用于声对声转换的系统和方法与流程
优先权
本专利申请要求2017年5月24日提交的名称为“利用对抗性神经网络的音色传递系统和方法(timbretransfersystemsandmethodsutilizingadversarialneuralnetworks)”并指定williamc.huffman作为发明人的美国临时专利申请第62/510,443号的优先权,其全部公开内容通过引用并入本文。
本发明总体上涉及语音转换,且更具体地,本发明涉及生成合成语音简档。
背景技术:
由于使用个人语音激活的助理,例如amazonalexa、applesiri和googleassistant,近来人们对语音技术的兴趣已经达到顶峰。此外,播客和有声读物服务最近也已经普及。
技术实现要素:
根据本发明的一个实施例,一种构建话音转换系统的方法使用来自目标语音的目标语音信息以及表示源语音的话音段的话音数据。该方法接收表示源语音的第一话音段的源话音数据。该方法还接收与目标语音相关的目标音色数据。目标音色数据在音色空间内。生成机器学习系统根据源话音数据和目标音色数据,产生第一候选话音数据,第一候选话音数据表示第一候选语音中的第一候选话音段。鉴别机器学习系统用于参照多个不同语音的音色数据将第一候选话音数据与目标音色数据进行比较。鉴别机器学习系统参照多个不同语音的音色数据来确定第一候选话音数据和目标音色数据之间的至少一个不一致性。鉴别机器学习系统还产生具有与第一候选话音数据和目标音色数据之间的不一致性有关的信息的不一致性消息。该方法还将不一致性消息反馈给生成机器学习系统。根据不一致性消息,生成机器学习系统产生第二候选话音数据,第二候选话音数据表示第二候选语音中的第二候选话音段。使用由生成机器学习系统和/或鉴别机器学习系统产生的作为反馈结果的信息来改进音色空间中的目标音色数据。
在一些实施例中,源话音数据变换成目标音色。其中,源话音数据可以来自源语音的音频输入。以类似的方式,可以从来自目标语音的音频输入中获得目标音色数据。可以从目标话音段提取目标音色数据。此外,目标音色数据可以由时间接受域滤波。
机器学习系统可以是神经网络,并且多个语音可以在向量空间中。因此,多个语音和第一候选语音可根据每一语音提供的话音段中的频率分布映射在向量空间中。此外,根据不一致性消息可以调整向量空间中与多个语音表示相关的第一候选语音表示,以表达第二候选语音。因此,系统可通过将候选语音与多个语音进行比较来将身份分配给候选语音。
在一些实施例中,当鉴别神经网络具有小于95%的第一候选语音是目标语音的置信区间时,产生不一致性消息。因此,第二候选话音段提供比第一候选话音段更高的被鉴别器识别为目标语音的概率。因此,一些实施例使用生成机器学习系统根据空不一致性消息在最终候选语音中产生最终候选话音段。最终候选话音段模仿源话音段,但是具有目标音色。
根据一个实施例,一种用于训练话音转换系统的系统包括表示源语音的第一话音段的源话音数据。该系统还包括与目标语音相关的目标音色数据。此外,该系统包括生成机器学习系统,该生成机器学习系统配置为根据源话音数据和目标音色数据,产生第一候选话音数据,第一候选话音数据表示第一候选语音中的第一候选话音段。该系统还具有鉴别机器学习系统,其配置为参考多个不同语音的音色数据,将第一候选话音数据与目标音色数据进行比较。此外,鉴别机器学习配置以参照多个不同语音的音色数据来确定第一候选话音数据与目标音色数据之间是否存在至少一个不一致性。当存在至少一个不一致性时,鉴别机器学习产生具有与第一候选话音数据和目标音色数据之间的不一致性有关的信息的不一致性消息。此外,鉴别机器学习将不一致性消息返回生成机器学习系统。
目标音色数据由时间接受域滤波。在一些实施例中,时间接受域在约10毫秒和2,000毫秒之间。更具体地,时间接受域可以在约10毫秒和1,000毫秒之间。
在一些实施例中,语音特征提取器配置为根据不一致性消息来调整向量空间中的与多个语音的表示相关的候选语音的表示,以更新和反映第二候选语音。此外,区分性机器学习系统可配置以通过将第一或第二候选语音与多个语音进行比较来确定候选语音的说话者的身份。
可以从目标音频输入中提取目标音色数据。源话音数据可以变换为目标音色中变换的话音段。该系统还可以向变换的话音段添加水印。
根据本发明的又一实施例,一种用于构建音色向量空间的音色向量空间构建系统包括输入端。输入配置为接收a)第一语音中的包括第一音色数据的第一话音段,以及b)第二语音中的包括第二音色数据的第二话音段。该系统还包括时间接受域,用于将第一话音段变换为第一多个更小的分析音频段。第一多个更小的分析音频段中的每一个具有表示第一音色数据的不同部分的频率分布。滤波器还配置为使用时间接受域来将第二话音段变换成第二多个更小的分析音频段。第二多个更小的分析音频段中的每一个具有表示第二音色数据的不同部分的频率分布。该系统还包括配置为在音色向量空间中相对于第二语音映射第一语音的机器学习系统。根据a)来自第一话音段的第一多个分析音频段和b)来自第二话音段的第二多个分析音频段的频率分布来映射语音。
数据库还配置为接收第三语音中的第三话音段。机器学习系统配置为使用时间接受域将第三话音段滤波为多个较小的分析音频段,并且在向量空间中相对于第一语音和第二语音映射第三语音。将第三语音相对于第一语音和第二语音进行映射改变向量空间中第一语音与第二语音的相对位置。
其中,该系统配置成在至少一个语音中映射英语中的每个人类音位。接受域足够小以便不捕获语音的话音速率和/或口音。例如,时间接受域可以在约10毫秒和约2,000毫秒之间。
根据另一实施例,一种用于构造用于变换话音段的音色向量空间的方法包括接收a)第一语音中的第一话音段和b)第二语音中的第二话音段。第一话音段和第二话音段都包括音色数据。该方法使用时间接受域将每一个第一话音段和第二话音段中进行滤波为多个更小的分析音频段。每个分析音频段具有表示音色数据的频率分布。该方法还根据来自第一话音段和第二话音段的多个分析音频段的至少一个中的频率分布,在向量空间中相对于第二语音映射第一语音。
另外,该方法可以接收第三语音中的第三话音段,并且使用时间接受域将第三话音段滤波为多个更小的分析音频段。可以在向量空间中相对于第一语音和第二语音映射第三语音。根据映射第三语音,可以在向量空间中调整第一语音与第二语音的相对位置。
根据另一实施例,一种用于构建音色向量空间的音色向量空间构造系统包括输入端,该输入端配置为接收a)第一语音中的包括第一音色数据的第一话音段,以及b)第二语音中的包括第二音色数据的第二话音段。该系统还包括用于将a)第一话音段滤波为具有表示第一音色数据的不同部分的频率分布的第一多个更小的分析音频段,以及b)将第二话音段滤波为第二多个更小的分析音频段的装置,第二多个更小的分析音频段中的每一个具有表示第二音色数据的不同部分的频率分布。此外,该系统具有用于根据a)来自第一话音段的第一多个分析音频段和b)来自第二话音段的第二多个分析音频段的频率分布在音色向量空间中相对于第二语音映射第一语音的装置。
根据本发明的另一实施例,一种使用音色向量空间构建具有新音色的新语音的方法包括接收使用时间接受域滤波的音色数据。在音色向量空间中映射音色数据。音色数据与多个不同的语音相关。多个不同语音中的每一个在音色向量空间中具有各自的音色数据。该方法通过机器学习系统使用多个不同语音的音色数据来构建新音色。
在一些实施例中,该方法从新语音接收新话音段。该方法还使用神经网络将新话音段滤波为新的分析音频段。该方法还参照多个映射的语音在向量空间中映射新语音。该方法还基于新语音与多个映射的语音的关系来确定新语音的至少一个特征。其中,该特征可以是性别、种族和/或年龄。来自多个语音中的每一个的话音段可以是不同的话音段。
在一些实施例中,根据对音色数据的数学运算,生成神经网络被用于产生候选语音中的第一候选话音段。例如,音色数据可以包括与第一语音和第二语音有关的数据。此外,向量空间中的语音表示群集可以表示特定的口音。
在一些实施例中,该方法提供源话音并且将源话音转换为新音色,同时保持源韵律和源口音。该系统可以包括用于对目标音色数据滤波的装置。
根据另一实施例,一种系统使用音色向量空间产生新目标语音。该系统包括配置为存储使用时间接受域合并的音色数据的音色向量空间。使用时间接受域对音色数据滤波。音色数据与多个不同的语音相关。机器学习系统配置为使用音色数据将音色数据转换为新目标语音。
其中,通过使用音色数据的至少一个语音特征作为变量执行数学运算,可以将音色数据转换为新目标语音。
根据又一实施例,一种方法将话音段从源音色转换为目标音色。该方法存储与多个不同语音相关的音色数据。多个不同语音中的每一个在音色向量空间中具有各自的音色数据。音色数据使用时间接受域滤波,并在音色向量空间中映射。该方法接收源语音中的源话音段,用于变换为目标语音。该方法还接收对目标语音的选择。目标语音具有目标音色。参照多个不同语音在音色向量空间中映射目标语音。该方法使用机器学习系统将源话音段从源语音的音色变换为目标语音的音色。
本发明的示例性实施例具体为一种计算机程序产品,该计算机程序产品为具有计算机可读程序代码的计算机可用介质。
附图说明
本领域的技术人员应当从参照下面总结的附图讨论的“具体实施方式”中更全面地理解本发明的各种实施例的优点。
图1示意性地示出了根据本发明的示例性实施例的声对声转换系统的简化版本。
图2示意性地示出了实现本发明的示例性实施例的系统的细节。
图3示出了根据本发明的示例性实施例的用于构建表示编码语音数据的多维空间的过程。
图4示意性地示出了根据本发明的示例性实施例的对话音样本进行过滤的时间接收滤波器。
图5a-5c示出了根据本发明的示例性实施例的具有从图4的相同话音段提取的不同分析音频段的频率分布的频谱图。
图5a示出了单词“call”中的“a”音素的频谱图。
图5b示出了“stella”中“a”音素的频谱图。图5c示出了“please”中“ea”音素的频谱图。
图6a-6d示意性地示出了根据本发明的示例性实施例的向量空间的片段。
图6a示意性地示出了仅映射图5b所示音素的目标语音的向量空间的片段。
图6b示意性地示出了映射目标语音和第二语音的图6a的向量空间的片段。
图6c示意性地示出了映射目标语音、第二语音和第三语音的图6a的向量空间的片段。
图6d示意性地示出了映射多个语音的图6a的向量空间的片段。
图7a示出了第二语音的音色中的单词“call”中的“a”音素的频谱图。
图7b示出了在第三语音的音色中的单词“call”中的“a”音素的频谱图。
图8a示意性地示出了根据本发明的示例性实施例的包括合成语音简档的向量空间的片段。
图8b示意性地示出了根据本发明的示例性实施例、在生成的对抗性神经网络改进合成语音简档之后,对应于“dog”中的音素“d”的向量空间的片段。
图8c示意性地示出了添加了第二语音和第四语音的图8b的向量空间的片段。
图9示出了根据本发明的示例性实施例的使用生成对抗性网络来改进增强语音简档的系统的框图。
图10示出了根据本发明的示例性实施例的用于将话音转换为话音的过程。
图11示出了根据本发明的示例性实施例使用语音来验证身份的过程。
具体实施方式
在示例性实施例中,声对声转换系统允许将源语音中所说的话音段实时或接近实时地变换为目标语音。为此,该系统具有语音特征提取器,该语音特征提取器从多个语音接收话音样本并提取与由每个语音产生的每个声音相关联的频率分量。基于所提取的频率分量在向量空间中相对于彼此映射语音,这使得能够为话音样本中未提供的声音外插合成频率分量。该系统具有机器学习,机器学习进一步经配置以将目标语音与其它语音进行比较,且改进合成频率分量以最佳地模仿该语音。因此,系统的用户可以输入话音段,选择目标音,并且系统将话音段变换为目标语音。
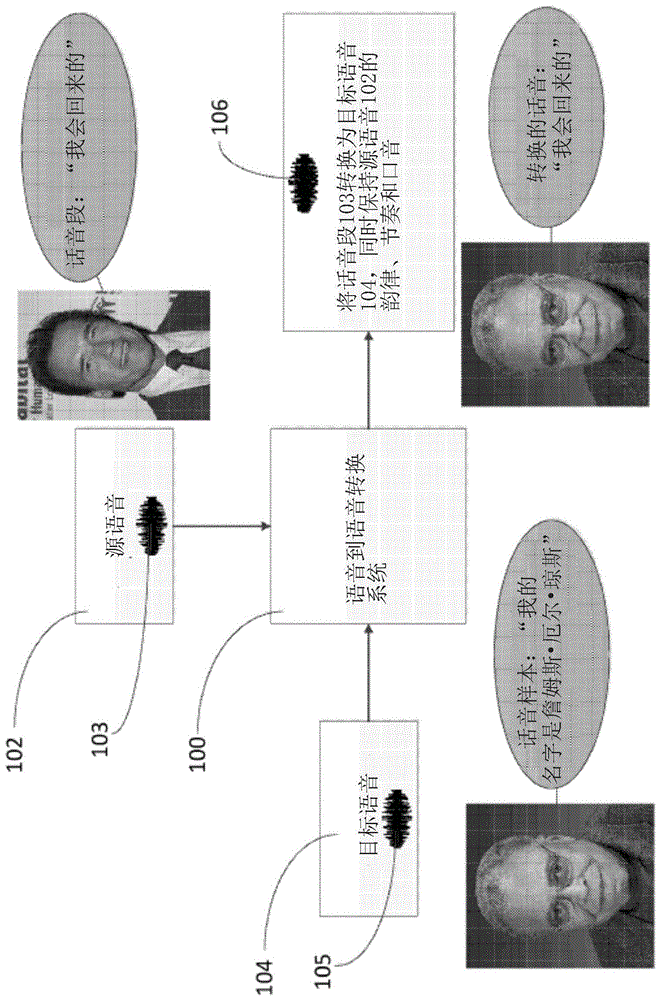
图1示意性地示出了根据本发明的示例性实施例的声对声转换系统100的简化版本。其中,系统100允许用户将他们的语音(或任何其他语音)转换成他们选择的目标语音104。更具体地,系统100将用户的话音段103转换为目标语音104。因此,本例中的用户语音称为源语音102,因为系统100将源语音102中所说的话音段103变换为目标语音104。变换的结果是变换的话音段106。尽管源语音102被示为人类说话者(例如,阿诺德),但是在一些实施例中,源语音102可以是合成语音。
声音的变换也称为音色转换。在整个申请中,“语音”和“音色”可互换使用。语音的音色允许收听者区分和识别以相同音调、口音、振幅和韵律另外说出相同单词的特定语音。音色是由说话者为特定声音做出的频率分量组产生的生理特性。在示例性实施例中,话音段103的音色转换为目标语音104的音色,同时保持源语音102的原来的韵律、节奏和口音/发音。
例如,阿诺德·斯瓦辛格可以使用系统100将他的话音段103(例如,“我会回来的”)转换为詹姆斯·厄尔·琼斯的语音/音色。在该示例中,阿诺德的语音是源语音102,詹姆斯的语音是目标语音104。阿诺德可以向系统100提供詹姆斯语音的话音样本105,系统100使用话音样本105来变换他的话音段(如下面进一步描述的)。系统100获取话音段103,将其变换为詹姆斯的语音104,并在目标语音104中输出变换的话音段106。因此,话音段103“我会回来的”以詹姆斯的语音104输出。然而,变换的话音段106保持原来的韵律、节奏和口音。因此,变换的话音段106听起来像詹姆斯试图模仿阿诺德的口音/发音/韵律和话音段103。换句话说,变换的话音段106是詹姆斯音色中的源话音段103。下面描述系统100如何完成该变换的细节。
图2示意性地示出了实现本发明的示例性实施例的系统100的细节。系统100具有经配置以接收音频文件(例如,目标语音104中的话音样本105)和来自源语音102的话音段103的输入端108。应当理解,虽然不同的术语用于“话音段103”和“话音样本105”,但是两者都可以包括口头单词。术语“话音样本105”和“话音段103”仅用于指示源,并且系统100利用这些音频文件中的每一个进行不同的变换。“话音样本105”指的是在目标语音104中输入到系统100中的话音。系统100使用话音样本105来提取目标语音104的频率分量。另一方面,系统100将“话音段103”从源语音102转换为目标语音104。
系统100具有经配置为提供用户界面的用户界面服务器110,用户可以通过用户界面与系统100通信。用户可以经由电子设备(诸如计算机、智能电话等)访问用户界面,并且使用该电子设备向输入端108提供话音段103。在一些实施例中,电子设备可以是联网设备,诸如连接因特网的智能电话或台式计算机。用户话音段103可以是例如由用户说出的句子(例如,“我会回来的”)。为此,用户设备可以具有用于记录用户话音段103的集成麦克风或辅助麦克风(例如,通过usb连接)。或者,用户可以上传包含用户话音段103的预先记录的数字文件(例如,音频文件)。应当理解,用户话音段103中的语音不必是用户的语音。术语“用户话音段103”用于方便地表示由用户提供的话音段,系统100将该话音段转换为目标音色。如前所述,以源语音102说出用户话音段103。
输入端108还被配置为接收目标语音104。为此,目标语音104可以由用户以类似于话音段103的方式上传到系统100。可替换地,目标语音104可以在先前提供给系统100的语音111的数据库中。如下文将进一步详细描述,如果目标语音104尚未在语音数据库111中,那么系统100使用变换引擎118处理语音104并且将其映射到表示编码的语音数据的多维离散或连续空间112中。该表示称为“映射”语音。当映射编码的语音数据时,向量空间112进行关于语音的表征,并在此基础上将它们相对于彼此放置。例如,表示的一部分可能必须与语音的音调或说话者的性别有关。
示例性实施例使用时间接收滤波器114(也称为时间接受域114)将目标语音104过滤为分析音频段,变换引擎118从分析音频段提取频率分量,当目标语音104首先由输入端108接收时,机器学习系统116映射向量空间112中的目标语音104的表示(例如,使用语音特征提取器120),并且机器学习系统116改进目标语音104的映射表示。然后,系统100可用于将话音段103变换为目标语音104。
具体地,在示例性实施例中,系统100将目标104话音样本105划分成(可能重叠的)音频段,每个音频段具有对应于语音特征提取器120的时间接受域114的大小。然后语音特征提取器120单独地对每个分析音频段进行操作,每个分析音频段可以包含由目标说话者的语音104中的目标产生的声音(例如音素、音位、音素的一部分或多个音素)。
在每个分析音频段中,语音特征提取器120提取目标说话者的语音104的特征,并基于这些特征在向量空间112中映射语音。例如,一个这样的特征可能是朝向放大用于产生一些元音声的几个频率的一些幅度的偏差,以及提取方法可将段中的声音识别为特定元音声,将所表达频率的振幅与其它语音所使用的振幅进行比较以产生类似声音,并且接着将此语音的频率与语音特征提取器120先前已暴露为作为特征的特定组的类似语音相比的差异进行编码。然后将这些特征组合在一起以改进目标语音104的映射表示。
在示例性实施例中,系统100(语音特征提取器120以及最终的组合)可以被认为是机器学习系统。一种实现方式可以包括作为语音特征提取器120的卷积神经网络,以及在末端组合所提取的特征的递归神经网络。其它例子可以包括卷积神经网络以及在末端具有注意机制的神经网络,或者在末端具有固定大小的神经网络,或者在末端简单地添加特征。
语音特征提取器120提取目标话音样本105的频率中的幅度之间的关系(例如,共振峰的相对幅度和/或共振峰的起音和衰减)。通过这样做,系统100正在学习目标的音色104。在一些实施例中,语音特征提取器120可以可选地包括频率-声音关联引擎122,其将特定分析音频段中的频率分量与特定声音关联。尽管上文将频率-声音关联引擎122描述为用于映射目标语音104,但所属领域的技术人员了解,机器学习系统116可使用额外或替代方法来映射语音。因此,该特定实现方式的讨论仅旨在作为便于讨论的示例,而不旨在限制所有示例性实施例。
每一个上述部件通过任何传统的互连机构可操作地连接。图2简单地示出了连通每个部件的总线。本领域技术人员应当理解,可以修改该一般化表示以包括其它传统的直接或间接连接。因此,对总线的讨论并不旨在限制各种实施例。
实际上,应当注意,图2仅仅示意性地示出了这些部件中的每一个。本领域技术人员应当理解,这些组件中的每一个可以以各种常规方式实现,例如通过使用硬件、软件或硬件和软件的组合,涵盖一个或多个其他功能部件。例如,语音提取器112可以使用执行固件的多个微处理器来实现。作为另一实例,机器学习系统116可使用一个或一个以上专用集成电路(即,“asic”)及相关软件,或者asic、离散电子部件(例如,晶体管)及微处理器的组合来实施。因此,图2的机器学习系统116和单个框中的其它部件的表示仅出于简化的目的。实际上,在一些实施例中,图2的机器学习系统116分布在多个不同的机器上,不必在相同的外壳或底盘内。另外,在一些实施例中,示出为分离的部件(诸如图2中的时间接受域114)可以由单个部件(诸如用于整个机器学习系统116的单个时间接受域115)替换。此外,图2中的某些部件和子部件是可选的。例如,一些实施例可以不使用关联引擎。作为另一个例子,在一些实施例中,生成器140、鉴别器142和/或语音特征提取器120可以不具有接受域114。
应当重申,图2的表示是实际声对声转换系统100的显著简化的表示。本领域技术人员应当理解,这种设备可以具有其它物理和功能部件,例如中央处理单元、其它分组处理模块和短期存储器。因此,此论述并非旨在暗示图2表示声对声转换系统100的所有元件。
图3示出了根据本发明的示例性实施例的用于构建表示编码语音数据的多维离散或连续向量空间112的过程300。应当注意,该过程实质上是根据通常用于构建向量空间112的较长过程简化而来。因此,构建向量空间112的过程可以具有本领域技术人员可能使用的许多步骤。另外,一些步骤可以以与所示顺序不同的顺序执行,或者同时执行。因此,本领域技术人员可以适当地修改该过程。
图3的过程开始于步骤302,步骤302接收目标音色104中的话音样本105。如前所述,话音样本105由输入端108接收,并且可以由系统100的用户提供给系统100。在一些实施例中,可以向系统100提供已经在向量空间112中映射的语音。已经在向量空间112中映射的语音已经经历了下面描述的过程。下面更详细地描述向量空间112。
图4示意性地示出了根据本发明的示例性实施例的对话音样本105滤波的示例性时间接收滤波器114。该过程继续到步骤304,其中话音样本105由时间接收滤波器114滤波为分析音频段124。此实例中的话音样本105是目标语音104中的1秒记录音频信号。话音样本105可以短于或长于1秒,但是出于下面讨论的原因,在一些实施例,话音样本105可以使用更长的长度。在这个例子中,时间接收滤波器114设置为100毫秒。因此,1秒话音样本105通过滤波器114分解成10个100毫秒的分析音频段124。
尽管时间接收滤波器114示出为设置成过滤100毫秒间隔,但是应当理解,可以在如下所述的参数内设置各种过滤间隔。时间接受域114(或滤波器114)的讨论涉及机器学习116的任何或所有部分(例如,生成器140、鉴别器142和/或特征提取器120)。在示例性实施例中,滤波间隔大于0毫秒且小于300毫秒。在一些其它实施例中,时间接受域114小于50毫秒、80毫秒、100毫秒、150毫秒、250毫秒、400毫秒、500毫秒、600毫秒、700毫秒、800毫秒、900毫秒、1000毫秒、1500毫秒或2000毫秒。在进一步的实施例中,时间接受域114大于5毫秒、10毫秒、15毫秒、20毫秒、30毫秒、40毫秒、50毫秒或60毫秒。尽管在图2中被示为单独的部件,但是时间接收滤波器114可以被构建到输入108中作为时间接受域114。此外,机器学习系统116可以具有单个接受域114(例如,代替所示的三个单独的接受域114)。
每个分析音频段124包含由特定目标语音104发出的一个或多个特定声音的频率数据(在步骤306中提取)。因此,分析音频段124越短,频率数据(例如,频率分布)对特定声音越具体。然而,如果分析音频段124太短,则系统100可以滤除某些低频声音。在优选实施例中,时间滤波器114设置为捕获话音样本105流中最小可区分的离散声音段。最小可区分的离散声音段被称为音素。从技术角度来看,分析音频段124应当足够短以捕获音素的共振峰特征。示例性实施例可以将分析音频段滤波到大约60毫秒和大约250毫秒之间。
人通常能够听到20hz到20khz范围内的声音。低频声音比高频声音具有更长的周期。例如,具有20hz频率的声波在整个周期内花费50毫秒,而具有2khz频率的声波在整个周期内花费0.5毫秒。因此,如果分析音频段124非常短(例如,1毫秒),则分析音频段124可能不包括足够可检测的20hz声音。然而,一些实施例可以使用预测建模(例如,仅使用低频声波的一部分)来检测低频声音。示例性实施例可以滤除或忽略一些较低频率的声音,并且仍然包含足够的频率数据以精确地模仿目标语音104的音色。因此,发明人相信短至约10毫秒的分析音频段124足以使系统100充分预测音素的频率特征。
人类话音中的基频通常在大于100hz的量级上。基频是音色的一部分,但不是音色本身。如果人的语音只在它们的基频上不同,则语音转换本质上是音调偏移,相当于在钢琴上弹奏低八度的同一首歌曲。但是,音色也是使钢琴和喇叭声音在演奏相同音符时不同的质量,它是频率中所有小的附加变化的集合,这些变化中没有一个具有与基频(通常)一样高的幅度,但是这些变化对声音的整体感觉有显著的贡献。
虽然基频对于音色可能是重要的,但是它不是唯一的音色指示符。考虑摩根·弗里曼和目标语音104都可以以相同的八度音程发出一些相同的音符的情况。这些音符隐含地具有相同的基频,但是目标语音104和摩根·弗里曼可以具有不同的音色,因此,单独的基频不足以识别语音。
系统100最终基于来自分析音频段124的频率数据来创建目标语音104的语音简档。因此,为了具有对应于特定音素的频率数据,时间接收滤波器114优选地将分析音频段124滤波到大约发音最小可区分音素所花费的时间。因为不同的音素可具有不同的时间长度(即,表达音素所花费的时间量),所以示例性实施例可将分析音频段124滤波到大于表达以人类语言产生的最长音素所花费的时间的长度。在示例性实施例中,由滤波器114设置的时域允许分析音频段124包含与至少整个单个音素有关的频率信息。发明人相信,将话音分解成100毫秒的分析音频段124足够短以对应于由人类语音产生的大多数音素。因此,各个分析音频段124包含对应于由话音样本105中的目标语音104产生的某些声音(例如,音素)的频率分布信息。
另一方面,示例性实施例还可以具有时间接受域114的上限。例如,示例性实施例具有足够短以避免一次捕获多于一个完整音素的接受域114。此外,如果时间接受域114较大(例如,大于1秒),则分析音频段124可以包含源102的口音和/或韵律。在一些实施例中,时间接受域114足够短(即具有上限)以避免捕获口音或韵律这些语音特征。在更长的时间间隔上获取这些语音特征。
一些现有技术的文本到话音转换系统包括口音。例如,美国口音可以将单词“zebra”发为
实际上,发明人已知的现有技术存在捕获纯音色的问题,因为接受域太长,例如,当试图映射音色(例如,口音)时,接受域使得语音映射固有地包括附加特征。映射口音的问题是说话者可以在保持说话者的音色的同时改变口音。因此,这种现有技术不能获得与这些其它特征分开的声音的真实音色。例如,诸如arik等人描述的现有技术文本到话音转换(sercano.arik,jitongchen,kainanpeng,weiping,以及yanqizhou:具有几个样本的神经语音克隆(neuralvoicecloningwithafewsamples),arxiv:1708.07524,2018)基于经转换的字合成整个语音。因为转换是文本到话音,而不是话音到话音,所以系统不仅需要做出关于音色的决定,而且需要做出关于韵律、变音、口音等的决定。大多数文本到话音系统并不孤立地确定这些特征中的每一个,而是相反地,对于训练它们所针对的每个人,学习那个人的所有这些元素的组合。这意味着没有单独针对音色调整语音。
相反,示例性实施例使用话音到话音转换(也称为声对声转换)来转换话音而不是合成话音。系统100不必选择所有其它特征,如韵律、口音等,因为这些特征由输入话音提供。因此,输入话音(例如,话音段103)特定地变换成不同的音色,同时保持其它语音特征。
回到图3,过程进行到步骤306,从分析音频段124中提取频率分布。任何特定分析音频段124的频率分布对于每个语音都是不同的。这就是为什么不同说话者的音色是可区分的。为了从特定的分析音频段124中提取频率信息,变换引擎118可以执行短时傅立叶变换(stft)。然而,应当理解,stft仅仅是获得频率数据的一种方式。在示例性实施例中,变换引擎118可以是机器学习的一部分,并构建其自己的也产生频率数据的滤波器组。话音样本105被分解成(可能重叠的)分析音频段124,并且变换引擎对每个分析音频段124执行fft。在一些实施例中,变换引擎118包括分析音频段124上的开窗功能,缓解边界条件的问题。即使在分析音频段124之间存在一些重叠,它们仍然被认为是不同的音频段124。在提取完成之后,获得分析音频段124的频率数据。结果是在各个时间点的一组频率强度在示例性实施例中布置为具有垂直轴上的频率和水平轴上的时间的图像(频谱图)。
图5a-5c示出了根据本发明的示例性实施例的具有从图4的相同话音样本105提取的不同分析音频段124的频率分布的频谱图126。术语“频率分布”是指存在于特定分析音频段124或其集合中的成组单独频率及其单独强度,这取决于上下文。图5a示出了由目标104产生的单词“call”中的“a”音素的频谱图126。如本领域技术人员已知的,频谱图126绘制时间对频率的曲线,并且还通过颜色强度示出频率的幅度/强度(例如,以db为单位)。在图5a中,频谱图126具有12个清晰可见的峰128(也称为共振峰128),并且每个峰具有与更可听频率相关的颜色强度。
系统100知道图5a的频谱图表示“a”声音。例如,关联引擎122可以分析分析音频段124的频率分布,并确定该频率分布表示单词“call”中的“a”音素。系统100使用分析音频段124的频率分量来确定音素。例如,不管谁在讲话,“call”中的“a”声音具有中频分量(接近2khz),而那些频率分量对于其它元音声音可能不存在。系统100使用频率分量中的区别来猜测声音。此外,系统100知道该频率分布和强度对目标104而言是特定的。如果目标104重复相同的“a”音素,则存在非常相似(如果不相同)的频率分布。
如果特征提取器120不能确定分析音频段124与它已知的任何特定声音相关,则它可以向时间接收滤波器114发送调整消息。具体地,调整消息可以使时间接收滤波器114调整各个或所有分析音频段124的滤波时间。因此,如果分析音频段124太短而不能捕获关于特定音素的足够有意义的信息,则时间接收滤波器可以调整分析音频段124的长度和/或界限以更好地捕获音素。因此,即使在没有声音识别步骤的示例性实施例中,也可以产生不确定性的估计并将其用于调整接受域。可替换地,可以有多个机器学习系统116(例如,语音特征提取器120的子部件),这些机器学习系统116使用全部同时操作的不同接受域,并且系统的其余部分可以在来自它们中的每一个的结果之间进行选择或合并。
特征提取器120不需要查看整个接受域114中的频率分布。例如,特征提取器120可以查看部分所提供的接受域114。此外,时间接受域114的大小和步幅可以通过机器学习来调整。
图5b示出了由目标104产生的口语单词“stella”中的“a”音素的频谱图126。该频谱图126具有七个清晰可见的峰128。当然,存在许多也具有频率数据的其它峰128,但是它们不具有与清晰可见的峰128一样大的强度。这些较不可见的峰表示由目标语音104产生的声音中的谐波130。虽然这些谐波130在频谱图126中对于人来说不是清晰可感知的,但是系统100知道基础数据并使用它来帮助创建目标语音104的语音简档。
图5c示出了由目标104产生的口头词“please”中的“ea”音素的频谱图126。频谱图126具有五个清晰可见的峰128。以类似于图5a和5b的方式,该谱图126也具有谐波频率130。通过访问频率数据(例如,在频谱图126中),系统100确定与特定频谱图126相关联的声音。此外,对话音样本105中的各个分析音频段124重复该过程。
返回到图3,过程前进到步骤308,步骤308在向量空间112中为目标语音104映射部分语音简档。部分语音简档包括与话音样本105中的各种音素的频率分布相关的数据。例如,可以基于图5a-5c中示出的用于目标104的三个音素来创建部分语音简档。本领域技术人员应当理解,这是部分语音简档的实质上简化的示例。通常,话音样本105包含多于三个的分析音频段124,但是可以包含更少的分析音频段。系统100获取为各个分析音频段124获得的频率数据,并将它们在向量空间112中映射。
向量空间112指的是数据库中对象的集合,称为向量,在其上定义了特定的运算组。这些运算包括向量的加法,在该运算下服从诸如关联性、交换性、恒等式和可逆的数学性质;以及与单独的对象类(称为标量)相乘,考虑在该运算下的兼容性、同一性和分布性的数学特性。向量空间112中的向量通常表示为n个数字的有序列表,其中n称为向量空间的维数。当使用这种表示时,标量通常只是单个数。在实数的三维向量空间中,[1,-1,3.7]是示例向量,并且2*[1,-1,3.7]=[2,-2,7.4]是与标量相乘的示例。
向量空间112的示例性实施例使用如上所述的数字,尽管通常在更高维的使用情况下。具体地,在示例性实施例中,音色向量空间112指的是表示音色元素(例如丰富度或清晰度)的映射,使得通过添加或减去向量的相应元素,实际音色的某些部分被改变。因此,目标语音104的特征由向量空间中的数字表示,使得向量空间中的运算对应于对目标语音104的运算。例如,在示例性实施例中,向量空间112中的向量可包括两个元素:[10hz频率的振幅,20hz频率的振幅]。实际上,向量可以包括更多数量的元素(例如,用于每个可听频率分量的向量中的元素)和/或更细粒度的(例如,1hz、1.5hz、2.0hz等)。
在示例性实施例中,在向量空间112中从高音调语音移动到低音调语音将需要修改所有频率元素。例如,这可以通过将几个高音调语音聚集在一起,将几个低音调语音聚集在一起,然后沿着通过聚类中心由线定义的方向行进来完成。采用高音调语音的几个示例和低音调语音的几个示例,并且这使你进行空间112的“音调”访问。每个语音可以由也许是多维(例如,32维)的单个向量来表示。一个维度可以是基频的音调,其近似地涉及男性语音和女性语音并区分二者。
语音数据库111保存在向量空间112中编码的对应于各种语音的向量。这些向量可以编码为数字列表,其在向量空间112的环境中具有含义。例如,数字列表的第一分量可以是-2,其在向量空间的环境中可以表示“高音调语音”,或者可以是2,其在向量空间的环境中可以表示“低音调语音”。机器学习系统116的参数确定如何处理那些数字,使得生成器140可以基于查看列表的第一分量中的a-2将输入话音转换成高音调语音,或者语音特征提取器可以将低音调语音编码为具有存储在数据库111中的数字列表的第二分量中的a2的向量。
在示例性实施例中,向量空间112通常表现出上述类型的特性。例如,低沉的语音和高音调语音的平均值应该是大致中等范围的语音;并且在清晰语音的方向上稍稍移动的沙哑语音(例如,从清晰语音中减去沙哑语音,得到从“沙哑”指向“清晰”的向量,将其乘以小标量使得向量仅改变一点,然后将其添加到沙哑语音)应当听起来稍微更清晰。
对频谱图执行数学运算(例如,对语音求平均)产生听起来不自然的声音(例如,对两个语音声音求平均,就像两个人同时说话)。因此,使用频谱图对低沉的语音和高音调语音求平均不会产生中音调语音。相反,向量空间112允许系统100对语音执行数学运算,例如“求平均”高音调语音和低音调语音,产生中音调语音。
图6a-6d示意性地示出了根据本发明的示例性实施例的向量空间112。过程300进行到判定310,判定310确定这是否是在向量空间中映射的第一语音。如果这是映射的第一语音,则其在向量空间112中的相对位置不会随之发生。系统100可在向量空间112中的任何位置处映射语音104,因为不存在用以比较语音104的相对标度。
图6a示意性地示出了仅包含如图5b所示的单词“stella”中的“a”声音的目标语音104的向量空间112。尽管示例性实施例讨论并示出了用于特定声音的向量空间112的图,但是本领域技术人员理解向量空间112映射独立于任何特定声音的音色。因此,听到特定的语音发出新的声音有助于向量空间112将说话者置于整个向量空间112中。示例性实施例出于简单说明机器学习系统116可映射语音的方式的目的而示出并参考用于特定声音的向量空间112。
因为目标语音104是在数据库112中映射的第一(且仅有)语音,所以整个数据库112反映仅与目标语音104相关的信息。因此,系统100认为所有语音都是目标语音104。因为这是第一语音,所以过程循环返回并映射第二语音,如前所述。
图7a示意性地示出了由第二(男性)语音132产生的单词“call”中的“a”声音的频谱图126。这与图5a中的目标104所表达的音素相同。然而,第二男性语音132只有11个可见峰128。另外,第二男性语音132的可见峰128超过2khz频率,而目标104的可见峰128小于2khz频率。尽管频率分布不同(例如,如频谱图126所显示),但在示例性实施例中,关联引擎122可确定频率分布表示“call”中的“a”音素,且相应地将其映射到向量空间112中。在示例性实施例中,在系统100确定存在用于同一音素的另一说话者(例如,如单词“call”中的“a”音素)的数据之后,系统100例如使用先前描述的过程在向量空间112中相对于彼此映射说话者。
图6b示意性地示出了音素的向量空间112:单词“stella”中的“a”声音,映射目标语音104和第二男性语音132。系统100比较与目标语音104和第二语音132所讲的音素有关的数据。频率分布特征允许系统100绘制相对于彼此的语音。因此,如果系统100接收到“a”声音的全新输入,则它可以基于哪个声音具有与输入最相似的频率特征来区分目标声音104和第二声音132。
尽管图6b示出映射为完全分离的段的语音104和132,但应了解,界限不是如此确定。实际上,这些界限表示了特定语音代表特定频率分布的概率。因此,实际上,一个语音可以产生与另一个语音的绘制区域重叠的声音(例如,重叠的频率特征)。然而,语音界限旨在示出具有特定频率分布的声音具有来自特定说话者的最大可能性。
过程中的步骤310还确定是否有更多的语音要映射。如果有更多的语音要映射,则重复步骤302-310。图7b示意性地示出了由第三语音(女性)134产生的单词“call”中的“a”音素的频谱图126。第三语音134具有六个可见峰128。第三语音134的峰128不像在目标语音104和第二语音132中那样被压缩。同样,尽管频率分布不同(例如,如频谱图126所显示),关联引擎122可确定频率分布以高概率表示“call”中的“a”音素。系统100在向量空间112中映射此附加语音。此外,系统100现在学习区分三个说话者之间关于单词“call”中的“a”声音,如图6c所示。在一些实施例中,语音特征提取器120和生成器140通过反向传播对抗鉴别器142而进行端到端训练。
图6d示出了在使用各种示例的过程300的几个循环之后的向量空间112。在向量空间112中映射了多个语音之后,系统100更准确地区分语音。由于向量空间112具有更多的要比较的音色数据,可归因于特定说话者的频率特征变得更具体。虽然语音示为虚线圆,但是应当理解,该虚线圆表示频谱图126中所示的一组复杂的频率及其变化(其可以被描述为音色“容限”,例如,各种稍微变化的频率分布可以听起来就好像它们来自相同的语音)。
此外,向量空间112开始与某些音色形成关联。例如,特征线136开始发展,区分男性语音和女性语音。尽管特征线136未显示为在语音之间完全区分,但预期其相当精确。通过特征(例如性别、种族、年龄等)来表征音色是可能的,因为特定语音的音色或频率分布的集合主要由生理因素引起。特定说话者发出的声音通过喉上声道滤波,喉上声道的形状决定了声音的音色。声带的尺寸(例如,厚度、宽度和长度)引起某些振动,这产生不同的频率,并因此带来不同的音色。例如,女性在遗传上倾向于具有比男性更高的共振峰频率以及峰128之间更大的间隙。因此,生理上相似的群体(例如男性与女性、白种人与非裔美国人)相对于特定音素具有更相似的频率分布。
在步骤312,该过程还推断目标语音104的合成语音简档。合成语音简档是机器学习系统116为不存在真实频率分布数据的音素预测的一组频率分布。例如,如图5a-5c所示,系统100可以具有与短语“callstellaplease”中的音素有关的实际数据。然而,系统100没有来自目标语音104的与dog中的“d”音素有关的真实数据。
图8a示意性地示出了根据本发明的示例性实施例的包括合成语音简档138的向量空间112。所示的向量空间112用于“dog”中的“d”音素。图8示出了关于已发出“d”音素的多个语音的经映射的真实数据。如图6d中所述,已针对不同音素(如“call”中的“a”)将目标语音104映射到这些语音。因为各种音素的频率分布的变化通常是可预测的,所以机器学习系统116对不存在真实数据的音素的频率分布进行预测。例如,机器学习相对于其它语音针对“d”音素映射目标语音104的合成语音简档138。
为了创建合成语音简档138,将目标语音104的部分简档与其它存储的语音简档进行比较,并且通过比较,外插目标语音104的合成语音简档138。因此,先前未提供给系统100的音素可从来自目标语音104的相对较小话音样本105外插。下面讨论示例性实施例的细节。
作为初始问题,应当理解,向量空间112是复杂的多维结构,因此,对于附图中的特定音素示出了向量空间112的二维片段。然而,所示的各种音素向量空间112仅仅是为了说明的目的,并且是较大的复杂三维向量空间112的一部分。将目标语音104的真实语音简档中的频率分布(例如,来自话音样本105的所有可用音素数据的频率分布)与其它映射语音简档进行比较。对于丢失的音素外插合成语音简档138。所属领域的技术人员将了解,尽管展示了针对特定音素的语音简档的片段的调整,但实际上,调整是对不容易说明的整个多维语音简档进行的。调整可以通过机器学习系统116,例如神经网络116来完成。
机器学习系统116优选地是一类专门的问题求解器,其使用自动反馈回路来优化其自身并提高其解决手头问题的能力。机器学习系统116从其试图解决的实际问题取得输入,但也具有各种参数或设置,它们完全在其自身内部。与数据科学系统相反,机器学习系统116可以配置为自动尝试针对各种输入来解决其给定问题,并且(有时,尽管不总是,借助于对其答案的自动反馈)更新其参数,使得将来的尝试产生更好的结果。该更新依照在机器学习系统116的训练开始之前选择的特定的、数学上明确限定的过程而发生。
虽然简单地参考附图进行描述,但是外插合成语音138不如比较两个音素的频率分布简单。目标语音104的部分语音简档包含与多个不同分析音频段124以及音素相关的数据。虽然不同音素的频率分布的波动具有一般趋势,但是音素之间没有通用的数学公式/转换比。例如,仅仅因为语音a直接落入针对音素“a”的语音b和语音c的中间,并不意味着语音a直接落入针对音素“d”的语音b和语音c的中间。预测语音分布的困难由于这些是复合信号(即,每个具有各自强度的频率范围)的事实而复杂化。此外,存在可以向特定音素提供类似的发声音色的大量不同频率分布。因此,机器学习系统116的任务是提供特定音素的频率分布范围。通常系统100映射的语音越多,合成语音简档138与目标语音104的音色匹配得越好。
为了帮助将目标语音104定位在向量空间112中,生成器140和鉴别器142可以执行图9描述的反馈回路。在一些实施例中,如果先前已针对许多语音训练了语音特征提取器120(即,先前使用反馈环路映射许多语音),则目标语音104可定位在向量空间中而不使用反馈环路。然而,即使已针对许多语音训练了语音特征提取器120,其它实施例仍然可以使用反馈回路。
在步骤314,该过程还改进合成语音简档138。图8b示意性地示出了根据本发明的示例性实施例、在使用生成对抗性神经网络116改进合成语音简档138之后,“dog”中的音素“d”的向量空间112。生成对抗性神经网络116包括生成神经网络140和鉴别神经网络142。
生成神经网络140是机器学习系统116的一种类型,其“问题”是创建属于预定类别的真实示例。例如,用于面部的生成神经网络将试图生成看起来逼真的面部图像。在示例性实施例中,生成神经网络140生成目标音色104的话音的真实示例。
鉴别神经网络142是机器学习系统116的一种类型,其“问题”是识别其输入所属的类别。例如,鉴别神经网络142可以识别在图像设置中是否已经给出狗或狼的图片。在示例性实施例中,鉴别神经网络142识别输入的话音是否来自目标104。可替换地或附加地,鉴别神经网络142识别输入的话音的说话者。
图9示出了根据本发明的示例性实施例的使用生成对抗性网络116来改进增强语音简档144的系统100的框图。除了由机器学习系统116创建的合成语音简档138之外,增强语音简档144是从话音样本105获得的(真实)语音简档的组合。向量空间112将增强语音简档144提供给生成神经网络140。生成神经网络140使用增强语音简档144来生成表示候选话音段146(即,假定模仿目标104但不是来自目标104的真实语音的话音)的话音数据。所产生的候选话音段146可以说是在候选语音中。表示候选话音段146的话音数据由鉴别神经网络142评估,鉴别神经网络142确定表示候选话音段146中的候选语音的话音数据是真实的还是合成的语音。
如果系统100产生音频候选话音段146,则它固有地包含表示候选话音段146的话音数据。然而,生成器140可以提供表示实际上从不作为音频文件输出的候选话音段146的数据。因此,表示候选话音段146的话音数据可以是作为波形的音频、频谱图、声码器参数,或编码候选话音段146的韵律和音素内容的其它数据的形式。此外,话音数据可以是神经网络116的某个中间的输出。正常人类观察者可能不理解该输出(例如,韵律数据和音素数据不必分开),但是神经网络116理解该信息并以机器学习116或其部分可理解的方式对其编码。为了方便起见,下面进一步的讨论涉及“候选话音段146”,但是应当理解为包括更宽泛的“表示候选话音段146的话音数据”。
在示例性实施例中,基于源话音段103生成候选话音段146。尽管在图1中示出存在用户(即,阿诺德),但是在训练时不必将源语音102输入到系统100。源语音102可以是已存储在系统100中或由系统100合成的输入到系统100中的任何语音。因此,源话音段103可以由用户提供,可以由来自已经在系统100中的语音(例如,映射的语音)的话音段提供,或者可以由系统100生成。当用户转换他们的语音,生成的语音,和/或具有已经在系统100中的话音的语音可以被认为是源语音102。此外,当在图9所示的反馈回路期间产生不同的候选话音段146时,可以使用不同的源话音段103。
鉴别神经网络142接收候选话音段146,以及与包括目标语音104的多个语音相关的数据。在示例性实施例中,生成器140和鉴别器142接收关于包括目标语音的多个语音简档的数据。这允许神经网络116参考其它语音的多个音色数据来识别使话音或多或少类似于目标104的变化。然而,应了解,与目标语音104本身相关的数据可隐含地与多个语音相关,因为其它语音的特征在其映射或改进目标语音104时已经由鉴别器142的学习参数在某种程度上进行了解。此外,当通过训练或向向量空间112添加更多语音来改进目标语音104时,目标语音104进一步提供关于多个语音的数据。因此,示例性实施例可以但不要求生成器140和/或鉴别器142明确地从多个语音简档接收数据。相反,生成器140和/或鉴别器142可以接收来自目标语音104简档的数据,该数据已经基于多个语音简档被修改。在任一前述情形中,可认为系统100参考多个语音简档接收数据。
在示例性实施例中,(由鉴别器142)影响生成器140以产生听起来像不同于目标104的语音的候选话音段146。在示例性实施例中,生成器140、语音特征提取器120和/或鉴别器142可以访问与多个语音简档有关的数据。因此,生成器140、鉴别器142和/或语音特征提取器120可以参考多个不同语音的音色数据做出决定。因此,即使说话者非常类似于目标104,生成器140也不改变使合成话音听起来像不同于目标104的某人的目标语音104简档。因为生成器140可以访问与多个语音简档有关的数据,所以它可以区分可能听起来相似的目标和其它说话者,产生更好质量的候选话音段146。接着,鉴别器142获取更精细的细节并提供更详细的不一致性消息148。尽管图中未示出,但是不一致性消息148可以被提供给语音特征提取器120,然后语音特征提取器120修改向量空间112中的语音简档。
如上所述,鉴别神经网络142(也称为“鉴别器142”)试图识别候选话音段146是否来自目标104。本领域技术人员理解可用于确定候选话音段146是否来自目标语音104的不同方法。具体地,鉴别器142确定某些频率和/或频率分布是或不可能是目标语音104的音色的一部分。鉴别器142可通过将候选话音段146与目标音色104和在向量空间112中映射的其它语音(即,参考多个不同语音的多个音色数据)进行比较来做到这一点。于是,在向量空间112中映射的语音越多,鉴别器142越好从合成话音中辨别真实话音。因此,在一些实施例中,鉴别器142可以将身份分配给候选语音和/或候选话音段146。
在示例性实施例中,鉴别器142具有时间接受域114,该时间接受域114防止鉴别器142基于诸如韵律、口音等之类的事物来“看到”/鉴别。另外,或者可替换地,生成器140具有时间接受域114,该时间接受域114防止鉴别器142基于诸如韵律、口音等之类的事物来生成。因此,候选话音段146可以生成得足够短,以避免包括更长的时间特征,例如韵律、口音等,和/或可以使用时间接受域114滤波。因此,鉴别器142基于音色而不是通过基于这些其它特征进行鉴别来区分真实话音和虚假话音。
鉴别器142例如可以通过比较某些音素的基频开始,查看哪个可能的音色最清晰地(即,具有最高的匹配概率)匹配。如前所述,有更多的特征来定义基频之外的音色。随着时间的推移,鉴别器142学习更复杂的识别语音的方式。
本发明人已知的现有技术话音到话音转换系统产生差的质量转换(例如,音频听起来不像目标语音)。相反,示例性实施例产生显著更高质量的转换,因为生成神经网络140(也称为“生成器140”)和鉴别器142不仅仅使用目标语音104来训练。例如,可以尝试现有技术的系统将来自日本女性的话音转换为巴拉克·奥巴马的语音。该现有技术系统尽可能地接近巴拉克·奥巴马,但是不管如何与其它语音相比较,它都如此。因为这种现有技术的系统不知道我们人类是如何区分不同的人的语音,所以现有技术的生成器可以作出折衷,其实际上使得声音更接近其他人的声音,以寻求超出现有技术的鉴别器。
如果鉴别器142没有检测到差异,则过程结束。然而,如果鉴别器142检测到候选话音段146不是来自目标语音104(例如,候选语音不同于目标语音),则创建不一致性消息148。不一致性消息148提供关于鉴别器142为什么确定候选话音段146不在目标音色104中的细节。鉴别器142将候选话音段146与多个语音(包括目标104)进行比较,确定候选话音段146是否在目标语音104中。例如,通过比较由在向量空间112中映射的多个语音定义的人类话音的某些参数,不一致性消息148可以确定候选话音段146是否在人类话音的正确参数内,或者它是否落在正常人类话音之外。此外,通过与在向量空间112中映射的多个语音进行比较,不一致性消息148可提供具体关于频率数据的细节,所述频率数据具有来自不同于目标语音104的语音的较高概率。因此,向量空间112可使用此不一致性消息148作为反馈来调整目标104的增强语音简档144和/或合成语音简档138的部分。
不一致性消息148可以提供如下信息,例如涉及峰128的数量、特定峰128的强度、起音129(图5a)、衰减131(图5c)、谐波130、基频、共振峰频率和/或音素和/或分析音频段124的允许系统100将候选话音段146与目标音色104区分开的其它特征中的不一致性(例如,具有不来自目标语音104的高概率的频率数据)。不一致性消息148可以在高度复杂的组合中有效地对应于波形的任何特征。不一致性消息148可以确定,例如,第四最大幅度频率具有“可疑”幅度,并且应当从中减去一些量以使其看起来真实。这是用于说明不一致性消息148中可用的信息类型的极其简化的示例。
向量空间112接收不一致性消息,并使用它来改进合成语音简档138(并且因而,改进增进语音简档144)。因此,如图8b所示,向量空间112缩小和/或调整分配给目标语音音色104的频率分布集合。不一致性消息148参考多个音色数据来确定候选话音段146和目标音色104之间的不一致性。例如,目标语音104不再与康纳·麦格雷戈或巴拉克·奥巴马重叠。本领域的技术人员应了解,神经网络116可继续改进(例如,缩小向量空间112中的代表圆)超过语音之间的清晰区分。鉴别器142识别说话者,但还进行进一步的步骤,确定候选话音段146是否具有作为真实话音的高概率(即使话音由生成器140合成生成)。例如,即使频率特征接近特定目标(例如,说话者a的概率为90%,说话者b的概率为8%,以及分布在其余说话者之间的概率为2%),鉴别器142也可以确定频率特征不产生任何可识别的人类话音并且是合成的。向量空间112使用该数据来帮助它更好地限定增强语音简档144的界限。
参考多个语音改进增强语音简档144提供了对现有技术方法的改进。这些改进包括改进的语音转换质量,这允许用户创建使用已知现有技术方法不可用的实际语音转换。使用仅具有单个语音(例如,目标语音)的生成对抗性神经网络116不能向生成对抗性神经网络116提供足够的数据以创建导致改进的反馈(例如,不一致性消息148)的逼真问题集(候选话音段146)。改进的反馈允许系统100最终提供更加逼真的语音转换。在一些实施例中,如果鉴别器142没有检测到候选音色和目标音色之间的任何差异,则可以产生指示确定没有差异的空不一致性消息。空不一致性消息指示反馈过程可以结束。或者,系统100可以并不产生不一致性消息。
修改后的增强语音简档144再次发送到生成神经网络140,并且生成另一(例如,第二)候选话音段146以供鉴别器142考虑。第二候选话音段146(等等)可以说是在第二候选语音(等等)中。然而,在一些实施例中,第一候选语音和第二候选语音从迭代到迭代可以是非常相似的发声。在一些实施例中,鉴别器142可以如此精细地调整,使得不一致性消息148可以检测到微小的差异。因此,第一候选语音和第二候选语音可以听起来非常类似于人类观察者,但是出于讨论的目的仍然可以被认为是不同的语音。
该过程继续,直到鉴别器不能将候选话音段146与目标音色104区分开。因此,随着时间的推移,增强语音简档144与目标语音104的真实话音之间的差异不应由鉴别器142辨别(例如,候选话音段146来自目标语音104的概率可被提高到99+百分比,尽管在某些实施例中较低的百分比可能足够)。在目标语音104的增强语音简档144已经充分改进之后,用户可以将他们的话音段103转换为目标语音104。
图8c示意性地示出了添加了第二语音132和第四语音的图8b的向量空间112。应注意,将更多语音添加到向量空间112中可进一步增强鉴别器142区分语音的能力。在示例性实施例中,来自第二语音132和第四语音的数据用于改进目标语音104的合成语音简档138。另外,第二语音132和第四语音可帮助改进其它说话者(例如康纳·麦格雷戈)的频率分布。
回到图3,过程300以步骤316结束,步骤316确定是否有更多的语音要映射。如果有,则整个过程重复必要的次数。合成语音简档138通常通过将更多语音添加到向量空间112中来改进(即,可能的频率分布且因此语音的声音)。然而,如果没有其它语音要映射,则该过程完成。
示例性实施例创建先前未听到的全新语音以及语音的各种组合。如参考特征线136所描述的,机器学习系统116开始为在向量空间112中映射的语音开发某些组织模式。例如,相似性别、种族和/或年龄的语音可以具有相似的频率特征,因此被分组在一起。
如前所述,向量空间112允许对其中的数据集进行数学运算。因此,示例性实施例提供向量空间112中的数学运算,例如在阿尔·帕西诺和詹姆斯·厄尔·琼斯之间的语音。另外,语音创建引擎也可使用关于分组的概括来创建新语音。例如,可以通过从平均中国女性语音中减去平均女性语音,并加上平均男性语音来创建新语音。
图10示出了根据本发明的示例性实施例的用于将话音转换为话音的过程1000。应当注意,该过程实质上是根据通常用于将话音转换为话音的较长过程简化而来。因此,将话音转换为话音的过程具有本领域技术人员可能使用的许多步骤。另外,一些步骤可以以与所示顺序不同的顺序执行,或者同时执行。因此,本领域技术人员可以适当地修改该过程。
该过程开始于步骤1002,步骤1002向系统100提供表示话音段103的话音数据。例如,可以将固有地包含表示话音段103的话音数据的话音段103提供给输入108。可替换地,生成器140可以提供表示话音段的数据(例如,来自文本输入)。因此,表示话音段103的话音数据可以是作为波形的音频、频谱图、声码器参数,或编码话音段103的韵律和音素内容的其它数据的形式。此外,话音数据可以是神经网络116的某个中间的输出。正常人类观察者可能不理解该输出(例如,韵律数据和音素数据不必分开),但是神经网络116理解该信息并以机器学习116或其部分可理解的方式对其编码。如前所述,话音段103不必来自人类话音,而是可以被合成。为了方便起见,下面进一步的讨论涉及“话音段103”,但是应当理解为包括更宽泛的“表示话音段103的话音数据”。
在步骤1004,用户选择目标语音104。使用参考图3描述的过程,目标语音104可能先前已经在向量空间112中映射。或者,也可使用参考图3描述的过程,将新语音映射到系统中。在输入话音段103的示例性实施例中,话音段103可以但不必用于帮助映射目标语音104(例如,候选话音146可以反映话音段103的音素、口音和/或韵律)。在步骤306中,获取目标104的增强语音简档144并将其应用于话音段103。换句话说,变换话音段103的频率,反映存在于目标语音104中的频率分布。这将话音段103变换为目标语音104。
应当注意,在对抗性训练期间,生成神经网络140接收输入话音并应用目标音色(正如它在图1中运行时进行的那样),但是鉴别器142查看输出话音并通过目标语音104确定它是否是“真实”人类话音(尽管通过限定,即使鉴别器相信它是真实的,话音也将是合成的)。相反,在图1所示的语音转换期间,已经针对足够的语音训练了系统100,使得转换可以相当顺利地发生,而不需要进一步的训练,导致实时或接近实时的话音到话音转换(尽管进一步的训练是可选的)。该目标说话者的真实人类话音的训练集示例不具有任何其他说话者(例如,输入的说话者)的任何“污染”,因此生成神经网络140学习移除输入的说话者的音色并代之以使用目标说话者的音色,否则鉴别器142不会被欺骗。
在步骤308中,在目标语音104中输出变换的话音段106。然后,步骤310的处理询问是否有更多的话音段103要转换。如果有更多的话音段103,则过程1000重复。否则,该过程完成。
在一些实施例中,可以要求目标104说话者提供预先编写的话音样本105。例如,可能存在要求目标读取的脚本,其捕获许多通常发音的(如果不是全部的话)音素。因此,示例性实施例可以具有每个音素的真实频率分布数据。此外,在示例性实施例中,向量空间112具有来自至少一个,优选地,多个语音的每个音素的真实频率分布数据。因此,示例性实施例可以至少部分地基于真实数据外插合成语音简档138。
尽管示例性实施例将话音样本105称为处于目标“语音”104中,但应了解,示例性实施例不限于说出的单词和/或人类语音。示例性实施例仅仅需要话音样本105中的音素(而不是人类话语本身的一部分),例如由乐器、机器人和/或动物产生的音素。因此,在示例性实施例中,话音样本105也可以称为音频样本105。这些声音可以通过系统分析,并且被映射以创建“声音简档”。
还应当理解,示例性实施例提供了优于现有技术的许多优点。从目标语音104的相对小的话音样本105实现实时或接近实时的语音转换。声对声转换可用于娱乐,转换有声读物语音(例如,在可听应用中),定制个人语音助理(例如,amazonalexa),为电影重建去世的演员的语音(例如,来自星球大战的leia公主),或人工智能机器人(例如,具有唯一语音或去世的家庭成员的语音)。其它用途可以包括“语音处理”,其中用户可以修改他们的话音的部分,或者“自动频带”,其使用任何声音输入来创建不同的歌曲/乐器部分并且将它们组合在一起成为单个频带/语音。其它用途包括使动物“说话”,即,将人类话音转换成特定动物的音色。
图11示出了根据本发明的示例性实施例使用语音来验证身份的过程。应当注意,与上面讨论的其它过程一样,该过程实质上是根据通常用于使用语音验证身份的较长过程简化而来。因此,使用语音验证身份的过程具有本领域技术人员可能使用的许多步骤。另外,一些步骤可以以与所示顺序不同的顺序执行,或者同时执行。因此,本领域技术人员可以适当地修改该过程。
过程1100开始于步骤1102,其提供具有多个映射的语音的向量空间112。向量空间可如上所述地填充有多个语音。优选地,向量空间112填充有多于1000个语音,并且每个语音已经被映射用于50个以上的音素。
在步骤1104,该方法从其身份正被验证的人接收输入话音。与机器学习系统116如何确定候选话音146是否对目标104真实的方式类似,机器学习系统116还可以通过任何输入话音确定对其身份正被验证的人的真实性。在步骤1106,为其身份正被验证的人生成真实语音简档。如前所述,可以通过使用时间接受域114滤波分析音频段124来创建语音简档。变换引擎118可以提取分析音频段124的频率分量,并且频率-声音关联引擎122可以将特定分析音频段中的频率分量与特定声音相关联。然后机器学习116可以在数据库112中映射目标语音104的真实语音简档。
在步骤1108,过程1100将真实语音简档(和/或增强语音简档144,如果已经生成的话)与向量空间112中的语音简档进行比较。类似地,在向量空间112中映射的任何语音也可以基于真实语音简档和/或增强语音简档144来验证。基于该比较,机器学习系统116可以确定向量空间112中的哪个语音(如果有的话)对应于所讨论的身份的语音。因此,在步骤1110,该过程验证和/或确认所讨论的身份的身份。
步骤1112询问身份是否被验证。在示例性实施例中,如果语音在基于频率分布的情况下达到95%匹配(例如,鉴别器提供95%置信区间)或更大,则验证语音。在一些实施例中,与系统中待验证的其它语音(称为“匹配”)相比,语音可能必须具有话音对应于身份语音的至少99%的置信度。在一些其它实施例中,语音可能必须至少99.9%匹配才能被验证。在进一步的实施例中,语音可能必须至少99.99%的匹配才能被验证。如果语音未被验证,则过程可请求接收语音的另一样本,返回到步骤1104。然而,如果语音被验证,则过程1100前进到步骤1114,其触发动作。
在步骤1114触发的动作可以是例如解锁口令。系统100可比较语音并确定特定话音的真实性/身份。因此,系统100允许使用语音口令。例如,iphone移动电话的更新版本可以利用语音验证来解锁电话(例如,作为面部识别和/或指纹扫描的补充或替代)。系统100分析话音(例如,将其与先前由向量空间112中的apple映射的多个语音进行比较)并在语音匹配的情况下解锁智能电话。这使得易用性和安全性得到增加。
在示例性实施例中,触发的动作解锁和/或提供语音允许控制智能家庭应用的信号。例如,锁定和/或解锁门,打开厨房设备等的命令都可以被验证和确认为来自具有适当访问(例如,所有者)的语音。示例性实施例可以结合到智能家庭助理(例如,amazonalexa)中,并且允许命令的验证。这包括允许将amazonalexa用于敏感技术,诸如银行转账、大额转账,或通过确认用户的语音访问私人信息(例如,医疗记录)。
此外,示例性实施例可以集成到识别系统(例如,警察和/或机场)和销售点系统(例如,商店的收入记录机)中,以便于识别的验证。因此,在销售点系统处,触发的动作可以是用户使用支付命令(例如,“支付$48.12”),通过他们的语音来支付。
可选地,为了防止话音到话音转换技术的潜在误用,系统100可以添加频率分量(“水印”),其可以被容易地检测以证明话音样本是不真实的(即,制造的)。这可以通过例如添加人类听不见的低频声音来实现。因此,人类可能觉察不到水印。
尽管通过上述示例性实施例描述了本发明,但是在不脱离这里公开的发明构思的情况下,可以对所示实施例进行修改和变化。此外,所公开的方面或其部分可以以上未列出和/或未明确要求的方式组合。因此,不应将本发明视为限于所公开的实施例。
本发明的各种实施例可以至少部分地以任何常规计算机编程语言来实现。例如,一些实施例可以用程序化编程语言(例如,“c”)或面向对象的编程语言(例如,“c++”)来实现。本发明的其它实施例可被实现为预配置的、独立的硬件元件和/或预编程的硬件元件(例如,专用集成电路、fpga和数字信号处理器)或其它相关部件。
在替换实施例中,所公开的装置和方法(例如,参见上述各种流程图)可以被实现为用于计算机系统的计算机程序产品。这种实现可以包括固定在有形的、非暂时性介质上的一系列计算机指令,例如计算机可读介质(例如,磁盘、cd-rom、rom或固定磁盘)。所述一系列计算机指令可体现本文先前关于所述系统描述的功能的全部或部分。
本领域技术人员应当理解,这样的计算机指令可以用多种编程语言来编写,以便与许多计算机体系结构或操作系统一起使用。此外,此类指令可存储在任何存储器装置(例如,半导体、磁性、光学或其它存储器装置)中,并且可使用任何通信技术(例如,光学、红外、微波或其它传输技术)来传输。
在其它方式中,这样的计算机程序产品可以作为具有附带的打印或电子文档(例如,压缩打包软件)的可移动介质来分发,预装载计算机系统(例如,在系统rom或固定磁盘上),或者通过网络(例如,因特网或万维网)从服务器或电子公告板分发。实际上,一些实施例可以在软件即服务模型(“saas”)或云计算模型中实现。当然,本发明的一些实施例可以实现为软件(例如,计算机程序产品)和硬件的组合。本发明还有的其它实施例完全实现为硬件或完全实现为软件。
上述本发明的实施例仅仅是示例性的;许多变化和修改对于本领域技术人员是容易想到的。这些变化和修改旨在落入由所附权利要求中任一项限定的本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!