用于生成双特异性鲨鱼可变抗体结构域的方法及其用途与流程
发明领域
本发明涉及双特异性鲨鱼可变抗体(vnar)结构域的生成及其用途。具体而言,本发明涉及用于生成和筛选随机化vnar结构域的多核苷酸文库以鉴定所需表型的vnar的方法。本发明方法对于生成新型双特异性抗体及其用途是特别有用的。
发明背景
如今生物实体是制药行业的主要驱动力之一,如其当前和预测的市场增长率显著超过整体行业的市场增长率所例举。在这组生物药物内,单克隆抗体(mab)是最高销售类型的生物制剂,随后分别是激素、生长因子和融合蛋白。与fc介导的免疫效应子功能组合的同源抗原的高特异性已经支持抗体成功作为医疗应用的有效工具。用许多约40种美国食品和药品管理局(fda)迄今为止批准的抗体和用临床开发中的数百种mab,mab的治疗和经济价值是显而易见的。
igg-型抗体是结构复杂的、大杂四聚体蛋白,分子量为约150kd。igg-型抗体由两条重链和两条轻链构成。两个相同的抗原结合位点、即互补位分别由轻链的一个可变结构域和重链的一个可变结构域构成。
由于存在不同的末端糖,igg分子的fc片段的ch2结构域含有经由n-糖基化连接的高度异质的聚糖。fc聚糖影响igg与fc受体和c1q的结合,因此对于igg效应子功能是重要的。具体地,末端糖诸如唾液酸、核心岩藻糖、二等分n-乙酰葡糖胺和甘露糖残基影响igg与fcγriiia受体的结合,从而影响adcc活性(参见例如stadlmann等人.proteomics.2008jul;8(14):2858-71)。
然而,在某些情况下,由于其固有的物理化学特性,抗体(诸如igg型抗体)的治疗和诊断效力可能受到限制。例如,经典抗体分子的组织穿透可能受到其大尺寸的约束(参见例如mordenti等人.(1999)toxicolpathol27:536-44),因此限制了其在体外以及体内诊断方法中的用途。此外,由于其延长的血浆半衰期,常规抗体的缓慢血液清除率另外构成体内肿瘤成像目的的问题。此外,健康组织对经典抗体的非特异性摄取进一步增加了对其在分子成像中的用途构成的限制。
为了试图克服经典抗体的上述限制并提高其总体治疗效力,已经设计了所谓的“下一代”抗体或抗体片段,以及非基于免疫球蛋白的蛋白支架。下一代抗体的实例包括例如单抗体、scfv、双抗体,或例如adnectins、亲和体、anticalins或半胱氨酸结蛋白(参见例如enever等人(2009)currentopinioninbiotechnology,vol20(4),405–411;löfblöm等人curropinbiotechnol.2011dec;22(6):843-8)。
在骆驼类动物和软骨鱼中发现了在过去几年由于其非典型结构而受到很多重视的另一类抗体,其具有仅由重链构成的天然抗体(参见例如greenberg等人(1995)nature374:168-73;hamers-casterman等人(1993)nature363:446-8)。在这些抗体中,抗原结合位点仅由一个单个结构域(分别称为vhh和vnar)形成。由于对应于常规抗体的疏水性vh-vl界面的溶剂暴露区域的极性和带电氨基酸的频率增加,vnar和vhh结构域是高度可溶的。
仅重链抗体(hcab)的抗原结合结构域组合了非基于免疫球蛋白的蛋白支架的大部分有益特征(例如小尺寸和高稳定性)以及经典抗体分子的有利特征(最显著的是通过免疫生成高度特异性和高亲和力结合剂的可行性)。有趣的是,hcab天然互补了上述种类的常规谱系:尽管经典抗体通常具有平面或凹面抗原结合位点,但vnar-和vhh-结构域具有多种额外(在vnar的情况下)和不同的环结构。这导致得到能够接近和结合更隐蔽的表位和酶的催化裂缝(其为经典抗体难以处理的)的可用互补位的剧烈扩展谱。
尽管骆驼vhh结构域已证明在早期临床试验中是成功的(参见例如holz等人(2012)transfusaphersci.2012jun;46(3):343-6),但用于生物医学应用的vnar结构域的工程改造到目前为止还没有进展。然而,在过去几年中已经取得了表明这些结构域的治疗效用的显著进展。
软骨鱼(鲨鱼、rays、skates和吐火银鲛(chimaeras))表达三种不同同种型的抗体,igm、ignar和原始igw(rumfeltll.等人bmcimmunology2004;5:8;rumfeltll等人journalofimmunology2004;173:1129-39)。在铰口鲨(ginglymostomacirratum)的血清中首先鉴定了ignar(greenbergas等人nature1995;374:168-73)。ignar是没有轻链的重链的同型二聚体。分泌形式的每条链由一个可变结构域、随后五个恒定结构域(最后四个与igw恒定结构域同源)组成。血清ignar水平范围为约0.1mg/ml至1mg/ml。
基于原子分辨率结构数据以及小角度x射线散射,获得了完整ignar分子的结构模型。在分子内,每个链的结构域c1和c3引起ignar的二聚化。尽管缺乏经典的铰链区域,但可变结构域的间隔足够宽,足以结合多种表位,其也可以通过c1二聚化界面的广角来促进。两个c3结构域之间的小角度诱导形成ignar分子的狭窄茎(narrowstalk)。然而,茎的柔性由连接结构域c3和c4的二硫化物桥联的接头诱导。仅重链分子大约在分子的中间、在柔性接头的位置处扭结,造成其特征性形状。目前还没有解决任何效应子功能是否由ignar的恒定区介导。
同型二聚体ignar展现几种独特的特征,其负责潜在轻链配对的抑制。在典型vh-vl相互作用位点,在哺乳动物中介导这种结合的残基的保守性不良。相反,这些典型疏水性氨基酸经常被极性或带电残基代替。对于经典抗体,特殊机制确保形成重链和轻链配对。在内质网内,重链经由与ch1结构域的相互作用被ig-结合蛋白(bip)来捕获。对于释放,轻链必须代替bip。因此,仅分泌重链和轻链配对抗体。
新抗原受体的可变结构域显示与t细胞受体(tcr)vα和还有免疫球蛋白vκ结构域的序列同源性,而结构上其与vα、vλ和vh结构域相关。此外,由于vnar结构域共享细胞粘附分子的结构特征,所以提示从细胞表面受体进化的ignar将其与vhh(其明显源自igg谱系)明显区别。vnar属于ig超家族,因此它具有β-夹心折叠。然而,与哺乳动物v结构域相比,该折叠仅由8个、而不是10个β链组成,这是由于在框架2-cdr2-区域中的缺失,其使得vnar结构域是迄今为止动物界中最小的抗体样抗原结合结构域,分子量为大约12kda(barellec等人,advexpmedbiol2009;655:49-62;stanfieldrl等人science2004;305:1770-3)。
因此,与哺乳动物可变结构域相反,vnar结构域仅具有两个互补决定区cdr1和cdr3。主要vnar谱的多样性主要发现于cdr3中。在cdr1中,在cdr2截短位点处(其中剩余环在分子底部形成带状结构)和在tcr中对应于hv4的环中观察到抗原接触后的高体细胞突变率。因此,这些突变易发区域已分别被命名为hv2和hv4(参见例如dooley等人,pnas(usa)2006;103:1846-51)。
尽管与经典抗体(跨越两条链的六个环)相比具有减少数目的可能的抗原结合环(跨越单链四个环),但vnar结构域以令人惊讶地高亲和力结合抗原。甚至从其中抗原结合仅由cdr3介导的主要谱,也可以产生以低纳摩尔范围内的亲和力针对给定抗原的vnar分子。然而,在用称为e06的抗白蛋白结合结构域免疫后,已观察到对于vnar结构域的最高记录的亲和力,达到皮摩尔水平的亲和力(muller等人,mabs2012;4:673-85)。
基于相应数目的非典型半胱氨酸残基,vnar分子已被分类为四种类型。所有类型都通常具有经典的ig规范半胱氨酸,其经由二硫键稳定免疫球蛋白折叠。i型可变结构域在框架区域2和4中携带额外的半胱氨酸,因此在cdr3中携带偶数数目的配偶体半胱氨酸残基。与溶菌酶复合的i型vnar的晶体结构的测定显示,两个非典型框架半胱氨酸各自与cdr3的那些形成二硫键,引起该环紧紧地保持在hv2的方向。到目前为止,仅在铰口鲨(ginglymostomacirratum)中鉴定了ignar的i型可变结构域。
ii型结构域分别借助cdr1和cdr3中的另外的半胱氨酸而不同于i型,所述另外的半胱氨酸导致分子内二硫键,其使两个环密切接近。然而,ii型结构域缺乏将cdr3锚定至i型vnar中的框架的两个半胱氨酸基序。因此,cdr3区域形成突出的“手指状”结构,其倾向于结合至口袋或凹槽(例如,酶的活性位点)中。
iii型结构域在新生鱼中表达。类似于ii型结构域,该同种型的特征在于分别在cdr1和cdr3中的另外的非经典半胱氨酸。然而,与ii型相反,iii型结构域包含受限制的cdr3多样性,氨基酸组成和长度高度相似,以及邻近位于两环之间二硫化物桥的cdr1中的保守的色氨酸残基。
iv型结构域不同于所有描述的vnar类型,因为它们仅包含经典二硫键。因此,iv型可变结构域的互补位的拓扑结构是更柔性的并且不受物理约束。iv型结构域也称为iib型(streltsov等人pnas2004;101:12444-9;liu等人,molecularimmunology2007;44:1775-83)。
已经鉴定了cdr1中具有不变色氨酸残基的iv型结构域,从而展现与iii型结构域的一定相似性。除了iii型vnar结构域外,所有类型的vnar结构域都会产生高亲合力结合剂。
基于抗体的疗法在癌症治疗中的用途在过去二十年中已经变得良好确立,并且现在是用于治疗具有血液恶性肿瘤和实体瘤的患者的最成功和重要的策略之一。基于抗体的肿瘤疗法的根本基础是与正常组织相比过表达、突变或选择性表达的肿瘤细胞的抗原表达。
大多数批准用于在美国销售的单克隆抗体(mab)靶向单细胞表面抗原,诸如例如,针对tnfα的阿达木单抗(humira;abbott/abbvie),针对egfr的panitumumab(vectibix;amgen),针对cd20的阿伐单抗(arzerra;genmab)。然而,肿瘤细胞通常上调不同的生长促进受体,其可以独立地起作用或在细胞内交叉对话。通过单特异性抗体靶向一种受体可导致与替代受体的上调以及途径转换相关的抗性(kontermann(2012)mabs4:2,182-197),表明其可能有益于靶向或阻断肿瘤细胞上的多种细胞表面抗原(靶标)。已经认识到这一点,并且目前在临床试验中存在超过15种双特异性抗体,即靶向两种不同细胞表面抗原的抗体(参见例如garber,natrevdrugdiscov.2014oct31;13(11):799-801)。然而,迄今为止的人双特异性抗体仅能够靶向平面或凹面抗原结合位点,从而排除可能治疗更有效的抗原结合位点。
因此,鉴于人或人源化双特异性抗体靶向的经典表位的限制,对新型和有效的基于双特异性抗体的癌症治疗剂存在持续需求。因此,本发明的目标是提供克服目前抗原靶向的限制的新型双特异性抗体。
发明概述
本发明人已令人惊讶地发现,可以通过将vnari型、ii型和iv型结构域的高变区2(hv2)的氨基酸序列随机化来获得双特异性vnar结构域。因此,本发明提供了用于生成具有以下结构的双特异性鲨鱼可变抗体结构域(vnar结构域)的方法:
fw1-cdr1-fw2-hv2-fw3a-hv4-fw3b-cdr3-fw4,
其中所述方法包括以下步骤:
a.将至少一个编码高变区2(hv2)的多核苷酸序列随机化,
b.检测vnar结构域,其中hv2以相比于参考样品改变的亲和力结合目标抗原,且第二目标抗原被由cdr3和cdr1形成的互补位特异性结合,
c.选择(b)的vnar结构域。
在一个实施方案中,可以通过本发明方法随机化的vnar结构域是vnari型、vnarii型或vnariv型之一。
在一个实施方案中,根据本发明的至少一个编码所述vnar的多核苷酸上包含的编码hv2的区域的多核苷酸的随机化包括基于密码子的随机化、nnb随机化、nnk随机化、nns随机化或偏倚随机化。
根据一个实施方案,编码根据本发明的hv2结构域的多核苷酸序列包含核苷酸序列nnn1(nnn)7nnn9,其中
-位置1中的密码子的50%编码氨基酸赖氨酸,而剩余50%编码除半胱氨酸以外的任何氨基酸,且
-密码子2-8可以编码任何氨基酸,且
-位置9中的密码子的50%编码氨基酸苏氨酸,而剩余50%编码除半胱氨酸以外的任何氨基酸。
在一个实施方案中,通过酵母表面展示、噬菌体展示、哺乳动物展示或蛋白阵列之一检测和/或选择根据本发明的展示与第一抗原的亲和力相比于参考样品改变的vnar。
根据一个实施方案,根据本发明的vnar还包含可检测标签。
在一个实施方案中,根据本发明的vnar的可检测标签位于vnar的氨基末端和/或羧基末端。
在一个实施方案中,通过流式细胞术、facs、elisa或微流体检测和/或选择本发明vnar。
根据一个实施方案,本发明方法的第一和第二目标抗原是细胞表面抗原,优选癌细胞表面抗原。
在一个实施方案中,本发明提供了融合蛋白,其包含根据本发明方法的随机化hv2结构域或包含根据本发明方法的随机化hv2结构域的本发明vnar结构域。
在一个实施方案中,本发明融合蛋白包含igg-fc结构域、vh、vl、vhh抗体结构域或其片段之一。
在一个实施方案中,本发明融合蛋白是人源化的。
在一个实施方案中,本发明融合蛋白的fc-结构域包含人igg-fc结构域或其序列变体。
根据一个实施方案,本发明融合蛋白当与所述第一目标抗原和所述第二目标抗原结合时,在体内诱导adcc。
在一个实施方案中,本发明提供了可通过本发明方法获得的vnar。
在一个实施方案中,本发明提供了载体,其包含编码本发明vnar或本发明融合体的多核苷酸序列。
在一个实施方案中,本发明提供了包含根据本发明的载体的宿主细胞。
在一个实施方案中,本发明提供了产生本发明vnar或vnar融合蛋白的方法,其中所述方法包括以下步骤:
-在足以使本发明vnar或vnar融合蛋白蛋白表达的条件下,培养至少一种根据本发明的宿主细胞,和
-分离和纯化本发明vnar蛋白或vnar融合蛋白。
根据一个实施方案,本发明提供了多核苷酸文库,其包含多个编码如本文公开的本发明hv2结构域的多核苷酸。
在一个实施方案中,本发明多核苷酸文库包含多个编码总体结构fw1-cdr1-fw2-hv2-fw3a-hv4-fw3b-cdr3-fw4的i型、ii型或iv型vnar结构域的多核苷酸,其中hv2结构域由根据本发明的随机化多核苷酸序列编码。
在一个实施方案中,本发明提供了包含根据seqidno:2、seqidno:4、seqidno:5的氨基酸序列的双特异性vnar。
在一个实施方案中,本发明涉及本发明vnar或本发明融合蛋白在制备药物中的用途。
在一个实施方案中,本发明提供了包含如本文公开的本发明vnar或本发明vnar融合蛋白和药学上可接受的载体或稀释剂的药物组合物。
在一个实施方案中,本发明涉及治疗患有病理状况的个体的方法,其包括向有需要的个体施用根据本发明的药物组合物。
在一个实施方案中,待通过本发明方法治疗的病理状况是癌症、自身免疫疾病或病毒感染。
在一个实施方案中,待通过本发明方法治疗的个体具有肿瘤。
根据一个实施方案,待通过本发明方法治疗的个体是人。
在一个实施方案中,本发明提供了部件试剂盒,其包含双特异性vnar或本发明vnar融合蛋白,以及用于检测本发明vnar的装置。
附图简述
图1:显示常规互补位(抗原结合位点)的vnar分子。经由hv2的随机化引入新的抗原结合位点,导致产生靶向两种不同抗原的双特异性分子。
图2:各种抗体分子(a)igg分子、(b、c)骆驼科动物和软骨鱼抗体分子(其仅天然仅由重链组成)的抗体结构。
图3:抗体结构的比较:vnar属于ig超家族且具有β-夹心折叠,然而,相比于哺乳动物v结构域,该折叠仅由8个、而不是10个β-链组成,这是由于框架2-cdr2-区域中的缺失。因此,与哺乳动物可变结构域相反,vnar结构域仅具有两个互补决定区cdr1和cdr3。主要vnar谱的多样性主要发现于cdr3中。在cdr1中、cdr2截短位点处和tcr中对应于hv4的环中观察到高体细胞突变率。因此,这些突变易发区域已分别被命名为hv2和hv4。
图4:已知的不同vnar类型,包括i型、ii型、iii型和iv型。
图5:酵母表面展示的说明。vnar在酿酒酵母的表面上分别被呈递为具有n-末端ha-表位和c-末端cmyc-标签的aga2p融合体,用于检测表面表达。
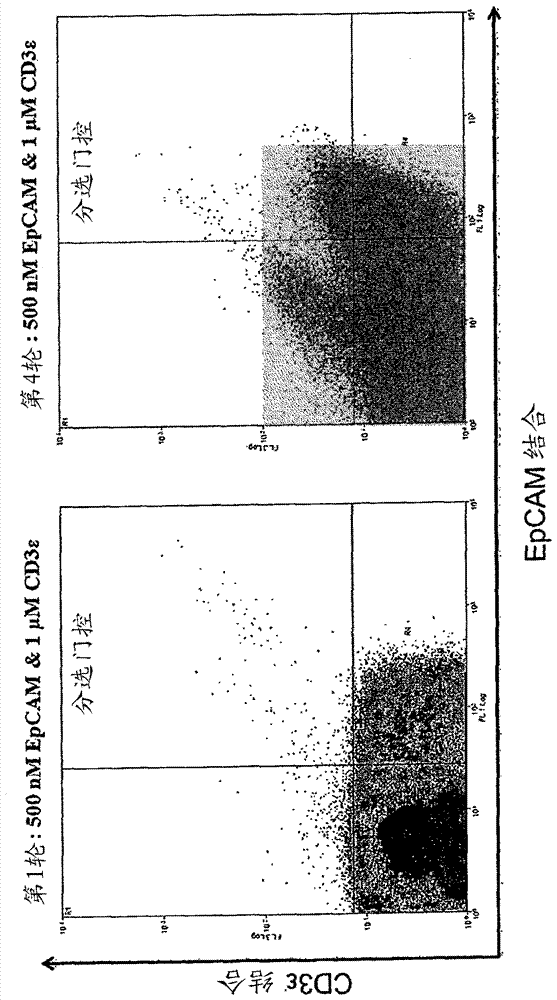
图6:用于同时结合epcam和cd3ε的文库筛选。二维进行分选。显示了文库筛选的第1轮和第4轮、分选门控以及靶浓度。
图7:使用酵母表面展示验证双特异性。与540nmepcam(黑色)或770nmcd3ε或仅与二级检测试剂孵育的在其表面上表达vnarb1的酵母细胞。
图8:epcam-和cd3ε-特异性vnar分子b1及其亲本分子5005(仅epcam特异性)的序列。以灰色显示hv2中的随机化残基。
图9:(a)使用酵母表面展示验证双特异性。与540nmepcam(黑色)或仅与二级检测试剂(灰色)孵育的在其表面上表达vnarf1的酵母细胞,(b)使用酵母表面展示验证双特异性。与约500nmfc-片段(黑色)或仅与二级检测试剂(灰色)孵育的在其表面上表达vnarf1的酵母细胞。
图10:包含竹鲨(chiloscylliumplagiosum)的vnar结构域的残基43-56的vnar结构域表面暴露的环hv2的模型;残基编号根据物种和vnar类型而不同。
图11:用于构建具有随机化hv2的插入物的soe-pcr方案。在2步pcr中生成插入片段。在第一步中,将vnar-片段扩增直至hv2的5'末端(1a)。在第二步中,使用hv2rand_up引物将hv2随机化。这导致产生在hv2编码区的5'末端开始至vnar分子编码区的3'末端的片段。在第二pcr中,两个片段充当自身的引物,以导致全长随机化hv2vnar插入物以得到引物。在6个循环后,添加引物以生成足够量的全长插入物。
序列表
seqidno:1用于hv2结构域的随机化的人工多核苷酸
seqidno:2vnar克隆b1的氨基酸序列
seqidno:3亲本vnar克隆5005的氨基酸序列
seqidno:4vnarepha2-fc的氨基酸序列
seqidno:5vnarepha2_4-fc的氨基酸序列
seqidno:6生物素-受体多肽的氨基酸序列
seqidno:7actev位点
seqidno:8寡核苷酸hv2rand_up
seqidno:9pct-seq-lo
seqidno:10pct-seq-up
seqidno:11hv2rand_soe-lo。
发明详述
尽管下面详细地描述了本发明,但要理解,本发明不限于本文所述具体的方法、方案和试剂,因为这些可改变。还要理解,本文所用术语仅用于描述具体实施方案的目的,并无意限制仅由随附权利要求书限定的本发明的范围。除非另有说明,否则本文所用的所有技术和科学术语具有本领域普通技术人员通常理解的相同含义。
下面,将描述本发明的要素。这些要素与具体实施方案一起列出,然而应理解,它们可以任何方式和以任何数目组合以产生额外的实施方案。各个描述的实例和优选的实施方案不应解释为仅将本发明限于明确描述的实施方案。该描述应理解为支持和包括将明确描述的实施方案与任何数目的公开的和/或优选的要素组合的实施方案。此外,本申请中所有所描述的要素的任何排列和组合都应视为通过本申请的描述而公开,除非上下文中另有说明。
在整个本说明书和随附的权利要求书中,除非上下文另有要求,否则术语“包含(comprise)”和变体诸如“包含(comprises)”和“包含(comprising)”应理解为必然包括规定的成员、整数或步骤,但不排除任何其它未规定的成员、整数或步骤。术语“由……组成”是术语“包含”的一个具体实施方案,其中不包括任何其它未规定的成员、整数或步骤。在本发明的上下文中,术语“包含”包括术语“由……组成”。
在描述本发明的上下文中(尤其在权利要求书的上下文中)使用的术语“一(a)”和“一(an)”和“该(the)”和类似指代要解释为涵盖单数和复数,除非本文另有说明或上下文显然抵触。本文值的范围的引述仅仅意在用作各别提及落入该范围的每个单独的值的简写方法。除非本文另有说明,否则每个单独的值都并入到本说明书中,就像本文分别引述其一样。本说明书的用语都不应解释为说明对实施本发明必要的任何非要求保护的要素。
在本说明书的整个文本中引用了若干文件。本文引用的每份文件(包括所有专利、专利申请、科技出版物、生产商说明书、使用说明等),不论在上文还是在下文,都通过引用以其整体并入到本文中。本文任何东西都不得解释为承认本发明因在前的发明而无资格先于这类公开内容。
所述目标通过本发明、优选通过随附权利要求书的主题解决。发明人令人惊讶地发现,双特异性vnar结构域可以通过本发明方法获得,所述方法包括以下步骤:(a)将至少一个编码高变区2(hv2)的多核苷酸序列随机化,(b)检测vnar结构域,其中hv2以相比于参考样品改变的亲和力结合目标抗原,且第二目标抗原被由cdr3和cdr1形成的互补位特异性结合,和(c)选择(b)的vnar结构域。因此,本发明方法包括将至少一种编码至少一种vnar的hv2结构域的多核苷酸序列随机化,和检测vnar,其以相比于参考样品改变的亲和力结合第一目标抗原和被由vnar结构域的cdr1和cdr3形成的互补位结合的第二目标抗原,随后选择vnar结构域,其显示对第一目标抗原的改变的亲和力。如本发明方法中使用的术语“vnar结构域”是指由在软骨鱼(诸如例如鲨鱼、ray和skate,例如铰口鲨(ginglymostomacirratum)或竹鲨(c.plagiosum))中发现的ignar上存在的仅一个单一结构域形成的抗原结合位点。根据本发明的vnar结构域可以是如上所公开或例如如kovaleva等人(2014),expertopinbiolther.oct;14(10):1527-39中所公开的vnari型、vnarii型或vnariv型。
在本发明方法中,第一目标抗原和第二目标抗原可以是例如细胞表面抗原,其例如是指蛋白、多肽或肽,其中蛋白、多肽或肽的至少一个抗原部分暴露在生物膜的表面上,并且可以具有以下共价连接的部分中的一种或多种:一种或多种简单或复合糖部分(如在糖蛋白中)、脂质部分(如在脂蛋白中)、脂质和糖部分的组合或其他翻译后修饰。“蛋白”通常是基于氨基酸的聚合物的长链(“多肽”)。蛋白可以由一条、两条或更多条多肽链构成,并且可以进一步含有与多肽链结合的一些其他类型的物质(诸如碳水化合物)。蛋白的大小涵盖5,000至几十万克/摩尔(的任意数字)的相当宽的范围。用于本发明方法的术语目标抗原或细胞表面抗原还包括例如受体酪氨酸激酶,诸如例如pdgfr、egfr、vegfr、hgfr、神经营养因子r、her2、her3、her4、胰岛素r、igfr、csfir、flk、kdr、vegfr2、cck4、met、trka、axl、tie、eph、ryk、ddr、ros、ret、ltk或musk。本发明方法中的目标抗原可以例如还包含聚糖,其中术语“聚糖”是指由糖苷连接的大量单糖组成的化合物。例如,聚糖可以包括糖胺聚糖,其包含以交替形式与糖醛酸连接的2-氨基糖,并且包括聚合物诸如肝素、硫酸乙酰肝素、软骨素、角蛋白和皮肤素。在本发明方法中,第一目标抗原和第二目标抗原可以例如位于相同分子或细胞表面抗原上,或者第一和第二目标抗原可以位于两个不同的分子上,例如,第一目标抗原可以由细胞表面蛋白或蛋白片段形成,而第二目标抗原可以由非蛋白细胞表面抗原诸如聚糖形成。本发明的第一和第二目标抗原还可以是肿瘤抗原或细胞表面癌细胞抗原、肿瘤相关抗原或肿瘤特异性抗原,其包含例如由肿瘤细胞表达的任何免疫原性表位。所述蛋白可以由非肿瘤细胞表达,但仅当由肿瘤细胞表达时才例如由于改变(增加或减少)的糖基化而具有免疫原性。或者,所述蛋白可以由肿瘤细胞或癌细胞、但非正常细胞表达。在一个实施方案中,肿瘤抗原、细胞表面癌细胞抗原或肿瘤相关抗原或肿瘤特异性抗原是人肿瘤抗原。例如,肿瘤抗原可以包括黑色素瘤相关的硫酸软骨素蛋白聚糖(mcsp,uniprotq6uvk1,ncbi登录np001888)、成纤维细胞活化蛋白(fap,uniprotq12884,q86z29,q99998;ncbi登录np004451)、表皮生长因子受体(egfr,也称为erbb1和herl,uniprotp00533;ncbi登录np_958439,np_958440)、癌胚抗原(cea,也称为癌胚抗原相关细胞粘附分子5或cd66e;uniprotp06731,ncbi登录np004354)和cd33(也称为gp76或唾液酸结合的ig样凝集素3(siglec-3),uniprotp20138,ncbi登录np001076087,np001171079)。
如用于本发明方法,术语“改变的”或“改变的亲和力”包括通过例如由vnarhv2形成的互补位,或例如通过由vnarcdr1和cdr3形成的互补位的vnar与一种或多种目标抗原(例如一种、两种、三种或四种目标抗原)的结合常数的变化。例如,改变的亲和力可以包括与给定目标抗原的降低或增加的亲和力,优选与目标抗原(可含有线性和/或不连续的)的增加的亲和力。片段的长度没有临界上限,其可以(例如)包含抗原序列的几乎全长,或甚至包含来自靶抗原的两个或更多个表位的融合蛋白。在一个实施方案中,vnarhv2结构域与第一目标抗原的改变的亲和力是至少例如10-7m、2.5x10-7m、5x10-7m、7.5x10-7m、1x10-8m、2.5x10-8m、5x10-8m、7.5x10-8m、10-9m、2.5x10-9m、5x10-9m、7.5x10-9m、10-10m、2.5x10-10m、5x10-10m、7.5x10-10m、10-11m、2.5x10-11m、5x10-11m、7.5x10-11m或10-12m。
与本发明方法一起使用的术语随机化是指产生多个序列的方法,其中一个或几个位置已被随机化。在一些实施方案中,随机化是完全的(即,所有四个核苷酸,a、t、g和c可以在随机化位置发生。在替代实施方案中,核苷酸的随机化限于四个核苷酸的子集。随机化可以应用于编码高变区2(hv2)的多核苷酸序列的一个或几个密码子。当表达时,所得文库产生hv2群体,其中一个或多个氨基酸位置可以含有所有20个氨基酸或氨基酸的子集的混合物。
在一个实施方案中,本发明方法中编码hv2的多核苷酸序列(hv2编码区)的随机化可以包括基于密码子的随机化、nnb随机化、nnk随机化、nns随机化或偏倚随机化。例如,如本发明方法中使用的基于密码子的随机化可以根据由gaytan等人(1998)chemistry&biology5:519-527描述的方法或根据monroy-lagos等人(2006),appliedandenvironmentalmicrobiology,may2006,p.3797–3801)进行。在本发明方法中,nnb随机化是指在前两个位置具有每种核苷酸的25%和在第三位置具有c、t和g的33%的简并密码子。tyr/ser是指酪氨酸和丝氨酸的均匀混合物。例如,如本发明方法中使用的“nnk随机化”可用于产生单一氨基酸变体,其中“n”是指任何碱基(例如a、c、g或t),而“k”是指g或t。nnk随机化方案可以编码覆盖所有20种天然存在的氨基酸的32种不同的密码子。蛋白的各位置的氨基酸残基可以被突变为不同于相同位置的野生型氨基酸的19种氨基酸中的任一种,导致沿着蛋白的单一氨基酸点突变。最终结果是蛋白变体文库,其涵盖具有在文库中成员与成员不同的一个残基的多个蛋白的组。
例如,为了减少本发明方法中编码本发明双特异性vnar的hv结构域的多核苷酸的随机化中的终止密码子的频率,可以包括nns随机化,其中n表示待包括的随机三联体的数目,n代表任何核苷酸,s代表标准iupac核苷酸命名中的c或g。由于三个终止密码子中的两个(tga和taa)在第三位置具有a,所以预期nns策略相比于nnn策略将终止密码子的频率从3/64降低至1/32。本发明方法中的随机化可以例如,也是偏倚随机化,例如序列中的一些位置保持不变,或者选自有限数量的可能性。例如,在一个实施方案中,包含hv2编码区的随机多核苷酸的第一个和最后一个密码子可以进行偏倚随机化,例如,第一密码子可以包含除了tgt、tgc之外的所有密码子,并且最后一个密码子可以是除了tgt、tgc之外的任何密码子,而在用于第一密码子的密码子的50%中,第一密码子可以选自tta、ttg、ctt、ctc、cta、ctg,而第二密码子可以选自act、acc、aca、acg。
在一个实施方案中,编码hv2结构域的多核苷酸序列包含根据seqidno:1的核苷酸序列,其可以例如根据上面公开的任何随机化技术随机化。优选地,根据本发明的多核苷酸的第一个密码子可以在50%的多核苷酸中编码氨基酸赖氨酸,例如,在50%的多核苷酸中,所述密码子选自aaa或aag,而在50%的多核苷酸中,可以存在任何密码子,除了编码半胱氨酸的tgt、tgc。编码根据本发明的hv2结构域的多核苷酸的密码子2-8可以编码任何氨基酸,例如,除taa、tag或tga以外,可存在任何密码子。编码根据本发明的hv2结构域的多核苷酸的密码子9可以在50%的多核苷酸中编码氨基酸苏氨酸,例如,在50%的多核苷酸中,所述密码子选自act、acc、aca或acg,除了tgt、tgc之外,可存在任何密码子。例如,根据seqidno:1的多核苷酸序列可以包含在寡核苷酸序列(诸如例如,根据seqidno:8的寡核苷酸序列)中,其可以用于基于pcr的技术(例如soepcr)中以产生多核苷酸文库,其包含或编码包含随机化hv2结构域的vnar蛋白。
在本发明的一个方面,vnar文库可以例如使用例如omniscript®逆转录试剂盒(qiagen)和odt-寡核苷酸从作为用于cdna合成的模板的来自鲨鱼的总rna获得。pcr扩增的vnar产物可以例如用作用于半合成文库构建的起始材料。初始文库可以例如在三个连续的pcr步骤中建立(参见例如所附实施例中,或例如zielonka,s.等人(2014)journalofbiotechnology)。
在一个实施方案中,通过酵母表面展示、噬菌体展示、哺乳动物展示或蛋白阵列之一检测和/或选择本发明的展示与第一抗原的亲和力相比于参考样品改变的vnar。因此,本发明方法包括例如使包含随机化hv2结构域的vnar进行酵母表面展示、噬菌体展示、哺乳动物展示或蛋白阵列之一。例如,编码包含根据本发明的随机化hv2结构域的vnar的多核苷酸可以进行酵母展示以检测和选择与第一抗原的亲和力相比于参考样品改变的vnar。例如,酵母展示可以根据如rakestraw(参见rakestraw(2011)proteinengineering,design&selectionvol.24,no.6:525-530)提供的方法进行。例如,可以将至少一种编码本发明的vnar的多核苷酸例如克隆入secant载体中,由此经由例如actev蛋白酶位点(enlyfqg)将本发明vnar与生物素-受体肽(bap:glndifeaqkiewhe)基因融合。载体可以例如还包含与vnar5'可操作连接的标签,诸如例如flag标签(sigma)或myc标签。标签和与之可操作连接的5'可以例如是前导序列,诸如源自wtαmfpp的前导序列。表达盒可以例如3'克隆,并在低拷贝prs314酵母/大肠杆菌穿梭载体(atccmanassas,va,usa)中与gal10(半乳糖诱导型)启动子可操作连接以产生具有不同分泌型前导序列和bap取向的载体组。所有载体都可以例如含有kpni和mlui限制性位点侧接的克隆位点,其便于在actev/bap和flag标签之间引入poi。宿主菌株(源自bj5464a)表达负责将生物素连接至bap标签上的大肠杆菌bira生物素连接酶。bira(codondevices,inc.)携带c末端his-asp-glu-leu内质网保留信号序列,并通过融合至酵母转化酶分泌前导序列而引导至分泌途径,并在细胞色素c(cyc1)启动子的控制下表达。蛋白二硫化物异构酶(pdi)在adh1启动子的控制下共表达。bira和pdi基因可以例如分别克隆至prs306和prs305载体(atcc)中,然后其可以例如稳定地整合至酵母染色体中以产生jac100hsecant表面展示菌株(mata,trp1,pep4::his3,dpdb1,adh-pdi::leu2,cyc1-bira::ura3)。酵母细胞的转化可以例如通过如所附实施例中所概述的根据benatuil等人(2011)proteinengineering,design&selectionvol.23,4:155-159的方法或例如根据rakestraw等人进行,例如如下:ez酵母转化试剂盒(zymoresearch,orange,ca,usa)可用于用含有本发明多核苷酸的secant载体转化jac100h展示菌株。然后可以在30℃下在sc葡萄糖、trp2板(teknova,hollister,ca,usa)上选择转化体2天。然后可以挑取单个菌落并将其接种至5ml补充有生物素(2%葡萄糖、0.67%酵母氮碱、0.54%na2hpo4、0.86%nah2po4.h2o、0.5%酪蛋白氨基酸和2.5mg/l生物素)的合成右旋糖酪蛋白氨基酸(sd-caa)氨基酸,并且可以例如在30℃下生长过夜。一旦培养物已例如生长至od600~0.5;可以将其沉淀,然后重悬浮于5ml磷酸盐缓冲、生物素补充酵母提取物、蛋白胨、半乳糖(ypg)培养基(2%半乳糖、2%蛋白胨、1%酵母提取物、0.025%牛血清白蛋白(bsa)、0.54%na2hpo4、0.86%nah2po4.h2o和2.5mg/l生物素)。然后可以例如将培养物在20℃下摇动24小时。这种ypg中的孵育开始poi的生产和生物素化,并被称为“预诱导”。
在预诱导后,可以取出2x107个细胞用于抗生物素蛋白标记:例如,可以将细胞首先沉淀并在1ml碳酸盐缓冲液(4.2%nahco3和0.034%na2co3,ph¼8.4)中洗涤三次,然后通过在室温下在溶解于40ml碳酸盐缓冲液中的4mg(40ml干体积)3.4kdanhs-peg-生物素(laysanbio,arab,al,usa)中孵育15分钟而生物素化。在生物素标记后,可以将细胞沉淀并在1ml磷酸盐缓冲盐水(pbs)/bsa(1mg/ml)中洗涤三次。在预诱导后,可以取出2x107个细胞用于抗生物素蛋白标记(图1b)。例如,可以将细胞例如首先沉淀并在1ml碳酸盐缓冲液(4.2%nahco3和0.034%na2co3,ph¼8.4)中洗涤三次,然后通过在室温下在溶解于40ml碳酸盐缓冲液中的4mg(40ml干体积)3.4kdanhs-peg-生物素(laysanbio,arab,al,usa)中孵育15分钟而生物素化。在生物素标记后,可以将细胞例如沉淀并在1ml磷酸盐缓冲盐水(pbs)/bsa(1mg/ml)中洗涤三次。然后可以例如通过向每个孔中添加1mlpbs/bsa并在室温下孵育2分钟而从板中洗涤细胞。然后可以例如通过上下移液而将细胞悬浮于pbs/bsa中并转移至1.5ml管。任何剩余的细胞可以例如通过至少一次额外应用1mlpbs/bsa而从板收集,然后转移至1.5ml管。然后可以例如将细胞沉淀,在1mlpbs/bsa中洗涤三次并置于冰上。然后可以例如将细胞悬浮于40µl20mg/ml抗生物素蛋白(sigma)中,并可以在室温下孵育10分钟。预先诱导、但未用抗生物素蛋白标记的细胞将可溶性、生物素化蛋白直接分泌至培养基中。在抗生物素蛋白标记后,可以将细胞沉淀,在1mlpbs/bsa中洗涤两次,并重悬浮于50µlpbs/bsa中。可以例如将二十五微升的细胞接种至1.2ml诱导培养基中并充分涡旋。通过将ypg/bsa(2%半乳糖、2%蛋白胨、1%酵母提取物和0.025%bsa)通过抗生物素蛋白-琼脂糖柱(pierce,rockford,il,usa)以除去培养基中天然发现的生物素来制备诱导培养基。然后,将20.6w/v%(对于hsa)或11w/v%8kda聚乙二醇(sigma)溶解于3ml生物素-过滤的培养基中,并用0.2μm注射器过滤器(bectondickinson,franklinlakes,nj,usa)过滤除菌。最后,可以例如添加100mg/ml抗生物素蛋白至1mg/ml的最终浓度。在诱导培养基中混合细胞后,可以例如将1.2ml培养基/细胞悬浮液添加至六孔板(bectondickinson)的一个孔中,并在20℃或25℃下孵育16小时而不摇动。该诱导允许细胞分泌生物素化的蛋白,其然后将被表面结合的抗生物素蛋白捕获。
在一个实施方案中,可以例如通过噬菌体展示检测和/或选择本发明的展示与第一抗原的亲和力相比于参考样品改变的vnar。
如本文所用,“噬菌体展示”描述了体外选择技术,其中根据本发明的vnar结构域或例如,包含本发明的hv2结构域的融合蛋白被基因融合至噬菌体的衣壳蛋白,导致在噬菌体病毒粒子的外部展示融合的蛋白,而编码融合蛋白或肽的dna位于病毒粒子内。展示的蛋白和其编码dna之间的该物理连接允许筛选大量本发明的vnarhv2结构域的变体,或例如包含本发明vnar结构域的融合蛋白。例如,噬菌体展示可以根据现有技术中已知的任何方案(诸如例如engberg等人.(1996)molbiotechnol.dec;6(3):287-310的方案)进行。
在一个实施方案中,通过哺乳动物展示检测和/或选择本发明的展示与第一抗原的亲和力相比于参考样品改变的vnar。例如,用于哺乳动物酵母展示的任何方案或技术可用于本发明方法,诸如例如,wo2008/070367a2中公开的方法。在一个实施方案中,蛋白阵列例如也可用于检测和/或选择本发明vnar结构域,或例如包含本发明vnar结构域的本发明融合蛋白。如本发明方法中使用的术语“蛋白阵列”是指蛋白阵列、蛋白微阵列或蛋白纳米阵列。蛋白阵列可以包括例如"protoarray™",人类蛋白高密度阵列(invitrogencorporation,可在互联网得自lnvitrogen.com)。protoarray™高密度蛋白阵列可用于筛选复杂生物混合物,诸如血清,以测定针对人蛋白的自身抗体的存在。术语“蛋白芯片”可以与本发明方法中的蛋白阵列同义使用。如本发明方法中使用的术语“参考样品”是指至少一个或多个,例如,至少10、100、103、104、105或106个未被随机化的vnar结构域,或者是指例如至少10、100、103、104、105或106个在其表面上展示至少一个vnar结构域的细胞,例如,10、100、103、104、105或106个未被随机化且其中与第一目标抗原结合未改变的vnar结构域。
在一个实施方案中,本发明vnar结构域包含可检测标签。如本发明方法中所用的术语可检测标签是指与本发明vnar结构域共价或非共价结合的部分。根据本发明的标签可以例如是可以直接(即,一级标记)或间接(即二级标签)检测的分子;例如,可以显现和/或测量或以其他方式识别标签,使得可以知道其存在或不存在。示例性标记包括荧光标记(例如绿色荧光蛋白、红色荧光蛋白、黄色荧光蛋白等)和标记酶,或者例如光学可检测的标记、结合对的配偶体和表面底物结合分子(或附接标签)。如技术人员将显而易见,取决于如何使用标签,许多分子可以用作多于一种类型的标签。在一个实施方案中,如下所述的标签或标记作为融合蛋白并入多肽。根据本发明的可检测标签可以例如还包括多肽,其提供为本发明的嵌合vnar分子的一部分,所述本发明的嵌合vnar分子包含与另一个异源多肽或氨基酸序列融合的第一多肽(例如本发明vnar结构域)。在一个实施方案中,此嵌合vnar分子包含第一多肽与标签多肽的融合体。可检测标签可以由多肽诸如flag、his、myc、ha、v5标签、s-标签、sbp标签或strep-标签组成,或者可以例如包含蛋白标签,诸如例如gst-标签、mbp-标签、gfp-标签。
根据本发明的可检测标签可以例如存在于本发明vnar结构域或在vnar结构域的氨基或羧基末端包含本发明vnar结构域的融合蛋白(例如,融合蛋白可以包含至少一个根据本发明的vnar结构域)或例如包含至少一个本发明vnar结构域的融合蛋白上。
在一个实施方案中,根据本发明的vnar结构域的检测和/或选择包含流式细胞术、facs、elisa或微流体。如本发明方法中使用的术语“选择”是指鉴定和/或分离vnar结构域或例如包含一个或多个本发明的vnar结构域的融合蛋白或例如在其表面上展示本发明vnar或例如包含一个或多个本发明的vnar结构域的融合蛋白的过程。本发明方法中的选择可包括技术人员已知的各种技术,诸如例如免疫淘选(immuno-panning)(参见例如wysocki等人,proc.nati.acad.sci.usa第75卷,第6期,第2844-2848页,1978年6月)、磁激活的细胞分选(macs)、流式细胞术、荧光激活的细胞分选(facs)或基于微滴的微流体法(参见例如mazutis等人,2013,natureprotocols8,870–891)。本发明的选择细胞可作为选择的一部分,例如与通过上文所公开的方法从不在其表面展示目标蛋白的宿主细胞分离或分开。例如,facs可用来将细胞分选至不同的小瓶或容器中,或macs可用来分离在其表面上展示蛋白的宿主细胞,或基于微滴的微流体法可用来选择和分离在其表面上展示目标蛋白的根据本发明的宿主细胞。
根据本发明的一个实施方案,第一目标抗原可以是细胞表面抗原,优选癌细胞表面抗原或癌细胞表面抗原,诸如上述公开的那些。
在一个实施方案中,本发明提供了包含本发明vnar结构域的融合蛋白。例如,本发明融合蛋白可以包含以下结构fw1-cdr1-fw2-hv2-fw3a-hv4-fw3b-cdr3-fw4的vnar结构域,其中fwx表示框架x,cdrx表示互补决定区x,hv2表示本发明hv2结构域,例如根据本发明的随机化hv2结构域。本发明vnar结构域可以是例如融合的fc结构域。如用于本发明方法中的术语“fc结构域”或“fc区”是指免疫球蛋白的一部分,例如与通过木瓜蛋白酶消化igg分子获得的可结晶片段有关的igg分子。fc区包含通过二硫键连接的igg分子的2条重链的c末端一半。它没有抗原结合活性,但含有碳水化合物部分以及补体和fc受体(包括fcrn受体)的结合位点。
fc结构域包含通过二硫键连接的igg分子的2条重链的c末端一半。它没有抗原结合活性,但含有碳水化合物部分以及补体和fc受体(包括fcrn受体)的结合位点。“fc结构域”包括例如天然序列fc区和变体fc区,例如诸如公开于wo02/094852中那些),以及在fc结构域的多个位置,包括但不限于位置270、272、312、315、356和358观察到多态性。在本发明方法内,术语“fc”可指分离的这个区域或在抗体、抗体片段或fc融合蛋白的背景下的这个区域。
例如,iggfc区可包含iggch2和iggch3结构域。人iggfc区的“ch2结构域”通常从约位置231的氨基酸残基延伸到约位置340的氨基酸残基,其中碳水化合物链可与ch2结构域连接。“ch3结构域”可包含氨基酸c末端至fc区中的ch2结构域的一段,例如从igg的约位置341的氨基酸残基至约位置447的氨基酸残基。所述融合蛋白可以例如还包含一个或多个本发明vnar结构域与血清白蛋白、优选人血清白蛋白的融合体。本发明融合蛋白可以例如包含vnar结构域作为氨基末端融合体或作为羧基末端融合体。例如,本发明融合蛋白还可以包含多于一个vndar结构域,例如,本发明融合蛋白可以包含两个、三个或四个本发明vnar结构域,例如,通过与相应融合蛋白的氨基和羧基末端融合。
在本发明的一个实施方案中,本发明融合蛋白包含人fc结构域或其序列变体。因此,本发明融合蛋白可以包含如上文所公开的fc结构域或其序列变体。本发明fc-vnar融合蛋白的fc结构域的序列变体与如上文所公开的fc结构域具有至少80%、85%、90%、95%或98%或约92%至约98%、例如92%、93%、94%、95%、96%、97%或98%同一性。可以如上所述计算本发明fc融合蛋白的序列相似性。序列相似性可以在fc结构域的氨基酸序列的整个长度上计算,但也可以在以下氨基酸序列的任何部分或位置上计算:长度为10-200个氨基酸或110-190个氨基酸或120-180个氨基酸或130-170个氨基酸或140-160个氨基酸或10-100个氨基酸或20-90个氨基酸、30-80个氨基酸、40-70个氨基酸、50-60个氨基酸,例如长度为约15-55个氨基酸或长度为约25-115个氨基酸或长度为约35-95个氨基酸或长度为约45-85个氨基酸或长度为约12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、32、34、35、36、37、38、39、40、42、46、48、51、54、56、57、59或60个氨基酸。
例如,本发明融合蛋白或如本发明中公开的任何蛋白的氨基酸序列的序列同一性定义为在比对序列和必要时引入空位以获得最大百分比序列同一性后,且不考虑任何保守取代作为序列同一性的一部分,与本发明的目标蛋白中的氨基酸残基相同的候选序列中的氨基酸残基的百分比。可用本领域技术内的各种方式,诸如应用可公开获得的计算机软件诸如blast、blast-2、align、align-2或megalign(dnastar)软件,实现用于测定百分比氨基酸序列同一性的目的的比对。本领域技术人员可确定用于测量比对的合适参数,包括实现所比较序列全长内的最大比对所需的任何算法。
例如,还可通过公开于altschul等,bullmath.bio.48:603(1986)和henikoff和henikoff,proc.natlacad.sci.usa1992nov15;89(22):10915-9中的方法,测定百分比序列同一性。简单地说,使用10的空位开放罚分(gapopeningpenalty)、1的空位延伸罚分(gapextensionpenalty)和下文公开的henikoff和henikoff的“blosum62”评分矩阵(氨基酸用标准一字母代码表示),对2个氨基酸序列进行比对以使比对评分最优化。然后如下计算百分比同一性:([相同匹配的总数]/[较长序列的长度加引入较长序列中以比对2个序列的空位数])*100)。
例如,可获得的其它确立的算法可用来比对和测定两个或更多个氨基酸序列的相似性。pearson和lipman的“fasta”相似性搜索算法是用于检查两个或更多个氨基酸序列共享的同一性水平的合适的蛋白比对方法(参见例如pearson和lipman,proc.natl.acad.sci.usa&5:2444(1988)和pearson,meth.enzymol.183:63(1990))。简单地说,fasta首先通过鉴定具有最高同一性密度(densityofidentities)(如果ktup变量为1)或成对同一性(pairsofidentities)(如果ktup=2)的查询序列和测试序列共有的区域,来表征序列相似性,而不考虑保守氨基酸取代、插入或缺失。然后通过使用氨基酸取代矩阵比较所有配对氨基酸的相似性,对具有最高同一性密度的10个区重新评分,并“修整”各区的末端以仅包括有助于最高评分的那些残基。如果有其评分大于“截止值(根据序列的长度和ktup值通过预先确定的方程式计算)”的几个区,则检测修整的起始区以确定各区是否可连接以形成具有空位的近似比对。最后,利用needleman-wunsch-sellers算法的修改(needleman和wunsch,j.molbiol.48:444(1970);sellers,siamj.appl.math.25:787(1974))(其允许氨基酸插入和缺失),对2个氨基酸序列的最高评分区进行比对。fasta分析的说明性参数为:ktup=1,空位开放罚分=10,空位延伸罚分=1,取代矩阵=blosum62。可如pearson,meth.enzymol.183:63(1990)的附录2中所解释,通过修改评分矩阵文件(“smatrk”),将这些参数引入fasta程序。
在一个实施方案中,本发明的融合蛋白可以包含本发明hv2结构域与vh抗体的融合体,例如,通过cdr2和cdr3之间的同框融合,由此替代cdr2和cdr3之间的β-折叠,或例如hv2可以包括在β-折叠中。本发明hv2-结构域也可以通过接枝至其他免疫球蛋白(诸如例如,igm型抗体)上,或可以例如与vhh抗体融合,代替vhh结构域。
在一个实施方案中,当在体内与第一和第二目标抗原结合时,例如,当本发明双特异性融合蛋白与肿瘤或癌细胞上的第一和第二抗原结合、例如与如上所公开的癌细胞表面抗原结合时,本发明融合蛋白诱导adcc。如用于本发明融合蛋白的术语adcc(抗体依赖性细胞毒性)是指细胞介导的免疫防御的机制,其中免疫系统的效应细胞活性地裂解靶细胞,其膜表面抗原已被特异性抗体结合。adcc通过例如在nk细胞上表达的cd16(fcγriii)与抗体的fc结构域的结合来介导(参见例如clynes等人(2000)naturemedicine6,443-446)。adcc可以例如通过影响fc结构域与cd16结合的fc结构域中的氨基酸取代而得到改善。例如,shields等人(jbiolchem9(2),6591-6604(2001))显示fc区的位置298、333和/或334的氨基酸取代(残基的eu编号)改善adcc。或者,增加的fc受体结合和效应子功能可以例如通过改变fc区的糖基化获得。与fc结构域的asn297连接的两个复杂双天线糖寡糖通常被掩埋在ch2结构域之间,与多肽骨架形成广泛的接触,并且它们的存在对于抗体介导效应子功能(包括adcc)是至关重要的(lifely等人,glycobiology5,813-822(1995);jefferis等人,immunolrev163,59-76(1998);wright和morrison,trendsbiotechnol15,26-32(1997))。例如β(1,4)-n-乙酰氨基葡糖基转移酶iii(gntiii)(催化二等分寡糖的形成的糖基转移酶)的过表达显著增加抗体的体外adcc活性。因此,用于产生本发明融合蛋白的细胞系中例如gntiii的过表达可导致本发明的富含二等分的寡糖的融合蛋白,其通常也是非岩藻糖基化的并且可以表现出增加的adcc。
本发明融合蛋白的adcc可以例如在宿主细胞或细胞系中额外过表达除了gntiii之外的甘露糖苷酶ii(manii)来进一步增加,因为所得本发明融合蛋白可以富含复合型的二等分、非岩藻糖基化寡糖(参见例如ferrara等人,biotechnbioeng93,851-861(2006))。例如,从存在于本发明fc融合蛋白中的寡糖核心的最内部n-乙酰葡糖胺残基消除岩藻糖也可以增加adcc活性(参见例如shinkawa等人,jbiolchem278,3466-3473(2003)),因此本发明fc融合蛋白也可以例如在宿主细胞或具有降低的岩藻糖基化的细胞系中产生,通过例如在α(1,6)-岩藻糖基转移酶缺陷宿主细胞中的表达(参见例如yamane-ohnuki等人,biotechbioeng87,614-622(2004);niwa等人,jimmunolmethods306,151-160(2006))。
在一个实施方案中,本发明提供了可通过本发明方法获得的vnar,例如如上所公开的vnar,其可以是如上所公开的vnari型、ii型或iv型。在一个实施方案中,本发明还提供了编码如上所公开的本发明vnar或vnar融合蛋白的多核苷酸或载体。用于本发明方法或本发明融合蛋白的术语载体或表达载体是指能够染色体外复制的核酸分子。优选的载体是能够自主复制和表达与其连接的核酸的载体。能够指导与其可操作连接的基因的表达的载体在本文中称为“表达载体”。通常,用于重组dna技术中的表达载体通常是“质粒”的形式,其通常是指环状双链dna环,其以其载体形式不与染色体结合。在真核细胞中表达本发明融合蛋白或本发明vnar所必需的核酸序列包含例如至少一个启动子,和增强子、终止和聚腺苷酸化信号以及选择性标记,诸如例如抗生素耐药性。可用于表达本发明vnar或vnar融合蛋白的表达载体可以例如包含pcmv、pcdna、p4x3、p4x4、p4x5、p4x6、pvl1392、pvl1393、pacyc177、prs420,或者(如果使用基于病毒的载体系统)例如pbabepuro、pwpxl、pxp-衍生的载体。
在一个实施方案中,本发明提供了包含如上所公开的多核苷酸序列或载体(例如,包含如本文所公开的本发明vnar或本发明融合蛋白的编码序列的多核苷酸或载体或表达载体)的宿主细胞。例如,用于本发明的宿主细胞可以是酵母细胞、昆虫细胞或哺乳动物细胞。例如,本发明的宿主细胞可以是选自sf9、sf21、s2、hi5或bti-tn-5b1-4细胞的昆虫细胞,或者例如本发明的宿主细胞可以是选自以下的酵母细胞:酿酒酵母(saccharomycescerevisiae)、多形汉逊酵母(hansenulapolymorpha)、粟酒裂殖酵母(schizosaccharomycespombe)、许旺酵母(schwanniomycesoccidentalis)、乳酸克鲁维酵母(kluyveromyceslactis)、解脂耶氏酵母(yarrowialipolytica)和巴斯德毕赤酵母(pichiapastoris),或者例如本发明的宿主细胞可以是选自以下的哺乳动物细胞:hek293、hek293t、hek293e、hek293f、ns0、per.c6、mcf-7、hela、cos-1、cos-7、pc-12、3t3、vero、vero-76、pc3、u87、saos-2、lncap、du145、a431、a549、b35、h1299、huvec、jurkat、mda-mb-231、mda-mb-468、mda-mb-435、caco-2、cho、cho-k1、cho-b11、cho-dg44、bhk、age1.hn、namalwa、wi-38、mrc-5、hepg2、l-929、rab-9、sirc、rk13、11b11、1d3、2.4g2、a-10、b-35、c-6、f4/80、iec-18、l2、mh1c1、nrk、nrk-49f、nrk-52e、rmc、cv-1、bt、mdbk、cpae、mdck.1、mdck.2和d-17。
在一个实施方案中,本发明提供了用于生产如本文所公开的本发明vnar或vnar融合蛋白的方法,其中本发明方法包括以下步骤:在足以使本发明vnar或vnar融合蛋白蛋白表达的条件下培养至少一种如上所公开的本发明的宿主细胞,以及分离和纯化本发明vnar蛋白或vnar融合蛋白。例如,可使本发明的宿主细胞在含有10%fbs的dmem中生长,并在37℃下在10%co2中孵育,或例如在无蛋白培养基中孵育以利于随后的分离和纯化,或例如在grace昆虫培养基、expressfive®sfm(lifetechnologies)或highfive®培养基(lifetechnologies)、ynm培养基、ypd液体培养基或例如pichiapink(lifetechnologies)中孵育。
可例如使本发明的宿主细胞生长12-408小时,例如约12-约400小时,例如14小时、16小时、18小时、20小时、24小时、36小时、48小时、72小时、96小时-约120小时、144小时、168小时、192、216小时、240小时、264小时、288小时、312小时、336小时、360小时、384小时、408小时。随后,可分离并纯化本发明vnar或本发明融合蛋白。例如,可通过层析法,例如离子交换层析法、大小排阻层析法、硫酸铵沉淀或超滤,分离并纯化本发明的蛋白。例如,本发明vnar或本发明融合蛋白还可以包含信号序列,其是指能够使例如通过肽键与之可操作连接的多肽穿入宿主细胞的内质网(er)的氨基酸序列。信号肽一般被内肽酶(例如特异性定位于er的信号肽酶)切割掉以释放(成熟的)多肽。信号肽的长度范围通常为约10-约40个氨基酸。
在一个实施方案中,本发明还提供了多核苷酸文库,其包含多个编码本发明的hv2结构域的多核苷酸。本发明的术语“多核苷酸文库”或“多个多核苷酸”表示至少两个不同dna序列的文库或集合,其至少编码本发明hv2结构域,或例如其编码包含本发明hv2结构域的vnari型、ii型或iv型之一。例如,所述多核苷酸文库包含至少1000个不同的dna序列,更优选至少104、105、106或至少100、1000或约103至约107个不同的dna序列,其编码本发明hv2结构域。优选地,本发明的多核苷酸文库包含多个编码总体结构fw1-cdr1-fw2-hv2-fw3a-hv4-fw3b-cdr3-fw的i型、ii型或iv型vnar结构域的多核苷酸。在一个实施方案中,本发明提供了根据seqidno:2、seqidno:4、seqidno:5的双特异性vnar分子。
在一个实施方案中,本发明涉及本发明vnar或本发明vnar融合蛋白在制备药物中的用途。因此,本发明vnar蛋白或本发明vnar融合蛋白可以例如用于制备药物,例如,配制成施用于有需要的个体。本发明的创造性药物可以例如为可注射液体、胶囊、锭剂、用于重构的冷冻干燥制剂,并且可以包含例如约0.01mg/ml至约25mg/ml本发明vnar蛋白或本发明vnar融合蛋白,或约0.02mg/ml至约20mg/ml、或约0.075mg/ml至约17.5mg/ml、或约0.1mg/ml、0.25mg/ml、0.5mg/ml、0.75mg/ml、1mg/ml、1.5mg/ml、2mg/ml、2.5mg/ml、3mg/ml、3.5mg/ml、3.75mg/ml、4mg/ml、4.25mg/ml、4.5mg/ml、5mg/ml、5.5mg/ml、6mg/ml、6.5mg/ml、7mg/ml、7.5mg/ml、8mg/ml、9mg/ml、9.5mg/ml、10mg/ml、10.5mg/ml、11mg/ml、11.5ml/ml、12mg/ml、12.5mg/ml、12.75mg/ml、13mg/ml、14mg/ml、14.5mg/ml、15mg/ml至约16mg/ml、17mg/ml、18mg/ml、19mg/ml、20mg/ml、21mg/ml、22mg/ml、23mg/ml、24mg/ml、25mg/ml、或例如约26mg/ml至约50mg/ml、例如27mg/ml、28mg/ml、29mg/ml、30mg/ml、31mg/ml、32mg/ml、33mg/ml、34mg/ml、35mg/ml、36mg/ml、37mg/ml、38mg/ml、39mg/ml、40mg/ml、41mg/ml、42mg/ml、43mg/ml、44mg/ml、45mg/ml、46mg/ml、47mg/ml、48mg/ml、49mg/ml、50mg/ml、或例如0.001mg/ml至约0.009mg/ml。
在一个实施方案中,本发明提供了药物组合物,其包含如本文所公开的本发明vnar或vnar融合蛋白和药学上可接受的载体或稀释剂。在本发明的药物组合物的上下文中,药学上可接受的载体是指药学上可接受的材料、组合物或媒介物,诸如液体或固体填充剂、稀释剂、赋形剂、溶剂或包封材料,诸如脂质体、聚乙二醇(peg)、聚乙二醇化脂质体、纳米颗粒等,其参与将主题组合物或治疗剂从身体的一个器官或部分携带或运输至身体的另一个器官或部分。每种载体在与制剂的其他成分相容且对患者无害的意义上必须是“可接受的”。可以充当药学上可接受的载体的材料的一些实例包括例如,糖类,诸如乳糖、葡萄糖和蔗糖;或例如淀粉类,诸如玉米淀粉和马铃薯淀粉;或例如纤维素及其衍生物,诸如羧甲基纤维素钠、乙基纤维素和乙酸纤维素;或例如明胶;或例如赋形剂,诸如可可脂和栓剂蜡;或例如油类,诸如花生油、棉籽油、红花油、芝麻油、橄榄油、玉米油和大豆油;或例如二醇类,诸如丙二醇;或例如多元醇类,诸如甘油、山梨糖醇、甘露糖醇和聚乙二醇;或例如酯类,诸如油酸乙酯和月桂酸乙酯;或例如还可以使用以下物质:等渗盐水或缓冲(水)溶液,例如磷酸盐、柠檬酸盐等,缓冲溶液、含水缓冲溶液,其含有例如钠盐,优选至少50mm的钠盐、钙盐,优选至少0.01mm的钙盐和/或钾盐,优选至少3mm的钾盐。根据一个优选实施方案,钠、钙和/或钾盐可以以其卤化物(例如,氯化物、碘化物或溴化物)的形式、其氢氧化物、碳酸盐、碳酸氢盐或硫酸盐等的形式存在。不限于此,钠盐的实例包括例如nacl、nai、nabr、na2co3、nahco3、na2so4,任选的钾盐的实例包括例如kcl、ki、kbr、k2co3、khco3、k2so4,钙盐的实例包括例如cacl2、cai2、cabr2、caco3、caso4、ca(oh)2。此外,上述阳离子的有机阴离子可以包含在本发明的组合物中。根据一个更优选实施方案,如上所定义的适用于注射目的的本发明组合物可以含有选自氯化钠(nacl)、氯化钙(cacl2)和任选氯化钾(kcl)的盐,其中还可存在除氯化物以外的其他阴离子。cacl2还可以被另一盐如kcl替代。本发明的组合物可以是相对于特定参考介质高渗、等渗或低渗的,即本发明的药物组合物可以具有相对于特定参考介质更高、相同或更低的盐含量,其中优选地,可以使用此类浓度的上述盐,其不会由于渗透或其他浓缩效应而导致细胞损伤。参考介质是例如以“体内”方法存在的液体,诸如血液、淋巴、胞质溶胶液体或其他体液,或例如液体,其可以在“体外”方法中用作参考介质,诸如常见的缓冲液或液体。此类常见的缓冲液或液体是技术人员已知的。
在一个实施方案中,本发明涉及治疗患有病理病况的有需要的个体的方法,其包括向有需要的人施用如本文所公开的本发明药物组合物。例如,本发明治疗方法可以包括向患有病理病况的有需要的人施用约0.001mg/kg至约50mg/kg本发明药物组合物,或约0.005mg/kg至约45mg/kg、或约0.01mg/kg至约40mg/kg、或约0.05mg/kg至约35mg/kg、或约0.1mg/kg、0.5mg/kg、0.75mg/kg、1mg/kg、1.5mg/kg、2mg/kg、2.5mg/kg、3mg/kg、4mg/kg、5mg/kg、6mg/kg、7mg/kg、8mg/kg、9mg/kg、10mg/kg、12.5mg/kg、15mg/kg、17.5mg/kg、20mg/kg、22.5mg/kg、25mg/kg至约26mg/kg、27mg/kg、28mg/kg、29mg/kg、30mg/kg、32.5mg/kg、35mg/kg、37.5mg/kg、40mg/kg、42.5mg/kg、45mg/kg。如所用,术语“mg/kg”是指mg本发明药物组合物/kg本发明中的体重。可以通过本发明方法治疗的病理病况可以是癌症、自身免疫疾病或病毒感染。如本发明治疗方法的上下文中使用的术语“癌症”是指由细胞的异常、不受控制的生长引起的多种病况,例如被称为“癌细胞”的能够引起癌症的细胞具有特征性特性,诸如不受控制的增殖、永生化、转移潜力,快速生长和增殖速度,和/或某些典型的形态特征。癌细胞可以是例如肿瘤的形式,但此类细胞也可以单独存在于受试者内,或者可以是非致瘤性癌细胞。如本发明治疗方法的上下文中使用的术语癌症可以例如是指前列腺癌、乳腺癌、肾上腺癌、白血病、淋巴瘤、骨髓瘤、瓦尔登斯特伦氏巨球蛋白血症、单克隆丙种球蛋白病、良性单克隆丙种球蛋白病、重链疾病、骨和结缔组织肉瘤、脑肿瘤、甲状腺癌、胰腺癌、垂体癌、眼癌、阴道癌、外阴癌、子宫颈癌、子宫癌、卵巢癌、食管癌、胃癌、结肠癌、直肠癌、肝癌、胆囊癌、胆管癌、肺癌、睾丸癌、阴茎癌(penalcancer)、口腔癌、皮肤癌、肾癌、wilms氏肿瘤和膀胱癌。在本发明治疗方法的上下文中,术语自身免疫疾病可以例如是指系统性红斑狼疮(sle)、格雷夫斯病、i型和ii型糖尿病、多发性硬化症、干燥综合征、硬皮病、肾小球肾炎、移植排斥反应,例如器官和组织同种异体移植物和异种移植物排斥反应和移植物抗宿主病。如本发明治疗方法的上下文中使用的术语“病毒感染”是指特征在于细胞的病毒转化、病毒复制和增殖的异常状态或病况,诸如例如,疱疹家族病毒、水痘带状疱疹病毒(vzv)、eb病毒(ebv)、巨细胞病毒(cmv)等感染。根据一个优选实施方案,待通过如本文公开的本发明方法治疗的个体是人。
在一个实施方案中,本发明提供了部件试剂盒,其包含如上文所公开的本发明vnar或vnar融合蛋白以及用于检测的装置。因此,本发明部件试剂盒可以例如包含本发明vnar或vnar融合蛋白,其呈稳定形式诸如例如,冻干的,或作为液体制剂,使得本发明vnar或vnar融合蛋白足够稳定用于储存,例如,用于在4℃-10℃下或在环境温度下储存例如至少1-12周,或例如至少1-6个月,或例如至少2-12个月,例如1、2、3、4、5、6、7、8、9、10或11个月。本发明试剂盒还可以包含用于检测本发明vnar蛋白或本发明vnar融合蛋白的装置,诸如例如量子点,可检测标记的抗体,诸如抗体-酶复合物,或与荧光标记偶联的抗体。
如本发明试剂盒的上下文中或如上面公开的本发明方法的上下文中使用的术语量子点是指半导体材料的单个球状纳米晶体,其中纳米晶体的半径小于或等于该半导体材料的激子玻尔半径的大小(激子玻尔半径的值可从存在于以下含有有关半导体性质信息的手册中的数据计算,诸如crchandbookofchemistryandphysics,第83版,lide,davidr.(编辑),crcpress,bocaraton,fla.(2002))。量子点是本领域已知的,因为它们描述于以下参考文献中,诸如weller,angew.chem.int.ed.engl.32:41-53(1993);alivisatos,j.phys.chem.100:13226-13239(1996);以及alivisatos,science271:933-937(1996)。量子点可为例如约1nm-约1000nm直径,例如10nm、20nm、30nm、40nm、50nm、60nm、70nm、80nm、90nm、100nm、150nm、200nm、250nm、300nm、350nm、400nm、450nm或500nm、优选至少约2nm-约50nm、更优选qd的直径为至少约2nm-约20nm(例如约2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20nm)。qd的特征在于其基本均一的纳米大小,常常显示约10%-15%多分散性或大小范围。qd在激发后能够发射电磁辐射(即qd是光致发光的),且包括一种或多种第一半导体材料的“核”,且可被第二半导体材料的“壳”包绕。被半导体壳包绕的qd核称为“核/壳”qd。包“壳”材料将优选具有大于核心材料的带隙能(bandgapenergy)的带隙能,并可选择为具有接近于“核”基质的原子间距的原子间距。核和/或壳可为半导体材料,包括但不限于第ii-vi族(zns、znse、znte、us、cdse、cdte、hgs、hgse、hgte、mgs、mgse、mgte、cas、case、cate、srs、srse、srte、bas、base、bate等)和第iii-v族(gan、gap、gaas、gasb、inn、inp、inas、insb等)和第iv族(ge、si等)材料的那些、pbs、pbse及其合金或混合物。优选的壳材料包括zns。
可以例如用于本发明用于标记抗体的试剂盒(其可以用于检测本发明vnar或vnar融合蛋白)的术语“荧光标记”或“荧光染料”或“荧光团”是指在规定激发波长下吸收光能并在不同波长下发射光能的部分。可用于本发明中的荧光标记的实例包括但不限于:丹酰氯、dapoxyl、二烷基氨基香豆素、异硫氰酸罗丹明、alexa350、alexa430、alexafluor488、alexafluor532、alexafluor546、alexafluor568、alexafluor594、alexafluor633、alexafluor660、alexafluor680、amca、氨基吖啶、bodipy630/650、bodipy650/665、bodipy-fl、bodipy-r6g、bodipy-tmr、bodipy-trx、bodipyfl、bodipyr6g、bodipytmr、bodipytr、bodipy530/550、bodipy558/568、bodipy564/570、bodipy576/589、bodipy581/591、bodipy630/650、bodipy650/665)、羧基罗丹明6g、羧基-x-罗丹明(rox)、cascade蓝、cascade黄、香豆素343、花青染料(cy3、cy5、cy3.5、cy5.5)、丹酰(dansyl)、dapoxyl、二烷基氨基香豆素、4',5'-二氯-2',7'-二甲氧基-荧光素、dm-nerf、伊红、赤藓红、荧光素、fam、羟基香豆素、irdyes(ird40、ird700、ird800)、joe、丽丝胺罗丹明b、marina蓝、甲氧基香豆素、naphtho荧光素、oregon绿488、oregon绿500、oregon绿514、pacific蓝、pympo、5-羧基-4',5'-二氯-2',7'-二甲氧基荧光素、5-羧基-2',4',5',7'-四氯荧光素、5-羧基荧光素、5-羧基罗丹明、6-羧基罗丹明、6-羧基四甲基氨基、cascade蓝、cy2、cy3、cy5,6-fam、丹酰氯、荧光素、hex、6-joe、nbd(7-硝基苯并-2-氧杂-l,3-二唑)、oregon绿488、oregon绿500、oregon绿514、pacific蓝、酞酸、对苯二甲酸、间苯二甲酸、甲酚固紫(cresylfastviolet)、甲酚蓝紫(cresylblueviolet)、亮甲酚蓝、对氨基苯甲酸、赤藓红、酞菁、偶氮甲碱、花青、黄嘌呤、琥珀酰荧光素、稀土金属穴状络合物、三联吡啶二胺铕(europiumtrisbipyridinediamine)、铕穴状化合物或螯合物、二胺、双花青、lajolla蓝染料、别藻蓝蛋白(allopycocyanin)、allococyaninb、藻青蛋白c、藻青蛋白r、硫胺、藻红青素、藻红蛋白r、reg、罗丹明绿、异硫氰酸罗丹明、罗丹明红、tamra、tet、trit(四甲基罗丹明异硫醇(tetramethylrhodamineisothiol))、四甲基罗丹明或德克萨斯红。例如,本发明试剂盒可以用于检测样品诸如例如组织活检样品、或石蜡切片、组织培养物或体液中如上所公开的癌细胞表面抗原。所述样品可以例如源自患有病理病况的患者,其中从患者获得样品不形成本发明的一部分。
要理解,本发明不限于本文所述具体的方法、方案和试剂,因为这些可变化。还要理解,本文所用术语仅用于描述具体实施方案的目的,并无意限制仅受随附权利要求书限制的本发明的范围。除非另有说明,否则本文所用的所有技术和科学术语具有本领域普通技术人员通常理解的相同含义。
实施例
实施例1:用于酵母展示的片段生成的soepcr
为了生成用于酵母表面展示的插入片段,使用来自epcam特异性结合剂5005的质粒dna作为起始材料。平行实施两次pcr反应,以生成用作第3次pcr的起始材料的两个dna-片段(参见图11)。pcr-条件如下:92℃持续30秒,[92℃持续30秒,52℃30秒,72℃30秒]x30,随后72℃持续5分钟。对于第3次pcr,将片段a和片段b(参见图11)以1:1摩尔比(各约50ng)混合并用作模板。在上述pcr-运行的6个循环后,添加寡核苷酸pct_seq_up和pct_seq_lo以得到具有随机化hv2编码区的最终pcr产物,其被用作用于文库生成的插入材料。
实施例2:文库生成
为了生成具有高序列多样性的酵母文库,根据benatuil等人,proteinengdessel2010;23:155-9的方案进行酿酒酵母的转化。使用酿酒酵母菌株eby100的过夜培养物,将100mlypd培养基接种至od600=0.3,继续孵育,直到达到od600=1.6的细胞密度。经由以3000rpm离心5分钟来将细胞与培养基分离。在进一步过程中,将细胞用50ml冰冷水洗涤两次,并用电穿孔缓冲液洗涤两次,随后在30℃下在以180rpm振荡下,在20ml锂缓冲液中调节酵母细胞30分钟。在用电穿孔缓冲液洗涤最后一个步骤之后,将细胞沉淀重悬浮于100-200μl电穿孔缓冲液中,导致1ml的最终体积,并保持在冰上。
对于每个电穿孔反应,在冷转化比色皿中将1μg消化的载体骨架和3μgdna插入物与400μl电感受态细胞混合。电穿孔(u=2.5kv;c=25μf;r<200ω;时间脉冲=5ms)之后,立即添加8ml1m山梨糖醇:ypd培养基的1:1混合物,然后在30℃下以180rpm孵育1小时。在最后一次离心步骤之后,将细胞重悬浮于sdcaa培养基中并孵育两天。通过在sdcaa板上划出连续稀释的细胞,可以在三天后从菌落计数测定文库大小。如果需要更多的电感受态细胞来制备较大文库,则将细胞培养和制备按比例放大。
sgcaa培养基:2%(w/v)半乳糖,0.17%(w/v)酵母氮碱,0.5%(w/v)酪蛋白氨基酸,0.5%(w/v)硫酸铵,10%w/v聚乙二醇8000,38mmna2hpo4,62mmnah2po4•h2o[ph7.4]。
实施例3:酿酒酵母中基因表达的诱导
用pct载体转化的酵母细胞(参见实施例2)用于细胞分选实验。因为在半乳糖启动子的控制下,在载体中编码鲨鱼抗体变体,所以可以通过将培养基从含有葡萄糖的培养基更换为含有半乳糖的sgcaa培养基来进行基因表达的诱导。因此,将相应体积的酵母过夜培养物的细胞沉降(14000u/分钟;2分钟),并用于将摇瓶中的50–1000mlsgcaa培养基接种至od600=0.5的细胞密度,在20℃下孵育时间为至少1天。
sgcaa培养基:2%(w/v)半乳糖,0.17%(w/v)酵母氮碱,0.5%(w/v)酪蛋白氨基酸,0.5%(w/v)硫酸铵,10%w/v聚乙二醇8000,38mmna2hpo4,62mmnah2po4•h2o[ph7.4]。
实施例4:用于facs的细胞染色和facs分析
使酵母细胞在sgcaa培养基中生长过夜,并沉淀并用pbs洗涤一次。然后将细胞在足够体积的1μmepcam中孵育。15分钟后,再次用pbs洗涤细胞,并添加cd3ε-生物素(1μm)。孵育30-60分钟后,再次洗涤细胞。使用pe-标记的抗epcam-抗体检测epcam-结合。使用生物素化的cd3ε和链霉抗生物素蛋白-apc或使用his-标记的cd3ε和alexaflur-标记的五his抗体检测cd3ε-结合。与二级试剂的孵育在冰上实施5分钟。在用pbs重复洗涤后,将酵母细胞进行二维facs分选(a维:epcam-结合;b维:cd3ε-结合)。类似于此,还实施筛选以选择针对epcam和人fc的双特异性结合剂。此处使用his-标记的epcam和alexaflur-标记的五his抗体检测epcam结合。使用pe-标记的抗人抗体检测与人fc的结合。
荧光-活化的细胞分选
荧光-活化的细胞分选使用moflocytomation装置进行,并经由summit4.3分析。该装置能够测量含有单个细胞的微滴的荧光。通过使用在488nm和640nm发射光的两种激光,平行测量单个酵母细胞上的vnar表面呈递和靶蛋白结合的荧光强度是可能的。在开始细胞分选程序之前,使用荧光标记的珠粒来调整分选装置的激光。此外,进行液滴-延迟,以确定应当分析的含有细胞的微滴的位置。对于每个分选轮,设置分选门控,其定义应当分选出的细胞的荧光特性。分选门控的设置通常允许0.1%假阳性细胞,如在抗原不存在的情况下通过对照染色所判断。
在本工作中用于细胞分选实验的moflo装置的参数:
侧面散射:650(lin模式)
fl1:650(log模式)
fl2:600(log模式)
fl3:640(log模式)
板的电荷:2,500v
事件率5,000-30,000个事件/s
样品压力:60.1psi
鞘压力:59psi
喷嘴直径:70μm
分选模式:分选纯化1。
在细胞分选后,通过分析已经分选的细胞的一小部分来测定分选效率。然后,使细胞在30℃下在sdcaa板上生长2天,随后用于诱导细胞表面呈递,用于以下分选轮。对于每个分选轮,在板上孵育后,将分选出的10倍过量的细胞悬浮于10%甘油中,用于低温保存。
使用的sdcaa培养基包含:2%(w/v)葡萄糖,0.17%(w/v)酵母氮碱,0.5%(w/v)酪蛋白氨基酸,0.5%(w/v)硫酸铵,38mmna2hpo4,62mmnah2po4•h2o[ph7.4]。facs结果显示于图6、7和9中。
序列表
<110>merckpatentgmbh
<120>用于生成双特异性鲨鱼可变抗体结构域的方法及其用途
<130>p14/207
<160>11
<170>patentinversion3.5
<210>1
<211>27
<212>dna
<213>人工序列
<220>
<223>用于hv2结构域的随机化的寡核苷酸
<220>
<221>misc_feature
<222>(1)..(3)
<223>第一个密码子(nnn)可以是除tgt、tgc以外的任何密码子,
其中在50%中,可以存在密码子tta、ttg、ctt、ctc、cta、ctg之一
<220>
<221>misc_feature
<222>(4)..(24)
<223>可以存在除taa、tga、tag以外的任何密码子
<220>
<221>misc_feature
<222>(25)..(27)
<223>最后一个密码子(nnn)可以是除tgt、tgc以外的任何密码子,
其中在50%中,可以存在密码子act、acc、aca、acg之一
<400>1
nnnnnnnnnnnnnnnnnnnnnnnnnnn27
<210>2
<211>110
<212>prt
<213>人工序列
<220>
<223>vnar克隆b1氨基酸序列
<400>2
metalaalaargleugluglnthrprothrthrthrthrlysgluala
151015
glygluserleuthrileasncysvalleulysproglutrpthrile
202530
leuglyargthrtyrtrptyrphethrlyslysglythralaphelys
354045
ileglylystrpmetglyglyargtyrseraspthrlysasnthrala
505560
serlysserleuserleuargileseraspleuargvalgluaspser
65707580
glythrtyrhiscysglualaleuiletyrseraspmetglymetile
859095
mettrplysilegluglyglyglythrthrvalthrvallys
100105110
<210>3
<211>110
<212>prt
<213>人工序列
<220>
<223>亲本vnar克隆5005
<400>3
metalaalaargleugluglnthrprothrthrthrthrlysgluala
151015
glygluserleuthrileasncysvalleulysproglutrpthrile
202530
leuglyargthrtyrtrptyrphethrlyslysglyalathrlyslys
354045
alaargleuserthrglyglyargtyrseraspthrlysasnthrala
505560
serlysserleuserleuargileseraspleuargvalgluaspser
65707580
glythrtyrhiscysglualaleuiletyrseraspmetglymetile
859095
mettrplysilegluglyglyglythrthrvalthrvallys
100105110
<210>4
<211>110
<212>prt
<213>人工序列
<220>
<223>vnarepha2-fc
<400>4
metalaalaargleugluglnthrprothrthrthrthrlysgluala
151015
glygluserleuthrileasncysvalleulysproglutrpthrile
202530
leuglyargthrtyrtrptyrphethrlyslysglylysleuasngly
354045
arglysleuarglysglyglyargtyrseraspthrlysasnthrala
505560
serlysserleuserleuargileseraspleuargvalgluaspser
65707580
glythrtyrhiscysglualaleuiletyrseraspmetglymetile
859095
mettrplysilegluglyglyglythrthrvalthrvallys
100105110
<210>5
<211>109
<212>prt
<213>人工序列
<220>
<223>epha2_4_fc
<400>5
metalaalaargleugluglnthrprothrthrthrthrlysgluala
151015
glygluserleuthrileasncysvalleulysproglutrpthrile
202530
leuglyargthrtyrtrptyrphethrlyslysglythrargargleu
354045
lysasnleulysthrglyglyargtyrseraspthrlysasnthrala
505560
serlysserleuserleuargileseraspleuargvalgluaspser
65707580
glythrtyrhiscysglualaleuiletyrsermetglymetilemet
859095
trplysilegluglyglyglythrthrvalthrvallys
100105
<210>6
<211>15
<212>prt
<213>人工序列
<220>
<223>生物素-受体肽
<400>6
glyleuasnaspilepheglualaglnlysileglutrphisglu
151015
<210>7
<211>7
<212>prt
<213>人工序列
<220>
<223>actev位点
<400>7
gluasnleutyrpheglngly
15
<210>8
<211>68
<212>dna
<213>人工序列
<220>
<223>寡核苷酸hv2rand_up
<220>
<221>misc_feature
<223>在位置22-24的第一个密码子(nnn)可以是除tgt、tgc以外的任何密码子,
其中在50%中,可以存在密码子tta、ttg、ctt、ctc、cta、ctg之一
<220>
<221>misc_feature
<223>在位置22-24的第一个密码子(nnn)可以是除tgt、tgc以外的任何密码子,
其中在50%中,可以存在密码子tta、ttg、ctt、ctc、cta、ctg之一
<220>
<221>misc_feature
<223>在位置45-47的最后一个简并密码子(nnn)可以是除tgt、tgc以外的任何密码子,
其中在50%中,可以存在密码子act、acc、aca、acg之一
<220>
<221>misc_feature
<223>在23-44的简并密码子(nnn)可以编码任何氨基酸
<220>
<221>misc_feature
<222>(22)..(47)
<223>n是a、c、g或t
<400>8
tggtatttcacaaagaagggcnnnnnnnnnnnnnnnnnnnnnnnnnnggcggacgatact60
cggacaca68
<210>9
<211>27
<212>dna
<213>人工序列
<220>
<223>pct-seq-lo
<400>9
gcgcgctaacggaacgaaaaatagaaa27
<210>10
<211>21
<212>dna
<213>人工序列
<220>
<223>pct-seq-up
<400>10
aggacaatagctcgacgattg21
<210>11
<211>21
<212>dna
<213>人工序列
<220>
<223>hv2rand_soe-lo
<400>11
gcccttctttgtgaaatacca21
- 还没有人留言评论。精彩留言会获得点赞!
- 用于治疗HBV感染和相关病症的三特异性结合分子的制造方法与工艺
- 对磺胺类药物具有特异性的固相微萃取纤维的制备方法与流程
- 一种检测猪初乳中抗PEDV特异性IgA抗体的夹心ELISA试剂盒的制造方法与工艺
- 用于施用CD19xCD3双特异性抗体的给药方案的制造方法与工艺
- 双特异性抗‑VEGF/抗‑ANG‑2抗体及其在治疗眼血管疾病中的应用的制造方法与工艺
- 特异性人EWS‑FLI1融合蛋白抗体的制备方法及在制备尤文肉瘤诊断抗体试剂的应用与制造工艺
- 双特异性四价抗体及其制造和使用方法与制造工艺
- 利用特异性挥发物筛选昆虫相关嗅觉蛋白的方法与制造工艺
- 使用与表面偶联的单特异性四聚抗体复合物组合物从样品中分离出靶实体的方法与制造工艺
- 抗-WT1/HLA双特异性抗体的制造方法与工艺
- 与CD56分子特异性结合的多肽及其应用的制造方法与工艺
- 用于治疗HBV感染和相关病症的三特异性结合分子的制造方法与工艺
- 对磺胺类药物具有特异性的固相微萃取纤维的制备方法与流程
- 避免信号干扰的肌原纤维蛋白丝氨酸磷酸化水平的测定方法与流程
- 一种检测猪初乳中抗PEDV特异性IgA抗体的夹心ELISA试剂盒的制造方法与工艺
- 用于施用CD19xCD3双特异性抗体的给药方案的制造方法与工艺
- 双特异性抗‑VEGF/抗‑ANG‑2抗体及其在治疗眼血管疾病中的应用的制造方法与工艺
- 特异性人EWS‑FLI1融合蛋白抗体的制备方法及在制备尤文肉瘤诊断抗体试剂的应用与制造工艺
- 活化人CD40的抗体和针对人PD‑L1的抗体的组合疗法的制造方法与工艺
- 双特异性四价抗体及其制造和使用方法与制造工艺