一种自动生成会议记录的方法与流程
本发明涉及信息处理技术领域,具体涉及一种自动生成会议记录的方法。
背景技术:
一般的会议记录是由专门的会议记录员通过录音笔、摄像机等设备摄录会议内容,然后进行人工整理得到,随着科技的进步,人们开始研究如何自动快速地得到会议记录,包括发言人、发言内容等。
专利申请cn201510530579公开了一种会议记录方法,由语音转化软件将语音信号转化成对应的文字信息,然后对错误的文字信息进行二次识别,并进行编辑显示;专利申请cn201410839533公开了一种会议记录装置及其自动生成会议记录的方法,根据会议上接收的语音信号与存储器中存储的用户语音特征表,辨识语音信号对应的用户,然后将语音信号转换为文字得到会议记录。
上述现有技术,在进行发言人识别时需要提前收集并存储参会相关人员的语音特征信息,然后通过录制的语音信息与存储的用户语音特征信息进行对比从而辨识出说话用户。但实际上开会的参会人员往往不固定甚至与合作公司人员一起开会,这往往导致无法提前收集参会人员的语音特征信息,同时参会人员的临时变化(增加人员)无法使用现有技术的工作流程,而且将参会人员的语音特征信息存储起来本身存在泄露的安全隐患(重要人物的语音特征信息如果泄露可能会被犯罪份子加以利用)。
技术实现要素:
有鉴于此,本发明提供一种自动生成会议记录的方法,无需提前收集存储参会人员的语音特征即可将说话人进行分类;进行说话人分类后会议记录整理人员可轻易知道会议中说话人的发言内容并进行整理。
为实现上述目的,本发明的技术方案是:一种自动生成会议记录的方法,包括以下步骤:
步骤s1:录制会议过程的语音;
步骤s2:通过vad技术提取仅包含说话内容的若干语音片段;
步骤s3:过语音识别技术将语音片段转换为文字;
步骤s4:从语音片段中提取出说话人声纹特征,并根据声纹特征对语音片段进行说话人分类,同时设置说话人标签;
步骤s5:将语音片段、对应的文字和说话人标签进行存储;
步骤s6:将说话人标签替换为具体的说话人,得到最终的会议记录。
进一步地,所述步骤s4具体如下:
根据语音片段的顺序,通过i-vector和gmm-ubm语音技术提取语音片段中的声纹特征;
将提取到的第一个声纹特征进行临时存储,将该声纹特征对应的语音片段所转换的文字设置说话人标签speakerx,x为计数位,x=1;
依次提取声纹特征,并与临时存储的声纹特征进行逐一匹配,如匹配成功,则将提取的声纹特征对应的语音片段所转换的文字设置相同的说话人标签speakerx;如匹配不成功,则将提取的声纹特征说话人标签计数位加1,并进行临时存储。
进一步地,还包括步骤s7:删除临时存储的声纹特征数据。
与现有技术相比,本发明具有有益效果:无需提前收集参会人员的语音特征、声纹信息,所以参会人员的临时变化不会影响本发明的工作流程;虽然在处理过程中提取了说话人的声纹特征信息,但在处理结束后便立即删除掉,确保了说话人声纹特征信息的安全性。
附图说明
图1是本发明一种自动生成会议记录的方法流程图;
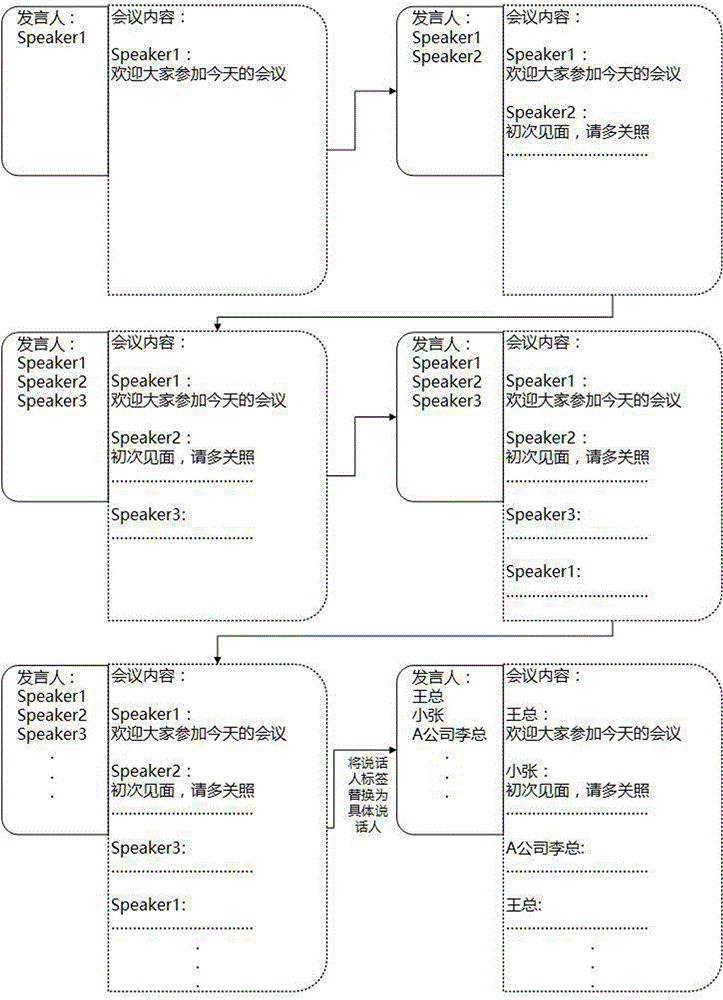
图2是本发明一实施例的处理过程示意图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
如图1所示,一种自动生成会议记录的方法,包括以下步骤:
步骤s1:录制会议过程的语音;
步骤s2:通过vad技术提取仅包含说话内容的若干语音片段;
步骤s3:通过语音识别技术将语音片段转换为文字;
步骤s4:从语音片段中提取出说话人声纹特征,并根据声纹特征对语音片段进行说话人分类,同时设置说话人标签;
具体如下:
根据语音片段的顺序,通过i-vector和gmm-ubm语音技术提取语音片段中的声纹特征;
将提取到的第一个声纹特征进行临时存储,将该声纹特征对应的语音片段所转换的文字设置说话人标签speakerx,x为计数位,x=1;
如图2所示,在本实施例中,提取的第一个声纹特征对应的语音片段所转换的文字是“欢迎大家参加今天的会议”,将其设置说话人标签speaker1;
依次提取声纹特征,并与临时存储的声纹特征进行匹配,如匹配成功,则将提取的声纹特征对应的语音片段所转换的文字设置相同的说话人标签speakerx;如匹配不成功,则将提取的声纹特征说话人标签计数位加1,并进行临时存储;
在本实施例中,提取的第二个声纹特征与临时存储的speaker1的声纹特征匹配不成功,则将第二个声纹特征对应的语音片段所转换的文字设置说话人标签计数位加1,即speaker2;然后将提取的第三个声纹特征与临时存储的speaker1和speaker2的声纹特征进行匹配,匹配不成功,则将第三个声纹特征对应的语音片段所转换的文字设置说话人标签计数位加1,即speaker3;在本实施例中,提取的第四个声纹特征与临时存储的speaker1、speaker2、speaker3进行逐一匹配,与speaker1匹配成功,则将第四个声纹特征对应的语音片段所转换的文字设置相同的说话人标签speaker1,依此类推,对所有语音片段进行处理;
步骤s5:将语音片段、对应的文字和说话人标签进行存储;
步骤s6:将说话人标签替换为具体的说话人,得到最终的会议记录;
步骤s7:删除临时存储的声纹特征数据。
本发明无需提前收集参会人员的语音特征、声纹信息,本地直接提取声纹信息并进行对比,自动进行说话人的分类,最后仅需将分类标签替换为实际说话人即可达到对会议记录的整理。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
技术特征:
技术总结
本发明提供一种自动生成会议记录的方法,包括步骤1)录制会议过程的语音;2)通过VAD技术提取仅包含说话内容的若干语音片段;3)通过语音识别技术将语音片段转换为文字;4)从语音片段中提取出说话人声纹特征,并根据声纹特征对语音片段进行说话人分类,同时设置说话人标签;5)将语音片段、对应的文字和说话人标签进行存储;6)将说话人标签替换为具体的说话人,得到最终的会议记录。本发明无需提前收集参会人员的语音特征、声纹信息,自动进行说话人分类。
技术研发人员:刘维;王贤俊;高刚强;郑文侃;邱霖恺;何逞
受保护的技术使用者:福建实达电脑设备有限公司
技术研发日:2017.09.29
技术公布日:2018.02.13
- 还没有人留言评论。精彩留言会获得点赞!