聊天机器人回声消除方法及装置与流程
本发明涉及计算机技术领域,尤其涉及一种聊天机器人回声消除方法及装置。
背景技术:
人机对话交互应用(例如,聊天机器人)已经逐渐实现了商业化,越来越接近人们的日常工作和生活。目前,常用的人机对话交互技术往往会在机器人讲话(机器人通过语音输出对用户输入的回复)时关闭机器人拾音的功能,即机器人不会对此时用户输入的语音产生反应,即将机器人的麦克风与机器人其它部分的数据或命令传输设置为关闭状态。这样做的好处是防止机器人在自身说话的时候,既拾取到用户发音又同时拾取到了自身发出的声音。本质上来说,这种被误拾取的由机器人自身发出的声音可以称为“自噪声”,习惯上我们也称其为回声。
但是,在实际使用过程中,用户在机器人说话时,通过语音打断机器人的讲话,是用户的客观需求之一。因此,需要设计一种拾音方案,保证机器人在自身讲话时,仍然可以准确地拾取用户的语音输入。
技术实现要素:
本发明要解决的技术问题是提供一种聊天机器人回声消除方法及装置,以克服现有技术中,聊天机器人为了不误拾取到自身说话的声音,而强制性设定机器人说话时不拾取外界声音,导致机器人在说话时,用户不能通过语音打断机器人讲话的问题。
为解决上述技术问题,本发明提供的技术方案为:
一方面,本发明提供一种聊天机器人回声消除方法,包括,
场景确定步骤,确定聊天场景;
函数确定步骤,确定出与聊天场景对应的脉冲响应函数;
回声估计步骤,根据脉冲响应函数确定机器人估计回声;
回声消除步骤,根据机器人拾取到的总信号,以及根据机器人估计回声,进行回声消除以确定用户实际输入的语音信号。
进一步地,确定出与聊天场景对应的脉冲响应函数,具体包括,
从预先构建的映射器中确定出与聊天场景对应的超参数组的值;
播放预置语音信号,以获取聊天场景下的机器人实际回声;
根据预置语音信号和机器人实际回声,并结合超参数组的值,确定出与聊天场景对应的脉冲响应函数。
进一步地,采用k-means方法或svm方法构建映射器。
进一步地,超参数组为{h(0),α,δ,m},其中,h(0)为零阶脉冲响应函数,α为步长,δ为补偿权值,m为脉冲响应函数的阶数。
进一步地,根据预置语音信号和机器人实际回声,并结合超参数组的值,确定出与聊天场景对应的脉冲响应函数,具体包括,将预置语音信号,机器人实际回声,超参数组的值代入预先构建的迭代方程,且在迭代方程满足收敛条件时,获取聊天场景对应的脉冲响应函数。
进一步地,确定出与聊天场景对应的脉冲响应函数,具体还包括,直接调用预存的与聊天场景对应的脉冲响应函数。
进一步地,还包括,将当前场景信息和预存的场景图谱进行比对,以验证脉冲函数的有效性。
进一步地,当前场景信息包括,场景位置,场景面积;场景图谱包括,场景名称,场景对应的脉冲响应函数,场景位置,场景面积,场景图。
进一步地,确定聊天场景,具体包括,根据询问用户并捕获用户回复语音中的场景相关信息,分析摄像装置获取的场景图像,接收用户直接设定的场景模式中的一种或多种方式的组合确定聊天场景。
另一方面,本发明还提供一种聊天机器人回声消除装置,包括,
场景确定单元,用于确定聊天场景;
函数确定单元,用于确定出与聊天场景对应的脉冲响应函数;
回声估计单元,用于根据脉冲响应函数确定机器人估计回声;
回声消除单元,用于根据机器人拾取到的总信号,以及根据机器人估计回声,进行回声消除以确定用户实际输入的语音信号。
本发明提供的聊天机器人回声消除方法及装置,根据聊天场景的不同确定对应的脉冲响应函数,继而估计出机器人的回声,最后,将机器人拾取到的总信号减去估计出的机器人回声,便可实现回声消除,继而实现确定用户实际输入的语音信号,可以克服现有技术中,聊天机器人为了不误拾取到自身说话的声音,而强制性设定机器人说话时不拾取外界声音,导致机器人在说话时,用户不能通过语音打断机器人讲话的问题。
附图说明
图1是本发明实施例提供的聊天机器人回声消除方法的流程图;
图2是本发明实施例提供的聊天机器人回声消除装置的框图。
具体实施方式
下面通过具体的实施例进一步说明本发明,但是,应当理解为,这些实施例仅仅是用于更详细具体地说明之用,而不应理解为用于以任何形式限制本发明。
实施例一
结合图1,本实施例提供的聊天机器人回声消除方法,包括,
场景确定步骤s1,确定聊天场景;
函数确定步骤s2,确定出与聊天场景对应的脉冲响应函数;
回声估计步骤s3,根据脉冲响应函数确定机器人估计回声;
回声消除步骤s4,根据机器人拾取到的总信号,以及根据机器人估计回声,进行回声消除以确定用户实际输入的语音信号。
本发明实施例提供的聊天机器人回声消除方法,根据聊天场景的不同确定对应的脉冲响应函数,继而估计出机器人的回声,最后,将机器人拾取到的总信号减去估计出的机器人回声,便可实现回声消除,继而实现确定用户实际输入的语音信号,可以克服现有技术中,聊天机器人为了不误拾取到自身说话的声音,而强制性设定机器人说话时不拾取外界声音,导致机器人在说话时,用户不能通过语音打断机器人讲话的问题。
优选地,确定出与聊天场景对应的脉冲响应函数,具体包括,
从预先构建的映射器中确定出与聊天场景对应的超参数组的值;
播放预置语音信号,以获取聊天场景下的机器人实际回声;
根据预置语音信号和机器人实际回声,并结合超参数组的值,确定出与聊天场景对应的脉冲响应函数。
具体地,本实施例中,将预置语音信号,机器人实际回声,超参数组的值代入预先构建的迭代方程,且在迭代方程满足收敛条件时,获取聊天场景对应的脉冲响应函数。本实施例中,超参数组为{h(0),α,δ,m},其中,h(0)为零阶脉冲响应函数,α为步长,δ为补偿权值,m为脉冲响应函数的阶数。
更加具体地,迭代方程为
需要说明的是,脉冲响应函数h(n):实际上是一组数字(h0,h1,...,hn),表示的是当前环境对信号的反射作用。且对于信号x(n),其作用于当前环境后的反射信号y(n)可表示为y(n)=h0x(n)+h1x(n-1)+...+hnx(n-n),其中,n是脉冲响应函数的阶数。
本实施例中,对于机器人自身输出信号x(n),若要获得其回声,则要进行回声估计,且所估计出的回声为y′(n)=h0x(n)+h1x(n-1)+...+hnx(n-n),也就是说,想要估计回声y′(n),就需要知道脉冲响应函数h(n)。
具体地,对于估计回声y′(n)和实际回声y(n),其误差可以表示为:e(n)=y(n)-y′(n)。当将h(0)作为已知参数初始化,本发明设计根据h(0)估计脉冲响应函数h(n+1)的方法为:
其中,h(0)、α、δ、m为超参数,α代表步长可以控制脉冲响应函数收敛的速度和脉冲响应函数的稳定性,δ用于补偿权值(防止由于||x(n)||2过小导致的权值过大),m表示脉冲响应函数的阶数。
进一步具体地,本实施例中的迭代方程,用于计算估计回声y′(n),因此,当估计回声y′(n)和实际回声y(n)误差足够小,且估计回声y′(n)和实际回声y(n)的变化的相关性足够高时可以结束对脉冲响应函数h(n+1)的更新,且将此时的脉冲响应函数确定为与聊天场景对应的脉冲响应函数。
优选地,本实施例中,脉冲响应函数h(n+1)的收敛条件为:
其中,r是相似度系数,且
进一步地,采用k-means方法或svm方法构建映射器。需要说明的是,采用k-means方法或svm方法构建映射器,仅为本实施例提供的优选技术方案,且实际应用中还可以使用其它机器学习方法构建映射器,本实施例不作具体限定。
本实施例中,为了快速获得最优的脉冲响应函数h(n+1),使用人工智能算法建立从具体场景到超参数组的映射器。具体构建方式为:将用户具体使用场景分为卧室、书房、客厅、草坪、ktv、party、马路、车内等,基于已有的用户数据统计每种具体场景对应的超参数的值,使用k-means(k均值)算法聚类得到每种具体场景的超参数值,或者使用支撑向量机(supportvectormachine,svm)等机器学习算法获得由具体场景到超参数的映射器。
需要说明的是,传统的k-means算法为:
1)将所有的超参数作为输入,根据场景的种类设置k值,选择k组随机的超参数,根据每个聚类对象的均值,
2)计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
3)重新计算每个聚类的均值;
4)当每个类中的点离中心对象的距离都小于预定值时,则算法终止;如果条件不满足则回到步骤2)。
本实施例中,采用改进的k-means算法建立映射器的方法为,采用1-means方法,即对每一个场景,求其超参数的均值,以均值为该场景对应的超参数。
优选地,确定出与聊天场景对应的脉冲响应函数,具体还包括,直接调用预存的与聊天场景对应的脉冲响应函数。
本实施例中,机器人在用户的使用过程中,能够对聊天场景以场景图谱形式进行存储,且场景图谱中的信息包括,场景名称、场景对应的脉冲响应函数、场景位置、场景面积、场景图等信息。如此,在用户习惯性使用的场景中,可以直接调取场景对应的脉冲响应函数,节省系统的运算资源并提升用户的使用体验。进一步地优选,还包括,将当前场景信息和预存的场景图谱进行比对,以验证脉冲函数的有效性。本实施例中,对直接调用的脉冲响应函数会执行有效性验证,并在所调用的脉冲响应函数无效时需要更新脉冲响应函数。具体地,通过对比当前的场景位置、场景面积、场景图等信息与场景图谱中记录的信息是否一致来验证脉冲响应函数的有效性。
优选地,确定聊天场景,具体包括,根据询问用户并捕获用户回复语音中的场景相关信息,分析摄像装置获取的场景图像,接收用户直接设定的场景模式中的一种或多种方式的组合确定聊天场景。
本实施例中,在用户具体使用机器人的时候,机器人通过询问用户、分析摄像头得到的外界环境图像、提供按钮供用户设定选择等方式得到当前环境,然后根据已知的映射器获得当前环境对应的超参数。其后,机器人通过播放一段预置的语音并使用麦克风拾取回声,根据语音和回声结合迭代方程计算并更新脉冲响应函数h(n+1)。得到脉冲响应函数之后,机器人可以在人机交互的过程中计算对于自身声音输出的环境回声,及时进行回声降噪。
需要说明的是,当用户动态更换使用机器人的场景时,机器人的陀螺仪、gps等传感器可以获知所处场景发生改变,机器人通过分析摄像头获取的图像获得更新后的场景名称,进而快速得到初始化的超参数值,且在播放预设语音的时候及时更新脉冲响应函数。
实施例二
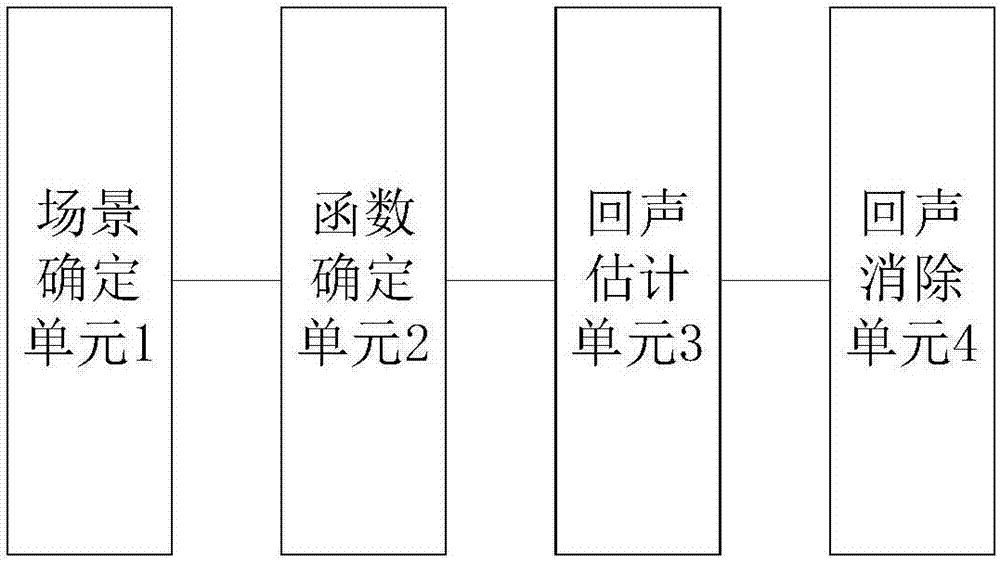
结合图2,本实施例提供一种聊天机器人回声消除装置,包括,
场景确定单元1,用于确定聊天场景;
函数确定单元2,用于确定出与聊天场景对应的脉冲响应函数;
回声估计单元3,用于根据脉冲响应函数确定机器人估计回声;
回声消除单元4,用于根据机器人拾取到的总信号,以及根据机器人估计回声,进行回声消除以确定用户实际输入的语音信号。
本发明实施例提供的聊天机器人回声消除方法,根据聊天场景的不同确定对应的脉冲响应函数,继而估计出机器人的回声,最后,将机器人拾取到的总信号减去估计出的机器人回声,便可实现回声消除,继而实现确定用户实际输入的语音信号,可以克服现有技术中,聊天机器人为了不误拾取到自身说话的声音,而强制性设定机器人说话时不拾取外界声音,导致机器人在说话时,用户不能通过语音打断机器人讲话的问题。
优选地,确定出与聊天场景对应的脉冲响应函数,具体包括,
从预先构建的映射器中确定出与聊天场景对应的超参数组的值;
播放预置语音信号,以获取聊天场景下的机器人实际回声;
根据预置语音信号和机器人实际回声,并结合超参数组的值,确定出与聊天场景对应的脉冲响应函数。
具体地,本实施例中,将预置语音信号,机器人实际回声,超参数组的值代入预先构建的迭代方程,且在迭代方程满足收敛条件时,获取聊天场景对应的脉冲响应函数。本实施例中,超参数组为{h(0),α,δ,m},其中,h(0)为零阶脉冲响应函数,α为步长,δ为补偿权值,m为脉冲响应函数的阶数。
更加具体地,迭代方程为
需要说明的是,脉冲响应函数h(n):实际上是一组数字(h0,h1,...,hn),表示的是当前环境对信号的反射作用。且对于信号x(n),其作用于当前环境后的反射信号y(n)可表示为y(n)=h0x(n)+h1x(n-1)+...+hnx(n-n),其中,n是脉冲响应函数的阶数。
本实施例中,对于机器人自身输出信号x(n),若要获得其回声,则要进行回声估计,且所估计出的回声为y′(n)=h0x(n)+h1x(n-1)+...+hnx(n-n),也就是说,想要估计回声y′(n),就需要知道脉冲响应函数h(n)。
具体地,对于估计回声y′(n)和实际回声y(n),其误差可以表示为:e(n)=y(n)-y′(n)。当将h(0)作为已知参数初始化,本发明设计根据h(0)估计脉冲响应函数h(n+1)的方法为:
其中,h(0)、α、δ、m为超参数,α代表步长可以控制脉冲响应函数收敛的速度和脉冲响应函数的稳定性,δ用于补偿权值(防止由于||x(n)||2过小导致的权值过大),m表示脉冲响应函数的阶数。
进一步具体地,本实施例中的迭代方程,用于计算估计回声y′(n),因此,当估计回声y′(n)和实际回声y(n)误差足够小,且估计回声y′(n)和实际回声y(n)的变化的相关性足够高时可以结束对脉冲响应函数h(n+1)的更新,且将此时的脉冲响应函数确定为与聊天场景对应的脉冲响应函数。
优选地,本实施例中,脉冲响应函数h(n+1)的收敛条件为:
其中,r是相似度系数,且
进一步地,采用k-means方法或svm方法构建映射器。需要说明的是,采用k-means方法或svm方法构建映射器,仅为本实施例提供的优选技术方案,且实际应用中还可以使用其它机器学习方法构建映射器,本实施例不作具体限定。
本实施例中,为了快速获得最优的脉冲响应函数h(n+1),使用人工智能算法建立从具体场景到超参数组的映射器。具体构建方式为:将用户具体使用场景分为卧室、书房、客厅、草坪、ktv、party、马路、车内等,基于已有的用户数据统计每种具体场景对应的超参数的值,使用k-means(k均值)算法聚类得到每种具体场景的超参数值,或者使用支撑向量机(supportvectormachine,svm)等机器学习算法获得由具体场景到超参数的映射器。
需要说明的是,传统的k-means算法为:
1)将所有的超参数作为输入,根据场景的种类设置k值,选择k组随机的超参数,根据每个聚类对象的均值,
2)计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
3)重新计算每个聚类的均值;
4)当每个类中的点离中心对象的距离都小于预定值时,则算法终止;如果条件不满足则回到步骤2)。
本实施例中,采用改进的k-means算法建立映射器的方法为,采用1-means方法,即对每一个场景,求其超参数的均值,以均值为该场景对应的超参数。
优选地,确定出与聊天场景对应的脉冲响应函数,具体还包括,直接调用预存的与聊天场景对应的脉冲响应函数。
本实施例中,机器人在用户的使用过程中,能够对聊天场景以场景图谱形式进行存储,且场景图谱中的信息包括,场景名称、场景对应的脉冲响应函数、场景位置、场景面积、场景图等信息。如此,在用户习惯性使用的场景中,可以直接调取场景对应的脉冲响应函数,节省系统的运算资源并提升用户的使用体验。进一步地优选,还包括,将当前场景信息和预存的场景图谱进行比对,以验证脉冲函数的有效性。本实施例中,对直接调用的脉冲响应函数会执行有效性验证,并在所调用的脉冲响应函数无效时需要更新脉冲响应函数。具体地,通过对比当前的场景位置、场景面积、场景图等信息与场景图谱中记录的信息是否一致来验证脉冲响应函数的有效性。
优选地,确定聊天场景,具体包括,根据询问用户并捕获用户回复语音中的场景相关信息,分析摄像装置获取的场景图像,接收用户直接设定的场景模式中的一种或多种方式的组合确定聊天场景。
本实施例中,在用户具体使用机器人的时候,机器人通过询问用户、分析摄像头得到的外界环境图像、提供按钮供用户设定选择等方式得到当前环境,然后根据已知的映射器获得当前环境对应的超参数。其后,机器人通过播放一段预置的语音并使用麦克风拾取回声,根据语音和回声结合迭代方程计算并更新脉冲响应函数h(n+1)。得到脉冲响应函数之后,机器人可以在人机交互的过程中计算对于自身声音输出的环境回声,及时进行回声降噪。
需要说明的是,当用户动态更换使用机器人的场景时,机器人的陀螺仪、gps等传感器可以获知所处场景发生改变,机器人通过分析摄像头获取的图像获得更新后的场景名称,进而快速得到初始化的超参数值,且在播放预设语音的时候及时更新脉冲响应函数。
尽管本发明已进行了一定程度的描述,明显地,在不脱离本发明的精神和范围的条件下,可进行各个条件的适当变化。可以理解,本发明不限于所述实施方案,而归于权利要求的范围,其包括所述每个因素的等同替换。
- 还没有人留言评论。精彩留言会获得点赞!