一种基于SVM的音频噪声检测方法与流程
本发明属于安防监控领域,尤其是涉及一种基于SVM的音频噪声检测方法。
背景技术:
安防监控领域不止是对图像要求的越来越高,对音频也不仅限于编解码,同时还要求检测不同的噪声,包括强噪声、啸叫、电流噪声等各种。而且各种噪声混杂在有效声音里面,需要从有效声音中将这些噪声分离出来并进行检测分类。以前简单只依靠时域或频域的检测方法无法很好的将噪声分离出来,所以会导致检测结果不正确。因此,研发一种基于SVM的音频噪声检测方法是个亟待解决的问题
技术实现要素:
有鉴于此,本发明旨在提出一种基于SVM的音频噪声检测方法,可以提高检测结果的准确性。
为达到上述目的,本发明的技术方案是这样实现的:
一种基于SVM的音频噪声检测方法,包括如下步骤:
A、准备声音样本数据(包括正样本和负样本);
B、提取声音样本的MFCC特征,用于音频噪声检测;
C、并将样本特征输入到SVM分类器进行训练,得到训练model文件;
D、使用PCA分离现场音频噪声;
E、将分离出来的音频进行MFCC特征提取;
F、将提取出来的特征输入到SVM分类器进行分类,得到分类结果。
进一步的,使用MFCC提取音频特征,其方法为:
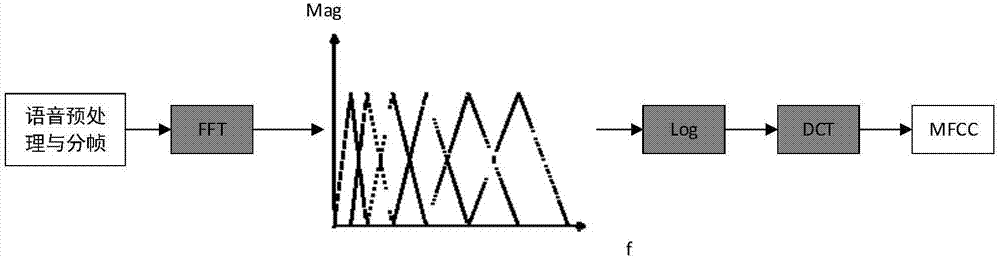
1)语音预处理与分帧;包括预加重、提升高频部分、使信号的频谱变得平坦、移除频谱倾斜、来补偿语音信号受到发音系统所抑制的高频部分;设置帧长和帧移,将音频信号分帧(一小段的音频信号可以看做是短时平稳的);信号加窗(选择合适的窗长N),减少频谱能量泄露;
2)傅里叶变换FFT并求能量谱;
3)Mel滤波器组(三角滤波器);
4)对M个通带的输出作DCT变换,得到M个倒谱系数;
5)取M个倒谱系数中的前L个(L一般为12~16),构成MFCC参数。
进一步的,SVM噪声检测,分为两部分:训练和测试。将提取到的MFCC特征参数输入到SVM训练器中,生成model文件;实时检测环境噪声,将实时提取出来的MFCC特征值输入SVM自动匹配识别,得到识别结果。
相对于现有技术,本发明所述的基于SVM的音频噪声检测方法具有以下优势:根据本发明的SVM训练检测音频噪声,能够排除噪声混杂到一起对检测结果的影响,能够准确的检测出各种噪声;同时这样只需要通过专家评估音频样本,可以提高检测效率,避免了个人的主观因素。
附图说明
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明基于SVM的音频噪声检测算法的执行流程图。
图2是MFCC音频特征提取流程图。
具体实施方式
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面将参考附图并结合实施例来详细说明本发明。
一种基于SVM的音频噪声检测方法,包括如下步骤:
A、准备声音样本数据(包括正样本和负样本);
B、提取声音样本的MFCC特征,用于音频噪声检测;
C、并将样本特征输入到SVM分类器进行训练,得到训练model文件;
D、使用PCA分离现场音频噪声;
E、将分离出来的音频进行MFCC特征提取;
F、将提取出来的特征输入到SVM分类器进行分类,得到分类结果。
首先使用MFCC提取音频特征,其方法为:
1)语音预处理与分帧;包括预加重、提升高频部分、使信号的频谱变得平坦、移除频谱倾斜、来补偿语音信号受到发音系统所抑制的高频部分;设置帧长和帧移,将音频信号分帧(一小段的音频信号可以看做是短时平稳的);信号加窗(选择合适的窗长N),减少频谱能量泄露;
2)傅里叶变换FFT并求能量谱;
3)Mel滤波器组(三角滤波器);
4)对M个通带的输出作DCT变换,得到M个倒谱系数;
5)取M个倒谱系数中的前L个(L一般为12~16),构成MFCC参数。
接下来是SVM噪声检测,分为两部分:训练和测试。将提取到的MFCC特征参数输入到SVM训练器中,生成model文件;实时检测环境噪声,将实时提取出来的MFCC特征值输入SVM自动匹配识别,得到识别结果。
本SVM分类方法并不固定,是一切可以用于分类的方式,SVM只是举例说明。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!