一种基于叠加序列的语音信号压缩存储与重构方法与流程
本发明涉及语音信号的压缩存储与重构技术领域,特别涉及一种基于叠加序列的语音信号压缩存储与重构方法。
背景技术
随着日益频繁的信息交互,语音信号是信息交互中非常常见的一种信号,其处理技术要求也日渐精进。由于语音信号本身的多样性以及人类听觉系统的独特性,使得语音信号在不同的变换域下是稀疏的。传统的语音信号采样通常需要满足奈奎斯特采样速率。压缩感知理论(compressedsensing,cs),指出具有稀疏性或可压缩性的信号可以通过压缩感知技术进行压缩采样与重构。因此将cs理论与语音信号处理领域相结合将降低采样频率、降低对采样器件的要求。
根据cs理论,将稀疏语音信号通过观测矩阵进行压缩,再利用重构算法重构出稀疏语音信号。然而,现有的重构算法如匹配追踪算法、正交匹配追踪算法、压缩采样匹配追踪算法、基追踪算法、子空间追踪算法等等,均不是专门针对稀疏语音信号的重构而提出的,继而没有考虑和利用稀疏语音信号的元素位置索引,使稀疏语音信号的重构精度受到限制。
技术实现要素:
本发明针对现有技术的缺陷,提供了一种基于叠加序列的语音信号压缩存储与重构方法。相比于传统的压缩感知语音压缩,本发明利用稀疏语音信号的元素的部分位置索引辅助重构,在不增加存储成本的情况下,提高语音信号的重构精度。
为了实现以上发明目的,本发明采取的技术方案如下:
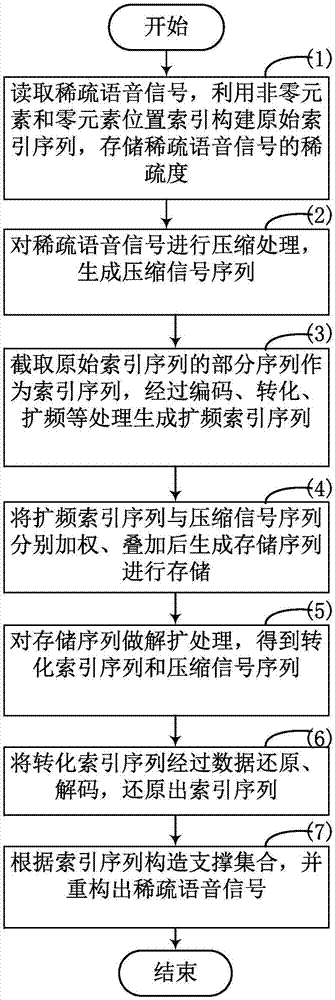
一种基于叠加序列的语音信号压缩存储与重构方法,包括以下步骤:(a)语音信号的压缩存储处理:
(a1)读取稀疏化后稀疏度为k,长度为n的语音信号x,用0,1元素构建长度为n的“原始索引序列”
(a2)读取预先存储的m×n的测量矩阵φ,并利用测量矩阵对语音信号进行压缩处理,生成长度为m的“压缩信号序列”y,所述的压缩处理表示为y=φx;
所述的测量矩阵诸如高斯随机矩阵、贝努利随机矩阵和部分哈达玛矩阵等已有的测量矩阵;
所述m,n通常满足m≤n;
(a3)对长度为n的“原始索引序列”
(a4)根据霍夫曼编码,对长度为βn的“索引序列”a做压缩编码处理,生成长度为l1的“压缩索引序列”b,再经数据转化处理后,得到长度为l2的“转化索引序列”c;
(a5)对长度为l2的“转化索引序列”c作扩频处理,并利用“添零”方式,构造长度为m的“扩频索引序列”
(a6)对长度同为m的“扩频索引序列”
所述权值α根据工程经验设定,且满足0≤α≤1。
(b)语音信号的重构再现处理:
(b1)对长度为m的存储序列z做解扩处理,还原出长度为l2“转化索引序列”c;
(b2)对长度为l2“转化索引序列”c进行扩频处理,并利用“添零”方式,构造出长度为m的“扩频索引序列”
(b3)利用公式
(b4)对长度为l2的“转化索引序列”c进行数据还原,还原出长度为l1的“压缩索引序列”b,再经霍夫曼解码,解码还原出长度为βn的“索引序列”a;
(b5)将长度为βn的“索引序列”a中非零元素的列序号记录在集合中,构成“固定支撑集合”
(b6)利用“固定支撑集合”
进一步的,步骤a1)所述的稀疏语音信号是指离散语音信号经过时频变换方法从时域信号变换为频域信号,并根据“心理声学模型”将低于静音门限的信号幅度置为零,得到长度为n的稀疏语音信号x。
所述的“心理声学模型”诸如mpeg(movingpictureexpertsgroup)心理声学模型和ogg(oggvobis)心理声学模型。
所述的时频变换方法可采用诸如离散余弦变换、短时傅里叶变换、小波变换。
进一步的,步骤a1)所述的用0,1元素构建长度为n的“原始索引序列”
进一步的,步骤a4)所述的数据转化过程为:将长度为l1的“压缩索引序列”b的数据以γ个数据为一组,分为l2组,若序列β的数据个数不能被γ整除,则用“添零”方式构造出能被γ整除的序列;将每组数据从二进制数转化为一个十进制实数值,从而实现转化处理,得到长度为l2的“转化索引序列”c。
进一步的,步骤a5)所述的利用长度为l2的“量化索引序列”c通过扩频和添零的方式构造长度为m的“扩频索引序列”
a5-1)“转化索引序列”
其中,扩频序列q可取为m序列,m序列,gold序列,zadoff-chu序列。
其中,符号
a5-2)计算kronecker积,
实现序列c的扩频展开,即s长度为(l2×q);
其中,上标“t”表示求转置操作。
a5-3)在矢量s末尾添加零,使其长度从(l2×q)增加到m,从而构造出“扩频索引序列”
度为m。
进一步的,步骤b2)所述的利用长度为l2的“量化索引序列”c通过扩频和添零的方式构造长度为m的“扩频索引序列”
进一步的,步骤b4)所述的数据还原过程为:将长度为l2的“转化索引序列”c中实数元素转化为二进制数,从转化得到的二进制数的尾部去掉幅度值为零的元素,使剩余元素的长度为l1,剩余元素组成的序列即为“压缩索引序列”b。
进一步的,步骤b6)所述的利用“固定支撑集合”
所述的重构方法诸如匹配追踪算法、正交匹配追踪算法和正则正交匹配追踪算法。
进一步的,以重构算法正交匹配追踪算法为例,步骤b6)包括:
b6-1)读取“压缩信号序列”y∈rm×1,测量矩阵φ∈rm×n,稀疏度k,t表示迭代次数,rt表示t次迭代的残差,ωt表示t次迭代的索引(列序号)集合,即t次迭代的支撑集合,kt表示索引集合ωt的元素个数,
b6-2)初始化
b6-3)如果kt<k,求解
b6-4)令ωt=ωt-1∪{λt},
b6-5)求
b6-6)更新残差
b6-7)t=t+1,返回步骤b6-3);
b6-8)稀疏语音信号
与现有技术相比本发明的优点在于:
在不增加存储成本的情况下存储稀疏语音信号的部分位置索引,相比于传统压缩感知语音压缩,有效提高重构精度。
附图说明
图1为本发明实施例基于叠加序列的语音信号采样存储与重构方法的流程示意图;
图2为本发明实施例基于叠加序列的语音信号采样存储与重构方法的语音信号的压缩存储处理的流程示意图。
图3为本发明实施例基于叠加序列的语音信号采样存储与重构方法的语音信号的重构再现处理的流程示意图
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图并列举实施例,对本发明做进一步详细说明。
基于叠加序列的语音信号采样存储与重构方法的流程示意图如图1所示。
下面具体描述本发明提出的基于叠加序列的语音信号压缩存储与重构方法的语音信号的压缩存储处理过程,如图2所示。
(a1)读取稀疏化后稀疏度为k,长度为n的语音信号x,用0,1元素构建长度为n的“原始索引序列”
其中,稀疏语音信号是指离散语音信号经过时频变换方法从时域信号变换为频域信号,并根据“心理声学模型”将低于静音门限的信号幅度置为零,得到长度为n的稀疏语音信号x。
其中,所述的“心理声学模型”诸如mpeg(movingpictureexpertsgroup)心理声学模型和ogg(oggvobis)心理声学模型,等等。
其中,所述的时频变换方法诸如离散余弦变换、短时傅里叶变换和小波变换,等等。
其中,所述的用0,1元素构建长度为n的“原始索引序列”
示例1:所述的“构建”示例如下:
假设n=18,稀疏语音信号
x=(5.4,3.2,6.7,0,0.9,0,7.8,0,0,1.2,0.8,0,4.2,0,0,0,0,0)t,则“原始索引序列”
其中,上标“t”表示求转置操作。
(a2)读取预先存储的m×n的测量矩阵φ,并利用测量矩阵对语音信号进行压缩处理,生成长度为m的“压缩信号序列”y,所述的压缩处理可表示为y=φx;
所述的测量矩阵诸如高斯随机矩阵、贝努利随机矩阵和部分哈达玛矩阵等已有的测量矩阵;
所述m,n通常满足m≤n;
(a3)对长度为n的“原始索引序列”
示例2:所述的“截取”示例如下:
在示例1的基础上,假设β=0.5,则βn=9,“原始索引序列”
(a4)根据霍夫曼编码,对长度为βn的“索引序列”a做压缩编码处理,生成长度为l1的“压缩索引序列”b,再经数据转化处理后,得到长度为l2的“转化索引序列”c;
其中,所述的数据转化过程为:将长度为l1的“压缩索引序列”b的数据以γ个数据为一组,分为l2组,若序列β的数据个数不能被γ整除,则用“添零”方式构造出能被γ整除的序列;将每组数据从二进制数转化为一个十进制实数值,从而实现转化处理,得到长度为l2的“转化索引序列”c。
示例3:所述的“转化”示例如下:
假设长度为l1=62的序列b=(1,0,0,1,0,1,0,1,0,1,0,1,1,1,0,1,0,0,0,1,0,1,1,0,0,0,1,0,1,0,1,0,1,1,1,0,0,1,0,1,0,1,1,1,0,1,0,1,0,0,1,0,1,1,1,0,0,0,1,1,0,0)t以γ=16个为一组,则分为4组,即l2=4,且需在末尾添两位0,则4组数据依次为1001010101011101、0001011000101010、1110010101110101、0010111000110000,从二进制转换为十进制实数依次为38237、5674、58741、11824,则“转化索引序列”c=(38237,5674,58741,11824)t,为4×1的矢量。
(a5)对长度为l2的“转化索引序列”c作扩频处理,并利用“添零”方式,构造长度为m的“扩频索引序列”
示例4:所述的利用长度为l2的“量化索引序列”c通过扩频和添零的方式构造“扩频索引序列”
a5-1)假设“转化索引序列”c=(3.8,5.6,5.8,1.2)t,l2=4,m=25,q∈rq×1为扩频序列,q=(1,1,1,1,1,1)t,其中q是扩频增益,满足
其中,q=(1,1,1,1,1,1)t为简便起见的取值,扩频序列可取为m序列,m序列,gold序列,zadoff-chu序列,等等。
其中,符号
a5-2)计算kronecker积,
a5-3)在矢量s末尾添加零,使其长度从(l2×q)增加到m,即从24增加到25,从而构造出“转化索引序列”
(a6)对长度同为m的“扩频索引序列”
所述权值α根据工程经验设定,且满足0≤α≤1;
示例5:所述的构造“存储序列”z示例如下:
在示例4的基础上,假设m=25,“扩频索引序列”
下面具体描述本发明提出的基于叠加序列的语音信号压缩存储与重构方法的语音信号的重构再现处理过程,如图3所示。
(b1)对长度为m的“存储序列”z做解扩处理,还原出长度为l2“转化索引序列”c;
示例6:所述的“解扩”示例如下:
在示例4和示例5的基础上,假设“存储序列”z∈rm×1,m=25,q∈rq×1为扩频序列,q=(1,1,1,1,1,1)t,其中q=6是扩频增益;
其中,q=(1,1,1,1,1,1)t为简便起见的取值,扩频序列可取为m序列,m序列,gold序列,zadoff-chu序列,等等。
b1-1)在示例4和示例5的基础上,已知:
b1-2)对序列z做分块处理,分为
其中,
b1-3)对z1,z2z3,z4进行解扩,假设解扩数据h=(4.56,6.96,1.44,6.72)t,即:
以i=1为例,即
b1-4)语音信号序列yi1,yi2,…,yi6与q1,q2,…,q6线性无关,故:
0.8yi1q1+0.8yi2q2+…+0.8yi6q6=0;
即:0.8y11q1+0.8y12q2+…+0.8y16q6=0;
b1-5)故:
即:
b1-6)已知扩频矩阵q=(q1,q2,…,q6)t,即q=(1,1,1,1,1,1)t;
b1-7)故,解扩还原出“转化索引序列”c=(c1,c2,c3,c4)t;
即:4.56=0.2c1+0.2c1+…+0.2c1,解出c1=3.8;
同理,解出c2,c3,c4,即解扩还原出“转化索引序列”c=(3.8,5.6,5.8,1.2)t。
(b2)对长度为l2“转化索引序列”c进行扩频处理,并利用“添零”方式,构造出长度为m的“扩频索引序列”
其中,所述的构造“扩频索引序列”
(b3)利用公式
(b4)对长度为l2的“转化索引序列”c进行数据还原,还原出长度为l1的“压缩索引序列”b,再经霍夫曼解码,解码还原出长度为βn的“索引序列”a;
其中,所述的数据还原过程为:将长度为l2的“转化索引序列”c中实数元素转化为二进制数,从转化得到的二进制数的尾部去掉幅度值为零的元素,使剩余元素的长度为l1,剩余元素组成的序列即为“压缩索引序列”b。
示例7:所述的“数据还原”的示例如下:
在示例3的基础上,假设“转化索引序列”c=(38237,5674,58741,11824)t,序列b长度为l1=62,将其实数元素转换为二进制得序列数据为1001010101011101000101100010101011100101011101010010111000110000,从转化所得的二进制末尾去掉后两位0,还原出序列b=(1,0,0,1,0,1,0,1,0,1,0,1,1,1,0,1,0,0,0,1,0,1,1,0,0,0,1,0,1,0,1,0,1,1,1,0,0,1,0,1,0,1,1,1,0,1,0,1,0,0,1,0,1,1,1,0,0,0,1,1,0,0)t
(b5)将长度为βn的“索引序列”a中非零元素的列序号记录在集合中,构成“固定支撑集合”
示例8:所述的构成“固定支撑集合”
假设“索引序列”a=(1,1,1,0,1,0,1,0,0)t,将“索引序列”a中非零元素的列序号记录在集合中,构成“固定支撑集合”
(b6)利用“固定支撑集合”
其中,所述的利用“固定支撑集合”
其中,所述的重构方法诸如匹配追踪算法、正交匹配追踪算法和正则正交匹配追踪算法,等等。
其中,以重构算正交匹配追踪算法为例,步骤b6)包括:
b6-1)读取“压缩信号序列”y∈rm×1,测量矩阵φ∈rm×n,稀疏度k,t表示迭代次数,rt表示t次迭代的残差,ωt表示t次迭代的索引(列序号)集合,即t次迭代的支撑集合,kt表示索引集合ωt的元素个数,
b6-2)初始化
b6-3)如果kt<k,求解
b6-4)令ωt=ωt∪{λt},
示例9:所述的步骤b6-4)示例如下:
在示例8的基础上,假设
b6-5)求
b6-6)更新残差
b6-7)t=t+1,返回步骤b6-3);
b6-8)稀疏语音信号
示例10:所述的稀疏语音信号x重构示例如下:
假设重构所得的稀疏语音信号
即重构出长度为n=25的稀疏语音信号
x=(x1,0,0,x4,x5,0,0,x7,x8,0,0,x10,0,0,0,x14,0,0,x17,0,x19,0,0,0,x23,0,0)
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的实施方法,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!