户202相对于麦克风208将他或她的头部从图2a的位置和方向转动到图2b的位置和方向时,计算设备检测到口头话语停止事件,同时继续口头话语100。用户202不必暂停或停止说话,而是可以从讲出口头话语206的语音命令104流畅地继续与用户204进行口头话语210的会话。作为示例,用户202可以说出说出“在我的购物列表中添加牛奶和鸡蛋”作为图2a中的语音命令104,然后立即将他或她的头部转向用户204,并向人204说出:“就像我说的,今晚我们需要去杂货店购物。”
计算设备可以以多种不同的方式来检测流100中的口头话语所源自的方向上的改变。例如,与图2b的口头话语210相比,在图2a中的口头话语206中可能存在更少的回波,这可以被麦克风208检测到。因此,在处理麦克风208从用户202处检测到的音频信号时,达到必须以超过阈值执行回波消除的程度,那么计算设备可以断定口头话语流100的方向已经从口头话语206改变到口头话语210。更一般地,可以根据多种其他声学定位技术来执行检测流100中的口头话语所源自的方向的改变,这些声学定位技术可以是主动的或被动的。
因此,在口头话语流中检测方向的改变不必涉及语音识别。也就是说,与用于关于用户202说了什么识别流100的语音的信号处理相比,可以执行不同的信号处理来检测流100内的话语方向的改变。类似地,与话语208相比,检测流100内的方向的改变不必涉及检测用户202在进行话语206时的语音模式。例如,与话语208相比,检测方向的改变可以撇开检测用户202的语音在话语206内的的音调、方式或风格。
检测流100内的方向改变作为口头话语停止事件106,构成了被动停止事件,这是因为用户202没有故意地向计算设备传送停止事件106的指示。相反,用户202自然地甚至潜意识地简单地将他或她的头部从麦克风208—或从远离人204的方向—转向人204。典型的人类本性就是将自己引向与之说话的人或物。因此,用户202甚至可能没有意识到他或她正在将口头话语206指向麦克风208(或者远离人204,如果用户202不知道麦克风208的位置),并且将语音话语210指向人204。
图3示出了图1的口头话语停止事件106的另一示例。通过图3描绘的停止事件106是由用户202改变图1的口头话语流100中的语音模式。在图3中,用户正在清楚地说出口头话语302,其对应于图1的从开始事件102之后直到停止事件106之后的口头话语100。在图3的示例中,用户202首先说出语音命令,然后例如与位于用户202附近的另一人进行正常会话。
如箭头所示,在口头话语302内在说出语音命令与进行会话之间存在用户202的语音模式改变304。这种语音模式改变304可以包括音调的改变、说话风格的改变或另一种类型的用户202说话方式改变。例如,与在进行会话时相比,在说出语音命令时,用户202可以讲得更大声、更慢、更单调、更无改变、更从容、和/或更清晰。作为另一例子,与在进行会话时相比,在讲出语音命令时,用户202可能以不同的音高、音调、方式或风格来讲话。因此,当发生语音模式改变304时,计算设备检测该改变304作为图1的口头话语停止事件106。
计算设备可以以多种不同的方式检测语音模式的改变304。例如,可以测量口头话语302内的用户202的声音的响度、速度和/或单调性,并且当在这些特性中的一个或多个中存在多于阈值的改变时,计算设备可以推断已经发生了口头话语停止事件106。可以采用机器学习,将正常的日常会话语音模式与在说出语音命令时使用的语音模式进行比较,作为检测口头话语停止事件的一种方式。
一般而言,检测语音模式改变304作为口头话语停止事件106,可以被看作利用与其他的人相比人们如何倾向于与机器(即,计算设备)交互。许多(如果不是大多数的话)语音识别技术仍然不能像典型的人那样擅长识别语音。当经由语音与机器进行交互时,许多人很快就会知道他们可能必须以特定方式说话(即,用特定的语音模式),来最大化机器理解他们的能力。这种语音模式的差异取决于人是正在对计算机设备讲话还是正在对人讲话,经常变成固习成性的老习惯,从而人甚至可能不会意识到他或她正在使用与和另一人说话不同的语音模式对计算设备说话。图3的例子因此利用这种语音模式差异作为检测口头话语流中不同于用户的停止或中止的口头话语停止事件的方式。
检测语音模式改变304不必涉及语音识别。也就是说,与用于关于用户202实际说了什么识别话语302的语音的信号处理相比,可以执行不同的信号处理以在口头话语302内检测语音模式改变304。类似地,检测语音模式改变304不必涉及检测用户的口头话语流100内的方向改变;即,图3的例子可以与图2a和2b的示例分开实现。
检测语音模式改变304作为口头话语停止事件106构成被动停止事件,因为用户202可能不会有目的地将停止事件106的指示传送到计算设备。相反,如上所述,用户202可以随着时间自然地以及因此甚至潜意识地使用与用户202在与其他人交谈时使用的语音模式不同的语音模式,来讲出针对计算设备的语音命令。这样,用户202甚至可能没有认识到他或她在表达语音命令时正在使用不同的语音模式。
图4示出了图1的口头话语停止事件106的第三示例。通过图4描绘的停止事件106是用户202改变图1的口头话语流100中的上下文。在图4中,用户正在说出口头话语302,其对应于图1的从开始事件102之后直到停止事件106之后的口头话语100。在图4的例子中,用户202首先说出语音命令,然后例如与位于用户202附近的其他人进行正常会话。
如箭头所示,在语音命令和会话之间存在口头话语402的上下文改变404。一般来说,针对语音命令所说的实际词语和短语的上下文将与在会话中说出的实际词语和短语的上下文不同。也就是说,与语音命令相关的口头话语402的上下文对应于用户202希望计算设备执行的动作。相比之下,与会话有关的口头话语402的上下文与用户202希望计算设备执行的动作不对应或不相关。
例如,父母可能正在载着他或她的孩子参加在中学举办的体育赛事,而该父母以前没有访问过该中学。因此,父母可能说:“请提供到主初级中学的导航指令。我的意思是在森特维尔的主初级中学,而不是在贝克尔斯菲。嘿,你们两个,我觉得我们明天应该看电影”。第二句话“我的意思是在森特维尔的主初级中学,而不是在贝克尔斯菲”的上下文对应于第一句话“请提供到主初级中学的导航指令”的语音命令的上下文。用户202具体澄清了他或她想要去往哪个主中学的导航指令。
相比之下,第三句话“嘿,你们两个,我觉得我们明天应该看电影”的上下文不对应于第一句和第二句的语音命令的上下文。通过几乎任何措施,第三句话与前两句话的关联性或相关性并不密切。因此,第三句话的上下文不同于前两句话的上下文。用户在口头话语402的前两句话中讲出语音命令,而在口头话语402的最后一句话中与他或她的孩子进行对话。因此,计算设备检测上下文改变404,作为口头话语停止事件,从而上下文改变404之前的前两句话是语音命令,而上下文改变404之后的句子不是。
计算设备通常可以通过在用户202说出话语402时对话语402执行语音识别,来检测上下文改变404。然后,计算设备可以例如使用语义模型经由自然语言处理来执行上下文分析,以连续地确定话语402的上下文。在发生口头话语402时例如当在话语402的上下文中存在超过阈值的改变时,计算设备可以断定已经发生了口头话语停止事件106。
因此,检测上下文改变404涉及语音识别。因此,用于理解用户202在语音命令中请求了什么的相同语音识别可以用于检测上下文改变404,以检测口头话语停止事件106。这样,检测上下文改变404不必涉及检测用户的口语话语流100内的方向改变,或者流100中的语音模式的改变。也就是说,图4的示例可以与图2a和2b的示例分开实现,以及与图3的示例分开实现。
检测上下文改变404作为口头话语停止事件106构成被动停止事件,因为用户202不必有目的地向计算设备传达他或她已经说完语音命令。相反,一旦用户202已经说完语音命令,用户就可以不暂停地简单地继续或开始例如与另一人进行会话。与用户202通知计算设备他或她已经讲完了语音命令不同,是计算设备经由上下文改变404确定用户202已经讲完了语音命令。
图5示出了图1的口头话语停止事件106的第四示例。通过图5描绘的停止事件106是用户202在图1的口头话语流100中发出一个或多个停止词语的短语。在图5中,用户正在说出口头话语502,其对应于图1的从开始事件102之后直到停止事件106的口头话语100。在图5的例子中,用户202首先说出语音命令,然后说出停止词语。
用户202可能预先知道一个或多个停止词语的短语是计算设备侦听的作为用户在口头话语502中说出的语音命令已经完成的指示的预定停止词语。作为示例,短语可以是“完成命令”。作为长度为一个词语的示例,该词语可以是不太可能作为语音命令的一部分或在正常会话中讲出的相对捏造或无意义的词语,如“shazam”。
然而,在另一实现方式中,用户202可以说出一个或多个停止词语的短语,其具有向计算设备指示用户已经说完语音命令的含义。在该实现方式中,一个或多个停止词语的短语不是预定的,并且用户可以使用可能不是计算设备预先知道的各种不同的短语。然而,这些短语都包含相同的含义,即用户202已经说完了语音命令。这种短语的例子包括“好的,我说完了语音命令”;“请处理我的请求,谢谢”;“执行该指令”;等等。
计算设备通常可以通过在用户202说出话语502时对话语502执行语音识别,来检测口头话语502内的一个或多个停止词语的短语的发出。如果停止词语的短语是预定的,则计算设备可以不执行自然语言处理来评估口头话语502的含义,而是确定用户202是否已经说出停止词语的短语。如果停止词语的短语不是预先确定的,则比较起来,计算设备可以执行自然语言处理(例如,使用语义模型)来评估口头话语502的含义,以确定用户202是否已经说出了具有与用户202指示他或她已经说完语音命令相对应的含义的词语的短语。计算设备还可以同时执行两种实现方式:侦听计算设备预先知道是停止短语的一个或多个词语的特定短语,同时还确定用户202是否已经说出与用户202指示他或她已经说完语音命令相对应的任何其他短语。
因此,检测一个或多个停止词语的短语涉及语音识别。用于理解用户202在语音命令中请求什么的相同语音识别可以用于检测该短语,以检测口头话语停止事件106。检测一个或多个停止词语的短语不必涉及如图1所示检测上下文改变404;或者如图2a和2b所示在口头语话流100内检测方向的改变;或如图3所示在流100内检测语音模式的改变。
检测一个或多个停止词语的短语作为口头话语停止事件106构成主动停止事件。这是因为用户202必须有目的地向计算设备传达他或她已经说完了语音命令。虽然计算设备必须检测短语,但是用户202有目的地且主动地通知计算设备他或她已经说完了语音命令。
已经关于图2a和2b、3、4和5描述的口头话语停止事件106的不同示例可以单独地以及彼此结合地被执行。利用多于一种方法来检测口头话语停止事件106可以有利于最大化用户友好性。与继续进行会话不同,用户202在讲出语音命令时可能不改变方向,从而不同于图2a和2b的方法可以替代地检测口头话语停止事件106。用户202可能在说出语音命令时不改变他或她的语音模式,从而不同于图3的方法可以代替地检测停止事件106。语音命令之后的会话的上下文可能与语音命令的上下文相同,从而不同于图4的方法可以代替地检测停止事件106。可能存在一个或多个停止词语的预定短语,但是用户202可能不知道或没记住该短语,或者可能甚至不知道他或她应该说出短语来结束语音命令,从而不同于图5的方法可以检测到口头话语停止事件106。
因此,通过和谐地使用图2a和2b、3、4和5的方法,计算设备更可能检测到口头话语停止事件106。此外,计算设备可能需要多于一种方法来成功地检测停止事件106,然后肯定地推断停止事件106已经发生。例如,计算设备在推断停止事件106确实发生之前,可能要求检测到方向改变、语音模式改变和上下文改变中的两个或多个。作为另一示例,计算设备在推断停止事件106确实发生之前,可能要求检测到主动停止事件(例如用户202发出的一个或多个停止词语的短语),或者检测两个或更多个被动停止事件(例如方向改变、语音模式改变或上下文改中的两个或更多个)。
图6示出了检测口头话语流100内的口头话语停止事件106的示例性方法600。计算设备(例如,智能电话或其他类型的计算设备)执行方法600。计算设备检测开始事件102(602),然后作为响应,可以发起或开始对用户正在说出的口头话语流100的语音识别(604)。然而,在另一实现方式中,在检测到开始事件102之前,计算设备之前可能已经开始了语音识别,例如在开始事件102是用户说出一个或多个预定开始词语的短语的情况下。
在发起语音识别之后,计算设备检测口头话语停止事件106(606)。计算设备可以根据已经关于图2a和2b、3、4和5描述的一种或多种方法来检测口头话语停止事件106。更一般地,计算设备可以根据停止事件106不是口头话语流100内的暂停或中止的任何方法来检测停止事件106。
响应于检测到口头话语停止事件106,计算设备可以停止口头话语流100的语音识别(608)。然而,在另一实现方式中,即使在检测到停止事件106之后,计算设备也可以继续执行语音识别,例如在开始事件102是用户说出一个或多个预定开始词语的短语的情况下。在这种情况下这样做可以允许计算设备检测例如停止事件106的另一出现。
然后,计算设备执行动作,或者引起动作被执行,该动作对应于用户202在口头语音流100中说出的语音命令104(610)。也就是说,计算设备执行动作或引起动作被执行,该动作对应于口头话语流100内的口头话语,该口头话语开始于检测到开始事件102之后,直到检测到停止事件106。这一部分的口头话语是对应于用户202希望执行的语音命令104的部分。计算设备引起动作被执行包括计算设备实际执行动作的情况。
图7示出了在口头话语流100内检测口头话语停止事件106的示例性系统700。系统700至少包括麦克风702、处理器704、以及存储计算机可执行代码706的非瞬态计算机可读数据存储介质706。除了图7所描绘的组件之外,系统700还可以并且确实通常还包括其他硬件组件。系统700可以实现于单个计算设备中,例如,智能电话或如台式或膝上型计算机的计算机。系统700还可以在多个计算设备上实现。例如,处理器704和介质706可以是智能电话的一部分,而麦克风可以是智能电话当前所在的汽车的一部分。
处理器704相对于由麦克风702检测到的口头话语流100执行来自计算机可读介质706的代码708,以执行已经描述的方法600。也就是说,由用户202发出的流100被麦克风702检测到。因此,处理器704以及因此系统700可以执行动作或引起动作被执行,该动作与流100内的语音命令104对应。为了确定用户何时停止说出语音命令104,处理器704以及因此系统700例如根据关于图2a和2b、3、4和5描述的一种或多种方法,来检测口头话语停止事件106。
因此,已经描述的技术允许用户和计算设备之间的更自然和用户友好的语音交互。在向计算设备发出语音命令之后,用户不必暂停或中止讲话。而是,计算设备检测主动或被动口头话语停止事件,以确定在讲出话语流的过程中用户何时已经说完语音命令本身。
最后应注意,尽管本文已经示出和描述了具体的实施例,但是本领域普通技术人员可以理解的是,为实现相同目的而计算出的任何布置可以代替所示的特定实施例。因此,本申请旨在覆盖本发明的实施例的任何适应或变化。非瞬态计算机可读介质的示例包括这样的易失性介质,如易失性半导体存储器,以及这样的非易失性介质,如非易失性半导体存储器和磁存储设备。显然,本发明旨在仅由权利要求及其等同物来限定。
- 还没有人留言评论。精彩留言会获得点赞!