声音识别装置以及声音识别方法与流程
本发明涉及对输入的声音进行识别的声音识别装置。
背景技术:
识别用户发出的声音、计算机使用其识别结果进行处理的声音识别技术得到普及。通过使用声音识别技术,能够以非接触的方式操作计算机,特别是搭载于汽车等移动体的计算机的便利性大幅提高。
进行声音识别时的识别精度根据识别时使用的词典的规模而不同。例如,特化为声音识别的工作站和未特化为声音识别的个人计算机在识别精度方面存在大的差异。
因此,当希望在规模小的计算机中利用声音识别的情况下,利用经由通信线路向规模大的计算机传送声音数据并获取识别结果的手法。
现有技术文献
专利文献1:日本特开2001-034292号公报
专利文献2:日本特开2013-154458号公报
技术实现要素:
比较所输入的声音和识别词典,根据得到的结果进行声音识别,所以有时会将发音或特征类似的不同的单词输出为识别结果。
本发明是考虑上述问题而完成的,其目的在于提高声音识别装置执行的声音识别的精度。
本发明的第一方案提供一种声音识别装置,其特征在于,具有:声音获取单元,获取用户发出的声音;声音识别单元,获取对获取到的所述声音进行识别的结果;类别分类单元,根据声音识别的结果对所述用户的发声内容的类别进行分类;信息获取单元,获取包括与所分类出的所述类别对应的单词的类别词典;以及校正单元,根据所述类别词典修正所述声音识别的结果。
本发明的声音识别装置具有如下特征:为了防止识别错误的单词而并用发音上的特征以外的特征来进行声音识别。
类别分类单元是根据对声音进行识别的结果对用户的发声内容的类别进行分类的单元。由此,能够获取用户作为话题的对象的类别。类别例如也可以从“场所”“人物”“食物”等事先定义的多个类别中选择。
信息获取单元是获取类别词典的单元,该类别词典包括与所分类出的类别对应的单词。类别词典既可以针对每个类别预先制作,也可以根据类别而动态地收集。例如,也可以是使用web服务等外部的信息资源而收集到的信息。
另外,校正单元是根据类别词典来校正声音识别的结果的单元。例如,在判定为进行针对场所的话题的情况下,使用与场所对应(例如包括大量固有名词)的类别词典来进行结果的校正。
根据上述结构,能够根据类别来区分在发音上近似的单词,所以声音识别的精度提高。
另外,所述类别词典包括与所述类别对应并且与所述用户关联的单词,在所述类别词典所包含的单词和所述声音识别的结果所包含的单词类似的情况下,所述校正单元用所述类别词典中包含的类似的单词中的一个单词置换所述声音识别的结果所包含的单词。
与用户关联的单词是指,例如与用户的位置信息、用户的移动路径、用户的爱好、用户的交友关系等有关的单词,但不限于这些。
例如,作为与“场所”这个类别对应并且与用户关联的单词,可以例举出存在于用户当前位置周边的地标的名称等。
另外,类似意味着在发音上类似。根据上述结构,能够提供适合于利用装置的用户的修正候补。
另外,本发明的声音识别装置的特征还可以在于具有位置信息获取单元,该位置获取单元获取位置信息,所述信息获取单元获取和与所述位置信息关联的地标的名称有关的信息来作为所述类别词典,在所述用户的发声内容是与场所有关的内容的情况下,所述校正单元使用与所述地标的名称有关的信息来修正所述声音识别的结果。
在用户的发声内容是与场所有关的内容的情况下,信息获取单元根据位置信息而获取与地标的名称有关的信息。位置信息既可以是表示当前位置的信息,也可以是直至目的地的路径信息等。此外,信息的获取目标也可以是与进行声音识别的装置独立的装置。根据上述结构,能够提高与地标有关的固有名词的识别精度。
另外,所述信息获取单元获取与处于用所述位置信息表示的场所附近的地标的名称有关的信息。
其原因在于处于用位置信息表示的场所附近的地标被用户提及的可能性高。
另外,本发明的声音识别装置的特征也可以在于还具有路径获取单元,该路径获取单元获取与所述用户的移动路径有关的信息,所述信息获取单元获取与处于所述用户的移动路径附近的地标名称有关的信息。
在能够获取用户的移动路径的情况下,信息获取单元获取与处于该移动路径附近的地标的名称有关的信息。因为处于移动路径附近的地标被用户提及的可能性高,所以能够进一步提高与地标有关的固有名词的识别精度。此外,用户的移动路径也可以从导航装置或用户所持有的便携终端获取。另外,移动路径既可以是从出发地至当前位置的路径,也可以是从当前位置至目的地的路径。另外,还可以是从出发地至目的地的路径。
另外,所述信息获取单元获取与所述用户的爱好有关的信息来作为所述类别词典,在所述用户的发声内容是与所述用户的爱好有关的内容的情况下,所述校正单元使用与所述用户的爱好有关的信息来校正所述声音识别的结果。
用户的爱好是指,例如,表示用户所关心的信息的风格、食物、爱好、电视节目、体育、web站点、音乐等,但不限于这些。
与用户的爱好有关的信息既可以是存储于声音识别装置的信息,也可以是从外部的装置(例如用户所持有的便携终端)获取的信息。另外,与用户的爱好有关的信息既可以根据事先制作出的配置文件信息获取,也可以根据web的阅览历史、音乐电影的再生历史等动态地生成。
另外,特征还可以在于所述信息获取单元从用户所持有的便携终端获取与登记的联络目标有关的信息来作为所述类别词典,在所述用户的发声内容是与人物有关的内容的情况下,所述校正单元使用与所述联络目标有关的信息来校正所述声音识别的结果。
根据上述结构,能够进一步提高与用户的熟人有关的固有名词的识别精度。
另外,所述声音识别单元经由声音识别服务器进行声音的识别。
一般来说,在使服务器进行声音识别的情况下会产生无法反映用户固有的信息的问题,当在本地进行声音识别的情况下会产生无法确保识别精度的问题,但根据本发明,在服务器进行声音识别之后,使用与用户关联的信息来修正识别结果,所以能够同时实现双方。
此外,本发明能够特定为包括上述单元的至少一部分的声音识别装置。另外,还能够特定为所述声音识别装置执行的声音识别方法。只要不产生技术上的矛盾,则上述处理或单元能够自由地组合来实施。
根据本发明,能够提高声音识别装置执行的声音识别的精度。
附图说明
图1是第一实施方式的对话系统的系统结构图。
图2是第一实施方式的车载终端进行的处理的流程图。
图3是第一实施方式的车载终端进行的处理的流程图。
图4是第二实施方式的对话系统的系统结构图。
图5是第二实施方式的对话系统进行的处理的流程图。
(符号说明)
10:车载终端;20:声音识别服务器;11:声音输入输出部;12:校正部;13:路径信息获取部;14:用户信息获取部;15、21:通信部;16:响应生成部;17:输入输出部;22:声音识别部。
具体实施方式
(第一实施方式)
以下,参照附图来说明本发明的优选的实施方式。
第一实施方式的对话系统是从搭乘于车辆的用户(例如驾驶员)获取声音命令来进行声音识别,根据识别结果生成响应句并提供给用户的系统。
<系统结构>
图1是第一实施方式的对话系统的系统结构图。
本实施方式的对话系统包括车载终端10和声音识别服务器20。
车载终端10是具有如下功能的装置:获取用户发出的声音并经由声音识别服务器20进行声音识别的功能;以及根据声音识别的结果生成响应句并提供给用户的功能。车载终端10例如既可以是车载的车辆导航装置,也可以是通用的计算机。另外,还可以是其它车载终端。
另外,声音识别服务器20是对从车载终端10发送的声音数据进行声音识别处理、变换为文本的装置。在后叙述声音识别服务器20的详细的结构。
车载终端10包括声音输入输出部11、校正部12、路径信息获取部13、用户信息获取部14、通信部15、响应生成部16、输入输出部17。
声音输入输出部11是输入输出声音的单元。具体而言,使用未图示的麦克风,将声音变换为电信号(以下称为“声音数据”)。获取到的声音数据被发送给后述声音识别服务器20。另外,声音输入输出部11使用未图示的扬声器,将从后述的响应生成部16发送的声音数据变换为声音。
校正部12是对声音识别服务器20执行声音识别的结果进行校正的单元。校正部12执行:(1)根据从声音识别服务器20获取到的文本对用户的发声内容的类别进行分类的处理;以及(2)根据分类出的类别、后述路径信息以及用户信息校正声音识别结果的处理。在后叙述具体的校正的方法。
路径信息获取部13是用于获取与用户的移动路径有关的信息(路径信息)的单元,是本发明中的路径获取单元。路径信息获取部13从搭载于车辆的导航装置或便携终端等具有路径引导功能的装置获取当前位置、目的地以及直至目的地的路径信息。
用户信息获取部14是获取与装置的用户有关的信息(用户信息)的单元。在本实施方式中,具体而言,从用户所持有的便携终端获取(1)被登记为该用户的联络目标的姓名信息、(2)该用户的配置文件信息、(3)音乐再生历史这三种信息。
通信部15是经由通信线路(例如便携电话网)访问网络、从而与声音识别服务器20进行通信的单元。
响应生成部16是根据声音识别服务器20发送的文本(即用户进行的发声的内容)生成作为向用户的回答的文章(发声句)的单元。响应生成部16例如也可以根据预先存储的对话脚本(对话词典)生成响应。向后述的输入输出部17以文本形式发送响应生成部16所生成的回答,之后,利用合成声音向用户输出。
声音识别服务器20是特化为声音识别的服务器装置,包括通信部21以及声音识别部22。
通信部21具有的功能与上述的通信部15相同,所以省略详细的说明。
声音识别部22是对获取到的声音数据进行声音识别并变换为文本的单元。声音识别能够通过既知的技术进行。例如,在声音识别部22中存储有音响模型和识别词典,通过比较所获取的声音数据和音响模型而抽出特征,使所抽出的特征与识别词典匹配而进行声音识别。声音识别的结果所得到的文本被发送给车载终端10。
车载终端10以及声音识别服务器20都能够构成为具有cpu、主存储装置、辅助存储装置的信息处理装置。存储于辅助存储装置的程序被加载到主存储装置,由cpu执行,从而图1图示的各单元发挥功能。此外,图示的功能的全部或者一部分也可以使用专门设计的电路来执行。
<处理流程图>
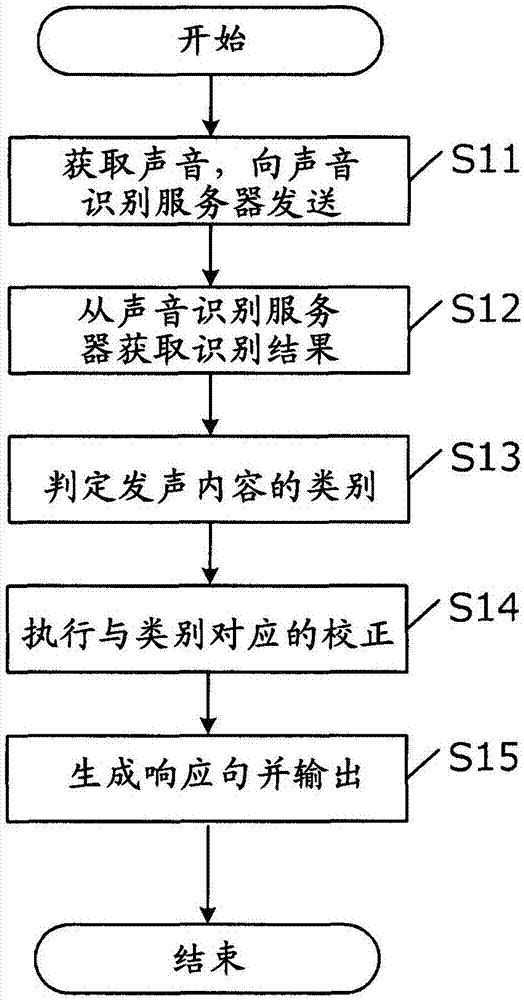
接下来,说明车载终端10进行的具体处理的内容。图2是示出车载终端10所执行的处理的流程图。
首先,在步骤s11中,声音输入输出部11经由未图示的麦克风从用户获取声音。获取到的声音被变换为声音数据,经由通信部15以及通信部21被发送给声音识别服务器20。
所发送的声音数据由声音识别部22变换为文本,变换完成之后马上经由通信部21以及通信部15发送给校正部12(步骤s12)。
接下来,在步骤s13中,校正部12判定发声内容的类别。
发声内容的类别例如能够根据单词的一致度来确定。例如,通过形态分析将文章分解为单词,对去掉助词以及副词等后的剩余的单词,验证是否与针对每个类别规定的预定的单词一致。然后,将针对每个单词规定的得分相加,计算每个类别的合计得分。最终,将得分最高的类别确定为该发声内容的类别。
此外,在本例子中根据单词的一致度确定了发声的类别,但也可以使用机械学习等手法来判定发声内容的类别。
接下来,在步骤s14中,校正部12根据所判定出的类别来校正识别结果的文本。
在此,参照图3,更具体地说明步骤s14中进行的处理。在本实施方式中,将发声内容的类别分类为“音乐”“场所”“爱好”“人物”这四种。
首先,说明类别为“音乐”的情况的例子。
在类别为“音乐”的情况下(步骤s141a),校正部12经由用户信息获取部14从用户所持有的便携终端获取音乐的再生历史,使用该再生历史所包含的曲名以及艺术家名来校正识别结果(步骤s142a)。
例如,声音识别服务器20输出的识别结果为“是否为ビーズ的新歌吗?”,根据“新歌”这个单词判定为该发声内容的类别为“音乐”。在该情况下,判定为再生历史所包含的“b’z”这个单词和识别结果所包含的“ビーズ”这个单词在发音上类似,将“ビーズ”校正为“b’z”。(注:b'z是日本的音乐团体)
之后,在步骤s15中,响应生成部16根据“是否为b’z的新歌?”这个文本而生成响应。响应生成部16例如检索web服务等来获取新专辑的发布预定,提供给用户。
接下来,说明类别为“场所”的情况的例子。
在类别为“场所”的情况下(步骤s141b),校正部12经由路径信息获取部13获取路径信息,获取沿着该路径存在的地标的名称,之后使用该地标的名称来校正识别结果(步骤s142b)。
在此,考虑对作为位于东京的复合设施的名称的“红坂sacas(akasakasacas)”发声的情况。
例如,声音识别服务器20输出的识别结果是“红坂sa-cas在附近?”,根据“附近”这个单词判定为该发声内容的类别为“场所”。在该情况下,判定为沿着路径存在的“红坂sacas”这个建筑物的名称和识别结果所包含的“sa-cas”这个单词在发音上类似,将“sa-cas”校正为“sacas”。
之后,在步骤s15中,响应生成部16根据“红坂sacas在附近?”这个文本生成响应。响应生成部16例如检索web服务等来检索红坂sacas的场所,并提供给用户。
此外,在本例子中,使用路径信息进行了校正,但未必一定使用路径信息。例如,既可以仅使用当前位置,也可以仅使用目的地的场所。此外,关于地标的名称既可以声音识别装置预先存储,也可以从便携终端或车辆导航装置获取。
接下来,说明类别为“爱好”的情况的例子。
在类别为“爱好”的情况下(步骤s141c),校正部12经由用户信息获取部14从用户所持有的便携终端获取该用户的配置文件信息,使用该配置文件信息所包含的关于爱好的信息来校正识别结果(步骤s142c)。
例如,声音识别服务器20输出的识别结果是“让朋友吃青椒”,根据“青椒”这个单词,判定为该发声内容的类别为“爱好”。另外,配置文件信息包含“讨厌的食物是松花蛋”这个信息。在该情况下,判定配置文件信息包含的“松花蛋”和识别结果所包含的“青椒”这个单词在发音上类似,将“青椒”校正成“松花蛋”。
(此外,注:青椒在日语中表示bellpepper(菜椒),松花蛋表示centuryegg(皮蛋))
之后,在步骤s15中,响应生成部16根据“让朋友吃松花蛋”这个文本生成响应。响应生成部16例如生成“不喜欢那个”的响应,并提供给用户。
接下来,说明类别为“人物”的情况的例子。
在类别为“人物”的情况下(步骤s141d),校正部12经由用户信息获取部14从用户所持有的便携终端获取联络目标信息,获取该联络目标信息所包含的人名,之后使用该人名来校正识别结果(步骤s142d)。
例如,声音识别服务器20输出的识别结果是“最近未见到樱坂”,根据“未见到”这个单词判定为该发声内容的类别是“人物”。在该情况下,判定为联络簿所包含的“神乐坂”这个姓名和识别结果所包含的“樱坂”这个单词在发音上类似,将“樱坂”校正为“神乐坂”。(注:樱坂和神乐坂都能作为日本的姓。另外,樱坂还是日本的流行歌曲的歌名)
之后,在步骤s15中,响应生成部16根据“最近未见到神乐坂”这个文本生成响应。响应生成部16例如生成“好久不见,试着给神乐坂君打电话?”的响应,并提供给用户。
此外,声音识别服务器20输出的识别结果是“最近未听樱坂”,根据“未听”这个单词判定为该发声的类别是“音乐”。在这样的情况下,在识别结果所包含的“樱坂”和音乐的再生历史所包含的“樱坂”相同的情况下,不进行校正。
此外,在发声不对应于任何类别的情况下,省略步骤s14的处理。也就是说跳过图3的处理。
如以上说明的那样,本实施方式的声音识别装置对用户的发声内容的类别进行分类,根据该类别来校正识别结果。由此,能够提高声音识别的精度。进而,在校正识别结果时使用路径信息或联络簿这样的、本地保持的用户固有的信息,所以能够进行更适合于用户的校正。
(第二实施方式)
第二实施方式是使独立的服务器装置具有第一实施方式中的校正部12以及响应生成部16的实施方式。
图4是第二实施方式的对话系统的系统结构图。此外,对具有与第一实施方式相同的功能的功能块附加同一符号而省略说明。
在第二实施方式中,作为生成响应句的服务器装置的响应生成服务器30具有响应生成部32以及校正部33。响应生成部32与第一实施方式中的响应生成部16对应,校正部33与第一实施方式中的校正部12对应。基本的功能相同,所以说明省略。
图5是第二实施方式的对话系统进行的处理流程图。步骤s11以及s12的处理与第一实施方式相同,所以说明省略。
在步骤s53中,车载终端10将从声音识别服务器20获取到的识别结果转送给响应生成服务器30,在步骤s54中,校正部33通过上述手法判定发声内容的类别。
接下来,在步骤s55中,校正部33对车载终端10请求与所判定出的类别对应的用户信息。由此,路径信息获取部13所获取的路径信息、或者用户信息获取部所获取的用户信息被发送给响应生成服务器30。
接下来,在步骤s56中,校正部12根据所判定出的类别来校正识别结果的文本。然后,响应生成部32根据校正后的文本生成响应句,发送给车载终端10(步骤s57)。
响应句最终在步骤s58中被变换为声音,经由声音输入输出部11提供给用户。
(变形例)
上述实施方式只是一个例子,本发明能够在不脱离其要旨的范围内适当地变更来实施。
例如,在实施方式的说明中,使用音乐的再生历史等用户固有的信息进行了校正,但只要是与所分类的类别对应的信息资源,则也可以使用其它的并非用户固有的信息资源。例如,在类别为音乐的情况下,也可以利用检索乐曲或艺术家名的web服务。另外,还可以获取特化为类别的词典并利用。
另外,在实施方式的说明中,例示出四种类别,但类别也可以是这四种类别以外的类别。另外,校正部12为了进行校正而使用的信息也不限于例示出的信息,只要是起到与所分类出的类别对应的词典的作用的信息,则可以使用任意的信息。例如,也可以从用户所持有的便携终端获取邮件或sns的发送接收历史等,作为词典使用。
另外,在实施方式的说明中设为本发明的声音识别装置为车载终端,但也可以实施为便携终端。在该情况下,路径信息获取部13也可以从便携终端具备的gps模块或启动中的应用获取位置信息或路径信息。另外,用户信息获取部14也可以从便携终端的存储设备获取用户信息。
- 还没有人留言评论。精彩留言会获得点赞!