语音通话数据处理方法、装置、存储介质及移动终端与流程
本申请实施例涉及语音通话技术领域,尤其涉及语音通话数据处理方法、装置、存储介质及移动终端。
背景技术:
目前,随着移动终端的快速普及,手机及平板电脑等移动终端已经成为人们必备的通信工具之一。移动终端用户之间的通信方式越来越丰富,早已不局限于移动通信运营商提供的传统的电话及短信息等服务,在许多场景下,用户更倾向于使用基于互联网的通信方式,如各种社交软件中的语音聊天及视频聊天功能等。
此外,移动终端中的应用程序(Application,APP)功能日益完善,许多应用程序中都设置了语音通话功能,方便使用同款应用程序的用户之间的沟通和交流。以游戏应用为例,一些需要玩家之间进行互动的游戏已经添加了内置的语音通话功能,用户可以在使用移动终端玩游戏的过程中,与其他玩家进行语音交流。然而,在语音通话过程中,语音通话数据中包含的声音种类较多,如包含各玩家说话的声音、应用程序本身的声音(如游戏的背景音或特效音等)以及移动终端所处环境中的其他声音等,由于声音比较复杂,很容易发生啸叫现象,严重影响用户的使用。
技术实现要素:
本申请实施例提供一种语音通话数据处理方法、装置、存储介质及移动终端,可以在移动终端应用程序中的语音通话功能开启后,选择合适的时机进行防啸叫处理。
第一方面,本申请实施例提供了一种语音通话数据处理方法,包括:
预设应用程序中的语音通话组建立成功后,检测到防啸叫处理事件被触发;
实时监控移动终端当前位置的环境音强度值;
若所述环境音强度值大于第一预设强度值,则对所述移动终端中的语音通话数据进行防啸叫处理。
第二方面,本申请实施例提供了一种语音通话数据处理装置,包括:
触发检测模块,用于预设应用程序中的语音通话组建立成功后,检测到防啸叫处理事件被触发;
环境音强度监控模块,用于实时监控移动终端当前位置的环境音强度值;
防啸叫处理模块,用于若所述环境音强度值大于第一预设强度值,则对所述移动终端中的语音通话数据进行防啸叫处理。
第三方面,本申请实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如本申请实施例所述的语音通话数据处理方法。
第四方面,本申请实施例提供了一种移动终端,包括存储器,处理器及存储在存储器上并可在处理器运行的计算机程序,所述处理器执行所述计算机程序时实现如本申请实施例所述的语音通话数据处理方法。
本申请实施例中提供的语音通话数据处理方案,在移动终端的预设应用程序中的语音通话组建立成功后,检测到防啸叫处理事件被触发,若监控到移动终端当前位置的环境音强度值大于第一预设强度值,则对移动终端中的语音通话数据进行防啸叫处理。通过采用上述技术方案,可以在移动终端中的预设应用程序的语音通话组建立成功后,检测到移动终端当前位置的环境音强度值较高时,及时对当前的移动终端的语音通话数据进行防啸叫处理,减少啸叫音给用户使用带来的不便。
附图说明
图1为本申请实施例提供的一种语音通话数据处理方法的流程示意图;
图2为本申请实施例提供的一种原始啸叫语音频谱分析示意图;
图3为本申请实施例提供的一种陷波滤波器示意图;
图4为本申请实施例提供的一种经过陷波滤波器处理后的啸叫语音频谱分析示意图;
图5为本申请实施例提供的另一种语音通话数据处理方法的流程示意图;
图6为本申请实施例提供的又一种语音通话数据处理方法的流程示意图;
图7为本申请实施例提供的一种语音通话数据处理装置的结构框图;
图8为本申请实施例提供的一种移动终端的结构示意图;
图9为本申请实施例提供的又一种移动终端的结构示意图。
具体实施方式
下面结合附图并通过具体实施方式来进一步说明本申请的技术方案。可以理解的是,此处所描述的具体实施例仅仅用于解释本申请,而非对本申请的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本申请相关的部分而非全部结构。
在更加详细地讨论示例性实施例之前应当提到的是,一些示例性实施例被描述成作为流程图描绘的处理或方法。虽然流程图将各步骤描述成顺序的处理,但是其中的许多步骤可以被并行地、并发地或者同时实施。此外,各步骤的顺序可以被重新安排。当其操作完成时所述处理可以被终止,但是还可以具有未包括在附图中的附加步骤。所述处理可以对应于方法、函数、规程、子例程、子程序等等。
图1为本申请实施例提供的一种语音通话数据处理方法的流程示意图,该方法可以由语音通话数据处理装置执行,其中该装置可由软件和/或硬件实现,一般可集成在移动终端中。如图1所示,该方法包括:
步骤101、预设应用程序中的语音通话组建立成功后,检测到防啸叫处理事件被触发。
示例性的,本申请实施例中的移动终端可包括手机及平板电脑等移动设备。预设应用程序可以是内置语音群组通话功能的网络游戏应用,如网络游戏应用、在线课堂应用、视频会议应用或者需要多人协作的其他应用程序等等。
示例性的,语音通话组中可以包含2个成员,但多数情况下,一般包含3个或3个以上的成员,即可实现3个或3个以上的移动终端之间的语音通话。语音通话组可以由在移动终端上使用预设应用程序的用户发起而建立,在语音通话组建立成功后,语音通话组中包含的所有移动终端之间可进行通信。一般的,当移动终端未处于静音模式,也未处于耳机模式时,可理解为移动终端处于外放模式,语音通话组中每个用户的声音会被自己正在使用的移动终端的麦克风采集,并经过网络传输及处理后通过其他用户的移动终端的扬声器进行播放。以王者荣耀游戏应用为例,如需要组队协战,可开启组队语音功能,假设队内有5个玩家,那么语音通话组建立成功后,这5个人相互之间可以进行通话,任意一个玩家可以同时听到另外4个玩家说的话,仿佛另外4个玩家在自己身边讲话一样,方便边交流边游戏。
一般的,当移动终端处于外放模式时,移动终端麦克风采集到的声音中不仅包含用户自身说话的声音,还可能包含扬声器播放的预设应用程序本身发出的声音,如背景音乐等,还可能包含周围环境的声音,还可能包含扬声器播放的语音通话组内其他人说话的声音,这样,当多个移动终端将各自采集的包含各种声音的数据经过网络发送至同一个移动终端时(例如语音通话组内包含5个移动终端,那么其中4个移动终端就会把各自采集的声音发送至服务器,服务器将4个移动终端的声音数据发送给第5个移动终端),这些声音由会在该移动终端中混合起来播放,可能会产生啸叫现象。
本申请实施例中,为了在合适的时机进行防啸叫处理,可以预先设置防啸叫处理事件被触发的条件。可选的,为了及时有效地进行防啸叫处理操作,可在预设应用程序中的语音通话组建立成功后,立即触发防啸叫处理事件;可选的,为了更有针对性的进行防啸叫,同时节省防啸叫处理操作所带来的额外功耗,可对容易发生啸叫的场景进行理论分析或调研等,设置合理的预设场景,在检测到移动终端处于预设场景时,触发防啸叫处理事件。
步骤102、实时监控移动终端当前位置的环境音强度值。
其中,在多人语音的应用场景下,发明人发现,当用户在嘈杂的环境中通过移动终端进行网络游戏时,通常由于外界环境噪音较大,在通过语音通话组进行沟通交流的过程中,为了能够更好地让对方更清楚地听到自己的通话语音,用户的通话语音的强度通常会比较大,此时极易发生啸叫。因此,本申请实施例中,实时监控移动终端当前位置的环境音强度值,并判断该环境音强度值是否较高,若是,则需要对移动终端中的语音通话数据进行防啸叫处理。
本申请实施例中,实时监控移动终端当前位置的环境音的强度值,以及环境音强度值。其中,移动终端当前位置的环境音可以理解为用户通过语音通话组进行语音通话时,周围环境的声音。其中,环境音强度值反应了用户进行网络游戏时移动终端所处环境的嘈杂程度,环境音强度值越大,表示用户进行网络游戏时所处环境越嘈杂,也即环境噪音越大,如用户家中其他成员在看电视或是播放音乐,甚至孩子嬉闹时的环境;环境音强度值越小,表示用户进行网络游戏时所处环境越安静,也即环境噪音越小,如在安静的会议室中。
可选的,实时监控移动终端当前位置的环境音强度值,可以包括:实时获取所述移动终端的麦克风采集的第一声音数据;根据预先存储的声纹信息从所述第一声音数据中提取人声;将从所述第一声音数据中分离出所述人声后的声音作为所述移动终端当前位置的环境音;获取所述环境音的环境音强度值。这样设置的好处在于,可以准确地获取移动终端当前位置的环境音,进一步精确确定环境音强度,从而可以进一步准确判断环境音强度值是否较高,以确定是否对移动终端中的语音通话数据进行防啸叫处理。
示例性的,每个用户的声纹信息是唯一确定的,采集当前移动终端对应的用户的声纹信息,并将其保存在移动终端中。当需要获取移动终端当前位置的环境音强度值时,通过移动终端的麦克风采集当前时段的第一声音数据,其中,第一声音数据中不仅可以包括用户说话的声音,还包括用户说话时,所处位置中其他环境音。根据预先存储的声纹信息从第一声音数据中提取出当前用户说话的声音,也即人声,并将第一声音数据中除当前用户说话的声音之外的声音数据作为移动终端当前位置的环境音。并获取环境音的环境音强度值,其中环境音强度值可以理解为环境音的音量大小,也即环境音的幅值大小。
可选的,实时监控移动终端当前位置的环境音强度值,可以包括:实时获取所述移动终端的麦克风采集的第二声音数据;获取所述第二声音数据对应的各个声源位置;将所述各个声源位置中,与所述移动终端之间的距离大于第一预设距离值的声源位置确定为目标声源位置;将所述第二声音数据中与所述目标声源位置对应的声音作为所述移动终端当前位置的环境音;获取所述环境音的环境音强度值。这样设置的好处在于,能够快速获取移动终端当前位置的环境音强度值。
示例性的,在移动终端中通常存在麦克风阵列(麦克风数量大于或等于2),通过麦克风阵列可以准确地判断出麦克风采集的第二声音数据对应的各个声源的位置,也即声源位置。将与当前移动终端之间的距离大于第一预设距离值的声源作为目标声源,将目标声源对应的声音作为环境音。例如,通常用户与移动终端的位置是固定的,且用户与移动终端间的距离也较近,因此可以将第一预设距离值设定为0.5米或1米,从各个声源位置中筛选出距离移动终端较远(如大于1米或大于0.5米)的声源作为目标声源,并将目标声源发出的声音作为环境音。并确定环境音的强度值。需要说明的是,本申请实施例对确定第二声源数据对应的各个声源位置的方式不做具体限定。示例性的,还可以通过对第二声音数据进行频谱分析,以确定第二声音数据中包含的各个声源频率和相应的带宽,然后基于声源频率和对应的带宽确定各个声源位置。
步骤103、若所述环境音强度值大于第一预设强度值,则对所述移动终端中的语音通话数据进行防啸叫处理。
在本申请实施例中,在确定环境音强度值大于第一预设强度值时,认为此时很容易发生啸叫,所以需要对语音通话数据进行防啸叫处理。语音通话数据可包括上行语音通话数据和/或下行语音通话数据,本申请不做具体限定。其中,上行语音通话数据可以包括移动终端的麦克风采集到的声音数据;下行语音通话数据可以是预设应用程序对应的服务器在接收到语音通话组内其他移动终端的声音数据后,经过混音等处理发送给移动终端的数据,或者直接转发给移动终端的数据,本申请对服务器处理语音通话数据的处理方式不做限定。对于防啸叫处理的具体方式本申请实施例也不做限定,下文中将给出具体的实现方式作为示意性说明。
本申请实施例中提供的语音通话数据处理方法,在移动终端的预设应用程序中的语音通话组建立成功后,检测到防啸叫处理事件被触发时,判断移动终端当前位置的环境音强度值是否大于第一预设强度值,若是,则对移动终端中的语音通话数据进行防啸叫处理。通过采用上述技术方案,可以在移动终端中的预设应用程序的语音通话组建立成功后,检测到移动终端当前位置的环境音强度值较高时,及时对当前的移动终端的语音通话数据进行防啸叫处理,减少啸叫音给用户使用带来的不便。
在一些实施例中,所述对所述移动终端中的语音通话数据进行防啸叫处理,包括:根据所述环境音强度值确定防啸叫处理的目标强度;其中,环境音强度值越大,对应的目标强度越大;根据所述目标强度对所述移动终端中的语音通话数据进行相应的防啸叫处理。发明人发现,当用户在嘈杂的环境中通过移动终端进行网络游戏时,通常由于外界环境噪音较大,在通过语音通话组进行沟通交流的过程中,为了能够更好地让对方更清楚地听到自己的通话语音,用户的通话语音的强度就会越大,越容易发生啸叫,而且通常发生啸叫的情况越严重,所以本申请实施例中可根据移动终端当前位置的环境音强度值的大小(或高低)来选择对应的防啸叫处理强度(即目标强度),可以做到更有针对性的防啸叫处理,提升防啸叫效果。
在一些实施例中,所述根据所述环境音强度值确定防啸叫处理的目标强度,包括:根据所述环境音强度值确定对所述移动终端中的上行语音通话数据和/或下行语音通话数据进行防啸叫处理。其中,当所述环境音强度值小于或等于第二预设强度值时,确定对所述移动终端中的上行语音通话数据进行防啸叫处理;当所述环境音强度值大于所述第二预设强度值且小于或等于第三预设强度值时,确定对所述移动终端中的下行语音通话数据进行防啸叫处理;当所述环境音强度值大于所述第三预设强度值时,确定对所述移动终端中的上行语音通话数据和下行语音通话数据进行防啸叫处理。下行语音通话数据一般数据量较大,啸叫抑制处理难度稍大,耗时稍长,因此,本申请实施例中,在环境音强度值大于第一预设强度值但小于或等于第二预设强度值时,说明若产生啸叫,啸叫程度并不严重,可以仅针对上行语音通话数据进行防啸叫处理。当环境音强度值大于第二预设强度值,但小于或等于第三预设强度值时,说明若产生啸叫,啸叫程度会比较严重,可以针对下行语音通话数据进行防啸叫处理,以得到较佳的防啸叫效果。当环境音强度值很大或很高,大于第三预设强度值时,说明若产生啸叫,啸叫程度会非常严重,可以同时针对下行语音通话数据和下行语音通话数据进行防啸叫处理,以得到最佳的防啸叫效果。本申请对第一预设强度值、第二预设强度值及第三预设强度值的数值依次增大,但对具体数值不做限定,示例性的,第一预设强度值为20分贝,第二预设强度值30分贝,第三预设强度值为40分贝。
示例性的,在对下行语音通话数据进行防啸叫处理时,可先对下行语音通话数据进行啸叫检测,在判断出存在啸叫音时,针对啸叫点进行衰减处理,从而达到防啸叫效果。
在一些实施例中,可采用如下方式判断下行语音通话数据中是否存在啸叫音:
第一种,对所述下行语音通话数据进行分块处理;对于每个数据块,采用预设分析方式确定当前数据块中存在的疑似啸叫点;当存在呈现周期性特征的多个疑似啸叫点群,且疑似啸叫点对应的能量值依照所属数据块的顺序呈上升趋势时,确定所述下行语音通话数据中存在啸叫音;其中,所述疑似啸叫点群为连续相邻数据块中的频率差异处于预设范围内的疑似啸叫点,所述连续相邻数据块的数量达到预设连续阈值。
第二种,对所述下行语音通话数据进行分块处理,得到M个数据块;采用预设分析方式依次分析当前数据块中是否存在疑似啸叫点,将首次出现疑似啸叫点的数据块确定为起始数据块;从所述起始数据块开始,依次以n个数据块为待分析的数据段,采用所述预设分析方式分析出当前数据段中包含的疑似啸叫点,当N个数据段中包含的疑似啸叫点之间的频率差异处于预设范围内时,确定所述下行语音通话数据中存在啸叫音;其中,n=2,3,…,N;N小于或等于M,大于或等于2;每个数据段的起始点均与所述起始数据块的起始点相同,所述起始数据块为第一个数据段。
当然,本申请实施例中还可采用其他方式来判断下行语音通话数据中是否存在啸叫音,本申请不做限定。下面以上述两种方式为例进行详细的说明。
对于第一种方式,对下行语音通话数据进行分块处理可以是按照预设单位长度进行分块处理,预设单位长度例如可以是40毫秒。假设预设时间长度为1.2秒,预设单位长度为40毫秒,那么可以分为30个数据块。
本申请实施例对预设分析方式不作具体限定。例如,所述预设分析方式可包括:在频域上获取高频区域中能量值高于预设能量阈值的待判定频点,计算所述待判定频点周围预设数量的频点的能量差异值,当所述能量差异值大于预设差异阈值时,确定所述待判定频点为疑似啸叫点;所述高频区域为频率高于预设频率阈值的频率范围。
具体的,对于当前数据块,可先将其从时域变换到频域,便于进行频谱分析。变换方式本申请实施例不做限定,可以采用傅里叶变换方式,如离散傅氏变换的快速算法(Fast Fourier Transformation,FFT)。以40ms为例,40ms的音频数据(16bit,16k采样率)大小为40*16*16/2=1280字节,适合于使用1024做FFT变换进行频谱分析,经过FFT处理后的频率分析中的频率范围为0~16K/2,步长为(16K/2)/1024,步长约为8Hz。
本申请实施例中,可以预设频率阈值作为分界值来划分高频区域和其他区域。预设频率阈值可根据实际情况进行设置,如可根据人声频率和容易出现啸叫声的频率特点进行设置,例如可以是1KHz,1.5KHz,或2KHz等等。例如预设频率阈值为2KHz,即大于2KHz的部分为高频区域。一般啸叫声的频率会出现在高频区域,且声音较大(即能量值较高),本申请实施例能够根据能量值分布特点快速确定一个数据块中的疑似啸叫点。
示例性的,获取数据块中每个频率点(简称频点)对应的能量值,然后从高频区域中找到能量值高于预设能量阈值的待判定频点,计算待判定频点周围预设数量的频点的能量差异值。预设能量阈值和预设数量可根据实际需求设置,例如预设能量阈值可以是-10dB,预设数量可以是8个(待判定频点前面4个和后面4个)。以上文步长约为8Hz为例,假设待判定频点的频率值为3362Hz,那么其周围预设数量的频点的频率值约为3330Hz、3338Hz、3346Hz、3354Hz、3370Hz、3378Hz、3386Hz和3394Hz。能量差异值用于衡量待判定频点与周围预设数量的频点之间相差程度,具体可以是最大能量值和最小能量值的差值,还可以是能量方差值或能量均方差值等等,本申请不做限定。预设差异阈值与能量差异值相对应,例如,能量差异值为能量方差值时,预设差异阈值为预设方差阈值。当能量差异值大于预设差异阈值时,说明待判定频点比较突出,非常有可能是啸叫点,因此,确定待判定频点为疑似啸叫点。这样设置能够快速准确地识别出疑似啸叫点,为提高啸叫检测效率打下基础。
示例性的,一个数据块中可能存在多个待判定频点,本申请可从对应能量最高的待判定频点开始进行疑似啸叫点的判定。
此外,所述预设分析方式还可包括:在频域上获取高频区域中能量值最大的第一频点和低频区域中能量值最大的第二频点,当所述第一频点满足预设疑似啸叫条件时,确定所述第一频点为当前数据块中的疑似啸叫点,所述预设疑似啸叫条件包括所述第一频点的能量值大于预设能量阈值,且所述第一频点与所述第二频点的能量差值大于预设差值阈值。
具体的,对于当前数据块,可先将其从时域变换到频域,便于进行频谱分析。同样也可以预设划分频率作为分界值来划分高频区域和低频区域。预设划分频率可根据实际情况进行设置,如可根据人声频率和容易出现啸叫声的频率特点进行设置,例如可以是1KHz,1.5KHz,或2KHz等等。例如预设划分频率为2KHz,即大于2KHz的部分为高频区域,小于或等于2KHz的部分为低频区域。
示例性的,获取数据块中每个频率点对应的能量值,然后从高频区域中找到能量值最大的第一频点,从低频区域找到能量值最大的第二频点,若第一频点的能量值大于预设能量阈值(如-30dB),且第一频点的能量值与第二频点的能量值的差值大于预设差值阈值(如60)时,可认为第一频点为当前数据块中的疑似啸叫点。这样设置能够快速准确地识别出疑似啸叫点,为提高啸叫检测效率打下基础。
示例性的,对于每个数据块,分别采用如上预设分析方式判断是否存在疑似啸叫点,若存在,则记录下疑似啸叫点,并进一步判断当前的下行语音通话数据中是否包含啸叫音。
可以理解的是,若某个数据块中存在疑似啸叫音,并不能认为整段下行语音通话音频中包含啸叫音,还可能是由于某些特殊声音被误识别为啸叫音,例如物体摩擦时产生的刺耳的声音,一般频率较高且声音较大,很可能被识别为疑似啸叫音,但这种声音一般比较短促,持续时间较短,不属于啸叫音,因此,需要增加进一步的判定。
本申请实施例中,对各数据块中存在的疑似啸叫音的分布特点进行分析。当连续多个相邻数据块中存在频率差异较小的疑似啸叫点时,可将这几个疑似啸叫点成为疑似啸叫点群。即,疑似啸叫点群为连续相邻数据块中的频率差异处于预设范围内的疑似啸叫点,所述连续相邻数据块的数量达到预设连续阈值。其中,预设连续阈值可根据实际情况确定,例如3个;频率差异对应的预设范围也可根据实际情况确定,例如40Hz。发明人发现,啸叫声一般在短时间内表现出持续性特征,并周期性出现,另外声音逐渐变大。因此,本申请实施例中,将多个(可理解为大于或等于2个)疑似啸叫点群呈现周期性特征,以及疑似啸叫点对应的能量值依照所属数据块的顺序呈上升趋势作为判定条件,来识别当前的下行语音通话数据中是否存在啸叫音,若满足上述条件,则确定存在啸叫音,这样能够快速准确地识别出啸叫音。
示例性的,假设下行语音通话数据被分为30个数据块。例如,若第1、2、3、7、8、9、13、14、15、19、20、21、25、26和27这15个数据块中都检测到了频率在(A-40,A+40)区间内的疑似啸叫点,每3个数据块对应的疑似啸叫点成为一个疑似啸叫点群,5个疑似啸叫点群呈周期性特征,且疑似啸叫点对应的能量值依次增大,因此,确定下行语音通话数据中包含啸叫音。又如,若仅第1、2和3这3个数据块中检测到了频率在(B-40,B+40)区间内的疑似啸叫点,这3个数据块对应的疑似啸叫点成为一个疑似啸叫点群,但仅存在这一个,并未呈现周期性特征,因此,可确定下行语音通话数据中不包含啸叫音。
对于第二种方式,分块处理方式以及预设分析方式可参考第一种方式中的相关内容,本申请实施例不再赘述。
具体的,采用上述预设分析方式分析第一个数据块中是否存在疑似啸叫点,若存在,则疑似啸叫点首次出现,将第一个数据块确定为起始数据块;若不存在,则将当前数据块的下一个数据块作为新的当前数据块,并采用上述预设分析方式分析新的当前数据块中是否存在疑似啸叫点。依次类推,直到首次出现疑似啸叫点的数据块确定为起始数据块,若M个数据块中均不存在疑似啸叫点,则可认为当前的下行语音通话数据中不包含啸叫音。
以上述分块方式为例,M=30,2≤N≤30。在进行频谱分析时,待分析的数据长度对分析结果会产生影响,因为数据点较少时,精度可能不是太准确,所以,使用长度大一些的数据再次进行分析,相当于有一个修正的处理,能够更加准确地确定是否为啸叫。本申请对N的具体取值不做限定,假设N=4,一个数据块的长度为40ms,那么起始数据块的时间范围可记为0至40ms,由于起始数据块已经分析完毕,并作为第一数据段,所以从n=2开始,为第二个数据段,第二个数据段的时间范围可记为0至80ms,依次类推,第三个数据段的时间范围可记为0至120ms,第三个数据段的时间范围可记为0至160ms。
示例性的,预设范围可以根据实际情况设置,例如可以是40Hz(如上述举例,可认为相当于5个步长)。假设4个数据段分析出来的疑似啸叫点的频率分别为A、B、C和D,而A、B、C和D相互之间的差异均在40Hz以内,那么可确定下行语音通话数据中存在啸叫音。
可选的,若当前数据段中包含的疑似啸叫点与前面的数据段中包含的疑似啸叫点之间的频率差异未处于所述预设范围内,则从当前数据段的下一个数据块开始获取所述预设时间长度的下行语音通话数据,并重复执行对下行语音通话数据进行分块处理的相关操作。这样设置的好处在于,当任意两个数据段中包含的疑似啸叫点的频率差距较大时,可说明前面的疑似啸叫点可能不是真正的啸叫点,需要继续检测,而不需要对后面的数据段进行疑似啸叫点检测,节省功耗,提高啸叫音检测效率及准确度。例如,当C与A或与B之间的差异超出40Hz时,则从120ms开始,重新获取移动终端中的预设时间长度的下行语音通话数据,并对所述下行语音通话数据进行分块处理,得到M个数据块,再确定新的起始数据块,并继续采用上述方式确定下行语音通话数据中是否存在啸叫音。
在确定所述下行语音通话数据中存在啸叫音之后,还包括:将所述疑似啸叫点确定为啸叫点;根据所述啸叫点对所述下行语音通话数据进行啸叫抑制处理。在确定下行语音通话数据中存在啸叫音后,说明之前识别出来的满足啸叫音判定条件的疑似啸叫点确实为啸叫点,那么需要根据啸叫点对下行语音进行啸叫抑制处理,防止啸叫音从扬声器或听筒播放出去,影响用户的使用。进一步的,在进行啸叫抑制处理后,通过扬声器或听筒播放经过啸叫抑制处理后的下行语音通话数据。
在一些实施例中,所述根据所述啸叫点对所述下行语音通话数据进行啸叫抑制处理,包括:选取预设数量的对应能量值较高的啸叫点的频率,作为目标频率,对所述下行语音通话数据中与所述目标频率对应的音频信号进行衰减处理。预设数量可自由设置,如1个,3个,甚至更多,还可以根据啸叫点的数量来动态确定。可将啸叫点按照能量值从高到低的顺序进行排序,选取排在前面预设数量的啸叫点,将选取出来的啸叫点的频率确定为目标频率。能量值越高,啸叫声的声音越大,对用户的影响程度越高,这样设置的好处在于,能够更有针对性地对能量值较高的频率进行啸叫抑制,提高啸叫抑制效率,保证语音通话的时效性。
在一些实施例中,所述根据所述啸叫点对所述下行语音通话数据进行啸叫抑制处理,也可包括:对所述下行语音通话数据中与所有啸叫点的频率对应的音频信号进行衰减处理。这样设置的好处在于,能够全面地对所有啸叫点进行啸叫抑制,阻止啸叫音的播放。
示例性的,可采用陷波滤波器来对需要进行抑制的啸叫点的频率(即目标频率)所对应的音频信号进行衰减处理。陷波滤波器能够在某一个频率点迅速衰减输入信号,以达到阻碍该频率信号通过的滤波效果。本申请对陷波滤波器的类型以及具体参数值不做限定。一般的,将目标频率作为陷波滤波器的中心频率,陷波滤波器的处理带宽及增益等参数可根据实际需求进行设置。
示例性的,在对上行语音通话数据进行防啸叫处理时,可获取移动终端采集的声音数据;对声音数据进行人声和背景音分离操作;对分离出的背景音进行削弱处理;将经过削弱处理后的背景音和分离出的人声进行混音处理后,作为处理后的上行语音通话数据发送至所述预设应用程序对应的服务器。这样设置的好处在于,能够有效削弱由于背景音引起的啸叫。示例性的,当移动终端中存在麦克风阵列(麦克风数量大于或等于2)时,可判断出声源位置,根据声源位置筛选出距离移动终端较远(如大于1米)的声音作为背景音;或者,可预先获取移动终端用户的声纹信息,根据声纹信息从声音数据中提取出用户说话的声音作为人声,剩余的声音作为背景音。示例性的,对分离出的背景音进行削弱处理可以是通过调整增益的方式减小背景音的声音,也可以滤除背景音。背景音经过削弱处理后,音量减小,破坏声音越来越大的条件,进而有效削弱由于背景音引起的啸叫。需要说明的是,此处的背景音可以理解为上述提及的环境音。
此外,针对上行语音通话数据的防啸叫处理,还可以根据下行语音通话数据的啸叫检测结果来进行。若下行语音通话数据中存在啸叫音,通过移动终端的扬声器或听筒播放下行语音通话数据时,就会播放啸叫音,用户能够听到,此外,移动终端的麦克风也能够采集到啸叫音,也即移动终端的上行语音通话数据中也会包含啸叫音。本申请实施例中,对上行语音通话数据进行防啸叫处理,避免啸叫音再次被传送至网络,被其他移动终端接收,从而可破坏啸叫音越来越大的条件,进而达到防啸叫的目的。具体的,可采用预设陷波滤波器对移动终端中的上行语音通话数据进行防啸叫处理,其中,预设陷波滤波器的中心频率为下行语音通话数据中的啸叫点对应的频率。
可选的,针对上行语音通话数据的防啸叫处理,还可以是:获取当前待上传的第一上行数据,以及缓存的上一时刻上传的第二上行数据,判断所述第一上行数据与所述第二上行数据的相似度是否高于预设相似度阈值,若是,则对所述第一上行数据进行削弱处理。这样设置的好处在于,能够快速判断是否需要进行衰减处理,提高防啸叫处理效率。其中,对所述第一上行数据进行削弱处理,可包括:将所述第一上行数据中与所述第二上行数据特征相同的音频数据进行削弱或滤除。这里的削弱可包括降低声音能量。进一步的,还可对所述第一上行数据和所述第二上行数据进行模拟叠加,判断叠加后的数据中是否包含啸叫特征,若包含,则对所述第一上行数据进行削弱处理。所述啸叫特征可包括能量集中、周期性以及频率高于预设频率阈值等。也可按照上述对下行语音通话数据进行啸叫检测的方式来判断叠加后的数据中是否包含啸叫特征,本申请实施例不做限定。
在一些实施例中,所述根据所述目标强度对所述移动终端中的语音通话数据进行相应的防啸叫处理,包括:获取移动终端中的预设时间长度的下行语音通话数据;确定所述下行语音通话数据中的啸叫点;采用预设陷波滤波器对所述移动终端中的语音通话数据进行啸叫抑制处理;其中,所述预设陷波器的中心频率为所述啸叫点对应的频率,处理宽度及增益值由所述目标强度确定,所述目标强度越高,对应的处理宽度越宽或对应的增益值越小。采用预设陷波滤波器对语音通话数据进行啸叫抑制处理,此处的语音通话数据可以包括上行语音通话数据和/或下行语音通话数据,本申请实施例不做限定。这样设置的好处在于,可以根据不同的环境音强度值有针对性的设置预设陷波滤波器的处理宽度或增益值,从而实现不同程度的啸叫抑制处理。
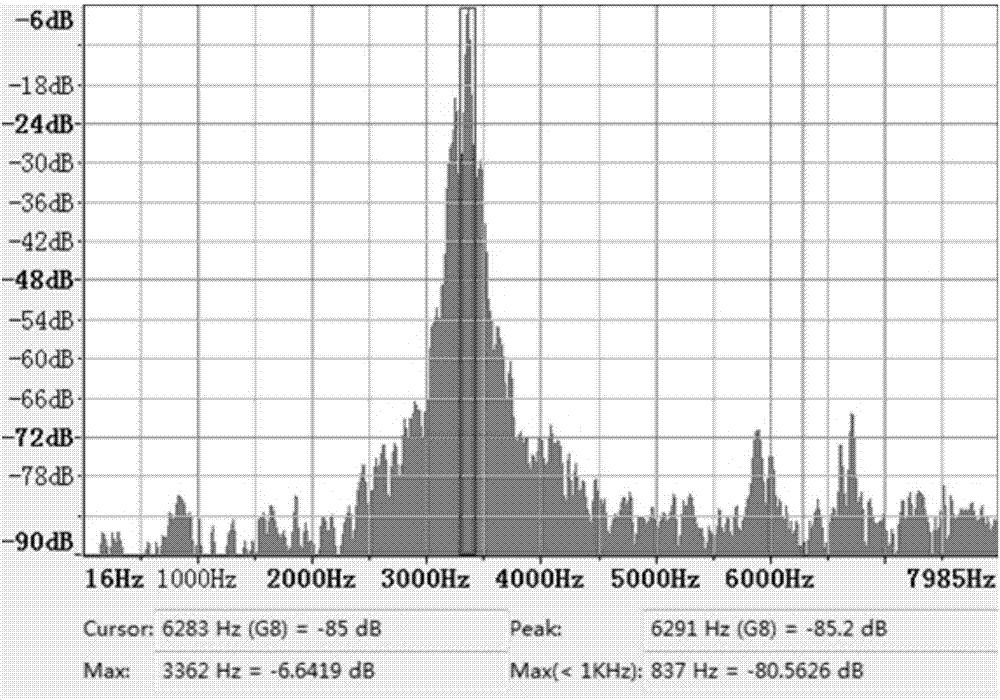
图2为本申请实施例提供的一种原始啸叫语音频谱分析示意图,该图中示出的是从某包含啸叫音的音频中截取的一个啸叫段,该音频中3362Hz对应的能量值最大,为-6.64dB,如果播放出去,声音会很大,需要进行啸叫抑制处理。图3为本申请实施例提供的一种陷波滤波器示意图。在对下行语音通话数据进行啸叫抑制处理时,预设陷波滤波器的中心频率为啸叫点对应的频率,如图2中的3362Hz,可根据目标强度确定对应的处理宽度。处理宽度为中心频率左右需要处理的范围,假设-6.64dB对应的处理宽度为50Hz,则需要处理的范围为3312Hz至3412Hz,即对这个范围内的音频信号进行处理。根据目标强度确定处理宽度的好处在于,啸叫点的能量值越高,其附近越可能出现能量大的频点,需要扩大处理范围,以得到更好的抑制效果。此外,如图3所示,陷波滤波器中设置有增益值,以g表示,图中的gmin表示增益值的最小值,取值范围一般为0至1,g值越大,衰减程度越小。因此,本申请中,可根据目标强度确定增益值,目标强度越高,增益值越小,使得处理范围内能量衰减程度越高,对啸叫音的抑制程度越高。图4为本申请实施例提供的一种经过陷波滤波器处理后的啸叫语音频谱分析示意图,如图4所示,3312Hz至3412Hz范围内的能量经过陷波滤波器处理后得到了明显的衰减,从而实现对啸叫音的抑制。
在一些实施例中,所述检测到防啸叫处理事件被触发,包括:判断所述语音通话组中是否存在与所述移动终端之间的距离小于第二预设距离值的目标移动终端,若存在,则确定检测到防啸叫处理事件被触发。在多人语音的应用场景下,发明人发现,当存在两个移动终端之间的距离比较近时,极易发生啸叫。假设语音通话组中的移动终端甲和移动终端乙距离较近,移动终端甲的扬声器会放大并播放接收到的移动终端乙的麦克风采集的声音,而由于两个移动终端比较近,这个声音就会被移动终端乙的麦克风再次采集并发送到移动终端甲,该声音被继续放大并播放,极易形成声音的正反馈放大,从而产生啸叫音。因此,本申请实施例中,可先判断语音通话中是否存在一个其他移动终端与当前的移动终端的距离比较近,若存在,则触发防啸叫处理事件,进而检测到防啸叫处理事件被触发。其中,第二预设距离值例如可以是20米或10米等,可根据实际需求进行设置。
本申请实施例中,判断所述语音通话组中是否存在与所述移动终端之间的距离小于第二预设距离值的目标移动终端的具体判断方式可以有很多种,并不做限定,以下给出几种方式作为示意性说明。
1、采用预设方式播放预设声音片段,并接收所述语音通话组中其他移动终端的反馈信息,所述反馈信息包含所述其他移动终端尝试采集与所述预设声音片段对应的声音信号的结果;根据所述反馈信息判断所述语音通话组中是否存在与所述移动终端之间的距离小于第二预设距离值的目标移动终端。
这样设置的好处在于,能够快速准确地判断出是否存在目标移动终端,进而快速确定是否需要触发防啸叫处理事件。示例性的,可通过扬声器以预设音量播放预先录制或预先获取的声音片段;或,通过超声波发射器播放预设频率及预设强度的超声波片段。可根据第二预设距离值对上述的预设音量,或预设频率及预设强度进行设置。反馈信息中包含的结果可以指其他移动终端是否能够采集到所述声音信号。当其他移动终端能够采集到预设声音片段对应的声音信号时,说明两个移动终端的距离小于第二预设距离值。反馈信息可由预设应用程序对应的服务器进行转发。此外,反馈信息中还可包括采集到的声音信号的属性信息,如声音强度等,由于移动终端播放的声音的强度是已知的,随着声音的传播会有所衰减,传播距离越远,衰减程度越高,可根据反馈信息中的声音信号的强度信息等来确定其他移动终端与当前移动终端的距离,并判断该距离是否小于第二预设距离值。
2、获取所述移动终端的第一定位信息以及所述语音通话组中其他移动终端的第二定位信息;根据所述第一定位信息和所述第二定位信息,判断所述语音通话组中是否存在与所述移动终端之间的距离小于所述第二预设距离值的目标移动终端。
这样设置的好处在于,移动终端普遍具备定位功能,能够利用定位信息快速准确地判断出是否存在目标移动终端,进而快速确定是否需要触发防啸叫处理事件。示例性的,移动终端可通过全球定位系统(Global Positioning System,GPS)或北斗等定位方式获取定位信息,也可通过基站定位或网络定位等方式获取定位信息。定位信息可包括经纬度坐标等。语音通话组中的其他移动终端的第二定位信息可通过预设应用程序对应的服务器转发至当前移动终端。当前移动终端将自身的第一定位信息与服务器转发来的至少一个第二定位信息逐一进行比对,判断是否存在一个第二定位信息与第一定位信息之间的距离小于第二预设距离值。
3、获取所述移动终端连接的第一WiFi信息以及所述语音通话组中其他移动终端连接的第二WiFi信息;根据所述第一WiFi信息和所述第二WiFi信息,判断所述语音通话组中是否存在与所述移动终端之间的距离小于所述第二预设距离值的目标移动终端。
这样设置的好处在于,用户为了节约流量费用,一般采用连接WiFi热点的方式进行语音通话,可以利用这一特点快速准确地判断出是否存在目标移动终端,进而快速确定是否需要触发防啸叫处理事件。示例性的,WiFi信息中可包括WiFi热点的属性信息,属性信息例如可以是WiFi热点名称或WiFi热点的媒介访问控制(Media Access Control,MAC)地址等,还可包括WiFi信号强度等。一般的,WiFi热点的信号有效范围有限,一般在50米左右,若第二预设距离值大于WiFi热点的信号有效范围,可根据是否存在一个第二WiFi信息的WiFi热点属性信息与第一WiFi信息的WiFi热点属性信息相同来确定所述语音通话组中是否存在与移动终端之间的距离小于第二预设距离值的目标移动终端,若存在任意一个第二WiFi信息的WiFi热点属性信息与第一WiFi信息的WiFi热点属性信息相同,则确定语音通话组中存在目标移动终端,也就是说,当语音通话组中有一个其他移动终端与当前移动终端连接同一个WiFi热点时,可认为该其他移动终端为目标移动终端。此外,若第二预设距离值小于WiFi热点的信号有效范围,如10米,那么可进一步根据WiFi信号强度估算连接同一个WiFi热点的移动终端分别与WiFi热点的距离,进而确定两个移动终端之间的距离,判断该距离是否小于第二预设距离值。
4、获取麦克风采集的第一声音数据,以及获取移动终端中的下行语音通话数据;其中,所述第一声音数据中不包含所述移动终端的扬声器播放的声音;根据所述第一声音数据和所述下行语音通话数据中是否包含同一个人的声音,判断所述语音通话组中是否存在与所述移动终端之间的距离小于所述第二预设距离值的目标移动终端。
这样设置的好处在于,可以不借助其他信息(如上述的定位信息或WiFi信息)快速准确地判断出是否存在目标移动终端,进而快速确定是否需要触发防啸叫处理事件。示例性的,第一声音数据中不包含所述移动终端的扬声器播放的声音,可通过以下方式实现:在获取第一声音数据和下行语音通话数据的过程中移动终端的扬声器处于关闭状态;或者,在获取第一声音数据和下行语音通话数据的过程中移动终端的扬声器处于开启状态,第一声音数据为在麦克风采集的所有声音数据中,滤除扬声器播放的声音数据后得到的声音数据。当两个用户手持移动终端且距离较近时,假设用户甲使用移动终端甲,用户乙使用移动终端乙,用户甲说话的声音被移动终端甲的麦克风采集并发送至移动终端乙,移动终端乙的下行语音通话数据中会包含用户甲说话的声音,而由于用户甲和用户乙距离较近,用户甲说话的声音也会被移动终端乙的麦克风采集,因此,对于移动终端乙来说,其麦克风采集的第一声音数据和获取的下行语音通话数据中包含同一个人(用户甲)的声音,从而确定语音通话组中存在移动终端甲与移动终端乙之间的距离小于第二预设距离值,即对于移动终端乙来说,移动终端甲为目标移动终端。
可以理解的是,可根据实际情况选取上述的任意一种或多种方式的组合来判断是否存在目标移动终端,本申请实施例不做限定。此外,判断是否存在目标移动终端的相关步骤也可由预设应用程序对应的服务器完成,当服务器判断出存在目标移动终端时,将判断结果发送至移动终端,所述判断结果用于指示移动终端触发防啸叫处理事件。相应的,本申请实施例的方法还包括,接收所述预设应用程序对应的服务器发送的判断结果,当所述判断结果中包含如下内容时,触发防啸叫处理事件:所述语音通话组中存在与所述移动终端之间的距离小于第二预设距离值的目标移动终端。服务器的具体判断过程可参照上述提供的几种判断方式,本申请实施例不做赘述。
图5为本申请实施例提供的另一种语音通话数据处理方法的流程示意图,以预设应用程序为网络游戏应用程序为例,该方法包括如下步骤:
步骤501、检测到预设游戏应用程序中的语音通话组建立成功。
示例性的,以团队对战游戏为例,如王者荣耀,每队有5个玩家,红蓝两队进行对战,每个队伍的5个玩家之间需要进行沟通交流商量对战策略,因此,许多玩家会选择开启队内语音通话功能,如一个玩家申请开启队内语音通话功能后,语音通话组建立成功。此后,同一战队的5个玩家中的任意一个,可听到其余4个玩家说话的声音。一般的,玩家会将移动终端设置为外放模式,方便游戏。
步骤502、判断语音通话组中是否存在与移动终端之间的距离小于第二预设距离值的目标移动终端,若是,则执行步骤503;否则,重复执行步骤502。
步骤503、实时获取移动终端的麦克风采集的第一声音数据。
步骤504、根据预先存储的声纹信息从第一声音数据中提取人声。
步骤505、将从第一声音数据中分离出人声后的声音作为移动终端当前位置的环境音。
步骤506、检测环境音的环境音强度值F。
步骤507、判断F是否大于X,若是,则执行步骤508;否则,执行步骤512。
若5个玩家中,当前移动终端当前位置的环境音强度值较高时,说明用户在嘈杂的环境中进行网络游戏,为了能够更好地让对方更清楚地听到自己的通话语音,用户的通话语音的强度通常会比较大,这样就非常容易引起啸叫。因此,本申请实施例中,可先判断环境音强度值是否大于第一预设强度值,若存在,则需要进行防啸叫处理。
步骤508、判断F与Y及Z的大小关系;F≤Y时,执行步骤509;Y<D≤Z时,执行步骤510;F>Z时,执行步骤511。
其中,X、Y及Z的数值依次增大。
步骤509、对移动终端中的上行语音通话数据进行防啸叫处理。
步骤510、移动终端中的下行语音通话数据进行防啸叫处理。
步骤511、对移动终端中的上行语音通话数据和下行语音通话数据进行防啸叫处理。
步骤512、保持正常的语音通话,不进行防啸叫处理。
本申请实施例在游戏应用中的语音通话组建立成功,并检测到防啸叫处理事件被触发时,根据预先存储的声纹信息从移动终端麦克风采集的第一声音数据中,提取人声,并将第一声音数据中分离出人声后的声音作为移动终端当前位置的环境音,检测该环境音强度值,并对环境音强度值与预设强度值进行比较,根据比较结果选择对上行和/或下行语音通话数据进行防啸叫处理,在开始语音通话后,对相应的语音通话数据进行防啸叫处理,削弱啸叫音对用户游戏过程产生的干扰,减少游戏玩家痛点,使移动终端的功能更加完善。
图6为本申请实施例提供的又一种语音通话数据处理方法的流程示意图,仍以网络游戏应用为例,该方法包括:
步骤601、检测到预设游戏应用程序中的语音通话组建立成功。
步骤602、判断语音通话组中是否存在与移动终端之间的距离小于第二预设距离值的目标移动终端,若是,则执行步骤603;否则,重复执行步骤602。
步骤603、实时获取移动终端的麦克风采集的第二声音数据。
步骤604、获取第二声音数据对应的各个声源位置。
步骤605、将各个声源位置中,与移动终端之间的距离大于第一预设距离值的声源位置确定为目标声源位置。
步骤606、将第二声音数据中与目标声源位置对应的声音作为移动终端当前位置的环境音。
步骤607、检测环境音的环境音强度值T。
步骤608、判断T是否大于第一预设强度值,若是,则执行步骤609;否则,执行步骤611。
步骤609、根据T确定预设陷波器的处理宽度和增益值。
其中,T值越大,对应的处理宽度越大,增益值越小。
步骤610、采用预设陷波滤波器对移动终端中的语音通话数据进行啸叫抑制处理。
示例性的,对下行语音通话数据进行啸叫检测,确定啸叫点,预设陷波器的中心频率为啸叫点对应的频率。
步骤611、保持正常的语音通话,不进行防啸叫处理。
本申请实施例在游戏应用中的语音通话组建立成功,并检测到防啸叫处理事件被触发后,实时获取移动终端的麦克风采集的第二声音数据,获取第二声音数据对应的各个声源位置,并将各个声源位置中,与移动终端之间的距离大于第一预设距离值的声源位置确定为目标声源位置,将第二声音数据中与目标声源位置对应的声音作为移动终端当前位置的环境音,进一步检测该环境音的环境音强度值,并对环境音强度值与第一预设强度值进行比较,当环境音强度值大于第一预设强度值时,根据环境音强度值对即将用于防啸叫处理的预设陷波滤波器的参数进行设置,在开始语音通话后,采用参数设置完毕的预设陷波滤波器对相应的语音通话数据进行防啸叫处理,削弱啸叫音对用户游戏过程产生的干扰,减少游戏玩家痛点,使移动终端的功能更加完善。
图7为本申请实施例提供的一种语音通话数据处理装置的结构框图,该装置可由软件和/或硬件实现,一般集成在移动终端中,可通过执行语音通话数据处理方法来对语音通话数据进行防啸叫处理。如图7所示,该装置包括:
触发检测模块701,用于预设应用程序中的语音通话组建立成功后,检测到防啸叫处理事件被触发;
环境音强度监控模块702,用于实时监控移动终端当前位置的环境音强度值;
防啸叫处理模块703,用于若所述环境音强度值大于第一预设强度值,则对所述移动终端中的语音通话数据进行防啸叫处理。
本申请实施例中提供的语音通话数据处理装置,可以在移动终端中的预设应用程序的语音通话组建立成功后,检测到移动终端当前位置的环境音强度值较高时,及时对当前的移动终端的语音通话数据进行防啸叫处理,减少啸叫音给用户使用带来的不便。
可选的,所述防啸叫处理模块,包括:
目标强度确定单元,用于根据所述环境音强度值确定防啸叫处理的目标强度;其中,环境音强度值越大,对应的目标强度越大;
防啸叫处理单元,用于根据所述目标强度对所述移动终端中的语音通话数据进行相应的防啸叫处理。
可选的,所述目标强度确定单元,用于:
根据所述环境音强度值确定对所述移动终端中的上行语音通话数据和/或下行语音通话数据进行防啸叫处理;
其中,当所述环境音强度值小于或等于第二预设强度值时,确定对所述移动终端中的上行语音通话数据进行防啸叫处理;
当所述环境音强度值大于所述第二预设强度值且小于或等于第三预设强度值时,确定对所述移动终端中的下行语音通话数据进行防啸叫处理;
当所述环境音强度值大于所述第三预设强度值时,确定对所述移动终端中的上行语音通话数据和下行语音通话数据进行防啸叫处理。
可选的,所述防啸叫处理单元,用于:
获取移动终端中的预设时间长度的下行语音通话数据;
确定所述下行语音通话数据中的啸叫点;
采用预设陷波滤波器对所述移动终端中的语音通话数据进行啸叫抑制处理;其中,所述预设陷波器的中心频率为所述啸叫点对应的频率,处理宽度及增益值由所述目标强度确定,所述目标强度越高,对应的处理宽度越宽或对应的增益值越小。
可选的,所述环境音强度监控模块,用于:
实时获取所述移动终端的麦克风采集的第一声音数据;
根据预先存储的声纹信息从所述第一声音数据中提取人声;
将从所述第一声音数据中分离出所述人声后的声音作为所述移动终端当前位置的环境音;
获取所述环境音的环境音强度值。
可选的,所述环境音强度监控模块,用于:
实时获取所述移动终端的麦克风采集的第二声音数据;
获取所述第二声音数据对应的各个声源位置;
将所述各个声源位置中,与所述移动终端之间的距离大于第一预设距离值的声源位置确定为目标声源位置;
将所述第二声音数据中与所述目标声源位置对应的声音作为所述移动终端当前位置的环境音;
获取所述环境音的环境音强度值。
可选的,所述检测到防啸叫处理事件被触发,包括:
判断所述语音通话组中是否存在与所述移动终端之间的距离小于第二预设距离值的目标移动终端,若存在,则确定检测到防啸叫处理事件被触发。
可选的,所述预设应用程序为网络游戏应用程序。
本申请实施例还提供一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行语音通话数据处理方法,该方法包括:
预设应用程序中的语音通话组建立成功后,检测到防啸叫处理事件被触发;
实时监控移动终端当前位置的环境音强度值;
若所述环境音强度值大于第一预设强度值,则对所述移动终端中的语音通话数据进行防啸叫处理。
存储介质——任何的各种类型的存储器设备或存储设备。术语“存储介质”旨在包括:安装介质,例如CD-ROM、软盘或磁带装置;计算机系统存储器或随机存取存储器,诸如DRAM、DDRRAM、SRAM、EDORAM,兰巴斯(Rambus)RAM等;非易失性存储器,诸如闪存、磁介质(例如硬盘或光存储);寄存器或其它相似类型的存储器元件等。存储介质可以还包括其它类型的存储器或其组合。另外,存储介质可以位于程序在其中被执行的第一计算机系统中,或者可以位于不同的第二计算机系统中,第二计算机系统通过网络(诸如因特网)连接到第一计算机系统。第二计算机系统可以提供程序指令给第一计算机用于执行。术语“存储介质”可以包括可以驻留在不同位置中(例如在通过网络连接的不同计算机系统中)的两个或更多存储介质。存储介质可以存储可由一个或多个处理器执行的程序指令(例如具体实现为计算机程序)。
当然,本申请实施例所提供的一种包含计算机可执行指令的存储介质,其计算机可执行指令不限于如上所述的语音通话数据处理操作,还可以执行本申请任意实施例所提供的语音通话数据处理方法中的相关操作。
本申请实施例提供了一种移动终端,该移动终端中可集成本申请实施例提供的语音通话数据处理装置。图8为本申请实施例提供的一种移动终端的结构示意图。移动终端800可以包括:存储器801,处理器802及存储在存储器801上并可在处理器802运行的计算机程序,所述处理器802执行所述计算机程序时实现如本申请实施例所述的语音通话数据处理方法。
本申请实施例提供的移动终端,可以在移动终端中的预设应用程序的语音通话组建立成功后,检测到移动终端当前位置的环境音强度值较高时,及时对当前的移动终端的语音通话数据进行防啸叫处理,减少啸叫音给用户使用带来的不便。
图9为本申请实施例提供的另一种移动终端的结构示意图,该移动终端可以包括:壳体(图中未示出)、存储器901、中央处理器(central processing unit,CPU)902(又称处理器,以下简称CPU)、电路板(图中未示出)和电源电路(图中未示出)。所述电路板安置在所述壳体围成的空间内部;所述CPU902和所述存储器901设置在所述电路板上;所述电源电路,用于为所述移动终端的各个电路或器件供电;所述存储器901,用于存储可执行程序代码;所述CPU902通过读取所述存储器901中存储的可执行程序代码来运行与所述可执行程序代码对应的计算机程序,以实现以下步骤:
预设应用程序中的语音通话组建立成功后,检测到防啸叫处理事件被触发;
实时监控移动终端当前位置的环境音强度值;
若所述环境音强度值大于第一预设强度值,则对所述移动终端中的语音通话数据进行防啸叫处理。
所述移动终端还包括:外设接口903、RF(Radio Frequency,射频)电路905、音频电路906、扬声器911、电源管理芯片908、输入/输出(I/O)子系统909、其他输入/控制设备910、触摸屏912、其他输入/控制设备910以及外部端口904,这些部件通过一个或多个通信总线或信号线907来通信。
应该理解的是,图示移动终端900仅仅是移动终端的一个范例,并且移动终端900可以具有比图中所示出的更多的或者更少的部件,可以组合两个或更多的部件,或者可以具有不同的部件配置。图中所示出的各种部件可以在包括一个或多个信号处理和/或专用集成电路在内的硬件、软件、或硬件和软件的组合中实现。
下面就本实施例提供的用于语音通话数据处理的移动终端进行详细的描述,该移动终端以手机为例。
存储器901,所述存储器901可以被CPU902、外设接口903等访问,所述存储器901可以包括高速随机存取存储器,还可以包括非易失性存储器,例如一个或多个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
外设接口903,所述外设接口903可以将设备的输入和输出外设连接到CPU902和存储器901。
I/O子系统909,所述I/O子系统909可以将设备上的输入输出外设,例如触摸屏912和其他输入/控制设备910,连接到外设接口903。I/O子系统909可以包括显示控制器9091和用于控制其他输入/控制设备910的一个或多个输入控制器9092。其中,一个或多个输入控制器9092从其他输入/控制设备910接收电信号或者向其他输入/控制设备910发送电信号,其他输入/控制设备910可以包括物理按钮(按压按钮、摇臂按钮等)、拨号盘、滑动开关、操纵杆、点击滚轮。值得说明的是,输入控制器9092可以与以下任一个连接:键盘、红外端口、USB接口以及诸如鼠标的指示设备。
触摸屏912,所述触摸屏912是用户移动终端与用户之间的输入接口和输出接口,将可视输出显示给用户,可视输出可以包括图形、文本、图标、视频等。
I/O子系统909中的显示控制器9091从触摸屏912接收电信号或者向触摸屏912发送电信号。触摸屏912检测触摸屏上的接触,显示控制器9091将检测到的接触转换为与显示在触摸屏912上的用户界面对象的交互,即实现人机交互,显示在触摸屏912上的用户界面对象可以是运行游戏的图标、联网到相应网络的图标等。值得说明的是,设备还可以包括光鼠,光鼠是不显示可视输出的触摸敏感表面,或者是由触摸屏形成的触摸敏感表面的延伸。
RF电路905,主要用于建立手机与无线网络(即网络侧)的通信,实现手机与无线网络的数据接收和发送。例如收发短信息、电子邮件等。具体地,RF电路905接收并发送RF信号,RF信号也称为电磁信号,RF电路905将电信号转换为电磁信号或将电磁信号转换为电信号,并且通过该电磁信号与通信网络以及其他设备进行通信。RF电路905可以包括用于执行这些功能的已知电路,其包括但不限于天线系统、RF收发机、一个或多个放大器、调谐器、一个或多个振荡器、数字信号处理器、CODEC(COder-DECoder,编译码器)芯片组、用户标识模块(Subscriber Identity Module,SIM)等等。
音频电路906,主要用于从外设接口903接收音频数据,将该音频数据转换为电信号,并且将该电信号发送给扬声器911。
扬声器911,用于将手机通过RF电路905从无线网络接收的语音信号,还原为声音并向用户播放该声音。
电源管理芯片908,用于为CPU902、I/O子系统及外设接口所连接的硬件进行供电及电源管理。
上述实施例中提供的语音通话数据处理装置、存储介质及移动终端可执行本申请任意实施例所提供的语音通话数据处理方法,具备执行该方法相应的功能模块和有益效果。未在上述实施例中详尽描述的技术细节,可参见本申请任意实施例所提供的语音通话数据处理方法。
注意,上述仅为本申请的较佳实施例及所运用技术原理。本领域技术人员会理解,本申请不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本申请的保护范围。因此,虽然通过以上实施例对本申请进行了较为详细的说明,但是本申请不仅仅限于以上实施例,在不脱离本申请构思的情况下,还可以包括更多其他等效实施例,而本申请的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!