抗病毒细胞及其用途的制作方法
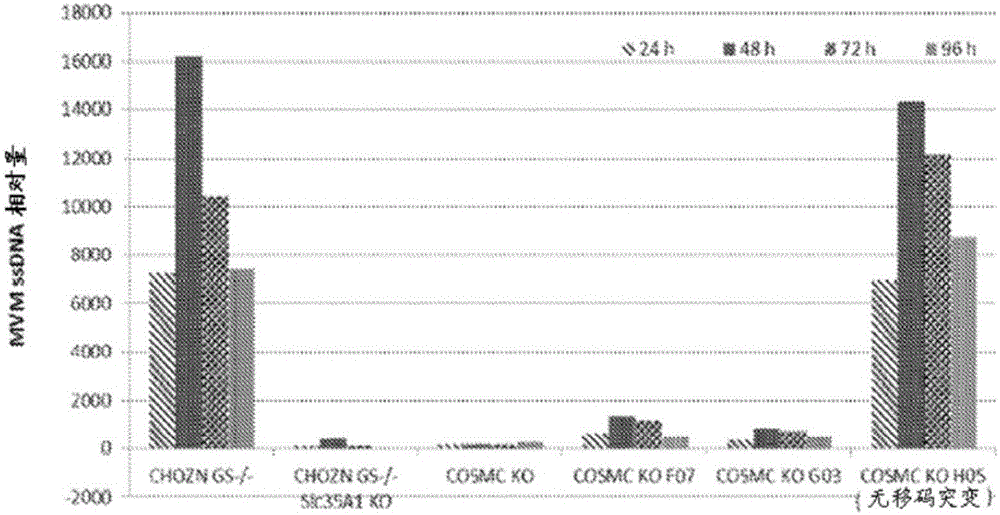
本发明涉及经工程改造而具有抗病毒性的哺乳动物细胞系和所述细胞系用于减少或防止生物生产系统的病毒污染的用途。背景重组产生的治疗性蛋白质用于治疗许多疾病或病状(诸如癌症和自身免疫性疾病)的用途不断增加。然而,这些蛋白质治疗剂的大规模生产仍然是一个挑战。举例来说,工业制造过程中必须实现可靠高收率,使得下游工艺产生极纯的产物,只允许痕量污染物至优选地无污染物。使用无动物成分的培养基已经显著地降低了外来病毒污染的发生率。另外,诸如超滤、高温短时间处理和/或对散装材料进行UVC照射之类的程序的实施进一步降低了污染的发生率。然而,病毒污染的风险仍然存在。就产品损失、暂时退出市场和昂贵的去污成本而言,污染事件对制造商将是灾难性的。因此,需要对病毒感染具有增加的抗性的哺乳动物细胞系。附图简述图1呈现了如通过Southern印迹分析所测定的MVM病毒感染的时间过程。利用在24、48、72和96小时针对野生型细胞(CHOZNGS-/-)、Slc35A1KO、COSMCKO、COSMCKO克隆F07、COSMCKO克隆G03和COSMCKO克隆H05所检测的MVM病毒DNA的相对量进行作图。克隆H05具有12bp的框内缺失(即,无移码突变)。图2示出了如通过空斑测定所检测的MVM病毒感染的时间过程。作图的是在24、48、72和96小时针对野生型细胞(CHOZN)、Slc.35A1KO、COSMCKO、COSMCKO克隆F07、COSMCKO克隆G03和COSMCKO克隆H05所检测的pfu/mL。图3示出了MMV感染对细胞生长的影响。作图的是野生型(2E3)(A)和COSMCKO克隆F07(B)细胞在MVM病毒不存在(实线)和以MOI1或8存在(断线)的情况下在120小时过程中的活细胞数目(细胞/ml)。图4呈现了MMV感染后的细胞相关病毒的时间过程。作图的是每个细胞的MVM病毒基因组拷贝数(vgc)(基于假定每一个已感染的细胞可以产生2x104vgc),如在MVM病毒以MOI1(A)或8(B)存在的情况下通过qPCR在120小时的过程中针对野生型(2E3)(实现)和COSMCKO克隆F07(断线)细胞所检测。图5示出了在指示的细胞系中的MMV复制的时间过程。作图的是用MVM病毒以MOI0.3(A)或0.03(B)感染后0和21小时的vgc/样品。图6呈现了所指示的细胞系中的呼肠孤病毒3复制的时间过程。作图的是在感染Reo-3病毒后0和24小时与野生型细胞(2E3)相关的vgc/样品。.图7呈现了在MVM病毒不存在(UN)或存在(IN)的情况下针对细胞生长进行的生长测定。图A呈现了野生型(GS)、Slc35A1KO、COSMCKO克隆F07和COSMCKO克隆G03在10天内的活细胞密度(VCD)。图B呈现了野生型(GS)、来源于COSMCKO克隆F07的IgG产生克隆71H1和71C3在8天内的VCD。图8呈现了在MVM病毒不存在(UN)或存在(IN)的情况下针对细胞生长进行的生长测定。作图的是野生型(GS)、St3Gal4KO克隆7D10、St3Gal4KO克隆1B08和St3Gal4KO克隆1B10在9天内的VCD。概要在本公开的各种方面中,提供了经工程改造以阻碍或防止细胞中的病毒进入和/或病毒繁殖的哺乳动物细胞系。在一些实施方案中,所述哺乳动物细胞系经过基因修饰,使得与未经修饰的亲本细胞系相比,至少一种病毒的进入和/或繁殖被减少或消除。在各种实施方案中,本文中所公开的哺乳动物细胞系包含至少一个经修饰的染色体序列。在其他实施方案中,所述经修饰的染色体序列是失活的,使得所述细胞系不产生或产生降低水平的编码蛋白质产物。在一个实施方案中,所述细胞系包含至少一个编码核心1酶伴侣(COSMC)的失活染色体序列。在另一个实施方案中,编码COSMC的染色体序列的所有拷贝都是失活的且所述细胞系不产生COSMC。在一个替代实施方案中,所述细胞系包含至少一个编码溶质载体家族35(CMP-唾液酸转运体)成员A1(Slc35A1)的失活染色体序列。在另一个实施方案中,编码Slc35A1的染色体序列的所有拷贝都是失活的且所述细胞系不产生Slc35A1。在又另一个实施方案中,所述细胞系包含至少一个编码核心1伸长酶(C1GalT1)的失活染色体序列。在另一个实施方案中,编码C1GalT1的染色体序列的所有拷贝都是失活的且所述细胞系不产生C1GalT1。在另一个实施方案中,所述细胞系包含至少一个编码St3β-半乳糖苷α-2,3-唾液酸转移酶1(St3Gal1)的失活染色体序列。在另一个实施方案中,编码St3Gal1的染色体序列的所有拷贝都是失活的且所述细胞系不产生St3Gal1。在一个替代实施方案中,所述细胞系包含至少一个编码St3β-半乳糖苷α-2,3-唾液酸转移酶2(St3Gal2)的失活染色体序列。在另一个实施方案中,编码St3Gal2的染色体序列的所有拷贝都是失活的且所述细胞系不产生St3Gal2。在又另一个实施方案中,所述细胞系包含至少一个编码St3β-半乳糖苷α-2,3-唾液酸转移酶3(St3Gal3)的失活染色体序列。在另一个实施方案中,编码St3Gal3的染色体序列的所有拷贝都是失活的且所述细胞系不产生St3Gal3。在又另一个实施方案中,所述细胞系包含至少一个编码St3β-半乳糖苷α-2,3-唾液酸转移酶4(St3Gal4)的失活染色体序列。在另一个实施方案中,编码St3Gal4的染色体序列的所有拷贝都是失活的且所述细胞系不产生St3Gal4。在一个替代实施方案中,所述细胞系包含至少一个编码St3β-半乳糖苷α-2,3-唾液酸转移酶5(St3Gal5)的失活染色体序列。在另一个实施方案中,编码St3Gal5的染色体序列的所有拷贝都是失活的且所述细胞系不产生St3Gal5。在又另一个实施方案中,所述细胞系包含至少一个编码St3β-半乳糖苷α-2,3-唾液酸转移酶6(St3Gal6)的失活染色体序列。在另一个实施方案中,编码St3Gal6的染色体序列的所有拷贝都是失活的且所述细胞系不产生St3Gal6。在一个替代实施方案中,所述细胞系包含编码St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和St3Gal6中的任两者的失活染色体序列。在又一个替代实施方案中,所述细胞系包含编码St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和St3Gal6中的任两者的失活染色体序列。在其他实施方案中,包含编码COSMC、Slc35A1、C1GalT1、St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的失活染色体序列的细胞系还包含编码甘露糖基(α-1,3-)-糖蛋白β-1,2-N-乙酰葡糖胺基转移酶1(Mgat1)、甘露糖基(α-1,6-)-糖蛋白β-1,2-N-乙酰葡糖胺基转移酶2(Mgat2)、甘露糖基(α-1,4-)-糖蛋白β-1,4-N-乙酰葡糖胺基转移酶3(Mgat3)、甘露糖基(α-1,3-)-糖蛋白β-1,4-N-乙酰葡糖胺基转移酶4(Mgat4)和/或甘露糖基(α-1,6-)-糖蛋白β-1,6-N-乙酰葡糖胺基转移酶5(Mgat5)的失活染色体序列。本文中所公开的包含经修饰的染色体序列的哺乳动物细胞系与未经修饰的亲本细胞系相比对病毒进入和/或病毒繁殖具有增加的抗性。在又其他实施方案中,包含编码St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的失活染色体序列的细胞系经过进一步工程改造以过度表达至少一种负责产生2,6-键联的唾液酸转移酶(例如,St6β-半乳糖酰胺α-2,6-唾液酸转移酶1(St6Gal1)、St6β-半乳糖酰胺α-2,6-唾液酸转移酶2(St6Gal2)、St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺1(St6GalNac1)、St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺2(St6GalNac2)、St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺3(St6GalNac3)、St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺4(ST6GalNac4)、St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺5(St6GalNac5)和/或St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺6(St6GalNac6)。在一些实施方案中,所述哺乳动物细胞系是非人细胞系。在其他实施方案中,所述哺乳动物细胞系是中国仓鼠卵巢(CHO)细胞系。在诸多具体实施方案中,所述细胞系是包含编码COSMC、Slc35A1、C1GalT1、St3Gall、St3Gal2、St3Gal3、St3Gal4、St3Gal5、St3Gal6或其组合的灭活染色体序列的CHO细胞系。在某些实施方案中,本文中所公开的哺乳动物细胞系对选自细小病毒、呼肠孤病毒、轮状病毒、流感病毒、腺相关病毒、杯状病毒、副流感病毒、风疹病毒、冠状病毒、诺罗病毒、脑心肌炎病毒、多瘤病毒或其组合的病毒的进入和/或繁殖表现出抗性。在一些实施方案中,所述细小病毒是小鼠微小病毒(MVM)、1型小鼠细小病毒、2型小鼠细小病毒、3型小鼠细小病毒、猪细小病毒1、牛细小病毒1、人细小病毒B19、人细小病毒4、人细小病毒5或其组合。在另外的实施方案中,所述呼肠孤病毒是哺乳动物呼肠孤病毒3、哺乳动物正呼肠孤病毒、禽正呼肠孤病毒或其组合。在各种实施方案中,本文中所公开的哺乳动物细胞系是通过使用靶向核酸内切酶介导的基因组修饰技术来修饰至少一个染色体序列而制得。所述靶向核酸内切酶可以是锌指核酸酶、CRISPR/Cas核酸内切酶、转录活化因子样效应因子(TALE)核酸酶、大范围核酸酶、位点特异性核酸内切酶或人工靶向DNA双链断裂诱导剂。在诸多具体实施方案中,所述靶向核酸内切酶是一对锌指核酸酶。在一些实施方案中,本文中所公开的哺乳动物细胞系还包含至少一种编码选自抗体、抗体片段、疫苗、生长因子、细胞因子、激素、凝血因子或另一种治疗蛋白质的重组蛋白的核酸。本公开的另一个方面涵盖一种减少或防止重组蛋白产物的病毒污染的方法,所述方法包括:获得如本文中所公开的抗病毒哺乳动物细胞系,并且在所述细胞系中表达重组蛋白产物。本公开的另一个方面提供一种减小生物生产系统的病毒污染的风险的方法,其中所述方法包括提供如本文中所公开的抗病毒哺乳动物细胞系以用于所述生物生产系统中。本公开的又另一个方面涵盖一种组合物,其包含如本文中所公开的抗病毒哺乳动物细胞系和至少一种病毒,其中所述细胞系表现出了对由所述至少一种病毒所致的感染的抗性。以下更详细地描述本公开的其他方面和迭代。详细说明本公开提供了经工程改造以阻碍或防止细胞系中的病毒进入和/或病毒繁殖的哺乳动物细胞系。具有抗病毒性的经工程改造的细胞系可以经过基因修饰以含有经修饰的(例如,灭活的)染色体序列。还提供了使用本文中所公开的细胞系产生重组蛋白的方法,其中该重组蛋白产物基本上没受到病毒污染。因此,使用对病毒感染具有抗性的细胞系能减小或消除生物生产系统和所得蛋白质产物的病毒污染的风险。(I)抗病毒细胞系本公开的一个方面涵盖经工程改造以具有病毒抗性的哺乳动物细胞系。换句话说,与未经修饰的亲本细胞系相比,本文中所公开的细胞系对由至少一种病毒所致的感染具有增加的抗性。更具体来说,与未经修饰的亲本细胞系相比,在本文中所公开的经工程改造的细胞系中,病毒进入和/或病毒繁殖被减少或消除。在一些实施方案中,该哺乳动物细胞系经过基因修饰并且含有至少一个经修饰的染色体序列。一般来说,该经修饰的序列包含突变。在诸多具体实施方案中,该经修饰的染色体序列是失活的(或被敲除),使得该细胞系不产生编码蛋白产物。一般来说,对病毒感染的抗性(或敏感性)可以通过比较经工程改造的哺乳动物细胞系对暴露于病毒的反应与未经修饰的(未经工程改造的)亲本细胞对相同病毒攻击的反应来确定。细胞系的病毒感染和/或细胞系中的病毒繁殖可以通过多种技术加以分析。合适的技术的非限制性实例包括核酸检测法(例如,用于检测具体病毒核酸的存在的南方核酸印迹测定、用于检测病毒核酸的PCR或RT-PCR、测序法等等)、基于抗体的技术(例如,使用抗病毒蛋白质抗体的西方免疫印迹技术、ELISA法,诸如此类)、生物测定(例如,斑点测定、细胞病变效应测定等等)和显微镜技术(例如,用于检测病毒颗粒的电子显微镜检查等)。在一些实施方案中,相对于未经修饰的亲本细胞,经工程改造的哺乳动物细胞系内的病毒感染和/或繁殖可以减少至少约10%、至少约20%、至少约40%、至少约60%、至少约80%、至少约90%、至少约99%或超过约99%。在诸多具体实施方案中,经工程改造的哺乳动物细胞系对病毒感染具有抗性,即,病毒不能进入和/或在该经工程改造的哺乳动物细胞系中繁殖。本文中所公开的哺乳动物细胞系可以用多种不同的方式加以工程改造以赋予病毒抗性。在一些实施方案中,该细胞系可以经过修饰,以使得通过细胞表面受体的病毒进入被减少或消除。在其他实施方案中,该细胞系可以经过工程改造以表达能抑制或阻断涉及复制和/或感染性的特定病毒蛋白的分子。在又其他实施方案中,该细胞系可以经过工程改造以过度表达特定细胞抗病毒蛋白。在一些实施方案中,该工程改造可以是基因工程改造,其中基因组或染色体序列经过修饰。换句话说,该细胞系经过基因修饰。在其他实施方案中,该工程改造可以是表观基因工程改造或染色体外工程改造。(a)抗病毒机制(i)扰乱细胞表面受体在某些实施方案中,该哺乳动物细胞系经过工程改造以含有经改变的细胞表面受体。病毒可以通过特异性附着于细胞表面上的互补受体而进入细胞。对于许多病毒来说,这些细胞表面受体包含与蛋白质(或脂质)连接的聚糖结构。唾液酸或其衍生物中的封端聚糖充当许多病毒的受体(Matrosovich等,2013,TopCurrChem,DOI:10.1007/128_2013_466)。因此,包含具有末端唾液酸残基的O连接型或N连接型聚糖的糖蛋白可以充当许多病毒的细胞表面受体。唾液酸是指神经氨酸的衍生物,并且包括例如N-乙酰基神经氨酸(Neu5Ac或NANA)和N-羟乙酰基神经氨酸(Neu5Gc或NGNA)。在一些实施方案中,该细胞系经过工程改造以包含缺乏末端唾液酸残基的糖蛋白。末端唾液酸残基可以通过缺失(即,敲除)或改变涉及聚糖链合成的酶和/或蛋白质而得以消除。合适的靶标包括涉及O连接型聚糖的合成的酶或蛋白质、涉及N连接型聚糖的合成的酶或蛋白质和/或涉及唾液酸的合成或转运的酶或蛋白质。在某些实施方案中,该细胞系可能缺乏以上提到的靶向酶或蛋白质中的至少一种(或以上提到的靶标的任何组合)。如本文中所使用,“缺乏”是指靶向酶或蛋白质的水平有所降低或不可检测,或者靶向酶或蛋白质的活性有所降低或不可检测。靶向酶或蛋白质的量或活性可以通过修饰至少一个编码靶向蛋白质或酶的染色体序列而被减少或消除。举例来说,染色体序列可以经过修饰以含有至少一个核苷酸的缺失、至少一个核苷酸的插入、至少一个核苷酸的取代或其组合。因此,缺失、插入和/或取代可以移动染色体序列的阅读框,以致不产生蛋白质产物(即,染色体序列是失活的)。或者,经修饰的染色体序列中的缺失、插入和/或取代可能导致产生改变的蛋白质产物。对感兴趣的染色体序列的修饰可以使用以下部分(III)(a)中详述的靶向核酸内切酶介导的基因组编辑技术来实现。在编码靶向酶或蛋白质的一个染色体序列失活的情况下,经工程改造的细胞系产生较低水平的靶向酶或蛋白质。在编码靶向酶或蛋白质的染色体序列的所有拷贝都失活的其他情况下,经工程改造的细胞系不产生靶向酶或蛋白质(即,该细胞系是敲除或KO)。在又其他实施方案中,靶向酶或蛋白质的水平可以使用以下部分(III)(b)中详述的RNA干扰介导的机制来减少或消除。在一些实施方案中,靶向酶或蛋白质的水平可以降低至少约5%、约5%至10%、约10%至20%、约20%至30%、约30%至40%、约40%至50%、约50%至60%、约60%至70%、约70%至80%、约80%至90%或约90%至约100%。在其他实施方案中,靶向酶或蛋白质的水平可以降至使用本领域中的标准技术(例如,西方免疫印迹测定、ELISA酶测定等等)不可检测的水平。在一些实施方案中,该细胞系可能缺乏涉及O连接型糖基化的酶或蛋白质。举例来说,该细胞系可能缺乏核心1伸长酶(也称为核心1合成酶糖蛋白-N-乙酰基半乳糖酰胺3-β-半乳糖苷转移酶1或C1GalT1)、核心1酶侣伴蛋白(也称为C1GalT1特异性侣伴蛋白或COSMC)或两者。COSMC促进C1GalT1的折叠、稳定性和活性,由此催化半乳糖残基转移至O-连接于蛋白质的丝氨酸或苏氨酸的N-乙酰基半乳糖酰胺(GalNAc)残基。在诸多具体实施方案中,该细胞系缺乏C1GalT1、COSMC或两者。该缺乏可能是由于编码C1GalT1和/或COSMC的失活染色体序列所致,从而产生了较低水平的C1GalT1和/或COSMC蛋白质或不产生C1GalT1和/或COSMC蛋白质。在一些情况下,至少一个编码C1GalT1和/或COSMC的染色体序列是失活的。在其他情况下,编码C1GalT1和/或COSMC的染色体序列的所有拷贝都是失活,导致该细胞系缺乏C1GalT1蛋白和/或COSMC蛋白。在其他实施方案中,该细胞系可能缺乏至少一种唾液酸转移酶(ST)。该唾液酸转移酶可以是将唾液酸添加至呈α-2,3键联构象的半乳糖的唾液酸转移酶、将唾液酸添加至呈α-2,6键联构象的半乳糖或N-乙酰半乳糖酰胺的唾液酸转移酶或将唾液酸添加至呈α-2,8键联构象的其他唾液酸单元的唾液酸转移酶。合适的唾液酸转移酶的非限制性实例包括St3β-半乳糖苷α-2,3-唾液酸转移酶1(St3Gal1)、St3β-半乳糖苷α-2,3-唾液酸转移酶2(St3Gal2)、St3β-半乳糖苷α-2,3-唾液酸转移酶3(St3Gal3)、St3β-半乳糖苷α-2,3-唾液酸转移酶4(St3Gal4)、St3β-半乳糖苷α-2,3-唾液酸转移酶5(St3Gal5)、St3β-半乳糖苷α-2,3-唾液酸转移酶6(St3Gal6)、St6β-半乳糖苷α-2,6-唾液酸转移酶1(St6Gal1)、St6β-半乳糖苷α-2,6-唾液酸转移酶2(St6Gal2)、St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺1(St6GalNac1)、St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺2(St6GalNac2)、St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺3(St6GalNac3)、St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺4(ST6GalNac4)、St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺5(St6GalNac5)、St6(α-N-乙酰基-神经氨酰基-2,3-β-半乳糖基-1,3)-N-乙酰半乳糖酰胺6(St6GalNac6)、St8α-N-乙酰基-神经氨酸苷α-2,8-唾液酸转移酶1(St8Sia1)、St8α-N-乙酰基-神经氨酸苷α-2,8-唾液酸转移酶2(St8Sia2)、St8α-N-乙酰基-神经氨酸苷α-2,8-唾液酸转移酶3(St8Sia3)、St8α-N-乙酰基-神经氨酸苷α-2,8-唾液酸转移酶4(St8Sia4)、St8α-N-乙酰基-神经氨酸苷α-2,8-唾液酸转移酶5(St8Sia5)或St8α-N-乙酰基-神经氨酸苷α-2,8-唾液酸转移酶6(St8Sia6)。在诸多具体实施方案中,该细胞系可能缺乏至少一种α-2,3-唾液酸转移酶(例如,St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6)。该缺乏可能是由于编码至少一种α-2,3-唾液酸转移酶的失活染色体序列所致,从而产生了较低水平的该至少一种α-2,3-唾液酸转移酶或不产生该α-2,3-唾液酸转移酶。在一些情况下,编码该至少一种α-2,3-唾液酸转移酶的至少一个染色体序列可以是失活的。在其他情况下,编码该至少一种α-2,3-唾液酸转移酶的染色体序列的所有拷贝都可以是失活的,使得该细胞系缺乏该至少一种α-2,3-唾液酸转移酶。换句话说,编码St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的染色体序列可能被敲除。在该细胞系包含编码至少一种α-2,3-唾液酸转移酶(例如,St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6)的至少一个失活染色体序列的一些情况下,该细胞系可以经过进一步工程改造以过度表达至少一种负责产生2,6-键联的唾液酸转移酶(例如,St6Gal1、St6Gal2、St6GalNac1、St6GalNac2、St6GalNac3、ST6GalNac4、St6GalNac5和/或St6GalNac6)。因此,这类细胞系可以包含具有减少数目的(或没有)末端2,3连接型唾液酸残基和增加数目的末端2,6连接型唾液酸残基的糖蛋白。在其他实施方案中,该细胞系可能缺乏至少一种涉及唾液酸合成或转运的酶或蛋白质。涉及唾液酸合成或转运的酶或蛋白质的实例包括但不限于葡糖胺(UDP-N-乙酰基)-2-表异构酶/N-乙酰甘露糖胺激酶(GNE)、N-乙酰神经氨酸合成酶(NANS)、N-乙酰神经氨酸磷酸酶(NANP)、单磷酸胞苷N-乙酰神经氨酸合成酶(CMAS)和单磷酸胞苷N-乙酰神经氨酸羟化酶(CMAH)、溶质载体家族35(CMP-唾液酸转运体)成员A1(Slc35A1)。在某些实施方案中,该细胞系可能缺乏将CMP-唾液酸转运至高尔基体中的Slc35A1。在一些情况下,编码Slc35A1的至少一个染色体序列可以是失活的。在其他情况下,编码Slc35A1的染色体序列的所有拷贝都可以是失活的,使得该细胞是缺乏Slc35A1蛋白。在另外的实施方案中,该细胞系可能缺乏涉及N-糖基化的至少一种酶或蛋白质。在一些情况下,涉及N-糖基化的酶或蛋白质可以是N-乙酰葡糖胺基转移酶,其给N连接型聚糖的β-连接型甘露糖残基增加了GlcNAc残基。实例包括甘露糖基(α-1,3-)-糖蛋白β-1,2-N-乙酰葡糖胺基转移酶1(Mgat-1)、甘露糖基(α-1,6-)-糖蛋白β-1,2-N-乙酰葡糖胺基转移酶2(Mgat-2)、甘露糖基(α-1,4-)-糖蛋白β-1,4-N-乙酰葡糖胺基转移酶3(Mgat-3)、甘露糖基(α-1,3-)-糖蛋白β-1,4-N-乙酰葡糖胺基转移酶4(Mgat-4)和甘露糖基(α-1,6-)-糖蛋白β-1,6-N-乙酰葡糖胺基转移酶5(Mgat-5)。在其他情况下,涉及N-糖基化的酶或蛋白质可以是半乳糖转移酶,其给N连接型聚糖的GlcNAc残基增加了处于β-1,4键联中的半乳糖残基。半乳糖转移酶可以是UDP-Gal:βGlcNAcβ1,4-半乳糖转移酶多肽1(B4GalT1)、UDP-Gal:βGlcNAcβ1,4-半乳糖转移酶多肽2(B4GalT2)、UDP-Gal:βGlcNAcβ1,4-半乳糖转移酶多肽3(B4GalT3)、UDP-Gal:βGlcNAcβ1,4-半乳糖转移酶多肽4(B4GalT4)、UDP-Gal:βGlcNAcβ1,4-半乳糖转移酶多肽5(B4GalT5)、UDP-Gal:βGlcNAcβ1,4-半乳糖转移酶多肽6(B4GalT6)或UDP-Gal:βGlcNAcβ1,4-半乳糖转移酶多肽7(B4GalT7)。在某些情况下,该细胞系可能缺乏至少一种N-乙酰葡糖胺基转移酶和/或半乳糖转移酶。在一些迭代中,编码至少一种N-乙酰葡糖胺基转移酶和/或半乳糖转移酶的至少一个染色体序列可以是失活的。在其他情况下,编码该至少一种N-乙酰葡糖胺基转移酶和/或半乳糖转移酶的染色体序列的所有拷贝都可以是失活的,使得该细胞系缺乏该至少一种N-乙酰葡糖胺基转移酶和/或半乳糖转移酶。(ii)干扰病毒蛋白质在其他实施方案中,该哺乳动物细胞系可以经过工程改造以表达能抑制或阻断病毒复制和/或感染性的分子。举例来说,该细胞系可以经过工程改造以稳定地表达至少一种针对涉及复制和/或感染性的特定病毒蛋白质的RNA干扰(RNAi)剂。合适的病毒蛋白质的非限制性实例包括非结构蛋白质,诸如NS1或NS2,和壳体蛋白质,诸如VP1或VP2。RNAi剂结合靶转录物且通过介导转录物裂解的裂解或破坏转录物的翻译而防止蛋白质表达。在一些实施方案中,RNAi剂可以是短干扰RNA(siRNA)。一般来说,siRNA包含介于约15至约29个核苷酸长,或更一般来说,约19至约23个核苷酸长的范围内的双链RNA分子。在诸多具体实施方案中,该siRNA可以是约21个核苷酸长。该siRNA可以任选地进一步包含一个或两个单链悬突,例如在一端或两端上的3′悬突。该siRNA可以由杂交在一起的两个RNA分子形成,或替代地,可以由短发夹RNA(shRNA)生成(见下文)。在一些实施方案中,该siRNA的两个链可以是完全互补的,使得两个序列之间所形成的双链体中不存在错配或隆凸。在其他实施方案中,该siRNA的两个链可以是基本上互补的,使得两个序列之间所形成的双链体中存在一个或多个错配和/或隆凸。在某些实施方案中,该siRNA的5′端中的一个或两个可以具有磷酸酯基,而在其他实施方案中,该5′端中的一个或两个可以缺乏磷酸酯基。该siRNA中被称为“反义链”或“引导链”的一个链包括能与靶转录物杂交的部分。在一些实施方案中,该siRNA的反义股可以与靶转录物的一个区域完全互补,即,其在整个siRNA长度上不存在单个错配或隆凸的情况下与靶转录物杂交。在其他实施方案中,该反义股可以与靶区域基本上互补,即,由该反义股和该靶转录物形成的双链体中可以存在一个或多个错配和/或隆凸。典型地,使siRNA靶向靶转录物的外显子序列。本领域技术人员应熟悉设计针对靶转录物的siRNA的程序、算法和/或商业服务。在其他实施方案中,RNAi剂可以是短发夹RNA(shRNA)。一般来说,shRNA是包含可杂交或能够杂交以形成长度足以介导RNA干扰(如以上所描述)的双链结构的至少两个互补部分和形成了连接形成该双链体的shRNA区域的环的至少一个单链部分的RNA分子。该结构还可以称为茎-环结构,其中该茎是双链体部分。在一些实施方案中,该结构的双链体部分可以是完全互补的,使得shRNA的双链体区域中不存在错配或隆凸。在其他实施方案中,该结构的双链体部分可以是基本上互补的,使得shRNA的双链体部分中可以存在一个或多个错配和/或隆凸。该结构的环可以是约1至约20个核苷酸长,具体来说是约6至约9个核苷酸长。该环可以位于与靶转录物互补的区域(即,shRNA的反义部分)的5′或3′端。该shRNA可以进一步包含处于5′或3′端上的悬突。该可选悬突可以是约1至约20个核苷酸长,或更具体来说是约2至约15个核苷酸长。在一些实施方案中,该悬突可以包含一个或多个U残基,例如介于约1个与约5个之间的U残基。在一些实施方案中,该shRNA的5′端可以具有磷酸酯基。一般来说,通过保守细胞RNAi机制将shRNA处理成siRNA。因此,shRNA是siRNA的前驱物,并且类似地能够抑制与shRNA的一部分(即,shRNA的反义部分)互补的靶转录物的表达。本领域技术人员应熟悉用于设计和合成shRNA的可用资源。一个示例性实例是shRNA(Sigma-Aldrich)。可以在活体内由RNAi表达构建体表达siRNA或shRNA。合适的构建体包括质粒载体、噬菌粒、粘粒、人工/微型染色体、转座子和病毒载体(例如,慢病毒载体、腺相关病毒载体等)。在一个实施方案中,该RNAi表达构建体可以是质粒载体(例如,pUC、pBR322、pET、pBluescript及其变体)。该RNAi表达构建体可以包含两个启动子控制序列,其中每一个可操作地连接适当的编码序列,使得两个独立的互补siRNA链可以被转录。该两个启动子控制序列可以呈相同的取向或相反的取向。在另一个实施方案中,该RNAi表达载体可以含有驱动包含两个互补区域的单个RNA分子的转录,从而使得转录物形成shRNA的启动子控制序列。一般来说,启动子控制序列将是RNA聚合酶III(PolIII)启动子,诸如U6或H1启动子。在其他实施方案中,可以使用RNA聚合酶II(PolII)启动子控制序列(以下给出了一些实例)。RNAi表达构建体可以含有额外的序列元件,诸如转录终止序列、可选标记序列等。可以使用标准程序将RNAi表达构建体引入感兴趣的细胞系中。可以将RNAi表达构建体染色体整合在该细胞系中以便稳定表达。或者,在该细胞系中,RNAi表达构建体可以在染色体外(例如,附加型)以便稳定表达。在又其他实施方案中,该细胞系可以经过工程改造以稳定地表达涉及复制和/或感染性的病毒蛋白质的显性阴性形式。使蛋白质的显性阴性形式发生改变或突变,以使其胜过或抑制野生型蛋白质。合适的蛋白质的非限制性实例包括病毒非结构蛋白质,诸如NS1或NS2,和病毒壳体蛋白,诸如VP1或VP2。在诸多具体实施方案中,该细胞系可以经过工程改造以表达一种或多种NS1蛋白的显性阴性形式。相对于野生型蛋白质,显性阴性蛋白质可以具有缺失、插入和/或取代(Lagna等,1998,Curr.TopicsDev.Biol,36:75-98)。缺失、插入和/或取代可以在蛋白质的N末端、C末端或内部位置。用于生成突变蛋白质的手段(通过定点诱变、基于PCR的诱变、随机诱变等)在本领域中是众所周知的,如同用于鉴定具有显性负面作用的那些的手段。可用包含编码显性阴性蛋白质的序列的表达构建体(见上文)来转染细胞系,其中该编码序列可操作地连接于PolII启动子控制序列以便表达。启动子控制序列可以是组成性的、调节型的或组织特异性的。合适的组成性启动子控制序列包括但不限于巨细胞病毒立即早期启动子(CMV)、猿猴病毒(SV40)启动子、腺病毒主要晚期启动子、劳斯肉瘤病毒(RSV)启动子、小鼠乳腺肿瘤病毒(MMTV)启动子、磷酸甘油酸激酶(PGK)启动子、伸长因子(ED1)-α启动子、泛素启动子、肌动蛋白启动子、微管蛋白启动子、免疫球蛋白启动子、其片段或上述任一者的组合。合适的调节型启动子控制序列的实例包括但不限于通过热激、金属、类固醇、抗生素或醇加以调节的那些。组织特异性启动子的非限制性实例包括B29启动子、CD14启动子、CD43启动子、CD45启动子、CD68启动子、结蛋白启动子、弹性蛋白酶1启动子、内皮糖蛋白启动子、纤连蛋白启动子、Flt-1启动子、GFAP启动子、GPIIb启动子、ICAM-2启动子、INF-β启动子、Mb启动子、NphsI启动子、OG-2启动子、SP-B启动子、SYN1启动子和WASP启动子。该启动子序列可以是野生型的,或其可以经过修饰以实现更高效或有效的表达。该表达构建体可以包含额外的表达控制序列(例如,增强子序列、Kozak序列、聚腺苷酸化序列、转录终止序列等)、可选标记序列(例如,抗生素抗性基因)、复制起点等等。额外信息可见于“CurrentProtocolsinMolecularBiology″Ausubel等,JohnWiley&Sons,NewYork,2003;或″MolecularCloning:ALaboratoryManual″Sambrook&Russell,ColdSpringHarborPress,ColdSpringHarbor,NY,第3版,2001。(iii)涉及抗病毒反应的细胞蛋白质的过度表现在诸多替代实施方案中,该哺乳动物细胞系可以经过工程改造以过度表达涉及宿主细胞抗病毒反应的细胞蛋白质。涉及抗病毒反应的蛋白质的非限制性实例包括双链RNA激活蛋白激酶R(PKR,其也被称为真核翻译起始因子2-α激酶2或Eif2ak2)、受体相互作用蛋白激酶2(RIPK2)、干扰素(例如,I型和II型)、白介素(例如,IL-1和IL-6)、肿瘤坏死因子α、干扰素调节因子1、STAT、p53、激活转录因子3、NF-κB、真核起始因子2(eIF2)、细胞凋亡蛋白抑制剂(IAP)和锌指抗病毒蛋白(ZAP)。在诸多具体实施方案中,该细胞系可以经过工程改造以过度表达PKR。过度表达可以通过引入编码感兴趣的蛋白质的核酸序列的一个或多个外源拷贝来实现。编码感兴趣的细胞蛋白质的序列一般被可操作地连接于PolII启动子控制序列(见上文)。可以将该编码序列的多个拷贝串联连接并且置于单个启动子控制序列的控制之下。可以将编码感兴趣的蛋白质的序列引入该细胞系中作为表达构建体的一部分(见上文)。因此,可以将该表达构建体插入染色体位置中,或替代地,该表达构建体可以在染色体外(例如,附加型),以便进行稳定表达。过度表达还可以通过修饰编码感兴趣的蛋白质的内源性染色体序列的启动子控制序列来实现。举例来说,内源启动子控制序列可以通过插入至少一个外源“强”启动子控制序列(即,对RNA聚合酶和/或相关因子具有高亲和力)(其实例呈现在上文中)而加以修饰。或者,内源启动子控制序列的序列可以经过修饰以模拟“强”启动子控制序列。内源染色体序列可以使用以下部分(III)中详述的靶向核酸内切酶介导的基因组修饰技术加以修饰。(b)细胞类型本文中所公开的抗病毒细胞系是哺乳动物细胞系。在一些实施方案中,对病毒感染具有抗性的细胞系可以来源于中国仓鼠卵巢(CHO)细胞;小鼠骨髓瘤NS0细胞;幼仓鼠肾(BHK)细胞;小鼠胚胎成纤维细胞3T3细胞(NIH3T3);鼠标B细胞淋巴瘤A20细胞;小鼠黑色素瘤B16细胞;小鼠成肌细胞C2C12细胞;小鼠骨髓瘤SP2/0细胞;小鼠胚胎间充质C3H-10T1/2细胞;小鼠癌瘤CT26细胞、小鼠前列腺DuCuP细胞;小鼠乳房EMT6细胞;小鼠肝癌Hepalc1c7细胞;小鼠骨髓瘤J5582细胞;小鼠上皮MTD-1A细胞;小鼠心肌MyEnd细胞;小鼠肾RenCa细胞;小鼠胰腺RIN-5F细胞;小鼠黑色素瘤X64细胞;小鼠淋巴瘤YAC-1细胞;大鼠成胶质细胞瘤9L细胞;大鼠B淋巴瘤RBL细胞;大鼠成神经细胞瘤B35细胞;大鼠肝癌细胞(HTC);水牛大鼠肝BRL3A细胞;犬肾细胞(MDCK);犬乳腺(CMT)细胞;大鼠骨肉瘤D17细胞;大鼠单核细胞/巨噬细胞DH82细胞;猴肾SV-40转化成纤维细胞(COS7)细胞;猴肾CVI-76细胞;非洲绿猴肾(VERO-76)细胞;人胚肾细胞(HEK293、HEK293T);人宫颈癌细胞(HELA);人肺细胞(W138);人肝细胞(HepG2);人U2-OS骨肉瘤细胞、人A549细胞、人A-431细胞或人K562细胞。哺乳动物细胞系的详尽列表可见于美国典型培养物保藏中心目录(ATCC,Manassas,VA)。在其他实施方案中,具有病毒抗性的细胞系是非人哺乳动物细胞系。在其他实施方案中,具有病毒抗性的细胞系是非人非小鼠哺乳动物细胞系。在某些实施方案中,具有病毒抗性的细胞系是CHO细胞系。众多CHO细胞系可购自ATCC。合适的CHO细胞系包括但不限于CHO-K1细胞和其衍生物。在各种实施方案中,该细胞系可能缺乏谷氨酰胺合成酶(GS)、二氢叶酸还原酶(DHFR)、次黄嘌呤-鸟嘌呤磷酸核糖基转移酶(HPRT)或其组合。举例来说,编码GS、DHFR和/或HPRT的染色体序列可以是失活的。在诸多具体实施方案中,编码GS的所有染色体序列在该细胞系中都是失活的。(c)病毒具有病毒抗性的经工程改造的哺乳动物细胞系可以抵抗多种哺乳动物病毒。该病毒可以是DNA病毒或RNA病毒,且该病毒可以有包膜或无包膜(“裸”)。可以通过唾液酸受体结合并进入哺乳动物细胞的病毒的非限制性实例包括细小病毒、呼肠孤病毒、轮状病毒、流感病毒、腺相关病毒、杯状病毒、副流感病毒、风疹病毒、冠状病毒、诺罗病毒、脑心肌炎病毒和多瘤病毒。在一些实施方案中,经工程改造的哺乳动物细胞系对由至少一种细小病毒所致的感染具有抗性。合适的细小病毒的非限制性实例包括小鼠的微小病毒(MVM)(其还被称为小鼠微小病毒(MMV)或啮齿类原细小病毒1)、1型小鼠细小病毒(MPV-1)、2型小鼠细小病毒(MPV-2)、3型小鼠细小病毒(MPV-3)、猪细小病毒1、牛细小病毒1和人细小病毒(例如,人细小病毒B19、人细小病毒4、人细小病毒5等)。在诸多具体实施方案中,该细小病毒可以是MVM。在其他实施方案中,该病毒可以是呼肠孤病毒,诸如哺乳动物呼肠孤病毒3、哺乳动物正呼肠孤病毒、禽正呼肠孤病毒等等)。在一些实施方案中,对病毒感染性具有抗性的经工程改造的哺乳动物细胞系还可以对由柔膜细菌目中的生物体所致的感染具有抗性。具体来说,本文中所公开的细胞系可以对由支原体属或螺原体属所致的感染具有抗性。(d)编码重组蛋白的可选核酸在一些实施方案中,对病毒感染具有抗性的哺乳动物细胞系可以进一步包含至少一种编码重组蛋白的核酸。一般来说,重组蛋白是异源的,这意味着该蛋白质对细胞来说不是天然的。该重组蛋白可以是但不限于选自以下的治疗性蛋白质:抗体、抗体片段、单克隆抗体、人源化抗体、人源化单克隆抗体、嵌合抗体、IgG分子、IgG重链、IgG轻链、IgA分子、IgD分子、IgE分子、IgM分子、疫苗、生长因子、细胞因子、干扰素、白介素、激素、凝血(或凝结)因子、血液组分、酶、治疗性蛋白质、营养性蛋白质、上述任一者的功能片段或功能变体、或包含上述蛋白质和/或其功能片段或变体中的任一者的融合蛋白。在一些实施方案中,编码重组蛋白的核酸可以被连接到编码次黄嘌呤-鸟嘌呤磷酸核糖基转移酶(HPRT)、二氢叶酸还原酶(DHFR)和/或谷氨酰胺合酶(GS)的序列,使得HPRT、DHFR和/或GS可以被用作可扩增的可选标记。编码重组蛋白的核酸还可以连接到编码至少一个抗生素抗性基因的序列和/或编码诸如荧光蛋白之类的标记蛋白的序列。在一些实施方案中,编码重组蛋白的核酸可以是表达构建体的一部分。如其他部分所详述,表达构建体或载体可以包含额外的表达控制序列(例如,增强子序列、Kozak序列、聚腺苷酸化序列、转录终止序列等)、可选标记序列、复制起点等等。额外的信息可见于Ausubel等,2003,同上和Sambrook&Russell,2001,同上。在一些实施方案中,编码重组蛋白的核酸可以位于染色体外。即,编码重组蛋白的核酸可以由质粒、粘粒、人工染色体、微型染色体或另一个染色体外构建体瞬时表达。在其他实施方案中,编码重组蛋白的核酸可以染色体整合到细胞的基因组中。该整合可以是随机的或靶向的。因此,该重组蛋白可以被稳定地表达。在这个实施方案的一些迭代中,编码重组蛋白的核酸序列可以可操作地连接到适当的异源表达控制序列(即,启动子)。在其他迭代中,编码重组蛋白的核酸序列可以被置于内源表达控制序列的控制之下。编码重组蛋白的核酸序列可以使用同源重组、靶向核酸内切酶介导的基因组编辑、病毒载体、转座子、质粒和其他众所周知的手段而整合到细胞系的基因组中。额外的指导可见于Ausubel等,2003,同上和Sambrook&Russell,2001,同上。(e)组合物在某些实施方案中,经工程改造而表现出病毒抗性的哺乳动物细胞系可以是组合物的一部分,该组合物还包含至少一种病毒。该组合物因此包含本文中所公开的经工程改造的细胞系(任选地进一步包含编码重组蛋白的核酸)和病毒,其中该至少一种病毒的进入和/或繁殖在该经工程改造的哺乳动物细胞系中被减少或消除。因此,该组合物中的细胞能够繁殖,但该组合物中的病毒不能够繁殖,因为其进入和/或复制在该细胞内被减少或消除。该组合物可以进一步包含至少一种细胞生长培养基以支持该经工程改造的哺乳动物细胞系细胞的生长。在一些情况下,该细胞生长培养基是无动物组分的培养基。(f)示例性实施方案在诸多具体实施方案中,具有病毒抗性的哺乳动物细胞系是CHO细胞系。该抗病毒CHO细胞系可以对由小鼠的微小病毒(MVM)(其还被称为小鼠微小病毒(MMV)或啮齿类原细小病毒1)和/或哺乳动物呼肠孤病毒3所致的感染具有抗性。具体来说,相对于未经修饰的亲本CHO细胞系,经基因修饰的CHO细胞系对MVM或呼肠孤病毒3感染的抗性已经有所提高。在一些实施方案中,该未经修饰的亲本细胞系是CHO(GS-/-)细胞系。该抗病毒CHO细胞系包含至少一个编码COSMC、Slc35A1、C1GalT1、St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的失活染色体序列。在一些实施方案中,在CHO细胞系中,编码COSMC、Slc35A1、C1GalT1、St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的染色体序列的所有拷贝都是失活的或被敲除。在其他实施方案中,包含编码COSMC、Slc35A1、C1GalT1、St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的失活染色体序列的CHO细胞进一步包含编码Mgat1、Mgat2、Mgat3、Mgat4和/或Mgat5的失活染色体序列。在其他实施方案中,包含编码St3Gal1、St3Gal2、St3Gal3、St3Gal4、St3Gal5和/或St3Gal6的失活染色体序列的CHO细胞经过进一步工程改造以过度表达St6Gal1、St6Gal2、St6GalNac1、St6GalNac2、St6GalNac3、ST6GalNac4、St6GalNac5和/或St6GalNac6。(II)用于减少或防止病毒污染的方法本公开的另一个方面涵盖用于减少或防止重组蛋白产物的病毒污染或减小生物生产系统的病毒污染的风险的方法。一般来说,该方法包括提供经工程改造的哺乳动物细胞系,其中至少一种病毒的进入和/或繁殖被减少或消除,和使用所述细胞系来产生该重组蛋白。该经工程改造的哺乳动物细胞系详述于以上部分(I)中。与未经修饰的亲本细胞系相比,该经工程改造的哺乳动物细胞系对病毒感染表现出抗性。该经工程改造的哺乳动物细胞系对部分(I)(c)中所描述的病毒表现出了抗性。合适的重组蛋白描述于部分(I)(d)中。用于产生或制造重组蛋白的手段在本领域中是众所周知的(参见例如“BiopharmaceuticalProductionTechnology”,Subramanian(编),2012,Wiley-VCH;ISBN:978-3-527-33029-4)。在诸多具体实施方案中,该经工程改造的哺乳动物细胞系经过基因修饰而包含至少一个经修饰的染色体序列,使得该细胞系对病毒感染具有抗性。一般来说,使用本文中所公开的经工程改造的哺乳动物细胞系能降低病毒在发酵罐或其他生物生产容器中复制的能力,使得可复制病毒的水平处在痕量水平,或者,理想地,处在工业标准最佳做法检测不到的水平。合适的方法包括核酸检测法(例如,用于检测病毒核酸的南方印迹、用于检测病毒核酸的PCR或RT-PCR、测序法等等)、基于抗体的技术(例如,使用抗病毒蛋白质抗体的西方免疫印迹、ELISA法,诸如此类)和显微镜技术(例如,细胞病变效应测定法、用于检测病毒颗粒的电子显微镜检查等)。(III)用于制备抗病毒细胞系的方法本公开的又另一个方面提供了制备如以上部分(I)(a)(i)中详述的具有改变的细胞表面受体的抗病毒细胞的方法。编码涉及糖链合成的酶或蛋白质的染色体序列可以使用各种技术敲低或敲除,以便生成抗病毒细胞系。在一些实施方案中,该抗病毒细胞系可以通过靶向核酸内切酶介导的基因组修饰方法来制备。在其他实施方案中,该抗病毒细胞系可以通过RNA干扰介导的机制来制备。在又其他实施方案中,该抗病毒细胞系可以通过位点特异性重组系统、随机诱变或本领域中已知的其他方法来制备。(a)靶向核酸内切酶介导的基因组编辑靶向核酸内切酶可以用于修饰(即,使失活或改变)感兴趣的特定染色体序列。可以通过向细胞中引入靶向特定的染色体序列的靶向核酸内切酶或编码该靶向核酸内切酶的核酸而使特定的染色体序列失活。在一个实施方案中,该靶向核酸内切酶识别并结合特定的染色体序列,并且引入了可由非同源端连接(NHEJ)修复过程修复的双链断裂。因为NHEJ容易出错,所以可能发生至少一个核苷酸的缺失、插入和/或取代,从而破坏染色体序列的阅读框,从而不产生蛋白质产物。在另一个实施方案中,该靶向核酸内切酶还可以被用于通过共引入与靶向染色体序列的一部分具有实质性序列同一性的多核苷酸经由同源重组反应来改变染色体序列。由该靶向核酸内切酶引入的双链断裂被同源定向修复过程修复,从而以使得染色体序列被改变或修改的方式使该染色体序列与该多核苷酸进行交换。多种靶向核酸内切酶可以用于修饰感兴趣的染色体序列。该靶向核酸内切酶可以是天然存在的蛋白质或经工程改造的蛋白质。合适的靶向核酸内切酶包括但不限于锌指核酸酶(ZFN)、CRISPR/Cas核酸内切酶、转录活化因子样效应因子(TALE)核酸酶(TALEN)、大范围核酸酶、位点特异性核酸内切酶和人工靶向DNA双链断裂诱导剂。(i)锌指核酸酶在诸多具体实施方案中,该靶向核酸内切酶可以是锌指核酸酶(ZFN)。ZFN结合特定靶向序列,并且将双链断裂引入该靶向序列中。典型地,ZFN包含DNA结合结构域(即,锌指)和裂解结构域(即,核酸酶),各自描述如下。DNA结合结构域。DNA结合结构域或锌指可以经过工程改造而识别并结合所选择的任何核酸序列。参见例如Beerli等,(2002)Nat.Biotechnol.20:135-141;Pabo等,(2001)Ann.Rev.Biochem.70∶313-340;Isalan等,(2001)Nat.Biotechnol.19∶656-660;Segal等,(2001)Curr.Opin.Biotechnol.12:632-637;Choo等,(2000)Curr.Opin.Stmct.Biol.10:411-416;Zhang等,(2000)J.Biol.Chem.275(43):33850-33860;Doyon等,(2008)Nat.Biotechnol.26:702-708;和Santiago等,(2008)Proc.Natl.Acad.Sci.USA105:5809-5814。与天然存在的锌指蛋白相比,经工程改造的锌指结合结构域可以具有新颖的结合特异性。工程改造方法包括但不限于合理的设计和各种类型的选择。合理的设计包括例如使用包括二联、三联和/或四联核苷酸序列和个别锌指氨基酸序列的数据库,其中各二联、三联或四联核苷酸序列与结合特定三联或四联序列的锌指的一个或多个氨基酸序列缔合。参见例如美国专利号6,453,242和6,534,261,其公开内容以全文引用的方式并入本文中。作为一个实例,可以使用美国专利6,453,242中所描述的算法来设计锌指结合结构域,以靶向预先选定的序列。还可以使用替代方法,诸如使用非简并识别密码表的合理设计来设计锌指结合结构域,以靶向特定序列(Sera等,(2002)Biochemistry41:7074-7081)。用于鉴别DNA序列中的潜在靶位点以及设计锌指结合结构域的公开可用的基于网络的工具在本领域中是公知的。举例来说,用于识别DNA序列中的潜在靶位点的工具可见于http://www.zincfingertools.org。用于设计锌指结合结构域的工具可见于http://zifit.partners.org/ZiFiT。(还参见Mandell等,(2006)Nuc.AcidRes.34:W516-W523;Sander等,(2007)Nuc.AcidRes.35:W599-W605。)锌指结合结构域可以经过设计以识别并结合介于约3个核苷酸至约21个核苷酸长的DNA序列。在一个实施方案中,该锌指结合结构域可以经过设计以识别并结合介于约9个至约18个核苷酸长的DNA序列。一般来说,本文中所使用的锌指核酸酶的锌指结合结构域包括至少三个锌指识别区或锌指,其中各锌指结合3个核苷酸。在一个实施方案中,该锌指结合结构域包括四个锌指识别区。在另一个实施方案中,该锌指结合结构域包括五个锌指识别区。在又另一个实施方案中,该锌指结合结构域包括六个锌指识别区。锌指结合结构域可以经过设计以结合任何合适的靶DNA序列。参见例如美国专利号6,607,882、6,534,261和6,453,242,其公开内容以全文引用的方式并入本文中。选择锌指识别区的示例性方法包括噬菌体呈现和双杂交系统,该方法描述于美国专利号5,789,538、5,925,523、6,007,988、6,013,453、6,410,248、6,140,466、6,200,759和6,242,568;以及WO98/37186、WO98/53057、WO00/27878、WO01/88197和GB2,338,237中,各专利以全文引用的方式并入本文中。另外,锌指结合结构域的结合特异性的增强已经描述于例如WO02/077227中,其全部公开内容以引用的方式并入本文中。用于设计和构建融合蛋白(和编码其的多核苷酸)的锌指结合结构域和方法对于本领域技术人员是已知的,并且详述于例如美国专利号7,888,121中,该专利以全文引用的方式并入本文中。锌指识别区和/或多指锌指蛋白可以使用合适的接头序列,包括例如五个或更多个氨基酸长的接头连接在一起。参见美国专利号6,479,626、6,903,185和7,153,949,该专利的公开内容以全文引用的方式并入本文中,从而得到六个或更多个氨基酸长的接头序列的非限制性实例。本文中所描述的锌指结合结构域可以包括介于蛋白质的个别锌指之间的合适的接头的组合。在一些实施方案中,该锌指核酸酶还包括核定位信号或序列(NLS)。NLS是氨基酸序列,其促进该锌指核酸酶蛋白靶向细胞核,从而在染色体中的靶序列处引入双链断裂。核定位信号在本领域中是已知的。参见例如Makkerh等,(1996)CurrentBiology6:1025-1027。裂解结构域。锌指核酸酶还包括裂解结构域。该锌指核酸酶的裂解结构域部分可以获自任何核酸内切酶或核酸外切酶。可以从中得到裂解结构域的内切核酸酶的非限制实例包括但不限于限制性核酸内切酶和归巢核酸内切酶。参见例如NewEnglandBiolabsCatalog或Belfort等,(1997)NucleicAcidsRes.25:3379-3388。使DNA裂解的额外的酶是已知的(例如,S1核酸酶、绿豆核酸酶、胰DNA酶I、微球菌核酸酶、酵母HO核酸内切酶)。也参见Linn等(编)Nucleases,ColdSpringHarborLaboratoryPress,1993。这些酶(或其功能片段)中的一种或多种可以用作裂解结构域的来源。裂解结构域还可以来源于酶或其部分,如以上所描述,这需要裂解活性的二聚化。裂解可能需要两个锌指核酸酶,因为各核酸酶包含活性酶二聚体的单体。或者,单个锌指核酸酶可以包含两种单体以形成活性酶二聚体。如本文中所使用,“活性酶二聚体”是能够使核酸分子裂解的酶二聚体。该两个裂解单体可以来源于同一核酸内切酶(或其功能片段),或各单体可以来源于不同的核酸内切酶(或其功能片段)。当使用两个裂解单体来形成活性酶二聚体时,两个锌指核酸酶的识别位点优选地经过布置以使得该两个锌指核酸酶与其相应的识别位点的结合将裂解单体相对于彼此置于允许裂解单体形成活性酶二聚体(例如,通过二聚化)的空间方向上。结果是,该识别位点的邻近边缘可以间隔约5个至约18个核苷酸。举例来说,邻近边缘可以间隔约5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个或18个核苷酸。然而,应理解,任何整数个核苷酸或核苷酸对可以介入两个识别位点之间(例如,约2个至约50个核苷酸对或更多)。该锌指核酸酶(诸如例如本文中详细描述的那些)的识别位点的邻近边缘可以间隔6个核苷酸。一般来说,裂解位点位于识别位点之间。限制性核酸内切酶(限制性酶)存在于许多物种中,并且能够序列特异性结合DNA(在识别位点处)且使结合位点处或附近的DNA裂解。某些限制性酶(例如,IIS型)在与识别位点相距较远的位点处使DNA裂解,并且具有可分离的结合结构域和裂解结构域。举例来说,IIS型酶FokI在与其一个链上的识别位点相距9个核苷酸且与其在另一个链上的识别位点相距13个核苷酸处催化DNA的双链裂解。参见例如美国专利号5,356,802、5,436,150和5,487,994;以及Li等,(1992)Proc.Natl.Acad.Sci.USA89:4275-4279;Li等,(1993)Proc.Natl.Acad.Sci.USA90:2764-2768;Kim等,(1994a)Proc.Natl.Acad.Sci.USA91:883-887;Kim等,(1994b)J.Biol.Chem.269:31978-31982。因此,锌指核酸酶可以包含来自至少一种IIS型限制性酶的裂解结构域和一个或多个锌指结合结构域,其可能经过或可能没经过工程改造。示例性IIS型限制性酶描述于例如国际公开WO07/014,275中,其公开内容以全文引用的方式并入本文中。额外的限制性酶还含有可分离的结合结构域和裂解结构域,并且这些也被本发明涵盖。参见例如Roberts等,(2003)NucleicAcidsRes.31:418-420。裂解结构域与结合结构域可分离的示例性IIS型限制性酶是FokI。这种特别的酶是活性二聚体(Bitinaite等,(1998)Proc.Natl.Acad.Sci.USA95:10,570-10,575)。因此,出于本公开的目的,锌指核酸酶中所使用的FokI酶部分被视为裂解单体。因此,对于使用FokI裂解结构域的靶向双链裂解,两个锌指核酸酶(各自包含FokI裂解单体)可以用来重建活性酶二聚体。或者,还可以使用含有锌指结合结构域和两个FokI裂解单体的单个多肽分子。在某些实施方案中,该裂解结构域包含一个或多个能减少或防止同源二聚化的经工程改造的裂解单体。作为非限制性实例,在FokI的位置446、447、479、483、484、486、487、490、491、496、498、499、500、531、534、537和538上的氨基酸残基是影响FokI裂解半结构域的二聚化的所有靶标。形成专性异源二聚体的示例性经工程改造的FokI裂解单体包括一对,其中第一裂解单体包括在FokI的氨基酸残基位置490和538上的突变,且第二裂解单体包括在氨基酸残基位置486和499上的突变。因此,在经工程改造的裂解单体的一个实施方案中,氨基酸位置490上的突变以Lys(K)置换Glu(E);氨基酸残基538上的突变以Lys(K)置换Iso(I);氨基酸残基486上的突变以Glu(E)置换Gln(Q);且499位上的突变以Lys(K)置换Iso(I)。具体来说,该经工程改造的裂解单体可以通过以下方式制得:在一个裂解单体中使490位从E突变至K且使538位从I突变至K,以产生经工程改造的裂解单体,命名为“E490K:I538K”,并且在另一个裂解单体中使486位从Q突变至E且使499位从I突变至K,以产生经工程改造的裂解单体,命名为“Q486E:I499K”。以上所描述的经工程改造的裂解单体是专性异源二聚体突变体,其中异常裂解被减至最少或被消除。可以使用合适的方法来制备经工程改造的裂解单体,例如通过如美国专利号7,888,121中所描述的野生型裂解单体(FokI)的定点诱变,该专利全文并入本文中。其他结构域。在一些实施方案中,该锌指核酸酶还包含至少一个核定位序列(NLS)。NLS是氨基酸序列,其促进该锌指核酸酶蛋白靶向细胞核,从而在染色体中的靶序列处引入双链断裂。核定位信号在本领域中是已知的(参见例如Lange等,J.Biol.Chem.,2007,282:5101-5105)。举例来说,在一个实施方案中,该NLS可以是单份序列,诸如PKKKRKV(SEQIDNO:1)或PKKKRRV(SEQIDNO:2)。在另一个实施方案中,该NLS可以是二分序列。在又另一个实施方案中,该NLS可以是KRPAATKKAGQAKKKK(SEQIDNO:3)。该NLS可以位于蛋白质的N末端、C末端或内部位置。在另外的实施方案中,该锌指核酸酶还可以包含至少一个细胞穿透结构域。在一个实施方案中,该细胞穿透结构域可以是来源于HIV-1TAT蛋白的细胞穿透肽序列。作为一个实例,该TAT细胞穿透序列可以是GRKKRRQRRRPPQPKKKRKV(SEQIDNO:4)。在另一个实施方案中,该细胞穿透结构域可以是来源于人乙型肝炎病毒的细胞穿透肽序列TLM(PLSSIFSRIGDPPKKKRKV,SEQIDNO:5)。在另一个实施方案中,该细胞穿透结构域可以是MPG(GALFLGWLGAAGSTMGAPKKKRKV,SEQIDNO:6;或GALFLGFLGAAGSTMGAWSQPKKKRKV,SEQIDNO:7)。在一个另外的实施方案中,该细胞穿透结构域可以是Pep-1(KETWWETWWTEWSQPKKKRKV,SEQIDNO:8)、VP22、来自单纯疱疹病毒的细胞穿透肽、或聚精氨酸肽序列。该细胞穿透结构域可以位于锌指核酸酶的N末端、C末端或内部位置。在又其他实施方案中,该锌指核酸酶还可以包含至少一个标记结构域。标记结构域的非限制性实例包括荧光蛋白、纯化标签和表位标签。在一个实施方案中,该标记结构域可以是荧光蛋白。合适的荧光蛋白的非限制性实例包括绿色荧光蛋白(例如,GFP、GFP-2、tagGFP、turboGFP、EGFP、Emerald、AzamiGreen、MonomericAzamiGreen、CopGFP、AceGFP、ZsGreen1)、黄色荧光蛋白(例如,YFP、EYFP、Citrine、Venus、YPet、PhiYFP、ZsYellow1)、蓝色荧光蛋白(例如,EBFP、EBFP2、Azurite、mKalama1、GFPuv、Sapphire、T-sapphire)、青色荧光蛋白(例如ECFP、Cerulean、CyPet、AmCyan1、Midoriishi-Cyan)、红色荧光蛋白(mKate、mKate2、mPlum、DsRed单体、mCherry、mRFP1、DsRed-Express、DsRed2、DsRed-Monomer、HcRed-Tandem、HcRed1、AsRed2、eqFP611、mRasberry、mStrawberry、Jred)和橙色荧光蛋白(mOrange、mKO、Kusabira-Orange、MonomericKusabira-Orange、mTangerine、tdTomato)或任何其他合适的荧光蛋白。在另一个实施方案中,该标记结构域可以是纯化标签和/或表位标签。合适的标签包括但不限于谷胱甘肽-S-转移酶(GST)、甲壳素结合蛋白(CBP)、麦芽糖结合蛋白、硫氧还蛋白(TRX)、聚(NANP)、串联亲和纯化(TAP)标签、myc、AcV5、AU1、AU5、E、ECS、E2、FLAG、HA、nus、Softag1、Softag3、Strep、SBP、Glu-Glu、HSV、KT3、S、S1、T7、V5、VSV-G、6xHis、生物素羧基载体蛋白(BCCP)和钙调蛋白。该标记结构域可以位于锌指核酸酶的N末端、C末端或内部位置。该标记结构域可以通过2A肽连接到锌指核酸酶(Szymczak等,2004,Nat.Biotechnol.,589(5):589-94)。该2A肽最初是在正链RNA病毒中被表征,该病毒产生在翻译成成熟个别蛋白质期间被“裂解”的多蛋白。更具体来说,该2A肽区(~20个氨基酸)在其自身的C末端介导“裂解”,以使其自身从该多蛋白的下游区域释放。一般来说,2A肽序列以甘氨酸和脯氨酸残基封端。在2A肽的翻译期间,核糖体在甘氨酸残基之后暂停,从而释放新生的多肽链。翻译恢复,同时2A序列的脯氨酸残基变成下游蛋白的第一个氨基酸。(ii)CRISPR/Cas核酸内切酶在其他实施方案中,该靶向核酸内切酶可以是CRISPR/Cas核酸内切酶。CRISPR/Cas核酸内切酶是来源于CRISPR/Cas系统的RNA引导型核酸内切酶。细菌和古细菌已经进化出使用CRISPR(成簇的规律间隔的短回文重复序列)和Cas(CRISPR相关)蛋白来检测和消灭入侵的病毒或质粒的基于RNA的适应性免疫系统。CRISPR/Cas核酸内切酶可以经过编程,以便通过提供靶特异性合成引导RNA而引入靶向位点特异性双链断裂(Jinek等,2012,Science,337:816-821)。核酸内切酶。该CRISPR/Cas核酸内切酶可以来源于I型、II型或III型CRISPR/Cas系统。合适的CRISPR/Cas蛋白的非限制性实例包括Cas3、Cas4、Cas5、Cas5e(或CasD)、Cas6、Cas6e、Cas6f、Cas7、Cas8a1、Cas8a2、Cas8b、Cas8c、Cas9、Cas10、Cas10d、CasF、CasG、CasH、Csy1、Csy2、Csy3、Cse1(或CasA)、Cse2(或CasB)、Cse3(或CasE)、Cse4(或CasC)、Csc1、Csc2、Csa5、Csn2、Csm2、Csm3、Csm4、Csm5、Csm6、Cmr1、Cmr3、Cmr4、Cmr5、Cmr6、Csb1、Csb2、Csb3、Csx17、Csx14、Csx10、Csx16、CsaX、Csx3、Csz1、Csx15、Csf1、Csf2、Csf3、Csf4和Cu1966。在一个实施方案中,该CRISPR/Cas核酸内切酶来源于II型CRISPR/Cas系统。在示例性实施方案中,该CRISPR/Cas核酸内切酶来源于Cas9蛋白。该Cas9蛋白可以来自化脓性链球菌、嗜热链球菌、链球菌属、达松维尔类诺卡菌、始旋链霉菌、绿产色链霉菌、绿产色链霉菌、玫瑰链孢囊菌、玫瑰链孢囊菌、酸热脂环酸杆菌、假真菌样芽孢杆菌、枯草芽孢杆菌、西伯利亚微小杆菌、保加利亚乳杆菌、唾液乳杆菌、海洋微颤蓝细菌、伯克霍尔德氏菌、萘降解极地单胞菌、极地单胞菌属、瓦氏鳄球藻、蓝杆藻属、铜绿微囊藻、聚球藻属、阿拉伯糖醋盐杆菌、丹氏制氨菌、极端嗜热纤维素降解厌氧菌、金矿菌、肉毒梭菌、难辨梭状芽孢杆菌、大芬戈尔德菌、嗜热盐碱厌氧菌、喜温丙酸互营菌、喜温嗜酸硫杆菌、氧化亚铁硫杆菌、紫色硫细菌、海杆菌属、嗜盐亚硝化球菌、瓦氏亚硝化球菌、游海假交替单胞菌、消旋纤线杆菌、极端嗜盐甲烷盐菌、多变鱼腥藻、泡沫节球藻、念珠藻属、极大节螺藻、节旋螺旋藻、节旋藻属、鞘丝藻属、原型微鞘藻、颤藻属、运动石油神袍菌、非洲栖热腔菌或海滨蓝藻菌。在一个具体实施方案中,该Cas9蛋白来自化脓性链球菌。一般来说,CRISPR/Cas蛋白包含至少一个RNA识别结构域和/或RNA结合结构域。RNA识别结构域和/或RNA结合结构域与引导RNA相互作用,从而将CRISPR/Cas蛋白引向特定的染色体或染色体序列(即,靶位点)。该CRISPR/Cas蛋白还可以包含核酸酶结构域(即,DNA酶或RNA酶结构域)、DNA结合结构域、解螺旋酶结构域、蛋白-蛋白相互作用结构域、二聚结构域以及其他结构域。该CRISPR/Cas蛋白可以来源于野生型CRISPR/Cas蛋白、经修饰的CRISPR/Cas蛋白或者野生型或经修饰的CRISPR/Cas蛋白的片段。该CRISPR/Cas蛋白可以经修饰以增加核酸结合亲和力和/或特异性,改变酶活性和/或改变该蛋白质的另一种性质。举例来说,该CRISPR/Cas蛋白的核酸酶(即,DNA酶、RNA酶)结构域可以被修饰、缺失或失活。该CRISPR/Cas蛋白可以被截短以去除对于该蛋白质的功能来说并非必不可少的结构域。该CRISPR/Cas蛋白还可以被截短或经修饰以使该蛋白质或与该CRISPR/Cas蛋白融合的效应因子结构域的活性最优化。在一些实施方案中,该CRISPR/Cas核酸内切酶可以来源于野生型Cas9蛋白或其片段。在其他实施方案中,该CRISPR/Cas核酸内切酶可以来源于经修饰的Cas9蛋白。举例来说,Cas9蛋白的氨基酸序列可以经修饰而改变该蛋白质的一种或多种性质(例如,核酸酶活性、亲和力、稳定性等)。或者,不涉及RNA引导型裂解的Cas9蛋白的结构域可以被从该蛋白质中消除,使得经修饰的Cas9蛋白比野生型Cas9蛋白小。一般来说,Cas9蛋白包含至少两个核酸酶(即,DNA酶)结构域。举例来说,Cas9蛋白可以包含RuvC样核酸酶结构域和HNH样核酸酶结构域。RuvC和HNH结构域一起起作用以切开单链,从而在DNA中产生双链断裂(Jinek等,Science,337:816-821)。在一个实施方案中,该基于CRISPR的核酸内切酶来源于Cas9蛋白且包含两个功能核酸酶结构域。由天然存在的CRISPR/Cas系统来识别典型地具有约14-15bp长度的靶位点(Cong等,Science,339:819-823)。该靶位点不具有序列限制,除了与引导RNA的5′端互补的序列(即,称为原型间隔序列)紧随(3′或下游)共有序列之后。这个共有序列也被称为原型间隔序列相邻基元(或PAM)。PAM的实例包括但不限于NGG、NGGNG和NNAGAAW(其中N被定义为任何核苷酸且W被定义为A或T)。在典型长度下,在靶基因组内只有约5-7%的靶位点将是唯一的,这表明脱靶效应可能是显著的。靶位点的长度可以通过命令两个结合事件而加以扩展。举例来说,基于CRISPR的核酸内切酶可以经过修改,使得其只能裂解双链序列的一个链(即,转化至切口酶)。因此,与两个不同的引导RNA组合使用基于CRISPR的切口酶将基本上使靶位点的长度翻倍,同时仍实现双链断裂。因此,在一些实施方案中,Cas9衍生核酸内切酶可以经修饰以含有一个功能核酸酶结构域(RuvC样或HNH样核酸酶结构域)。举例来说,Cas9衍生蛋白可以经修饰以使核酸酶结构域之一缺失或突变,使其不再具有功能性(即,该结构域缺乏核酸酶活性)。在一些实施方案中,核酸酶结构域之一是无活性的,该Cas9衍生蛋白能够向双链核酸中引入缺口(这类蛋白质被称为“切口酶”),但不能使双链DNA裂解。举例来说,RuvC样结构域中的天冬氨酸至丙氨酸(D10A)转化将Cas9衍生蛋白转化成“HNH”切口酶。同样,HNH结构域中的组氨酸至丙氨酸(H840A)转化(在一些情况下,该组氨酸位于839位)将Cas9衍生蛋白质转化成“RuvC”切口酶。因此,举例来说,在一个实施方案中,该Cas9衍生切口酶在RuvC样结构域中具有天冬氨酸至丙氨酸(D10A)转化。在另一个实施方案中,该Cas9衍生切口酶在HNH结构域中具有组氨酸至丙氨酸(H840A或H839A)转化。该Cas9衍生切口酶的RuvC样或HNH样核酸酶结构域可以使用众所周知的方法,诸如定点诱变、PCR介导的诱变和全基因合成以及本领域中已知的其他方法加以修饰。其他结构域。该CRISPR/Cas核酸内切酶或切口酶一般包括至少一个核定位信号(NLS)。举例来说,在一个实施方案中,该NLS可以是单份序列,诸如PKKKRKV(SEQIDNO:1)或PKKKRRV(SEQIDNO:2)。在另一个实施方案中,该NLS可以是二分序列。在又另一个实施方案中,该NLS可以是KRPAATKKAGQAKKKK(SEQIDNO:3)。该NLS可以位于蛋白质的N末端、C末端或内部位置。在一些实施方案中,该CRISPR/Cas核酸内切酶或切口酶可以进一步包括至少一个细胞穿透结构域。该细胞穿透结构域可以是来源于HIV-1TAT蛋白的细胞穿透肽序列。作为一个实例,该TAT细胞穿透序列可以是GRKKRRQRRRPPQPKKKRKV(SEQIDNO:4)。在另一个实施方案中,该细胞穿透结构域可以是来源于人乙型肝炎病毒的细胞穿透肽序列TLM(PLSSIFSRIGDPPKKKRKV,SEQIDNO:5)。在另一个实施方案中,该细胞穿透结构域可以是MPG(GALFLGWLGAAGSTMGAPKKKRKV,SEQIDNO:6;或GALFLGFLGAAGSTMGAWSQPKKKRKV,SEQIDNO:7)。在一个另外的实施方案中,该细胞穿透结构域可以是Pep-1(KETWWETWWTEWSQPKKKRKV,SEQIDNO:8)、VP22、来自单纯疱疹病毒的细胞穿透肽、或聚精氨酸肽序列。该细胞穿透结构域可以位于该蛋白质的N末端、C末端或内部位置。在又其他实施方案中,该CRISPR/Cas核酸内切酶或切口酶可以进一步包括至少一个标记结构域。标记结构域的非限制性实例包括荧光蛋白、纯化标签和表位标签。在一个实施方案中,该标记结构域可以是荧光蛋白。合适的荧光蛋白的非限制性实例包括绿色荧光蛋白(例如,GFP、GFP-2、tagGFP、turboGFP、EGFP、Emerald、AzamiGreen、MonomericAzamiGreen、CopGFP、AceGFP、ZsGreen1)、黄色荧光蛋白(例如,YFP、EYFP、Citrine、Venus、YPet、PhiYFP、ZsYellow1)、蓝色荧光蛋白(例如,EBFP、EBFP2、Azurite、mKalama1、GFPuv、Sapphire、T-sapphire)、青色荧光蛋白(例如ECFP、Cerulean、CyPet、AmCyan1、Midoriishi-Cyan)、红色荧光蛋白(mKate、mKate2、mPlum、DsRed单体、mCherry、mRFP1、DsRed-Express、DsRed2、DsRed-Monomer、HcRed-Tandem、HcRed1、AsRed2、eqFP611、mRasberry、mStrawberry、Jred)和橙色荧光蛋白(mOrange、mKO、Kusabira-Orange、MonomericKusabira-Orange、mTangerine、tdTomato)或任何其他合适的荧光蛋白。在另一个实施方案中,该标记结构域可以是纯化标签和/或表位标签。合适的标签包括但不限于谷胱甘肽-S-转移酶(GST)、甲壳素结合蛋白(CBP)、麦芽糖结合蛋白、硫氧还蛋白(TRX)、聚(NANP)、串联亲和纯化(TAP)标签、myc、AcV5、AU1、AU5、E、ECS、E2、FLAG、HA、nus、Softag1、Softag3、Strep、SBP、Glu-Glu、HSV、KT3、S、S1、T7、V5、VSV-G、6xHis、生物素羧基载体蛋白(BCCP)和钙调蛋白。该标记结构域可以位于该蛋白质的N末端、C末端或内部位置。该标记结构域可以通过2A肽连接到该CRISPR/Cas核酸内切酶或切口酶(Szymczak等,2004,Nat.Biotechnol.,589(5):589-94)。引导RNA。该CRISPR/Cas核酸内切酶由引导RNA引导至靶位点。引导RNA在染色体中与该CRISPR/Cas核酸内切酶和该靶位点相互作用,在该位点处,该CRISPR/Cas核酸内切酶或切口酶使该双链序列的至少一个链裂解。可以将该引导RNA与CRISPR/Cas核酸内切酶或编码该CRISPR/Cas核酸内切酶的核酸一起引入细胞中。或者,可以将编码CRISPR/Cas核酸内切酶和引导RNA的DNA引入到细胞中。引导RNA包含三个区域:5′端上与靶位点上的序列互补的第一区域;形成茎环结构的第二内部区域;和基本上保持单链的第三3′区域。各引导RNA的第一区域是不同的,使得各引导RNA将CRISPR/Cas核酸内切酶或切口酶引导至特定的靶位点。各引导RNA的第二区域和第三区域(也称为支架区域)在所有的引导RNA中可以相同。引导RNA的第一区域与靶位点上的序列(即,原型间隔序列)互补,使得引导RNA的第一区域可以与靶位点上的序列进行碱基配对。一般来说,引导RNA的第一区域的序列与靶位点上的序列之间没有错配(即,完全互补)。在各种实施方案中,引导RNA的第一区域可以包含约10个核苷酸至超过约25个核苷酸。举例来说,引导RNA的第一区域与染色体序列中的靶位点之间进行碱基配对的区域的长度可以是约10、11、12、13、14、15、16、17、18、19、20、22、23、24、25或超过25个核苷酸。在示例性实施方案中,引导RNA的第一区域的长度是约19或20个核苷酸。引导RNA还包含形成二级结构的第二区域。在一些实施方案中,该二级结构包括茎(或发夹)和环。该环和该茎的长度可以变化。举例来说,该环的长度可以介于约3至约10个核苷酸的范围内,且该茎的长度可以介于约6至约20个碱基对的范围内。该茎可以包括一个或多个具有1至约10个核苷酸的隆凸。因此,该第二区域的整个长度可以介于约16至约60个核苷酸的长度范围内。在一个示例性实施方案中,该环的长度是约4个核苷酸,且该茎包括约12个碱基对。该引导RNA还包括处于3′端上的基本上保持单链的第三区域。因此,该第三区域与感兴趣的细胞中的任何染色体序列都不具有互补性,而且与引导RNA的其余部分不具有互补性。该第三区域的长度可以变化。一般来说,该第三区域的长度超过约4个核苷酸。举例来说,该第三区域的长度可以介于约5至约60个核苷酸的长度范围内。该引导RNA的第二和第三区域(或支架)的组合长度可以介于约30至约120个核苷酸的长度范围内。在一个方面,该引导RNA的第二和第三区域的组合长度在约70至约100个核苷酸的长度范围内。在一些实施方案中,该引导RNA包含一个包括所有三个区域的分子。在其他实施方案中,该引导RNA可以包括两个独立的分子。该第一RNA分子可以包含该引导RNA的第一区域和该引导RNA的第二区域的“茎”的一半。该第二RNA分子可以包括该引导RNA的第二区域的“茎”的另一半和该引导RNA的第三区域。因此,在这个实施方案中,该第一RNA分子和该第二RNA分子各自含有彼此互补的核苷酸序列。举例来说,在一个实施方案中,该第一RNA分子和该第二RNA各自包含与另一序列进行碱基配对以形成功能性引导RNA的序列(约6至约20个核苷酸)。(iii)其他靶向核酸内切酶在其他实施方案中,该靶向核酸内切酶可以是大范围核酸酶。大范围核酸酶是以长识别序列为特征的脱氧核糖核酸内切酶,即,该识别序列一般介于约12个碱基对至约40个碱基对的范围内。作为这种要求的结果,该识别序列一般仅在任何给定的基因组中出现一次。在大范围核酸酶中,被命名为LAGLIDADG的归巢核酸内切酶家族已经成为用于基因组和基因组工程改造研究的有价值的工具(参见例如Amould等,2011,ProteinEngDesSel,24(1-2):27-31)。大范围核酸酶可以通过使用本领域技术人员众所周知的技术来修饰其识别序列而靶向特定的染色体序列。在另外的实施方案中,靶向核酸内切酶可以是转录活化因子样效应因子(TALE)核酸酶。TALE是可以容易进行工程改造以结合新的DNA靶标的来自植物病原体黄单胞菌的转录因子。TALE或其截短版本可连接到核酸内切酶的催化结构域,诸如FokI,以建立被称为TALE核酸酶或TALEN的靶向核酸内切酶(Sanjana等,2012,NatProtoc,7(1):171-192)。在又其他实施方案中,该靶向核酸内切酶可以是位点特异性核酸内切酶。具体来说,该位点特异性核酸内切酶可以是“稀有切割”核酸内切酶,其识别序列很少出现在基因组中。或者,该位点特异性核酸内切酶可以经工程改造以使感兴趣的位点裂解(Friedhoff等,2007,MethodsMolBiol352:1110123)。一般来说,该位点特异性核酸内切酶的识别序列只在基因组中出现一次。在替代其他实施方案中,该靶向核酸内切酶可以是人工靶向DNA双链断裂诱导剂。(iv)可选多核苷酸靶向基因组修饰方法可以进一步包括向细胞中引入至少一种多核苷酸,该多核苷酸包含与靶向裂解位点的至少一侧上的序列具有实质性序列同一性的序列,使得由该靶向核酸内切酶引入的双股断裂可以通过同源性定向修复方法加以修复;和使该多核苷酸的序列与内源染色体序列进行交换,从而修饰该内源染色体序列。举例来说,该多核苷酸包含与该靶向裂解位点的一侧上的序列具有实质性序列同一性的第一序列和与该靶向裂解位点的另一侧上的序列具有实质性序列一致性的第二序列。或者,该多核苷酸包含与该靶向裂解位点的一侧上的序列具有实质性序列同一性的第一序列和与位于远离该靶向裂解位点处的序列具有实质性序列一致性的第二序列。该位于远离该靶向裂解位点处的序列可以是该靶向裂解位点上游或下游的数十、数百或数千个核苷酸。该多核苷酸中与该靶向染色体序列中的序列具有实质性序列同一性的第一序列和第二序列的长度可以并且将会变化。一般来说,该多核苷酸中的第一序列和第二序列各自的长度是至少约10个核苷酸。在各种实施方案中,与染色体序列具有实质性序列同一性的多核苷酸序列的长度可以是约15个核苷酸、约20个核苷酸、约25个核苷酸、约30个核苷酸、约40个核苷酸、约50个核苷酸、约100个核苷酸或超过100个核苷酸。短语“实质性序列同一性”意指多核苷酸中的序列与感兴趣的染色体序列具有至少约75%的序列同一性。在一些实施方案中,该聚核苷酸中的序列与感兴趣的染色体序列具有75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性。该多核苷酸的长度可以并且将会变化。举例来说,该多核苷酸可以介于约20个核苷酸的长度直至约200,000个核苷酸的长度的范围内。在各种实施方案中,该多核苷酸介于约20个核苷酸至约100个核苷酸的长度、约100个核苷酸约1000个核苷酸的长度、约1000个核苷酸至约10,000个核苷酸的长度、约10,000个核苷酸至约100,000个核苷酸的长度或约100,000个核苷酸至约200,000个核苷酸的长度的范围内。典型地,该多核苷酸是DNA。该DNA可以是单链或双链的。该多核苷酸可以是DNA质粒、细菌人工染色体(BAC)、酵母人工染色体(YAC)、病毒载体、线性DNA片、PCR片段、裸核酸、或核酸与诸如脂质体或泊洛沙姆之类的递送媒剂的复合物。在某些实施方案中,该多核苷酸是单链的。在诸多示例性实施方案中,该多核苷酸是包含少于约200个核苷酸的单链寡核苷酸。在一些实施方案中,该多核苷酸进一步包括标记。这种标记可以使得能够筛选靶向整合。在一些实施方案中,该标记是限制性核酸内切酶位点。在其他实施方案中,该标记物是荧光蛋白、纯化标签或表位标签。合适的荧光蛋白的非限制性实例包括绿色荧光蛋白(例如,GFP、GFP-2、tagGFP、turboGFP、EGFP、Emerald、AzamiGreen、MonomericAzamiGreen、CopGFP、AceGFP、ZsGreen1)、黄色荧光蛋白(例如,YFP、EYFP、Citrine、Venus、YPet、PhiYFP、ZsYellow1)、蓝色荧光蛋白(例如,EBFP、EBFP2、Azurite、mKalama1、GFPuv、Sapphire、T-sapphire)、青色荧光蛋白(例如ECFP、Cerulean、CyPet、AmCyan1、Midoriishi-Cyan)、红色荧光蛋白(mKate、mKate2、mPlum、DsRed单体、mCherry、mRFP1、DsRed-Express、DsRed2、DsRed-Monomer、HcRed-Tandem、HcRed1、AsRed2、eqFP611、mRasberry、mStrawberry、Jred)和橙色荧光蛋白(mOrange、mKO、Kusabira-Orange、MonomericKusabira-Orange、mTangerine、tdTomato)或任何其他合适的荧光蛋白。在其他实施方案中,该标记可以是纯化标签和/或表位标签。示例性标签包括但不限于谷胱甘肽-S-转移酶(GST)、甲壳素结合蛋白(CBP)、麦芽糖结合蛋白、硫氧还蛋白(TRX)、聚(NANP)、串联亲和纯化(TAP)标签、myc、AcV5、AU1、AU5、E、ECS、E2、FLAG、HA、nus、Softag1、Softag3、Strep、SBP、Glu-Glu、HSV、KT3、S、S1、T7、V5、VSV-G、6xHis、生物素羧基载体蛋白(BCCP)和钙调蛋白。(v)递送至细胞该方法包括该靶向核酸内切酶将引入感兴趣的细胞中。可以将该靶向核酸内切酶作为已纯化的分离蛋白质或编码该靶向核酸内切酶的核酸引入细胞中。该核酸可以是DNA或RNA。在编码核酸是mRNA的实施方案中,该mRNA可以是5′封端的和/或3′聚腺苷酸化的。在编码核酸是DNA的实施方案中,该DNA可以是线性或环状的。该DNA可以是载体的一部分,其中该编码DNA可以可操作地连接到合适的启动子。本领域技术人员应熟悉适当的载体、启动子、其他控制元件和将该载体引入感兴趣的细胞中的手段。该靶向核酸内切酶分子和上述可选多核苷酸可以通过多种手段引入到细胞中。合适的递送手段包括显微注射、电穿孔、超声波穿孔、基因枪法、磷酸钙介导的转染、阳离子转染、脂质体转染、树枝状聚合物转染、热激转染、核转染转染、磁转染、脂质转染、刺穿转染、光学转染、专有剂增强核酸吸收,和经由脂质体、免疫脂质体、病毒体或人工病毒体进行递送。在一个具体实施方案中,通过核转染将该靶向核酸内切酶分子和多核苷酸引入细胞中。在将多于一个靶向核酸内切酶分子和多于一个多核苷酸引入细胞中的实施方案中,可以同时或依次引入该分子。举例来说,可以在同时引入诸多靶向核酸内切酶分子,各分子对靶向裂解位点(和可选多核苷酸)具有特异性。或者,可以依次引入各靶向核酸内切酶分子以及可选多核苷酸。该靶向核酸内切酶分子与可选多核苷酸的比率可以并且将会变化。一般来说,靶向核酸内切酶分子与多核苷酸的比率介于约1∶10至约10∶1的范围内。在各种实施方案中,该靶向核酸内切酶分子与多核苷酸的比率可以是约1∶10、1∶9、1∶8、1∶7、1∶6、1∶5、1∶4、1∶3、1∶2、1∶1、2∶1、3∶1、4∶1、5∶1、6∶1、7∶1、8∶1、9∶1或10∶1。在一个实施方案中,该比率是约1∶1。(vi)培养细胞该方法还包括将细胞维持在适当的条件下,使得通过靶向核酸内切酶引入的双链断裂可以通过以下方式得以修复:(i)非同源末端连接修复方法,使得染色体序列通过至少一个核苷酸的缺失、插入和/或取代而被修饰,或者,任选地,(ii)同源定向修复方法,使得染色体序列与多核苷酸的序列交换,从而对染色体序列进行修饰。在将编码靶向核酸内切酶的核酸引入细胞中的实施方案中,该方法包括将该细胞维持在适当的条件下,使得该细胞表达该靶向核酸内切酶。一般来说,将该细胞维持在适于细胞生长和/或维持的条件下。合适的细胞培养条件在本领域中是众所周知的并且描述于例如以下文献中:Santiago等,(2008)PNAS105:5809-5814;Moehle等,(2007)PNAS104:3055-3060;Umov等,(2005)Nature435:646-651;和Lombardo等,(2007)Nat.Biotechnology25:1298-1306。本领域技术人员应了解,用于培养细胞的方法在本领域中是已知的,而且可以并且将会取决于细胞类型而变化。在所有情况下,可以使用常规优化来确定用于特定细胞类型的最佳技术。在该方法的这个步骤期间,该靶向核酸内切酶在染色体序列中的靶向裂解位点上识别、结合并创建双链断裂,而在双链断裂修复期间,至少一个核苷酸的缺失、插入和/或取代被引入该靶向染色体序列中。在诸多具体实施方案中,该靶向染色体序列是失活的。在证实已经修饰了感兴趣的染色体序列后,可以分离单个细胞克隆并且进行基因分型(通过DNA测序和/或蛋白质分析)。包含一个经修饰的染色体序列的细胞可以进行一轮或多轮额外的靶向基因组修饰以修饰其他染色体序列(例如,参见实施例1)。(b)RNA干扰在另一个实施方案中,可以使用能抑制靶mRNA或转录物的表达的RNA干扰(RNAi)剂来制备该抗病毒细胞系。该RNAi剂可能引起靶mRNA或转录物的裂解。或者,该RNAi剂可以防止或破坏靶mRNA翻译成蛋白质。在一些实施方案中,RNAi剂可以是短干扰RNA(siRNA)。一般来说,siRNA包含长度介于约15至约29个核苷酸范围内的双链RNA分子。该siRNA的长度可以是约16-18、17-19、21-23、24-27或27-29个核苷酸。在一个具体实施方案中,该siRNA的长度是约21个核苷酸。该siRNA可以任选地进一步包含一个或两个单链悬突,例如在一端或两端上的3′悬突。该siRNA可以由杂交在一起的两个RNA分子形成,或替代地,可以由短发夹RNA(shRNA)生成(见下文)。在一些实施方案中,该siRNA的两个链是完全互补的,使得两个序列之间所形成的双链体中不存在错配或隆凸。在其他实施方案中,该siRNA的两个链是基本上互补的,使得两个序列之间所形成的双链体中存在一个或多个错配和/或隆凸。在某些实施方案中,该siRNA的5′端中的一个或两个具有磷酸酯基,而在其他实施方案中,该5′端中的一个或两个缺乏磷酸酯基。在其他实施方案中,该siRNA的3′端中的一个或两个具有羟基,而在其他实施方案中,该5′端中的一个或两个缺乏羟基。该siRNA中被称为“反义链”或“引导链”的一个链包括能与靶转录物杂交的部分。在某些实施方案中,该siRNA的反义链与靶转录物的一个区域完全互补,即,其在介于约15至约29个核苷酸之间长、优选地至少16个核苷酸长且更优选地约18-20个核苷酸长的靶区域上不具有单个错配或隆凸的情况下与靶转录物杂交。在其他实施方案中,该反义股与靶区域基本上互补,即,由该反义股和该靶转录物形成的双链体中可能存在一个或多个错配和/或隆凸。典型地,使siRNA靶向靶转录物的外显子序列。本领域技术人员应熟悉设计针对靶转录物的siRNA的程序、算法和/或商业服务。一个示例性实例是RosettasiRNADesignAlgorithm(RosettaInpharmatics,NorthSeattle,WA)和siRNA(Sigma-A1drich,St.Louis,MO)。可以使用本领域技术人员众所周知的方法在活体外酶促合成该siRNA。或者,可以使用本领域中众所周知的寡核苷酸合成技术化学合成该siRNA。在其他实施方案中,RNAi剂可以是短发夹RNA(shRNA)。一般来说,shRNA是包含可杂交或能够杂交以形成长度足以介导RNA干扰(如以上所描述)的双链结构的至少两个互补部分和形成了连接形成该双链体的shRNA区域的环的至少一个单链部分的RNA分子。该结构还被称为茎-环结构,其中该茎是双链体部分。在一些实施方案中,该结构的双链体部分是完全互补的,使得shRNA的双链体区域中不存在错配或隆凸。在其他实施方案中,该结构的双链体部分是基本上互补的,使得shRNA的双链体部分中存在一个或多个错配和/或隆凸。该结构的环可以是约1至约20个核苷酸长,优选地约4至约10个左右核苷酸长,且更优选地约6至约9个核苷酸长。该环可以位于与靶转录物互补的区域(即,shRNA的反义部分)的5′或3′端。该shRNA可以进一步包含处于5′或3′端上的悬突。该可选悬突可以是约1至约20个核苷酸长,且更优选地约2至约15个核苷酸长。在一些实施方案中,该悬突包含一个或多个U残基,例如介于约1个与约5个之间的U残基。在一些实施方案中,该shRNA的5′端具有磷酸酯基,而在其他实施方案中则不然。在其他实施方案中,该shRNA的3′端具有羟基,而在其他实施方案中则不然。一般来说,通过保守细胞RNAi机制将shRNA处理成siRNA。因此,shRNA是siRNA的前驱物,并且类似地能够抑制与shRNA的一部分(即,shRNA的反义部分)互补的靶转录物的表达。本领域技术人员应熟悉用于设计和合成shRNA的可用资源(如以上所详述)。在又其他实施方案中,该RNAi剂可以是RNAi表达载体。典型地,RNAi表达载体被用于细胞内(活体内)合成RNAi剂,诸如siRNA或shRNA。在一个实施方案中,使用含有两个启动子的单个载体来转录两个独立的互补siRNA链,各启动子指导单个siRNA链的转录(即,各启动子被可操作地连接到该siRNA的模板,使得可以发生转录)。该两个启动子可以呈相同取向,在这种情况下,各启动子可操作地连接到互补siRNA链之一的模板。或者,该两个启动子可以呈相反的取向,从而侧接单个模板,以便启动子的转录可合成两个互补siRNA链。在另一个实施方案中,该RNAi表达载体可以含有驱动包含两个互补区域的单个RNA分子的转录,从而使得转录物形成shRNA的启动子。本领域技术人员应了解,优选在活体内通过多于一个转录单元的转录来产生siRNA和shRNA剂。一般来讲,用于指导一个或多个siRNA或shRNA转录单元的活体内表达的启动子可能是针对RNA聚合酶III(PolIII)的启动子。某些PolIII启动子,诸如U6或H1启动子,并不需要所转录区域内的顺式作用调节元件,且因此,在某些实施方案中是优选的。在其他实施方案中,针对PolII的启动子可以用于驱动一个或多个siRNA或shRNA转录单元的表达。在一些实施方案中,可以使用组织特异性、细胞特异性或可诱导性PolII启动子。可以使用标准重组DNA方法来产生为合成siRNA或shRNA提供模板的构建体,并且插入到多种适于在真核细胞中表达的不同载体中的任一种中。重组DNA技术描述于以下文献中:Ausubel等,2003,同上和Sambrook&Russell,2001,同上。本领域技术人员还应了解,载体可以包含额外的调节序列(例如,终止序列、翻译控制序列等),以及可选标记序列。DNA质粒在本领域中是已知的,包括基于pBR322、PUC等等的那些。由于许多表达载体已经含有合适的启动子,所以可能只需要将编码感兴趣的RNAi剂的核酸序列插入在相对于该启动子而言适当的位置上。病毒载体还可以用于提供RNAi剂的细胞内表达。合适的病毒载体包括逆转录病毒载体、慢病毒载体、腺病毒载体、腺相关病毒载体、疱疹病毒载体等等。在一个具体实施方案中,该RNAi表达载体是shRNA慢病毒基载体或慢病毒颗粒,诸如TRCshRNA产品(Sigma-Aldrich)中所提供的那个。可以使用本领域技术人员众所周知的方法将该RNAi剂或RNAi表达载体引入该细胞中。这类技术描述于例如以下文献中:Ausubel等,2003,同上;或Sambrook&Russell,2001,同上。在某些实施方案中,将该RNAi表达载体(例如病毒载体)稳定地整合到该细胞的基因组中,以便在随后的细胞世代中破坏Mgat1表达。(c)位点特异性重组在替代实施方案中,可以使用位点特异性重组技术来制备该病毒抗性细胞系。举例来说,可以使用位点特异性重组技术来缺失所有或部分感兴趣的染色体序列,或向感兴趣的染色体序列中引入单核苷酸多态性(SNP)。在一个实施方案中,使用Cre-loxP位点特异性重组系统、Flp-FRT位点特异性重组系统或其变化形式来靶向感兴趣的染色体序列。这类重组系统可购自市面,并且这些技术的额外教授内容见于例如Ausubel等,2003,同上。定义除非另外定义,否则本文中所使用的所有技术和科学术语都具有本发明所属领域的技术人员通常所理解的含义。以下参考文献给本领域技术人员提供了本发明中所使用的许多术语的一般定义:Singleton等,DictionaryofMicrobiologyandMolecularBiology(第2版,1994);TheCambridgeDictionaryofScienceandTechnology(Walker编,1988);TheGlossaryofGenetics,第5版,R.Rieger等(编),SpringerVerlag(1991);和Hale&Marham,TheHarperCollinsDictionaryofBiology(1991)。如本文中所使用,除非另外规定,否则以下术语具有赋予它们的含义。当介绍本发明的要素或其优选实施方案时,冠词“一个”、“一种”、“该”和“所述”意图指存在一个或多个要素。术语“包含”、“包括”和“具有”意图是包括性的,并且意指可能存在除了所列出的要素以外的额外要素。如本文中所使用,“缺乏”是指靶向酶或蛋白质的水平有所降低或不可检测,或者靶向酶或蛋白质的活性有所降低或不可检测。如本文中所使用,术语“内源序列”是指对细胞来说是天然的染色体序列。术语“外源序列”是指对细胞来说不是天然的染色体序列,或被移动到不同的染色体位置的染色体序列。“经基因修饰的”细胞是指基因组已经被修饰的细胞,即,该细胞至少含有已经过工程改造而含有至少一个核苷酸的插入、至少一个核苷酸的缺失和/或至少一个核苷酸的取代的染色体序列。术语“基因组修饰”和“基因组编辑”是指藉以改变特定染色体序列,使得该染色体序列被修饰的方法。该染色体序列可以经过修饰以包含至少一个核苷酸的插入、至少一个核苷酸的缺失和/或至少一个核苷酸的取代。经修饰的染色体序列是失活的,从而不产生产物。或者,该染色体序列可以经过修饰,从而产生经改变的产物。如本文中所使用的“基因”是指编码基因产物的DNA区(包括外显子和内含子),以及调节基因产物的产生的所有DNA区域,无论这类调节序列是否与编码序列和/或所转录的序列相邻。因此,基因包括但未必限于启动子序列、终止子、翻译调节序列(诸如核糖体结合位点和内部核糖体进入位点)、增强子、沉默子、隔离子、边界元件、复制起点、基质附着位点和基因座控制区。术语“异源”是指对于感兴趣的细胞或物种来说不是天然的实体。术语“核酸”和“多核苷酸”是指呈线性或环状构象的脱氧核糖核苷酸或核糖核苷酸聚合物。出于本公开的目的,这些术语不应被视为对于聚合物的长度具有限制性。该术语可以涵盖天然核苷酸的已知类似物,以及在碱基、糖和/或磷酸部分中经修饰的核苷酸。一般来说,特定核苷酸的类似物具有相同的碱基配对特异性;即,A的类似物将与T碱基配对。核酸或多核苷酸的核苷酸可以通过磷酸二酯、硫代磷酸酯、亚磷酰胺、二氨基磷酸酯键或其组合来连接。.术语“核苷酸”是指脱氧核糖核苷酸或核糖核苷酸。该核苷酸可以是标准核苷酸(即,腺苷、鸟苷、胞苷、胸苷和尿苷)或核苷酸类似物。核苷酸类似物是指具有经修饰的嘌呤或嘧啶碱基或者经修饰的核糖部分的核苷酸。核苷酸类似物可以是天然存在的核苷酸(例如,肌苷)或非天然存在的核苷酸。核苷酸的糖或碱基部分的修饰的非限制性实例包括乙酰基、氨基、羧基、羧甲基、羟基、甲基、磷酰基和巯基的添加(或去除),以及用其他原子对碱基的碳原子和氮原子的取代(例如,7-脱氮嘌呤)。核苷酸类似物还包括二脱氧核苷酸、2′-O-甲基核苷酸、锁核酸(LNA)、肽核酸(PNA)和吗啉基。术语“多肽”和“蛋白质”可以互换使用来指氨基酸残基的聚合物。如本文中所使用,术语“靶位点”或“靶序列”是指定义欲修饰或编辑的且对靶向核酸内切酶进行工程改造以识别并结合其(条件是存在足以结合的条件)的染色体序列的一部分的核酸序列。术语“上游”和“下游”是指核酸序列中相对于固定位置的位置。上游是指相对于该位置是5′(即,靠近该链的5′端)的区域,而下游是指相对于该位置是3′(即,靠近该链的3′端)的区域。如本文中所使用,“病毒抗性”是指细胞抵抗病毒感染的能力。更具体来说,与未经修饰的亲本细胞系相比,在本文中所公开的经工程改造的细胞系中,病毒进入和/或病毒繁殖有所减少或被消除。用于确定核酸和氨基酸序列同一性的技术在本领域中是已知的。典型地,这类技术包括确定基因的mRNA的核苷酸序列和/或确定由其编码的氨基酸序列,并且将这些序列与第二核苷酸或氨基酸序列相比较。还可以用这种方式确定并且比较基因组序列。一般来说,同一性是指两个多核苷酸或多肽序列分别的确切核苷酸与核苷酸或氨基酸与氨基酸对应性。两个或更多个序列(多核苷酸或氨基酸)可以通过确定其同一性百分比来进行比较。两个序列(不论是核酸序列还是氨基酸序列)的同一性百分比是两个对齐的序列之间的确切匹配数除以较短序列的长度并乘以100。Smith和Waterman,AdvancesinAppliedMathematics2:482-489(1981)的局部同源性算法提供了核酸序列的近似比对法。这种算法可以通过使用评分矩阵而应用于氨基酸序列,该评分矩阵是由Dayhoff,AtlasofProteinSequencesandStructure,M.O.Dayhoff编,5增刊3∶353-358,NationalBiomedicalResearchFoundation,Washington,D.C.,USA开发,且由Gribskov,Nucl.AcidsRes.14(6):6745-6763(1986)正规化。用于确定序列同一性百分比的这种算法的一种示例性实现方式是由“BestFit”实用应用程序中的GeneticsComputerGroup(Madison,Wis.)提供。用于计算序列之间的同一性或相似性百分比的其他合适的程序在本领域中一般是已知的,例如,另一个比对程序是以缺省参数使用的BLAST。举例来说,可以使用BLASTN和BLASTP,使用以下缺省参数:遗传密码=标准;过滤器=无;链=两个;截止值=60;期望值=10;矩阵=BLOSUM62;描述=50个序列;分选=高评分;数据库=非冗余,GenBank+EMBL+DDBJ+PDB+GenBankCDS翻译+Swiss蛋白+Spupdate+PIR。这些程序的细节可以在GenBank网站上找到。相对于本文中所描述的序列,所期望的序列同一性程度的范围是大约80%至100%和介于其之间的任何整数值。典型地,序列之间的同一性百分比是至少70-75%,优选地80-82%,更优选地85-90%,甚至更优选地92%,又更优选地95%,且最优选地98%序列同一性。由于可以在不偏离本发明的范围的情况下在上述细胞和方法中进行各种改变,所以意图以上描述中和以下给出的实施例中所含有的所有内容都应该被解释为说明性的而不具有限制意义。实施例以下实施例说明了本发明的某些方面。实施例1:靶向基因经修饰的CHO细胞系的制备采用ZFN介导的基因修饰技术来使编码涉及N连接型或O连接型糖基化反应的酶或蛋白质的基因失活(即,敲除)。一般来说,使用专有算法来设计靶向感兴趣的基因的编码区内的特定位点的数对ZFN。使用标准程序来制备ZFN表达构建体,并且使用活体外转录、mRNA聚腺苷酸化和封端方法,由如敲除锌指核酸酶(ZFN)(Sigma-Aldrich)产品信息中所描述的ZFN质粒DNA产生ZFNmRNA。简要地说,将质粒ZFNDNA线性化,并且使用苯酚/氯仿DNA提取进行纯化。使用MessageMaxTMT7ARCA-CappedMessageTranscriptionKit(CellScriptInc.)对线性化DNA进行封端。使用Poly(A)PolymeraseTailingKit(EpiCentre)来添加聚(A)尾。使用MEGAclearTM试剂盒(Ambion)来纯化ZFNmRNA。将亲本细胞作为悬浮液培养物维持在CHOCD融合培养基(Sigma-Aldrich)中。在转染前一天,将细胞以0.5×106个细胞/mL接种在生物反应器管中。典型地,各转染含有处于150μL生长培养基中的1×106个细胞和5μgZFNDNA或mRNA。通过在0.2cm试管中在140V和950uF下电穿孔来进行转染。将已电穿孔的细胞放在处于6孔板静态培养中的2mL生长培养基中。在转染后第3天和第10天,将细胞从培养中取出,并且使用GeneEluteTM哺乳动物基因组DNA微型制备试剂盒(Sigma-Aldrich)分离基因组DNA。如敲除ZFN产品信息中所描述,使用Cel-1核酸酶测定来验证ZFN诱导的裂解。进行该测定以确定如先前所描述的ZFN介导的基因突变的效率(Miller等,Nat.Biotechnol.2007,25:778-785)。该测定法检测由于对ZFN诱导的DNA双链断裂的非同源末端连接(NHEJ)介导的不完美修复而来源于野生型的靶向基因座的等位基因。对来自经ZFN处理的细胞池的靶向区域进行PCR扩增产生了野生型(WT)与突变扩增子的混合物。对该混合物进行的熔融和重退火导致了WT和突变等位基因的异源双链体之间的错配形成。通过Surveyor核酸酶Cel-1使错配位点上所形成的DNA“泡”裂解,并且可以通过凝胶电泳来拆分裂解产物。在证实ZFN活性后,使用有限稀释对经ZFN转染的细胞进行单细胞克隆。为此,使用80%CHO无血清克隆培养基、20%条件培养基和4mML-谷氨酰胺的混合物将细胞以约0.5个细胞/孔的近似密度铺板。分别在铺板后第7天和第14天以显微镜验证克隆度和生长。通过PCR和DNA测序对有生长的克隆进行扩增和基因分型。Mgat1KO细胞系。作为复杂N聚糖合成的一部分,Mgat1将GlnNac添加到Man5GlcNAc2N连接型多糖结构。设计一对ZFN以靶向CHOMgat1基因中的5′-AACAAGTTCAAGTTCccagcaGCTGTGGTAGTGGAGGAC-3′(SEQIDNO:9;ZFN结合位点以大写字母表示且裂解位点以小写字母表示)。亲本细胞系是CHOK1(GS-/-)(SigmaAldrich),其中谷氨酸合成酶被敲除。该亲本细胞系产生野生型N-聚糖和O-聚糖结构。基本上如以上所详述,将CHOK1(GS-/-)细胞系用Mgat1ZFNDNA进行转染。Cel-1测定证实转染后第3天和第10天都存在两个裂解片段,220和197bp,从而表明ZFN活性。经鉴定,单细胞克隆在一个等位基因中具有介于2bp至55bp范围内的缺失(未检测第二个等位基因)。该细胞系产生了以五个甘露糖残基封端的截短型N连接型结构(即,Man5NeuAc2糖型)和野生型O聚糖结构。COSMCKO细胞系。O-糖基化中最常见的第二生物合成步骤是核心-1伸长。核心-1伸长是由需要专用伴侣COSMC以发挥功能的单一酶C1GalT1(akaT-synthase)催化。COSMC是看起来特异性结合T-合酶且确保其在高尔基体中具有充分活性的ER蛋白。为了破坏COSMC基因,将CHOK1(GS-/-)细胞用编码经设计以靶向CHOCOSMC基因中的序列5′-GCCTTCTCAGTGTTCCGGAaaagtgTCCTGAACAAGGTGGGAT-3′(SEQIDNO:10)的ZFN的DNA或RNA加以转染。Cel-1核酸酶测定证实经ZFN转染的细胞中存在三个裂解片段(即,318bp、184bp、134bp)。分离在COSMC的一个等位基因中具有4bp缺失(未检测第二个等位基因)的单细胞克隆。该细胞系产生了截短型(即,未成熟)O-聚糖结构和野生型N-聚糖。COSMC/Mgat3KO细胞系。设计一对ZFN以靶向Mgat3的编码区中的5′-TTCCTGGACCACTTCCCAcccggtGGCCGGCAGGATGGC-3′(SEQIDNO:11)。将以上详述的COSMCKO细胞系用如以上详述的ZFNDNA进行转染。在证实ZFN裂解之后,分离单细胞克隆。测序显示,突变克隆在Mgat3基因中具有9、10、11或41bp缺失。该细胞系产生了野生型N-聚糖和截短型O-聚糖(即,类似于亲本细胞系)。COSMC/Mgat3/Mgat5KO细胞系。将以上详述的COSMC/Mgat3KO细胞系用编码经设计以靶向Mgat5的编码区中的5′-TTCTGCACTTCACCATCCAgcagcgGACTCAGCCTGAGAGCAGCT-3′(SEQIDNO:12)的ZFN的质粒DNA进行转染。分离在Mgat5基因中具有129bp缺失的单细胞克隆。该细胞系产生了具有较少侧分支的N-聚糖和截短型O-聚糖。实施例2:病毒感染和病毒抗性测试测定使上述CHO细胞系生长且测试其在用原型MVM病毒(病毒株MVMp)攻击后支持或抵抗感染的能力。简要地说,使细胞在适当的培养基中生长,且以1或10的感染复数(MOI)加入MVMp病毒,并且在测定之前将已感染的细胞再孵育24、48或72小时。作为对照,在无病毒的情况下使细胞生长且进行孵育。未感染的细胞也用酶神经氨酸酶加以处理,以去除来自表面聚糖(N连接型和O连接型)的末端唾液酸,且随后以所指示的MOI进行感染。用肉眼观察已感染的和未感染的细胞中细胞病变效应(CPE)的存在,并且在所指示的时间点,通过离心收集细胞。使用对总基因组DNA的南方印迹分析和使用抗病毒蛋白抗体的西方免疫印迹分析来筛检病毒DNA感染性和产量。对于南方分析,收集来自24h时获取的两份样品的细胞小球且分离总基因组DNA。通过Nanodrop光谱来定量DNA,并且将样品正规化以确保琼脂糖凝胶上具有相等负载,以便进行大小分级。将经过大小分级的DNA转移到带电膜上(南方印迹),并且使用32P标记的病毒DNA探针对该膜探测病毒DNA合成。对特定32P标记的病毒双链DNA谱带的定量是通过磷成像获取且相对值报告在表1中。对于西方分析,将24h时收集的细胞小球溶解在SDS缓冲液中,并且使用SDS-PAGE来分离蛋白质。在电泳后,将蛋白质转移到PVDF膜上,加以阻断并且使用抗NS1抗体针对病毒NS1蛋白的存在进行免疫印迹(西方免疫测定法)。通过西方印迹检测到的病毒蛋白水平在表2中表示。当感染了病毒的MVMp病毒株时,该亲本细胞系CHOK1(GS-/-)(即,具有野生型聚糖结构)表现出了正如所预期的经典感染性和病毒DNA产量和蛋白质合成。当细胞在任一MOI下被感染时,感染后24小时病毒DNA和病毒蛋白产物显而易见。在稍后的时间点还见到了病毒产物的强产生。正如所预期,不管时间点如何,未受感染的野生型细胞都没有表现出感染的证据。当用酶神经氨酸酶(NA)处理野生型细胞以去除细胞表面唾液酸且随后用MVMp感染细胞时,还观察到病毒产量减少(表明感染减轻)(介于从MOI=10时的5.32倍至MOI=1时的7.34倍的范围内)。尽管经NA处理的细胞仍表现出对感染轻微敏感性,但已知CHO细胞在这种处理后快速再生出唾液酸(SA)结构。因此,所见到的低感染水平可能来自已再生出末端SA聚糖且因此为病毒提供入口的细胞。CHOMgat1基因失活且不产生Mgat1酶的Mgat1KO细胞的病毒感染只引起轻微抗性(例如,降低2.1至2.7倍,如通过对印迹进行磷成像所测量)。因为该细胞系具有截短型N-聚糖,所以这些结果表明,具有2-3连接型唾液酸的高阶N-聚糖受体可能在最初病毒衣壳结合和病毒进入细胞中只能发挥次要作用。当COSMCKO细胞感染有MVMp病毒时,该细胞系对病毒感染表现出显著抗性。抗性倍数(当与野生型细胞系相比时)在5.5倍(MOI=10)至190倍(MOI=1)的范围内。靶向Mgat3基因(假定是CHO细胞中的假基因)和Mgat5基因(负责高阶N连接型分支)的额外基因敲除得到了类似的结果。西方印迹分析得到了类似的结果,表明当O-聚糖结构被截短时发生病毒抗性。这些研究揭示了破坏唾液酸受体可大幅减少MVM结合和/或进入细胞。实施例3:其他COSMCKO和Slc35A1KO细胞系的产生如以上实施例1中所描述,使用CHOK1(GS-/-)细胞和经设计以靶向CHOCOSMC基因的外显子2中的序列5′-GCCTTCTCAGTGTTCCGGAaaagtgTCCTGAACAAGGTGGGAT-3′(SEQIDNO:10)的一对ZFN来产生新的COSMCKO细胞系克隆。Cel-1核酸酶测定证实经ZFN转染的细胞中存在三个裂解片段(即,318bp、184bp、134bp)。分离五个单细胞克隆,且测序显示1至12bp的缺失,如以下所示。克隆基因型COSMCF072bp缺失COSMCG031bp插入COSMCH041bp插入COSMCA099bp缺失COSMCH0512bp缺失使用标准程序对克隆F07进行进一步修饰以表达人IgG。在所鉴定的许多克隆中,分离了两个产生IgG的克隆(鉴定为71H1、71C3)以便进一步测试(见下文)。使用经设计以靶向5′-AGCTTATACCGTAGCTTTaagataCACAAGGACAACAGCTAAA-3′(SEQIDNO:13)的ZFN或经设计以靶向CHOSlc35A1基因的外显子1中的5′-TTCAAGCTATACTGCTTGGCAGTGATGACTCTGGTGGCT-3′(SEQIDNO:17)的ZFN将编码核苷酸糖转运子(CMP-唾液酸转运子)的Slc35A1基因从CHOK1(GS-/-)细胞中敲除。Cel-1核酸酶测定证实经ZFN转染的细胞中存在两个裂解片段。分离出一个单细胞克隆(B12),且测序显示了在ZFN结合位点周围的1bp缺失。Slc35A1KO细胞系形成了不具有末端唾液酸的N连接型和O连接型聚糖结构。利用生物素标记的山槐凝集素II(MALII;20μg/mL)和AlexaFluor647标记的链霉亲和素(5μg/mL)的染色显示了COSMCKO克隆F07、COSMCKO克隆G03和Slc35A1KO细胞系中的染色与亲本细胞系相比显著减少(表明KO细胞系中不存在末端唾液酸残基)。实施例4:COSMCKO和Slc35A1KO细胞系对MMV病毒的抗性基本上如以上实施例2中所述,用MVMp病毒以MOI0.3感染野生型(即,CHOZNGS-/-)、COSMCKO(以上实施例1和实施例3中所产生的)和Slc35A1KO(以上实施例3中所产生的)细胞。通过南方分析(基本上如以上所描述)和标准噬菌斑测定法来测定感染。如图1中所示,野生型细胞表现出高水平的病毒DNA,而Slc35A1KO和COSMCKO细胞系具有非常低水平的病毒DNA;COSMCF07KO和COSMCG03KO克隆具有低水平的病毒DNA;且具有12bp缺失的COSMCH05FO克隆具有与亲本细胞系类似的水平的病毒DNA。由于H05中的缺失是同框的,所以该细胞表现出接近野生型水平的病毒敏感性并不奇怪。噬菌斑测定结果示于图2中。Slc35A1KO、COSMCKO、COSMCF07KO和COSMCG03KO细胞具有极低的病毒水平。使用野生型(即,CHOZNGS-/-,也称为2E3)、COSMCKO克隆F07和G03以及Slc35A1KO克隆B12进行了额外的病毒抗性测试。使细胞在补充有6mML-谷氨酰胺的培养基中生长且用MMVp以MOI1或8进行感染,并且在合适的条件下孵育。在0、24、48、72、96和120小时取出细胞样品;用锥虫蓝染色来测定细胞活力,并且通过qPCR来确定MMV定量。细胞活力呈现于图3中。在感染后120小时,野生型细胞(即,2E3)中细胞活力降至约50%(参见图A),而在COSMC克隆F07中,至少93%的细胞在感染后120小时是活的(参见图B)。图4示出了在野生型(2E3)和COSMC克隆F07中以MOI1(参见图A)或MOI8(参见图B)进行MMV感染之后细胞相关病毒(每个细胞的病毒基因组拷贝(vgc))的时间过程(计算是基于各感染细胞可以产生2×104vgc的假设)。以下呈现已感染的细胞在各条件下的级分。在时间-3小时用MMVp以MOI0.3或0.03感染野生型(即,2E3)、COSMCKO克隆F07、G03和H04以及Slc35A1KO克隆B12细胞。在时间0小时,用生长培养基将细胞洗涤三次,然后孵育21小时(即,单个复制周期)。通过在0和21小时确定细胞相关病毒来测定病毒复制。如图5中所示,病毒复制在COSMCKO细胞系中有所减少且在Slc35A1KO细胞系中被消除。实施例5:COSMCKO和Slc35A1KO细胞系对呼肠孤病毒3的抗性在时间-3小时用呼肠孤病毒3以两个稀释度感染野生型(即,2E3)、COSMCKO克隆F07和Slc35A1KO克隆B12细胞(TCID50=5.6E+07和5.6E+06)。在时间0小时,将细胞洗涤三次,然后孵育24小时(即,单个复制周期)。通过在0和24小时确定细胞相关病毒来测定病毒复制。在24小时,细胞相关病毒的水平在COSMCKO克隆中大幅降低,且在Slc35A1KO克隆中几乎被消除(参见图6)。实施例6:COSMCKO和Slc35A1KO细胞系的生长测定在不存在或存在MVMp病毒(MOI0.1)的情况下使野生型(即,CHOZNGS-/-)、COSMCKO克隆F07和G03以及Slc35A1KO克隆B12细胞生长8至10天。通过在第0天、第1天、第2天、第3天、第6天、第7天、第8天和第10天测量活细胞密度(通过锥虫蓝染色)来监测细胞生长。如图7的图A中所示,各种KO细胞在存在或不存在病毒的情况下具有类似的生长概况,表明了对病毒注入的抗性。与此相反,当与未感染的培养物相比时,野生型细胞表现出经典感染性、受损的生长和低细胞活力。基本上如以上所详述在不存在或存在病毒的情况下监测COSMCKO克隆F07的野生型和IgG产生克隆(即,71H1和71C3)的细胞生长。如图7的图B所示,产生IgG的KO细胞系也对病毒感染表现出显著抗性。已感染的培养物以与未感染的培养物类似的速率生长且达到峰值细胞密度。这些数据表明,分泌细胞表面IgG对COSMCKO亲本所表现出的病毒抗性程度没有明显影响。虽然产生IgG的细胞系与野生型细胞相比以较慢速率增长,但两种IgG生产者都对病毒感染表现出了抗性(即,当与未感染的培养物相比时,没有差别)。实施例7:St3Gal4KO细胞系的产生和细胞生长测定基本上如实施例1中所描述,使用经设计以靶向CHOSt3Gal4基因中的5′-GGCAGCCTCCAGTGTCGTCgttgtgTTGTGGTGGGGAATGGGC(SEQIDNO:14)的ZFN来产生St3Gal4KO细胞。Cel-1核酸酶测定证实经ZFN转染的细胞中存在三个裂解片段(即,344bp、210bp和135bp)。分离出四个单细胞克隆,且测序显示了以下突变。St3Gal4KO细胞具有较低水平的2-3连接型唾液酸结构。克隆等位基因1基因型等位基因2基因型St3Gal41B084bp插入5bp缺失St3Gal47D102bp缺失8bp缺失St3Gal41B105bp缺失11bp缺失St3Gal41H113bp插入11bp缺失在不存在或存在MVMp病毒(MOI0.1)的情况下使St3Gal4KO(即,克隆7D10、1B8和1B10)和野生型细胞生长,并且监测细胞生长,持续9天。St3Gal4KO细胞也对病毒感染表现出显著抗性,如图8中所示。已感染的KO培养物以与未感染的KO培养物类似的速率生长且达到峰值细胞密度。这些研究显示了破坏细胞表面上的特定2-3连接型唾液酸结构似乎也能大幅减少MVM进入这种细胞。实施例8:St3Gal4和St3Gal6双KO细胞系的产生使用St3Gal4KO(即,克隆7D10、1B8和1B10)细胞系作为起始细胞,以产生也含有敲除的St3Gal6基因的细胞系。ZFN被设计为靶向5′-CGGTACCTCTGATTTTGCTttgccCTATGGGACAAGGCC-3′(SEQIDNO:15),且基本上如实施例1中所描述来进行基因编辑。Cel-1核酸酶测定证实经ZFN转染的细胞中存在三个裂解片段(即,308bp、171bp和137bp)。分离出六个单细胞克隆,且测序显示了以下突变。实施例9:C1GalT1KO细胞系的产生基本上如实施例1中所描述,使用经设计以靶向5′-ACCCTCATGCTAGACatttaGATGATAACGAACCCAGTC-3′(SEQIDNO:16)的ZFN来敲除CHOK1(GS-/-)细胞中的C1GalT1基因。Cel-1核酸酶测定证实经ZFN转染的细胞中存在两个裂解片段(即,223bp和148bp)。分离出七个单细胞克隆,且测序显示了以下突变。C1GalT1克隆等位基因1基因型等位基因2基因型2A88bp缺失8bp缺失2A115bp缺失90bp插入2C128bp缺失未检测到2G125bp缺失未检测到3D128bp缺失未检测到3E61bp缺失2bp缺失和97bp插入3F25bp缺失5bp缺失和31bp插入利用生物素标记的MALII和AlexaFluor647标记的链霉亲和素的染色显示了C1GalT1KO克隆2C12中的染色与亲本细胞系相比显著减少。实施例10:过度表达St6Gal1的细胞系的产生因为假设MVM病毒不结合α-2,6连接型唾液酸,所以产生了过度表达St6Gal1的CHO细胞系。中国仓鼠St6Gal1的编码序列是获自GenBank(AB492855)和chogenome.orgAQ2(AFTD01061789和AFTD01061790)。批量合成Kozak序列(5′-GCCGCCACCAatg-3′;SEQIDNO:18)被添加至5′-未翻译区(UTR)的开放阅读框。将所合成的片段克隆到表达载体pJ602(DNA2.0;MenloPark,CA)中。用该构建体转染(通过电穿孔)CHO(GS-/-)宿主细胞系和表达IgG的CHO细胞系。使用FACSAriaTMIII细胞分选仪分离出单细胞克隆。为此,用可结合α-2,6连接型唾液酸的FITC缀合型黑接骨木凝集素(FITC-SNA)将细胞染色,并且将具有前5%荧光的细胞以1个细胞/孔铺板并培养。在用可结合α-2,3连接型唾液酸的经生物素标记的MALII和AlexaFluor647标记的链酶亲和素染色之后,在MACSQuantVR分析仪(MiltenyiBiotec,SanDiego,CA)上对单细胞克隆进行双色FACS分析。过度表达St6Gal1的单细胞克隆与未经转染的亲本细胞系相比具有增高的FITC与AlexaFluor之比。从两个过度表达St6Gal1的克隆(即,克隆31和克隆32)和亲本细胞克隆中分离出IgG。根据标准程序对IgG或总细胞蛋白提取物进行还原和羧酰胺基甲基化,随后在37℃下进行胰蛋白酶处理过夜(12-16h)。通过在100℃下加热5分钟将胰蛋白酶灭活。利用C18SPE滤筒(Waters,300mg填料)进行片段的纯化。在用5%乙酸(AcOH)洗涤之后,依次在20%异丙醇/5%AcOH、40%异丙醇/5%AcOH和100%异丙醇中洗脱肽/糖肽。干燥洗脱液以减少体积,在含有PNG酶F的磷酸盐缓冲液中重构,并且在37℃下孵育过夜。使用C18滤筒来纯化所释放的聚糖,进行全甲基化且稀释至1mM碳酸锂/50%MeOH中,并且以0.5mL/min的流速直接输注到LTQOrbitrapDiscovery质谱仪(ThermoScientific)中以便进行纳米喷雾电离。在30,000分辨率下获得了各样品的完整傅立叶变换质谱仪(FTMS)谱图以确定哪些聚糖含有唾液酸。通过MSn分析来确定唾液酸化聚糖的唾液酸键联。在离子阱内对各样品进行多个离子选择和碎裂步骤,以使复合型聚糖分解成单个半乳糖,然后观察碎裂模式。GS(-/-)宿主细胞系与两个过度表达St6Gall的细胞系(即,克隆31和32)的N-聚糖分布之间存在惊人的差异。具体来说,在宿主细胞系中没有鉴定出唾液酸化的聚糖,这是由于其丰度较低。相比之下,在两个过度表达St6Gal1的细胞系中都鉴定出了单唾液酸化、二唾液酸化、三唾液酸化和四唾液酸化N-聚糖。具体来说,克隆32中除了一个唾液酸化群体以外的所有唾液酸化群体都表现出含有α-2,3键联和α-2,6键联。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1