一种从音频中提取目标源的方法及装置与流程
本发明涉及音频信号处理
技术领域:
,具体涉及一种从音频中提取目标源的方法及装置。
背景技术:
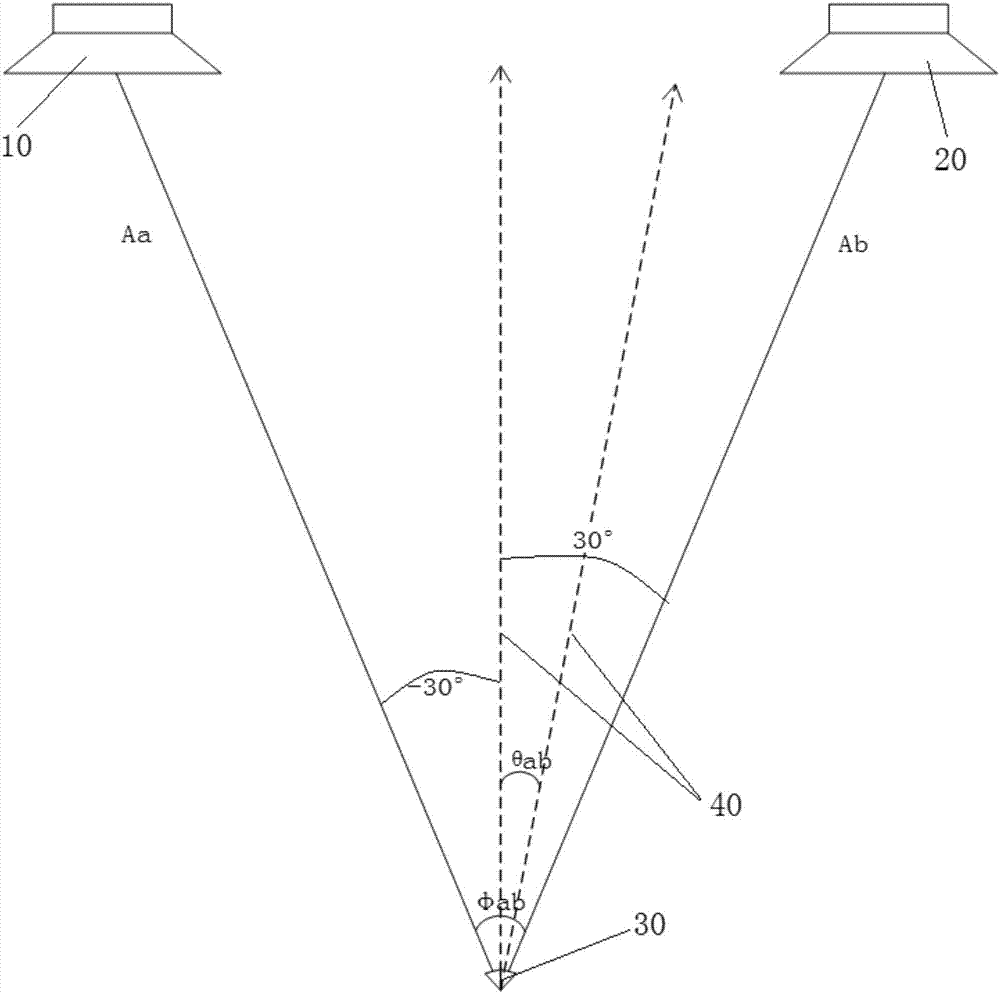
:目前ktv市场上的唱歌打分系统大部分是以演唱的音调起伏或是音量大小来评分的,不能真正根据演唱者的声音进行评分,这种低精度的评分系统正越来越无法满足消费者的需求。试想一个唱歌非常好听的人和一个唱歌不是那么好的人他们分数相同,或者因为音量的关系唱的不好的人分数反而很高,这样的打分大大降低的一部分人的评分积极性。所以对于ktv评分系统的改进变得非常重要,为了改善ktv评分系统,使评分变得更加精准,我们可以用歌曲中原唱的人声对比消费者在ktv演唱的人声,二者的吻合度越高则评分就会越高。而这样做的第一步则是将歌曲中的原唱人声从歌曲的伴奏加人声中单独提取出来,然而如何从自包含有人声与伴奏的歌曲音频中将原唱的人声很好地提取出来,成为难题。技术实现要素:本发明的目的是针对现有技术中存在的技术缺陷,而提供一种从音频中提取目标源的方法及装置。为实现本发明的目的所采用的技术方案是:一种从音频中提取目标源的方法,包括步骤:对采集的音频信号逐帧进行时频变换,将时域信号变换为频域信号,利用窗函数对频域信号进行分割,形成第一路信号与第二路信号;遍历计算给定频率下每帧频域信号的第一路信号与第二路信号的各频点对应的虚拟源的虚拟夹角;比较所述虚拟夹角与预定角度阈值的大小,根据比较结果将第一路信号或第二路信号作为目标源信号并提取该目标源信号的频域信号存储;利用时频逆变换将存储的目标源信号的频域信号转换为时域信号,输出目标源时域信号。本发明的另一方面还在于提供一种从音频中提取目标源的装置,包括:时域频域转化分割模块,用于对采集的音频信号逐帧进行时频变换,将时域信号变换为频域信号,利用窗函数对频域信号进行分割,形成第一路信号与第二路信号;虚拟夹角计算模块,用于遍历计算给定频率下每帧频域信号的第一路信号与第二路信号的各频点对应的虚拟源的虚拟夹角;目标源信号存储模块,用于比较所述虚拟夹角与预定角度阈值的大小,根据比较结果将第一路信号或第二路信号作为目标源信号并提取该目标源信号的频域信号存储;频域时域转化输出模块,用于利用时频逆变换将存储的目标源信号的频域信号转换为时域信号,输出目标源时域信号。本发明方法通过将待分离音频信号逐帧进行时域频域转化后,分别形成第一路信号与第二路信号,然后通过遍历计算频率下每帧频域信号的第一路信号与第二路信号的各频点对应的虚拟源的虚拟夹角,根据该虚拟夹角与预定角度阈值比较,实现将符合要求的目标源信号分离出来存储,之后再经过频域到时域的转化后输出,实现将目标源信号自音频信号中分离提取出来,方便后续对目标源信号的处理使用。附图说明图1是从音频中提取目标源的方法的流程图;图2是虚拟源的虚拟夹角的计算示意图;图3是从音频中提取目标源的装置的结构示意图。具体实施方式以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。参见图1所示,一种从音频中提取目标源的方法,包括步骤:对采集的音频信号逐帧进行时频变换,将时域信号变换为频域信号,利用窗函数对频域信号进行分割,形成第一路信号a与第二路信号b;遍历计算给定频率k下,每帧频域信号的第一路信号与第二路信号各频点所对应的虚拟源的虚拟夹角θab(k);比较所述虚拟夹角θab(k)与预定角度阈值的大小,根据比较结果将第一路信号或第二路信号作为目标源信号并提取该目标源信号的频域信号存储;利用时频逆变换将存储的目标源信号的频域信号转换为时域信号,输出目标源时域信号。本发明方法可以实现将在ktv系统中歌曲的人声与伴奏混合音频中的人声(目标源)分离出来单独存储后输出,这样为后续ktv评分系统中的准确地评估演唱者的真空演唱水平提供了基础,当用于ktv系统中歌曲的人声与伴奏混合音频中提取人声时,如将上述的第一路信号作为伴奏信号,第二路信号作为人声信号,通过计算虚拟源的虚拟夹角,然后比较虚拟夹角与预定角度阈值的大小,根据人声与伴奏的信号的虚拟源的虚拟夹角的不同,通过设置一个预定角度阈值来比较判断,根据比较判断结果,即将该符合要求的虚拟夹角对应的虚拟源所对应的信号作为人声信号单独存储,依次对每帧音频信号采用同样方式遍历处理,就可以实现将歌曲的人声从人声与伴奏的混合音频信号中分离存储。所述预定角度阈值根据经验来确定,可以是5度,3度或是其它角度,所述窗函数可根据需要选择同一大小的窗函数或不同大小的窗函数,以尽可能地减少窗函数分割频域信号时的频谱能量泄漏。在利用时频逆变换(istft)将存储的目标源信号的频域信号转换为时域信号,输出目标源时域信号时,相应要采用对应的截取时的窗函数大小进行还原。其中,所述虚拟源的虚拟夹角的计算方式如下:式中,θab(k)表示频率k呈现的第一路信号a与第二路信号b各频点对应的虚拟源的虚拟夹角,aa(k)与ab(k)分别表示第一路信号a与第二路信号b呈现的频率k的振幅,表示第一路信号a与第二路信号b的夹角。由于音频信号的稀疏性原理,在同一时间同一个频率上,第一路信号a的一个时频点的输出和第二路信号b的一个时频点的输出,总有一个远远大于另一个;时频点是以y轴为频率(hz),x轴为时间的一个坐标系里信号所表示的信号的振幅大小,单位db。如下表所示:频率(hz)204060……第一路信号aa1a2a3……第一路信号bb1b2b3……根据稀疏性原理,在第一路信号a与第二路信号b的比较中,a1表示第一路信号a在频率为20hz下,时频变换stft(短时傅立叶变换)的一个时频点的输出,b1表示第二路信号b在频率为20hz下,时频变换stft的一个时频点的输出,则a1、b1应为复数。总有|a1|>>|b1|,且b1≈0,或|a1|<<|b1|,且a1≈0,后面同理。因此,利用该信号的稀疏性原理,可以实现利用虚拟源的虚拟夹角来判断区别两个信号,将需要的目标信号分离出来存储。具体见附图2所示,该图2示出了如何计算呈现第一路信号a和第二路信号b的振幅的虚拟源40的虚拟夹角θab,aa,ab为第一路信号a和第二路信号b的振幅,两个信号的夹角为-30°至30°,图2中两个扬声器,左扬声器10、右扬声器20传送出的音频信号给位于两个扬声器中间位置的听者30,这样两个扬声音器的传送的声音到达听者30的人耳的频率k可用虚拟源40来呈现第一路信号a和第二路信号b振幅aa(k)与ab(k)。在时频变换后得到的第一路信号a和第二路信号b所呈现的频率k的虚拟源来呈现两个信号的振幅aa(k)与ab(k),当然本发明并不限于第一路信号a和第二路信号b所呈现的频率k的虚拟源来呈现两个信号的振幅aa(k)与ab(k)的处理,也可是多个信号,如有多个信号(多于两个),则有已知信号(含目标源的信号)与其他信号ai加和:sum(|aii)=∑iiaii=a1+…+ai,(1≤i≤i).所形成的另一信号而所呈现的虚拟源来处理,实际上也按两个信号处理所呈现的虚拟源来处理。这样就可以根据前面所述虚拟源的虚拟角度计算公式,计算出给定频率k下虚拟源的虚拟角θab(k)的大小,为正数值或负数值:虚拟源由选择的第一路信号a,第二路信号b的振幅和虚拟夹角表示为:{aa(k),ab(k),θab}。θab即为边信息(sideinformation),即第二路信号a、第二路信号b虚拟夹角,即虚拟源夹角,通过边信息(sideinformation)的辅助可以对原信号进行分析,判断是否为目标源----人声。计算出虚拟源夹角后,在给定的两个信号的信号夹角范围内(-30°至30°,大小固定),在同一帧中的某一频率中,若第一路信号a的时频点的输出大于第二路信号b时(假设第一路信号a为伴奏,第二路信号b为人声)则虚拟夹角θab会向第一路信号a倾斜,反之则会向第二路信号b倾斜。为了方便判断处理,可根据经验在两个信号夹角之间方向确定一个预设角度阈值,如零度,即当虚拟夹角θab的大小超过该零度角度阈值时,将它分类为人声,如图2所示。利用这种方法遍历频率上每一帧进行分类,即可实现将目标源从混合音频中分离;最后利用时频逆变换将存储的频域信号转换为时域,输出目标源信号---人声。具体的,在根据所述的虚拟夹角判断是否为人声时,采用以下方式进行,即当所述虚拟源的虚拟夹角θab(k)大于预定角度阈值时,将所述虚拟源所对应的第一路信号或第二路信号视为目标源信号,然后提取该目标源信号的频域信号存储。其中,提取该目标源信号的计算方式如下(假设第一路信号a为目标源信号,对应的aa(k)中含有需要提取的目标源信号):s(k)=aa(k)·m(k),其中,m(k)为目标源信号提取向量;t为给定阈值,s(k)为目标源信号。其中,在时域频域转换时,包括但不限于使用傅里叶变换,小波变换,mdct变换等方法。本发明的目的还在于提供一种从音频中提取目标源的装置,参见图3所示,包括:时域频域转化分割模块,用于对采集的音频信号逐帧进行时频变换,将时域信号变换为频域信号,利用窗函数对频域信号进行分割,形成第一路信号与第二路信号;虚拟夹角计算模块,用于遍历计算给定频率下每帧频域信号的第一路信号与第二路信号的各频点所对应的虚拟源的虚拟夹角θab(k);目标源信号存储模块,用于比较所述虚拟夹角θab(k)与预定角度阈值的大小,根据比较结果将第一路信号或第二路信号作为目标源信号并提取该目标源信号的频域信号存储;频域时域转化输出模块,用于利用时频逆变换将存储的目标源信号的频域信号转换为时域信号,输出目标源时域信号。本发明装置可以实现将在ktv系统中歌曲的人声与伴奏混合音频中的人声(目标源)分离出来单独存储后输出,这样为ktv系统中的准确地评估演唱者的真空演唱水平提供了基础,当用于提取ktv系统中歌曲的人声与伴奏混合音频中的人声时,如将上述的第一路信号作为伴奏信号,第二路信号作为人声信号,通过计算虚拟源的虚拟夹角,然后比较虚拟夹角与预定角度阈值的大小,根据人声与伴奏的信号虚拟源的虚拟夹角的不同,通过设置一个预定角度阈值来比较判断,根据比较判断结果,即将该符合要求的虚拟夹角对应的虚拟源所对应的信号作为人声信号单独存储,依次对每帧音频信号采用同样方式遍历处理,就可以实现将歌曲中原唱的人声从人声与伴奏的混合音频信号中分离存储。所述预定角度阈值根据经验来确定,可以是5度,3度或是其它角度。所述窗函数可根据需要选择同一大小的窗函数或不同大小的窗函数,以尽可能地减少窗函数分割频域信号时的频谱能量泄漏。在利用时频逆变换(如短时傅立叶逆变换istft)将存储的目标源信号的频域信号转换为时域信号,输出目标源时域信号时,相应要采用对应的截取时的窗函数大小进行还原。其中,所述虚拟源的虚拟夹角的计算方式如下:θab(k)表示虚拟源的虚拟夹角,aa(k)与ab(k)分别表示第一路信号与第二路信号呈现的频率k的振幅,表示第一路信号与第二路信号的夹角。具体的,在根据虚拟夹角判断是否为人声时,采用以下方式进行,即当所述虚拟源的虚拟夹角θab(k)大于预定角度阈值时,将所述虚拟源所对应的第一路信号或第二路信号视为目标源信号,然后提取该目标源信号的频域信号存储。关于虚拟源及虚拟夹角的说明,请参阅前述有关如何计算呈现第一路信号a和第二路信号b的振幅的虚拟源的虚拟夹角的说明以及附图2。以上所述仅是本发明的优选实施方式,应当指出的是,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1