一种基于融合特征的加性噪声环境下手机来源识别方法与流程
本发明涉及手机来源识别技术领域,尤其涉及一种基于融合特征的加性噪声环境下手机来源识别方法。
背景技术:
随着信息技术的发展,易于携带的手机越来越普及,很多人习惯用手机来录制语音,也因此,基于手机录音设备来源识别的研究受到了广泛关注。近些年,基于安静环境下对手机录音设备来源识别取得了一定的研究成果。
c.hanilci等从录音文件中提取梅尔频率倒谱系数(mfcc)作为设备区分性特征,并比较svm、vq这两种分类器对设备的识别情况,经对14款不同型号手机识别的闭集识别率分析发现,svm分类器识别效果突出;随后,c.hanilci等人又从静音段中提取mfcc作为设备的区分性特征,采用svm分类器比较mfcc、线性频率倒谱系数(lfcc)、bark频率倒谱系数(bfcc)和线性预测倒谱系数(lpcc)这四种声学的倒谱特征以及其与动态特征的组合特征在手机来源识别中的性能优劣,得出mfcc分类效果较好;c.kotropoulos等借鉴对固定麦克风的识别研究,将频谱轮廓特征作为设备指纹,使用稀疏表示分类器对7个不同品牌的21款手机进行识别,闭集识别率达到为95%;金超提出从静音段中提取录音设备的设备噪声方法,将设备噪声作为提取表征录音设备之间区分性信息的载体,以区别手机品牌和型号;simengqi等采用去噪处理和谱减法得到噪声信号,将噪声信号的傅里叶直方图系数作为深度模型的输入,比较三种不同的深度学习分类算法softmax、mlp、cnn的识别效果。
虽然手机来源识别算法取得了一定发展,但仍存在一些局限性,主要表现为:同品牌不同型号手机误识,由于相同品牌的手机录音设备在电路设计和电子元器件选配方面有着较高相似性和一致性,导致嵌入在语音文件中的设备信息差异较小,难以识别;目前手机来源识别应用背景基本都是在安静环境下,而实际生活中的录音更多是在不同噪音环境中形成,环境噪声会影响设备识别性能,这就导致现有研究算法在噪声攻击情况下鲁棒性差。
技术实现要素:
鉴于上述问题,本发明的目的在于提供一种手机来源辨识度高,计算复杂度低,噪声鲁棒性强的基于融合特征的加性噪声环境下手机来源识别方法。
本发明解决上述技术问题所采用的技术方案为:一种基于融合特征的加性噪声环境下手机来源识别方法,其特征在于:所述方法包括,
步骤一、选取m个不同型号手机,每个手机获取n个人的p个语音样本,得到语音样本n×p个,并形成一个子集,将m个子集共m×n×p个语音样本构成基础语音库;其中,m≥10,n≥10,p≥10;
步骤二、选取噪声类型x种,噪声强度y种,得到场景噪声共x×y种,对所述基础语音库中的每个子集中的所有语音样本添加每种场景噪声,形成m个含噪子集共m×n×p个含噪语音样本,形成一个含噪语音库,x×y种场景噪声共得到x×y个含噪语音库,其中,x≥2,y≥2;
步骤三、对所述基础语音库中每个子集中的每个语音样本进行常q变换,得到基础语音库中第m个子集中的第n个语音样本中的第k个频率点的常q变换域频率值fm,n(k),
对所述x×y个含噪语音库中每个含噪子集的每个含噪语音样本进行相同操作,得到第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本对应的第k个频率点的常q变换域频率值fi,m,n(k),频率值的幅值hi,m,n(k),常q变换域频谱分布特征值cqtsdfi,m,n(k)以及第n个含噪语音样本对应的k个频率点的常q变换域频谱分布特征向量cqtsdfi,m,n,i为正整数,1≤i≤x×y,cqtsdfi,m,n的维数为1×k;
其中,m为正整数,1≤m≤m,n为正整数,1≤n≤n×p,k为正整数,1≤k≤k,k表示常q变换的频率点的总点数,k≥9,gk为正整数,1≤gk≤gk,gk表示常q变换的过程中分帧的窗口长度,zm,n(gk)表示基础语音库中的第m个子集中的第n个语音样本,w(gk)表示常q变换的过程中采用的窗函数,e为自然基数,j为虚数单位,fk表示常q变换的过程中采用的滤波器的中心频率,
步骤四、对所述基础语音库中的每个子集中的每个语音样本进行傅里叶变换,得到所述基础语音库中第m个子集中的第n个语音样本对应的第d个频率点的傅里叶变换域频率值sm,n(d),
对所述x×y个含噪语音库中每个含噪子集的每个含噪语音样本进行相同操作,得到第i个含噪语音库中第m个含噪子集中的第n个含噪语音样本对应的第d个频率点的傅里叶变换域频率值si,m,n(d),频率值的幅值qi,m,n(d),傅里叶变换域频谱分布特征值stftsdfi,m,n(d),第n个含噪语音样本对应的的d个频率点的傅里叶变换域频谱分布特征向量stftsdfi,m,n,i为正整数,1≤i≤x×y,stftsdfi,m,n的维数为1×d;
其中,m为正整数,1≤m≤m,n为正整数,1≤n≤n×p,d为正整数,1≤d≤d,d表示傅里叶变换的频率点的总点数,g为正整数,1≤g≤g,g表示傅里叶变换过程中分帧的窗口长度,zm,n(g)表示基础语音库中的第m个子集中的第n个语音样本,w(g)表示傅里叶变换过程中采用的窗函数,e为自然基数,j为虚数单位,
步骤五、对所述基础语音库中每个子集中的每个语音样本进行傅里叶变换,得到所述基础语音库中第m个子集中的第n个语音样本中的第d个频率点的傅里叶变换域频率值sm,n(d),
对所述x×y个含噪语音库中每个含噪子集的每个含噪语音样本进行相同操作,得到第i个含噪语音库中第m个含噪子集中的第n个含噪语音样本对应的第a个阶特征值mfcci,m,n(a),i为正整数,1≤i≤x×y,mfcci,m,n的维数为1×a;
其中,m为正整数,1≤m≤m,n为正整数,1≤n≤n×p,f(p)表示中心频率,p为三角滤波器组的数量,p=1,…,p,lp(d)的约束条件为
步骤六、将所述基础语音库中每个子集中的每个语音样本的常q变换域频谱分布特征、傅里叶变换域频谱分布特征、mfcc特征按序排列组成一个维数为k+d+a的行向量,形成融合特征向量,得到基础语音库中第m个子集中的第n个语音样本的融合特征向量rm,n,rm,n=[cqtsdfm,n(1),…,cqtsdfm,n(k),stftsdfm,n(1),…,stftsdfm,n(d),mfccm,n(1),…,mfccm,n(a)];
对所述x×y个含噪语音库中每个含噪子集的每个含噪语音样本进行相同操作,得到第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本的融合特征向量ri,m,n,ri,m,n=[cqtsdfi,m,n(1),…,cqtsdfi,m,n(k),stftsdfi,m,n(1),…,stftsdfi,m,n(d),mfcci,m,n(1),…,mfcci,m,n(a)],该ri,m,n为一个维数为k+d+a的行向量;
步骤七、将所述基础语音库中第m个子集中的所有语音样本对应的融合特征向量及所有含噪语音库中的第m个含噪子集中的所有含噪语音样本对应的融合特征向量标记为第m种类别,并将其作为输入特征,输入到cnn模型中进行训练,得到m分类模型,m分类模型输出端输出类别,输出类别为m种,与选取的m个手机对应;
步骤八、取一个待识别录音,记为vtest,按照步骤三至六操作,获得vtest对应的融合特征向量rtest,将rtest输入到m分类模型,m分类模型输出端输出rtest类别,即得到rtest的手机来源,rtest的维数为k+d+a。
优选的,所述步骤一中的每个手机获取n个人的p个语音样本的具体过程为:
将手机置于静环境下分别采集n个不同人的语音,将采集到的每个语音转换成wav格式并将每个wav格式语音分割成多个语音片段,再从每个wav格式语音的所有语音片段中随机选取p个语音片段作为语音样本。
优选的,所述步骤一中每个手机获取n个人的p个语音样本的具体过程为:
将手机置于静环境下分别采集由高保真音箱回放的n个人各自对应的p个语句,将每个语句转换成wav格式语音以作为语音样本。
优选的,所述步骤三中的
优选的,所述步骤七中cnn模型的网络框架包括输入层、第一卷积层、第一非线性激活层、第二卷积层、第二非线性激活层、最大池化层、全连接层、第三非线性激活层、输出层,输入层的输入端输入的输入特征维数为k+d+a,第一卷积层有72个卷积核、卷积核的大小为1×3、卷积核的移动步长为1,第二卷积层有72个卷积核、卷积核的大小为1×2、卷积核的移动步长为1,最大池化层的核的大小为1×26、核的移动步长为1,全连接层有64个神经元,输出层的输出端输出类别,第一非线性激活层、第二非线性激活层、第三非线性激活层均采用relu函数,cnn模型中的dropout损失函数的值为0.25,cnn模型中的分类器为softmax。
优选的,所述语音片段时长为3~10秒。
优选的,所述语句时长为3秒。
优选的,所述d取值256或512或1024。
与现有技术相比,本发明的优点在于:
1)本发明利用了来自不同频域获取的特征的融合特征,相比于单一特征,融合特征从多角度更精细的表征了设备差异信息,不仅提升了对干净语音的识别效果,也提升了大部分含噪语音的识别效果。
2)本发明在训练阶段集中了干净语音样本和含有不同场景噪声类型和噪声强度的含噪语音样本,使得训练得到的m分类模型具有通用性,确保了手机来源识别的准确性。
3)本发明使用深度学习的cnn模型建立m分类模型,相比于传统算法,cnn模型不仅提升了对干净语音样本的来源识别准确性,还大幅度提升了含噪语音样本的手机来源识别效果,噪声鲁棒性强。
附图说明
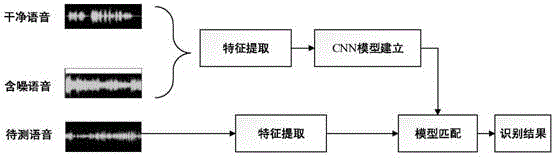
图1为本发明方法的总体实现框图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种基于融合特征的加性噪声环境下手机来源识别方法,其总体实现框图如图1所示,其包括以下步骤:
步骤一:选取m个不同主流品牌不同型号的手机;然后使用每个手机获取n个人各自对应的p个语音样本,每个手机对应的语音样本共有n×p个;再将每个手机对应的所有语音样本构成一个子集,将m个子集共m×n×p个语音样本构成基础语音库;其中,m≥10,在本实施例中取m=24,n≥10,在本实施例中取n=12,p≥10,在本实施例中取p=50。
在本实施例中,在步骤一中使用每个手机获取n个人各自对应的p个语音样本的方式有两种。第一种为:使用每个手机获取n个人各自对应的p个语音样本的具体过程为:选取n个不同年龄不同性别的人,如选取6个不同年龄的男性参与者和6个不同年龄的女性参与者,使用m个手机在安静办公室环境下同时采集每个人用正常的语速朗读固定内容的语音,每个手机共采集到n个语音,m个手机共采集到m×n个语音,要求每个语音的时长至少为3分钟;然后将每个手机采集到的每个语音转换成wav格式语音;接着将每个手机对应的每个wav格式语音分割成多个时长为3~10秒的语音片段;再从每个手机对应的每个wav格式语音的所有语音片段中随机选取p个语音片段作为语音样本,将利用这种方式构成的基础语音库记为ckc-sd。第二种为:使用每个手机获取n个人各自对应的p个语音样本的具体过程为:使用m个手机在安静办公室环境下同时采集由高保真音箱回放的timit库中的n个人各自对应的p个时长为3秒的语句;然后将每个手机采集到的每个语句转换成wav格式语音;再将每个手机对应的每个wav格式语音作为语音样本,将利用这种方式构成的基础语音库记为timit-rd。
表1给出了获取基础语音库ckc-sd和基础语音库timit-rd使用的m个手机的主流品牌和型号的信息。
表1获取基础语音库ckc-sd和基础语音库timit-rd使用的m个手机的主流品牌和型号的信息表
步骤二:选取不同噪声类型不同噪声强度的场景噪声共x×y种,噪声类型共x种,噪声强度共y种;然后采用噪声添加工具在基础语音库中的每个子集中的所有语音样本中添加每种场景噪声,将基础语音库中的每个子集中的所有语音样本添加一种场景噪声后得到的含噪语音样本构成一个含噪子集,将针对添加一种场景噪声得到的m个含噪子集共m×n×p个含噪语音样本构成一个含噪语音库,针对x×y种场景噪声共得到x×y个含噪语音库;其中,x≥2,在本实施例中取x=5,y≥2,在本实施例中取y=3。
在本实施例中,选取来自noisex-92噪声数据库中的白噪声(whitenoise)、嘈杂噪声(babblenoise)、街道噪声(streetnoise)、餐厅噪声(cafenoise)和汽车噪声(volvonoise)这五种噪声类型,并且对于每种噪声类型,考虑3个信噪比(snr)等级(即噪声强度),即0db、10db和20db;噪声添加工具选用遵循国际电联有关噪声添加和滤波的开源工具fant;针对基础语音库ckc-sd,对应有15个含噪语音库;针对基础语音库timit-rd,也对应有15个含噪语音库。
步骤三:对基础语音库中的每个子集中的每个语音样本进行常q变换,将基础语音库中的每个子集中的每个语音样本变换到频域,将基础语音库中的第m个子集中的第n个语音样本对应的第k个频率点的常q变换域频率值记为fm,n(k),
采用相同的操作方式对每个含噪语音库中的每个含噪子集中的每个含噪语音样本进行处理,获得每个含噪语音库中的每个含噪子集中的每个含噪语音样本对应的各个频率点的常q变换域频率值、各个频率点的频率值的幅值、各个频率点的频谱分布特征值、常q变换域频谱分布特征向量,将第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本对应的第k个频率点的常q变换域频率值记为fi,m,n(k),将第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本对应的第k个频率点的频率值的幅值记为hi,m,n(k),将第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本对应的第k个频率点的常q变换域频谱分布特征值记为cqtsdfi,m,n(k),将第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本对应的常q变换域频谱分布特征向量记为cqtsdfi,m,n;其中,i为正整数,1≤i≤x×y,cqtsdfi,m,n的维数为1×k。
在本实施例中,步骤三中,
步骤四:对基础语音库中的每个子集中的每个语音样本进行傅里叶变换,将基础语音库中的每个子集中的每个语音样本变换到频域,将基础语音库中的第m个子集中的第n个语音样本对应的第d个频率点的傅里叶变换域频率值记为sm,n(d),
采用相同的操作方式对每个含噪语音库中的每个含噪子集中的每个含噪语音样本进行处理,获得每个含噪语音库中的每个含噪子集中的每个含噪语音样本对应的各个频率点的傅里叶变换域频率值、各个频率点的频率值的幅值、各个频率点的傅里叶变换域频谱分布特征值、傅里叶变换域频谱分布特征向量,将第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本对应的第d个频率点的频率值记为si,m,n(d),将第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本对应的第d个频率点的频率值的幅值记为qi,m,n(d),将第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本对应的第d个频率点的傅里叶变换域频谱分布特征值记为stftsdfi,m,n(d),将第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本对应的傅里叶变换域频谱分布特征向量记为stftsdfim,n;其中,i为正整数,1≤i≤x×y,stftsdfi,m,n的维数为1×d。
步骤五:对基础语音库中的每个子集中的每个语音样本进行傅里叶变换,得到所述基础语音库中第m个子集中的第n个语音样本中的第d个频率点的傅里叶变换域频率值sm,n(d),
采用相同的操作方式对每个含噪语音库中的每个含噪子集中的每个含噪语音样本进行处理,获得每个含噪语音库中的每个含噪子集中的每个含噪语音样本对应的各阶特征值,将第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本对应的第a个阶特征值记为mfcci,m,n(a);其中,i为正整数,1≤i≤x×y,mfcci,m,n的维数为1×a;
步骤六:将基础语音库中的每个子集中的每个语音样本的常q变换域频谱分布特征、傅里叶域频谱分布特征、mfcc特征按序排列组成一个维数为k+d+a的行向量,作为每个子集中的每个语音样本的融合特征向量,将基础语音库中的第m个子集中的第n个语音样本的融合特征向量记为rm,n,rm,n=[cqtsdfm,n(1),…,cqtsdfm,n(k),stftsdfm,n(1),…,stftsdfm,n(d),mfccm,n(1),…,mfccm,n(a)]。
采用相同的操作方式将每个含噪语音库中的每个含噪子集中的每个含噪语音样本的常q变换域频谱分布特征、傅里叶域频谱分布特征、mfcc特征按序排列组成一个维数为k+d+a的行向量,作为每个子集中的每个语音样本的融合特征,将第i个含噪语音库中的第m个含噪子集中的第n个含噪语音样本的融合特征向量记为ri,m,n,ri,m,n=[cqtsdfi,m,n(1),…,cqtsdfi,m,n(k),stftsdfi,m,n(1),…,stftsdfi,m,n(d),mfcci,m,n(1),…,mfcci,m,n(a)]
步骤六:对基础语音库中的每个子集中的每个语音样本对应的融合特征向量及每个含噪语音库中的每个含噪子集中的每个含噪语音样本对应的融合特征向量进行类别标记,将基础语音库中的第m个子集中的所有语音样本对应的融合特征向量及所有含噪语音库中的第m个含噪子集中的所有含噪语音样本对应的融合特征向量标记为第m种类别;然后将基础语音库中的所有子集中的语音样本对应的融合特征向量及所有含噪语音库中的含噪子集中的含噪语音样本对应的融合特征向量作为输入特征,输入到cnn模型中进行训练,训练得到m分类模型,m分类模型的输出端用于输出类别,输出的类别为m种,与选取的m个手机一一对应。
在本实施例中,步骤七中,cnn模型的网络框架包括输入层、第一卷积层、第一非线性激活层、第二卷积层、第二非线性激活层、最大池化层、全连接层、第三非线性激活层、输出层,输入层的输入端输入的输入特征的维数为1×k,第一卷积层有72个卷积核、卷积核的大小为1×3、卷积核的移动步长为1,第二卷积层有72个卷积核、卷积核的大小为1×2、卷积核的移动步长为1,最大池化层的核的大小为1×26、核的移动步长为1,全连接层有64个神经元,输出层的输出端输出类别,第一非线性激活层、第二非线性激活层、第三非线性激活层均采用relu函数,cnn模型中的dropout损失函数的值为0.25,cnn模型中的分类器为softmax。
步骤八:取一个待识别的语音,记为vtest;然后按照步骤三至六的过程,以相同的操作方式获得vtest对应的融合特征向量,记为rtest;再将rtest输入到训练得到的m分类模型中进行分类别,m分类模型的输出端输出rtest的类别,即得到rtest的手机来源;其中,rtest的维数为1×(k+d+a)。
为了验证本发明方法的可行性和有效性,对本发明方法进行实验。
将基础语音库ckc-sd中的每个子集中的一半数量的语音样本及基础语音库ckc-sd对应的9个含噪语音库(包括添加白噪声且信噪比为20db的含噪语音库、添加白噪声且信噪比为10db的含噪语音库、添加白噪声且信噪比为0db的含噪语音库、添加嘈杂噪声且信噪比为20db的含噪语音库、添加嘈杂噪声且信噪比为10db的含噪语音库、添加嘈杂噪声且信噪比为0db的含噪语音库、添加街道噪声且信噪比为20db的含噪语音库、添加街道噪声且信噪比为10db的含噪语音库、添加街道噪声且信噪比为0db的含噪语音库)中的每个含噪子集中的一半数量的含噪语音样本构成训练集,提取训练集中的所有语音样本的频谱分布特征向量用于训练cnn模型;而将基础语音库ckc-sd中的所有子集中的剩余一半数量的语音样本构成一个测试集,并将基础语音库ckc-sd对应的每个含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成一个测试集,共有16个测试集;同样,将基础语音库timit-rd中的每个子集中的一半数量的语音样本及基础语音库timit-rd对应的9个含噪语音库中的每个含噪子集中的一半数量的含噪语音样本构成训练集,提取训练集中的所有语音样本的频谱分布特征向量用于训练cnn模型;而将基础语音库timit-rd中的所有子集中的剩余一半数量的语音样本构成一个测试集,并将基础语音库timit-rd对应的每个含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成一个测试集,共有16个测试集。
一、融合向量的识别性能
为验证本发明方法提出的融合特征向量的识别性能,对单一特征cqtsdf、stftsdf、mfcc及本发明方法提出的融合特征向量分别在基础语音库ckc-sd对应的训练集下进行训练,并使用基础语音库ckc-sd对应的16个测试集进行测试,识别结果如表2所示。其中,clean表示基础语音库ckc-sd中的所有子集中的剩余一半数量的语音样本构成的测试集,white-20db表示基础语音库ckc-sd对应的添加白噪声且信噪比为20db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,white-10db表示基础语音库ckc-sd对应的添加白噪声且信噪比为10db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,white-0db表示基础语音库ckc-sd对应的添加白噪声且信噪比为0db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,babble-20db表示基础语音库ckc-sd对应的添加嘈杂噪声且信噪比为20db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,babble-10db表示基础语音库ckc-sd对应的添加嘈杂噪声且信噪比为10db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,babble-0db表示基础语音库ckc-sd对应的添加嘈杂噪声且信噪比为0db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,street-20db表示基础语音库ckc-sd对应的添加街道噪声且信噪比为20db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,street-10db表示基础语音库ckc-sd对应的添加街道噪声且信噪比为10db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,street-0db表示基础语音库ckc-sd对应的添加街道噪声且信噪比为0db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,cafe-20db表示基础语音库ckc-sd对应的添加餐厅噪声且信噪比为20db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,cafe-10db表示基础语音库ckc-sd对应的添加餐厅噪声且信噪比为10db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,cafe-0db表示基础语音库ckc-sd对应的添加餐厅噪声且信噪比为0db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,volvo-20db表示基础语音库ckc-sd对应的添加汽车噪声且信噪比为20db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,volvo-10db表示基础语音库ckc-sd对应的添加汽车噪声且信噪比为10db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集,volvo-0db表示基础语音库ckc-sd对应的添加汽车噪声且信噪比为0db的含噪语音库中的所有含噪子集中的剩余一半数量的含噪语音样本构成的测试集。
从表2中可以看出,融合特征,相比于单一特征,不仅提升了对干净语音的识别效果,也提升了大部分含噪语音的识别效果。语音文件经过不同的时频变换方法会得到不同的频域信息,由于傅里叶变换和常q变换这两种时频转换方式采用的频率分辨率不同的,所以这三种特征表征的频域信息在不同频带精度是不同的,反映的设备区分性信息不同,因此能够更精确的表征设备区分信息。
表2不同特征的分类准确性(%)
- 还没有人留言评论。精彩留言会获得点赞!