一种文本改编方法及装置与流程
本申请涉及自然语言处理技术领域,尤其涉及一种文本改编方法及装置。
背景技术
随着社会的发展,家长越来越注重对孩子的陪伴和教育,儿童都喜欢听故事,故事对于孩子的成长,具有非常重要的教育和陪伴意义。
现有的故事机一般都是机械的将故事合成语音或由真人录音后播放出来,用户在听故事的时候纯粹是听音频,而故事情节与用户基本没有相关性,用户的参与度很低,导致用户体验较差。
技术实现要素:
本申请实施例的主要目的在于提供一种文本改编方法及装置,能够使用户融入到故事情节中,提升了用户体验。
本申请实施例提供了一种文本改编方法,包括:
获取新增角色信息,所述新增角色信息为新增角色的角色信息,所述新增角色为原始故事文本中没有的角色;
根据所述新增角色信息对所述原始故事文本进行改编,得到改编后的故事文本,所述改编后的故事文本是融入了所述新增角色的故事文本。
可选的,所述根据所述新增角色信息对原始故事文本进行改编,得到改编后的故事文本,包括:
确定原始故事情节,所述原始故事情节为所述原始故事文本的故事情节;
根据所述原始故事情节与所述新增角色信息确定新增故事情节,所述新增故事情节是融入了所述新增角色且与所述原始故事情节关联的故事情节;
在所述原始故事文本中添加所述新增故事情节,得到改编后的故事文本。
可选的,所述确定原始故事情节,包括:
从所述原始故事文本中抽取主要故事情节,作为所述原始故事情节。
可选的,所述新增角色信息包括基本信息和/或故事信息,其中:
所述基本信息包括所述新增角色的姓名、性别、年龄、爱好、居住地中的至少一项,所述故事信息包括所述新增角色插入所述原始故事情节的方式。
可选的,所述根据所述原始故事情节与所述新增角色信息确定新增故事情节,包括:
利用预先构建的文本资源库,确定与所述新增角色信息匹配的至少一版故事情节,所述文本资源库中存储了具有不同故事情节的样本文本;
从所述至少一版故事情节中,选择与所述原始故事情节最相关的故事情节作为所述新增故事情节。
可选的,所述利用预先构建的文本资源库,确定与所述新增角色信息匹配的至少一版故事情节,包括:
在信息树的各条路径形成的故事情节中进行搜索,确定与所述新增角色信息匹配的至少一版故事情节;
其中,所述信息树是将所述文本资源库中的各个样本文本进行分词处理后,利用分词得到的全部词语或主要词语构建的具有依存关系的树,所述主要词语是反映所述样本文本的主要故事情节的词语。
可选的,所述方法还包括:
在所述原始故事文本中,确定具有说话内容的每条句子文本;
确定每条句子文本分别对应的候选说话人,所述候选说话人为所述原始故事文本中的一个角色;
使用不同发音人的音色特征,为不同候选说话人对应的句子文本、所述新增角色的说话内容、以及故事讲述人的讲述内容进行语音合成。
可选的,所述原始故事文本中的每一角色被定义为候选角色,则所述确定每条句子文本分别对应的候选说话人,包括:
确定所述句子文本对应的说话词,所述说话词为代表说话动作的词语;
若所述说话词所属句子的主语为一个候选角色的角色名称,则将该候选角色作为所述句子文本对应的候选说话人;
若所述说话词所属句子的主语为人称代词,则确定所述人称代词对应的候选角色,并将该候选角色作为所述句子文本对应的候选说话人;
若所述说话词所属句子不存在主语,则预测得到所述句子文本对应的候选说话人。
可选的,所述为所述新增角色的说话内容进行语音合成,包括:
使用第一发音人的音色特征,为所述新增角色的说话内容进行语音合成,所述第一发音人是利用第一用户的朗读文本训练的发音人。
可选的,所述为故事讲述人的讲述内容进行语音合成,包括:
使用第二发音人的音色特征,为故事讲述人的讲述内容进行语音合成,所述第二发音人是利用第二用户的朗读文本训练的发音人。
可选的,所述方法还包括:
在播放所述改编后的故事文本的过程中,根据播放的故事情节,同步播放与所述故事情节匹配的背景音乐。
本申请实施例还提供了一种文本改编装置,包括:
新增角色信息获取单元,用于获取新增角色信息,所述新增角色信息为新增角色的角色信息,所述新增角色为原始故事文本中没有的角色;
改编故事文本获得单元,用于根据所述新增角色信息对所述原始故事文本进行改编,得到改编后的故事文本,所述改编后的故事文本是融入了所述新增角色的故事文本。
可选的,所述改编故事文本获得单元包括:
原始故事情节确定子单元,用于确定原始故事情节,所述原始故事情节为所述原始故事文本的故事情节;
新增故事情节确定子单元,用于根据所述原始故事情节与所述新增角色信息确定新增故事情节,所述新增故事情节是融入了所述新增角色且与所述原始故事情节关联的故事情节;
改编故事文本获得子单元,用于在所述原始故事文本中添加所述新增故事情节,得到改编后的故事文本。
可选的,所述原始故事情节确定子单元,具体用于从所述原始故事文本中抽取主要故事情节,作为所述原始故事情节。
可选的,所述新增角色信息包括基本信息和/或故事信息,其中:
所述基本信息包括所述新增角色的姓名、性别、年龄、爱好、居住地中的至少一项,所述故事信息包括所述新增角色插入所述原始故事情节的方式。
可选的,所述新增故事情节确定子单元包括:
故事情节确定子单元,用于利用预先构建的文本资源库,确定与所述新增角色信息匹配的至少一版故事情节,所述文本资源库中存储了具有不同故事情节的样本文本;
故事情节选择子单元,用于从所述至少一版故事情节中,选择与所述原始故事情节最相关的故事情节作为所述新增故事情节。
可选的,所述故事情节确定子单元,具体用于在信息树的各条路径形成的故事情节中进行搜索,确定与所述新增角色信息匹配的至少一版故事情节;
其中,所述信息树是将所述文本资源库中的各个样本文本进行分词处理后,利用分词得到的全部词语或主要词语构建的具有依存关系的树,所述主要词语是反映所述样本文本的主要故事情节的词语。
可选的,所述装置还包括:
句子文本确定单元,用于在所述原始故事文本中,确定具有说话内容的每条句子文本;
候选说话人确定单元,用于确定每条句子文本分别对应的候选说话人,所述候选说话人为所述原始故事文本中的一个角色;
故事语音合成单元,用于使用不同发音人的音色特征,为不同候选说话人对应的句子文本、所述新增角色的说话内容、以及故事讲述人的讲述内容进行语音合成。
可选的,所述原始故事文本中的每一角色被定义为候选角色,则所述候选说话人确定单元包括:
说话词确定子单元,用于确定所述句子文本对应的说话词,所述说话词为代表说话动作的词语;
第一候选人确定子单元,用于若所述说话词所属句子的主语为一个候选角色的角色名称,则将该候选角色作为所述句子文本对应的候选说话人;
第二候选人确定子单元,用于若所述说话词所属句子的主语为人称代词,则确定所述人称代词对应的候选角色,并将该候选角色作为所述句子文本对应的候选说话人;
第三候选人确定子单元,用于若所述说话词所属句子不存在主语,则预测得到所述句子文本对应的候选说话人。
可选的,所述故事语音合成单元,具体用于使用第一发音人的音色特征,为所述新增角色的说话内容进行语音合成,所述第一发音人是利用第一用户的朗读文本训练的发音人。
可选的,所述故事语音合成单元,具体用于使用第二发音人的音色特征,为故事讲述人的讲述内容进行语音合成,所述第二发音人是利用第二用户的朗读文本训练的发音人。
可选的,所述装置还包括:
背景音乐播放单元,用于在播放所述改编后的故事文本的过程中,根据播放的故事情节,同步播放与所述故事情节匹配的背景音乐。
本申请实施例还提供了一种文本改编装置,包括:处理器、存储器、系统总线;
所述处理器以及所述存储器通过所述系统总线相连;
所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行上述文本改编方法中的任意一种实现方式。
本申请实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行上述文本改编方法中的任意一种实现方式。
本申请实施例还提供了一种计算机程序产品,所述计算机程序产品在终端设备上运行时,使得所述终端设备执行上述文本改编方法中的任意一种实现方式。
本申请实施例提供的一种文本改编方法及装置,首先,将原始故事文本中没有的角色的信息作为新增角色信息,然后,根据新增角色信息,实现对原始故事文本的改编,得到改编后的故事文本,其中,改编后的故事文本是融入了新增角色的故事文本。可见,本申请实施例通过将新增角色添加到原始故事文本中,实现了对原始故事文本的改编,从而提高了用户的参与度,进而提升了用户体验。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种文本改编方法的流程示意图;
图2为本申请实施例提供的确定新增故事情节的流程示意图;
图3为本申请实施例提供的故事文本的改编过程示意图;
图4为本申请实施例提供的对改编后的故事文本进行个性化语音合成的流程示意图;
图5为本申请实施例提供的确定每条句子文本分别对应的候选说话人的流程示意图;
图6为本申请实施例提供的一种文本改编装置的组成示意图。
具体实施方式
目前,现有的故事机通常是直接将故事文本合成语音或真人录音后播放给用户听,用户在听故事的时候纯粹是听音频,故事的文本内容与听故事的用户基本没有相关性,这导致用户在听故事的时候,不易融入到故事情节中,会感到自身的参与感很低、体验较差。
为解决上述缺陷,本申请实施例提供了一种文本改编方法,首先,可以采用向用户提问或用户自定义的方式,获取用户在原始故事文本基础上提出的一些该文本中没有的角色,作为新增角色,并且,进一步可以获取用户根据自身需求预先设置的新增角色的角色信息,作为新增角色信息,然后,可以根据该新增角色信息,实现对原始故事文本的改编,得到改编后的故事文本,其中,改编后的故事文本是融入了新增角色的故事文本,这样,可以将用户输入的新增角色融入到原故事文本中,特别是当该新增角色是用户本人时,提高了用户在故事中的参与度,使得用户能够更好的融入到故事情节中,进而提升了用户体验。
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
第一实施例
参见图1,为本实施例提供的一种文本改编方法的流程示意图,该方法包括以下步骤:
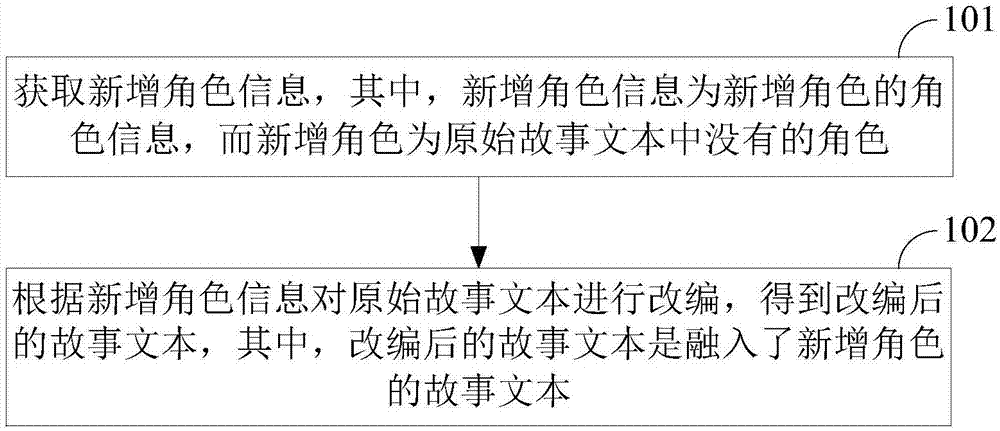
s101:获取新增角色信息,其中,新增角色信息为新增角色的角色信息,而新增角色为原始故事文本中没有的角色。
在本实施例中,将采用本实施例实现文本改编的任一故事文本称为原始故事文本,原始故事文本是具有故事情节的文本,例如,原始故事文本是白雪公主和七个小矮人的故事中的部分或全部文本。
并且,本实施例不限制原始故事文本的语种类型,比如,原始故事文本可以是中文文本、或英文文本等;本实施例也不限制原始故事文本的来源,比如,原始故事文本可以是故事书、杂志文章、小说、文学作品等中的部分或全部文本。
在本实施例中,可以采用向用户提问或用户自定义的方式,获取用户在原始故事文本基础上提出的一些该文本中没有的角色,作为新增角色,并且,进一步还可以获取用户根据自身需求预先设置的新增角色的角色信息,作为新增角色信息。需要说明的是,一种可选的实现方式是,新增角色信息可以包括基本信息和/或故事信息;其中,基本信息可以包括新增角色的姓名、性别、年龄、爱好、居住地中的至少一项,如用户可以将新增角色的名字设置为用户自己的名字或自己小孩的名字等;而故事信息则可以包括新增角色插入原始故事情节的方式。
具体来讲,新增角色信息可以仅包括新增角色的基本信息,即用户可以预先仅设置新增角色的基本信息,比如,仅设置新增角色的姓名、性别、年龄、爱好、居住地中的至少一项,当然,也可以设置新增角色的婚姻状况、出生日期、性格气质相貌以及思想观念等其他基本信息;或者,新增角色信息可以仅包括故事信息,即新增角色插入原始故事情节的方式,用户可以仅设置新增角色插入原始故事情节的方式,而不对新增角色的姓名、性别、年龄、爱好等基本信息进行设置,在进行故事文本改编时,可以通过系统默认的新增角色的姓名、年龄、性别等基本信息来填补当前新增角色基本信息的缺失;或者,新增角色信息可以包括基本信息和故事信息,即用户预先设置了新增角色的基本信息和故事信息,比如,用户既设置了新增角色的姓名、性别、年龄等基本信息,也设置了新增角色插入原始故事情节的方式,例如,用户可以提出新增角色并设置其基本信息为“安安,女孩,4-6周岁,喜欢听故事”,并预先设置该新增角色插入原始故事情节的方式为“做梦”。
可以理解的是,具体的信息内容以及插入方式可根据实际情况进行设置,本申请实施例对此不进行限制。
s102:根据新增角色信息对原始故事文本进行改编,得到改编后的故事文本,其中,改编后的故事文本是融入了新增角色的故事文本。
在本实施例中,通过步骤s101获取到新增角色信息后,可以根据新增角色信息,将新增角色融入到原始故事文本,实现对原始故事文本的改编,进而得到融入了新增角色的、改编后的故事文本。
其中,改编后的故事文本可以是在原始故事文本的开头、结尾、故事无意义的文本段落增加对新增角色的描述内容,或者,在原始故事文本中的任意位置贯穿对新增角色的描述内容。本实施例不限制新增描述内容的形式,比如,该新增描述内容可以是新增角色与故事中角色的闲聊内容、也可以是新增角色与故事中角色之间发生的肢体动作、亦可以是新增角色对原始故事文本中的角色和/或事物的所见所想,等等。
具体来讲,在本实施例的一种实现方式中,s102具体可以包括步骤a-c:
步骤a:确定原始故事情节,其中,原始故事情节为原始故事文本的故事情节。
在本实施例中,为了能够使用户融入到故事情节中,提升用户体验,首先需要从原始故事文本中确定出原始故事情节,一种可选的实现方式是,可以从原始故事文本中抽取主要故事情节,作为原始故事情节。
为了抽取原始故事文本的主要故事情节,需要对原始故事文本进行分析,并根据原始故事文本中包含的故事情节元素来抽取主要故事情节,对原始故事文本进行信息抽取的过程主要包括文本预处理、角色识别、故事情节元素抽取三部分。
首先,进行文本预处理,具体地,除去原始故事文本中非故事内容的部分,并以句子为单位,利用现有或未来出现的分词方法,对去除非故事内容后的原始故事文本进行分词处理,并对分词得到的每一词语进行词性标注(part-of-speech,简称pos)。
然后,进行角色识别,具体地,可以基于上述词性标注结果,利用语法分析器(parser)抽取原始故事文本中各个句子的主语(其词性一般为名词),再利用改进的命名实体规则模型匹配角色名称,也就是判断出抽取的主语是否为原始故事文本中的角色名称,如果该主语符合人物名称,则其可能为原始故事文本中的角色名称,其中,改进的命名实体规则模型是基于规则和统计的方法,对预先收集的大量小说和故事语料中出现的姓名实体进行训练和学习,包括对中英文姓名、简称、昵称、外号、职业、社会关系、以及故事中常出现的一些表示动物或者非生物的名词拟人化表达等,并且在去除掉代词后,对确定出的人物名称进行训练和学习,例如,“国王”、“医生”、“外婆”等人物名称都属于姓名实体范畴,进而可以利用该改进的命名实体规则模型对抽取出的原始故事文本中各个句子的主语进行识别,识别出各个主语是否属于人物名称范畴,如果属于,即可确定其为原始故事文本中的角色。
最后,进行故事情节元素抽取,具体地,可以基于上述词性标注结果抽取原始故事文本中的故事情节元素,其中,故事情节元素指的是原始故事文本中故事发生的时间、地点、任务、道具(其词性一般为名词)和动作(其词性一般为动词)等,可以在利用分词方法对原始故事文本进行分词处理,得到原始故事文本中的各个词语后,选择出能够代表主要故事情节元素的词语用以概述原始故事文本的主要故事情节,例如,对各个词语基于重要性进行选择,比如选择出现频率比较高的词语作为代表主要故事情节元素的词语。
以《白雪公主》的故事作为原始故事文本为例,可以从其中抽取出主要故事情节为:很久以前,一个遥远的国度里,国王娶了新王后,白雪公主比王后美丽,王后送了毒苹果给白雪公主,白雪公主吃了毒苹果死去,王子救活白雪公主,王子和白雪公主结婚。王后气晕过去。
步骤b:根据原始故事情节与新增角色信息确定新增故事情节,其中,新增故事情节是融入了新增角色且与原始故事情节关联的故事情节。
在本实施例中,在获得原始故事情节和新增角色信息后,可以根据二者的内容确定出新增故事情节,其中,新增故事情节是融入了新增角色且与原始故事情节关联的故事情节。也就是说,新增故事情节是在原始故事情节的基础上,围绕着新增角色展开的故事情节,比如,基于上述举例,新增故事情节可以是在《白雪公主》开头文本对应的故事情节的基础上,围绕着“安安”展开的故事情节,可以为“安安梦见飞到一个地方,看见白雪公主……安安祝福王子和公主,最后梦醒回到现实中”。
需要说明的是,具体的根据原始故事情节与新增角色信息确定新增故事情节的实现过程可参见后续第二实施例的相关介绍。
步骤c:在原始故事文本中添加新增故事情节,得到改编后的故事文本。
在本实施例中,通过步骤b确定出新增故事情节后,可以将该新增故事情节添加到原始故事文本中,得到改编后的故事文本。
具体来讲,为了保持原始故事文本中故事的逻辑性和叙事完整性,添加的新增故事情节可以不干扰到原始故事文本的原始故事情节,所以,应尽量添加在原始故事文本的开头、结尾、故事无意义的文本段落或者与故事中角色的闲聊,从而可以实现按照用户的改编需求,将新增角色的角色信息加入到原始故事本文的故事情节中,获取到改编后的故事文本。
当然,也可以将新增故事情节添加在原始故事文本的任意位置,需要说明的是,本实施例不对新增故事情节的情节内容进行限制,比如新增故事情节可以包括新增角色与原始故事文本中的任意角色的对话信息以及新增角色自身的动作信息等,以将新增角色融入到原始故事文本中。例如,仍以白雪公主和七个小矮人的故事作为原始故事文本,新增角色仍为“安安”,在改编后的故事文本中可以增加安安的自身的动作信息以及与七个小矮人的对话,改编后的部分故事文本如下:
安安发现在第七个小矮人的床上睡着一位美丽的小女孩,安安把七个小矮人叫过来一起观察了小女孩好一阵后,安安惊奇的对七个小矮人说“天呀,我知道了,这是白雪公主,是童话王国里最漂亮的人,她睡得这么香甜,我们可千万不能把她吵醒了呀”。
进一步的,在本实施例的一种实现方式中,还可以在播放改编后的故事文本的过程中,根据播放的故事情节,同步播放与故事情节匹配的背景音乐。
在本实施例中,通过上述步骤s102获得了改编后的故事文本后,在将该改编后的故事文本向用户播放的过程中,为了进一步提高故事的趣味性,增加用户的代入感,可以根据播放的故事情节,同步播放与故事情节匹配的背景音乐。比如,当播放的是平实的故事情节时,可以同步播放一些舒缓、安静的背景音乐;当播放的是感人的故事情节时,如播放的是与父爱相关的故事情节时,则可以同步播放一些与父亲、亲情相关的背景音乐,以更好的引起用户的共鸣,使得故事更加生动、亲切。
再进一步的,由于现有的故事机通常是直接将故事文本合成语音或真人录音后播放给用户听,用户在听故事的时候纯粹是听音频,而且在音频中,包含的仅是该故事的单一讲述人的声音,该音频对故事中不同角色的对话内容并未加以区分,这种单一音频对用户来说是比较枯燥的,为了提高用户体验,还可以针对改编后的故事文本,使用个性化语音合成的方法,对其进行个性化语音合成,这样,可以使得讲故事的过程更加生动、形象。需要说明的是,具体的个性化语音合成的实现过程可参见后续第三实施例的相关介绍。
综上,本实施例提供的一种文本改编方法,首先,将原始故事文本中没有的角色的信息作为新增角色信息,然后,根据新增角色信息,实现对原始故事文本的改编,得到改编后的故事文本,其中,改编后的故事文本是融入了新增角色的故事文本。可见,本实施例通过将新增角色添加到原始故事文本中,实现了对原始故事文本的改编,从而提高了用户的参与度,进而提升了用户体验。
第二实施例
本实施例将对第一实施例中步骤s103“根据原始故事情节与新增角色信息确定新增故事情节”的具体实现过程进行介绍。
参见图2,其示出了本实施例提供的根据原始故事情节与新增角色信息确定新增故事情节的流程示意图,该流程包括以下步骤:
s201:利用预先构建的文本资源库,确定与新增角色信息匹配的至少一版故事情节,其中,该文本资源库中存储了具有不同故事情节的样本文本。
在本实施例中,为了确定新增故事情节,可以预先收集大量具有故事情节的文本语料(比如小说和故事文本等)构成一个语料库,如图3所示。在从语料库中抽取描述故事中人物因果关系的句子时,可以按照不同故事和小说的语言、风格、故事背景(比如国内还是国外、人物故事还是动物故事等)和读者年龄等信息,进行分类抽取,用以建立根据故事背景、语言、风格、读者年龄等信息进行分类的多个常识omcs(openmindcommonscene)文本资源库,比如,可以建立读者年龄为6周岁以下的文本资源库、文本风格为纪实类的文本资源库以及文本风格为童话类的文本资源库等。每个文本资源库中均包含了一系列符合其分类的一般故事情节的相关句子,比如,文本风格为童话类的文本资源库中可能包含的句子为“小飞象真的飞了起来,飞啊飞啊,飞到了一个陌生的地方”等。
在本实施例中,当获取到新增角色信息后,可以根据新增角色信息所属的故事背景及风格类型等,利用预先构建的与之分类相匹配的文本资源库(比如,若新增角色信息为一位5周岁儿童的基本信息,则与之匹配的文本资源库可以为预先构建的6周岁以下的文本资源库等),确定出与新增角色信息匹配的至少一版故事情节。
具体来讲,每个文本资源库中均包含了一系列符合其分类的一般故事情节的相关句子,并且,这些句子又分别构成了不同的故事情节,每个句子均可以称为其所属文本资源库中的一个样本文本。进而可以从这些具有不同故事情节的样本文本中,确定出至少一版故事情节与新增角色信息相匹配,比如,基于上述举例,若新增角色信息为一位5周岁儿童的基本信息,则可以从对应的文本资源库中确定出一版“儿童在梦中与小红帽聊天”的故事情节与之匹配。
一种可选的实现方式是,本实施例中利用预先构建的文本资源库,确定与新增角色信息匹配的至少一版故事情节包括:在信息树的各条路径形成的故事情节中进行搜索,确定与新增角色信息匹配的至少一版故事情节。
在本实现方式中,信息树指的是将文本资源库中的各个样本文本进行分词处理后,利用分词得到的全部词语或主要词语构建的具有依存关系的树,该主要词语是反映样本文本的主要故事情节的词语。
具体来讲,由于文本资源库中的各个样本文本是由一系列符合文本资源库分类的一般故事情节的相关句子组成,所以,可以利用分词方法将各个样本文本进行分词处理,得到文本资源库中各个样本文本的全部词语,然后可以按照故事中句子之间各个词语的依存关系,利用分词得到的全部词语或主要词语构建具有依存关系的、符合故事逻辑的信息树,其中,构成该信息树的主要词语指的是能够反映各个样本文本的主要故事情节的词语,比如,基于上述举例,可以从句子“小飞象真的飞了起来,飞啊飞啊,飞到了一个陌生的地方”中抽取角色—动作—对象的信息(如小飞象—飞到—地方)作为主要词语,用以构建信息树。
进而可以根据新增角色信息,在信息树的各条路径形成的故事情节中进行搜索,以确定出与新增角色信息相匹配的至少一版故事情节,再将这至少一版故事情节的主语和背景等均替换成新增角色和待改编的文本故事背景,最终生成新增角色的故事情节。其中,在具体的匹配过程中,可以按照不同的搜索顺序进行故事情节的搜索,并且,搜索出的与新增角色信息相匹配的故事情节的主要词语在组成信息树时的路径也可能是不同的,比如,通过搜索信息树确定出的故事情节可能是从信息树的根节点直至叶子节点这一整条路径中的词语对应的故事情节,也可能是根节点与叶子节点之间的某段路径中的词语对应的故事情节等。
s202:从至少一版故事情节中,选择与原始故事情节最相关的故事情节作为新增故事情节。
在本实施例中,通过步骤s201可以确定出至少一版与新增角色信息相匹配的故事情节,此时,可以在对原始故事情节进行分析的基础上,例如参考原始故事发生的时间、地点等因素后,从已确定出的至少一版故事情节中,选择出与原始故事情节最相关的故事情节作为新增故事情节。
进而可以通过一般故事衔接的模板规则(比如具有看见、听说等衔接性词语的一个或多个模板),将新增故事情节插入到原始故事文本中,进一步的,还可以插入新增角色的说话内容,如加入与故事中前一句内容相似的重复性话语等,以增加新增角色的代入感等。
当第一实施例中步骤s103采用上述图2所示流程实现时,基于此,具体的故事文本的改编过程如图3所示,首先通过对原始故事文本进行文本预处理、角色识别、故事情节元素抽取等操作(具体实现请参见第一实施例),确定原始故事情节后,然后,获取用户在原始故事文本基础上提出的一些该文本中没有的角色,作为新增角色,并且,进一步还可以获取用户根据自身需求预先设置的新增角色的角色信息,作为新增角色信息,接着,利用预先构建的文本资源库,确定与新增角色信息匹配的至少一版故事情节,再通过对原始故事情节进行分析的基础上,例如参考原始故事发生的时间、地点等因素后,从已确定出的至少一版故事情节中,选择与原始故事情节最相关的故事情节作为新增故事情节。最后,通过一般故事衔接的模板规则(如看见、听说等),将新增故事情节插入到原始故事文本中,比如“安安看见白雪公主”等,完成对原始故事文本的改编。
举例说明:仍以《白雪公主》的开头为例,原始故事文本为:在遥远的一个国度里,住着一个国王和王后,他们渴望有一个孩子,于是非常诚意地向上苍祈祷。“上帝啊!我们都是好国王好王后,请您赐给我们一个孩子吧!”不久以后,王后果然生下了一个可爱的小公主,这个女孩的皮肤白得像雪一般,双颊红得有如苹果,国王和王后就把她取名为“白雪公主”。全国的人民都为白雪公主深深祝福。
而新增角色信息为:安安,女孩,4-6周岁,喜欢听故事,且将新增角色插入原始故事情节的方式为“做梦”。则在通过步骤s101获取到《白雪公主》的原始故事情节的基础上,加上“安安梦见飞到一个地方,看见白雪公主……安安祝福王子和公主,最后梦醒回到现实中”的“做梦”情节,再根据该“做梦”情节去对应分类的文本资源库中搜索出与原始故事情节最相关的故事情节,比如“从前有个聪明可爱的小女孩,她的名字叫安安,特别喜欢听童话故事。一天晚上,安安抱着故事书,躺在床上想:“要是我能到童话故事里去,那该多好啊!”就在安安闭上眼睛,快要睡着的时候,她感觉自己飞了起来,飞啊飞啊,就真的来到了童话般的世界”,将其作为新增故事情节,此外,新增故事情节中还可以包括安安认同白雪公主可爱的一句话,比如“安安看见白雪公主后,也说:“白雪公主,你真可爱。”,将该新增故事情节插入到原始故事文本,得到改编后的故事文本如下:
从前有个聪明可爱的小女孩,她的名字叫安安,特别喜欢听童话故事。一天晚上,安安抱着故事书,躺在床上想:“要是我能到童话故事里去,那该多好啊!”就在安安闭上眼睛,快要睡着的时候,她感觉自己飞了起来,飞啊飞啊,就真的来到了童话般的世界。在遥远的一个国度里,住着一个国王和王后,他们渴望有一个孩子,于是非常诚意地向上苍祈祷。“上帝啊!我们都是好国王好王后,请您赐给我们一个孩子吧!”不久以后,王后果然生下了一个可爱的小公主,这个女孩的皮肤白得像雪一般,双颊红得有如苹果,国王和王后就把她取名为“白雪公主”。安安看见白雪公主后,也说:“白雪公主,你真可爱。”全国的人民都为白雪公主深深祝福。
综上,本实施例通过利用预先构建的文本资源库搜索出至少一版与新增角色信息相匹配的故事情节后,进一步可以在对原始故事情节进行分析的基础上,从已确定出的至少一版故事情节中,选择出与原始故事情节最相关的故事情节作为新增故事情节,以便后续将该新增故事情节添加到原始故事情节中,得到改编后的故事文本,能够使用户更好的融入到故事情节中,进一步提升了用户体验。
第三实施例
需要说明的是,通过上述实施例得到改编的故事文本后,为了提高用户体验,还可以针对改编后的故事文本,使用个性化语音合成的方法,对其进行个性化语音合成,具体来讲,可以对改编后故事的讲述人、不同角色的对话内容和新增角色的对话内容使用不同发音人的语音进行合成。其中,故事的讲述人和新增角色说话的声音可以由用户指定特定发音人的声音进行合成,同时,用户也可以加入自己的声音作为角色发音人,比如,故事讲述人的声音可以采用家长的声音、新增角色的声音采用小孩的声音,这样用户或小孩在听故事时,故事会更生动、听者的代入感也更强。
接下来,本实施例将通过下述步骤s401-s403对改编后的故事文本进行个性化语音合成的具体实现过程进行介绍。
参见图4,其示出了本实施例提供的对改编后的故事文本进行个性化语音合成流程示意图,该流程包括以下步骤:
s401:在原始故事文本中,确定具有说话内容的每条句子文本。
在本实施例中,为了对改编后的故事文本进行个性化语音合成,首先需要在原始故事文本中,确定出具有说话内容的每条句子文本,具体来讲,可以以双引号为标识,找出具有说话内容的句子文本,但需要说明的是,在故事文本中,双引号不但可以标识说话内容,还可以标识需要强调的词语、拟声词等。比如为了强调某个词语的重要性,会将其用双引号进行标识,因此,在以双引号为标识确定具有说话内容的每条句子文本时,还需要利用正则匹配等规则排除掉双引号标识强调以及拟声词等情况,再确定出具有说话内容的每条句子文本。
s402:确定每条句子文本分别对应的候选说话人,其中,候选说话人为原始故事文本中的一个角色。
在本实施例中,通过步骤s401确定出具有说话内容的每条句子文本后,为了对不同说话内容进行个性化语音合成,还需要确定出每条句子文本分别对应的候选说话人,进而可根据候选说话人的基本信息,对其说话内容进行个性化语音合成,其中,候选说话人为原始故事文本中的一个角色。
在本实施例的一种实现方式中,本步骤s402具体可以包括下述步骤s4021-s4024。
参见图5,其示出了本实施例提供的确定每条句子文本分别对应的候选说话人的流程示意图,该流程包括以下步骤:
s4021:确定句子文本对应的说话词,其中,说话词为代表说话动作的词语。
在本实施例中,在确定每条句子文本对应的说话词之前,预先对一般故事和小说等文本中的说话词进行统计,形成候选说话词集合s={说,讲,道,念,想,叫,喊,回答,回复,嘀咕,say,speak,talk,ask…}。针对通过步骤s401确定出的具有说话内容的每条句子文本,可以通过以下方式,确定出每条句子文本中代表说话动作的说话词:
1、对于具有说话内容的任一句子文本a来讲,当对每条句子文本a之前或之后文本中的各个词语进行词性标注后,比如利用自然语言处理工具包(naturallanguagetoolkit,简称nltk)进行标注后,搜索该句子文本a之前是否存在冒号,若该句子文本a之前存有冒号、且该冒号之前句子中包括属于上述候选说话词集合s的一个或多个说话词,则以最接近该句子文本a的说话词对应于该句子文本a。
2、若该句子文本a之前不存有冒号,则搜索句子文本a之前或之后文本中的动词,若该句子文本a之前和之后句子中包括上述候选说话词集合s中的一个或多个说话词,则以最接近该句子文本a的说话词对应于该句子文本a。
在确定出句子文本对应的说话词后,可继续执行后续步骤以确定出每条句子文本分别对应的候选说话人。
需要说明的是,本实施例需要预先识别出原始故事文本中有哪些角色,原始故事文本中各个角色的识别方法请参见第一实施例,这里,将原始故事文本中任一角色定义为候选角色,通过后续步骤从这些候选角色中确定每个句子文本对应的说话人,即确定候选说话人。
s4022:若说话词所属句子的主语为一个候选角色的角色名称,则将该候选角色作为句子文本对应的候选说话人。
在本实施例中,通过步骤s4021确定出句子文本对应的说话词后,可以利用句法分析方法对具有说话词的句子进行分析,比如,可以利用斯坦福句法分析器(stanfordparser)对具有说话词的句子进行分析,构建以说话词为根节点的句法树,进一步的可以通过对该句法树进行搜索,以搜索出该说话词所属句子的主语。若搜索出该说话词所属句子的主语为原始故事文本中的一个角色名称,即为一个候选角色的角色名称,则可以将该候选角色作为该说话词对应的句子文本所对应的候选说话人。
s4023:若说话词所属句子的主语为人称代词,则确定该人称代词对应的候选角色,并将该候选角色作为句子文本对应的候选说话人。
在本实施例中,若通过对上述句法树进行搜索后,搜索出说话词所属句子的主语为人称代词(比如他、她等),则可以对该人称代词进行指代消解,利用该人称代词的性别信息、代词的上下文关系、段内出现的角色名称等信息,对该人称代词可能对应的候选角色进行打分,并将得分最高的候选角色确定为该人称代词对应的候选角色,并将该候选角色作为该说话词对应的句子文本所对应的候选说话人。
s4024:若说话词所属句子不存在主语,则预测得到句子文本对应的候选说话人。
在本实施例中,若通过对上述句法树进行搜索后,搜索出说话词所属句子不存在主语,则可以以后续规则进行特殊判断,以预测到该说话词对应的句子文本所对应的候选说话人。
具体来讲,可以根据候选角色距离说话内容的距离d、候选角色出现的频次f、候选角色是否出现在自己以及相邻的说话内容(说话人一般不会出现在自己的说话内容中,而可能出现在相邻说话内容中)、前后句一般不是同一个说话人等特征,对所有候选角色进行打分,可以将得分最高的候选角色作为该条句子文本对应的候选说话人,或者,也可以通过训练这几项特征与各个候选角色之间的相关模型,从各个候选角色中预测出该句子文本对应的候选说话人等。
需要说明的是,本实施例不限制步骤s4022-s4024的执行顺序。
举例说明:仍以《白雪公主》中的一段对话内容为例,原始故事文本为:白雪公主把头从窗户里探出来说道:“我不敢让人进来,因为小矮人们告诫我,任何人来了都不要开门。(第1句)”“就随你吧,(第2句)”王后拿出那个毒苹果说道,“可是这苹果实在是太漂亮可爱了,我就作一个礼物送给你吧。(第3句)”白雪公主说道:“不,我可不敢要。(第4句)”王后急了,“你这傻孩子,你担心什么?难道这苹果有毒吗?来!你吃一半,我吃一半。(第5句)”…….王后一见,脸上露出了快意的狞笑。她回到王宫,来到魔镜前,问道:“告诉我,镜子,谁是全国最漂亮的女人?(第6句)”“是你,王后(第7句)”。
则上述原始故事文本中的各个候选角色可以包括:国王,新王后,白雪公主,七个小矮人,镜子,王子。并且,上述原始故事文本中共包括7句包含说话内容的句子文本,其中,第1句句子文本对应的说话词是“道”,主语为白雪公主,其是一个候选角色,进而可以将白雪公主作为第1句句子文本对应的候选说话人;第2句句子文本前面已经是另一句话了,说话词是后面的“说”,主语是王后,其也是一个候选角色,进而可以将王后作为第2句句子文本对应的候选说话人;第3句句子文本的说话词是“道”,主语是王后,同理,其是一个候选角色,进而可以将王后作为第3句句子文本对应的候选说话人;第4句句子文本的说话词是“道”,主语是白雪公主,同理,其是一个候选角色,进而可以将白雪公主作为第4句句子文本对应的候选说话人;第5句句子文本没有说话词,但最近的主语为王后,王后是一个候选角色的角色名称,进而可以确定第5句句子文本对应的候选说话人为王后;第6句句子文本的说话词是“道”,主语是代词“她”,对该代词进行指代消解后,确定出该代词对应的候选角色为王后,进而可以将王后作为第6句句子文本对应的候选说话人;第7句句子文本没有说话词,但上一句句子文本内容内出现了镜子,则可以预测该句子文本对应的候选说话人是镜子。
s403:使用不同发音人的音色特征,为不同候选说话人对应的句子文本、新增角色的说话内容、以及故事讲述人的讲述内容进行语音合成。
在本实施例中,通过步骤s402确定出具有说话内容的每条句子文本分别对应的候选说话人后,进一步可以使用不同发音人的音色特征,为不同的候选说话人对应的句子文本、新增角色的说话内容、以及故事讲述人的讲述内容进行语音合成。
具体来讲,在对改编后的故事文本进行语音合成之前,本实施例将预先构建一个包含多种发音人的音库,其中,该音库不仅可以包含现有的不同性别、年龄等类型的发音人,还可以包括通过用户训练的自定义发音人,比如用户可以在相对安静的环境下,通过朗读系统提供的n段文本,如5-10段文本,输入自己或他人的声音,系统通过对语音的采样获取梅尔倒谱、基频以及相应的动态参数,利用文本转换模型,如有记忆的神经网络(lstm-rnn)模型结构进行声学建模,训练能与用户音色相似的发音人,加入到预先构建的音库中。
接下来,可以由系统或用户为改编后故事中的故事讲述人以及每个角色分别指定一个发音人,可以从上述预先构建的音库中指定,其中,故事讲述人和/或至少一个角色,可以分别为其指定一个由用户语音训练而成的发音人,可以理解的是,故事讲述人以及不同角色之间通常对应不同的发音人。然后,利用语音合成方法,比如从文本到语音(texttospeech,简称tts)技术,利用为故事讲述人以及每个角色分别指定的发音人进行语音合成,使故事讲述人的讲述内容以及每个角色的说话内容具有指定发音人的音色特征。
在本步骤s403中,一种可选的实现方式是,为新增角色的说话内容进行语音合成的过程可以包括:使用第一发音人的音色特征,为新增角色的说话内容进行语音合成,其中,第一发音人是利用第一用户的朗读文本训练的发音人。
在本实现方式中,在对新增角色的说话内容进行语音合成之前,可以将听故事的一个用户定义为第一用户,然后,可以先获取该第一用户预先朗读的几段文本,接着,通过训练这几段文本,训练出具有第一用户音色的发音人,作为第一发音人,进而可以使用第一发音人的音色特征,为新增角色的说话内容进行语音合成。
举例说明:可以将听故事的孩子作为第一用户,通过训练预先获取到的孩子朗读的几段文本,训练出与孩子的音色类似的发音人,然后,可以使用该发音人的音色特征为新增角色的说话内容进行语音合成,进而使得小孩在听故事时,故事会更生动、小孩的代入感也更强。
相类似的,在本步骤s403中,另一种可选的实现方式是,为故事讲述人的讲述内容进行语音合成的过程可以包括:使用第二发音人的音色特征,为故事讲述人的讲述内容进行语音合成,其中,第二发音人是利用第二用户的朗读文本训练的发音人。
在本实现方式中,在对故事讲述人的讲述内容进行语音合成之前,可以将听故事的另一用户定义为第二用户,然后,可以先获取该第二用户预先朗读的几段文本,接着,通过训练这几段文本,训练出具有第二用户音色的发音人,作为第二发音人,进而可以使用第二发音人的音色特征,为故事讲述人的讲述内容进行语音合成。
举例说明:可以将听故事的孩子的家长作为第二用户,通过训练预先获取到的家长朗读的几段文本,训练出与家长的音色类似的发音人,然后,可以使用该发音人的音色特征为故事讲述人的讲述内容进行语音合成,进而使得小孩在听故事时,能够听到家长的声音,感觉听到的故事会更亲切、小孩听故事的兴趣也更高。
综上,本实施例在对故事中不同角色的性别、年龄、说话方式和情感加以区分的基础上,采用不同的发音人对故事文本中的不同角色进行个性化语音合成,使得在播放故事给用户听时,不再只是一个发音人从头到尾朗读或合成,而是进行个性化语音播放,使得故事更加生动、形象,能够使用户更好的融入到故事情节中,提升了用户体验。
第四实施例
本实施例将对一种文本改编装置进行介绍,相关内容请参见上述方法实施例。
参见图6,为本实施例提供的一种文本改编装置的组成示意图,该装置600包括:
新增角色信息获取单元601,用于获取新增角色信息,所述新增角色信息为新增角色的角色信息,所述新增角色为原始故事文本中没有的角色;
改编故事文本获得单元602,用于根据所述新增角色信息对所述原始故事文本进行改编,得到改编后的故事文本,所述改编后的故事文本是融入了所述新增角色的故事文本。
在本实施例的一种实现方式中,所述改编故事文本获得单元602包括:
原始故事情节确定子单元,用于确定原始故事情节,所述原始故事情节为所述原始故事文本的故事情节;
新增故事情节确定子单元,用于根据所述原始故事情节与所述新增角色信息确定新增故事情节,所述新增故事情节是融入了所述新增角色且与所述原始故事情节关联的故事情节;
改编故事文本获得子单元,用于在所述原始故事文本中添加所述新增故事情节,得到改编后的故事文本。
在本实施例的一种实现方式中,所述原始故事情节确定子单元,具体用于从所述原始故事文本中抽取主要故事情节,作为所述原始故事情节。
在本实施例的一种实现方式中,所述新增角色信息包括基本信息和/或故事信息,其中:
所述基本信息包括所述新增角色的姓名、性别、年龄、爱好、居住地中的至少一项,所述故事信息包括所述新增角色插入所述原始故事情节的方式。
在本实施例的一种实现方式中,所述新增故事情节确定子单元包括:
故事情节确定子单元,用于利用预先构建的文本资源库,确定与所述新增角色信息匹配的至少一版故事情节,所述文本资源库中存储了具有不同故事情节的样本文本;
故事情节选择子单元,用于从所述至少一版故事情节中,选择与所述原始故事情节最相关的故事情节作为所述新增故事情节。
在本实施例的一种实现方式中,所述故事情节确定子单元,具体用于在信息树的各条路径形成的故事情节中进行搜索,确定与所述新增角色信息匹配的至少一版故事情节;
其中,所述信息树是将所述文本资源库中的各个样本文本进行分词处理后,利用分词得到的全部词语或主要词语构建的具有依存关系的树,所述主要词语是反映所述样本文本的主要故事情节的词语。
在本实施例的一种实现方式中,所述装置还包括:
句子文本确定单元,用于在所述原始故事文本中,确定具有说话内容的每条句子文本;
候选说话人确定单元,用于确定每条句子文本分别对应的候选说话人,所述候选说话人为所述原始故事文本中的一个角色;
故事语音合成单元,用于使用不同发音人的音色特征,为不同候选说话人对应的句子文本、所述新增角色的说话内容、以及故事讲述人的讲述内容进行语音合成。
在本实施例的一种实现方式中,所述原始故事文本中的每一角色被定义为候选角色,则所述候选说话人确定单元包括:
说话词确定子单元,用于确定所述句子文本对应的说话词,所述说话词为代表说话动作的词语;
第一候选人确定子单元,用于若所述说话词所属句子的主语为一个候选角色的角色名称,则将该候选角色作为所述句子文本对应的候选说话人;
第二候选人确定子单元,用于若所述说话词所属句子的主语为人称代词,则确定所述人称代词对应的候选角色,并将该候选角色作为所述句子文本对应的候选说话人;
第三候选人确定子单元,用于若所述说话词所属句子不存在主语,则预测得到所述句子文本对应的候选说话人。
在本实施例的一种实现方式中,所述故事语音合成单元,具体用于使用第一发音人的音色特征,为所述新增角色的说话内容进行语音合成,所述第一发音人是利用第一用户的朗读文本训练的发音人。
在本实施例的一种实现方式中,所述故事语音合成单元,具体用于使用第二发音人的音色特征,为故事讲述人的讲述内容进行语音合成,所述第二发音人是利用第二用户的朗读文本训练的发音人。
在本实施例的一种实现方式中,所述装置还包括:
背景音乐播放单元,用于在播放所述改编后的故事文本的过程中,根据播放的故事情节,同步播放与所述故事情节匹配的背景音乐。
进一步地,本申请实施例还提供了一种文本改编装置,包括:处理器、存储器、系统总线;
所述处理器以及所述存储器通过所述系统总线相连;
所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行上述文本改编方法的任一种实现方法。
进一步地,本申请实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行上述文本改编方法的任一种实现方法。
进一步地,本申请实施例还提供了一种计算机程序产品,所述计算机程序产品在终端设备上运行时,使得所述终端设备执行上述文本改编方法的任一种实现方法。
通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到上述实施例方法中的全部或部分步骤可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者诸如媒体网关等网络通信设备,等等)执行本申请各个实施例或者实施例的某些部分所述的方法。
需要说明的是,本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!