基因突变体及其应用的制作方法
本发明涉及基因突变体及其应用。具体地,本发明涉及分离的核酸、分离的多肽、筛选易患复发性流产的生物样品的方法、筛选易患复发性流产的生物样品的系统、用于筛选易患复发性流产的的生物样品的试剂盒、构建体以及重组细胞。
背景技术:
临床上多将连续2次或者2次以上的妊娠周期不足20周的自然流产定义为反复自然流产(recurrentspontaneoussabortion,rsa)。rsa可能是由很多因素造成的,例如年龄因素、生活习惯、遗传因素、免疫因素、感染因素、内分泌因素,生殖系统因素等。除已知因素外仍有约50%的rsa发病原因不明,这类已排除已知病因的不明原因反复流产被称为特发性反复流产(idiopathicrecurrentmiscarriage,irm)。
irm对于临床医生是一个棘手的问题,由于发病机制不明,无法确定有效的治疗方法且无法提供给患者合适的生育建议。对于患者而言,反复流产带来的身体创伤和各种心理精神障碍,以及下一个妊娠结果的不确定性,对育龄夫妻都是沉重的负担。因此,研究irm的病因,对更加全面清晰地认识其发病机制,寻找有效的干预、治疗方法起着十分重要的作用。
现有研究表明,某些基因多态性影响复发性流产:hla-dqb1/drb1、pai-1、tgfb1、ogg1、gpx4、comt和abcb1等;一些基因纯合突变具有胚胎致死性,如哺乳动物胚胎致死性基因:lig4、nfat5、smad2和tbx5,tdp43、opa1和ryr2纯合突变。但仍存在着相当一部分未知致病基因位点。
因而,目前对复发性流产的研究仍有待深入。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明的一个目的在于提出一种能够有效筛选易患复发性流产的生物样品的方法。
本发明是基于发明人的下列工作而完成的:发明人通过高通量外显子组测序联合候选基因突变验证的方法确定了复发性流产的新的致病突变。
在本发明的第一方面,本发明提出了一种分离的核酸。根据本发明的实施例,与seqidno:1相比,所述核酸具有选自下列的至少一种突变:c.1501c>t突变和c.17c>t突变;或 者与seqidno:2相比,所述核酸具有选自下列的至少一种突变:c.270g>t突变和c.1191c>g突变。其中,seqidno:1是野生型esr2基因的序列,seqidno:2是野生型ar基因的序列。根据本发明的实施例,发明人确定了esr2、ar基因突变体,这些新突变体与复发性流产的发病密切相关,从而通过检测这些新突变体在生物样品中是否存在,可以有效地检测生物样品是否易患复发性流产。
在发明的第二方面,本发明提出了一种分离的多肽。根据本发明的实施例,与seqidno:3相比,所述多肽具有选自下列的至少一种突变:p.r501c突变和p.s6l突变;或者与seqidno:4相比,所述多肽具有选自下列的至少一种突变:p.q90h突变和p.s397r突变。通过检测生物样品中是否表达该多肽,可以有效地检测生物样品是否易患复发性流产。
在本发明的第三方面,本发明提出了一种筛选易患复发性流产的生物样品的系统。根据本发明的实施例,该系统包括:核酸提取装置,所述核酸提取装置用于提取所述生物样品中的核酸样本;核酸序列确定装置,所述核酸序列确定装置与所述核酸提取装置相连,用于对所述核酸样本进行分析,以便确定所述核酸样本的核酸序列;以及判断装置,所述判断装置与所述核酸序列确定装置相连,以便基于所述核酸样本的核酸序列或其互补序列与seqidno:1相比,是否具有选自下列的至少一种突变:c.1501c>t突变和c.17c>t突变;或者与seqidno:2相比,是否具有选自下列的至少一种突变:c.270g>t突变和c.1191c>g突变,判断所述生物样品是否易患复发性流产。利用该系统,能够有效地实施前述筛选易患复发性流产的生物样品的方法,从而可以有效地筛选易患复发性流产的生物样品。
在本发明的第四方面,本发明提出了一种用于筛选易患复发性流产的生物样品的试剂盒。根据本发明的实施例,该试剂盒含有:适于检测esr2、ar基因突变体的至少一种的试剂,其中与seqidno:1相比,所述esr2基因突变体具有选自下列的至少一种突变:c.1501c>t突变和c.17c>t突变;或者与seqidno:2相比,所述ar基因突变体具有选自下列的至少一种突变:c.270g>t突变和c.1191c>g突变。利用根据本发明的实施例的试剂盒,能够有效地筛选易患复发性流产的生物样品。
在本发明的第五方面,本发明还提出了一种构建体。根据本发明的实施例,该构建体包含前面所述的分离的核酸。需要说明的是,“构建体包含前面所述的分离的核酸”表示,本发明的构建体包含与seqidno:1相比的具有选自下列的至少一种突变:c.1501c>t突变和c.17c>t突变的核苷酸序列或者与seqidno:2相比的具有选自下列的至少一种突变:c.270g>t突变和c.1191c>g突变的核苷酸序列。由此,本发明的构建体转化受体细胞获得的重组细胞,能够有效地用作复发性流产相关研究的模型。
在本发明的第六方面,本发明还提出了一种重组细胞。根据本发明的实施例,该重组细胞是通过前面所述的构建体转化受体细胞而获得的。根据本发明的一些实施例,本发明的重组细胞,能够有效地用作复发性流产相关研究的模型。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
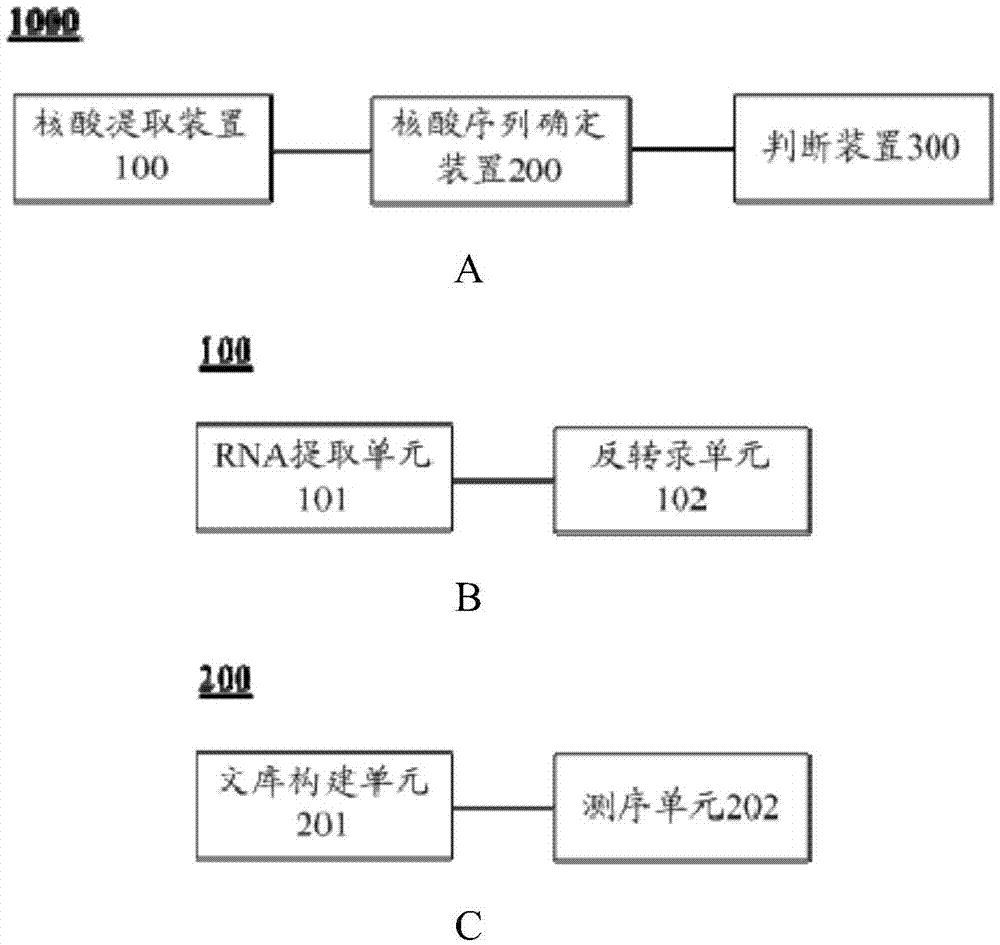
图1显示了根据本发明一个实施例的筛选易患复发性流产的生物样品的系统及其组成部分的示意图,其中,
a为根据本发明实施例的筛选易患复发性流产的生物样品的系统的示意图,
b为根据本发明实施例的核酸提取装置的示意图,
c为根据本发明实施例的核酸序列确定装置的示意图;
图2显示了根据本发明一个实施例,检出新突变的患者的相应复发性流产致病基因突变位点的sanger测序验证峰图,其中,
a是复发性流产患者esr2基因c.1501c>t突变位点的测序验证峰图,
b是复发性流产患者esr2基因c.17c>t突变位点的测序验证峰图,
c是复发性流产患者ar基因c.270g>t突变位点的测序图,
d是复发性流产患者ar基因c.1191c>g突变位点的测序图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
基因突变体
在本发明的第一方面,本发明提出了一种分离的核酸。根据本发明的实施例,与seqidno:1相比,该核酸具有选自下列的至少一种突变:c.1501c>t突变和c.17c>t突变;或者与seqidno:2相比,该核酸具有选自下列的至少一种突变:c.270g>t突变和c.1191c>g突变。在本文中所使用的表达方式“编码基因突变体的核酸”,是指与编码基因突变体的基因相对应的核酸物质,即核酸的类型不受特别限制,可以是任何包含与基因突变体的编码基因相对应的脱氧核糖核苷酸和/或核糖核苷酸的聚合物,包括但不限于dna、rna或 cdna。其中,seqidno:1是野生型esr2基因序列,seqidno:2是野生型ar基因序列。根据本发明的一个具体示例,前面所述的编码基因突变体的核酸为dna。根据本发明的实施例,发明人确定了esr2基因或ar基因的新突变体,这些新突变体与复发性流产的发病密切相关,从而通过检测该新突变体在生物样品中是否存在,可以有效地检测生物样品是否易患复发性流产,也可以通过检测这些突变体在生物体中是否存在,可以有效地预测生物体是否易患复发性流产。
对于本发明说明书和权利要求书中所提及的核酸,本领域技术人员应当理解,实际包括互补双链的任意一条,或者两条。为了方便,在本说明书和权利要求书中,虽然多数情况下只给出了一条链,但实际上也公开了与之互补的另一条链。例如,提及seqidno:1,实际包括其互补序列。本领域技术人员还可以理解,利用一条链可以检测另一条链,反之亦然。
本申请中的基因序列包括dna形式或rna形式,公开其中一种,意味着另一种也被公开。例如提及esr2或ar基因序列,实际也包括相应的rna序列。
该编码esr2或ar突变体的核酸,是本申请的发明人通过目标区域捕获测序联合候选基因突变验证的方法确定的复发性流产的致病基因esr2或ar基因的新的致病突变。该致病突变位点在现有技术中并未被提到。需要说明的是,在本文中所使用的表达方式“目标区域捕获测序”是指利用特制的探针对客户感兴趣的某段特定序列进行捕获富集后,再利用第二代测序技术进行高通量测序及基因组分析的方法。利用该方法能够获得指定目标区域的遗传信息,极大的提高了基因组中目标区域的研究效率,显著降低了研究成本。在本发明中,将该方法用于识别和研究与疾病相关的编码区域内的结构变异,进而,结合大量的公共数据库提供的数据,有利于更好地解释所得变异结构之间的关联和致病机理。
其中,野生型esr2基因序列如下所示:
1atggatataaaaaactcaccatctagccttaattctccttcctcctacaactgcagtcaa
61tccatcttacccctggagcacggctccatatacataccttcctcctatgtagacagccac
121catgaatatccagccatgacattctatagccctgctgtgatgaattacagcattcccagc
181aatgtcactaacttggaaggtgggcctggtcggcagaccacaagcccaaatgtgttgtgg
241ccaacacctgggcacctttctcctttagtggtccatcgccagttatcacatctgtatgcg
301gaacctcaaaagagtccctggtgtgaagcaagatcgctagaacacaccttacctgtaaac
361agagagacactgaaaaggaaggttagtgggaaccgttgcgccagccctgttactggtcca
421ggttcaaagagggatgctcacttctgcgctgtctgcagcgattacgcatcgggatatcac
481tatggagtctggtcgtgtgaaggatgtaaggccttttttaaaagaagcattcaaggacat
541aatgattatatttgtccagctacaaatcagtgtacaatcgataaaaaccggcgcaagagc
601tgccaggcctgccgacttcggaagtgttacgaagtgggaatggtgaagtgtggctcccgg
661agagagagatgtgggtaccgccttgtgcggagacagagaagtgccgacgagcagctgcac
721tgtgccggcaaggccaagagaagtggcggccacgcgccccgagtgcgggagctgctgctg
781gacgccctgagccccgagcagctagtgctcaccctcctggaggctgagccgccccatgtg
841ctgatcagccgccccagtgcgcccttcaccgaggcctccatgatgatgtccctgaccaag
901ttggccgacaaggagttggtacacatgatcagctgggccaagaagattcccggctttgtg
961gagctcagcctgttcgaccaagtgcggctcttggagagctgttggatggaggtgttaatg
1021atggggctgatgtggcgctcaattgaccaccccggcaagctcatctttgctccagatctt
1081gttctggacagggatgaggggaaatgcgtagaaggaattctggaaatctttgacatgctc
1141ctggcaactacttcaaggtttcgagagttaaaactccaacacaaagaatatctctgtgtc
1201aaggccatgatcctgctcaattccagtatgtaccctctggtcacagcgacccaggatgct
1261gacagcagccggaagctggctcacttgctgaacgccgtgaccgatgctttggtttgggtg
1321attgccaagagcggcatctcctcccagcagcaatccatgcgcctggctaacctcctgatg
1381ctcctgtcccacgtcaggcatgcgagtaacaagggcatggaacatctgctcaacatgaag
1441tgcaaaaatgtggtcccagtgtatgacctgctgctggagatgctgaatgcccacgtgctt
1501cgcgggtgcaagtcctccatcacggggtccgagtgcagcccggcagaggacagtaaaagc
1561aaagagggctcccagaacccacagtctcagtga(seqidno:1).
与seqidno:1相比,本发明的发生c.1501c>t突变的esr2基因突变体的核酸序列如下,其中突变碱基下划线示出:
1atggatataaaaaactcaccatctagccttaattctccttcctcctacaactgcagtcaa
61tccatcttacccctggagcacggctccatatacataccttcctcctatgtagacagccac
121catgaatatccagccatgacattctatagccctgctgtgatgaattacagcattcccagc
181aatgtcactaacttggaaggtgggcctggtcggcagaccacaagcccaaatgtgttgtgg
241ccaacacctgggcacctttctcctttagtggtccatcgccagttatcacatctgtatgcg
301gaacctcaaaagagtccctggtgtgaagcaagatcgctagaacacaccttacctgtaaac
361agagagacactgaaaaggaaggttagtgggaaccgttgcgccagccctgttactggtcca
421ggttcaaagagggatgctcacttctgcgctgtctgcagcgattacgcatcgggatatcac
481tatggagtctggtcgtgtgaaggatgtaaggccttttttaaaagaagcattcaaggacat
541aatgattatatttgtccagctacaaatcagtgtacaatcgataaaaaccggcgcaagagc
601tgccaggcctgccgacttcggaagtgttacgaagtgggaatggtgaagtgtggctcccgg
661agagagagatgtgggtaccgccttgtgcggagacagagaagtgccgacgagcagctgcac
721tgtgccggcaaggccaagagaagtggcggccacgcgccccgagtgcgggagctgctgctg
781gacgccctgagccccgagcagctagtgctcaccctcctggaggctgagccgccccatgtg
841ctgatcagccgccccagtgcgcccttcaccgaggcctccatgatgatgtccctgaccaag
901ttggccgacaaggagttggtacacatgatcagctgggccaagaagattcccggctttgtg
961gagctcagcctgttcgaccaagtgcggctcttggagagctgttggatggaggtgttaatg
1021atggggctgatgtggcgctcaattgaccaccccggcaagctcatctttgctccagatctt
1081gttctggacagggatgaggggaaatgcgtagaaggaattctggaaatctttgacatgctc
1141ctggcaactacttcaaggtttcgagagttaaaactccaacacaaagaatatctctgtgtc
1201aaggccatgatcctgctcaattccagtatgtaccctctggtcacagcgacccaggatgct
1261gacagcagccggaagctggctcacttgctgaacgccgtgaccgatgctttggtttgggtg
1321attgccaagagcggcatctcctcccagcagcaatccatgcgcctggctaacctcctgatg
1381ctcctgtcccacgtcaggcatgcgagtaacaagggcatggaacatctgctcaacatgaag
1441tgcaaaaatgtggtcccagtgtatgacctgctgctggagatgctgaatgcccacgtgctt
1501tgcgggtgcaagtcctccatcacggggtccgagtgcagcccggcagaggacagtaaaagc
1561aaagagggctcccagaacccacagtctcagtga(seqidno:13)
与seqidno:1相比,本发明的发生c.17c>t突变的esr2基因突变体的核酸序列如下,其中突变碱基下划线示出:
1atggatataaaaaacttaccatctagccttaattctccttcctcctacaactgcagtcaa
61tccatcttacccctggagcacggctccatatacataccttcctcctatgtagacagccac
121catgaatatccagccatgacattctatagccctgctgtgatgaattacagcattcccagc
181aatgtcactaacttggaaggtgggcctggtcggcagaccacaagcccaaatgtgttgtgg
241ccaacacctgggcacctttctcctttagtggtccatcgccagttatcacatctgtatgcg
301gaacctcaaaagagtccctggtgtgaagcaagatcgctagaacacaccttacctgtaaac
361agagagacactgaaaaggaaggttagtgggaaccgttgcgccagccctgttactggtcca
421ggttcaaagagggatgctcacttctgcgctgtctgcagcgattacgcatcgggatatcac
481tatggagtctggtcgtgtgaaggatgtaaggccttttttaaaagaagcattcaaggacat
541aatgattatatttgtccagctacaaatcagtgtacaatcgataaaaaccggcgcaagagc
601tgccaggcctgccgacttcggaagtgttacgaagtgggaatggtgaagtgtggctcccgg
661agagagagatgtgggtaccgccttgtgcggagacagagaagtgccgacgagcagctgcac
721tgtgccggcaaggccaagagaagtggcggccacgcgccccgagtgcgggagctgctgctg
781gacgccctgagccccgagcagctagtgctcaccctcctggaggctgagccgccccatgtg
841ctgatcagccgccccagtgcgcccttcaccgaggcctccatgatgatgtccctgaccaag
901ttggccgacaaggagttggtacacatgatcagctgggccaagaagattcccggctttgtg
961gagctcagcctgttcgaccaagtgcggctcttggagagctgttggatggaggtgttaatg
1021atggggctgatgtggcgctcaattgaccaccccggcaagctcatctttgctccagatctt
1081gttctggacagggatgaggggaaatgcgtagaaggaattctggaaatctttgacatgctc
1141ctggcaactacttcaaggtttcgagagttaaaactccaacacaaagaatatctctgtgtc
1201aaggccatgatcctgctcaattccagtatgtaccctctggtcacagcgacccaggatgct
1261gacagcagccggaagctggctcacttgctgaacgccgtgaccgatgctttggtttgggtg
1321attgccaagagcggcatctcctcccagcagcaatccatgcgcctggctaacctcctgatg
1381ctcctgtcccacgtcaggcatgcgagtaacaagggcatggaacatctgctcaacatgaag
1441tgcaaaaatgtggtcccagtgtatgacctgctgctggagatgctgaatgcccacgtgctt
1501tgcgggtgcaagtcctccatcacggggtccgagtgcagcccggcagaggacagtaaaagc
1561aaagagggctcccagaacccacagtctcagtga(seqidno:14)
野生型ar基因的序列如下所示:
1atggaagtgcagttagggctgggaagggtctaccctcggccgccgtccaagacctaccga
61ggagctttccagaatctgttccagagcgtgcgcgaagtgatccagaacccgggccccagg
121cacccagaggccgcgagcgcagcacctcccggcgccagtttgctgctgctgcagcagcag
181cagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcaa
241gagactagccccaggcagcagcagcagcagcagggtgaggatggttctccccaagcccat
301cgtagaggccccacaggctacctggtcctggatgaggaacagcaaccttcacagccgcag
361tcggccctggagtgccaccccgagagaggttgcgtcccagagcctggagccgccgtggcc
421gccagcaaggggctgccgcagcagctgccagcacctccggacgaggatgactcagctgcc
481ccatccacgttgtccctgctgggccccactttccccggcttaagcagctgctccgctgac
541cttaaagacatcctgagcgaggccagcaccatgcaactccttcagcaacagcagcaggaa
601gcagtatccgaaggcagcagcagcgggagagcgagggaggcctcgggggctcccacttcc
661tccaaggacaattacttagggggcacttcgaccatttctgacaacgccaaggagttgtgt
721aaggcagtgtcggtgtccatgggcctgggtgtggaggcgttggagcatctgagtccaggg
781gaacagcttcggggggattgcatgtacgccccacttttgggagttccacccgctgtgcgt
841cccactccttgtgccccattggccgaatgcaaaggttctctgctagacgacagcgcaggc
901aagagcactgaagatactgctgagtattcccctttcaagggaggttacaccaaagggcta
961gaaggcgagagcctaggctgctctggcagcgctgcagcagggagctccgggacacttgaa
1021ctgccgtctaccctgtctctctacaagtccggagcactggacgaggcagctgcgtaccag
1081agtcgcgactactacaactttccactggctctggccggaccgccgccccctccgccgcct
1141ccccatccccacgctcgcatcaagctggagaacccgctggactacggcagcgcctgggcg
1201gctgcggcggcgcagtgccgctatggggacctggcgagcctgcatggcgcgggtgcagcg
1261ggacccggttctgggtcaccctcagccgccgcttcctcatcctggcacactctcttcaca
1321gccgaagaaggccagttgtatggaccgtgtggtggtggtgggggtggtggcggcggcggc
1381ggcggcggcggcggcggcggcggcggcggcggcggcggcgaggcgggagctgtagccccc
1441tacggctacactcggccccctcaggggctggcgggccaggaaagcgacttcaccgcacct
1501gatgtgtggtaccctggcggcatggtgagcagagtgccctatcccagtcccacttgtgtc
1561aaaagcgaaatgggcccctggatggatagctactccggaccttacggggacatgcgtttg
1621gagactgccagggaccatgttttgcccattgactattactttccaccccagaagacctgc
1681ctgatctgtggagatgaagcttctgggtgtcactatggagctctcacatgtggaagctgc
1741aaggtcttcttcaaaagagccgctgaagggaaacagaagtacctgtgcgccagcagaaat
1801gattgcactattgataaattccgaaggaaaaattgtccatcttgtcgtcttcggaaatgt
1861tatgaagcagggatgactctgggagcccggaagctgaagaaacttggtaatctgaaacta
1921caggaggaaggagaggcttccagcaccaccagccccactgaggagacaacccagaagctg
1981acagtgtcacacattgaaggctatgaatgtcagcccatctttctgaatgtcctggaagcc
2041attgagccaggtgtagtgtgtgctggacacgacaacaaccagcccgactcctttgcagcc
2101ttgctctctagcctcaatgaactgggagagagacagcttgtacacgtggtcaagtgggcc
2161aaggccttgcctggcttccgcaacttacacgtggacgaccagatggctgtcattcagtac
2221tcctggatggggctcatggtgtttgccatgggctggcgatccttcaccaatgtcaactcc
2281aggatgctctacttcgcccctgatctggttttcaatgagtaccgcatgcacaagtcccgg
2341atgtacagccagtgtgtccgaatgaggcacctctctcaagagtttggatggctccaaatc
2401accccccaggaattcctgtgcatgaaagcactgctactcttcagcattattccagtggat
2461gggctgaaaaatcaaaaattctttgatgaacttcgaatgaactacatcaaggaactcgat
2521cgtatcattgcatgcaaaagaaaaaatcccacatcctgctcaagacgcttctaccagctc
2581accaagctcctggactccgtgcagcctattgcgagagagctgcatcagttcacttttgac
2641ctgctaatcaagtcacacatggtgagcgtggactttccggaaatgatggcagagatcatc
2701tctgtgcaagtgcccaagatcctttctgggaaagtcaagcccatctatttccacacccag
2761tga(seqidno:2)
与seqidno:2相比,本发明的发生c.270g>t突变的ar基因突变体的核酸序列如下,其中突变碱基下划线示出:
1atggaagtgcagttagggctgggaagggtctaccctcggccgccgtccaagacctaccga
61ggagctttccagaatctgttccagagcgtgcgcgaagtgatccagaacccgggccccagg
121cacccagaggccgcgagcgcagcacctcccggcgccagtttgctgctgctgcagcagcag
181cagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcaa
241gagactagccccaggcagcagcagcagcatcagggtgaggatggttctccccaagcccat
301cgtagaggccccacaggctacctggtcctggatgaggaacagcaaccttcacagccgcag
361tcggccctggagtgccaccccgagagaggttgcgtcccagagcctggagccgccgtggcc
421gccagcaaggggctgccgcagcagctgccagcacctccggacgaggatgactcagctgcc
481ccatccacgttgtccctgctgggccccactttccccggcttaagcagctgctccgctgac
541cttaaagacatcctgagcgaggccagcaccatgcaactccttcagcaacagcagcaggaa
601gcagtatccgaaggcagcagcagcgggagagcgagggaggcctcgggggctcccacttcc
661tccaaggacaattacttagggggcacttcgaccatttctgacaacgccaaggagttgtgt
721aaggcagtgtcggtgtccatgggcctgggtgtggaggcgttggagcatctgagtccaggg
781gaacagcttcggggggattgcatgtacgccccacttttgggagttccacccgctgtgcgt
841cccactccttgtgccccattggccgaatgcaaaggttctctgctagacgacagcgcaggc
901aagagcactgaagatactgctgagtattcccctttcaagggaggttacaccaaagggcta
961gaaggcgagagcctaggctgctctggcagcgctgcagcagggagctccgggacacttgaa
1021ctgccgtctaccctgtctctctacaagtccggagcactggacgaggcagctgcgtaccag
1081agtcgcgactactacaactttccactggctctggccggaccgccgccccctccgccgcct
1141ccccatccccacgctcgcatcaagctggagaacccgctggactacggcagcgcctgggcg
1201gctgcggcggcgcagtgccgctatggggacctggcgagcctgcatggcgcgggtgcagcg
1261ggacccggttctgggtcaccctcagccgccgcttcctcatcctggcacactctcttcaca
1321gccgaagaaggccagttgtatggaccgtgtggtggtggtgggggtggtggcggcggcggc
1381ggcggcggcggcggcggcggcggcggcggcggcggcggcgaggcgggagctgtagccccc
1441tacggctacactcggccccctcaggggctggcgggccaggaaagcgacttcaccgcacct
1501gatgtgtggtaccctggcggcatggtgagcagagtgccctatcccagtcccacttgtgtc
1561aaaagcgaaatgggcccctggatggatagctactccggaccttacggggacatgcgtttg
1621gagactgccagggaccatgttttgcccattgactattactttccaccccagaagacctgc
1681ctgatctgtggagatgaagcttctgggtgtcactatggagctctcacatgtggaagctgc
1741aaggtcttcttcaaaagagccgctgaagggaaacagaagtacctgtgcgccagcagaaat
1801gattgcactattgataaattccgaaggaaaaattgtccatcttgtcgtcttcggaaatgt
1861tatgaagcagggatgactctgggagcccggaagctgaagaaacttggtaatctgaaacta
1921caggaggaaggagaggcttccagcaccaccagccccactgaggagacaacccagaagctg
1981acagtgtcacacattgaaggctatgaatgtcagcccatctttctgaatgtcctggaagcc
2041attgagccaggtgtagtgtgtgctggacacgacaacaaccagcccgactcctttgcagcc
2101ttgctctctagcctcaatgaactgggagagagacagcttgtacacgtggtcaagtgggcc
2161aaggccttgcctggcttccgcaacttacacgtggacgaccagatggctgtcattcagtac
2221tcctggatggggctcatggtgtttgccatgggctggcgatccttcaccaatgtcaactcc
2281aggatgctctacttcgcccctgatctggttttcaatgagtaccgcatgcacaagtcccgg
2341atgtacagccagtgtgtccgaatgaggcacctctctcaagagtttggatggctccaaatc
2401accccccaggaattcctgtgcatgaaagcactgctactcttcagcattattccagtggat
2461gggctgaaaaatcaaaaattctttgatgaacttcgaatgaactacatcaaggaactcgat
2521cgtatcattgcatgcaaaagaaaaaatcccacatcctgctcaagacgcttctaccagctc
2581accaagctcctggactccgtgcagcctattgcgagagagctgcatcagttcacttttgac
2641ctgctaatcaagtcacacatggtgagcgtggactttccggaaatgatggcagagatcatc
2701tctgtgcaagtgcccaagatcctttctgggaaagtcaagcccatctatttccacacccag
2761tga(seqidno:15)
与seqidno:2相比,本发明的发生c.1191c>g突变的ar基因突变体的核酸序列如下,其中突变碱基下划线示出:
1atggaagtgcagttagggctgggaagggtctaccctcggccgccgtccaagacctaccga
61ggagctttccagaatctgttccagagcgtgcgcgaagtgatccagaacccgggccccagg
121cacccagaggccgcgagcgcagcacctcccggcgccagtttgctgctgctgcagcagcag
181cagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcagcaa
241gagactagccccaggcagcagcagcagcagcagggtgaggatggttctccccaagcccat
301cgtagaggccccacaggctacctggtcctggatgaggaacagcaaccttcacagccgcag
361tcggccctggagtgccaccccgagagaggttgcgtcccagagcctggagccgccgtggcc
421gccagcaaggggctgccgcagcagctgccagcacctccggacgaggatgactcagctgcc
481ccatccacgttgtccctgctgggccccactttccccggcttaagcagctgctccgctgac
541cttaaagacatcctgagcgaggccagcaccatgcaactccttcagcaacagcagcaggaa
601gcagtatccgaaggcagcagcagcgggagagcgagggaggcctcgggggctcccacttcc
661tccaaggacaattacttagggggcacttcgaccatttctgacaacgccaaggagttgtgt
721aaggcagtgtcggtgtccatgggcctgggtgtggaggcgttggagcatctgagtccaggg
781gaacagcttcggggggattgcatgtacgccccacttttgggagttccacccgctgtgcgt
841cccactccttgtgccccattggccgaatgcaaaggttctctgctagacgacagcgcaggc
901aagagcactgaagatactgctgagtattcccctttcaagggaggttacaccaaagggcta
961gaaggcgagagcctaggctgctctggcagcgctgcagcagggagctccgggacacttgaa
1021ctgccgtctaccctgtctctctacaagtccggagcactggacgaggcagctgcgtaccag
1081agtcgcgactactacaactttccactggctctggccggaccgccgccccctccgccgcct
1141ccccatccccacgctcgcatcaagctggagaacccgctggactacggcagggcctgggcg
1201gctgcggcggcgcagtgccgctatggggacctggcgagcctgcatggcgcgggtgcagcg
1261ggacccggttctgggtcaccctcagccgccgcttcctcatcctggcacactctcttcaca
1321gccgaagaaggccagttgtatggaccgtgtggtggtggtgggggtggtggcggcggcggc
1381ggcggcggcggcggcggcggcggcggcggcggcggcggcgaggcgggagctgtagccccc
1441tacggctacactcggccccctcaggggctggcgggccaggaaagcgacttcaccgcacct
1501gatgtgtggtaccctggcggcatggtgagcagagtgccctatcccagtcccacttgtgtc
1561aaaagcgaaatgggcccctggatggatagctactccggaccttacggggacatgcgtttg
1621gagactgccagggaccatgttttgcccattgactattactttccaccccagaagacctgc
1681ctgatctgtggagatgaagcttctgggtgtcactatggagctctcacatgtggaagctgc
1741aaggtcttcttcaaaagagccgctgaagggaaacagaagtacctgtgcgccagcagaaat
1801gattgcactattgataaattccgaaggaaaaattgtccatcttgtcgtcttcggaaatgt
1861tatgaagcagggatgactctgggagcccggaagctgaagaaacttggtaatctgaaacta
1921caggaggaaggagaggcttccagcaccaccagccccactgaggagacaacccagaagctg
1981acagtgtcacacattgaaggctatgaatgtcagcccatctttctgaatgtcctggaagcc
2041attgagccaggtgtagtgtgtgctggacacgacaacaaccagcccgactcctttgcagcc
2101ttgctctctagcctcaatgaactgggagagagacagcttgtacacgtggtcaagtgggcc
2161aaggccttgcctggcttccgcaacttacacgtggacgaccagatggctgtcattcagtac
2221tcctggatggggctcatggtgtttgccatgggctggcgatccttcaccaatgtcaactcc
2281aggatgctctacttcgcccctgatctggttttcaatgagtaccgcatgcacaagtcccgg
2341atgtacagccagtgtgtccgaatgaggcacctctctcaagagtttggatggctccaaatc
2401accccccaggaattcctgtgcatgaaagcactgctactcttcagcattattccagtggat
2461gggctgaaaaatcaaaaattctttgatgaacttcgaatgaactacatcaaggaactcgat
2521cgtatcattgcatgcaaaagaaaaaatcccacatcctgctcaagacgcttctaccagctc
2581accaagctcctggactccgtgcagcctattgcgagagagctgcatcagttcacttttgac
2641ctgctaatcaagtcacacatggtgagcgtggactttccggaaatgatggcagagatcatc
2701tctgtgcaagtgcccaagatcctttctgggaaagtcaagcccatctatttccacacccag
2761tga(seqidno:16)
发明人惊奇的发现,上述突变体与复发性流产的发病密切相关,从而通过检测上述突变体在生物样品中是否存在,可以有效地检测生物样品是否易患复发性流产。esr2基因是雌激素受体蛋白esr2的编码基因,ar基因是雄性激素受体蛋白ar的编码基因,在目前的人群研究中,没有任何有关复发性流产与esr2基因或ar基因之间关系的报道。根据本发明的实施例,该突变体的核酸进一步丰富了esr2或ar基因的致病突变图谱,并且更深入地阐明了复发性流产的分子发病机制,为复发性流产的早期致病基因筛查和干预治疗提供科学依据。
根据本发明的第二方面,本发明还提供了一种分离的多肽。根据本发明的实施例,与seqidno:3相比,所述多肽具有选自下列的至少一种突变:p.r501c突变和p.s6l突变;或者与seqidno:4相比,所述多肽具有选自下列的至少一种突变:p.q90h突变和p.s397r突变。具体地,esr2基因的c.1501c>t突变,导致esr2蛋白发生p.r501c错义突变,esr2基因的c.17c>t突变,导致esr2蛋白发生p.s6l错义突变,ar基因的c.270g>t突变,导致ar蛋白发生p.q90h错义突变,ar基因的c.1191c>g突变,导致ar蛋白发生p.s397r错义突变。通过检测生物样品中是否表达上述多肽,可以有效地检测生物样品是否易患复发性流产。
根据本发明的一些具体示例,所述多肽由上述分离的核酸编码的。其中,野生型的esr2基因的cdna编码的多肽的氨基酸序列如seqidno:3所示:
1mdiknspsslnspssyncsqsilplehgsiyipssyvdshheypamtfyspavmnysips
61nvtnleggpgrqttspnvlwptpghlsplvvhrqlshlyaepqkspwcearslehtlpvn
121retlkrkvsgnrcaspvtgpgskrdahfcavcsdyasgyhygvwscegckaffkrsiqgh
181ndyicpatnqctidknrrkscqacrlrkcyevgmvkcgsrrercgyrlvrrqrsadeqlh
241cagkakrsgghaprvrellldalspeqlvltlleaepphvlisrpsapfteasmmmsltk
301ladkelvhmiswakkipgfvelslfdqvrllescwmevlmmglmwrsidhpgklifapdl
361vldrdegkcvegileifdmllattsrfrelklqhkeylcvkamillnssmyplvtatqda
421dssrklahllnavtdalvwviaksgissqqqsmrlanllmllshvrhasnkgmehllnmk
481cknvvpvydlllemlnahvlrgckssitgsecspaedskskegsqnpqsq(seqidno:3)
发生c.1501c>t突变的esr2突变体的氨基酸序列如下,其中突变氨基酸下划线示出:
1mdiknspsslnspssyncsqsilplehgsiyipssyvdshheypamtfyspavmnysips
61nvtnleggpgrqttspnvlwptpghlsplvvhrqlshlyaepqkspwcearslehtlpvn
121retlkrkvsgnrcaspvtgpgskrdahfcavcsdyasgyhygvwscegckaffkrsiqgh
181ndyicpatnqctidknrrkscqacrlrkcyevgmvkcgsrrercgyrlvrrqrsadeqlh
241cagkakrsgghaprvrellldalspeqlvltlleaepphvlisrpsapfteasmmmsltk
301ladkelvhmiswakkipgfvelslfdqvrllescwmevlmmglmwrsidhpgklifapdl
361vldrdegkcvegileifdmllattsrfrelklqhkeylcvkamillnssmyplvtatqda
421dssrklahllnavtdalvwviaksgissqqqsmrlanllmllshvrhasnkgmehllnmk
481cknvvpvydlllemlnahvlcgckssitgsecspaedskskegsqnpqsq(seqidno:17)
发生c.17c>t突变的esr2突变体的氨基酸序列如下,其中突变氨基酸下划线示出:
1mdiknlpsslnspssyncsqsilplehgsiyipssyvdshheypamtfyspavmnysips
61nvtnleggpgrqttspnvlwptpghlsplvvhrqlshlyaepqkspwcearslehtlpvn
121retlkrkvsgnrcaspvtgpgskrdahfcavcsdyasgyhygvwscegckaffkrsiqgh
181ndyicpatnqctidknrrkscqacrlrkcyevgmvkcgsrrercgyrlvrrqrsadeqlh
241cagkakrsgghaprvrellldalspeqlvltlleaepphvlisrpsapfteasmmmsltk
301ladkelvhmiswakkipgfvelslfdqvrllescwmevlmmglmwrsidhpgklifapdl
361vldrdegkcvegileifdmllattsrfrelklqhkeylcvkamillnssmyplvtatqda
421dssrklahllnavtdalvwviaksgissqqqsmrlanllmllshvrhasnkgmehllnmk
481cknvvpvydlllemlnahvlrgckssitgsecspaedskskegsqnpqsq(seqidno:18)
野生型的ar基因的cdna编码的多肽的氨基酸序列如seqidno:4所示:
1mevqlglgrvyprppsktyrgafqnlfqsvreviqnpgprhpeaasaappgasllllqqq
61qqqqqqqqqqqqqqqqqqqqetsprqqqqqqgedgspqahrrgptgylvldeeqqpsqpq
121salechpergcvpepgaavaaskglpqqlpappdeddsaapstlsllgptfpglsscsad
181lkdilseastmqllqqqqqeavsegsssgrareasgaptsskdnylggtstisdnakelc
241kavsvsmglgvealehlspgeqlrgdcmyapllgvppavrptpcaplaeckgsllddsag
301kstedtaeyspfkggytkglegeslgcsgsaaagssgtlelpstlslyksgaldeaaayq
361srdyynfplalagpppppppphphariklenpldygsawaaaaaqcrygdlaslhgagaa
421gpgsgspsaaassswhtlftaeegqlygpcgggggggggggggggggggggggeagavap
481ygytrppqglagqesdftapdvwypggmvsrvpypsptcvksemgpwmdsysgpygdmrl
541etardhvlpidyyfppqktclicgdeasgchygaltcgsckvffkraaegkqkylcasrn
601dctidkfrrkncpscrlrkcyeagmtlgarklkklgnlklqeegeassttspteettqkl
661tvshiegyecqpiflnvleaiepgvvcaghdnnqpdsfaallsslnelgerqlvhvvkwa
721kalpgfrnlhvddqmaviqyswmglmvfamgwrsftnvnsrmlyfapdlvfneyrmhksr
781mysqcvrmrhlsqefgwlqitpqeflcmkalllfsiipvdglknqkffdelrmnyikeld
841riiackrknptscsrrfyqltklldsvqpiarelhqftfdllikshmvsvdfpemmaeii
901svqvpkilsgkvkpiyfhtq(seqidno:4)
发生c.270g>t突变的ar突变体的氨基酸序列如下,其中突变氨基酸下划线示出:
1mevqlglgrvyprppsktyrgafqnlfqsvreviqnpgprhpeaasaappgasllllqqq
61qqqqqqqqqqqqqqqqqqqqetsprqqqqhqgedgspqahrrgptgylvldeeqqpsqpq
121salechpergcvpepgaavaaskglpqqlpappdeddsaapstlsllgptfpglsscsad
181lkdilseastmqllqqqqqeavsegsssgrareasgaptsskdnylggtstisdnakelc
241kavsvsmglgvealehlspgeqlrgdcmyapllgvppavrptpcaplaeckgsllddsag
301kstedtaeyspfkggytkglegeslgcsgsaaagssgtlelpstlslyksgaldeaaayq
361srdyynfplalagpppppppphphariklenpldygsawaaaaaqcrygdlaslhgagaa
421gpgsgspsaaassswhtlftaeegqlygpcgggggggggggggggggggggggeagavap
481ygytrppqglagqesdftapdvwypggmvsrvpypsptcvksemgpwmdsysgpygdmrl
541etardhvlpidyyfppqktclicgdeasgchygaltcgsckvffkraaegkqkylcasrn
601dctidkfrrkncpscrlrkcyeagmtlgarklkklgnlklqeegeassttspteettqkl
661tvshiegyecqpiflnvleaiepgvvcaghdnnqpdsfaallsslnelgerqlvhvvkwa
721kalpgfrnlhvddqmaviqyswmglmvfamgwrsftnvnsrmlyfapdlvfneyrmhksr
781mysqcvrmrhlsqefgwlqitpqeflcmkalllfsiipvdglknqkffdelrmnyikeld
841riiackrknptscsrrfyqltklldsvqpiarelhqftfdllikshmvsvdfpemmaeii
901svqvpkilsgkvkpiyfhtq(seqidno:19)
发生c.1191c>g突变的ar突变体的氨基酸序列如下,其中突变氨基酸下划线示出:
1mevqlglgrvyprppsktyrgafqnlfqsvreviqnpgprhpeaasaappgasllllqqq
61qqqqqqqqqqqqqqqqqqqqetsprqqqqqqgedgspqahrrgptgylvldeeqqpsqpq
121salechpergcvpepgaavaaskglpqqlpappdeddsaapstlsllgptfpglsscsad
181lkdilseastmqllqqqqqeavsegsssgrareasgaptsskdnylggtstisdnakelc
241kavsvsmglgvealehlspgeqlrgdcmyapllgvppavrptpcaplaeckgsllddsag
301kstedtaeyspfkggytkglegeslgcsgsaaagssgtlelpstlslyksgaldeaaayq
361srdyynfplalagpppppppphphariklenpldygrawaaaaaqcrygdlaslhgagaa
421gpgsgspsaaassswhtlftaeegqlygpcgggggggggggggggggggggggeagavap
481ygytrppqglagqesdftapdvwypggmvsrvpypsptcvksemgpwmdsysgpygdmrl
541etardhvlpidyyfppqktclicgdeasgchygaltcgsckvffkraaegkqkylcasrn
601dctidkfrrkncpscrlrkcyeagmtlgarklkklgnlklqeegeassttspteettqkl
661tvshiegyecqpiflnvleaiepgvvcaghdnnqpdsfaallsslnelgerqlvhvvkwa
721kalpgfrnlhvddqmaviqyswmglmvfamgwrsftnvnsrmlyfapdlvfneyrmhksr
781mysqcvrmrhlsqefgwlqitpqeflcmkalllfsiipvdglknqkffdelrmnyikeld
841riiackrknptscsrrfyqltklldsvqpiarelhqftfdllikshmvsvdfpemmaeii
901svqvpkilsgkvkpiyfhtq(seqidno:20)
通过比对发现,与seqidno:1相比,发生c.1501c>t突变的esr2突变体具有c.1501c>t突变,进而,其编码产物与野生型的esr2多肽的氨基酸序列相比,具有p.r501c错义突变,即arg突变为cys;与seqidno:1相比,发生c.17c>t突变的esr2突变体具有c.17c>t突变,进而,其编码产物与野生型的esr2多肽的氨基酸序列相比,具有p.s6l错义突变,即ser突变为leu;与seqidno:2相比,发生c.270g>t突变的ar突变体具有c.270g>t突变,进而,其编码产物与野生型的ar多肽的氨基酸序列相比,具有p.q90h错义突变,即gln突变为his;与seqidno:2相比,发生c.1191c>g突变的ar突变体具有c.1191c>g突变,进而,其编码产物与野生型的ar多肽的氨基酸序列相比,具有p.s397r错义突变,即ser突变为arg。综上,上述四种突变均可引起复发性流产。
另外,本发明所提出的基因突变体可用于筛选易患复发性流产的生物样品,根据本发明的具体实施例,筛选易患复发性流产的生物样品的方法可以包括以下步骤:
首先,从生物样品提取核酸样本。根据本发明的实施例,生物样品的类型并不受特别限制,只要从该生物样品中能够提取到反映生物样品esr2和ar基因是否存在突变的核酸样本即可。生物样品可以为选自人体血液、皮肤、毛发、唾液和肌肉的至少一种,根据本发明的实施例,本发明实施例的生物样本为血液。由此,可以方便地进行取样和检测,从而能够进一步提高筛选易患复发性流产的生物样品的效率。根据本发明的实施例,这里所使用的术语“核酸样本”应做广义理解,其可以是任何能够反映生物样品中esr2和ar基因是否存在突变的样本,例如可以是从生物样品中直接提取的全基因组dna,也可以是该全基因组中包含esr2和ar基因编码序列的一部分,可以是从生物样品中提取的总rna,也可以是从生物样品中提取的mrna。根据本发明的一个实施例,所述核酸样本为全基因组dna。由此,可以扩大生物样品的来源范围,并且可以同时对生物样品的多种信息进行确定,从而能够提高筛选易患复发性流产的生物样品的效率。另外,根据本发明的实施例,针对采用rna作为核酸样本,从生物样品提取核酸样本可以进一步包括:从生物样品提取rna样本,优选rna样本为mrna;以及基于所得到的rna样本,通过反转录反应,获得cdna样本,所得到的cdna样本构成核酸样本。由此,可以进一步提高利用rna作为核酸样本筛选易患复发性流产的生物样品的效率。
接下来,在得到核酸样本之后,可以对核酸样本进行分析,从而能够确定所得到核酸样本的核酸序列。根据本发明的实施例,确定所得到核酸样本的核酸序列的方法和设备并不受特别限制。根据本发明的具体实施例,可以通过测序方法,确定核酸样本的核酸序列。 根据本发明的实施例,可以用于进行测序的方法和设备并不受特别限制。根据本发明的实施例,可以采用第一代、第二代测序技术,也可以采用第三代以及第四代或者更先进的测序技术。根据本发明的具体示例,可以利用选自hiseq2000、solid、454和单分子测序装置的至少一种对核酸序列进行测序。由此,结合最新的测序技术,针对单个位点可以达到较高的测序深度,检测灵敏度和准确性大大提高,因而能够利用这些测序装置的高通量、深度测序的特点,进一步提高对核酸样本进行检测分析的效率。从而,能够提高后续对测序数据进行分析时的精确性和准确度。由此,根据本发明的实施例,确定核酸样本的核酸序列可以进一步包括:首先,针对所得到的核酸样本,构建核酸测序文库;以及对所得到的核酸测序文库进行测序,以便获得由多个测序数据构成的测序结果。根据本发明的一些实施例,可以采用选自hiseq2000、solid、454和单分子测序装置的至少一种对所得到的核酸测序文库进行测序。另外,根据本发明的实施例,可以对核酸样本进行筛选,富集esr2和ar基因外显子,该筛选富集可以在构建测序文库之前,构建测序文库过程中,或者构建测序文库之后进行。根据本发明的一个实施例,针对核酸样本,构建核酸测序文库进一步包括:利用选自esr2和ar基因外显子特异性引物的至少一种,对核酸样本进行pcr扩增;以及针对所得到的扩增产物,构建核酸测序文库。由此,可以通过pcr扩增,富集esr2和ar基因外显子,从而能够进一步提高筛选易患复发性流产的生物样品的效率。根据本发明的实施例,esr2和ar基因外显子特异性引物的序列不受特别限制,例如可以参考人类基因组序列数据库grch37.1/hg19,采用primer3.0在线设计获得。根据本发明的优选实施例,所述esr2基因外显子特异性引物具有如seqidno:6-9所示的核苷酸序列;所述ar基因外显子特异性引物具有如seqidno:10-13所示的核苷酸序列。根据本发明的一些具体示例,针对c.1501c>t突变,所述esr2基因外显子特异性引物具有如seqidno:5-6所示的核苷酸序列;针对c.c.17c>t突变,所述esr2基因外显子特异性引物具有如seqidno:7-8所示的核苷酸序列。根据本发明的另一些实施例,针对c.270g>t突变,所述ar基因外显子特异性引物具有如seqidno:9-10所示的核苷酸序列;针对c.1191c>g突变,所述ar基因外显子特异性引物具有如seqidno:11-12所示的核苷酸序列。发明人惊奇地发现,通过采用seqidno:5-12所示的引物,可以在pcr反应体系中显著有效地完成对相应基因突变所在外显子序列的扩增。需要说明的是,下表中的这些seqidno:5-12所示的核苷酸序列是本发明的发明人在付出了艰苦的劳动后,意外获得的。
关于针对核酸样本,构建测序文库的方法和流程,本领域技术人员可以根据不同的测序技术进行适当选择,关于流程的细节,可以参见测序仪器的厂商例如illumina公司所提供的规程,例如参见illumina公司multiplexingsamplepreparationguide(part#1005361;feb2010)或paired-endsampleprepguide(part#1005063;feb2010),通过参照将其并入本文。根据本发明的实施例,从生物样品提取核酸样本的方法和设备,也不受特别限制,可以采用商品化的核酸提取试剂盒进行。
需要说明的是,在这里所使用的术语“核酸序列”应作广义理解,其可以是在对核酸样本进行测序得到的测序数据进行组装后,得到的完整的核酸序列信息,也可以是直接采用通过对核酸样本进行测序所得到的测序数据(reads)作为核酸序列,只要这些核酸序列中含有对应esr2和ar基因的编码序列即可。
最后,在确定核酸样本的核酸序列之后,将所得到的核酸样本的核酸序列相应的参考序列进行比对,当所得到的核酸序列中具有前述各突变的至少之一时,即指示生物样品易患复发性流产。由此,通过根据本发明实施例的筛选易患复发性流产的生物样品的方法,可以有效地筛选易患复发性流产的生物样品。根据本发明的实施例,对核酸序列与相应野生型基因序列进行比对的方法和设备并不受特别限制,可以采用任意常规的软件进行操作,根据本发明的具体实例,可以采用soapaligner/soap2进行比对。
需要说明的是,根据本发明实施例的“筛选易患复发性流产的生物样品的方法”的用途不受特别限制,例如可以用作非诊断目的的筛选方法。
筛选易患复发性流产的生物样品的系统和试剂盒
在本发明的第三方面,本发明提出了一种能够有效实施筛选易患复发性流产的生物样品的系统。
参考图1,根据本发明的实施例,该筛选易患复发性流产的生物样品的系统1000包括:核酸提取装置100、核酸序列确定装置200以及判断装置300。
根据本发明的实施例,核酸提取装置100用于从生物样品提取核酸样本。如前所述,根据本发明的实施例,核酸样本的类型并不受特别限制,对于采用rna作为核酸样本,则核酸提取装置进一步包括rna提取单元101和反转录单元102,其中,提取单元101用于从生物样品提取rna样本,反转录单元102与rna提取单元101相连,用于对rna样本进行反转录反应,以便获得cdna样本,所得到的cdna样本构成核酸样本。
根据本发明的实施例,核酸序列确定装置200与核酸提取装置100相连,用于对核酸样本进行分析,以便确定核酸样本的核酸序列。如前所示,可以采用测序的方法确定核酸样本的核酸序列。由此,根据本发明的一个实施例,所述核酸序列确定装置200可以进一步包括:文库构建单元201以及测序单元202。文库构建单元201用于针对核酸样本,构建核酸测序文库;测序单元202与文库构建单元201相连,用于对核酸测序文库进行测序,以便获得由多个测序数据构成的测序结果。如前所述,可以通过pcr扩增,富集esr2和ar基因外显子,进一步提高筛选易患复发性流产的生物样品的效率。由此,文库构建单元201可以进一步包括pcr扩增模块(图中未示出),在该pcr扩增模块中设置有选自esr2和ar基因外显子特异性引物的至少一种,以便利用esr2和ar基因外显子特异性引物的至少一种,对所述核酸样本进行pcr扩增。根据本发明的实施例,esr2和ar基因外显子特异性引物的序列不受特别限制,例如可以参考人类基因组序列数据库grch37.1/hg19,采用primer3.0在线设计获得。根据本发明的优选实施例,所述esr2基因外显子特异性引物具有如seqidno:5-8所示的核苷酸序列;所述ar基因外显子特异性引物具有如seqidno:9-12所示的核苷酸序列。根据本发明的一些具体示例,针对c.1501c>t突变,所述esr2基因外显子特异性引物具有如seqidno:5-6所示的核苷酸序列;针对c.17c>t突变,所述esr2基因外显子特异性引物具有如seqidno:7-8所示的核苷酸序列。根据本发明的另一些实施例,针对c.270g>t突变,所述ar基因外显子特异性引物具有如seqidno:9-10所示的核苷酸序列;针对c.1191c>g突变,所述ar基因外显子特异性引物具有如seqidno:11-12所示的核苷酸序列。根据本发明的实施例,测序单元202可以包括选自hiseq2000、solid、454和单分子测序装置的至少一种。由此,结合最新的测序技术,针对单个位点可以达到较高的测序深度,检测灵敏度和准确性大大提高,因而能够利用这些测序装置的高通量、深度测序的特点,进一步提高对核酸样本进行检测分析的效 率。从而,提高后续对测序数据进行分析时的精确性和准确度。
根据本发明的实施例,判断装置300与核酸序列确定装置200相连,适于将核酸样本的核酸序列进行比对,以便基于核酸样本的核酸序列与相应的野生型基因序列的区别判断生物样品是否易患复发性流产。具体地,基于所述核酸样本的核酸序列或其互补序列,与seqidno:1相比(野生型esr2基因序列)具有选自下列的至少一种突变:c.1501c>t和c.17c>t,或者与seqidno:2相比(野生型ar基因序列)具有选自下列的至少一种突变:c.270g>t和c.1191c>g,判断所述生物样品是否易患复发性流产。如前所述,根据本发明的实施例,对核酸序列与相应的野生型基因序列进行比对的设备并不受特别限制,可以采用任意常规的软件进行操作,例如根据本发明的具体实例,可以采用soapaligner/soap2进行比对。
由此,利用该系统,能够有效地筛选易患复发性流产的生物样品。
在本发明的第四方面,本发明提出了一种用于筛选易患复发性流产的生物样品的试剂盒。根据本发明的实施例,该用于筛选易患复发性流产的生物样品的试剂盒包括:适于检测esr2和ar基因突变体的至少一种的试剂,其中与seqidno:1(野生型esr2基因序列)相比,esr2基因突变体具有选自下列的至少一种突变:c.1501c>t突变和c.17c>t突变;或者与seqidno:2(野生型ar基因序列)相比,ar基因突变体具有选自下列的至少一种突变:c.270g>t突变和c.1191c>g突变。利用根据本发明的实施例的试剂盒,能够有效地筛选易患复发性流产的生物样品。在本文中,所使用的术语“适于检测esr2和ar基因突变体的至少一种的试剂”应做广义理解,即可以是检测esr2和ar突变体编码基因的至少一种的试剂,也可以是检测esr2和ar蛋白突变体的至少一种的试剂,例如可以采用识别特异性位点的抗体。根据本发明的一个实施例,该试剂为核酸探针。由此,可以高效地筛选易患复发性流产的生物样品。
构建体及重组细胞
在本发明的第五方面,本发明还提出了一种构建体。根据本发明的实施例,该构建体包含前面所述的分离的核酸。需要说明的是,“构建体包含前面所述的分离的核酸”表示,本发明的构建体包含与seqidno:1(野生型esr2基因序列)相比具有选自下列的至少一种突变:c.1501c>t突变和c.17c>t突变的esr2基因突变体的核酸序列,或者与seqidno:2(野生型ar基因序列)相比具有选自下列的至少一种突变:c.270g>t突变和c.1191c>g突变的ar基因突变体的核酸序列,或者同时包含上述各种基因突变体的核酸序列。由此,本发明的构建体转化受体细胞获得的重组细胞,能够有效地用作复发性流产相关研究的模型。其中,所述受体细胞的种类不受特别限制,例如可以为大肠杆菌细胞、哺乳动物细胞,优选该受体细胞来源于哺乳动物。
在本发明中所使用的术语“构建体”是指这样的一种遗传载体,其包含特定核酸序列,并且能够将目的核酸序列转入宿主细胞中,以获得重组细胞。根据本发明的实施例,构建体的形式不受特别限制。根据本发明的实施例,其可以为质粒、噬菌体、人工染色体、粘粒(cosmid)、病毒的至少一种,优选质粒。质粒作为遗传载体,具有操作简单,可以携带较大片段的性质,便于操作和处理。质粒的形式也不受特别限制,既可以是环形质粒,也可以是线性质粒,即可以是单链的,也可以是双链的。本领域技术人员可以根据需要进行选择。在本发明中所使用的术语“核酸”可以是任何包含脱氧核糖核苷酸或者核糖核苷酸的聚合物,包括但不限于经过修饰的或者未经修饰的dna、rna,其长度不受任何特别限制。对于用于构建重组细胞的构建体,优选所述核酸为dna,因为dna相对于rna而言,其更稳定,并且易于操作。
在本发明的第六方面,本发明还提出了一种重组细胞。根据本发明的实施例,该重组细胞是通过前面所述的构建体转化受体细胞而获得的。从而,本发明的重组细胞能够有效表达构建体所携带的esr2和ar基因突变体的至少一种。根据本发明的一些实施例,本发明的重组细胞,能够有效地用作复发性流产相关研究的模型。根据本发明的实施例,受体细胞的种类不受特别限制,例如可以为大肠杆菌细胞、哺乳动物细胞,优选所述受体细胞来源于非人哺乳动物。
需要说明的是,在本文前面筛选易患复发性流产的生物样品的方法部分中所描述的特征和优点,同样适用于筛选易患复发性流产的生物样品的系统或者试剂盒,在此不再赘述。
此外,还需要说明的是,根据本发明实施例的筛选易患复发性流产的生物样品的方法、系统以及试剂盒,是本申请的发明人经过艰苦的创造性劳动和优化工作才完成的。
下面参考具体实施例,对本发明进行说明,需要说明的是,这些实施例仅仅是说明性的,而不能理解为对本发明的限制。若未特别指明,实施例中所采用的技术手段为本领域技术人员所熟知的常规手段,可以参照《分子克隆实验指南》第三版或者相关产品进行,所采用的试剂和产品也均为可商业获得的。未详细描述的各种过程和方法是本领域中公知的常规方法,所用试剂的来源、商品名以及有必要列出其组成成分者,均在首次出现时标明,其后所用相同试剂如无特殊说明,均以首次标明的内容相同。
实施例1全外显子组测序确定致病基因及突变位点
1、样本收集:
发明人收集到96例复发性流产病例,均为散发病例,均未在临床检测中在年龄因素、生活习惯、免疫因素、感染因素、内分泌因素,生殖系统因素等方面发现异常,但所有患者均表现为连续发生2次或2次以上的自然流产。
2、全外显子组测序确定致病基因及突变位点
发明人利用nimblegenseqcapezhumanexomelibraryv2.0全外显子捕获平台,结合comletegenomics高通量测序技术,对上述96例复发性流产病例进行了全外显子组捕获测序,具体步骤如下:
2.1样品制备
分别取上述96例复发性流产病例的外周血,利用常规盐析法抽提基因组dna,并利用分光光度计及凝胶电泳法测量dna的浓度及纯度,所得的每个标本基因组dna的od260/od280均位于1.7-2.0之间,浓度不少于200ng/μl,总量不少于30μg,备用。
2.2文库构建及测序
利用自适应高聚焦超声技术(covaris)将各基因组dna样本随机打断成200-400bp左右的片段,随后在片段的5’和3’端分别加上接头a,加有接头a通过pcr方式进行片段扩增。扩增产物接下来用目标区域探针进行杂交捕获。在杂交反应的过程中,目标区域片段与捕获探针稳定结合从而达到有效捕获。捕获的目标区域片段被dynabeadsm-280链霉亲和素磁珠进行纯化,纯化后的片段用ecop15酶进行酶切,并用磁珠回收酶切后的片段。与接头a的连接相类似,在纯化回收后的片段5’和3’端分别加上接头b,用于单链环化。最终生成的单链环就是在测序平台进行上机测序的文库(可参见:http://www.illumina.com/提供的illumina/solexa标准建库说明书,通过参照将其全文并入本文)。文库经纯化后经过ligation-mediatedpcr(lm-pcr)的线性扩增与捕获试剂nimblegenseqcapezexome(44m)array进行杂交富集,再经过lm-pcr的线性扩增,文库检测合格后即可上机测序,以便获得原始测序数据。其中,参照cgblackbird标准的成簇和测序的protocol进行测序,测序平台为cgblackbird,读取长度为26bp,样本的平均测序深度为492×。
g平台采用的是联合探针锚定测序方式,文库构建的最终产物dna单链环经过滚环复制后获得的dna纳米球(dnb:dnananobal),dnb将填充高密度的dna纳米阵列,通过合探针锚定测序方法来识别序列定位、结合多种探针进行未知序列分析。通过成像荧光在每个连接的步骤,发明人可以确定每个dnb的核苷酸序列。
2.3变异检测及注释
在进行basecalling之后,得到了大量的reads序列,继而使用completegenomics内部开发的比对工具进行初始比对;基于初始比对的结果,软件将识别出与参考基因组可能有差别的区域,并收集一部分可能在该区域的reads进行局部denovo组装;接着流程基于初始比对结果和局部组装结果,使用一个概率统计模型进行变异检测,最后提取高可信度的变异结果进行注释。
根据测序结果,每个样品平均有1060mb的测序reads可用于分析,96个样品的捕获率为37%-44%。只有一个样品的目标区域区域覆盖度为94%,其余样品的目标区域覆盖度为97%以上。96个样品的目标区域测序深度为492x。针对该研究的目的,发明人只取目标区域内检测到的变异用于进一步的分析。
另一方面,针对杂合突变发明人采用突变测序深度/整体测序深度为0.24作为过滤标准。通过以上过滤条件后,发明人再采用千人iii期数据库、国际hapmap数据库、dbsnp138数据库和外显子数据库对变异结果进行注释。为了有效地调查irm的发病机理,发明人专注那些位于cds的变异,并且这些变异并未在已有数据库中没有提及与irm存在潜在的遗传原因。然后,发明人将这些变异用sift和polyphen2两个软件来进行变异危害性预测。其中有21个基因的24个突变在sift中的预测为“有害变异”,有15个基因的17个突变在polypphen2中被预测为“有害变异”,两者共同的预测结果有9个基因的10个突变。
结果,发明人在2例病例中发现esr2基因的杂合突变,在2例病例中发现ar基因的杂合突变。随后对结果通过dbsnp数据(http://www.ncbi.nlm.nih.gov/projects/snp/snp_summary.cgi),千人基因组数据库(www.1000genomes.org/),hapmap8数据库(http://hapmap.ncbi.nlm.nih.gov/)等公共数据库的过滤,去掉所有已知变异。利用sift软件和polypphen2软件进行snp功能预测,最终得到3个杂合和1个纯和可能具有致病意义的denovosnp位点,即esr2基因的c.1501c>t杂合突变,该突变导致esr2蛋白发生p.r501c错义突变;esr2基因的c.17c>t杂合突变,该突变导致esr2蛋白发生p.s6l错义突变;ar基因的c.270g>t杂合突变,该突变导致ar蛋白发生p.q90h错义突变;ar基因的c.1191c>g纯合突变,该突变导致ar蛋白发生p.s397r错义突变。
实施例2sanger法测序验证复发性流产的致病突变
由于目标区域测序存在一定程度的假阳性,发明人利用sanger测序方法,对4个杂合可能具有致病意义的罕见突变位点进行了验证,
分别对实施例1检测获得的4个新突变进行检测,针对esr2和ar基因涉及的4个新的突变位点所在序列设计引物,然后通过pcr扩增、产物纯化和测序的方法获得上述突变的有关序列,根据确定序列测定结果属于突变型还是野生型,是杂合突变还是纯合突变,以及序列与表型与复发性流产之间的相关性。
具体方法步骤如下:
1、dna提取
按照实施例1中所述的提取dna的方法,分别提取制备受试者(包括复发性流产患者和正常人)外周静脉血中的基因组dna,备用。
2、引物设计及pcr反应
首先,参考人类基因组序列数据库grch37.1/hg19,采用primer3.0分别设计得到esr2和ar基因外显子特异性引物,具体见下表:
接着,于96孔反应板中,分别按照以下配比配制各基因组dna样本的pcr反应体系以及进行pcr反应。
反应体系:25μl
然后,于perkinelmer9700热循环仪上,采用touchdown方法将配制获得各pcr反应体系按照以下反应条件分别进行pcr反应(不同的突变位点采用相同的反应条件):
反应条件:
预变性:94℃1分钟;
前10个循环:变性94℃,30秒,
退火60℃,30秒(退火温度每个循环降0.5℃),
延伸72℃,30秒;
后25个循环:变性94℃,30秒,
退火55℃,30秒,
延伸72℃,30秒;
最后延伸:72℃,10分钟;
4℃保存。
由此,获得上述各受试者的pcr扩增产物。
3、测序
将步骤2中获得各受试者的pcr扩增产物,进行dna测序。其中,测序采用abi3730型测序仪进行。
基于测序结果,对上述各样本进行esr2和ar基因编码序列比对。发明人发现,实施例1中检测获得的4个新突变位点在各患者和正常人中表现为基因型与疾病表型的共分离,也不存在于正常对照中。其中,图2显示了检出新突变的4个致病基因突变位点的sanger测序验证峰图。结果显示证明上述各变异是致病性突变而不是一个多态性。
此外,需要说明的是,esr2和ar基因目前没有任何有关复发性流产的相关性报道。
综上,发明人证明了,esr2和ar基因为复发性流产的致病基因,并且本发明发现新突变:esr2(c.1501c>t,c.17c>t),ar(rpgrip1(c.270g>t,c.1191c>g)是复发性流产的致病突变。
实施例3检测试剂盒
制备一检测试剂盒,其包含适于检测esr2和ar基因突变体的至少一种的引物(其中与seqidno:1相比,<野生型esr2基因序列>相比具有选自下列的至少一种突变:c.1501c>t突变和c.17c>t突变,或者与seqidno:2相比<野生型ar基因的序列>具有选自下列的至少一种突变:c.270g>t和c.1191c>g,),以便用于筛选易患复发性流产的生物样品,其中这些引物的具体序列见实施例2。
利用上述试剂盒筛选易患复发性流产的生物样品的具体步骤为:按照实施例2的步骤1所述的方法提取待测者dna,以所提取的dna为模板与上述外显子特异性引物进行pcr反应,并按照本领域常规方法对pcr产物纯化,将纯化的产物进行测序,然后通过观察测序所得到的序列是否具有选自上述基因的至少一种突变,从而有效地检测待测者是否易患复发性流产,进一步,能够从待测者中筛选出易患复发性流产的生物样品。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料者特点可以在任 何的一个或多个实施例或示例中以合适的方式结合。
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!