一种基于高拍仪获得语音播放方法和系统与流程
[0001]
本发明涉及一种基于高拍仪获得语音播放方法和系统。
背景技术:
[0002]
高拍仪是一款靠高速影像拍摄文稿、实物等来识别信息的智能影像设备,主要应用于文件档案等资料翻拍/扫描,将重要文书数据翻拍扫描成电子档案,方便调阅保存。通常在使用拍摄仪进行文档扫描时,需要将扫描的文档与拍摄仪的相对位置进行定位。
[0003]
现有高拍仪在进行文件拍摄时,只能将拍摄后的电子图像进一步处理成word/excel/pdf等格式,但无法转换成可阅读的mp3或wav格式,导致高拍仪使用功能单一。
[0004]
针对目前高拍仪无法将拍摄的图片转换成可阅读的mp3或wav格式,导致使用功能单一的问题,是本领域亟待解决的问题。
技术实现要素:
[0005]
本发明的目的是提供一种基于高拍仪获得语音播放方法和系统,以解决目前高拍仪无法将拍摄的图片转换成可阅读的mp3或wav格式,导致使用功能单一的问题。
[0006]
为解决上述技术问题,本发明提供了一种基于高拍仪获得语音播放方法,包括:
[0007]
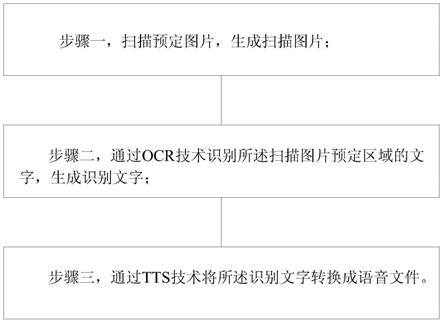
步骤一,扫描预定图片,生成扫描图片;
[0008]
步骤二,通过ocr技术识别所述扫描图片预定区域的文字,生成识别文字;
[0009]
步骤三,通过tts技术将所述识别文字转换成语音文件。
[0010]
其中,所述步骤一还包括:
[0011]
根据预定位置对所述扫描图片进行裁切,生成扫描图片预定区域。
[0012]
其中,所述步骤二还包括:
[0013]
通过ocr技术识别所述扫描图片预定区域的文字,生成原始文字;
[0014]
对所述原始文字进行自动处理,生成识别文字。
[0015]
其中,所述步骤三还包括:
[0016]
通过tts技术中声音大小选择属性将所述识别文字转换成语音文件;和/或,
[0017]
通过tts技术中声音快慢选择属性将所述识别文字转换成语音文件。
[0018]
其中,还包括:
[0019]
步骤四,将所述识别文字生成区块链文字信息,并将所述区块链文字信息上传到高拍仪区块链支链;
[0020]
步骤五,将所述高拍仪区块链支链上预定节点共享到备份区块链总链的共享节点上;
[0021]
将所述语音文件在预定的时间内上传到所述共享节点上。
[0022]
根据本发明的另一方面,本发明还提供一种基于高拍仪获得语音播放系统,包括:
[0023]
扫描单元,其配置为,扫描预定图片,生成扫描图片;
[0024]
文字识别单元,其配置为,通过ocr技术识别所述扫描图片预定区域的文字,生成
识别文字;
[0025]
语音生成单元,其配置为,通过tts技术将所述识别文字转换成语音文件。
[0026]
其中,所述扫描单元还包括:
[0027]
根据预定位置对所述扫描图片进行裁切,生成扫描图片预定区域。
[0028]
其中,所述文字识别单元还包括:
[0029]
通过ocr技术识别所述扫描图片预定区域的文字,生成原始文字;
[0030]
对所述原始文字进行自动处理,生成识别文字。
[0031]
其中,所述语音生成单元还包括:
[0032]
通过tts技术中声音大小选择属性将所述识别文字转换成语音文件;和/或,
[0033]
通过tts技术中声音快慢选择属性将所述识别文字转换成语音文件。
[0034]
其中,还包括:
[0035]
区块链上传单元,将所述识别文字生成区块链文字信息,并将所述区块链文字信息上传到高拍仪区块链支链;
[0036]
区块链备份单元,将所述高拍仪区块链支链上预定节点共享到备份区块链总链的共享节点上;
[0037]
将所述语音文件在预定的时间内上传到所述共享节点上。
[0038]
与现有技术相比,本发明的有意效果在于:
[0039]
发明提供本发明提供一种基于高拍仪获得语音播放方法,包括:步骤一,扫描预定图片,生成扫描图片;步骤二,通过ocr技术识别所述扫描图片预定区域的文字,生成识别文字;步骤三,通过tts技术将所述识别文字转换成语音文件。通过先将预定的图片进行拍摄扫描,生存扫描图片,然后将扫描图片上预定区域的文字通过ocr技术进行识别,生成识别文字,识别文字可以为可编辑的文字,然后通过tts技术将识别文字转换成语音文件,从而实现从图片到语音文件(mp3或wav)的直接输出,提高拍摄仪等设备可以直接输出成语音文件的能力,提高使用便利性。
附图说明
[0040]
图1是本发明示意性视出了一种基于高拍仪获得语音播放方法的流程图。
[0041]
图2是本本发明示意性视出了一种基于高拍仪获得语音播放系统的结构示意框图。
具体实施方式
[0042]
以下对本发明的实施例进行详细说明,但是本发明可以由权利要求限定和覆盖的多种不同方式实施。
[0043]
实施例一
[0044]
如图1所示,本发明提供一种基于高拍仪获得语音播放方法,包括:
[0045]
步骤一,扫描预定图片,生成扫描图片;
[0046]
步骤二,通过ocr技术识别所述扫描图片预定区域的文字,生成识别文字;
[0047]
步骤三,通过tts技术将所述识别文字转换成语音文件。
[0048]
通过先将预定的图片进行拍摄扫描,生存扫描图片,然后将扫描图片上预定区域
的文字通过ocr技术进行识别,生成识别文字,识别文字可以为可编辑的文字,然后通过tts技术将识别文字转换成语音文件,从而实现从图片到语音文件(mp3或wav)的直接输出,提高拍摄仪等设备可以直接输出成语音文件的能力,提高使用便利性。
[0049]
让拍摄仪可以实现拍摄图片,再进行文字识别,最后转存为计算机可朗读语音文件的目的,也可以通过将之前已经扫描过的本地现有图像,进行文字识别,转存为计算机可朗读的语音文件。
[0050]
如果有一种技术能将高拍仪采集的图像或本地电子图像,再进行一个mp3或wav格式的转换,人们可享受到利用碎片化时间进行听取的便利。
[0051]
所述步骤一还包括:
[0052]
根据预定位置对所述扫描图片进行裁切,生成扫描图片预定区域。
[0053]
通过将扫描图片进行裁切,只对扫描图片的预定区域进ocr文字识别,提高识别的定向性和准确性,目前通常用的裁切方法为,识别图片中文字区域,并对图片区域中的文字区域进行识别裁切,生存带文字区域的预定区域。
[0054]
所述步骤二还包括:
[0055]
通过ocr技术识别所述扫描图片预定区域的文字,生成原始文字;
[0056]
对所述原始文字进行自动处理,生成识别文字。
[0057]
通过ocr技术识别所述扫描图片预定区域的文字后,会带一些错误乱码文字或多余文字,此时,需要对乱码文字进行删除,多余文字进行删除或自动修订,修订的方式可以参照现有人工智能技术进行自动修改处理,当然可以不限于这些修改,还可以自动增加一些常用词语,比如,“中国首都京”中可能缺少“北”,就会自动增加为“中国首都北京”等,详细内容不再赘述。
[0058]
其中,所述步骤三还包括:
[0059]
通过tts技术中声音大小选择属性将所述识别文字转换成语音文件;和/或,通过tts技术中声音快慢选择属性将所述识别文字转换成语音文件。
[0060]
通过通过tts技术中声音大小和快慢选择属性将所述识别文字转换成预定音量和预定播放速度语音文件,可以根据个性化需求调节输出语音文件的属性,使该技术更人性化。
[0061]
在其他实施例中,本发明一种高拍仪获得语音方法还包括:
[0062]
步骤四,将所述识别文字生成区块链文字信息,并将所述区块链文字信息上传到高拍仪区块链支链;
[0063]
步骤五,将所述高拍仪区块链支链上预定节点共享到备份区块链总链的共享节点上;
[0064]
将所述语音文件在预定的时间内上传到所述共享节点上。
[0065]
通过将存储量比较小的区块链文字信息上传到高拍仪区块链支链上,可以大大减小高拍仪区块链支链的存储量,提高高拍仪区块链支链上节点交易速度,提高使用率。
[0066]
另外,设置高拍仪区块链支链与备份区块链总链存在共享的节点,即将所述高拍仪区块链支链上预定节点共享到备份区块链总链的共享节点上,使该高拍仪区块链支链上预定节点可以在其他区块链上进行备份存储,防止丢失和被篡改,提高存储信息的安全性和唯一性。
[0067]
另外,将所述语音文件在预定的时间内上传到所述共享节点上。不占用高拍仪区块链支链的区块链交易速度,可以利用其他空余时间将所述语音文件在预定的时间内上传到所述共享节点上,后续在验证或查找高拍仪区块链支链的交易信息时,可以到共享节点上查找语音文件来验证,进一步提高存储信息的安全性和唯一性。
[0068]
实施例二
[0069]
如图2所示。本发明还提供一种基于高拍仪获得语音播放系统,包括:
[0070]
扫描单元,其配置为,扫描预定图片,生成扫描图片;
[0071]
文字识别单元,其配置为,通过ocr技术识别所述扫描图片预定区域的文字,生成识别文字;
[0072]
语音生成单元,其配置为,通过tts技术将所述识别文字转换成语音文件。
[0073]
通过先将预定的图片进行拍摄扫描,生存扫描图片,然后将扫描图片上预定区域的文字通过ocr技术进行识别,生成识别文字,识别文字可以为可编辑的文字,然后通过tts技术将识别文字转换成语音文件,从而实现从图片到语音文件(mp3或wav)的直接输出,提高拍摄仪等设备可以直接输出成语音文件的能力,提高使用便利性。
[0074]
让拍摄仪可以实现拍摄图片,再进行文字识别,最后转存为计算机可朗读语音文件的目的,也可以通过将之前已经扫描过的本地现有图像,进行文字识别,转存为计算机可朗读的语音文件。
[0075]
如果有一种技术能将高拍仪采集的图像或本地电子图像,再进行一个mp3或wav格式的转换,人们可享受到利用碎片化时间进行听取的便利。
[0076]
其中,所述扫描单元还包括:
[0077]
根据预定位置对所述扫描图片进行裁切,生成扫描图片预定区域。
[0078]
通过将扫描图片进行裁切,只对扫描图片的预定区域进ocr文字识别,提高识别的定向性和准确性,目前通常用的裁切方法为,识别图片中文字区域,并对图片区域中的文字区域进行识别裁切,生存带文字区域的预定区域。
[0079]
所述文字识别单元还包括:
[0080]
通过ocr技术识别所述扫描图片预定区域的文字,生成原始文字;
[0081]
对所述原始文字进行自动处理,生成识别文字。
[0082]
通过ocr技术识别所述扫描图片预定区域的文字后,会带一些错误乱码文字或多余文字,此时,需要对乱码文字进行删除,多余文字进行删除或自动修订,修订的方式可以参照现有人工智能技术进行自动修改处理,当然可以不限于这些修改,还可以自动增加一些常用词语,比如,“中国首都京”中可能缺少“北”,就会自动增加为“中国首都北京”等,详细内容不再赘述。
[0083]
其中,所述语音生成单元还包括:
[0084]
通过tts技术中声音大小选择属性将所述识别文字转换成语音文件;和/或,
[0085]
通过tts技术中声音快慢选择属性将所述识别文字转换成语音文件。
[0086]
通过通过tts技术中声音大小和快慢选择属性将所述识别文字转换成预定音量和预定播放速度语音文件,可以根据个性化需求调节输出语音文件的属性,使该技术更人性化。
[0087]
在其他实施例中,提供的一种基于高拍仪获得语音播放系统还包括:
[0088]
区块链上传单元,将所述识别文字生成区块链文字信息,并将所述区块链文字信息上传到高拍仪区块链支链;
[0089]
区块链备份单元,将所述高拍仪区块链支链上预定节点共享到备份区块链总链的共享节点上;
[0090]
将所述语音文件在预定的时间内上传到所述共享节点上。
[0091]
通过将存储量比较小的区块链文字信息上传到高拍仪区块链支链上,可以大大减小高拍仪区块链支链的存储量,提高高拍仪区块链支链上节点交易速度,提高使用率。
[0092]
另外,设置高拍仪区块链支链与备份区块链总链存在共享的节点,即将所述高拍仪区块链支链上预定节点共享到备份区块链总链的共享节点上,使该高拍仪区块链支链上预定节点可以在其他区块链上进行备份存储,防止丢失和被篡改,提高存储信息的安全性和唯一性。
[0093]
另外,将所述语音文件在预定的时间内上传到所述共享节点上。不占用高拍仪区块链支链的区块链交易速度,可以利用其他空余时间将所述语音文件在预定的时间内上传到所述共享节点上,后续在验证或查找高拍仪区块链支链的交易信息时,可以到共享节点上查找语音文件来验证,进一步提高存储信息的安全性和唯一性。
[0094]
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人才员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1