一种AI语音对话系统的制作方法
本发明涉及人工智能语音技术领域,尤其涉及一种ai语音对话系统。
背景技术:
近年来,随着人工智能的迅速发展,人工智能语音技术更是受到智能电视行业的追捧,不少电视厂商纷纷发布了具有语音交互功能的电视新品,而且智能电视语音交互也成为了吸引消费者的重要因素之一。而如何打造一款既稳定高效,又有具有高可扩展性和松耦合的ai语音对话系统,就成为首先要解决的架构问题,因为只有首先保证ai语音对话系统架构的先进性,我们才能基于此持续快速地开发更多语音功能。
以前,我们语音系统的核心架构主要在终端,而云端仅仅提供一些必要的识别和服务接口,这就导致,一方面架构的调整需要升级终端,另一方面,各个子系统耦合较高,不利于各自的扩展。而本发明提供一种创新的架构方法,将相对固定的语音处理逻辑放在终端,而将相对容易变化的意图分发、服务接入等子系统放在云端,形成了各子系统端云一体,但又相对独立的端云架构,这也为长虹智能电视在人工智能语音领域持续领先于行业提供了坚实的技术基础。
技术实现要素:
本发明的目的就在于为了解决上述问题而提供一种ai语音对话系统,本发明通过以下技术方案来实现上述目的:
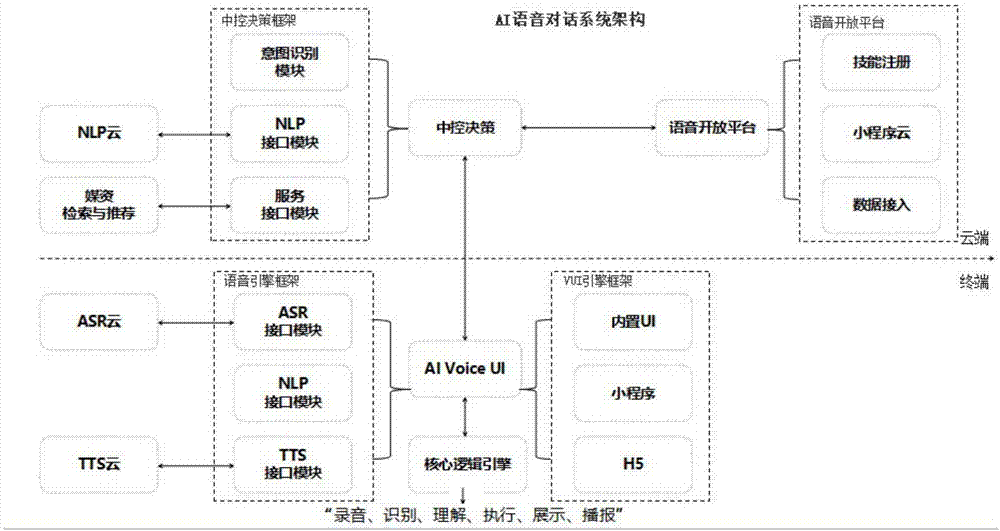
一种ai语音对话系统,包括终端系统和云端系统:
所述终端系统包括名称为aivoiceui的终端语音系统,所述终端语音系统包括核心逻辑引擎、语音处理引擎和ui引擎三个模块;
所述核心逻辑引擎包括录音、语音识别、语义处理、功能执行、ui展示和播报六个核心逻辑,“录音”模块负责获取各种输入设备的音频数据,并将其作为输出,发送给下一个模块“语音识别”;“语音识别”模块将输入的录音数据转换为文本数据,输出给下一个模块“语义处理”;“语义处理”模块将输入的文本数据转换为结构化数据,输出给后面三个模块“功能执行”、“ui展示”和“语音播报”,“功能执行”模块负责调用本地功能接口,“ui展示”模块负责向用户以图形化的方式展示结果,“语音播报”模块负责以声音的方式给用户展示结果;
所述语音处理引擎包括asr、nlp和tts,提供抽象接口和具体实现,语音处理引擎提供抽象接口,供具体的asr、nlp和tts实现,同时供前述的核心逻辑引擎调用;
所述ui引擎主要提供对本地ui模板和云端ui模板的方式,而云端ui模板支持标准的h5方式和小程序方式,本地ui模板支持的样式固定且有限,供语音技能开发者选取;云端ui模板支持语音技能开发者自定义,以满足其个性化需求;
所述云端系统包括云端中控决策系统和语音开放平台;
所述中控决策模块包括核心策略模块、意图识别模块、语义接入模块和服务接口模块,“核心策略”模块以用户请求作为输入,并先调用“意图识别”模块,以获得用户的意图,然后根据用户意图调用“语义接入”模块,最后再根据语义结果调用对应的“服务接入”模块,最终将服务数据输出给请求端;
所述语音开放平台为语音技能开发者提供开发、测试和发布语音技能的平台,语音技能开发者登录语音开放平台,输入技能名称、添加技能的意图数据、选取技能的ui模板、上传服务数据获取脚本,最后提交。
更进一步的方案是:
所述核心逻辑引擎包含6类基本逻辑:录音、语音识别、语义理解、功能执行、ui展示和语音播报。
更进一步的方案是:
所述ui引擎支持本地ui模板、webui模板两种方式。
本发明的有益效果在于:
本发明的一种ai语音对话系统,解决原核心架构在终端,迭代速度慢;各个核心子系统之间耦合较深,不易独立扩展。该架构是着眼于未来ai语音对话系统的技术发展趋势而设计的,让人工智能语音电视持续发展具备了坚实基础。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要实用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本实施例的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1本发明的系统示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本发明所保护的范围。
如图1所示,一种ai语音对话系统,包括终端系统和云端系统:
所述终端系统包括名称为aivoiceui的终端语音系统,所述终端语音系统包括核心逻辑引擎、语音处理引擎和ui引擎三个模块;
所述核心逻辑引擎包括录音、语音识别、语义处理、功能执行、ui展示和播报六个核心逻辑,“录音”模块负责获取各种输入设备的音频数据,并将其作为输出,发送给下一个模块“语音识别”;“语音识别”模块将输入的录音数据转换为文本数据,输出给下一个模块“语义处理”;“语义处理”模块将输入的文本数据转换为结构化数据,输出给后面三个模块“功能执行”、“ui展示”和“语音播报”,“功能执行”模块负责调用本地功能接口,“ui展示”模块负责向用户以图形化的方式展示结果,“语音播报”模块负责以声音的方式给用户展示结果;
所述语音处理引擎包括asr(语音识别)、nlp(语义处理)和tts(语音播报),提供抽象接口和具体实现,语音处理引擎提供抽象接口,供具体的asr、nlp和tts实现,同时供前述的核心逻辑引擎调用;asr接口模块和tts接口模块处理的数据最终分别储存至相应的云端平台;
所述ui引擎主要提供对本地ui模板和云端ui模板的方式,而云端ui模板支持标准的h5方式和小程序方式,本地ui模板支持的样式固定且有限,供语音技能开发者选取;云端ui模板支持语音技能开发者自定义,以满足其个性化需求;
所述云端系统包括云端中控决策系统和语音开放平台;
所述中控决策模块包括核心策略模块、意图识别模块、语义接入模块和服务接口模块,“核心策略”模块以用户请求作为输入,并先调用“意图识别”模块,以获得用户的意图,然后根据用户意图调用“语义接入”模块,最后再根据语义结果调用对应的“服务接入”模块,最终将服务数据输出给请求端;
所述语音开放平台为语音技能开发者提供开发、测试和发布语音技能的平台,语音技能开发者登录语音开放平台,输入技能名称、添加技能的意图数据、选取技能的ui模板、上传服务数据获取脚本,最后提交。
所述核心逻辑引擎包含6类基本逻辑:录音、语音识别、语义理解、功能执行、ui展示和语音播报。所述ui引擎支持本地ui模板、webui模板两种方式。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!