用于生成用于语音控制电子设备的命令的技术的制作方法
本公开总体上涉及电子设备领域。具体地,提出了一种用于生成要由语音控制电子设备处理的命令的技术。该技术可以体现在方法、计算机程序以及电子设备中。
背景技术:
近几十年来,语音识别技术(也称为“语音到文本”技术)得到了发展,为将口语转录成文本提供计算机实现的帮助,同时也被广泛应用于各个领域。特别地,近年来,语音识别技术已经越来越多地用于电子设备的语音控制,诸如用于家用电器的语音控制或用于虚拟助理(即,能够根据用户的口头请求执行任务或提供服务的软件代理)的实现。例如,已知的虚拟助理包括苹果siri、谷歌助理、亚马逊alexa和微软cortana。
当包括在语音命令中的关键字无法被明确地识别时,电子设备的语音控制通常可以达到其极限,使得输入的命令潜在地包含可能导致执行的控制的不期望结果的非期望元素。当语音命令包含与语音识别的默认语言不同的语言的术语时,当语音命令包含不包括在用于语音识别的词汇表中的术语时,或者当语音命令包含由用户以模糊方式发音的术语时,这种情况尤其可能发生。
作为示例,当语音识别的默认语言是英语并且用户尝试输入日语表达(例如,询问“電視是什么”)作为语音命令的元素时,由于用户的错误发音或由于不同语言的识别(其甚至可能基于不同字符集)不受识别引擎支持,日语表达的识别可能失败。作为另一示例,当用户试图输入一个不常见的名称作为语音命令的元素(例如,询问“谁是vladimirbeschastnykh”)时,名称的识别可能会失败,这可能是再次由于用户的发音错误,也可能是因为该名称不是用于语音识别的词汇的一部分。在另一个示例中,当用户试图输入术语(尽管包含在词汇表中),如果发音不清楚,可能会导致不明确的转录,则由于用户发音不清楚(例如,询问“vestel(伟视达)在哪里”,但识别“vessel(船)在哪里”),对该术语的识别可能会失败。
考虑到这些示例,很明显,将命令输入到电子设备中的仅仅口头方式可能不总是产生令人满意的语音控制结果。因此,本公开的目的是提供一种用于生成要由语音控制电子设备处理的命令的技术,该技术避免了这些或其他问题中的一个或多个。
技术实现要素:
根据第一方面,提供了一种用于生成将由语音控制电子设备处理的命令的方法。该方法包括:接收表示要由所述电子设备处理的命令的第一部分的语音输入;接收对显示在所述电子设备的屏幕上的内容的选择,所选择的内容表示要由所述电子设备处理的命令的第二部分;以及基于所述语音输入和所选择的内容的组合来生成命令。
所述电子设备可以是能够被语音控制的任何种类的电子设备。这可以包括消费电子设备,例如智能手机、平板计算机、膝上型计算机和个人计算机,以及家用电器,例如冰箱、炊具、洗碗机、洗衣机和空调,但不限于此。电子设备可以包括用于接收语音命令(或者更一般地,语音输入)的麦克风,并且可以执行代理(例如,软件代理),该代理可以被配置为处理所接收的语音命令并根据其来采取动作。在一个实现中,可以以虚拟助理的形式来提供代理,该虚拟助理能够响应于从用户接收的语音命令(即,换句话说,基于用户的口头请求)来提供服务。
代替使用完全基于语音的命令,根据本文呈现的技术,要处理的命令可以对应于根据语音输入和从电子设备的屏幕选择的内容的组合而生成的命令。因此,可以从两种类型的输入创建命令,即,表示命令的第一部分的语音输入以及从表示要生成的命令的第二部分的显示器(对应于对电子设备的屏幕上的显示内容的选择)中选择的视觉输入。然后,可以通过将命令的第一部分和第二部分进行组合来生成完整命令。一旦生成了完整命令,就可以由电子设备处理该命令。应当理解,当在本文中被称为要生成的命令的第一部分和第二部分时,术语“第一”和“第二”可以仅仅区分要生成的命令的各个部分,但是可以不必暗示要生成的命令的各个部分的顺序(或它们之间的时间关系)。因此可以想象的是,第二部分在命令的第一部分之前输入并且表示命令的初始部分,该初始部分之后是命令的第一部分,或者反之亦然。
虽然在不清楚的发音或语音识别引擎未知的单词的情况下对语音输入执行语音识别可能遭受模糊或不正确的识别,如上所述,电子设备的显示器上的内容的选择通常可以提供更准确的输入方法,并且因此可以优选地作为用于否则难以从语音输入中识别的命令部分的输入方法。具体地,内容的视觉选择可以用于命令的部分的输入,该部分包括具有与语音识别引擎的默认语言不同的语言的项、不包括在语音识别引擎的词汇表中的项和/或可能导致不明确转录的项(例如,平均转录歧义高于预定阈值的术语,例如由用户发音)。通过使用视觉选择,可以更精确地创建命令,并且通常可以避免不适当的命令元素的产生。因此,可以防止正在执行的语音控制的不希望的结果。
所述命令可对应于可由电子设备解释的任何类型的命令。具体地,该命令可以对应于用于控制电子设备的功能的控制命令,例如用于控制家用电器的行为或控制在电子设备上执行的虚拟助理的命令。命令可以对应于响应于电子设备的语音控制功能的激活而输入的命令,并且因此该命令可以反映要由电子设备的语音控制功能处理的命令。例如,可以在输入激活电子设备的语音控制功能的网络时输入命令。作为示例,命令可以对应于对在电子设备上执行的虚拟助理的查询,例如,向虚拟助理请求服务的查询。例如,苹果siri的虚拟助理热词是“嘿siri”,谷歌assistant的虚拟助理热词则是“ok谷歌”。
虽然将理解,在电子设备的屏幕上的内容的选择可以使用任何种类的输入装置来进行,诸如在例如个人计算机的情况下使用鼠标或键盘,但是在一个实现中,屏幕可以是触摸屏,并且可以通过触摸屏上的触摸输入来进行内容的选择。触摸输入可以对应于指定屏幕上要选择内容的显示区域的触摸手势。作为示例,触摸输入可以对应于覆盖要选择的内容的滑动手势。例如,这可以涉及在要选择的内容(例如,文本部分)上滑动或者包围/框选要选择的内容。
要选择的内容可以对应于当前正显示在电子设备的屏幕上的文本的一部分。文本部分可以包括可选择的文本(例如,可使用公知用于普通拷贝/粘贴操作的普通用户界面功能标记/可选择的文本),或者否则,文本部分可以包括不可选择的文本。在文本部分可以包括不可选择的文本的情况下,所选择的内容可以对应于屏幕上包含不可选择的文本部分的所选择的显示区域,其中,文本部分可以形成非文本显示元素的一部分,诸如例如显示在屏幕上的图像。要选择的内容可以不对应于来自在电子设备的屏幕上显示的键盘的输入。
在将语音输入和所选择的内容(再次,分别表示要处理的命令的第一部分和第二部分)进行组合之前,可以将语音输入和所选择的内容两者转换成相同的格式,例如转换成(但不限于)文本。为此,可以使用语音识别将语音输入转录成文本。当选择的内容对应于可选择的文本时,可以不需要进一步转换选择的文本。另一方面,当所选择的内容对应于包含不可选择文本(例如,包含在屏幕上显示的图像中的文本)的显示区域时,可以对所选择的显示区域进行文本识别,以便获得所选择的内容的文本表示。
因此,在一个变型中,当对内容的选择包括对文本(即,可选择文本)的选择时,将语音输入与所选内容进行组合可以包括将语音输入的转录与所选择的文本进行组合(例如,将语音输入与所选择的文本的转录进行级联)。在另一变型中,当对内容的选择包括对屏幕上的显示区域(例如,对应于显示在屏幕上的包含要用作命令的第二部分的文本的图像)的选择时,将语音输入与所选内容进行组合可以包括在所选显示区域上执行文本识别以获得其中包括的文本作为所选择的文本,以及将语音输入的转录与所选择的文本进行组合(例如,将语音输入和所选择的文本的转录进行级联)。换句话说,当通过指定显示区域的触摸输入进行内容的选择时,电子设备可以被配置为识别在显示区域中书写的内容,并且可以使用识别的文本作为要生成的命令的第二部分。以此方式,显示在屏幕上的任何文本部分通常可被选择为用于要生成的命令的第二部分。这可以包括例如在网络浏览器中显示的文本部分或在智能电话上执行的消息收发应用,并且例如可以通过在屏幕上的单词或短语上的触摸来简单地选择要用作命令的第二部分的单词或短语。
在一种实现中,语音输入的转录的语言和所选择的文本的语言可以不同。而且,语音输入的转录的字符集和所选择的文本的字符集可以不同。因此,作为示例,尽管语音输入的转录的语言和字符集两者都可以基于英文,但是用户可以选择以日文显示的文本作为要生成的命令的第二部分。仅作为一个示例,用户可以将“是什么”作为表示命令的第一部分的语音输入,然后在表示命令的第二输入的屏幕上选择“電視”,以便生成完整的命令“電視是什么”。在类似的使用情况下,用户可以使用电子设备的相机应用来捕捉感兴趣内容的图像,并且在所捕捉的图像中选择要用作要生成的命令的第二部分的区域。例如,用户可以捕捉日语标志牌,说出“是什么”,并且在捕捉的图像上的标志牌的日文文本上滑动他的手指,以生成将由电子设备处理的对应命令。
在一些实现中,语音输入可以包括要由电子设备处理的指令,其中所选择的内容可以对应于与该指令相关联的参数。作为示例,指令可以对应于复制操作,并且与指令相关联的参数可以对应于要被复制的项。例如,如果用户阅读网页并且想要与朋友分享网页的文本部分,则用户可以说“复制单词”并且在屏幕上选择期望的文本部分以生成相应的命令。当处理该命令时,电子设备可以将所选择的文本部分复制到电子设备的剪贴板中,准备好粘贴到其他地方以便与朋友分享。
虽然将理解接收表示命令的第一部分的语音输入和接收表示命令的第二部分的内容的选择可以以独立的两步输入过程的形式来执行,还可以想到,作为将命令转录为全语音命令的失败尝试的回退过程来执行两步输入过程。在一个变型中,内容的选择因此可以在未能正确地转录表示内容的语音输入时接收到。例如,用户在查看对屏幕上的语音输入的转录时可以确定未能正确地转录语音输入。
如果命令的第一部分表示要在命令的第二部分之前输入的命令的初始部分,则电子设备还可以识别在第一步骤中接收的语音输入可能还不表示完整命令(例如,说出“是什么”而没有任何进一步的规范),并且因此,电子设备可以被配置为等待来自用户的附加输入。在识别出表示命令的第一部分的语音输入不代表完整命令时,电子设备因此可以等待对内容的选择。在一个这样的变型中,当检测到完整命令还不可用时,电子设备可以主动地提示用户执行对屏幕上的内容的选择。
根据第二方面,提供了一种计算机程序产品。计算机程序产品包括用于当在一个或多个计算设备上执行计算机程序产品时执行第一方面的方法的程序代码部分。计算机程序产品可以存储在计算机可读记录介质上,诸如半导体存储器、dvd、cd-rom等。
根据第三方面,提供了一种用于生成要由电子设备处理的命令的语音控制电子设备。所述电子设备包括至少一个处理器和至少一个存储器,其中,所述至少一个存储器包含可由所述至少一个处理器执行的指令,使得所述电子设备可操作以执行本文中关于所述第一方面所呈现的方法步骤。
本文描述的所有方面可由硬件电路和/或软件来实现。即使在本文中关于电子设备描述了这些方面中的一些方面,这些方面也可以被实现为用于执行或执行该方法的方法或计算机程序。同样,被描述为方法或参考方法的方面可以通过电子设备的组件或处理装置、或通过计算机程序来实现。
附图说明
在下文中,将参照附图中所示的示例性实现来进一步描述本公开,其中:
图1示意性地示出了根据本公开的语音控制电子设备的示例性硬件组成;
图2示出了可由图1的电子设备执行的方法的流程图;以及
图3示出了根据本公开的对显示在电子设备的屏幕上的内容的示例性选择。
具体实施方式
在以下描述中,出于解释而非限制的目的,阐述了具体细节,以便提供对本公开的透彻理解。对本领域技术人员来说显而易见的是,本公开可以在脱离这些具体细节的其他实现方式中实践。
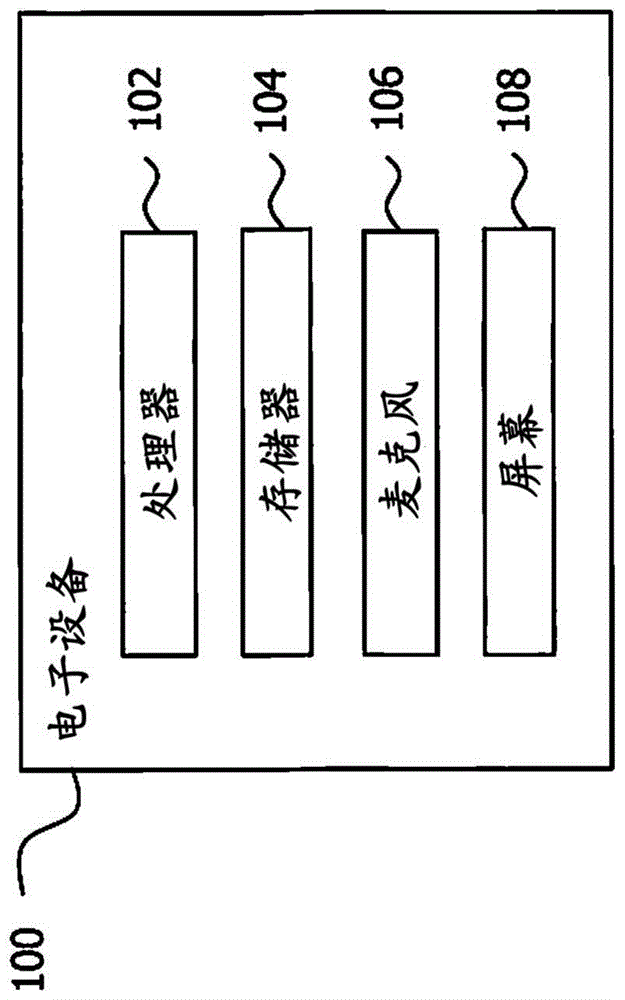
图1示出了电子设备100的示例性硬件组成。电子设备100包括至少一个处理器102和至少一个存储器104,其中,至少一个存储器104包含可由至少一个处理器执行的指令,使得电子设备可操作以执行下文中描述的功能、服务或步骤。电子设备100可以是能够被语音控制的任何种类的电子设备。这可以包括消费电子设备,例如智能手机、平板计算机、膝上型计算机和个人计算机,以及家用电器,例如冰箱、炊具、洗碗机、洗衣机和空调,但不限于此。电子设备100包括用于接收语音命令(或者更一般地,语音输入)的麦克风106,并且可以执行代理(例如,软件代理),该代理可以被配置为处理所接收的语音命令并根据其来采取动作。在一个实现中,可以以虚拟助理的形式来提供代理,该虚拟助理能够响应于来自用户的语音命令(即,换句话说,基于用户的口头请求)来提供服务。电子设备100还包括用于显示用户可选择的内容的屏幕108。
图2示出了可由根据本公开的电子设备100执行的方法。该方法专用于生成要由电子设备100处理的命令,并且包括:在步骤s202中接收表示要由所述电子设备100处理的命令的第一部分的语音输入;在步骤s204中接收对显示在所述电子设备100的屏幕上的内容的选择,所选择的内容表示要由所述电子设备100处理的命令的第二部分;以及在步骤s206中基于所述语音输入和所选择的内容的组合来生成命令。最后,在步骤s208中,电子设备100可处理所生成的命令。
代替使用完全基于语音的命令,根据本文中所呈现的技术,要由电子设备100处理的命令可以对应于根据语音输入和从电子设备100的屏幕108选择的内容的组合而生成的命令。因此,可以从两种类型的输入创建命令,即,表示命令的第一部分的语音输入以及从表示要生成的命令的第二部分的显示器(对应于对电子设备100的屏幕108上的显示内容的选择)中选择的视觉输入。然后,可以通过将命令的第一部分和第二部分进行组合来生成完整命令。应当理解,当在本文中被称为要生成的命令的第一部分和第二部分时,术语“第一”和“第二”可以仅仅区分要生成的命令的各个部分,但是可以不必暗示要生成的命令的各个部分的顺序(或它们之间的时间关系)。因此可以想象的是,第二部分在命令的第一部分之前输入并且表示命令的初始部分,该初始部分之后是命令的第一部分,或者反之亦然。
虽然在不清楚的发音或语音识别引擎未知的单词的情况下对语音输入执行语音识别可能遭受模糊或不正确的识别,如上所述,电子设备100的显示器上的内容的选择通常可以提供更准确的输入方法,并且因此可以优选地作为用于否则难以从语音输入中识别的命令部分的输入方法。具体地,内容的视觉选择可以用于命令的部分的输入,该部分包括具有与语音识别引擎的默认语言不同的语言的项、不包括在语音识别引擎的词汇表中的项和/或可能导致不明确转录的项(例如,平均转录歧义高于预定阈值的术语,例如由用户发音)。通过使用视觉选择,可以更精确地创建命令,并且通常可以避免不适当的命令元素的产生。因此,可以防止正在执行的语音控制的不希望的结果。
所述命令可以对应于可由电子设备100解释的任何类型的命令。具体地,该命令可以对应于用于控制电子设备100的功能的控制命令,例如用于控制家用电器的行为或控制在电子设备100上执行的虚拟助理的命令。命令可以对应于响应于电子设备100的语音控制功能的激活而输入的命令,并且因此该命令可以反映要由电子设备100的语音控制功能处理的命令。例如,可以在输入激活电子设备100的语音控制功能的网络时输入命令。作为示例,命令可以对应于对在电子设备100上执行的虚拟助理的查询,例如,向虚拟助理请求服务的查询。例如,苹果siri的虚拟助理热词是“嘿siri”,谷歌assistant的虚拟助理热词则是“ok谷歌”。
虽然将理解,在电子设备100的屏幕108上的内容的选择可以使用任何种类的输入装置来进行,诸如在例如个人计算机的情况下使用鼠标或键盘,但是在一个实现中,屏幕108可以是触摸屏,并且可以通过触摸屏上的触摸输入来进行内容的选择。触摸输入可以对应于指定屏幕108上要选择内容的显示区域的触摸手势。作为示例,触摸输入可以对应于覆盖要选择的内容的滑动手势。例如,这可以涉及在要选择的内容(例如,文本部分)上滑动或者包围/框选要选择的内容。
要选择的内容可以对应于当前正显示在电子设备100的屏幕108上的文本的一部分。文本部分可以包括可选择的文本(例如,可使用公知用于普通拷贝/粘贴操作的普通用户界面功能标记/可选择的文本),或者否则,文本部分可以包括不可选择的文本。在文本部分可以包括不可选择的文本的情况下,所选择的内容可以对应于屏幕108上包含不可选择的文本部分的所选择的显示区域,其中,文本部分可以形成非文本显示元素的一部分,诸如例如显示在屏幕上的图像。要选择的内容可以不对应于来自在电子设备100的屏幕上显示的键盘的输入。
在将语音输入和所选择的内容(再次,分别表示要处理的命令的第一部分和第二部分)进行组合之前,可以将语音输入和所选择的内容两者转换成相同的格式,例如转换成(但不限于)文本。为此,可以使用语音识别将语音输入转录成文本。当选择的内容对应于可选择的文本时,可以不需要进一步转换选择的文本。另一方面,当所选择的内容对应于包含不可选择文本(例如,包含在屏幕上显示的图像中的文本)的显示区域时,可以对所选择的显示区域进行文本识别,以便获得所选择的内容的文本表示。
因此,在一个变型中,当对内容的选择包括对文本(即,可选择文本)的选择时,将语音输入与所选内容进行组合可以包括将语音输入的转录与所选择的文本进行组合(例如,将语音输入与所选择的文本的转录进行级联)。在另一变型中,当对内容的选择包括对屏幕108上的显示区域(例如,对应于显示在屏幕108上的包含要用作命令的第二部分的文本的图像)的选择时,将语音输入与所选内容进行组合可以包括在所选显示区域上执行文本识别以获得其中包括的文本作为所选择的文本,以及将语音输入的转录与所选择的文本进行组合(例如,将语音输入和所选择的文本的转录进行级联)。换句话说,当通过指定显示区域的触摸输入进行内容的选择时,电子设备100可以被配置为识别在显示区域中书写的内容,并且可以使用识别的文本作为要生成的命令的第二部分。以此方式,显示在屏幕108上的任何文本部分通常可被选择为用于要生成的命令的第二部分。这可以包括例如在网络浏览器中显示的文本部分或在智能电话上执行的消息收发应用,并且例如可以通过在屏幕上的单词或短语上的触摸来简单地选择要用作命令的第二部分的单词或短语。
在一种实现中,语音输入的转录的语言和所选择的文本的语言可以不同。而且,语音输入的转录的字符集和所选择的文本的字符集可以不同。因此,作为示例,尽管语音输入的转录的语言和字符集两者都可以基于英文,但是用户可以选择以日文显示的文本作为要生成的命令的第二部分。仅作为一个示例,用户可以将“是什么”作为表示命令的第一部分的语音输入,然后在表示命令的第二输入的屏幕上选择“電視”,以便生成完整的命令“電視是什么”。在类似的使用情况下,用户可以使用电子设备100的相机应用来捕捉感兴趣内容的图像,并且在所捕捉的图像中选择要用作要生成的命令的第二部分的区域。例如,用户可以捕捉日语标志牌,说出“是什么”,并且在捕捉的图像上的标志牌的日文文本上滑动他的手指,以生成将由电子设备处理的对应命令。
在一些实现中,语音输入可以包括要由电子设备100处理的指令,其中所选择的内容可以对应于与该指令相关联的参数。作为示例,指令可以对应于复制操作,并且与指令相关联的参数可以对应于要被复制的项。例如,如果用户阅读网页并且想要与朋友分享网页的文本部分,则用户可以说“复制单词”并且在屏幕上选择期望的文本部分以生成相应的命令。当处理该命令时,电子设备可以将所选择的文本部分复制到电子设备100的剪贴板中,准备好粘贴到其他地方以便与朋友分享。
虽然将理解接收表示命令的第一部分的语音输入和接收表示命令的第二部分的内容的选择可以以独立的两步输入过程的形式来执行,还可以想到,作为将命令转录为全语音命令的失败尝试的回退过程来执行两步输入过程。在一个变型中,内容的选择因此可以在未能正确地转录表示内容的语音输入时接收到。例如,用户在查看对屏幕108上的语音输入的转录时可以确定未能正确地转录语音输入。
如果命令的第一部分表示要在命令的第二部分之前输入的命令的初始部分,则电子设备100还可以识别在第一步骤中接收的语音输入可能还不表示完整命令(例如,说出“是什么”而没有任何进一步的规范),并且因此,电子设备100可以被配置为等待来自用户的附加输入。在识别出表示命令的第一部分的语音输入不代表完整命令时,电子设备100因此可以等待对内容的选择。在一个这样的变型中,当检测到完整命令还不可用时,电子设备100可以主动地提示用户执行对屏幕108上的内容的选择。
图3示出了在电子设备100的屏幕108上显示的内容的示例性选择,在该图中,该电子设备被给出为具有触摸屏的智能电话。在所示的示例中,假设智能电话100的用户经由消息收发应用与人“a”通信。如所示出的,用户可能已经接收到来自人a的消息,说“嗨,我现在在vestel(伟视达)”。假设用户不知道vestel在哪里,则用户可以询问智能手机100的虚拟助理“vestel在哪里”。由于用户的发音不完全清楚,虚拟助手可能错误地将“vessel在哪里”识别为用户输入的语音指令(图中未示出)。为了纠正这种不正确的识别,用户可以重复他的问题,但是这次使用这里给出的技术。因此,用户可以说出“在哪里”,并且虚拟助理可以识别出“在哪里”还不表示完整的命令。因此,虚拟助理可以等待来自用户的附加输入。如图所示,然后通过在屏幕108上的用户手指在词“vestel”上滑动来提供附加输入,以便选择词“vestel”作为用于要生成的命令的后续输入。然后,虚拟助理可以将语音输入“在哪里”与内容选择“vestel”进行组合,以便获得完整命令“vestel在哪里”。之后,虚拟助理可以处理该命令并提供对用户的问题的相应回答。以这种方式,确保用户获得对正确问题的答案,而不是对最初识别的和不正确的问题“vessel在哪里”的答案。
相信本文中所呈现的技术的优点将从前述描述中完全理解,并且将显而易见的是,在不脱离本公开的范围或不牺牲其所有有利效果的情况下,可以其示例性方面的形式、构造及布置方面做出各种改变。因为本文中所呈现的技术可以以许多方式变化,所以将认识到,本公开应仅由所附权利要求书的范围来限制。
- 还没有人留言评论。精彩留言会获得点赞!