车载系统的多屏语音交互方法及装置、存储介质和车机与流程
本发明涉及车载系统设计领域,特别涉及一种车载系统的多屏语音交互方法及装置、存储介质和车机。
背景技术:
随着车辆的普及,车载系统的优化设计和用户体验为越来越多的车辆用户所重视。起初,车载系统一般以车载导航系统为主,通过商业通信卫星,将全球定位系统(globalpositionsystem,简称gps)应用到车辆导航中,提供准确的地图、地理信息和清晰的行进路线,可以为汽车驾驶者指路。而后,随着车载系统内容逐渐丰富,具有了越来越多的多媒体功能,以丰富用户体验。
在现有技术中,用户可以通过语音交互的方式对车载系统的屏幕进行控制,例如可以通过车载系统的语音助手软件实现。然而,车载系统由主驾位设置的主屏幕向着多个屏幕发展。以五座车辆为例,除主驾位设置有主屏幕外,副驾驶和后排座位前方也设置有副屏幕。用户对车载系统内的多个屏幕均存在语音交互的需求。
因此,为了进一步提高用户的使用体验,车载系统的多屏语音交互如何去实现是一个亟待解决的问题。
技术实现要素:
本发明解决的技术问题是如何通过实现车载系统的多屏语音交互,提高用户对多屏车载系统的使用体验。
为解决上述技术问题,本发明实施例提供一种车载系统的多屏语音交互方法,所述车载系统包括多个屏幕,所述多屏语音交互方法包括:采集用户的语音交互请求;对所述语音交互请求的声源位置进行定位,以得到定位结果;利用所述语音交互请求对距离所述定位结果最近的屏幕进行控制。
可选地,所述利用所述语音交互请求对距离所述定位结果最近的屏幕进行控制包括:对距离所述定位结果最近的屏幕进行唤醒;控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应。
可选地,所述控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应包括:识别所述语音交互请求的声纹信息,以确定用户身份;基于所述用户身份,加载与所述声纹信息相匹配的个性化设置信息;基于所述个性化设置信息,控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应。
可选地,采集用户的语音交互请求包括:采集车内的用户语音;对所述用户语音进行验证,在验证通过时得到所述语音交互请求。
可选地,所述对所述用户语音进行验证包括:识别所述用户语音的内容;当所述用户语音的内容包含预设的控制指令词时,验证通过。
可选地,所述对所述语音交互请求的声源位置进行定位包括:比较各个屏幕接收到的所述语音交互请求的声音强度;和/或,对车辆内各个用户的发声动作进行图像识别。
为解决上述技术问题,本发明实施例还提供一种车载系统的多屏语音交互装置,所述车载系统包括多个屏幕,所述装置包括:语音请求采集模块,适于采集用户的语音交互请求;位置定位模块,适于对所述语音交互请求的声源位置进行定位,以得到定位结果;屏幕控制模块,适于利用所述语音交互请求对距离所述定位结果最近的屏幕进行控制。
可选地,所述屏幕控制模块包括:唤醒子模块,适于对距离所述定位结果最近的屏幕进行唤醒;屏幕控制子模块,适于控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应。
可选地,所述屏幕控制子模块包括:身份确认子模块,适于识别所述语音交互请求的声纹信息,以确定用户身份;信息加载子模块,适于基于所述用户身份,加载与所述声纹信息相匹配的个性化设置信息;个性化控制子模块,适于基于所述个性化设置信息,控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应。
可选地,所述语音请求采集模块包括:语音采集子模块,适于采集车内的用户语音;语音验证子模块,适于对所述用户语音进行验证,在验证通过时得到所述语音交互请求。
可选地,所述语音验证子模块包括:内容识别子模块,适于识别所述用户语音的内容;当所述用户语音的内容包含预设的控制指令词时,验证通过。
可选地,所述位置定位模块包括:强度比较子模块,适于比较各个屏幕接收到的所述语音交互请求的声音强度;和/或,图像识别子模块,适于对车辆内各个用户的发声动作进行图像识别。
为解决上述技术问题,本发明实施例还提供一种存储介质,其上存储有计算机指令,所述计算机指令运行时执行上述车载系统的多屏语音交互方法的步骤。
为解决上述技术问题,本发明实施例还提供一种车机,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机指令,所述处理器运行所述计算机指令时执行上述车载系统的多屏语音交互方法的步骤。
与现有技术相比,本发明实施例的技术方案具有以下有益效果:
本发明实施例方案的多屏语音交互方法可以通过采集用户的语音交互请求,对所述语音交互请求的声源位置进行定位,以得到定位结果,利用所述语音交互请求对距离所述定位结果最近的屏幕进行控制。一方面实现了车载系统的多屏语音控制,易于操作,可以有效地提高用户对车载系统的使用体验;另一方面,在控制距离所述定位结果最近的屏幕对用户的语音交互请求进行响应时,可以有针对性地仅开启该屏幕与用户进行语音交互,其他屏幕可以不开启(也即,维持休眠状态),节约能耗。
进一步而言,本发明实施例中的多屏语音交互方法中的步骤适于在同一操作系统下进行执行,通过分别独立地设置所述主屏幕数据接口和副屏幕数据接口的显示信息来设置主、副屏幕显示内容。一方面可以根据不同的驾驶位调整不同的屏幕显示内容,很好地适应用户的个性化需求;另一方面,由于运行于同一操作系统,因此在硬件配置上仅需一个控制器,可适当地降低车载系统的硬件成本。
进一步而言,在本发明实施例方案中,采集用户的语音交互请求可以包括:采集车内的用户语音;对所述用户语音进行验证,在验证通过时得到所述语音交互请求。也即保证并非所有的用户语音内容均可以作为启动相应的屏幕进行语音交互的条件,可以有效地提高多屏语音交互的有效性。
进一步而言,在本发明实施例方案中,所述对所述语音交互请求的声源位置进行定位可以采用声音强度比较和发声动作图像识别相结合的方式进行声源位置定位,有利于保证声源位置定位的准确性。
进一步而言,在本发明实施例方案中,由于通过识别所述语音交互请求的声纹信息,确定了用户身份,并基于所述用户身份,加载了与所述声纹信息相匹配的个性化设置信息,则可以基于所述个性化设置信息,控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应,可以使得用户对车载系统中的语音交互过程更符合用户的个人化需求,可以极大地提高用户的使用体验。
附图说明
图1是本发明实施例的一种车载系统的多屏语音交互方法的流程图。
图2是本发明实施例的另一种车载系统的多屏语音交互方法的流程图。
图3是本发明实施例的一种车载系统的多屏语音交互装置的示意性结构框图。
具体实施方式
如背景技术部分所述,在现有技术中,用户可以通过语音交互的方式对车载系统的屏幕进行控制。然而,车载系统由主驾位设置的主屏幕向着多个屏幕发展。用户对车载系统内的多个屏幕均存在语音交互的需求。因此,为了进一步提高用户的使用体验,车载系统的多屏语音交互如何去实现是一个亟待解决的问题。
本发明实施例提出一种车载系统的多屏语音交互方法,通过采集用户的语音交互请求,对所述语音交互请求的声源位置进行定位,以得到定位结果,利用所述语音交互请求对距离所述定位结果最近的屏幕进行控制,可以实现车载系统的多屏语音控制,可以有效地提高用户对车载系统的使用体验。
为使本发明的上述目的、特征和有益效果能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
本发明实施例公开了一种车载系统的终端同步显示方法,该多屏控制方法可以应用于车载系统。其中,本发明实施例的车载系统可以包括多个屏幕,例如主屏幕和副屏幕。所述主屏幕设置于主驾驶位;所述副屏幕的数量可以为一个或多个,所述副屏幕设置于副驾驶位,或者以双排座为例,所述副屏幕还可以设置于副驾驶位和后排座位的前方,本实施例不进行特殊限制。
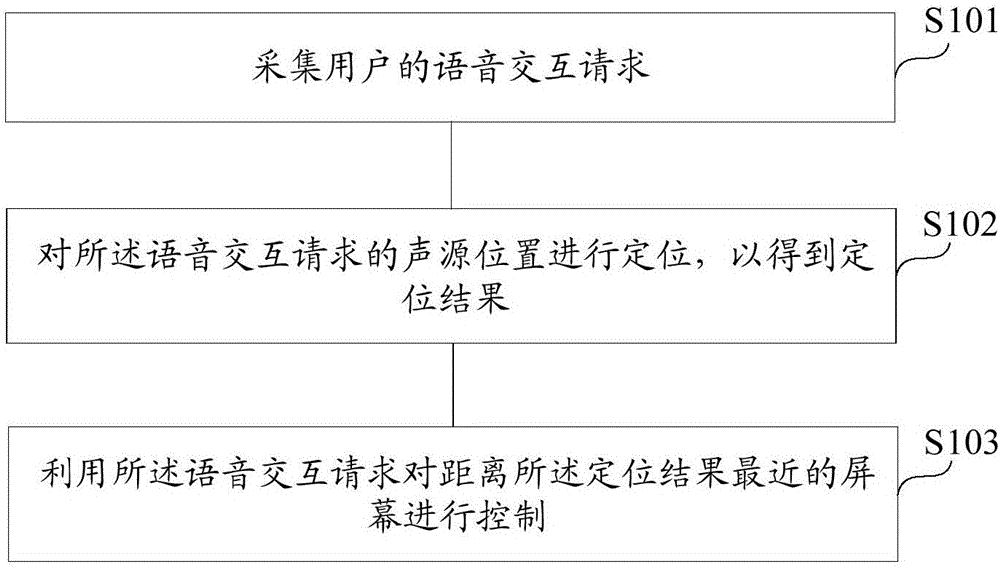
图1是本发明实施例的一种车载系统的终端同步显示方法的流程图。
如图1所示,本实施例的车载系统的多屏语音交互方法可以包括以下步骤:
步骤s101,采集用户的语音交互请求。
步骤s102,对所述语音交互请求的声源位置进行定位,以得到定位结果。
步骤s103,利用所述语音交互请求对距离所述定位结果最近的屏幕进行控制。
在本发明实施例中,所述车载系统中的主屏幕和副屏幕上分别可以预安装有智能应用模块,简称应用或应用程序(application,简称app)或应用模块。在所述主屏幕上打开的应用在所述主屏幕上显示,在所述副屏幕上打开的应用在所述副屏幕上显示。例如,所述应用模块可以包括有与驾驶相关的应用,例如导航相关的应用,还可以包括有多媒体项目相关的应用,例如视频,音频,收音机频道,生活搜索等等。其中,所述生活搜索可以是点评类搜索或团购类搜索,但不限于此。
在具体实施中,所述主屏幕和副屏幕上可以预设有不同类型的应用,也可以预设有完全相同的应用,本实施例不进行特殊限制。然而,考虑到行车安全性和不同用户的个性化设置,优选地,按照屏幕类型的不同进行应用类型区分。设于驾驶座的主屏幕上的应用仅与驾驶相关,各副屏幕上的应用可以与多媒体项目相关,进而可以在较大程度上保证驾驶人员的行车安全,并同时将多媒体娱乐功能充分地设置在各个副屏幕上,增添车辆中用户的乘车乐趣。
首先,在步骤s101的具体实施中,对用户的语音交互请求进行采集。采集是由车载系统中的硬件设备实现的,例如语音传感器。采用声音采集技术,将语音信号转换为电信号,并传输至车载系统中的中控器进行进一步地分析和处理。在用户的语音中包含的信息至少可以包括:语音内容,音色也即声纹信息,语音强度等。经采集后,在所述中控器中可以分别对所述用户的语音中包含的信息的一项或多项进行识别。其中,在识别时,可以至少识别出用户语音的内容,其他的信息是可选的。
本领域技术人员应当理解的是,对语音进行识别,包括对语音内容,声纹信息,语音强度等信息的识别,可以采用任意可实施的语音处理算法,本发明实施例对此不做限制。
其次,在步骤s102的具体实施中,由于本实施例中的车载系统包括有多个屏幕,因此,如何去确认用户的语音交互请求所指向的屏幕可以通过对所述语音交互请求的声源位置进行定位来实现。在得到定位结果后,所述定位结果指示出用户在车辆中的某个位置发出了语音。
再次,在步骤s103的具体实施中,本实施例则将距离所述定位结果最近的屏幕作为用户欲进行语音交互请求的屏幕,并利用所述语音交互请求对所述屏幕进行控制。一般来说,用户进入车辆后,将会坐入车辆内的不同位置,如驾驶座、副驾驶座或者后排座。在大多数场景中,用户在车内入座后才开始提出语音交互请求。也就是说,可以通过声源定位的方式确定用户入座的实际位置,在用户提出语音交互请求时,控制其面前的屏幕(也即距离声源最近的屏幕)对其语音交互请求进行响应是最为合理、最满足用户需求和用户体验最佳的方式。
在具体实施中,对所述屏幕进行控制可以包括以下形式:例如:用户的语音请求为“今天上海天气怎么样?”,或“查询从上海至北京明天上午的航班”,或“播放一首歌”或“播放一个电影”等等,对应地,语音交互中受控的屏幕则显示出今日上海的天气信息,或显示上海至北京明天上午6:00-12:00起飞的所有航班班次,或者播放一首歌或电影。
进一步而言,本发明实施例的多屏语音交互方法可以通过采集用户的语音交互请求,对所述语音交互请求的声源位置进行定位,以得到定位结果,利用所述语音交互请求对距离所述定位结果最近的屏幕进行控制。一方面实现了车载系统的多屏语音控制,易于操作,可以有效地提高用户对车载系统的使用体验;另一方面,在控制距离所述定位结果最近的屏幕对用户的语音交互请求进行响应时,可以有针对性地仅开启该屏幕与用户进行语音交互,其他屏幕可以不开启(也即,维持休眠状态),节约能耗。
在本发明实施例中,所述车载系统可以包括主屏幕数据接口和副屏幕数据接口,其中,所述主屏幕数据接口与所述主屏幕一一对应,所述副屏幕数据接口与所述副屏幕一一对应。当所述主、副屏幕数据接口存储的显示信息调整或更新时,所述主、副屏幕的显示内容被调整或更新。也即在本实施例中,利用所述语音交互请求对距离所述定位结果最近的屏幕进行控制,以实现车载系统的多屏语音交互,可以通过对所述主屏幕数据接口和副屏幕数据接口中数据内容的调整进行实现。
进一步而言,本实施例中的多屏语音交互方法中的步骤适于在同一操作系统下进行执行,通过分别独立地设置所述主屏幕数据接口和副屏幕数据接口的显示信息来设置主、副屏幕显示内容。一方面可以根据不同的驾驶位调整不同的屏幕显示内容,很好地适应用户的个性化需求;另一方面,由于运行于同一操作系统,因此在硬件配置上仅需一个控制器,可适当地降低车载系统的硬件成本。
在具体实施中,所述车载系统中可以运行有安卓(android)操作系统,但不限于此,所述车载系统中可以运行有其他任何适当的操作系统,例如linux等嵌入式操作系统。
一并参见图1和图2,在本发明一优选实施例中,所述步骤s101可以包括以下各个步骤:
步骤s1011,采集车内的用户语音。
步骤s1012,对所述用户语音进行验证,在验证通过时得到所述语音交互请求。
进一步而言,在本实施例中,并非所有的用户语音均可以作为启动相应的屏幕进行语音交互的条件。例如,在用户在车内聊天、打电话等非语音交互请求的语音内容出现时,为了防止用户在车内的非语音请求错误地被识别为语音交互请求,对所述用户语音进行验证是必要的,可以有效地提高多屏语音交互的有效性。
在实际实施时,所述步骤s1012中的所述对所述用户语音进行验证可以采用以下方式进行实施:识别所述用户语音的内容;当所述用户语音的内容包含预设的控制指令词时,验证通过。其中,所述预设的控制指令词可以是预先录入的。所述车载系统中的存储器中可以存储有由多个控制指令词组成的指令词库。
需要说明的是,在本实施例中,只要用户的语音内容能够通过上述验证,对用户的身份无任何特殊限定,也即任何包含有预设的控制指令词的语音内容所代表的语音交互请求均可以被车载系统所识别。
此外,本发明实施例对所述控制指令词的内容不进行特殊限定,只要可以被所述车载系统所识别并产生预设的响应即可。例如,“今天上海天气怎么样?”所对应的控制指令词可以分别为“今天”、“上海”和“天气”;“查询从上海至北京明天上午的航班”所对应的控制指令词可以分别为“上海”、“北京”、“航班”和“明天上午”;“播放一首歌”或“播放一个电影”所对应的控制指令词可以分别为“播放”和“歌”或“电影”。
进一步优选地,在所述步骤s1012的具体实施中,对识别所述用户语音的内容的验证,也即将其与预设的控制指令词的匹配验证可以按照模糊匹配的方式进行。例如,当用户的语音内容为“天气怎么样?”,其包含的控制指令词为“天气”,则此时可以被识别为语音交互请求。此时,车载系统可以通过屏幕进一步提问“请问您关心的是何时何地的天气?”,在用户进一步发出语音“今天上海天气怎么样?”后所述屏幕进行响应。或者可选地,用户并未进一步提供“何时何地”的信息,车载系统可以将默认的当前车辆所在地和当前时间为依据对“天气怎么样?”在所述屏幕上进行响应。
在本发明一优选实施例中,所述步骤s102中对所述语音交互请求的声源位置进行定位可以包括以下各个步骤:比较各个屏幕接收到的所述语音交互请求的声音强度;和/或,对车辆内各个用户的发声动作进行图像识别。
在具体实施中,可以通过采集各个屏幕接收到的所述语音交互请求的声音强度对所述语音交互请求的声源位置进行定位,例如,用户a乘坐于副驾驶座,则位于车辆中驾驶座和乘客座(包括副驾驶座和后排座)的传感器所接收到的用户a的声音强度是完全不同的,可以通过对接收到的声音强度值进行比较,很容易得出,位于副驾驶座的传感器接收到的声音强度值最大,由于可判断出声源位置在副驾驶座,则开启所述副驾驶座前的副屏幕作为语音交互的屏幕。
此外,还可以采用对车辆内各个用户的发声动作进行图像识别的方式进行声音定位。首先,需要采用语音传感器采集用户a的语音,别对其进行语音识别以得到语音内容;其次,采用车载摄像头对车内的各个用户的发声动作进行回放,并对其进行图像识别,以发声动作和语音内容匹配验证的方式判断发出语音的是哪个用户;最后,在锁定是用户a发出了语音时,通过车载摄像头提取用户a是乘坐于副驾驶座的,则开启所述副驾驶座前的副屏幕作为语音交互的屏幕。
进一步而言,优选地,还可以采用上述两种方式结合的方式进行声源位置定位,也即采用声音强度比较和发声动作图像识别相结合的方式,更有利于保证声源位置定位的准确性。
本领域技术人员理解的是,本实施例中的声源位置的定位可以采用任何可实施的方式进行,并不限于此上述两种或二者结合的方案,在此不再一一举例。
继续一并参见图1和图2,在具体实施中,所述步骤s103可以包括以下各个步骤:
步骤s1031,对距离所述定位结果最近的屏幕进行唤醒。
步骤s1032,控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应。
在步骤s1031的具体实施中,对距离所述定位结果最近的屏幕进行唤醒可以表示将距离所述定位结果最近的屏幕从待机状态(例如屏幕处于黑屏状态)到工作状态,也可以表示车载系统中的中控器从消息处理进程或其优先级上,控制所述距离所述定位结果最近的屏幕对所述语音交互请求的响应被唤醒。
优选地,所述步骤s1032可以包括以下各个步骤:
识别所述语音交互请求的声纹信息,以确定用户身份;基于所述用户身份,加载与所述声纹信息相匹配的个性化设置信息;基于所述个性化设置信息,控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应。
在本实施例中,所述语音交互请求的声纹信息在用户的语音信号中被提取、分析和识别。特定的声纹信息与特定的用户身份是一一关联的。例如,所述车载系统可以将用户的声纹信息作为登陆信息注册并登陆至车载系统的各个屏幕。当车载系统识别到用户的声纹信息是“注册”过的声纹信息时,则可以通过关联性确认用户身份。
而在用户以其声纹信息作为登录信息登陆至屏幕后,在车辆中会记录有其个性化设置信息,例如,其对系统的设置方式,可包括屏幕背景、字体、字号等,再例如其使用习惯和个人偏好,可包括其喜欢的歌曲、电影或图片等。因此,在确认用户身份后,可以基于所述用户身份,加载与所述声纹信息相匹配的个性化设置信息。该个性化设置信息可以以数据的形式存储于车载系统的存储器中,也可以体现于响应其语音交互请求的屏幕上。
在本实施例中,可以基于所述个性化设置信息,控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应。例如,在用户的语音内容为“天气怎么样?”时,根据用户的个性化设置信息,所述屏幕直接提供上海今天的天气信息,或在用户的语音内容为“播放一首歌”或“播放一个电影”时,根据用户的个性化设置信息,所述屏幕直接在用户的喜爱的播放列表中挑选一首歌曲或一个电影进行播放。相应地,无需再向用户对其询问天气的“何时何地”进一步确认,也无需随机地、毫无个人特色地随机选择歌曲或电影进行播放。
进一步而言,在本实施例中,由于通过识别所述语音交互请求的声纹信息,确定了用户身份,并基于所述用户身份,加载了与所述声纹信息相匹配的个性化设置信息,则可以基于所述个性化设置信息,控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应,可以使得用户对车载系统中的语音交互过程更符合用户的个人化需求,可以极大地提高用户的使用体验。
本领域技术人员理解的是,本实施例中的利用所述语音交互请求对相应的屏幕进行控制可以采用任何可实施的方式进行,并不限于基于用户身份的个性化设置信息进行。
如图3所示,本发明实施例还公开了一种车载系统的多屏语音交互装置,其中,所述车载系统可以包括多个屏幕。本领域技术人员理解,本实施例所述车载系统的多屏语音交互装置30用于实施上述图1至图2所示实施例中所述的方法技术方案。
具体地,所述车载系统的多屏语音交互装置30可以包括语音请求采集模块301、位置定位模块302和屏幕控制模块303。
其中,所述语音请求采集模块301适于采集用户的语音交互请求;所述位置定位模块302适于对所述语音交互请求的声源位置进行定位,以得到定位结果;所述屏幕控制模块303适于利用所述语音交互请求对距离所述定位结果最近的屏幕进行控制。
进一步而言,本发明实施例可以通过采集用户的语音交互请求,对所述语音交互请求的声源位置进行定位,以得到定位结果,利用所述语音交互请求对距离所述定位结果最近的屏幕进行控制。一方面实现了车载系统的多屏语音控制,易于操作,可以有效地提高用户对车载系统的使用体验;另一方面,在控制距离所述定位结果最近的屏幕对用户的语音交互请求进行响应时,可以有针对性地仅开启该屏幕与用户进行语音交互,其他屏幕可以不开启,节约能耗。
在具体实施中,所述屏幕控制模块303可以包括唤醒子模块3031和屏幕控制子模块3032。其中,所述唤醒子模块3031适于对距离所述定位结果最近的屏幕进行唤醒;所述屏幕控制子模块3032适于控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应。
优选地,所述屏幕控制子模块3032可以包括身份确认子模块30321、信息加载子模块30322和个性化控制子模块30323。
其中,所述身份确认子模块30321适于识别所述语音交互请求的声纹信息,以确定用户身份;所述信息加载子模块30322适于基于所述用户身份,加载与所述声纹信息相匹配的个性化设置信息;所述个性化控制子模块30323适于基于所述个性化设置信息,控制距离所述定位结果最近的屏幕对所述语音交互请求进行响应。
在具体实施中,所述语音请求采集模块301可以包括语音采集子模块3011和语音验证子模块3012。其中,所述语音采集子模块3011适于采集车内的用户语音;所述语音验证子模块3012适于对所述用户语音进行验证,在验证通过时得到所述语音交互请求。
优选地,所述语音验证子模块3012可以包括内容识别子模块30121,所述内容识别子模块30121适于识别所述用户语音的内容;当所述用户语音的内容包含预设的控制指令词时,验证通过。
在具体实施中,所述位置定位模块302可以包括强度比较子模块3021和/或图像识别子模块3022。其中,所述强度比较子模块3021适于比较各个屏幕接收到的所述语音交互请求的声音强度;所述图像识别子模块3022适于对车辆内各个用户的发声动作进行图像识别。
关于所述车载系统的多屏语音交互装置30的更多信息可以参照对图1至图2中所述车载系统的多屏语音交互方法的相关描述,此处不再一一赘述。
本发明实施例还公开了一种存储介质,其上可以存储有计算机指令,所述计算机指令运行时执行图1至图2所示出的车载系统的多屏语音交互方法的步骤。所述存储介质可以包括rom、ram、磁盘或光盘等。
本发明实施例还公开了一种车机,所述车机可以包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机指令,所述处理器运行所述计算机指令时执行图1至图2所示出的车载系统的多屏语音交互方法的步骤。在具体实施中,所述车机可以设置于汽车内,例如可以是设置有多屏的车载系统。
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!