一种语音激活检测方法与流程
本发明涉及语音激活检测技术领域,尤其涉及一种语音激活检测方法。
背景技术:
语音激活检测(vad,voiceactivitydetection),目的是检测当前语音信号中是否包含话音信号存在,即对输入信号进行判断,将话音信号与各种背景噪声信号区分出来,分别对两种信号采用不同的处理方法。话音激活检测是数字语音信号处理的基础环节,在许多实际应用系统中都必须首先进行语音信号检测,使后面处理的数据为实际的有效语音信号数据,从而可以减少数据量和运算量,进而减少系统的处理时间。
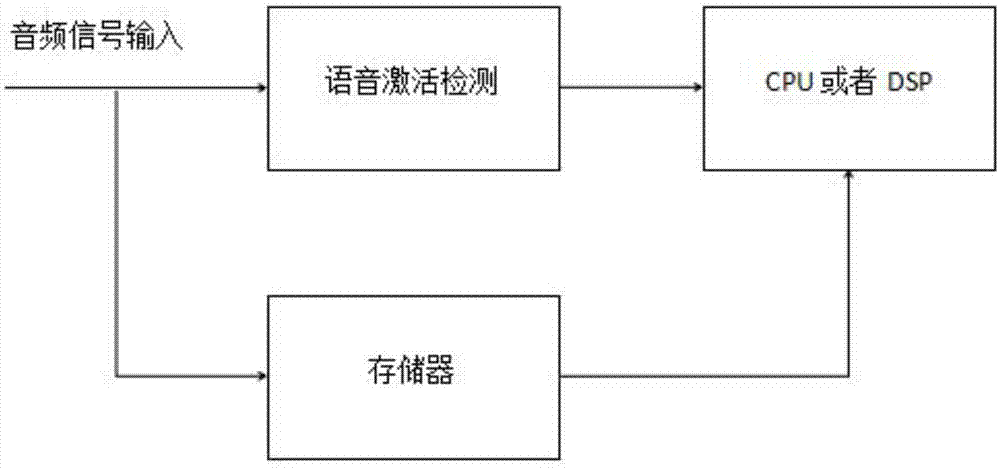
如图1所示,传统的语音激活检测可以检测出所有时间是否为语音,当前的语音激活检测,主要分为两种:(1)传统的基于能量,时域,频域等信号处理方法,(2)最近流行的神经网络的检测方法;其中,神经网络算法,性能很好,但是计算量很大,一般要几百万次的运算,才能完成一帧的信号处理,而且由于需要存储神经网络权重也需要几mbyte,这对于硬件的实现是很大的资源开销,非常昂贵,因此,这并不适用于低功耗低成本的应用.如果在cpu或者dsp上实现神经网络vad算法,功耗极大。
由于语音识别技术的发展,因此,急需要有合适的语音激活检测,当检测到有语音的时候才开始语音识别处理,这样来满足系统待机状态低功耗的要求。
技术实现要素:
针对现有技术中存在的上述问题,现提供一种语音激活检测方法。
具体技术方案如下:
一种语音激活检测方法,其中包括:
提供一采集单元,以采集外界一声音信号;
提供一判断单元,以判断所述声音信号是否为语音信号;
若是,则启动一语音处理单元,以对所述声音信号进行处理;
若否,则保持所述语音处理单元处于休眠状态。
优选的,所述判断单元判断所述声音信号是否为语音信号的方法具体包括以下步骤:
步骤s1、降低所述声音信号的采样率,以得到一第一处理信号;
步骤s2、对所述第一处理信号进行高通滤波处理,以得到一第二处理信号;
步骤s3、以一预设时间间隔对所述第二处理信号进行分帧;
步骤s4、对分帧后的所述第二处理信号进行检测,以得到是否为语音信号的检测结果;
将所述检测结果处理为激活信号输出至所述语音处理单元。
优选的,对分帧后的所述第二处理信号进行检测的方法包括,对分帧后的所述第二处理信号进行能量检测,以输出一布尔值序列的能量检测结果作为所述检测结果。
优选的,对分帧后的所述第二处理信号进行检测的方法包括,对分帧后的所述第二处理信号进行熵检测,以输出一布尔值序列的熵检测结果作为所述检测结果。
优选的,对分帧后的所述第二处理信号进行检测的方法包括,对分帧后的所述第二处理信号进行倒谱检测,以输出一布尔值序列的倒谱检测结果作为所述检测结果。
优选的,对分帧后的所述第二处理信号进行检测的方法包括:
对分帧后的所述第二处理信号进行能量检测,以输出以布尔值序列的能量检测结果,将所述能量检测结果作为对分帧后的所述第二处理信号进行熵检测的使能信号,并以所述熵检测输出的布尔值序列的熵检测结果作为所述检测结果输出;或者
对分帧后的所述第二处理信号同步进行能量检测及熵检测,并同步获得布尔值序列的能量检测结果及布尔值序列的熵检测结果,以一预置策略对所述能量检测结果及所述熵检测结果进行判决,将判决结果作为所述检测结果输出。
优选的,对分帧后的所述第二处理信号进行检测的方法包括:
对分帧后的所述第二处理信号进行能量检测,以输出以布尔值序列的能量检测结果,将所述能量检测结果作为对分帧后的所述第二处理信号进行倒谱检测的使能信号,并以所述倒谱检测输出的布尔值序列的倒谱检测结果作为所述检测结果输出;或者
对分帧后的所述第二处理信号同步进行能量检测及倒谱检测,并同步获得布尔值序列的能量检测结果及布尔值序列的倒谱检测结果,以一预置策略对所述能量检测结果及所述倒谱检测结果进行判决,将判决结果作为所述检测结果输出。
优选的,对分帧后的所述第二处理信号进行检测的方法包括:
对分帧后的所述第二处理信号进行熵检测,以输出以布尔值序列的熵检测结果,将所述熵检测结果作为对分帧后的所述第二处理信号进行倒谱检测的使能信号,并以所述倒谱检测输出的布尔值序列的倒谱检测结果作为所述检测结果输出;或者
对分帧后的所述第二处理信号同步进行熵检测及倒谱检测,并同步获得布尔值序列的熵检测结果及布尔值序列的倒谱检测结果,以一预置策略对所述熵检测结果及所述倒谱检测结果进行判决,将判决结果作为所述检测结果输出。
优选的,对分帧后的所述第二处理信号进行检测的方法包括:
对分帧后的所述第二处理信号进行能量检测,以输出以布尔值序列的能量检测结果,将所述能量检测结果作为对分帧后的所述第二处理信号进行熵检测的使能信号,将所述熵检测输出的布尔值序列的熵检测结果作为对分帧后的所述第二处理信号进行倒谱检测的使能信号,并以所述倒谱检测输出的布尔值序列的倒谱检测结果作为所述检测结果输出;或者
对分帧后的所述第二处理信号同步进行能量检测、熵检测及倒谱检测,并同步获得布尔值序列的能量检测结果、布尔值序列的熵检测结果以及布尔值序列的倒谱检测结果,以一预置策略对所述能量检测结果、所述熵检测结果以及所述倒谱检测结果进行判决,将判决结果作为所述检测结果输出。
优选的,于所述步骤s4中,将所述检测结果处理为所述激活信号的方法为,以帧为单位对所述检测结果进行平滑处理。
优选的,所述步骤s3中,所述第二处理信号通过以下公式进行分帧:
frame(n,m)=y_emp(fs*t*n+m);
其中,
frame(n,m)用于表示分帧后的每帧所述第二处理信号;
y_emp用于表示所述第二处理信号;
fs用于表示所述语音信号的采样率;
t用于表示所述预设时间间隔;
n用于表示第n帧;
m用于表示n帧中的第m个点。
优选的,所述能量检测结果通过以下公式进行:
其中,
flag_pow(n)用于表示所述能量检测结果;
avgpow(n)用于表示当前帧的平均能量;
avgpowold(n)用于表示之前帧的平均能量;
thresh1为调整参数。
优选的,thresh1的取值范围在3-100之间。
优选的,当前帧的所述平均能量通过以下公式得到:
其中,
frame(n,m)用于表示分帧后的每帧所述第二处理信号;avgpow(n)用于表示当前帧的平均能量;
framelen用于表示每一帧的长度;
avgpowold(n)用于表示之前帧的平均能量;
avglen用于表示向前采样的帧数量。
优选的,所述熵检测结果通过以下公式进行:
其中,
flag_sen(n)用于表示所述熵检测结果;
h(n)用于表示分帧后的所述第二处理信号的熵函数;
thresh2用于表示熵判断阈值。
优选的,thresh2的取值范围在-7-0之间。
优选的,所述窗函数的熵函数通过以下公式得到:
ypow(n,m)=abs(y(n,m))2;
y(n,m)=fft(xw(n,m));
xw(n,m)=frame(n,m)*win(m);
其中,
h(n)用于表示分帧后的所述第二处理信号的的熵函数;
win(m)用于表示窗函数;
xw(n,m)用于表示对分帧后的所述第二处理信号进行加窗后获得的信号;
y(n,m)用于表示对xw(n,m)做快速傅里叶变换后获得的信号;
ypow(n,m)用于表示xw(n,m)的功率谱;
prob(n,m)用于表示ypow(n,m)的概率。
优选的,所述倒谱检测结果通过以下公式进行:
tmax(n)=max(ceps(n,speech_range));
tmin(n)=min(ceps(n,speech_range));
ceps(n,m)=ifft(ypow_log(n,m));
ypow_log(n,m)=log2(ypow(n,m));
其中,
flag_ceps(n)用于表示所述倒谱检测结果;
ypow(n,m)用于表示xw(n,m)的功率谱;
xw(n,m)用于表示对分帧后的所述第二处理信号进行加窗后获得的信号;
ypow_log(n,m)用于表示xw(n,m)的倒谱;
ceps(n,m)用于表示对ypow_log(n,m)进行反快速傅里叶变换后获得的信号;
tmax(n)用于表示ceps(n,m)的当前帧在人声输出段的最大值;
tmin(n)用于表示ceps(n,m)的当前帧在人声输出段的最小值;
speech_range用于表示人声输出段的范围;
thresh3用于表示倒谱判断阈值。
优选的,thresh3的取值范围在0.5-1.5之间。
本发明的技术方案有益效果在于:公开一种语音激活检测方法,首先采集声音信号,并判断声音信号是否为语音信号,当检测到声音信号是语音信号时,则启动语音处理单元对声音信号进行识别处理,当检测到声音信号不是语音信号时,则使语音处理单元一直处于休眠状态,该语音激活检测方法使功耗较大的语音处理单元长时间保持休眠状态,因而可使整个系统保持低功耗,并且该语音激活检测方法实现成本较低,且可通过较小的计算量,以及较少的资源消耗获取较优的性能。
附图说明
参考所附附图,以更加充分的描述本发明的实施例。然而,所附附图仅用于说明和阐述,并不构成对本发明范围的限制。
图1为现有技术中,语音激活检测方法的原理框图;
图2为本发明的实施例的语音激活检测方法的步骤流程图;
图3为本发明的实施例的语音激活检测系统的原理框图;
图4为本发明的实施例的语音激活检测方法的判断单元判断声音信号是否为语音信号的的原理框图;
图5为本发明的实施例的语音激活检测方法的判断单元判断声音信号是否为语音信号的步骤流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
如图1所示,传统的语音激活检测可以检测出所有时间是否为语音,当前的语音激活检测,主要分为两种:(1)传统的基于能量,时域,频域等信号处理方法,(2)最近流行的神经网络的检测方法;其中,神经网络算法,性能很好,但是计算量很大,一般要几百万次的运算,才能完成一帧的信号处理,而且由于需要存储神经网络权重也需要几mbyte,这对于硬件的实现是很大的资源开销,非常昂贵,因此,这并不适用于低功耗低成本的应用.如果在cpu或者dsp上实现神经网络vad算法,功耗极大。
由于语音识别技术的发展,因此,急需要有合适的语音激活检测,当检测到有语音的时候才开始语音识别处理,这样来满足系统待机状态低功耗的要求。
针对现有技术中存在的上述问题,本发明公开一种语音激活检测方法,如图2所示,其中包括:
提供一采集单元1,以采集外界一声音信号;
提供一判断单元2,以判断声音信号是否为语音信号;
若是,则启动一语音处理单元3,以对声音信号进行处理;
若否,则保持语音处理单元3处于休眠状态。
通过上述语音激活检测方法的技术方案,公开一种语音激活检测方法,应用于一语音激活检测系统中,如图3所示,该语音激活检测系统包括采集单元1、判断单元2及语音处理单元3,其中采集单元1连接判断单元2,语音处理单元3连接判断单元2。
首先,提供采集单元1以采集声音信号,提供判断单元2以判断声音信号是否为语音信号,当检测到声音信号是语音信号时,则启动语音处理单元3对声音信号进行识别处理,当检测到声音信号不是语音信号时,则使语音处理单元3一直处于休眠状态。
进一步地,该语音激活检测方法使功耗较大的语音处理单元3长时间保持休眠状态,因而可使整个系统保持低功耗,并且该语音激活检测方法实现成本较低,且可通过较小的计算量,以及较少的资源消耗获取较优的性能。
在一种较优的实施例中,判断单元判断声音信号是否为语音信号的方法具体包括以下步骤:
步骤s1、降低声音信号的采样率,以得到一第一处理信号;
步骤s2、对第一处理信号进行高通滤波处理,以得到一第二处理信号y_emp;
步骤s3、以一预设时间间隔对第二处理信号y_emp进行分帧;
步骤s4、对分帧后的第二处理信号y_emp进行检测,以得到是否为语音信号的检测结果;
将检测结果处理为激活信号输出至语音处理单元。
上述技术方案中,如图4、5所示,首先对输入信号做低通滤波,把采样率降低到8000hz,得到第一处理信号,然后把第一处理信号通过高通滤波器,优选的,高通滤波器可以是预加重滤波器,以进行高通滤波得到信号第二处理信号y_emp,以一预设时间间隔对第二处理信号y_emp进行分帧,其中,预设时间间隔可以设置为10ms,帧长为lms,其中,l可以取值为20-32之间。
进一步地,对分帧后的第二处理信号y_emp进行检测,以得到是否为语音信号的检测结果,将检测结果处理为激活信号输出至语音处理单元;具体地,将检测结果处理为激活信号的方法为,以帧为单位对检测结果进行平滑处理,需要说明的是,对检测结果进行平滑处理可以采样多种方式,比如,m中取n的算法,进一步避免前一帧信号的平滑处理,以提供一种低成本,低功耗的平滑处理,并且在降低检测概率的情况下,大幅度降低虚警概率。
进一步地,该语音激活检测方法使功耗较大的语音处理单元3长时间保持休眠状态,因而可使整个系统保持低功耗,并且该语音激活检测方法实现成本较低,且可通过较小的计算量,以及较少的资源消耗获取较优的性能。
在一种较优的实施例中,步骤s3中,第二处理信号y_emp通过以下公式进行分帧:
frame(n,m)=y_emp(fs*t*n+m);
其中,
frame(n,m)用于表示分帧后的每帧第二处理信号y_emp;
y_emp用于表示第二处理信号y_emp;
fs用于表示语音信号的采样率;
t用于表示预设时间间隔;
n用于表示第n帧;
m用于表示n帧中的第m个点。
上述技术方案中,每帧长度framelen=l*0.001*8000,因此,framelen的取值范围是160-256;优选的,每帧第二处理信号y_emp可以通过以下公式进行分帧,frame(n,m)=y_emp(80*n+m),其中,80表示80个采样点,即fs*t=8000*10ms=80个采样点。
进一步地,对分帧后的每帧第二处理信号y_emp进行检测,以得到是否为语音信号的检测结果,将检测结果处理为激活信号输出至语音处理单元;进一步地,该语音激活检测方法使功耗较大的语音处理单元3长时间保持休眠状态,因而可使整个系统保持低功耗,并且该语音激活检测方法实现成本较低,且可通过较小的计算量,以及较少的资源消耗获取较优的性能。
在一种较优的实施例中,能量检测包括,对分帧后的第二处理信号y_emp进行检测的方法包括,对分帧后的第二处理信号y_emp进行能量检测,以输出一布尔值序列的能量检测结果作为检测结果。
上述技术方案中,能量检测结果通过以下公式进行:
其中,
flag_pow(n)用于表示能量检测结果;
avgpow(n)用于表示当前帧的平均能量;
avgpowold(n)用于表示之前帧的平均能量;
thresh1为调整参数;
其中,当前帧的平均能量通过以下公式得到:
其中,
frame(n,m)用于表示分帧后的每帧第二处理信号y_emp;
avgpow(n)用于表示当前帧的平均能量;
framelen用于表示每一帧的长度;
avgpowold(n)用于表示之前帧的平均能量;
avglen用于表示向前采样的帧数量。
上述技术方案中,thresh1为调整参数,可以根据应用的场景来配置,在本实施例中,thresh1的取值范围在3-100之间,并且,avglen表示向前采样的帧数量,可以是配置参数,可以取值在4-32之间。
进一步地,该语音激活检测方法使功耗较大的语音处理单元3长时间保持休眠状态,因而可使整个系统保持低功耗,并且该语音激活检测方法实现成本较低,且可通过较小的计算量,以及较少的资源消耗获取较优的性能。
在一种较优的实施例中,对分帧后的第二处理信号y_emp进行检测的方法包括,对分帧后的第二处理信号y_emp进行熵检测,以输出一布尔值序列的熵检测结果作为检测结果。
上述技术方案中,熵检测结果通过以下公式进行:
其中,
flag_sen(n)用于表示熵检测结果;
h(n)用于表示分帧后的第二处理信号y_emp的熵函数;
thresh2用于表示熵判断阈值;
其中,分帧后的第二处理信号y_emp的熵函数通过以下公式得到:
ypow(n,m)=abs(y(n,m))2;
y(n,m)=fft(xw(n,m));
xw(n,m)=frame(n,m)*win(m);
其中,
h(n)用于表示分帧后的第二处理信号y_emp的的熵函数;
win(m)用于表示窗函数;
xw(n,m)用于表示对分帧后的第二处理信号y_emp进行加窗后获得的信号;
y(n,m)用于表示对xw(n,m)做快速傅里叶变换后获得的信号;
ypow(n,m)用于表示xw(n,m)的功率谱;
prob(n,m)用于表示ypow(n,m)的概率。
优选的,thresh2用于表示熵判断阈值,可以根据应用的场景进行配置,在本实施例中,预先配置的熵参数thresh2维持在-7-0之间,加窗处理为采样方式,选用哈明窗(hamming)或者汉宁窗(hanning)都可以。
进一步地,该语音激活检测方法使功耗较大的语音处理单元3长时间保持休眠状态,因而可使整个系统保持低功耗,并且该语音激活检测方法实现成本较低,且可通过较小的计算量,以及较少的资源消耗获取较优的性能。
在一种较优的实施例中,对分帧后的第二处理信号y_emp进行检测的方法包括,对分帧后的第二处理信号y_emp进行倒谱检测,以输出一布尔值序列的倒谱检测结果作为检测结果。
上述技术方案中,倒谱检测结果通过以下公式进行:
tmax(n)=max(ceps(n,speech_range));
tmin(n)=min(ceps(n,speech_range));
ceps(n,m)=ifft(ypow_log(n,m));
ypow_log(n,m)=log2(ypow(n,m));
其中,
flag_ceps(n)用于表示倒谱检测结果;
ypow(n,m)用于表示xw(n,m)的功率谱;
xw(n,m)用于表示对分帧后的第二处理信号y_emp进行加窗后获得的信号;
ypow_log(n,m)用于表示xw(n,m)的倒谱;
ceps(n,m)用于表示对ypow_log(n,m)进行反快速傅里叶变换后获得的信号;
tmax(n)用于表示ceps(n,m)的当前帧在人声输出段的最大值;
tmin(n)用于表示ceps(n,m)的当前帧在人声输出段的最小值;
speech_range用于表示人声输出段的范围;
thresh3用于表示倒谱判断阈值。
具体地,当前帧表示当前处理的一帧,thresh3表示倒谱判断阈值,可配置参数,优选的,在本实施例中,thresh3的取值范围在0.5-1.5之间,并且,fft表示反快速傅里叶变换,优选的,每一帧的长度framelen为256点,如若每帧长度framelen小于256,则fft的输入补零至256点;speech_range表示人声输出段的范围,优选的,从2.5ms-16ms,speech_range取值范围为从20-128。
进一步地,该语音激活检测方法使功耗较大的语音处理单元3长时间保持休眠状态,因而可使整个系统保持低功耗,并且该语音激活检测方法实现成本较低,且可通过较小的计算量,以及较少的资源消耗获取较优的性能。
在一种较优的实施例中,为了提高语音激活检测方法的灵活性,可以做一些灵活的配置,比如说熵检测和倒谱检测同步开启或者关闭,把熵检测和倒谱检测的结果一起做时域平滑来做判决;并且,如果想检测清音,清音的倒谱是没有峰值的,但是熵比较大,也可以选择把倒谱检测一直关闭,只考虑能量检测和熵检测的结果.;这样在待机状态下,绝大部分时间,不会触发耗电的熵检测和倒谱检测的计算,这样保证了系统的低功耗运行。
具体地,对分帧后的第二处理信号进行检测的方法包括:
实施例一:
对分帧后的第二处理信号y_emp进行能量检测,以输出以布尔值序列的能量检测结果,将能量检测结果作为对分帧后的第二处理信号y_emp进行熵检测的使能信号,并以熵检测输出的布尔值序列的熵检测结果作为检测结果输出;或者
对分帧后的第二处理信号y_emp同步进行能量检测及熵检测,并同步获得布尔值序列的能量检测结果及布尔值序列的熵检测结果,以一预置策略对能量检测结果及熵检测结果进行判决,将判决结果作为检测结果输出。
实施例二:
对分帧后的第二处理信号y_emp进行能量检测,以输出以布尔值序列的能量检测结果,将能量检测结果作为对分帧后的第二处理信号y_emp进行倒谱检测的使能信号,并以倒谱检测输出的布尔值序列的倒谱检测结果作为检测结果输出;或者
对分帧后的第二处理信号y_emp同步进行能量检测及倒谱检测,并同步获得布尔值序列的能量检测结果及布尔值序列的倒谱检测结果,以一预置策略对能量检测结果及倒谱检测结果进行判决,将判决结果作为检测结果输出。
实施例三:
对分帧后的第二处理信号y_emp进行熵检测,以输出以布尔值序列的熵检测结果,将熵检测结果作为对分帧后的第二处理信号y_emp进行倒谱检测的使能信号,并以倒谱检测输出的布尔值序列的倒谱检测结果作为检测结果输出;或者
对分帧后的第二处理信号y_emp同步进行熵检测及倒谱检测,并同步获得布尔值序列的熵检测结果及布尔值序列的倒谱检测结果,以一预置策略对熵检测结果及倒谱检测结果进行判决,将判决结果作为检测结果输出。
实施例四:
对分帧后的第二处理信号y_emp进行能量检测,以输出以布尔值序列的能量检测结果,将能量检测结果作为对分帧后的第二处理信号y_emp进行熵检测的使能信号,将熵检测输出的布尔值序列的熵检测结果作为对分帧后的第二处理信号y_emp进行倒谱检测的使能信号,并以倒谱检测输出的布尔值序列的倒谱检测结果作为检测结果输出;或者
对分帧后的第二处理信号y_emp同步进行能量检测、熵检测及倒谱检测,并同步获得布尔值序列的能量检测结果、布尔值序列的熵检测结果以及布尔值序列的倒谱检测结果,以一预置策略对能量检测结果、熵检测结果以及倒谱检测结果进行判决,将判决结果作为检测结果输出。
上述实施例的技术方案中,该语音激活检测方法组合能量检测、熵检测及倒谱检测这三种检测方法,采用分级使能计算,计算量逐级增大,并且于同步进行能量检测及熵检测,或同步进行能量检测及倒谱检测,或同步进行能量检测、熵检测及倒谱检测,分别采用对应的预置策略判决,以得到对应的判决结果作为检测结果输出,其中,对应的预置策略判决根据应用应用场景的不同,而预先配置,在此不再赘述。
进一步地,该语音激活检测方法使功耗较大的语音处理单元3长时间保持休眠状态,因而可使整个系统保持低功耗,并且该语音激活检测方法实现成本较低,且可通过较小的计算量,以及较少的资源消耗获取较优的性能。
以上所述仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!