计算机系统、语音识别方法以及程序与流程
本发明涉及一种执行语音识别的计算机系统、语音识别方法以及程序。
背景技术:
近年来,在各种领域中盛行语音输入。作为这样的语音输入的例子,包括对智能手机、平板终端等便携式终端、智能音箱等进行语音输入,并进行这些终端类的操作、信息的检索或配套家电的操作等。因此,更准确的语音识别技术的需求正在不断提高。
作为这样的语音识别技术,公开了一种通过结合音响模型、言语模型这些不同的模型中的各个语音识别的识别结果,输出最终的识别结果的构成(参照专利文献1)。
现有技术文献
专利文献
专利文献1:日本特开2017-40919号公报
技术实现要素:
发明所要解决的问题
然而,在专利文献1的构成中,仅仅是单个语音识别引擎而不是多个语音识别引擎在多个模型中进行语音识别,因此语音识别的准确性不足。
本发明的目的在于提供一种容易提高对语音识别的识别结果的准确性的计算机系统、语音识别方法以及程序。
用于解决问题的方案
在本发明中,提供了如下所述的解决方案。
本发明提供一种计算机系统,其特征在于,具备:
获取单元,获取语音数据;
第一识别单元,进行获取到的所述语音数据的语音识别;
第二识别单元,利用与所述第一识别单元不同的算法或数据库来进行获取到的所述语音数据的语音识别;以及
输出单元,在各个语音识别的识别结果不同的情况下,输出双方的识别结果。
根据本发明,计算机系统获取语音数据,进行获取到的所述语音数据的语音识别,利用与所述第一识别单元不同的算法或数据库来进行获取到的所述语音数据的语音识别,在各个语音识别的识别结果不同的情况下,输出双方的识别结果。
本发明是计算机系统的类别,但在方法和程序等其他类别中,也会发挥与其类别对应的相同的作用/效果。
此外,本发明提供一种计算机系统,其特征在于,具备:
获取单元,获取语音数据;
n种方式识别单元,进行获取到的所述语音数据的语音识别,利用相互不同的算法或数据库来进行n种方式的语音识别;以及
输出单元,仅输出以所述n种方式进行的语音识别中识别结果不同的识别结果。
根据本发明,计算机系统获取语音数据,进行获取到的所述语音数据的语音识别,利用相互不同的算法或数据库来进行n种方式的语音识别,仅输出以所述n种方式进行的语音识别中识别结果不同的识别结果。
本发明是计算机系统的类别,但在方法和程序等其他类别中,也会发挥与其类别对应的相同的作用/效果。
发明效果
根据本发明,容易提供一种容易提高对语音识别的识别结果的准确性的计算机系统、语音识别方法以及程序。
附图说明
图1是表示语音识别系统1的概要的图。
[图2]图2是语音识别系统1的整体构成图。
[图3]图3是表示由计算机10执行的第一语音识别处理的流程图。
[图4]图4是表示由计算机10执行的第二语音识别处理的流程图。
[图5]图5是表示计算机10将识别结果数据输出至用户终端的显示部的状态的图。
[图6]图6是表示计算机10将识别结果数据输出至用户终端的显示部的状态的图。
[图7]图7是表示计算机10将识别结果数据输出至用户终端的显示部的状态的图。
具体实施方式
以下,参照附图对对用于实施本发明的最佳方式进行说明。需要说明的是,这仅是一个例子,本发明的技术范围并不限于此。
[语音识别系统1的概要]
基于图1,对本发明的优选的实施方式的概要进行说明。图1是用于说明作为本发明的优选的实施方式的语音识别系统1的概要的图。语音识别系统1是由计算机10构成,执行语音识别的计算机系统。
需要说明的是,语音识别系统1也可以包括用户所持的用户终端(便携式终端、智能音箱等)等其他终端类。
计算机10获取用户所发出的语音来作为语音数据。该语音数据通过内置于用户终端的麦克风等语音收集装置来收集用户所发出的语音,用户终端将该收集到的语音作为语音数据发送至计算机10。计算机10通过接收该语音数据,获取语音数据。
计算机10通过第一语音解析引擎对该获取到的语音数据进行语音识别。此外,计算机10同时通过第二语音解析引擎对该获取到的语音数据进行语音识别。该第一语音解析引擎和第二语音解析引擎分别利用不同的算法或数据库。
计算机10在第一语音解析引擎的识别结果和第二语音解析引擎的识别结果不同的情况下,向用户终端输出双方的识别结果。用户终端将该双方的识别结果显示于自身的显示部等或从扬声器等发出,由此向用户通知双方的识别结果。其结果是,计算机10将双方的识别结果通知给用户。
计算机10从用户接受已输出的双方的识别结果中正确的识别结果的选择。用户终端接受对显示出的识别结果的点击操作等输入,并接受正确的识别结果的选择。此外,用户终端接受对发出的识别结果的语音输入,并接受正确的识别结果的选择。用户终端将该选择出的识别结果发送至计算机10。计算机10通过获取该识别结果,获取用户所选择出的正确的识别结果。其结果是,计算机10接受正确的识别结果的选择。
计算机10使第一语音解析引擎和第二语音解析引擎中没有被选择为正确的识别结果的语音解析引擎基于选择出的正确的识别结果进行学习。例如,在第一语音解析引擎的识别结果被接受选择为正确的识别结果的情况下,使第二语音解析引擎学习该第一语音解析引擎的识别结果。
此外,计算机10通过n种方式语音解析引擎对该获取到的语音数据进行语音识别。此时,n种方式语音解析引擎分别利用相互不同的算法或数据库。
计算机10向用户终端输出由n种方式语音解析引擎得到的识别结果中识别结果不同的识别结果。用户终端通过将该识别结果不同的识别结果显示于自身的显示部等或从扬声器等发出,向用户通知识别结果不同的识别结果。其结果是,计算机10向用户通知n种方式的识别结果中识别结果不同的识别结果。
计算机10从用户接受已输出的识别结果不同的识别结果中正确的识别结果的选择。用户终端接受对显示出的识别结果的点击操作等输入,并接受正确的识别结果的选择。此外,用户终端接受对发出的识别结果的语音输入,接受正确的识别结果的选择。用户终端将该选择出的识别结果发送至计算机10。计算机10通过获取该识别结果,获取用户所选择出的正确的识别结果。其结果是,计算机10接受正确的识别结果的选择。
计算机10使识别结果不同的识别结果中的没有被选择为正确的识别结果的语音解析引擎基于选择出的正确的识别结果进行学习。例如,在第一语音解析引擎的识别结果被接受选择为正确的识别结果的情况下,使除此以外的识别结果的语音解析引擎学习该第一语音解析引擎的识别结果。
对由语音识别系统1执行的处理的概要进行说明。
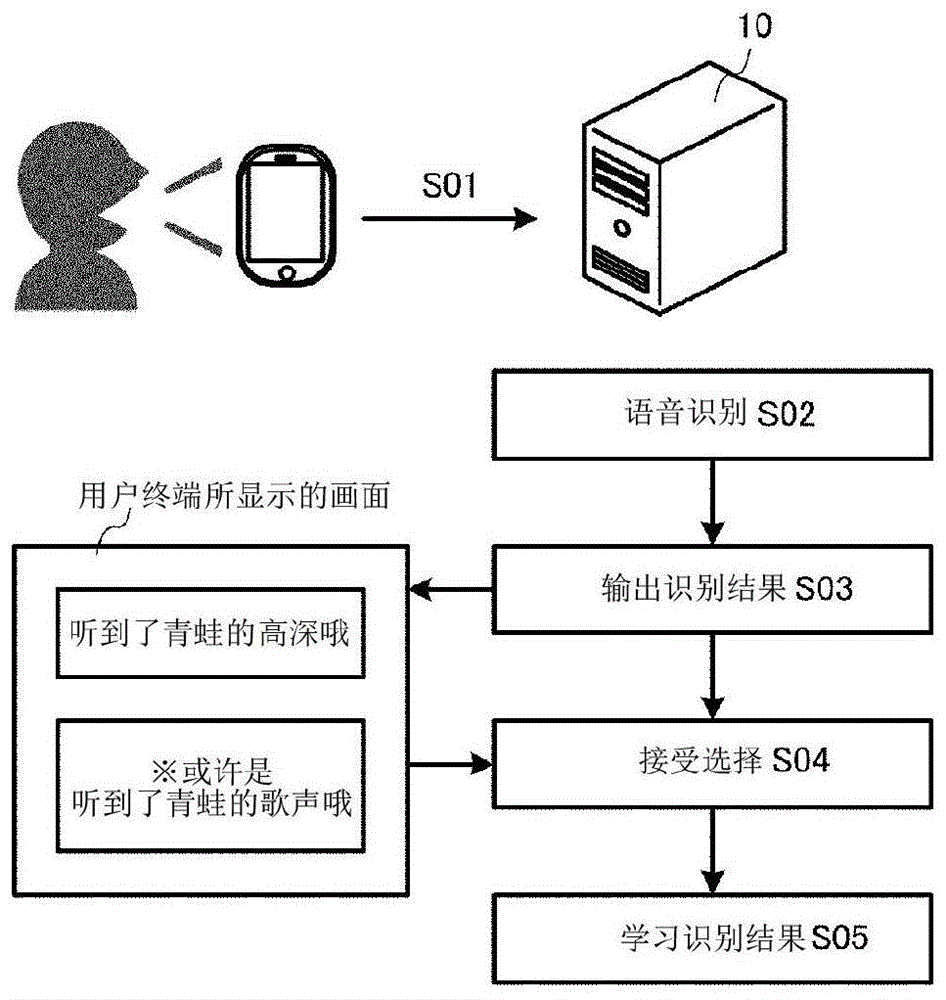
首先,计算机10获取语音数据(步骤s01)。计算机10获取由用户终端接受输入的语音来作为语音数据。用户终端通过内置于自身的语音收集装置收集用户所发出的语音,将该收集到的语音作为语音数据发送至计算机10。计算机10通过接收该语音数据,获取语音数据。
计算机10通过第一语音解析引擎和第二语音解析引擎对该语音数据进行语音识别(步骤s02)。第一语音解析引擎和第二语音解析引擎分别利用不同的算法或数据库,计算机10对一个语音数据执行两种语音识别。计算机10例如通过频谱分析仪等进行语音识别,基于语音波形来识别语音。计算机10使用提供者不同的语音解析引擎或由不同的软件实现的语音解析引擎来执行语音识别。计算机10将语音转换为各个识别结果的文本来作为各个语音识别的结果。
计算机10在第一语音解析引擎的识别结果和第二语音解析引擎的识别结果不同的情况下,向用户终端输出双方的识别结果(步骤s03)。计算机10向用户终端输出双方的识别结果的文本。用户终端将该双方的识别结果的文本显示于自身的显示部或通过语音发出。此时,识别结果的文本的一方中包括使用户对识别结果不同的情况进行类推的文本。
计算机10从用户接受输出至用户终端的双方的识别结果中正确的识别结果的选择(步骤s04)。计算机10通过来自用户的点击操作、语音输入,接受对识别结果的正解的选择。例如,计算机10通过接收对显示于用户终端的文本中的任一个的选择操作,接收对识别结果的正解的选择。
计算机10使没有从用户接受已输出的识别结果中正确的识别结果的选择的语音解析引擎以该选择出的正确的识别结果为正解数据,使执行了错误的语音识别的语音解析引擎进行学习(步骤s05)。计算机10在由第一语音解析引擎得到的识别结果是正解数据的情况下,使第二语音解析引擎基于该正解数据进行学习。此外,计算机10在由第二语音解析引擎得到的识别结果是正解数据的情况下,使第一语音解析引擎基于该正解数据进行学习。
需要说明的是,计算机10并不限于两个语音解析引擎,也可以通过三个以上的n种方式语音解析引擎执行语音识别。该n种方式语音解析引擎分别利用不同的算法或数据库。在该情况下,计算机10通过n种方式语音解析引擎对获取到的语音数据进行语音识别。计算机10对一个语音数据执行n种方式的语音识别。计算机10将语音转换为各个识别结果的文本来作为n种方式的语音识别的结果。
计算机10在n种方式语音解析引擎的识别结果中将识别结果不同的识别结果输出至用户终端。计算机10将识别结果不同的文本输出至用户终端。用户终端将该不同的识别结果的文本显示于自身的显示部或通过语音发出。此时,识别结果的文本中包括由用户对识别结果不同情况进行类推的文本。
计算机10从用户接受输出至用户终端的识别结果中正确的识别结果的选择。计算机10通过来自用户的点击操作、语音输入,接受对识别结果的正解的选择。例如,计算机10通过接受对显示于用户终端的文本中的任一个的选择操作,接受对识别结果的正解的选择。
计算机10使没有从用户接受已输出的识别结果中正确的识别结果的选择的语音解析引擎以该选择出的正确的识别结果为正解数据,使执行了错误的语音识别的语音解析引擎进行学习。
以上是语音识别系统1的概要。
[语音识别系统1的系统构成]
基于图2,对作为本发明的优选的实施方式的语音识别系统1的系统构成进行说明。图2是表示作为本发明的优选的实施方式的语音识别系统1的系统构成的图。在图2中,语音识别系统1是由计算机10构成,执行语音识别的计算机系统。
需要说明的是,语音识别系统1也可以包括未图示的用户终端等其他终端类。
如上所述,计算机10经由公共线路网等与未图示的用户终端等可数据通信地连接,执行必要的数据的收发,并且执行语音识别。
计算机10具备cpu(centralprocessingunit:中央处理单元)、ram(randomaccessmemory:随机接入存储器)、rom(readonlymemory:只读存储器)等,作为通信部具备用于能与用户终端、其他计算机进行通信的设备,例如遵照ieee802.11的wi-fi(wireless-fidelity:无线保真)对应设备等。此外,计算机10作为存储部具备由硬盘、半导体存储器、记录介质、存储卡等实现的数据的存储部。此外,计算机10作为处理部具备执行各种处理的各种设备等。
在计算机10中,控制部读取规定的程序,由此与通信部协作来实现语音获取模块20、输出模块21、选择接受模块22以及正解获取模块23。此外,在计算机10中,控制部读取规定的程序,由此与处理部协作来实现语音识别模块40和识别结果判定模块41。
[第一语音识别处理]
基于图3,对由语音识别系统1执行的第一语音识别处理进行说明。图3是表示由计算机10执行的第一语音识别处理的流程图的图。关于由上述的各模块执行的处理,在本处理中一并说明。
语音获取模块20获取语音数据(步骤s10)。在步骤s10中,语音获取模块20获取用户终端接受输入的语音来作为语音数据。用户终端通过内置于自身的语音收集装置来收集用户所发出的语音。用户终端将该收集到的语音作为语音数据发送至计算机10。语音获取模块20通过接收该语音数据,获取语音数据。
语音识别模块40通过第一语音解析引擎对该语音数据进行语音识别(步骤s11)。在步骤s11中,语音识别模块40基于由频谱分析仪等得到的声波波形来识别语音。语音识别模块40对识别出的语音进行文本转换。将该文本称为第一识别文本。即,由第一语音解析引擎得到的识别结果是第一识别文本。
语音识别模块40通过第二语音解析引擎对该语音数据进行语音识别(步骤s12)。在步骤s12中,语音识别模块40基于由频谱分析仪等得到的声波波形来识别语音。语音识别模块40对识别出的语音进行文本转换。将该文本称为第二识别文本。即,由第二语音解析引擎得到的识别结果是第二识别文本。
上述的第一语音解析引擎和第二语音解析引擎分别利用不同的算法或数据库。其结果是,语音识别模块40基于一个语音数据来执行两种语音识别。该第一语音解析引擎和第二语音解析引擎分别可以使用提供者不同的语音解析引擎或由不同的软件实现的语音解析引擎来执行语音识别。
识别结果判定模块41判定各个识别结果是否一致(步骤s13)。在步骤s13中,识别结果判定模块41判定第一识别文本和第二识别文本是否一致。
在步骤s13中,在识别结果判定模块41判定为一致的情况下(步骤s13为是),输出模块21将第一识别文本和第二识别文本中的任一方来作为识别结果数据输出至用户终端(步骤s14)。在步骤s14中,输出模块21仅输出由各个语音解析引擎得到的识别结果中的任一方的识别结果来作为识别结果数据。在本例子中,对输出模块21输出第一识别文本来作为识别结果数据进行说明。
用户终端接收该识别结果数据,基于该识别结果数据,将第一识别文本显示于自身的显示部。或者,用户终端基于该识别结果数据,从自身的扬声器输出基于第一识别文本的语音。
选择接受模块22接受该第一识别文本是正确的识别结果的情况或是错误的识别结果的情况的选择(步骤s15)。在步骤s15中,选择接受模块22通过使用户终端接受来自用户的点击操作、语音输入等操作,接受正误识别结果的选择。在是正确的识别结果的情况下,接受正确的识别结果的选择。此外,在是错误的识别结果的情况下,接受错误的识别结果的选择,并且通过接受点击操作、语音输入等操作来接受正确的识别结果(正确的文本)的输入。
图5是表示用户终端将识别结果数据显示于自身的显示部的状态的图。在图5中,用户终端显示识别文本显示栏100、正解图标110以及错误图标120。识别文本显示栏100显示作为识别结果的文本。即,识别文本显示栏100显示第一识别文本“听到了青蛙的歌声哦”。
选择接受模块22通过接受对正解图标110或错误图标120的输入,接受该第一识别文本是正确的识别结果或是错误的识别结果的选择。选择接受模块22在是正确的识别结果的情况下,接受用户对正解图标110的选择来作为正确的识别结果的操作,在是错误的识别结果的情况下,接受用户对错误图标120的选择来作为错误的识别结果的操作。选择接受模块22在接受对错误图标120的输入的情况下,还接受正确的文本的输入来作为正确的识别结果。
正解获取模块23获取接受选择的正误识别结果来作为正解数据(步骤s16)。在步骤s16中,正解获取模块23通过接收用户终端所发送的正解数据,获取正解数据。
语音识别模块40使语音解析引擎基于该正解数据学习正误识别结果(步骤s17)。在步骤s17中,语音识别模块40在获取到正确的识别结果来作为正解数据的情况下,分别使第一语音解析引擎和第二语音解析引擎学习本次的识别结果是正确的。另一方面,语音识别模块40在获取到错误的识别结果来作为正解数据的情况下,分别使第一语音解析引擎和第二语音解析引擎学习被接受为正确的识别结果的正确的文本。
另一方面,在步骤s13中,识别结果判定模块41在判定为不一致的情况下(步骤s13为否),输出模块21将第一识别文本和第二识别文本双方作为识别结果数据输出至用户终端(步骤s18)。在步骤s18中,输出模块21输出由各个语音解析引擎得到的识别结果的双方来作为识别结果数据。在该识别结果数据中,在一方的识别文本中包括由用户对识别结果不同的情况进行类推的文本(或许是、也许是等确认可能性的表达)。在本例子中,对输出模块21在第二识别文本中包括由用户对该识别结果不同的情况进行类推的文本的情况进行说明。
用户终端接收该识别结果数据,基于该识别结果数据,将第一识别文本和第二识别文本双方显示于自身的显示部。或者,用户终端基于该识别结果数据,从自身的扬声器输出基于第一识别文本和第二识别文本的语音。
选择接受模块22从用户接受输出至用户终端的识别结果中正确的识别结果的选择(步骤s19)。在步骤s19中,选择接受模块22通过使用户终端接受点击操作、语音输入等操作,接受哪一个识别文本是正确的识别结果的选择。使识别文本中正确的识别结果的识别结果接受正确的识别结果的选择(例如,点击输入该识别文本、语音输入该识别文本)。
需要说明的是,选择接受模块22在哪一个识别文本都不是正确的识别结果的情况下,接受错误的识别结果的选择,并且通过接受点击操作、语音输入等选择,接受正确的识别结果(正确的文本)的输入。
图6是表示用户终端将识别结果数据显示于自身的显示部的状态的图。在图6中,用户终端显示第一识别文本显示栏200、第二识别文本显示栏210以及错误图标220。第一识别文本显示栏200显示第一识别文本。第二识别文本显示栏210显示第二识别文本。在该第二识别文本中包括由用户对识别结果与上述的第一识别文本不同情况进行类推的文本。即,第一识别文本显示栏200显示第一识别文本“听到了青蛙的高深哦”。此外,第二识别文本显示栏210显示“※或许是听到了青蛙的歌声哦”。
选择接受模块22通过接受对第一识别文本显示栏200或第二识别文本显示栏210中的任一个的输入,接受该第一识别文本或第二识别文本中的哪一个是正确的识别结果的选择。选择接受模块22在第一识别文本是正确的识别结果的情况下,接受由对第一识别文本显示栏200的点击操作、语音实现的选择来作为正确的识别结果的操作。此外,选择接受模块22在第二识别文本是正确的识别结果的情况下,接受由对第二识别文本显示栏210的点击操作、语音实现的选择来作为正确的识别结果的操作。此外,选择接受模块22在第一识别文本和第二识别文本中的哪一个识别文本都不是正确的识别结果的情况下,接受对错误图标220的选择来作为错误的识别结果的选择。选择接受模块22在接收对错误图标220的选择的情况下,还接受正确的文本的输入来作为正确的识别结果。
正解获取模块23获取接受选择的正确的识别结果来作为正解数据(步骤s20)。在步骤s20中,正解获取模块23通过接收用户终端所发送的正解数据,获取正解数据。
语音识别模块40基于该正解数据,使没有接受正确的识别结果的选择的语音解析引擎学习该选择出的正确的识别结果(步骤s21)。在步骤s21中,语音识别模块40在正解数据是第一识别文本的情况下,使第二语音解析引擎学习作为正确的识别结果的第一识别文本,并且使第一语音解析引擎学习本次的识别结果是正确的。此外,语音识别模块40在正解数据是第二识别文本的情况下,将作为正确的识别结果的第二识别文本作为正解数据,使第一语音解析引擎进行学习,并且使第二语音解析引擎学习本次的识别结果是正确的。此外,语音识别模块40在正解数据不是第一识别文本和第二识别文本中的任一个的情况下,使第一语音解析引擎和第二语音解析引擎学习被接受为正确的识别结果的正确的文本。
语音识别模块23在下次之后的语音识别中,使用结合了学习的结果的第一语音解析引擎和第二语音解析引擎。
以上是第一语音识别处理。
[第二语音识别处理]
基于图4,对由语音识别系统1执行的第二语音识别处理进行说明。图4是表示由计算机10执行的第二语音识别处理的流程图的图。关于由上述的各模块执行的处理,在本处理中一并说明。
需要说明的是,关于与上述的第一语音识别处理相同的处理,省略其详细说明。此外,在第一语音识别处理和第二语音处理中,语音识别模块40所使用的语音解析引擎的总数不同。
语音获取模块20获取语音数据(步骤s30)。步骤s30的处理与上述的步骤s10的处理相同。
语音识别模块40通过第一语音解析引擎对该语音数据进行语音识别(步骤s31)。步骤s31的处理与上述的步骤s11的处理相同。
语音识别模块40通过第二语音解析引擎对该语音数据进行语音识别(步骤s32)。步骤s32的处理与上述的步骤s12的处理相同。
语音识别模块40通过第三语音解析引擎对该语音数据进行语音识别(步骤s33)。在步骤s33中,语音识别模块40基于由频谱分析仪等得到的声波波形来识别语音。语音识别模块40对识别出的语音进行文本转换。将该文本称为第三识别文本。即,由第三语音解析引擎得到的识别结果是第三识别文本。
上述的第一语音解析引擎、第二语音解析引擎以及第三语音解析引擎分别利用不同的算法或数据库。其结果是,语音识别模块40基于一个语音数据来执行三种语音识别。该第一语音解析引擎、第二语音解析引擎以及第三语音解析引擎分别使用提供者不同的语音解析引擎或由不同的软件实现的语音解析引擎来执行语音识别。
需要说明的是,上述的处理通过三种语音解析引擎执行语音识别,但语音解析引擎的数量也可以是三种以上的n种方式。在该情况下,n种方式的语音解析分别利用不同的算法或数据库来进行语音识别。在使用n种方式语音解析引擎的情况下,在后述的处理中,在n种方式的识别文本中执行后述的处理。
识别结果判定模块41判定各个识别结果是否一致(步骤s34)。在步骤s34中,识别结果判定模块41判定第一识别文本、第二识别文本以及第三识别文本是否一致。
在步骤s34中,识别结果判定模块41在判定为一致的情况下(步骤s34为是),输出模块21向用户终端输出第一识别文本、第二识别文本或第三识别文本中的任一个来作为识别结果数据(步骤s35)。步骤s35的处理与上述的步骤s14的处理大致相同,不同点在于包括第三识别文本。在本例子中,对输出模块21输出第一识别文本来作为识别结果数据进行说明。
用户终端接收该识别结果数据,基于该识别结果数据,将第一识别文本显示于自身的显示部。或者,用户终端基于该识别结果数据,从自身的扬声器输出基于第一识别文本的语音。
选择接受模块22接受该第一识别文本是正确的识别结果的情况或是错误的识别结果的情况的选择(步骤s36)。步骤s36的处理与上述的步骤s15的处理相同。
正解获取模块23获取接受选择的正误识别结果来作为正解数据(步骤s37)。步骤s37的处理与上述的步骤s16的处理相同。
语音识别模块40基于该正解数据,使语音解析引擎学习正误识别结果(步骤s38)。在步骤s38中,语音识别模块40在获取到正确的识别结果来作为正解数据的情况下,分别使第一语音解析引擎、第二语音解析引擎以及第三语音解析引擎学习本次的识别结果是正确的。另一方面,语音识别模块40在获取到错误的识别结果来作为正解数据的情况下,分别使第一语音解析引擎、第二语音解析引擎以及第三语音解析引擎学习被接受为正确的识别结果的正确的文本。
另一方面,在步骤s34中,识别结果判定模块41在判定为不一致的情况下(步骤s34为否),输出模块21仅向用户终端输出第一识别文本、第二识别文本或第三识别文本中识别结果不同的识别结果来作为识别结果数据(步骤s39)。在步骤s39中,输出模块21输出由各个语音解析引擎得到的识别结果中识别结果不同的识别结果来作为识别结果数据。此外,在该识别结果数据中包括由用户对识别结果不同的情况进行类推的文本。
例如,输出模块21在第一识别文本、第二识别文本以及第三识别文本分别不同的情况下,向用户终端输入这三个识别文本来作为识别结果数据。此时,第二识别文本和第三识别文本中包括由用户对识别结果不同的情况进行类推的文本。
此外,例如,输出模块21在第一识别文本和第二识别文本相同而第三识别文本不同的情况下,向用户终端输出第一识别文本和第三识别文本来作为识别结果数据。此时,第三识别文本中包括由用户对识别结果不同的情况进行类推的文本。此外,输出模块21在第一识别文本和第三识别文本相同而第二识别文本不同的情况下,向用户终端输出第一识别文本和第二识别文本来作为识别结果数据。此时,第二识别文本中包括由用户对识别结果不同的情况进行类推的文本。此外,输出模块21在第二识别文本和第三识别文本相同而第一识别文本不同的情况下,向用户终端输出第一识别文本和第二识别文本来作为识别结果数据。此时,第二识别文本中包括由用户对识别结果不同的情况进行类推的文本。如此,在识别结果数据中,输出识别文本的一致率(由多个语音解析引擎得到的识别结果中一致的识别结果的比例)最高的被直接作为识别文本,并以在除此以外的识别文本中包括由用户对识别结果不同的情况进行类推的文本的方式进行输出。即使语音解析引擎的数量为四个以上也同样。
在本例子中,以在输出模块21中所有的识别文本都不同的情况、以及第一识别文本和第二识别文本相同而第三识别文本不同的情况为例进行说明。
用户终端接收该识别结果数据,基于该识别结果数据,将第一识别文本、第二识别文本以及第三识别文本分别显示于自身的显示部。或者,用户终端基于该识别结果数据,从自身的扬声器输出分别基于第一识别文本、第二识别文本以及第三识别文本的语音。
此外,用户终端接收该识别结果数据,基于该识别结果数据,将第一识别文本和第三识别文本显示于自身的显示部。或者,用户终端基于该识别结果数据,从自身的扬声器输出分别基于第一识别文本和第三识别文本的语音。
选择接受模块22从用户接受输出至用户终端的识别结果中正确的识别结果的选择(步骤s40)。步骤s40的处理与上述的步骤s19的处理相同。
对用户终端分别将第一识别文本、第二识别文本以及第三识别文本显示于自身的显示部的例子进行说明。
图7是表示用户终端将识别结果数据显示于自身的显示部的状态的图。在图7中,用户终端显示第一识别文本显示栏300、第二识别文本显示栏310、第三识别文本显示栏312以及错误图标330。第一识别文本显示栏300显示第一识别文本。第二识别文本显示栏310显示第二识别文本。该第二识别文本中包括由用户对识别结果与上述的第一识别文本和第三识别文本不同的情况进行类推文本。第三识别文本显示栏320显示第三识别文本。该第三识别文本中包括由用户对识别结果与上述的第一识别文本和第二识别文本不同的情况进行类推的文本。即,第一识别文本显示栏300显示第一识别文本“听到了青蛙的高深哦”。此外,第二识别文本显示栏310显示“※或许是听到了青蛙的歌声哦”。此外,第三识别文本320显示“※或许是听到了青蛙的高声哦”。
选择接受模块22通过接受第一识别文本显示栏300、第二识别文本显示栏310或第三识别文本显示栏320中的任一个的选择,接受该第一识别文本、第二识别文本或第三识别文本中的哪一个是正确的识别结果的选择。选择接受模块22在第一识别文本是正确的识别结果的情况下,接受由对第一识别文本显示栏300的点击操作、语音实现的选择来作为正确的识别结果的操作。此外,选择接受模块22在第二识别文本是正确的识别结果的情况下,接受由对第二识别文本显示栏310的点击操作、语音实现的选择来作为正确的识别结果的操作。此外,选择接受模块22在第三识别文本是正确的识别结果的情况下,接受由对第三识别文本显示栏320的点击操作、语音实现的选择来作为正确的识别结果的操作。此外,选择接受模块22在第一识别文本、第二识别文本以及第三识别文本中的哪一个识别文本都不是正确的识别结果的情况下,接受对错误图标330的选择来作为错误的识别结果的操作。选择接受模块22在接受对错误图标330的选择的情况下,还接受正确的文本的输入来作为正确的识别结果。
关于用户终端将第一识别文本和第三识别文本分别显示于自身的显示部的例子与上述的图6相同,因此省略说明,但不同点是在第二识别文本显示栏210中显示第三识别文本。
正解获取模块23获取接受选择的正确的识别结果来作为正解数据(步骤s41)。步骤s41的处理与上述的步骤s20的处理相同。
语音识别模块40基于该正解数据,使没有接受正确的识别结果的选择的语音解析引擎学习该选择出的正确的识别结果(步骤s42)。在步骤s42中,语音识别模块40在正解数据是第一识别文本的情况下,使第二语音解析引擎和第三语音解析引擎学习作为正确的识别结果的第一识别文本,并且使第一语音解析引擎学习本次的识别结果是正确的。此外,语音识别模块40在正解数据是第二识别文本的情况下,将作为正确的识别结果的第二识别文本作为正解数据,使第一语音解析引擎和第三语音解析引擎进行学习,并且使第二语音解析引擎学习本次的识别结果是正确的。此外,语音识别模块40在正解数据是第三识别文本的情况下,将作为正确的识别结果的第三识别文本作为正解数据,使第一语音解析引擎和第二语音解析引擎进行学习,并且使第三语音解析引擎学习本次的识别结果是正确的。此外,语音识别模块40在正解数据不是第一识别文本、第二识别文本以及第三识别文本中的任一个的情况下,使第一语音解析引擎、第二语音解析引擎以及第三语音解析引擎学习被接受为正确的识别结果的正确的文本。
以上是第二语音识别处理。
需要说明的是,语音识别系统1也可以通过n种方式语音解析引擎来进行与通过三个语音解析引擎进行的处理相同的处理。即,语音识别系统1仅输出进行了n种方式的语音识别中语音识别结果不同的识别结果,并从用户接受该输出的识别结果中正确的语音识别的选择。语音识别系统1在没有被选择为正确的语音识别的情况下,基于选择出的正确的语音识别结果进行学习。
上述的单元、功能通过由计算机(包括cpu、信息处理装置、各种终端)读取规定的程序并执行来实现。程序例如以从计算机经由网络提供(saas:softwareasaservice(软件即服务))的方式进行提供。此外,程序例如以记录于软盘、cd(cd-rom等)、dvd(dvd-rom、dvd-ram等)等计算机可读记录介质的方式被提供。在该情况下,计算机从其记录介质读取程序并传输、存储至内部存储装置或外部存储装置来执行。此外,也可以将此程序预先记录于例如磁盘、光盘、光磁盘等存储装置(记录介质),从该存储装置经由通信线路提供至计算机。
以上,针对本发明的实施方式进行了说明,但本发明并不限于上述的这些实施方式。此外,本发明的实施方式中记载的效果只不过是列举出根据本发明产生的最优选的效果,根据本发明产生的效果并不限于本发明的实施方式中记载的效果。
附图标记说明:
1、语音识别系统;
10、计算机。
- 还没有人留言评论。精彩留言会获得点赞!