信息处理设备、信息处理方法和程序与流程
本公开涉及一种信息处理设备、一种信息处理方法和一种程序。
背景技术:
近年来,已经广泛使用基于语音识别处理执行动作的各种设备。此外,还开发了许多提高语音识别处理精度的技术。例如,专利文献1公开了一种通过降低可能是噪声声源的其他装置的音量水平来提高语音识别精度的技术。
引用列表
专利文献
专利文献1:特开2017-138476号公报
技术实现要素:
技术问题
然而,还假设收集用户的语音的设备本身进行自主动作等。在这种情况下,设备本身的操作噪声可能是语音识别精度降低的原因。
问题的解决方案
根据本公开,提供了一种信息处理设备,包括:控制单元,其控制自主操作单元的动作,其中,所述控制单元基于检测到的触发,通过所述自主操作单元控制与语音识别处理相关的多个状态的转换,并且这些状态包括限制自主操作单元的操作的第一活动状态以及执行语音识别处理的第二活动状态。
此外,根据本公开,提供了一种信息处理方法,包括:控制自主操作单元的动作,其中,所述控制包括基于检测到的触发,控制与经由所述自主操作单元的语音识别处理相关的多个状态的转换,并且这些状态包括限制自主操作单元的动作的第一活动状态以及执行语音识别处理的第二活动状态。
此外,根据本公开,提供了一种使计算机用作信息处理设备的程序,包括:控制单元,其控制自主操作单元的动作,其中,所述控制单元基于检测到的触发,控制与经由所述自主操作单元的语音识别处理相关的多个状态的转换,并且这些状态包括限制自主操作单元的动作的第一活动状态以及执行语音识别处理的第二活动状态。
附图说明
图1是用于解释本公开的一个实施例的概述的示图;
图2是示出根据实施例的触发器的具体示例的示图;
图3是示出根据实施例的信息处理系统的配置示例的示图;
图4是示出根据实施例的自主操作单元的功能配置示例的框图;
图5是示出根据实施例的信息处理服务器的功能配置示例的框图;
图6是示出根据实施例的从正常状态到第一活动状态的转换流程的流程图;
图7是用于解释根据实施例的基于触发组合的状态转换的示图;
图8是用于解释根据实施例的通过眼部表情表达状态的示图;
图9是示出根据实施例的从第一活动状态到第二活动状态的转换流程的流程图;
图10是用于解释根据实施例的后续触发的示图;
图11是用于解释根据实施例的后续触发的示图;
图12是用于解释根据实施例的对应于用户之间的会话的后续触发的示图;
图13是用于解释根据实施例的通过主动语音和行为到自主操作单元的第二活动状态的转换的示图;
图14是用于解释根据实施例的保持第一活动状态的示图;
图15是示出根据实施例的从正常状态到第二活动状态的转换流程的流程图;
图16是示出根据该实施例的通过眼部或装置主体的移动来表达状态的示例的示图;
图17是示出根据实施例的从第二活动状态转换的示例的示图;
图18是示出根据实施例的从第二活动状态转换的流程的流程图;
图19是根据该实施例的自主操作单元的前视图和后视图;
图20是根据实施例的自主操作单元的透视图;
图21是根据实施例的自主操作单元的侧视图;
图22是根据该实施例的自主操作单元的俯视图;
图23是根据实施例的自主操作单元的仰视图;
图24是用于解释根据实施例的自主操作单元的内部结构的示意图;
图25是示出根据实施例的衬底的配置的示图;
图26是根据该实施例的衬底的局部横截面;
图27是示出根据该实施例的车轮的外围结构的示图;
图28是示出根据该实施例的车轮的外围结构的示图。
具体实施方式
在下文中,将参考附图详细解释本公开的示例性实施例。在本说明书和附图中,相同的附图标记被分配给具有基本相同的功能配置的组件,因此将省略重复的解释。
将按以下顺序给出说明。
1.实施例
1.1.概述
1.2.系统配置示例
1.3自主操作单元10的功能配置示例
1.4.信息处理服务器20的功能配置
1.5.功能细节
1.6.硬件配置示例
2.结论
<1.实施例>
<<1.1.概述>>
首先,将解释本公开的一个实施例的概述。如上所述,近年来,已广泛使用基于语音识别处理执行动作的各种设备。如上所述的设备,通常通过网络将收集的用户语音传输到服务器装置,并接收服务器装置的语音识别处理的结果,以实现各种动作。
在这种情况下,对于将语音传输到服务器装置,需要考虑隐私和通信量。
例如,假设用户的语音中包含了大量不打算向系统询问的内容。因此,收集语音的设备优选地仅向服务器装置传输想要向系统询问的用户的语音,并且通知执行该语音的传输。
此外,语音的传输需要通信费用,并且服务器装置的语音识别处理也需要计算成本。因此,收集语音的设备优选地仅向服务器装置传输最小必要的语音,以抑制通信费用和计算成本。
从上述观点来看,大多数设备采用这样的方法,其中,设置固定的唤醒词(wuw,wakeupword),并且在识别所说出的唤醒词之后,仅在预定活动周期期间将用户的语音传输到服务器,并且在活动周期结束之后中断通信。
然而,在使用如上所述的唤醒词的控制中,用户必须在每次向系统询问时说出唤醒词,并且必须在每次通过光源等的照明可视地确认已经识别出唤醒词之后,说出预期的语音。因此,操作变得复杂,很难进行自然的会话。
此外,近年来,存在基于估计的环境自主地做出动作的自主操作单元收集用于语音识别处理的语音的情况。在这种情况下,在自主操作单元的作用下产生的操作噪声会降低收集语音的准确度,结果,会导致语音识别准确度的降低。
通过关注如上所述的要点而想到根据本公开的一个实施例的技术思想,并且能够提高通过自主操作单元执行的语音识别处理的精度,并且进行自然的会话。
例如,当在由自主操作单元收集用户的语音时,并且在基于相关语音的语音识别处理中,执行仅使用唤醒词的控制时,存在以下问题。
1.在有操作噪声和讨厌的声音的环境中,唤醒词识别的精度降低。
2.每次都要说出一个唤醒词,让事情变得复杂。
3.需要时间来完成唤醒词的语音以及完成唤醒词的识别。
4.因为每次都要说出一个唤醒,所以很难进行自然的会话。
5.根据用户,固定的唤醒词可能很难发出。
6.当与语音传输相关的表达方法仅仅是简单地点亮光源时,它的表达性较差。
在本公开的一个实施例中,基于各种触发来控制与语音识别处理相关的自主操作单元的多个状态之间的转换,并且使自主操作单元对各种状态做出不同的表示,从而解决上述问题。
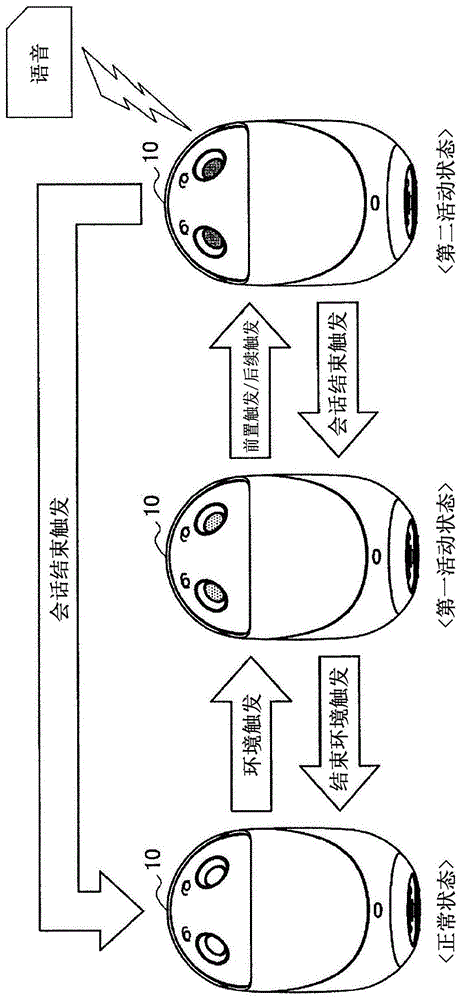
图1是用于解释本实施例的概述的示图。在图1中,示出了根据本实施例的自主操作单元10的状态转换。图1示出了自主操作单元10是具有长椭圆形主体的机器人的情况,该机器人基于各种识别处理的结果自主移动。根据本实施例的自主操作单元10可以是例如紧凑的机器人装置,其尺寸和重量使得用户可以用一只手容易地举起。
在这种情况下,根据本实施例的自主操作单元10的控制单元150基于各种检测到的触发,根据自主操作单元10的语音识别处理来控制状态转换。这些状态包括例如正常状态、第一活动状态和第二活动状态。
根据本实施例的正常状态可以是不限制自主操作单元10的自主动作的状态。此外,根据本实施例的第一活动状态可以是限制自主操作单元10的一些自主动作的状态。此外,第二活动状态可以是用户的语音被传输到执行语音识别处理的信息处理服务器20的状态,即,对应于上述活动周期的状态。在根据本实施例的第二活动状态中,无论是否检测到如上所述的各种类型的触发,都可以一直向服务器装置执行声音流传送,并且可以一直执行语音识别处理。通过这样的控制,可以进行更自然的会话,不像每次启动语音识别处理都需要某种触发的情况。
例如,当在正常状态下检测到指示用户对自主操作单元10说话的可能性增加的环境触发时,根据本实施例的控制单元150将自主操作单元10转换到第一活动状态。即,当检测到用户与自主操作单元10说话的可能性增加时,根据本实施例的控制单元150使得自主操作单元10转换到限制自主操作单元10的自主动作的第一活动状态,以准备用户的询问。
根据本实施例的环境触发器包括对自主操作单元10的接触,特别是对举起的检测、通过点亮照明等来检测照度的增加、对诸如用户的面部或身体等移动物体的检测、对不同于正常声音的突发声音的检测等。图2示出了根据本实施例的触发器的具体示例。
当检测到如上所述的环境触发时,用户对自主操作单元10说话的可能性很高,因此,自主操作单元10转换到第一活动状态,以通过停止自主动作等来降低其自身的操作噪声,从而可以有效地收集用户的语音。如上所述,根据本实施例的控制单元150可以在第一活动状态下控制自主操作单元10的操作噪声的音量低于阈值。
此外,如图1所示,当在第一活动状态中检测到指示用户对自主操作单元10说话的可能性变低的结束环境触发时,根据本实施例的控制单元150使自主操作单元10转换到正常状态。
根据本实施例的结束环境触发包括对自主操作单元的接触结束的检测,特别是自主操作单元10的静止、通过关闭照明等来检测照度的降低、检测环境噪声的降低等。
即,根据本实施例的自主操作单元10可以在估计当用户已经离开该地方、手持的自主操作单元10已经放在地板上等时来自用户的询问的发生的可能性暂时较低时,返回到正常状态。
另一方面,当在第一活动状态中检测到前置触发(prefixtrigger)或后续触发(postfixtrigger)时,根据本实施例的控制单元150使自主操作单元10转换到第二活动状态。根据本实施例的前置触发和后续触发是用户指示对系统进行先前或后续询问意图的词语和动作,并且可以分别在对应于询问的话语之前或之后被检测到。
例如,如图2所示,根据本实施例的前置触发和后续触发包括特定单词(即,唤醒词)的检测、特定手势的检测、对自主操作单元10的接触的检测、用户面部等的检测、突发声音的检测、移动体的检测等。传感器单元130可以例如基于由红外传感器检测到的温度变化、人体检测传感器的反应等来检测移动体。
如上所述,根据本实施例的自主操作单元10基于除了唤醒词之外的各种触发使得自主操作单元10转换到第二活动状态,并且能够使得自主操作单元10将由自主操作单元10收集的用户的语音传输到信息处理传感器20。
此外,当在第二活动状态中检测到对应于会话结束的会话结束触发时,根据本实施例的控制单元150使自主操作单元10转换到第一活动状态或正常状态。
例如,如图2所示,根据本实施例的会话结束触发包括特定单词的检测、特定手势的检测、对自主操作单元10的接触的检测、用户面部的检测等、突发声音的检测等。
如上所述,根据本实施例的自主操作单元10可以通过检测各种触发来估计用户询问的结束,并且可以防止语音在其后被不必要地传输到信息处理服务器20。
如上所述,已经描述了根据本实施例的自主操作单元10的状态转换的概述。根据上述状态转换的控制,可以解决上述问题1至5,可以提高语音识别精度,并且能够进行更自然的会话。
此外,例如,如图1所示,根据本实施例的控制单元150根据状态改变眼睛的颜色,或者根据状态控制使用面部和身体进行不同的动作。因此,控制单元150控制自主操作单元10分别在正常状态、第一活动状态和第二活动状态下做出不同的表达,从而解决了上述问题6,并且可以通知用户正在明确地传输语音。
在下文中,将更详细地解释实现上述功能的配置以及由该配置产生的效果。
<<1.2.系统配置示例>>
首先,将解释根据本实施例的信息处理系统的系统配置示例。图3是示出根据实施例的信息处理系统的配置示例的示图。如图3所示,根据本实施例的信息处理系统包括自主操作单元10和信息处理服务器20。此外,自主操作单元10和信息处理服务器20通过网络30相互连接,使得相互通信成为可能。
自主操作单元10
根据本实施例的自主操作单元10是其状态基于检测到的触发在与语音识别处理相关的多个状态之间转换的信息处理设备。如上所述,根据本实施例的自主操作单元10可以是基于识别的环境进行自主移动的机器人装置。注意,根据本实施例的自主操作单元10的形状不限于所示的椭圆形,而是可以是模仿动物、人等的各种机器人装置。
信息处理服务器20
根据本实施例的信息处理服务器20是基于从自主操作单元10接收的语音执行语音识别处理的信息处理设备。此外,根据本实施例的信息处理服务器20可以被配置为针对语音识别结果执行自然语言处理,并且生成对用户的语音意图的响应。
网络30
网络30具有连接自主操作单元10和信息处理服务器20的功能。网络30可以包括公共网络,例如,互联网、电话线网络和卫星通信网络、包括以太网(注册商标)的各种局域网(lan)、广域网(wan)等。此外,网络30可以包括专用网络,例如,互联网协议虚拟专用网络(ip-vpn)。此外,网络30可以包括无线通信网络,例如,wi-fi(注册商标)和蓝牙(注册商标)。
如上所述,已经说明了根据本实施例的信息处理系统的配置示例。注意,以上利用图3解释的配置仅是一个示例,并且根据本实施例的信息处理系统的配置不限于该示例。根据本实施例的信息处理系统的配置可以根据规范和用途灵活地改变。
<<1.3.自主操作单元10的功能配置示例>>
接下来,将解释根据本实施例的自主操作单元10的功能配置示例。图4是示出根据实施例的自主操作单元10的功能配置示例的框图。如图4所示,根据本实施例的自主操作单元10包括声音输入单元110、成像单元120、传感器单元130、触发检测单元140、控制单元150、驱动单元160、声音输出单元170、显示单元180和服务器通信单元190。
声音输入单元110
根据本实施例的声音输入单元110收集用户的语音、环境噪声等。为此,根据本实施例的声音输入单元110包括麦克风。
成像单元120
根据本实施例的成像单元120捕捉用户或周围环境的图像。为此,根据本实施例的成像单元120包括成像装置。
传感器单元130
根据本实施例的传感器单元130通过各种感测装置收集与用户、周围环境或自主操作单元10相关的感测数据。根据本实施例的传感器单元130包括例如tof传感器、惯性传感器、红外传感器、照度传感器、毫米波雷达、接触传感器、全球导航卫星系统(gnss)信号接收器等。
触发检测单元140
根据本实施例的触发检测单元140基于由声音输入单元110、成像单元120和传感器单元130收集的各种数据来检测上述各种触发。
例如,根据本实施例的触发检测单元140基于声音输入单元110收集的语音和用户自由注册的特定语音表达来检测特定单词(唤醒词)。
此外,例如,根据本实施例的触发检测单元140基于由成像单元120捕捉的图像来执行用户的面部或身体或特定姿势的检测。
此外,根据本实施例的触发检测单元140基于由传感器单元130收集的加速度数据来检测用户提起自主操作单元10或使其静止。
控制单元150
根据本实施例的控制单元150控制自主操作单元10中包括的各个组件。如上所述,根据本实施例的控制单元150基于由触发检测单元140检测到的各个触发来控制与自主操作单元10的语音识别处理相关的多个状态的转换。稍后将单独描述根据本实施例的控制单元150的功能的细节。
驱动单元160
根据本实施例的驱动单元160基于控制单元150的控制来执行各种动作。根据本实施例的驱动单元160可以包括例如多个致动器(马达等)、车轮等。
声音输出单元170
根据本实施例的声音输出单元170基于控制单元150的控制来执行系统声音等的输出。为此,根据本实施例的声音输出单元170包括放大器和扬声器。
显示单元180
根据本实施例的显示单元180基于控制单元150的控制来执行视觉信息的呈现。根据本实施例的显示单元180包括例如对应于眼睛的led、oled等。
服务器通信单元190
根据本实施例的服务器通信单元190通过网络30执行与信息处理服务器20的数据通信。例如,根据本实施例的服务器通信单元190将由声音输入单元110收集的用户的语音传输到信息处理服务器20,并且接收对应于语音的语音识别结果和响应数据。
如上所述,已经说明了根据本实施例的自主操作单元10的功能配置示例。注意,利用图4解释的配置仅是一个示例,并且根据本实施例的自主操作单元10的功能配置不限于该示例。根据本实施例的自主操作单元10的功能配置可以根据规范和用途灵活地改变。
<<1.4.信息处理服务器的功能配置示例20>>
接下来,将解释根据本实施例的信息处理服务器20的功能配置示例。图5是示出根据本实施例的信息处理服务器20的功能配置示例的框图。如图5所示,根据本实施例的信息处理服务器20包括语音识别单元210、自然语言处理单元220、响应生成单元230和终端通信单元240。
语音识别单元210
根据本实施例的语音识别单元210基于从自主操作单元10接收的语音执行自动语音识别(asr),并将语音转换成字符串。
自然语言处理单元220
根据本实施例的自然语言处理单元220基于由语音识别单元210生成的字符串执行自然语言理解(nlu)处理,并提取用户的语音意图。
响应生成单元230
根据本实施例的响应生成单元230基于由自然语言处理单元220提取的用户的语音意图来生成对语音意图的响应数据。响应生成单元230生成例如对用户问题的回答语音等。
终端通信单元240
根据本实施例的终端通信单元240通过网络30执行与自主操作单元10的数据通信。例如,根据本实施例的终端通信单元240从自主操作单元10接收语音,并且向自主操作单元10传输对应于语音、响应数据等的字符串。
如上所述,已经说明了根据本实施例的信息处理服务器20的功能配置示例。注意,利用图5解释的上述配置仅是一个示例,并且根据本实施例的信息处理服务器20的功能配置不限于该示例。根据本实施例的信息处理服务器20的功能配置可以根据规范和用途灵活地改变。
<<1.5.功能细节>>
接下来,将详细解释根据本实施例的自主操作单元10的功能。首先,将解释从正常状态到第一活动状态的转换。如上所述,根据本实施例的控制单元150基于由触发检测单元140检测到的各种环境触发,使自主操作单元10从正常状态转换到第一活动状态。
图6是示出根据实施例的从正常状态到第一活动状态的转换的流程的流程图。参考图6,首先,控制单元150使自主操作单元10根据正常状态执行自主动作(s1101)。
随后,根据本实施例的触发检测单元140基于由声音输入单元110、成像单元120和传感器单元130收集的各种数据来尝试检测环境触发(s1102)。
当没有检测到环境触发时(s1102:否),自主操作单元10返回到步骤s1101。
另一方面,当触发检测单元140检测到环境触发时(s1102:是),控制单元150使自主操作单元10停止根据正常状态的自主动作,并且转向环境触发检测的方向,例如,转向检测到移动体(用户的身体等)或突发声音的方向(s1103)。
随后,控制单元150使自主操作单元10转换到第一活动状态,并使显示单元180、驱动单元160等做出指示其处于第一活动状态的表达(s1104)。
如上所述,已经解释了根据本实施例的从正常状态到第一活动状态的转换的流程。如上所述,根据本实施例的自主操作单元10通过从各种环境触发中估计用户说话的可能性来准备来自用户的询问,并且试图通过停止自主动作等来降低操作噪声的音量。利用这种控制,当用户输出语音时,可以避免操作噪声干扰来自语音的声音的收集,并且以更高的精度实现语音识别。
当触发检测单元140检测到图2所示的各种环境触发中的单个触发时,根据本实施例的控制单元150可以控制向第一活动状态的转换,或者可以基于多个环境触发的组合来控制向第一活动状态的转换。
图7是用于解释根据实施例的基于触发组合的状态转换的示图。例如,在图7左侧所示的情况下,基于检测到用户u提起自主操作单元10并且检测到用户u的面部,控制单元150使自主操作单元10转换到第一活动状态。
此外,在图7右侧所示的示例的情况下,控制单元150基于对自主操作单元10的接触(例如,戳等)以及检测到用户u的身体,使得自主操作单元10转换到第一活动状态。
如上所述,根据本实施例的控制单元150可以基于多个触发的检测来控制自主操作单元10的状态转换。根据该控制,与使用单个触发的情况相比,可以更精确地估计情况,并且可以根据情况实现适当的状态转换。
虽然图7示出了控制单元150基于多个环境触发来控制从正常状态到第一活动状态的转换的情况,但是根据本实施例的控制单元可以基于相应触发的组合来控制状态转换,而不管触发的类型如何。
如图6中的步骤s1104所解释的,根据本实施例的控制单元150控制显示单元180和驱动单元160转换到第一活动状态,并且使得自主操作单元10做出指示其处于第一活动状态的表达。
图8是用于解释根据实施例的眼部表情的来表示状态的示图。如图8所示,根据本实施例的自主操作单元10的眼部包括多个rgb_led182和白色led184。
在图8所示的一个示例中,眼部包括对应于瞳孔和虹膜的三个rgb_led182以及对应于所谓的眼白的四个白色led184。
根据上述配置,可以做出例如,如图所示,半开眼睛等的表情、眨眼、转动等的表情、各种颜色或低亮度值的照明等的各种眼睛表情。
根据本实施例的控制单元150通过使显示单元180根据状态做出相应不同的表情来使显示单元180做出处于相应状态的表达。例如,控制单元150可以被配置为随着从正常状态到第一活动状态的转换而改变由rgb_led182发射的光的颜色,以表示其处于第一活动状态。
虽然图8示出了根据本实施例的眼部由多个led实现的情况,但是根据本实施例的眼部可以由单个或独立的两个oled等实现。
随后,将解释根据本实施例的从第一活动状态到第二活动状态的转换的流程。如上所述,根据本实施例的控制单元150基于由触发检测单元140检测到的前置触发或后续触发,使自主操作单元10从第一活动状态转换到第二活动状态。
图9是示出根据实施例的从第一活动状态到第二活动状态的转换流程的流程图。参考图9,首先,控制单元150让自主操作单元10根据第一活动状态执行自主动作或停止动作(s1201)。
随后,触发检测单元140试图检测指示关于自主操作单元10的先前询问的意图的前置触发(s1202)。
此外,触发检测单元140试图检测指示关于自主操作单元10的后续询问的意图的后续触发(s1203)。
当没有检测到前置触发时(s1202:否),并且当没有检测到后续触发时(s1203:否),自主操作单元10返回到步骤s1201。
另一方面,当检测到前置触发时(s1202:是),或者当检测到后续触发时(s1203:是),控制单元150使自主操作单元10转换到第二活动状态,并且使自主操作单元10做出指示其处于第二活动状态的表达(s1204)。
如上所述,已经解释了根据本实施例的从第一活动状态到第二活动状态的转换的流程。如上所述,除了特定词(唤醒词)之外,根据本实施例的前置触发还包括对特定手势、对自主操作单元的接触(戳等)、突然声音、面部等的检测。
在第一活动状态中,当在用户的语音开始之前检测到如上所述的前置触发时,根据本实施例的控制单元150可以使自主操作单元10转换到第二活动状态,并且将在检测到前置触发之后收集的语音传输到信息处理服务器20。
如上所述,在根据本实施例的通过自主操作单元10的语音识别处理中,不一定需要说出唤醒词。因此,根据本实施例的自主操作单元10即使在嘈杂的环境中也可以高精度地检测来自用户的开始语音识别的指令,并且可以改善与唤醒词的语音相关的复杂过程以及识别处理所需的处理时间。此外,通过使用除了唤醒词之外的各种前置触发,可以进行自然的会话,而无需每次都说唤醒词。
此外,通过使用除了唤醒词之外的前置触发,可以广泛地支持难以说出特定单词的用户,例如,避免外国人需要用非母语说唤醒词的情况等。
此外,即使当使用唤醒词时,本实施例也允许将其设计成使得唤醒词可以如用户所希望的那样被注册。
接下来,将详细描述根据本实施例的后续触发。根据本实施例的后续触发包括与上述前置触发类似的要检测的内容,但是关于语音的触发检测时间不同于前置触发的检测时间。
图10和图11是用于解释根据实施例的后续触发的示图。例如,在图10的上部,示出了后续触发是对应于自主操作单元10的名称为“迈克尔”的语音的示例。
首先,根据本实施例的控制单元150执行控制,使得在第一活动状态下累积由声音输入单元110收集的用户的语音。此时,当如图10的上部所示检测到后续触发时,控制单元150使自主操作单元10转换到第二活动状态,并且随着该转换,将在第一活动状态中累积的语音传输到信息处理服务器20。
在这种情况下,控制单元150可以控制向信息处理服务器20发送从检测到后续触发的时间点直到其之前的预定时间的预定周期中累积的语音。
此外,当在用户的讲话中间检测到对应于后续触发的特定单词时,控制单元150可以将该特定单词作为后续触发和前置触发来处理。
例如,在图10的中间部分所示的示例的情况下,在语音的中间检测到特定单词“迈克尔”。在这种情况下,控制单元150可以被配置为将特定单词作为后续触发来处理,并且控制将从检测到特定单词的时间点直到预定时间的预定周期内累积的声音传输到信息处理服务器20。
此外,同时,控制单元150可以被配置为将特定单词“迈克尔”处理为前置触发,并且控制将在检测到特定单词的时间点之后收集的语音传输到信息处理服务器20。
根据本实施例的后续触发不限于如上所述的特定单词,而是可以是例如特定手势。例如,在图10的下部所示的示例的情况下,用户在说话之前执行对应于前置触发的特定手势。
如本文所示,即使触发检测单元140不能检测到上述特定手势,通过检测在说话之后再次执行的特定手势作为后续触发,在从检测到后续触发的时间点直到其之前的预定时间的周期中累积的声音被传输到信息处理服务器20。
在以上描述中,已经说明了控制单元150基于从检测到后续触发的时间点起的预定时间来控制累积声音的传输的情况,但是根据本实施例的控制单元150可以基于语音活动检测(vad)结果来控制要传输到信息处理服务器20的累积声音的一部分。
例如,在图11的上部所示的示例的情况下,控制单元150可以控制向信息处理服务器20传输在从包括后续触发的声音部分的开始点(vadbegin)直到结束点(vadend)的周期中累积的声音。
此外,当在语音中间检测到后续触发时,控制单元150也可以执行类似的控制。在图11的下部所示的示例的情况下,在语音的中间检测到后续触发,但是在这种情况下,通过使用语音活动检测的结果,所讲的内容可以被传输到信息处理服务器20,而不会被遗漏。
此外,当在预定时间内连续收集语音时,控制单元150可以控制基于单个后续触发将多个连续累积的声音批量传输到信息处理服务器20。
例如,在图11所示的示例的情况下,用户进行连续的三次讲话,并且后续触发仅包括在第三语音中。在这种情况下,控制单元150可以基于在预定时间内连续输出这三个语音这一事实,通过检测到的单个后续触发来控制将对应于这三个语音的累积声音批量传输到信息处理服务器20。
如上所述的连续语音可以是多个用户的语音。图12是用于解释根据实施例的对应于用户之间的会话的后续触发的示图。例如,作为图12的上部所示的示例,假设用户u1和用户u2正在进行会话的情况。
此时,控制单元150基于触发检测单元140已经检测到用户u1的身体和用户u2的面部这一事实,即在该示例中已经检测到环境触发,使自主操作单元10从正常状态转换到第一活动状态,并且执行语音uo1和uo2的收集和累积。
如图12的下部所示,当用户u1输出包括特定单词“迈克尔”的语音时,控制单元150基于由触发检测单元140检测到的上述特定单词,即后续触发,控制转换到第二活动状态,并将对应于在第一活动状态中累积的语音uo1和uo2的语音传输到信息处理服务器20。
根据上述控制,如图所示,可以按时间顺序语音识别用户之间会话的语音的语音识别,并且可以通过系统语音so1输出适合于语音上下文的回复。
如上所述,已经用具体示例解释了根据本实施例的后续触发。因此,根据本实施例的控制单元150可以被配置为当在用户的语音已经开始之后检测到指示关于自主操作单元10的后续询问的意图的后续触发时,使得自主操作单元10转换到第二活动状态,并且将至少在后续触发的检测之前累积的语音传输到信息处理服务器20。
按照根据本实施例的控制单元150的上述功能,即使每次在询问之前不说唤醒词,也能够进行语音识别处理,并且能够进行更自然的会话。
接下来,将解释根据本实施例的自主操作单元10通过主动语音和行为转换到第二活动状态。根据本实施例的控制单元150可以被配置为使得自主操作单元10向用户输出主动的语音和行为,并且引导与用户的会话的开始。当用户对语音和行为做出响应时,控制单元150可以使自主操作单元10转换到第二活动状态。
图13是用于解释根据实施例的通过主动语音和行为转换到自主操作单元的第二活动状态的示图。例如,当触发检测单元140检测到用户u处于如图所示的第一活动状态时,控制单元150控制驱动单元160和声音输出单元170,以使自主操作单元10向用户做出主动语音和行为。
在图13所示的示例的情况下,控制单元150控制驱动单元160将自主操作单元10移动到靠近用户u前方的位置,并使声音输出单元170输出对应于对用户u的呼叫的系统声音so2。
在这种情况下,用户对系统声音so2做出反应,例如,uo4,并且此后会话继续的可能性估计很高。因此,当触发检测单元140检测到反应(例如,语音uo4)时,控制单元150可以使自主操作单元10从第一活动状态转换到第二活动状态。
如上所述,根据本实施例的自主操作单元10不仅做出被动响应,还可以通过做出关于用户的主动语音和行为来与用户进行会话。根据该功能,可以进行更自然和更丰富的会话,并且可以向用户提供高质量的体验。
此外,当在第一活动状态中没有检测到前置触发或后续触发时,根据本实施例的控制单元150可以使自主操作单元10执行保持第一活动状态的语音和行为。图14是用于解释根据实施例的保持第一活动状态的示图。
当在第一活动状态中没有检测到前置触发或后续触发时,控制单元150可以使自主操作单元10执行搜索用户的动作,如图的左上所示。在这种情况下,控制单元150可以使自主操作单元10以低速移动,使得操作噪声不会妨碍语音收集。
此外,例如,如图的右上部所示,控制单元150可以使自主操作单元10的声音输出单元170输出系统语音so3,以引起用户的注意。此外,类似地,控制单元150可以使自主操作单元10发出语音和动作,来引起用户的注意,如该图的右下部分所示。
此外,例如,控制单元150可以向自主操作单元10的另一单元询问用户检测状况或语音累积状况,如图的左下部分所示。因此,根据本实施例的自主操作单元10可以通过与其他自主操作单元10通信来共享各种信息并执行协作处理。
例如,当环境中存在自主操作单元10的多个单元时,可以被设置成划分角色,使得一个单元负责搜索,而另一单元负责语音的累积等。在这种情况下,当检测到用户的语音时,已经累积语音的自主操作单元10可以与另一自主操作单元10共享累积的语音和语音的识别结果。根据该控制,未能收集用户的语音的自主操作单元10也可以加入与用户的会话,并且可以实现由自主操作单元10的多个单元和用户进行的更丰富的会话。
如上所述,已经解释了根据本实施例的从第一活动状态到第二活动状态的转换。注意,根据本实施例的控制单元150还可以使自主操作单元10直接从第二活动状态转换到第二活动状态,而不经过第一活动状态。
图15是示出根据实施例的从正常状态到第二活动状态的转换的流程的流程图。参考图15,首先,控制单元150使自主操作单元10根据正常状态执行自主动作(s1301)。
接下来,触发检测单元140试图检测例如用户对自主操作单元10的接触等(s1302)。
当没有检测到对自主操作单元10的接触时(s1302:否),自主操作单元10返回到步骤s1301。
另一方面,当触发检测单元140检测到对自主操作单元10的接触时(s1302:是),控制单元150停止自主操作单元10的动作,并使其朝向从传感器数据估计的接触方向转动装置主体(s1303)。
接下来,触发检测单元140尝试检测用户的面部(s1304)。
当不能检测到用户的面部时(s1304:否),触发检测单元140随后尝试检测人(人体)(s1305)。
当触发检测单元140不能检测到人时(s1305:否),自主操作单元10返回到步骤s1301。
另一方面,当触发检测单元140检测到人时(s1305:是),控制单元150停止自主操作单元10的动作(s1306),并且随后调整自主操作单元10的姿势和位置,使得可以看到估计为面部的位置(s1307)。此外,自主操作单元10返回到s1304。
另一方面,当触发检测单元检测到用户的面部时(s1304:是),控制单元150停止自主操作单元10的动作(s1308)。
随后,控制单元150调整自主操作单元10的姿势,以保持眼睛接触,并使其转换到第二活动状态,并执行指示其处于第二活动状态的表达(s1309)。
如上所述,已经描述了根据本实施例的从正常状态到第二活动状态的转换的流程的示例。虽然在以上使用图15的说明中描述了基于对自主操作单元10的接触、面部检测和人的检测来执行转换的示例,但是这些仅仅是一个示例。根据本实施例的自主操作单元10可以基于特定单词或突发声音的检测、笑脸的检测等从正常状态转换到第二活动状态。
接下来,将描述根据本实施例的通过装置主体的移动来表达状态的示例。在图8中,已经描述了根据本实施例的控制单元150使显示单元180根据各个状态改变眼部表达。
根据本实施例的控制单元150可以通过控制驱动单元160而不是通过上述控制,使自主操作单元10做出表示其处于第一活动状态或第二活动状态的表达。图16是示出根据本实施例的通过眼部或装置主体的移动来表达状态的示例的示图。
例如,如图16的上部所示,控制单元150可以控制驱动单元160向上和向下移动整个眼部,以表示点头,并且可以表示听到用户的语音。控制单元150可以通过前后摆动整个装置主体来表示点头。
此外,例如,如图16的中间部分所示,控制单元150可以控制驱动单元160滚动整个眼部,从而表示头部的倾斜,并且表示听到用户的语音。
此外,例如,如图16的下部所示,控制单元150可以控制驱动单元160左右摆动整个装置主体,以表示听到用户的语音。
如上所述,根据本实施例的自主操作单元10可以通过眼部或装置主体的移动,根据相应状态做出丰富的表达,例如,聆听用户的说话的手势。根据这种设置,可以向用户清楚地显示语音正在被传输到外部,并且可以实现尊重用户隐私的交互。
随后,将详细说明根据本实施例的从第二活动状态或第一活动状态到正常状态的转换。图17是示出根据实施例的从第二活动状态的转换的示例的示图。在图17的上部,示出了在自主操作单元10和用户u之间用系统声音so5和语音uo5进行会话的情况。
随后,如中间部分所示,用户u通过接触自主操作单元10来指示会话结束。此时,触发检测单元140检测上述接触,作为会话结束触发。
此时,控制单元150可以使自主操作单元10输出指示会话结束的系统声音so6,或者执行离开用户的动作,如下部分所示。此外,此时,控制单元150使自主操作单元10转换到第一活动状态或正常状态。控制单元150可以被配置为基于检测到的会话结束触发的类型或程度来选择转换目的地的状态。
如上所述,在使用根据本实施例的自主操作单元10的语音识别处理中,用户可以明确地指示会话结束。根据这种设置,用户可以根据他/她自己的决定结束向外部传输语音,并且可以更安全地保护用户的隐私。
另一方面,根据本实施例的自主操作单元10可以基于作为会话结束触发的系统条件自主地结束与用户的会话。例如,当语音的累积量或传输量超过阈值时,或者当语音识别处理中的计算成本超过阈值时,控制单元150可以使自主操作单元10做出导致会话结束的语音和行为。上面描述的语音和行为被假设为例如系统语音说“我累了。我明天再和你谈”的语音、一脸困倦的表达等。通过这种控制,可以有效地减少通信量和计算成本。
此外,控制单元150可以通过停止对用户的主动语音和行为,或者通过控制不超过必要的响应,来减少通信量和计算成本。此外,控制单元150可以执行抑制语音的累积量的控制。
如上所述,已经描述了根据本实施例的从第二活动状态的转换的具体示例。随后,将描述根据本实施例的从第二活动状态的转换的流程。图18是示出根据本实施例的从第二活动状态转换的流程的流程图。
参考图18,首先,控制单元150在第二活动状态下控制与用户的会话(s1401)。
随后,触发检测单元140尝试检测会话结束触发(s1402)。
当此时没有检测到会话结束触发时(s1402:否),自主操作单元10返回到步骤s1401。
另一方面,当触发检测单元140已经检测到会话结束触发时(s1402:是),控制单元150使自主操作单元10做出与会话结束相关的表达,并转换到第一活动状态或正常状态(s1403)。
<<1.6.硬件配置示例>>
接下来,将解释根据本实施例的自主操作单元10的硬件配置示例。首先,参考图19至图23,将描述根据本实施例的自主操作单元10的外部的示例。图19是根据本实施例的自主操作单元10的前视图和后视图。此外,图20是根据本实施例的自主操作单元10的透视图。此外,图21是根据本实施例的自主操作单元10的侧视图。此外,图22和图23是根据本实施例的自主操作单元10的俯视图和仰视图。
如图19至图22所示,根据本实施例的自主操作单元10在主单元的上部包括对应于右眼和左眼的两个眼部510。眼部510由例如上述rgb_led182或白色led184等实现,并且可以表示视线、眨眼等。眼部510不限于上述示例,而是也可以由单个或两个独立的有机发光二极管(oled)等来实现。
此外,根据本实施例的自主操作单元10在眼部510上方具有两个相机515。相机515具有对用户或周围环境成像的功能。此外,自主操作单元10可以基于由相机515捕捉的图像来实现同步定位和建图(slam)。
根据本实施例的眼部510和相机515设置在衬底505上,该衬底设置在外部表面内部。此外,根据本实施例的自主操作单元10的外部表面由不透明材料形成,但是在对应于其上设置眼部和相机151的衬底的部分,提供使用透明或半透明材料的头罩550。因此,用户可以识别自主操作单元10的眼部510,并且自主操作单元10可以对外部世界进行成像。
此外,如图19、图20和图23所示,根据本实施例的自主操作单元10包括位于下前部的tof传感器520。tof传感器520具有检测到前方存在的物体的距离的功能。根据tof传感器520,可以高精度地检测到与各种物体的距离,并且通过检测台阶等,可以防止跌倒或摔倒。
此外,如图19、图21所示,根据本实施例的自主操作单元10可以在背面上具有用于外部装置的连接端子555和电源开关560。自主操作单元10可以通过连接端子555连接到外部装置来执行数据通信。
此外,如图23所示,根据本实施例的自主操作单元10包括底面上的两个车轮570。根据本实施例的车轮570分别由不同的马达565驱动。因此,自主操作单元10可以执行移动动作,例如,向前移动、向后移动、转动和旋转。此外,根据本实施例的车轮570被设置成可向内部缩回,并且可向外部弹出。根据本实施例的自主操作单元10还可以通过用力将两个车轮570弹出到外部来进行跳跃动作。图23示出了车轮570存储在主单元内部的状态。
如上所述,已经说明了根据本实施例的自主操作单元10的外部。随后,将解释根据本实施例的自主操作单元10的内部结构。图24是用于解释根据本实施例的自主操作单元10的内部结构的示意图。
如图24的左侧所示,根据本实施例的自主操作单元10包括设置在电子衬底上的惯性传感器525和通信装置530。惯性传感器525检测自主操作单元10的加速度和角速度。此外,通信装置530是实现与外部的无线通信的组件,并且包括例如蓝牙(注册商标)、wi-fi(注册商标)天线等。
此外,自主操作单元10包括例如主单元的侧表面内部的扬声器535。自主操作单元10可以通过扬声器535输出包括语音在内的各种声音信息。
此外,如图24的右侧所示,根据本实施例的自主操作单元10包括主单元的上部内部的多个麦克风540。麦克风540收集用户的语音和周围的环境噪声。此外,由于配备有多个麦克风540,自主操作单元10能够以高灵敏度收集周围环境中产生的声音,并且能够执行声源的定位。
此外,如图24所示,自主操作单元10包括多个马达565。自主操作单元10可以包括例如:驱动衬底的两个电机单元565,其中,在衬底上,眼部510和相机515沿垂直方向设置;驱动左右轮570的两个电机单元565;以及使自主操作单元10能够向前倾斜的一个电机单元565。根据本实施例的自主操作单元10可以通过上述多个马达565表现出丰富的运动。
接下来,将详细说明其上设置有根据本实施例的眼部510和相机515的衬底505的配置以及眼部510的配置。图25是示出根据本实施例的衬底505的配置的示图。此外,图26是根据本实施例的衬底505的局部横截面。参考图25,根据本实施例的衬底505连接到两个马达565。如上所述,两个马达565可以驱动衬底505,其中,在衬底505上,眼部510和相机515沿垂直方向和水平方向设置。通过这种设置,自主操作单元10的眼部510可以沿垂直方向和水平方向灵活地移动,并且可以根据情况和动作表现丰富的眼部运动。
此外,如图25和图26所示,眼部510由对应于虹膜的中央部分512和对应于眼白的外围部分514构成。中央部分512可以包括上述rgb_led182,外围部分514可以包括白色led184。如上所述,根据本实施例的自主操作单元10将眼部510的组件分成两部分,从而能够表达类似于实际生物的自然眼睛表达。
接下来,参考图27和图28,将详细说明根据本实施例的车轮570的结构。图27和图28是示出根据本实施例的车轮570的外围结构的示图。根据本实施例的两个车轮570由相应独立的马达565驱动。通过这种配置,除了简单的向前和向后移动之外,还可以精确地表达移动动作,例如,在原地转动和旋转。
此外,如上所述,根据本实施例的车轮570设置成可向主单元的内部缩回,并且可向外部弹出。此外,根据本实施例,通过将阻尼器(dumper)575与车轮同轴设置,可以有效地减少冲击和振动向轴和车身的传递。
此外,如图28所示,根据本实施例,辅助弹簧580可以设置在车轮570中。根据本实施例的车轮的驱动在包括在自主操作单元10中的驱动部件中需要最高扭矩,但是通过提供辅助弹簧580,所有的马达565可以共用,而不需要对各个驱动部件使用不同的马达。
<2.结论>
如上所述,根据本公开的一个实施例的控制单元150基于检测到的触发通过自主操作单元控制与语音识别处理相关的多个状态之间的转换。上述多个状态包括自主操作单元的动作受到限制的第一活动状态以及执行语音识别处理的第二活动状态。根据这样的配置,可以提高语音识别精度,并且可以进行自然的会话。
如上所述,已经参考附图详细解释了本公开的示例性实施例,但是本公开的技术范围不限于这些示例。显然,在本公开的技术领域中具有普通知识的人可以想到在权利要求中描述的技术思想的范围内的各种变更示例和修正示例,并且这些也被理解为自然地属于本公开的技术范围。
此外,本申请中描述的效果仅是说明性的或示例性的,并且不受限制。即,除了上述效果之外,或者代替上述效果,通过本申请的描述,根据本公开的技术可以产生对于本领域技术人员来说显而易见的其他效果。
此外,还可以创建使计算机中配备的硬件(例如,cpu、rom以及ram)发挥与控制单元150的功能等同的功能的程序,并且还可以提供记录该程序的计算机可读非暂时性记录介质。
此外,根据由本申请中的自主操作单元10执行的处理的相应步骤不一定需要以流程图中描述的顺序按时间顺序执行。例如,根据由自主操作单元10执行的处理的相应步骤可以以不同于流程图中描述的顺序来处理,或者可以并行执行。
以下配置也属于本公开的技术范围。
(1)一种信息处理设备,包括
控制单元,其控制自主操作单元的动作,其中,
所述控制单元基于检测到的触发,通过所述自主操作单元控制与语音识别处理相关的多个状态的转换,并且
这些状态包括自主操作单元的动作受到限制的第一活动状态以及执行语音识别处理的第二活动状态。
(2)根据(1)所述的信息处理设备,其中,
这些状态还包括自主操作单元的动作不受限制的正常状态。
(3)根据(2)所述的信息处理设备,其中,
所述控制单元控制自主操作单元的动作,使得在第一活动状态下操作噪声的音量低于阈值。
(4)根据(3)所述的信息处理设备,其中,
所述控制单元使自主操作单元在第二活动状态下向语音识别设备传输由自主操作单元收集的语音。
(5)根据(4)所述的信息处理设备,其中,
所述控制单元使自主操作单元在第一活动状态下累积语音。
(6)根据(5)所述的信息处理设备,其中,
所述控制单元控制在转换到所述第二活动状态的同时,将在第一活动状态中累积的语音发送到所述语音识别设备。
(7)根据(6)所述的信息处理设备,其中,
当在用户的语音已经在第一活动状态中开始之后检测到指示关于自主操作单元的后续询问意图的后续触发时,所述控制单元使自主操作单元转换到第二活动状态,并且至少将在检测到后续触发之前累积的语音传输到语音识别设备。
(8)根据(7)所述的信息处理设备,其中,
所述后续触发包括特定单词的检测、特定手势的检测、对自主操作单元的接触的检测、用户面部的检测、突发声音的检测和移动体的检测中的至少一个。
(9)根据(4)至(8)中任一项所述的信息处理设备,其中,
所述控制单元使自主操作单元在第一活动状态下对用户进行主动语音和行为,并且当用户对语音和行为做出反应时,使自主操作单元转换到第二活动状态。
(10)根据(4)至(9)中任一项所述的信息处理设备,其中,
当在第一活动状态中用户的语音开始之前检测到指示关于自主操作单元的先前询问意图的前置触发时,所述控制单元使自主操作单元转换到第二活动状态,并且将在检测到前置触发之后收集的语音传输到语音识别设备。
(11)根据(2)至(10)中任一项所述的信息处理设备,其中,
当在正常状态下检测到指示用户相对于自主操作单元发出语音的可能性变高的环境触发时,所述控制单元使自主操作单元转换到第一活动状态。
(12)根据(11)所述的信息处理设备,其中,
所述环境触发包括对自主操作单元的接触的检测、照度变化的检测、移动体的检测和突发声音的检测中的至少一个。
(13)根据(2)至(12)中任一项所述的信息处理设备,其中,
当在第一活动状态中检测到指示用户对自主操作单元发出语音的可能性变低的结束环境触发时,所述控制单元使自主操作单元转换到正常状态。
(14)根据(13)所述的信息处理设备,其中,
所述结束环境触发包括对自主操作单元的接触结束的检测、照度降低的检测和环境声音降低的检测中的至少一个。
(15)根据(2)至(14)中任一项所述的信息处理设备,其中,
当在第二活动状态中检测到与会话结束相关的会话结束触发时,所述控制单元使自主操作单元转换到第一活动状态和正常状态中的任何一个。
(16)根据(15)所述的信息处理设备,其中,
所述会话结束触发包括特定单词的检测、特定手势的检测、对自主操作单元的接触的检测、用户面部的检测结束和突发声音的检测中的至少一个。
(17)根据(2)至(16)中任一项所述的信息处理设备,其中,
所述控制单元使自主操作单元分别在正常状态、第一活动状态和第二活动状态下做出不同的表达。
(18)根据(1)至(17)中任一项所述的信息处理设备,为自主操作单元。
(19)一种信息处理方法,包括:
控制自主操作单元的动作,其中,
所述控制包括基于检测到的触发,通过所述自主操作单元控制与语音识别处理相关的多个状态的转换,并且
这些状态包括自主操作单元的动作受到限制的第一活动状态以及执行语音识别处理的第二活动状态。
(20)一种使计算机用作信息处理设备的程序,包括:
控制单元,其控制自主操作单元的动作,其中,
所述控制单元基于检测到的触发,通过所述自主操作单元控制与语音识别处理相关的多个状态的转换,并且
这些状态包括自主操作单元的动作受到限制的第一活动状态以及执行语音识别处理的第二活动状态。
附图标记列表
10自主操作单元
110声音输入单元
120成像单元
130传感器单元
140触发检测单元
150控制单元
160驱动单元
170声音输出单元
180显示单元
20信息处理服务器
210语音识别单元
220自然语言处理单元
230响应生成单元
- 还没有人留言评论。精彩留言会获得点赞!