语音控制终端的制作方法
本发明涉及智能语音控制技术领域,尤其涉及一种语音控制终端。
背景技术:
随着科技的发展,科技越来越智能化,其中语音控制终端越来越普及,现有的语音控制终端都具备用户身份识别功能,但是大多都是通过声纹来进行识别的,也有的是通过动作手势来识别,这就导致功能较为单一,且云端部署方式也较为单一,导致语音控制终端对于音频信息的处理效率较为低下,且并不具备语音指令回溯功能,因此,解决这一类的问题显得尤为重要。
技术实现要素:
针对现有技术的不足,本发明提供了一种语音控制终端,由语音控制盒将采集到的音频数据通过aiui服务送到云端中的云端语音识别/语义分析引擎,并通过语义理解将语音转换成需要的文字,语音控制盒将该文字转换成相应的控制指令,通过网络、串口形式发送给控制中心,通过部署在云端上的云端语音识别/语义分析引擎配合部署在语音控制盒上的本地语音识别/语义分析引擎来进行语音识别和语义分析处理。
为了解决上述问题,本发明提供了一种语音控制终端,包括有
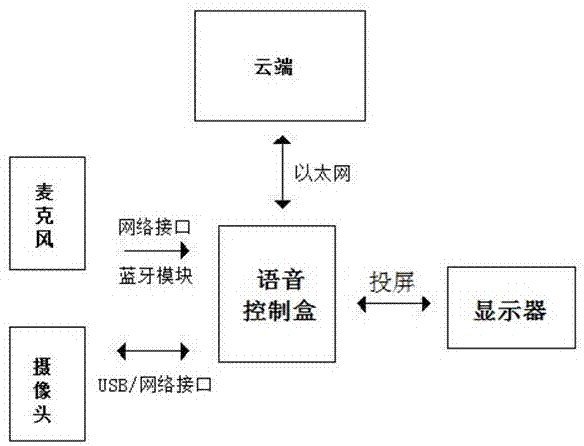
语音控制盒:将采集到的音频数据通过aiui服务送到云端中的云端语音识别/语义分析引擎,并通过语义理解将语音转换成需要的文字,语音控制盒将该文字转换成相应的控制指令,通过网络、串口形式发送给控制中心,所述语音控制盒中还设置有本地语音识别/语义分析引擎用于语音识别和语义分析;
云端:用于接受并识别语音控制盒传输过来的音频数据,所述云端包括有私有云端和公有云端,所述公有云端部署部署在开放网络中,所述私有云端部署部署在局域网络内,所述云端中设置有云端语音识别/语义分析引擎,所述云端语音识别/语义分析引擎部署在私有云端和公有云端上;
投屏:用于显示处理后的音频数据、内容反馈、引导和配置;
麦克风:用于采集音频数据,所述麦克风通过蓝牙或网络接口连接在语音控制盒上;
摄像头:用于采集用户人脸数据,所述摄像头通过usb或网络接口连接在语音控制盒上。
进一步改进在于:所述语音控制盒通过人脸识别、指纹认证和声纹识别来识别发出控制语音的人的身份,并通过身份识别来决定是否发送语音指令。
进一步改进在于:所述语音控制盒中设置有扬声器,扬声器可以自带也可以外接。
进一步改进在于:所述麦克风采用阵列算法降噪,支持近场和远场拾音。
进一步改进在于:所述语音控制盒中设置有回溯模块,用于对发出的指令进行用户身份的追溯。
进一步改进在于:所述语义理解包括有标准语意的理解和扩展语意的理解。
本发明的有益效果是:本发明通过麦克风采集音频数据,麦克风通过usb、蓝牙等有线或者无线与语音控制终端相连,语音控制盒将采集到的音频数据通过aiui服务送到云端语音识别/语义分析引擎,并通过语音分析、语义理解等将语音转换成需要的文字,语音控制盒将该文字转换成相应的控制指令,通过网络、串口等传输形式发送给集成厂商的控制中心;语音控制盒通过人脸识别、指纹认证和声纹识别来识别发出控制语音的人的身份,并通过身份识别来决定是否发送语音指令,并同时具有回溯功能,方便用户对发出的指令进行追踪;且语音控制盒自带扬声器,支持全双工语音交互和语音打断功能;麦克风采用麦克风阵列降噪算法,支持近场和远场拾音,通过部署在云端上的云端语音识别/语义分析引擎配合部署在语音控制盒上的本地语音识别/语义分析引擎来进行语音识别和语义分析处理,大大解放了人工劳动,提高了工作效率。
附图说明
图1是本发明的系统连接图。
图2是本发明的云端部署示意图。
图3是本发明的本地语音识别引擎系统框架图。
具体实施方式
为了加深对本发明的理解,下面将结合实施例对本发明做进一步详述,本实施例仅用于解释本发明,并不构成对本发明保护范围的限定。
如图1、2、3所示,本实施例提供了一种语音控制终端,包括有
语音控制盒:将采集到的音频数据通过aiui服务送到云端的语音识别引擎,并通过语义理解将语音转换成需要的文字,语音控制盒将该文字转换成相应的控制指令,通过网络、串口形式发送给控制中心,所述语音控制盒中设置有本地语音识别引擎;
云端:用于接受并识别语音控制盒传输过来的音频数据,所述云端包括有私有云端和公有云端,所述公有云端部署部署在开放网络中,所述私有云端部署部署在局域网络内,所述云端中设置有云端语音识别/语义分析引擎,所述云端语音识别/语义分析引擎部署在私有云端和公有云端上;
投屏:用于显示处理后的音频数据;
麦克风:用于采集音频数据,所述麦克风通过蓝牙或mic接口连接在语音控制盒上;
摄像头:用于采集用户人脸数据,所述摄像头通过usb或网络接口连接在语音控制盒上。
所述语音控制盒通过人脸识别、指纹认证和声纹识别来识别发出控制语音的人的身份,并通过身份识别来决定是否发送语音指令。所述语音控制盒中设置有扬声器。所述麦克风采用阵列算法降噪,支持近场和远场拾音。所述语音控制盒中设置有回溯模块,用于对发出的指令进行用户身份的追溯。所述本地语音识别引擎用于语音识别和语义分析。所述语义理解包括有标准语意的理解和扩展语意的理解。
本发明通过麦克风采集音频数据,麦克风通过usb、蓝牙等有线或者无线与语音控制终端相连,语音控制盒将采集到的音频数据通过aiui服务送到云端语音识别/语义分析引擎,并通过语音分析、语义理解等将语音转换成需要的文字,语音控制盒将该文字转换成相应的控制指令,通过网络、串口等传输形式发送给集成厂商的控制中心;语音控制盒通过人脸识别、指纹认证和声纹识别来识别发出控制语音的人的身份,并通过身份识别来决定是否发送语音指令,并同时具有回溯功能,方便用户对发出的指令进行追踪;且语音控制盒自带扬声器,支持全双工语音交互和语音打断功能;麦克风采用麦克风阵列降噪算法,支持近场和远场拾音,通过部署在云端上的云端语音识别/语义分析引擎配合部署在语音控制盒上的本地语音识别/语义分析引擎来进行语音识别和语义分析处理,大大解放了人工劳动,提高了工作效率。
技术特征:
技术总结
本发明公开一种语音控制终端,包括语音控制盒、云端、投屏、麦克风、摄像头,由语音控制盒将采集到的音频数据通过AIUI服务送到云端中的云端语音识别/语义分析引擎,并通过语义理解将语音转换成需要的文字,语音控制盒将该文字转换成相应的控制指令,通过网络、串口等传输形式发送给控制中心;语音控制盒通过人脸识别、指纹认证和声纹识别来识别发出控制语音的人的身份,并通过身份识别来决定是否发送语音指令,且语音控制盒中设置有扬声器,支持全双工语音交互和语音打断功能,通过部署在云端上的云端语音识别/语义分析引擎配合部署在语音控制盒上的本地语音识别/语义分析引擎来进行语音识别和语义分析处理,大大解放人工劳动,提高工作效率。
技术研发人员:陈琦;陈志军;占文;刘倩茹;梁毅;武文强
受保护的技术使用者:芜湖星途机器人科技有限公司
技术研发日:2018.09.29
技术公布日:2018.12.18
- 还没有人留言评论。精彩留言会获得点赞!