用于确定编码模式的设备以及音频编码设备的制作方法
本申请是向中国知识产权局提交的申请日为2013年11月13日的标题为“用于确定编码模式的方法和设备、用于对音频信号进行编码的方法和设备以及用于对音频信号进行解码的方法和设备”的第201380070268.6号申请的分案申请。
与示例性实施例一致的设备和方法涉及音频编码和音频解码,更具体地讲,涉及一种通过确定适合于音频信号的特性的编码模式并防止频繁的编码模式切换来确定用于提高重构的音频信号的质量的编码模式的方法和设备,一种用于对音频信号进行编码的方法和设备以及一种用于对音频信号进行解码的方法和设备。
背景技术:
广为人知的是,在频域对音乐信号进行编码是有效率的并且在时域对语音信号进行编码是有效率的。因此,已提出了用于确定混合有音乐信号和语音信号的音频信号的类别并确定与所确定的类别相应的编码模式的各种技术。
然而,由于频率编码模式切换,不仅发生延迟,还使解码的声音质量降低。此外,由于不存在用于校正最初确定的编码模式(即,类别)的技术,因此,如果在确定编码模式期间发生错误,则重构的音频信号的质量降低。
技术实现要素:
技术问题
一个或更多个示例性实施例的多个方面提供了一种用于通过确定适合于音频信号的特性的编码模式来确定用于提高重构的音频信号的质量的编码模式的方法和设备,一种用于对音频信号进行编码的方法和设备以及一种用于对音频信号进行解码的方法和设备。
一个或更多个示例性实施例的多个方面提供了一种用于确定适合于音频信号的特性的编码模式并减少由于频繁的编码模式切换而引起的时延的方法和设备,一种用于对音频信号进行编码的方法和设备以及一种用于对音频信号进行解码的方法和设备。
解决方案
根据一个或更多个示例性实施例的一方面,一种确定编码模式的方法,所述方法包括:根据音频信号的特性,将包括第一编码模式和第二编码模式的多个编码模式之中的一个编码模式确定为初始编码模式;如果在对初始编码模式的确定中存在错误,则通过将初始编码模式校正为第三编码模式来产生经过校正的编码模式。
根据一个或更多个示例性实施例的一方面,一种对音频信号进行编码的方法,所述方法包括:根据音频信号的特性,将包括第一编码模式和第二编码模式的多个编码模式之中的一个编码模式确定为初始编码模式;如果在对初始编码模式的确定中存在错误,则通过将初始编码模式校正为第三编码模式来产生经过校正的编码模式;基于初始编码模式或经过校正的编码模式对音频信号执行不同的编码处理。
根据一个或更多个示例性实施例的一方面,一种对音频信号进行解码的方法,所述方法包括:对包括初始编码模式和第三编码模式之一的比特流进行解析,并基于初始编码模式或第三编码模式对所述比特流执行不同的解码处理,其中,所述初始编码模式是通过根据音频信号的特性在包括第一编码模式和第二编码模式的多个编码模式之中确定一个编码模式而获得的,所述第三编码模式是在对初始编码模式的确定中存在错误的情况下从初始编码模式进行校正而得到的。
有益效果
根据示例性实施例,通过基于对初始编码模式的校正以及与拖尾长度相应的帧的编码模式来确定当前帧的最终编码模式,可在防止多个帧之间的频繁的编码模式切换的同时选择出适应于音频信号的特性的编码模式。
附图说明
图1是示出根据示例性实施例的音频编码设备的配置的框图;
图2是示出根据另一示例性实施例的音频编码设备的配置的框图;
图3是示出根据示例性实施例的编码模式确定单元的配置的框图;
图4是示出根据示例性实施例的初始编码模式确定单元的配置的框图;
图5是示出根据示例性实施例的特征参数提取单元的配置的框图;
图6是示出根据示例性实施例的线性预测域编码和谱域之间的自适应切换方法的示图;
图7是示出根据示例性实施例的编码模式校正单元的操作的示图;
图8是示出根据示例性实施例的音频解码设备的配置的框图;
图9是示出根据另一示例性实施例的音频解码设备的配置的框图。
具体实施方式
现在将详细描述实施例,其示例在附图中被示出,其中,相同的标号始终是指相同的元件。在这一点上,本实施例可具有不同的形式并且不应该被解释为受限于在此阐述的描述。因此,通过参照附图,在下面实施例仅被描述用于解释本说明书的多个方面。
诸如“连接的”和“链接的”的术语可被用于指示直接连接或链接的状态,但应理解,另一组件可被置于其间。
诸如“第一”和“第二”的术语可被用于描述各种组件,但所述组件不应受限于所述术语。所述术语可仅被用于使一个组件与另一组件区分开。
在示例性实施例中描述的单元被独立示出以指示不同的特性功能,并且它不意味着每个单元由一个单独的硬件组件或软件组件形成。为了便于解释而示出每个单元,并且多个单元可形成一个单元,一个单元可被划分为多个单元。
图1是示出根据示例性实施例的音频编码设备100的配置的框图。
图1中示出的音频编码设备100可包括编码模式确定单元110、切换单元120、谱域编码单元130、线性预测域编码单元140和比特流产生单元150。线性预测域编码单元140可包括时域激励编码单元141和频域激励编码单元143,其中,线性预测域编码单元140可被实现为时域激励编码单元141和频域激励编码单元143中的至少一个。除非必须被实现为单独的硬件,否则上述组件可被集成为至少一个模块并且可被实现为至少一个处理器(未示出)。这里,术语音频信号可指音乐信号、语音信号或它们的混合信号。
参照图1,编码模式确定单元110可分析音频信号的特性以确定音频信号的类别,并根据分类的结果来确定编码模式。对编码模式的确定可以以超帧、帧或频段为单位来执行。可选择地,对编码模式的确定可以以多个超帧组、多个帧组或多个频段组为单位来执行。这里,编码模式的示例可包括谱域和时域或线性预测域,但不限于此。如果处理器的性能和处理速度足够并且由于编码模式切换引起的时延可被解决,则编码模式可被细分,并且编码方案也可根据编码模式被细分。根据示例性实施例,编码模式确定单元110可将音频信号的初始编码模式确定为谱域编码模式和时域编码模式之一。根据另一示例性实施例,编码模式确定单元110可将音频信号的初始编码模式确定为谱域编码模式、时域激励编码模式和频域激励编码模式之一。如果谱域编码模式被确定为初始编码模式,则编码模式确定单元110可将初始编码模式校正为谱域编码模式和频域激励编码模式之一。如果时域编码模式(即,时域激励编码模式)被确定为初始编码模式,则编码模式确定单元110可将初始编码模式校正为时域激励编码模式和频域激励编码模式之一。如果时域激励编码模式被确定为初始编码模式,则对最终编码模式的确定可被选择性地执行。换句话说,初始编码模式(即,时域激励编码模式)可被保持。编码模式确定单元110可确定与拖尾长度(hangoverlength)相应的多个帧的编码模式,并可为当前帧确定最终编码模式。根据示例性实施例,如果当前帧的初始编码模式或经过校正的编码模式与多个先前帧(例如,7个先前帧)的编码模式相同,则相应的初始编码模式或经过校正的编码模式可被确定为当前帧的最终编码模式。同时,如果当前帧的初始编码模式或经过校正的编码模式与多个先前帧(例如,7个先前帧)的编码模式不相同,则编码模式确定单元110可将恰在当前帧之前的帧的编码模式确定为当前帧的最终编码模式。
如上所述,通过基于对初始编码模式的校正以及与拖尾长度相应的帧的编码模式来确定当前帧的最终编码模式,可在防止帧之间的频繁的编码模式切换的同时选择出适应于音频信号的特性的编码模式。
一般来说,时域编码(即,时域激励编码)对于语音信号会是有效率的,谱域编码对于音乐信号会是有效率的,并且频域激励编码对于言语(vocal)信号和/或谐波信号会是有效率的。
根据由编码模式确定单元110确定的编码模式,切换单元120可向谱域编码单元130或线性预测域编码单元140提供音频信号。如果线性预测域编码单元140被实现为时域激励编码单元141,则切换单元120可包括总共两个分支。如果线性预测域编码单元140被实现为时域激励编码单元141和频域激励编码单元143,则切换单元120可具有总共3个分支。
谱域编码单元130可在谱域对音频信号进行编码。谱域可指频域或变换域。适合于谱域编码单元130的编码方法的示例可包括高级音频编码(aac)或包括改进离散余弦变换(mdct)和阶乘脉冲编码(fpc)的组合,但不限于此。详细地讲,其它量化技术和熵编码技术可用来代替fpc。在谱域编码单元130中对音乐信号进行编码会是有效率的。
线性预测域编码单元140可在线性预测域对音频信号进行编码。线性预测域可指激励域或时域。线性预测域编码单元140可被实现为时域激励编码单元141,或者可被实现为包括时域激励编码单元141和频域激励编码单元143。适合于时域激励编码单元141的编码方法的示例可包括码激励线性预测(celp)或代数celp(acelp),但不限于此。适合于频域激励编码单元143的编码方法的示例可包括通用信号编码(gsc)或变换码激励(tcx),但不限于此。在时域激励编码单元141中对语音信号进行编码会是有效率的,而在频域激励编码单元143中对言语信号和/或谐波信号进行编码会是有效率的。
比特流产生单元150可产生比特流来包括由编码模式确定单元110提供的编码模式、由谱域编码单元130提供的编码结果以及由线性预测域编码单元140提供的编码结果。
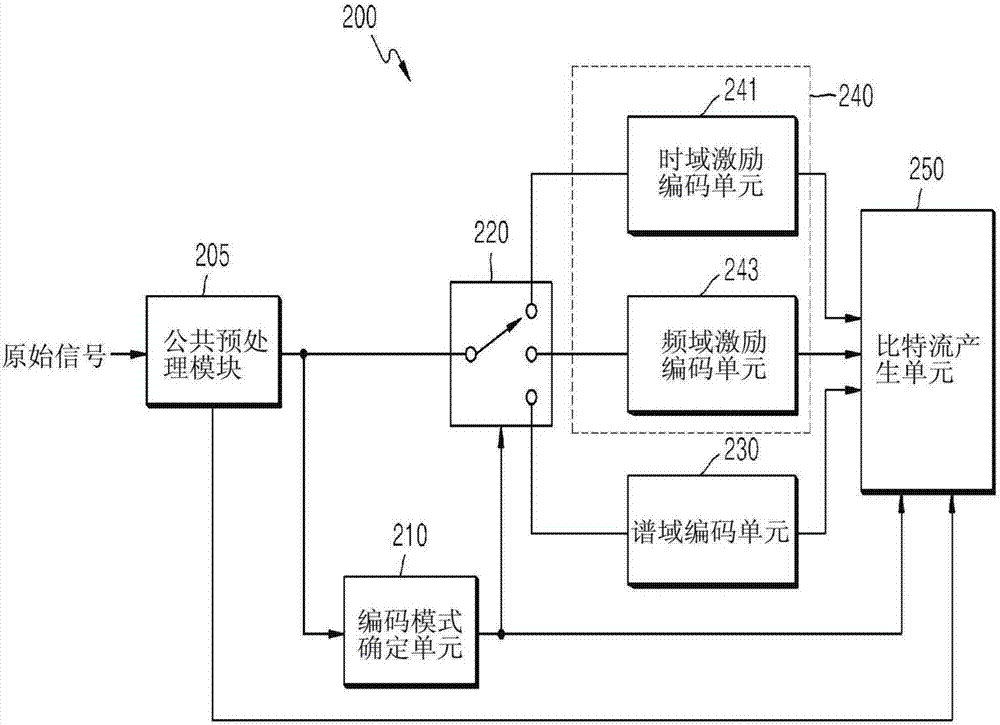
图2是示出根据另一示例性实施例的音频编码设备200的配置的框图。
图2中示出的音频编码设备200可包括公共预处理模块205、编码模式确定单元210、切换单元220、谱域编码单元230、线性预测域编码单元240和比特流产生单元250。这里,线性预测域编码单元240可包括时域激励编码单元241和频域激励编码单元243,线性预测域编码单元240可被实现为时域激励编码单元或频域激励编码单元243。与图1中示出的音频编码设备100相比,音频编码设备200还可包括公共预处理模块205,因此,与音频编码设备100的组件相同的组件的描述将被省略。
参照图2,公共预处理模块205可执行联合立体声处理、环绕处理和/或带宽扩展处理。联合立体声处理、环绕处理和带宽扩展处理可与由特定标准(例如,mpeg标准)采用的那些处理相同,但不限于此。公共预处理模块205的输出可以是在单声道、立体声声道或多声道中。根据由公共预处理模块205输出的信号的声道的数量,切换单元220可包括至少一个开关。例如,如果公共预处理模块205输出两个或更多个声道(即,立体声声道或多声道)的信号,则与各个声道相应的开关可被布置。例如,立体声信号的第一声道可以是语音声道,立体声信号的第二声道可以是音乐声道。在这种情况下,音频信号可被同时提供给两个开关。由公共预处理模块205产生的附加信息可被提供给比特流产生单元250并被包括在比特流中。所述附加信息对于在解码端执行联合立体声处理、环绕处理和/或带宽扩展处理是必要的,并且可包括空间参数、包络信息、能量信息等。然而,基于所应用的处理技术,可存在各种附加信息。
根据示例性实施例,在公共预处理模块205,可基于编码域而不同地执行带宽扩展处理。核心频段中的音频信号可通过使用时域激励编码模式或频域激励编码模式来处理,而带宽扩展频段中的音频信号可在时域中被处理。时域中的带宽扩展处理可包括多个模式(包括浊音模式或清音模式)。可选择地,核心频段中的音频信号可通过使用谱域编码模式来处理,而带宽扩展频段中的音频信号可在频域中被处理。频域中的带宽扩展处理可包括多个模式(包括瞬变模式、一般模式或谐波模式)。为了在不同域中执行带宽扩展处理,由编码模式确定单元110确定的编码模式可作为信令信息被提供给公共预处理模块205。根据示例性实施例,核心频段的最后部分和带宽扩展频段的开始部分可能在一定程度上彼此重叠。重叠部分的位置和尺寸可被预先设置。
图3是示出根据示例性实施例的编码模式确定单元300的配置的框图。
图3中示出的编码模式确定单元300可包括初始编码模式确定单元310和编码模式校正单元330。
参照图3,初始编码模式确定单元310可通过使用从音频信号提取出的特征参数来确定音频信号是音乐信号还是语音信号。如果音频信号被确定为语音信号,则线性预测域编码会是合适的。同时,如果音频信号被确定为音乐信号,则谱域编码会是适合的。初始编码模式确定单元310可通过使用从音频信号提取出的特征参数来确定音频信号的类别,其中,音频信号的类别指示是谱域编码、时域激励编码还是频域激励编码适合于该音频信号。可基于音频信号的类别来确定相应编码模式。如果(图1的)切换单元(120)具有两个分支,则编码模式可以以1比特来表示。如果(图1的)切换单元(120)具有三个分支,则编码模式可以以2比特来表示。初始编码模式确定单元310可通过使用现有技术中已知的各种技术中的任意技术来确定音频信号是音乐信号还是语音信号。其示例可包括usac标准的编码器部分中公开的fd/lpd分类或acelp/tcx分类以及amr标准中使用的acelp/tcx分类,但不限于此。换句话说,可通过使用除在此描述的根据实施例的方法以外的各种任意方法来确定初始编码模式。
编码模式校正单元330可通过使用校正参数对由初始编码模式确定单元310确定的初始编码模式进行校正来确定经过校正的编码模式。根据示例性实施例,如果谱域编码模式被确定为初始编码模式,则基于校正参数,初始编码模式可被校正为频域激励编码模式。如果时域编码模式被确定为初始编码模式,则基于校正参数,初始编码模式可被校正为频域激励编码模式。换句话说,通过使用校正参数,确定在对初始编码模式的确定中是否存在错误。如果确定在对初始编码模式的确定中不存在错误,则初始编码模式可被保持。相反,如果确定在对初始编码模式的确定中存在错误,则初始编码模式可被校正。可获得从谱域编码模式到频域激励编码模式以及从时域激励编码模式到频域激励编码模式的对初始编码模式的校正。
同时,初始编码模式或经过校正的编码模式可以是用于当前帧的临时编码模式,其中,可将用于当前帧的临时编码模式与用于预设拖尾长度内的先前帧的编码模式进行比较,并可确定用于当前帧的最终编码模式。
图4是示出根据示例性实施例的初始编码模式确定单元400的配置的框图。
图4中示出的初始编码模式确定单元400可包括特征参数提取单元410和确定单元430。
参照图4,特征参数提取单元410可从音频信号提取用于确定编码模式的所必要的特征参数。提取的特征参数的示例包括音高(pitch)参数、浊音参数、相关度参数和线性预测误差之中的至少一个或两个,但不限于此。以下将给出对各个参数的详细描述。
首先,第一特征参数f1与音高参数有关,其中,可通过使用在当前帧和至少一个先前帧中检测到的n个音高值来确定音高的表现。为了防止效果随机偏离或防止错误的音高值,可去除与所述n个音高值的平均值明显不同的m个音高值。这里,n和m可以是预先经由实验或仿真而被获取的值。此外,n可被预先设置,并且将被移除的音高值与所述n个音高值之间的平均值之间的差可预先经由实验或仿真而被确定。通过使用关于(n-m)个音高值的均值mp’和方差σp’,第一特征参数f1可如下面的等式1中所示被表达。
[等式1]
第二特征参数f2也与音高参数有关,并可指示在当前帧中检测到的音高值的可靠性。通过使用在当前帧的两个子帧sf1和sf2中分别检测到的音高值的方差σsf1和σsf2,第二特征参数f2可如下面的等式2中所示被表达。
[等式2]
这里,cov(sf1,sf2)表示子帧sf1和子帧sf2之间的协方差。换句话说,第二特征参数f2将两个子帧之间的相关度指示为音高距离。根据示例性实施例,当前帧可包括两个或更多个子帧,等式2可基于子帧的数量而被修改。
基于浊音参数voicing和相关度参数corr,第三特征参数f3可如下面的等式3中所示被表达。
[等式3]
这里,浊音参数voicing与声音的言语特征相关,并且可通过现有技术中已知的各种方法中的任意方法来获取,而相关度参数corr可通过对针对每个频段的帧之间的相关度求和来获取。
第四特征参数f4与线性预测误差elpc相关并可如下面的等式4中所示被表达。
[等式4]
这里,m(elpc)表示n个线性预测误差的平均值。
确定单元430可通过使用由特征参数提取单元410提供的至少一个特征参数来确定音频信号的类别,并可基于所确定的类别来确定初始编码模式。确定单元430可采用软判决机制,其中,在软判决机制中,可根据每个特征参数形成至少一个混合。根据示例性实施例,可通过基于混合(mixture)概率使用高斯混合模型(gmm)来确定音频信号的类别。关于一个混合的概率f(x)可根据下面的等式5来计算。
[等式5]
x=(x1,...,xn)
m(cx1c,...,cxnc)
这里,x表示特征参数的输入矢量,m表示混合,c表示协方差矩阵。
确定单元430可通过使用下面的等式6来计算音乐概率pm和语音概率ps。
[等式6]
这里,可通过将与适合用于音乐确定的特征参数相关的m个混合的概率pi相加来计算音乐概率pm,而可通过将与适合用于语音确定的特征参数相关的s个混合的概率pi相加来计算语音概率ps。
同时,为了提高精确度,可根据下面的等式7来计算音乐概率pm和语音概率ps。
[等式7]
这里,
接下来,可根据下面的等式8,针对与恒定拖尾长度相同数量的多个帧,计算所有帧仅包括音乐信号的音乐概率pm和所有帧仅包括语音信号的语音概率ps。拖尾长度可被设置为8,但不限于此。八个帧可包括当前帧和7个先前帧。
[等式8]
接下来,可通过使用利用等式5或等式6获取的音乐概率pm或语音概率ps来计算多个状况(condition)集合
参照图6,在操作610和操作620,可从通过使用音乐概率pm和语音概率ps计算出的多个状况集合
[等式9]
在操作630,将音乐状况之和m与指定的阈值tm进行比较。如果音乐状况之和m大于所述阈值tm,则当前帧的编码模式被切换为音乐模式(即,谱域编码模式)。如果音乐状况之和m小于或等于阈值tm,则当前帧的编码模式不被改变。
在操作640,将语音状况之和s与指定阈值ts进行比较。如果语音状况之和s大于阈值ts,则当前帧的编码模式被切换为语音模式(即,线性预测域编码模式)。如果语音状况之和s小于或等于阈值ts,则当前帧的编码模式不被改变。
阈值tm和阈值ts可被设置为预先经由实验或仿真而获取的值。
图5是示出根据示例性实施例的特征参数提取单元500的配置的框图。
图5中示出的初始编码模式确定单元500可包括变换单元510、频谱参数提取单元520、时间参数提取单元530和确定单元540。
在图5中,变换单元510可将原始音频信号从时域变换到频域。这里,变换单元510可应用各种任意变换技术以将音频信号从时域表示为谱域。所述技术的实例可包括快速傅里叶变换(fft)、离散余弦变换(dct)或改进离散余弦变换(mdct),但不限于此。
频谱参数提取单元520可从由变换单元510提供的频域音频信号提取至少一个频谱参数。频谱参数可被归类为短期特征参数和长期特征参数。可从当前帧获取短期特征参数,而可从包括当前帧和至少一个先前帧的多个帧获取长期特征参数。
时间参数提取单元530可从时域音频信号提取至少一个时间参数。时间参数也可被归类为短期特征参数和长期特征参数。可从当前帧获取短期特征参数,而可从包括当前帧和至少一个先前帧的多个帧获取长期特征参数。
(图4的)确定单元(430)可通过使用由频谱参数提取单元520提供的频谱参数以及由时间参数提取单元530提供的时间参数来确定音频信号的类别,并可基于所确定的类别来确定初始编码模式。(图4的)确定单元(430)可采用软判决机制。
图7是示出根据示例性实施例的编码模式校正单元310的操作的示图。
参照图7,在操作700,由初始编码模式确定单元310确定的初始编码模式被接收,并且可确定编码模式是时域模式(即,时域激励模式)还是谱域模式。
在操作701,如果在操作700确定初始编码模式是谱域模式(statets==1),则可检查指示频域激励编码是否更加合适的索引statettss。可通过使用不同频段的音调来获取指示频域激励编码(例如,gsc)是否更加合适的索引statettss。下面将给出其详细描述。
低频段信号的音调可被获取为具有包括最小值的多个较小值的多个频谱系数之和与具有针对给定频段的最大值的频谱系数之间的比率。如果给定频段是0~1khz、1~2khz和2~4khz,则各个频段的音高t01、t12和t24以及低频段信号(即,核心频段)的音调tl可如下面的等式10中所示被表达。
[等式10]
tl=max(t01,t12,t24)
同时,线性预测误差可通过使用线性预测编码(lpc)滤波器来获取并可被用于去除强音调分量。换句话说针对强音调分量,谱域编码模式比频域激励编码模式更加有效。
用于通过使用如上所述获取的音调和线性预测误差切换到频域激励编码模式的前置条件condfront可如下面的等式11中所示被表达。
[等式11]
condfront=t12>t12front且t24>t24front且tl>tlfront且err>errfront
这里,t12front、t24front、tlfront和errfront是阈值,并可具有预先经由实验或仿真而获取的值。
同时,用于通过使用如上所述获取的音调和线性预测误差来完成频域激励编码模式的后置条件condback可如下面的等式12中所示被表达。
[等式12]
condback=t12<t12back且t24<t24back且tl<tlback
这里,t12back、t24back、tlback是阈值并可具有预先经由实验或仿真而获取的值。
换句话说,可通过确定等式11中所示的前置条件是否被满足或是等式12中所示的后置条件是否被满足来确定索引statettss是否为1,其中,索引statettss指示频域激励编码(例如,gsc)是否比谱域编码更加合适。这里,对等式12中示出的后置条件的确定可以是可选的。
在操作702,如果索引statettss是1,则频域激励编码模式可被确定为最终编码模式。在这种情况下,作为初始编码模式的谱域编码模式被校正为作为最终编码模式的频域激励编码模式。
在操作705,如果在操作701确定索引statettss是0,则可检查用于确定音频信号是否包括强语音特性的索引statess。如果在对谱域编码模式的确定中存在错误,则频域激励编码模式会比谱域编码模式更加有效。可通过使用浊音参数和相关度参数之间的差vc来获取用于确定音频信号是否包括强语音特性的索引statess。
用于通过使用浊音参数和相关度参数之间的差vc来切换到强语音模式的前置条件condfront可如下面的等式13中所示被表达。
[等式13]
condfront=vc>vcfront
这里,vcfront是阈值并可具有预先经由实验或仿真而获取的值。
同时,用于通过使用浊音参数和相关度参数之间的差vc来结束强语音模式的后置条件condback可如下面的等式14中所示被表达。
[等式14]
condback=vc<vcback
这里,vcback是阈值并可具有预先经由实验或仿真而获取的值。
换句话说,在操作705,可通过确定等式13中示出的前置条件是否被满足或是等式14中示出的后置条件是否未被满足来确定索引statess是否为1,其中,索引statess指示频域激励编码(例如,gsc)是否比谱域编码更加合适。这里,对等式14中示出的对后置条件的确定可以是可选的。
在操作706,如果在操作705确定索引statess为0(即,音频信号不包括强语音特性),则谱域编码模式可被确定为最终编码模式。在这种情况下,作为初始编码模式的谱域编码模式被保持为最终编码模式。
在操作707,如果在操作705确定索引statess为1(即,音频信号包括强语音特性),则频域激励编码模式可被确定为最终编码模式。在这种情况下,作为初始编码模式的谱域编码模式被校正为作为最终编码模式的频域激励编码模式。
通过执行操作700、701和705,对作为初始编码模式的谱域编码模式的确定中的错误可被校正。详细地讲,作为初始编码模式的谱域编码模式可被保持作为最终编码模式,或可被切换为频域激励编码模式作为最终编码模式。
同时,如果在操作700确定初始编码模式是线性预测域编码模式(statets==0),则用于确定音频信号是否包括强音乐特性的索引statesm可被检查。如果在对线性预测域编码模式(即,时域激励编码模式)的确定中存在错误,则频域激励编码模式可能比时域激励编码模式更加有效。可通过使用从1减去浊音参数和相关度参数之间的差vc而获取的值1-vc来获取用于确定音频信号是否包括强音乐特性的statesm。
用于通过使用通过从1减去浊音参数和相关度参数之间的差vc而获取的值1-vc而切换到强音乐模式的前置条件condfront可如下面的等式15中所示被表达。
[等式15]
condfront=1-vc>vcmfront
这里,vcmfront是阈值并可具有预先经由实验或仿真而获取的值。
同时,用于通过使用通过从1减去浊音参数和相关度参数之间的差vc而获取的值1-vc而结束强音乐模式的后置条件condback可如下面的等式16中所示被表达。
[等式16]
condback=1-vc<vcmback
这里,vcmback是阈值并可具有预先经由实验或仿真而获取的值。
换句话说,在操作709,可通过确定等式15中示出的前置条件是否被满足或是等式16中示出的后置条件是否未被满足来确定索引statesm是否为1,其中,索引statesm指示频域激励编码(例如,gsc)是否比时域激励编码更适合。这里,对等式16中示出的后置条件的确定可以是可选的。
在操作710,如果在操作709确定索引statesm为0(即,音频信号不包括强音乐特性),则时域激励编码模式可被确定为最终编码模式。在这种情况下,作为初始编码模式的线性预测域编码模式被切换为作为最终编码模式的时域激励编码模式。根据示例性实施例,如果线性预测域编码模式与时域激励编码模式对应,则可考虑初始编码模式保持不变。
在操作707,如果在操作709确定索引statesm为1(即,音频信号包括强音乐特性),则频域激励编码模式可被确定为最终编码模式。在这种情况下,作为初始编码模式的线性预测域编码模式被校正为作为最终编码模式的频域激励编码模式。
通过执行操作700和709,对初始编码模式的确定中的错误可被校正。详细地讲,作为初始编码模式的线性预测域编码模式(例如,时域激励编码模式)可被保持作为最终编码模式,或者可被切换为频域激励编码模式作为最终编码模式。
根据示例性实施例,用于确定音频信号是否包括强音乐特性以校正对线性预测域编码模式的确定中的错误的操作709可以是可选的。
根据另一示例性实施例,执行用于确定音频信号是否包括强语音特性的操作705以及用于确定频域激励编码模式是否适合的操作701的顺序可被颠倒。换句话说,在操作700之后,可首先执行操作705,然后可执行操作701。在这种情况下,用于进行确定的参数可按照必要的需求而被改变。
图8是示出根据示例性实施例的音频解码设备800的配置的框图。
图8中示出的音频解码设备800可包括比特流解析单元810、谱域解码单元820、线性预测域解码单元830和切换单元840。线性预测域解码单元830可包括时域激励解码单元831和频域激励解码单元833,其中,线性预测域解码单元830可被实现为时域激励解码单元831和频域激励解码单元833中的至少一个。除非必须被实现为单独的硬件,否则上述组件可被集成为至少一个模块,并可被实现为至少一个处理器(未示出)。
参照图8,比特流解析单元810可对接收到的比特流进行解析并对关于编码模式和编码数据的信息进行分离。编码模式可与通过根据音频信号的特性在包括第一编码模式和第二编码模式的多个编码模式之中确定一个编码模式而获取的初始编码模式相应,或者可与在对初始编码模式的确定中存在错误的情况下从初始编码模式校正得到的第三编码模式相应。
谱域解码单元820可对来自分离的编码数据的在谱域中被编码的数据进行解码。
线性预测域解码单元830可对来自分离的编码数据的在线性预测域中被编码的数据进行解码。如果线性预测域解码单元830包括时域激励解码单元831和频域激励解码单元833,则线性预测域解码单元830可针对分离的编码数据执行时域激励解码或频域激励解码。
切换单元840可对由谱域解码单元820重构的信号或由线性预测域解码单元830重构的信号进行切换,并可提供切换的信号作为最终重构的信号。
图9是示出根据另一示例性实施例的音频解码设备900的配置的框图。
音频解码设备900可包括比特流解析单元910、谱域解码单元920、线性预测域解码单元930、切换单元940和公共后处理模块950。线性预测域解码单元930可包括时域激励解码单元931和频域激励解码单元933,其中,线性预测域解码单元930可被实现为时域激励解码单元931和频域激励解码单元933中的至少一个。除非必须被实现为单独的硬件,否则上述组件可被集成为至少一个模块,并可被实现为至少一个处理器(未示出)。与图8中示出的音频解码设备800相比,音频解码设备900还可包括公共后处理模块950,因此,将省略对与音频解码设备800的组件相同的组件的描述。
参照图9,公共后处理模块950可执行与(图2的)公共预处理模块(205)相应的联合立体声处理、环绕处理和/或带宽扩展处理。
根据示例性实施例的方法可被编写为计算机可执行程序并可被实现在通用数字计算机中,其中,所述通用数字计算机通过使用非暂时性计算机可读记录介质来执行程序。此外,可在实施例中使用的数据结构、程序指令或数据文件可以以各种方式被记录在非暂时性计算机可读记录介质中。非暂时性计算机可读记录介质是可存储其后可由计算机系统读出的数据的任意数据存储装置。非暂时性计算机可读记录介质的示例包括:磁介质(诸如硬盘、软盘和磁带)、光学记录介质(诸如cdrom盘和dvd)、磁光介质(诸如光盘)以及专门配置为存储和执行程序指令的硬件装置(诸如rom、ram、闪存等)。此外,非暂时性计算机可读记录介质可以是用于传输指定程序指令、数据结构等的信号的传输介质。程序指令的示例可不仅包括由编译器产生的机器语言代码,还可包括可由计算机使用解释器等执行的高级语言代码。
尽管在上面已具体显示和描述了示例性实施例,但是本领域的普通技术人员将理解,在不脱离权利要求所限定的本发明构思的精神和范围的情况下,可以对其进行形式和细节上的各种改变。示例性实施例应被认为仅是描述性的意义而不是为了限制的目的。因此,本发明构思的范围不是由示例性实施例的详细描述来限定,而是由权利要求来限定,并且所述范围内的所有差异将被解释为包括在本发明构思中。
- 还没有人留言评论。精彩留言会获得点赞!
- 用于编码音频信号的编码器、音频发送系统和用于确定校正值的方法
- 用于对降混合矩阵进行解码及编码的方法、用于呈现音频内容的方法、用于降混合矩阵的 ...的制作方法
- 用于编码音频信号的编码器、音频发送系统和用于确定校正值的方法
- 用于对降混合矩阵进行解码及编码的方法、用于呈现音频内容的方法、用于降混合矩阵的 ...的制作方法
- 音频编码器和解码器的制造方法
- 联合声道间和声道内预测的立体声误码隐藏方法及系统的制作方法
- 基于qmf的处理数据的时间对齐的制作方法
- 针对音频声道及音频对象的音频编码及解码的概念的制作方法
- 根据室内脉冲响应处理音频信号的方法、信号处理单元、音频编码器、音频解码器及立体 ...的制作方法
- 将第一和第二输入声道映射至至少一个输出声道的装置,方法和计算机程序的制作方法