基于维纳后置滤波的LS波束形成混响抑制方法与流程
本发明涉及一种基于维纳后置滤波的最小二乘(LS)波束形成混响抑制方法,属于麦克风阵列波束形成技术领域。
背景技术:
麦克风阵列是语音获取的有效工具,它被广泛地应用于语音识别、视频会议助听设备等。波束形成是一种重要的麦克风阵列处理技术,其主要目的是对特定方向的有用信号形成波束,同时抑制其它方向的干扰信号和噪声[2]。近年随着人们对语音通信研究的深入,麦克风阵列得到更加广泛的应用。
封闭空间环境中的语音信号经常被混响所扭曲。在具有多个分布式麦克风的语音通信应用中,通常期望量化每个传感器处感知信号的混响量,以便选择具有最高质量或最小混响的频道。假设不同信道上的噪声之间不相关的前提下,R.Zelinski提出具有维纳后置滤波的波束形成器,利用空间信息解决了维纳滤波器的估计问题。但这种非相干噪声场实际上很少遇到,特别是低频噪声场。Berkun和Claude Marro提出基于麦克阵列与维纳后置滤波器结合的降噪和去混响算法。McCowan运用扩散噪声场的数学模型讨论了解决扩散噪声场中不同通道噪声相关的问题,该算法要求预先得到噪声相干函数,适用范围受到限制。K.U.Simmer提出的多通道维纳滤波器(MCWF),其可以分解为最小方差无失真响应波束形成器和单通道后置滤波器,求最优解表达式,对混响中语音质量改善明显。Alejandro Luebs在白噪声和漫反射噪声的基础上增加点干扰处理,通过提供全局最优的最小二乘解决方案,更有效地利用麦克风阵列收集的信息,提高语音质量。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的缺陷,提供一种基于维纳后置滤波的LS波束形成混响抑制方法,其特征在于,麦克风的接收信号x(t)经过维纳后置滤波的最小二乘波束形成混响抑制方法处理得到的输出信号:y(t)=WHx(t),其中,W表示麦克风阵列响应的权矢量,()H表示共轭转置,t表示时间序列,表示t时刻第m麦克风的接收信号,M为麦克风阵元数目,L为房间冲击响应长度,G为房间冲击响应,sm(t)为t时刻第m麦克风采集的纯净语音信号。
进一步的,所述接收信号x(t)=[x1(t),x2(t),…,xM(t)]。
进一步的,所述麦克风阵列响应权矢量W的获取,步骤如下:
步骤a:在波束形成器设计时应用最小二乘波束形成算法,将目标函数定义为式中n,k分别表示角度和频率的离散点数;Nφ、Nf分别为角度和频率范围,Fnk为正实值的加权函数,Ynk为实际波束形成器响应函数,ank是空时二维导向矢量,Dnk为期望波束响应,h为波束形成器权矢量;
步骤b:将步骤a所描述的目标函数展开,展开后的公式为J(h)=hTRh-2qTh+dLS,其中对展开后的公式进行梯度求导求得波束形成器权矢量h,h=R-1q,T表示对矩阵的转置。
步骤c:基于房间脉冲响应h(k)是一个随机过程,表示为式中b(k)为零均值的高斯白噪声,Δ是与混响时间T60相联系的衰减因子,从房间脉冲响应h(k)的角度看,可以把h(k)近似分成直达部分语音信号的脉冲响应函数hd(k)和形成混响信号的响应函数hr(k),β是本位设定的临界时间,房间冲击响应在k<β时的混响效应不明显,与干净语音的卷积可以看作直达声,分别表示为假设sd(k)与sr(k)分别表示纯净语音信号s(t)与hd(k)和hr(k)的卷积,则sd(k)为待处理语音信号的直达信号部分,sr(k)为待处理语音信号的混响部分,得到改进维纳滤波器的估计增益式中为直达信号的自相关函数,为麦克风接收信号的自相关函数,E[]为取均值,R[]为取实部,M为麦克风阵元数目,下标i,j是麦克风通道标号。
步骤d:根据步骤a,b,c得到基于维纳后置滤波的LS改进波束形成混响抑制方法,麦克风阵列响应权矢量α为加权矩阵系数,hL,hH分别表示信号在低频和高频波束形成器权矢量,高频和低频分量的频率分界点取为1kHz。
进一步的,所述步骤c中的本位设定的临界时间β=50ms。
进一步的,所述步骤c,单通道维纳滤波器为是语音信号的直达信号部分功率谱,再计算所有可能阵元组合的互功率谱则可得步骤c中的估计增益
进一步的,所述步骤d,将步骤a中波束形成器权矢量h,以1kHz为高频和低频分量的频率分界点划分为hL,hH,α为加权矩阵系数,将高低频权矢量分别相加,即αhL+(1-α)hH;再与步骤c中改进维纳滤波器的估计增益相乘,得到麦克风阵列响应权矢量
本发明所达到的有益效果:为了提高封闭空间环境中麦克风阵列接收的语音信号质量,提出一种具有维纳后置滤波的最小二乘波束形成混响抑制方法。算法将混响后的信号分为直达部分和混响部分得到改进维纳后置滤波器增益估计,并针对语音信号在低频部分噪声相干性较强的特点,将混响后的语音信号分为高频和低频分量,然后用最小二乘波束形成算法分别求解高、低频分量的最优权值,提高混响抑制精度和语音质量。
附图说明
图1是本发明的基于维纳后置滤波的LS波束形成混响抑制方法原理图;
图2是纯净语音信号语谱图;
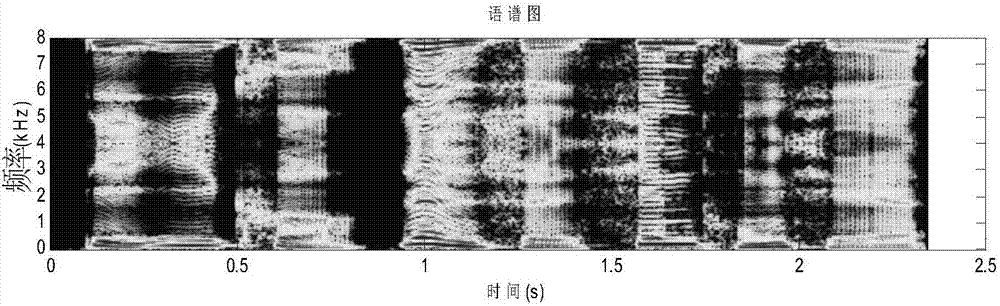
图3是混响后信号语谱图;
图4是本发明的算法去混响语谱图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
图1是基于维纳后置滤波的LS波束形成混响抑制方法原理图,在图1中由M个相同的全向性麦克风组成均匀线阵,有N个语音信号(M>N)。
步骤1、假设麦克风采集的信号都是延迟和衰减之后的原始语音信号加上一定的加性噪声。则第m个麦克风接收的信号xm(k)=αmsn(k)+vm(k),其中,αm,m=1,…M表示传播效应引起的衰减因子;sn(k),n=1,…N是第n个语音到第m个麦克风的语音信号;vm(k)表示第m个麦克风接收的噪声信号,k是离散时间。假设在封闭的室内环境下,第m个麦克风接收的信号可以表示为式中Gnm,l是第n个语音到第m个麦克风,长度为l的房间冲激响应,且m=1,…M;n=1,…N;l=1,…L。由于语音信号的动态非平稳特性,对采用傅里叶变换(FFT)得,sn(ω,k)表示sn(k)第k帧信号短时谱。
步骤2、随着特定房间对不同频率的衰减和反射程度而改变的,即不同频率的声信号产生的混响有一定的差异,并且在实际声场中低频部分噪声相干性较强,因此采用分频处理的思想,将傅里叶变换后的信号分为高频和低频分量,频率分界点取为1kHz。将分频后的信号,用LS波束形成算法分别进行处理后再求和,将得到的信号Y(ω)进行维纳后置滤波。
在最小二乘波束形成器的设计方法中,将目标函数定义为
式中Nφ、Nf分别为角度和频率,Fnk为正实值的加权函数,Ynk为实际波束形成器响应函数,ank是空时二维导向矢量,Dnk为期望波束响应。
将式(1)目标函数展开,并缩写为
则式(1)可写为
J(h)=hTRh-2qTh+dLS (4)
令得到权矢量为
h=R-1q (5)
步骤3、在封闭环境内,麦克风阵列采集到的信号不仅包含直达路径传播的信号,而且包含了由于房间反射而产生的延迟衰减信号,这种多径传播效应在接收信号中导致谱失真,称为混响,混响后的语音信号与谱图为图3。基于房间脉冲响应h(k)是一个随机过程,表示为
式中b(k)为零均值的高斯白噪声,Δ是与混响时间T60相联系的衰减因子,从房间脉冲响应h(k)的角度看,可以把h(k)近似分成直达部分语音信号的脉冲响应函数hd(k)和形成混响信号的响应函数hr(k),β=50ms是本位设定的临界时间,房间冲击响应在k<50ms时的混响效应不明显,与干净语音的卷积可以看作直达声。分别表示为
假设sd(k)与sr(k)分别表示纯净语音信号s(t)与hd(k)和hr(k)的卷积,则sd(k)为待处理语音信号的直达信号部分,sr(k)为待处理语音信号的混响部分。由以上分析得到改进维纳滤波器的估计增益。
后置维纳滤波器的增益为基于以上分析得到基于维纳后置滤波的LS改进波束形成混响抑制方法的麦克风阵列响应权矢量最后将信号进行逆傅里叶变换(IFFT)得到去混响后的语音信号,其与谱图为图4。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!