交替响应生成的制作方法
相关申请数据的交叉引用
本申请要求以gregorynewell等人的名义于2018年12月10日提交的名称为“alternateresponsegeneration”的美国专利申请号16/214,758的优先权权益。
背景技术:
言语识别系统已经发展到人们可使用他们的语音与计算装置进行交互的程度。此类系统采用基于所接收到音频输入的各种质量来标识人类用户所说出的字词的技术。言语识别与自然语言理解处理技术相结合使得计算装置的基于言语的用户控制能够基于用户的口头命令执行任务。言语识别和自然语言理解处理技术的组合在本文中称为言语处理。言语处理还可涉及将用户的言语转变成文本数据,接着可将文本数据提供至各种基于文本的软件应用程序。
言语处理可由计算机、手持装置、电话计算机系统、电话亭和广泛多种其他装置使用以改进人机交互。
附图说明
为了更完全地理解本公开,现在结合附图来参考以下描述。
图1a和图1b例示根据本公开的实施方案的被配置来执行会话恢复的系统。
图2a是根据本公开的实施方案的系统的组件的概念图。
图2b是根据本公开的实施方案的自动言语识别组件的概念图。
图2c是根据本公开的实施方案的可如何执行自然语言理解处理的概念图。
图2d是根据本公开的实施方案的可如何执行自然语言理解处理的概念图。
图3是例示根据本公开的实施方案的可如何执行会话恢复的过程流程图。
图4是根据本公开的实施方案例示会话恢复组件可如何确定对话题切换技术连同其他会话恢复技术进行排名的过程流程图。
图5是根据本公开的实施方案例示会话恢复组件可如何确定对话题切换技术连同其他会话恢复技术进行排名的过程流程图。
图6是根据本公开的实施方案的会话恢复组件在确定要推荐的话题时可考虑的数据类型的概念图。
图7是根据本公开的实施方案的其中传感器数据被组合以识别一个或多个用户的说明性体系结构的概念图。
图8是例示根据本公开的实施方案的用户识别的系统流程图。
图9是概念性地例示根据本公开的实施方案的装置的示例性组件的框图。
图10是概念性地例示根据本公开的实施方案的系统的示例性组件的框图。
图11例示用于与言语处理系统一起使用的计算机网络的实例。
具体实施方式
自动言语识别(asr)是计算机科学、人工智能和语言学的领域,其涉及将与言语相关联的音频数据变换成代表所述言语的文本。类似地,自然语言理解(nlu)是计算机科学、人工智能和语言学的领域,其涉及使计算机能够从包含自然语言的文本输入中导出含义。asr和nlu通常一起用作言语处理系统的一部分。文本转言语(tts)是涉及将文本数据变换成被合成为类似于人类言语的音频数据的领域。
某些系统可被配置来响应于用户输入执行动作。例如,对于用户输入“alexa,播放adele音乐”,系统可输出由名为adele的艺人演唱的音乐。另如,对于用户输入“alexa,天气怎么样”,系统可输出表示用户的地理位置的天气信息的合成言语。在另外的实例中,对于用户输入“alexa,向john发送消息”,系统可捕获口头消息内容,并且使口头消息内容经由登记到“john”的装置输出。
系统可能会遇到错误状况,例如,系统可能无法执行响应于用户输入的动作,或者可能不确定响应于用户输入的适当动作。例如,用户可输入“alexa,您知道如何演唱brunomars的歌曲吗”。系统可能被配置来输出由名为brunomars的艺人演唱的歌曲的音频记录,但系统可能不会被配置来“演唱”此类歌曲(例如,呈合成言语的形式)。在此实例中,系统可输出通用错误消息,诸如“抱歉,我不确定如何响应”、“抱歉,我不明白”、“我不确定”等。系统进行的此类输出可能会产生不期望的用户体验。
作为在处置此类潜在错误方面可取得专利权的改进,系统可被配置来在指示系统无法执行响应于用户输入的动作、不确定响应于用户输入的适当动作或以其他方式指示错误之前进一步揣摩用户。例如,当系统以其他方式输出表达响应不确定性的内容时,系统可确定对应于用户输入的可能的用户意图,并且可查询用户有关用户是否意图执行对应于可能的意图的特定动作。系统接着可采取不同的动作,以按恢复用户与系统之间的交谈式交换而不是简单地返回错误的方式向用户提供替代内容。这种方法可生成更有益的用户体验。
本公开通过分析上下文信息以推荐系统确定可能与用户相关的话题来改进此类会话恢复。在至少一些情况下,此类会话恢复处理可能与先前用户输入的主旨无关。
所述系统可访问表示上下文的各种数据,在所述上下文中用户向系统提供输入。系统可在运行时使用这些输入来确定有关是否应向用户推荐话题以及所述话题应是什么。即使系统无法满足用户的原始意图,话题也可选择为向用户提供可能对用户有用的信息。可使用一个或多个经训练的机器学习模型来做出此类确定。
系统可使问题输出给用户。问题可询问用户是否可能会对不同动作和/或替代话题感兴趣,例如,“我不明白,您想了解一些有趣的内容吗”?响应于用户作出肯定响应,系统可输出表示用户可如何请求系统执行关于替代话题的动作的内容。例如,系统可输出表示以下的内容:用户可如何使系统播放歌曲、用户可如何使系统输出关于特定个体(例如,艺人)的信息、用户可如何使系统输出关于特定技能(例如,在系统的用户当中具有显著高人气的技能)的信息、或用户可如何使系统输出关于某一其他话题的信息。“技能”可以是在类似于在传统计算装置上运行的软件应用程序的系统中运行的软件。也就是说,技能可使系统能够执行具体功能,以便提供数据或产生某一其他请求的输出。此类系统输出可对应于框架“对不起,我没听明白。但是,这里是您可能想要的一些其他内容:您想了解[话题]吗”。
在至少一些实例中,系统可在用户特定的基础上做出确定。例如,系统可在运行时考虑各种用户特定的数据,以确定是否应向具体用户推荐话题,以及所述特定话题应是什么。因此,可基于不同用户的信息向他们推荐不同话题。
系统可被配置来并入用户许可,并且可仅在提供了用户许可的情况下将用户的数据用于本文所述的过程。系统可被配置来使用户能够按用户的判断撤销此类许可。系统可默认不将用户的数据用于本文所述的过程,并且因此可被配置来仅在已经提供了明确许可的情况下将用户的数据用于此类过程。
如果所述用户对所述推荐的话题作出肯定响应,则所述系统可将用户体验传递到所述系统的适当组件(例如,被配置来执行与所述话题相关的动作的组件)。如果所述用户作出否定响应、根本不做出响应或所述系统不确定所述用户的响应是肯定的还是否定的,则所述系统可停止与所述用户的交互,从而使所述用户能够根据所述用户的需要与所述系统进行交互。
本公开具有各种益处。一个益处在于,本公开提供了更有益的用户体验。这至少部分地是由于以下事实:本公开的教导内容降低了系统执行无响应动作的频率。通过减少执行此类动作的情况,可改进用户/系统交互。
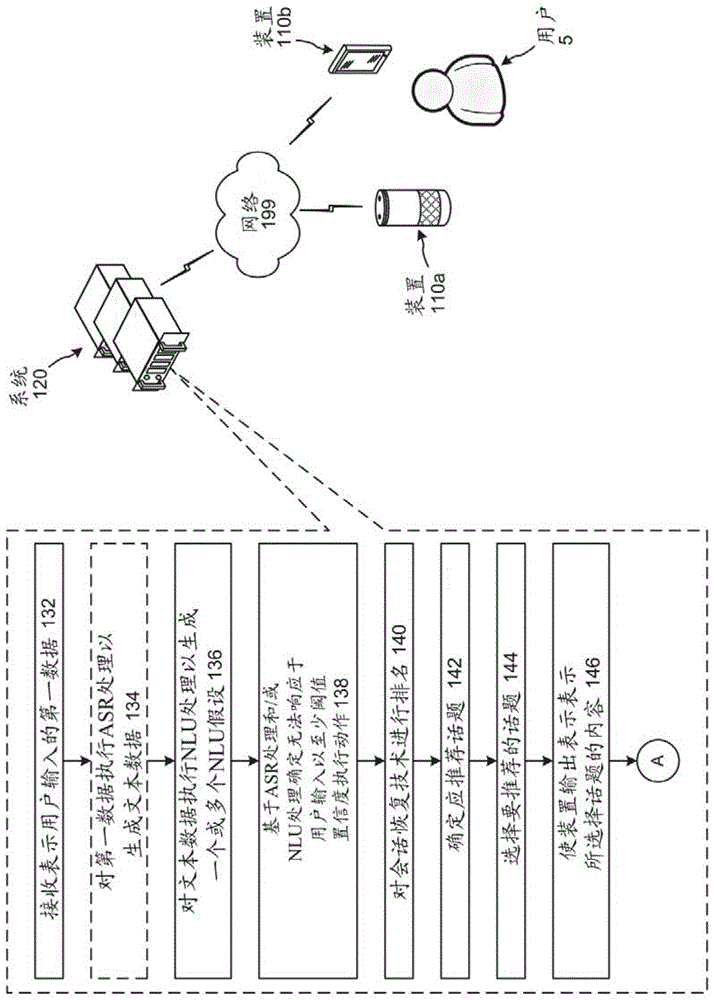
图1a和图1b例示被配置来执行会话恢复的系统。尽管本文附图和论述按特定次序例示系统的某些操作步骤,但在不脱离本公开的意图的情况下,可按不同次序执行所描述的步骤(以及移除或添加的某些步骤)。如图1a和图1b所示,系统可包括用户5本地的跨一个或多个网络199与一个或多个系统120通信的一个或多个装置(110a/110b)。
装置110a可接收表示用户5的口头用户输入的音频。装置110a可生成表示音频的音频数据,并且将音频数据发送到一个或多个系统120,系统120接收(132)所述音频数据。替代地,装置110b可接收表示用户5的基于文本的用户输入的文本输入。装置110b可生成表示文本输入的文本数据,并且可将文本数据发送到一个或多个系统120,系统系统120接收(132)所述文本数据。取决于配置,装置(110a/110b)可经由安装在装置(110a/110b)上的伴随应用程序将音频数据和/或文本数据发送到一个或多个系统120。伴随应用程序可使装置(110a/110b)能够经由网络199与一个或多个系统120通信。伴随应用程序的实例是在手机/平板电脑上操作的amazonalexa应用程序。
如果一个或多个系统120接收用户输入作为音频数据,则一个或多个系统120可对音频数据执行(134)asr处理以生成文本数据。一个或多个系统120可对(例如,如在步骤132处接收的或在步骤134处生成的)文本数据执行(136)nlu处理,以生成一个或多个nlu假设。nlu假设是指意图指示符(表示用户的潜在意图)和一个或多个对应属性槽(slot)(其中每个属性槽对应于文本数据的与系统已知的实体相对应的部分)。
一个或多个系统120可确定错误状况。例如,系统可基于asr处理和/或nlu处理来确定(138)响应于用户输入无法以至少阈值置信度执行动作。换句话说,一个或多个系统120可确定一个或多个系统120无法正确地响应于用户输入。一个或多个系统120在asr处理中的置信度可能不满足阈值置信度,这例如归因于不良音频品质、用户发音错误等。在此情况下,一个或多个系统120可能不理解用户输入。同样地或替代地,没有任何与nlu假设相关联的置信度值可满足阈值置信度。这可能源于不良asr结果(例如,一个或多个系统120无法理解用户输入)、一个或多个系统120理解用户输入但用户输入请求系统未被配置来执行的操作等。由于一个或多个系统120确定错误状况,例如,一个或多个系统120确定一个或多个系统120无法正确地响应于用户输入,因此一个或多个系统120可生成表示错误消息应被输出给用户的指示符。错误消息可指示一个或多个系统120无法理解用户输入,可指示一个或多个系统120理解用户输入但无法执行所请求的动作等。
在确定响应于用户输入无法以至少最小置信度执行动作之后(即,在确定错误状况之后),一个或多个系统120可对会话恢复技术进行排名(140)。一个或多个系统120可被配置来执行各种会话恢复技术,包括但不限于要求用户重复用户输入(例如,当asr置信度为低时);标识评分最高的nlu假设(但仍不满足阈值置信度)并询问用户是否希望一个或多个系统120执行响应于nlu假设的动作;话题切换技术等。每种会话恢复技术可与具体标准相关联。当对会话恢复技术进行排名时,可考虑对特定会话恢复技术的标准的满意程度。
在排名之后,一个或多个系统120可确定(142)应向用户推荐话题。此类确定可源于确定每种会话恢复技术的至少一个标准(不考虑话题切换技术)未得到满足(例如,并非与重复用户输入技术相关联的所有标准得到满足、并非请求确认技术的所有标准得到满足等)。替代地,此类确定可源于所有会话恢复技术,包括被排名的话题切换技术和排名最高的话题切换技术。
在确定应推荐话题之后,一个或多个系统120可选择(144)要推荐的话题。可推荐的说明性话题包括例如对应于由一个或多个系统120的各个用户在过去时间量内收听最多的艺人的艺人、对应于由一个或多个系统120的各个用户在过去时间量内收听最多的专辑的专辑、对应于如根据一个或多个系统120的各个用户的反馈确定的排名最高的技能(例如,排名最高的游戏技能、排名最高的儿童技能、最佳放松技能等)的技能、名人、用户可定制由一个或多个系统120执行的动作的方式(例如,指示可如何用特定类型的音乐唤醒用户的信息、指示用户可如何定制他们在伴随应用程序中维护的列表的名称、指示用户可如何定制他们的新闻推送的信息等)等。要推荐的话题可不对应于任何特定技能。要推荐的话题可与目前的用户输入的主旨无关。例如,要推荐的话题可基于用户5的用户简档数据和/或对应于一个或多个系统120的一个或多个用户的系统使用数据(诸如表示被收听最多的艺人、被收听最多的专辑、排名最高的技能等的系统使用数据)。
要推荐的话题可对应于热门报导。例如,如果nlu结果数据指示对应于热门报导的实体,则一个或多个系统120可选择热门报导。一个或多个系统120可订阅热门话题推送(或可包括热门话题推送)。在选择话题时,一个或多个系统120可确定nlu结果数据中表示的一个或多个实体是否表示在热门报导推送中。报导可基于人工输入或使用自动化方法(例如,基于计算组件确定其已在阈值时间量内从至少阈值量的不同数据提供者接收到报导(或一组相关报导))而视为热门。
要推荐的话题可能与用户输入无关。例如,用户输入可能请求播放音乐。音乐技能可能无法播放所请求音乐。作为响应,一个或多个系统120可推荐非音乐话题(例如,与并非音乐技能的高评级技能相关的信息等)。
一个或多个系统120可使(146)装置(110a/110b)输出推荐话题的内容。装置(110a/110b)可输出推荐话题的音频和/或可显示推荐话题的文本。此类内容可对应于框架“对不起,我不明白,您想要了解[话题]吗”。
在输出内容之后或与之同时,装置110a可接收表示用户5的口头用户输入的音频。装置110a可生成表示音频的音频数据,并且将音频数据发送到一个或多个系统120,一个或多个系统120接收(148)所述音频数据。替代地,装置110b可接收表示用户5的基于文本的用户输入的文本输入。装置110b可生成表示文本输入的文本数据,并且可将文本数据发送到一个或多个系统120,一个或多个系统系统120接收(148)所述文本数据。
一个或多个系统120可确定(150)第二用户输入指示用户想要输出关于话题的信息。此类确定可包括对(在步骤146处接收到的或根据在步骤146处接收到的音频数据的asr处理确定的)文本数据执行nlu处理。之后,一个或多个系统120可使(152)装置(110a/110b)输出信息连同询问用户是否期望系统执行与话题相关的动作的问题。例如,如果话题与特定技能相关,则问题可询问用户系统是否应启用关于用户的简档的技能和/或系统是否应发动所述技能。另如,如果话题与艺人相关,则问题可询问用户系统是否应播放由所述艺人演唱的歌曲。其他实例是可能的。
在输出信息和问题之后或同时,装置110a可接收表示用户5的口头用户输入的音频。装置110a可生成表示音频的音频数据,并且将音频数据发送到一个或多个系统120,一个或多个系统120接收(154)所述音频数据。替代地,装置110b可接收表示用户5的基于文本的用户输入的文本输入。装置110b可生成表示文本输入的文本数据,并且可将文本数据发送到一个或多个系统120,一个或多个系统系统120接收(154)所述文本数据。
一个或多个系统120可确定(156)第三用户输入指示用户想要执行动作。此类确定可包括对(在步骤154处接收的或根据在步骤154处接收到的音频数据的asr处理确定的)文本数据执行nlu处理。之后,一个或多个系统120可使(158)动作被执行。
在一些实例中,一个或多个系统120可能不会询问用户5用户5是否想要执行动作。而是,一个或多个系统120可只是输出信息并且执行动作,而无需另外的用户输入。系统120是否在不征求用户输入准许执行动作的情况下执行动作可基于用户偏好。例如,用户5可向一个或多个系统120指示如果用户5请求输出信息,则之后一个或多个系统120也可在不接收另外的用户输入的情况下执行动作。
在至少一些实例中,用户5可能不会提供(在步骤148处接收的)第二用户输入或(在步骤154处接收的)第三用户输入,用户5可提供(在步骤146处接收的)拒绝所推荐话题(或动作)的第二(或第三)用户输入,或一个或多个系统120可能无法确定第二(或第三)用户输入是接受还是拒绝所推荐话题(或动作)。在此类情况下,一个或多个系统120可停止处理。这可关闭用户5与系统120之间的对话会话,从而使用户5在用户5如此期望时能够与一个或多个系统120开始新的对话会话。
如本文所用,“对话”、“对话会话”、“会话”等是指各种相关的用户输入和系统输出,例如,同用户与系统之间正在进行的交流相关的输入和输出。当一个或多个系统120接收到用户输入时,一个或多个系统120可将表示用户输入的数据(例如,音频数据或文本数据)与会话标识符相关联。会话标识符可同与用户输入的处理相关的各种言语处理数据(例如,asr结果数据、nlu结果数据等)相关联。当一个或多个系统120调用技能时,除了nlu结果数据之外,一个或多个系统120还可将会话标识符发送到技能。如果技能输出数据以呈现给用户,则技能可将数据与会话标识符相关联。前述内容是说明性的,因此本领域技术人员将了解,会话标识符可用于跟踪在一个或多个系统120的各种组件之间传输的数据。
用户输入和响应于用户输入的对应动作的执行可称为对话“轮(turn)”。会话标识符可与对应于连续相关用户输入的多个相关轮相关联。一个用户输入可被视为与后续用户输入相关,从而基于例如接收到第一用户输入与接收到后续用户输入之间的时间长度和/或执行响应于第一用户输入的动作与接收到后续用户输入之间的时间长度而使单个会话标识符与两个用户输入相关联。
系统可使用如图2a所示的各种组件来操作。各种组件可位于同一或不同物理装置上。各种组件之间的通信可直接发生,或通过一个或多个网络199发生。
一个或多个音频捕获组件(诸如装置110的传声器或传声器阵列)捕获音频11。装置110处理表示音频11的音频数据,以确定是否检测到言语。装置110可使用各种技术来确定音频数据是否包括言语。在一些实例中,装置110可应用语音活动检测(vad)技术。此类技术可基于音频数据的各种定量方面(诸如音频数据的一个或多个帧之间的频谱斜率;一个或多个频谱带中的音频数据的能级;一个或多个频谱带中的音频数据的信噪比;或其他定量方面)来确定音频数据中是否存在言语。在其他实例中,装置110可实现被配置来将言语与背景噪声区分开的有限分类器。可通过诸如线性分类器、支持向量机和决策树的技术来实现分类器。在再一些其他实例中,装置110可应用隐马尔可夫模型(hmm)或高斯混合模型(gmm)技术来将音频数据与所存储的一个或多个声学模型进行比较,所述声学模型可包括对应于言语、噪声(例如,环境噪音或背景噪音)或静音的模型。还可使用再一些其他技术来确定音频数据中是否存在言语。
一旦在表示音频11的音频数据中检测到言语,装置110就可使用唤醒词检测组件220来执行唤醒词检测,以确定用户意图何时对装置110说出输入。示例性唤醒词是“alexa”。
通常执行唤醒词检测而不执行语言学分析、文本分析或语义分析。而是,分析表示音频11的音频数据,以确定音频数据的具体特性是否匹配预先配置的声波波形、音频签名或其他数据,以确定音频数据是否“匹配”对应于唤醒词的所存储音频数据。
唤醒词检测组件220可将音频数据与所存储模型或数据进行比较以检测唤醒词。用于唤醒词检测的一种方法应用通用大词汇量连续言语识别(lvcsr)系统以解码音频信号,其中在所得网格或混淆网络中进行唤醒词搜索。lvcsr解码可能需要相对高的计算资源。用于唤醒词检测的另一种方法分别为每个唤醒词和非唤醒词言语信号构建hmm。非唤醒词言语包括其他口头字词、背景噪音等。可构建一个或多个hmm来对非唤醒词言语特性进行建模,称为填充器模型。使用维特比解码来在解码图中搜索最佳路径,并且解码输出被进一步处理以关于唤醒字存在进行决策。这种方法可通过并入混合dnn-hmm解码框架而扩展为包括判别信息。在另一实例中,唤醒词检测组件220可直接构建在深度神经网络(dnn)/递归神经网络(rnn)结构上,而不涉及hmm。这种体系结构可通过在dnn的上下文窗内堆叠帧或使用rnn来估计具有上下文信息的唤醒词的后验概率。后续后验阈值调整或平滑化应用于决策制定。也可使用诸如本领域已知的那些的其他唤醒词检测技术。
一旦检测到唤醒词,装置110就可“唤醒”系统120并且开始将表示音频11的音频数据211传输到一个或多个系统120。音频数据211可包括对应于唤醒词的数据,或可在将音频数据211发送到一个或多个系统120之前由装置110去除音频数据211的对应于唤醒词的部分。
音频数据211在由系统120接收到时可被发送到协调器(orchestrator)组件230。协调器组件230可包括存储器和逻辑,所述存储器和逻辑使协调器组件230能够将各种数据片和形式传输到一个或多个系统120的各种组件,以及执行如本文所述的其他操作。
协调器组件230可将音频数据211发送到asr组件250。asr组件250将音频数据211转录成文本数据。图2b例示asr组件250的示例性组件。asr组件250将音频数据转录成表示包含在音频数据中言语的字词的文本数据。文本数据接着可由其他组件用于各种目的,诸如执行系统命令、输入数据等。asr组件250基于口头用户输入与存储在asr模型存储装置252中的预先建立的语言模型254之间的类似性来解译音频数据211。例如,asr组件250可将音频数据211与语音(例如,子字词单元或音素)和语音序列的模型进行比较,以标识匹配音频数据211的用户输入中说出的语音序列的字词。替代地,asr组件250可使用有限状态置换器(fst)255来实现语言模型功能,如下所解释。
可解译口头用户输入的不同方式(即,不同asr假设)可各自被分配置信度值,所述置信度值表示特定字词集匹配用户输入中说出的那些字词集的似然。置信度值可基于多种因素,包括例如用户输入中的语音与语言语音的模型(例如,存储在asr模型存储装置252中的声学模型253)的类似性以及匹配语音的特定字词在具体位置处包括在语句中(例如,使用语言或语法模型)的似然。因此,口头用户输入的每个潜在的文本解译(每个潜在的asr假设)与置信度值相关联。基于所考虑的因素和所分配的置信度值,asr组件250输出对应于音频数据211的最可能的文本。asr组件250还可输出呈n-最佳列表的形式的多个asr假设,其中每个asr假设与相应置信度值相关联。
asr组件250可包括声学前端(afe)256和言语识别引擎258。afe256将音频数据211变换成供言语识别引擎258处理的数据。言语识别引擎258将(从afe256接收的)数据与声学模型253、语言模型254、fst255和/或其他数据模型和信息进行比较以用于识别音频数据211中表示的言语。afe256可减少音频数据211中的噪声并且将数字化音频数据划分成表示时间间隔的帧,对于所述帧,afe256确定表示音频数据的质量的多个值(称为特征),以及表示帧内音频数据的特征/质量的那些值的集合(称为特征向量)。通常,音频帧各自可以是10毫秒。如本领域中已知的,可确定许多不同特征,并且每个特征表示音频的可用于asr处理的某一品质。多种方法可由afe256用于处理音频数据,诸如梅尔频率倒谱系数(mfcc)、感知线性预测(plp)技术、神经网络特征向量技术、线性判别分析、半绑定协方差矩阵或本领域技术人员已知的其他方法。
言语识别引擎258可参考存储在asr模型存储装置252中的信息来处理afe256的输出。替代地,后前端处理数据(诸如特征向量)可由言语识别引擎258从afe256之外的其他来源接收。例如,装置110可将音频数据处理成特征向量(例如,使用装置上afe),并且通过一个或多个网络199将所述信息传输到一个或多个系统120。特征向量可以编码的形式到达一个或多个系统120,在这种情况下,它们可在由言语识别引擎258处理之前进行解码。
言语识别引擎258尝试将所接收的特征向量与所存储的声学模型253、语言模型254和fst255中已知的语言音素和字词进行匹配。言语识别引擎258基于声学信息和语言信息来计算特征向量的识别得分。声学信息用于计算声学得分,所述声学得分表示由一组特征向量表示的预期语音匹配语言音素的似然。语言信息用于通过考虑在彼此上下文中使用什么语音和/或字词来调节声学得分,从而提高asr处理将输出在语法上讲得通的一个或多个asr假设的似然。所使用的具体模型可以是通用模型,或可以是对应于特定领域(诸如音乐、银行业等)的模型。
言语识别引擎258可使用多种技术将特征向量与音素或其他语音单位(诸如双音素、三音素等)进行匹配。一种常见的技术是使用隐马尔可夫模型(hmm)。hmm用于确定特征向量可匹配音素的概率。使用hmm会呈现多个状态,其中状态一起表示潜在的音素(或其他言语单位,诸如三音素),并且每个状态与模型(诸如高斯混合模型或深度信任网络)相关联。状态之间的转换也可具有表示从先前状态可达到当前状态的似然的相关联概率。接收到的语音可表示为hmm的状态之间的路径,并且多个路径可表示同一语音的多个可能文本匹配。每个音素可由对应于音素及其部分的不同已知发音(诸如口头语言语音的开始、中间和结尾)的多个潜在状态表示。潜在音素的概率的初始确定可与一个状态相关联。在新特征向量由言语识别引擎258处理时,状态可基于新特征向量的处理而改变或保持不变。维特比算法可用于基于所处理的特征向量来查找最可能的状态序列。
可使用多种技术来计算概率和状态。例如,可使用高斯模型、高斯混合模型或基于特征向量的其他技术来计算每种状态的概率。可使用诸如最大似然估计(mle)的技术来估计音素状态的概率。
除了计算一个音素的潜在状态作为特征向量的潜在匹配之外,言语识别引擎258还可计算其他音素的潜在状态。以此方式,可计算多个状态和状态转换概率。
由言语识别引擎258计算出的可能状态和可能状态转换被形成为路径。每个路径表示潜在地匹配由特征向量表示的音频数据的音素的进程。一个路径可与一个或多个其他路径重叠,这取决于针对每个音素计算出的识别得分。某些概率与各自从一个状态到另一个状态的每次转换相关联。还可针对每个路径计算累积路径得分。当组合得分作为asr处理的一部分时,可将得分一起相乘(或以其他方式组合)以达到期望组合得分,或可将概率转变为对数域并进行添加以辅助处理。
言语识别引擎258还可基于语言模型或语法来计算路径分支的得分。语言建模涉及确定可能将什么字词一起使用以形成连贯的字词和语句的得分。语言模型的应用可提高asr组件250正确地解译包含在音频数据中的言语的似然。例如,可通过语言模型来调节返回“bat”、“bad”和“bed”的潜在音素路径的声学模型处理,以基于口头用户输入内每个字词的语言上下文调节“bat”(解译为字词“bat”)、“bad”(解译为字词“bad”)和“bed”(解译为字词“bed”)的识别得分。语言建模可根据文本语料库确定,并且可针对特定应用进行定制。
在言语识别引擎258根据音频确定潜在字词时,网格可能由于许多潜在语音和字词被视为音频的潜在匹配而变得非常大。潜在匹配可被例示为字词结果网络,其表示可被识别的可字词序列以及每个序列的似然
由asr组件250输出的文本数据表示一个或多于一个(例如,呈n-最佳列表形式)asr假设,所述asr假设表示音频数据211中表示的言语。asr组件250可输出包括评分最高的asr假设的文本数据,或可包括有包括多个asr假设的n-最佳列表。
在某些情形中,asr组件250可能对asr处理没有信心。例如,所处理的音频数据可能具有使言语难以被asr组件250理解的噪声水平。此类情形可由评分最高的asr假设未能满足条件(例如,阈值置信度)表示。此类情形在本文中可被视为错误状况。
返回参考图2a,装置110可将文本数据213发送到一个或多个系统120。在由一个或多个系统120接收时,音频数据213可被发送到协调器组件230。协调器组件230可将文本数据(例如,由asr组件250输出的文本数据或所接收的文本数据213)发送到nlu组件260。
图2c例示可如何对文本数据执行nlu处理。一般来说,nlu组件260尝试对输入到其中的文本数据进行语义解译。也就是说,nlu组件260基于其中表示的个别字词和/或短语来确定文本数据背后的含义。nlu组件260解译文本数据以导出用户的意图以及允许装置(例如,装置110、一个或多个系统120、一个或多个技能系统225等)执行所述意图的文本数据片。例如,如果nlu组件260接收到对应于“告诉我天气”的文本数据,则nlu组件260可确定用户意图让系统输出天气信息。
nlu组件260可处理对应于若干asr假设的文本数据。例如,如果asr组件250输出包括asr假设的n-最佳列表的文本数据,则nlu组件260可相对于其中表示的所有(或一部分)asr假设来处理文本数据。即使asr组件250可输出asr假设的n-最佳列表,nlu组件260也可被配置来仅相对于n-最佳列表中的一个或多个评分最高的asr假设进行处理。
nlu组件260可通过解析和/或标记文本数据来注释文本数据。例如,对于文本数据“告诉我西雅图的天气”,nlu组件260可将“西雅图”标记为天气信息的位置。
nlu组件260可包括一个或多个识别器263。每个识别器263可与不同技能290相关联。每个识别器263可相对于输入到nlu组件260的文本数据进行处理。每个识别器263可与nlu组件260的其他识别器263至少部分地并行地操作。
每个识别器263可包括命名实体识别(ner)组件262。ner组件262尝试标识可用于解释相对于其中输入的文本数据的含义的语法和词汇信息。ner组件262标识文本数据的对应于命名实体的部分,所述命名实体可适用于由与实现ner组件262的识别器263相关联的技能290执行的处理。ner组件262(或nlu组件260的其他组件)还可确定字词是否是指在文本数据中未明确提及其身份的实体,例如,“他”、“她”、“它”或其他回指、外指等。
每个识别器263,并且更确切地每个ner组件262,可与特定语法模型和/或数据库273、特定意图/动作集合274和特定个性化词典286相关联。每个地名辞典284可包括与特定用户和/或装置110相关联的技能索引词汇信息。例如,地名辞典a(284a)包括按技能索引的词汇信息286aa至286an。用户的音乐技能词汇信息可能包括例如专辑名、艺人姓名和歌曲名,而用户的联系人列表技能词汇信息可能包括联系人姓名。因为每个用户的音乐收藏和联系人列表想必不同。此个性化信息改进稍后执行的实体解析。
ner组件262应用与技能290相关联(与实现ner组件262的识别器263相关联)的语法模型276和词汇信息286,以确定对文本数据中一个或多个实体的提及。以此方式,ner组件262标识可用于稍后处理的“属性槽”(每个属性槽对应于文本数据中的一个或多个特定字词)。ner组件262还可用类型(例如,名词、地点、城市、艺人姓名、歌曲名等)来标记每个属性槽。
每个语法模型276包括通常存在于言语中语法模型276与之相关的特定技能290的实体名称(即,名词),而词汇信息286是针对用户输入所来自的用户和/或装置110进行个性化。例如,与购物技能相关联的语法模型276可包括在人们讨论购物时通常使用的字词数据库。
称作实体解析的下游过程(在本文中别处详细论述)将文本数据属性槽与系统已知的具体实体关联。为了执行实体解析,nlu组件260可利用存储在实体库存储装置282中的地名辞典信息(284a至284n)。地名辞典信息284可用于将文本数据(表示用户输入的一部分)与表示已知实体(诸如歌曲名称、联系人姓名等)的文本数据进行匹配。地名辞典284可与用户关联(例如,特定地名辞典可与具体用户的音乐收藏相关联),可与某些技能290(例如,购物技能、音乐技能、视频技能等)关联,或者可以多种其他方式进行组织。
每个识别器263还可包括意图分类(ic)组件264。ic组件264解析文本数据以确定潜在地表示用户输入的一个或多个意图(同与实现ic组件264的识别器263相关联的技能290相关联)。意图表示用户期望执行的动作。ic组件264可同与意图关联的字词的数据库274通信。例如,音乐意图数据库可将字词和短语(诸如“安静”、“音量关闭”和“静音”)与<mute>意图关联。ic组件264通过将文本数据中的字词和短语(表示用户输入的至少一部分)与意图数据库274中的字词和短语(同与实现ic组件264的识别器263相关联的技能290相关联)进行比较来标识潜在意图。
具体ic组件264可标识的意图与具有要填充的“属性槽”的技能特定的(即,与实现ic组件264的识别器263相关联的技能290)语法框架276关联。语法框架276的每个属性槽对应于文本数据的系统认为对应于实体的一部分。例如,对应于<playmusic>意图的语法框架276可对应于文本数据语句结构,诸如“播放{艺人姓名}”、“播放{专辑名}”、“播放{歌曲名}”、“播放{艺人姓名}的{歌曲名}”等。然而,为了使实体解析更加灵活,语法框架276可不被构造为语句,而是基于将属性槽与语法标签相关联。
例如,ner组件262可在识别文本数据中的命名实体之前基于语法规则和/或模型来解析文本数据以将字词标识为主语、宾语、动词、介词等。ic组件264(由与ner组件262相同的识别器263实现)可使用所标识的动词来标识意图。ner组件262接着可确定与所标识的意图相关联的语法模型276。例如,对应于<playmusic>的意图的语法模型276可指定适用于播放所标识的“宾语”和任何宾语修饰语(例如,介词短语)的属性槽列表,诸如{艺人姓名}、{专辑名}、{歌曲名}等。ner组件262接着可在词典286中搜索对应字段(同与实现ner组件262的识别器263相关联的技能290相关联),从而尝试将文本数据中ner组件262先前标记为语法宾语或宾语修饰语的字词和短语与词典286中所标识的那些字词和短语进行匹配。
ner组件262可执行语义标记,所述语义标记是根据字词或字词组合的类型/语义含义对它们进行标记。ner组件262可使用启发式语法规则来解析文本数据,或者可使用诸如隐马尔可夫模型、最大熵模型、对数线性模型、条件随机域(crf)等技术来构造模型。例如,由音乐技能识别器实现的ner组件262可将对应于“播放滚石乐队的mother’slittlehelper”的文本数据解析和标记为{动词}:“播放”、{宾语}:“mother’slittlehelper”、{宾语介词}:“由”以及{宾语修饰语}:“滚石乐队”。ner组件262基于与音乐技能相关联的字词数据库将“播放”标识为动词,ic组件264(也由音乐技能识别器实现)可将其确定为对应于<playmusic>意图。在此阶段,尚未确定“mother’slittlehelper”或“滚石乐队”的含义,但基于语法规则和模型,ner组件262已确定这些短语的文本与文本数据中表示的用户输入的语法宾语(即,实体)相关。
ner组件262可标记文本数据以赋予其含义。例如,ner组件262可将“播放滚石乐队的mother’slittlehelper”标记为:{技能}音乐、{意图}<playmusic>、{艺人姓名}滚石乐队、{媒体类型}song和{歌曲名称}mother’slittlehelper。另如,ner组件262可将“播放滚石乐队的歌曲”标记为:{技能}音乐、{意图}<playmusic>、{艺人姓名}滚石乐队和{媒体类型}song。
nlu组件260可生成技能交叉n-最佳列表数据231,所述技能交叉n-最佳列表数据231可包括由每个识别器263输出的nlu假设列表(如图2d所示)。识别器263可输出由识别器263操作的ner组件262和ic组件264生成的标记文本数据,如上所述。包括由ner组件262标识的意图指示符和文本/属性槽的每个nlu假设可被分组为技能交叉n-最佳列表数据231中表示的nlu假设。每个nlu假设还可与表示nlu组件在nlu假设中的置信度的值相关联。例如,技能交叉n-最佳列表数据540可表示为每行表示单独的nlu假设:
[0.95]意图:<playmusic>artistname:ladygagasongname:pokerface
[0.95]意图:<playvideo>artistname:ladygagavideoname:pokerface
[0.01]意图:<playmusic>artistname:ladygagaalbumname:pokerface
[0.01]意图:<playmusic>songname:pokerface
nlu组件260可将技能交叉n-最佳列表数据231发送到剪枝组件232。剪枝组件232可根据技能交叉n最佳列表数据231中表示的nlu假设的相应得分对它们进行分类。剪枝组件232接着可相对于技能交叉n-最佳列表数据231执行值阈值化。例如,剪枝组件232可选择技能交叉的n最佳列表数据231中表示的与满足(例如,符合和/或超出)阈值置信度值的置信度值相关联的nlu假设。剪枝组件232还可或替代地执行多个nlu假设阈值化。例如,剪枝组件232可选择最大阈值数量的评分最高的nlu假设。剪枝组件232可生成包括所选择nlu假设的技能交叉n-最佳列表数据236。剪枝组件232的目的是创建nlu假设的缩减列表,使得下游资源更密集过程可仅对最有可能表示用户意图的nlu假设进行操作。
nlu组件260还可包括轻型属性槽填充器组件234。轻型属性槽填充器组件234可从由剪枝组件232输出的nlu假设中表示的属性槽中获取文本数据,并且将其更改为使文本数据更容易由下游组件处理。轻型属性槽填充器组件234可执行低时延操作,所述操作不涉及重型操作,诸如参考一个或多个实体存储装置。轻型属性槽填充器组件234的目的是将字词替换为下游系统组件可更容易理解的其他字词或值。例如,如果nlu假设包括字词“明天”,则出于下游处理的目的,轻型属性槽填充器组件234可将字词“明天”替换为实际日期。类似地,轻型属性槽填充器组件552可将字词“cd”替换为“专辑”或字词“光盘”。被替换的字词接着包括在技能交叉n-最佳列表数据236中。
nlu组件260将技能交叉n-最佳列表数据236发送到实体解析组件238。实体解析组件238可应用将来自先前阶段的标签或令牌标准化为意图/属性槽表示的规则或其他指令。精确变换可取决于技能290。例如,对于旅行技能,实体解析组件238可将对应于“波士顿机场”的文本数据变换成指代所述机场的标准bos三字母代码。实体解析组件238可是指用于解析技能交叉n-最佳列表数据236中表示的每个nlu假设的每个属性槽中提到的精确实体的实体存储装置(包括表示系统已知的实体的文本数据)。具体意图/属性槽组合也可绑定到特定来源,接着可用于解析文本数据。在实例“播放滚石乐队的歌曲”中,实体解析组件238可引用个人音乐目录、亚马逊音乐账户、用户简档数据等。实体解析组件238可输出包括更改n-最佳列表的文本数据,所述更改n-最佳列表的基于技能交叉n-最佳列表数据236,并且包括关于在属性槽中提及的具体实体的更详细信息(例如,实体id)和/或最终可由技能290使用的更详细的属性槽数据。nlu组件260可包括多个实体解析组件238,并且每个实体解析组件238可与一个或多个特定技能290相关联。
实体解析组件238可使用与意图关联的框架来确定应搜索什么数据库字段以确定标记实体的含义,诸如搜索用户的地名辞典284以获得与框架属性槽的类似性。例如,<playmusic>意图的框架可能指示尝试基于{艺人姓名}、{专辑名}和{歌曲名}来解析所标识宾语,并且同一意图的另一框架可能指示尝试基于{艺人姓名}来解析宾语修饰语,并且基于与所标识的{艺人姓名}关联的{专辑名}和{歌曲名}来解析宾语。如果地名辞典284的搜索未使用地名辞典信息解析属性槽/字段,则实体解析组件238可搜索与技能290相关联的通用字词的数据库(在一个或多个实体存储装置272中)。例如,如果文本数据包括“播放滚石乐队的歌曲”,则在未能确定称作“滚石乐队”的“歌曲”的专辑名或歌曲名之后,实体解析组件238可搜索技能词汇表的字词“歌曲”。在替代方案中,可在地名辞典信息之前检查通用字词,或可尝试两者,从而潜在地产生两个不同结果。
实体解析组件238可能无法成功解析每个实体并且填充技能交叉n-最佳列表数据236中表示的每个属性槽。这可导致实体解析组件238输出不完整结果。
nlu组件260可包括排名组件240。排名组件240可向其中输入的每个nlu假设分配特定置信度值。nlu假设的置信度值可表示系统在相对于nlu假设执行的nlu处理中的置信度。特定nlu假设的置信度值可能会受到nlu假设是否具有未填充属性槽的影响。例如,如果与第一技能组件相关联的nlu假设包括全部被填充/解析的属性槽,则所述nlu假设相比包括实体解析组件238未填充/未解析的至少一些属性槽的另一nlu假设可被分配更高置信度值。
排名组件240可应用重新评分、偏差或其他技术来确定评分最高的nlu假设。为此,排名组件240不仅可考虑由实体解析组件238输出的数据,而且还可考虑其他数据242。其他数据242可包括多种信息。其他数据242可包括技能评级或人气数据。例如,如果一个技能290具有特别高的评级,则排名组件240可增大与所述技能290相关联的nlu假设的置信度值。其他数据242还可包括关于已经针对与当前用户输入相关联的用户标识符和/或装置标识符启用的技能290的信息。例如,与和未启用技能290相关联的nlu假设相比,排名组件240可向与启用技能290相关联的nlu假设分配更高的置信度值。其他数据242还可包括指示用户使用历史的数据,诸如与当前用户输入相关联的用户标识符是定期地与调用特定技能290的用户输入相关联还是在当日特定时间相关联。其他数据242可另外包括指示日期、时间、位置、天气、装置110的类型、用户标识符、装置标识符、上下文以及其他信息的数据。例如,排名组件240可考虑相对于与当前用户输入相关联的用户或装置,任何特定技能290当前活跃(例如,正在播放音乐、正在玩游戏等)的时间。其他数据242还可包括装置类型信息。例如,如果装置110不包括显示器,则排名组件240可降低与将导致可显示内容由系统输出的nlu假设相关联的置信度值。
在由排名组件240进行排名之后,nlu组件260可将nlu结果数据244输出到协调器组件230。nlu结果数据244可包括如由排名组件240确定的多个评分最高的nlu假设(例如,呈n-最佳列表的形式)540可表示为每行表示单独的nlu假设。替代地,nlu结果数据244可包括如由排名组件240确定的评分最高的nlu假设。nlu结果数据244可以是表示意图和所解析实体的富数据对象。
如果至少一个nlu假设(在nlu结果数据244中表示)满足条件(例如,阈值置信度),则协调器组件230可将nlu结果数据244的至少一部分发送到技能290,从而调用执行响应于用户输入的操作的技能290。如果没有任何nlu假设(在nlu结果数据244中表示)满足条件,则nlu组件260在nlu处理中可能没有足够的信心来合理地将nlu结果数据244发送到技能以相对于nlu结果数据244中表示的意图执行。这种情形在本文中可被视为错误状况。
“技能”可以是一个或多个系统120上运行的软件,其类似于在传统计算装置上运行的软件应用程序。也就是说,技能组件290可使一个或多个系统120能够执行具体功能,以便提供数据或产生某一其他所请求输出。系统120可配置有多于一个技能290。例如,天气服务技能可使一个或多个系统120能够输出天气信息,汽车服务技能可使一个或多个系统120能够相对于出租车或拼车服务预订旅行,餐馆技能可使一个或多个系统120能够相对于餐馆的线上订购系统订购一份比萨等。技能290可在一个或多个系统120与其他装置(诸如装置110)之间协调操作以便完成某些功能。技能290的输入可来自言语处理交互或者通过其他交互或输入源。技能290可包括可专用于特定技能290或在不同技能290之间共享的硬件、软件、固件等。
除了由一个或多个系统120实现之外或替代地,技能290可至少部分地由一个或多个技能系统225实现。这样可使一个或多个技能系统225能够执行具体功能,以便提供数据或执行用户所请求的某一其他动作。
技能类型包括家庭自动化技能(例如,使用户能够控制诸如灯、门锁、相机、恒温器等家用装置的技能)、娱乐装置技能(例如,使用户能够控制诸如智能电视的娱乐装置的技能)、视频技能、新闻简讯技能以及不与任何预配置的技能类型相关联的定制技能。
一个或多个系统120可配置有专用于与多于一个技能系统225交互的单个技能290。一个或多个系统120可配置有与多于一种类型的装置(例如,不同类型的家庭自动化装置)通信的技能组件290。
除非另外明确陈述,否则对技能、技能装置或技能组件的引用可包括由一个或多个系统120和/或一个或多个技能系统225操作的技能290。如本文描述为技能的功能可使用许多不同的术语(诸如动作、机器人程序、应用程序(app)等)被提到。
如图2a所示,一个或多个系统120可包括使用一种或多种不同的方法从文本数据生成音频数据(例如,合成言语)的tts组件280。输入到tts组件280的文本数据可来自技能290、协调器组件230或系统的另一组件。
在称作单元选择的一种合成方法中,tts组件280将文本数据与所记录言语数据库进行匹配。tts组件280选择所记录言语的匹配单元,并且将这些单元串接在一起以形成音频数据。在称作参数合成的另一种合成方法中,tts组件280改变诸如频率、音量和噪声的参数以创建包括人工言语波形的音频数据。参数合成使用计算机化的语音发生器(有时称为语音编码器)。
一个或多个系统120可包括简档存储装置270。简档存储装置270可包括同与系统交互的个体用户、用户组、装置等相关的多种信息。“简档”是指与用户、装置等相关联的一组数据。简档数据可包括特定于用户、装置等的偏好;装置的输入和输出能力;互联网连接信息;用户书目信息;订阅信息;以及其他信息。
简档存储装置270可包括一个或多个用户简档,其中每个用户简档与不同用户标识符相关联。每个用户简档可包括各种用户标识信息。每个用户简档还可包括用户的偏好和/或表示用户的一个或多个装置的一个或多个装置标识符。
简档存储装置270可包括一个或多个群群组简档。每个群组简档可与不同群组简档标识符相关联。群组简档可特定于一组用户。也就是说,群组简档可与两个或更多个单独用户简档相关联。例如,群组简档可以是同与单个家庭的多个用户相关联的用户简档相关联的家庭简档。群组简档可包括由与之相关联的所有用户简档共享的偏好。与群组简档相关联的每个用户简档可另外包括特定于与之相关联的用户的偏好。也就是说,每个用户简档可包括唯一于与同一群组简档相关联的一个或多个其他用户简档的偏好。用户简档可以是独立简档,或者可与群组简档相关联。群组简档可包括表示与所述群组简档相关联的一个或多个装置的一个或多个装置标识符。
简档存储装置270可包括一个或多个装置简档。每个装置简档可与不同装置标识符相关联。每个装置简档可包括各种装置标识信息。每个装置简档还可包括表示与所述装置相关联的一个或多个用户的一个或多个用户标识符。例如,家庭装置的简档可包括家庭的用户的用户标识符。每个装置简档可包括例如每个装置的输入/输出能力、每个装置可执行的一个或多个能力以及每个装置的互联网连接信息。
系统可被配置来并入用户许可,并且仅在被用户批准的情况下才可执行本文所公开的活动。这样,本文所述的系统、装置、组件和技术通常被配置来在适当的情况下约束处理,并且仅以确保符合所有适当的法律、法规、标准等的方式来处理用户信息。所述系统和技术可在地理基础上实现,以确保符合系统和/或用户的组件所在的各种管辖区和实体中的法律。
一个或多个系统120可包括识别与输入到一个或多个系统120的数据相关联的一个或多个用户的用户识别组件295。用户识别组件295可将音频数据211视为输入。用户识别组件295可通过将音频数据211中的言语特性与所存储用户言语特性进行比较来执行用户识别。用户识别组件295还可或替代地通过将由一个或多个系统120接收到的与用户输入相关的生物计量数据(例如,指纹数据、虹膜数据等)与所存储用户生物计量数据进行比较来执行用户识别。用户识别组件295还可或替代地通过将由一个或多个系统120接收到的与用户输入相关的图像数据(例如,包括用户的至少一个特征的表示)与存储的图像数据(包括不同用户的特征的表示)进行比较来执行用户识别。用户识别组件295可执行另外的用户识别过程,包括本领域中已知的那些过程。对于特定用户输入,用户识别组件295可相对于与捕获用户输入的装置110相关联的所存储用户数据执行处理。
用户识别组件295确定用户输入是否源自特定用户。例如,用户识别组件295可生成表示用户输入源自第一用户的似然的第一值、表示用户输入源自第二用户的似然的第二值等。用户识别组件295还可确定有关用户识别操作的准确度的总体置信度。
用户识别组件295可输出对应于发起用户输入的最有可能的用户的单个用户标识符。替代地,用户识别组件295可输出多个用户标识符(例如,呈n最佳列表的形式),其中相应值表示相应用户发起用户输入的可能性。用户识别组件295的输出可用于通知nlu处理、由技能290执行的处理以及由一个或多个系统120和/或其他系统的其他组件执行的处理。
一个或多个系统120可包括话题推荐存储装置275。话题推荐存储装置275可存储表示由一个或多个系统120输出的先前话题推荐的数据。每个先前话题推荐可与话题推荐存储装置275中的用户标识符相关联,其中所述用户标识符表示发起产生话题推荐的用户输入的用户。每个先前话题推荐可与表示话题推荐由系统120输出的时间的时间戳相关联。每个先前话题推荐可与表示对应用户是接受了话题推荐、拒绝了话题推荐、未对话题推荐作出响应、还是响应了话题推荐但一个或多个系统120无法确定用户的响应是拒绝还是接受的数据相关联。
系统120可包括会话恢复组件285,所述会话恢复组件285被配置来执行如本文所述的会话恢复。会话恢复组件285可被实现为技能,或可被实现为一个或多个系统120的不同组件(如图所示)。
当一个或多个系统120对有关应调用哪一技能290来执行响应于用户输入的动作没有信心时,可调用会话恢复组件285来执行。协调器组件230可确定评分最高的asr假设的置信度值不满足阈值置信度值和/或可确定评分最高的nlu假设不满足阈值置信度值。一个或多个系统120可包括问答(q&a)技能,所述问答技能至少部分地与nlu组件260并行地执行以确定用户输入是否对应于q&a技能要回答的问题。协调器组件230可确定q&a技能已指示用户输入不是q&a技能要回答的问题,同时还确定nlu结果数据表示用户输入是q&a技能要回答的问题。如果协调器组件230做出前述任何确定,则协调器组件230可被配置来将nlu结果数据发送到会话恢复组件285而不是技能290。
在另一实例中,协调器组件230可将nlu结果数据发送到技能290,但技能230可确定所述协调器组件230并非被配置来执行响应于用户输入的动作。实例包括:音乐技能被调用来输出歌曲但音乐技能确定其不能访问对应于歌曲的音频数据。技能230可将表示此类确定的指示符输出到协调器组件230,并且协调器组件230可接着将nlu结果数据发送到会话恢复组件285。
会话恢复组件285可被配置来在没有其他会话恢复技术可用时以及在过去的阈值时间量内(例如,在过去的30秒内)已经向用户提供“notunderstand”提示或“cannotperformaction”提示时推荐话题(如图3所例示)。notunderstand提示是指向用户指示一个或多个系统120无法理解用户的最近用户输入的提示。notundertood提示可对应于“我没听懂,请您再说一遍”等。cannotperformaction提示是指向用户指示一个或多个系统120能够理解用户的最近用户输入的提示但无法执行响应于用户输入的动作的提示。会话恢复组件285进行的此类处理可防止响应于紧接的用户输入而将两个或更多个notundertood和/或cannotperformaction提示输出给用户。
在接收到(302)nlu结果数据之后,会话恢复组件285使用至少nlu结果数据来对非话题切换会话恢复技术进行排名(304)。如本文所用,非话题切换技术是引起尝试执行响应于初始用户输入的动作的进一步用户交互的技术。会话恢复组件285可被配置来执行各种非话题切换会话恢复技术,包括但不限于要求用户重复用户输入(例如,当asr置信度为低时);确定评分最高的nlu假设(但仍不满足阈值置信度)并询问用户是否希望一个或多个系统120执行响应于nlu假设的动作等。每种会话恢复技术可与具体标准相关联。可至少部分地基于是否满足所有会话恢复技术的标准来确定会话恢复技术的排名。确定是否满足会话恢复技术的标准可包括分析nlu结果数据中的一个或多个意图和一个或多个属性槽。
一种非话题切换会话恢复技术可包括调用被配置来输出用户输入中表示的内容的技能。用户输入可仅包括实体(例如,“alexa,brunomars”、“alexa,adele,”等)。这种用户输入可对应于表示一个或多个系统120应输出内容的<content>意图。使用非话题切换会话恢复技术,会话恢复组件285可确定可输出与用户输入中的实体相关的内容的技能。使用用户输入“alexa,brunomars”为例,会话恢复技术可用于调用音乐技能以输出由brunomars演唱的一首或多首歌曲。
另一非话题切换会话恢复技术可包括:当评分最高的nlu假设表示用户输入是问题但q&a技能指示其未被配置来相对于用户输入执行时,路由至与nlu假设相关联的技能。在此类情形下,会话恢复技术可用于确定次最高排名的nlu假设,并且如果次最高排名的nlu假设与满足阈值置信度的置信度值相关联,则使与次最高排名的nlu相关联的技能相对于对应nlu假设来执行。
会话恢复组件285可确定(306)没有任何非话题切换会话恢复技术适用于当前情形。例如,会话恢复组件285可确定每种非话题切换会话恢复技术的至少一个标准未满足。
会话恢复组件285可确定(308)在过去的阈值时间量内(例如,在过去的30秒内)已经向用户输出了notundertood提示。例如,在过去的阈值时间量内,用户可能已向一个或多个系统120提供一个或多个系统120无法理解(例如,由于低asr置信度、低nlu置信度等)的用户输入。作为响应,一个或多个系统120可使装置110输出音频和/或显示文本,指示一个或多个系统120无法理解用户的输入。用户可接着向一个或多个系统120提供表示为步骤302处所接收的nlu结果数据的后续用户输入。
会话恢复组件285可向话题推荐存储装置275查询表示特定用户标识符(表示已提供当前用户输入的用户)是否与在过去的阈值时间量内输出的notundertood提示相关联的数据。会话恢复组件285可将步骤306的确定基于响应于询问接收到的数据。
会话恢复组件285可确定(310)用户是否已拒绝至少阈值数量的先前推荐话题,因为已拒绝过去推荐的用户可被认为未来推荐的不适当候选项。会话恢复组件285可确定表示提供了用户输入的用户的用户标识符,并且向话题推荐存储装置275查询表示用户过去何时拒绝(或未响应于)推荐的数据。会话恢复组件285可确定在阈值时间量内拒绝(或响应缺失)是否达到至少阈值数量的拒绝(或响应缺失)。如果会话恢复组件285确定用户在过去的阈值时间量内已拒绝(或未响应于)至少阈值数量的推荐,则会话恢复组件285可停止(312)处理,这可能导致本对话会话关闭。
如果会话恢复组件285确定用户在过去的阈值时间量内尚未拒绝(或未响应于)至少阈值数量的推荐,则会话恢复组件285可确定(314)在过去的阈值时间量内(例如,在同一日历日内)是否已向用户推荐了话题。这种确定可防止用户对话题推荐不知所措。会话恢复组件285可确定表示提供了用户输入的用户的用户标识符,并且可向话题推荐存储装置275查询表示与用户标识符相关联的最近话题推荐的数据。如果会话恢复组件285确定最近话题推荐发生在过去的阈值时间量内,则会话恢复组件285可停止(312)处理。相反地,如果会话恢复组件285确定最近话题推荐发生在过去的阈值时间量之前,则会话恢复组件285可确定(142)应推荐话题。本领域的技术人员将了解,可以各种次序执行步骤308和312。
在至少一些情况下,可基于话题的类型来执行关于步骤312描述的处理。例如,会话恢复组件285可确定表示提供了用户输入的用户的用户标识符,并且可确定在过去的阈值时间量内已经向用户推荐的一种或多种类型的话题。会话恢复组件285可消除响应于目前用户输入而推荐给用户的那些类型的话题。这防止在特定时间内向用户推荐相同类型的话题(这可能是不期望的用户体验)。
如上所述,会话恢复组件285可对非话题切换会话恢复技术进行排名,并且仅当没有任何非话题切换会话恢复技术可用时才可确定话题切换技术可用。在一些实现方式中,当满足某些条件时,诸如如果提供了用户输入的用户例行接受话题推荐,则会话恢复组件285可对包括话题切换技术的所有会话恢复技术进行排名(如图4所示)。
会话恢复组件285可确定(402)与用户输入相关联的用户标识符(例如,表示发起用户输入的用户)。会话恢复组件285可确定(404)与用户标识符相关联的先前话题推荐。会话恢复组件285可确定(406)发生在过去的时间阈值内的先前话题推荐的子集,并且可确定(408)子集中的先前话题推荐的数量满足话题推荐的阈值数量。在做出这种确定之后,会话恢复组件285可确定对各种会话恢复技术(包括话题切换技术)进行排名(410)。通过执行此类处理和排名,即使满足至少一种其他会话恢复技术的所有标准(例如,话题切换技术的排名高于其他技术的情况),也可考虑话题切换技术。
会话恢复组件285还可或替代地确定话题切换技术应与其他会话恢复技术一起基于用户的先前用户输入对应于哪些意图进行排名(如图5所例示)。会话恢复组件285可确定(402)与用户输入相关联的用户标识符(例如,表示发起用户输入的用户)。会话恢复组件285可确定(502)与用户标识符相关联的先前nlu假设,其中先前nlu假设表示用户的先前用户输入。会话恢复组件285可确定(504)nlu假设中表示的一个或多个意图,并且可确定(506)这一个或多个意图表示于表示用户是话题切换技术的良好候选项(例如,表示用户可能接受所推荐话题)的意图列表中。此类意图可包括<telljoke>意图(例如,表示用户先前已一个或多个要求系统120向用户讲笑话)、<phatic>意图(例如,表示用户先前已向一个或多个系统120输入笑话)或表示用户是可能乐于尝试新事物(例如,接受推荐的话题)的“随和的”或“外向的”个体的某一其他意图。在做出这种确定之后,会话恢复组件285可确定对各种会话恢复技术(包括话题切换技术)进行排名(410)。
在会话恢复组件285确定应向用户推荐话题之后,会话恢复组件285可确定要推荐哪一话题。如图6所示,会话恢复组件285可在确定要推荐哪一话题时考虑各种数据。图6中表示的数据是说明性的。本领域的技术人员将了解,当确定要推荐什么话题时以及在一些情况下当确定是否对话题切换技术连同其他会话恢复技术进行排名时,会话恢复组件285可考虑其他类型的上下文数据。
会话恢复组件285可考虑从简档存储装置270接收的用户简档数据605和/或从系统使用存储装置610接收的系统使用数据615。会话恢复组件285可向简档存储装置270查询与用户标识符相关联的用户简档数据605,所述用户标识符表示发起用户输入的用户。会话恢复组件285还可或替代地向系统使用存储器610查询与用户标识符相关联的系统使用数据615。
会话恢复组件285可接收表示用户是否订阅了一个或多个系统102的付费音乐服务的用户简档数据605。会话恢复组件285还可接收表示用户是否先前已经提供了导致系统120的付费音乐服务被调用的用户输入的系统使用数据615。在实例中,如果用户简档数据605表示用户订阅了音乐服务但系统使用数据615表示用户先前尚未(或最近(例如,在过去的时间量内)尚未)提供导致音乐服务被调用的用户输入,则会话恢复组件285可确定应向用户推荐付费音乐服务。
会话恢复组件285可接收表示用户已经启用了一个或多个系统120的哪些技能的用户简档数据605。当用户启用技能时,用户已向一个或多个系统120提供了调用所述技能以相对于用户的用户输入来执行的许可。如果用户尚未启用技能,则可阻止一个或多个系统120相对于用户的用户输入来调用技能。
会话恢复组件285可接收表示用户的年龄的用户简档数据605。此类年龄信息可向会话恢复组件285指示要推荐哪种类型的技能或其他话题。当对话题切换技术连同其他会话恢复技术进行排名时,会话恢复组件285也可使用此类年龄信息,原因是不同年龄的用户相比其他年龄的用户更可能接受话题推荐。
会话恢复组件285可接收表示用户的地理位置的用户简档数据605。此类地理位置可对应于大洲、国家、州、县、城市、街道地址等。此类位置信息可向会话恢复组件285指示要推荐哪种类型的技能或其他话题。当对话题切换技术连同其他会话恢复技术进行排名时,会话恢复组件285也可使用此类位置信息,原因是不同位置的用户相比其他位置的用户更可能接受动作推荐。
会话恢复组件285可接收表示用户输入的音频数据211。会话恢复组件285可在确定要推荐哪一话题时考虑音频数据211的各种方面,诸如话语的塑造、话语的类型、话语的品质等。话语的状态(shape)和类型可映射到话语的意图。在一些情况下,此意图可用于确定要推荐哪一话题。
会话恢复组件285可接收表示针对当前对话会话执行的处理的系统使用数据615。例如,系统使用数据615可与对应于当前和相关先前用户输入的会话标识符相关联。会话恢复组件285可基于例如用户在对话会话的过程中的参与程度来确定要推荐哪一话题。作为实例,如果用户已参与(例如,用户已向一个或多个系统120提供了至少阈值时间量(诸如过去的5分钟)的用户输入),则会话恢复组件285可推荐一个话题,而如果用户未参与(例如,对话会话已经发生了几分钟,但大部分时间系统120是在输出音乐或其他多媒体内容),则会话恢复组件285可推荐不同的话题。当对话题切换技术连同其他会话恢复技术进行排名时,会话恢复组件285也可使用此类会话信息,原因是更多参与的用户相比不太活跃的用户更可能接受话题推荐。
会话恢复组件285可从一个或多个系统120的多装置管理服务620接收装置上下文数据625。用户可将各种装置登记到他们的用户简档。例如,用户简档可表示用户的登记装置中的每一个的装置标识符。用户可向用户的装置中的一个提供用户输入。会话恢复组件285可确定对应于用户的用户标识符,并且可向多装置管理服务620查询表示用户的登记装置中的每一个的上下文的装置上下文数据625。此类上下文可表示例如装置是否正在其显示器上显示内容、装置正显示什么内容、装置是否正输出音频、装置正输出什么可听内容等。作为实例,如果会话恢复组件285确定装置上下文数据625表示装置正显示内容,则会话恢复组件285可确定推荐不需要内容显示的话题。另如,如果会话恢复组件285确定装置上下文数据625表示装置正输出音频,则会话恢复组件285可确定推荐不需要音频输出的话题。
会话恢复组件285可从一个或多个系统120的暗示服务630接收暗示数据635。暗示服务230可生成可向用户的系统/用户体验提供最大值的表示一个或多个话题的暗示数据。暗示可包括诸如定制新闻推送、定制用户简档、订阅一个或多个系统120的服务等动作以及其他动作。暗示服务630在针对特定用户标识符生成一个或多个暗示时可考虑用户简档数据。会话恢复组件285可向暗示服务630查询与表示发起用户输入的用户的用户标识符相关联的暗示数据635。
会话恢复组件285可实现一个或多个经训练的机器学习模型。可根据各种机器学习技术来训练和操作一个或多个机器学习模型。此类技术可包括例如神经网络(诸如深度神经网络和/或递归神经网络)、推理引擎、经训练的分类器等。经训练的分类器的实例包括支持向量机(svm)、神经网络、决策树、结合决策树的adaboost(“自适应增强”的缩写)以及随机森林。以svm为例,svm是具有相关联学习算法的监督式学习模型,所述相关联学习算法可分析数据并且识别数据中的模式并且通常用于分类和回归分析。给定各自被标记为属于两个类别中的一个的一组训练实例,svm训练算法构建模型,所述模型将新实例分配成一个类别或另一类别,从而使其成为非概率二进制线性分类器。可利用标识多于两个类别的训练集来构建更复杂的svm模型,其中svm确定哪个类别最类似于输入数据。svm模型可被映射成使得单独类别的实例通过清楚的间隙划分。新实例被映射到相同空间中,并且基于它们落在间隙的哪一侧上来预测属于一个类别。分类器可发布指示数据最紧密匹配哪一类别的“得分”。得分可提供数据与类别的紧密匹配程度的指示。
为了应用机器学习技术,需要训练机器学习过程本身。训练机器学习组件需要建立训练实例的“真实值(groundtruth)”。在机器学习中,术语“真实值”是指监督式学习技术的训练集的分类的准确度。各种技术可用于训练模型,包括反向传播、统计学习、监督学习、半监督学习、随机学习或其他已知技术。
如本文所述,一个或多个系统120可包括识别发起用户输入的用户的用户识别组件295。如图7所示,用户识别组件295可包括一个或多个子组件,包括视觉组件708、音频组件710、生物计量组件712、射频(rf)组件714、机器学习(ml)组件716和识别置信度组件718。在一些情况下,用户识别组件295可监视来自一个或多个子组件的数据和确定以确定与输入到一个或多个系统120的数据相关联的一个或多个用户的身份。用户识别组件295可输出用户识别数据795,所述用户识别数据795可包括与用户识别组件295认为发起用户输入的用户相关联的用户标识符。用户识别数据795可用于通知由协调器组件230、会话恢复组件285和/或系统120的其他组件执行的过程。
视觉组件708可从能够提供图像的一个或多个传感器(例如,相机)或指示运动的传感器(例如,运动传感器)接收数据。视觉组件708可执行面部识别或图像分析以确定用户的身份并且将所述身份与对应于用户的用户标识符相关联。在一些情况下,当用户面向相机时,视觉组件708可执行面部识别并且以高置信度来标识用户。在其他情况下,视觉组件708可对用户的身份具有低置信度,并且用户识别组件295可利用来自另外的组件的确定来确定用户的身份。视觉组件708可与其他组件结合使用以确定用户的身份。例如,用户识别组件295可将来自视觉组件708的数据与来自音频组件710的数据一起使用,以标识在装置110捕获音频以便标识向系统120说出输入的用户的同时用户的面部似乎在说出什么内容。
系统可包括将数据传输到生物计量组件712的生物计量传感器。例如,生物计量组件712可接收对应于指纹、虹膜或视网膜扫描、热扫描、用户的体重、用户的身高、压力(例如,在地板传感器内)等的数据,并且可确定对应于用户的生物计量简档。生物计量组件712可在例如用户与来自电视的语音之间进行区分。因此,生物计量组件712可将生物计量信息并入置信度中以用于确定用户的身份。由生物计量组件712输出的生物计量信息可与具体用户标识符(和对应用户简档)相关联。
rf组件714可使用rf定位来跟踪用户可携带或佩戴的装置。例如,用户(并且更具体地与用户相关联的用户简档)可与装置相关联。装置可发射rf信号(例如,wi-fi、
在一些情况下,装置110可包括一些rf或其他检测处理能力,使得说出输入的用户可扫描、轻击装置110或以其他方式向其确认他/她的个人装置(诸如电话)。以此方式,用户可出于一个或多个系统120确定谁说出特定输入的目的而向系统120“登记”。这种登记可发生在输入的说出之前、期间或之后。
ml组件716可跟踪各种用户的行为,作为确定用户的身份的置信度水平的因素。通过举例,用户可遵守常规时间表,使得用户在白天期间处于特定位置(例如,在工作或在学校)。在此实例中,ml组件716将过去行为和/或趋势考虑在内以确定向一个或多个系统120提供输入的用户的身份。因此,ml组件716可随时间使用历史数据和/或使用模式来增大或降低用户的身份的置信度水平。
在一些情况下,识别置信度组件718接收来自各种组件708、710、712、714和/或716的确定,并且可确定与用户的身份相关联的最终置信度水平。在一些情况下,置信度水平可确定动作是否被执行。例如,如果用户输入包括解锁门的请求,则置信度水平可能需要高于阈值,所述阈值可高于执行与播放列表或发送消息相关联的用户请求所需的阈值置信度水平。置信度水平或其他得分数据可包括在用户识别数据795中。
音频组件710可从能够提供音频信号的一个或多个传感器(例如,一个或多个传声器)接收数据以促进用户的识别。音频组件710可对音频信号执行音频识别以确定用户的身份和相关联用户标识符。在一些情况下,可在计算装置(例如,本地服务器)处配置一个或多个系统120的各方面。因此,在一些情况下,在计算装置上操作的音频组件710可分析所有语音以促进对用户的识别。在一些情况下,音频组件710可执行语音识别以确定用户的身份。
音频组件710还可基于输入到系统120中的用于言语处理的音频数据211来执行用户识别。音频组件710可确定指示音频数据211中的言语是否源自特定用户的得分。例如,第一得分可指示音频数据211中的言语源自与第一用户标识符相关联的第一用户的似然,第二得分可指示音频数据211中的言语源自与第二用户标识符相关联的第二用户的似然等。音频组件710可通过将表示音频数据211中的言语的言语特性与用户的所存储言语特性(与捕获口头用户输入的装置110相关联)进行比较来执行用户识别。
图8例示用户识别可由用户识别组件295执行的方式。asr组件250对asr特征向量数据803执行asr。将asr置信度数据807传递到用户识别组件295。
用户识别组件295使用各种数据执行用户识别,所述数据包括表示音频数据211的言语特性的用户识别特征向量数据809、表示已知语音简档的特征向量805、asr置信度数据807和其他数据809。用户识别组件295可输出反映言语由一个或多个特定用户说出的置信度的用户识别置信度数据795。用户识别置信度数据795可包括一个或多个用户标识符。用户识别置信度数据795中的每个用户标识符可与相应置信度值相关联,所述置信度值表示言语对应于用户标识符的似然。置信度值可以是数字值或分区值(binnedvalue)。
输入到用户识别组件295的一个或多个特征向量805可对应于一个或多个语音简档(存储在语音简档存储装置865中)。用户识别组件295可将一个或多个特征向量805与表示音频数据211中的言语的用户识别特征向量809进行比较,以确定用户识别特征向量809是否对应于特征向量805中与已知语音简档对应的一个或多个。
每个特征向量805可具有与用户识别特征向量809相同的大小。
为了执行用户识别,用户识别组件295可确定音频数据211所源自的装置110。例如,音频数据211可与元数据相关联,所述元数据包括表示装置110的装置标识符。装置110或一个或多个系统120可生成元数据。一个或多个系统120可确定与装置标识符相关联的群组简档标识符,可确定与群组简档标识符相关联的用户简档标识符,并且可在元数据中包括群组简档标识符和/或用户简档标识符。系统120可将元数据与从音频数据211产生的用户识别特征向量809相关联。用户识别组件295可将信号发送到语音简档特征存储装置865,其中所述信号仅请求与在元数据中表示的装置标识符、群组简档标识符和/或用户简档标识符相关联的特征向量805。这限制了用户识别组件295可考虑的可能特征向量805的全域,并且因此通过减少需要处理的特征向量805的数量来减少执行用户识别的时间量。替代地,用户识别组件295可访问用户识别组件295可用的所有特征向量805(或其某一其他子集)。然而,访问所有特征向量805将可能增大基于要处理的特征向量的幅度执行用户识别所需的时间量。
用户识别组件295可尝试通过将用户识别特征向量809与一个或多个所接收的特征向量805进行比较来标识说出音频数据211中表示的言语的用户。用户识别组件295可包括评分组件822,所述评分组件822确定指示言语(由用户识别特征向量809表示)是否由一个或多个特定用户说出(由一个或多个特征向量805表示)的得分。用户识别组件295还可包括置信度组件718,所述置信度组件718确定用户识别操作(诸如评分组件822的那些用户识别操作)的总体准确度和/或相对于潜在地由评分组件822标识的每个用户的个别置信度值。来自评分组件822的输出可包括针对每个所接收的特征向量805的不同置信度值。例如,输出可包括第一特征向量的第一置信度值、第二特征向量的第二置信度等。尽管被例示为两个单独的组件,但评分组件822和置信度组件718可被组合成单个组件或可被分成多于两个组件。
评分组件822和置信度组件718可实现如本领域已知的一个或多个训练的机器学习模型(诸如神经网络、分类器等)。例如,评分组件822可使用概率线性判别分析(plda)技术。plda评分确定用户识别特征向量809对应于特定特征向量805的可能性。plda评分可针对所考虑的每个特征向量805生成置信度值,并且可输出与相应用户标识符相关联的置信度值的列表。评分组件822还可使用其他技术(诸如gmm、生成贝叶斯模型等)来确定置信度值。
置信度组件718可输入各种数据,包括有关asr置信度807、言语长度(例如,用户输入的帧数或时间)、音频状况/品质数据(诸如信号干扰数据或其他度量数据)、指纹数据、图像数据或其他因素的信息,以考虑用户识别组件295对于将用户链接到用户输入的置信度值的信心程度。置信度组件718还可考虑由评分组件822输出的置信度值和相关联用户标识符。因此,置信度组件718可确定更低asr置信度807或者不良音频品质或其他因素可导致用户识别组件295的置信度更低。而更高asr置信度807或者更好音频品质或其他因素可导致用户识别组件295的置信度更高。置信度的精确确定可取决于置信度组件718和由此实现的模型的配置和训练。置信度组件718可使用多种不同的机器学习模型/技术(诸如gmm、神经网络等)进行操作。例如,置信度组件718可以是被配置来将由评分组件822输出的得分映射到置信度值的分类器。
用户识别组件295可输出特定于单个用户标识符(或呈n最佳列表形式的多于一个用户标识符)的用户识别置信度数据795。用户识别置信度数据795可包括数字置信度值(例如,0.0至1.0、0至1000或系统被配置来操作的任何数值范围)。因此,用户识别置信度数据795可输出具有数字置信度值(例如,用户标识符123-0.2、用户标识符234-0.8)的潜在用户的n-最佳列表。替代地或此外,用户识别置信度数据795可包括分区置信度值。例如,计算识别得分的第一范围(例如,0.0至0.33)可输出为“低”,计算识别得分的第二范围(例如,0.34至0.66)可输出为“中”,并且计算识别得分的第三范围(例如,0.67至1.0)可输出为“高”。因此,用户识别组件295可输出具有分区置信度值(例如,用户标识符123-低、用户简档标识符234-高)的潜在用户的n-最佳列表。组合的分区和数字置信度值输出也是可能的。不是用户标识符及其相应置信度值的列表,用户识别置信度数据795可仅包括与如由用户识别组件295确定的评分最高的用户标识符相关的信息。用户识别组件295还可输出个别置信度值正确的总体置信度值,其中总体置信度值指示用户识别组件295对输出结果的信心程度。总体置信度值可由置信度组件718确定。
置信度组件718可在确定用户识别置信度数据795时确定个别置信度值之间的差。例如,如果第一置信度值与第二置信度值之间的差较大并且第一置信度值高于阈值置信度值,则用户识别组件295能够以相比置信度值之间的差较小的情况更高的置信度将第一用户(同与第一置信度值相关联的特征向量805相关联)识别为说出用户输入的用户。
用户识别组件295可执行阈值化以避免输出不正确的用户识别结果。例如,用户识别组件295可将由置信度组件718输出的置信度值与阈值置信度值进行比较。如果置信度值不满足(例如,不符合或超出)阈值置信度,则用户识别组件295可不输出用户识别置信度数据795,或可仅在所述数据795中包括用户无法被识别的指示。此外,用户识别组件295可在累积并处理足够的用户识别特征向量数据809以核实用户是否高于阈值置信度之前不输出用户识别置信度数据795。因此,用户识别组件295可等待到在输出用户识别置信度数据795之前阈值数量的音频数据211已被处理。置信度组件718还可考虑所接收的音频数据211的数量。
用户识别组件295可默认输出分区(例如,低、中、高)用户识别置信度值。然而,在某些情形下,这可能是有问题的。例如,如果用户识别组件295相对于多个特征向量805计算单个分区置信度值,则一个或多个系统120可能无法有效地确定哪个用户发起了用户输入。在此情形下,用户识别组件295可被配置来覆写其默认设置并且输出数字置信度值。这使一个或多个系统120能够与最高数字置信度值相关联地确定发起了用户输入的用户。
用户识别组件295可使用其他数据811以通知用户识别处理。因此,可对用户识别组件295的训练模型或其他组件进行训练以在执行识别时将其他数据811视为输入特征。其他数据811可根据系统配置包括广泛多种数据类型,并且可从其他传感器、装置或存储装置获得。其他数据811可包括音频数据211由装置110生成或从装置110接收的当日时间、音频数据211由装置110生成或从装置110接收的当周时间等。
其他数据811可包括图像数据或视频数据。例如,可对从装置110(从其(或另一装置)接收音频数据211)接收的图像数据或视频数据执行面部识别。面部识别可由用户识别组件295或一个或多个系统120的另一组件执行。面部识别处理的输出可由用户识别组件295使用。也就是说,面部识别输出数据可与用户识别特征向量809和一个或多个特征向量805的比较结合使用,以执行更准确的用户识别。
其他数据811可包括装置110的位置数据。位置数据可特定于装置110所在的建筑物。例如,如果装置110位于用户a的卧室中,则此类位置可增大与用户a相关联的用户识别置信度值和/或降低与用户b相关联的用户识别置信度值。
其他数据811可包括指示装置类型的数据。不同类型的装置可包括例如智能手表、智能电话、平板计算机和车辆。装置110的类型可在与装置110相关联的简档中指示。例如,如果从中接收到音频数据211的装置110是属于用户a的智能手表或车辆,则装置110属于用户a的事实可增大与用户a相关联的用户识别置信度值和/或降低与用户b相关联的用户识别置信度值。
其他数据811可包括与装置110相关联的地理坐标数据。例如,与车辆相关联的群组简档可指示多个用户(例如,用户a和用户b)。车辆可包括在音频数据211由车辆生成时指示车辆的纬度和经度坐标的全球定位系统(gps)。这样,如果车辆位于对应于用户a的工作位置/建筑物的坐标处,则这可增大与用户a相关联的用户识别置信度值和/或降低在与车辆关联的群组简档中指示的所有其他用户的用户识别置信度值。可在与装置110相关联的简档中指示全球坐标和相关联位置(例如,工厂、家庭等)。全坐标和相关联位置可与一个或多个相应用户标识符(和对应用户简档)相关联。
其他数据811可包括表示特定用户的活动的可用于执行用户识别的另外的数据。例如,如果用户最近键入了禁用家庭安全警报的代码,并且音频数据211是从在与家庭相关联的群组简档中表示的装置110接收的,则来自家庭安全警报的有关禁用用户、禁用时间等的信号可反映在其他数据811中并且由用户识别组件295考虑。如果检测到已知与特定用户相关联的移动装置(诸如智能手机、磁贴、加密狗或其他装置)接近装置110(例如,与之物理上靠近、与之连接到相同的wi-fi网络或以其他方式靠近),则这可在其他数据811中反映并且由用户识别组件295考虑。
根据系统配置,其他数据811可被配置成包括在用户识别特征向量数据809中,使得与装置110的情形相关的所有数据包括在单个特征向量中。替代地,其他数据811可在一个或多个不同数据结构中反映,以由评分组件822进行处理。
图9是概念性地例示可与系统一起使用的装置110的框图。图10是概念性地例示可辅助asr处理、nlu处理等的远程装置(诸如一个或多个系统120)以及一个或多个技能系统225的示例性组件的框图。系统(120/225)可包括一个或多个服务器。如本文所用的“服务器”可是指如在服务器/客户端计算结构中理解的传统服务器,但也可是指可辅助本文所论述的操作的多个不同计算组件。例如,服务器可包括在物理上和/或通过网络连接到其他装置/组件的一个或多个物理计算组件(诸如机架服务器),并且能够执行计算操作。服务器还可包括模拟计算机系统并且在一个或多个装置上运行的一个或多个虚拟机。服务器还可包括执行本文所论述的操作的硬件、软件、固件等的其他组合。一个或多个服务器可被配置来使用客户端-服务器模型、计算机局模型、网格计算技术、雾计算技术、大型机技术、效用计算技术、对等模型、沙箱技术或其他计算技术中的一种或多种进行操作。
多个系统(120/225)可包括在本公开的总体系统中,诸如用于执行asr处理的一个或多个系统120、用于执行nlu处理的一个或多个系统120、用于执行动作的一个或多个技能系统225等。在操作中,这些系统中的每一个可包括驻留在相应装置(120/225)上的计算机可读和计算机可执行指令,如以下将进一步论述。
这些装置(110/120/225)中的每一个可包括:一个或多个控制器/处理器(904/1004),所述一个或多个控制器/处理器(904/1004)可各自包括用于处理数据和计算机可读指令的中央处理单元(cpu);和存储器(906/1006),所述存储器(906/1006)用于存储相应装置的数据和指令。存储器(906/1006)可独立地包括易失性随机存取存储器(ram)、非易失性只读存储器(rom)、非易失性磁阻存储器(mram)和/或其他类型的存储器。每个装置(110/120/225)还可包括用于存储数据和控制器/处理器可执行指令的数据存储组件(908/1008)。每个数据存储组件(908/1008)可独立地包括一个或多个非易失性存储类型,诸如磁存储、光存储、固态存储等。每个装置(110/120/225)还可通过相应输入/输出装置接口(902/1002)连接到可移除或外部非易失性存储器和/或存储装置(诸如可移除存储卡、存储密钥驱动器、联网存储装置等)。
用于操作每个装置(110/120/225)及其各种组件的计算机指令可由相应装置的控制器/处理器(904/1004)使用存储器(906/1006)作为运行时的临时“工作”存储装置来执行。装置的计算机指令可以非暂时性方式存储在非易失性存储器(906/1006)、存储装置(908/1008)或一个或多个外部装置中。替代地,除软件之外或代替软件,可执行指令中的一些或全部可嵌入相应装置上的硬件或固件中。
每个装置(110/120/225)包括输入/输出装置接口(902/1002)。多种组件可通过输入/输出装置接口(902/1002)进行连接,如以下将进一步论述。另外,每个装置(110/120/225)可包括用于在相应装置的组件之间传送数据的地址/数据总线(924/1024)。除了(或代替)通过总线(924/1024)连接到其他组件之外,装置(110/120/225)内的每个组件还可直接连接到其他组件。
参考图9,装置110可包括输入/输出装置接口902,所述输入/输出装置接口902连接到多种组件,诸如音频输出组件(诸如扬声器912、有线头戴式耳机或无线头戴式耳机(未示出)或能够输出音频的其他组件)。装置110还可包括音频捕获组件。音频捕获组件可以是例如传声器920或传声器阵列、有线头戴式耳机或无线头戴式耳机(未示出)等。如果包括传声器阵列,则距语音的原点的近似距离可通过声学定位基于由阵列中的不同传声器捕获的语音之间的时间差和振幅差来确定。装置110可另外包括用于显示内容的显示器916。装置110还可包括相机918。
经由一根或多根天线914,输入/输出装置接口902可经由无线局域网(wlan)(诸如wifi)无线电、蓝牙和/或无线网络无线电(诸如能够与无线通信网络诸如长期演进(lte)网络、wimax网络、3g网络、4g网络、5g网络等通信的无线电)连接到一个或多个网络199。也可支持诸如以太网的有线连接。通过一个或多个网络199,系统可跨联网环境分布。i/o装置接口(902/1002)还可包括通信组件,所述通信组件允许在诸如服务器或其他组件的集合中的不同物理服务器等装置之间交换数据。
一个或多个装置110、一个或多个系统120或一个或多个技能系统225的组件可包括它们自己的专用处理器、存储器和/或存储装置。替代地,一个或多个装置110、一个或多个系统120或一个或多个技能系统225的组件中的一个或多个可分别利用一个或多个装置110、一个或多个系统120或技能系统225的i/o接口(902/1002)、一个或多个处理器(904/1004)、存储器(906/1006)和/或存储装置(908/1008)。因此,asr组件250可具有其自己的一个或多个i/o接口、一个或多个处理器、存储器和/或存储装置;nlu组件260可具有其自己的一个或多个i/o接口、一个或多个处理器、存储器和/或存储装置;并且对于本文所论述的各种组件,依此类推。
如上所指出,可在单个系统中采用多个装置。在这种多装置系统中,装置中的每一个可包括用于执行系统的处理的不同方面的不同组件。多个装置可包括重叠的组件。如本文所述,装置110、一个或多个系统120和一个或多个技能系统225的组件是说明性的,并且可被定位为独立装置或可整体地或部分地包括为较大装置或系统的组件。
如图11所示,多个装置(110a至110j、120、225)可包含系统的组件,并且装置可通过一个或多个网络199连接。一个或多个网络199可包括局域网或私用网,或可包括诸如因特网的广域网。装置可通过有线连接或无线连接连接到一个或多个网络199。例如,言语检测装置110a、智能电话110b、智能手表110c、平板计算机110d、车辆110e、显示装置110f、智能电视110g、洗衣机/烘干机110h、冰箱110i和/或微波炉110j可通过无线服务提供商、通过wi-fi或蜂窝网络连接等连接到一个或多个网络199。包括其他装置作为网络连接的支持装置,所述支持装置诸如一个或多个系统120、一个或多个技能系统225和/或其他装置。支持装置可通过有线连接或无线连接而连接到一个或多个网络199。联网装置可使用一个或多个内置或连接的传声器或其他音频捕获装置来捕获音频,其中处理由相同装置或另一装置的经由一个或多个网络199连接的asr组件、nlu组件或者其他组件(诸如一个或多个系统120的asr组件250、nlu组件260等)执行。
根据以下条款也可理解上文。
1.一种方法,其包括:
从第一装置接收表示第一用户输入的第一音频数据;
对所述第一音频数据执行自动言语识别(asr)处理;
确定与所述asr处理相关联的错误状况;
标识用于去除所述错误状况的多种技术,所述多种技术包括:(i)使所述用户重复所述第一用户输入,以及(ii)至少部分地基于系统使用数据来选择话题;
确定至少部分地基于第一系统使用数据来选择第一话题;
生成表示所述第一话题的第二音频数据;以及
使所述第一装置输出对应于所述第二音频数据的音频。
2.如条款1所述的方法,其还包括:
使所述第一装置输出请求是否要执行与所述第一话题相关的动作的第二音频;
从所述第一装置接收表示第二用户输入的第四音频数据;
对所述第四音频数据执行言语处理以确定所述第二用户输入表示要执行所述动作;
确定被配置来执行所述动作的第二技能;以及
使所述第二技能执行所述动作。
3.如条款1或2所述的方法,其还包括:
从第一装置接收表示第二用户输入的第三音频数据;
对所述第三音频数据执行言语处理;
至少部分地基于所述言语处理,确定第二错误状况;
确定表示要请求所述用户重复所述第二用户输入的第一排名;
确定表示要请求所述用户阐明被配置来相对于所述第二用户输入执行的技能的第二排名;
确定表示要向所述用户推荐第二话题的第三排名;
确定所述第三排名大于所述第一排名和所述第二排名;
至少部分地基于所述第三排名大于所述第一排名和所述第二排名,生成表示所述第二话题的第四音频数据;以及
使所述第一装置输出对应于所述第四音频数据的第二音频。
4.如条款1、2或3所述的方法,其还包括:
从所述第一装置接收表示第二用户输入的第三音频数据;
对所述第三音频数据执行言语处理;
至少部分地基于所述言语处理,确定第二错误状况;
生成表示无法对所述第二用户输入作出正确响应的第四音频数据;
使所述第一装置输出对应于所述第四音频数据的第二音频;以及
至少部分地基于使所述第一装置输出所述第二音频,选择所述第一话题。
5.一种方法,其包括:
从第一装置接收表示第一用户输入的第一数据;
响应于所述第一用户输入确定错误状况;
标识用于通过与用户的会话从所述错误状况恢复的多种技术,所述多种技术包括:(i)使所述用户重复所述第一用户输入,以及(ii)至少部分地基于系统使用数据或用户简档数据中的至少一者选择话题;
生成第二数据,所述第二数据表示基于第一系统使用数据或第一用户简档数据中的至少一者选择的第一话题;以及
将所述第二数据发送到所述第一装置。
6.如条款5所述的方法,其还包括:
从所述第一装置接收表示第二用户输入的第三数据;
确定所述第三数据表示要输出对应于所述话题的信息;
生成对应于所述信息的第四数据;以及
将所述第四数据发送到所述第一装置。
7.如条款6所述的方法,其还包括:
使所述第一装置输出请求是否要执行与所述话题相关的动作的内容;
从所述第一装置接收表示第三用户输入的第五数据;
确定所述第五数据表示要执行所述动作;
确定被配置来执行所述动作的技能;以及
使所述技能执行。
8.如条款5或6所述的方法,其还包括:
从所述第一装置接收表示第二用户输入的第三数据;
响应于所述第二用户输入确定第二错误状况;
确定表示要请求所述用户重复所述第二用户输入的第三排名;
确定所述第三排名未能满足阈值排名;
至少部分地基于确定所述第三排名未能满足所述阈值排名,确定要向所述用户推荐第二话题;
生成表示所述第二话题的第四数据;以及
将所述第四数据发送到所述第一装置。
9.如条款5、6、7或8所述的方法,其还包括:
确定与所述第一数据相关联的用户标识符;
与所述用户标识符相关联地确定对应于输出到所述用户的先前信息的第一数量,所述先前信息对应于至少一个话题;
确定对应于在过去的阈值时间量内输出到所述用户的所述先前信息的子集的第二数量;
确定所述第二数量满足阈值数量;以及
至少部分地基于所述第二数量满足所述阈值数量,生成所述第二数据。
10.如条款5、6、7、8或9所述的方法,其还包括:
确定与所述第一数据相关联的用户标识符;
确定表示与所述用户标识符相关联的先前用户输入的意图指示符;
确定所述意图指示符表示在意图指示符的列表中;以及
至少部分地基于所述意图指示符表示在所述列表中,生成所述第二数据。
11.如条款5、6、7、8、9或10所述的方法,其还包括:
确定与所述第一数据相关联的用户标识符;
与用户标识符相关联地确定对应于所述用户已阻止输出对应于至少一个话题的先前信息时的先前情况的数量;
确定所述数量未能满足先前情况的阈值数量;以及
至少部分地基于所述数量未能满足所述阈值数量,确定所述话题。
12.如条款5、6、7、8、9、10或11所述的方法,其还包括:
确定与所述第一数据相关联的用户标识符;
与所述用户标识符相关联地确定输出与第二话题相关的第二信息时的最近情况;
确定所述最近情况在过去的阈值时间量之外;以及
基于所述最近情况在所述过去的阈值时间量之外,确定所述话题。
13.如条款5、6、7、8、9、10、11或12所述的方法,其还包括:
对所述第一数据执行自动言语识别(asr)处理以生成asr置信度值;
确定所述asr置信度值未能满足阈值asr置信度值;以及
至少部分地基于所述确定所述asr置信度值未能满足所述阈值asr置信度值,确定要输出错误消息。
14.如条款5、6、7、8、9、10、11、12或13所述的方法,其还包括:
对所述第一数据执行自动言语识别(asr)处理以生成文本数据;
对所述文本数据执行自然语言理解(nlu)处理以生成nlu置信度值;
确定所述nlu置信度值未能满足阈值nlu置信度值;以及
至少部分地基于所述确定所述nlu置信度值未能满足所述阈值nlu置信度值,确定要输出错误消息。
15.一种系统,其包括:
至少一个处理器;以及
至少一个存储器,所述至少一个存储器包括指令,所述指令在由所述至少一个计算装置处理器执行时使所述系统:
从第一装置接收表示第一用户输入的第一数据;
响应于所述第一用户输入确定错误状况;
标识用于通过与用户的会话从所述错误状况恢复的多种技术,所述多种技术包括:(i)使所述用户重复所述第一用户输入,以及(ii)至少部分地基于系统使用数据或用户简档数据中的至少一者选择话题;
生成第二数据,所述第二数据表示基于第一系统使用数据或第一用户简档数据中的至少一者选择的第一话题;并且
将所述第二数据发送到所述第一装置。
16.如条款15所述的系统,其中所述至少一个存储器还包括指令,所述指令在由所述至少一个处理器执行时进一步使所述系统:
从所述第一装置接收表示第二用户输入的第三数据;
确定所述第三数据表示要输出对应于所述话题的信息;
生成对应于所述信息的第四数据;并且
将所述第四数据发送到所述第一装置。
17.如条款15或16所述的系统,其中所述至少一个存储器还包括指令,所述指令在由所述至少一个处理器执行时进一步使所述系统:
使所述第一装置输出请求是否要执行与所述话题相关的动作的内容;
从所述第一装置接收表示第三用户输入的第五数据;
确定所述第五数据表示要执行所述动作;
确定被配置来执行所述动作的技能;并且
使所述技能执行。
18.如条款15、16或17所述的系统,其中所述至少一个存储器还包括指令,所述指令在由所述至少一个处理器执行时进一步使所述系统:
从所述第一装置接收表示第二用户输入的第三数据;
响应于所述第二用户输入确定第二错误状况;
确定表示要请求所述用户重复所述第二用户输入的第三排名;
确定所述第三排名未能满足阈值排名;
至少部分地基于确定所述第三排名未能满足所述阈值排名,确定要向所述用户推荐第二话题;
生成表示所述第二话题的第四数据;并且
将所述第四数据发送到所述第一装置。
19.如条款15、16、17、18或19所述的系统,其中所述至少一个存储器还包括指令,所述指令在由所述至少一个处理器执行时进一步使所述系统:
确定与所述第一数据相关联的用户标识符;
与所述用户标识符相关联地确定对应于输出到所述用户的先前信息的第一数量,所述先前信息对应于至少一个话题;
确定对应于在过去的阈值时间量内输出到所述用户的所述先前信息的子集的第二数量;
确定所述第二数量满足阈值数量;并且
至少部分地基于所述第二数量满足所述阈值数量,生成所述第二数据。
20.如条款15、16、17、18或19所述的系统,其中所述至少一个存储器还包括指令,所述指令在由所述至少一个处理器执行时进一步使所述系统:
确定与所述第一数据相关联的用户标识符;
确定表示与所述用户标识符相关联的先前用户输入的意图指示符;
确定所述意图指示符表示在意图指示符的列表中;并且
至少部分地基于所述意图指示符表示在所述列表中,生成所述第二数据。
本文所公开的概念可应用于多个不同装置和计算机系统(包括例如通用计算系统、言语处理系统和分布式计算环境)中。
本公开的以上方面意图是说明性的。这些方面被选择来解释本公开的原理和应用,而并不意图是穷举性的或限制本公开。所公开方面的许多修改和变型对本领域技术人员而言是显而易见的。计算机和言语处理领域中的普通技术人员应认识到,本文所述的组件和处理步骤可能够与其他组件或步骤或者组件或步骤的组合互换,并且仍可实现本公开的益处和优点。此外,本领域的技术人员应显而易见,可在不具有本文所公开的具体细节和步骤中的一些或全部的情况下实践本公开。
所公开系统的各方面可被实现为计算机方法或诸如存储装置或非暂时性计算机可读存储介质的制品。计算机可读存储介质可能够由计算机读取,并且可包括用于使计算机或其他装置执行本公开中所述的过程的指令。计算机可读存储介质可由易失性计算机存储器、非易失性计算机存储器、硬盘驱动器、固态存储器、闪存驱动器、可移除磁盘和/或其他介质来实现。此外,系统的组件可被实现为固件或硬件,诸如声学前端(afe),其尤其包括模拟和/或数字滤波器(例如,被配置为数字信号处理器(dsp)的固件的滤波器)。
除非另有特别说明或在所使用的上下文中以其他方式理解,否则本文所用的诸如“能够”、“可以”、“可能”、“可”、“例如”等条件语言通常意图表达某些实施方案包括而其他实施方案不包括某些特征、元件和/或步骤。因此,此类条件语言通常绝不意图暗指一个或多个实施方案需要特征、元件和/或步骤,或者一个或多个实施方案必需包括用于在具有或不具有其他输入或提示的情况下决定是否在任何特定实施方案中包括或将执行这些特征、元件和/或步骤的逻辑。术语“包括(comprising)”、“包括(including)”、“具有”等是同义的,并且以开放形式包括性地使用,且不排除另外的元件、特征、动作、操作等。此外,术语“或”以其包括性意义(而非排他性意义)使用,使得当用于例如连接要素列表时,术语“或”意指列表中要素中的一个、一些或全部。
除非另有具体说明,否则诸如短语“x、y、z中的至少一个”的析取语言以如总体来说用于标识项、术语等可以是x、y或z或者它们的任何组合(例如,x、y或z)的上下文来理解。因此,此类析取语言通常并不意图并且将不暗示某些实施方案要求存在x中的至少一者、y中的至少一者或z中的至少一者。
如在本公开中所用,除非另有具体说明,否则术语“一个”或“一种”可包括一个或多个项。此外,除非另有具体说明,否则短语“基于”意图意指“至少部分地基于”。
- 还没有人留言评论。精彩留言会获得点赞!