一种基于声纹的点餐控制方法、电子设备及存储介质与流程
本发明涉及一种点餐技术领域,尤其涉及一种基于声纹的点餐控制方法、电子设备及存储介质。
背景技术:
市面上现有的自助服务机包括有自助点餐机,在一些餐厅中,可以通过自助点餐机自助点餐,这样可以减轻工作人员的工作量。但是这样的点餐机器铺设成本相对较高。随着社会的进步,餐饮业也在不断的进步当中,时下有一种新的点餐方式正在逐渐流行开来,这个便是电子点餐,比较常用的方式是通过扫描二维码的方式进行。目前的电子点餐系统中,用户可以快速浏览和选择菜品,并进行下单,速度高于传统菜谱,这使用户的点餐过程变得非常随意自由,给用户带来美好的用餐体验。但是这种方式还是应用于比较常规的需要服务员服务的方式,对于更智能的无人餐厅来说,如何降低顾客的使用负担,使得用户可以只是通过讲话就实现点餐成为本领域技术人员所要解决的技术问题。
技术实现要素:
为了克服现有技术的不足,本发明的目的之一在于提供一种基于声纹的点餐控制方法,其能解决高效点餐的技术问题。
本发明的目的之二在于提供一种电子设备,其能解决高效点餐的技术问题。
本发明的目的之三在于提供一种计算机可读存储介质,其能解决高效点餐的技术问题。
本发明的目的之一采用如下技术方案实现:
一种基于声纹的点餐控制方法,包括以下步骤:
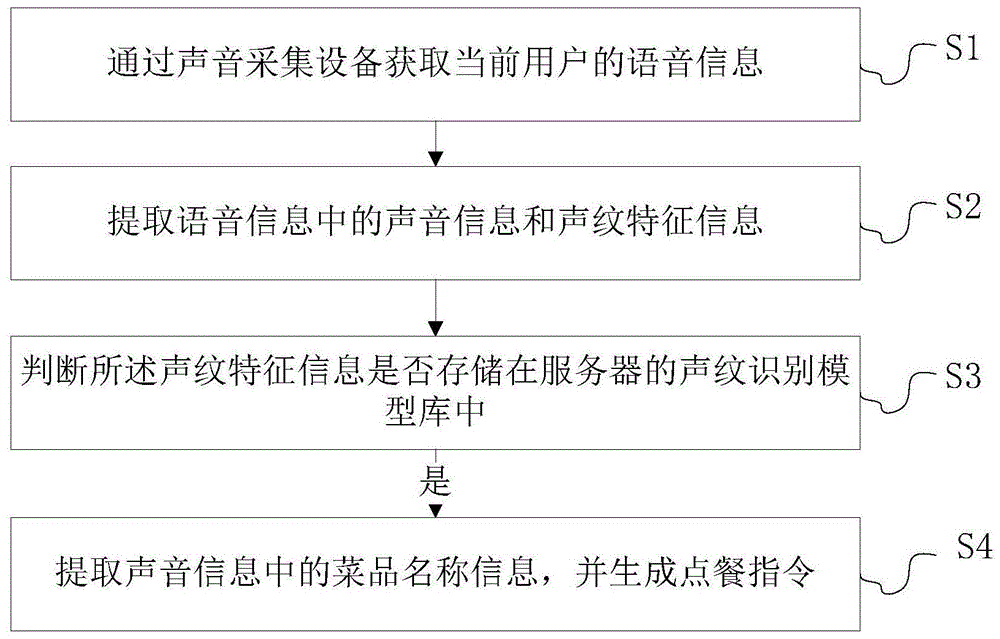
获取步骤:通过声音采集设备获取当前用户的语音信息;
提取步骤:提取语音信息中的声音信息和声纹特征信息;
第一判断步骤:判断所述声纹特征信息是否存储在服务器的声纹识别模型库中,如果是,则执行信息提取步骤;
信息提取步骤:提取声音信息中的菜品名称信息,并生成点餐指令。
进一步地,所述第一判断步骤中的声纹识别模型库通过如下步骤构建:
获取所有待注册用户的语音信息;
提取所有待注册用户的语音信息中的声纹特征信息;
对所有的声纹信息进行存储以完成声纹识别模型库的构建。
进一步地,所述声纹特征信息采用经典的梅尔倒谱系数mfcc或者感知线性预测系数plp或者深度特征deepfeature或者能量规整谱系数pncc表示。
进一步地,在信息提取步骤之后还包括信息读取步骤:当接收到点餐结束指令时,通过扬声器读取获取到的所有的菜品名称信息。
进一步地,在信息读取步骤之后还包括以下步骤:
接收步骤:接收当前用户发出的信息确认指令;
第二判断步骤:根据信息确认指令以判断是否需要修改对应的点餐指令,如果是,则修改对应的点餐指令;
点餐步骤:将最终的点餐指令发送至服务器端以完成点餐。
进一步地,在点餐步骤之后还包括设备关闭步骤:控制关闭声音采集设备或者使得声音采集设备处于休眠状态。
进一步地,在获取步骤之前还包括唤醒步骤:当接收到预设唤醒词时,启动声音采集设备。
进一步地,所述唤醒步骤具体为:当接收到的预设唤醒词时,判断与预设唤醒词对应的声纹信息是否存储在服务器中,如果是,则启动声音采集设备,且所述获取步骤中具体为:通过环形麦克风阵列获取当前用户的声音信息。
本发明的目的之二采用如下技术方案实现:
一种电子设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现本发明目的之一中任意一项所述的一种基于声纹的点餐控制方法。
本发明的目的之三采用如下技术方案实现:
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如本发明目的之一中任意一项所述的一种基于声纹的点餐控制方法。
相比现有技术,本发明的有益效果在于:
本发明的基于位置的点餐控制方法通过区分声纹特征信息来进一步判断是否对其声音进行提取识别,这样能够使得点餐过程更为的高效。
附图说明
图1为实施例一的基于位置的点餐控制方法的流程图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例。
实施例一
如图1所示,本实施例提供了一种基于声纹的点餐控制方法,包括以下步骤:
s1:通过声音采集设备获取当前用户的语音信息;所述声音采集设备最为优选的,采用环形麦克风阵列以采集当前用户的声音信息;这一步主要是为了获取到对应用户的声音信息,这也是下面所有步骤的基础。通过环形麦克风可以更为高效准确的获取圆桌四周的声音信息,获取到的声音源信息越清晰,那么后期进行语音翻译也就会使得其越准确。该环形麦克风一般设置于餐桌上,针对于不同的餐桌设置有不同的数量的麦克风数,比如针对于四人桌,环形麦克风中拥有麦克风的数量为四个,针对于六人桌,环形麦克风中拥有麦克风的数量为六个,针对于十人桌,环形麦克风中拥有麦克风的数量为十个;这样在进行具体操作的时候,可以设定每个座位有对应一个麦克风。除了上述这样的方式之外,还可以设置固定数量的麦克风,比如不论是几人桌,环形麦克风中拥有麦克风的数量均为六个;因为在这个过程中只需要获取固定人的声音信息即可,而不需要使得每个人都可以分配得到一个麦克风,不过,在进行设置的时候,拥有录音权限的那个用户必须有分配对应的一个麦克风,以便于更好的进行信息接收。
在本实施例中还提供了另外一种实施方式来进行该控制方法的唤醒,一般的唤醒方式可以直接通过电源按键来实现语音识别系统的开关,这种是最为原始的,也不够智能;在本实施例中其作为一种可以替代的方式可以进行选择,还可以设置语音识别系统处于常开的状态,只是这样会比较耗费电量,并且很容易形成很多不必要的“点餐指令”,但是其也可以作为一种方式来进行实施,只是不属于本发明中所要着重描述的最为优选的方式。
在本实施例中最为优选地,是可以采用关键词唤醒的方式来进行语音识别系统的唤醒,比如将唤醒关键词设置为“点餐开始”或者“开始点菜”,当声音采集设备采集到这样的信息的时候,则将处于待机状态下的语音识别系统唤醒以进行工作,从而实现真正的自动化处理。使得点餐可以进行的更为的顺畅。由于并非是所有人都可以来控制会议的进行,故而需要设置一个或者多个用户来进行统筹,最为优选地是设定一个用户来进行统筹,因为点餐人数一般不会特别多,所以只需要一个用户来进行统一管理比较合适。将这个用户的声纹信息预先存储在服务器中,只有他说出来的预设唤醒词才具备启动的功能。所谓声纹(voiceprint),是用电声学仪器显示的携带言语信息的声波频谱。现代科学研究表明,声纹不仅具有特定性,而且有相对稳定性的特点。成年以后,人的声音可保持长期相对稳定不变。实验证明,无论讲话者是故意模仿他人声音和语气,还是耳语轻声讲话,即使模仿得惟妙惟肖,其声纹却始终不相同。所以采用声纹这种识别方式,识别更为的高效。
当接收到的预设唤醒词时,判断与预设唤醒词对应的声纹信息是否存储在服务器中,如果是,则启动声音采集设备。这里进行预设唤醒词的设置的时候,可以依照用户的习惯来进行设置,比如通常的可以设置“会议开始”,这样的常规性词句,对应的饭店也可以依据自己的企业文化,设定不同的唤醒词。比如外婆家的唤醒词可以设置“外婆,我来了”这样的更个性,更具备特色的唤醒方式,使得该系统能够具备更高的用户黏性。从而使得单一的系统能够通过这样不同的方式具有较高的区分度,也更加便于不同的企业具有更个性化的定制。
在进行唤醒词设置的时候,可以设置为以下方式,“请大家安静,准备开始点菜。”当这样设置的时候,具备更高的抗干扰性。因为,当用户进行一间餐厅的时候,这时候朋友之间会交谈,有时候会不经意间触发语音识别系统,这样就会造成一定的启动失误,会从一定程度上降低用户对系统稳定性的信任。因此设置相对较长的话语,可以使得其唤醒难度加大。更为重要的是,当说完“请大家安静”的时候,可以通过检测环境噪声这样的信息来确认,是否是点餐主持者发出的明确指令,如果说完之后,环境噪声明显降低,那么说明确实是要正式进入点餐模式,此时,启动语音识别系统。在启动之后,该语音识别系统,还可以进一步发出询问,以确认点餐是否开始,当该信息为肯定回答时,则完全启动。
s2:提取语音信息中的声音信息和声纹特征信息;所述声纹特征信息采用经典的梅尔倒谱系数mfcc或者感知线性预测系数plp或者深度特征deepfeature或者能量规整谱系数pncc表示。
对于声纹识别系统而言,如果从用户所说语音内容的角度出发,则可以分为内容相关和内容无关两大类技术。顾名思义,“内容相关”就是指系统假定用户只说系统提示内容或者小范围内允许的内容,而“内容无关”则并不限定用户所说内容。前者只需要识别系统能够在较小的范围内处理不同用户之间的声音特性的差异就可以,由于内容大致类似,只需要考虑声音本身的差异,难度相对较小;而后者由于不限定内容,识别系统不仅需要考虑用户声音之间的特定差异,还需要处理内容不同而引起的语音差异,难度较大。
目前有一种介于两者之间的技术,可以称之为“有限内容相关”,系统会随机搭配一些数字或符号,用户需正确念出对应的内容才可识别声纹,这种随机性的引入使得文本相关识别中每一次采集到的声纹都有内容时序上的差异,这种特性正好与互联网上广泛存在的短随机数字串(如数字验证码)相契合,可以用来校验身份,或者和其他人脸等生物特征结合起来组成多因子认证手段。在本实施例中采用的是内容无关方面的技术,因为在这里只需要识别到对应的用户是谁即可,而不必进行进一步的验证。因为这个声音识别系统的搭建是处于一个密闭环境中,而不是处于一种开放环境中。但是在进行设计的时候可以设置为有限内容相关或者是内容相关,这样通过在每句话中加入特定的词语,使得记录更为精确。上述只是简单的从大致技术方向进行阐述,接下来对具体设计的声纹识别算法的技术细节进行描述。
具体到声纹识别算法的技术细节,在特征层面,经典的梅尔倒谱系数mfcc,感知线性预测系数plp、深度特征deepfeature、以及能量规整谱系数pncc等,都可以作为优秀的声学特征用于模型学习的输入,但使用最多的还是mfcc特征,也可以将多种特征在特征层面或者模型层面进行组合使用。在机器学习模型层面,还有一种方式是采用ivector框架来进行学习。由于深度学习目前处于正研究的热门,在声纹领域也难免被其影响,因此在传统的ubm-ivector框架下衍化出了dnn-ivector,也仅仅是使用dnn(或者bn)提取特征代替mfcc或者作为mfcc的补充,后端学习框架依然是ivector。这些都是具体进行声纹特征信息提取的方式,由于本发明不针对于具体方式的改进,在此仅仅列举出对应的方式,本领域技术人员根据对应的方式以及实际需求可以搭建出比较合适的识别模块。
s3:判断所述声纹特征信息是否存储在服务器的声纹识别模型库中,如果是,则执行信息提取步骤;所述步骤s3中的声纹识别模型库通过如下步骤构建:
获取所有待注册用户的语音信息;
提取所有待注册用户的语音信息中的声纹特征信息;所述声纹特征信息采用经典的梅尔倒谱系数mfcc或者感知线性预测系数plp或者深度特征deepfeature或者能量规整谱系数pncc表示。
对所有的声纹信息进行存储以完成声纹识别模型库的构建。
本发明的最主要的方式是针对于特定的人员进行点餐指令信息的获取,而不是针对于所有人。当需要对该餐桌进行点餐的时候,最开始需要获取到该餐桌上某一个或者几个对应的声纹信息,比如在这个饭局中,必然是占据主导地位的肯定是饭局的邀请者,其说话的声音应该是被识别和记录的。所以在最开始的时候,需要将其声纹信息录入该系统中,从而使得其作为一个判别条件从而能够完成对应的判断。在进行信息注册的时候,其说话可以是任何的话语,比如“我要注册成为会员”这样的话语,然后通过提取该用户的声纹特征信息来作为其一个身份信息进行存储。这样设置有一个好处是不会限定用户的位置,而是根据用户独有的声音特征来进行识别的。并且由于设置的环形麦克风来拾取用户的声音信息,那么在无论用户移动到那个地方,均可以通过环形麦克风阵列完成对其声音的定位。
采用声源定位技术定位声音所在位置后,关闭除了与声音信息所在位置最近的麦克风外的其余麦克风。当定位到具体的位置的时候,最好的是只开启其面前的麦克风,而将其余的麦克风关闭,这样能够更为有效的获取当前说话者的声音信息,而屏蔽掉一部分说话者的低语,不会因为产生多处声源而造成声音获取处于一种比较混乱的状态。因为如果当说话的人不是一个的时候,而此时又同时开启有多个麦克风,那么就无法判断他们的来源强弱,而会将所有的声音信息都录入,从而会产生一定的混乱,而只开启说话者面前的麦克风的话,其可以通过声音强弱,声音方向等来定位是否需要记录对应的信息,并且判断是否需要进行录音更换等。所述声源定位技术为基于时延估计的算法或者基于高分辨率谱估计的算法或者基于稀疏表示的算法。所述声源定位技术其是基于tde的算法核心在于对传播时延的准确估计,一般通过对麦克风间信号做互相关处理得到。进一步获得声源位置信息,可以通过简单的延时求和、几何计算或是直接利用互相关结果进行可控功率响应搜索等方法。这种类型的算法实现相对简单,运算量小,便于实时处理,因此在实际中运用最广。
当有多个用户拥有点餐权限的时候,还会出现位置变化的问题,为了使得其拥有更高的自动化程度,本实施例还提供了这样的方式来进行实施。当获取到的声音信息所在位置改变时,则对声音信息进行重新定位;当语音的方向改变之后,要重新对语音的方向进行定位。
在进行声纹识别模型库构建的时候,其可以设置两部分,一部分是永久有效的注册用户,一种是临时有效的注册用户。永久有效的注册用时即是其比较重要,也是通常对应餐厅的会员,他的声音是必须被记录的,因为其经常出入这家餐厅,所以为了使得整个就餐过程更为的方便,所以需要将其声音记录为永久有效。而不必下次再进行输入。还有一种方式是临时有效的注册用户,就是属于非本餐厅的会员,其使用频率相对没有那么高,所以为了不占用存储资源,所以只提供临时有效的身份。还有一种方式是不进行区分,只要在该餐厅就餐过的用户均记录其声音,使得就餐者有被重视的感觉,提高用户体验。
s4:提取声音信息中的菜品名称信息,并生成点餐指令。这一步主要是为了提取声音信息中包括的菜品名称信息,但是这个菜品名称信息的确认不单单是识别到其中拥有菜品名称信息之后就直接进行提取,而是需要进一步判断的;只有在确认点这个菜品的时候才提取并生成点餐指令。比如,当出现有“鱼香肉丝怎么样?”这样的信息的时候,肯定是不需要提取,只有出现陈述句的时候才提取,“我要鱼香肉丝。”所以在这个过程中还需要对获取到的声音信息进行语义识别,只有再确认该语句是进行点餐的时候,才进行点餐操作。
s5:当接收到点餐结束指令时,通过扬声器读取获取到的所有的菜品名称信息。为了使得整个点餐过程中的服务信息能够更为的准确,在接收到点餐结束指令的时候,通过扬声器来进行读取所获得的所有的菜品的名称。因为点餐与会议不同,会议结束的时候,其会有停顿的发生,而点餐这个过程却不同,点餐结束后不会有停顿,朋友之间还会进行交谈,所以需要采用直接的方式对该系统进行关闭,以防止点到不必要的菜品。在进行关闭的时候,也是可有物理关闭方式和软件关闭方式,物理关闭方式是直接点击电源开关;而软件关闭方式是通过说“点餐结束”这样的词语来进行关闭的;在本实施例中优选的采用软件关闭的方式。当接收到这样的指令之后,会发送完成的点餐目录给当前的用户确认是否是所有的这些菜品。
s6:接收当前用户发出的信息确认指令;用户听完所有的菜品之后,如果准确无误,则直接回复不需要修改或者是点餐没有错误这样的信息给到系统去进行进一步确认。而当出现有修改的时候,比如用户中间有一个菜品突然不想要或者是用户没有点,则其说出“不要鱼香肉丝”这样的话语指令给到系统去进行进一步判断。
s7:根据信息确认指令以判断是否需要修改对应的点餐指令,如果是,则修改对应的点餐指令;系统在接收到这样的指令之后,需要进一步分析这句话中包含的内容信息,比如“不要鱼香肉丝”通过语义分析是确认将菜单目录中的鱼香肉丝这个条目给删除,而当出现“增加茄子煲”这样的话语的时候,通过语义分析确认是需要通过增加菜品来实现的,这时候则在菜单目录中增加对应的菜品信息。
s8:将最终的点餐指令发送至服务器端以完成点餐。最终的点餐指令指的是经过用户确认的所有的菜品信息,当获取到这样的最终的菜品信息的时候,只需要将这些信息发送至后台服务器去确认即可,这时候后台服务器发送至后厨去进行备餐。这样就可以实现整个点餐操作。由于点餐操作已经完成,所以这时候需要控制关闭声音采集设备或者使得声音采集设备处于休眠状态,从而使得该系统不能够接收点菜指令去进行点餐,以防止用户误点。
当在就餐过程中,该餐桌的用户需要加菜的时候,这时候还是对应的拥有点餐权限的用户去对该声音采集设备进行唤醒。这时候的唤醒词最好与开始的时候唤醒词不一样,可以将其设定为“需要加菜”。这样有利于一个完成的就餐过程中的判断,使得在进行结算的时候能够更方便。
实施例二
实施例二公开了一种电子设备,该电子设备包括处理器、存储器以及程序,其中处理器和存储器均可采用一个或多个,程序被存储在存储器中,并且被配置成由处理器执行,处理器执行该程序时,实现实施例一的一种基于声纹的点餐控制方法。该电子设备可以是手机、电脑、平板电脑等等一系列的电子设备。
实施例三
实施例三公开了一种计算机可读存储介质,该存储介质用于存储程序,并且该程序被处理器执行时,实现实施例一的一种基于声纹的点餐控制方法。
当然,本发明实施例所提供的一种包含计算机可执行指令的存储介质,其计算机可执行指令不限于如上所述的方法操作,还可以执行本发明任意实施例所提供的方法中的相关操作。
通过以上关于实施方式的描述,所属领域的技术人员可以清楚地了解到,本发明可借助软件及必需的通用硬件来实现,当然也可以通过硬件实现,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如计算机的软盘、只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、闪存(flash)、硬盘或光盘等,包括若干指令用以使得一台电子设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
值得注意的是,上述基于内容更新通知装置的实施例中,所包括的各个单元和模块只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明的保护范围。
上述实施方式仅为本发明的优选实施方式,不能以此来限定本发明保护的范围,本领域的技术人员在本发明的基础上所做的任何非实质性的变化及替换均属于本发明所要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!