结合声效模式检测的语音识别方法与流程
本发明涉及语音识别领域,特别涉及一种结合声效模式检测的语音识别方法。
背景技术:
声音效果(Vocal Effort)简称声效,是正常人的一种发音变化的衡量,而这种发音变化是人出于正常交流的需要,根据交流时双方距离的远近或背景噪声的高低自动调整发音方式所产生的。通常将声效由低到高分为五个量级/模式:耳语、轻声、正常、大声、高喊。在现实的环境中,人们不可能一直都在同一种声效水平下交流:在图书馆或者自习室里需要通过耳语的方式交流;在吵杂的场合需要大声说话对方才能听见;而在嘈杂的工厂车间可能就需要通过高喊的方式才能够交流。
近年来语音识别技术已进入实用的阶段,并取得很好的效果。但是目前的语音识别技术主要还是针对正常声音效果下的语音信号。声效模式的改变使得语音信号的声学特性发生了变化,因此正常声效模式的语音识别系统在识别其它四种声效模式(特别是耳语模式)的语音信号时识别精度会有较大幅度的下降,使得语音识别技术的适用范围较窄。
技术实现要素:
本发明的目的在于针对现有技术中的语音识别方法在识别其它四种声效模式的语音信号时精度不高的缺陷,提出一种结合声效模式检测的语音识别方法,能够精确地检测待识别语音信号所属的声效模式,并在此基础上提高对所有声效模式的语音信号的识别精度,扩展语音识别技术的适用范围。
本发明公开了一种结合声效模式检测的语音识别方法,其具体包括以下步骤:
步骤1、接收语音信号;
步骤2、检测所述语音信号中的元音,生成元音集合;
步骤3、提取所述元音集合中每一个元音的声学特征序列;
步骤4、根据回声状态网络将所述元音集合中每一个元音的声学特征序列转换为用于声效模式检测的段特征矢量;
步骤5、根据所述元音集合中每一个元音的段特征矢量检测所述语音信号的声效模式;
步骤6、从预置的声学模型集中选择所述语音信号的声效模式对应的声学模型子集;
步骤7、根据所述声学模型子集对所述语音信号进行解码。
上述技术方案中,步骤4利用回声状态网络将声学特征序列转换为声效相关特征矢量,即将基于语音帧的特征序列转换为描述语音段的特征矢量。在这个过程中由于回声状态网络储备池存在自反馈环节,能有效利用相邻语音帧之间存在的内在联系,提高声效模式识别精度。在此基础上,步骤6中预置的声学模型集共包含了5个声学模型子集,每个声学模型子集分别对应一种声效模式,而每一个声学模型子集在训练时使用的是对应声效模式的语料库,这样每个声学模型子集中的声学模型能很好地拟合其对应声效模式语音的声学特性。在识别时先准确地检测出语音信号的声效模式,再利用对应的声学模型子集来进行解码,就可以有效地提高语音识别的精度,扩展语音识别技术的应用范围。
附图说明
图1是根据本发明的一种结合声效模式检测的语音识别方法的流程图;
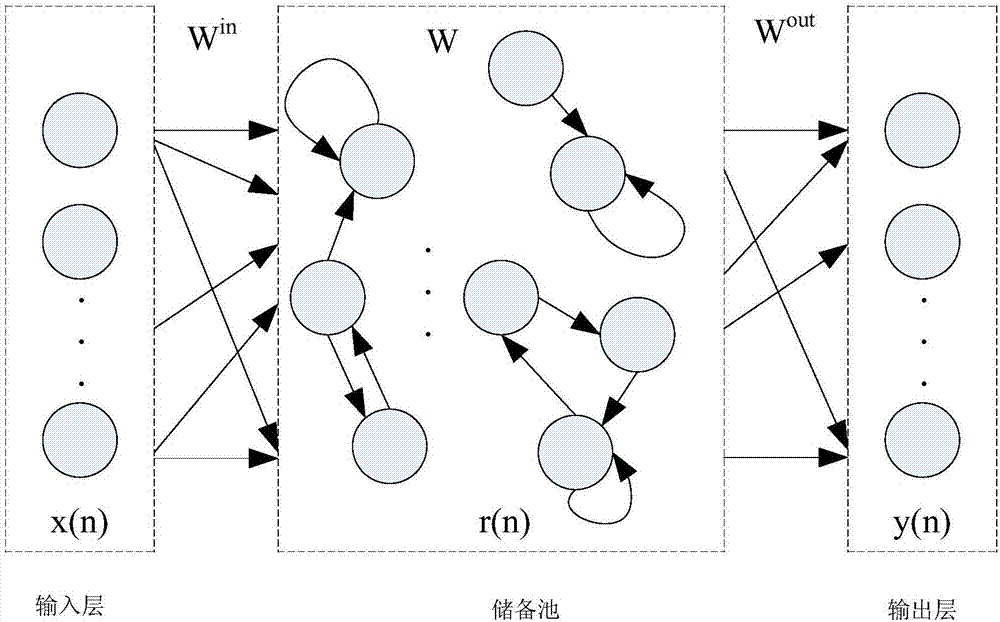
图2是根据本发明的一个回声状态网络的结构示意图。。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
图1为根据本发明的一种结合声效模式检测的语音识别方法的流程图。其中,接收的语音信号为连续语音,对应一个语句。
如图1所示,所述结合声效模式检测的语音识别方法包括如下步骤:
步骤101、接收语音信号;
步骤102、检测语音信号中的元音,生成元音集合;
步骤103、提取元音集合中每一个元音的声学特征序列;其中,声学特征为基于帧的12维梅尔频率倒谱系数以及它们的一阶及二阶差分,共36维;
步骤104、根据回声状态网络将元音集合中每一个元音的声学特征序列转换为用于声效模式检测的段特征矢量;
步骤105、根据元音集合中每一个元音的段特征矢量检测语音信号的声效模式;
步骤106、从预置的声学模型集中选择语音信号的声效模式对应的声学模型子集;
步骤107、根据声学模型子集对语音信号进行解码。
在步骤104中,所述回声状态网络的结构如图2所示:
在图2中,该回声状态网络包含输入层、储备池和输出层。输入层包含了36个节点,用于接收所述声学特征序列中当前帧n的声学特征x(n);储备池包含了100个稀疏连接的节点;y(n)表示输出层的输出值向量,Win表示回声状态网络中输入层和储备池之间的连接权重矩阵,W表示储备池内部连接的权重矩阵,Wout表示储备池和输出层之间的连接权重矩阵;其中,Win和W随机产生,一经产生就固定不变。
当前帧n的声学特征x(n)输入回声状态网络后,计算得到储备池中各节点的输出值组成的向量,即是储备池的第n步状态值向量r(n),r(n)通过如下公式更新得到:
r(n)=g(W·r(n-1)+Win·x(n))
其中,r(n-1)表示储备池的第n-1步状态值向量,g(·)表示储备池结点的激励函数,为双曲正切函数。
步骤104的具体步骤包含:
步骤1041、随机初始化回声状态网络中储备池的起始状态值向量r(0);
步骤1042、将该元音的声学特征序列中前5个特征向量依次输入到回声状态网络,并更新储备池的状态值向量;
步骤1043、将储备池当前的状态值向量r(5)作为起始状态值向量r(0),即r(0)=r(5);其中步骤1042和步骤1043主要是为了降低步骤1041中随机初始化的负面影响;
步骤1044、将该元音的声学特征序列中的各个特征向量依次输入到回声状态网络,并更新储备池的状态值向量;
步骤1045、把储备池当前的状态值向量作为该元音的段特征矢量。
通过步骤104可以将元音信号基于帧的特征序列转换为描述整个元音信号段的段特征矢量,其中所述段特征矢量包含了100个分量,对应储备池中100个稀疏连接的节点。
步骤105的具体步骤包含:
步骤1051:根据元音集合中每一个元音的段特征矢量将元音集合分别与多个候选声效模式进行匹配,生成每一个候选声效模式的匹配值;
步骤1052、将匹配值最大的候选声效模式确定为语音信号的声效模式。
在步骤1051中,每一个候选声效模式的匹配值通过如下公式确定:
其中,E表示该候选声效模式,ME表示该候选声效模式的匹配值,Vset表示所述元音集合,v表示所述元音集合Vset中的某个元音,P(E|v)表示元音v的声效模式为E的概率,N表示元音集合Vset中的元音个数。
而元音v的声效模式为E的概率P(E|v)的具体计算过程如下:将元音v的段特征矢量输入到候选声效模式E的径向基函数网络,并计算所述径向基函数网络的输出值,所述输出值即为P(E|v)。由于径向基函数网络用于估计概率值,所以其输出层只有一个节点。
上述技术方案中,步骤104利用回声状态网络将基于帧的特征序列转换为段特征。由于回声状态网络的储备池存在自反馈环节,能有效利用相邻语音帧之间存在的内在联系。因此,相比基于帧的特征序列,段特征对于声效模式具有更强的区分能力。同时,径向基函数网络被用于计算元音属于某种声效模式的概率值,并以此判断语音信号的声效模式,从而能够有效地提高声效模式检测的精度。
在此基础上,步骤106中预置的声学模型集共包含了5个声学模型子集,每个声学模型子集分别对应一种声效模式,而每一个声学模型子集在训练时使用的是对应声效模式的语料库,这样每个声学模型子集中的声学模型能很好地拟合其对应声效模式语音的声学特性。在识别时先准确地检测出语音信号的声效模式,再利用对应的声学模型子集来进行解码,就可以有效地提高语音识别的精度,扩展语音识别技术的应用范围。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!